1.1. Recent Research on Seaport Operations
Approximately 90% of products that are globally commercialized are transported by sea, and in one decade, the average capacity of cargo ships has doubled, with ports being the ones that allow the execution of exchanges. Seaports facilitate trading and make logistics costs more competitive. They allow the transportation of products without several checkpoints, making the process and the supply chain more efficient.
The geographic location of each seaport, combined with the quantity of active seaports, provides significant advantages in this industry for any economy.
Seaports are geographical areas and economic units of the specific place where the terminals may be found, the terminals are operating units of a seaport, which are actively able to provide modal interchange and seaport services.
The connectivity among seaports must be constantly improved to facilitate the movement of products by sea or land, and, within this connectivity, intermodal schemes must be defined to establish, for example, the transportation of products by rail or carrier.
The International Seaport System has been constantly modernized with a vision to improve logistics and multimodal connectivity, where the projects regarding seaport, road and rail infrastructures are more integrated in order to respond to the increasing demand of national and international trade. Currently, the capacity of seaports has been increased by millions of tons per year.
As was previously mentioned, seaports have been, are and shall be, a great entry gate to the different continents of the world. Supported by the great advantage of having access to the oceans, countries have an extensive growth potential regarding foreign trade; it is only a matter of continuously improving governmental management and support.
One of the greatest challenges of trading by sea is the existence of the international market, countries have reached the maximum uses of their seaports, the demand for infrastructure and comprehensive logistic service offered at lower costs is still increasing.
Additionally, trained staff are required to put into operation the resources acquired in an efficient and safe manner. Another significant challenge is environmental protection, for example, in the Caribbean Sea, a Mesoamerican Reef System was designed, which is a sensitive area for navigating and preventing pollution from ships.
There is still a gap to consider: cabotage routes must be reinforced and transport routes must be developed; however, maritime transport is encouraged every year, the development of the industry is increasing and governments are considering it as a significant matter.
Therefore, the role of international transportation, maritime shipping, and marine container terminals in the economic development of numerous countries has been widely studied using different approaches. Seaport problems continue to be attracted to developing new optimization techniques. Recently, important contributions have been published in order to improve the performance of seaport operations. A representative example is the study of [
1]. This study details a tailored global optimization algorithm for deploying, scheduling, and sequencing heterogeneous vessels in a container liner shipping route. The key advantage is that the weekly dependent shipping demand is considered to incorporate fluctuations in the planning horizon. In addition, the authors consider the distinct fuel efficiencies, cost structures of the ships, and capacities. These conditions determine the number of containers transported, the bunker fuel consumption, and the operating cost of a shipping route. A mixed integer-programming model minimizes the total cost by considering, from a set of candidate ships, the optimal ships. In addition, the proposed model integrates the sequences, schedules, and sailing speeds of the shipping route.
Ref. [
2] is a seaport study that considers emergent ship arrivals for building berth schedules. The authors propose an optimization procedure to schedule ships by reducing disturbances in the service and maximizing the number of emergent ships served. A case study illustrates the aforementioned optimization procedure. The proposed procedure provides key concerns to decision makers dealing with the berth scheduling issues of emergent ship arrivals.
Ref. [
3] attends to real world situations, such as water depth and tide conditions, in seaport operations. An enriched particle swarm optimization procedure is depicted to solve the continuous berth allocation, quay crane assignment and quay crane scheduling problems. The authors incorporate, in the solution, safety operations between quay cranes. Their results are compared with the results of the exact solution and the basic particle swarm optimization procedure.
Ref. [
4] concerns the increase in seaport operations in the last thirty years, and argues that berth scheduling can improve the throughput of marine container terminals. The authors detail an innovative evolutionary algorithm to minimize handling costs, waiting costs, and the late departure costs of the vessels that are to be served at a marine container terminal. The scheme of the authors relies on an augmented self adaptive parameter control strategy, which changes algorithmic parameters throughout the search process.
Another important example is the research of [
5]. The author develops a novel memetic algorithm to help the marine container terminal operators to build proper schedules, and to tackle congestion issues caused by the increasing number of large size vessels. Although this study does not account for uncertainty in vessel arrivals, the proposed algorithm serves as an efficient planning tool for marine container terminal operators and assists with efficient the berth scheduling.
1.2. The Quay Crane Scheduling Problem
Based on the preliminary review, it is clear that the performance of seaport operations, for the international supply chain, continues to be highly important. Solving problems, such as the quay crane scheduling problem (QCSP), a combinatorial problem, contributes to improving the efficiency of any seaport. The QCSP is selected in this research due to its complex nature.
Quay cranes are very important resources at container terminals. They are used to load containers onto, and discharge containers from vessels at, the quayside of terminals. Quay cranes along the same berth operate on a common set of rails.
Jobs represent container unloading/loading work, and arise at specific locations along the quayside. The collection of jobs may represent work for a single ship, or multiple ships.
Normally, an optimization formulation for the QCSP considers reducing the makespan, i.e., the total completion time. Any proposed solution should consider scheduling operations restrictions, such as
- -
A minimum distance being left between quay cranes to avoid boom collision.
- -
Each quay crane should work when it will not be busy.
- -
Like a traditional shop environment, precedence between operations may exist.
A mathematical formulation considers
the processing time of task .
the release time of quay crane .
the travel time of a quay crane from the bay position of task to the bay position of task .
a sufficient large constant.
a set of all tasks.
a set of ordered pairs of tasks between which there is a precedence relationship.
if task immediately follows task on quay crane ; 0, otherwise. Tasks 0 and T will be considered the initial and final states of each quay crane, respectively. Thus, when task is the first task of quay crane , . In addition, when task is the last of quay crane ,.
the completion time of quay crane .
the completion time of task .
makespan.
Therefore, the QCSP can be formulated as follows
subject to
The objective function (1) minimizes the average waiting time. Constraint (2) determines the makespan, which corresponds to the completion time of all tasks. Constraints (3) and (4) define the first and the last tasks for each quay crane, respectively. Constraint (5) ensures that every task must be completed by exactly one crane. Constraints (6) and (7) determine the completion time for each task. Constraint (8) defines the completion time of each quay crane. Constraint (9) ensures that the first task of a crane is not started before the crane is ready. Finally, (10) and (11) define the domains of the decision variables.
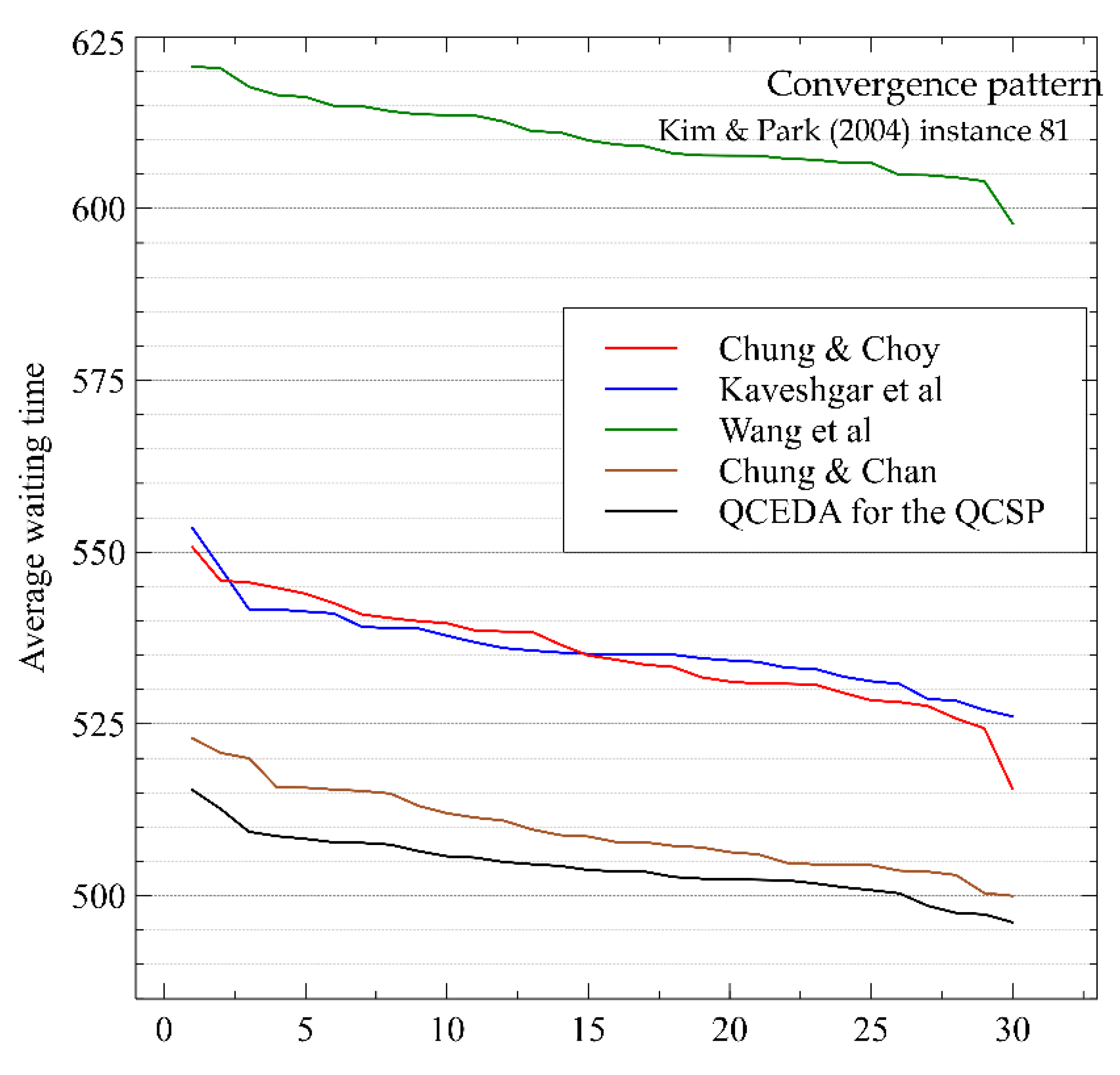
The objective of our study is to identify the best schedule to minimize the quays’ overall average waiting time. The methodology used in this research details how a solution can be built by two decisions, i.e., operation scheduling and crane assignment.
1.3. Solving Combinatorial Problems through Evolutionary Algorithms
In a wide set of studies, evolutionary algorithms have been proposed to offer useful solutions for high scale optimization problems. The solutions are required in different engineering fields. Particularly, evolutionary algorithms are competitive in the combinatorial optimization field. Some relevant studies of evolutionary algorithms can be appreciated in the research of [
6], for job shop operations and process integration. The authors use and apply the concept of interaction between different species to tackle the problem. This interaction is not considered in any traditional genetic algorithm. The study of [
7] is representative of the evolutionary algorithms family for tackling job shop problems. In this applied case, an ant colony optimisation based approach is proposed to address flexible job shop scheduling with routing flexibility and setup times problems. Recent publications are found in [
8]. This research group employs a genetic algorithm with the Pareto front technique. The approach is applied on a mail-order pharmacy system. Ref. [
9] utilizes a bee colony method with the Pareto front technique for solving the single machine group-scheduling problem with sequence dependent setup times. Ref. [
10] uses an enriched discrete particle swarm optimization method to solve a flexible job shop scheduling problem. Ref. [
11] detail a bat based approach to tackle a dual flexible job shop scheduling problem. Moreover, recently, the use of hybrid evolutionary algorithms is remarkable. The aim is to offer more efficient methods, or better solutions, to those previously found. The work of [
12] falls into this category for solving the vehicle routing problem. The author employs a genetic algorithm and local search. The research of [
13] also utilizes a genetic technique with a variable neighborhood descent method to address flexible job shop scheduling problems. The study of [
14] integrates a genetic algorithm with a neural network to improve container-loading sequences in seaports. The practical implementation of their algorithm is confirmed by using a simulation in the research. The work of [
15] uses a genetic technique with a minimum cost flow network model to solve a dispatching problem for vehicles in a transshipment hub scenario. Their experiments show that the proposal is more effective than a neighborhood search algorithm. The research of [
16] details an efficient parameter free greedy randomized adaptive search method, plus a variable neighborhood descent technique, to tackle a school bus routing problem with bus stop selection. The study of [
17] proposes a genetic technique with a tabu search to address more than 200 flexible job shop scheduling open problems. Following the previous review, we can appreciate that there exist different types of evolutionary algorithms for solving different combinatorial problems.
1.4. Estimation of Distribution Algorithms
This article focuses on the use of estimation of distribution algorithms (EDAs) as a section of the classification of evolutionary algorithms. There exists a vast literature about EDAs. Studies, such as [
18], designed for solving permutation flowshop scheduling problems. The research of [
19] contributes guidelines for developing effective EDAs for single machine scheduling problems. Furthermore, the work of [
20] proposes an EDA for solving lot-streaming flowshop problems with setup times. These investigations are robust in the solution of combinatorial problems using EDAs.
When using EDAs, as with other evolutionary algorithms, the main task is to produce a population of solutions through some generations. However, with EDAs, a probability model, i.e., a distribution, is built based on a set of solutions to the problem, to produce new solutions. Traditionally, the performance of EDAs lies in how efficient the probability distribution is. The probability distribution is built using the members of the population to obtain better solutions. It has been widely documented, in papers such as [
21,
22], that the probability model should consider the structure of a problem with more precision. The aim of EDAs is to consider high order interactions between the variables of the problem. Thus, complex probability models are employed to improve the efficiency of EDAs. Nonetheless, one of the drawback of EDAs is the lack of the diversity of the solutions and the poor ability of exploitation [
22]. There is more than one way to counter the drawbacks of EDAs. Nevertheless, most studies suggest hybridization. In the literature review section, some of the studies are listed.
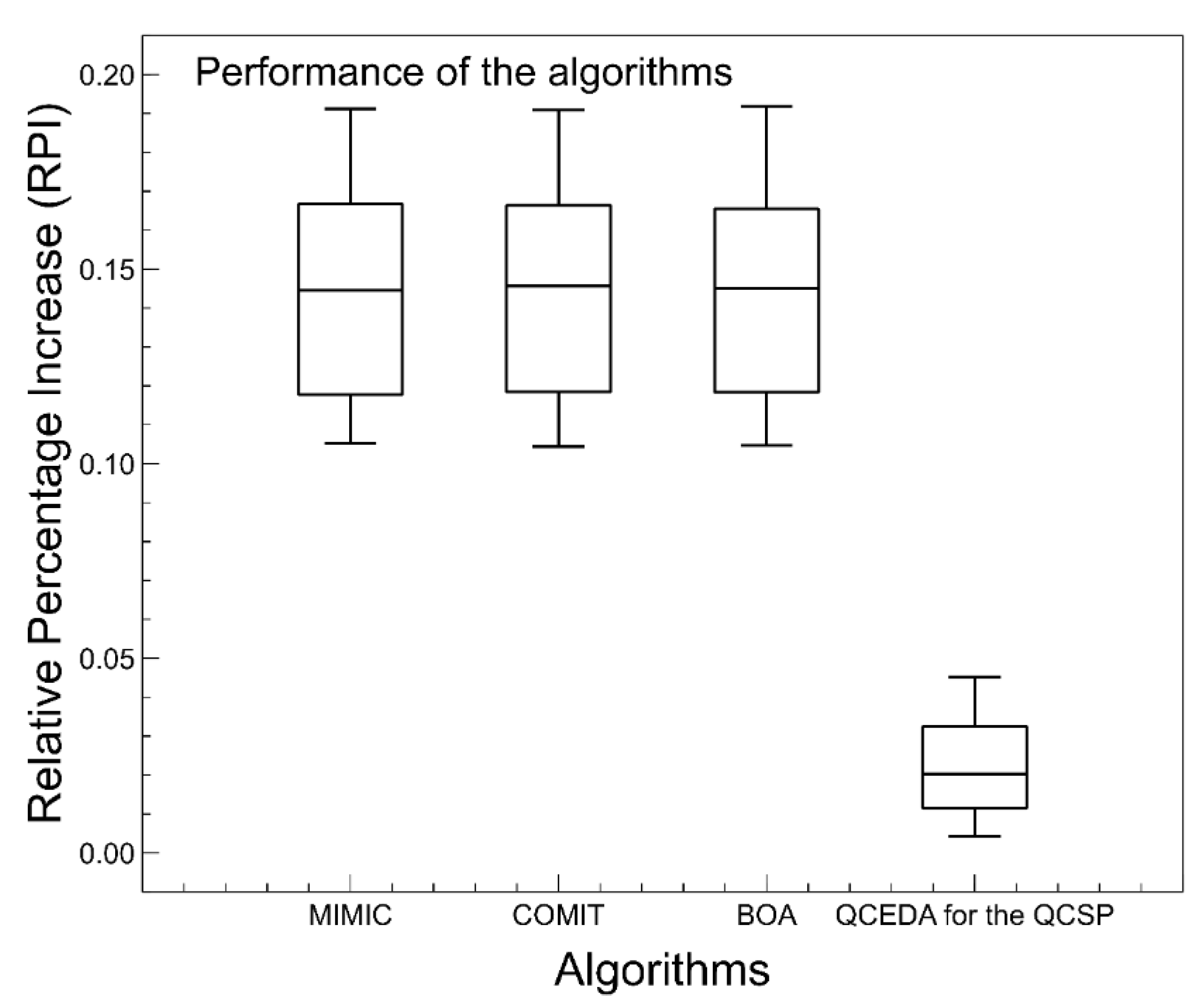
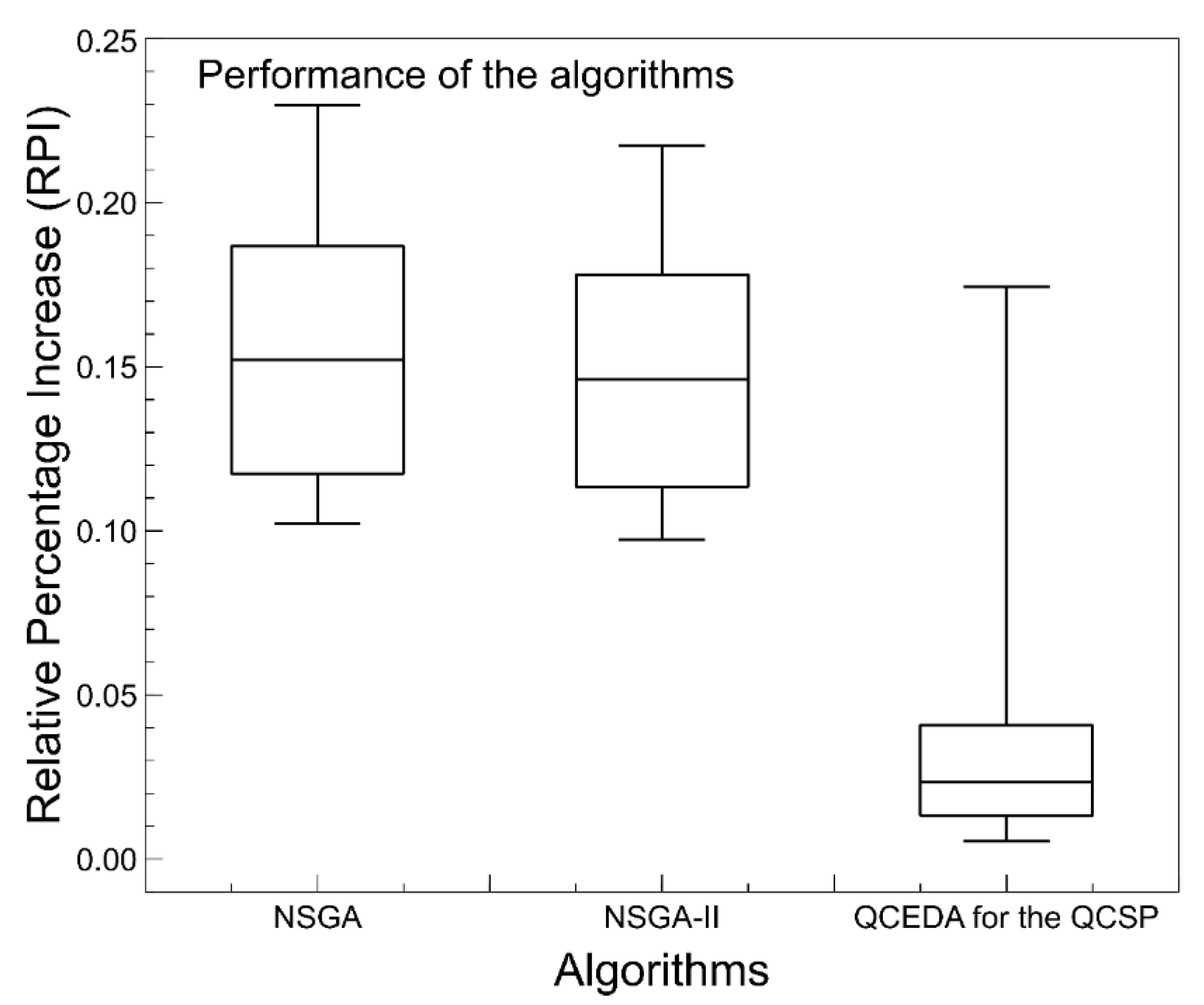
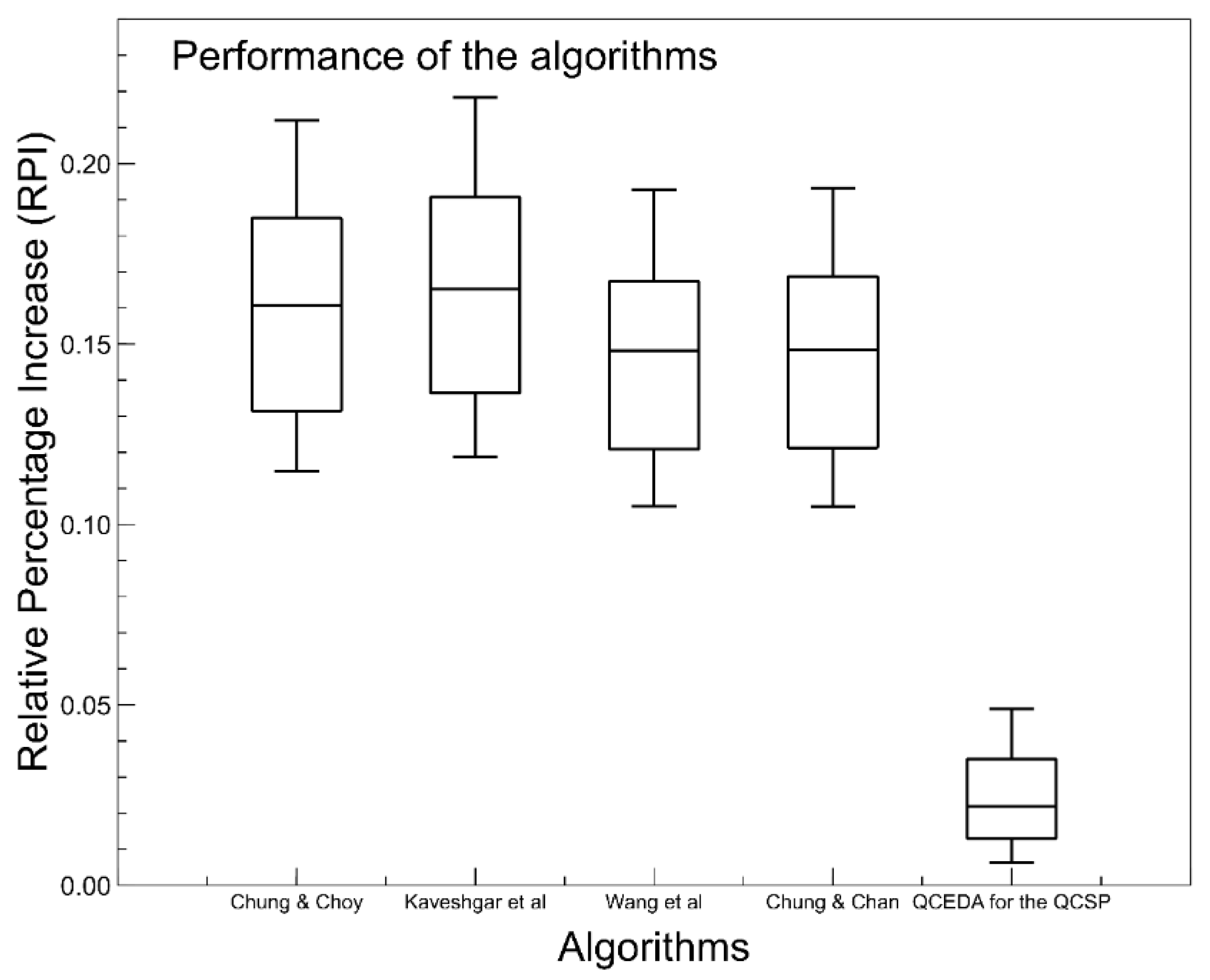
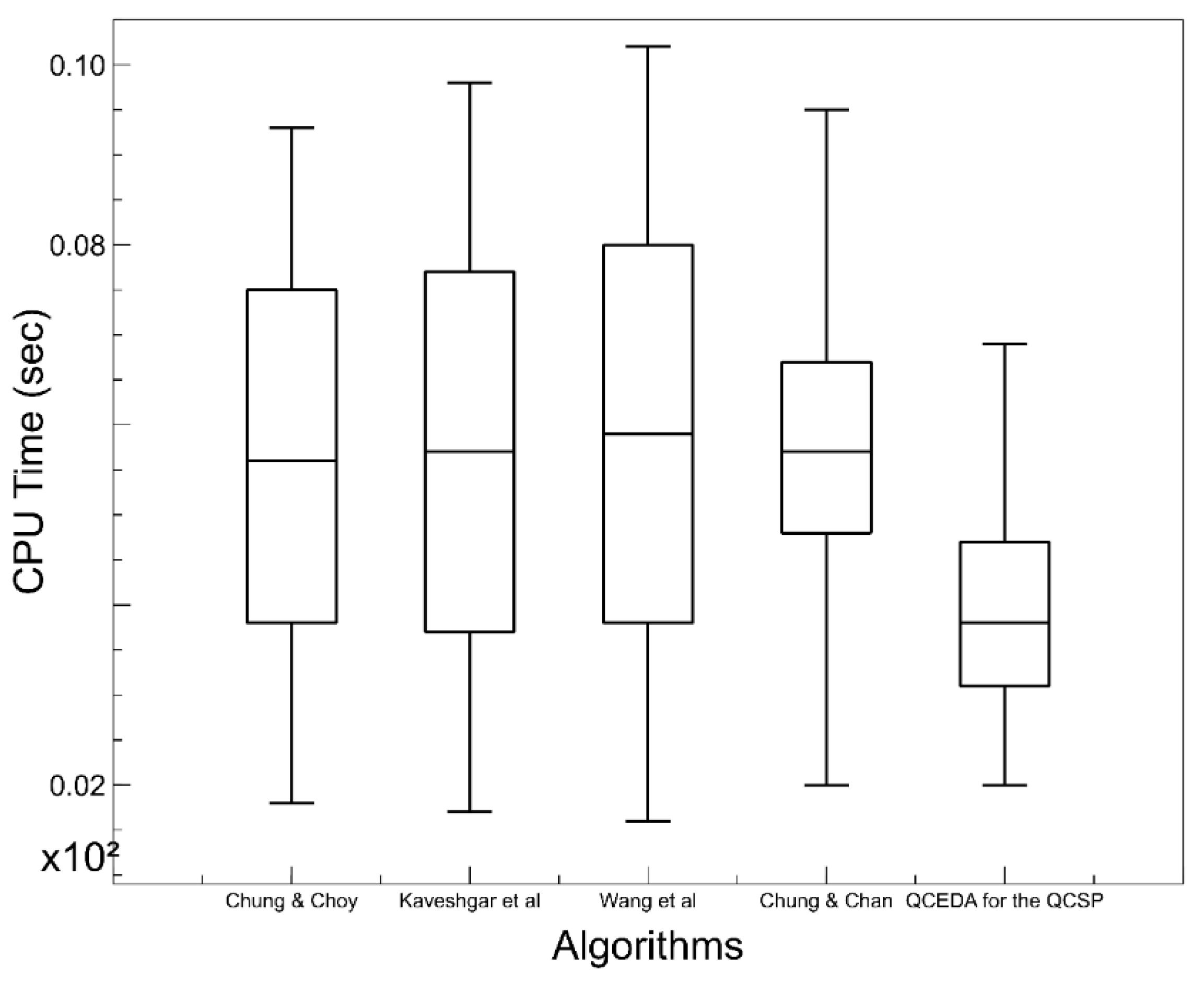
In this paper, we can visualize the importance of the effective estimation of the solution space distribution to build a competitive EDA. In addition, if we analyze the results shown in the corresponding results and comparison section, we are going to reach the conclusion that the hybridization of EDAs with other methods should practically always be considered in the design and development of such algorithms. According to the results of this research, hybridization is not only a reason for publication, it also avoids the necessity of requiring building complex probability models. If this occurs, the algorithm could be difficult to understand.
The main reason for performing this research was to determine what is most useful, i.e., the development of complex probability models or the hybridization of the EDA with other methods to obtain the same or better solutions. Most published articles, related to EDAs and to solve optimization problems, have a lack of diversity in the process of the generation of solutions. The aforementioned drawback can be tackled through the hybridization of an EDA and other methods. However, there exists a wide field of development to determine which methods are more suitable to obtain the better performance of an EDA. This research aims to use bioinspired techniques to help to reduce the deficiencies of an EDA. In addition, it is preferable that the methods used, in the hybridization process, should contain some well defined math expressions. This helps to understand how the solutions are generated. Therefore, the aim is to use new methods and to establish the search process of explicitly new solutions.
The hybridization approach used for this investigation considers a distance based ranking model coupled with a moth-flame algorithm, a novel nature inspired heuristic paradigm [
23]. Therefore, the QCSP is solved by the proposed approach in order to show how hybridization helps to enhance the performance of the EDA. Distance based ranking models appear sparingly in the literature to tackle the drawback of the EDAs. There are few papers available about it. For example, Ref. [
24] introduces an EDA based on a distance based ranking model for the flowshop scheduling problem. The distance based ranking model is used as a probability model in the permutations field.
1.5. The Proposed Hybrid Approach, a Brief Explanation
In this research, the members of the population are considered as rankings.
Table 1 shows a ranking of five items or elements as an example.
In this sense, the members of the population are permutations of elements. A ranking defines a solution for the problem to solve.
Table 2 depicts some rankings as flowshop-scheduling solutions, where each item represents a job, and then a processing sequence is executed according to each ranking.
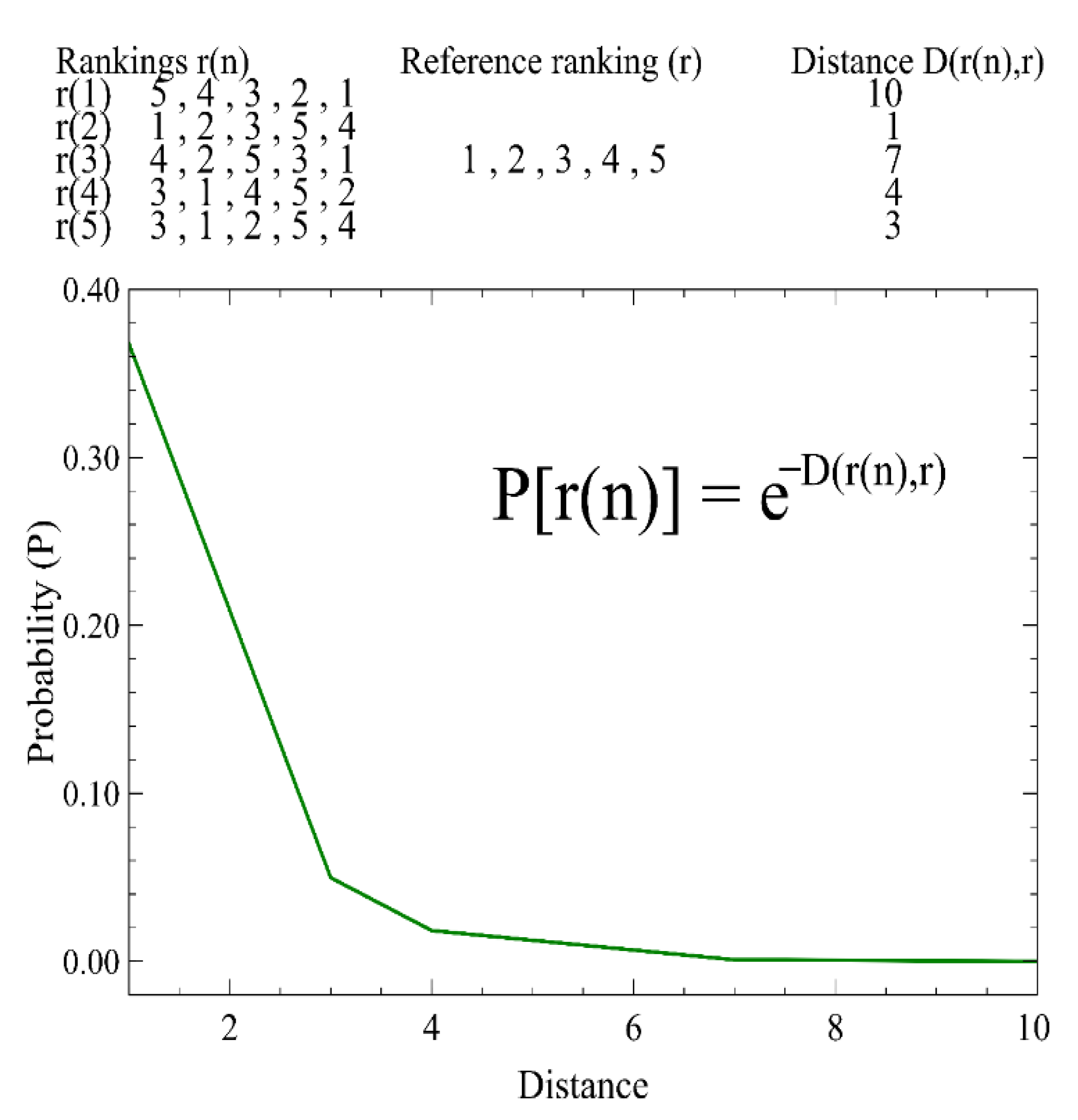
Then, a distance metric is computed between rankings, by the algebra of permutations. After that, a distribution probability is built, i.e., an exponential distribution. The aforementioned exponential distribution occupies, as an input parameter, the distance between each of the permutations and a reference permutation. A known distance based ranking model is the model of [
25]. In general terms, it concerns assigning a probability to each permutation that declines exponentially based on its distance from a reference permutation. It is then said that such a permutation is more (or less) likely to be chosen as a good solution, according to the [
25]’s model.
Figure 1 illustrates such a distribution, with five rankings.
However, [
25]’s model is not able to generate offspring by itself. The reason is because there can be many permutations with the same distance to the reference permutation. This causes confusion regarding which permutation is the offspring. It is solved by the factorization (decomposition) of the distance previously obtained. The factorization is computed by a procedure called GMD (the Generalized Mallows Model), proposed by [
26,
27]. Such authors propose how to factorize in
elements, the distance between two rankings where
is the size of the rankings. With that factorization, it is possible to obtain the offspring.
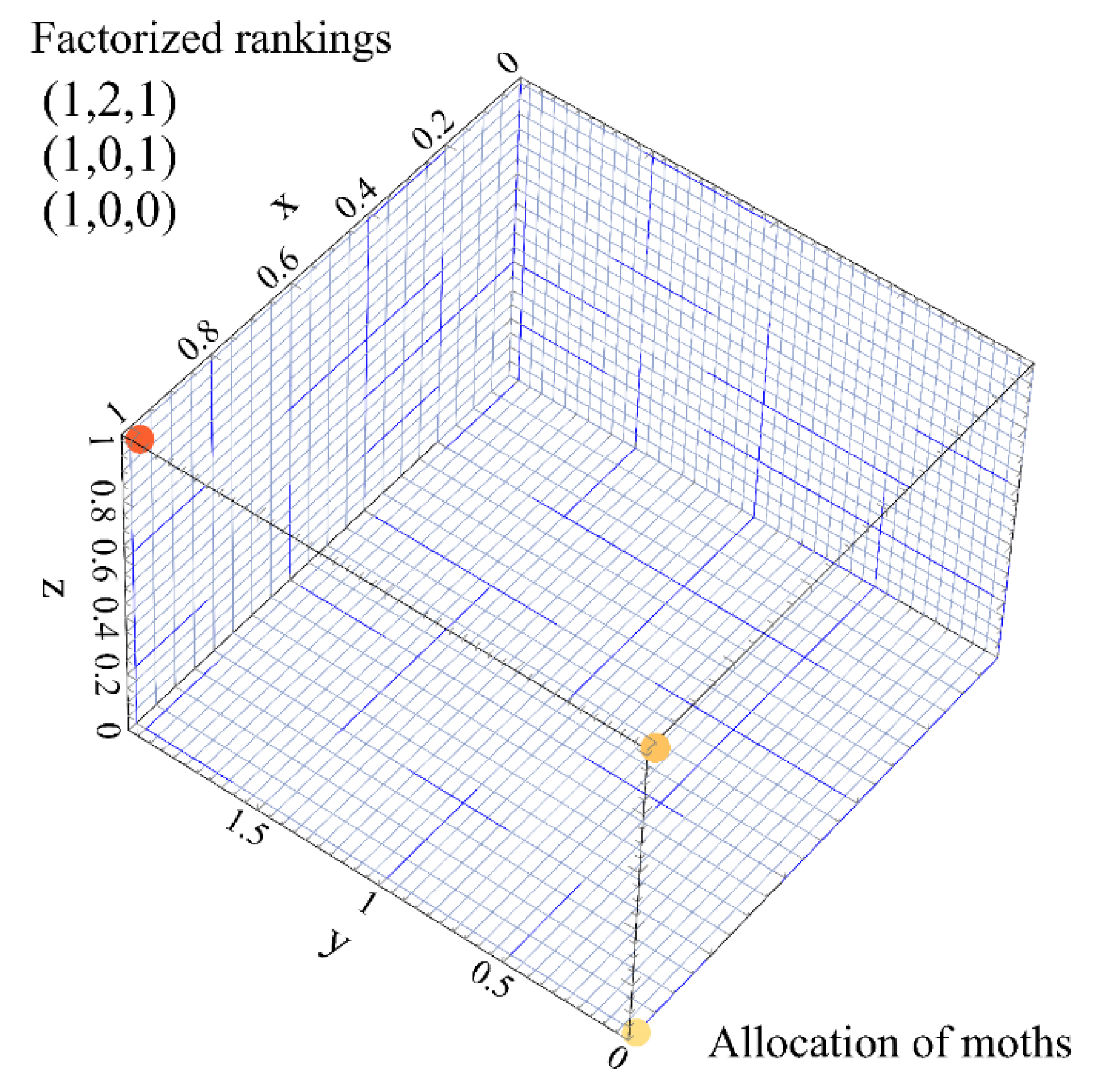
Table 3 details such factorization.
Then, such factorization (decomposition) serves as input parameter in the moth-flame heuristic to generate new offspring. Based on the results obtained in this study, it is more efficient to produce new and better offspring through such hybridization. The novelty of this study is to show how this hybridization is better than the direct use of a distance based ranking model.
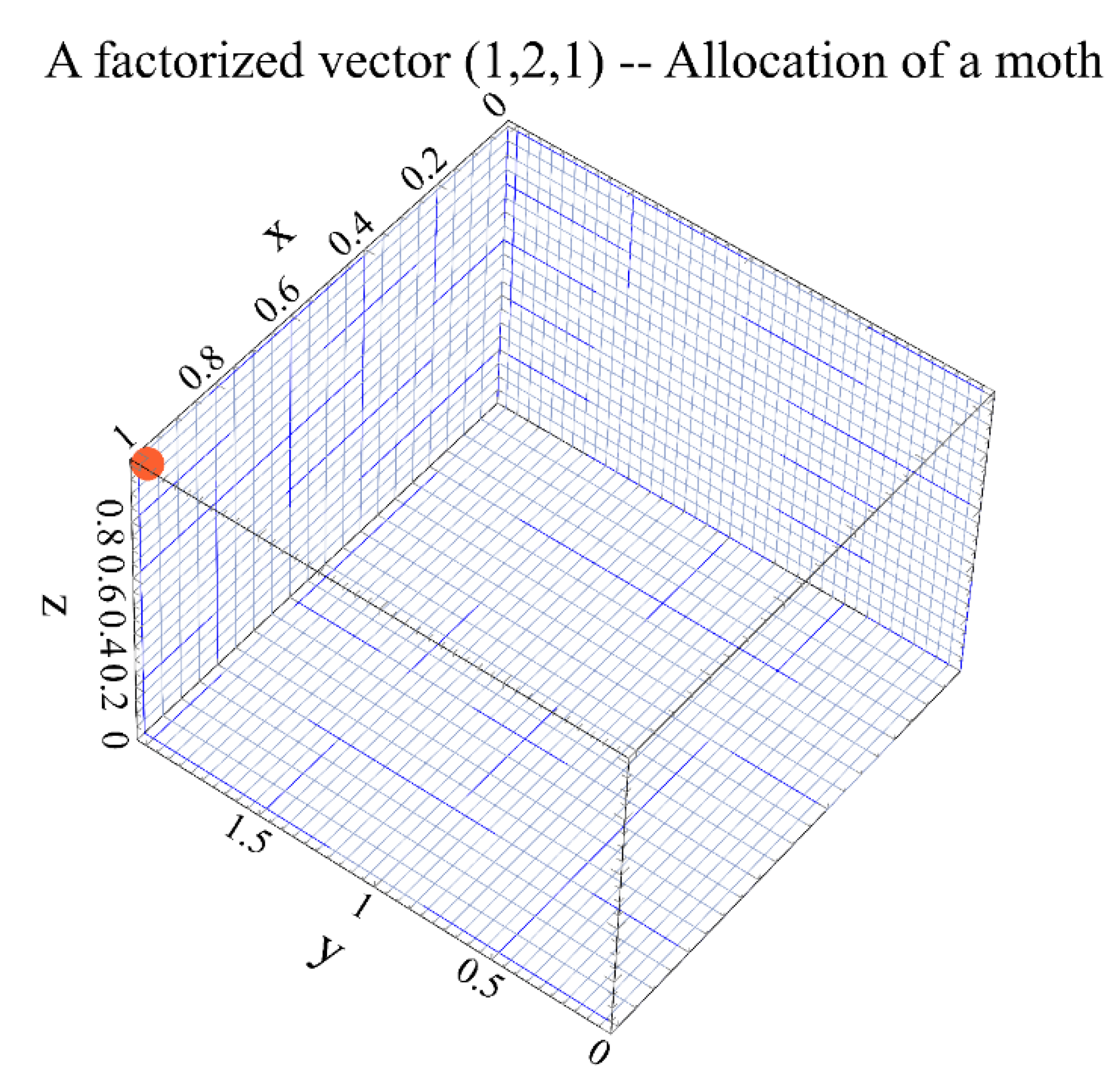
Roughly, the factorization (decomposition) obtained in the previous step is used to determine where a moth is located in the solution space. That is, the decomposition of the distance between rankings (permutations) is seen as a moth’s location coordinate in the feasible space of solutions.
Figure 2 shows such factorized rankings, and the moths´ location coordinates.
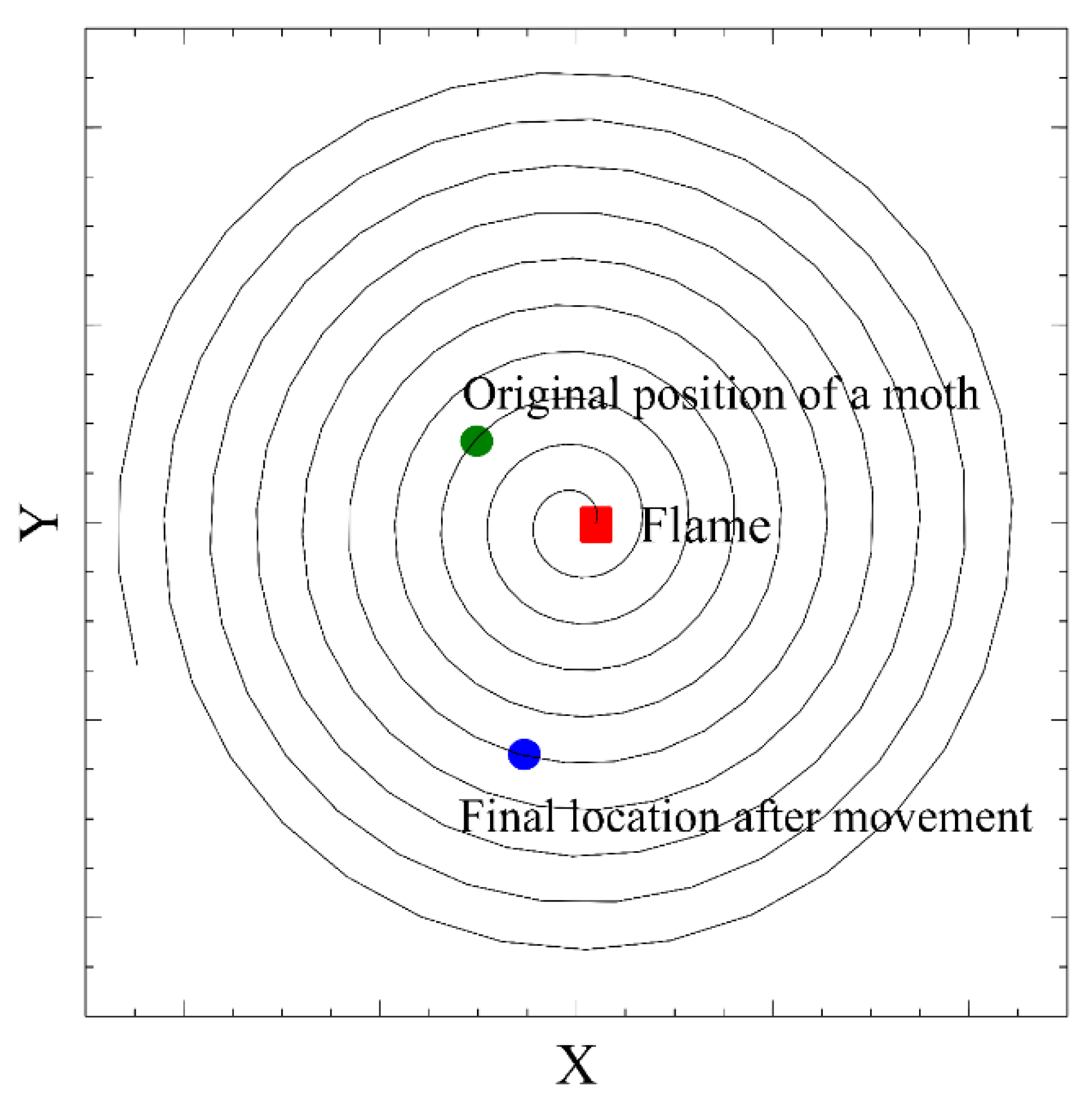
A moth is a search agent that moves in a feasible space, whereas a flame is located at the best position obtained so far [
23]. A spiral-flying path, using a defined mathematical model, of moths around flames is the way to execute the movement of the moths to new locations. Thus, the GMD is in charge of modelling the solution space distribution; meanwhile the heuristic moth-flame is in charge of determining who would be the offspring. That is how this proposed algorithm works to enhance the results obtained from those algorithms that use complex probability models.
The rest of the paper is organized as follows.
Section 2 reviews the literature of EDAs and different approaches to tackle the problem.
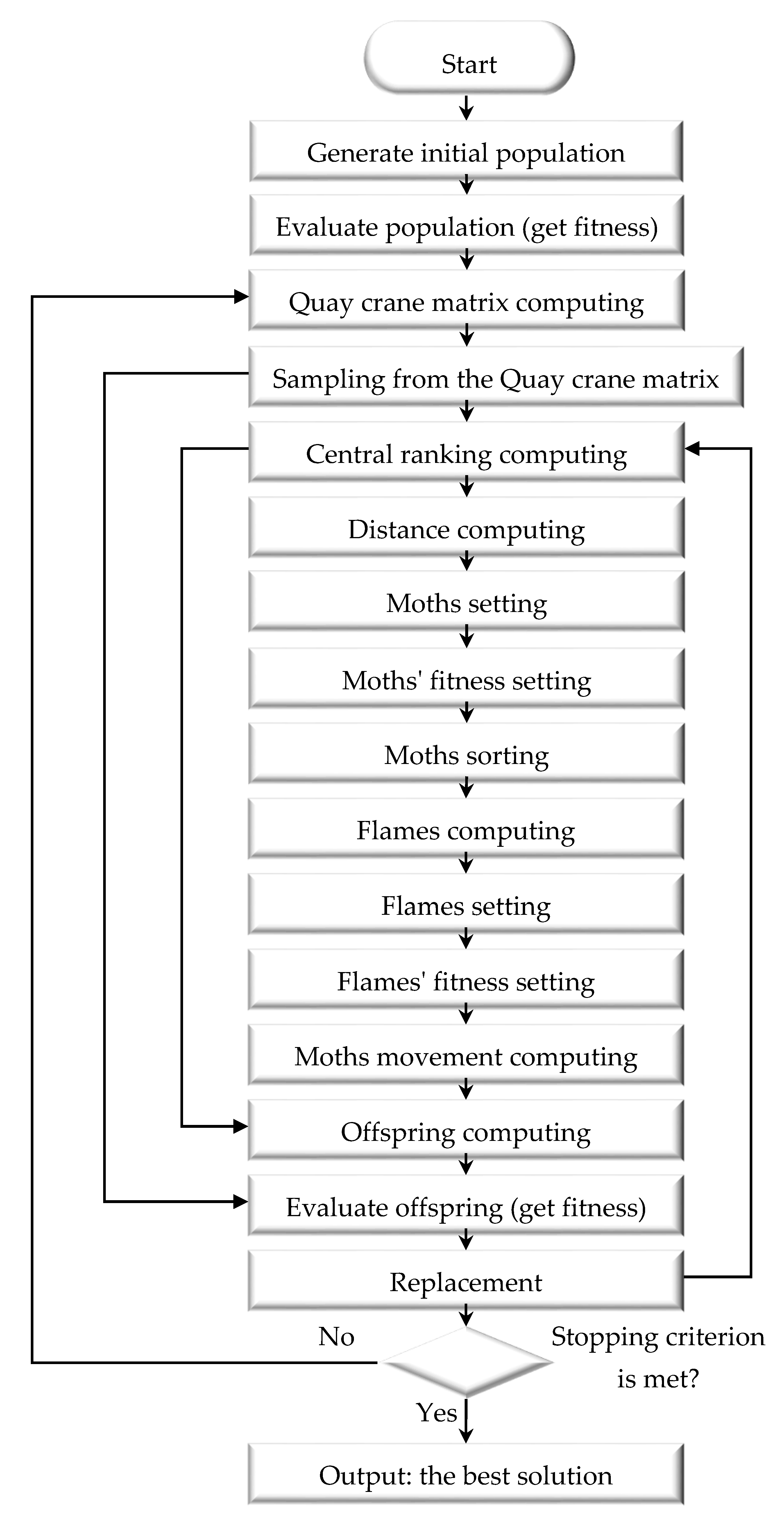
Section 3 presents the inspiration of this work and proposes the quay crane estimation of distribution algorithm, with the Mallows model and a moth-flame structure, called QCEDA. The experimental setup and results are provided in
Section 4.
Section 5 concludes the work and suggests several directions for future studies.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
