Efficient Pipeline Conflict Resolution for Layered QC-LDPC Decoders in OFDM-PON

 ,
,
Abstract
1. Introduction
1.1. Related Works
1.2. Overview and Contribution
- A decoding method based on a patched variable-to-check message is proposed. When necessary, it is preferable to read the un-updated LLR and apply a patch to the variable-to-check message, rather than waiting to read the updated LLR. This approach effectively reduces pipeline conflicts.
- A more flexible rearrangement of the inter-layer and intra-layer submatrix processing order is allowed in the proposed hardware architecture. It effectively eliminates pipeline conflicts caused by overlapping submatrices among three or more successive layers of traditional decoding.
- The proposed decoding architecture is implemented on hardware and the performance improvement is demonstrated experimentally on the OFDM-PON platform. The experimental results demonstrate that the proposed architecture has a performance improvement of 0.125 dBm compared to our previous work [22] and 0.375 dBm over the residual-based decoder in the literature [19] under the maximum 10 iterations of decoding and a 64-QAM modulation format.
2. Conflict Problems in Pipelined Layered Decoders
2.1. Layered Decoding Algorithm
| Algorithm 1. Algorithm of Layered OMSA |
| Initialization: set to Channel LLR set to set and to 1 While () or () For it = For End for For End for Hard decision: Compute: End for End while |
2.2. Pipeline Conflict Problem
3. A Reordered QC-LDPC Decoder with Patched Variable-to-Check Message
3.1. Inter-Layer and Intra-Layer Processing Scheduling
3.2. Patch Method Based on Variable-to-Check Message
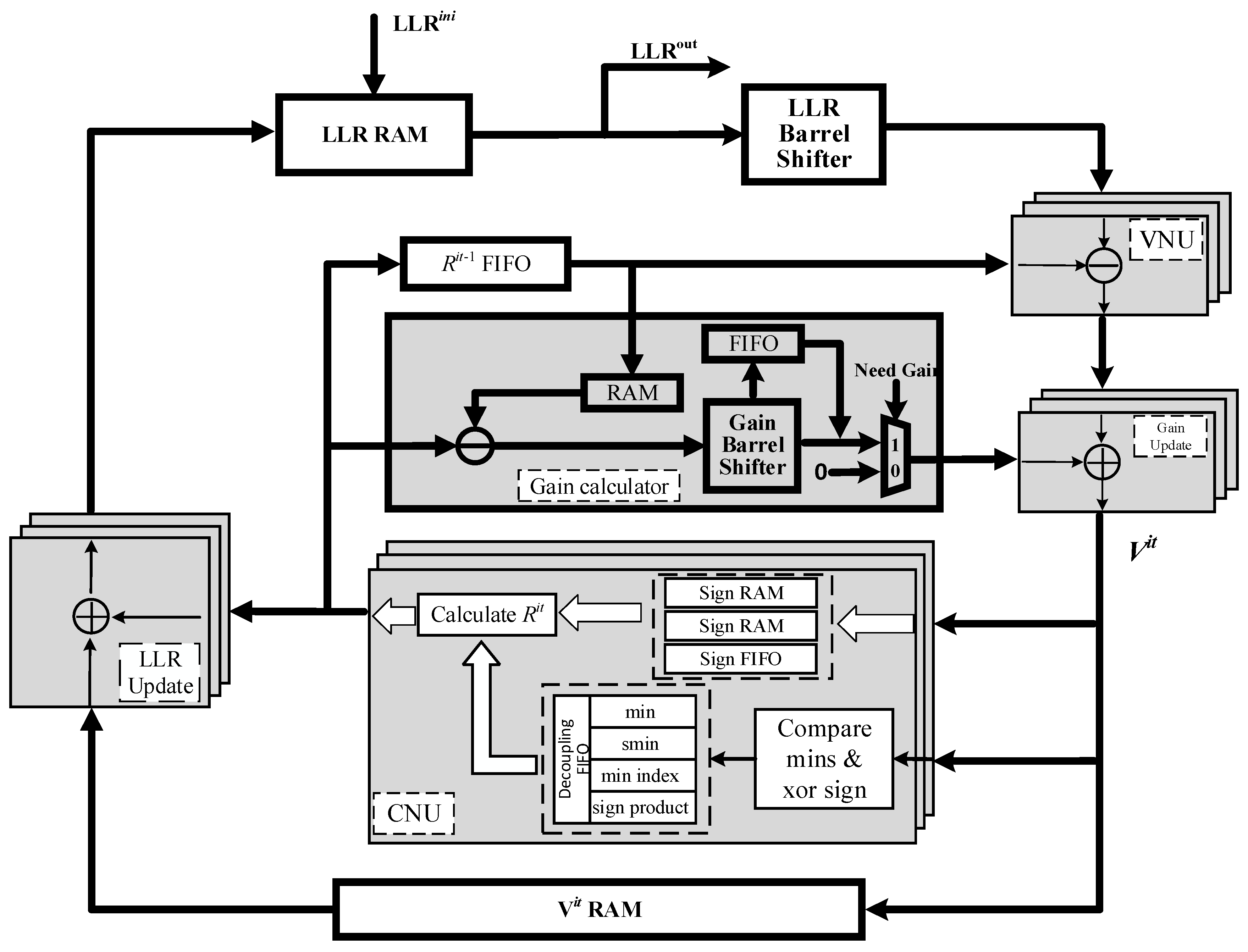
3.3. Proposed Hardware Implementation Structure
4. Results and Analysis
4.1. Experimental Setup
4.2. Schedule Optimization Results
- Reordering the processing of the inter-layer.
- Reordering the processing of the intra-layer.
- Allowing each layer to read and write back LLRs in a different order.
- Using the patch method based on variable-to-check messages.
4.3. Comparison of Decoding Performance
4.4. Hardware Implementation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Acronyms
| LDPC | Low-Density Parity-Check |
| QC-LDPC | Quasi-Cyclic Low-Density Parity-Check |
| TDM-PON | Time Division Multiplexing Passive Optical Network |
| WDM-PON | Wavelength Division Multiplexing Passive Optical Network |
| OFDM-PON | Orthogonal Frequency Division Multiplexing Passive Optical Access Network |
| PAPR | Peak-to-Average Power Ratio |
| FEC | Forward Error Correction |
| PCM | Parity-Check Matrix |
| LLR | Log-Likelihood Ratio |
| MSA | Min-Sum Algorithm |
| OMSA | Offset Min-Sum Algorithm |
| NMSA | Normalized Min-Sum Algorithm |
| FIFO | First In First Out |
| RAM | Random Access Memory |
| DFB-LD | Distributed Feedback Laser |
| SSMF | Standard Single-Mode Fiber |
| OA | Optical Attenuator |
| BER | Bit Error Rate |
| ROP | Received Optical Power |
| MIMO | Multiple-Input Multiple-Output |
References
- Mohammadani, K.H.; Butt, R.A.; Memon, K.A.; Pirzado, A.A.; Faheem, M.; Abro, A.; Ali, B.; Ain, N. A QoS provisioning architecture of fiber wireless network based on XGPON and IEEE 802.11ac. J. Opt. Commun. 2023, 44, 1017–1022. [Google Scholar] [CrossRef]
- Butt, R.A.; Waqar Ashraf, M.; Faheem, M.; Idrus, S.M. A Survey of Dynamic Bandwidth Assignment Schemes for TDM-Based Passive Optical Network. J. Opt. Commun. 2020, 41, 279–293. [Google Scholar] [CrossRef]
- Cheng, L.; Wen, H.; Zheng, X.; Zhang, H.; Zhou, B. Channel characteristic division OFDM-PON for next generation optical access. Opt. Express 2011, 19, 19129–19134. [Google Scholar] [CrossRef] [PubMed]
- Gallager, R. Low-Density Parity-Check Codes. IEEE Trans. Inform. Theory 1962, 8, 21–28. [Google Scholar] [CrossRef]
- Brink, S.; Kramer, G.; Ashikhmin, A. Design of Low-Density Parity-Check Codes for Modulation and Detection. IEEE Trans. Commun. 2004, 52, 670–678. [Google Scholar] [CrossRef]
- Li, M.; Chou, H.; Ueng, Y.; Chen, Y. A low-complexity LDPC decoder for NAND flash applications. In Proceedings of the 2014 IEEE International Symposium on Circuits and Systems (ISCAS), Melbourne, Australia, 1–5 June 2014; pp. 213–216. [Google Scholar]
- 3rd Generation Partnership Project. Technical Specification Group Radio Access Network; NR; Multiplexing and Channel Coding (Release 16), 3GPP TS 38.212 V16.5.0 (2021-03); 3GPP: Valbonne, France, 2021. [Google Scholar]
- Yang, M.; Li, L.; Liu, X.; Djordjevic, I.B. Real-time verification of soft-decision LDPC coding for burst mode upstream reception in 50G-PON. J. Light. Technol. 2020, 38, 1693–1701. [Google Scholar] [CrossRef]
- Mo, W.; Zhou, J.; Liu, G.; Huang, Y.; Li, L.; Cui, H.; Wang, H.; Lu, Q.; Liu, W.; Yu, C. Simplified LDPC-assisted CNC algorithm for entropy-loaded discrete multi-tone in a 100G flexible-rate PON. Opt. Express 2023, 31, 6956–6964. [Google Scholar] [CrossRef] [PubMed]
- Gong, X.; Guo, L.; Wu, J.; Ning, Z. Design and performance investigation of LDPC-coded upstream transmission systems in IM/DD OFDM-PONs. Opt. Commun. 2016, 380, 154–160. [Google Scholar] [CrossRef]
- Djordjevic, I.B.; Batshon, H.G. LDPC-coded OFDM for heterogeneous access optical networks. IEEE Photonics J. 2010, 2, 611–619. [Google Scholar] [CrossRef]
- Sharon, E.; Litsyn, S.; Goldberger, J. Convergence analysis of serial message-passing schedules for LDPC decoding. In Proceedings of the 4th International Symposium on Turbo Codes & Related Topics, Munich, Germany, 3–7 April 2006; pp. 1–6. [Google Scholar]
- Shimizu, K.; Ishikawa, T.; Togawa, N.; Ikenaga, N. Partially-parallel LDPC decoder based on high-efficiency message-passing algorithm. In Proceedings of the 2005 International Conference on Computer Design, San Jose, CA, USA, 2–5 October 2005; pp. 503–510. [Google Scholar]
- Kumawat, S.; Shrestha, R.; Daga, N.; Paily, R. High-throughput LDPC-decoder architecture using efficient comparison techniques & dynamic multi-frame processing schedule. IEEE Trans. Circuits Syst. I 2015, 62, 1421–1430. [Google Scholar]
- Lee, H.C.; Li, M.R.; Hu, J.K.; Chou, P.C.; Ueng, Y.L. Optimization Techniques for the Efficient Implementation of High-Rate Layered QC-LDPC Decoders. IEEE Trans. Circuits Syst. I Regul. Pap. 2017, 64, 457–470. [Google Scholar] [CrossRef]
- Marchand, C.; Dore, J.; Conde-Canencia, L.; Boutillon, E. Conflict resolution for pipelined layered LDPC decoders. In Proceedings of the IEEE Workshop on Signal Processing Systems, Tampere, Finland, 7–9 October 2009; pp. 220–225. [Google Scholar]
- Li, F.; Zhang, C.; Peng, K. An Optimal Block-Scheduling Algorithm for Pipelined Block-Parallel LDPC Decoder. In Proceedings of the 2022 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Bilbao, Spain, 15–17 June 2022; pp. 1–6. [Google Scholar]
- Petrovic, V.L.; Markovic, M.M.; Mezeni, D.M.E.; Saranovac, L.V.; Radosevic, A. Flexible High Throughput QC-LDPC Decoder with Perfect Pipeline Conflicts Resolution and Efficient Hardware Utilization. IEEE Trans. Circuits Syst. I 2020, 67, 5454–5467. [Google Scholar] [CrossRef]
- Boncalo, O.; Kolumban-Antal, G.; Amaricai, A.; Savin, V.; Declercq, D. Layered LDPC Decoders with Efficient Memory Access Scheduling and Mapping and Built-In Support for Pipeline Hazards Mitigation. IEEE Trans. Circuits Syst. I 2019, 66, 1643–1656. [Google Scholar] [CrossRef]
- Marchand, C.; Dore, J.; Conde-Canencia, L.; Boutillon, E. Conflict Resolution by Matrix Reordering for DVB-T2 LDPC Decoders. In Proceedings of the GLOBECOM 2009—2009 IEEE Global Telecommunications Conference, Honolulu, HI, USA, 30 November–4 December 2009; pp. 1–6. [Google Scholar]
- Yet, Z.; Zhai, X.; Mot, J.; Han, J. A High Flexibility Decoding Structure with High Hardware Utilization Efficiency for QC-LDPC. In Proceedings of the 2023 IEEE Globecom Workshops (GC Wkshps), Kuala Lumpur, Malaysia, 4–8 December 2023; pp. 1686–1691. [Google Scholar]
- Li, Y.; Li, Y.; Ye, N.; Chen, T.; Wang, Z.; Zhang, J. High Throughput Priority-Based Layered QC-LDPC Decoder with Double Update Queues for Mitigating Pipeline Conflicts. Sensors 2022, 22, 3508. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Zhao, J.; Huang, H.; Ye, N.; Giddings, R.P.; Li, Z.; Qin, D.; Zhang, Q.; Tang, J. A Clock-Gating-Based Energy-Efficient Scheme for ONUs in Real-Time IMDD OFDM-PONs. J. Light. Technol. 2020, 38, 3573–3583. [Google Scholar] [CrossRef]
- Peng, J.; Sun, Y.; Chen, H.; Xu, T.; Li, Z.; Zhang, Q.; Zhang, J. High-Precision and Low-Complexity Symbol Synchronization Algorithm Based on Dual-Threshold Amplitude Decision for Real-Time IMDD OFDM-PON. IEEE Photonics J. 2019, 11, 7201514. [Google Scholar] [CrossRef]
- Chen, L.; Halabi, F.; Giddings, R.P.; Zhang, J.; Tang, J. Subcarrier Index-Power Modulated-Optical OFDM With Dual Superposition Multiplexing for Directly Modulated DFB-Based IMDD PON Systems. IEEE Photonics J. 2018, 10, 7908113. [Google Scholar] [CrossRef]
- Qin, Y.; Zhang, J. Novel toggle-rate based energy-efficient scheme for heavy load real-time IM-DD OFDM-PON with ONU LLID identification in time-domain using amplitude decision. Opt. Express. 2017, 25, 16771–16782. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Wang, W.; Giddings, R.P.; Zhang, Q.; Peng, J.; Chen, J.; Tang, J. Analytical Solution of Stage-Dependent Bit Resolution of Full Parallel Variable Point FFTs for Real-Time DSP Implementation. J. Light. Technol. 2018, 36, 5177–5187. [Google Scholar] [CrossRef]
- IEEE 802.16e/D5-2004; Part 16: Air Interface for Fixed and Mobile Broadband Wireless Access Systems—Amendment for Physical and Medium Access Control Layers for Combined Fixed and Mobile Operation in Licensed Bands. IEEE: Piscataway, NJ, USA, 2004.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PON Technology | Pros/Cons | Application Scenarios |
|---|---|---|
| TDM-PON |
|
|
| WDM-PON |
|
|
| OFDM-PON |
|
|
| Parameter | Value |
|---|---|
| FFT/IFFT points | 64 |
| Data-carrying subcarriers | From 2 to 28 |
| Modulation format | 16-QAM/64-QAM |
| ADC/DAC resolution | 10/12-bit |
| ADC and DAC sample rate | 4 GS/s |
| OFDM frame CP | 16 samples (4 ns) |
| Transmitter output power | +7.75 dBm |
| DFB wavelength | 1549.98 nm |
| DFB modulation bandwidth | 2.7 GHz |
| DFB bias current | 45 mA |
| DFB driving voltage | 2 Vpp |
| PIN detector bandwidth | 40 MHz~3 GHz |
| PIN responsivity | 0.9 mA/mW |
| Standard | 802.16 |
| Code rate | 3/4 |
| Code length | 2304 |
| Size of submatrices | 96 × 96 |
| Parallelism | 96 |
| Resource Utilization | fmax [MHz] | Tnorm [Gbps] | HUE (Tnorm/Resources) | |||||
|---|---|---|---|---|---|---|---|---|
| Algorithm | LUTs | FFs | 36 k BRAMs | Mbps/kLUT | Mbps/kFF | Mbps/BRAM | ||
| [19] | 40,700 | 26,925 | 40.5 | 142.8 | 10.8 | 265.3 | 401.1 | 266.7 |
| [22] | 26,744 | 19,594 | 27 | 310.0 | 8.2 | 306.3 | 418.5 | 303.7 |
| This work | 24,985 | 15,688 | 41 | 350.0 | 9.3 | 372.2 | 592.8 | 226.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Xu, Z.; Chen, K.; Qu, Y.; Liu, X.; Li, Y.; Zhang, J. Efficient Pipeline Conflict Resolution for Layered QC-LDPC Decoders in OFDM-PON. Photonics 2024, 11, 429. https://doi.org/10.3390/photonics11050429
Wang Z, Xu Z, Chen K, Qu Y, Liu X, Li Y, Zhang J. Efficient Pipeline Conflict Resolution for Layered QC-LDPC Decoders in OFDM-PON. Photonics. 2024; 11(5):429. https://doi.org/10.3390/photonics11050429
Chicago/Turabian StyleWang, Zhijie, Zhengjun Xu, Kun Chen, Yuanzhe Qu, Xiaoqun Liu, Yingchun Li, and Junjie Zhang. 2024. "Efficient Pipeline Conflict Resolution for Layered QC-LDPC Decoders in OFDM-PON" Photonics 11, no. 5: 429. https://doi.org/10.3390/photonics11050429
APA StyleWang, Z., Xu, Z., Chen, K., Qu, Y., Liu, X., Li, Y., & Zhang, J. (2024). Efficient Pipeline Conflict Resolution for Layered QC-LDPC Decoders in OFDM-PON. Photonics, 11(5), 429. https://doi.org/10.3390/photonics11050429