Target Detection Method for Low-Resolution Remote Sensing Image Based on ESRGAN and ReDet


Abstract
:1. Introduction
2. Related Work
2.1. Bicubic Interpolation
2.2. Effective Algorithms for SISR
2.2.1. Generative Adversarial Network (GAN)
2.2.2. SRGAN
2.2.3. EDSR
3. Experimental Method
3.1. ESRGAN
3.2. Rotating Equivariant Detector
3.3. TDoSR
4. Experimental Results and Analysis
4.1. Experimental Data
4.2. Comparative Experiment
4.3. Results and Analysis
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Steve, L.; Giles, C.L.; Tsoi, A.C.; Back, A.D. Face Recognition: A Convolutional Neural-Network Approach. IEEE Trans. Neural Netw. 1997, 8, 98–113. [Google Scholar]
- Claus, N. Evaluation of Convolutional Neural Networks for Visual Recognition. IEEE Trans. Neural Netw. 1998, 9, 685–696. [Google Scholar]
- Christian, S.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Chao, D.; Loy, C.C.; He, K.; Tang, X. Part IV—Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the Computer Vision—ECCV 2014—13th European Conference, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Christian, L.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ian, J.G.; Abadie, J.P.; Mirza, M.; Xu, B.; WardeFarley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Sergey, I.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on Imagenet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Bee, L.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Part V—Esrgan: Enhanced Super-Resolution Generative Adversarial Networks. In Proceedings of the Computer Vision—ECCV 2018 Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Karen, S.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Kwan, C.; Dao, M.; Chou, B.; Kwan, L.M.; Ayhan, B. Mastcam Image Enhancement Using Estimated Point Spread Functions. In Proceedings of the 8th IEEE Annual Ubiquitous Computing, Electronics and Mobile Communication Conference, UEMCON, New York, NY, USA, 19–21 October 2017. [Google Scholar]
- Han, J.; Ding, J.; Xue, N.; Xia, G.S. Redet: A Rotation-Equivariant Detector for Aerial Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Jian, D.; Xue, N.; Long, Y.; Xia, G.; Lu, Q. Learning Roi Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Xue, Y.; Yan, J. Part VIII—Arbitrary-Oriented Object Detection with Circular Smooth Label. In Proceedings of the Computer Vision—ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. Dota: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Chao, D.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar]
- Joan, B.; Sprechmann, P.; LeCun, Y. Super-Resolution with Deep Convolutional Sufficient Statistics. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Justin, J.; Alahi, A.; FeiFei, L. Part II—Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Alec, R.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Christian, S.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-V4, Inception-Resnet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- TsungYi, L.; Dollr, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-Cnn: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar]
- Diederik, P.K.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Adam, P.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Kai, C.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. Mmdetection: Open Mmlab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Ying, T.; Yang, J.; Liu, X. Image Super-Resolution via Deep Recursive Residual Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
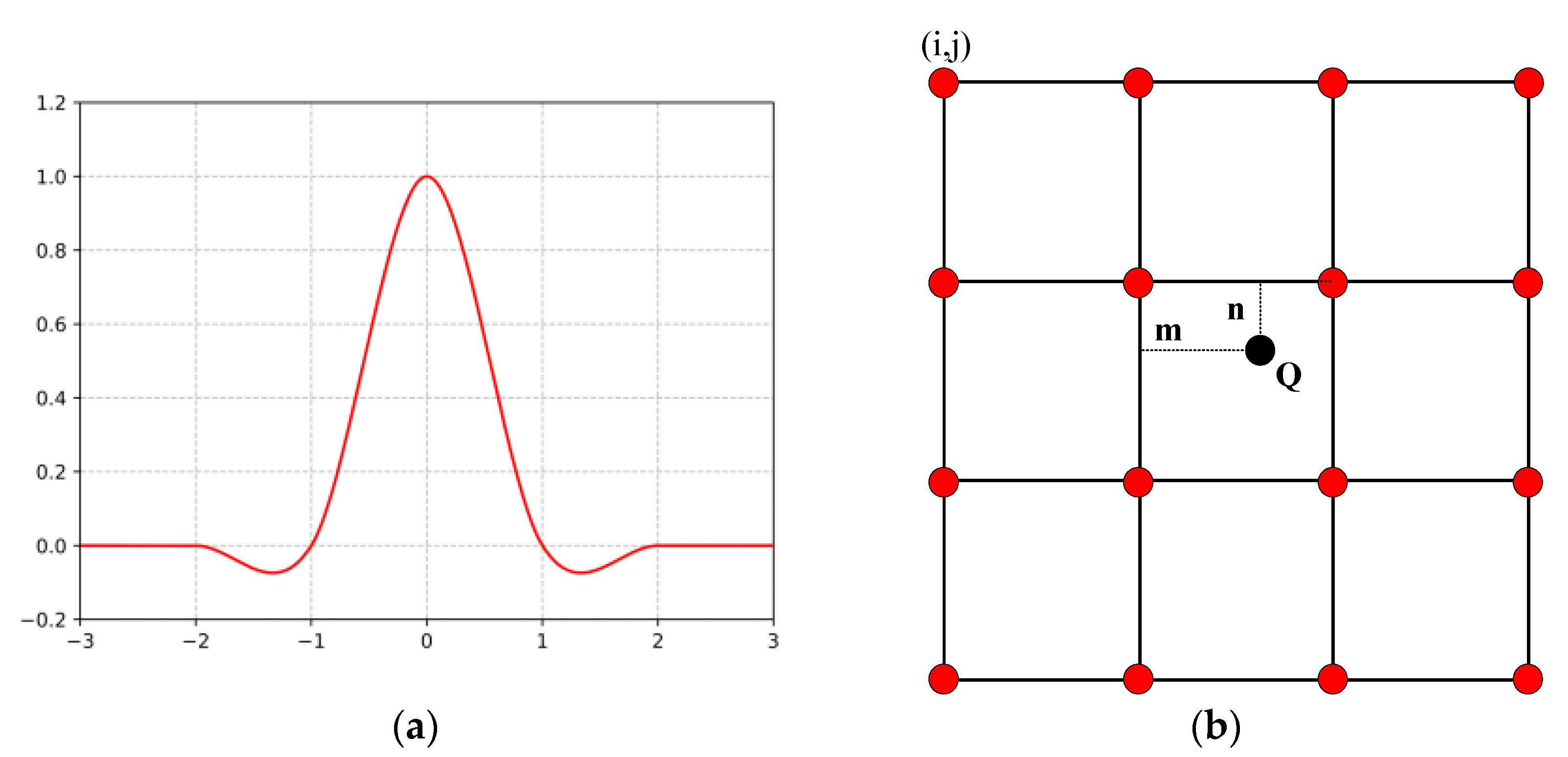





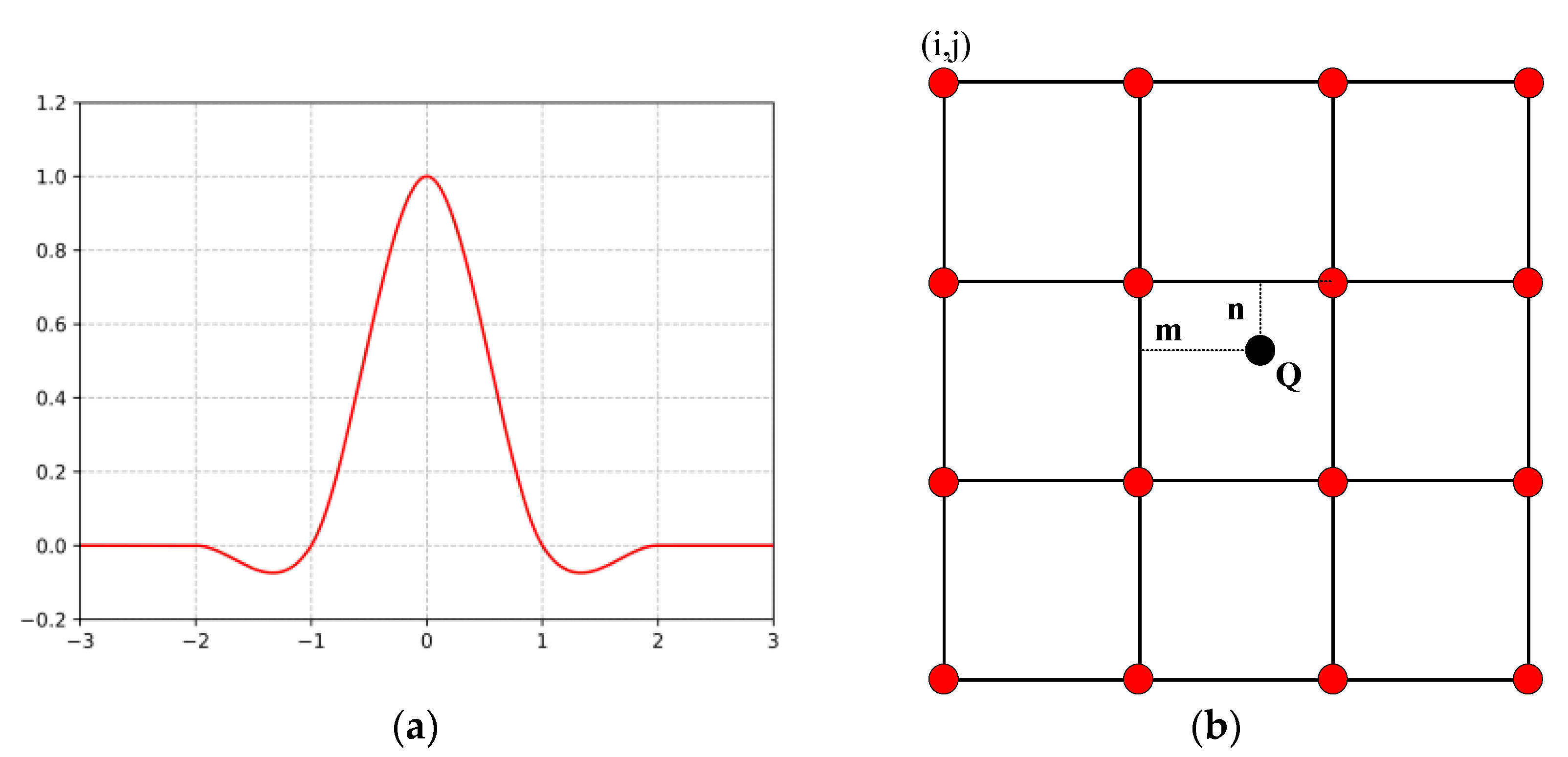{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PSNR | SSIM |
|---|---|---|
| Bicubic | 28.3841 | 0.7345 |
| SRGAN | 36.3838 | 0.8830 |
| EDSR | 36.4970 | 0.8841 |
| ESRGAN | 36.5556 | 0.8846 |
| Method | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | CC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GT | 88.51 | 86.45 | 61.23 | 81.20 | 67.60 | 83.65 | 90.00 | 90.86 | 84.30 | 75.33 | 71.49 | 72.06 | 78.32 | 74.73 | 76.10 | 46.98 |
| LR | 67.89 | 66.93 | 42.01 | 61.33 | 47.72 | 63.74 | 70.12 | 71.05 | 64.41 | 55.56 | 51.62 | 52.17 | 58.29 | 54.68 | 56.67 | 15.33 |
| Bicubic | 78.37 | 77.65 | 52.40 | 72.43 | 59.71 | 74.73 | 81.72 | 82.34 | 75.60 | 66.71 | 63.12 | 64.01 | 70.03 | 65.28 | 67.91 | 23.47 |
| SRGAN | 84.39 | 82.57 | 57.61 | 77.51 | 63.59 | 79.82 | 86.21 | 86.72 | 80.39 | 71.42 | 67.53 | 68.11 | 74.51 | 70.82 | 72.33 | 39.56 |
| EDSR | 85.60 | 84.71 | 59.90 | 78.72 | 65.32 | 81.03 | 87.08 | 88.11 | 81.89 | 72.35 | 68.79 | 69.02 | 75.84 | 72.31 | 74.87 | 41.64 |
| TDoSR (Our) | 87.63 | 85.37 | 60.12 | 80.01 | 66.72 | 82.59 | 88.97 | 89.43 | 83.18 | 74.36 | 70.38 | 70.98 | 77.29 | 73.82 | 75.13 | 45.03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Sun, G.; Guo, S. Target Detection Method for Low-Resolution Remote Sensing Image Based on ESRGAN and ReDet. Photonics 2021, 8, 431. https://doi.org/10.3390/photonics8100431
Wang Y, Sun G, Guo S. Target Detection Method for Low-Resolution Remote Sensing Image Based on ESRGAN and ReDet. Photonics. 2021; 8(10):431. https://doi.org/10.3390/photonics8100431
Chicago/Turabian StyleWang, Yuwu, Guobing Sun, and Shengwei Guo. 2021. "Target Detection Method for Low-Resolution Remote Sensing Image Based on ESRGAN and ReDet" Photonics 8, no. 10: 431. https://doi.org/10.3390/photonics8100431
APA StyleWang, Y., Sun, G., & Guo, S. (2021). Target Detection Method for Low-Resolution Remote Sensing Image Based on ESRGAN and ReDet. Photonics, 8(10), 431. https://doi.org/10.3390/photonics8100431