
Identification of Granule Growth Regimes in High Shear Wet Granulation Processes Using a Physics-Constrained Neural Network

Abstract
1. Introduction
Objectives
2. Background
2.1. Wet Granulation and Population Balance Model
2.2. Artificial Neural Networks
2.3. Previous ANN Studies in Granulation
2.4. Physics-Constrained Neural Networks
3. Method and Implementation
3.1. Data Generation
3.2. Development of Artificial Neural Network
3.2.1. Physical Constraints for Granule Growth
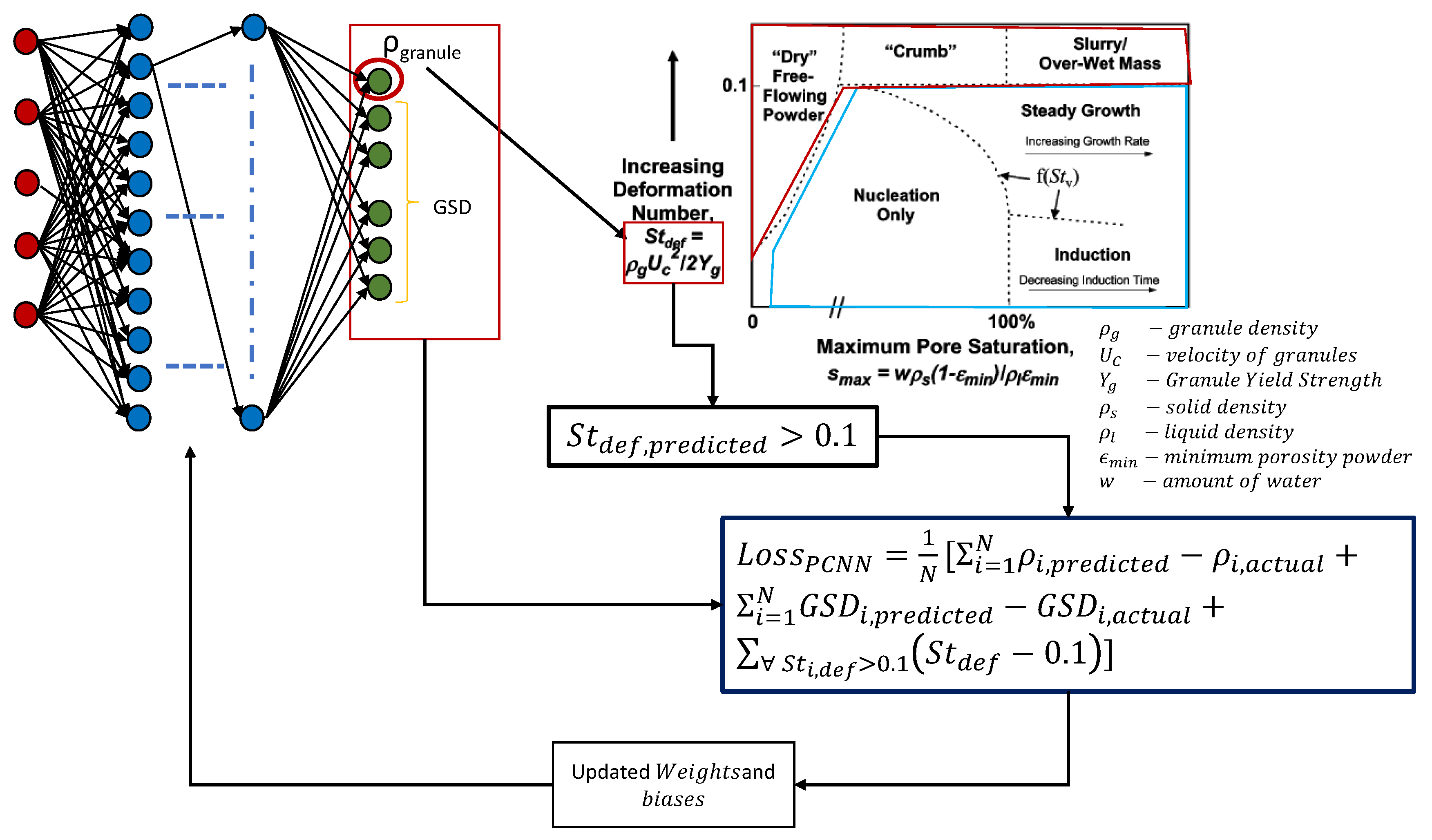
3.2.2. Physics Constrained Neural Network for Granulation
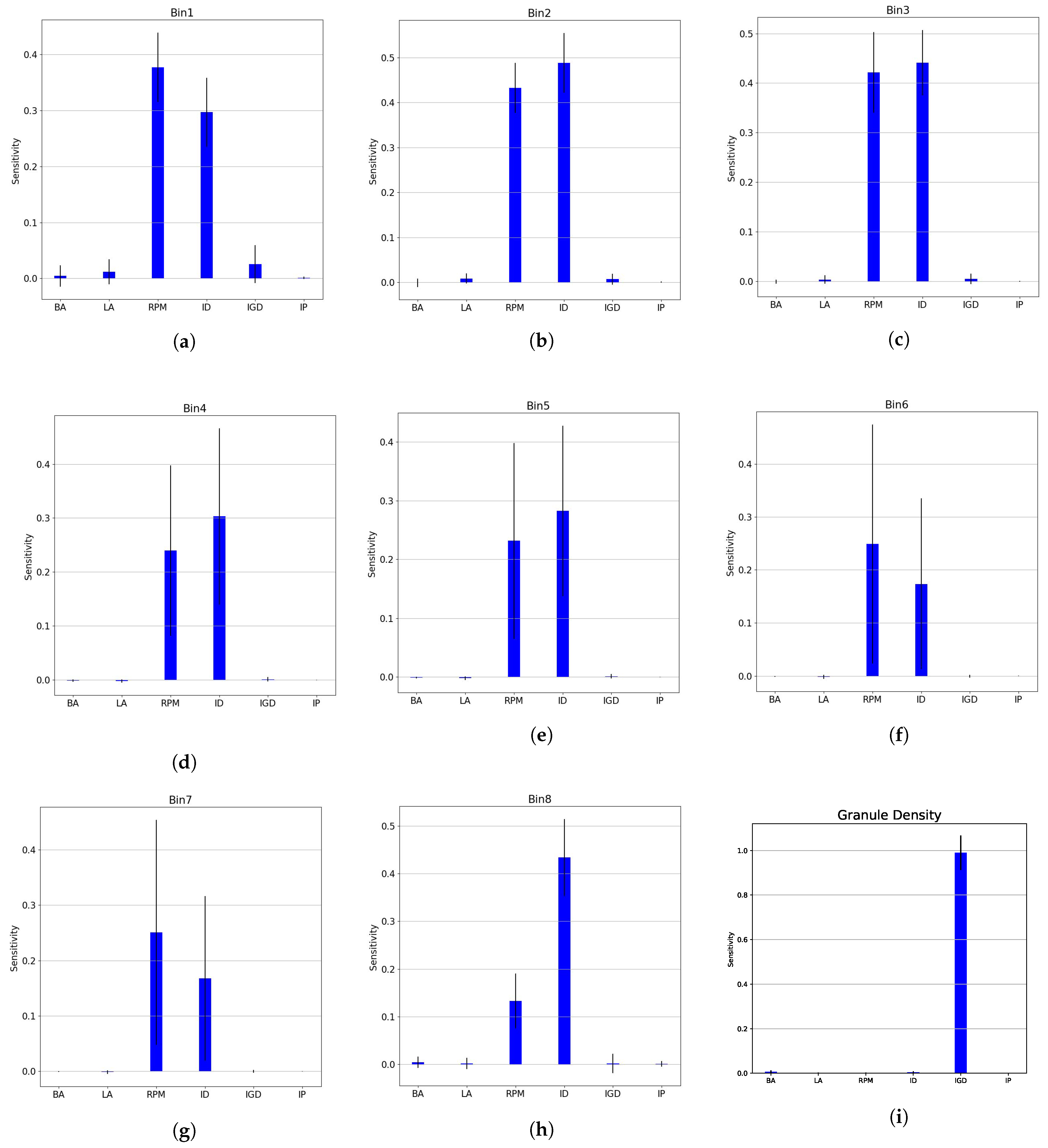
3.3. Input Parameter Sensitivity Analysis
4. Results and Discussion
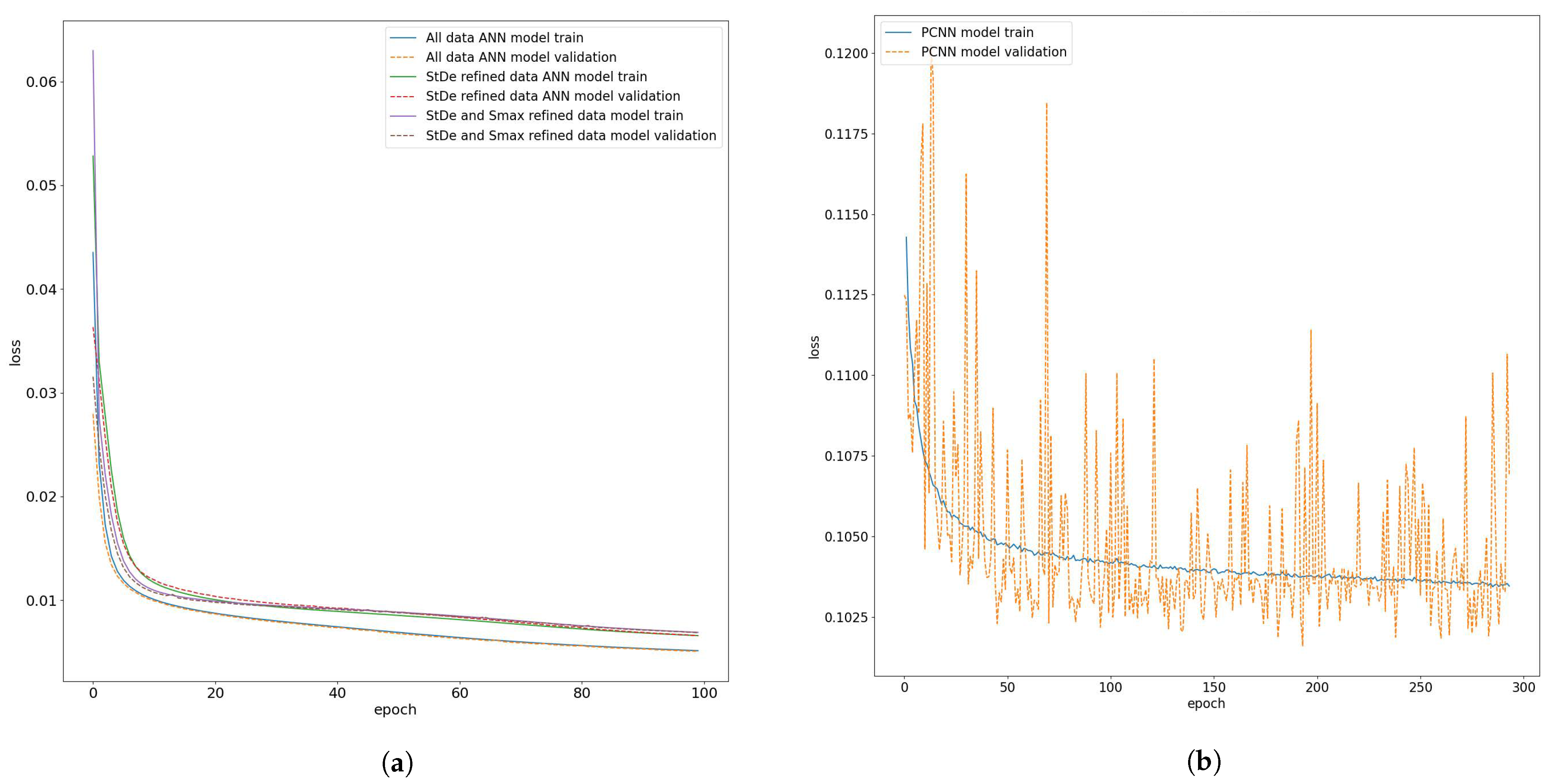
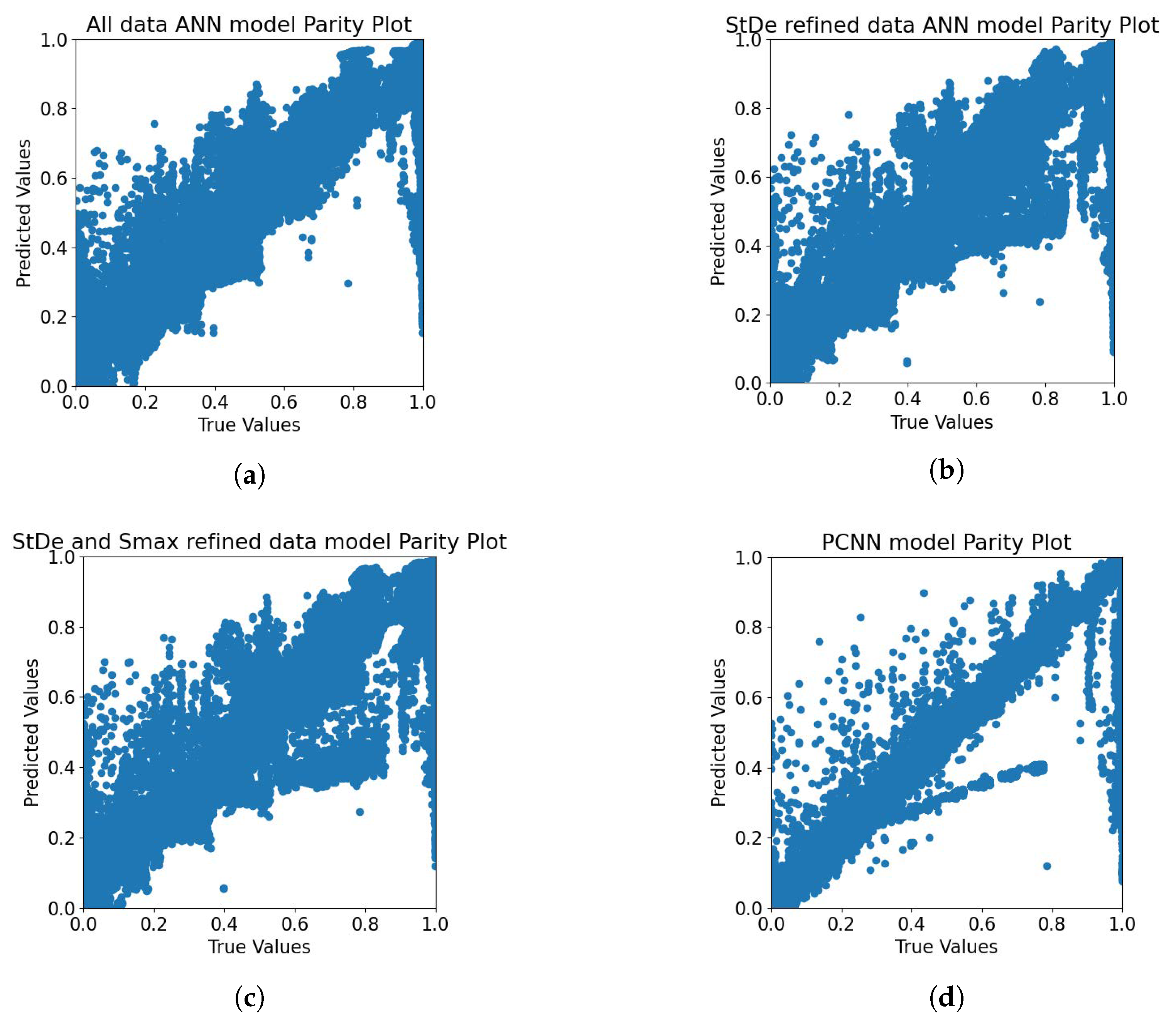
4.1. Comparing Artificial Neural Network and Physics-Constrained Neural Network Models
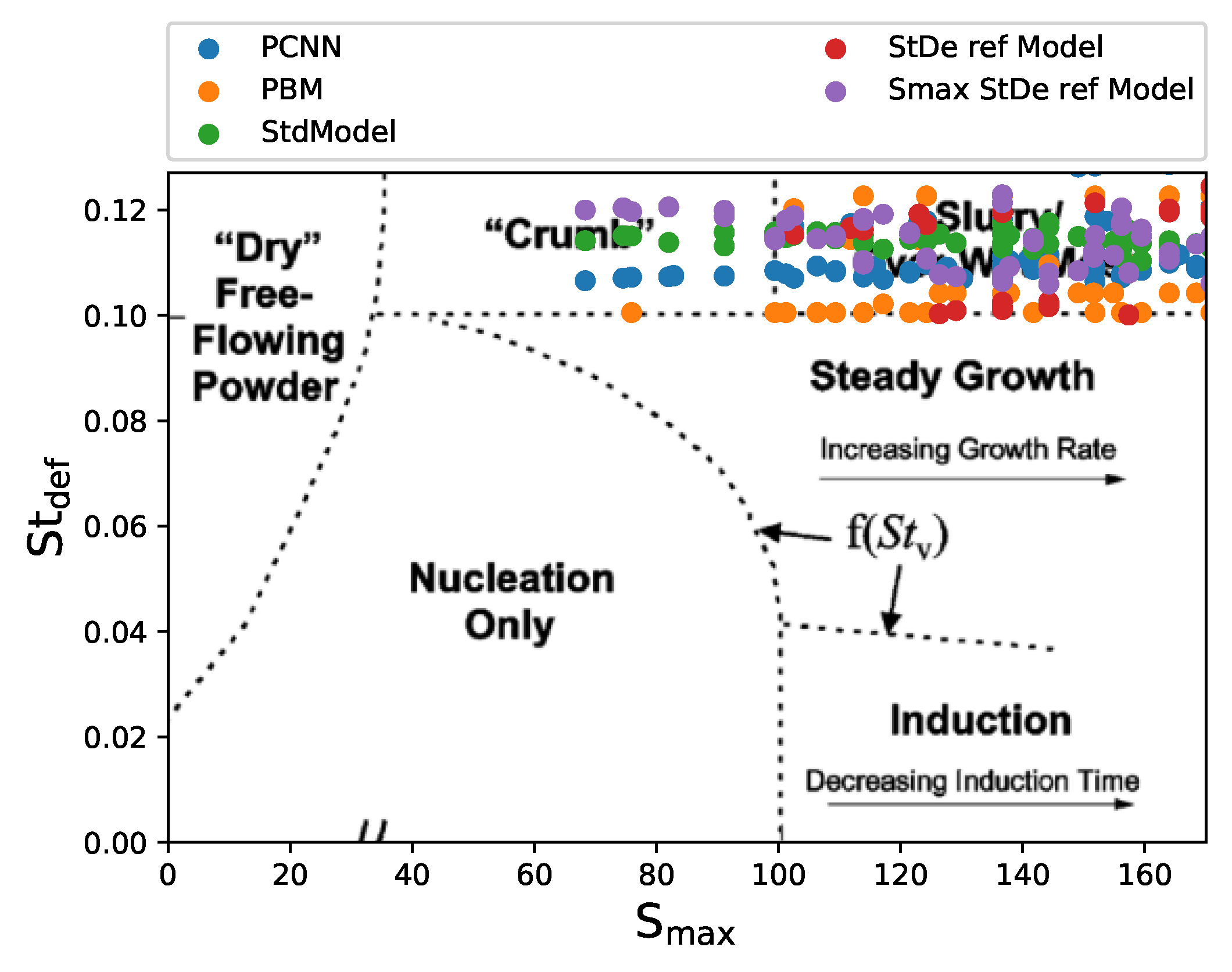
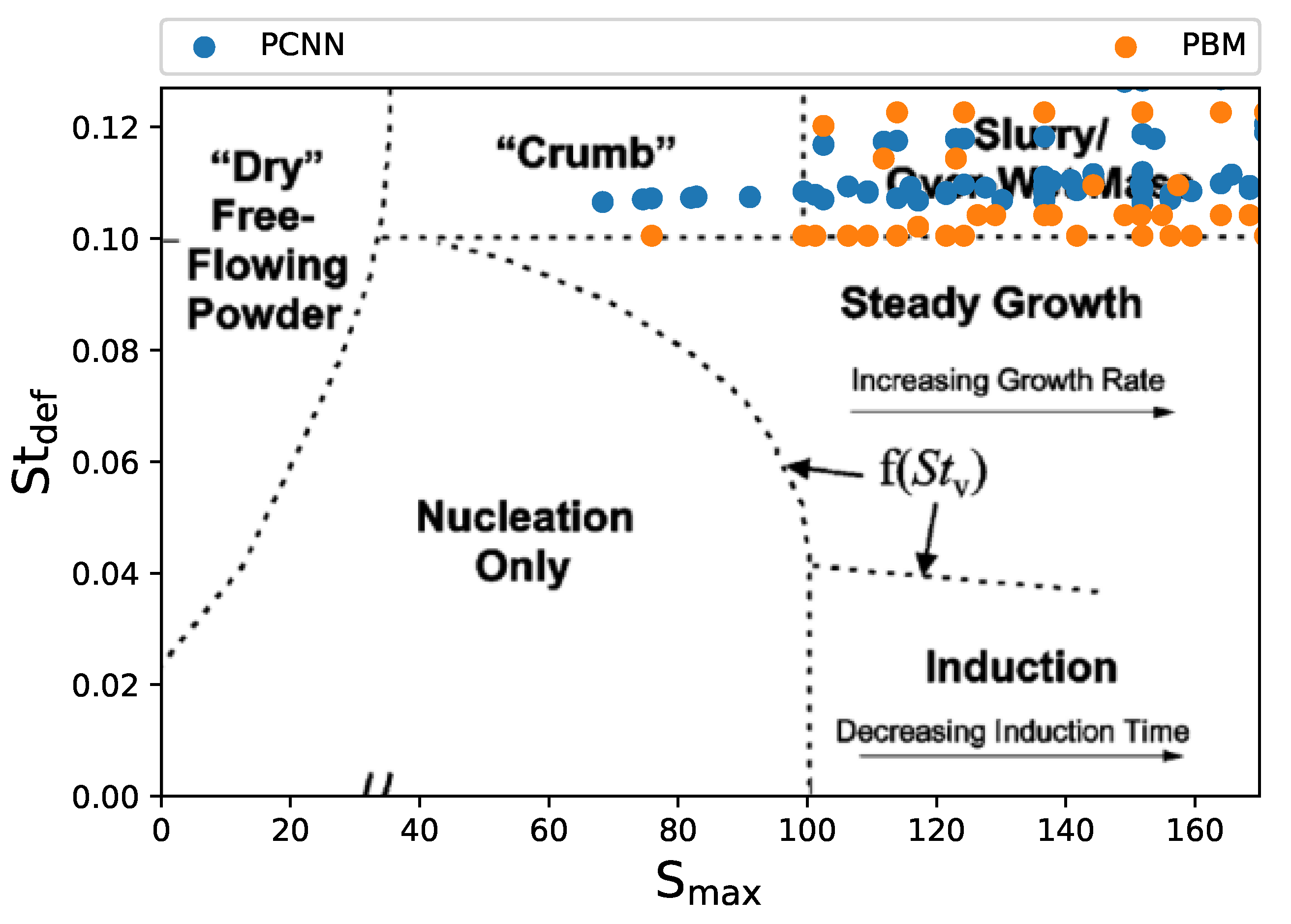
4.2. Comparing Artificial Neural Networks and Physics-Constrained Neural Network at Growth Regime Boundary Conditions
4.3. Input Parameters Sensitivity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. PBM Equations
Appendix B. Comparing Regime Predictions for PBM and PCNN

References
- Chand, S.; Davis, J. What is Smart Manufacturing? Time Magazine, 7 July 2010. [Google Scholar]
- Venkatasubramanian, V. The promise of artificial intelligence in chemical engineering: Is it here, finally? AIChE J. 2019, 65, 466–478. [Google Scholar] [CrossRef]
- Pham, D.T.; Afify, A.A. Machine-learning techniques and their applications in manufacturing. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2005, 219, 395–412. [Google Scholar] [CrossRef]
- GE. Deep Machine Learning: GE and BP Will Connect Thousands of Subsea Oil Wells to the Industrial Internet. 2015. Available online: https://www.ge.com/news/reports/deep-machine-learning-ge-and-bp-will-connect-2 (accessed on 23 September 2020).
- Huang, E.; Xu, J.; Zhang, S.; Chen, C.H. Multi-fidelity Model Integration for Engineering Design. Procedia Comput. Sci. 2015, 44, 336–344. [Google Scholar] [CrossRef][Green Version]
- Raissi, M.; Karniadakis, G.E. Hidden physics models: Machine learning of nonlinear partial differential equations. J. Comput. Phys. 2018, 357, 125–141. [Google Scholar] [CrossRef]
- Seville, J.; Tüzün, U.; Clift, R. Processing of Particulate Solids; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 9. [Google Scholar]
- Litster, J.; Bogle, I.D.L. Smart Process Manufacturing for Formulated Products. Engineering 2019, 5, 1003–1009. [Google Scholar] [CrossRef]
- Litster, J. Design and Processing of Particulate Products; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Rogers, A.J.; Hashemi, A.; Ierapetritou, M.G. Modeling of particulate processes for the continuous manufacture of solid-based pharmaceutical dosage forms. Processes 2013, 1, 67–127. [Google Scholar] [CrossRef]
- US-FDA. Guidance for Industry Q8(R2) Pharmaceutical Development; ICH: Silver Spring, MD, USA, 2009.
- Azarpour, A.; Borhani, T.N.; Alwi, S.R.W.; Manan, Z.A.; Mutalib, M.I.A. A generic hybrid model development for process analysis of industrial fixed-bed catalytic reactors. Chem. Eng. Res. Des. 2017, 117, 149–167. [Google Scholar] [CrossRef]
- Chen, Y.; Ierapetritou, M. A framework of hybrid model development with identification of plant-model mismatch. AIChE J. 2020, 66, e16996. [Google Scholar] [CrossRef]
- Katare, S.; Caruthers, J.M.; Delgass, W.N.; Venkatasubramanian, V. An Intelligent System for Reaction Kinetic Modeling and Catalyst Design. Ind. Eng. Chem. Res. 2004, 43, 3484–3512. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Jagtap, A.D.; Kawaguchi, K.; Karniadakis, G.E. Adaptive activation functions accelerate convergence in deep and physics-informed neural networks. J. Comput. Phys. 2020, 404, 109136. [Google Scholar] [CrossRef]
- Zhu, Y.; Zabaras, N.; Koutsourelakis, P.S.; Perdikaris, P. Physics-constrained deep learning for high-dimensional surrogate modeling and uncertainty quantification without labeled data. J. Comput. Phys. 2019, 394, 56–81. [Google Scholar] [CrossRef]
- Iveson, S.M.; Litster, J.D.; Hapgood, K.; Ennis, B.J. Nucleation, growth and breakage phenomena in agitated wet granulation processes: A review. Powder Technol. 2001, 117, 3–39. [Google Scholar] [CrossRef]
- Iveson, S.M.; Wauters, P.A.; Forrest, S.; Litster, J.D.; Meesters, G.M.; Scarlett, B. Growth regime map for liquid-bound granules: Further development and experimental validation. Powder Technol. 2001, 117, 83–97. [Google Scholar] [CrossRef]
- Cameron, I.T.; Wang, F.Y.; Immanuel, C.D.; Stepanek, F. Process systems modelling and applications in granulation: A review. Chem. Eng. Sci. 2005, 60, 3723–3750. [Google Scholar] [CrossRef]
- Ramkrishna, D.; Singh, M.R. Population balance modeling: Current status and future prospects. Annu. Rev. Chem. Biomol. Eng. 2014, 5, 123–146. [Google Scholar] [CrossRef] [PubMed]
- Barrasso, D.; Hagrasy, A.E.; Litster, J.; Ramachandran, R. Multi-dimensional population balance model development and validation for a twin screw granulation process. Powder Technol. 2015, 270, 612–621. [Google Scholar] [CrossRef]
- Barrasso, D.; Walia, S.; Ramachandran, R. Multi-component population balance modeling of continuous granulation processes: A parametric study and comparison with experimental trends. Powder Technol. 2013, 241, 85–97. [Google Scholar] [CrossRef]
- Barrasso, D.; Tamrakar, A.; Ramachandran, R. Model Order Reduction of a Multi-scale PBM-DEM Description of a Wet Granulation Process via ANN. Procedia Eng. 2015, 102, 1295–1304. [Google Scholar] [CrossRef]
- Chaudhury, A.; Kapadia, A.; Prakash, A.V.; Barrasso, D.; Ramachandran, R. An extended cell-average technique for a multi-dimensional population balance of granulation describing aggregation and breakage. Adv. Powder Technol. 2013, 24, 962–971. [Google Scholar] [CrossRef]
- Immanuel, C.D.; Doyle, F.J. Solution technique for a multi-dimensional population balance model describing granulation processes. Powder Technol. 2005, 156, 213–225. [Google Scholar] [CrossRef]
- Gunawan, R.; Fusman, I.; Braatz, R.D. Parallel high-resolution finite volume simulation of particulate processes. AIChE J. 2008, 54, 1449–1458. [Google Scholar] [CrossRef]
- Prakash, A.V.; Chaudhury, A.; Barrasso, D.; Ramachandran, R. Simulation of population balance model-based particulate processes via parallel and distributed computing. Chem. Eng. Res. Des. 2013, 91, 1259–1271. [Google Scholar] [CrossRef]
- Bettencourt, F.E.; Chaturbedi, A.; Ramachandran, R. Parallelization methods for efficient simulation of high dimensional population balance models of granulation. Comput. Chem. Eng. 2017, 107, 158–170. [Google Scholar] [CrossRef]
- Prakash, A.V.; Chaudhury, A.; Ramachandran, R. Parallel simulation of population balance model-based particulate processes using multicore {CPUs} and {GPUs}. Model. Simul. Eng. 2013, 2013, 475478. [Google Scholar] [CrossRef]
- Sampat, C.; Baranwal, Y.; Ramachandran, R. Accelerating multi-dimensional population balance model simulations via a highly scalable framework using GPUs. Comput. Chem. Eng. 2020, 140, 106935. [Google Scholar] [CrossRef]
- Sampat, C.; Bettencourt, F.; Baranwal, Y.; Paraskevakos, I.; Chaturbedi, A.; Karkala, S.; Jha, S.; Ramachandran, R.; Ierapetritou, M. A parallel unidirectional coupled DEM-PBM model for the efficient simulation of computationally intensive particulate process systems. Comput. Chem. Eng. 2018, 119, 128–142. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Fletcher, L.; Katkovnik, V.; Steffens, F.E.; Engelbrecht, A.P. Optimizing the number of hidden nodes of a feedforward artificial neural network. In Proceedings of the 1998 IEEE International Joint Conference on Neural Networks Proceedings, IEEE World Congress on Computational Intelligence (Cat. No.98CH36227), Anchorage, AK, USA, 4–9 May 1998; Volume 2, pp. 1608–1612. [Google Scholar]
- Baydin, A.G.; Pearlmutter, B.A.; Radul, A.A.; Siskind, J.M. Automatic differentiation in machine learning: A survey. J. Mach. Learn. Res. 2018, 18, 1–43. [Google Scholar]
- Murtoniemi, E.; Yliruusi, J.; Kinnunen, P.; Merkku, P.; Leiviskä, K. The advantages by the use of neural networks in modelling the fluidized bed granulation process. Int. J. Pharm. 1994, 108, 155–164. [Google Scholar] [CrossRef]
- Aksu, B.; Paradkar, A.; de Matas, M.; Özgen, Ö.; Güneri, T.; York, P. A quality by design approach using artificial intelligence techniques to control the critical quality attributes of ramipril tablets manufactured by wet granulation. Pharm. Dev. Technol. 2013, 18, 236–245. [Google Scholar] [CrossRef]
- Pishnamazi, M.; Ismail, H.Y.; Shirazian, S.; Iqbal, J.; Walker, G.M.; Collins, M.N. Application of lignin in controlled release: Development of predictive model based on artificial neural network for API release. Cellulose 2019, 26, 6165–6178. [Google Scholar] [CrossRef]
- Ismail, H.Y.; Singh, M.; Darwish, S.; Kuhs, M.; Shirazian, S.; Croker, D.M.; Khraisheh, M.; Albadarin, A.B.; Walker, G.M. Developing ANN-Kriging hybrid model based on process parameters for prediction of mean residence time distribution in twin-screw wet granulation. Powder Technol. 2019, 343, 568–577. [Google Scholar] [CrossRef]
- Shirazian, S.; Kuhs, M.; Darwish, S.; Croker, D.; Walker, G.M. Artificial neural network modelling of continuous wet granulation using a twin-screw extruder. Int. J. Pharm. 2017, 521, 102–109. [Google Scholar] [CrossRef]
- Rantanen, J.; Räsänen, E.; Antikainen, O.; Mannermaa, J.P.; Yliruusi, J. In-line moisture measurement during granulation with a four-wavelength near-infrared sensor: An evaluation of process-related variables and a development of non-linear calibration model. Chemom. Intell. Lab. Syst. 2001, 56, 51–58. [Google Scholar] [CrossRef]
- Van Hauwermeiren, D.; Stock, M.; De Beer, T.; Nopens, I. Predicting Pharmaceutical Particle Size Distributions Using Kernel Mean Embedding. Pharmaceutics 2020, 12, 271. [Google Scholar] [CrossRef] [PubMed]
- Barrasso, D.; Tamrakar, A.; Ramachandran, R. A reduced order PBM–ANN model of a multi-scale PBM–DEM description of a wet granulation process. Chem. Eng. Sci. 2014, 119, 319–329. [Google Scholar] [CrossRef]
- Liu, D.; Wang, Y. A Dual-Dimer Method for Training Physics-Constrained Neural Networks with Minimax Architecture. arXiv 2020, arXiv:2005.00615. [Google Scholar]
- Goswami, S.; Anitescu, C.; Chakraborty, S.; Rabczuk, T. Transfer learning enhanced physics informed neural network for phase-field modeling of fracture. Theor. Appl. Fract. Mech. 2020, 106, 102447. [Google Scholar] [CrossRef]
- Sahli Costabal, F.; Yang, Y.; Perdikaris, P.; Hurtado, D.E.; Kuhl, E. Physics-Informed Neural Networks for Cardiac Activation Mapping. Front. Phys. 2020, 8, 42. [Google Scholar] [CrossRef]
- Chaturbedi, A.; Bandi, C.K.; Reddy, D.; Pandey, P.; Narang, A.; Bindra, D.; Tao, L.; Zhao, J.; Li, J.; Hussain, M.; et al. Compartment based population balance model development of a high shear wet granulation process via dry and wet binder addition. Chem. Eng. Res. Des. 2017, 123, 187–200. [Google Scholar] [CrossRef]
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 19 April 2021).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org/ (accessed on 19 April 2021).
- LeCun, Y.A.; Bottou, L.; Orr, G.B.; Müller, K.R. Efficient BackProp. In Neural Networks: Tricks of the Trade, 2nd ed.; Montavon, G., Orr, G.B., Müller, K.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 9–48. [Google Scholar]
- Dhenge, R.M.; Cartwright, J.J.; Hounslow, M.J.; Salman, A.D. Twin screw wet granulation: Effects of properties of granulation liquid. Powder Technol. 2012, 229, 126–136. [Google Scholar] [CrossRef]
- Sobol, I.M. Sensitivity analysis for non-linear mathematical models. Math. Model. Comput. Exp. 1993, 1, 407–414. [Google Scholar]
- Herman, J.; Usher, W. SALib: An open-source Python library for Sensitivity Analysis. J. Open Source Softw. 2017, 2, 97. [Google Scholar] [CrossRef]
- Saltelli, A.; Tarantola, S.; Chan, K.S. A quantitative model-independent method for global sensitivity analysis of model output. Technometrics 1999, 41, 39–56. [Google Scholar] [CrossRef]
- Chaudhury, A.; Barrasso, D.; Pandey, P.; Wu, H.; Ramachandran, R. Population balance model development, validation, and prediction of CQAs of a high-shear wet granulation process: Towards QbD in drug product pharmaceutical manufacturing. J. Pharm. Innov. 2014, 9, 53–64. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Parameter | Minimum Value | Maximum Value |
|---|---|---|
| Batch amount (kg) | 800 | 2000 |
| Liquid amount (kg) | 600 | 1200 |
| RPM | 100 | 600 |
| Impeller diameter (m) | ||
| Initial granule density (kg/m) | 100 | 600 |
| Initial porosity |
| Hyperparameter | ANN Value | PCNN Value |
|---|---|---|
| No. of hidden layers | 2 | 3 |
| Neurons in each hidden layer | 16 | 16 |
| Optimizer algorithm | Adam | Adam |
| Optimizer learning rate | ||
| No. of epochs | 200 | 300 |
| Regularization constant | ||
| Hidden layer activation function | ‘tanh’ | ‘tanh’ |
| Last layer activation function | ‘tanh’ | ‘tanh’ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sampat, C.; Ramachandran, R. Identification of Granule Growth Regimes in High Shear Wet Granulation Processes Using a Physics-Constrained Neural Network. Processes 2021, 9, 737. https://doi.org/10.3390/pr9050737
Sampat C, Ramachandran R. Identification of Granule Growth Regimes in High Shear Wet Granulation Processes Using a Physics-Constrained Neural Network. Processes. 2021; 9(5):737. https://doi.org/10.3390/pr9050737
Chicago/Turabian StyleSampat, Chaitanya, and Rohit Ramachandran. 2021. "Identification of Granule Growth Regimes in High Shear Wet Granulation Processes Using a Physics-Constrained Neural Network" Processes 9, no. 5: 737. https://doi.org/10.3390/pr9050737
APA StyleSampat, C., & Ramachandran, R. (2021). Identification of Granule Growth Regimes in High Shear Wet Granulation Processes Using a Physics-Constrained Neural Network. Processes, 9(5), 737. https://doi.org/10.3390/pr9050737