Applying the Swept Rule for Solving Two-Dimensional Partial Differential Equations on Heterogeneous Architectures


Abstract
1. Introduction
2. Related Work
3. Materials and Methods
3.1. Implementation & Objectives
- its performance on distributed heterogeneous computing systems,
- its performance with simple and complex numerical problems on heterogeneous systems,
- the impact of different computing hardware on its performance, and
- the impact of input parameters on its performance.
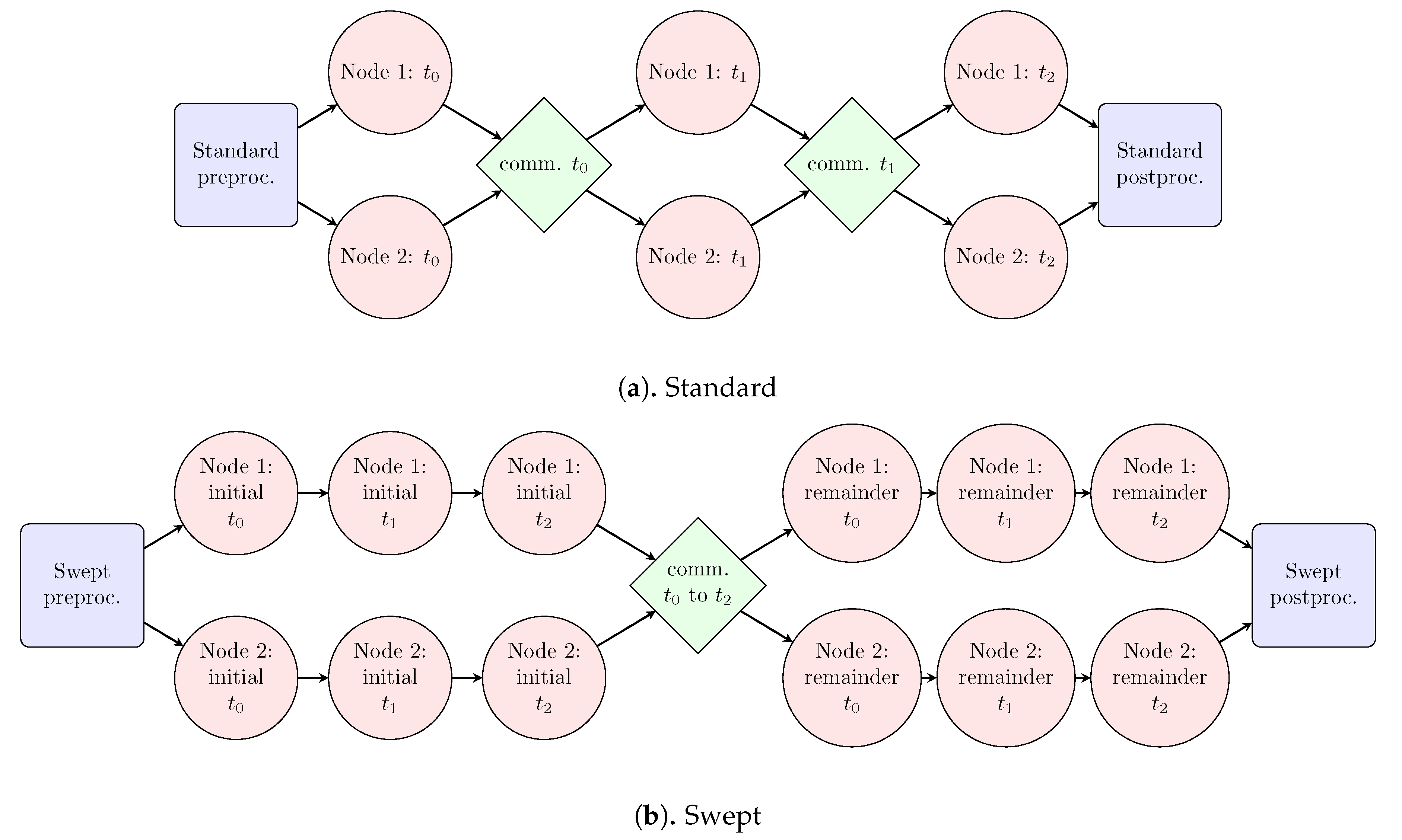
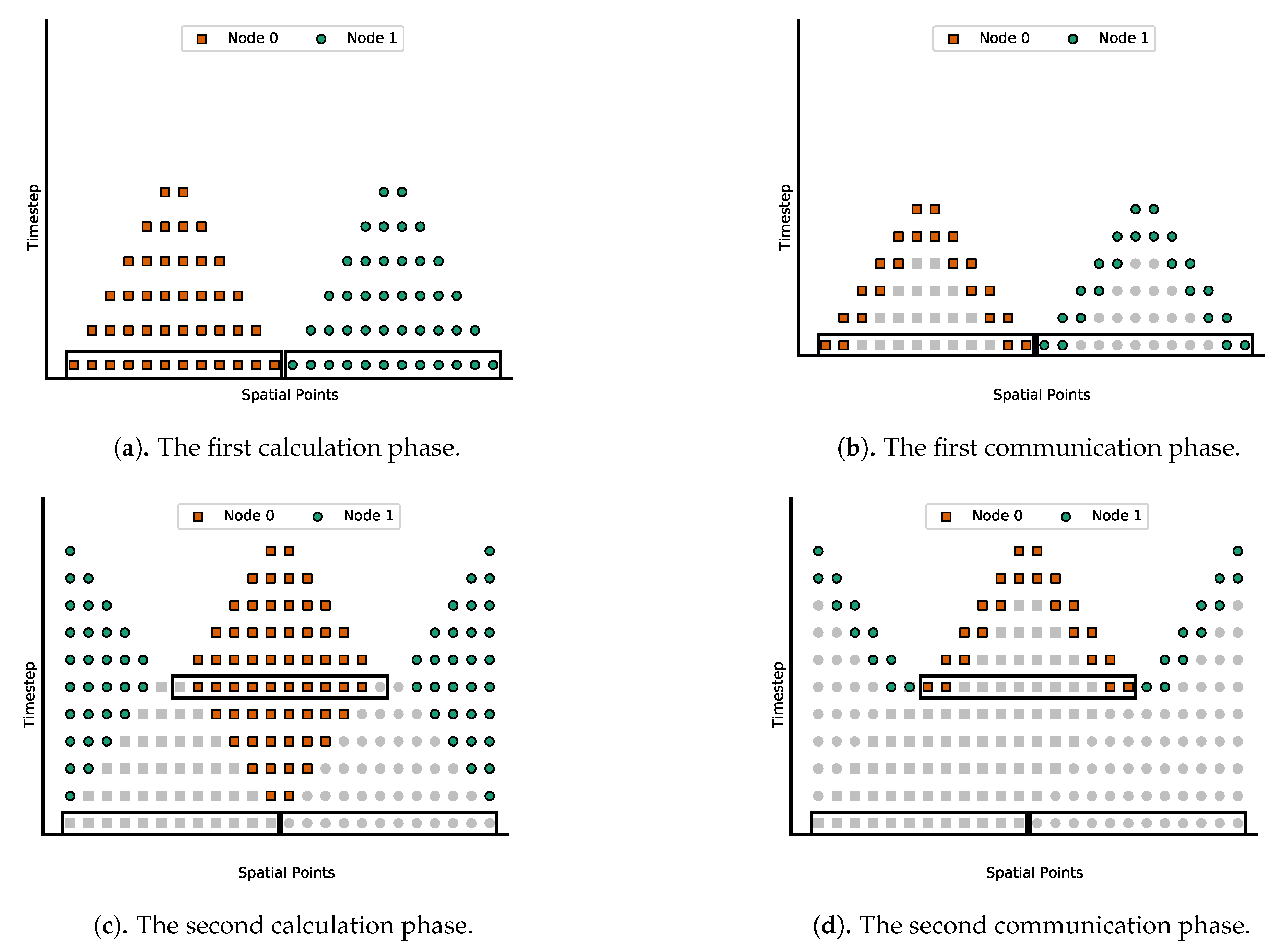
3.2. Introduction to the Swept Rule
3.3. Parameters & Testing
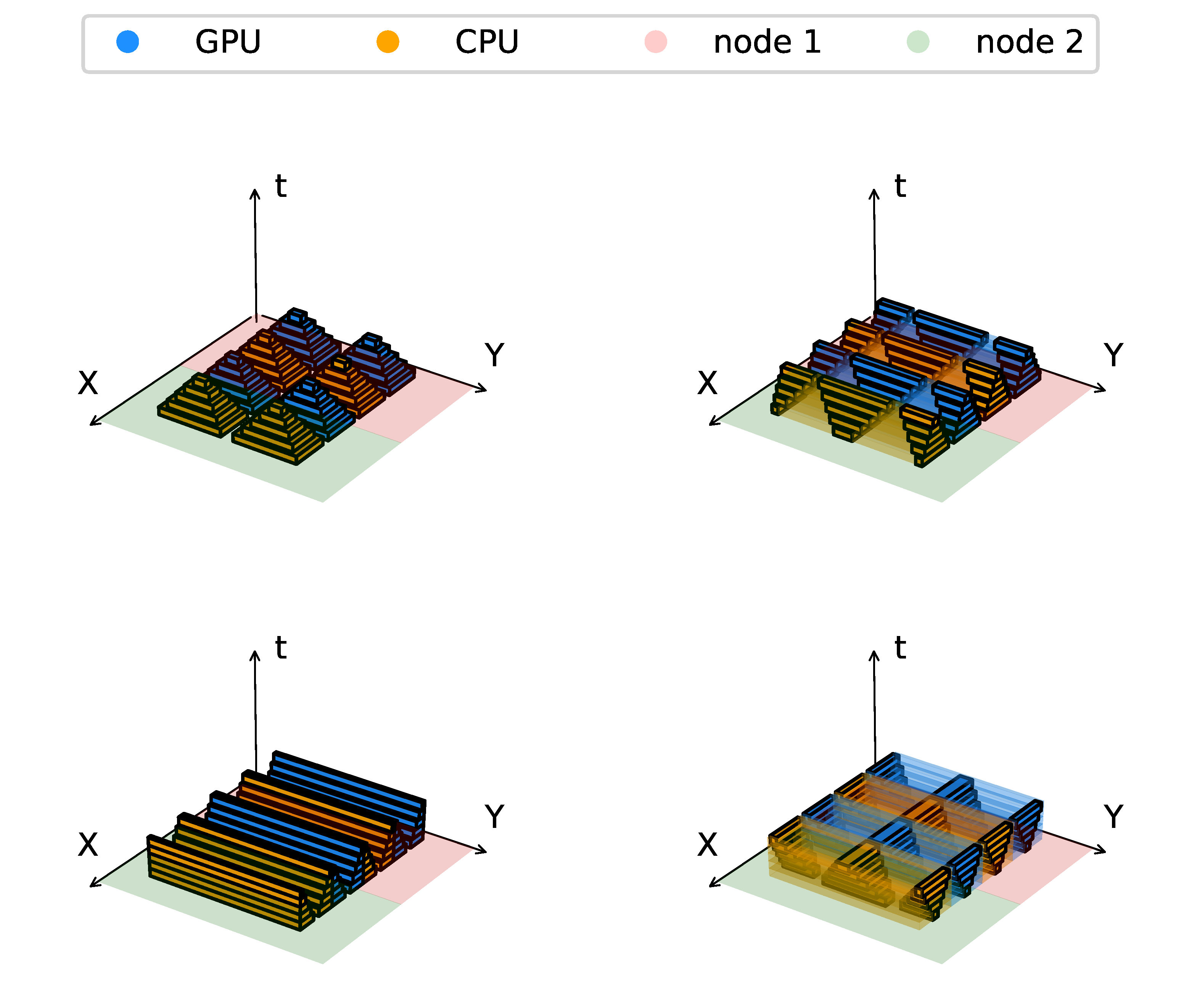
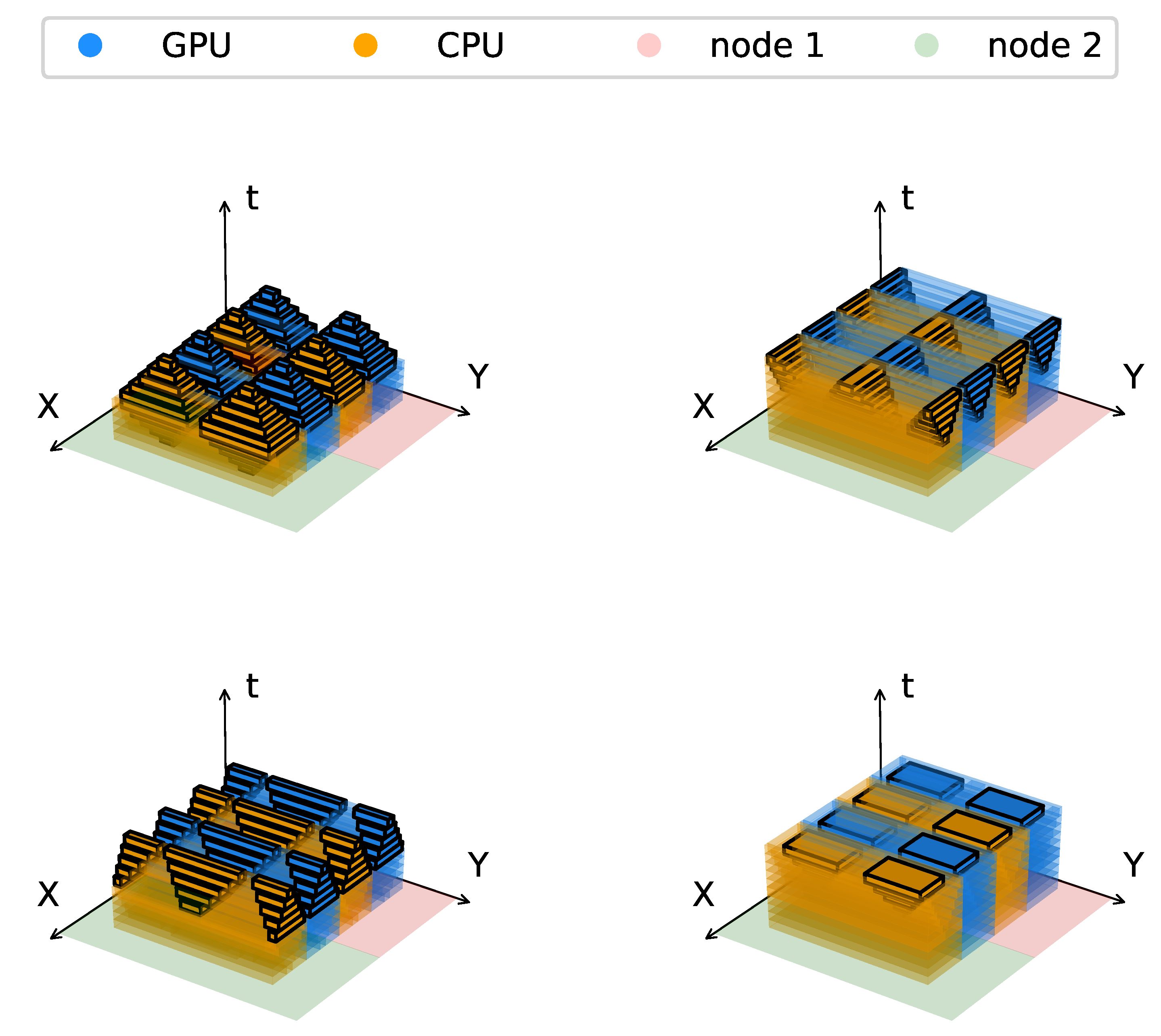
3.4. Swept Solution Process
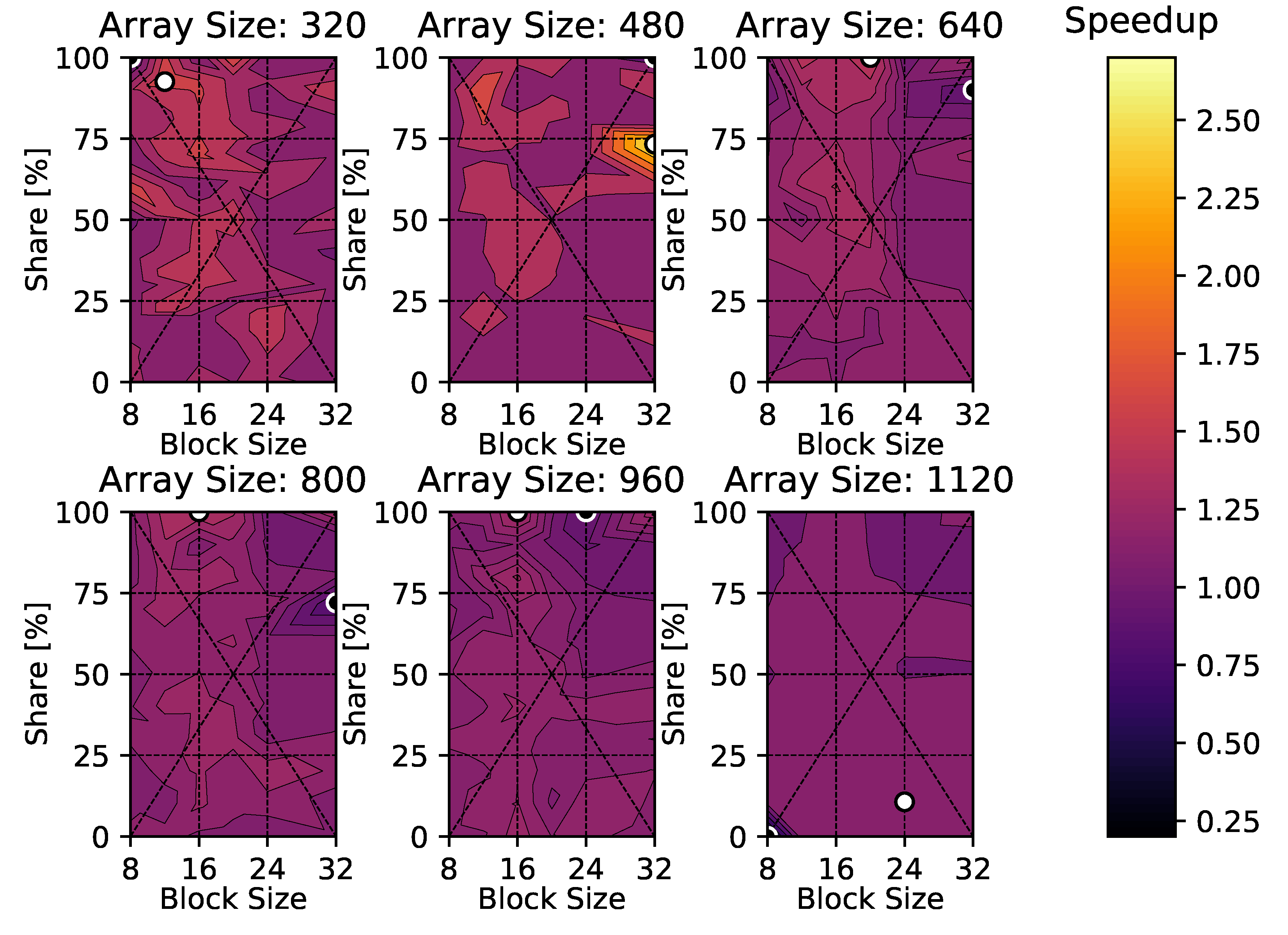
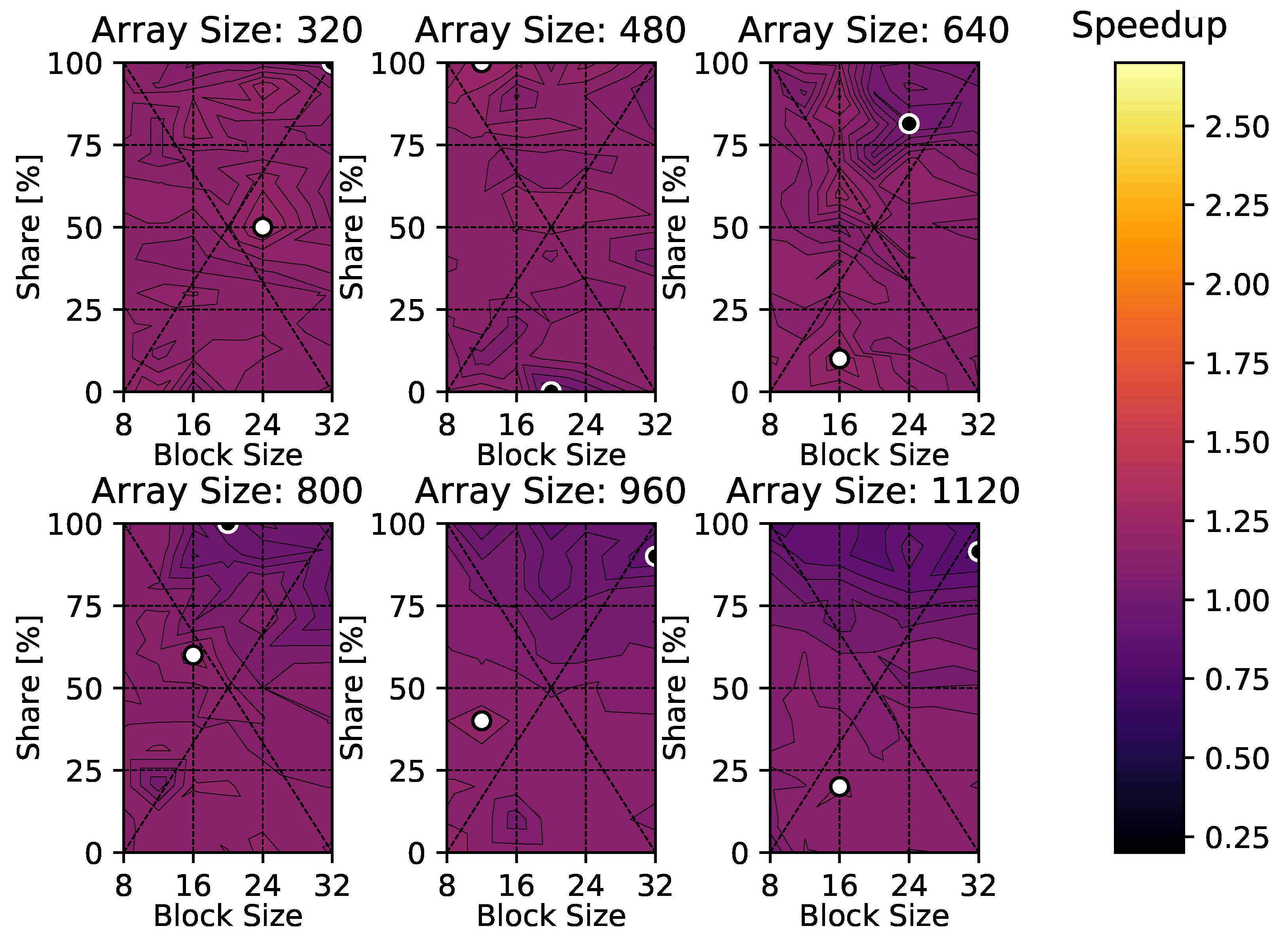
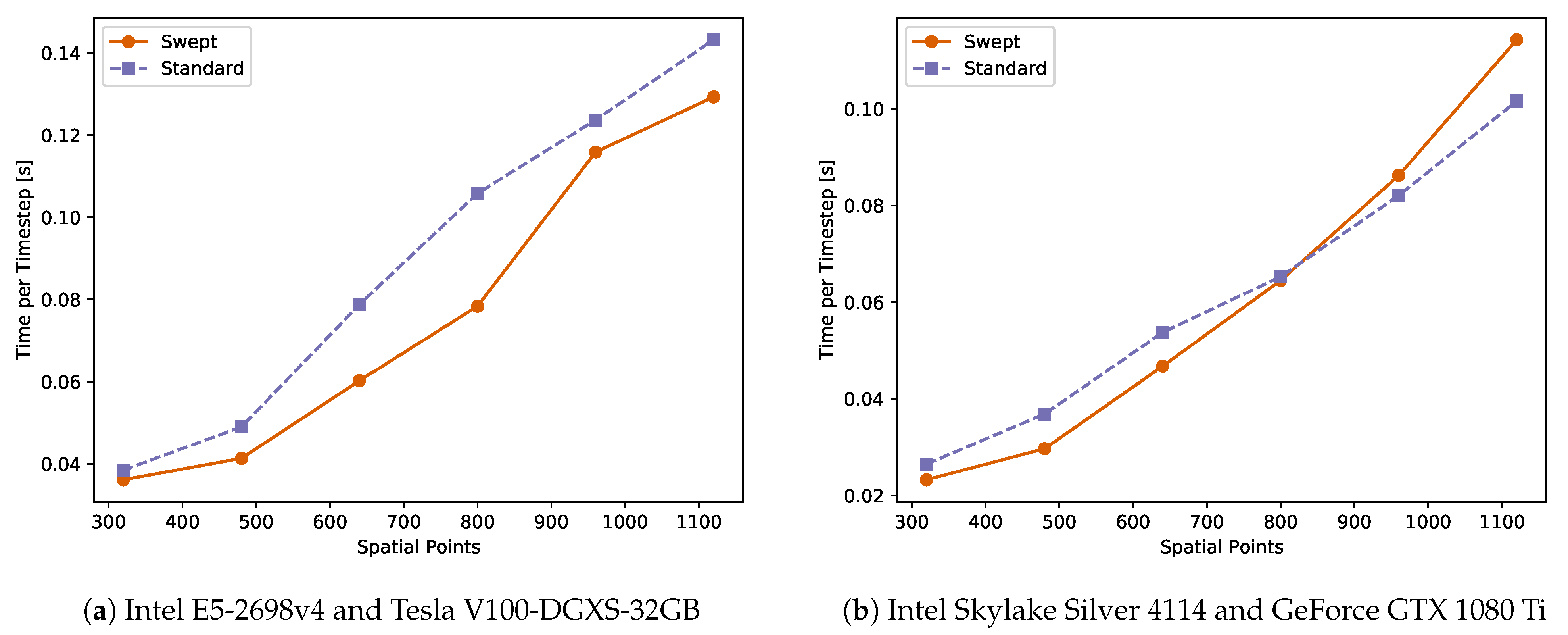
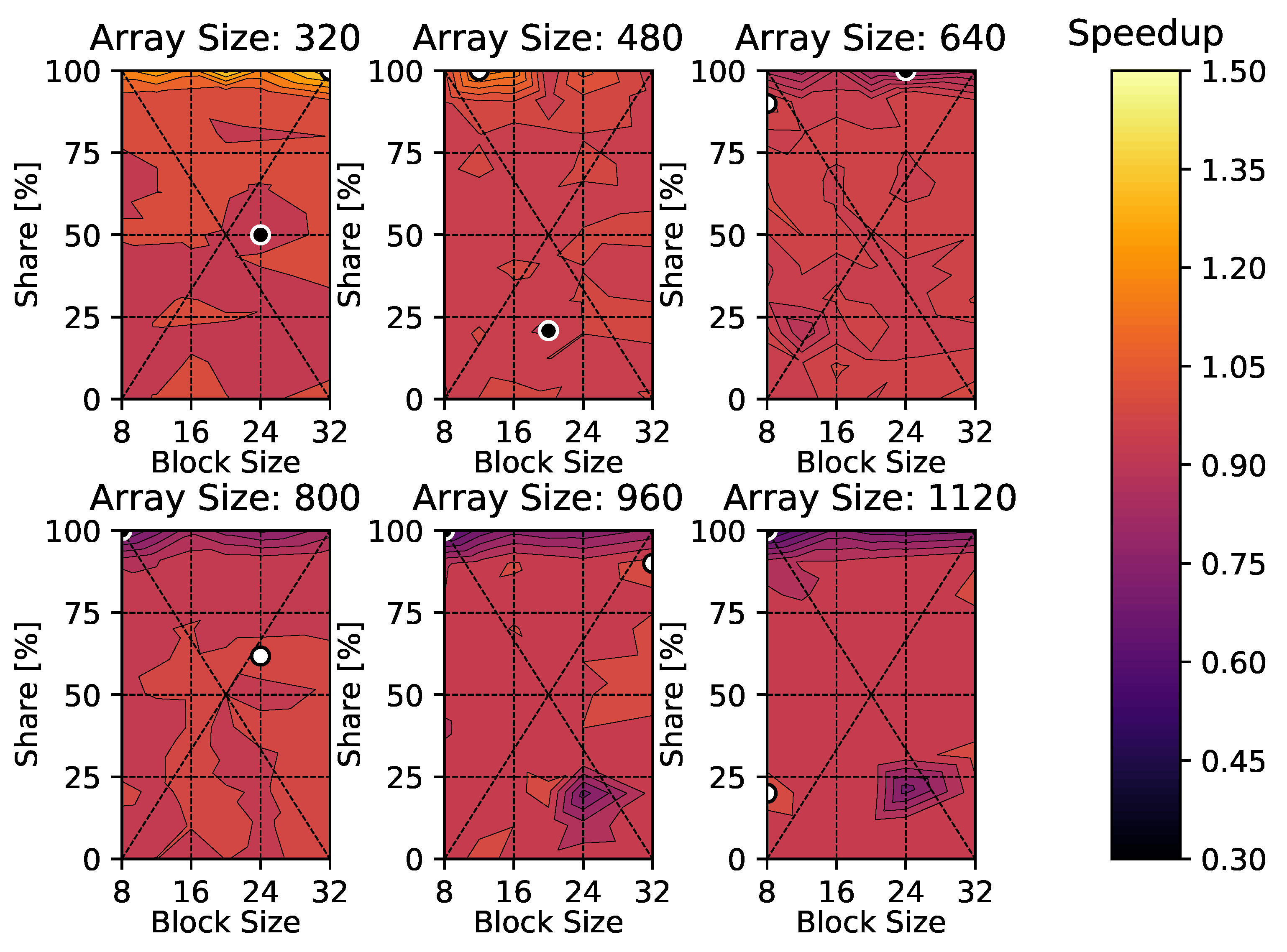
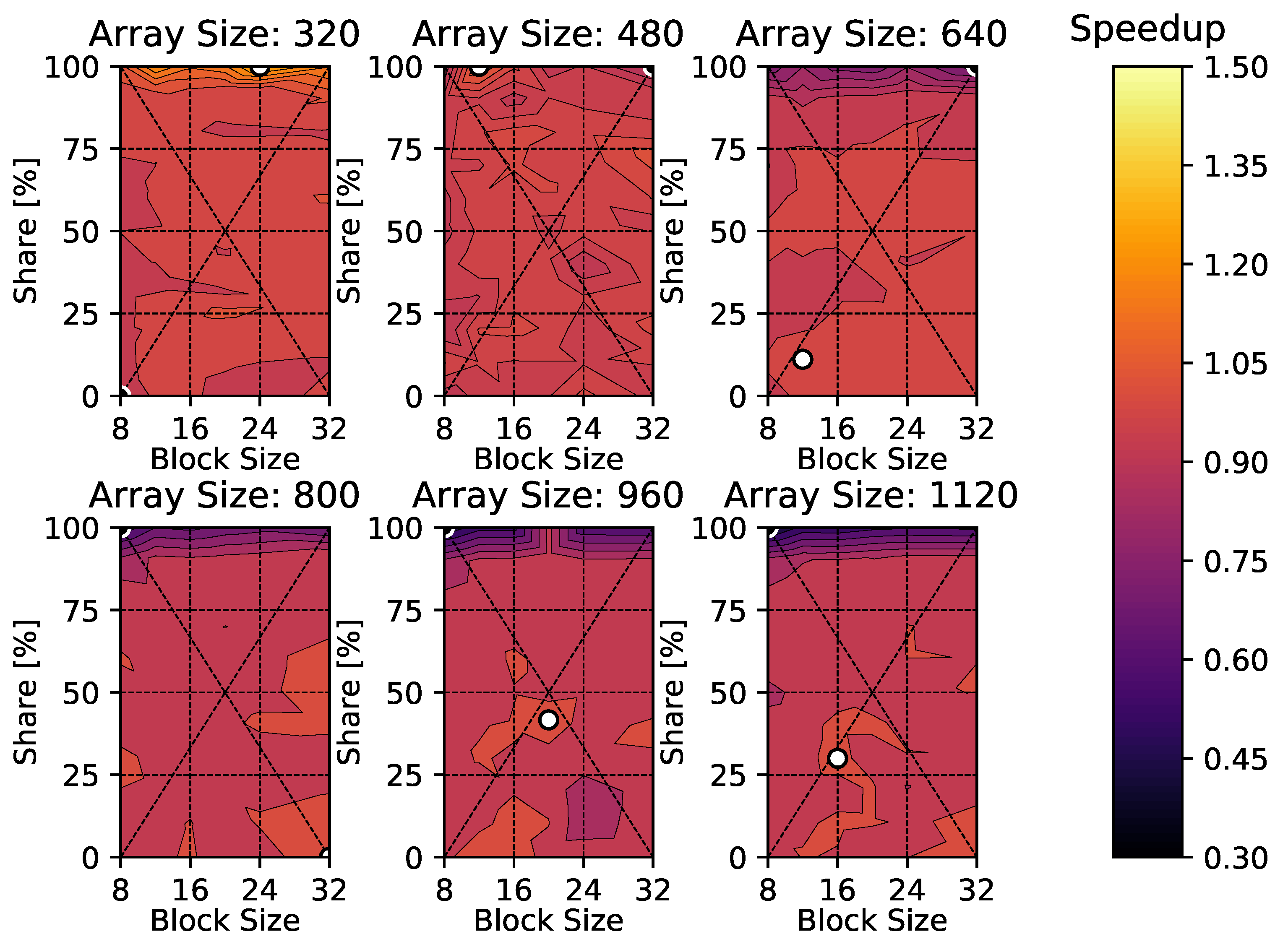
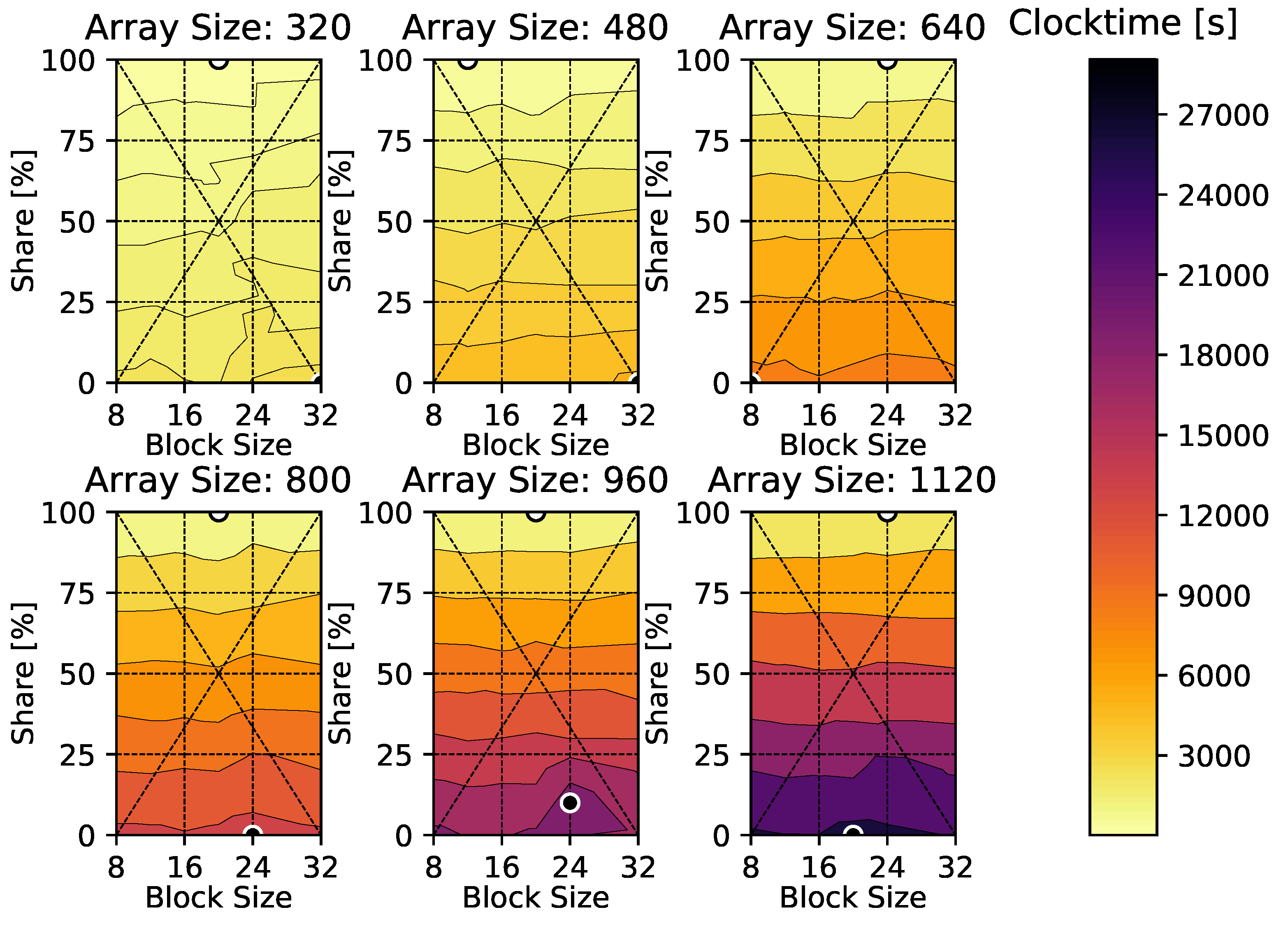
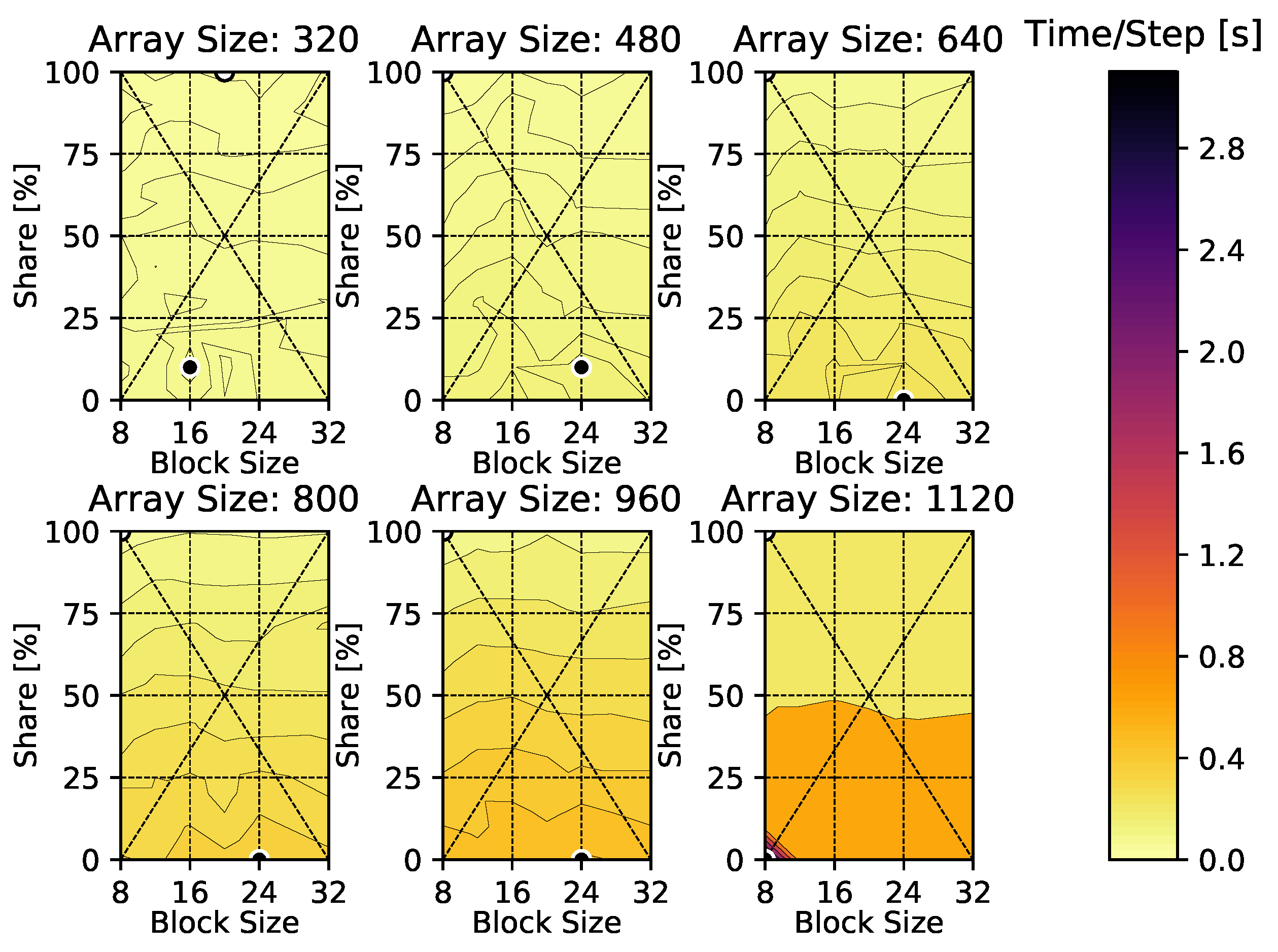
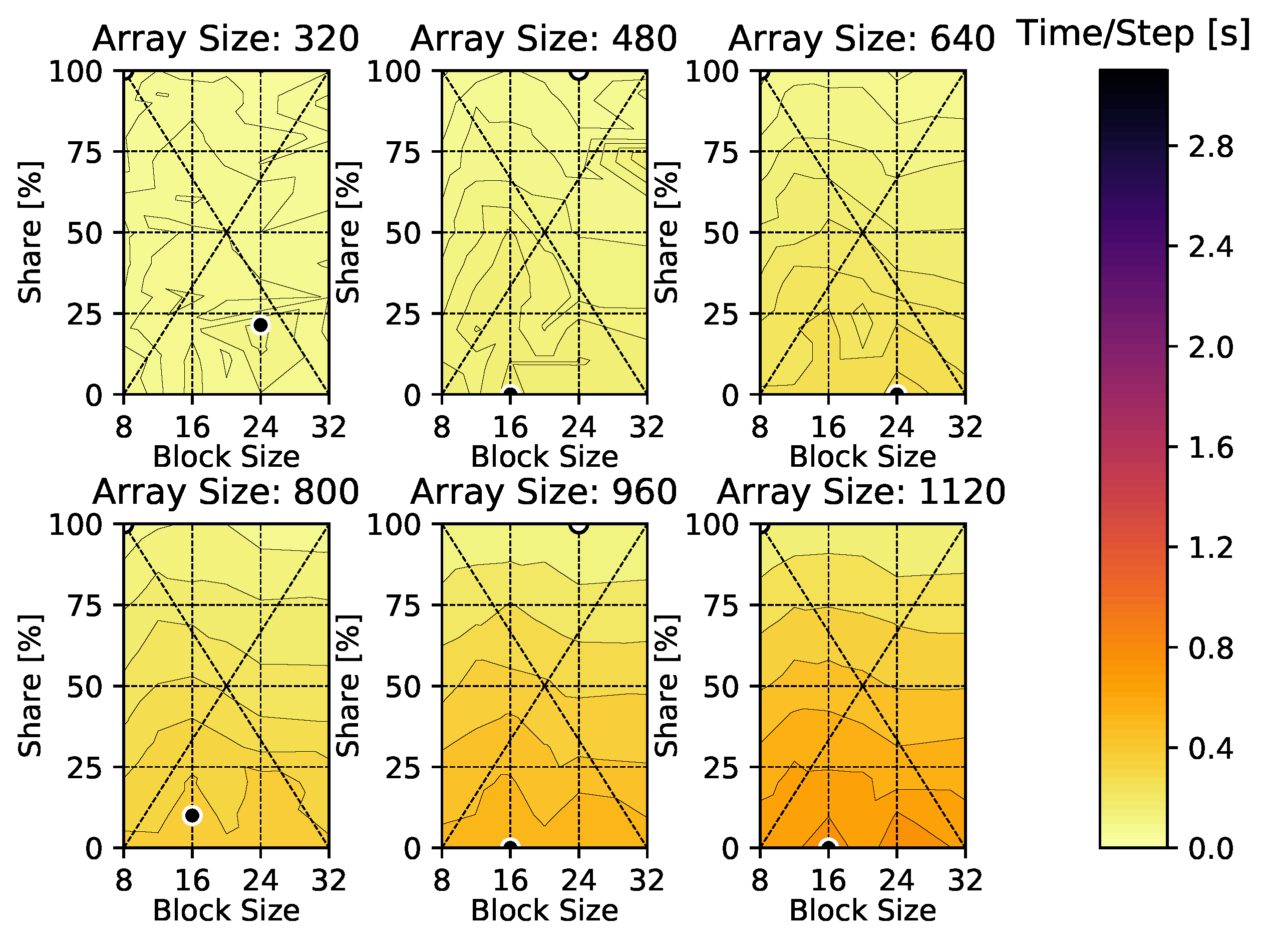
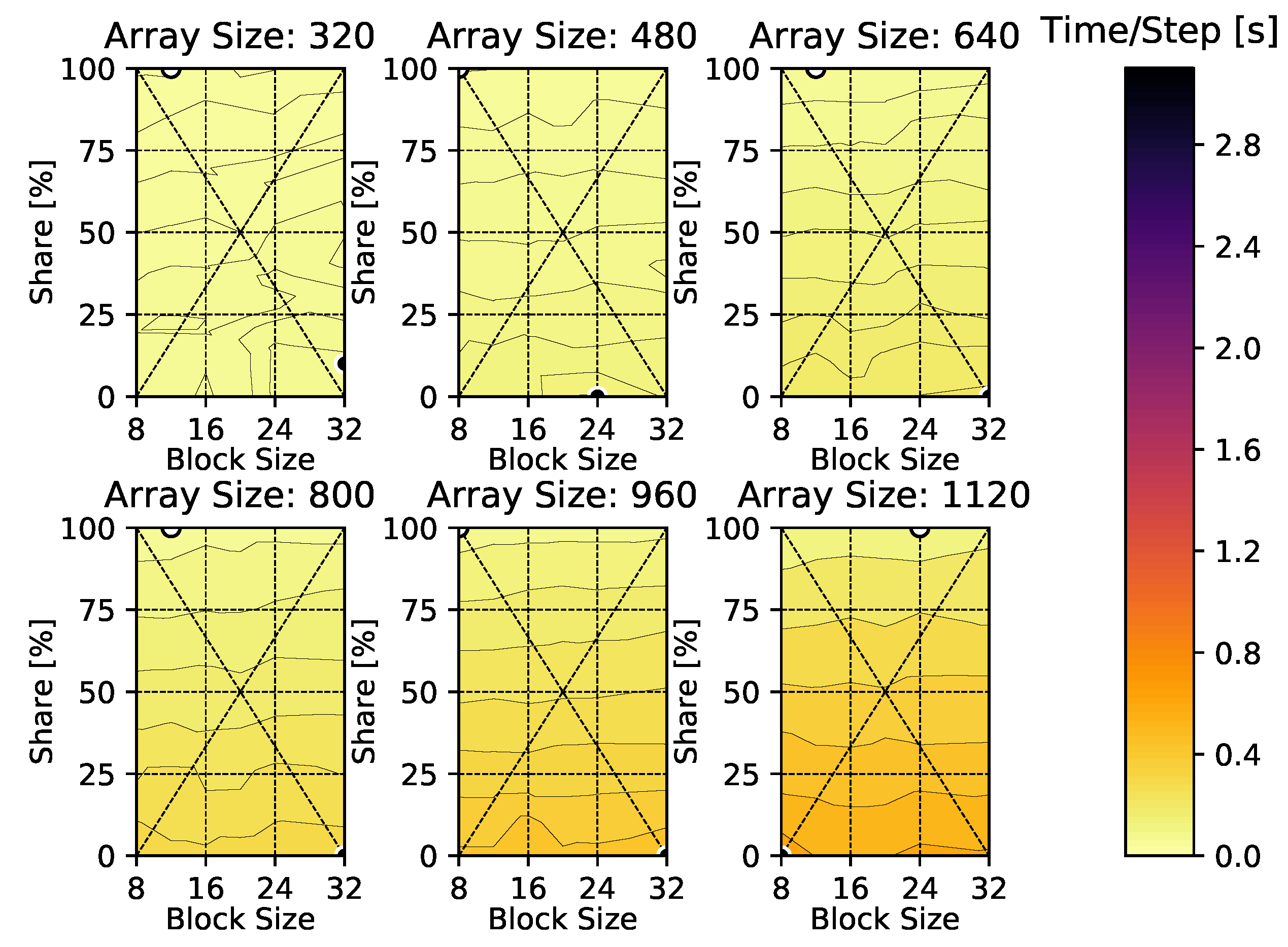
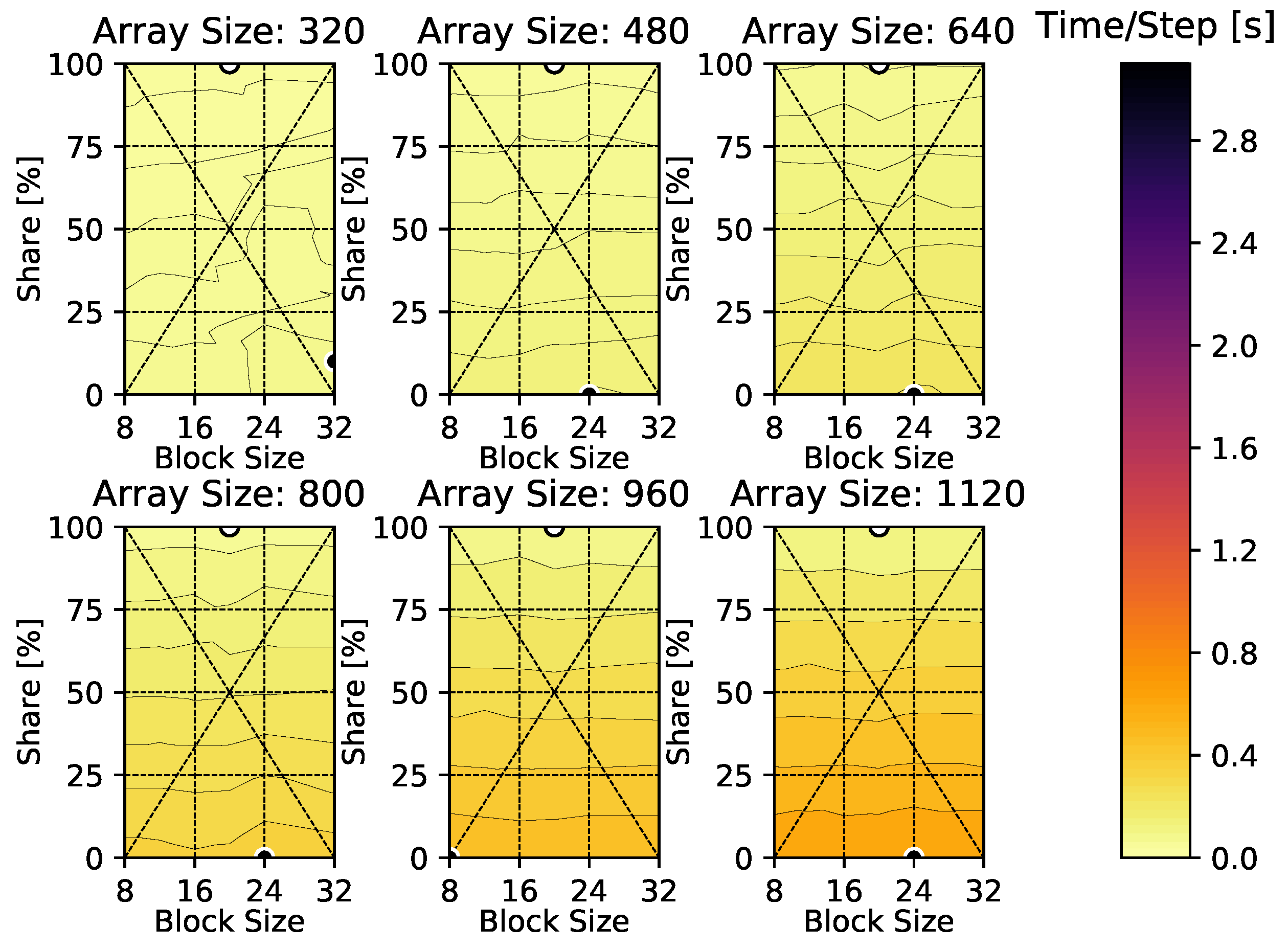
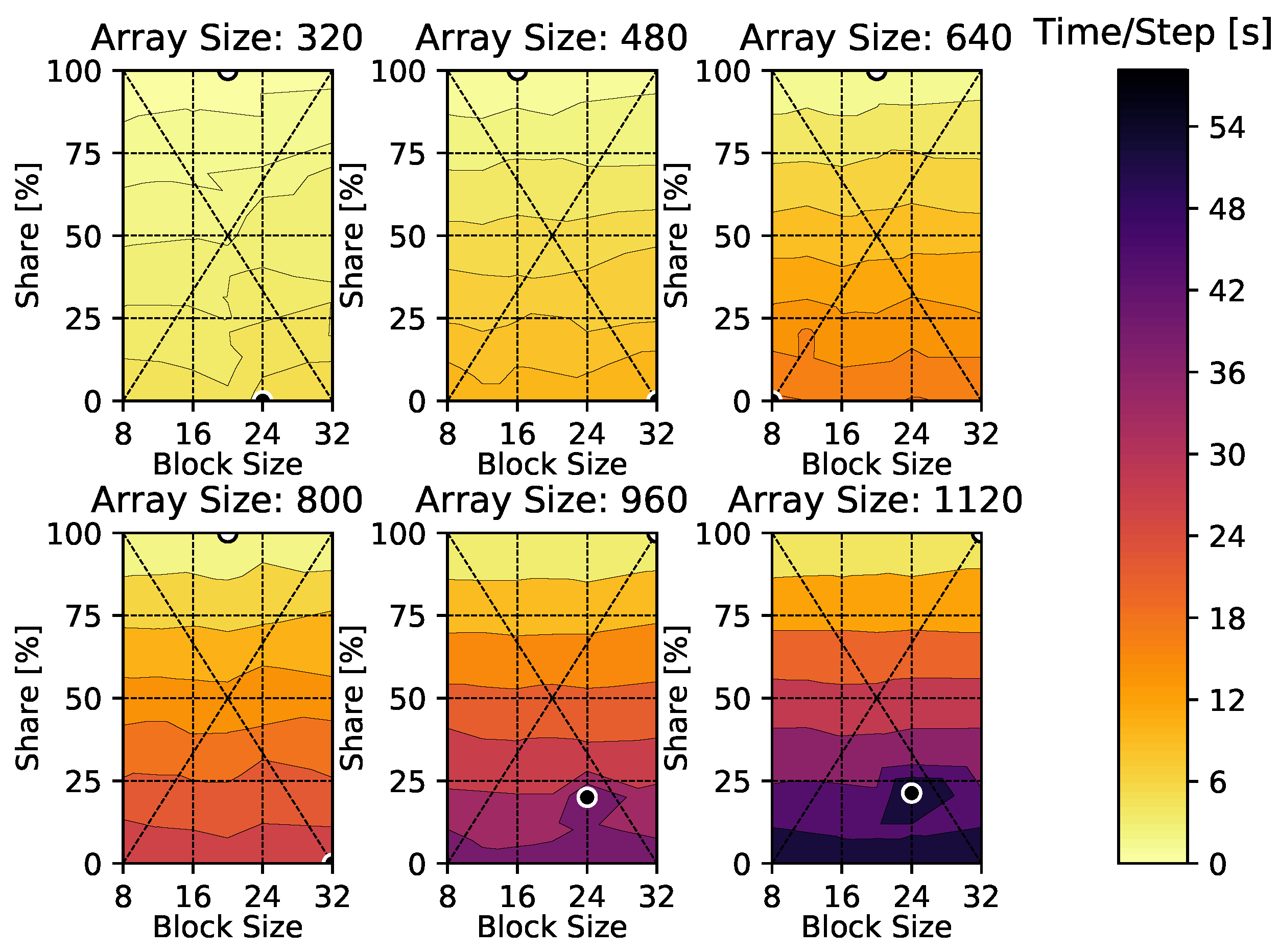
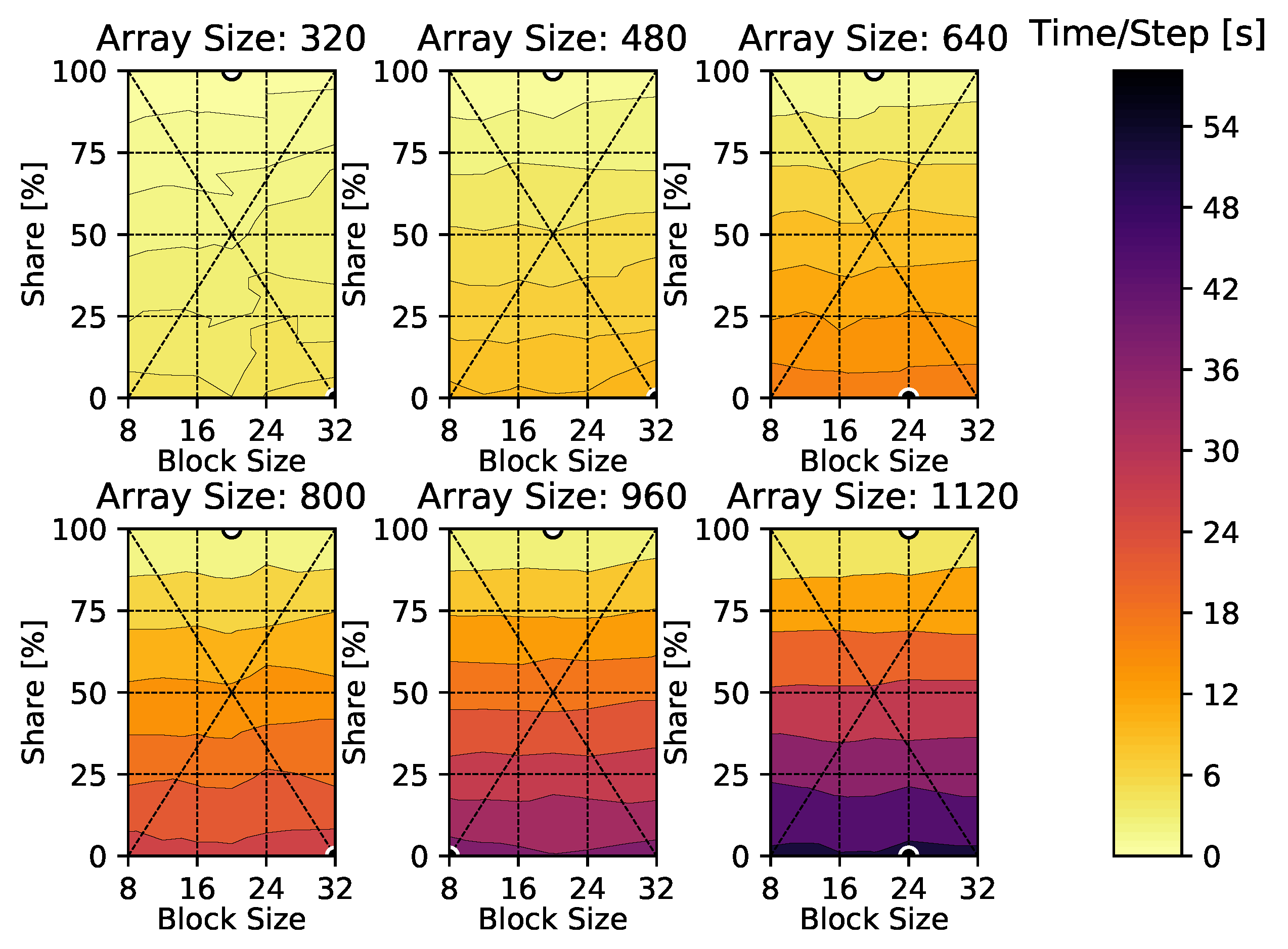
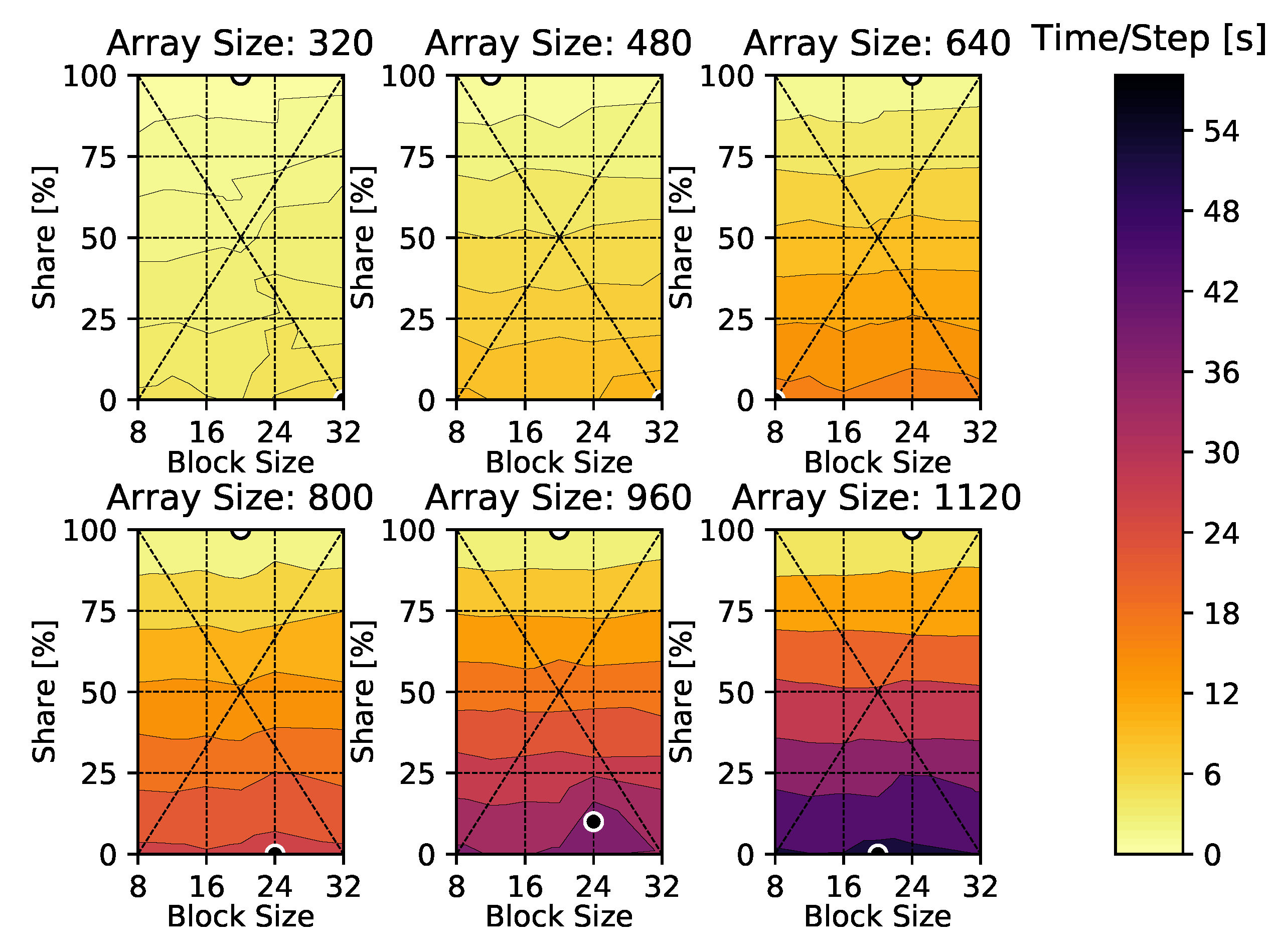
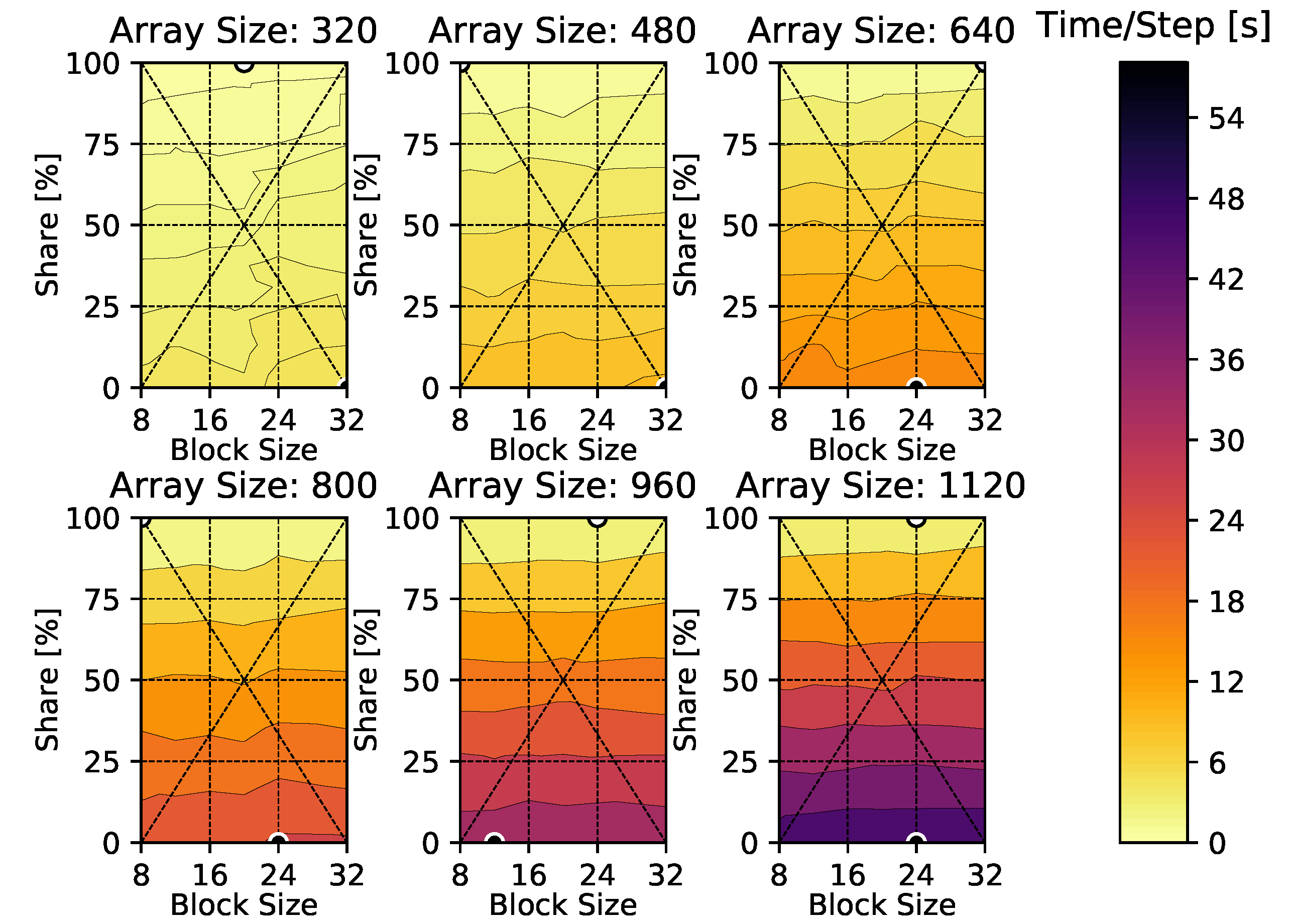
4. Results
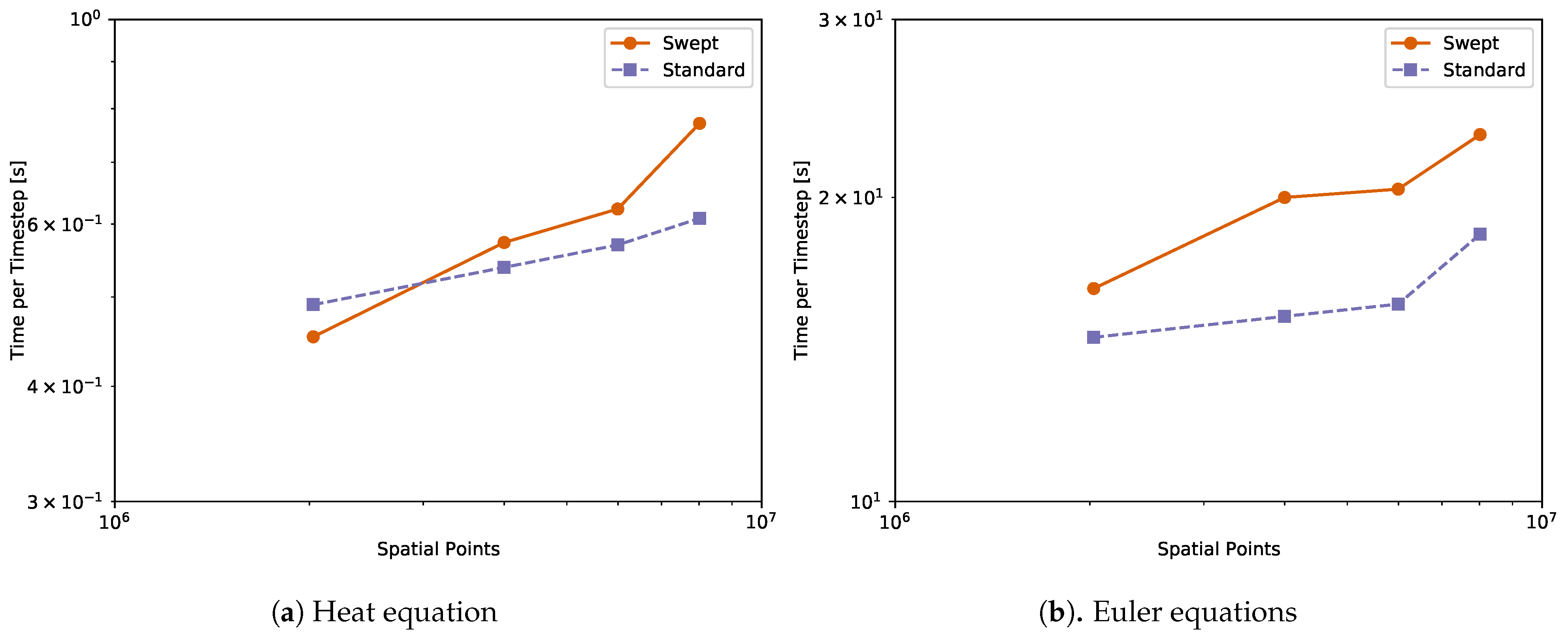
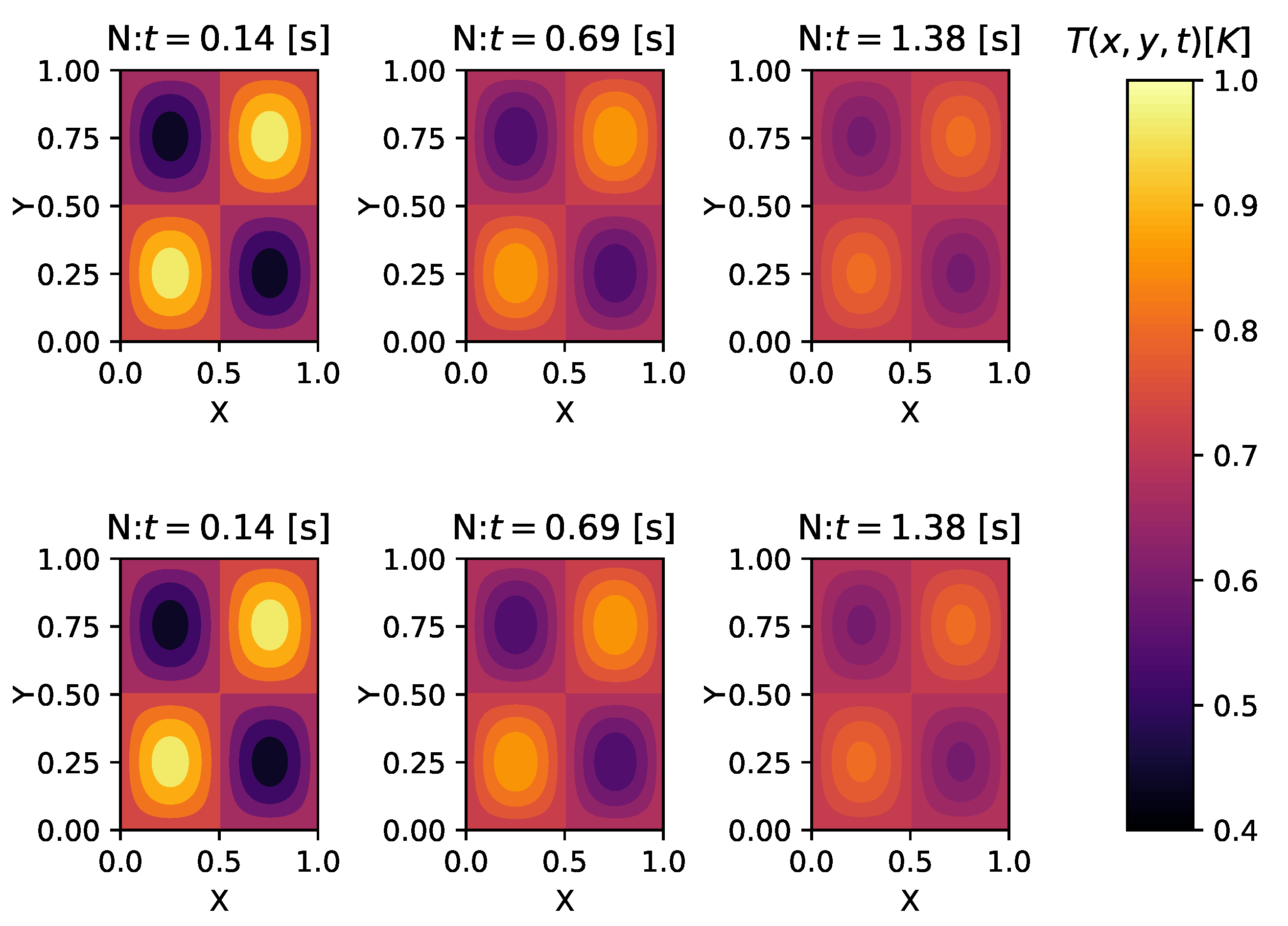
4.1. Heat Diffusion Equation
4.2. Compressible Euler Equations
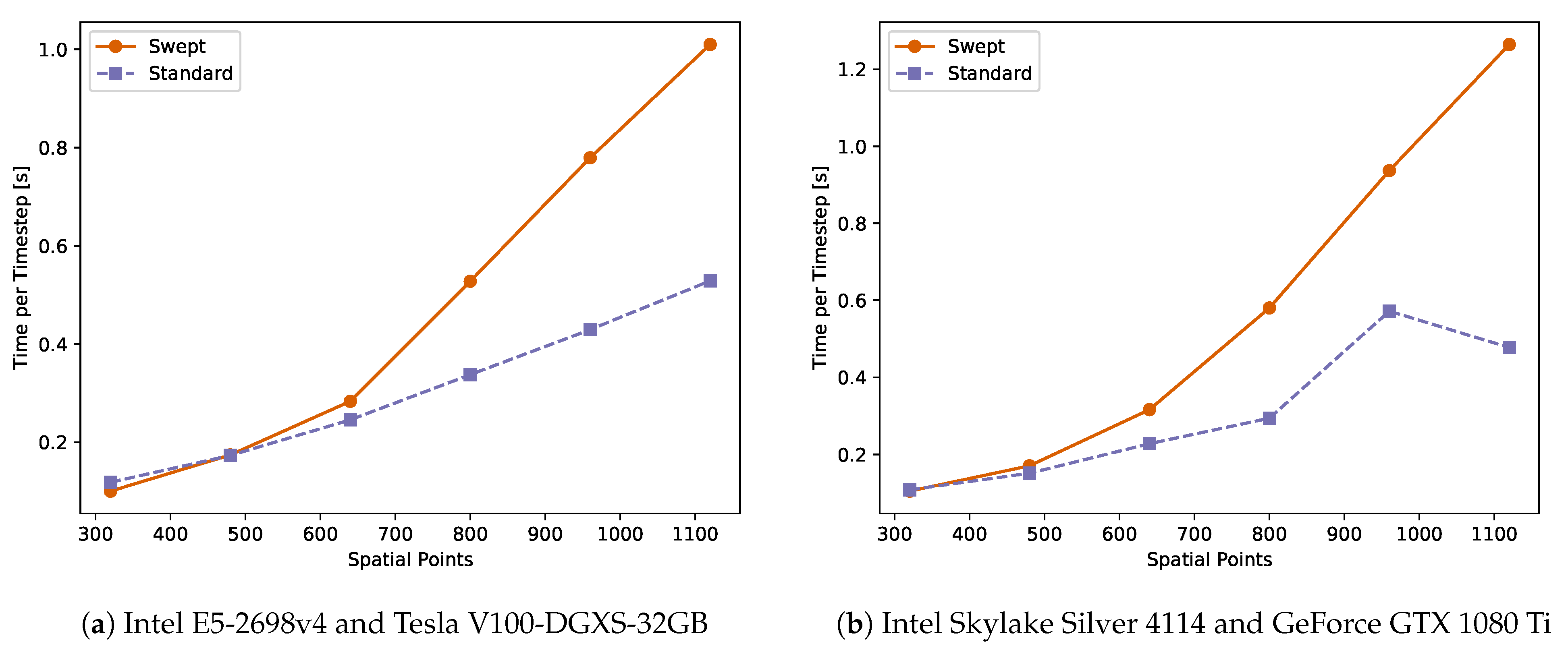
4.3. Weak Scalability
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Time-Per-Time-Step Results








Appendix B. Heat Diffusion Equation

Appendix C. Compressible Euler Vortex

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
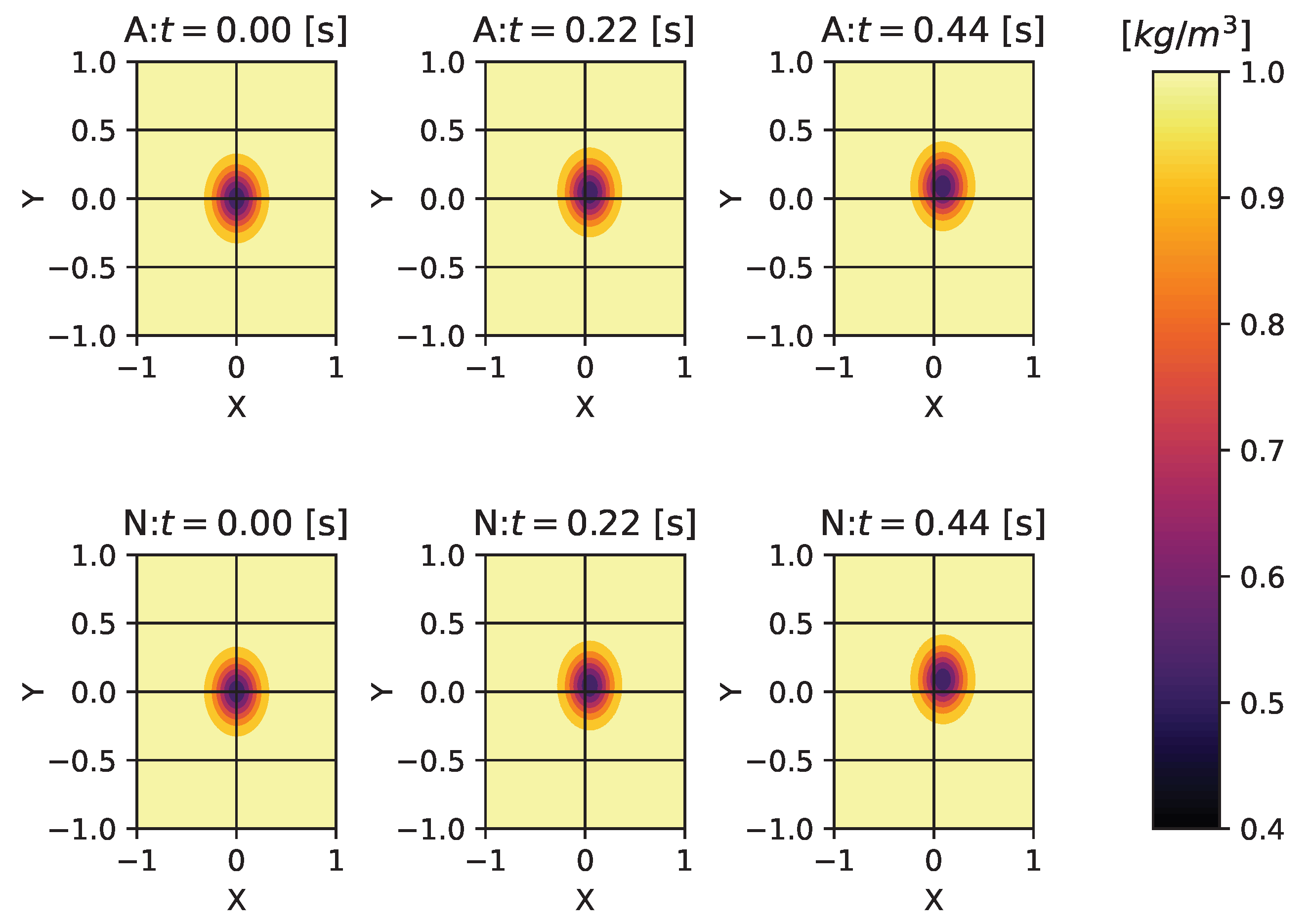{kind=link}
| R | L | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 5 |

References
- Slotnick, J.; Khoudadoust, A.; Alonso, J.; Darmofal, D.; Gropp, W.; Lurie, E.; Mavriplis, D. CFD Vision 2030 Study: A Path to Revolutionary Computational Aerosciences; NASA Technical Report; NASA/CR-2014-218178; NF1676L-18332; NASA: Washington, DC, USA, 2014.
- Patterson, D.A. Latency lags bandwith. Commun. ACM 2004, 47, 71–75. [Google Scholar] [CrossRef]
- Owens, J.D.; Luebke, D.; Govindaraju, N.; Harris, M.; Krüger, J.; Lefohn, A.E.; Purcell, T.J. A survey of general-purpose computation on graphics hardware. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2007; Volume 26, pp. 80–113. [Google Scholar] [CrossRef]
- Owens, J.D.; Houston, M.; Luebke, D.; Green, S.; Stone, J.E.; Phillips, J.C. GPU computing. Proc. IEEE 2008, 96, 879–899. [Google Scholar] [CrossRef]
- Alexandrov, V. Route to exascale: Novel mathematical methods, scalable algorithms and Computational Science skills. J. Comput. Sci. 2016, 14, 1–4. [Google Scholar] [CrossRef]
- Alhubail, M.; Wang, Q. The swept rule for breaking the latency barrier in time advancing PDEs. J. Comput. Phys. 2016. [Google Scholar] [CrossRef]
- Alhubail, M.M.; Wang, Q.; Williams, J. The swept rule for breaking the latency barrier in time advancing two-dimensional PDEs. arXiv 2016, arXiv:1602.07558. [Google Scholar]
- Magee, D.J.; Niemeyer, K.E. Accelerating solutions of one-dimensional unsteady PDEs with GPU-based swept time–space decomposition. J. Comput. Phys. 2018, 357, 338–352. [Google Scholar] [CrossRef]
- Magee, D.J.; Walker, A.S.; Niemeyer, K.E. Applying the swept rule for solving explicit partial differential equations on heterogeneous computing systems. J. Supercomput. 2020, 77, 1976–1997. [Google Scholar] [CrossRef]
- Gander, M.J. 50 Years of Time Parallel Time Integration. In Multiple Shooting and Time Domain Decomposition Methods; Carraro, T., Geiger, M., Körkel, S., Rannacher, R., Eds.; Contributions in Mathematical and Computational Sciences; Springer: Cham, Switzerland, 2015; Volume 9. [Google Scholar] [CrossRef]
- Falgout, R.D.; Friedhoff, S.; Kolev, T.V.; MacLachlan, S.P.; Schroder, J.B. Parallel time integration with multigrid. SIAM J. Sci. Comput. 2014, 36, C635–C661. [Google Scholar] [CrossRef]
- Maday, Y.; Mula, O. An adaptive parareal algorithm. J. Comput. Appl. Math. 2020, 377. [Google Scholar] [CrossRef] [PubMed]
- Wu, S.L.; Zhou, T. Parareal algorithms with local time-integrators for time fractional differential equations. J. Comput. Phys. 2018, 358, 135–149. [Google Scholar] [CrossRef]
- Emmett, M.; Minion, M.L. Toward an efficient parallel in time method for partial differential equations. Commun. Appl. Math. Comput. Sci. 2012, 7, 105–132. [Google Scholar] [CrossRef]
- Minion, M.L.; Speck, R.; Bolten, M.; Emmett, M.; Ruprecht, D. Interweaving PFASST and parallel multigrid. SIAM J. Sci. Comput. 2015, 37, S244–S263. [Google Scholar] [CrossRef][Green Version]
- Hahne, J.; Friedhoff, S.; Bolten, M. PyMGRIT: A Python Package for the parallel-in-time method MGRIT. arXiv 2020, arXiv:2008.05172. [Google Scholar]
- Kowarschik, M.; Weiß, C. An Overview of Cache Optimization Techniques and Cache-Aware Numerical Algorithms. In Algorithms for Memory Hierarchies; Springer: Berlin/Heidelberg, Germany, 2003; pp. 213–232. [Google Scholar] [CrossRef]
- Wolfe, M. More iteration space tiling. In Proceedings of the 1989 ACM/IEEE Conference on Supercomputing, Reno, NV, USA, 12–17 November 1989; pp. 655–664. [Google Scholar] [CrossRef]
- Song, Y.; Li, Z. New tiling techniques to improve cache temporal locality. ACM SIGPLAN Notes 1999, 34, 215–228. [Google Scholar] [CrossRef]
- Wonnacott, D. Using time skewing to eliminate idle time due to memory bandwidth and network limitations. In Proceedings of the 14th International Parallel and Distributed Processing Symposium, Cancun, Mexico, 1–5 May 2000; pp. 171–180. [Google Scholar] [CrossRef]
- Demmel, J.; Hoemmen, M.; Mohiyuddin, M.; Yelick, K. Avoiding communication in sparse matrix computations. In Proceedings of the 2008 IEEE International Symposium on Parallel and Distributed Processing, Miami, FL, USA, 14–18 April 2008. [Google Scholar] [CrossRef]
- Ballard, G.; Demmel, J.; Holtz, O.; Schwartz, O. Minimizing communication in numerical linear algebra. SIAM J. Matrix Anal. Appl. 2011, 32, 866–901. [Google Scholar] [CrossRef]
- Baboulin, M.; Donfack, S.; Dongarra, J.; Grigori, L.; Rémy, A.; Tomov, S. A class of communication-avoiding algorithms for solving general dense linear systems on CPU/GPU parallel machines. Procedia Comput. Sci. 2012, 9, 17–26. [Google Scholar] [CrossRef][Green Version]
- Khabou, A.; Demmel, J.W.; Grigori, L.; Gu, M. LU Factorization with Panel Rank Revealing Pivoting and Its Communication Avoiding Version. SIAM J. Matrix Anal. Appl. 2013, 34, 1401–1429. [Google Scholar] [CrossRef]
- Solomonik, E.; Ballard, G.; Demmel, J.; Hoefler, T. A Communication-Avoiding Parallel Algorithm for the Symmetric Eigenvalue Problem. In Proceedings of the 29th ACM Symposium on Parallelism in Algorithms and Architectures, Washington, DC, USA, 24–26 July 2017. [Google Scholar] [CrossRef]
- Levchenko, V.; Perepelkina, A.; Zakirov, A. DiamondTorre algorithm for high-performance wave modeling. Computation 2016, 4, 29. [Google Scholar] [CrossRef]
- Mesnard, O.; Barba, L.A. Reproducible Workflow on a Public Cloud for Computational Fluid Dynamics. Comput. Sci. Eng. 2019, 22, 102–116. [Google Scholar] [CrossRef]
- Amazon Web Services. Amazon EC2 Pricing; Amazon: Washington, DC, USA, 2021. [Google Scholar]
- Walker, A.S.; Niemeyer, K.E. PySweep. Available online: https://github.com/anthony-walker/pysweep-git (accessed on 15 July 2021).
- Dalcín, L.; Paz, R.; Storti, M. MPI for Python. J. Parallel Distrib. Comput. 2005, 65, 1108–1115. [Google Scholar] [CrossRef]
- Klöckner, A.; Pinto, N.; Lee, Y.; Catanzaro, B.; Ivanov, P.; Fasih, A. PyCUDA and PyOpenCL: A scripting-based approach to GPU run-time code generation. Parallel Comput. 2012, 38, 157–174. [Google Scholar] [CrossRef]
- Spiegel, S.C.; Huynh, H.T.; DeBonis, J.R. A Survey of the Isentropic Euler Vortex Problem using High-Order Methods. In Proceedings of the 22nd AIAA Computational Fluid Dynamics Conference, Dallas, TX, USA, 22–26 June 2015. [Google Scholar] [CrossRef]
- Leveque, R.J. Finite Volume Methods for Hyperbolic Problems; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Hoefler, T.; Dinan, J.; Buntinas, D.; Balaji, P.; Barrett, B.; Brightwell, R.; Gropp, W.; Kale, V.; Thakur, R. MPI+MPI: A new hybrid approach to parallel programming with MPI plus shared memory. Computing 2013, 95, 1121–1136. [Google Scholar] [CrossRef]
- Collette, A. Python and HDF5; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2013. [Google Scholar]
- Shu, C.W. Essentially non-oscillatory and weighted essentially non-oscillatory schemes for hyperbolic conservation laws. In Advanced Numerical Approximation of Nonlinear Hyperbolic Equations; Lecture Notes in Mathematics; Springer: Berlin/Heidelberg, Germany, 1998; pp. 325–432. [Google Scholar] [CrossRef]












Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Walker, A.S.; Niemeyer, K.E. Applying the Swept Rule for Solving Two-Dimensional Partial Differential Equations on Heterogeneous Architectures. Math. Comput. Appl. 2021, 26, 52. https://doi.org/10.3390/mca26030052
Walker AS, Niemeyer KE. Applying the Swept Rule for Solving Two-Dimensional Partial Differential Equations on Heterogeneous Architectures. Mathematical and Computational Applications. 2021; 26(3):52. https://doi.org/10.3390/mca26030052
Chicago/Turabian StyleWalker, Anthony S., and Kyle E. Niemeyer. 2021. "Applying the Swept Rule for Solving Two-Dimensional Partial Differential Equations on Heterogeneous Architectures" Mathematical and Computational Applications 26, no. 3: 52. https://doi.org/10.3390/mca26030052
APA StyleWalker, A. S., & Niemeyer, K. E. (2021). Applying the Swept Rule for Solving Two-Dimensional Partial Differential Equations on Heterogeneous Architectures. Mathematical and Computational Applications, 26(3), 52. https://doi.org/10.3390/mca26030052