A Machine Learning Approach for Automated Detection of Critical PCB Flaws in Optical Sensing Systems

Abstract
:1. Introduction
2. Materials and Methods
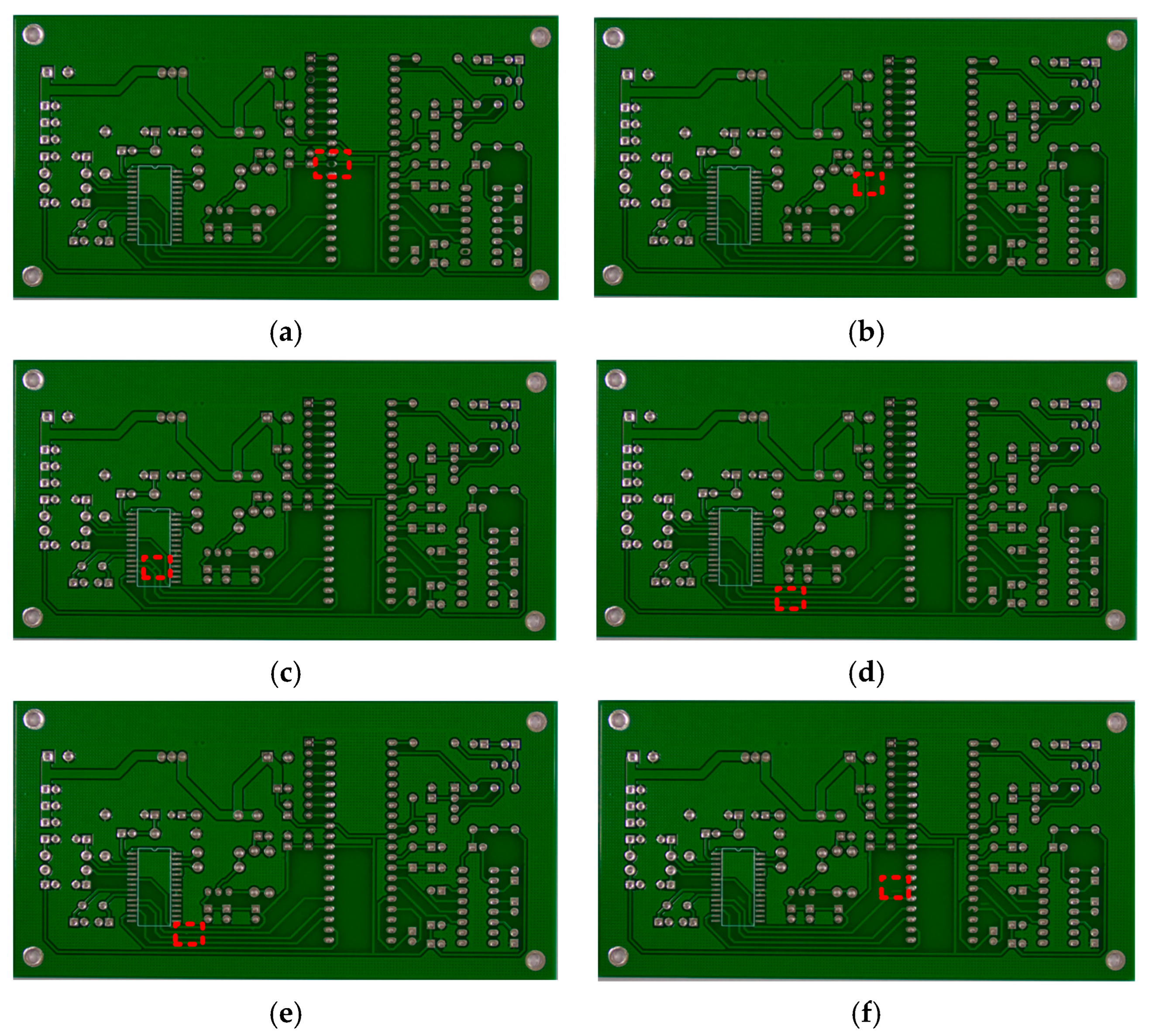
2.1. Datasets
2.2. Related Defect Detection Algorithm
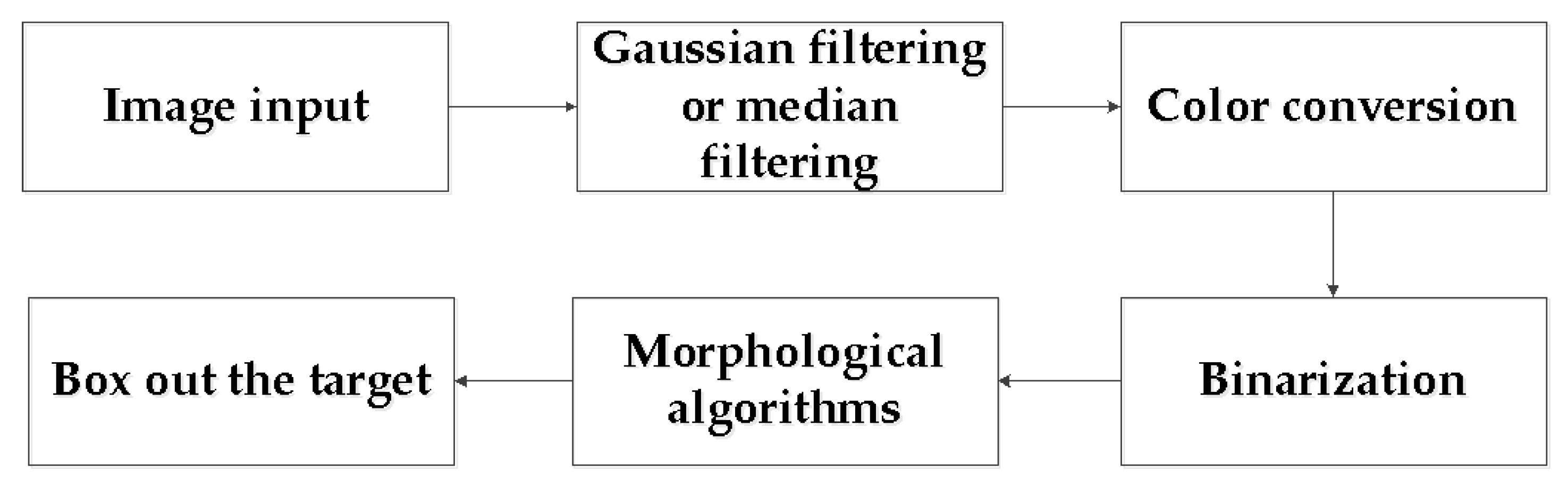
2.2.1. OpenCV
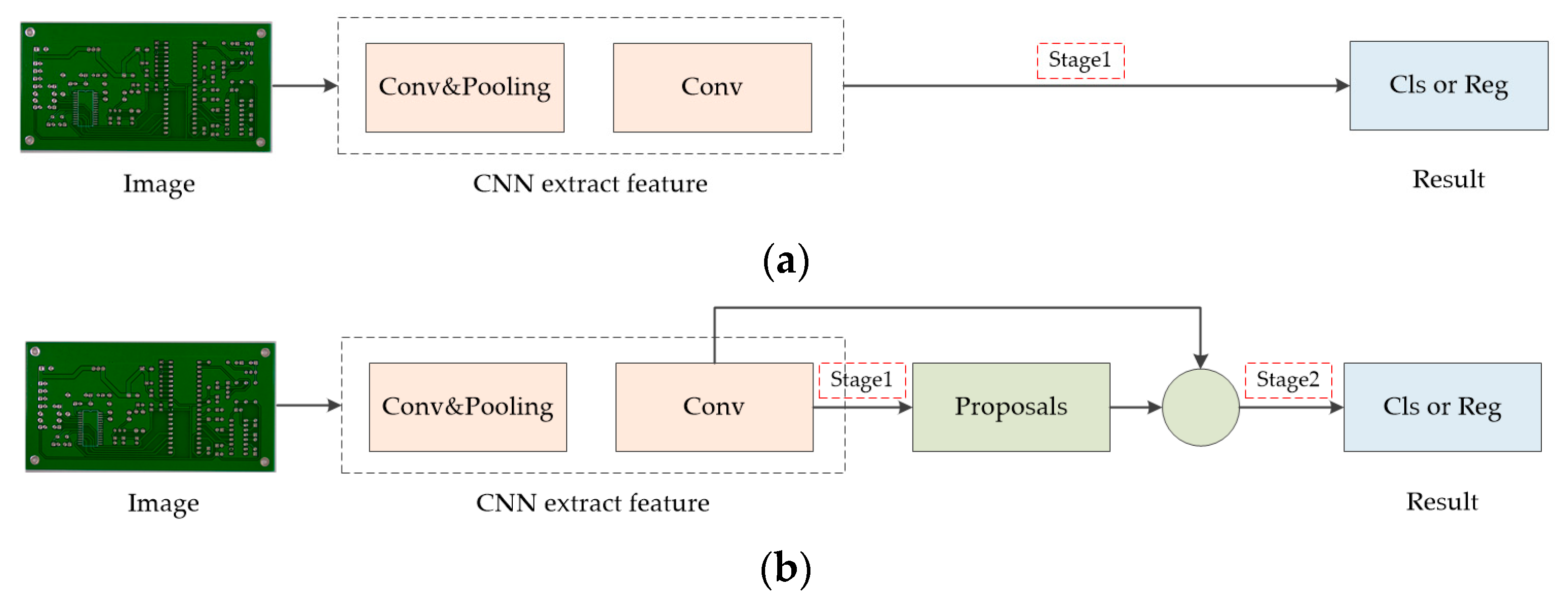
2.2.2. Deep Learning
2.3. Model
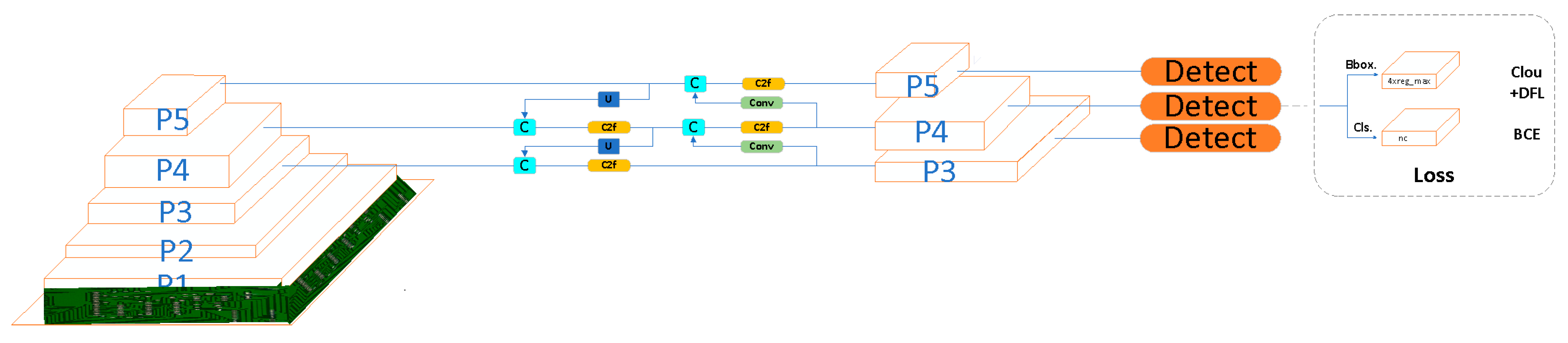
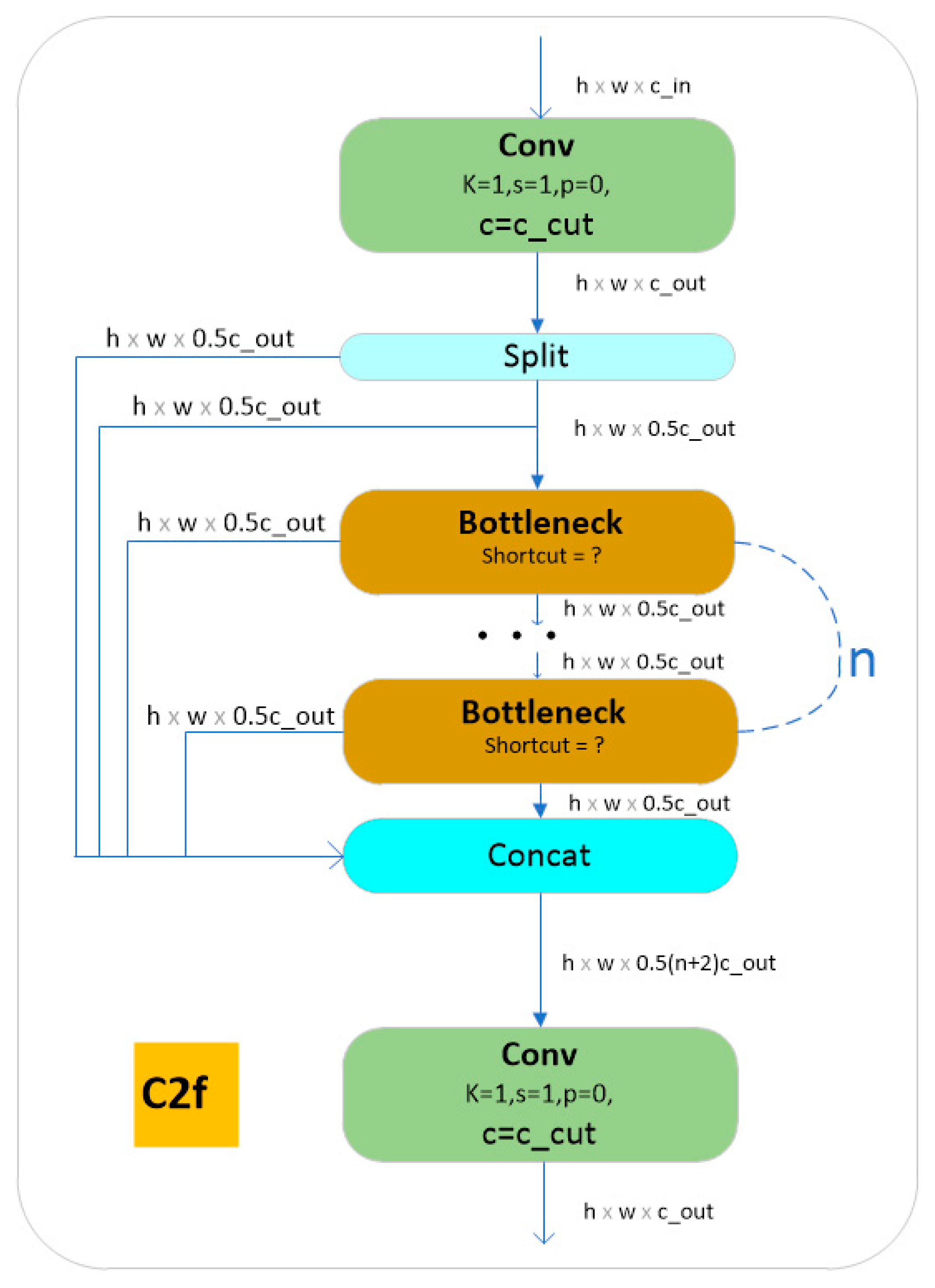
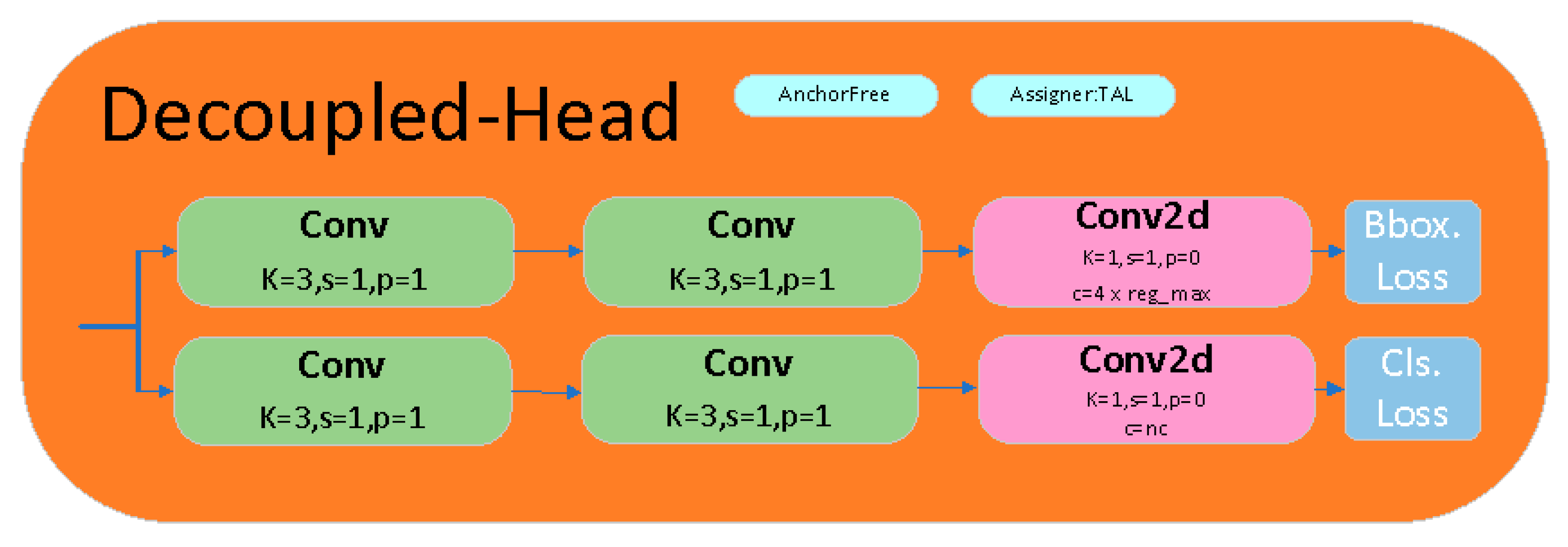
2.3.1. YOLOv8
2.3.2. W–YOLOv8
2.3.3. Model Evaluation
3. Experimental Results and Discussion
3.1. Model
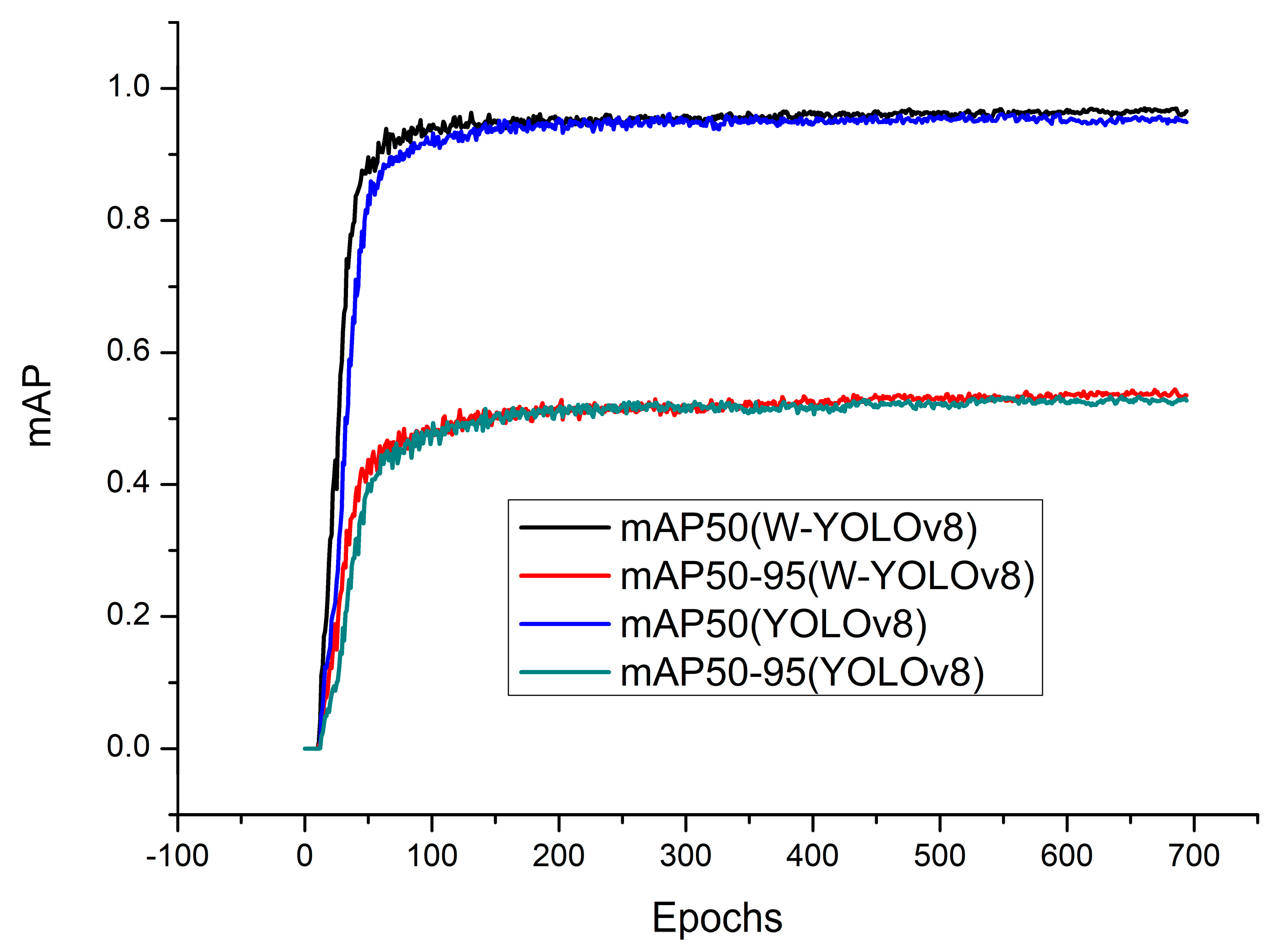
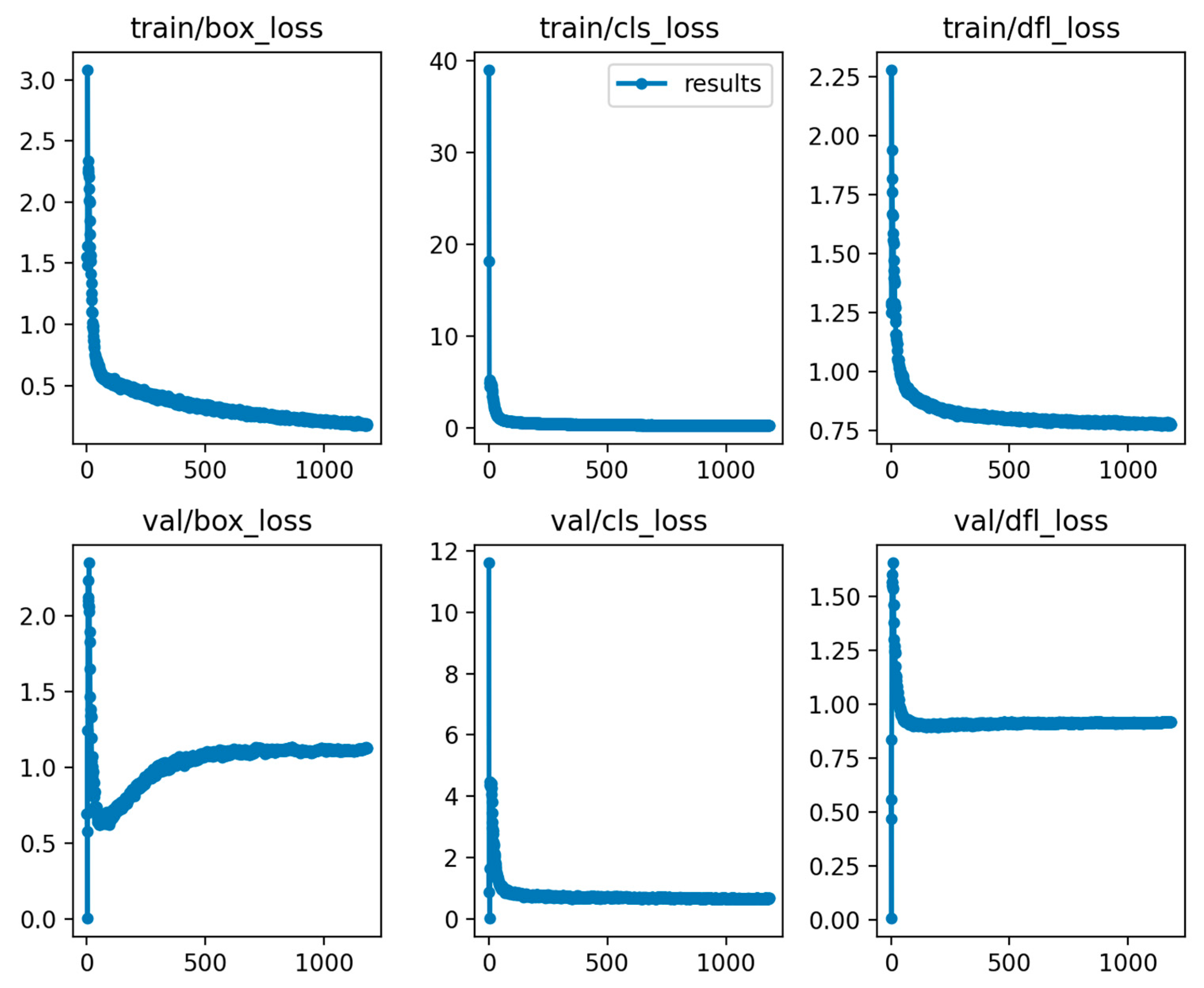
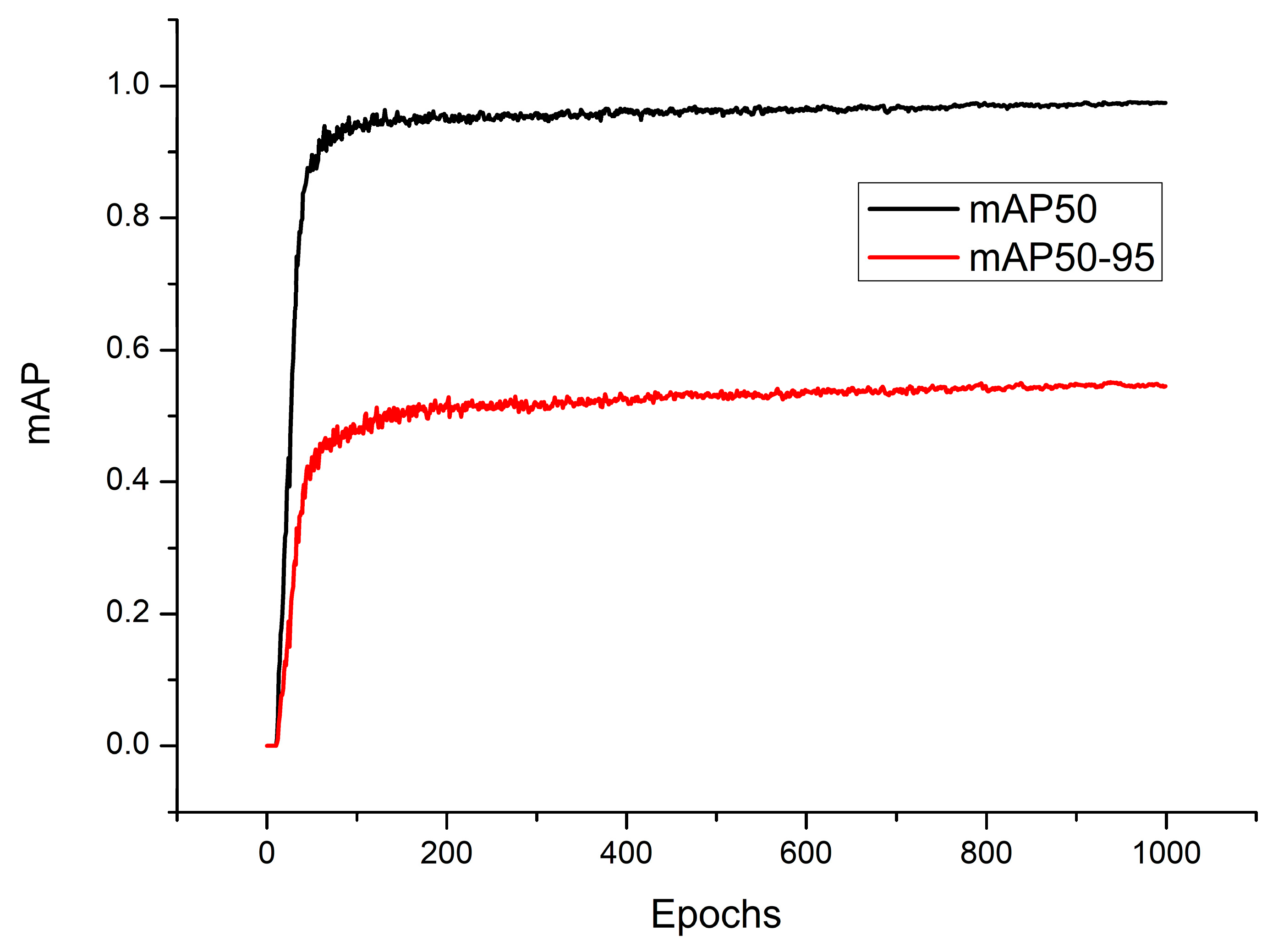
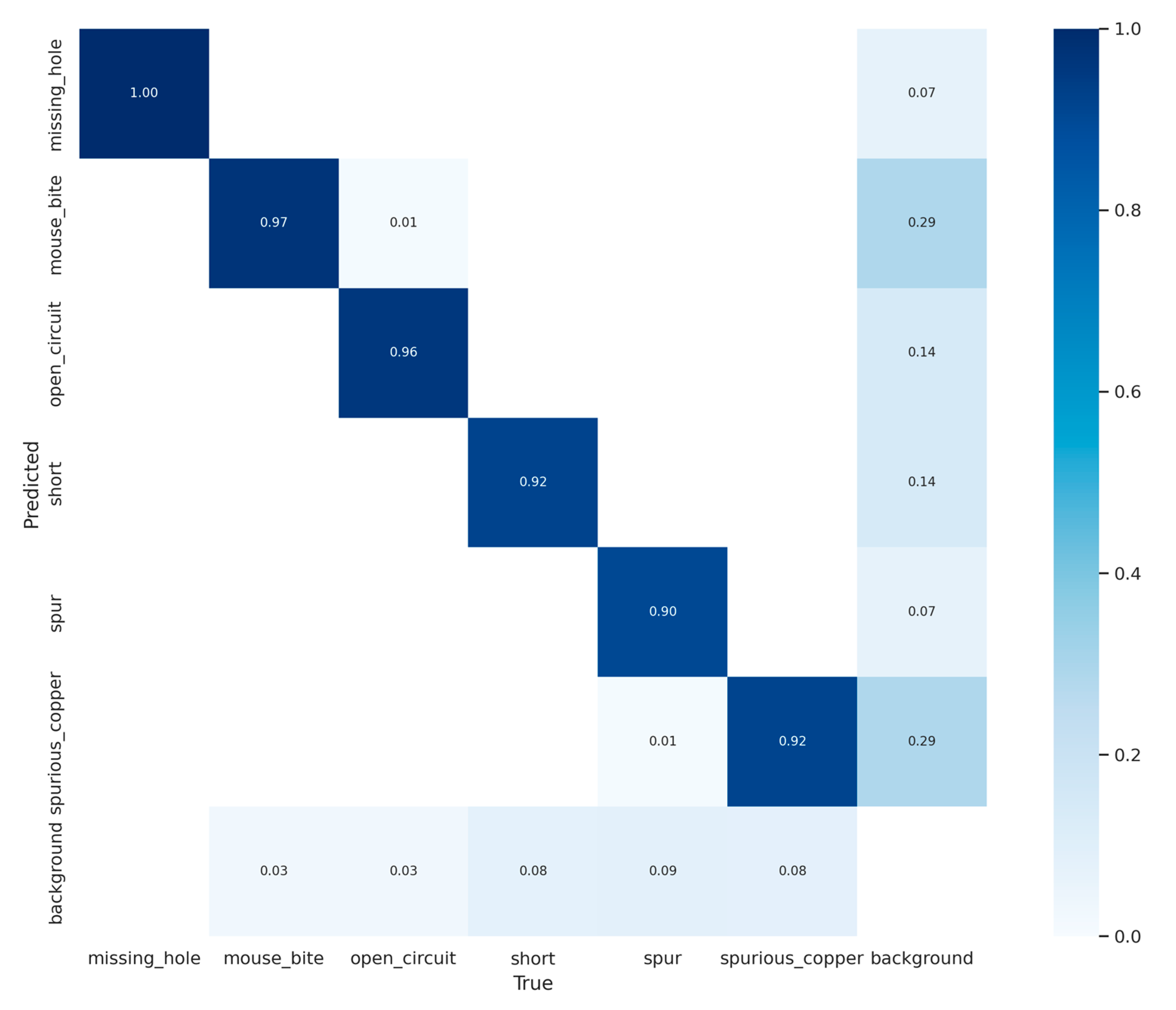
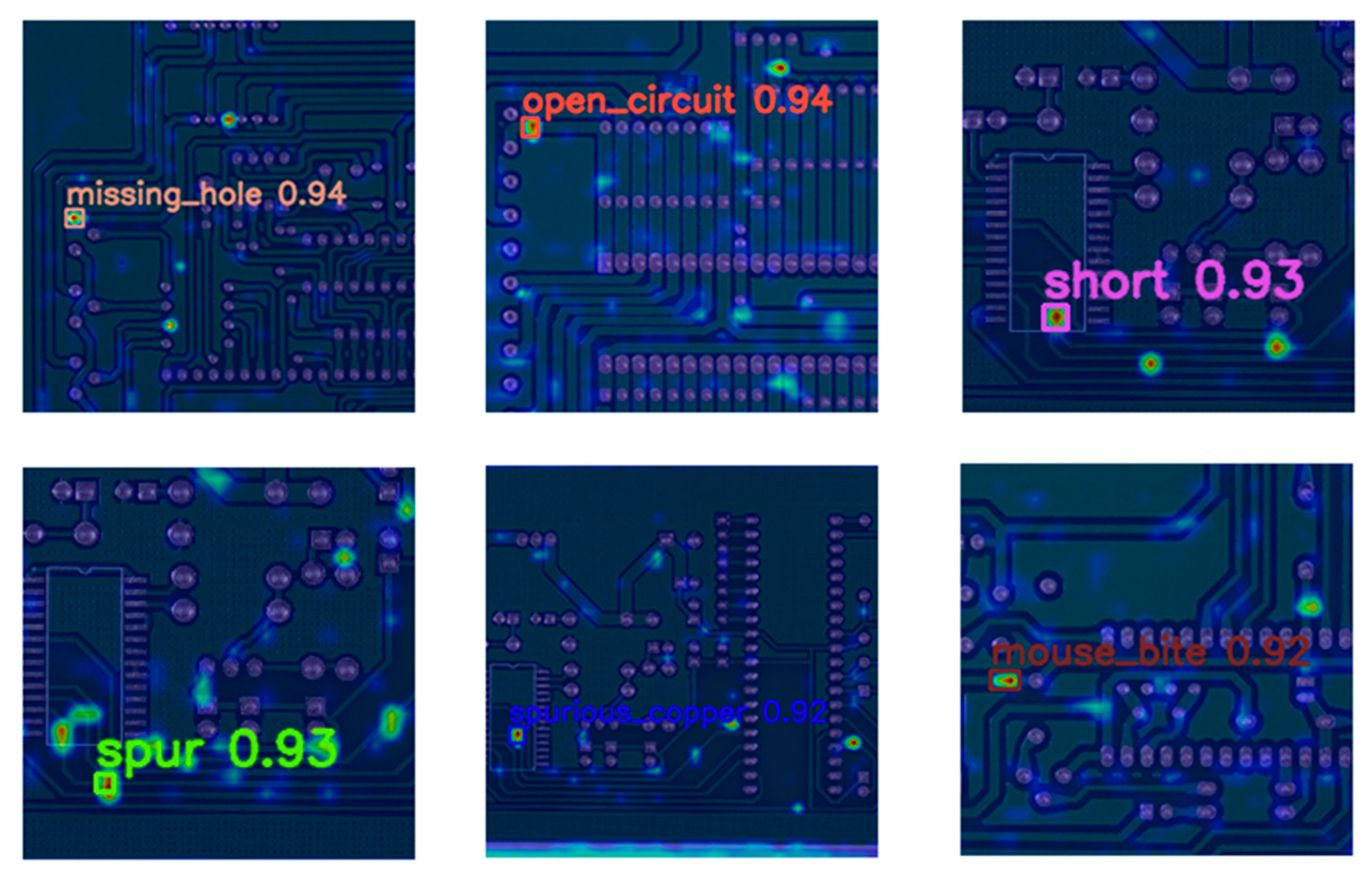
3.2. Training Results of W–YOLOv8
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fridman, Y.; Rusanovsky, M.; Oren, G. ChangeChip: A Reference-Based Unsupervised Change Detection for PCB Defect Detection. In Proceedings of the 2021 IEEE International Conference on Physical Assurance and Inspection on Electronics, PAINE 2021, Virtual, 30 November–2 December 2021. [Google Scholar]
- Ibrahim, I.; Ibrahim, Z.; Khalil, K.; Mokji, M.M.; Abu-Bakar, S.A.R.S. An Algorithm for Classification of Five Types of Defects on Bare Printed Circuit Board. Int. J. Comput. Sci. Eng. Syst. 2018, 13, 57–64. [Google Scholar]
- Putera, S.; Ibrahim, Z. In Printed circuit board defect detection using mathematical morphology and MATLAB image processing tools. In Proceedings of the 2010 2nd International Conference on Education Technology and Computer, Shanghai, China, 22–24 June 2010. [Google Scholar]
- Xie, L.; Rui, H.; Cao, Z. In Detection and Classification of Defect Patterns in Optical Inspection Using Support Vector Machines. In Proceedings of the 9th International Conference on Intelligent Computing Theories, Nanning, China, 28–31 July 2013. [Google Scholar]
- Wan, Y.; Gao, L.; Li, X.; Gao, Y. Semi-Supervised Defect Detection Method with Data-Expanding Strategy for PCB Quality Inspection. Sensors 2022, 22, 7971. [Google Scholar] [CrossRef]
- Pham, T.T.A.; Thoi, D.K.T.; Choi, H.; Park, S. Defect Detection in Printed Circuit Boards Using Semi-Supervised Learning. Sensors 2023, 23, 3246. [Google Scholar] [CrossRef] [PubMed]
- Park, J.H.; Kim, Y.S.; Seo, H.; Cho, Y.J. Analysis of Training Deep Learning Models for PCB Defect Detection. Sensors 2023, 23, 2766. [Google Scholar] [CrossRef]
- Bhattacharya, A.; Cloutier, S.G. End-to-end deep learning framework for printed circuit board manufacturing defect classification. Sci. Rep. 2022, 12, 12559. [Google Scholar] [CrossRef]
- Li, J.; Gu, J.; Huang, Z.; Wen, J. Application research of improved YOLO V3 algorithm in PCB electronic component detection. Appl. Sci. 2019, 9, 3750. [Google Scholar] [CrossRef]
- Wang, Y.; Guan, Y.; Liu, H.; Jin, L.; Li, X.; Guo, B.; Zhang, Z. VV-YOLO: A Vehicle View Object Detection Model Based on Improved YOLOv4. Sensors 2023, 23, 3385. [Google Scholar] [CrossRef]
- Huang, W.; Wei, P. A PCB dataset for defects detection and classification. arXiv 2016, arXiv:1901.08204. [Google Scholar]
- Gaidhane, V.H.; Hote, Y.V.; Singh, V. An efficient similarity measure approach for PCB surface defect detection. Pattern Anal. Appl. 2018, 21, 277–289. [Google Scholar] [CrossRef]
- Liu, Z.; Qu, B. Machine vision based online detection of PCB defect. Microprocess. Microsyst. 2021, 82, 103807. [Google Scholar] [CrossRef]
- Ling, Q.; Isa, N.A.M. Printed Circuit Board Defect Detection Methods Based on Image Processing, Machine Learning and Deep Learning: A Survey. IEEE Access 2023, 11, 15921–15944. [Google Scholar] [CrossRef]
- Farhan, A.; Saputra, F.; Suryanto, M.E.; Humayun, F.; Pajimna, R.M.B.; Vasquez, R.D.; Roldan, M.J.M.; Audira, G.; Lai, H.T.; Lai, Y.H.; et al. OpenBloodFlow: A User-Friendly OpenCV-Based Software Package for Blood Flow Velocity and Blood Cell Count Measurement for Fish Embryos. Biology 2022, 11, 1471. [Google Scholar] [CrossRef]
- Wahab, F.; Ullah, I.; Shah, A.; Khan, R.A.; Choi, A.; Anwar, M.S. Design and implementation of real-time object detection system based on single-shoot detector and OpenCV. Front. Psychol. 2022, 13, 1039645. [Google Scholar] [CrossRef]
- Farhan, A.; Kurnia, K.A.; Saputra, F.; Chen, K.H.; Huang, J.C.; Roldan, M.J.M.; Lai, Y.H.; Hsiao, C.D. An OpenCV-Based Approach for Automated Cardiac Rhythm Measurement in Zebrafish from Video Datasets. Biomolecules 2021, 11, 1476. [Google Scholar] [CrossRef]
- Lin, Q.; Li, S.; Wang, R.; Wang, Y.; Zhou, F.; Chen, Z.; Guo, N. Research on Small Target Detection Technology Based on the MPH-SSD Algorithm. Comput. Intell. Neurosci. 2022, 2022, 9654930. [Google Scholar] [CrossRef]
- Zhang, Q.; Hu, X.; Yue, Y.; Gu, Y.; Sun, Y. Multi-object detection at night for traffic investigations based on improved SSD framework. Heliyon 2022, 8, e11570. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; He, D. Apple detection and instance segmentation in natural environments using an improved Mask Scoring R-CNN Model. Front. Plant Sci. 2022, 13, 1016470. [Google Scholar] [CrossRef]
- Lee, Y.S.; Park, W.H. Diagnosis of Depressive Disorder Model on Facial Expression Based on Fast R-CNN. Diagnostics 2022, 12, 317. [Google Scholar] [CrossRef]
- Youssouf, N. Traffic sign classification using CNN and detection using faster-RCNN and YOLOV4. Heliyon 2022, 8, e11792. [Google Scholar] [CrossRef]
- Ruiz-Ponce, P.; Ortiz-Perez, D.; Garcia-Rodriguez, J.; Kiefer, B. POSEIDON: A Data Augmentation Tool for Small Object Detection Datasets in Maritime Environments. Sensors 2023, 23, 3691. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Jiang, X.; Hu, H.; Liu, X.; Ding, R.; Xu, Y.; Shi, J.; Du, Y.; Da, C. A smoking behavior detection method based on the YOLOv5 network. J. Phys. Conf. Ser. 2022, 2232, 012001. [Google Scholar] [CrossRef]
- Ren, F.; Zhang, Y.; Liu, X.; Zhang, Y.; Liu, Y.; Zhang, F. Identification of Plant Stomata Based on YOLO v5 Deep Learning Model. In Proceedings of the CSAI 2021: 2021 5th International Conference on Computer Science and Artificial Intelligence, Beijing, China, 4–6 December 2021. [Google Scholar]
- Wu, T.H.; Wang, T.W.; Liu, Y.Q. Real-Time Vehicle and Distance Detection Based on Improved Yolo v5 Network. In Proceedings of the 3rd World Symposium on Artificial Intelligence, Guangzhou, China, 18–20 June 2021. [Google Scholar]
- Qiu, M.; Huang, L.; Tang, B.-H. Bridge detection method for HSRRSIs based on YOLOv5 with a decoupled head. Int. J. Digit. Earth 2023, 16, 113–129. [Google Scholar] [CrossRef]
- Wang, H.; Jin, Y.; Ke, H.; Zhang, X. DDH-YOLOv5: Improved YOLOv5 based on Double IoU-aware Decoupled Head for object detection. J. Real-Time Image Process. 2022, 19, 1023–1033. [Google Scholar] [CrossRef]
- Qiu, M.; Huang, L.; Tang, B.-H. ASFF-YOLOv5: Multielement detection method for road traffic in UAV images based on multiscale feature fusion. Remote Sens. 2022, 14, 3498. [Google Scholar] [CrossRef]
- Xue, Z.; Lin, H.; Wang, F. A small target forest fire detection model based on YOLOv5 improvement. Forests 2022, 13, 1332. [Google Scholar] [CrossRef]
- Tang, H.; Liang, S.; Yao, D.; Qiao, Y. A visual defect detection for optics lens based on the YOLOv5-C3CA-SPPF network model. Opt. Express 2023, 31, 2628–2643. [Google Scholar] [CrossRef] [PubMed]
- Rahman, M.A.; Wang, Y. In Optimizing intersection-over-union in deep neural networks for image segmentation. In International Symposium on Visual Computing; Springer: Berlin/Heidelberg, Germany, 2016; pp. 234–244. [Google Scholar]
- Jiang, K.; Itoh, H.; Oda, M.; Okumura, T.; Mori, Y.; Misawa, M.; Hayashi, T.; Kudo, S.E.; Mori, K. Gaussian affinity and GIoU-based loss for perforation detection and localization from colonoscopy videos. Int. J. Comput. Assist. Radiol. Surg. 2023, 18, 795–805. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Li, H.; Gao, R.; Zhao, D. Boost 3-D Object Detection via Point Clouds Segmentation and Fused 3-D GIoU-L(1) Loss. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 762–773. [Google Scholar] [CrossRef] [PubMed]
- Xue, J.; Cheng, F.; Li, Y.; Song, Y.; Mao, T. Detection of Farmland Obstacles Based on an Improved YOLOv5s Algorithm by Using CIoU and Anchor Box Scale Clustering. Sensors 2022, 22, 1790. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Chen, Y.; Wei, Y.; Li, J. Detection of Specific Building in Remote Sensing Images Using a Novel YOLO-S-CIOU Model. Case: Gas Station Identification. Sensors 2021, 21, 1375. [Google Scholar] [CrossRef] [PubMed]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Cho, Y.-J. Weighted Intersection over Union (wIoU): A New Evaluation Metric for Image Segmentation. arXiv 2021, arXiv:2107.09858. [Google Scholar]
- Huang, K.; Li, C.; Zhang, J.; Wang, B. Cascade and fusion: A deep learning approach for camouflaged object sensing. Sensors 2021, 21, 5455. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Liu, X.; Hao, K.; Zheng, T.; Xu, J.; Cui, S. PIS-YOLO: Real-Time Detection for Medical Mask Specification in an Edge Device. Comput. Intell. Neurosci. 2022, 2022, 6170245. [Google Scholar] [CrossRef]
- Huang, L.; Huang, W. RD-YOLO: An Effective and Efficient Object Detector for Roadside Perception System. Sensors 2022, 22, 8097. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Y.; Zhao, J. MGA-YOLO: A lightweight one-stage network for apple leaf disease detection. Front. Plant Sci. 2022, 13, 927424. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Category | Number of Images |
|---|---|---|
| Missing Hole | 497 | 115 |
| Mouse Bite | 492 | 115 |
| Open-Circuit | 482 | 116 |
| Short | 491 | 116 |
| Spur | 488 | 115 |
| Spurious Copper | 503 | 116 |
| Total | 2953 | 693 |
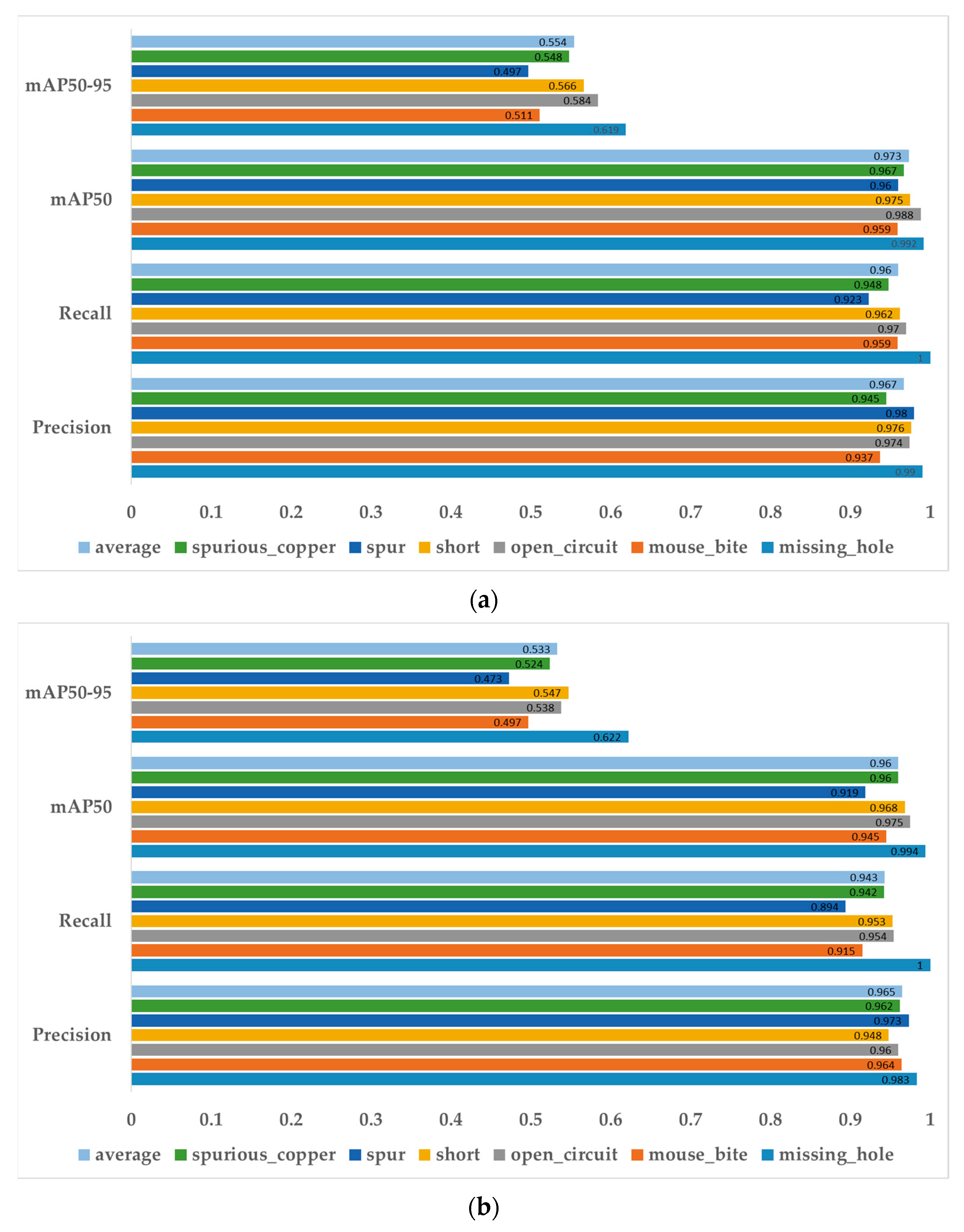
| Class | Models | Precision | Recall | mAP50 | mAP50-95 |
|---|---|---|---|---|---|
| Missing hole | YOLOv8 | 0.983 | 1 | 0.994 | 0.622 |
| W–YOLOv8 | 0.99 | 1 | 0.992 | 0.619 | |
| Mouse bite | YOLOv8 | 0.964 | 0.915 | 0.945 | 0.497 |
| W–YOLOv8 | 0.937 | 0.959 | 0.959 | 0.511 | |
| Open-circuit | YOLOv8 | 0.96 | 0.954 | 0.975 | 0.538 |
| W–YOLOv8 | 0.974 | 0.97 | 0.988 | 0.584 | |
| Short | YOLOv8 | 0.948 | 0.953 | 0.968 | 0.547 |
| W–YOLOv8 | 0.976 | 0.962 | 0.975 | 0.566 | |
| Spur | YOLOv8 | 0.973 | 0.894 | 0.919 | 0.473 |
| W–YOLOv8 | 0.98 | 0.923 | 0.96 | 0.497 | |
| Spurious copper | YOLOv8 | 0.962 | 0.942 | 0.96 | 0.524 |
| W–YOLOv8 | 0.945 | 0.948 | 0.967 | 0.548 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, P.; Xie, F. A Machine Learning Approach for Automated Detection of Critical PCB Flaws in Optical Sensing Systems. Photonics 2023, 10, 984. https://doi.org/10.3390/photonics10090984
Chen P, Xie F. A Machine Learning Approach for Automated Detection of Critical PCB Flaws in Optical Sensing Systems. Photonics. 2023; 10(9):984. https://doi.org/10.3390/photonics10090984
Chicago/Turabian StyleChen, Pinliang, and Feng Xie. 2023. "A Machine Learning Approach for Automated Detection of Critical PCB Flaws in Optical Sensing Systems" Photonics 10, no. 9: 984. https://doi.org/10.3390/photonics10090984
APA StyleChen, P., & Xie, F. (2023). A Machine Learning Approach for Automated Detection of Critical PCB Flaws in Optical Sensing Systems. Photonics, 10(9), 984. https://doi.org/10.3390/photonics10090984