
A Deep Learning Approach to Unveil Types of Mental Illness by Analyzing Social Media Posts


Abstract
1. Introduction
- A multiclass classification framework is developed using LSTM to identify a wide array of mental disorders, including depression, anxiety, bipolar disorder, Post-Traumatic Stress Disorder (PTSD), schizophrenia, suicidal ideation, and a neutral category.
- The effectiveness of the LSTM-based model is also validated by comparing its performance against three traditional ML models, LR, RF, and MNB.
- Along with feature engineering, this study also examines how data balancing improves LSTM’s performance in handling the multiclass classification problem with an unbalanced dataset.
2. Materials and Methods
2.1. Dataset Description
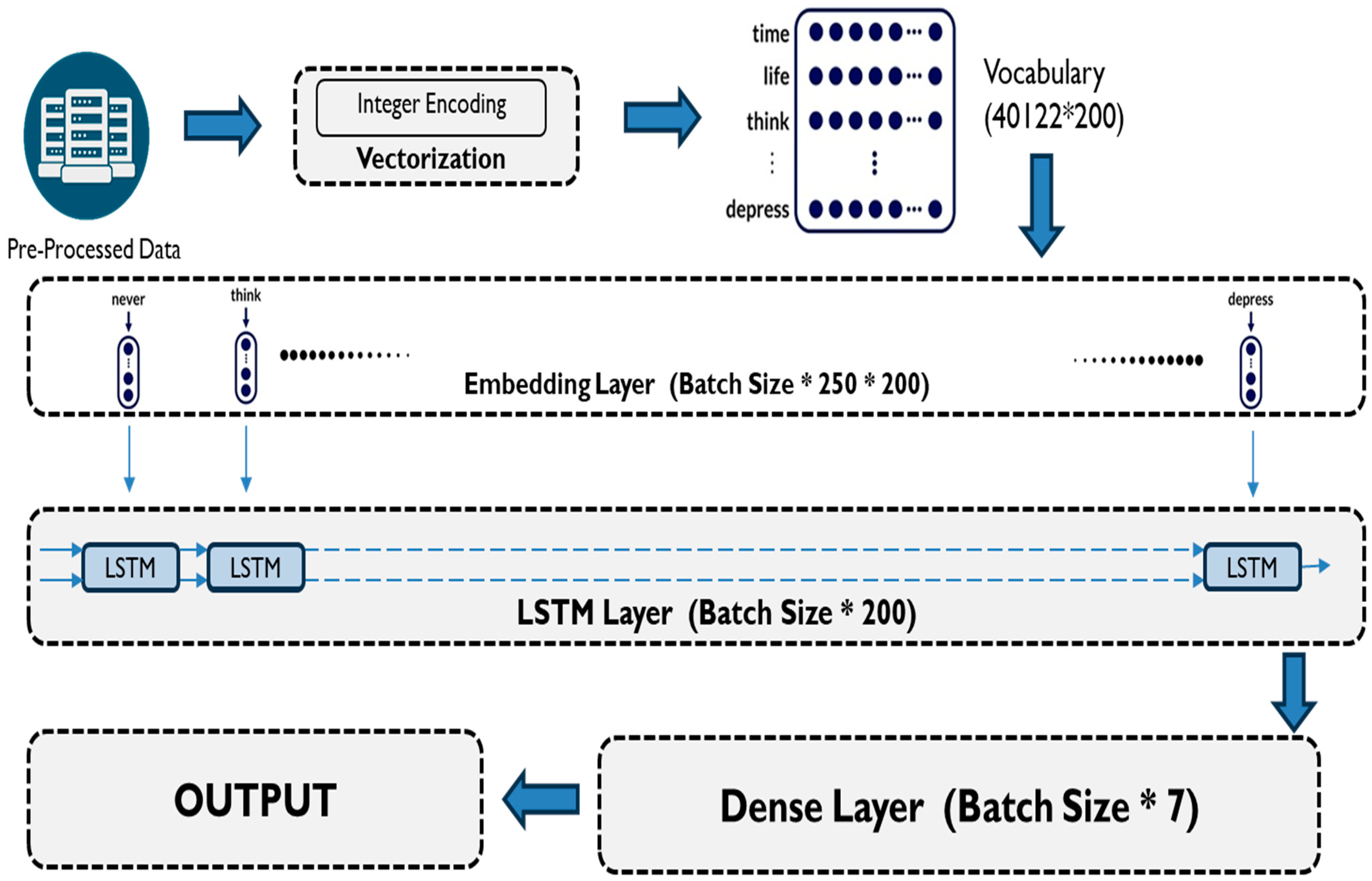
2.2. Proposed Model for Predicting Type of Mental Illness Through Social Media Post Analysis
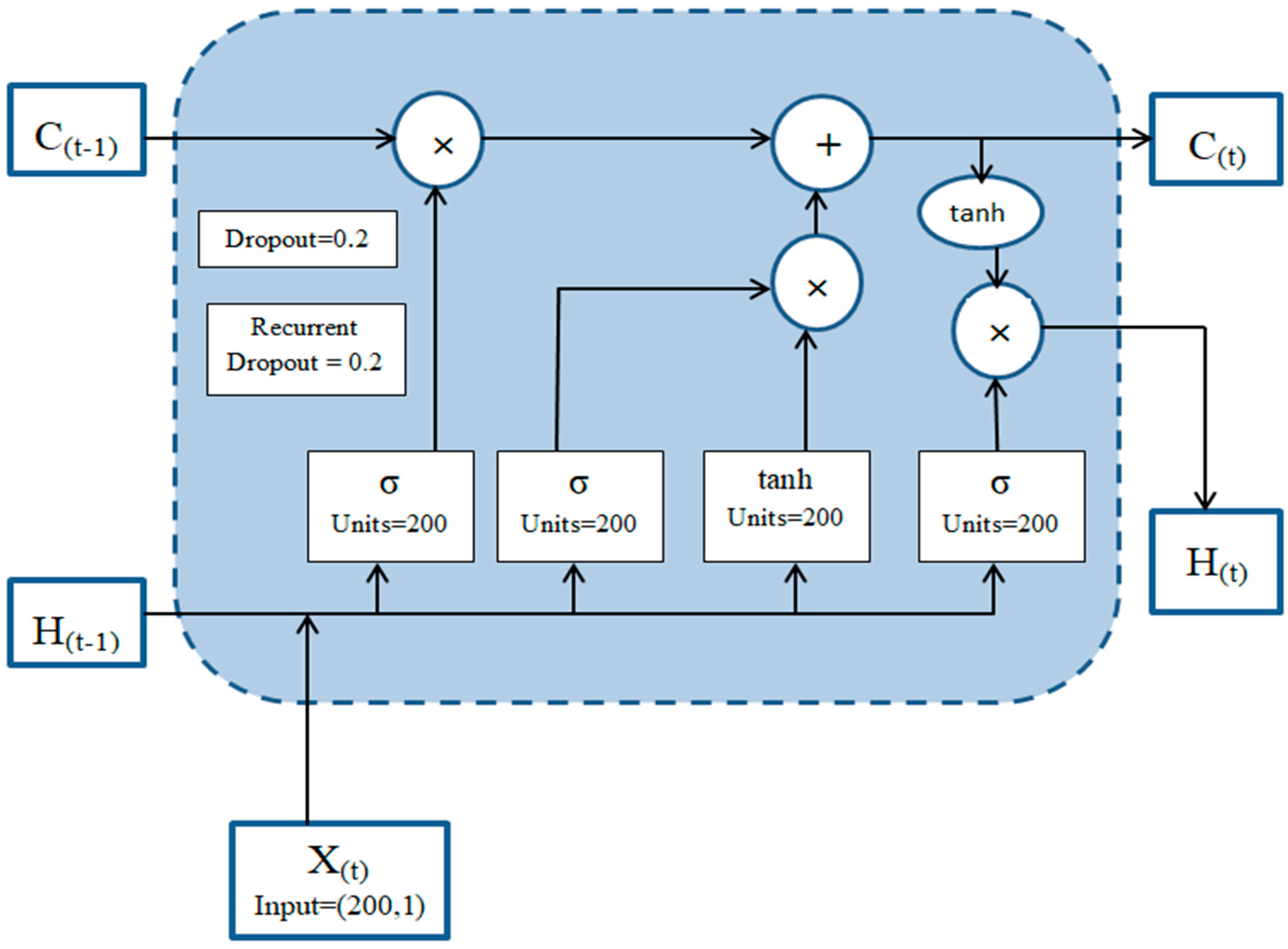
- Input and Hidden State Combination: At each step, the current word embedding layer is combined with the hidden state obtained from the previous step. This integration ensures that the model considers both the current input and the contextual information from prior words.
- Gate Control and Information Flow: The LSTM unit’s internal gates (forget gate, input gate, and output gate) play a pivotal role in controlling the flow of information within the cell. These gates determine which aspects of the past are relevant to remember and which can be forgotten, allowing for selective memory retention.
- New Hidden State Generation: The LSTM unit generates a new hidden state that encapsulates the most pertinent information from the current word and the contextual cues derived from previous words. This new hidden state then serves as the input for the next step in the sequence, perpetuating the learning process.
3. Experimentation and Results
4. Discussion
- Multiclass mental illness prediction. Unlike many studies that focus on detecting the presence or absence of a single mental health condition, this project aims to classify users into a range of potential mental illnesses. This multiclass approach provides a more nuanced and comprehensive understanding of mental health in the digital sphere.
- LSTM-based classification. The project leverages the power of LSTM networks, a type of deep learning algorithm particularly adept at understanding sequential data like text. This allows the model to capture complex relationships between words and phrases within social media posts, potentially revealing subtle linguistic patterns indicative of specific mental health conditions. The dataset is created as a 74,824 × 250 × 200 matrix and is fed into the LSTM model.
- Comparative analysis with data balancing. By recognizing the challenges posed by imbalanced datasets in mental health research, this study investigates the impact of data balancing on model performance by taking different target values, namely 910, 8000, and 12,000. This rigorous evaluation ensures the model’s reliability and generalizability across various mental health categories.
Ablation Analysis
- Table 5 shows that with an accuracy of 74%, LR utilizing the TF-IDF vectorizer outperforms MNB and RF. Analyzing the outcomes of the three ML models with and without FS clearly reveals that LR performs better than RF and MNB with the TF-IDF vectorizer with respect to all criteria.
- When analyzing the effect of FS on the LR and LSTM models, as indicated in Table 7, it is observed that the LSTM model achieves an accuracy of 77% with 200 features selected using the embedded matrix, whereas the LR model achieves an accuracy of 75% with 15,000 features selected by Chi-square. By employing Chi-square, the accuracy of LR is increased by 13.5%. However, using Chi-square with LSTM does not yield satisfactory results. Rather, LSTM outperforms LR when utilizing the pre-trained embedded matrix with just 200 features.
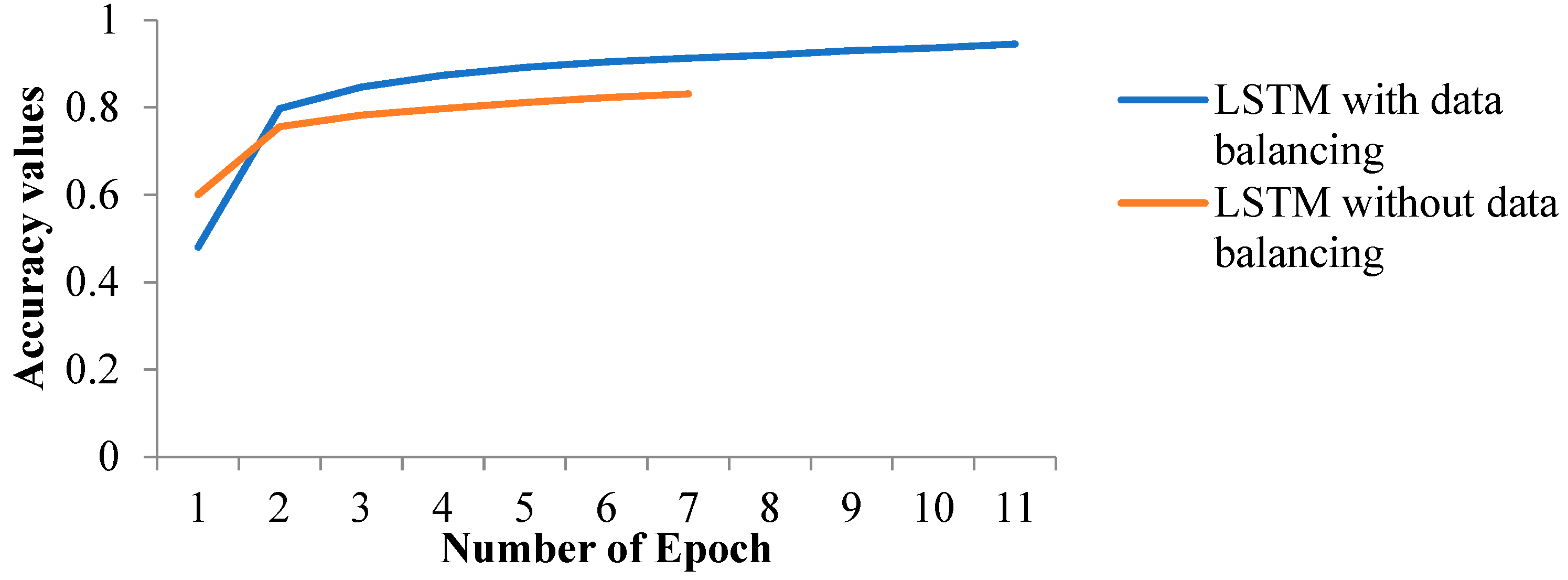
- Furthermore, when analyzing the performance of the LSTM model with different data balancing techniques, as shown in Table 8, it is clear that the hybrid data balancing technique using random sampling in oversampling and undersampling showed impressive results, and the accuracy of LSTM increases to 88% from 77%, while the Hamming loss is reduced to 0.04.
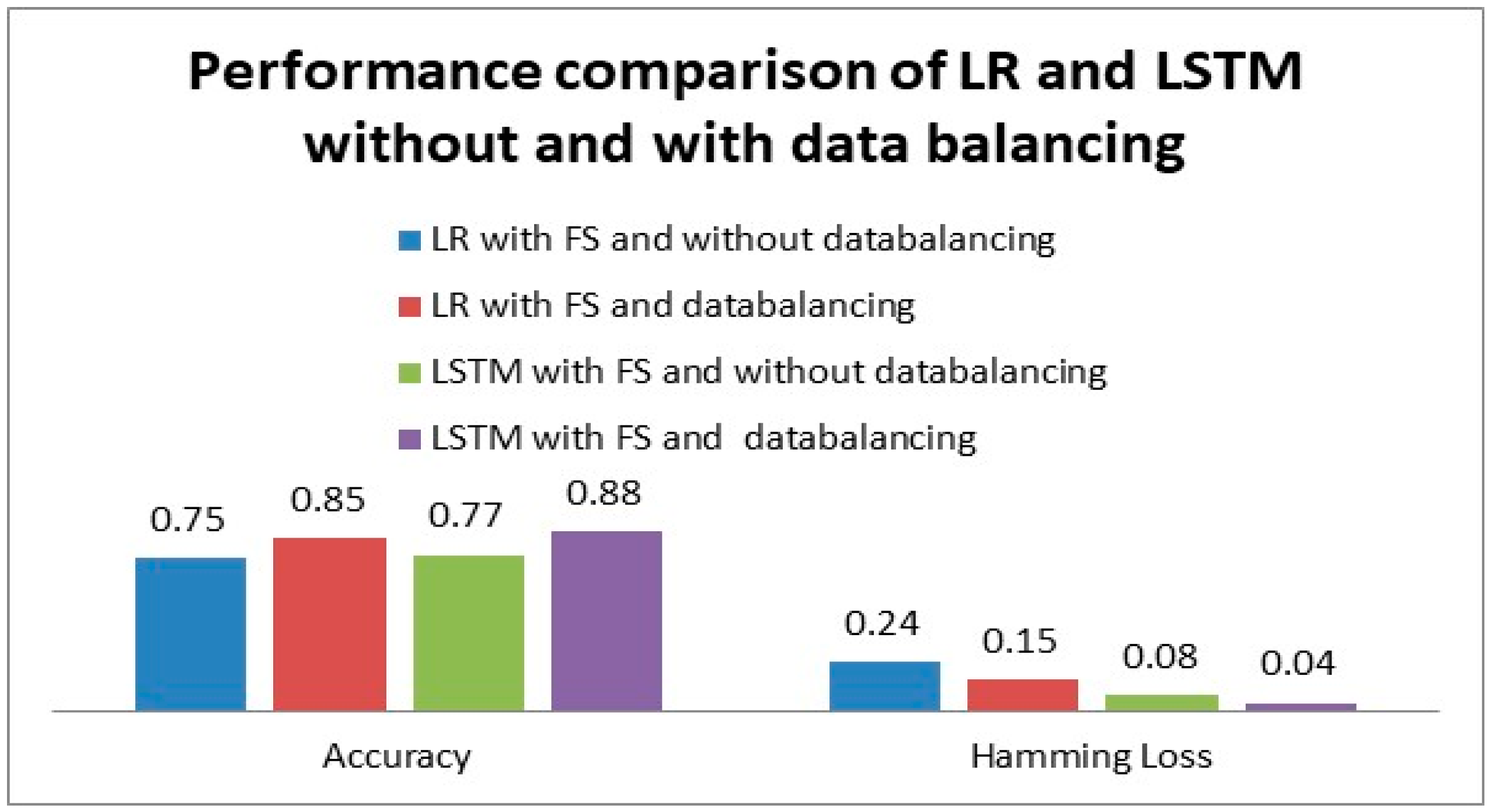
- Using the reduced feature set and the same balanced dataset used for LSTM, the impact of data balancing on LR is further examined. As shown in Figure 5, it is found that data balancing improves LR’s accuracy from 0.75 to 0.85 and lowers the Hamming loss from 0.24 to 0.15.
- When the performance of LSTM and LR is compared with the same balanced dataset using a reduced feature set, it is evident from Figure 5 that LSTM performs better than LR, improving accuracy by 3.5% and Hamming loss by 73%. Overall, data balancing improves both models, with LSTM showing a greater relative gain.
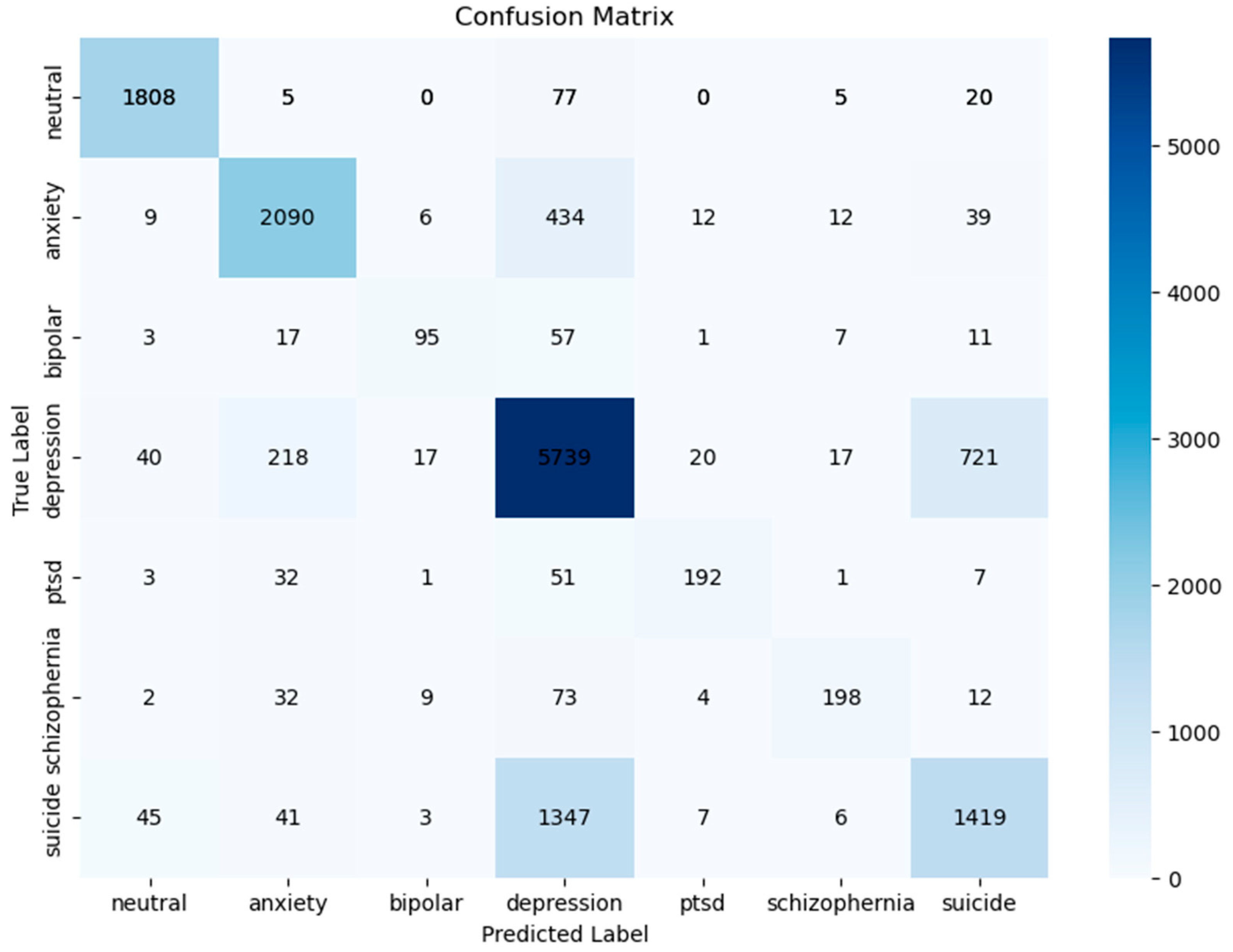
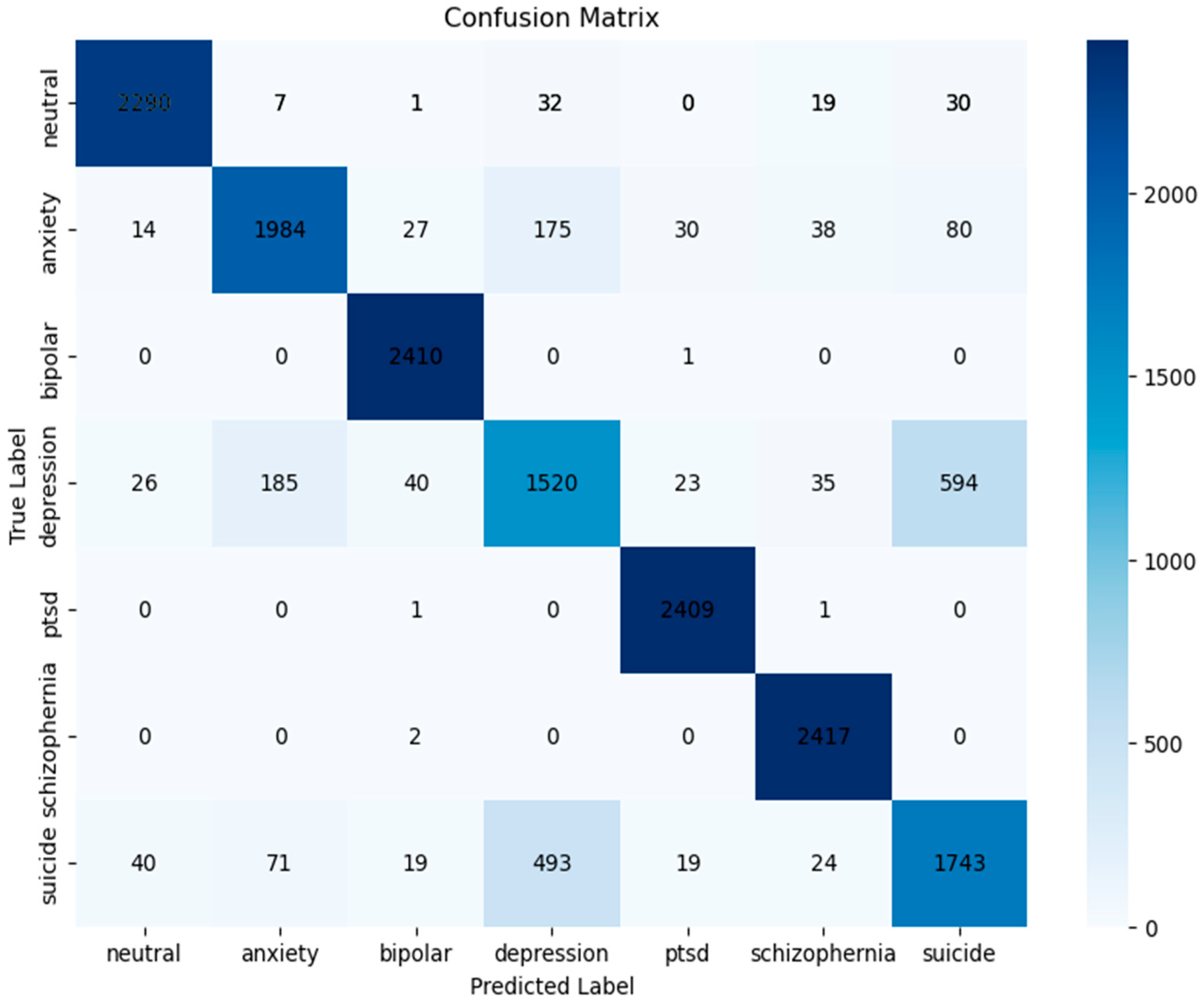
- From the visual comparison of the confusion matrix depicted in Figure 6 and Figure 7, it is observed that the model exhibits a more uniform distribution of prediction across classes when balancing is used. This implies that data balancing improves overall classification across all categories by reducing the model’s propensity to favor the majority class.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Joshi, D.; Patwardhan, M. An analysis of mental health of social media users using unsupervised approach. Comput. Hum. Behav. Rep. 2020, 2, 100036. [Google Scholar] [CrossRef]
- Chancellor, S.; De Choudhury, M. Methods in predictive techniques for mental health status on social media: A critical review. NPJ Digit. Med. 2020, 3, 43. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Schoene, A.M.; Ji, S.; Ananiadou, S. Natural language processing applied to mental illness detection: A narrative review. NPJ Digit. Med. 2022, 5, 46. [Google Scholar] [CrossRef]
- Chung, J.; Teo, J. Mental health prediction using machine learning: Taxonomy, applications, and challenges. Appl. Comput. Intell. Soft Comput. 2022, 2022, 9970363. [Google Scholar] [CrossRef]
- Garg, M. Mental health analysis in social media posts: A survey. Arch. Comput. Methods Eng. 2023, 30, 1819–1842. [Google Scholar] [CrossRef]
- Safa, R.; Edalatpanah, S.A.; Sorourkhah, A. Predicting mental health using social media: A roadmap for future development. In Deep Learning in Personalized Healthcare and Decision Support; Academic Press: Cambridge, MA, USA, 2023; pp. 285–303. [Google Scholar]
- Aldarwish, M.M.; Ahmad, H.F. Predicting depression levels using social media posts. In Proceedings of the 2017 IEEE 13th International Symposium on Autonomous decentralized system (ISADS), Bangkok, Thailand, 22–24 March 2017; pp. 277–280. [Google Scholar]
- Hao, B.; Li, L.; Li, A.; Zhu, T. Predicting mental health status on social media: A preliminary study on microblog. In Cross-Cultural Design. Cultural Differences in Everyday Life: 5th International Conference, CCD 2013, Held as Part of HCI International 2013, Las Vegas, NV, USA, 21–26 July 2013; Proceedings; Part II 5; Springer: Berlin/Heidelberg, Germany, 2013; pp. 101–110. [Google Scholar]
- Thorstad, R.; Wolff, P. Predicting future mental illness from social media: A big-data approach. Behav. Res. Methods 2019, 51, 1586–1600. [Google Scholar] [CrossRef]
- Hussain, S.; Nasir, A.; Aslam, K.; Tariq, S.; Ullah, M.F. Predicting mental illness using social media posts and comments. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 607–613. [Google Scholar]
- Ansari, G.; Garg, M.; Saxena, C. Data augmentation for mental health classification on social media. arXiv 2021, arXiv:2112.10064. [Google Scholar]
- Vaishnavi, K.; Kamath, U.N.; Rao, B.A.; Reddy, N.S. Predicting mental health illness using machine learning algorithms. J. Phys. Conf. Ser. 2022, 2161, 012021. [Google Scholar]
- Kim, J.; Lee, J.; Park, E.; Han, J. A deep learning model for detecting mental illness from user content on social media. Sci. Rep. 2020, 10, 11846. [Google Scholar] [CrossRef]
- Ang, C.S.; Venkatachala, R. Generalizability of Machine Learning to Categorize Various Mental Illness Using Social Media Activity Patterns. Societies 2023, 13, 117. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Dysthe, K.K.; Følstad, A.; Brandtzaeg, P.B. Deep learning for prediction of depressive symptoms in a large textual dataset. Neural Comput. Appl. 2022, 34, 721–744. [Google Scholar] [CrossRef]
- Kour, H.; Gupta, M.K. An hybrid deep learning approach for depression prediction from user tweets using feature-rich CNN and bi-directional LSTM. Multimed. Tools Appl. 2022, 81, 23649–23685. [Google Scholar] [CrossRef]
- Murarka, A.; Radhakrishnan, B.; Ravichandran, S. Detection and classification of mental illnesses on social media using roberta. arXiv 2020, arXiv:2011.11226. [Google Scholar]
- Narayanan, S.R.; Babu, S.; Thandayantavida, A. Detection of depression from social media using deep learning approach. J. Posit. Sch. Psychol. 2022, 6, 4909–4915. [Google Scholar]
- Bokolo, B.G.; Liu, Q. Deep learning-based depression detection from social media: Comparative evaluation of ml and transformer techniques. Electronics 2023, 12, 4396. [Google Scholar] [CrossRef]
- Alkahtani, H.; Aldhyani, T.H.; Alqarni, A.A. Artificial Intelligence Models to Predict Disability for Mental Health Disorders. J. Disabil. Res. 2024, 3, 20240022. [Google Scholar] [CrossRef]
- Bhavani, B.H.; Naveen, N.C. An Approach to Determine and Categorize Mental Health Condition using Machine Learning and Deep Learning Models. Eng. Technol. Appl. Sci. Res. 2024, 14, 13780–13786. [Google Scholar] [CrossRef]
- Revathy, J.S.; Maheswari, N.U.; Sasikala, S.; Venkatesh, R. Automatic diagnosis of mental illness using optimized dynamically stabilized recurrent neural network. Biomed. Signal Process. Control 2024, 95, 106321. [Google Scholar]
- Ezerceli, Ö.; Dehkharghani, R. Mental disorder and suicidal ideation detection from social media using deep neural networks. J. Comput. Soc. Sci. 2024, 7, 2277–2307. [Google Scholar] [CrossRef]
- Zhu, L.; Hou, S.; Cheng, T. Mental Health Status Detection Model Based on LSTM Neural Network. Procedia Comput. Sci. 2024, 243, 842–849. [Google Scholar] [CrossRef]
- Bendebane, L.; Laboudi, Z.; Saighi, A.; Al-Tarawneh, H.; Ouannas, A.; Grassi, G. A Multi-class deep learning approach for early detection of depressive and anxiety disorders using Twitter data. Algorithms 2023, 16, 543. [Google Scholar] [CrossRef]
- Karamat, A.; Imran, M.; Yaseen, M.U.; Bukhsh, R.; Aslam, S.; Ashraf, N. A Hybrid Transformer Architecture for Multiclass Mental Illness Prediction using Social Media Text. IEEE Access 2024, 13, 12148–12167. [Google Scholar] [CrossRef]
- Yang, K.; Zhang, T.; Kuang, Z.; Xie, Q.; Huang, J.; Ananiadou, S. MentaLLaMA: Interpretable mental health analysis on social media with large language models. In Proceedings of the ACM Web Conference 2024, Singapore, 13–17 May 2024; pp. 4489–4500. [Google Scholar]
- Low, D.M.; Rumker, L.; Torous, J.; Cecchi, G.; Ghosh, S.S.; Talkar, T. Natural Language Processing Reveals Vulnerable Mental Health Support Groups and Heightened Health Anxiety on Reddit During COVID-19: Observational Study. J. Med. Internet Res. 2020, 22, e22635. Available online: https://zenodo.org/records/3941387#.Y5L6O_fMKUl (accessed on 27 December 2024.). [CrossRef]
- He, H.; Ma, Y. (Eds.) Imbalanced Learning: Foundations, Algorithms, and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Padurariu, C.; Breaban, M.E. Dealing with data imbalance in text classification. Procedia Comput. Sci. 2019, 159, 736–745. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Wang, Q. A hybrid sampling SVM approach to imbalanced data classification. In Abstract and Applied Analysis; Hindawi Publishing Corporation: New York, NY, USA, 2014; Volume 2014, p. 972786. [Google Scholar]
- Koziarski, M. CSMOUTE: Combined synthetic oversampling and undersampling technique for imbalanced data classification. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Ependi, U.; Rochim, A.F.; Wibowo, A. A hybrid sampling approach for improving the classification of imbalanced data using ROS and NCL methods. Int. J. Intell. Eng. Syst. 2023, 16, 345–361. [Google Scholar]
- Wongvorachan, T.; He, S.; Bulut, O. A comparison of undersampling, oversampling, and SMOTE methods for dealing with imbalanced classification in educational data mining. Information 2023, 14, 54. [Google Scholar] [CrossRef]


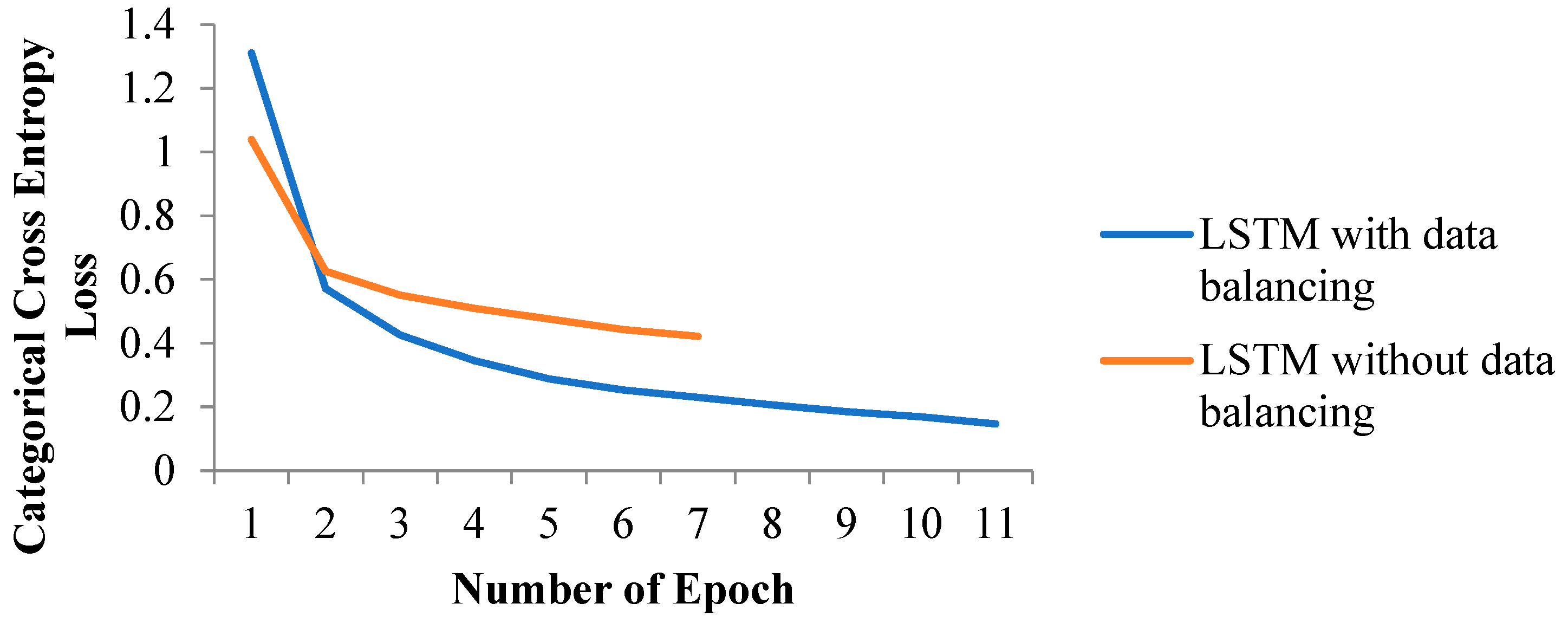

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Techniques Used | Dataset Used | Evaluation Metrics Used | Type of Classification | Research Limitations |
|---|---|---|---|---|---|
| [7] | SVM, NB | Facebook, Live Journal, and Twitter dataset | Accuracy, Precision, Recall | Binary |
|
| [8] | SVM, NB | Sina Weibo dataset | RAE, RRSE, Pearson Correlation Coefficient, Accuracy | Binary |
|
| [9] | L2-Penalized LR | Reddit dataset | Accuracy, Precision, Recall, F1-score, Clustering Analysis | Multiclass (4 classes) |
|
| [10] | XGBoost, NB, SVM | Reddit dataset | Accuracy, Precision, Recall, F1-score | Multiclass (4 classes) |
|
| [11] | RF, SVM, LR | Reddit dataset and SDCNL dataset | Precision, Recall, F1-score, t-test, p-value | Binary |
|
| [12] | LR, KNN, Decision Tree, RF, | Reddit dataset | Accuracy, ROC Curve | Binary |
|
| [13] | XGBoost, CNN | Reddit dataset | Accuracy, Precision, Recall, F1-score | Binary |
|
| [14] | CNN | Twitter, Reddit | Accuracy, Precision, Recall, F1-score | Binary |
|
| [15] | LSTM, RNN | Norwegian information website ung.no | Accuracy, Precision, Recall, F1-score, Support | Binary |
|
| [16] | CNN, RNN, LSTM, CNN-biLSTM | Twitter dataset | Accuracy, Precision, Recall, F1-score, Error Rate, AUC curve | Binary |
|
| [17] | LSTM, BERT, RoBERTa | Reddit dataset | Accuracy, Precision, Recall, F1-score | Multiclass (6 classes) |
|
| [18] | CNN, LSTM, Hybrid CNN-LSTM | Twitter dataset | Accuracy, Precision, Recall, F1-score, Support | Binary |
|
| [19] | LR, NB, RF, BERT, RoBERT | Twitter dataset | Accuracy, Precision, Recall, F1-score, Confusion Matrix Diagram | Binary |
|
| [20] | KNN, RF, LSTM | Mental health disorder dataset Kaggle | Accuracy, Precision, Recall, F1-score | Multiclass (12 classes) |
|
| [21] | LSTM, KNN, RF, SVM, LR, ADABoost | Self-prepared dataset through questionnaires | Accuracy, Precision, Recall, F1-score | Binary |
|
| [22] | RNN, CNN, SVM | OSMI dataset | Accuracy, F1-score | Binary |
|
| [23] | RNN, CNN, LSTM, BERT, SVM, NB, RF, LR, DT | Reddit dataset | AUC, Precision, Recall, F1-score | Binary |
|
| [24] | LSTM | Self-prepared dataset | Accuracy, Precision, Recall | Binary |
|
| [25] | CNN-BiGRU, CNN-BiLSTM CNN-BiRNN, CNN-GRU, CNN-LSTM, CNN-RNN | Twitter dataset | Accuracy, F1-score | Multiclass (3 classes) |
|
| [26] | Hybrid transformer (MentalBERT/MelBERT)-based CNN, BiLSTM-CNNBERT/RoBERTa (CNN) | Reddit dataset | Accuracy, Precision, Recall, F1-score | Multiclass (4 classes) |
|
| [27] | LLaMA, BERT, RoBERTa, MentalBERT, MentalRoBERTa | IMHI dataset | Weighted F1-score, BART Score | Multiclass (6 classes) |
|
| Name of Class | No. of Posts |
|---|---|
| Neutral | 9628 |
| Anxiety | 13,211 |
| Bipolar Disorder | 910 |
| Depression | 33,549 |
| PTSD | 1397 |
| Schizophrenia | 1548 |
| Suicide | 14,581 |
| Total | 74,824 |
| Classifier | Parameters |
|---|---|
| LR |
|
| RF |
|
| MNB |
|
| LSTM |
|
| Name of Class | No. of Posts | No. of Posts (Training) | No. of Posts (Testing) |
|---|---|---|---|
| Neutral | 12,000 | 9621 | 2379 |
| Anxiety | 12,000 | 9652 | 2348 |
| Bipolar Disorder | 12,000 | 9589 | 2411 |
| Depression | 12,000 | 9577 | 2423 |
| PTSD | 12,000 | 9589 | 2411 |
| Schizophrenia | 12,000 | 9581 | 2419 |
| Suicide | 12,000 | 9591 | 2409 |
| Total | 84,000 | 67,200 | 16,800 |
| Classifier | Vectorizer | Accuracy | Precision | Recall | F1-Score | Hamming Loss |
|---|---|---|---|---|---|---|
| LR | TF-IDF | 0.74 | 0.81 | 0.62 | 0.68 | 0.25 |
| MNB | TF-IDF | 0.52 | 0.58 | 0.22 | 0.22 | 0.47 |
| RF | TF-IDF | 0.66 | 0.62 | 0.38 | 0.38 | 0.33 |
| LR | Count | 0.73 | 0.74 | 0.66 | 0.69 | 0.26 |
| MNB | Count | 0.67 | 0.72 | 0.49 | 0.55 | 0.32 |
| RF | Count | 0.66 | 0.58 | 0.37 | 0.37 | 0.33 |
| Classifier | Vectorizer | Accuracy | Precision | Recall | F1-Score | Hamming Loss |
|---|---|---|---|---|---|---|
| LR | TF-IDF | 0.75 | 0.82 | 0.63 | 0.69 | 0.24 |
| MNB | TF-IDF | 0.57 | 0.55 | 0.27 | 0.28 | 0.42 |
| RF | TF-IDF | 0.67 | 0.66 | 0.40 | 0.41 | 0.32 |
| LR | Count | 0.73 | 0.75 | 0.66 | 0.70 | 0.26 |
| MNB | Count | 0.68 | 0.67 | 0.60 | 0.63 | 0.31 |
| RF | Count | 0.67 | 0.59 | 0.40 | 0.40 | 0.32 |
| Model | Number of Features | Accuracy | Precision | Recall | F1-Score | Hamming Loss |
|---|---|---|---|---|---|---|
| LR + TF-IDF + Chi-square | 15,000 | 0.75 | 0.82 | 0.63 | 0.69 | 0.24 |
| LR + TF-IDF + Chi-square | 250 | 0.73 | 0.79 | 0.59 | 0.65 | 27.10 |
| LSTM + TF-IDF + Chi-square | 250 | 0.45 | 0.06 | 0.14 | 0.09 | 0.20 |
| LSTM with pre-trained embedding matrix | 200 | 0.77 | 0.77 | 0.70 | 0.73 | 0.08 |
| Data Balancing Techniques | Number of Documents per Class | Accuracy | Precision | Recall | F1-Score | Hamming Loss |
|---|---|---|---|---|---|---|
| Without data balancing | (9628, 13,211, 910, 33,549, 1397, 1548, 14,581) | 0.77 | 0.77 | 0.70 | 0.73 | 0.08 |
| Hybrid (random oversampling + random undersampling) | 12,000 | 0.88 | 0.88 | 0.88 | 0.88 | 0.04 |
| Hybrid (oversampling using SMOTE + random undersampling) | 8000 | 0.63 | 0.62 | 0.63 | 0.62 | 0.11 |
| Undersampling | 910 | 0.74 | 0.75 | 0.74 | 0.74 | 0.08 |
| Class | Without Data Balancing | With Data Balancing | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| Neutral | 0.95 | 0.94 | 0.95 | 0.96 | 0.98 | 0.97 |
| Anxiety | 0.86 | 0.80 | 0.83 | 0.87 | 0.86 | 0.86 |
| Bipolar Disorder | 0.73 | 0.50 | 0.59 | 0.98 | 1.00 | 0.99 |
| Depression | 0.74 | 0.85 | 0.79 | 0.70 | 0.60 | 0.65 |
| PTSD | 0.81 | 0.67 | 0.73 | 0.96 | 1.00 | 0.98 |
| Schizophrenia | 0.80 | 0.60 | 0.69 | 0.96 | 1.00 | 0.98 |
| Suicide | 0.64 | 0.49 | 0.56 | 0.71 | 0.74 | 0.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dash, R.; Udgata, S.; Mohapatra, R.K.; Dash, V.; Das, A. A Deep Learning Approach to Unveil Types of Mental Illness by Analyzing Social Media Posts. Math. Comput. Appl. 2025, 30, 49. https://doi.org/10.3390/mca30030049
Dash R, Udgata S, Mohapatra RK, Dash V, Das A. A Deep Learning Approach to Unveil Types of Mental Illness by Analyzing Social Media Posts. Mathematical and Computational Applications. 2025; 30(3):49. https://doi.org/10.3390/mca30030049
Chicago/Turabian StyleDash, Rajashree, Spandan Udgata, Rupesh K. Mohapatra, Vishanka Dash, and Ashrita Das. 2025. "A Deep Learning Approach to Unveil Types of Mental Illness by Analyzing Social Media Posts" Mathematical and Computational Applications 30, no. 3: 49. https://doi.org/10.3390/mca30030049
APA StyleDash, R., Udgata, S., Mohapatra, R. K., Dash, V., & Das, A. (2025). A Deep Learning Approach to Unveil Types of Mental Illness by Analyzing Social Media Posts. Mathematical and Computational Applications, 30(3), 49. https://doi.org/10.3390/mca30030049