1. Introduction
The last few years in applied sciences have been marked by the need and volume of data to be analyzed. To meet this need, new models have been proposed, and their improvement is a hot topic. These require, among other things, the underlying development of new (statistical or probabilistic) distributions. In this regard, one idea is to modify existing distributions in order to make the corresponding models more flexible and adaptable to several kinds of data. Hence, several modifications based on mathematical techniques have been proposed, generating distributions classified under “families of distributions”. The readers are referred to [
1] for a bird’s-eye view. In recent times, the families described by ”trigonometric transformations" have gained a lot of interest because of their applicability and working capability in a variety of situations. Related to this topic, Refs. [
2,
3,
4] were among the first to study the sinusoidal transformation that leads to the sine generated (S-G) family. For this family, the cumulative distribution function (cdf) and probability density function (pdf) are given by
and
respectively, where
and
represent the cdf and pdf of a certain continuous distribution with a parameter vector denoted by
. Thus, the functions
and
are linked to a baseline or parent distribution determined beforehand, relying on the purpose of study. It is worth noting that the baseline cdf has not been supplemented with any additional parameters. The S-G family was developed as a viable substitute for the parent distribution; we can see it from the following first-order stochastic ordering (FOSO) property:
for all
, as well as the possibility of creating versatile statistical distributions that can accept a wide range of data. To make the statement clearer, the exponential distribution is used as a parent distribution by [
2] to define the sine exponential distribution. The inverse Weibull (IW) distribution proposed by [
5] is used as the reference distribution by [
4], thus creating the sine IW (SIW) distribution. The sine power Lomax distribution investigated by [
6] is one of the most recent works highlighting the importance of the S-G family. It enhances the parental power Lomax distribution on several functional aspects. Among the trigonometric families of distributions, a few of them, including the C-S family by [
7], SKum-G family by [
8], STL-G family by [
9], and T-G family by [
10], were influenced by these efforts.
In this research, we contribute to the developments of the S-G family by linking it to a particular one-parameter distribution introduced by [
11]: the modified Lindley (ML) distribution. The sine ML (S-ML) distribution is thus introduced. In order to comprehend the outlined approach, a review of the ML distribution is essential. As a first comment, the ML distribution presented by [
11] is achieved by implementing the tuning exponential function
, with
, to the Lindley distribution, with the motive of modifying its capabilities for new modeling perspectives. On the mathematical side, the cdf and pdf of the ML distribution are defined by
and
respectively. Basically, the ML distribution satisfies the following FOSO property:
for all
, where
and
represent the cdfs of the Lindley and exponential distributions, respectively. In this sense, the ML distribution constitutes a real alternative to these two classical distributions. The ML distribution is also identified as a linear combination of the exponential distribution with parameter
and the gamma distribution with parameters
, and it has an “increasing-reverse bathtub-constant” hazard rate function (hrf). The real benefit is quite noteworthy; the ML model is superior to the Lindley and exponential models for the three data sets seen in [
11]. A few inspired distributions enhancing or generalising the ML distribution were proposed for the purpose of optimality. These include the Poisson ML distribution by [
12], wrapped ML distribution by [
13], and discrete ML distribution by [
14].
The immediate aim of the S-ML distribution is to use the S-G technique to enhance the effectiveness of the ML distribution on diverse data sets. In particular, thanks to the FOSO properties in Equations (
3) and (
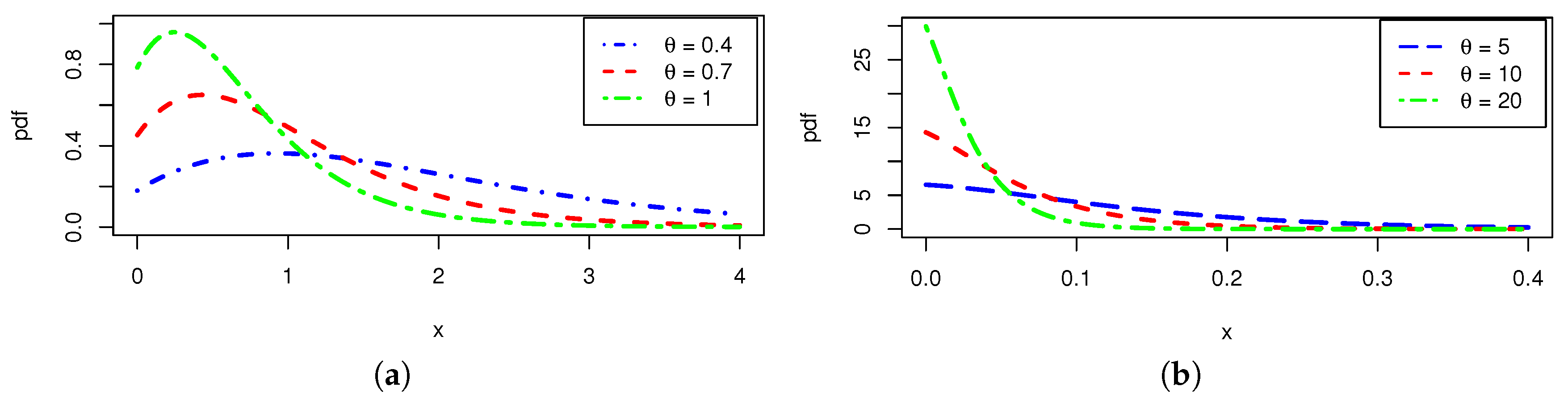
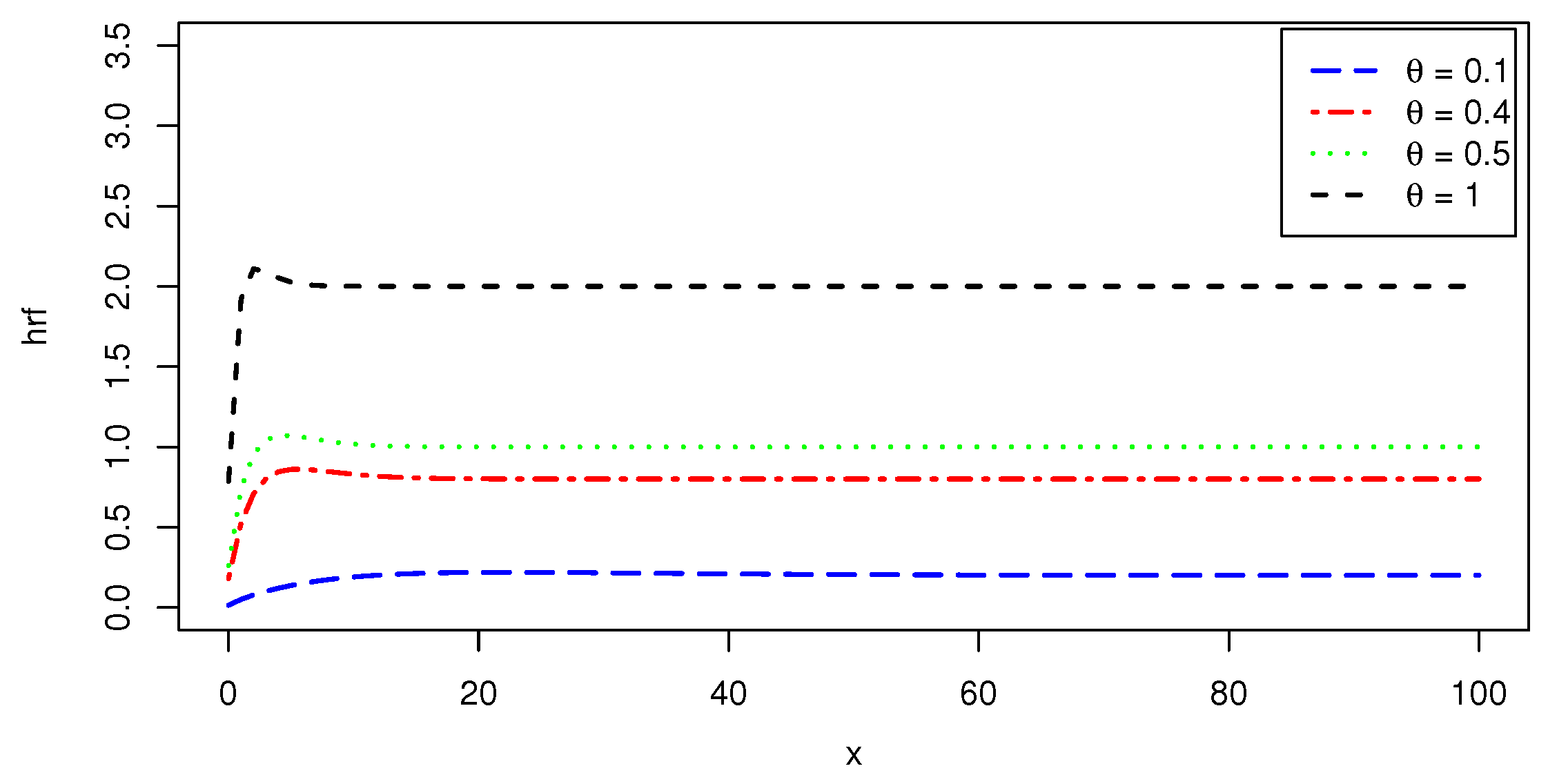
6), it is a real and attractive alternative to the Lindley and ML distributions. Further exploration in the following research will reveal deeper motives. To summarise, the S-ML model’s utility and adaptability make it particularly appealing to fit data from various fields. Remarkably, the characterized pdf shows a variety of curve shapes, some of which have only one mode, are decreasing, and are asymmetrical to the right. In comparison to the pdf of the ML distribution, when it is unimodal, the pdf of the S-ML distribution has a more rounded peak, meaning that it is better adapted to fit a data histogram presenting a high kurtosis level. Furthermore, the S-ML distribution exhibits a non-monotonic hrf which is “increasing-reverse bathtub-constant” shaped. The hrf of the ML distribution has this feature as well. As with other competent models, the accuracy of the fits is persistent in the case of the S-ML model due to their characteristics. The claim is demonstrated by examining two published real-world data sets, primarily from engineering and climate data, against twelve competent models.
We prepare the rest of the paper in the following manner. The concept, quality, and key aspects of the S-ML distribution are covered in
Section 2. A moment analysis is conducted in
Section 3. The maximum likelihood estimation of the parameter
is explained in
Section 4. A simulation study is presented in
Section 5.
Section 6 assesses the proposed model’s applicability to real-world data. Finally, in
Section 7, the conclusions are provided.
3. Moment Analysis
For any lifetime distribution, a moment analysis is necessary to handle numerically its modeling capacities, identifying the behavior of various central and dispersion moment parameters, as well as moment skewness and kurtosis coefficients.
As a first notion, for any positive integer
, and a random variable
X with the S-ML distribution, the
r-th moment of
X exists. It can be expressed as
Integral developments in the classical sense are limited. Computer software, on the other hand, can be used to quantitatively evaluate it for a given
.
We propose a series development of in the next result, which can be used for computational purposes in a less opaq method than a “ready to use but black box” computer program.
Proposition 1. The r-th moment of X can be expanded as Proof. For the proof, we do not directly use the integral expression of
as described in (
8). An integration by part gives
Now, by utilizing the series expansion of the cosine function and the classical binomial formula, we obtain
Hence, after some developments including the change of variable
(so that
), and the calculus of gamma-type integral, we get
Proposition 1 is proved. □
Then, based on Proposition 1, the following finite sum approximation remains acceptable:
where
U represents any large integer.
From the above moment formulas, we can easily derive the mean, variance, moment skewness coefficient and moment kurtosis coefficient; the mean is given by , the variance is obtained as , the moment skewness coefficient can be derived as and the moment kurtosis coefficient can be derived as .
Table 1 gives a glimpse of these values for different values of
.
From
Table 1, we can observe that, as the value of the parameter
of the S-ML distribution increases, all the considered measures increase. Furthermore, since
, it is clear that the S-ML distribution is mainly right-skewed, and since
, it is mainly leptokurtic.
We can complete the previous moment results by investigating the incomplete moments. To begin, let
be an integer,
, and
X be a random variable with the S-ML distribution. Based on this variable, we define its incomplete version by
if
and
if
. Then, the
r-th incomplete moment of
X given at
t exists, and it is defined by
It is involved in developments of important probabilistic objects, such as mean deviations, income curves, etc. More basically, it can be viewed as a truncated version of the standard
r-moment. We may refer to [
15] in this regard.
In the next results, we present a series expansion of , which can be used for approximation purposes.
Proposition 2. The r-th incomplete moment of X given at t exists and can be expanded aswhere denotes the incomplete gamma function defined by , where and . Proof. The proof follows the lines of the one of Proposition 1. An integration by part gives
It follows from the series expansion in Equation (
9) and the change of variable
that
This concludes the proof of Proposition 2. □
In some sense, Proposition 2 generalizes Proposition 1; by taking , Proposition 2 becomes Proposition 1.
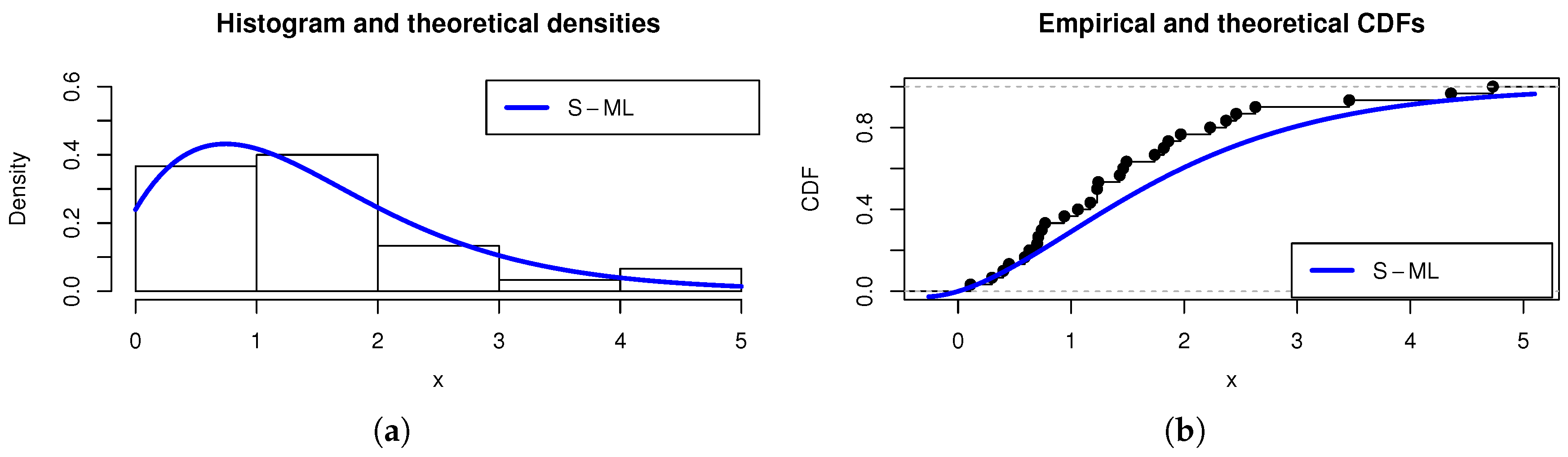
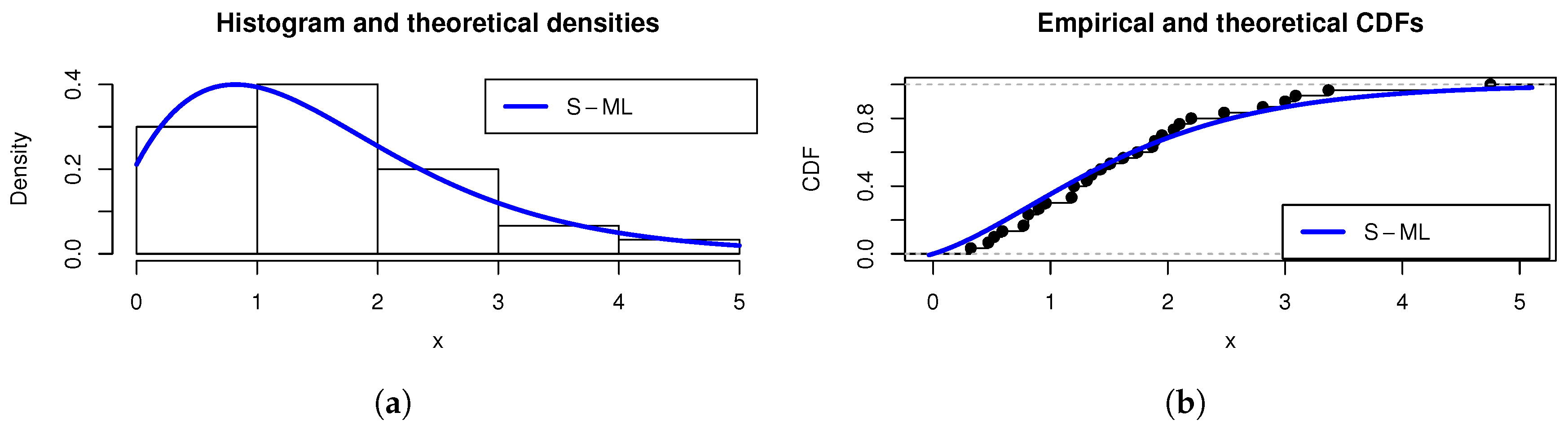
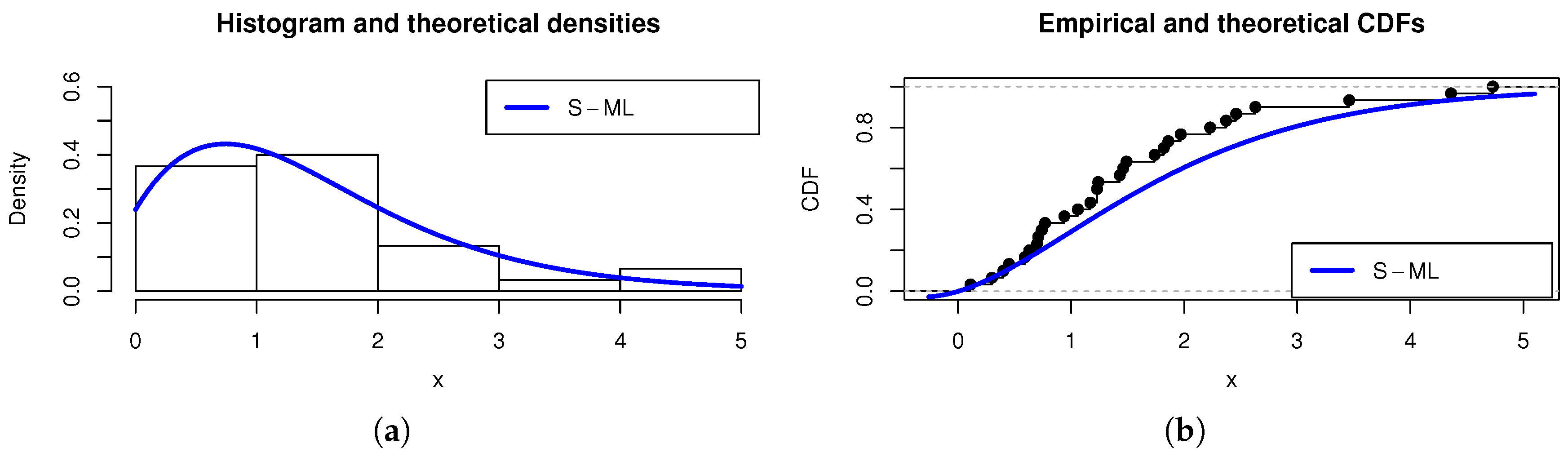
The rest of the study is devoted to the applicability of the S-ML model, illustrated with concrete examples of data analysis.
4. Inferential Analysis
The inference of the S-ML model is covered in this section. The parameter
is supposed to be unknown. In order to estimate it, the maximum likelihood estimation method is employed. We adopt the methodology as described in a broader context, as seen in [
16].
Thus, the next is a mathematical representation of this methodology in the setting of the S-ML distribution. First, let
n be a positive integer and
be observations drawn from a random variable
X following the S-ML distribution. Then, the corresponding likelihood function and log-likelihood function are as follows
and
respectively. The maximum likelihood estimate (MLE) of
can be defined via the following argmax definition:
This estimate can be formalized through the solution of the non-linear equations expressed as
, where
There is no analytical solution for this equation, but
can be determined at least numerically with any statistical software such as the R software (see [
17]). Based on
, the estimated pdf (epdf) of the S-ML model is given by
and the estimated cdf (ecdf) of the S-ML model is given by
.
Let be the expected Fisher information matrix. Then, the estimated standard error (SE) of is achieved by considering the value of the diagonal component of raised to half.
5. Simulation Study
In the framework of the S-ML model, a simulation study is carried out to study the performance of
given as Equation (
10) in terms of their bias (bias) and mean squared error (MSE). The simulated procedure can be described as follows:
We generate samples of sizes
20, 50, 100, 200, 500, 1000 from the S-ML distribution with
. For each sample, the MLE
is calculated. Here, 1000 such repetitions are made to calculate the standard mean MLE (MMLE), bias and MSE of these estimates using the formula:
and
respectively, where
is the estimate of
for each iteration in the simulation study;
i is from 1 to 1000. The results of the study are reported in
Table 2.
From
Table 2, it is observed that as sample size
n increases,
Bias decreases, which shows the accuracy of ;
MSE decreases, which indicates the consistency (or preciseness) of .








{kind=link}
{kind=link}
{kind=link}
{kind=link}