1. Introduction
Adaptive optics systems are widely used in ground-based telescopes [
1,
2], biological imaging [
3], laser communications [
4,
5], human eye aberration correction [
6], and other fields. In the field of astronomy, adaptive optics systems are effective technologies to resist atmospheric turbulence interference and make the angular resolution of ground-based telescopes close to or even reach the diffraction limit. Compared with space telescopes, adaptive optics systems provide a technology roadmap for ground-based telescopes to obtain high-quality star photos in a low-cost way. Almost all ground-based high-resolution imaging telescopes with apertures greater than 1 m have installed adaptive optics systems to correct the negative effects caused by atmospheric turbulence [
7]. Owing to advancements in contemporary adaptive optics systems, the frontiers of ground-based optical and infrared astronomy are constantly being expanded [
8]. In adaptive optics systems, Shack–Hartmann wavefront sensors (SHWFSs) are widely used because of their simple and easy-to-use structure, high utilization of light energy, and strong adaptability [
9].
SHWFSs consist of a microlens array and a rear photoelectric sensor [
10]. During the working process, SHWFSs sample the incident wavefront through a microlens array, and each sampled wavefront is assumed to be a planar wavefront. Then, the slope of each subaperture is calculated using the spot images obtained by the photoelectric sensor, and the incident wavefront is reconstructed using the modal [
11,
12] or zonal method [
13,
14].
In recent years, with the development of machine learning, deep learning algorithms have made significant breakthroughs in image recognition [
15,
16], natural language processing [
17], and other fields. Therefore, deep learning algorithms have also been applied to the processing of data related to SHWFSs.
Z. Li and X. Li proposed a model based on fully connected neural networks, which converts the task of finding the centroid of the SHWFS subaperture into a classification task to resist external interference and improve the accuracy of the search [
18]. In another study, Xu et al. also developed a model based on fully connected neural networks to convert the slopes of SHWFSs into corresponding Zernike coefficients [
9]. Close et al. used U-net to convert the subaperture slopes of the SHWFSs to wavefront difference maps [
19]. Similarly, DuBose et al. proposed a U-net-based model to eliminate the interference from non-uniform illumination and branch points in the phase distribution caused by atmospheric turbulence [
20]. This model inputs the x slopes, y slopes, and total light intensity of each subaperture spot image of SHWFSs, directly outputting wavefront difference maps. These algorithms are non-end-to-end wavefront reconstruction methods that use the slopes of SHWFSs as input variables. However, for algorithms that calculate and reconstruct wavefront using the slopes of SHWFSs, the accuracy of these algorithms may be affected by the centroid positioning error and the averaged wavefront slope of SHWFSs [
21]. Moreover, during the process of converting the subaperture spot image of SHWFSs into a slope, some pieces of information characterizing higher-order aberrations, which could be more effectively utilized, are lost [
21].
In order to fully utilize the information of the subaperture spot images of SHWFSs, some researchers have developed end-to-end deep learning models that directly input complete SHWFS images. Hu et al. proposed an end-to-end U-net-based model that combines residual neural networks and can directly input images from SHWFSs and output reconstructed wavefront difference maps [
21]. He et al. proposed another model to address the difficulty that SHWFSs face when capturing high-order aberrations with low subaperture counts. This model is based on convolutional neural networks to analyze individual subaperture spot images and a fully connected neural network to calculate the final Zernike coefficients [
22]. Guo et al. and Hu et al. both utilized convolutional neural networks (CNNs) for the processing of light intensity images from SHWFSs. The former introduced a model that converts the light intensity image of SHWFSs directly into the corresponding Zernike coefficients [
23]. The latter proposed another model that takes a downsampled light intensity image from SHWFSs as input and outputs Zernike coefficients ranging from the 2nd to the 120th terms [
24].
As shown above, the underlying working model of the current deep learning algorithm for processing traditional SHWFSs is basically composed of a fully connected neural network, a convolutional neural network, and U-net. However, these deep learning models are not the best models for processing SHWFS data. The fully connected neural networks extract features layer-by-layer through fully connected layers, while the convolutional neural network and U-net extract features and produce results mainly through the convolution operation of the convolution kernel shared by all parts of the image in the convolution layer. The working principle of these models leads to the inability of the models to selectively process the data at different positions of the SHWFSs in the working process, while in the case of high turbulence intensity or low guide star brightness, the signal-to-noise ratio of some subaperture spot images in the SHWFSs decreases, and these low signal-to-noise ratio subaperture spot images often contaminate the final wavefront reconstruction results [
10].
In addition, the data obtained by SHWFSs have sparsity, which makes it unnecessary for us to reconstruct the wavefront with all the subaperture spot image information. In order to fully utilize the sparsity of SHWFSs, some scholars have proposed sparse wavefront reconstruction algorithms specifically for SHWFSs. In 2014, Polans et al. first proposed a sparse wavefront reconstruction algorithm using Zernike polynomials to represent wavefront difference maps [
25]. Then, Ke et al. proposed a similar algorithm [
26]. The algorithms developed by these researchers use the Zernike coefficient as the basis function, and then they randomly select the slopes of the subapertures of the SHWFS and calculate the parameters of each Zernike coefficient through a recursive method. In their research, they found that we only need about ten percent of the subaperture spot image information of SHWFSs to reconstruct the entire wavefront. To reduce reconstruction error, a new basis function, which is called golden section sparse basis function, was proposed [
27]. The majority of the previously discussed algorithms utilize a selection process applied to the subapertures of SHWFSs. However, these selections are all made randomly, and the repetitive nature of the iterations consequently contributes to an extended computational time for these algorithms. In 2021, Peng Jia et al. proposed an algorithm based on deep neural networks for compressive sensing wavefront reconstruction, which uses the signal-to-noise ratio of subaperture spot images as a selection criterion to filter out good subaperture information and uses CNNs to complete subaperture slope information and reconstruct phase difference maps [
10]. This algorithm uses signal-to-noise ratio as the selection criterion and avoids the problem of long processing times caused by repeated iterations.
However, neural networks themselves have the ability to resist noise interference, so even low signal-to-noise ratio subaperture spot image information may still contain valuable information for reconstructing a wavefront. The method of directly discarding low signal-to-noise ratio subaperture spot image information in this algorithm is not appropriate. Moreover, beyond the spot image information of the subaperture, the position of the subaperture within the SHWFS holds significant value for wavefront reconstruction. This positional information can enhance the reconstruction accuracy, aiding in differentiating distortions that arise due to the physical location of subapertures within the sensor grid, such as the nonuniform illumination of the edge subapertures [
28]. It can provide a more spatially accurate depiction of the wavefront distortions, allowing for a more precise correction. Despite these advantages, the positional information is not considered in all existing compressive sensing wavefront reconstruction algorithms for SHWFSs. The most important thing is that existing algorithms often need to compare the performance under various screening situations to determine the optimal screening method. However, the optimal subaperture selection method is influenced by various aspects such as the hardware structure of the SHWFS and specific situation of atmospheric turbulence, which makes it difficult for us to determine the optimal subaperture selection method.
Considering these difficulties, we introduce a novel algorithm that employs the self-attention mechanism of the Vision Transformer model [
29] to automatically select the subapertures of SHWFSs. This innovative approach enables the Vision Transformer model to allocate weight values to each subaperture by taking into account both spot image information and the subaperture’s position information within the SHWFSs. In order to fully utilize the hardware resources of adaptive optical systems and avoid errors caused by the truncation of higher-order Zernike coefficients after using Zernike coefficients, we have the Vision Transformer model directly output the Deformable Mirror (DM) command vector.
For the first time, the Vision Transformer model is applied to SHWFS information processing. Simultaneously, we utilize a Residual Neural Network (ResNet) model [
16], representing the CNN-based approach commonly employed in current scholarship [
10,
19,
20,
21,
22,
23,
24,
30]. To further extend our investigation, we train both the Vision Transformer and ResNet models under two scenarios: with and without data normalization. In doing so, we reassess the impact of normalization—a prevalent data preprocessing methodology—on the performance of these models. Normalization is a processing method that divides each pixel in the subaperture spot image of a SHWFS by the maximum pixel value of that spot image. Traditionally, normalization has been a common preprocessing method in CNN-based deep learning algorithms for SHWFSs because this preprocessing method can reduce the error caused by the non-uniformity of the spot intensity of each subaperture [
23]. However, its effect on the performance of our proposed Vision Transformer model and the comparative ResNet model is a point of renewed investigation in this study.
The following sections of this article are as follows. In
Section 2, we expound on the underlying principles of the Vision Transformer and ResNet models, elaborating on their specific hyperparameters. In
Section 3, we delineate the methods employed for generating training and testing data and outline the processes involved in both training and testing, as well as the results obtained from these activities. In
Section 4, we assess the corrective performance of the two models under two distinct data preprocessing approaches, differing primarily in the application of normalization. This evaluation considers aspects such as the residual phase difference, the energy distribution of the point spread function, and the performance of the models under varying R0 (Fried parameter, expressed in meters) values and guide star magnitudes. To mitigate the potential impact of model training randomness on the results and to test the algorithm’s repeatability, we trained ten models across four cases, subsequently illustrating the distribution of the model’s loss function. In
Section 5, we summarize our findings and envisage future research directions.
2. Deep Learning Architectures and Principles
2.1. Detailed Exploration of ResNet
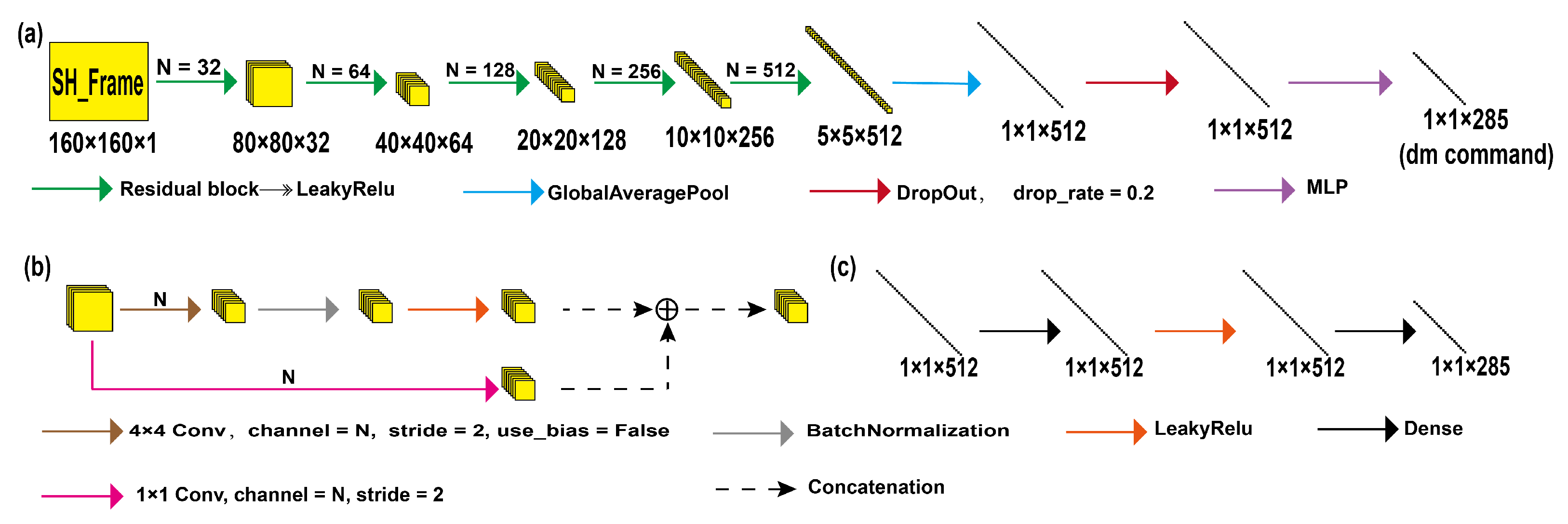
ResNet is a typical deep CNN, which has added residual connections to solve the problem of gradient vanishing and explosion caused by model deepening [
16]. And
Figure 1 is a diagram showing the structure of ResNet. In order to adapt to the size of the input data, we made appropriate modifications to this model and removed some layers of the neural network. The process begins with the input of the light intensity images from the SHWFS into the ResNet model. These images undergo the process of feature extraction by multilayer Residual Blocks. These blocks are essentially convolutional layers supplemented with residual connections, which facilitate the extraction of feature vectors pertinent to the light intensity image. To mitigate model overfitting, dropout layers are incorporated into the network for additional processing of these feature vectors. Ultimately, these feature vectors are passed through a fully connected layer that directly yields the final DM command vector.
2.2. Thorough Analysis of Vision Transformer
The Vision Transformer model, first proposed by Dosovitskiy et al. [
29], provides a unique perspective on addressing computer vision problems. Unlike conventional methods that primarily leverage CNNs, the Vision Transformer model utilizes a Transformer architecture, a concept traditionally associated with natural language processing tasks.
In the Vision Transformer, images are segmented into numerous patches. And these image patches are then fed into the Transformer model, which allows for the capture of both local and global inter-patch relationships. A crucial component of the Transformer, the attention mechanism, enables the model to assign varying degrees of importance to different patches, focusing on information-rich areas.
This architecture has been shown to perform remarkably well, even surpassing traditional convolutional neural networks when applied to large-scale image datasets [
29]. While the original application of the Vision Transformer was not in the field of SHWFS data processing, its design principle opens up new possibilities for innovative applications, such as those explored in our study.
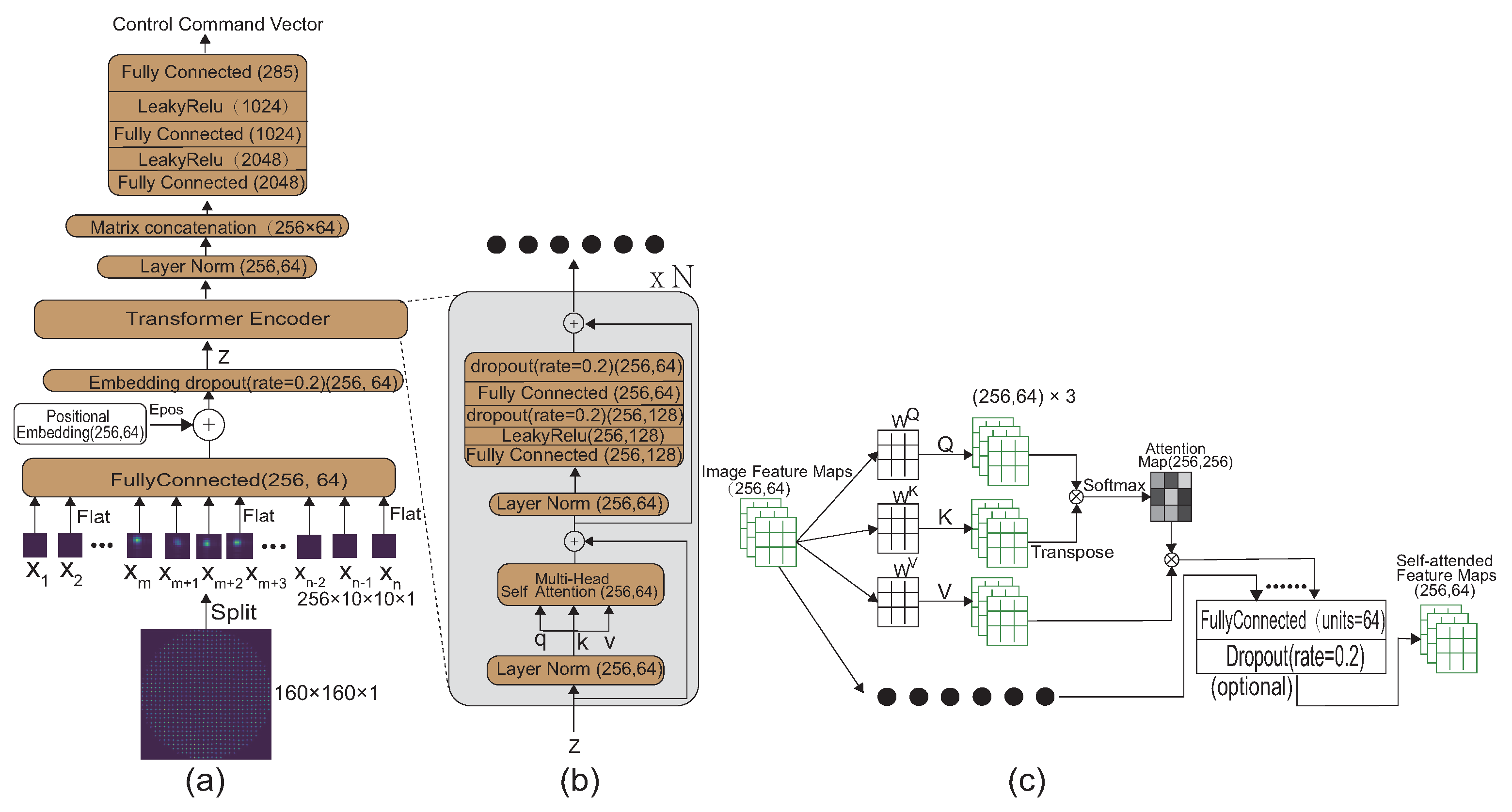
In our proposed algorithm, as shown in
Figure 2a, each light intensity image from the SHWFS is segmented into a series of spot images following subaperture segmentation. Subsequently, each of these spot images is mapped into embedding vectors encapsulating spot image information via fully connected layers. These embedding vectors are then coupled with a series of one-dimensional vectors representing positional information. This results in a set of comprehensive embedding vectors, each embodying both image and positional information for individual subapertures within the SHWFS.
To mitigate potential overfitting during the training process, we employ a dropout layer with a dropout rate of 0.2 to refine the embedding vectors before passing them into the transformer encoder.
As shown in
Figure 2b, the transformer encoder mainly consists of two parts, namely, the multi-head attention mechanism in the front and the multi-layer perceptron in the back. Each layer has residual connections to prevent gradient vanishing and exploding after the model deepens in the process of training.
The multi-head attention mechanism primarily comprises a layer normalization phase followed by a multi-head attention computation layer. While batch normalization [
31], as used in ResNet [
16], performs normalization across a set of features derived from light intensity images of varying guide star magnitudes and R0 values, layer normalization standardizes the embedding vectors of each subaperture of the SHWFS [
32]. This normalization by subaperture stabilizes the layer inputs for subsequent computations, enabling more effective processing of the individualized subaperture information. The next multi-head attention mechanism, just as shown in
Figure 2c, is represented by the following steps. The matrix of embedding vectors for all subapertures, denoted as
, is transformed into query, key, and value matrices for each attention head:
where
,
, and
are the query, key, and value matrices;
is the matrix of the input embedding vectors; and
,
, and
are the weight matrices of the learnable linear transformations.
For each attention head, the attention scores between all pairs of subapertures are calculated using the scaled dot-product attention:
where
is the dimension of the key vectors,
is the output of a one-head attention value matrix, and the softmax function is applied along the rows. The result calculated by softmax is the Attention Map, which is the weight distribution of each subaperture of the SHWFS calculated by the Vision Transformer. By multiplying the Attention Map with the value matrix representing each subaperture information, we obtain the calculation result that assigns a certain weight value to each subaperture information.
Finally, if the number of attention heads is one and the dimension of the matrix is equal to the output dimension of the multi-head attention mechanism, we directly output the matrix as the output result of the multi-head attention mechanism. Otherwise, we concatenate all the matrices from all attention heads and use a fully connected layer and a dropout layer to calculate the final output result.
The subsequent multi-layer perceptron module, essentially a multilayer perceptron featuring residual connections, is tasked with further processing the obtained information.
These are the principles of the encoder in the Vision Transformer model. In practical applications, encoders often need to stack multiple layers to extract higher-order abstract features.
The information processed by the encoder, after undergoing a layer normalization process, is consolidated into a single vector. This vector is then input into a multi-layer perceptron for further processing to ultimately output a DM command vector.
In our Vision Transformer model, we set the number of heads in the multi-head attention mechanism to one, while the number of Transformer encoders is also configured to one to enhance real-time performance. With these configuration choices, we now proceed with a comparative analysis between the Vision Transformer and ResNet models to elucidate the performance advantages of our approach.
2.3. Comparative Examination of ResNet and Vision Transformer
In our study, we compare the performance of two neural network models, ResNet and Vision Transformer, in the context of processing light intensity images from SHWFSs. Both models exhibit robust capabilities in dealing with complex image-based tasks, but there are underlying differences in their working principles that render Vision Transformer more favorable in our specific use case.
ResNet functions chiefly by learning hierarchical features from images using convolutional layers. It employs the concept of residual connections to counteract the vanishing and exploding gradient problem that emerges in deeper networks, thereby substantially enhancing its performance across various visual tasks [
16]. Nevertheless, when tasked with processing SHWFS light intensity images, ResNet’s shared convolutional kernel treats all regions of an image uniformly. This uniform treatment may not be optimal, considering the unique nature of SHWFS images: SHWFSs often experience low signal-to-noise ratios for certain subapertures due to low turbulence R0 and low guide star brightness, which can affect the final wavefront reconstruction results. The shared convolutional kernel approach of ResNet lacks the ability to distinguish and appropriately handle these subapertures, thus rendering it less efficient for this task, even though it is widely used in similar tasks.
In contrast, the Vision Transformer applies the principles of the Transformer architecture to vision-based tasks. This strategy introduces an attention mechanism, allowing the model to allocate diverse levels of focus to various parts of an image based on their significance. The Vision Transformer utilizes a multi-head attention mechanism to assign a specific weight value to each embedding vector, which encapsulates both corresponding subaperture spot image information and position information. This selective extraction of information and computation of the final result effectively mitigates the problem of low signal-to-noise ratios in subaperture spot images under conditions of a low R0 and low guide star brightness in SHWFSs. This approach ultimately enhances the robustness and accuracy of wavefront reconstruction results.
Therefore, the Vision Transformer model, with its unique approach to handling image data and its ability to focus adaptively on different parts of an image, presents a more tailored solution for our task of processing SHWFS light intensity images. However, theoretically speaking, the preprocessing operation of normalization can effectively reduce the error caused by the non-uniformity of spot intensity of each subaperture [
23], thereby improving the performance of ResNet, which operates on the principle of feature extraction through convolution operations, while the preprocessing of normalization can normalize the pixel values of the subaperture spot image to a range of zero to one, which directly affects the calculation results of weight values in the multi-head attention mechanism in the Vision Transformer, so the impact of the normalization preprocessing on the performance of the Vision Transformer needs to be reevaluated.
5. Conclusions and Discussion
Our research demonstrates the innovative application of Vision Transformers to the analysis of SHWFS light intensity images, providing a robust alternative to traditional CNNs. Our evaluations reveal that Vision Transformers excel in accuracy and robustness under varied atmospheric and luminosity conditions, outperforming the commonly used CNNs, such as ResNet. The effectiveness of normalization preprocessing varies; it enhances CNN performance but has a mixed impact on Vision Transformers, enhancing them under conditions of low turbulence and high luminosity yet impairing their function in scenarios of high turbulence and low light levels. Despite these variations, the Vision Transformer maintains a consistent edge over CNNs in all conditions tested.
Vision Transformers distinguish themselves by employing a multi-head attention mechanism, which selectively processes subaperture information, optimizing the phase reconstruction by filtering detrimental inputs and enhancing beneficial ones. This advanced feature extraction method offers superior noise resistance, which is crucial under low light and high-turbulence conditions.
Traditionally favored for SHWFS light intensity image processing, CNNs leverage convolutional kernels for feature extraction, yet they struggle with the sparsity caused by atmospheric turbulence, especially under low guide star brightness and small R0 values. This limitation has prompted approaches like compressive sensing techniques. And the sparsity of atmospheric turbulence has also prompted deep-learning-based Peng Jia’s manual subaperture selection. But they are both facing the same challenging task of adapting to varying atmospheric and hardware conditions. In contrast, the Vision Transformer model, utilizing its multi-head attention mechanism, automatically adjusts weights to each subaperture, thereby enhancing the wavefront reconstruction’s accuracy and robustness without manual intervention. This capability not only underscores the model’s potential for SHWFS but also suggests its applicability to other sensors that also have a sparsity property, like pyramid wavefront sensors, and multi-sensor information fusion technology [
35] within wide-field adaptive optics systems, which are promising areas for further exploration. And in order to verify the performance of the Vision Transformer model in practice, we will conduct relevant experiments to verify the actual performance of this algorithm.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}