1. Introduction
In order to tackle the explosive escalation of wireless data traffic and the emerging application services, the Sixth-Generation (6G) communication research is widely assumed to shift towards the higher-frequency spectrum since the current radio frequency (RF) band is becoming more and more crowded [
1,
2]. The millimeter-wave and terahertz spectrum can be widely developed to fulfill this demand; however, the corresponding equipment has an extremely high cost. Visible light communication (VLC) is expected to provide a potential supplement for 6G since it relies on the unlicensed spectrum spanning from 400 to 800 THz and has the benefits of electromagnetic interference resistance, green technology, safety, and low cost. In addition, VLC can be equipped with common lighting systems to allow simultaneous illumination and communication. During the last decade, various research works have been conducted to establish the theoretical foundation and application paradigm for high-speed VLC systems [
3,
4].
The spectral efficiency of VLC can be improved with the help of high-order modulation schemes [
5,
6]. Nevertheless, the special undesirable nonlinearities introduced by the electro-optical and photoelectric conversions will contaminate the useful signal [
7], and the optical diffuse channel will also bring in an inevitable inter-symbol interference (ISI). The overall channel impairments should be relieved since they indeed significantly impair the signal performance and hinder the high-speed VLC transmission. Traditional schemes and algorithms can generally estimate the transfer function of the communication channel and remove the channel impairments by constructing nonlinear post-equalization (NPE) [
7,
8]. However, these methodologies still have a performance difference from the ideal case and would confront certain restrictions and requirements for different application scenarios.
The deep learning (DL) has shown great success in pattern identification, image recognition, and data mining. It has been already applied to physical layer communication due to its strong ability in learn the unknown or complex communication block [
9,
10], especially for modeling nonlinear phenomena. With the development of advanced network structures and optimized training algorithms, DL-based NPE shows unparalleled superiority compared to traditional approaches in channel impairment compensation. A comprehensive introduction and overview of DL-based methods can be found in [
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25]. In [
12,
13,
14], the deep neural network (DNN) was employed to learn the channel characteristics and demodulate the output signals directly. In [
15,
16], the Gaussian-kernel-aided DNN networks were proposed as the pre-equalization and post-equalization, respectively, to mitigate the nonlinear degradation in high-order modulated VLC systems. In [
17], a low-complexity memory-polynomial-aided neural network was created to replace the traditional post-equalization filters of carrierless amplitude and phase (CAP) modulation. These schemes utilizing the DNN can achieve the mitigation of the linear and nonlinear distortion of the VLC channel and exhibit better bit error rate (BER) performance than some existing methods. However, the learning ability of these DL models is limited in high-speed VLC since the system is mainly restricted by the inherent memory nonlinearity of the light-emitting diode (LED), resulting in a slow convergence speed and relatively poor generalization of the DNN.
For a nonlinear VLC channel with memory, the recurrent neural network (RNN) with long short-term memory (LSTM) cells seems to be a better choice for memory sequence prediction, because the long-term memory parameters can store the channel characteristics. In [
18], a memory-controlled LSTM equalizer was proposed to compensate both the linear and nonlinear distortions. In [
19], an LSTM network was proposed to handle with the nonlinear distortions for a pulse amplitude modulation (PAM) system with the intensity modulation and direct detection (IM/DD) link over 100 km standard single-mode fiber. These proposed LSTM models outperform the conventional model-solving-based equalizers; nevertheless, the output equalization accuracy does not possess a good robustness to the noise variation, leading to the degradation of learning efficiency. In order to learn more suitable channel features, the convolutional neural network (CNN) can be used for memory sequence prediction from raw channel outputs [
20], since a function could be learned that maps a sequence of past observations as the input to an output observation. In [
21], an equalization scheme using the CNN was proposed in an orthogonal-frequency-division-multiplexing (OFDM)-based VLC system for direct equalization. In [
22], a novel blind algorithm based on the CNN was introduced to jointly perform equalization and soft demapping for M-ary quadrature amplitude modulation (M-QAM). The results showed that the proposed CNN schemes outperform the existing equalization algorithms and can maintain an excellent BER performance in the linear and nonlinear channel. However, for dynamic and deep memory scenarios, it obtains the optimal equalization performance at the cost of computational complexity, because the dimension of the input spatial information increases sharply and the convolution layer has to undertake tremendous computational pressure, resulting in the increase of network complexity [
23]. In order to shrink the network complexity, a specific architecture combination was proposed to distribute the learning task [
24,
25]. However, the original input data hardly experienced effective transformation, resulting in a large amount of time cost in the training process to extract the implicit features contained in the samples. Hence, the trade-off among computational complexity, training times, robustness, and generalization is one of the critical challenges and should be further developed in practical VLC applications. Besides, it is also necessary to consider how to consolidate the virgin data into alternate forms by changing the value, structure, or format so that the data may be easily parsed by the machine.
In this paper, inspired by the approaches in [
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25], the channel impairment compensation is formulated as a spatial memory pattern prediction problem, and an efficient impairment compensation scheme in terms of a model-driven-based CNN-LSTM is proposed to undo the memory nonlinearity of VLC. The underlying idea is that the Volterra structure is applied to pre-emphasize the original sequence and the appropriate pattern is formed as the spatial input accordingly. Then, a hybrid CNN and LSTM neural network is elaborately designed to learn the implicit feature of nonlinearity and predict the memory sequence directly, which can speed up the convergence process and improve the equalization accuracy. The main contribution of this work can be summarized as follows:
The structure information of the Volterra model is involved in the proposed DL equalizer to pre-emphasize the virgin data, which is favorable for the memory feature learning. Therefore, it can relax the learning pressure and reduce the structural complexity and training time.
Based on the traditional model-solving procedure, the channel impairment compensation is formulated as a spatial memory pattern prediction problem, and the proposed DL model is ingeniously used to achieve the accurate prediction.
Both the memory nonlinearity of the LED and the dispersive effect of the optical channel in a VLC system are simultaneously considered during the training stage.
The proposed scheme can still provide an excellent BER performance under the mismatched conditions of training and testing, showing a good robustness.
Numerical simulations in terms of the learning and generalization show that the proposed scheme is able to predict the original transmitted signal and compensate the impairments with high accuracy and resolution. In addition, it can converge relatively fast to achieve a better normalized-mean-squared error (NMSE), which confirms its superiority to some existing methods.
The remainder of this paper is organized as follows. In
Section 2, the overall channel nonlinearity is analyzed and the impairment compensation is formulated as a spatial memory pattern prediction problem. The corresponding network architecture and training specification are illustrated in
Section 3. Simulation results and discussions are demonstrated in
Section 4, and conclusions are given in
Section 5.
Notations: Matrices and column vectors are denoted by upper and lower boldface letters, respectively. denotes the n-th element of . The set of real numbers is denoted by . In addition, *, ⊗, , and are employed to represent the convolution, the Kronecker product, the transpose, and the absolute operators, respectively. Let denote the -norm and be an estimation of the parameter of interest a. is the Gaussian distribution with mean and variance .
2. System Nonlinearity
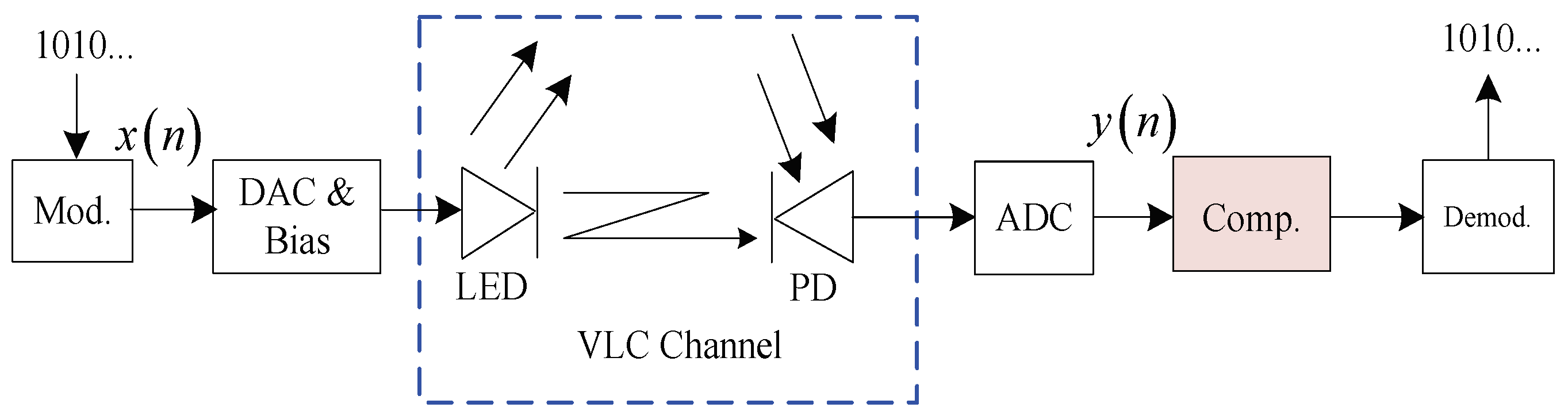
A typical VLC system employing an IM/DD structure is illustrated in
Figure 1. The end-to-end VLC channel includes an electrical modulator, digital-to-analog converter (DAC), bias tee, LED, optical transmission channel, analog-to-digital converter (ADC), and electrical demodulator. Numerous modules will generate nonlinearities. However, the overall nonlinearity of the VLC channel is mainly introduced by both the LED and multipath propagation of the optical link. In addition, the memory nonlinearity is more significant as the signal bandwidth is increased. The LED behaviors are usually described by the Wiener model, which is a cascade of linear and nonlinear blocks. Let
denote the 3 dB cut-off frequency, then the memory nonlinearity of the LED can be expressed as
The memoryless nonlinearity block can be modeled by
where
is input real-valued transmitting signal,
is the coefficient, and
Q is the polynomial order. The channel impulse response (CIR) of the multipath propagation effect in VLC can be expressed by the following:
where
is the optical power,
is the propagation time of the
i-th light ray, and
is the number of received rays at the photodetector (PD), respectively. In fact, the PD also exhibits nonlinear behavior as the optical intensity of the injected signal is very large, leading to the saturation of the PD. However, the optical intensity can be lowered with the help of an optical attenuator. Therefore, the PD can be regarded as a linear component, which is always modeled by the Dirac function. Note that the quantification effect in the ADC is not considered here. After optical-to-electrical conversion in the PD, the received electrical signal can be expressed as
where
denotes the responsivity of the PD,
is the DC bias, and
is the Gaussian noise following
.
At the receiver,
is fed into the Volterra-based NPE. Then, the corresponding outputs can be expressed as
where
L denotes the memory length,
P is the nonlinear order,
is the
p-th order of the Volterra kernels, and
is the modeling error. Let
represent the truncated samples with length
L, which contains both the current and the past channel outputs.
As seen from (
5), the calculation of
is mainly related to
and
. As we known, the main goal of the NPE is to produce the desired
from
to minimize the error with respect to
, which indicates that the useful information of
is involved in
. In other words, we can infer that
can be predicted from
once all the
are well obtained. Therefore, from the perspective of learning and classification, both the
and
can be learned from the training sample set
, and the implement of the NPE can be formulated as a prediction problem, where the DL approach is very appropriate.
3. The Proposed Scheme
As we know, LSTM is more powerful in dealing with the memory sequences’ prediction problem since it could handle the long-term dependencies and store the memory parameters, which are related to the channel characteristics. As regards the VLC system, experiences the complex optical-to-electrical and electrical-to-optical conversion, and the complicated overall channel nonlinearity involved in is very implicit and not very intuitive, which will greatly increase the computational complexity and learning difficulty. Furthermore, it leads to a slow convergence speed and the decrease of equalization performance. In order to improve the learning ability and accelerate the convergence speed, we therefore propose a novel impairment compensation scheme, which utilizes the Volterra structure to construct the spatial features and feed them into the CNN-LSTM network to extract the characteristic of memory nonlinearity. In the following analysis, we assume that the system synchronization has been already achieved at the receiver.
3.1. Input Preprocessing Based on Volterra Feature
The composition and structure of the virgin input data can directly affect the performance of deep learning. Due to the complexity of the VLC channel, it is very necessary to transform or encode
so that it may be easily parsed by the machine. The main agenda for the proposed model to be accurate and precise in its predictions is that the algorithm should be able to easily interpret the data’s features. As demonstrated in (
5), for
,
can be considered as the sum of the response for each
and
, shown as
where
, and
denotes the corresponding kernel coefficients for
. Let
. (
7) can be further formed as
where
is the Volterra kernel vector and
contains the corresponding kernel coefficients
, which are arranged sequentially for the index
.
Therefore,
should be firstly stacked for the last
L points shown in (
6) and then transformed into the sequence
by using the above approach based on the Volterra structure feature. In order to shrink the computational complexity and speed up the learning progress, the sequence
is truncated with a
length. Then, the first appropriate pattern can be formed by the following way, shown as
With the time sliding window moving forward one step, the second pattern can be generated by
Until the last N-th points, multiple patterns can be obtained subsequently, which will enter the neural network as the features for the input layer. Note that the step of the sliding window was set as 1 in this paper, and m also denotes the time step used in the following DL model.
3.2. Network Structure
The architecture of the proposed model is depicted in
Figure 2, which is composed by subnet
with
convolution layers, subnet
with
LSTM layers, and subnet
with
dense layers.
The samples are then fed into for feature extraction. The structure of is composed of a convolution layer, pooling layer, flatten layer, and dense layer. The convolution layer employs a series of two-dimensional convolution filters (2D-Conv) to , so as to extract different feature maps of received signals. Let and denote the size of the convolutional kernel and the number of filters of the l-th convolutional layer, respectively. For simplicity, the stride was fixed to 1, and the Relu function and the same padding were employed in 2D-Conv. After the convolution calculation, the max-pooling layer is used to extract the invariant features with the non-linear downsampling, which will eliminate the non-maximal values. The same signal processing is implemented in the next 2D-Conv and max-pooling layer. After that, the flatten layer is employed to reshape the data size, and then, the dense layer is linked behind accordingly.
The CNN outputs should be firstly transformed as a three-dimensional vector
and fed into
, where
denotes the cell number of the first layer of
. The structure of
is made up by cascaded sub-layer blocks composed by multiple LSTM cells. In addition, different amounts of LSTM cells can be deployed in different sub-layers. The internal structure of a single LSTM cell, as shown in
Figure 2, contains three Sigmoid gates in terms of the forget gate, input gate, and output gate. These gates can selectively influence the model state at each time step. The forget gate is also the core of a single LSTM cell, since it determines the information that should be retained or discarded according to the current input
and the previous output
. The output of forget gate can be expressed as
where
is the Sigmoid function and
and
represent the parameter matrix and bias matrix of the forget gate, respectively. After forgetting part of the previous state, the input gate picks up some new information and then adds it into the former state
. Therefore, the new cell state is formed as
where
denotes the temporary cell state and
is the output of the input gate. Furthermore, the expression of
is given as
and the output
can be expressed as
where
,
,
, and
denote the parameter matrix and bias matrix, respectively. Therefore, the value
and
between 0 and 1 also indicates the proportion of the important information in
and
, thereby determining which information is to be updated. Then, the output of the LSTM cell can be calculated by
As a result, the outputs of this layer are fed into the corresponding LSTM cell of the next layer. However, as for the last layer, only the at the last time step is selected and then composed as the final output , where denotes the cell number of the last layer in . In this case, should be transformed as a column vector to be fed into the dense net to refine the output results. Note that the linear activation function is deployed in without normalization. Finally, the equalized can be directly obtained at the output of , and the overall VLC nonlinearity will be efficiently compensated by using the proposed scheme.
3.3. Complexity
For the computational complexity, it is worth noting that the calculation of
and
is dominant in each time step. Let
be the spatial size of the output feature map in the
l-th convolutional layer, which can be calculate by
where
is the input matrix size and
is the padding length. Furthermore, we define the cell number of each layer in
as equal to
. Accordingly, the overall complexity of the proposed model per time step can be approximately expressed as
3.4. Training Strategy
The proposed scheme was trained by viewing the VLC channel as a black box. Fortunately, researchers have developed several reference channel models for indoor environments for VLC [
26]. Therefore, the training data can be easily obtained by simulations [
12]. As for collecting the training set, the receiving plane is divided into several grid units with equidistant spacing used as potential locations for the PD. After VLC transmission and optical-to-electrical conversion, the received signals are collected under different PD locations. With the skillful preprocessing of the received signal, every spatial pattern and one sample of the transmitted signals are combined as the training data. Practically, we should collect a diverse and abundant training set, including the potential PD locations, to enhance the parameters learning ability of the proposed scheme.
The direct-current-biased optical (DCO)-OFDM, containing in total 512 sub-carriers with 16-QAM constellation mapping, is adopted as the training symbol, and only five symbols are randomly generated in each training epoch. Moreover, the NMSE between the raw
and the equalized
is employed as the training loss function, demonstrated by
Note that the DC gain is removed from the training set so that the training loss of the proposed scheme can be fairly evaluated. Furthermore, the training procedure was implemented using TensorFlow on a work station running with a graphics processing unit (GPU) of NVIDIA GeForce 2080Ti; the adaptive moment estimation (Adam) was adopted as the optimizer, and the learning rate was fixed to 0.0001. As in the testing stage, only several special links were adopted to evaluate the system performance for the simplicity of the demonstration.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}