1. Introduction
Convolutional Neural Networks (CNNs) are one of the most popular and successful Deep Learning (DL) models for image processing. Their basic structure comprises convolutional, pooling, and fully connected layers, which enable the network to automatically extract features from the input data [
1]. CNNs have been applied in various computer vision applications, such as image classification, object detection, and image segmentation. Nonetheless, their design requires selecting various network hyperparameters, which influence performance. In addition, no combination of them is guaranteed to provide a competitive configuration in all cases [
2,
3]. Therefore, manually designing CNNs requires DL experience, knowledge, and a considerable amount of computational resources in specialized hardware like Graphics Processing Units (GPUs) [
4,
5].
Neural Architecture Search (NAS) provides an alternative to the aforementioned problem by automating the design of the network and its hyperparameter configuration. This way, less domain expertise is required, and the by-hand trial-and-error design process is avoided [
6]. As exposed in [
7,
8], NAS can be divided into three stages: the search space, the search strategy, and the performance estimation method. The search space is determined by the selected encoding mechanism for the network architectures [
9]. The search strategy is how the search space is explored. In this case, Evolutionary Computation (EC) algorithms, as population-based meta-heuristics, are a promising approach to guide the search, giving place to the field of Evolutionary Neural Architecture Search (ENAS) [
10]. Finally, an efficient way to estimate the performance of a candidate architecture is an open problem, given that its training and testing process is costly [
11]. A situation that accumulates and demands more resources as several candidate architectures are explored during the search.
A series of efforts to reduce the computational burden of NAS, one of its main disadvantages, is shown in [
12]. Four categories of efficient evaluation methods (EEMs) are proposed: N-shot, few-shot, one-shot, and zero-shot. In N-shot methods, the number of architectures explored during the search and the number of trained architectures are the same; however, a strategy is employed to lighten the evaluations. The previous is also known as low-fidelity evaluations. Examples include using low-resolution images or a subset of the training set, and early stopping, which reduces the number of training epochs [
4,
13]. As presented in [
14], training an architecture for a few epochs allows for identifying its performance tendency, which is enough to conduct the search process.
Few-shot EEMs follow a scheme where not all architectures examined in the search are trained. Surrogate models are included in this category [
15]. An alternative useful for ENAS is population memory, where the encoding and fitness of an architecture are stored in memory. This way, if the search process finds an architecture that has been previously evaluated, the fitness is retrieved from memory, avoiding repeated evaluations [
6]. In [
16], population memory is included in a Genetic Algorithm (GA) for NAS in image classification. Population memory is also known as a cache for the search process.
One-shot EEMs perform a single training process and are based on transfer learning. Usually, a super-net is trained, and the candidate architectures are sampled from it using weight-sharing mechanisms [
11]. Finally, in zero-shot EEMs, no architecture is trained throughout the search process. Instead, training-free score functions rank the architectures [
17]. A training-free proxy is usually designed based on a theoretical analysis of Deep Neural Networks (DNNs). The proxies can be classified into two categories: gradient-based and gradient-free [
18]. A gradient-based proxy, such as the logarithm of the synaptic flow (Logsynflow) [
19], considers the network’s weights and gradient to estimate the network’s trainability. While proxies such as Linear Regions [
20] and noise immunity [
21] consider activation patterns in the network for scoring, they are deemed gradient-free.
One of the advantages of NAS is that multiple design criteria can be considered to guide the search. For example, the user can define that the search process will not only be guided by the accuracy performance of the architecture but also consider the complexity, prioritizing a model with decent performance and a reduced number of parameters. ENAS leverages the capabilities of EC algorithms to conduct single- and multi-objective optimization processes [
7].
The previous is also considered in zero-shot EEMs, where more than one proxy is used during the search. Some approaches combine proxies into a single function to conduct a single-objective optimization process, while others adopt a multi-objective process. Examples of the former include a linear combination of Logsynflow, Linear Regions, and skipped layers in [
19], as well as Linear Regions and noise immunity in [
22]. A linear combination of proxies introduces an additional complication due to the requirement of normalizing the scores to adjust their ranges. An alternative is presented in [
23] with a ranking-based method considering noise immunity, Linear Regions, and Logsynflow. Multi-objective approaches are presented in [
24], where synaptic flow is considered in conjunction with the network’s complexity, and [
25], where different proxies are tested and combined for comparison with training-based metrics to guide the search.
One of the main drawbacks of training-free proxies is presented in [
18], where a series of tested proxies derived in low correlation with test accuracy. Consequently, highly accurate architectures can be discarded in favor of low-performing ones. Most training-free NAS proposals are evaluated in benchmarks like NAS-bench-101 [
26], where a cell-based encoding is used, and limited network operations are considered for the search. In addition, a few zero-shot EEM-based works incorporate complexity limitations into the search process. Examples are presented in [
20] where the Linear Regions proxy is tested in an unconstrained and a constrained scenario; in [
24,
25] where the complexity of the network is used as an objective; and in [
27] where latency is considered in a hardware-aware network. In the opposite sense, a maximization of the number of trainable parameters and the number of convolutional layers guides the search in [
28].
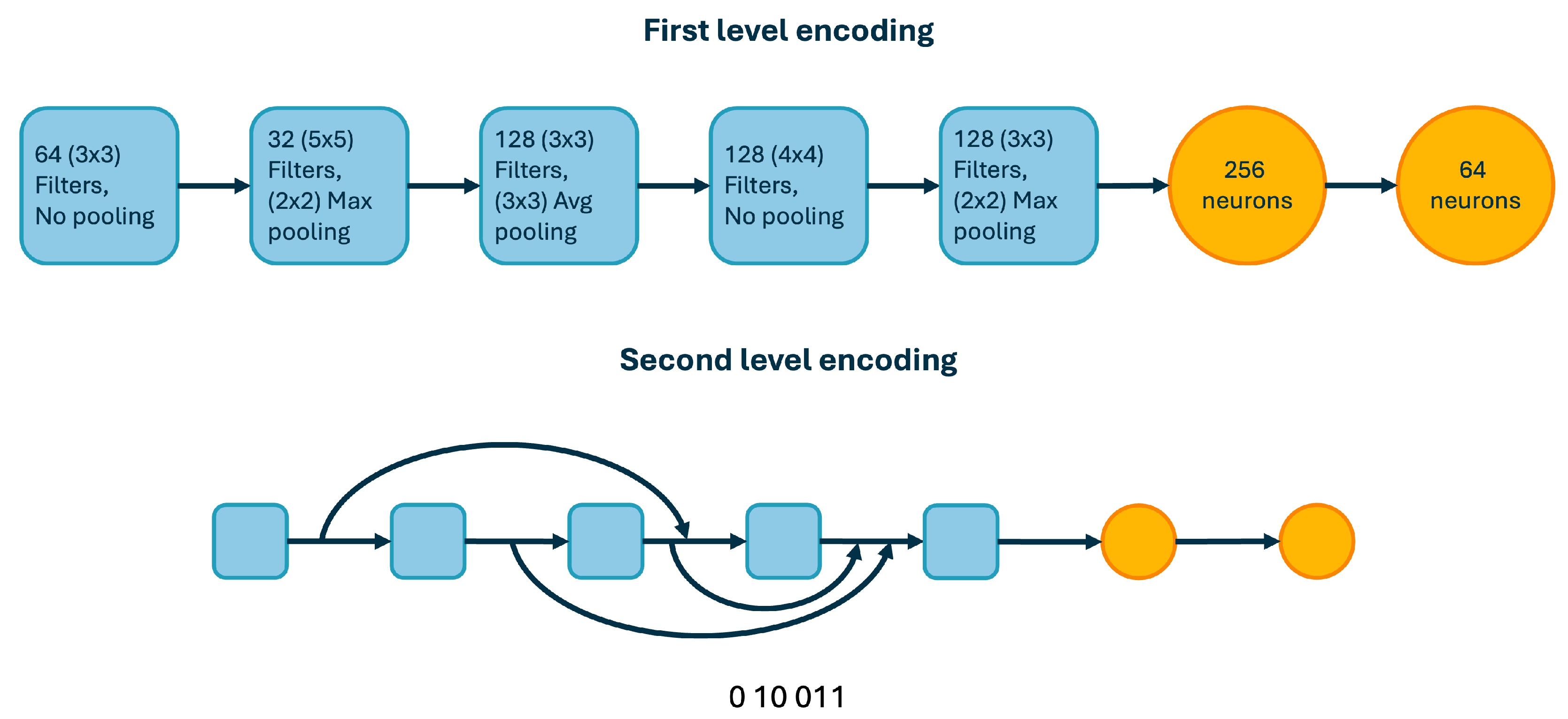
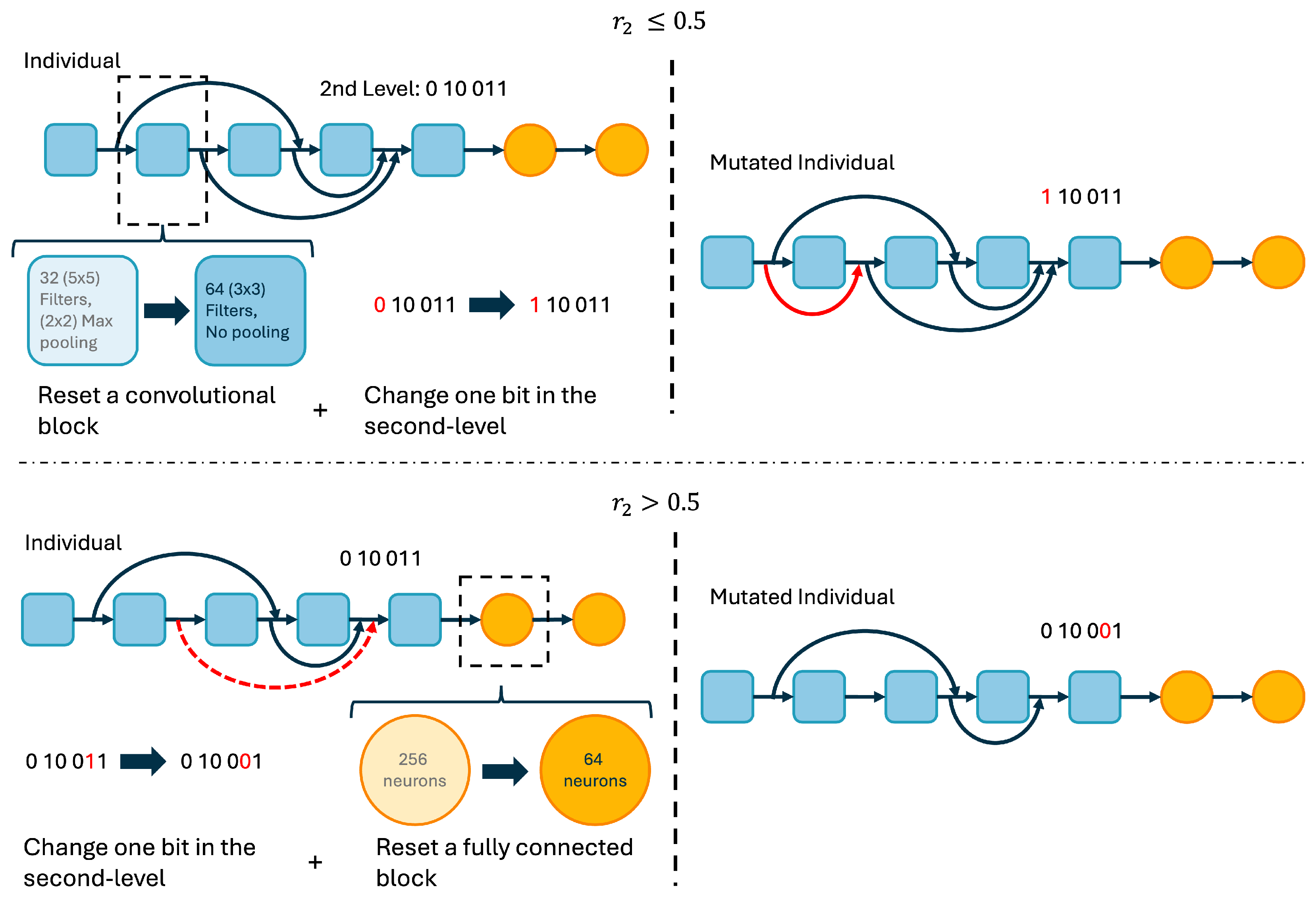
This work extends the research proposal from [
29], where cost-reduction mechanisms were applied in the Deep Genetic Algorithm (DeepGA). DeepGA was initially proposed in [
30], optimizing the design of CNNs for classifying chest X-ray images to detect COVID-19 and pneumonia cases. The algorithm employs a two-level hybrid encoding considering blocks for the configuration of the network layers at the first level and the skip connections at the second level. One key aspect of the search process is that it is guided by the performance of the network as well as its complexity, measured as the number of trainable parameters. The previous is performed with a weighted combination of both design criteria in the fitness function or through a multi-objective optimization process. DeepGA has also been applied in [
31] for breast cancer diagnosis, in [
32] for vehicle make and model recognition, in [
33] for the estimation of anthocyanins in heterogeneous and homogeneous bean landraces, and in [
34] for steering wheel angle estimation.
The EEMs tested in [
29] were early stopping, reducing the number of epochs in an evaluation, and population memory to avoid repeated evaluations. The results for the Fashion MNIST dataset [
35] indicated that the performance of DeepGA was not diminished, but a significant reduction in running time was achieved. Nonetheless, the results were limited to only one dataset with a reduced number of algorithm runs. In light of the above, the first step of this paper’s research proposal is to extend the experimentation using early stopping and population memory to more challenging datasets and analyze if the findings hold. The CIFAR-10 and CIFAR-100 datasets [
36], two benchmark datasets in image classification, are considered in addition to Fashion MNIST for evaluating the cost-reduction mechanisms. Moreover, this paper proposes a zero-shot EEM scheme for DeepGA, aiming to reduce costs further. The proposal is based on implementing the training-free proxies of Logsynflow and Linear Regions, as well as a combination of these, in the weighted fitness function of single-objective DeepGA. The above implies testing the capabilities of the zero-shot EEM approach to guide the search, where network complexity is considered as a design criterion.
The efforts to reduce the computational cost of DeepGA align with the Green Artificial Intelligence trend [
37], following a more efficient search process. This way, the search process of future applications using DeepGA to find CNN architectures is lightened, and fewer energy resources are required. The main contributions of the paper are presented next:
The effects of using the population memory and the early stopping mechanisms (5 and 10 training epochs) in the search process of DeepGA are reported using the Fashion MNIST, CIFAR-10, and CIFAR-100 datasets.
Two different training-free proxies are used to guide the search process of DeepGA with the consideration of network complexity as design criteria. Two normalization methods are tested to evaluate which one allows a more suitable implementation in the fitness function of DeepGA.
The resulting architectures from the accuracy-guided and the training-free-based search processes are compared in detail. The performance, complexity, required computational resources, and the resulting network elements and hyperparameters are analyzed to detect trends in the use of cost-reduction mechanisms.
The rest of the paper is divided into five sections.
Section 2 provides the NAS foundations.
Section 3 details the materials and methods used in this study, describing the DeepGA methods (
Section 3.1), exposing the training free proxies considered (
Section 3.2), and addressing the data used for experimentation (
Section 3.3). In
Section 4, the experimental results are displayed, including performance metrics and statistical evidence. Those are later discussed in
Section 5, where assessments are derived based on evidence from results. Finally,
Section 6 summarizes outcomes and highlights important conclusions and directions for future work.
4. Results
The experimentation was divided into two: the accuracy-guided search and the training-free search. The population memory mechanism is used in all the configurations for experimentation. For a fair comparison, the best architecture found in each run is trained for 50 epochs, a configuration proposed in [
29]. In the accuracy-guided search, the early stopping mechanism is used in DeepGA to assess the effects on the performance of the resulting architecture and the computational resources required (see
Section 4.1).
Section 4.2 presents the results of the training-free search. The normalization strategies are first evaluated using the training-free proxies. Then, the Logsynflow and linear region proxies are used independently to guide the search in DeepGA. Finally, a combination of Logsynflow and Linear Regions is used for searching. A comparison among the configurations tested is provided. At the end of this section (
Section 4.3), details of the resulting architectures from the different algorithm configurations are compared.
The experimentation consisted of ten runs for each configuration in DeepGA. The value of
w was set to 0.1 for the accuracy-guided configurations. The networks were trained using the Adam optimizer with a learning rate of
and the cross-entropy loss function. The code was executed using Google Colab Pro+ virtual environments with an NVIDIA T4 GPU. The CPU corresponds to a 2.2 GHz Intel Xeon. The code is based on the PyTorch library [
41], and the 2.6.0 version was used.
4.1. Accuracy-Guided Search
Two configurations of DeepGA are tested, considering five and ten training epochs, as in [
29], to evaluate individuals during the search and analyze the effect of early stopping mechanisms. The performance of both algorithm configurations is presented in
Table 2. The tested configurations are identified as Accuracy-10 and Accuracy-5, respectively. The Wilcoxon signed-rank test is performed for pairwise comparison, yielding p-values of 0.7519 for Fashion MNIST, 0.0273 for CIFAR-10, and 0.1930 for CIFAR-100. According to the CIFAR-10 dataset statistics, the configuration with five epochs performed better. Conversely, no significant differences were detected in the methods for the Fashion MNIST and CIFAR-100 datasets. The considerations above show that the early stopping mechanism is capable of maintaining a competitive performance while using fewer training epochs in an evaluation.
Table 3 presents the average complexity of the models considering the number of training parameters and a measure of the mega FLOPS in the model. It is observed that the Accuracy-5 configuration yielded networks with a larger number of parameters. A similar tendency is seen with the MFLOPS, with the only difference occurring with the CIFAR-100 dataset, where Accuracy-10 required more MFLOPS.
Table 4 presents the number of evaluations and the computational time required by the DeepGA configurations. The time measure is divided into the Search time of the procedure and the time needed for the final evaluation. Additionally, the reduction in search time achieved by the Accuracy-5 configuration compared to Accuracy-10 is presented. It is observed that the number of evaluations is similar between the configurations. The population memory has the effect of reducing the total number of evaluations. The search process without memory would have required 420 evaluations. This way, population memory avoids between 43% and 46% of the evaluations. The achieved time reduction ranges, on average, from 45.99% to 64.47%. As presented above, Accuracy-5 exhibits competitive performance, and it is now evident that it results in a considerable time reduction.
As mentioned earlier, 50 epochs were used to evaluate the best architecture found in each run.
Table 5 presents the mean results of the accuracy-guided search considering a longer training for the final evaluation. 100 and 200 were considered, respectively. The Wilcoxon rank sum test is also conducted based on the results of the longer training. With CIFAR-100 and Fashion MNIST, no significant difference is found in any of the cases. For CIFAR-10, the superiority of the method that uses five epochs during the search is not detected when the final evaluation is performed with 100 and 200 epochs. An interesting trend is observed in the CIFAR-100 and Fashion MNIST results, where the performance is even worse in some cases when training is longer. The previous observations can indicate overfitting in the network. More analysis and mechanisms to counter it are expected in future changes to the algorithm. Conversely, the results with CIFAR-10 improve if more training epochs are set for the final evaluation.
4.2. Training-Free Search
Logsynflow, Linear Regions, and a combination of both proxies are incorporated to guide the search in DeepGA. Nonetheless, as mentioned in
Section 3.2, the training-free proxies must be normalized to be used in the fitness function of DeepGA (Equation (
2)) as a substitute for the accuracy metric. Max and z-score normalization were tested with different values of
w to perform the search process with DeepGA. Ten runs of each configuration were conducted, and the final evaluation was omitted.
Table 6,
Table 7 and
Table 8 presents the results.
It is observed that the max-normalization guides the search towards less complex architectures when the Linear Regions proxy is used. The z-score normalization presents a more consistent behavior with both proxies, which is the desired behavior given that Logsynflow and Linear Regions will be combined to guide the search. The proxies tend to favor more complex architectures, so the value of w is crucial for finding a network configuration with limited complexity. and the z-score normalization are selected for the experimentation with the training-free proxies and their combination.
4.2.1. Fashion MNIST
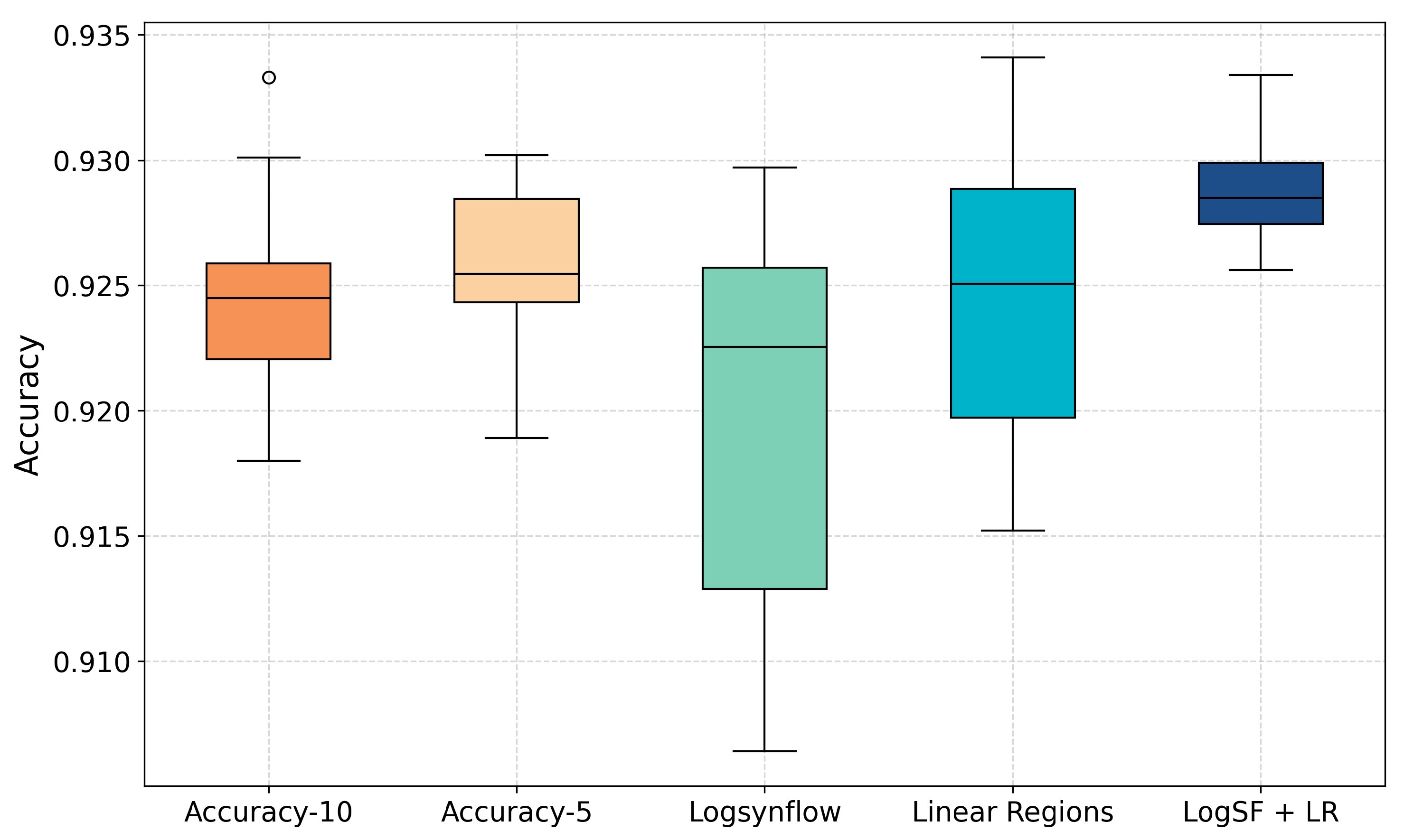
Table 9 presents the accuracy performance of the resulting architectures with the training-free proxies guiding the search using the Fashion MNIST dataset. The accuracy-guided search results are also included for comparison. It is seen that the highest values are obtained with the training-free configuration. Nonetheless, the Friedman non-parametric test is conducted to analyze if there are significant differences among the means of the populations of results. With a
p-value of 0.083, the test did not indicate a significant difference in the accuracy performance.
Figure 5 presents a boxplot of the accuracy results. It is observed that the medians of the results are positioned closely. The Logsynflow configuration has the highest standard deviation, as shown in the respective box, which spans more than the other configurations.
The comparison presented in
Table 10 corresponds to the average network complexity of the resulting models with the different configurations tested. The number of trainable parameters and the MFLOPS are included. It is observed that the training-free configurations resulted in networks with a considerably higher complexity. In the analysis of the MFLOPS, the Logsynflow configuration achieves a similar number of MFLOPS compared to the accuracy-based search. Conversely, the Linear Regions configuration and the combination of proxies have a considerably higher number of MFLOPS.
The effects of using the training-free proxies regarding the computational time are presented in
Table 11. The training-free used more evaluations. Nonetheless, the search time reduction achieved by the zero-shot approach is above 99.81%. The training-free DeepGA completes the search in a matter of seconds. Regarding the final evaluation, it is observed that the Linear Regions proxy and the combined version with Logsynflow required more time to be completed. This observation aligns with being the architectures with considerably higher MFLOPS.
4.2.2. CIFAR-10
Table 12 presents the accuracy performance of the different EEMs incorporated in DeepGA for the CIFAR-10 dataset. The highest values are obtained with the Accuracy-5 configuration.
Figure 6 presents a box plot visualization of the results. It is seen that the accuracy-guided configurations are positioned above the training-free ones. In addition, Accuracy-10 and Accuracy-5 obtained the smallest standard deviation. An interesting point to observe is that the best result of the LogSf + LR configuration is higher than the best result from Accuracy-10. Statistical tests are conducted for a deeper analysis. The Friedman test detected significant differences among the means of the populations with a
p-value of
.
The Nemenyi post-hoc test was used for a deeper analysis. The results are presented in
Table 13. In this case, Accuracy-5 outperformed all the training-free configurations. On the other hand, the Accuracy-10 configuration only outmatched the Logsynflow configuration; no significant differences were detected when compared with the Linear Regions and the combined configurations. Unlike the reported pairwise comparison of the accuracy-guided search configurations, the Nemenyi post hoc procedure did not detect significant differences between using 5 or 10 training epochs during the search. Finally, there were no significant differences among the training-free configurations, i.e., no training-free configuration was better than the others.
Table 14 presents the average complexity of the networks generated by DeepGA with the EEMs using the CIFAR-10 dataset. The trends are similar to those observed with the Fashion MNIST dataset. The training-free configurations present a considerably higher number of training parameters. Regarding the FLOPS, Linear Regions is again the configuration with the highest value, followed by the configuration with the combination of the training free proxies. Logsymflow required, on average, the least number of MFLOPS. The time comparison is presented in
Table 15. The search time reduction achieved by the zero-shot search processes exceeds 99.8%. The final evaluation took considerably more time with the Linear Regions configuration and LogSF+LR, the configurations with the highest MFLOPS values.
4.2.3. CIFAR-100
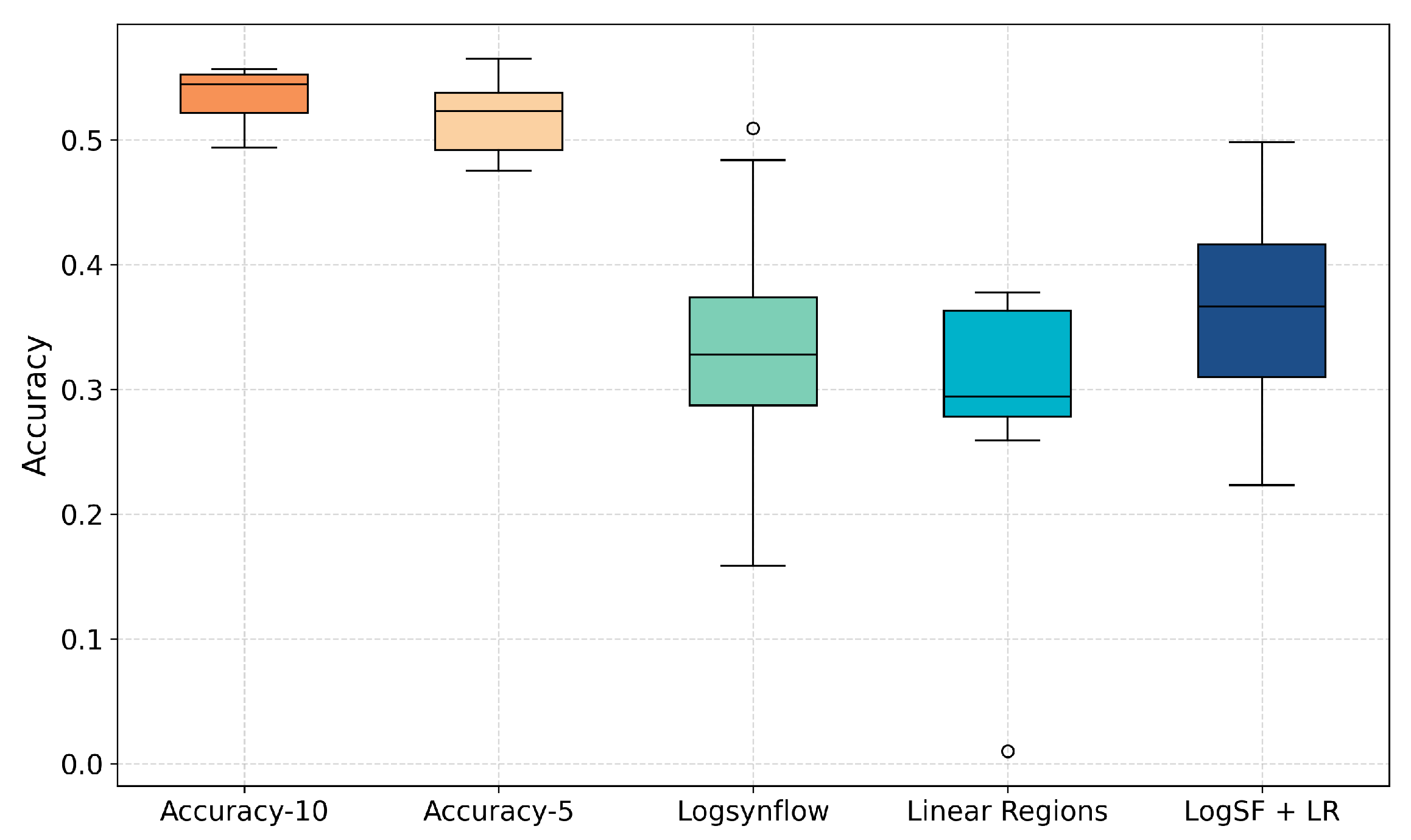
The accuracy performance of the DeepGA configurations using EEMs is presented in
Table 16, considering the CIFAR-100 dataset. It is seen that the best values are obtained with the accuracy-guided search. In this case, the Accuracy-10 is the configuration that has the highest mean value, but Accuracy-5 achieved the highest of the best values. An interesting behavior is observed in the worst cases of the training-free configurations with the CIFAR-100 dataset, where the search process resulted in architectures with particularly low performance.
Figure 7 presents a box plot with the accuracy results. It is observed that the most compact boxes correspond to the accuracy-guided configurations, which are characterized by small standard deviation values. As shown in the figure, the worst result of the Linear Regions configuration, which exhibits poor performance, is an outlier.
Statistical tests were conducted. The Friedman test detected, with a
p-value of
, that there are significant differences among the means of the results for the CIFAR-100 dataset. The Nemenyi post hoc procedure is then used. The details are presented in
Table 17. It is seen that Accuracy-10 outperformed all of the training-free configurations. Nonetheless, no significant differences were detected when considering Accuracy-5 and the Logsynflow and LogSF + LR configurations. Additionally, no significant differences were observed among the training-free configurations.
The network complexity comparison for the CIFAR-100 datasets is presented in
Table 18. Similarly to the other datasets, the trends in the number of parameters are that the training-free configurations resulted in higher network complexity. Nonetheless, the average number of parameters from Accuracy-5 is closer to the values of LogSf + LR than the same comparison with Fashion MNIST and CIFAR-10. The Linear Regions proxy exhibits consistent behavior in MFLOPS; it is again the configuration that requires a considerably higher number of MFLOPS.
Table 19 presents the time comparison for the CIFAR-100 dataset. The number of evaluations is higher in the training-free search process. However, the reduced cost of each evaluation in the zero-shot approaches is minimal compared to the accuracy-guided search. Therefore, the search time is immensely reduced by at least 97.42%. The final evaluations in the Linear Regions and LogSF + LR configurations are the most expensive.
4.3. Comparison of the Architectures
The first step in comparing the resulting architectures across different configurations of DeepGA with EEMs is to visualize the differences in the elements considered for the networks.
Figure 8 presents the architectures from the best result of each configuration with the CIFAR-10 dataset (
Table 12 presents their accuracy performance). The differences are evident. The accuracy-guided configurations considered resulted in architectures with no skip connections. The training-free search obtained deeper networks, which aligns with their larger number of parameters. The network with more convolutional layers (9) was the one obtained with the Linear Regions configuration. In addition, 15 skip connections were considered.
From
Figure 8, the top-performing architecture is the one from Accuracy-5, which is the one presented in the figure with the smallest depth. The main difference between Accuracy-5 and Accuracy-10 in this case is the number of fully connected layers. The architecture with the second-best performance is the one from LogSF + LR, which features the most significant number of fully connected layers. The above observations demonstrate the difficulty in designing CNNs; there is a large number of possible designs and many paths that can be explored. Thus, the importance of NAS lies in automating the design process.
For a deeper understanding of the differences in the resulting architectures from the different DeepGA configurations, a comparison among their characteristics is presented in this subsection. For each architecture, the mean values of the following design and hyperparameter configurations are considered:
Number of convolutional layers.
Number of fully connected layers.
Average number of filters per convolutional layer.
Average filter size selected for the convolutional layers.
Average number of neurons per fully connected layer.
The frequency of using max pooling.
The frequency of using average pooling.
Average kernel size for pooling.
Number of skip connections.
The results are presented in
Table 20 for the Fashion MNIST dataset, in
Table 21 for CIFAR-10, and in
Table 22 for the CIFAR-100 dataset.
The training-free configurations yielded deeper networks, featuring more convolutional and fully connected layers. Notably, it is observed that the accuracy-guided resulting architectures have a reduced number of fully connected layers, whereas the training-free configurations select more of them. With the accuracy-guided configurations, the primary difference observed between the configurations for the CIFAR-100 and CIFAR-10 datasets is the number of neurons in the fully connected layers. The previous explains the additional complexity of the CIFAR-100 architectures. Finally, the number of skip connections is considerably higher in the architectures from the training-free configurations.
Focusing on the number of filters per convolutional layer and the number of neurons in the fully connected ones, interesting patterns emerge. Linear Regions is the configuration that positions more filters on average in the convolutional layers. The behavior is consistent for the three datasets. In addition, Linear Regions positions a small number of neurons in the fully connected layers, as evident in the descriptions of the architectures for the CIFAR-100 dataset. On the other hand, Logsynflow consistently places more neurons in the fully connected layers and fewer filters in the convolutional layers. The combination of the proxies results in a middle point for both values.
5. Discussion
Early stopping, population memory, and training-free proxies are used in this paper as EEMs for NAS. Each of the mechanisms accelerated the search process of DeepGA in designing CNNs for image classification. First, as proposed in [
29], 5 and 10 training epochs are used for the accuracy-based search process. The results showed that performing the search with only 5 epochs provides competitive results compared to the 10-epoch configuration. Consequently, time reductions of 45.99%, 64.47%, and 53.15% are achieved for Fashion MNIST, CIFAR-100, and CIFAR-10, respectively. Nonetheless, the resulting architecture is more complex with Accuracy-5.
Using the z-score normalization with a sigmoid function for scaling the training-free proxies resulted in a more consistent behavior than max normalization. The approach mentioned above enables the incorporation of training-free proxies into fitness functions that combine more than one proxy, as well as considering other design criteria, such as complexity limitations in DeepGA. The results showed that the training-free methods were partially competitive compared to the accuracy-guided search. The training-free methods were competitive with the Fashion MNIST data. In addition, no significant differences were detected in particular comparison cases, like Accuracy-5 and Logsynflow in CIFAR-100, or Linear Regions and Accuracy-10 in CIFAR-10. Nonetheless, in both datasets, an accuracy-based configuration outperformed all training-free configurations. It was observed that as the difficulty of the dataset increases, the proxies struggle to remain competitive.
No training-free configuration outperformed the others: using a combination of proxies does not yield better performance than using one of them independently. Nevertheless, it was observed that the resulting architectures from the combination of proxies presented trade-offs for particular network characteristics, such as the number of filters and number of neurons per convolutional and fully connected layers, respectively. The key point for using training-free proxies as EEMs is the expected high time reduction, which is confirmed in the results with a computational time reduction of above 99%. The comparison of the characteristics from the resulting architectures showed that the training-free configurations found deeper networks with considerably more fully connected layers and used more skip connections. Those network characteristics imply that training-free configurations tend to find more complex architectures than accuracy-based ones. Notably, the configurations that considered the Linear Regions proxy resulted in considerably more FLOPS than the other configurations, thereby increasing the time required for the final evaluation.
Lastly, the population memory mechanism enabled DeepGA to avoid more than 40% of the evaluations in the accuracy-based configurations and at least 20% of them in the training-free configurations. The percentage of avoided evaluations indicates the number of repeated architectures that the algorithm explores. It provides insights into the work of the selected variation operators of an EC algorithm and its parameter configuration.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}