Abstract
Nonlinear noise power (NLNP) estimation, optical signal-to-noise ratio (OSNR) monitoring, and modulation format identification (MFI) are crucial for optical performance monitoring (OPM) in future dynamic WDM optical networks. This paper proposes an OPM scheme to simultaneously implement these three tasks in both single-channel and WDM systems by combining amplitude-differential phase histograms (ADPH) with the MAML-CNN-ATT algorithm that integrates model-agnostic meta-learning (MAML), the convolutional neural network (CNN), and the attention mechanism (ATT). The meta-learning algorithms can learn optimal initial model parameters across multiple related tasks, enabling them to quickly adapt to new tasks through fine-tuning with a small amount of data. This results in superior self-adaptability and generalizability, making them more suitable for WDM scenarios than the transfer learning (TL) algorithms. The CNN-ATT algorithm can effectively extract comprehensive features, capturing both local and global dependencies, thus improving the quality of the feature representation. The ADPH sequence data combine the amplitude information and the differential phase information that indicate the signal’s overall characteristics. The results demonstrate that the MAML-CNN-ATT algorithm achieves errors of less than 1 dB in both NLNP estimation and OSNR monitoring tasks while achieving 100% accuracy in the MFI task. It exhibits excellent OPM performance not only in the single channel but also in the WDM transmission, with only a few steps of fine-tuning. The MAML-CNN-ATT algorithm provides a solution with high performance and rapid self-adaptation for the multi-task OPM in dynamic optical networks.
1. Introduction
Under the driving force of the ever-growing training demand for large AI models, the computational power of GPU clusters keeps on expanding. Long-distance optical interconnects also play a key role in constructing intelligent data centers, making high-speed, high-capacity, and multi-channel flexible optical communication systems the development trend. In dynamic optical networks, it is essential to maintain real-time multi-parameter optical performance monitoring (OPM) for intelligent operation. The OPM, particularly the simultaneous nonlinear noise power (NLNP) estimation, optical signal-to-noise ratio (OSNR) monitoring, and modulation format identification (MFI) in WDM systems, is key for maintaining flexibility, health estimation, and fault evaluation in elastic optical networks [1,2,3,4,5]. Currently, with the continuous increase of the parameters and channel numbers required for the OPM, it is no longer enough for the monitoring strategies to target only a single channel or parameter. However, attentions on the OPM solutions for WDM systems remain limited so far. If the existing single-channel OPM strategy is directly adapted to a multi-channel WDM system, the model training would need to be repeated individually for each channel, incurring exponentially increased training costs. Especially in a dynamic WDM system with varied channel conditions and system parameters, multi-factors like nonlinearity, modulation formats, signal power, and various types of noise further complicate performance evaluation and optimization. This not only increases the difficulty in acquiring training data but also puts extra demand on the generalization abilities of the OPM models. It is necessary to develop high performance OPM schemes with robust generalization for multi-channel applications in order to meet the evolving needs of optical communication systems.
In recent years, machine learning algorithms have been widely applied in OPM due to their powerful learning and computational capabilities. However, most of these OPM schemes primarily focus on MFI and OSNR monitoring in single-channel transmissions [6,7,8,9,10,11,12,13]. In WDM systems, the cross-channel interference (XCI) induced by nonlinearity has to be taken into account, which becomes the critical factor affecting the signal transmission quality. Only a few OPM studies addressed the NLNP estimation issue in WDM systems. And there has been no solution that simultaneously monitors NLNP, OSNR, and modulation formats in WDM systems. For instance, Wang et al. employed long short-term memory (LSTM) networks to estimate OSNR and NLNP individually in WDM systems, but this single-task OPM approach cannot meet the demand for multi-parameter joint monitoring [14]. Similarly, Yang et al. used artificial neural networks (ANNs) for MFI, OSNR monitoring, and NLNP estimation, but they only considered single-channel transmission and relied on the prior knowledge of specific modulation formats for data preprocessing [15]. Li et al. adopted deep neural networks (DNNs) for OSNR monitoring and NLNP estimation but did not incorporate MFI, and the OSNR intervals considered were large, up to 2 dB, which limits the adaptability of their OPM method [16]. These works have addressed various OPM tasks. Most of them studied the single-channel transmission scenarios. When the channel conditions, system parameters, or channel numbers change, those models require retraining, which significantly increases training costs. Therefore, there is an urgent need for a model with high accuracy and strong generalization abilities, which can perform the aforementioned three-task or multi-task joint OPM in multiple channels.
To address this challenge, transfer learning (TL) algorithms offer an effective solution by enabling the transfer of the models trained in a source domain to a similar target domain [17,18]. However, TL algorithms also have some limitations. They often do not fully consider the generalization of a model in advance as their training mechanisms are typically based on the high precision fitting to a specific task, and their performance mostly relies on a high correlation between the source and target tasks [19]. TL may struggle to achieve satisfactory generalization and even result in a negative transfer when significant differences exist between the two tasks [19,20]. In contrast, the meta-learning algorithms, represented by the model-agnostic meta-learning (MAML), offer a more effective way by enabling the models to “learn how to learn”. This capability allows these models to capture the correlations among tasks, thereby enhancing self-adaptability and generalizability [21]. Specifically, the meta-learning algorithms can learn the optimal initial model parameters across a wide range of related tasks, allowing the models to achieve good performance with just a few updates on the new tasks. Even with limited similarities between the new tasks and the training tasks, the models can still rapidly learn and make accurate predictions with only a small amount of new data, significantly reducing training time and requirement for data [21,22,23,24]. This makes meta-learning an ideal approach for addressing the challenges of the multi-task OPM in dynamic WDM scenarios. It is noticed that some studies have also applied meta-learning algorithms to the OPM [6,7,25]. These works used meta-learning to achieve efficient learning in the MFI and OSNR monitoring, mostly in single-channel transmission scenarios. However, meta-learning has excellent generalization capabilities, which can be used to explore the performance of multi-task OPM in multi-channel WDM scenarios. For dynamic optical networks, especially dynamic multi-channel WDM systems, enabling the meta-learning to quickly adapt to new transmission scenarios remains a key issue that needs to be investigated. This paper attempts to use one meta-learning algorithm to achieve three-task OPM across the multi-channel WDM transmission scenarios with high performance and generalizability.
This paper proposes a novel three-task joint OPM scheme for the simultaneous NLNP estimation, OSNR monitoring, and MFI, using a combined MAML-convolutional neural network-attention mechanism (MAML-CNN-ATT) algorithm with the amplitude-differential phase histogram (ADPH) sequence data. To our knowledge, we are the first to apply meta-learning and attention mechanism to this type of OPM. MAML can enhance the generalizability of the model by learning optimal initial parameters, which enables it to quickly adapt to new tasks through fine-tuning with a small amount of data. It is noticed that obtaining a large amount of effective data for algorithm training in different transmission scenarios is relatively difficult. To some extent, it limits the widespread commercial applications of OPM models based on machine learning algorithms. To address this issue, we hope to enable our OPM model to learn the comprehensive and diverse features from the limited data and achieve good performance. Therefore, we used the combination of a CNN and attention modules to extract features. The CNN module is good at effectively capturing local features, while the attention module excels at capturing long-range dependencies and global features [26]. The combination of them enriches and enhances the representations of the features. However, the improvement in the performance is accompanied by a slight increase in complexity. The adoption of the MAML increases the complexity of the training process as it requires optimization under the meta-learning framework. However, since the training is typically a one-time process, this slightly increased complexity has minimal impact on the actual deployment of the model. Instead, the MAML enhances the generalizability of the model, enabling it to adapt more effectively to new tasks. On the other hand, the CNN module has reduced the feature dimensions repeatedly before forwarding the features to the attention module, resulting in only minimal increases in computational complexity and runtime. These slight complexities trade off an enhancement of the feature representation capability of the model by capturing and highlighting the key characteristics comprehensively. Overall, they are acceptable and worthwhile as they evidently improve performance and generalization.
Additionally, ADPH sequence data integrate amplitude information and differential phase information, comprehensively reflecting the signal’s characteristics on amplitude distribution and phase variation simultaneously. Our work demonstrates that the ADPH sequence data improves the OPM performance. This paper first trained the MAML-CNN-ATT in a single-channel transmission scenario, where data are relatively easier to obtain, and gained excellent performance. Considering that one-dimensional CNN and LSTM are effective for processing sequence data, the OPM performance of the MAML-CNN and the MAML-CNN-LSTM in the single-channel transmission scenario was also evaluated. The results show that MAML-CNN-ATT outperforms both MAML-CNN and MAML-CNN-LSTM in this case, demonstrating its good feature extraction and overall performance. Then, to leverage the rapid adaptation capability of the meta-learning algorithm, we performed a few iterative updates on the MAML-CNN-ATT in order to adapt it to the data affected by the more complex nonlinear XCI effect in a WDM transmission scenario. This approach allows for the quick optimization of the model and the effective application to the WDM transmission. This process not only demonstrates the model’s good OPM performance in the single-channel transmission but also validates its self-adaptability and generalization in the WDM transmission. In addition, by comparing the fine-tuning abilities of the MAML-CNN-ATT algorithm to the TL-CNN-ATT algorithm on the same OPM tasks in a new transmission scenario, we found that the meta-learning enabled the model to adapt more quickly to the new tasks with only a small amount of data and minimal fine-tuning steps, compared to the traditional TL algorithms, thus showing the faster self-adaptability and the better generalization. The results also indicate that this algorithm demonstrates high performance and superior generalizability in the NLNP estimation, OSNR monitoring, and MFI across both the single-channel and five-channel WDM transmissions. Additionally, the algorithm can be appropriately extended to perform more OPM tasks simultaneously, arriving at an efficient, reliable, and generalizable solution for the multi-task OPM in dynamic optical networks.
2. Simulation Setup
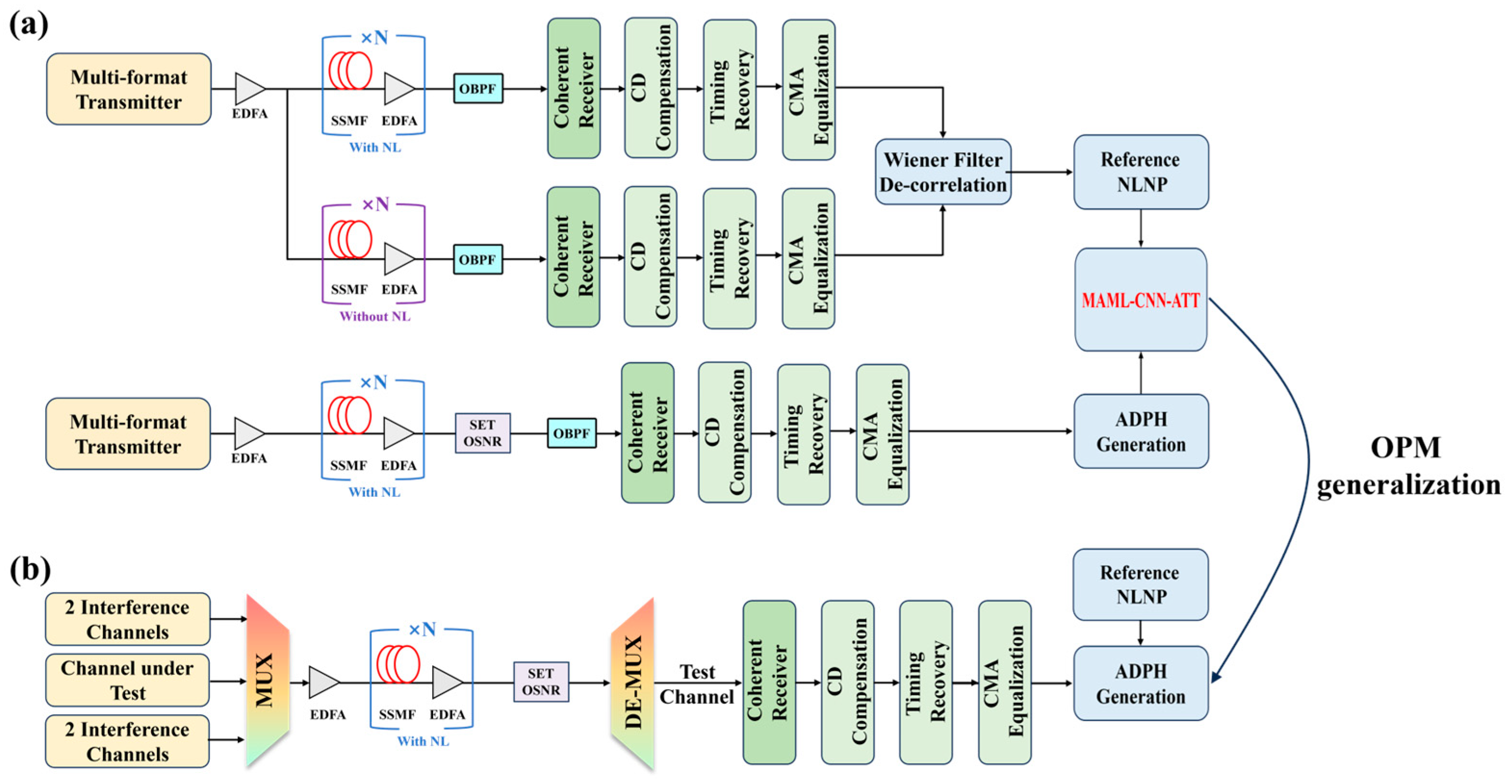
In this study, we set up a single-channel and a five-channel WDM dual-polarization coherent optical communication system by using the simulation software. Four commonly used modulation formats, QPSK, 16QAM, 32QAM, and 64QAM are selected. The signal transmission rate for each modulation format is set to be 28 Gbaud. An OSNR setting module is used to vary the OSNR values (see Table 1). The transmission link is with N spans of a 100 km standard single-mode fiber (SSMF) with a dispersion parameter D of 16.75 ps/nm/km, an attenuation coefficient α of 0.2 dB/km, and Kerr nonlinearity coefficient γ of 2.6 × 10−20 m2/W. At first, we define NLNP as the noise power induced by the fiber Kerr nonlinearity. The different launch powers and transmission distances are set to represent the varying nonlinear effects and to acquire the different NLNP reference values shown in Table 1. The NLNP reference values are obtained using the Wiener filter decorrelation method [14,15,27].

Table 1.
Main parameters used in the simulation.
For the single-channel transmission scenario shown in Figure 1a, our method consists of two stages. In the first stage, a single-channel transmission system is constructed without considering the amplified spontaneous emission (ASE) noise and the laser phase noise to compute the reference NLNP values. This system consists of two parallel and equal fiber links, one with Kerr nonlinearity and the other without. A Wiener decorrelation filter is placed after the coherent reception, chromatic dispersion (CD) compensation, timing recovery, and constant modulus algorithm (CMA) equalization to calculate the reference NLNP serving as the output label for the MAML-CNN-ATT algorithm. In the second stage, we consider a single-channel optical communication system under the combined influence of Kerr nonlinearity, ASE noise, and the laser phase noise, with the laser linewidth set to 100 kHz. Similarly, following the coherent reception, CD compensation, timing recovery, and CMA equalization, the IQ signals are further processed to generate the ADPH sequence data with the labels of OSNR, NLNP, and modulation format information as the inputs for training and testing the algorithm. Forty ADPH samples are collected for each combination of modulation format, OSNR, and NLNP and equally divided into the training and testing sets. After completing the model training with the single-channel transmission data, we further constructed a five-channel WDM system in Figure 1b to verify the model’s generalization to multi-channel WDM transmission data with the channel spacing setting to be 75 GHz. The central channel is used as the test channel, and the remaining four channels serve as interference channels. We also employed the Wiener decorrelation filter to obtain reference NLNP values in the WDM system. For each combination of NLNP, OSNR, and modulation format, only twenty ADPH samples are required for testing.
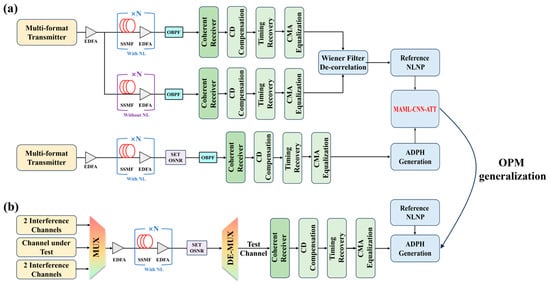
Figure 1.
Schematic diagram of the following: (a) a single-channel; (b) a five-channel WDM transmission system.
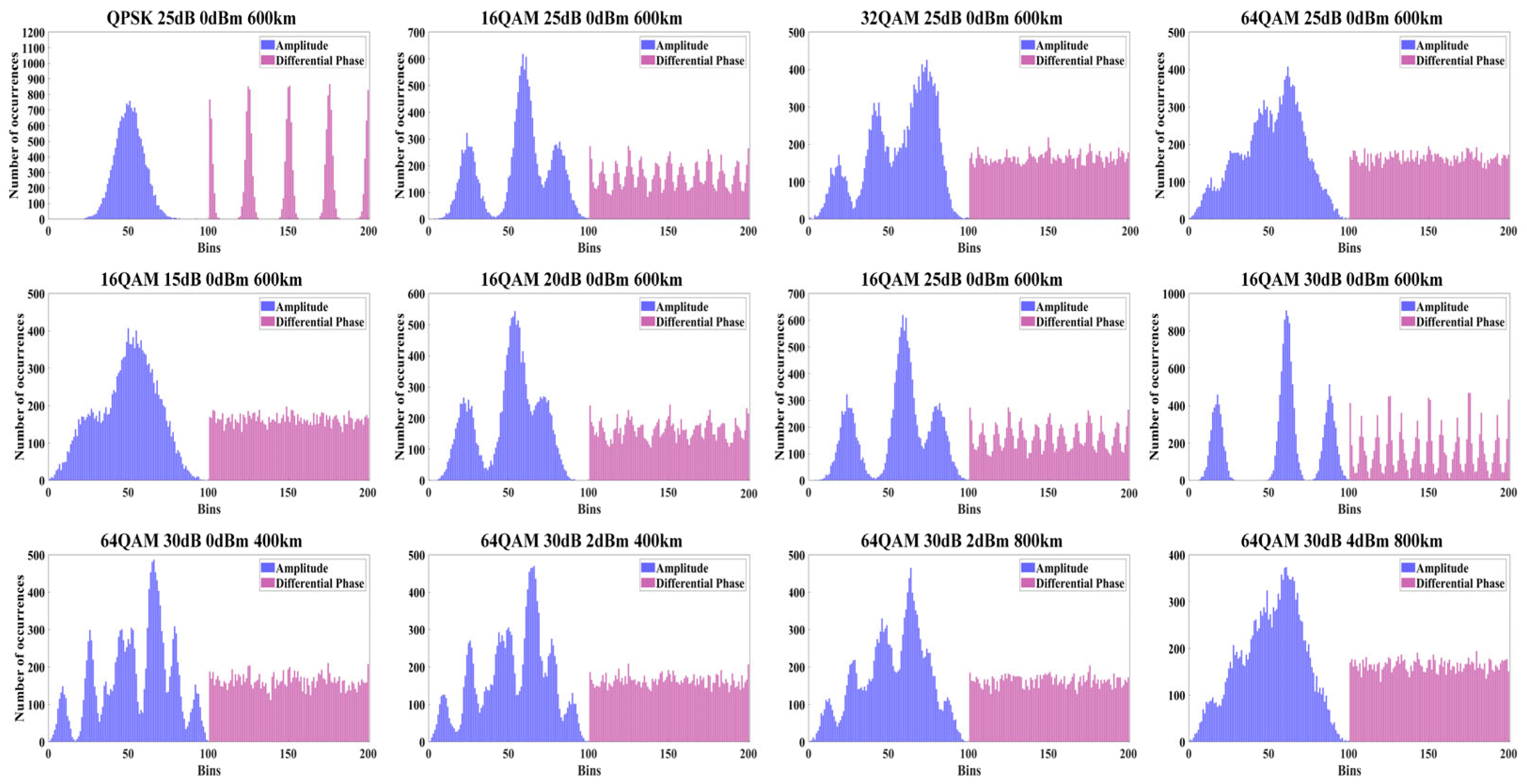
Figure 2 presents some ADPHs under the various modulation formats and OSNR and NLNP values, prompting the feature changes in ADPH across the different parameters, which are important for training the OPM model. Each ADPH includes a blue amplitude histogram and a red differential phase histogram. The first row shows the ADPHs for different modulation formats. As modulation complexity increases, the differential phase histogram exhibits progressively intricate patterns, while the amplitude histogram shows significant changes in both peak numbers and widths. The second row displays the ADPHs for 16QAM at the different OSNR values. As OSNR increases, the signal’s background noise decreases, resulting in more distinct features in the ADPHs. The third row shows the ADPHs for 64QAM under the different launch powers and transmission distances, representing the various NLNP values. As the launch power and transmission distance increase, nonlinear effects become more pronounced, leading to more noticeable changes in both the amplitude and differential phase histograms. It can be observed that the ADPHs exhibit distinct shape characteristics under the different modulation formats and OSNR and NLNP values. The widths, numbers, and distribution of their peaks change following the variation of parameters. This is because the ADPHs combine the statistical information of both the signal’s amplitude and phase, effectively reflecting the variations in the signal’s characteristics under the different transmission conditions, thus demonstrating high discriminability. Therefore, ADPH is highly suitable as an input feature for the MAML-CNN-ATT model to enable the joint monitoring of NLNP, OSNR, and modulation format, facilitating the signal transmission quality assessment and system optimization. Due to the space limitations, detailed discussions of the ADPH characteristics will be presented in a separate paper.
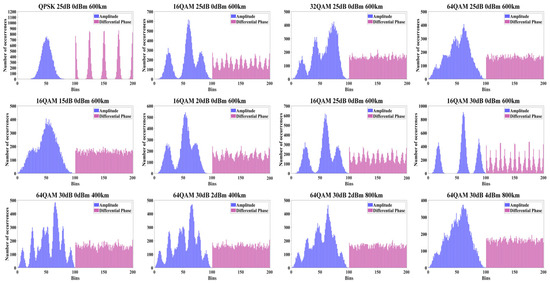
Figure 2.
The ADPH data collected for the different modulation formats (first row), the different OSNR values of 16QAM (second row), and the various combinations of launch power and transmission distance of 64QAM (third row).
3. Model Framework and Operating Mechanism
3.1. MAML-CNN-ATT Algorithm
3.1.1. MAML Algorithm
In the MAML-CNN-ATT algorithm, MAML serves as the core meta-learning module, enabling the rapid adaptation to new tasks through gradient-based optimization and facilitating efficient learning from limited samples. The CNN serves as the backbone for feature extraction, effectively capturing the local features within the data. ATT complements the CNN’s feature extraction by assigning more weights to the key features, enabling the model to capture the long-range dependencies and the global contextual information. Their synergistic combination enhances the overall feature representation capability and ultimately improves the OPM performance. Through the integration of MAML’s quick self-adaptation ability, CNN’s local feature extraction, and ATT’s global context modeling, the MAML-CNN-ATT algorithm achieves efficient feature utilization from data, enabling precise prediction and optimization for complex OPM tasks.
The MAML algorithms are designed to address the limitations of the traditional CNN on generalizability, equipping the models with the ability to “learn how to learn” and allowing the models to rapidly adapt to new tasks using only a small number of samples. The purpose of introducing this training idea is to enhance the self-adaptability and generalizability of the OPM model, enabling it to better meet the complex and dynamic requirements of various tasks. The basic idea of the MAML is to obtain a set of task-agnostic initial parameters through optimization, allowing the model to achieve a quick convergence on new tasks. However, given the complexity and diversity of real OPM tasks, it may be insufficient to capture the correlations across the different tasks to rely solely on single-task meta-learning. Therefore, we implement a multi-task meta-learning framework to allow the model to share the knowledge across multiple related tasks, improving its generalizability and self-adaptability.
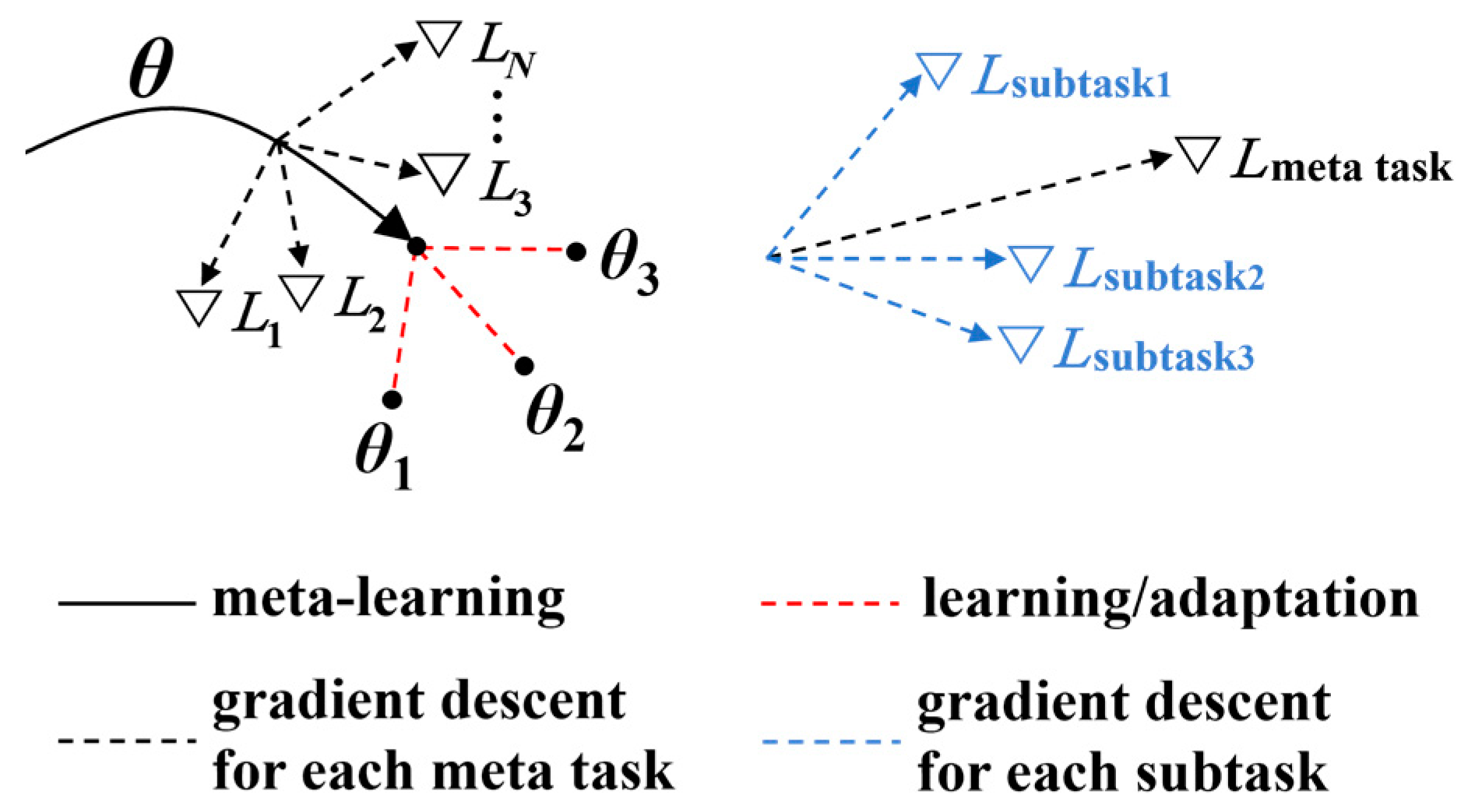
In the multi-task meta-learning framework, the episode training mechanism is implemented. An epoch is composed of multiple episodes, where each episode corresponds to a meta task. Each meta task consists of multiple interrelated subtasks. The gradient descent direction of each meta task is jointly determined by multiple subtasks, and then the gradient updates are performed individually for each meta task. A single gradient step is displayed in Figure 3. A unified optimization direction applicable to all meta tasks is selected to update the global model parameters. This design not only speeds up the model’s adaptation to new tasks but also significantly enhances the overall performance by sharing the knowledge learned across tasks. In this paper, the NLNP estimation, OSNR monitoring, and MFI are treated as three subtasks. The task batches are divided based on the modulation formats and NLNP values with data selected from the corresponding OSNR ranges for training the model. Such task division and sampling strategy ensure sufficient correlations between the subtasks for the promotion of the learned knowledge transfer while also maintaining some diversity necessary to enhance the generalizability. By adopting this multi-task meta-learning framework, the model can effectively capture the correlations between tasks, thereby enhancing its self-adaptability and generalizability. It is worth noting that this multi-task meta-learning framework has good extensibility. It is not limited to the three subtasks presented in this paper but can flexibly and moderately expand the number of OPM tasks according to the actual needs of the dynamic optical networks. Considering that handling too many tasks simultaneously may increase the complexity and training difficulty, the expansion of subtasks should strike a balance between the model’s capability and practical requirements.
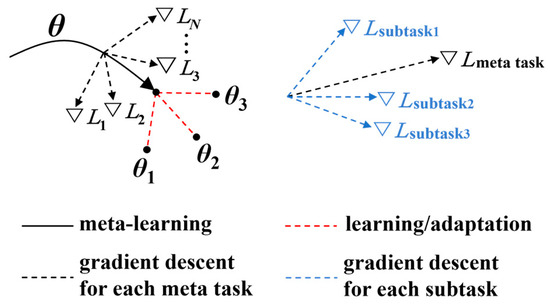
Figure 3.
Schematic diagram of MAML algorithm.
A typical meta-learning framework consists of the meta-training stage and the fine-tuning stage. Training data are used in the meta-training stage while testing data are used in the fine-tuning stage to evaluate the performance of the model. Formally, we consider a model represented by a parameterized function with initialized randomly. In the meta-training stage, the model randomly samples small-scale task batches from the training distribution for training. The data of each task are divided into a support set and a query set in a ratio of . In the support set, the model updates the parameters using gradient descent for a single meta-task. In the query set, the model optimizes the overall performance across all meta-tasks, thereby obtaining a set of initial parameters with improved generalizability. For each training iteration of a single task, the model performs the gradient descent according to Equation (1) and updates its parameters:
where denotes the loss of the model represented by a parametrized function with parameters in the i-th task . The learning rate α in the inner iteration of each task is set to 0.01 to obtain the updated parameters . To simplify the notation, a single gradient update is considered here, which can be directly extended to multiple gradient updates. It is noticed that the parameters calculated using Equation (1) are not directly used to update the parameter vector of the base network. Instead, they are utilized to compute the total loss of the query set after the gradient descent. The NLNP estimation and OSNR monitoring are regression tasks, while the MFI is a classification task. Two common loss functions for the regression and classification tasks are mean squared error (MSE) and cross-entropy, respectively. The loss functions for NLNP estimation and OSNR monitoring over a batch of tasks can be expressed as follows:
where and represent the predicted values for NLNP and OSNR, respectively, while and are the corresponding true value labels for the NLNP estimation and OSNR monitoring tasks, respectively. For the MFI task, the loss over the entire can be expressed as follows:
where corresponds to one of the predicted output values for the M types of modulation formats in the fully connected layer, and denotes the true class label for the MFI task. Each meta-task loss is a weighted sum of the losses from the three subtasks. The task weights for the NLNP estimation, OSNR monitoring, and MFI, denoted as , , , are set to be 0.4, 0.4, and 0.2, respectively. These weights are determined based on the relative difficulty of each task, allowing for a more balanced optimization of their learning objectives and ultimately enhancing the overall performance. The meta-objective of the MAML is to minimize the average loss across N tasks by
The meta-optimization is performed by minimizing the average weighted loss across the tasks using the Adam optimizer with a step size β of 0.001. The model parameters are updated according to the following:
This constitutes a complete training epoch, with the detailed steps outlined in Algorithm 1. In our meta-learning framework, a higher learning rate is employed for the inner loop relative to the outer loop. This strategy enables the model to achieve rapid task-specific adaptation with only a few update steps, while a lower learning rate in the outer loop ensures stable meta-parameter updates when aggregating gradients from multiple tasks, thereby mitigating the convergence issues. The objective of the meta-training is to learn the general meta-parameters from the task distribution, enabling the model to quickly adapt to new tasks. After the meta-training is completed, the model proceeds to the fine-tuning stage. During this stage, the principles of the data sampling and the task division remain consistent with those in the meta-training. Specifically, the data are also divided into a support set and a query set. The model can quickly adapt to new tasks with only a few fine-tuning steps using a small amount of data in the support set. The query set is only used to evaluate the generalization performance of the model on the new tasks and does not participate in the parameter updates. Therefore, the steps in Algorithm 1 that involve the parameter updates using the query set (steps 8 and 10) can be excluded during the fine-tuning stage.
| Algorithm 1 MAML Algorithm |
| Require: : distribution over tasks Require: ,: step size hyperparameters 1: randomly initialize 2: while not done do 3: Sample N tasks 4: Divide the data of each task into a support set and a query set in a ratio of 5: for all do 6: Calculate on the support set 7: Update adapted parameters with one gradient descent step: 8: Calculate on the query set 9: end for 10: Update 11: end while |
3.1.2. CNN-ATT Algorithm
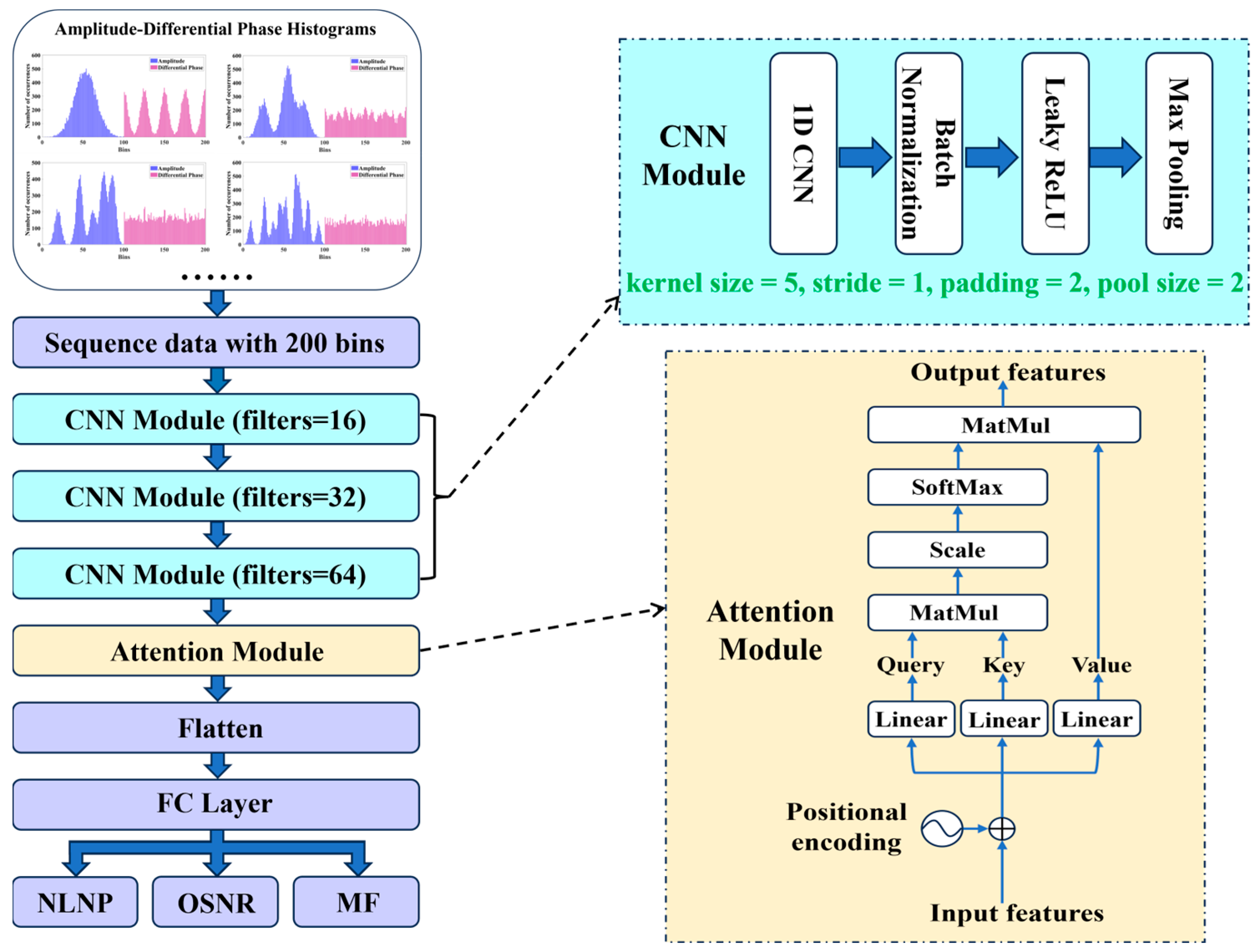
As shown in Figure 4, the CNN-ATT algorithm primarily consists of an input layer, three CNN modules, an attention module, a fully connected (FC) layer, and an output layer. The input is amplitude-differential phase histogram (ADPH) sequence data, represented as a 200 × 1 array. Compared to the image-based datasets, this sequence-based feature representation significantly reduces the data dimensionality while preserving the key signal characteristics. The ADPH combines amplitude and phase variation information, providing a comprehensive reflection of signal characteristics. The final output results are NLNP, OSNR, and MF.
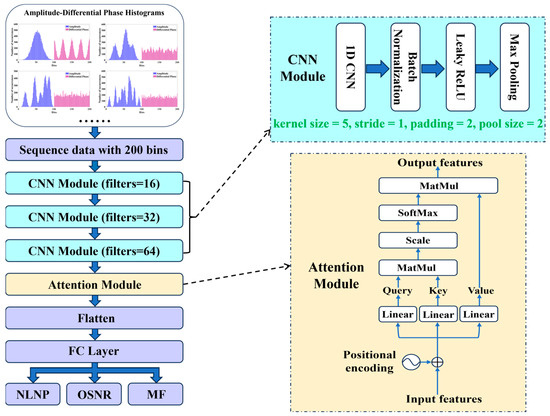
Figure 4.
Schematic diagram of the CNN-ATT algorithm.
The CNN module comprises a one-dimensional (1D) CNN layer (kernel size = 5, stride = 1, padding = 2), followed by a batch normalization layer, a Leaky ReLU layer, and a max pooling layer (pool size = 2). The number of convolution kernels in the three sequential CNN modules is set to 16, 32, and 64, respectively. These parameter settings ensure effective local feature extraction, dimensionality reduction, and enhanced feature representation. The CNN module is used to extract local features from the input data, enhance the data representation, and reduce the feature dimensions. The features processed by the CNN modules are then fed into an attention module that includes the positional encoding and the self-attention mechanism with a single-head structure for further feature extraction. Initially, the features are combined with the positional encoding. These encoded features are subsequently linearly transformed to obtain query vectors (Q), key vectors (K), and value vectors (V), each with 64 as the dimension. The query vectors are then projected onto the key vectors to compute the correlations between the vectors. The matrix dot product of the query and key vectors is scaled by the square root of the dimension of the key vector. After scaling, the matrix dot product is normalized using the softmax function to obtain the attention weights. These attention weights are used to perform a weighted sum with the value vectors, thereby emphasizing the features with higher weights. The corresponding mathematical expression is the following:
Adding an attention module after three CNN modules can further enhance the model’s representation capability. The CNN modules can capture the local patterns and effectively extract the local features from the input data. However, due to the limited receptive field, the CNN modules may not effectively capture the global features of the data. Not all information in the sequence contributes to the model’s learning task. By introducing the self-attention mechanism, the model can better capture the long-range dependencies, which improves feature extraction and further enhances its representation capability. It can significantly enhance the model’s learning efficiency and performance by assigning the positional encoding to the more effective information, thereby enhancing the feature extraction effectiveness and the overall performance. The attention mechanism can further integrate the local feature information extracted by the CNN modules, compensating for the CNN’s limitations in capturing global contextual relationships. By adjusting the weights of the local features extracted by the CNN, the attention mechanism enables the model to focus on the critical information across the entire sequence, thereby improving the robustness and discriminative power of the feature representations. The features processed by the attention module are then passed through the flatten layer and the fully connected layer to perform the NLNP estimation, OSNR monitoring, and MFI. When designing the architecture of the MAML-CNN-ATT algorithm, the parameters and hyperparameters are selected based on manual tuning and Bayesian optimization, taking into account the complexity of the algorithm. The algorithm is implemented using PyTorch version 1.12.0.
3.2. The Workflow of the MAML-CNN-ATT Algorithm
In this study, we conducted 1000 epochs during the meta-training stage to fully train the model. For each combination of the NLNP values, OSNR values, and modulation formats, only 20 data samples were collected with a total of 6 × 3 × 16 × 4 × 20 = 23,040 data used for training. In each epoch, 72 meta tasks were generated based on the different NLNP values and modulation formats with data from the different OSNR ranges selected for each meta task. The data for each task are divided into a support set and a query set. The support set includes five samples for each combination of the NLNP values, OSNR values, and modulation formats. It is used to perform one gradient update to quickly adapt the model to the task. The remaining data are assigned to the query set, which is used to calculate the loss and update the global parameters of the base model. In the fine-tuning stage, the principles of the task division and the data sampling remain consistent with those in the meta-training. The model is rapidly optimized using the data from the support set to adapt to the new tasks, while the query set is used solely for evaluating the performance of the model without further updating the model.
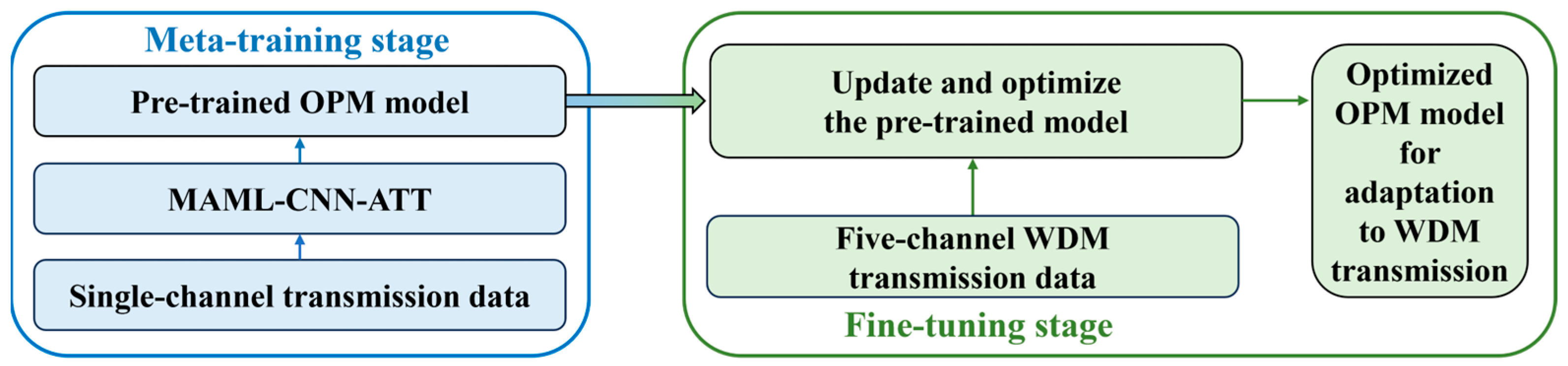
To evaluate the generalizability and robustness of the OPM model based on the MAML-CNN-ATT algorithm in different transmission scenarios, this paper considers a single-channel and a WDM transmission scenario. The workflow of the OPM model in different transmission scenarios is shown in Figure 5. Specifically, the MAML-CNN-ATT algorithm is trained using the single-channel transmission data to build a baseline OPM model. The evaluation results show that this model demonstrates excellent OPM performance in the single-channel transmission scenario. For the WDM transmission, the model is fine-tuned and optimized using a small amount of data from the WDM transmission scenario, enabling the model to adapt to the more complex WDM transmission, thereby improving its OPM performance in the WDM transmission. This process successfully extends the OPM scheme from the single-channel transmission to the WDM transmission. It is worth noting that the fundamental signal characteristics used for the OPM in the WDM transmission still resemble those in the single-channel transmission despite the existing cross-channel nonlinear interference which is introduced into the WDM system through fine-tuning and optimization. Benefiting from the algorithm’s superior generalizability, the optimized OPM model after the fine-tuning demonstrates high performance in the WDM transmission scenario.
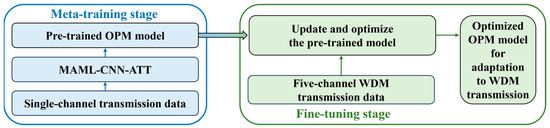
Figure 5.
The workflow of the MAML-CNN-ATT algorithm for the OPM in the different transmission scenarios.
4. Results and Discussion
4.1. The OPM Performance of MAML-CNN-ATT in the Single-Channel Transmission Scenario
4.1.1. NLNP Estimation
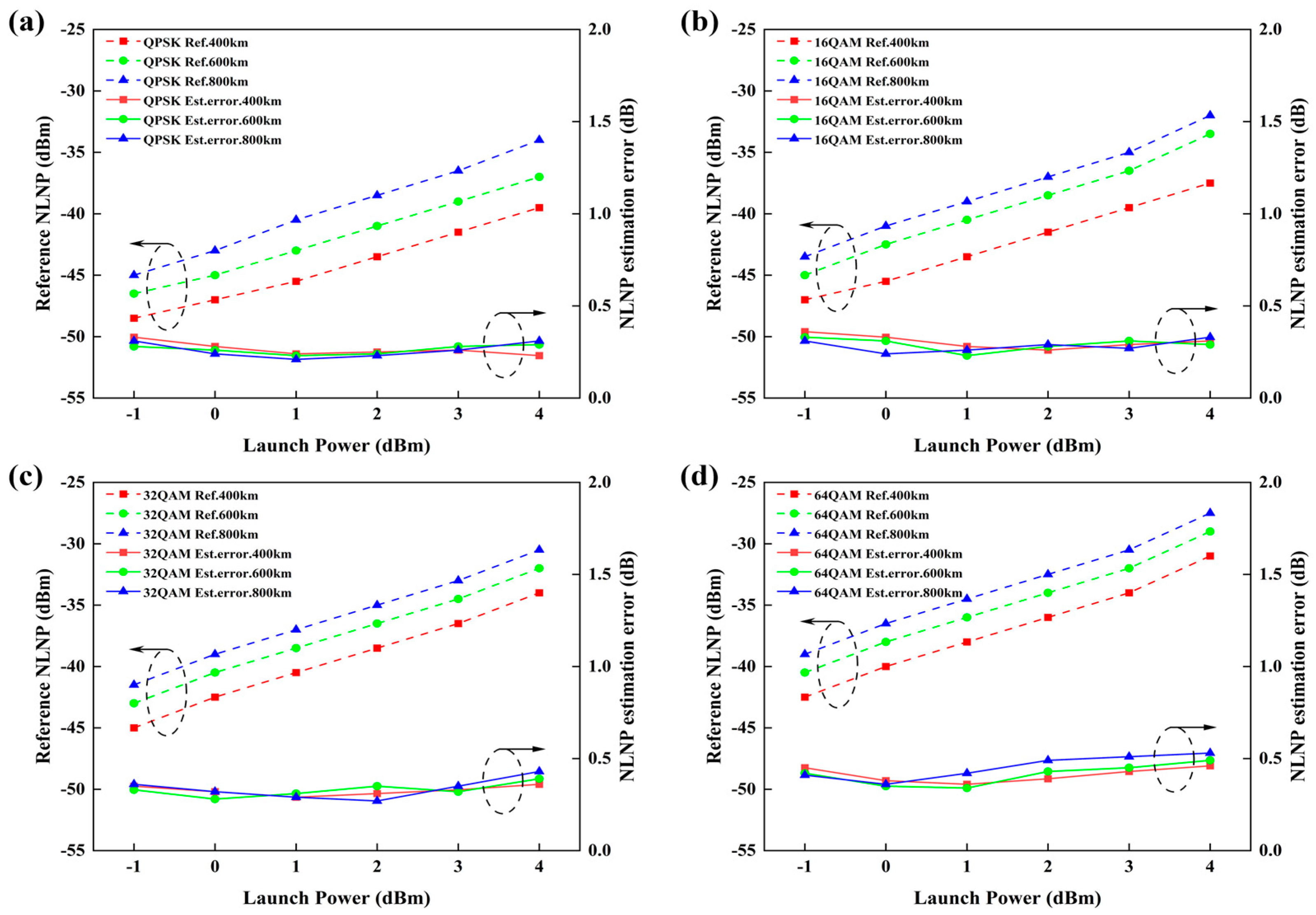
We first evaluated the performance of the MAML-CNN-ATT on the NLNP estimation in the single-channel transmission scenario by calculating the NLNP estimation error for QPSK, 16QAM, 32QAM, and 64QAM at the different launch powers and transmission distances. The results are shown in Figure 6. The root mean square error (RMSE) was used as the evaluation metric for the NLNP estimation task. The launch power ranges from −1 to 4 dBm, and the transmission distances are set to 400 km, 600 km, and 800 km. As shown in Figure 6, the reference NLNP of the four modulated signals rises with increasing the launch power and transmission distance since the nonlinear noise is closely related to these two parameters [28,29]. The NLNP estimation error for each modulation format shows no significant linear trend across the different launch powers and transmission distances, remaining within a reasonable estimation error range below 1 dB. The NLNP estimation errors of QPSK, 16QAM, 32QAM, and 64QAM are 0.26 dB, 0.29 dB, 0.33 dB, and 0.42 dB, respectively. The results indicate that the MAML-CNN-ATT demonstrates good performance on the NLNP task in the single-channel transmission.
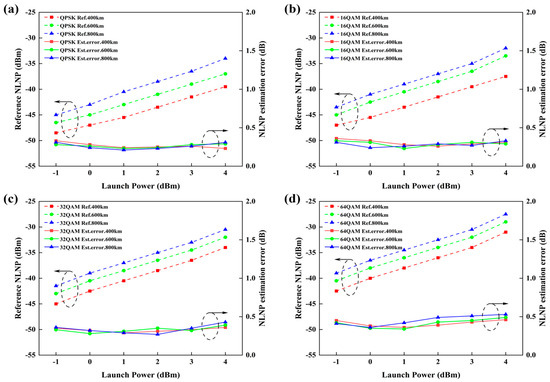
Figure 6.
Reference NLNP and NLNP estimation error of the MAML-CNN-ATT for the single-channel transmission scenario for (a) QPSK, (b) 16QAM, (c) 32QAM, and (d) 64QAM.
4.1.2. OSNR Monitoring
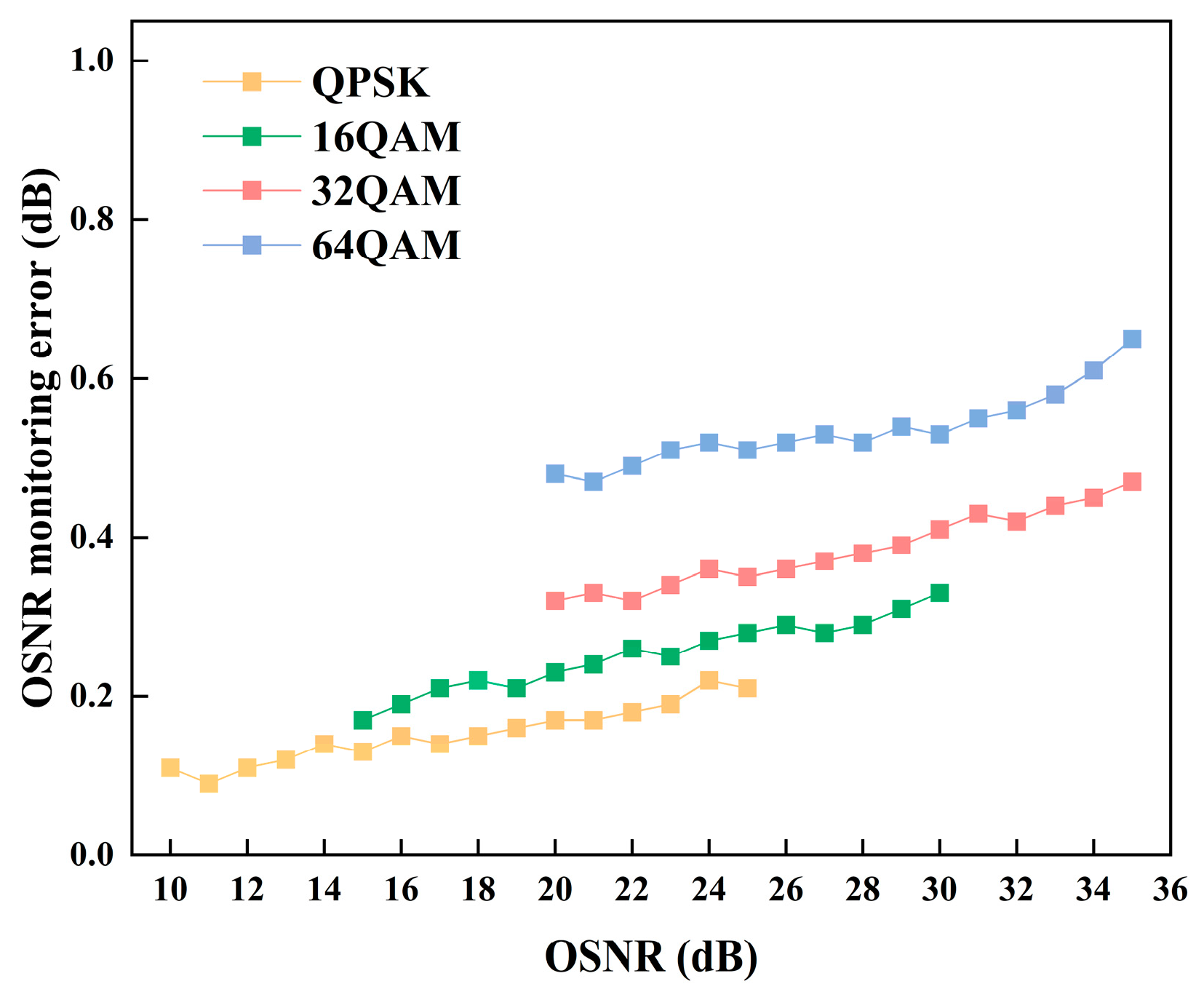
The performance of the MAML-CNN-ATT in the OSNR monitoring for the single-channel transmission was evaluated. To assess the robustness of the OSNR monitoring across different OSNR values, the RMSE of OSNR monitoring for the four modulation formats as a performance metric was calculated in Figure 7. The OSNR monitoring error of the four modulation signals generally shows an increasing trend as OSNR increases. This is because as OSNR increases and ASE noise decreases, the nonlinear effects become the primary constraint, resulting in a higher OSNR monitoring error. Additionally, it can be observed that the OSNR monitoring errors are relatively higher for higher-order modulation formats. This is due to the increased sensitivity of higher-order modulated signals, which are more sensitive to noise and make OSNR monitoring more challenging. The OSNR monitoring errors for QPSK, 16QAM, 32QAM, and 64QAM are 0.14 dB, 0.21 dB, 0.35 dB, and 0.53 dB, respectively. These results indicate that the MAML-CNN-ATT demonstrates high performance in the OSNR monitoring with feasibility and robustness.
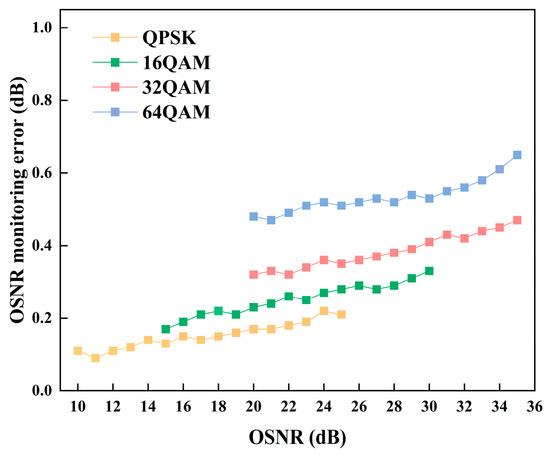
Figure 7.
The OSNR monitoring error of the MAML-CNN-ATT for the single-channel transmission scenario.
4.1.3. MFI
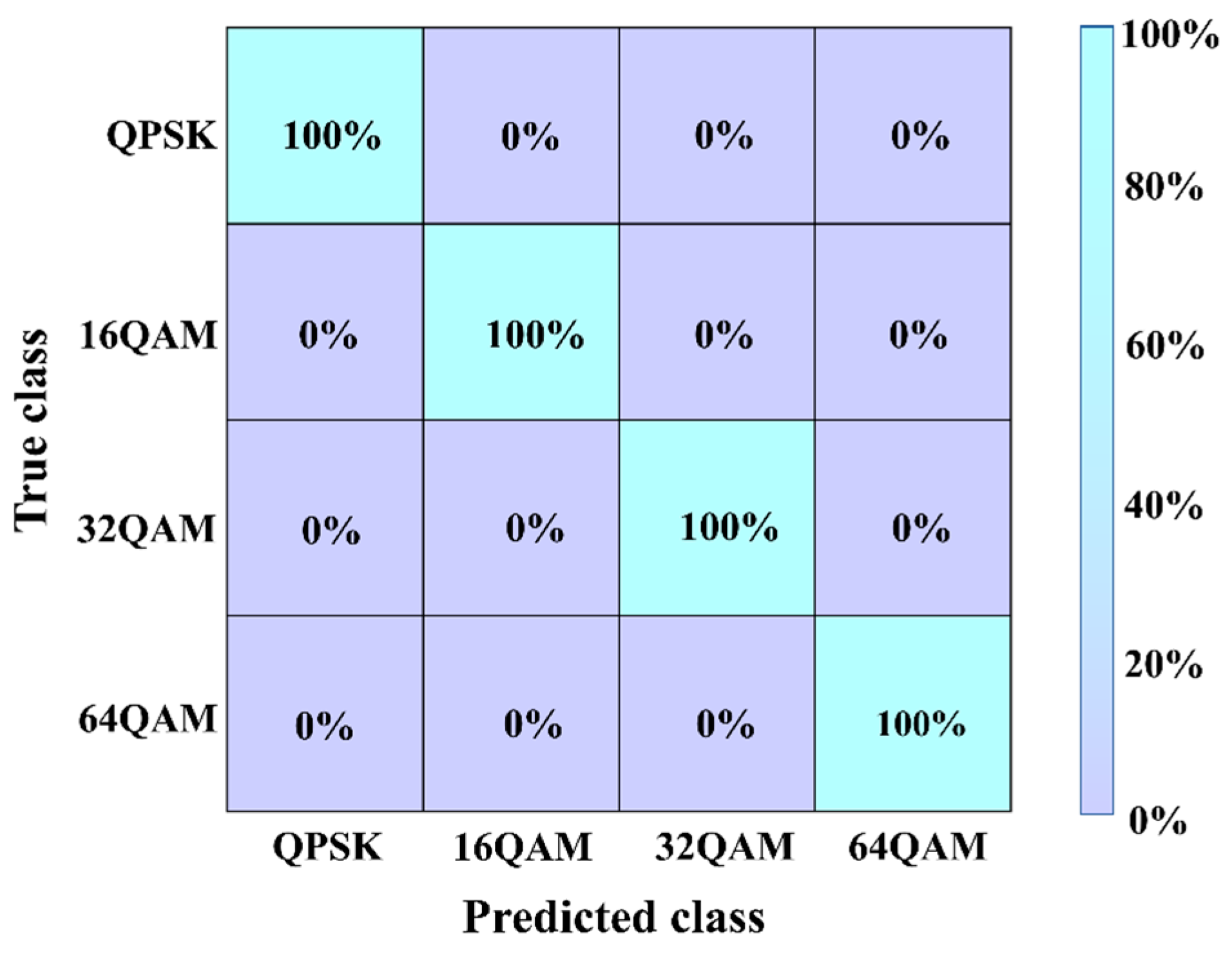
Finally, the performance of the MAML-CNN-ATT algorithm for MFI in the single-channel transmission scenario was investigated. The accuracy for the modulation format identification of the MAML-CNN-ATT was calculated. As shown in Figure 8, the MFI accuracy for all four formats reaches 100%. Compared to the NLNP estimation and OSNR monitoring, MFI is the least challenging task, as the differences between the modulation formats are more distinct, allowing the MAML-CNN-ATT algorithm to easily identify the four modulation formats.
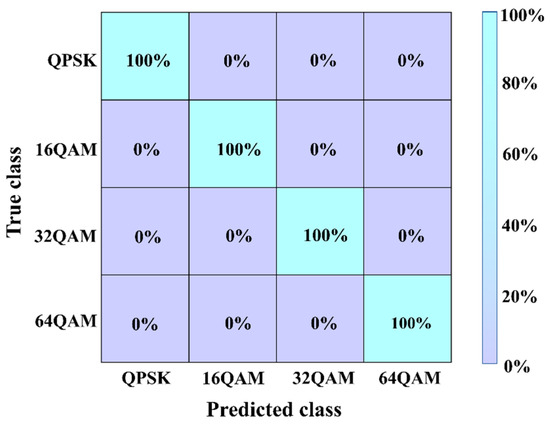
Figure 8.
The MFI accuracy of the MAML-CNN-ATT for the single-channel transmission scenario.
4.1.4. Comparison of the OPM Performance and Complexity Among the MAML-CNN-ATT, MAML-CNN and MAML-CNN-LSTM Algorithms
Next, we compared the OPM performance and the computational complexity of the MAML-CNN-ATT, MAML-CNN, and MAML-CNN-LSTM algorithms in the single-channel transmission scenario. To ensure a fair comparison, all models were trained under the MAML framework with identical hyperparameter settings for both the MAML framework and the CNN architecture. To demonstrate the benefits of incorporating a self-attention mechanism into the model, an ablation study was conducted by comparing the performance of MAML-CNN-ATT and MAML-CNN on the joint three-task OPM (see Table 2). Specifically, compared to the MAML-CNN algorithm, the MAML-CNN-ATT achieves an average reduction of 13.85% in NLNP estimation error and 17.35% in OSNR monitoring error across the four modulation formats. The improved performance of the MAML-CNN-ATT on the ADPH sequence data is mainly due to the ability of the self-attention mechanism to capture the global dependencies within the sequence. Traditional CNN typically only extracts features within a local range and struggles to obtain global context information. By calculating the correlation between different positions in the sequence, the self-attention mechanism assigns different weights to each data point, emphasizing those critical to the current task, which significantly enhances the model’s feature extraction accuracy and generalization capability. Thus, with the self-attention mechanism, the model demonstrates superior performance in handling the ADPH sequence data, achieving higher accuracy and more robust performance in complex OPM tasks.
Table 2.
Comparison of the OPM performance and complexity among the MAML-CNN-ATT, MAML-CNN, and MAML-CNN-LSTM algorithms in the single-channel transmission scenario.
Furthermore, considering the effectiveness of one-dimensional CNN and LSTM in processing sequence data, we also include the MAML-CNN-LSTM algorithm as an additional baseline to extend our comparison. Under the specific simulation conditions used in this paper, the MAML-CNN-LSTM algorithm outperforms MAML-CNN in terms of OPM performance. When compared with MAML-CNN-ATT, MAML-CNN-LSTM exhibits comparable performance for the lower-order modulation formats but shows performance degradation for the higher-order modulation formats. Specifically, compared to the MAML-CNN-LSTM algorithm, the MAML-CNN-ATT achieves an average reduction of 6.58% in NLNP estimation error and 8.65% in OSNR monitoring error across the four modulation formats. This can be attributed to the fact that, in our OPM application scenario, the sequence data are compressed after the CNN modules, making the capture of global dependencies relatively simple. The CNN-ATT architecture leverages an attention mechanism to reweight the key features following local feature extraction, thereby more effectively extracting the key information associated with noise and distortion. Meanwhile, the primary strength of LSTM lies in handling the long-term temporal sequence data. For such compressed short sequences, its modeling advantages are not fully realized. Moreover, LSTM typically involves a larger number of parameters, which may introduce additional complexity. Consequently, under these specific transmission conditions and data characteristics, the MAML-CNN-ATT outperforms the MAML-CNN-LSTM in OPM tasks.
Additionally, the comparison of the model’s parameter number and computation time was performed to evaluate the trade-off between the performance improvement and the increasing computational complexity. The effect on computation time was evaluated by comparing the runtime per episode of each algorithm during the testing phase. Notably, the testing time is a critical factor affecting the processing performance, as once the model is trained, it can be directly applied to the OPM without retraining. It is also worth noting that since the features are already down-sampled by the CNN module, the followed attention module complements the feature extraction, further enhancing the feature representation while only slightly increasing the complexity. As shown in Table 2, the MAML-CNN-ATT algorithm introduces a modest increase in complexity compared to MAML-CNN. This is acceptable given the substantial improvements in the NLNP estimation and OSNR monitoring accuracy, especially for the higher-order modulation formats. Although MAML-CNN-LSTM also offers performance improvements over MAML-CNN, it comes with a higher computational complexity and still falls short of MAML-CNN-ATT in complex OPM tasks. For practical deployment, our numerical experiment provides guidance for selecting suitable algorithms. That is, when dealing with the simpler OPM scenarios involving the lower-order modulation formats or the less complex parameter settings, MAML-CNN may be sufficient. Conversely, for those scenarios with higher complexity or higher-order modulation formats, the moderate additional computational overhead introduced by MAML-CNN-ATT can be counterbalanced by the notably improved monitoring performance. Consequently, MAML-CNN-ATT is the preferred choice in high-complexity scenarios, while MAML-CNN remains a viable option for simpler cases.
4.2. Comparison of the MAML-CNN-ATT and the TL-CNN-ATT on the OPM Performance in the Five-Channel WDM Transmission Scenario
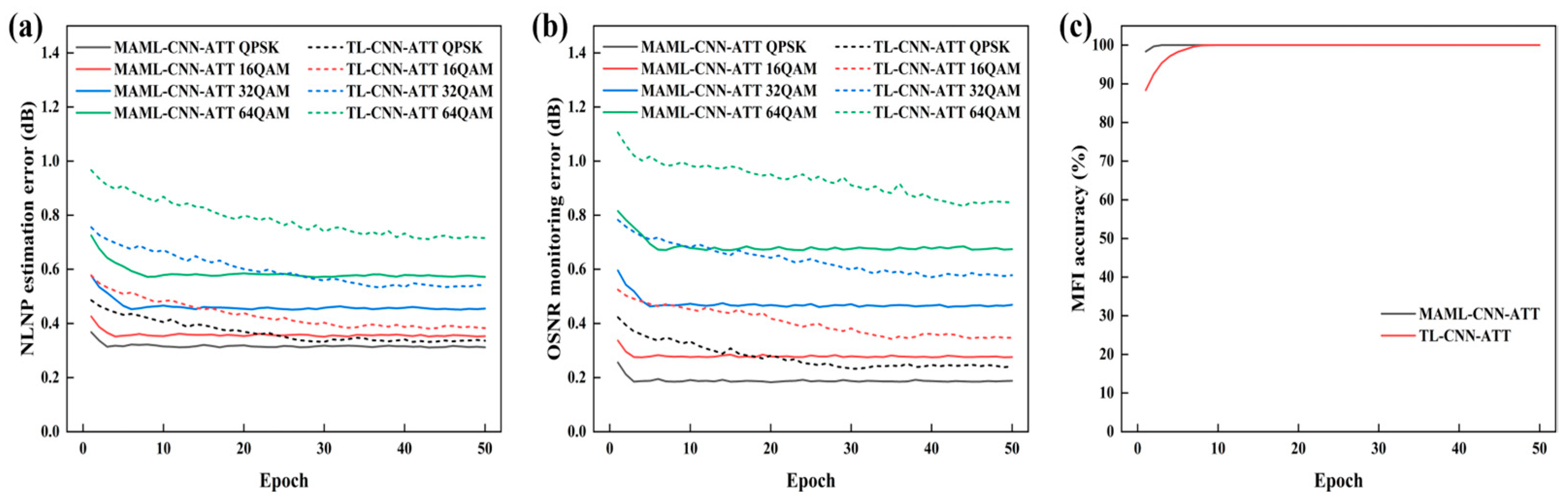
To investigate the generalization capability of the MAML-CNN-ATT algorithm across different transmission scenarios, we fine-tuned the model trained in the single-channel transmission scenario by using data from a five-channel WDM transmission scenario, enabling it to perform the OPM in this new context. To validate the role of MAML, the performance of both the MAML-CNN-ATT and TL-CNN-ATT algorithms on the above-mentioned three OPM tasks is compared, where TL-CNN-ATT represents a baseline model, serving as a reference for evaluating the contribution of MAML. The OPM performance of both algorithms over 50 fine-tuning iterations was plotted. As shown in Figure 9a, the MAML-CNN-ATT outperforms the TL-CNN-ATT in both the convergence speed and the minimum estimation error for the NLNP estimation task, with a particularly notable performance advantage for the high-order modulation formats. The minimum estimation errors for the MAML-CNN-ATT with QPSK, 16QAM, 32QAM, and 64QAM are 0.31 dB, 0.35 dB, 0.45 dB, and 0.57 dB, respectively, all within an estimation error of less than 1 dB. Compared to the TL-CNN-ATT, the MAML-CNN-ATT achieves an average reduction of 12.19% in the minimum estimation error across the four modulation formats. The results in Figure 9b demonstrate that the MAML-CNN-ATT algorithm also exhibits strong generalization in the OSNR monitoring task. With only a few fine-tuning steps, it achieves excellent performance and shows the advantages over the TL-CNN-ATT algorithm in both the adaptation speed and the monitoring accuracy. The minimum monitoring errors for the MAML-CNN-ATT across the four modulation formats are 0.19 dB, 0.28 dB, 0.46 dB, and 0.67 dB, all within the reasonable range of less than 1 dB. Compared to the TL-CNN-ATT, the MAML-CNN-ATT achieves an average reduction of 18.16% in the minimum monitoring error across the four modulation formats. For the MFI task, which is relatively easier than the previous two tasks, the MAML-CNN-ATT reaches a 100% identification rate under only three fine-tuning steps, whereas the TL-CNN-ATT requires ten fine-tuning steps to achieve a stable 100% identification rate, as shown in Figure 9c.
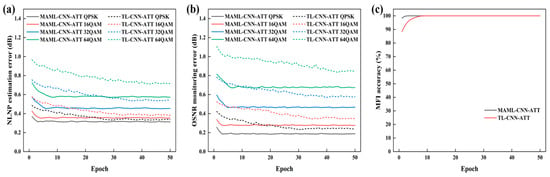
Figure 9.
Comparison of the MAML-CNN-ATT and TL-CNN-ATT after the fine-tuning on the following: (a) NLNP estimation error; (b) OSNR monitoring error; (c) MFI accuracy in the five-channel WDM transmission scenario.
For transfer learning, the fundamental training of the model primarily focused on highly fitting the training data without fully considering the model’s generalization. Consequently, its performance tends to depend on the similarity between the source and target tasks. If there is a large difference, the transfer results may not be good enough. In contrast, meta-learning considers the generalization across tasks from the initial model training stage. By training on various tasks, the meta-learning learns an optimal initialization that can quickly adapt to new tasks. The meta-learning-assisted training can also be viewed as a form of data augmentation, enhancing the model’s robustness across different scenarios. As a result, the meta-learning effectively improves the model’s self-adaptability, prevents overfitting, and enables efficient rapid learning. The results show when adapting to the new transmission scenario, the MAML-CNN-ATT demonstrates faster self-adaptability and stronger generalization compared to the TL-CNN-ATT, achieving excellent OPM performance with only a few fine-tuning iterations.
5. Conclusions
In this paper, we proposed an OPM scheme that combines the MAML-CNN-ATT algorithm with ADPH for the joint tasks of NLNP estimation, OSNR monitoring, and MFI. Compared to the TL algorithms that depend on task relevance, the meta-learning algorithms learn the optimal initial parameters through extensive training across various related tasks, enabling the model to learn the task-agnostic representations and quickly adapt to new tasks with only a few fine-tuning steps. To further enhance the effectiveness of the feature extraction, we also adopted the CNN-ATT algorithm that captures both local and global features, allowing for the more comprehensive and effective extraction of the feature information, significantly improving the accuracy and reliability of the OPM. Although the addition of MAML and attention mechanism slightly increases the complexity of the training process and the model, it has relatively little impact on the practical application of the model. Moreover, the performance improvements and enhanced generalization ability they brought make this increased complexity acceptable. The ADPH sequence data integrate both the signal’s amplitude and phase information, providing comprehensive signal characteristics for the feature representation. We evaluated the OPM performance of the MAML-CNN-ATT algorithm in both the single-channel and the WDM transmission scenarios. The results demonstrate the algorithm’s excellent performance for joint three-task OPM under single-channel conditions and the rapid adaptation to the WDM scenario with only a few fine-tuning steps. Compared to the MAML-CNN and MAML-CNN-LSTM algorithms, the MAML-CNN-ATT algorithm exhibits better OPM performance in the single-channel transmission scenario. Compared to the TL-CNN-ATT algorithm, the MAML-CNN-ATT exhibits faster adaptation speed and better generalization abilities in the WDM transmission scenario. The MAML-CNN-ATT algorithm provides an efficient, reliable, and generalizable solution for the multi-task OPM in future dynamic optical networks.
Author Contributions
Conceptualization, D.Z., J.S., Y.C. and Y.L.X.; methodology, D.Z.; software, D.Z. and J.S.; formal analysis, D.Z., J.S., Y.C. and Y.L.X.; investigation, D.Z. and Y.C.; data curation, D.Z.; writing—original draft preparation, D.Z.; writing—review and editing, D.Z. and Y.L.X.; visualization, D.Z.; supervision, Y.L.X.; project administration, Y.L.X.; funding acquisition, Y.L.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Innovation Program for Quantum Science and Technology (Grant NO. 2021ZD0303200), the National Natural Science Foundation of China (Grant NO. 12234014 and 11654005), and the Shanghai Municipal Science and Technology Major Project (Grant NO. 2019SHZDZX01 and 22DZ2229004).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data underlying the results presented in this paper are not publicly available at this time but may be obtained from the authors upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Hauske, F.N.; Kuschnerov, M.; Spinnler, B.; Lankl, B. Optical performance monitoring in digital coherent receivers. J. Light. Technol. 2009, 27, 3623–3631. [Google Scholar] [CrossRef]
- Dong, Z.; Khan, F.N.; Sui, Q.; Zhong, K.; Lu, C.; Lau, A.P.T. Optical performance monitoring: A review of current and future technologies. J. Light. Technol. 2015, 34, 525–543. [Google Scholar] [CrossRef]
- Zhuge, Q.; Zeng, X.; Lun, H.; Cai, M.; Liu, X.; Yi, L.; Hu, W. Application of machine learning in fiber nonlinearity modeling and monitoring for elastic optical networks. J. Light. Technol. 2019, 37, 3055–3063. [Google Scholar] [CrossRef]
- Lun, H.; Fu, M.; Liu, X.; Wu, Y.; Yi, L.; Hu, W.; Zhuge, Q. Soft failure identification for long-haul optical communication systems based on one-dimensional convolutional neural network. J. Light. Technol. 2020, 38, 2992–2999. [Google Scholar]
- Cho, H.J.; Varughese, S.; Lippiatt, D.; Desalvo, R.; Tibuleac, S.; Ralph, S.E. Optical performance monitoring using digital coherent receivers and convolutional neural networks. Opt. Express 2020, 28, 32087–32104. [Google Scholar]
- Zhang, Y.; Zhou, P.; Liu, Y.; Wang, J.; Li, C.; Lu, Y. Fast adaptation of multi-task meta-learning for optical performance monitoring. Opt. Express 2023, 31, 23183–23197. [Google Scholar]
- Cheng, Y.; Yang, Z.; Yan, Z.; Liu, D.; Fu, S.; Qin, Y. Meta-learning-enabled accurate OSNR monitoring of directly detected QAM signals with one-shot training. Opt. Lett. 2022, 47, 2218–2221. [Google Scholar]
- Khan, F.N.; Zhong, K.; Zhou, X.; Al-Arashi, W.H.; Yu, C.; Lu, C.; Lau, A.P.T. Joint OSNR monitoring and modulation format identification in digital coherent receivers using deep neural networks. Opt. Express 2017, 25, 17767–17776. [Google Scholar]
- Xiang, Q.; Yang, Y.; Zhang, Q.; Yao, Y. Joint, accurate and robust optical signal-to-noise ratio and modulation format monitoring scheme using a single Stokes-parameter-based artificial neural network. Opt. Express 2021, 29, 7276–7287. [Google Scholar]
- Yu, Z.; Wan, Z.; Shu, L.; Hu, S.; Zhao, Y.; Zhang, J.; Xu, K. Loss weight adaptive multi-task learning based optical performance monitor for multiple parameters estimation. Opt. Express 2019, 27, 37041–37055. [Google Scholar]
- Feng, J.; Jiang, L.; Yan, L.; Yi, A.; Pan, W.; Luo, B. Intelligent optical performance monitoring based on intensity and differential-phase features for digital coherent receivers. J. Light. Technol. 2022, 40, 3592–3601. [Google Scholar]
- Wang, D.; Wang, M.; Zhang, M.; Zhang, Z.; Yang, H.; Li, J.; Li, J.; Chen, X. Cost-effective and data size–adaptive OPM at intermediated node using convolutional neural network-based image processor. Opt. Express 2019, 27, 9403–9419. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, M.; Li, J.; Li, Z.; Li, J.; Song, C.; Chen, X. Intelligent constellation diagram analyzer using convolutional neural network-based deep learning. Opt. Express 2017, 25, 17150–17166. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, A.; Guo, P.; He, P. OSNR and nonlinear noise power estimation for optical fiber communication systems using LSTM based deep learning technique. Opt. Express 2018, 26, 21346–21357. [Google Scholar] [CrossRef]
- Yang, S.; Yang, L.; Luo, F.; Li, B.; Wang, X.; Du, Y.; Liu, D. Joint fiber nonlinear noise estimation, OSNR estimation and modulation format identification based on asynchronous complex histograms and deep learning for digital coherent receivers. Sensors 2021, 21, 380. [Google Scholar] [CrossRef]
- Li, M.; Zhang, L.; Zhang, T.; Jiang, G.; Yang, L.; Luo, F.; Hu, Y. Joint OSNR and Nonlinear Noise Power Estimation Based on Deep Learning for Coherent Optical Communication Systems. IEEE Photon. J. 2023, 15, 1–8. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Zhou, Q.; Zhao, Q. Flexible clustered multi-task learning by learning representative tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 266–278. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, T.; Jin, T.; Jiang, W.; Hu, S.; Huang, X.; Xu, B.; Yu, Z.; Yi, X.; Qiu, K. Meta-learning assisted source domain optimization for transfer learning based optical fiber nonlinear equalization. J. Light. Technol. 2022, 41, 1269–1277. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-learning in neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5149–5169. [Google Scholar] [CrossRef] [PubMed]
- Huisman, M.; Van Rijn, J.N.; Plaat, A. A survey of deep meta-learning. Artif. Intell. Rev. 2021, 54, 4483–4541. [Google Scholar] [CrossRef]
- Vettoruzzo, A.; Bouguelia, M.-R.; Vanschoren, J.; Rögnvaldsson, T.; Santosh, K. Advances and challenges in meta-learning: A technical review. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 4763–4779. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhou, X.; Du, J.; Tian, P. Fast self-learning modulation recognition method for smart underwater optical communication systems. Opt. Express 2020, 28, 38223–38240. [Google Scholar] [CrossRef]
- Waswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the IEEE Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Wu, J.; Droppo, J.; Deng, L.; Acero, A. A noise-robust ASR front-end using Wiener filter constructed from MMSE estimation of clean speech and noise. In Proceedings of the 2003 IEEE Workshop on Automatic Speech Recognition and Understanding, St Thomas, VI, USA, 30 November–4 December 2003; pp. 321–326. [Google Scholar]
- Agrawal, G. Nonlinear Fiber Optics, 5th ed.; Academic Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Caballero, F.V.; Ives, D.J.; Laperle, C.; Charlton, D.; Zhuge, Q.; O’Sullivan, M.; Savory, S.J. Machine learning based linear and nonlinear noise estimation. J. Opt. Commun. Netw. 2018, 10, D42–D51. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).