
Knowledge Production: Analysing Gender- and Country-Dependent Factors in Research Topics through Term Communities


Abstract
1. Introduction
1.1. Motivation and Objectives
- To provide a case study as proof of concept for the suggested method with publication abstracts from four sample years in seven diverse research areas.
- To make some observations about gender and country differences in research topics within those research fields.
1.2. Related Work
2. Materials and Methods
2.1. Document Sets Used
- Language and linguistics (Scopus sub-area 1203)
- Literature and literary Theory (Scopus sub-area 1208)
- Strategy and management (Scopus sub-area 1408)
- Human-computer interaction (Scopus sub-area 1709)
- Aerospace engineering (Scopus sub-area 2202)
- Toxicology (Scopus sub-area 3005)
- Gender studies (Scopus sub-area 3318)
- In order to keep the sample set sizes sufficiently small for the purposes of a pilot study, we avoided extremely active sub-areas that produce well over 30,000 publications per year.
- Automatic topic detection algorithms still need some subject expertise for topic interpretation. Therefore, we chose topics about which we know sufficiently well ourselves or where we can access expertise easily.
- We wanted to include a diverse range of disciplines.
- From the more technical areas, we chose one sub-area with notably low female representation (aerospace engineering), one with a relatively high amount of female representation (toxicology), and in the male-dominated field of computer sciences, the sub-area with the highest female participation (human-computer interaction).
2.2. Gender Attribution
- First, we determined all given names and all affiliation countries of the author.
- We took the first of the given names and—using Gender-API—calculated the average over all affiliation countries of the probabilities that it is female.
- If the result was unclear, we added the average female probabilities for the second and further given names in case they existed.
- If we ended up with an averaged female probability of at least 0.95, we considered the author female. If the female probability was less than 0.05, we considered the author male. In all other cases, we classified the gender of the author as unknown.
- Publications with all male authors;
- Publications with all female authors;
- Publications with male and female authors.
- Publications with some male authors (and some authors of unknown gender);
- Publications with some female authors (and some authors of unknown gender);
- Publications where all authors have unknown gender.
2.3. Topic Detection Methodology
2.3.1. Term Extraction
- (E1)
- Throughout the documents, we identified word combinations that are likely to be meaningful compound terms, such as “European Union” or “Leonardo Da Vinci”. Here, we modified the original procedure of [1], where compound terms were discovered by named entity recognition [39]. Instead, we used Wikification, i.e., we checked for word combinations that are titles of a Wikipedia page or linked to a Wikipedia page. In this way, we could also recognise compound terms that are not named entities but rather concepts, for instance, “artificial intelligence”.
- (E2)
- We normalised and cleaned the remaining words in the following way: we lemmatised the words, removed stop words, words consisting only of one or two characters, words consisting mostly of digits, and words containing control characters.
- (E3)
- We retained only compound terms, nouns, proper nouns, and adjectives.
- (E4)
- We ranked the remaining terms according to their significance for characterising the content of the document. The method we used for ranking term significance, called posIdfRank, derives from graph-based keyword extraction methods such as TextRank [40] and PositionRank [41] but also involves the inverse document frequency (Idf) (where the document frequency of a term denotes the number of documents within the corpus that contain that term), similar to its role for capturing term specificity in tf-idf [42]. Technically, this is achieved by computing a probability distribution on the terms of a document which is constructed in a way that favours specific terms standing close to each other, tendentially more at the beginning of the text than at its end. The details of the algorithm are described in [1]. We set its parameter values as follows: the damping factor , the exponent of decrease , and the window size for counting terms as being close .
- (E5)
- We removed from the documents all terms in the lower half of this significance ranking as they are unlikely to contribute to insights about the document’s topic. (The percentage of terms we kept is actually a parameter of the method and should be chosen depending on the average length of the corpus documents (see [1]). Here, we fixed it to 50% based on experience with documents of similar length.)
- (E6)
- We added one further step, which was not included in [1]: we omitted all terms falling below a minimum document frequency , which here was set to 3 (in corpora with significantly more documents, one should choose a greater value). The motivation for this was to omit terms which appear in only one or two documents of the corpus, as these terms are not likely to represent any topic broadly addressed in the corpus. Introducing does not only remove the noise introduced by terms accidentally appearing in just one or two documents but also speeds up computations.
 |
|---|
2.3.2. Term Community Detection
2.3.3. Term Community Presentation
2.3.4. Assessing Topic Shares in Documents and in Document Groups
2.3.5. Relation of Term Community Detection to LDA
3. Results
- If was so small that only four or five topics were detected, those topics would be very broad, and group-specific tendencies could get blurred.
- If was large, the method would detect finer topics, which could be expected to be group-specific; however, there would be only a few publications dealing with each topic so that the statistical relevance of observations would be low.
4. Discussion
4.1. Method Validation
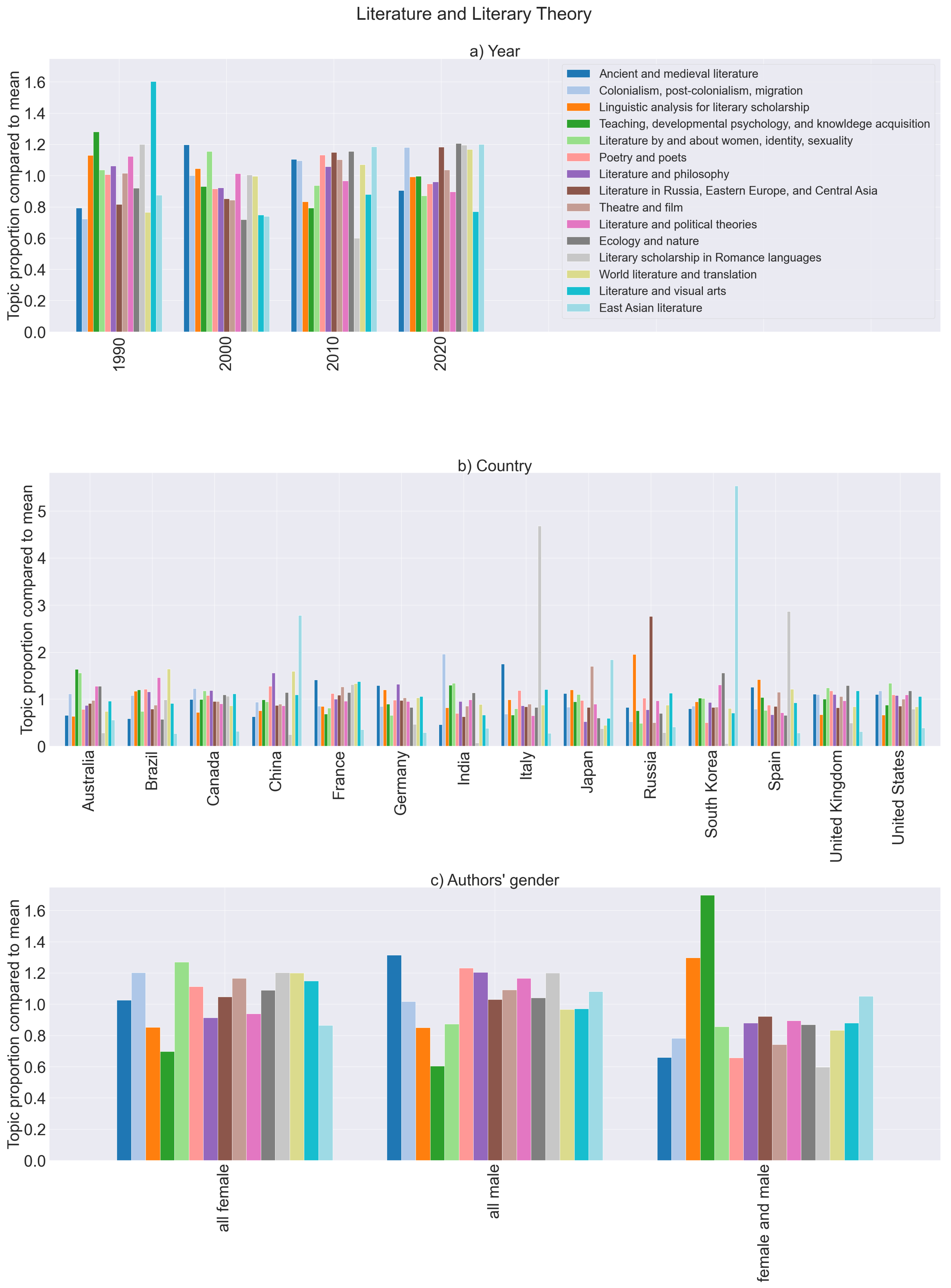
- Literature in Russia, Eastern Europe, and Central Asia
- Literary scholarship in Romance languages
- East Asian literature
4.2. Temporal Tendencies
4.3. Country-Dependent Tendencies
4.4. Gender-Dependent Tendencies
- In the sub-area literature and literary theory (Figure 5c): literature by and about women, identity, sexuality as well as colonialism, post-colonialism, migration;
- In the sub-area human-computer interactions (Figure 7c): E-learning and social computer applications;
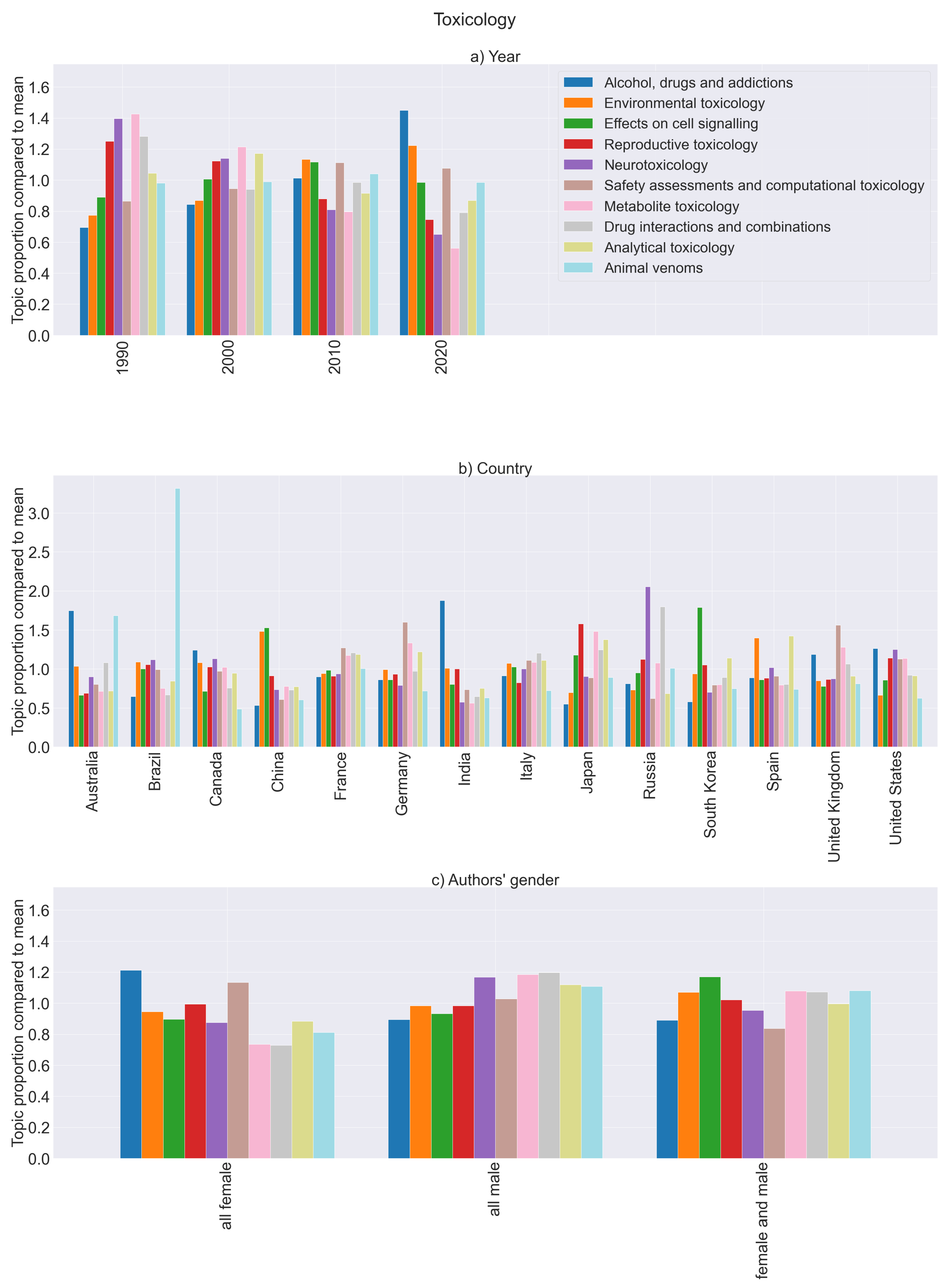
- In the sub-area toxicology (Figure 9c): alcohol, drugs and addictions, and to a somewhat smaller degree safety assessments and computational toxicology;
- In the sub-area gender studies (Figure 10c): feminism as well as sexualisation and sexual objectification.
- In the sub-area language and linguistics (Figure 4c): computational linguistics as well as language and perception;
- In the sub-area literature and literary theory (Figure 5c): teaching, developmental psychology, and knowledge acquisition;
- In the sub-area strategy and management (Figure 6c): process optimisation and modelling as well as raw materials and resource efficiency;
- In the sub-area human-computer interactions (Figure 7c): robotics, uncertainty, stability, and control as well as image recognition, machine learning applications;
- In the sub-area aerospace engineering (Figure 8c): hydrodynamics and aerodynamics, electric propulsion and energy storage as well as dynamics analysis and stability;
- In the sub-area toxicology (Figure 9c): drug interactions and combinations as well as metabolite toxicology;
- In the sub-area gender studies (Figure 10c): sexual norms as well as gender differences in medical issues.
- The topic language of literary works is also covered above average when all authors are male, but it is relatively weakly represented among mixed-gender author teams.
- The topic literature by and about women, identity, sexuality has a below-average proportion when all authors are male but also when at least one author is male.
- The topic colonialism, post-colonialism, migration shows an average proportion in publications of all-male authors but is underrepresented in mixed-gender teams.
- The topic personnel management and work ethics has a proportion below average when all authors are men. In mixed-author groups it has an average proportion.
- The topic E-learning and social computer applications is also underrepresented with all-male authors but average for mixed-gender author teams.
- The topic aerospace economy has a below-average proportion when all authors are—or even if one author is—male.
- The topic alcohol, drugs and addictions is slightly below average in all-male and in mixed-gender author teams.
- The topic safety assessments and computational toxicology shows an average proportion among publications authored by men only but is underrepresented in publications with mixed-author groups.
- The topics feminism as well as sexualisation and sexual objectification are also comparatively often chosen in publication where all authors are male, but it is relatively rare that these topics are dealt with by mixed-gender authors.
- The topic computational linguistics takes an average proportion when all authors are male, but mixed-gender author teams chose it comparatively often.
- The topic language and perception also has an above-average proportion in mixed-gender author teams but not when all authors are male.
- The topic teaching, developmental psychology, and knowledge acquisition is also relatively rarely chosen by all-male authors, but there is a significant tendency to publish on this topic in mixed-gender author teams.
- The topic process optimisation and modelling has a significantly above-average proportion when all authors are male but only an average proportion when women and men co-author a publication.
- The topic raw materials and resource efficiency, in contrast, is represented above average in mixed teams and only on average in completely male teams.
- The three topics robotics, uncertainty, stability, and control, and image recognition, machine learning applications appear comparatively often in publications where all authors are men. Their proportion in mixed-gender author groups is only average.
- The topic hydrodynamics and aerodynamics is another example where purely male author teams are prevalent, while there is an average proportion with both female and male authors.
- The topic electric propulsion and energy storage, on the other hand, is relatively often chosen by mixed-gender teams, whereas its proportion is average in cases where all authors are male.
- The topic dynamics analysis and stability does not show clear tendencies neither for all-male nor for mixed teams.
- The topics drug interactions and combinations and metabolite toxicology also do not show significant deviations from the mean for male or mixed-author groups.
- The topics sexual norms and gender differences in medical issues show significant tendencies to surpass the average proportions in mixed-gender author teams and not in completely male teams.
4.5. Combined Country- and Gender-Dependent Tendencies
5. Conclusions
- The method correctly reconstructs all obvious topic preferences, for instance, country-dependent language-related preferences; this forms a basic proof of concept for the method.
- All other country- and gender-dependent topic preferences deduced with the method either confirm the expected behaviour or provide convincing insights.
- The method is less appropriate for discovering time-dependent tendencies in subject areas for which the coverage in Scopus varies significantly in time, which is especially true in the arts and humanities.
- Insight into group-specific topic tendencies can be used as an important building block for understanding differences in publication behaviour.
- In all seven subject sub-areas studied, topic preferences are significantly different depending on whether all authors are women, all authors are men, or there are female and male co-authors.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACL | Association of Computational Machinery |
| API | Application Programming Interface |
| LDA | Latent Dirichlet allocation |
| STM | Structural topic modeling |
| STEM | Science, technology, engineering, and mathematics |
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | https://dev.elsevier.com/search.html#/Scopus_Search (accessed on 15 July 2021) |
| 9 | |
| 10 | https://conceptnet.s3.amazonaws.com/downloads/2019/numberbatch/numberbatch-19.08.txt.gz (accessed on 20 December 2021) |
References
- Hamm, A.; Odrowski, S. Term-Community-Based Topic Detection with Variable Resolution. Information 2021, 12, 221. [Google Scholar] [CrossRef]
- King, D.A. The scientific impact of nations. Nature 2004, 430, 311–316. [Google Scholar] [CrossRef]
- Leydesdorff, L.; Bornmann, L.; Wagner, C.S. The Relative Influences of Government Funding and International Collaboration on Citation Impact. J. Assoc. Inf. Sci. Technol. 2018, 70, 198–201. [Google Scholar] [CrossRef] [PubMed]
- Scimago. SJR - SCImage Country Rank, 2022. Available online: https://www.scimagojr.com/countryrank.php (accessed on 19 April 2022).
- Holman, L.; Stuart-Fox, D.; Hauser, C.E. The gender gap in science: How long until women are equally represented? PLOS Biol. 2018, 16, e2004956. [Google Scholar] [CrossRef]
- Cole, J.R.; Zuckerman, H. The productivity puzzle. In Advances in Motivation and Achievement; Women in Science; JAI Press: Greenwich, CT, USA, 1984. [Google Scholar]
- Huang, J.; Gates, A.J.; Sinatra, R.; Barabási, A.L. Historical comparison of gender inequality in scientific careers across countries and disciplines. Proc. Natl. Acad. Sci. USA 2020, 117, 4609–4616. [Google Scholar] [CrossRef]
- Larivière, V.; Ni, C.; Gingras, Y.; Cronin, B.; Sugimoto, C.R. Bibliometrics: Global gender disparities in science. Nature 2013, 504, 211–213. [Google Scholar] [CrossRef] [PubMed]
- West, J.D.; Jacquet, J.; King, M.M.; Correll, S.J.; Bergstrom, C.T. The Role of Gender in Scholarly Authorship. PLoS ONE 2013, 8, e66212. [Google Scholar] [CrossRef]
- Mohammad, S.M. Gender Gap in Natural Language Processing Research: Disparities in Authorship and Citations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 6–8 July 2020; Association for Computational Linguistics: Stroudsburg, PN, USA, 2020; pp. 7860–7870. [Google Scholar] [CrossRef]
- Duch, J.; Zeng, X.H.T.; Sales-Pardo, M.; Radicchi, F.; Otis, S.; Woodruff, T.K.; Amaral, L.A.N. The Possible Role of Resource Requirements and Academic Career-Choice Risk on Gender Differences in Publication Rate and Impact. PLoS ONE 2012, 7, e51332. [Google Scholar] [CrossRef]
- Abramo, G.; D’Angelo, C.A.; Caprasecca, A. Gender differences in research productivity: A bibliometric analysis of the Italian academic system. Scientometrics 2009, 79, 517–539. [Google Scholar] [CrossRef]
- Rørstad, K.; Aksnes, D.W. Publication rate expressed by age, gender and academic position – A large-scale analysis of Norwegian academic staff. J. Inf. 2015, 9, 317–333. [Google Scholar] [CrossRef]
- De Kleijn, M.; Jayabalasingham, B.; Holly, J.; Falk-Krzesinski, T.; Collins, L.; Kuiper-Hoyng, I.; Cingolani, J.; Zhang, G.; Roberge. The Researcher Journey Through a Gender Lens: An Examination of Research Participation, Career Progression and Perceptions Across the Globe, 2020. Available online: https://www.elsevier.com/connect/gender-report (accessed on 4 March 2020).
- Yamamoto, J.; Frachtenberg, E. Gender Differences in Collaboration Patterns in Computer Science. Publications 2022, 10, 10. [Google Scholar] [CrossRef]
- Rip, A.; Courtial, J.P. Co-word maps of biotechnology: An example of cognitive scientometrics. Scientometrics 1984, 6, 381–400. [Google Scholar] [CrossRef]
- van Eck, N.J.; Waltman, L. Visualizing Bibliometric Networks. In Measuring Scholarly Impact; Springer: Cham, Switzerland, 2014; pp. 285–320. [Google Scholar] [CrossRef]
- Aria, M.; Cuccurullo, C. bibliometrix: An R-tool for comprehensive science mapping analysis. J. Inf. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Firoozeh, N.; Nazarenko, A.; Alizon, F.; Daille, B. Keyword extraction: Issues and methods. Nat. Lang. Eng. 2019, 26, 259–291. [Google Scholar] [CrossRef]
- Lee, Y.; Lee, Y.; Seong, J.; Stanescu, A.; Hwang, C. A comparison of network clustering algorithms in keyword network analysis: A case study with geography conference presentations. Int. J. Geospat. Environ. Res. 2020, 7, 1–16. [Google Scholar]
- Fortunato, S.; Hric, D. Community detection in networks: A user guide. Physics Rep. 2016, 659, 1–44. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Vogel, A.; Jurafsky, D. He Said, She Said: Gender in the ACL Anthology. In Proceedings of the ACL-2012 Special Workshop on Rediscovering 50 Years of Discoveries, Jeju Island, Korea, 10 July 2012; pp. 33–41. [Google Scholar]
- Nielsen, M.W.; Börjeson, L. Gender diversity in the management field: Does it matter for research outcomes? Res. Policy 2019, 48, 1617–1632. [Google Scholar] [CrossRef]
- Key, E.M.; Sumner, J.L. You Research Like a Girl: Gendered Research Agendas and Their Implications. PS Political Sci. Politics 2019, 52, 663–668. [Google Scholar] [CrossRef]
- Roberts, M.E.; Stewart, B.M.; Tingley, D.; Airoldi, E.M. The structural topic model and applied social science. In Proceedings of the ICONIP 2013, Daegu, Korea, 3–7 November 2013. [Google Scholar]
- Heiberger, R.H. Applying Machine Learning in Sociology: How to Predict Gender and Reveal Research Preferences. KZfSS Kölner Z. Für Soziologie Und Sozialpsychologie 2022, 74, 383–406. [Google Scholar] [CrossRef]
- Conde-Ruiz, J.I.; Ganuza, J.J.; García, M.; Puch, L.A. Gender distribution across topics in the top five economics journals: A machine learning approach. SERIEs 2021, 13, 269–308. [Google Scholar] [CrossRef]
- Bittermann, A.; Greiner, N.; Fischer, A. Unterscheiden sich die Forschungsinteressen von Frauen und Männern in der Psychologie? Psychol. Rundsch. 2020, 71, 103–110. [Google Scholar] [CrossRef]
- Su, R.; Rounds, J.; Armstrong, P.I. Men and things, women and people: A meta-analysis of sex differences in interests. Psychol. Bull. 2009, 135, 859–884. [Google Scholar] [CrossRef] [PubMed]
- Thelwall, M.; Bailey, C.; Tobin, C.; Bradshaw, N.A. Gender differences in research areas, methods and topics: Can people and thing orientations explain the results? J. Inf. 2019, 13, 149–169. [Google Scholar] [CrossRef]
- Mongeon, P.; Paul-Hus, A. The journal coverage of Web of Science and Scopus: A comparative analysis. Scientometrics 2015, 106, 213–228. [Google Scholar] [CrossRef]
- Thelwall, M.; Sud, P. Scopus 1900–2020: Growth in articles, abstracts, countries, fields, and journals. Quant. Sci. Stud. 2022, 3, 37–50. [Google Scholar] [CrossRef]
- Huang, P.C.C. Citation Indexes: Uses and Misuses. Mod. China 2018, 44, 559–590. [Google Scholar] [CrossRef]
- Tennant, J. Web of Science and Scopus are not global databases of knowledge. Eur. Sci. Ed. 2020, 46, e51987. [Google Scholar] [CrossRef]
- Santamaría, L.; Mihaljević, H. Comparison and benchmark of name-to-gender inference services. PeerJ Comput. Sci. 2018, 4, e156. [Google Scholar] [CrossRef]
- Sebo, P. Performance of gender detection tools: A comparative study of name-to-gender inference services. J. Med. Libr. Assoc. 2021, 109. [Google Scholar] [CrossRef]
- Sayyadi, H.; Raschid, L. A Graph Analytical Approach for Topic Detection. ACM Trans. Internet Technol. 2013, 13, 1–23. [Google Scholar] [CrossRef]
- Montani, I.; Honnibal, M.; Honnibal, M.; Van Landeghem, S.; Boyd, A.; Peters, H.; McCann, P.O.; Samsonov, M.; Geovedi, J.; O’Regan, J.; et al. Explosion/spaCy: V3.3.0: Improved Speed, New Trainable Lemmatizer, and Pipelines for Finnish, Korean and Swedish, 2022. Available online: https://zenodo.org/record/6504092#.Y3MAFORByUk (accessed on 29 April 2022).
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Florescu, C.; Caragea, C. PositionRank: An Unsupervised Approach to Keyphrase Extraction from Scholarly Documents. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1105–1115. [Google Scholar] [CrossRef]
- Sparck Jones, K. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Barton, M.A.; Christianson, M.; Myers, C.G.; Sutcliffe, K. Resilience in action: Leading for resilience in response to COVID-19. BMJ Lead. 2020, 4, 117–119. [Google Scholar] [CrossRef]
- Reichardt, J.; Bornholdt, S. Statistical mechanics of community detection. Physical Rev. E 2006, 74, 016110. [Google Scholar] [CrossRef] [PubMed]
- Newman, M.E.J. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef] [PubMed]
- Traag, V.A.; Waltman, L.; van Eck, N.J. From Louvain to Leiden: Guaranteeing well-connected communities. Sci. Rep. 2019, 9, 5233. [Google Scholar] [CrossRef] [PubMed]
- Hamm, A.; Thelen, J.; Beckmann, R.; Odrowski, S. TeCoMiner: Topic Discovery Through Term Community Detection. arXiv 2021, arXiv:cs.CL/2103.12882. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. arXiv 2016, arXiv:1607.04606. [Google Scholar] [CrossRef]
- Speer, R.; Chin, J.; Havasi, C. ConceptNet 5.5: An Open Multilingual Graph of General Knowledge. arXiv 2017, arXiv:1612.03975. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, Z. Combining prestige and relevance ranking for personalized recommendation. In Proceedings of the 22nd ACM International Conference on INFORMATION & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Sirer, M.I.; Wang, J.X.; Acuna, D.; Körding, K.; Amaral, L.A.N. High-Reproducibility and High-Accuracy Method for Automated Topic Classification. Phys. Rev. X 2015, 5, 011007. [Google Scholar] [CrossRef]
- Leydesdorff, L.; Nerghes, A. Co-word maps and topic modeling: A comparison using small and medium-sized corpora. J. Assoc. Inf. Sci. Technol. 2016, 68, 1024–1035. [Google Scholar] [CrossRef]
- Gerlach, M.; Peixoto, T.P.; Altmann, E.G. A network approach to topic models. Sci. Adv. 2018, 4. [Google Scholar] [CrossRef] [PubMed]
- Odrowski, S. Text Mining durch die politikwissenschaftliche Brille. Neue Ansätze für eine sozialwissenschaftlich ausgerichtete und transdisziplinär fundierte Erschließung von Text-as-Data-Verfahren und Big Text Data. Ph.D. Thesis, University of Cologne, Köln, Germany, 2022. submitted. [Google Scholar]
- Armed Forces Pest Management Board. Living Hazards Database, 2022. Available online: https://www.acq.osd.mil/eie/afpmb/livinghazards.html (accessed on 9 July 2022).
- Scopus Blog. Scopus Content Update: The Arts & Humanities, 2014. Available online: https://blog.scopus.com/posts/scopus-content-update-the-arts-humanities (accessed on 9 July 2022).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sub-Area | 1990 | 2000 | 2010 | 2020 | Sum of Four Years |
|---|---|---|---|---|---|
| Language and Linguistics | 1699 | 4239 | 11,420 | 24,200 | 41,558 |
| Literature and Literary Theory | 264 | 694 | 5904 | 12,531 | 19,393 |
| Strategy and Management | 2524 | 5389 | 13,050 | 32,246 | 53,209 |
| Human-Computer Interaction | 530 | 1718 | 17,840 | 28,932 | 49,020 |
| Aerospace Engineering | 4298 | 9633 | 20,648 | 30,355 | 64,934 |
| Toxicology | 5586 | 6613 | 10,734 | 17,962 | 40,895 |
| Gender Studies | 495 | 1041 | 2158 | 5152 | 8846 |
| Sub-Area | US | CN | GB | DE | IN | JP | CA | ES | FR | IT | AU | RU | BR | KR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Language/Ling. | 10,170 | 2114 | 3719 | 2471 | 472 | 1348 | 1437 | 2577 | 1499 | 1225 | 1365 | 1450 | 802 | 432 |
| Lit./Lit. Theory | 3694 | 593 | 1709 | 628 | 143 | 71 | 520 | 1313 | 681 | 626 | 499 | 743 | 411 | 113 |
| Strategy/Manag. | 12,431 | 7133 | 5551 | 2067 | 2521 | 662 | 2080 | 1734 | 1491 | 1794 | 2260 | 799 | 1071 | 1036 |
| Human-Computer | 10,583 | 9648 | 3368 | 3333 | 1382 | 3487 | 1931 | 1150 | 1544 | 1388 | 1628 | 527 | 994 | 1469 |
| Aerospace Eng. | 20,593 | 16,268 | 3034 | 3080 | 3600 | 2345 | 1745 | 890 | 2172 | 2353 | 978 | 1992 | 689 | 1253 |
| Toxicology | 12,427 | 4850 | 2328 | 1983 | 3146 | 2472 | 1437 | 991 | 1381 | 1278 | 872 | 468 | 1286 | 1095 |
| Gender Studies | 3758 | 112 | 1045 | 131 | 164 | 49 | 600 | 199 | 63 | 96 | 455 | 61 | 252 | 64 |
| Sub-Area | Publications | Nodes (Terms) | Links |
|---|---|---|---|
| Language and Linguistics | 41,558 | 34,023 | 5,766,126 |
| Literature and Literary Theory | 19,393 | 24,194 | 2,818,821 |
| Strategy and Management | 53,209 | 35,876 | 7,694,237 |
| Human-Computer Interactions | 49,020 | 33,633 | 6,390,920 |
| Aerospace Engineering | 64,934 | 43,231 | 9,900,516 |
| Toxicology | 40,895 | 41,406 | 8,266,924 |
| Gender Studies | 8846 | 11,590 | 1,307,635 |
| Document | Author Gender | s1 | s2 | s3 |
|---|---|---|---|---|
| female | 0.5 | 0 | 0.5 | |
| female | 0.6 | 0 | 0.4 | |
| male | 0.5 | 0.1 | 0.4 | |
| male | 0.5 | 0.3 | 0.2 | |
| male | 0.6 | 0.2 | 0.2 | |
| male | 0.6 | 0 | 0.4 |
| Sub-Corpus | a1 | a2 | a3 | r1 | r2 | r3 | c1 | c2 | c3 |
|---|---|---|---|---|---|---|---|---|---|
| 1.1 | 0 | 0.9 | 0.55 | 0 | 0.45 | 1 | 0 | 1.2 | |
| 2.2 | 0.6 | 1.2 | 0.55 | 0.15 | 0.3 | 1 | 2 | 0.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bakshi-Hamm, P.; Hamm, A. Knowledge Production: Analysing Gender- and Country-Dependent Factors in Research Topics through Term Communities. Publications 2022, 10, 45. https://doi.org/10.3390/publications10040045
Bakshi-Hamm P, Hamm A. Knowledge Production: Analysing Gender- and Country-Dependent Factors in Research Topics through Term Communities. Publications. 2022; 10(4):45. https://doi.org/10.3390/publications10040045
Chicago/Turabian StyleBakshi-Hamm, Parminder, and Andreas Hamm. 2022. "Knowledge Production: Analysing Gender- and Country-Dependent Factors in Research Topics through Term Communities" Publications 10, no. 4: 45. https://doi.org/10.3390/publications10040045
APA StyleBakshi-Hamm, P., & Hamm, A. (2022). Knowledge Production: Analysing Gender- and Country-Dependent Factors in Research Topics through Term Communities. Publications, 10(4), 45. https://doi.org/10.3390/publications10040045