
Exploring the Multiverse of Analytical Decisions in Scaling Educational Large-Scale Assessment Data: A Specification Curve Analysis for PISA 2018 Mathematics Data


Abstract
:1. Introduction
2. Method
2.1. Data
2.2. Analytical Choices in Specification Curve Analysis
2.2.1. Functional Form of the Item Response Model (Factor “Model”)
2.2.2. Treatment of Differential Item Functioning Based on the RMSD Item Fit Statistic (Factor “RMSD”)
2.2.3. Treatment of Missing Item Responses (Factor “Score0”)
2.2.4. Impact of Item Choice (Factor “Items”)
2.2.5. Impact of Position Effects (Factor “Pos”)
2.3. Analysis
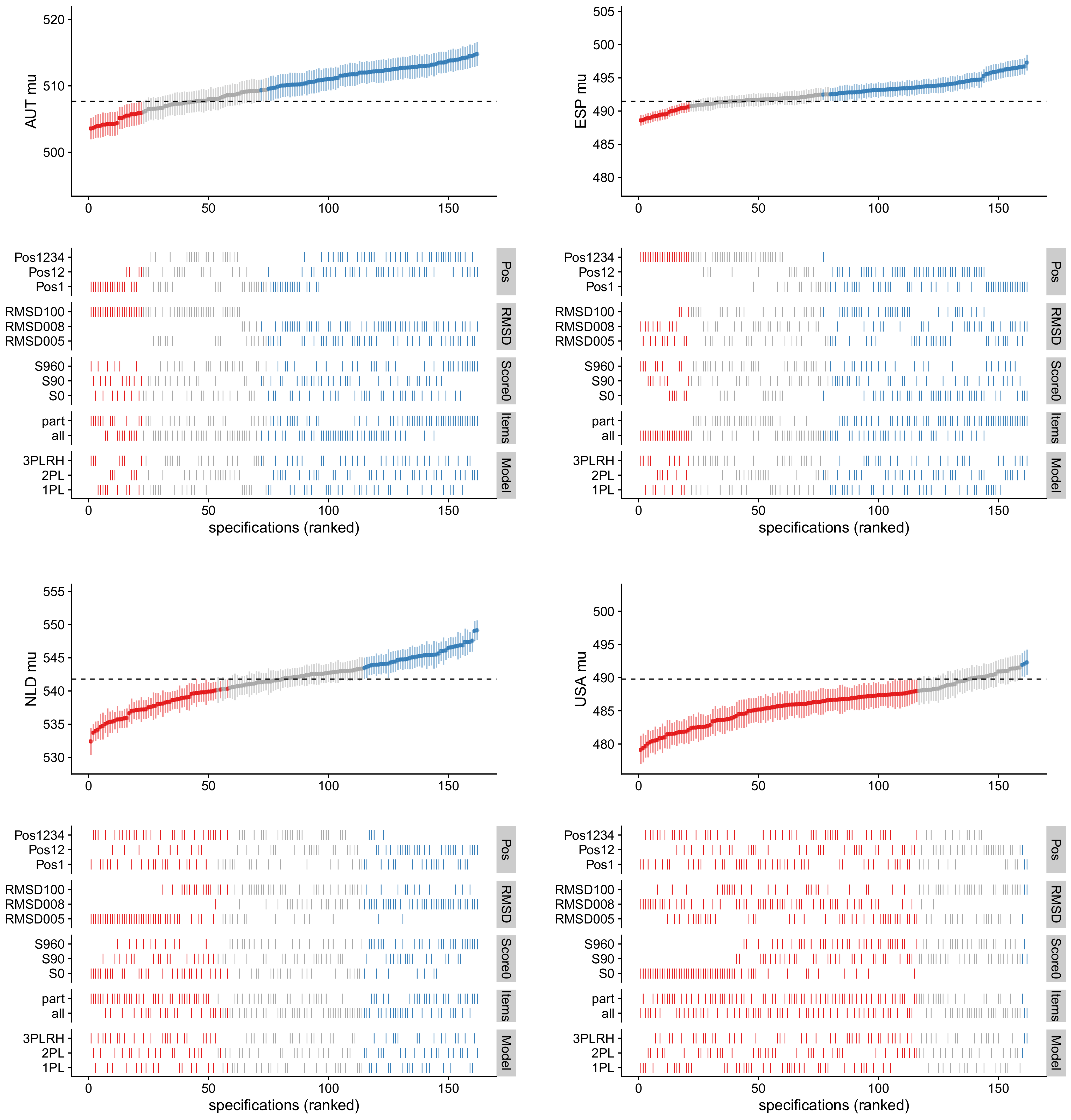
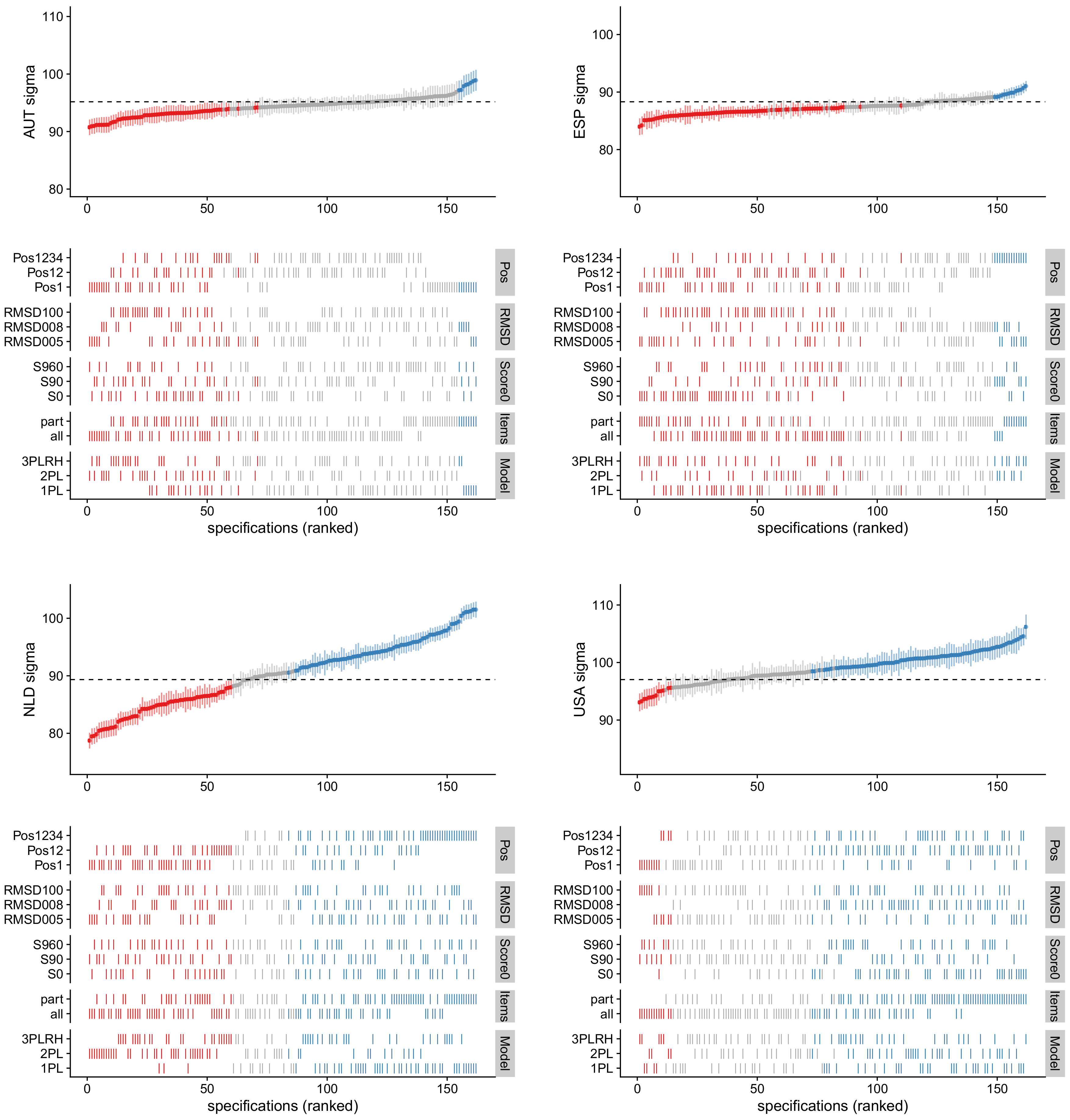
3. Results
4. Discussion
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 1PL | one-parameter logistic model |
| 2PL | two-parameter logistic model |
| 3PL | three-parameter logistic model |
| 3PLRH | three-parameter logistic model with residual heterogeneity |
| ANOVA | analysis of variance |
| DIF | differential item functioning |
| ER | error ratio |
| IRF | item response function |
| IRT | item response theory |
| LSA | large-scale assessment |
| ME | model error |
| MML | marginal maximum likelihood |
| PIAAC | programme for the international assessment of adult competencies |
| PISA | programme for international student assessment |
| SE | standard error |
| SRVC | square root of variance component |
| TIMSS | trends in international mathematics and science study |
Appendix A. Country Labels for PISA 2018 Mathematics Study
Appendix B. International Item Parameters for PISA 2018 Mathematics Study

{kind=link}
{kind=link}
| 1PL | 2PL | 3PLRH | |||||
|---|---|---|---|---|---|---|---|
| Item | |||||||
| CM033Q01S | 1.273 | −1.818 | 0.903 | −1.615 | 0.656 | −1.149 | 0.026 |
| CM474Q01S | 1.273 | −0.951 | 0.924 | −0.834 | 0.690 | −0.668 | 0.763 |
| DM155Q02C | 1.273 | −0.133 | 1.594 | −0.113 | 1.045 | −0.271 | 1.454 |
| CM155Q01S | 1.273 | −0.999 | 1.482 | −1.040 | 1.059 | −0.864 | 1.142 |
| DM155Q03C | 1.273 | 2.259 | 1.357 | 2.318 | 0.962 | 1.643 | −0.283 |
| CM155Q04S | 1.273 | −0.176 | 0.995 | −0.138 | 0.652 | −0.220 | 1.091 |
| CM411Q01S | 1.273 | 0.072 | 1.683 | 0.119 | 1.090 | −0.122 | 1.524 |
| CM411Q02S | 1.273 | 0.394 | 0.912 | 0.375 | 0.639 | 0.349 | −0.832 |
| CM803Q01S | 1.273 | 1.482 | 1.918 | 1.824 | 1.282 | 1.205 | 0.626 |
| CM442Q02S | 1.273 | 1.223 | 1.940 | 1.528 | 1.296 | 0.971 | 0.769 |
| DM462Q01C | 1.273 | 3.612 | 1.413 | 3.726 | 1.010 | 2.623 | −0.189 |
| CM034Q01S | 1.273 | 0.706 | 1.331 | 0.744 | 0.845 | 0.396 | 0.907 |
| CM305Q01S | 1.273 | 0.505 | 0.314 | 0.414 | 0.226 | 0.300 | −0.155 |
| CM496Q01S | 1.273 | 0.240 | 1.500 | 0.287 | 1.025 | 0.125 | 0.506 |
| CM496Q02S | 1.273 | −0.782 | 1.240 | −0.771 | 0.881 | −0.651 | 0.884 |
| CM423Q01S | 1.273 | −1.489 | 0.833 | −1.324 | 0.633 | −0.974 | 0.393 |
| CM192Q01S | 1.273 | 0.541 | 1.428 | 0.601 | 0.991 | 0.459 | −0.303 |
| DM406Q01C | 1.273 | 1.653 | 1.810 | 1.997 | 1.267 | 1.457 | −0.824 |
| DM406Q02C | 1.273 | 2.575 | 2.595 | 3.802 | 1.865 | 2.743 | −0.088 |
| CM603Q01S | 1.273 | 0.799 | 0.916 | 0.746 | 0.658 | 0.569 | −0.416 |
| CM571Q01S | 1.273 | 0.374 | 1.376 | 0.416 | 0.955 | 0.342 | −0.395 |
| CM564Q01S | 1.273 | 0.194 | 0.737 | 0.184 | 0.489 | 0.219 | −0.988 |
| CM564Q02S | 1.273 | 0.275 | 0.718 | 0.253 | 0.455 | 0.295 | −1.489 |
| CM447Q01S | 1.273 | −0.638 | 1.440 | −0.653 | 0.979 | −0.392 | −0.554 |
| CM273Q01S | 1.273 | 0.379 | 0.997 | 0.364 | 0.700 | 0.259 | −0.036 |
| CM408Q01S | 1.273 | 0.885 | 1.290 | 0.921 | 0.850 | 0.557 | 0.680 |
| CM420Q01S | 1.273 | 0.118 | 1.041 | 0.125 | 0.715 | 0.023 | 0.481 |
| CM446Q01S | 1.273 | −0.779 | 1.775 | −0.886 | 1.264 | −0.728 | 0.678 |
| DM446Q02C | 1.273 | 3.121 | 2.280 | 4.190 | 1.595 | 3.060 | 0.544 |
| CM559Q01S | 1.273 | −0.458 | 0.876 | −0.401 | 0.591 | −0.241 | −0.371 |
| DM828Q02C | 1.273 | −0.498 | 1.082 | −0.459 | 0.755 | −0.446 | 1.053 |
| CM828Q03S | 1.273 | 1.154 | 1.271 | 1.185 | 0.768 | 0.699 | 1.038 |
| CM464Q01S | 1.273 | 1.545 | 2.006 | 2.001 | 1.389 | 1.379 | 0.280 |
| CM800Q01S | 1.273 | −2.329 | 0.639 | −1.988 | 0.711 | −1.450 | 1.417 |
| CM982Q01S | 1.273 | −2.075 | 0.922 | −1.889 | 0.829 | −1.407 | 1.387 |
| CM982Q02S | 1.273 | 0.995 | 0.977 | 0.912 | 0.603 | 0.552 | 0.725 |
| CM982Q03S | 1.273 | −0.718 | 1.082 | −0.673 | 0.772 | −0.514 | 0.272 |
| CM982Q04S | 1.273 | 0.188 | 1.463 | 0.219 | 1.007 | 0.206 | −0.426 |
| CM992Q01S | 1.273 | −1.188 | 1.207 | −1.164 | 0.792 | −0.759 | −0.530 |
| CM992Q02S | 1.273 | 2.333 | 1.846 | 2.779 | 1.291 | 1.961 | −0.064 |
| DM992Q03C | 1.273 | 3.310 | 2.817 | 5.055 | 2.141 | 3.942 | 0.802 |
| CM915Q01S | 1.273 | 0.548 | 0.938 | 0.499 | 0.654 | 0.426 | −0.718 |
| CM915Q02S | 1.273 | −0.976 | 1.215 | −0.956 | 0.889 | −0.819 | 1.427 |
| CM906Q01S | 1.273 | −0.485 | 1.233 | −0.470 | 0.830 | −0.283 | −0.391 |
| DM906Q02C | 1.273 | 0.888 | 1.824 | 1.086 | 1.201 | 0.598 | 1.370 |
| DM00KQ02C | 1.273 | 2.551 | 1.166 | 2.464 | 0.883 | 1.763 | −0.426 |
| CM909Q01S | 1.273 | −2.383 | 1.710 | −2.707 | 1.263 | −1.941 | 0.322 |
| CM909Q02S | 1.273 | −0.429 | 1.595 | −0.455 | 1.110 | −0.266 | −0.520 |
| CM909Q03S | 1.273 | 1.024 | 2.379 | 1.445 | 1.677 | 0.927 | 0.760 |
| CM949Q01S | 1.273 | −1.072 | 1.639 | −1.183 | 1.177 | −0.899 | 0.418 |
| CM949Q02S | 1.273 | 0.876 | 1.353 | 0.905 | 0.951 | 0.682 | −0.447 |
| DM949Q03C | 1.273 | 1.093 | 1.456 | 1.160 | 1.000 | 0.785 | 0.177 |
| CM00GQ01S | 1.273 | 3.207 | 1.839 | 3.700 | 1.310 | 2.582 | −0.430 |
| DM955Q01C | 1.273 | −1.083 | 0.977 | −0.978 | 0.735 | −0.785 | 1.012 |
| DM955Q02C | 1.273 | 0.914 | 1.414 | 0.961 | 0.957 | 0.621 | 0.349 |
| CM955Q03S | 1.273 | 2.982 | 2.255 | 3.876 | 1.543 | 2.809 | 0.818 |
| DM998Q02C | 1.273 | −0.854 | 1.185 | −0.817 | 0.857 | −0.655 | 0.614 |
| CM998Q04S | 1.273 | 0.690 | 0.236 | 0.529 | 0.264 | 0.414 | −1.939 |
| CM905Q01S | 1.273 | −1.436 | 1.020 | −1.300 | 0.709 | −0.908 | −0.123 |
| DM905Q02C | 1.273 | 0.611 | 1.965 | 0.778 | 1.335 | 0.413 | 0.865 |
| CM919Q01S | 1.273 | −1.781 | 1.672 | −1.980 | 1.250 | −1.490 | 1.185 |
| CM919Q02S | 1.273 | 0.391 | 1.106 | 0.384 | 0.654 | 0.110 | 1.327 |
| CM954Q01S | 1.273 | −0.966 | 2.022 | −1.177 | 1.456 | −0.901 | 0.343 |
| DM954Q02C | 1.273 | 0.947 | 1.636 | 1.066 | 1.096 | 0.668 | 0.508 |
| CM954Q04S | 1.273 | 1.406 | 2.065 | 1.782 | 1.305 | 1.070 | 2.059 |
| CM943Q01S | 1.273 | −0.053 | 0.855 | −0.029 | 0.559 | 0.074 | −0.930 |
| CM943Q02S | 1.273 | 3.979 | 2.474 | 5.277 | 1.723 | 3.909 | 0.478 |
| DM953Q02C | 1.273 | 0.690 | 1.435 | 0.735 | 0.982 | 0.469 | 0.273 |
| CM953Q03S | 1.273 | 0.052 | 2.007 | 0.098 | 1.394 | −0.060 | 0.760 |
| DM953Q04C | 1.273 | 2.727 | 2.707 | 3.968 | 1.882 | 2.894 | 1.052 |
References
- Holland, P.W. On the sampling theory foundations of item response theory models. Psychometrika 1990, 55, 577–601. [Google Scholar] [CrossRef]
- Van der Linden, W.J.; Hambleton, R.K. (Eds.) Handbook of Modern Item Response Theory; Springer: New York, NY, USA, 1997. [Google Scholar] [CrossRef]
- Rutkowski, L.; von Davier, M.; Rutkowski, D. (Eds.) A Handbook of International Large-Scale Assessment: Background, Technical Issues, and Methods of Data Analysis; Chapman Hall/CRC Press: London, UK, 2013. [Google Scholar] [CrossRef]
- OECD. PISA 2009; Technical Report; OECD: Paris, France, 2012; Available online: https://bit.ly/3xfxdwD (accessed on 28 May 2022).
- Yamamoto, K.; Khorramdel, L.; von Davier, M. Scaling PIAAC cognitive data. In Technical Report of the Survey of Adult Skills (PIAAC); OECD, Ed.; OECD Publishing: Paris, France, 2013; pp. 408–440. Available online: https://bit.ly/32Y1TVt (accessed on 28 May 2022).
- Foy, P.; Yin, L. Scaling the TIMSS 2015 achievement data. In Methods and Procedures in TIMSS 2015; Martin, M.O., Mullis, I.V., Hooper, M., Eds.; IEA: Boston, MA, USA, 2016. [Google Scholar]
- OECD. PISA 2012; Technical Report; OECD: Paris, France, 2014; Available online: https://bit.ly/2YLG24g. (accessed on 28 May 2022).
- OECD. PISA 2015; Technical Report; OECD: Paris, France, 2017; Available online: https://bit.ly/32buWnZ (accessed on 28 May 2022).
- OECD. PISA 2018; Technical Report; OECD: Paris, France, 2020; Available online: https://bit.ly/3zWbidA (accessed on 28 May 2022).
- Longford, N.T. An alternative to model selection in ordinary regression. Stat. Comput. 2003, 13, 67–80. [Google Scholar] [CrossRef]
- Longford, N.T. ’Which model?’ is the wrong question. Stat. Neerl. 2012, 66, 237–252. [Google Scholar] [CrossRef]
- Buckland, S.T.; Burnham, K.P.; Augustin, N.H. Model selection: An integral part of inference. Biometrics 1997, 53, 603–618. [Google Scholar] [CrossRef]
- Burnham, K.P.; Anderson, D.R. Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach; Springer: New York, NY, USA, 2002. [Google Scholar] [CrossRef] [Green Version]
- Chatfield, C. Model uncertainty, data mining and statistical inference. J. R. Stat. Soc. Series A Stat. Soc. 1995, 158, 419–444. [Google Scholar] [CrossRef]
- Clyde, M.; George, E.I. Model uncertainty. Stat. Sci. 2004, 19, 81–94. [Google Scholar] [CrossRef]
- Athey, S.; Imbens, G. A measure of robustness to misspecification. Am. Econ. Rev. 2015, 105, 476–480. [Google Scholar] [CrossRef] [Green Version]
- Brock, W.A.; Durlauf, S.N.; West, K.D. Model uncertainty and policy evaluation: Some theory and empirics. J. Econom. 2007, 136, 629–664. [Google Scholar] [CrossRef] [Green Version]
- Brock, W.A.; Durlauf, S.N. On sturdy policy evaluation. J. Leg. Stud. 2015, 44, S447–S473. [Google Scholar] [CrossRef] [Green Version]
- Muñoz, J.; Young, C. We ran 9 billion regressions: Eliminating false positives through computational model robustness. Sociol. Methodol. 2018, 48, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Young, C. Model uncertainty in sociological research: An application to religion and economic growth. Am. Sociol. Rev. 2009, 74, 380–397. [Google Scholar] [CrossRef] [Green Version]
- Young, C.; Holsteen, K. Model uncertainty and robustness: A computational framework for multimodel analysis. Sociol. Methods Res. 2017, 46, 3–40. [Google Scholar] [CrossRef] [Green Version]
- Young, C. Model uncertainty and the crisis in science. Socius 2018, 4, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Knutti, R.; Baumberger, C.; Hadorn, G.H. Uncertainty quantification using multiple models—Prospects and challenges. In Computer Simulation Validation; Beisbart, C., Saam, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; pp. 835–855. [Google Scholar] [CrossRef]
- Baumberger, C.; Knutti, R.; Hirsch Hadorn, G. Building confidence in climate model projections: An analysis of inferences from fit. WIREs Clim. Chang. 2017, 8, e454. [Google Scholar] [CrossRef] [Green Version]
- Dormann, C.F.; Calabrese, J.M.; Guillera-Arroita, G.; Matechou, E.; Bahn, V.; Bartoń, K.; Beale, C.M.; Ciuti, S.; Elith, J.; Gerstner, K.; et al. Model averaging in ecology: A review of Bayesian, information-theoretic, and tactical approaches for predictive inference. Ecol. Monogr. 2018, 88, 485–504. [Google Scholar] [CrossRef] [Green Version]
- Hoffmann, S.; Schönbrodt, F.D.; Elsas, R.; Wilson, R.; Strasser, U.; Boulesteix, A.L. The multiplicity of analysis strategies jeopardizes replicability: Lessons learned across disciplines. MetaArXiv 2020. [Google Scholar] [CrossRef]
- Steegen, S.; Tuerlinckx, F.; Gelman, A.; Vanpaemel, W. Increasing transparency through a multiverse analysis. Perspect. Psychol. Sci. 2016, 11, 702–712. [Google Scholar] [CrossRef]
- Harder, J.A. The multiverse of methods: Extending the multiverse analysis to address data-collection decisions. Perspect. Psychol. Sci. 2020, 15, 1158–1177. [Google Scholar] [CrossRef]
- Simonsohn, U.; Simmons, J.P.; Nelson, L.D. Specification curve: Descriptive and inferential statistics on all reasonable specifications. SSRN 2015. [Google Scholar] [CrossRef] [Green Version]
- Simonsohn, U.; Simmons, J.P.; Nelson, L.D. Specification curve analysis. Nat. Hum. Behav. 2020, 4, 1208–1214. [Google Scholar] [CrossRef]
- Camilli, G. IRT scoring and test blueprint fidelity. Appl. Psychol. Meas. 2018, 42, 393–400. [Google Scholar] [CrossRef] [PubMed]
- Camilli, G. The case against item bias detection techniques based on internal criteria: Do item bias procedures obscure test fairness issues? In Differential Item Functioning: Theory and Practice; Holland, P.W., Wainer, H., Eds.; Erlbaum: Hillsdale, NJ, USA, 1993; pp. 397–417. [Google Scholar]
- Pohl, S.; Ulitzsch, E.; von Davier, M. Reframing rankings in educational assessments. Science 2021, 372, 338–340. [Google Scholar] [CrossRef] [PubMed]
- Wu, M. Measurement, sampling, and equating errors in large-scale assessments. Educ. Meas. 2010, 29, 15–27. [Google Scholar] [CrossRef]
- Hartig, J.; Buchholz, J. A multilevel item response model for item position effects and individual persistence. Psych. Test Assess. Model. 2012, 54, 418–431. [Google Scholar]
- Rutkowski, L.; Rutkowski, D.; Zhou, Y. Item calibration samples and the stability of achievement estimates and system rankings: Another look at the PISA model. Int. J. Test. 2016, 16, 1–20. [Google Scholar] [CrossRef]
- Van der Linden, W.J. Unidimensional logistic response models. In Handbook of Item Response Theory, Volume 1: Models; van der Linden, W.J., Ed.; CRC Press: Boca Raton, FL, USA, 2016; pp. 11–30. [Google Scholar] [CrossRef]
- Yen, W.M.; Fitzpatrick, A.R. Item response theory. In Educational Measurement; Brennan, R.L., Ed.; Praeger Publishers: Westport, CT, USA, 2006; pp. 111–154. [Google Scholar]
- Douglas, J.A. Asymptotic identifiability of nonparametric item response models. Psychometrika 2001, 66, 531–540. [Google Scholar] [CrossRef]
- Levine, M.V. Dimension in latent variable models. J. Math. Psychol. 2003, 47, 450–466. [Google Scholar] [CrossRef]
- Peress, M. Identification of a semiparametric item response model. Psychometrika 2012, 77, 223–243. [Google Scholar] [CrossRef]
- Stout, W. A nonparametric approach for assessing latent trait unidimensionality. Psychometrika 1987, 52, 589–617. [Google Scholar] [CrossRef]
- Ip, E.H.; Molenberghs, G.; Chen, S.H.; Goegebeur, Y.; De Boeck, P. Functionally unidimensional item response models for multivariate binary data. Multivar. Behav. Res. 2013, 48, 534–562. [Google Scholar] [CrossRef]
- Kirisci, L.; Hsu, T.c.; Yu, L. Robustness of item parameter estimation programs to assumptions of unidimensionality and normality. Appl. Psychol. Meas. 2001, 25, 146–162. [Google Scholar] [CrossRef]
- Robitzsch, A.; Lüdtke, O. Reflections on analytical choices in the scaling model for test scores in international large-scale assessment studies. PsyArXiv 2021. [Google Scholar] [CrossRef]
- Zhang, B. Application of unidimensional item response models to tests with items sensitive to secondary dimensions. J. Exp. Educ. 2008, 77, 147–166. [Google Scholar] [CrossRef]
- Rasch, G. Probabilistic Models for Some Intelligence and Attainment Tests; Danish Institute for Educational Research: Copenhagen, Denmark, 1960. [Google Scholar]
- Birnbaum, A. Some latent trait models and their use in inferring an examinee’s ability. In Statistical Theories of Mental Test Scores; Lord, F.M., Novick, M.R., Eds.; MIT Press: Reading, MA, USA, 1968; pp. 397–479. [Google Scholar]
- Molenaar, D.; Dolan, C.V.; De Boeck, P. The heteroscedastic graded response model with a skewed latent trait: Testing statistical and substantive hypotheses related to skewed item category functions. Psychometrika 2012, 77, 455–478. [Google Scholar] [CrossRef] [PubMed]
- Molenaar, D. Heteroscedastic latent trait models for dichotomous data. Psychometrika 2015, 80, 625–644. [Google Scholar] [CrossRef]
- Lee, S.; Bolt, D.M. An alternative to the 3PL: Using asymmetric item characteristic curves to address guessing effects. J. Educ. Meas. 2018, 55, 90–111. [Google Scholar] [CrossRef]
- Lee, S.; Bolt, D.M. Asymmetric item characteristic curves and item complexity: Insights from simulation and real data analyses. Psychometrika 2018, 83, 453–475. [Google Scholar] [CrossRef]
- Liao, X.; Bolt, D.M. Item characteristic curve asymmetry: A better way to accommodate slips and guesses than a four-parameter model? J. Educ. Behav. Stat. 2021, 46, 753–775. [Google Scholar] [CrossRef]
- Robitzsch, A. On the choice of the item response model for scaling PISA data: Model selection based on information criteria and quantifying model uncertainty. Entropy 2022, 24, 760. [Google Scholar] [CrossRef]
- Aitkin, M.; Aitkin, I. Investigation of the Identifiability of the 3PL Model in the NAEP 1986 Math Survey; Technical Report; US Department of Education, Office of Educational Research and Improvement National Center for Education Statistics: Washington, DC, USA, 2006. Available online: https://bit.ly/35b79X0 (accessed on 28 May 2022).
- von Davier, M. Is there need for the 3PL model? Guess what? Meas. Interdiscip. Res. Persp. 2009, 7, 110–114. [Google Scholar] [CrossRef]
- San Martín, E.; Del Pino, G.; De Boeck, P. IRT models for ability-based guessing. Appl. Psychol. Meas. 2006, 30, 183–203. [Google Scholar] [CrossRef] [Green Version]
- Brown, G.; Micklewright, J.; Schnepf, S.V.; Waldmann, R. International surveys of educational achievement: How robust are the findings? J. R. Stat. Soc. Series A Stat. Soc. 2007, 170, 623–646. [Google Scholar] [CrossRef] [Green Version]
- Jerrim, J.; Parker, P.; Choi, A.; Chmielewski, A.K.; Sälzer, C.; Shure, N. How robust are cross-country comparisons of PISA scores to the scaling model used? Educ. Meas. 2018, 37, 28–39. [Google Scholar] [CrossRef] [Green Version]
- Macaskill, G. Alternative scaling models and dependencies in PISA. In Proceedings of the TAG(0809)6a, TAG Meeting, Sydney, Australia, 7–11 July 2008; Available online: https://bit.ly/35WwBPg (accessed on 28 May 2022).
- Schnepf, S.V. Insights into Survey Errors of Large Scale Educational Achievement Surveys; JRC Working Papers in Economics and Finance, No. 2018/5; Publications Office of the European Union: Luxembourg, 2018. [Google Scholar] [CrossRef]
- Holland, P.W.; Wainer, H. (Eds.) Differential Item Functioning: Theory and Practice; Lawrence Erlbaum: Hillsdale, NJ, USA, 1993. [Google Scholar] [CrossRef]
- Penfield, R.D.; Camilli, G. Differential item functioning and item bias. In Handbook of Statistics, Vol. 26: Psychometrics; Rao, C.R., Sinharay, S., Eds.; Elsevier: Amsterdam, The Netherlands, 2007; pp. 125–167. [Google Scholar] [CrossRef]
- Byrne, B.M.; Shavelson, R.J.; Muthén, B. Testing for the equivalence of factor covariance and mean structures: The issue of partial measurement invariance. Psychol. Bull. 1989, 105, 456–466. [Google Scholar] [CrossRef]
- Van de Schoot, R.; Kluytmans, A.; Tummers, L.; Lugtig, P.; Hox, J.; Muthén, B. Facing off with scylla and charybdis: A comparison of scalar, partial, and the novel possibility of approximate measurement invariance. Front. Psychol. 2013, 4, 770. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kunina-Habenicht, O.; Rupp, A.A.; Wilhelm, O. A practical illustration of multidimensional diagnostic skills profiling: Comparing results from confirmatory factor analysis and diagnostic classification models. Stud. Educ. Eval. 2009, 35, 64–70. [Google Scholar] [CrossRef]
- Oliveri, M.E.; von Davier, M. Investigation of model fit and score scale comparability in international assessments. Psych. Test Assess. Model. 2011, 53, 315–333. Available online: https://bit.ly/3k4K9kt (accessed on 28 May 2022).
- Oliveri, M.E.; von Davier, M. Toward increasing fairness in score scale calibrations employed in international large-scale assessments. Int. J. Test. 2014, 14, 1–21. [Google Scholar] [CrossRef]
- Von Davier, M.; Khorramdel, L.; He, Q.; Shin, H.J.; Chen, H. Developments in psychometric population models for technology-based large-scale assessments: An overview of challenges and opportunities. J. Educ. Behav. Stat. 2019, 44, 671–705. [Google Scholar] [CrossRef]
- Von Davier, M.; Yamamoto, K.; Shin, H.J.; Chen, H.; Khorramdel, L.; Weeks, J.; Davis, S.; Kong, N.; Kandathil, M. Evaluating item response theory linking and model fit for data from PISA 2000–2012. Assess. Educ. 2019, 26, 466–488. [Google Scholar] [CrossRef]
- Khorramdel, L.; Shin, H.J.; von Davier, M. GDM software mdltm including parallel EM algorithm. In Handbook of Diagnostic Classification Models; von Davier, M., Lee, Y.S., Eds.; Springer: Cham, Switzerland, 2019; pp. 603–628. [Google Scholar] [CrossRef]
- Tijmstra, J.; Bolsinova, M.; Liaw, Y.L.; Rutkowski, L.; Rutkowski, D. Sensitivity of the RMSD for detecting item-level misfit in low-performing countries. J. Educ. Meas. 2020, 57, 566–583. [Google Scholar] [CrossRef]
- Köhler, C.; Robitzsch, A.; Hartig, J. A bias-corrected RMSD item fit statistic: An evaluation and comparison to alternatives. J. Educ. Behav. Stat. 2020, 45, 251–273. [Google Scholar] [CrossRef]
- Robitzsch, A. Statistical properties of estimators of the RMSD item fit statistic. Foundations 2022, 2, 488–503. [Google Scholar] [CrossRef]
- Von Davier, M.; Bezirhan, U. A robust method for detecting item misfit in large scale assessments. Educ. Psychol. Meas. 2022. Epub ahead of print. [Google Scholar] [CrossRef]
- Joo, S.H.; Khorramdel, L.; Yamamoto, K.; Shin, H.J.; Robin, F. Evaluating item fit statistic thresholds in PISA: Analysis of cross-country comparability of cognitive items. Educ. Meas. 2021, 40, 37–48. [Google Scholar] [CrossRef]
- Buchholz, J.; Hartig, J. Comparing attitudes across groups: An IRT-based item-fit statistic for the analysis of measurement invariance. Appl. Psychol. Meas. 2019, 43, 241–250. [Google Scholar] [CrossRef]
- Robitzsch, A.; Lüdtke, O. A review of different scaling approaches under full invariance, partial invariance, and noninvariance for cross-sectional country comparisons in large-scale assessments. Psych. Test Assess. Model. 2020, 62, 233–279. Available online: https://bit.ly/3ezBB05 (accessed on 28 May 2022).
- Robitzsch, A.; Lüdtke, O. Mean comparisons of many groups in the presence of DIF: An evaluation of linking and concurrent scaling approaches. J. Educ. Behav. Stat. 2022, 47, 36–68. [Google Scholar] [CrossRef]
- Robitzsch, A. Robust and nonrobust linking of two groups for the Rasch model with balanced and unbalanced random DIF: A comparative simulation study and the simultaneous assessment of standard errors and linking errors with resampling techniques. Symmetry 2021, 13, 2198. [Google Scholar] [CrossRef]
- Dai, S. Handling missing responses in psychometrics: Methods and software. Psych 2021, 3, 673–693. [Google Scholar] [CrossRef]
- Finch, H. Estimation of item response theory parameters in the presence of missing data. J. Educ. Meas. 2008, 45, 225–245. [Google Scholar] [CrossRef]
- Frey, A.; Spoden, C.; Goldhammer, F.; Wenzel, S.F.C. Response time-based treatment of omitted responses in computer-based testing. Behaviormetrika 2018, 45, 505–526. [Google Scholar] [CrossRef] [Green Version]
- Kalkan, Ö.K.; Kara, Y.; Kelecioğlu, H. Evaluating performance of missing data imputation methods in IRT analyses. Int. J. Assess. Tool. Educ. 2018, 5, 403–416. [Google Scholar] [CrossRef]
- Pohl, S.; Becker, B. Performance of missing data approaches under nonignorable missing data conditions. Methodology 2020, 16, 147–165. [Google Scholar] [CrossRef]
- Rose, N.; von Davier, M.; Nagengast, B. Commonalities and differences in IRT-based methods for nonignorable item nonresponses. Psych. Test Assess. Model. 2015, 57, 472–498. Available online: https://bit.ly/3kD3t89 (accessed on 28 May 2022).
- Rose, N.; von Davier, M.; Nagengast, B. Modeling omitted and not-reached items in IRT models. Psychometrika 2017, 82, 795–819. [Google Scholar] [CrossRef]
- Robitzsch, A. On the treatment of missing item responses in educational large-scale assessment data: An illustrative simulation study and a case study using PISA 2018 mathematics data. Eur. J. Investig. Health Psychol. Educ. 2021, 11, 1653–1687. [Google Scholar] [CrossRef]
- Gorgun, G.; Bulut, O. A polytomous scoring approach to handle not-reached items in low-stakes assessments. Educ. Psychol. Meas. 2021, 81, 847–871. [Google Scholar] [CrossRef]
- Debeer, D.; Janssen, R.; De Boeck, P. Modeling skipped and not-reached items using IRTrees. J. Educ. Meas. 2017, 54, 333–363. [Google Scholar] [CrossRef]
- Köhler, C.; Pohl, S.; Carstensen, C.H. Taking the missing propensity into account when estimating competence scores: Evaluation of item response theory models for nonignorable omissions. Educ. Psychol. Meas. 2015, 75, 850–874. [Google Scholar] [CrossRef] [Green Version]
- Köhler, C.; Pohl, S.; Carstensen, C.H. Dealing with item nonresponse in large-scale cognitive assessments: The impact of missing data methods on estimated explanatory relationships. J. Educ. Meas. 2017, 54, 397–419. [Google Scholar] [CrossRef] [Green Version]
- Pohl, S.; Carstensen, C.H. NEPS Technical Report—Scaling the Data of the Competence Tests; (NEPS Working Paper No. 14); Otto-Friedrich-Universität, Nationales Bildungspanel: Bamberg, Germany, 2012; Available online: https://bit.ly/2XThQww (accessed on 28 May 2022).
- Pohl, S.; Carstensen, C.H. Scaling of competence tests in the national educational panel study – Many questions, some answers, and further challenges. J. Educ. Res. Online 2013, 5, 189–216. [Google Scholar]
- Pohl, S.; Gräfe, L.; Rose, N. Dealing with omitted and not-reached items in competence tests: Evaluating approaches accounting for missing responses in item response theory models. Educ. Psychol. Meas. 2014, 74, 423–452. [Google Scholar] [CrossRef]
- Rose, N.; von Davier, M.; Xu, X. Modeling Nonignorable Missing Data with Item Response Theory (IRT); Research Report No. RR-10-11; Educational Testing Service: Princeton, NJ, USA, 2010. [Google Scholar] [CrossRef]
- Rohwer, G. Making Sense of Missing Answers in Competence Tests; (NEPS Working Paper No. 30); Otto-Friedrich-Universität, Nationales Bildungspanel: Bamberg, Germany, 2013; Available online: https://bit.ly/3AGfsr5 (accessed on 28 May 2022).
- Robitzsch, A. About still nonignorable consequences of (partially) ignoring missing item responses in large-scale assessment. OSF Preprints 2020. [Google Scholar] [CrossRef]
- Sachse, K.A.; Mahler, N.; Pohl, S. When nonresponse mechanisms change: Effects on trends and group comparisons in international large-scale assessments. Educ. Psychol. Meas. 2019, 79, 699–726. [Google Scholar] [CrossRef]
- Brennan, R.L. Generalizability theory. Educ. Meas. 1992, 11, 27–34. [Google Scholar] [CrossRef]
- Brennan, R.L. Generalizabilty Theory; Springer: New York, NY, USA, 2001. [Google Scholar] [CrossRef]
- Brennan, R.L. Perspectives on the evolution and future of educational measurement. In Educational Measurement; Brennan, R.L., Ed.; Praeger Publishers: Westport, CT, USA, 2006; pp. 1–16. [Google Scholar]
- Cronbach, L.J.; Rajaratnam, N.; Gleser, G.C. Theory of generalizability: A liberalization of reliability theory. Brit. J. Stat. Psychol. 1963, 16, 137–163. [Google Scholar] [CrossRef]
- Cronbach, L.J.; Gleser, G.C.; Nanda, H.; Rajaratnam, N. The Dependability of Behavioral Measurements: Theory of Generalizability for Scores and Profiles; John Wiley: New York, NY, USA, 1972. [Google Scholar]
- Hunter, J.E. Probabilistic foundations for coefficients of generalizability. Psychometrika 1968, 33, 1–18. [Google Scholar] [CrossRef]
- Husek, T.R.; Sirotnik, K. Item Sampling in Educational Research; CSEIP Occasional Report No. 2; University of California: Los Angeles, CA, USA, 1967; Available online: https://bit.ly/3k47t1s (accessed on 28 May 2022).
- Kane, M.T.; Brennan, R.L. The generalizability of class means. Rev. Educ. Res. 1977, 47, 267–292. [Google Scholar] [CrossRef]
- Robitzsch, A.; Dörfler, T.; Pfost, M.; Artelt, C. Die Bedeutung der Itemauswahl und der Modellwahl für die längsschnittliche Erfassung von Kompetenzen [Relevance of item selection and model selection for assessing the development of competencies: The development in reading competence in primary school students]. Z. Entwicklungspsychol. Pädagog. Psychol. 2011, 43, 213–227. [Google Scholar] [CrossRef]
- Monseur, C.; Berezner, A. The computation of equating errors in international surveys in education. J. Appl. Meas. 2007, 8, 323–335. Available online: https://bit.ly/2WDPeqD (accessed on 28 May 2022). [PubMed]
- Sachse, K.A.; Roppelt, A.; Haag, N. A comparison of linking methods for estimating national trends in international comparative large-scale assessments in the presence of cross-national DIF. J. Educ. Meas. 2016, 53, 152–171. [Google Scholar] [CrossRef]
- Sachse, K.A.; Haag, N. Standard errors for national trends in international large-scale assessments in the case of cross-national differential item functioning. Appl. Meas. Educ. 2017, 30, 102–116. [Google Scholar] [CrossRef]
- Robitzsch, A.; Lüdtke, O. Linking errors in international large-scale assessments: Calculation of standard errors for trend estimation. Assess. Educ. 2019, 26, 444–465. [Google Scholar] [CrossRef]
- Robitzsch, A.; Lüdtke, O.; Goldhammer, F.; Kroehne, U.; Köller, O. Reanalysis of the German PISA data: A comparison of different approaches for trend estimation with a particular emphasis on mode effects. Front. Psychol. 2020, 11, 884. [Google Scholar] [CrossRef]
- Kolenikov, S. Resampling variance estimation for complex survey data. Stata J. 2010, 10, 165–199. [Google Scholar] [CrossRef] [Green Version]
- Sireci, S.G.; Thissen, D.; Wainer, H. On the reliability of testlet-based tests. J. Educ. Meas. 1991, 28, 237–247. [Google Scholar] [CrossRef]
- Bolt, D.M.; Cohen, A.S.; Wollack, J.A. Item parameter estimation under conditions of test speededness: Application of a mixture Rasch model with ordinal constraints. J. Educ. Meas. 2002, 39, 331–348. [Google Scholar] [CrossRef]
- Jin, K.Y.; Wang, W.C. Item response theory models for performance decline during testing. J. Educ. Meas. 2014, 51, 178–200. [Google Scholar] [CrossRef]
- Kanopka, K.; Domingue, B. A position sensitive IRT mixture model. PsyArXiv 2022. [Google Scholar] [CrossRef]
- List, M.K.; Robitzsch, A.; Lüdtke, O.; Köller, O.; Nagy, G. Performance decline in low-stakes educational assessments: Different mixture modeling approaches. Large-Scale Assess. Educ. 2017, 5, 15. [Google Scholar] [CrossRef] [Green Version]
- Nagy, G.; Robitzsch, A. A continuous HYBRID IRT model for modeling changes in guessing behavior in proficiency tests. Psych. Test Assess. Model. 2021, 63, 361–395. Available online: https://bit.ly/3FHtA6l (accessed on 28 May 2022).
- Alexandrowicz, R.; Matschinger, H. Estimation of item location effects by means of the generalized logistic regression model: A simulation study and an application. Psychol. Sci. 2008, 50, 64–74. Available online: https://bit.ly/3MEHM3n (accessed on 28 May 2022).
- Hecht, M.; Weirich, S.; Siegle, T.; Frey, A. Effects of design properties on parameter estimation in large-scale assessments. Educ. Psychol. Meas. 2015, 75, 1021–1044. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Robitzsch, A. Methodische Herausforderungen bei der Kalibrierung von Leistungstests [Methodological challenges in calibrating performance tests]. In Bildungsstandards Deutsch und Mathematik; Bremerich-Vos, A., Granzer, D., Köller, O., Eds.; Beltz Pädagogik: Weinheim, Germany, 2009; pp. 42–106. [Google Scholar]
- Bulut, O.; Quo, Q.; Gierl, M.J. A structural equation modeling approach for examining position effects in large-scale assessments. Large-Scale Assess. Educ. 2017, 5, 8. [Google Scholar] [CrossRef] [Green Version]
- Debeer, D.; Janssen, R. Modeling item-position effects within an IRT framework. J. Educ. Meas. 2013, 50, 164–185. [Google Scholar] [CrossRef]
- Debeer, D.; Buchholz, J.; Hartig, J.; Janssen, R. Student, school, and country differences in sustained test-taking effort in the 2009 PISA reading assessment. J. Educ. Behav. Stat. 2014, 39, 502–523. [Google Scholar] [CrossRef] [Green Version]
- Demirkol, S.; Kelecioğlu, H. Investigating the effect of item position on person and item parameters: PISA 2015 Turkey sample. J. Meas. Eval. Educ. Psychol. 2022, 13, 69–85. [Google Scholar] [CrossRef]
- Rose, N.; Nagy, G.; Nagengast, B.; Frey, A.; Becker, M. Modeling multiple item context effects with generalized linear mixed models. Front. Psychol. 2019, 10, 248. [Google Scholar] [CrossRef]
- Trendtel, M.; Robitzsch, A. Modeling item position effects with a Bayesian item response model applied to PISA 2009–2015 data. Psych. Test Assess. Model. 2018, 60, 241–263. Available online: https://bit.ly/3l4Zi5u (accessed on 28 May 2022).
- Weirich, S.; Hecht, M.; Böhme, K. Modeling item position effects using generalized linear mixed models. Appl. Psychol. Meas. 2014, 38, 535–548. [Google Scholar] [CrossRef]
- Nagy, G.; Lüdtke, O.; Köller, O. Modeling test context effects in longitudinal achievement data: Examining position effects in the longitudinal German PISA 2012 assessment. Psych. Test Assess. Model. 2016, 58, 641–670. Available online: https://bit.ly/39Z4iFw (accessed on 28 May 2022). [CrossRef]
- Nagy, G.; Nagengast, B.; Becker, M.; Rose, N.; Frey, A. Item position effects in a reading comprehension test: An IRT study of individual differences and individual correlates. Psych. Test Assess. Model. 2018, 60, 165–187. Available online: https://bit.ly/3Biw74g. (accessed on 28 May 2022).
- Nagy, G.; Nagengast, B.; Frey, A.; Becker, M.; Rose, N. A multilevel study of position effects in PISA achievement tests: Student-and school-level predictors in the German tracked school system. Assess. Educ. 2019, 26, 422–443. [Google Scholar] [CrossRef] [Green Version]
- Garthwaite, P.H.; Mubwandarikwa, E. Selection of weights for weighted model averaging. Aust. N. Z. J. Stat. 2010, 52, 363–382. [Google Scholar] [CrossRef]
- Knutti, R. The end of model democracy? Clim. Chang. 2010, 102, 395–404. [Google Scholar] [CrossRef]
- Lorenz, R.; Herger, N.; Sedláček, J.; Eyring, V.; Fischer, E.M.; Knutti, R. Prospects and caveats of weighting climate models for summer maximum temperature projections over North America. J. Geophys. Res. Atmosph. 2018, 123, 4509–4526. [Google Scholar] [CrossRef]
- Sanderson, B.M.; Knutti, R.; Caldwell, P. A representative democracy to reduce interdependency in a multimodel ensemble. J. Clim. 2015, 28, 5171–5194. [Google Scholar] [CrossRef] [Green Version]
- Sanderson, B.M.; Wehner, M.; Knutti, R. Skill and independence weighting for multi-model assessments. Geosci. Model Dev. 2017, 10, 2379–2395. [Google Scholar] [CrossRef] [Green Version]
- Scharkow, M. Getting More Information Out of the Specification Curve. 15 January 2019. Available online: https://bit.ly/3z9ebLz (accessed on 28 May 2022).
- Gelman, A. Analysis of variance—Why it is more important than ever. Ann. Stat. 2005, 33, 1–53. [Google Scholar] [CrossRef] [Green Version]
- Gelman, A.; Hill, J. Data Analysis Using Regression and Multilevel/Hierarchical Models; Cambridge University Press: Cambridge, MA, USA, 2006. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Core Team: Vienna, Austria, 2022; Available online: https://www.R-project.org/ (accessed on 11 January 2022).
- Robitzsch, A.; Kiefer, T.; Wu, M. TAM: Test Analysis Modules. R Package Version 4.0-16. 2022. Available online: https://CRAN.R-project.org/package=TAM (accessed on 14 May 2022).
- Robitzsch, A. sirt: Supplementary Item Response Theory Models. R Package Version 3.12-66. 2022. Available online: https://CRAN.R-project.org/package=sirt (accessed on 17 May 2022).
- Masur, P.K.; Scharkow, M. specr: Conducting and Visualizing Specification Curve Analyses. R Package Version 0.2.1. 2020. Available online: https://CRAN.R-project.org/package=specr (accessed on 26 March 2020).
- Kane, M.T. A sampling model for validity. Appl. Psychol. Meas. 1982, 6, 125–160. [Google Scholar] [CrossRef]
- Kane, M.T. Validating the interpretations and uses of test scores. J. Educ. Meas. 2013, 50, 1–73. [Google Scholar] [CrossRef]
- Adams, R.J. Response to ’Cautions on OECD’s recent educational survey (PISA)’. Oxf. Rev. Educ. 2003, 29, 379–389. [Google Scholar] [CrossRef]
- Adams, R.J. Comments on Kreiner 2011: Is the Foundation under PISA Solid? A Critical Look at the Scaling Model Underlying International Comparisons of Student Attainment; Technical Report; OECD: Paris, France, 2011; Available online: https://bit.ly/3wVUKo0 (accessed on 28 May 2022).
- Kreiner, S.; Christensen, K.B. Analyses of model fit and robustness. A new look at the PISA scaling model underlying ranking of countries according to reading literacy. Psychometrika 2014, 79, 210–231. [Google Scholar] [CrossRef]
- McDonald, R.P. Generalizability in factorable domains: “Domain validity and generalizability”. Educ. Psychol. Meas. 1978, 38, 75–79. [Google Scholar] [CrossRef]
- McDonald, R.P. Behavior domains in theory and in practice. Alta. J. Educ. Res. 2003, 49, 212–230. Available online: https://bit.ly/3O4s2I5 (accessed on 28 May 2022).
- Brennan, R.L. Misconceptions at the intersection of measurement theory and practice. Educ. Meas. 1998, 17, 5–9. [Google Scholar] [CrossRef]
- Leutner, D.; Hartig, J.; Jude, N. Measuring competencies: Introduction to concepts and questions of assessment in education. In Assessment of Competencies in Educational Contexts; Hartig, J., Klieme, E., Leutner, D., Eds.; Hogrefe: Göttingen, Germany, 2008; pp. 177–192. [Google Scholar]
- Holland, P.W. The Dutch identity: A new tool for the study of item response models. Psychometrika 1990, 55, 5–18. [Google Scholar] [CrossRef]
- Zhang, J.; Stout, W. On Holland’s Dutch identity conjecture. Psychometrika 1997, 62, 375–392. [Google Scholar] [CrossRef]
- Frey, A.; Seitz, N.N.; Kröhne, U. Reporting differentiated literacy results in PISA by using multidimensional adaptive testing. In Research on PISA; Prenzel, M., Kobarg, M., Schöps, K., Rönnebeck, S., Eds.; Springer: Dordrecht, The Netherlands, 2013; pp. 103–120. [Google Scholar] [CrossRef]
- Goldstein, H. International comparisons of student attainment: Some issues arising from the PISA study. Assess. Educ. 2004, 11, 319–330. [Google Scholar] [CrossRef]
- Goldstein, H.; Bonnet, G.; Rocher, T. Multilevel structural equation models for the analysis of comparative data on educational performance. J. Educ. Behav. Stat. 2007, 32, 252–286. [Google Scholar] [CrossRef]
- VanderWeele, T.J. Constructed measures and causal inference: Towards a new model of measurement for psychosocial constructs. Epidemiology 2022, 33, 141–151. [Google Scholar] [CrossRef] [PubMed]
- Frey, A.; Hartig, J. Methodological challenges of international student assessment. In Monitoring Student Achievement in the 21st Century; Harju-Luukkainen, H., McElvany, N., Stang, J., Eds.; Springer: Cham, Switzerland, 2020; pp. 39–49. [Google Scholar] [CrossRef]
| Total | 3.05 | 2.98 |
| Items | 0.89 | 1.13 |
| Model | 0.60 | 1.48 |
| Pos | 1.83 | 1.76 |
| RMSD | 1.52 | 0.91 |
| Score | 1.37 | 0.84 |
| Model × Items | 0.20 | 0.35 |
| Model × Pos | 0.20 | 0.42 |
| Model × RMSD | 0.36 | 0.54 |
| Model × Score | 0.09 | 0.19 |
| Pos × Items | 0.41 | 0.69 |
| Pos × RMSD | 0.43 | 0.44 |
| Pos × Score | 0.41 | 0.29 |
| RMSD × Items | 0.89 | 0.55 |
| Score × Items | 0.22 | 0.15 |
| Score × RMSD | 0.14 | 0.10 |
| Reference Model | Multi-Model Inference | Square Root of Variance Component (SRVC) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cnt | N | Est | SE | M | Min | Max | ME | ER | Pos | RMSD | Score0 | Items | Model |
| ALB | 2116 | 439.7 | 3.39 | 442.8 | 434.7 | 450.1 | 3.38 | 1.00 | 2.44 | 0.46 | 1.12 | 0.00 | 1.00 |
| AUS | 6508 | 504.4 | 2.17 | 505.8 | 499.6 | 510.3 | 2.80 | 1.29 | 2.37 | 0.82 | 0.60 | 0.82 | 0.15 |
| AUT | 3104 | 508.7 | 3.20 | 509.7 | 503.6 | 514.8 | 2.97 | 0.93 | 1.50 | 2.34 | 0.36 | 0.44 | 0.38 |
| BEL | 3763 | 523.6 | 2.39 | 525.3 | 522.4 | 529.4 | 1.63 | 0.68 | 1.08 | 0.23 | 0.61 | 0.78 | 0.34 |
| BIH | 2934 | 415.4 | 3.21 | 418.0 | 405.4 | 426.8 | 4.18 | 1.30 | 0.73 | 1.78 | 2.72 | 0.46 | 1.52 |
| BLR | 2681 | 482.5 | 2.88 | 478.0 | 472.9 | 483.6 | 2.52 | 0.88 | 1.95 | 0.65 | 0.97 | 0.35 | 0.04 |
| BRN | 2259 | 439.0 | 2.08 | 430.1 | 420.0 | 446.7 | 5.74 | 2.75 | 3.57 | 2.99 | 2.09 | 0.08 | 1.16 |
| CAN | 7200 | 530.4 | 2.54 | 527.7 | 522.8 | 531.4 | 1.96 | 0.77 | 0.88 | 0.93 | 0.59 | 1.17 | 0.32 |
| CHE | 2679 | 522.7 | 2.96 | 524.3 | 519.5 | 530.4 | 2.59 | 0.88 | 1.93 | 0.82 | 0.58 | 1.24 | 0.33 |
| CZE | 3199 | 510.8 | 2.70 | 512.5 | 507.0 | 518.6 | 2.31 | 0.86 | 1.41 | 0.85 | 1.03 | 0.91 | 0.35 |
| DEU | 2482 | 514.6 | 3.18 | 514.1 | 508.0 | 518.9 | 2.39 | 0.75 | 1.23 | 1.11 | 1.25 | 0.69 | 0.35 |
| DNK | 3304 | 522.5 | 2.30 | 522.3 | 515.9 | 527.8 | 3.06 | 1.33 | 0.81 | 2.18 | 0.79 | 1.53 | 0.36 |
| ESP | 11855 | 491.3 | 1.63 | 492.7 | 488.6 | 497.3 | 1.91 | 1.17 | 1.40 | 0.06 | 0.45 | 0.77 | 0.20 |
| EST | 2467 | 532.7 | 2.36 | 534.4 | 529.7 | 539.7 | 1.95 | 0.83 | 1.21 | 1.15 | 0.23 | 0.50 | 0.22 |
| FIN | 2573 | 514.2 | 2.40 | 515.1 | 512.1 | 517.4 | 1.22 | 0.51 | 0.25 | 0.43 | 0.55 | 0.08 | 0.70 |
| FRA | 2880 | 506.0 | 2.64 | 506.5 | 502.4 | 511.1 | 2.24 | 0.85 | 0.58 | 1.49 | 0.67 | 0.99 | 0.26 |
| GBR | 5979 | 513.3 | 3.16 | 516.4 | 511.7 | 521.6 | 1.96 | 0.62 | 1.32 | 0.57 | 0.42 | 1.04 | 0.17 |
| GRC | 2114 | 458.9 | 3.74 | 456.0 | 450.2 | 459.7 | 2.15 | 0.58 | 1.56 | 0.83 | 0.34 | 0.13 | 0.23 |
| HKG | 2008 | 564.2 | 3.74 | 560.5 | 546.0 | 571.9 | 4.85 | 1.30 | 2.44 | 2.82 | 1.21 | 0.80 | 0.70 |
| HRV | 2150 | 471.1 | 3.08 | 470.9 | 464.0 | 476.7 | 3.16 | 1.03 | 2.46 | 0.48 | 0.69 | 1.65 | 0.19 |
| HUN | 2361 | 492.1 | 2.77 | 486.3 | 476.6 | 494.9 | 3.97 | 1.43 | 2.90 | 1.73 | 0.13 | 1.12 | 0.27 |
| IRL | 2581 | 510.4 | 2.54 | 502.7 | 493.7 | 510.4 | 3.59 | 1.41 | 2.87 | 1.17 | 1.41 | 0.38 | 0.56 |
| ISL | 1485 | 501.3 | 2.64 | 506.6 | 494.8 | 517.6 | 4.83 | 1.83 | 3.68 | 1.35 | 1.60 | 0.71 | 1.04 |
| ISR | 1944 | 465.5 | 4.85 | 470.0 | 462.2 | 478.2 | 3.57 | 0.74 | 2.20 | 1.38 | 1.88 | 0.20 | 0.94 |
| ITA | 5475 | 496.8 | 3.00 | 499.6 | 494.0 | 507.8 | 3.03 | 1.01 | 1.17 | 1.72 | 1.51 | 1.28 | 0.29 |
| JPN | 2814 | 539.5 | 3.08 | 542.2 | 537.0 | 549.1 | 2.63 | 0.85 | 0.09 | 1.48 | 1.62 | 0.21 | 0.23 |
| KOR | 2200 | 535.2 | 3.76 | 534.3 | 530.0 | 541.6 | 2.66 | 0.71 | 0.28 | 1.94 | 0.26 | 0.12 | 0.06 |
| LTU | 2265 | 491.1 | 2.33 | 488.7 | 481.5 | 495.5 | 2.99 | 1.28 | 1.87 | 1.16 | 1.12 | 1.31 | 0.89 |
| LUX | 2407 | 491.8 | 2.23 | 493.6 | 489.3 | 499.4 | 1.89 | 0.85 | 1.28 | 0.57 | 0.79 | 0.47 | 0.25 |
| LVA | 1751 | 503.9 | 2.46 | 500.5 | 491.4 | 508.7 | 3.34 | 1.36 | 2.23 | 1.81 | 1.23 | 0.11 | 0.69 |
| MLT | 1113 | 481.3 | 3.77 | 486.1 | 480.4 | 495.9 | 3.34 | 0.89 | 2.08 | 1.10 | 1.34 | 0.99 | 0.31 |
| MNE | 3066 | 435.6 | 1.84 | 441.8 | 434.4 | 449.6 | 3.40 | 1.84 | 0.92 | 1.17 | 2.29 | 1.33 | 1.10 |
| MYS | 2797 | 445.4 | 3.17 | 441.3 | 430.2 | 453.5 | 5.05 | 1.60 | 2.37 | 0.97 | 3.76 | 0.73 | 0.56 |
| NLD | 1787 | 542.6 | 2.71 | 541.5 | 532.4 | 549.1 | 3.50 | 1.29 | 1.36 | 2.61 | 1.23 | 0.52 | 0.31 |
| NOR | 2679 | 507.5 | 2.07 | 511.1 | 502.5 | 519.1 | 3.41 | 1.64 | 1.79 | 0.91 | 1.58 | 1.82 | 0.68 |
| NZL | 2821 | 508.0 | 2.29 | 505.3 | 501.9 | 509.1 | 1.60 | 0.70 | 0.34 | 0.93 | 0.29 | 0.38 | 0.31 |
| POL | 2577 | 524.4 | 3.32 | 521.6 | 516.3 | 526.0 | 2.29 | 0.69 | 2.04 | 0.35 | 0.20 | 0.15 | 0.68 |
| PRT | 2730 | 501.1 | 2.74 | 503.3 | 497.8 | 513.5 | 3.46 | 1.26 | 0.38 | 2.03 | 0.95 | 2.30 | 0.48 |
| RUS | 2510 | 495.4 | 3.46 | 497.1 | 488.9 | 504.0 | 3.21 | 0.93 | 1.93 | 1.73 | 0.66 | 1.15 | 0.78 |
| SGP | 2201 | 584.2 | 2.03 | 580.3 | 567.8 | 592.8 | 5.21 | 2.57 | 3.01 | 2.95 | 1.31 | 0.29 | 1.07 |
| SVK | 1904 | 496.4 | 3.00 | 498.9 | 493.7 | 506.6 | 2.90 | 0.97 | 1.54 | 2.04 | 0.42 | 0.58 | 0.76 |
| SVN | 2863 | 522.0 | 2.49 | 523.6 | 520.0 | 527.6 | 1.82 | 0.73 | 1.08 | 0.89 | 0.34 | 0.14 | 0.50 |
| SWE | 2539 | 503.4 | 3.20 | 511.4 | 498.9 | 519.6 | 4.83 | 1.51 | 2.21 | 2.10 | 2.93 | 1.08 | 0.34 |
| TUR | 3172 | 469.1 | 2.42 | 462.7 | 456.1 | 469.5 | 2.86 | 1.18 | 0.86 | 1.63 | 1.90 | 0.31 | 0.28 |
| USA | 2218 | 490.0 | 3.43 | 486.3 | 479.1 | 492.3 | 3.08 | 0.90 | 0.90 | 1.29 | 2.32 | 0.37 | 0.28 |
| Reference Model | Multi-Model Inference | Square Root of Variance Component (SRVC) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cnt | Est | SE | M | Min | Max | ME | ER | Pos | RMSD | Score0 | Items | Model | |
| ALB | 2116 | 87.9 | 2.03 | 84.9 | 75.9 | 96.2 | 5.09 | 2.50 | 3.12 | 1.27 | 0.67 | 0.18 | 3.11 |
| AUS | 6508 | 98.2 | 1.56 | 95.7 | 90.3 | 100.8 | 2.23 | 1.43 | 1.91 | 0.54 | 0.62 | 0.18 | 0.17 |
| AUT | 3104 | 95.5 | 2.16 | 94.3 | 90.7 | 98.9 | 1.60 | 0.74 | 0.13 | 0.25 | 0.24 | 0.43 | 0.43 |
| BEL | 3763 | 95.2 | 1.89 | 96.4 | 92.2 | 100.1 | 1.73 | 0.91 | 0.90 | 0.22 | 0.28 | 0.56 | 0.89 |
| BIH | 2934 | 87.1 | 1.78 | 84.7 | 74.3 | 104.0 | 5.43 | 3.05 | 3.07 | 1.00 | 0.96 | 0.12 | 3.72 |
| BLR | 2681 | 95.0 | 2.33 | 100.1 | 92.7 | 108.5 | 3.63 | 1.56 | 3.05 | 0.13 | 0.86 | 1.20 | 0.41 |
| BRN | 2259 | 96.5 | 1.73 | 94.3 | 88.8 | 102.5 | 3.12 | 1.81 | 1.15 | 0.55 | 0.30 | 0.29 | 2.19 |
| CAN | 7200 | 92.8 | 1.43 | 93.2 | 88.9 | 97.5 | 1.88 | 1.32 | 0.56 | 0.24 | 0.42 | 0.84 | 1.02 |
| CHE | 2679 | 97.8 | 2.00 | 97.3 | 90.9 | 101.0 | 2.00 | 1.00 | 1.24 | 0.32 | 0.55 | 0.75 | 0.64 |
| CZE | 3199 | 94.3 | 1.94 | 98.0 | 94.3 | 103.5 | 1.75 | 0.90 | 0.69 | 0.70 | 0.87 | 0.66 | 0.56 |
| DEU | 2482 | 97.6 | 1.73 | 98.1 | 93.0 | 104.0 | 2.30 | 1.33 | 0.63 | 0.60 | 0.24 | 1.47 | 0.43 |
| DNK | 3304 | 86.1 | 1.78 | 84.9 | 77.8 | 90.3 | 2.89 | 1.62 | 2.45 | 0.72 | 0.37 | 0.38 | 1.03 |
| ESP | 11855 | 87.8 | 1.31 | 87.4 | 84.0 | 91.0 | 1.27 | 0.97 | 0.60 | 0.48 | 0.35 | 0.21 | 0.25 |
| EST | 2467 | 85.4 | 1.70 | 87.6 | 79.0 | 95.1 | 3.49 | 2.05 | 0.64 | 0.31 | 0.68 | 1.96 | 2.30 |
| FIN | 2573 | 83.2 | 1.84 | 85.4 | 81.0 | 90.2 | 2.12 | 1.15 | 0.67 | 0.90 | 0.68 | 0.40 | 0.87 |
| FRA | 2880 | 95.4 | 2.10 | 93.1 | 86.1 | 96.2 | 1.87 | 0.89 | 1.17 | 0.53 | 0.44 | 0.48 | 0.74 |
| GBR | 5979 | 100.4 | 1.90 | 98.7 | 91.8 | 105.0 | 2.83 | 1.49 | 1.69 | 0.17 | 1.59 | 1.04 | 0.42 |
| GRC | 2114 | 91.8 | 2.45 | 92.8 | 86.5 | 103.4 | 3.87 | 1.58 | 2.76 | 0.83 | 0.70 | 0.66 | 1.90 |
| HKG | 2008 | 98.9 | 2.79 | 96.8 | 85.7 | 107.0 | 5.03 | 1.80 | 3.45 | 1.92 | 0.57 | 0.02 | 2.62 |
| HRV | 2150 | 86.8 | 2.54 | 87.8 | 82.1 | 94.8 | 2.71 | 1.07 | 1.70 | 0.56 | 0.38 | 0.46 | 1.58 |
| HUN | 2361 | 94.7 | 2.15 | 98.7 | 92.8 | 106.9 | 3.52 | 1.64 | 1.36 | 1.35 | 0.26 | 2.47 | 1.21 |
| IRL | 2581 | 80.0 | 1.42 | 80.1 | 76.5 | 84.3 | 2.11 | 1.49 | 1.31 | 0.53 | 0.28 | 1.11 | 0.29 |
| ISL | 1485 | 93.5 | 2.33 | 93.4 | 88.2 | 97.5 | 2.03 | 0.87 | 0.51 | 0.51 | 0.43 | 0.29 | 0.47 |
| ISR | 1944 | 119.8 | 3.15 | 117.9 | 109.8 | 128.8 | 3.97 | 1.26 | 2.05 | 0.69 | 1.38 | 1.29 | 1.81 |
| ITA | 5475 | 94.6 | 2.49 | 93.9 | 87.6 | 97.1 | 2.11 | 0.85 | 0.92 | 0.34 | 0.30 | 1.59 | 0.19 |
| JPN | 2814 | 91.4 | 2.33 | 89.1 | 79.0 | 97.8 | 4.33 | 1.86 | 3.08 | 0.90 | 0.39 | 1.68 | 1.64 |
| KOR | 2200 | 103.4 | 2.48 | 98.0 | 86.3 | 107.8 | 3.99 | 1.61 | 1.36 | 1.47 | 1.30 | 1.16 | 1.71 |
| LTU | 2265 | 93.3 | 2.07 | 95.6 | 90.8 | 101.5 | 2.29 | 1.11 | 0.65 | 0.35 | 1.11 | 1.52 | 0.02 |
| LUX | 2407 | 101.2 | 1.64 | 101.0 | 95.7 | 106.1 | 2.05 | 1.25 | 0.33 | 0.28 | 0.67 | 1.33 | 0.78 |
| LVA | 1751 | 84.1 | 2.08 | 83.0 | 73.3 | 88.5 | 3.33 | 1.60 | 0.85 | 1.10 | 0.23 | 2.51 | 0.87 |
| MLT | 1113 | 112.8 | 3.17 | 104.2 | 95.3 | 114.7 | 4.27 | 1.35 | 2.16 | 1.35 | 2.96 | 0.23 | 0.45 |
| MNE | 3066 | 89.2 | 1.57 | 84.3 | 78.2 | 92.4 | 2.84 | 1.81 | 0.97 | 0.35 | 1.03 | 1.23 | 1.61 |
| MYS | 2797 | 88.2 | 1.90 | 88.5 | 80.0 | 96.9 | 3.72 | 1.95 | 1.44 | 1.42 | 1.04 | 0.05 | 2.19 |
| NLD | 1787 | 90.0 | 2.54 | 90.2 | 78.7 | 101.5 | 5.55 | 2.19 | 3.75 | 0.31 | 0.22 | 1.80 | 2.96 |
| NOR | 2679 | 95.2 | 1.78 | 91.7 | 86.2 | 96.5 | 2.08 | 1.17 | 0.71 | 1.10 | 0.33 | 0.99 | 0.59 |
| NZL | 2821 | 97.9 | 1.64 | 99.4 | 95.9 | 103.4 | 1.79 | 1.09 | 0.36 | 0.05 | 0.37 | 1.33 | 0.43 |
| POL | 2577 | 94.2 | 2.12 | 95.4 | 89.7 | 99.3 | 1.94 | 0.92 | 1.18 | 0.87 | 0.14 | 0.70 | 0.75 |
| PRT | 2730 | 97.6 | 2.17 | 103.5 | 94.9 | 113.1 | 4.13 | 1.90 | 3.23 | 0.48 | 1.21 | 1.90 | 0.26 |
| RUS | 2510 | 84.6 | 2.16 | 85.7 | 81.0 | 93.0 | 2.59 | 1.20 | 2.01 | 1.01 | 0.24 | 0.38 | 0.30 |
| SGP | 2201 | 101.5 | 1.90 | 102.2 | 89.6 | 111.6 | 4.73 | 2.49 | 0.23 | 1.78 | 0.81 | 1.09 | 3.92 |
| SVK | 1904 | 97.8 | 2.26 | 99.2 | 92.0 | 109.8 | 3.06 | 1.35 | 0.71 | 1.28 | 0.73 | 1.41 | 0.96 |
| SVN | 2863 | 91.1 | 1.97 | 92.9 | 89.0 | 96.6 | 1.79 | 0.91 | 0.91 | 0.63 | 0.22 | 0.06 | 0.72 |
| SWE | 2539 | 95.1 | 1.89 | 97.0 | 89.3 | 103.3 | 3.23 | 1.71 | 2.25 | 1.23 | 0.84 | 0.88 | 0.20 |
| TUR | 3172 | 94.2 | 2.37 | 96.9 | 89.1 | 107.6 | 3.44 | 1.45 | 0.87 | 2.14 | 1.27 | 1.21 | 0.45 |
| USA | 2218 | 97.1 | 2.34 | 98.9 | 93.1 | 106.2 | 2.60 | 1.11 | 0.94 | 0.76 | 0.91 | 1.39 | 0.38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Robitzsch, A. Exploring the Multiverse of Analytical Decisions in Scaling Educational Large-Scale Assessment Data: A Specification Curve Analysis for PISA 2018 Mathematics Data. Eur. J. Investig. Health Psychol. Educ. 2022, 12, 731-753. https://doi.org/10.3390/ejihpe12070054
Robitzsch A. Exploring the Multiverse of Analytical Decisions in Scaling Educational Large-Scale Assessment Data: A Specification Curve Analysis for PISA 2018 Mathematics Data. European Journal of Investigation in Health, Psychology and Education. 2022; 12(7):731-753. https://doi.org/10.3390/ejihpe12070054
Chicago/Turabian StyleRobitzsch, Alexander. 2022. "Exploring the Multiverse of Analytical Decisions in Scaling Educational Large-Scale Assessment Data: A Specification Curve Analysis for PISA 2018 Mathematics Data" European Journal of Investigation in Health, Psychology and Education 12, no. 7: 731-753. https://doi.org/10.3390/ejihpe12070054
APA StyleRobitzsch, A. (2022). Exploring the Multiverse of Analytical Decisions in Scaling Educational Large-Scale Assessment Data: A Specification Curve Analysis for PISA 2018 Mathematics Data. European Journal of Investigation in Health, Psychology and Education, 12(7), 731-753. https://doi.org/10.3390/ejihpe12070054