Privacy-Preserved Approximate Classification Based on Homomorphic Encryption


Abstract
:1. Introduction
- When we ensemble a set of decision trees to produce online prediction, we obtain a linear algorithm but shallower circuit depth. In other words, a GBDT algorithm achieves more accurate prediction but much smaller computational overhead compared with a traditional decision tree algorithm.
- Due to many machine learning tasks being based on datasets with error, an approximate GBDT algorithm also works in real world problems if we can carefully investigate the error bound of an algorithm,
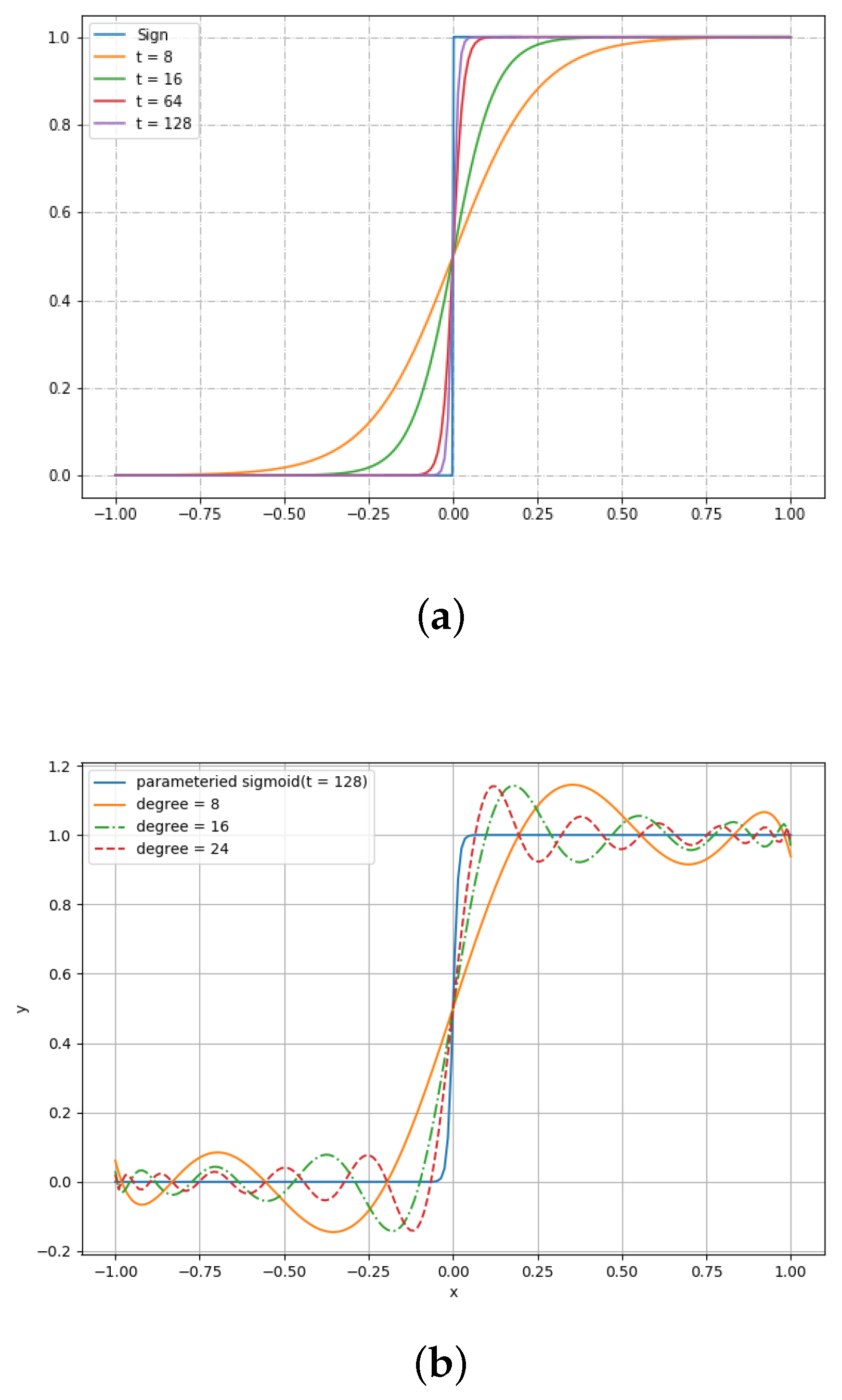
- Chebyshev approximation of the parameterized sigmoid function. We propose a new algorithm called homomorphic approximate GBDT, which enables performing approximate classification on encrypted data using Chebyshev approximation of the parameterized sigmoid function.
- Significant reduction in computation time. We propose an improved strategy for evaluating polynomials corresponding to the decision tree. Our novel method requires homomorphic multiplication to compute an approximate output of a decision tree, compared to of the naive method, where n is denoted as the number of attribute of clients’ data.
- Vertical packing. In contrast to a horizontal packing technique that packs several data instances into a single plaintext, we apply a vertical packing technique to reduce space overhead substantially. We argue that a vertical packing technique is more scalable and feasible than horizontal packing in practice.
2. Preliminaries
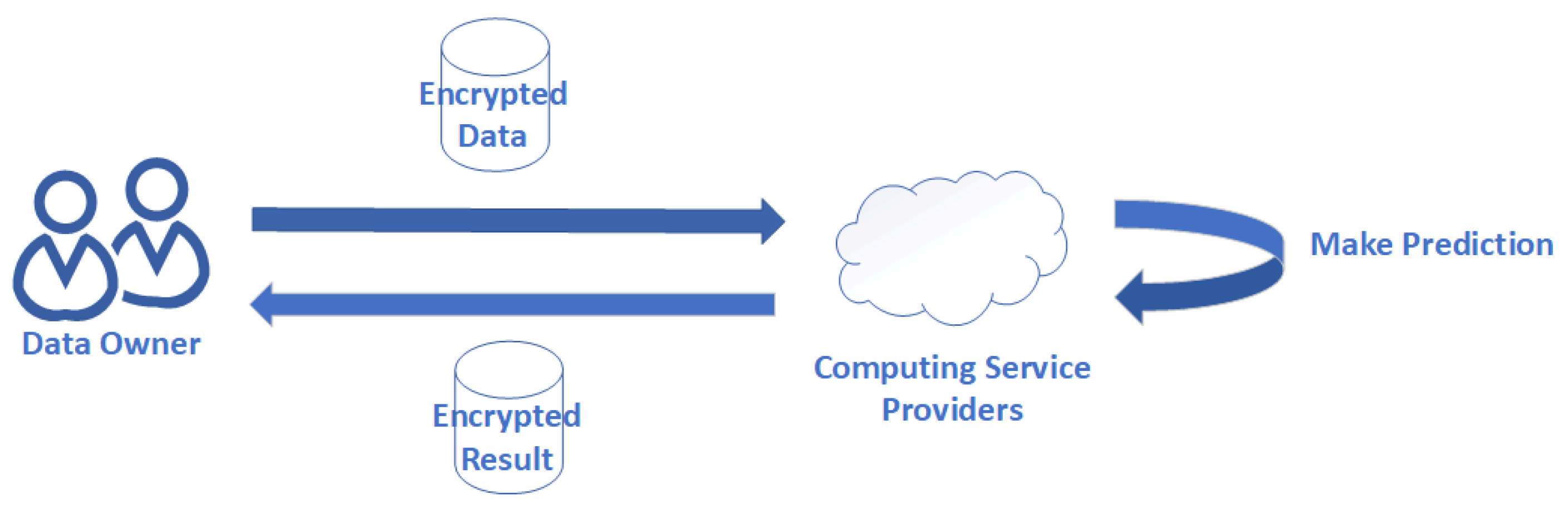
2.1. Problem Statement
2.2. Error Bound of Multivariate Function
2.3. Homomorphic Encryption
| CKKS homomorphic encryption scheme |
| is the ring of integer polynomials modulo . We use to denote with integer coefficients modulo q. We use to denote . The inner product between vectors and is denoted by . Given the security parameter , select integer , set , where . Generate and then output it. : Let and Output . Output . Output . : Let , compute , Output . Output . |
2.4. Gradient Boosting Decision Tree
3. Computational Polynomial
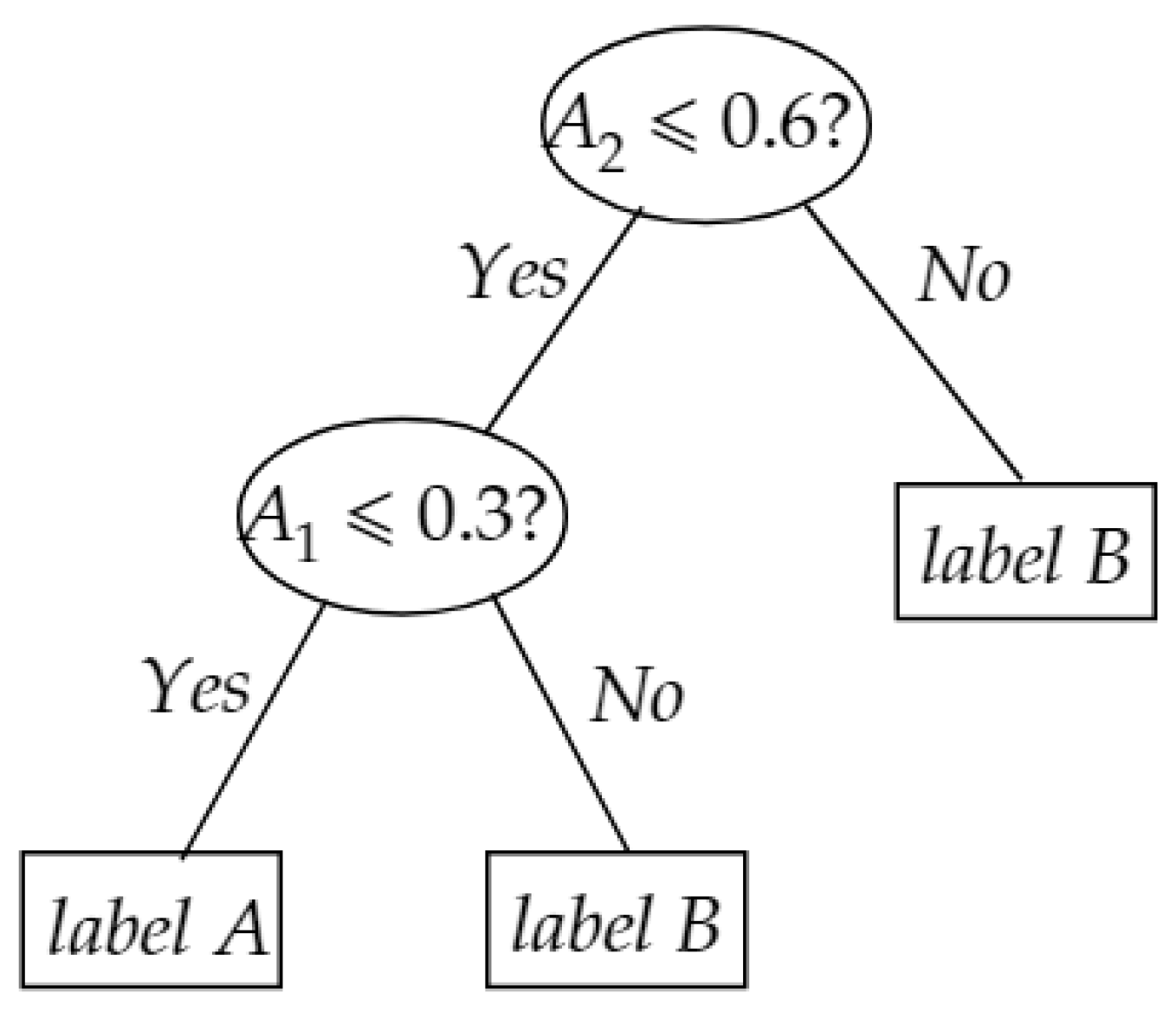
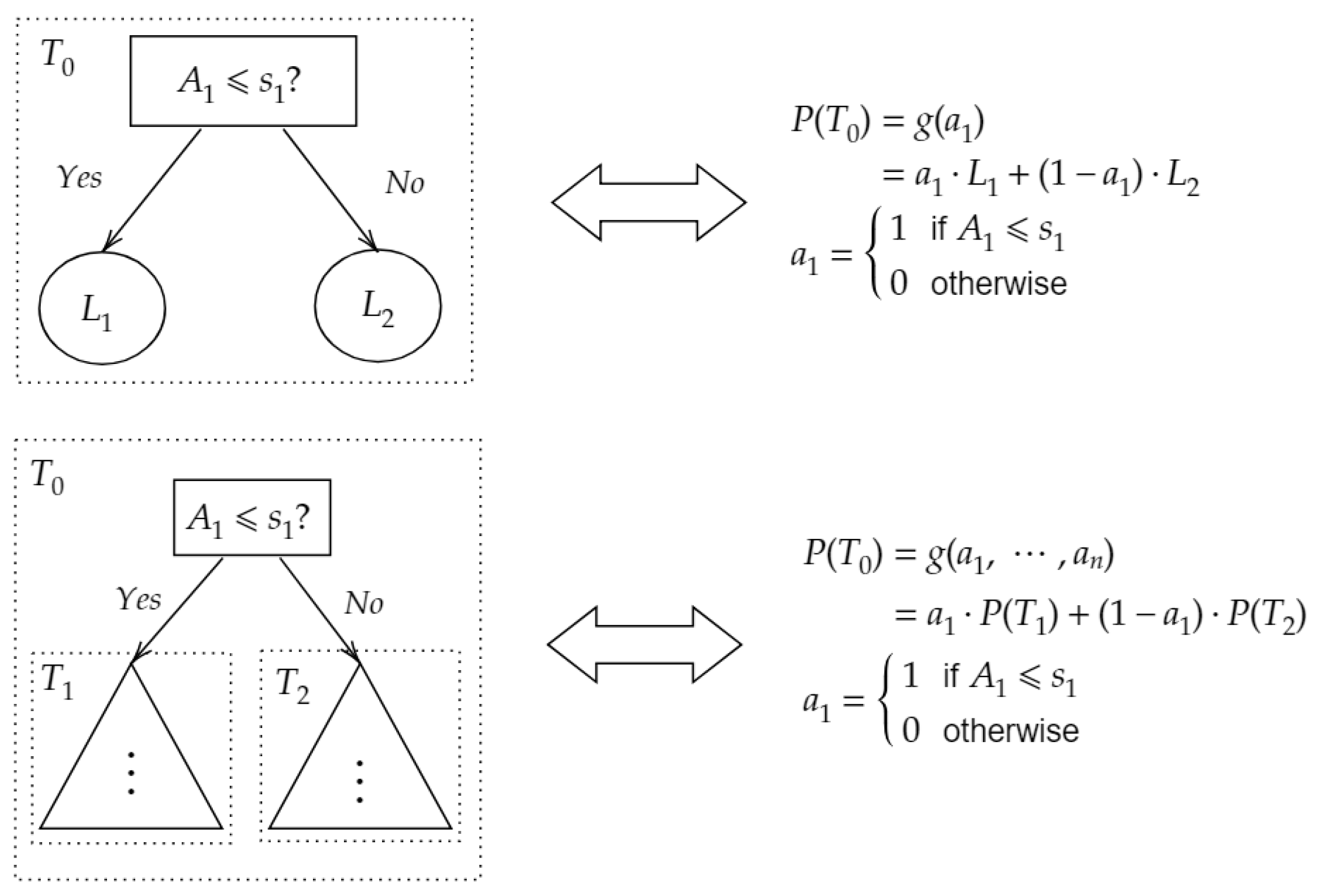
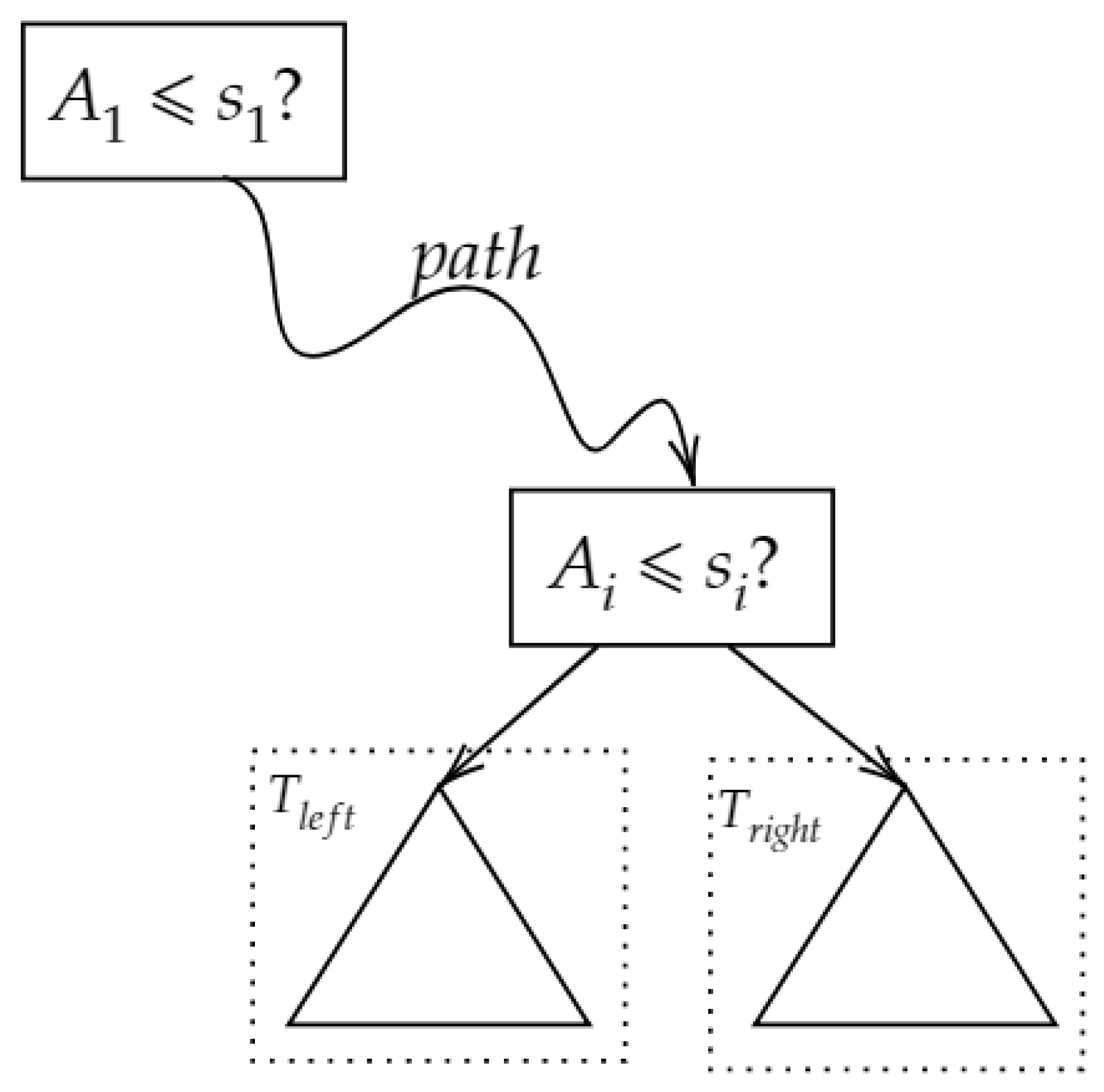
3.1. Decision Tree Polynomial
3.2. GBDT Computational Polynomial
4. Homomorphic Approximate GBDT Prediction
4.1. Homomorphic Approximate GBDT Algorithm
4.2. Security Analysis
4.3. The Error Bound of a Decision Tree
- : The lower the error we want, the higher degree polynomial we have to evaluate, which leads to heavy computational time. In Section 5, we elaborate on how affects the performance.
- n: It is a hyperparameter controlled by the service provider. A large n leads to an outstanding model but is at risk of overfitting, and a small n leads to lower approximate error, which is what we want. In order to obtain lower approximate error , it is a judicious way to increase the number of decision trees in GBDT. In this manner, we get an outstanding model that is also a lower approximate error model.
- : Given this parameter, we can evaluate the error bound of our approximate prediction. Note that .
4.4. The Error Bound of GBDT
| Algorithm 1: Homo Approx. GBDT Inference |
 |
5. Experiments and Discussion
5.1. Experimental Settings
5.2. Packing Technique
5.3. Classification Performance on Encrypted Data
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Kuznetsov, V.; Mohri, M.; Syed, U. Multi-class deep boosting. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 8–11 December 2014; pp. 2501–2509. [Google Scholar]
- Wang, Y.; Feng, D.; Li, D.; Chen, X.; Zhao, Y.; Niu, X. A mobile recommendation system based on logistic regression and Gradient Boosting Decision Trees. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1896–1902. [Google Scholar]
- Li, P.; Wu, Q.; Burges, C.J. Mcrank: Learning to rank using multiple classification and gradient boosting. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 897–904. [Google Scholar]
- Badawi, A.A.; Chao, J.; Lin, J.; Mun, C.F.; Jie, S.J.; Tan, B.H.M.; Nan, X.; Aung, K.M.M.; Chandrasekhar, V.R. The AlexNet moment for homomorphic encryption: HCNN, the first homomorphic CNN on encrypted data with GPUs. arXiv 2018, arXiv:1811.00778. [Google Scholar]
- Cheon, J.H.; Kim, D.; Kim, Y.; Song, Y. Ensemble method for privacy-preserving logistic regression based on homomorphic encryption. IEEE Access 2018, 6, 46938–46948. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, C.; Wu, H.; Xin, C.; Phuong, T.V. GELU-Net: A Globally Encrypted, Locally Unencrypted Deep Neural Network for Privacy-Preserved Learning. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; pp. 3933–3939. [Google Scholar]
- Zhou, G.; Xie, J. Numerical Computation, 2nd ed.; Higher Education Press: Beijing, China, 2013; pp. 28–29. [Google Scholar]
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the 41st Annual ACM Symposium on Theory of Computing (STOC 2009), Bethesda, MD, USA, 31 May–2 June 2009; Volume 9, pp. 169–178. [Google Scholar]
- Cheon, J.H.; Kim, A.; Kim, M.; Song, Y. Homomorphic encryption for arithmetic of approximate numbers. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Hong Kong, China, 3–7 December 2017; Springer: Cham, Switzerland, 2017; pp. 409–437. [Google Scholar]
- Jiang, X.; Kim, M.; Lauter, K.; Song, Y. Secure outsourced matrix computation and application to neural networks. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; ACM: New York, NY, USA, 2018; pp. 1209–1222. [Google Scholar]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. (Leveled) fully homomorphic encryption without bootstrapping. ACM Trans. Comput. Theory 2014, 6, 13. [Google Scholar] [CrossRef]
- Fan, J.; Vercauteren, F. Somewhat Practical Fully Homomorphic Encryption. IACR Cryptol. ePrint Arch. 2012, 2012, 144. [Google Scholar]
- Gentry, C.; Sahai, A.; Waters, B. Homomorphic encryption from learning with errors: Conceptually-simpler, asymptotically-faster, attribute-based. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 75–92. [Google Scholar]
- Cheon, J.H.; Kim, A.; Kim, M.; Song, Y. Implementation of HEAAN. 2016. Available online: https://github.com/kimandrik/HEAAN (accessed on 3 September 2019).
- LeCun, Y.; Cortes, C.; Burges, C. MNIST Handwritten Digit Database. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 28 August 2019).
- Default of Credit Card Clients Data Set. Available online: https://archive.ics.uci.edu/ml/datasets/default+of+credit+card+clients (accessed on 28 August 2019).
- Chillotti, I.; Gama, N.; Georgieva, M.; Izabachène, M. Faster packed homomorphic operations and efficient circuit bootstrapping for TFHE. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Hong Kong, China, 3–7 December 2017; Springer: Cham, Switzerland, 2017; pp. 377–408. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Parameters | Performance | ||
|---|---|---|---|---|
| Learning Rate | # of Base Learner | Max Depth | Micro-F1 Score | |
| MNIST | 0.1 | 100 | 7 | 0.912 |
| Credit | 0.1 | 300 | 3 | 0.613 |
| Setting-A | MNIST | Credits | ||||||
|---|---|---|---|---|---|---|---|---|
| Micro Score | Micro Score | |||||||
| Unencrypted | Encrypted | Gap | Err. Rate | Unencrypted | Encrypted | Gap | Err. Rate | |
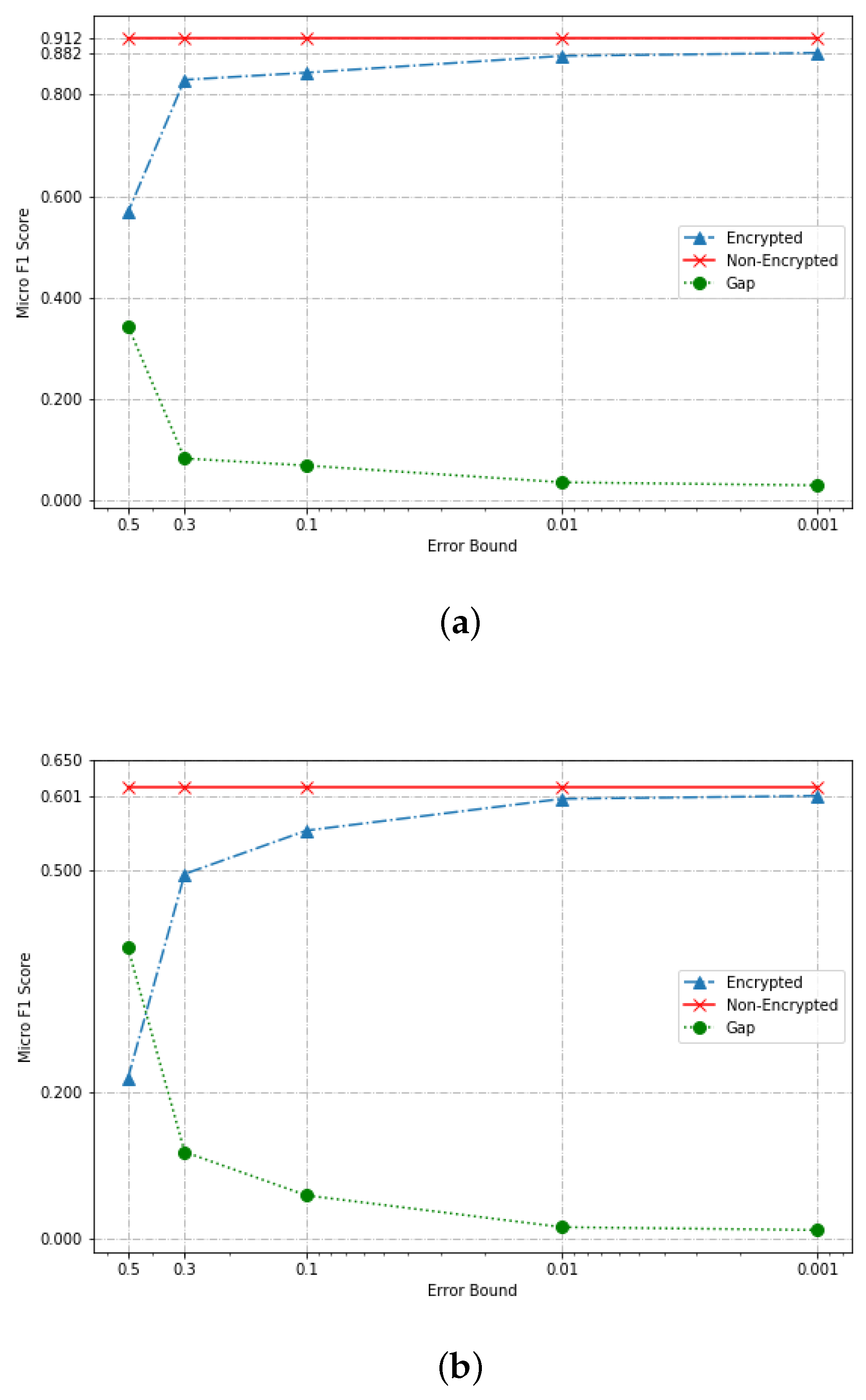
| 0.001 | 0.912 | 0.882 | 0.030 | 3.3% | 0.613 | 0.601 | 0.012 | 2.0% |
| 0.01 | 0.912 | 0.876 | 0.036 | 3.9% | 0.613 | 0.597 | 0.016 | 2.6% |
| 0.1 | 0.912 | 0.843 | 0.069 | 7.6% | 0.613 | 0.554 | 0.058 | 9.5% |
| 0.3 | 0.912 | 0.829 | 0.083 | 9.1% | 0.613 | 0.495 | 0.118 | 19.2% |
| 0.5 | 0.912 | 0.568 | 0.344 | 37.7% | 0.613 | 0.218 | 0.395 | 64.4% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, X.; Wu, T.; Chen, Y.; Fan, X. Privacy-Preserved Approximate Classification Based on Homomorphic Encryption. Math. Comput. Appl. 2019, 24, 92. https://doi.org/10.3390/mca24040092
Xiao X, Wu T, Chen Y, Fan X. Privacy-Preserved Approximate Classification Based on Homomorphic Encryption. Mathematical and Computational Applications. 2019; 24(4):92. https://doi.org/10.3390/mca24040092
Chicago/Turabian StyleXiao, Xiaodong, Ting Wu, Yuanfang Chen, and Xingyue Fan. 2019. "Privacy-Preserved Approximate Classification Based on Homomorphic Encryption" Mathematical and Computational Applications 24, no. 4: 92. https://doi.org/10.3390/mca24040092
APA StyleXiao, X., Wu, T., Chen, Y., & Fan, X. (2019). Privacy-Preserved Approximate Classification Based on Homomorphic Encryption. Mathematical and Computational Applications, 24(4), 92. https://doi.org/10.3390/mca24040092