
Real-World Failure Prevention Framework for Manufacturing Facilities Using Text Data


Abstract
1. Introduction
2. Literature Review
3. Materials and Methods
3.1. Deferred Time Process: Overall Process Description
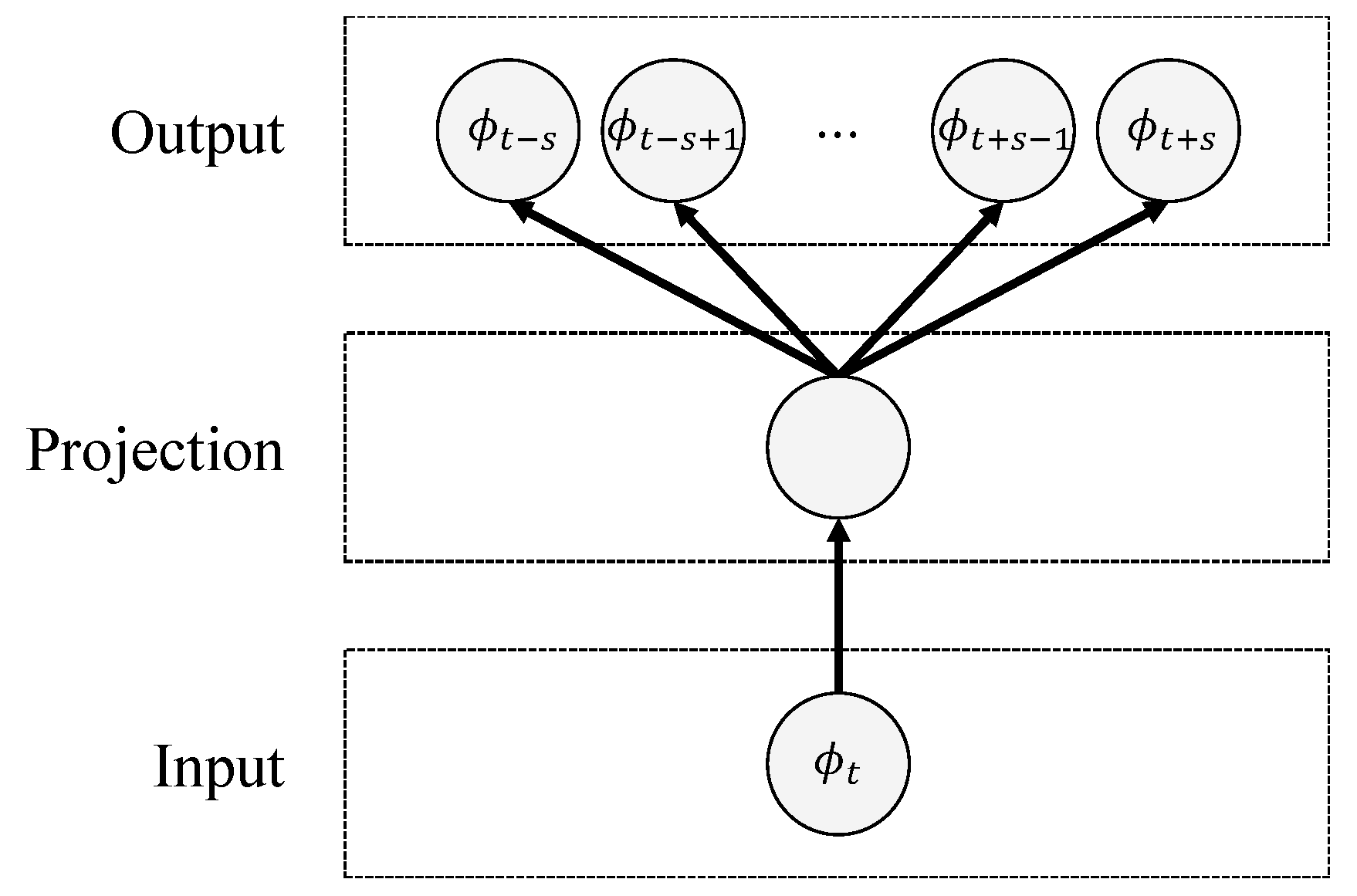
3.2. Deferred Time Process: Phrase Extraction
3.3. Deferred Time Process: Failure Categorization
| Algorithm 1: Weighted k-means clustering. | |
| Randomly select k centroids from all ; | |
| Set limit of iterations, ; | |
| ; | |
| repeat | |
| For all , calculate the weighted distance to each centroid , | |
| ; | |
| Assign all to its nearest centroid; | |
| Compute the new controids by using Equation (4); | |
| ; | |
| until The centroids do not change or ; | |
3.4. Deferred Time Process: Data Extension
3.5. Deferred Time Process: Failure Pattern Mining
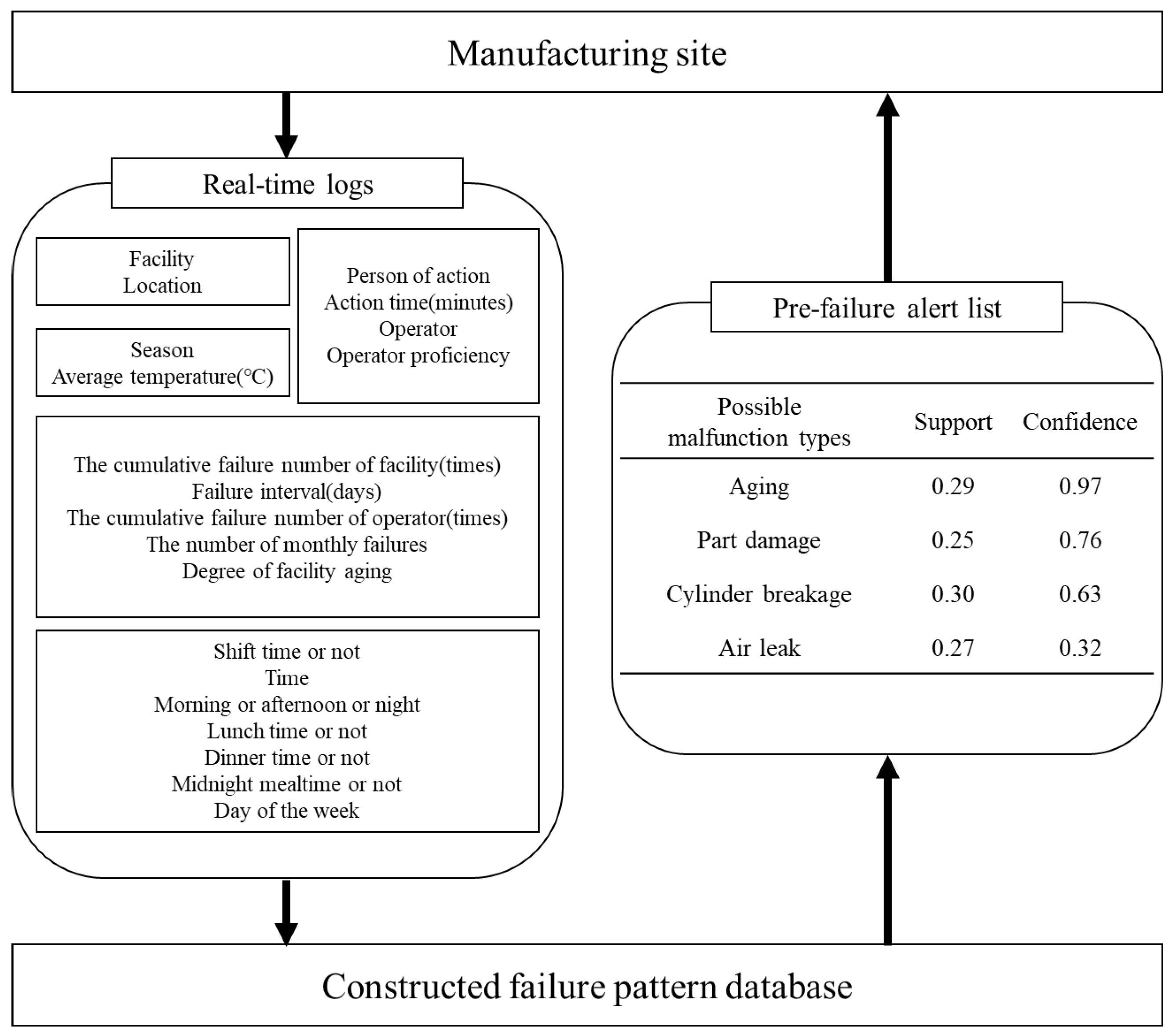
3.6. Real-Time Process: Pre-Failure Alert Based on Failure Pattern Database
4. Results
4.1. Experimental Settings
4.2. Experiment Results
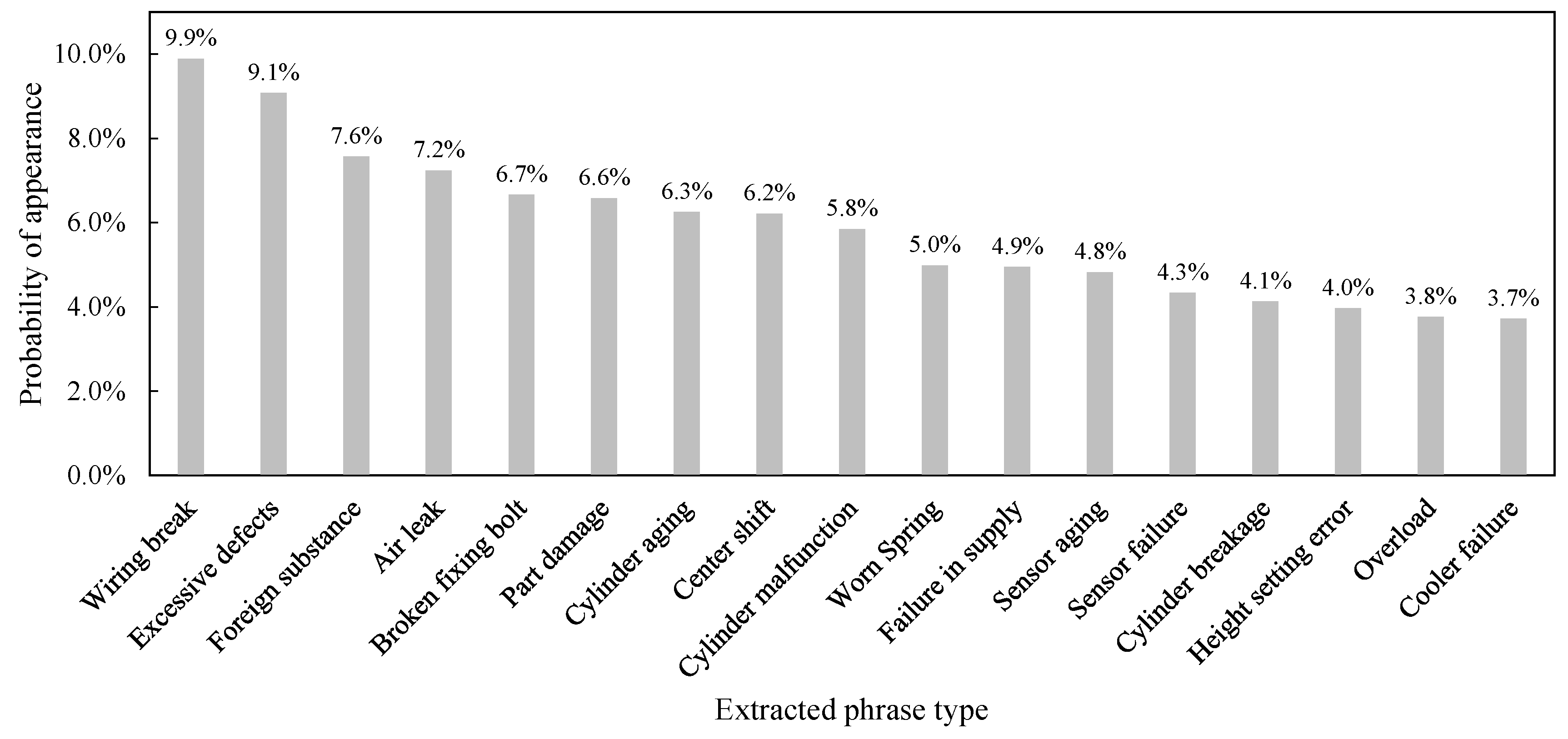
4.2.1. Phrase Extraction Results
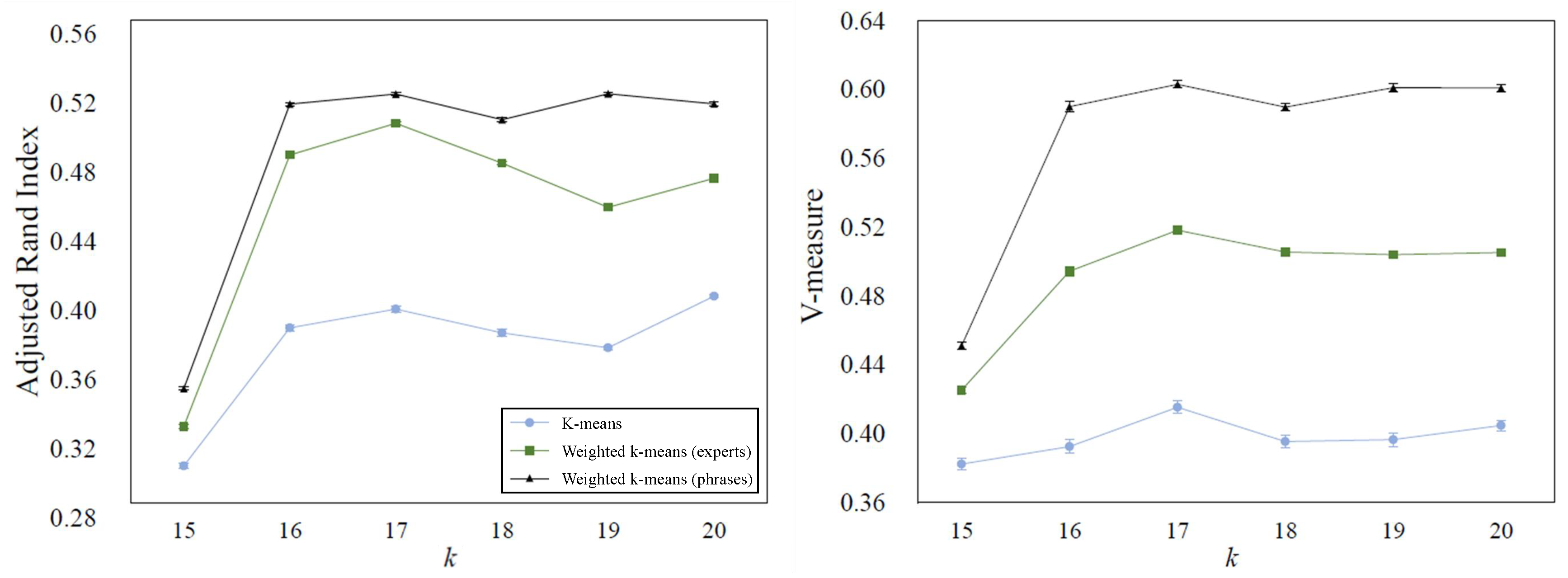
4.2.2. Failure Categorization Results
4.2.3. Data Extension Results
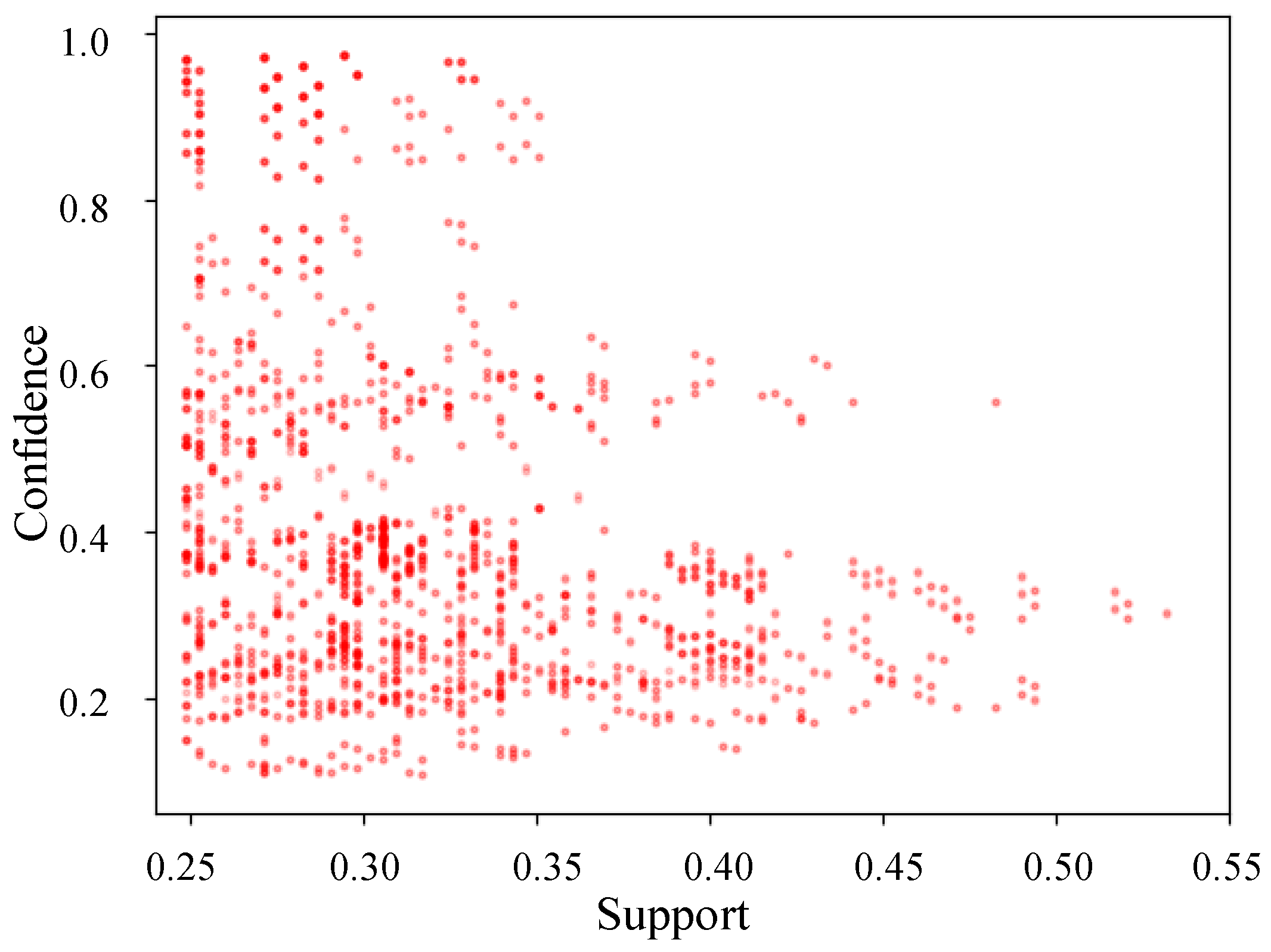
4.2.4. Pattern Mining Results
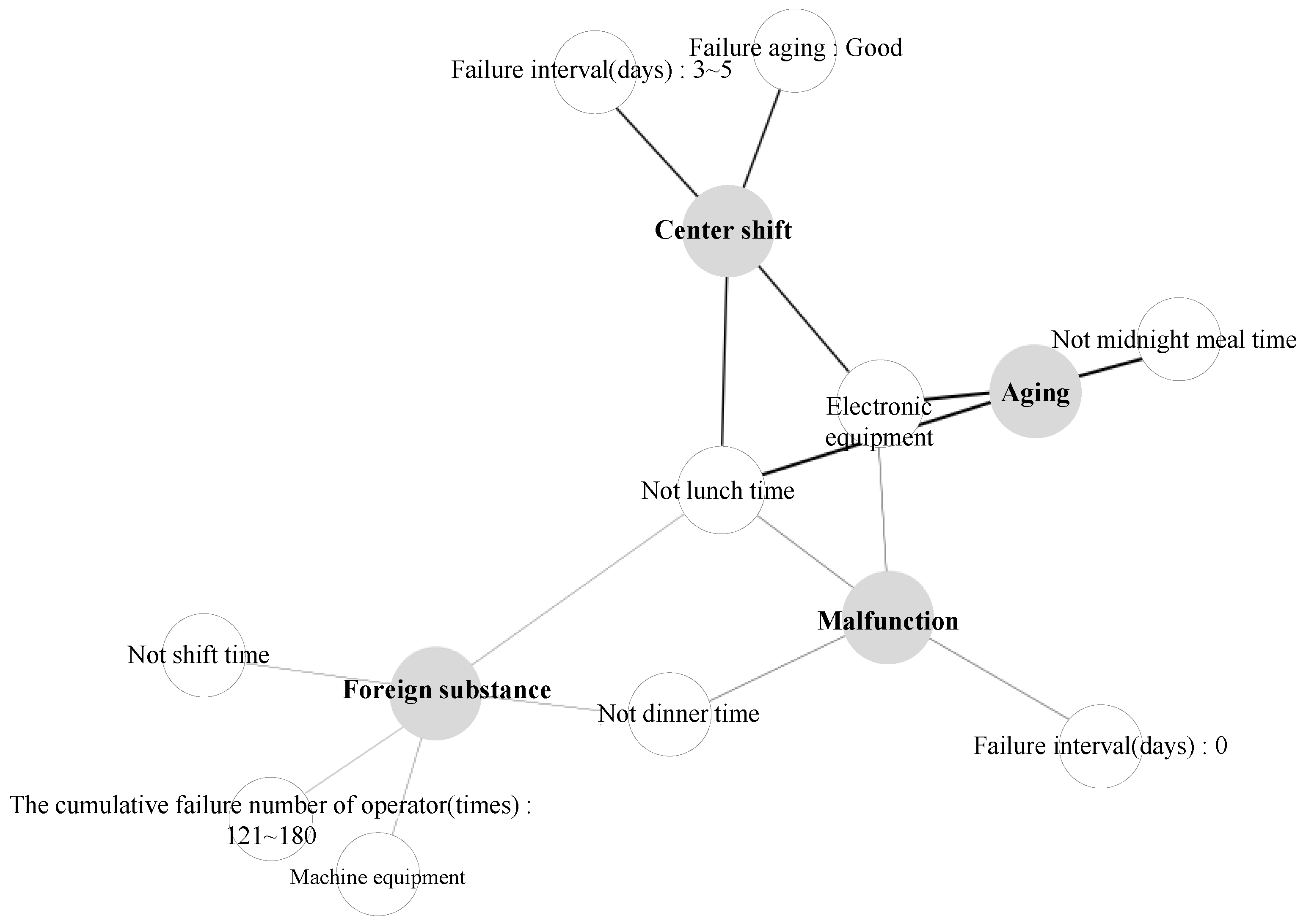
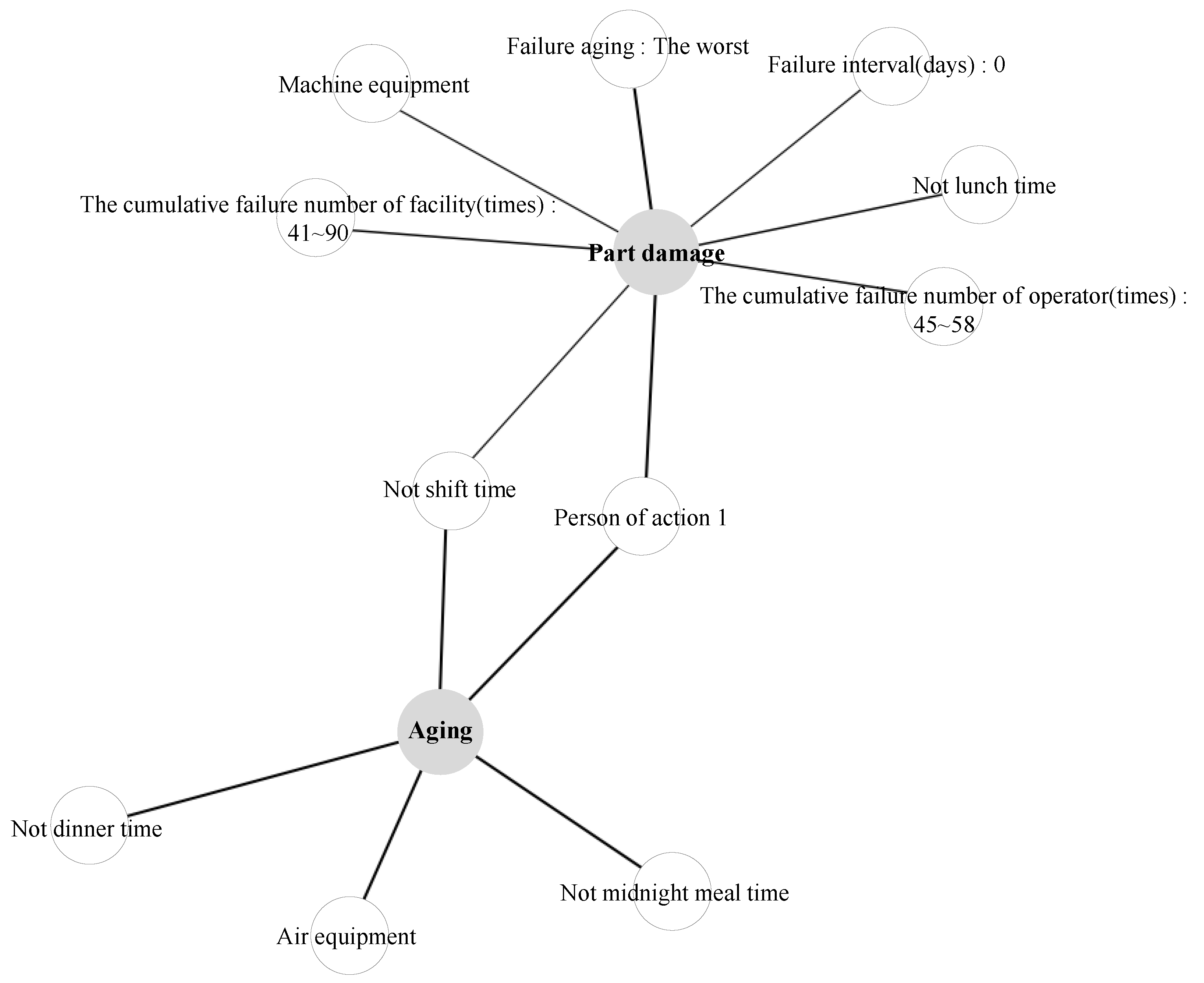
5. Real-World Facility Failure Scenario
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, S.; Rho, S.H.; Lee, S.; Lee, J.; Lee, S.W.; Lim, D.; Jeong, W. Implementation of an Automated Manufacturing Process for Smart Clothing: The Case Study of a Smart Sports Bra. Processes 2021, 9, 289. [Google Scholar] [CrossRef]
- Lu, Y.W.; Hsu, C.Y.; Huang, K.C. An Autoencoder Gated Recurrent Unit for Remaining Useful Life Prediction. Processes 2020, 8, 1155. [Google Scholar] [CrossRef]
- Moyne, J.; Iskandar, J. Big Data Analytics for Smart Manufacturing: Case Studies in Semiconductor Manufacturing. Processes 2017, 5, 39. [Google Scholar] [CrossRef]
- O’Donovan, P.; Bruton, K.; O’Sullivan, D.T.J. Case study: The implementation of a data-driven industrial analytics methodology and platform for smart manufacturing. Int. J. Progn. Health Manag. 2016, 7, 1–22. [Google Scholar]
- Wang, J.; Ma, Y.; Zhang, L.; Gao, R.X.; Wu, D. Deep learning for smart manufacturing: Methods and applications. J. Manuf. Syst. 2018, 48, 144–156. [Google Scholar] [CrossRef]
- Ding, K.; Chan, F.; Zhang, X.; Zhou, G.; Zhang, F. Defining a digital twin-based cyber-physical production system for autonomous manufacturing in smart shop floors. Int. J. Prod. Res. 2019, 57, 1–20. [Google Scholar] [CrossRef]
- Machado, C.G.; Winroth, M.P.; Silva, E.H. Sustainable manufacturing in Industry 4.0: An emerging research agenda. Int. J. Prod. Res. 2019, 58, 1–23. [Google Scholar] [CrossRef]
- Tao, F.; Qi, Q.; Liu, A.; Kusiak, A. Data-driven smart manufacturing. J. Adv. Manuf. Syst. 2018, 48, 157–169. [Google Scholar] [CrossRef]
- Salierno, G.; Cabri, G.; Leonardi, L. Different perspectives of a factory of the future: An overview. Adv. Res. Syst. Eng. Workshops 2019, 349, 107–119. [Google Scholar]
- Julsereewong, A.; Thepmanee, T. Safety instrumented system design in consideration of cost-benefit analysis: A case study of tail gas treating process. In Proceedings of the 17th International Conference on Control, Automation and Systems (ICCAS), Jeju, Korea, 18–21 October 2017; pp. 637–642. [Google Scholar]
- Muller, G.; Andersen, J.H. Factory production line as SoS; a case study in airplane engine component manufacturing. In Proceedings of the 10th System of Systems Engineering Conference (SoSE), Antonio, TX, USA, 17–20 May 2015; pp. 42–46. [Google Scholar]
- Li, Z.; Li, J.; Wang, Y.; Wang, K. A deep learning approach for anomaly detection based on SAE and LSTM in mechanical equipment. Int. J. Adv. Manuf. Technol. 2019, 103, 499–510. [Google Scholar] [CrossRef]
- Li, G.; Wang, X.; Yang, A.; Rong, M.; Yang, K. Failure prognosis of high voltage circuit breakers with temporal latent Dirichlet allocation. Energies 2017, 10, 1913. [Google Scholar] [CrossRef]
- Ai, P.; Yue, Z.X. A framework for processing water resources big data and application. Appl. Mech. Mater. 2014, 519, 3–8. [Google Scholar] [CrossRef]
- Ma, J.; Ni, S.; Xie, W.; Dong, W. Deep auto-encoder observer multiple-model fast aircraft actuator fault diagnosis algorithm. Int. J. Control Autom. Syst. 2017, 15, 1641–1650. [Google Scholar] [CrossRef]
- Liu, G.; Bao, H.; Han, B. A stacked autoencoder-based deep neural network for achieving Gearbox fault diagnosis. Math. Probl. Eng. 2018, 2018. [Google Scholar] [CrossRef]
- Yang, C.; Su, X.; Yuan, H.; Liu, Y.; Zhang, W.; Wang, X. Automatic diagnosis technology of lightning fault in transmission line. In Proceedings of the 2nd International Conference on Electrical, Control and Automation Engineering (ECAE 2017), Xiamen, China, 24–25 December 2017. [Google Scholar]
- Bai, Z.; Sun, G.; Zang, H.; Zhang, M.; Shen, P.; Liu, Y.; Wei, Z. Identification technology of grid monitoring alarm event based on natural language processing and deep learning in China. Energies 2019, 12, 3258. [Google Scholar] [CrossRef]
- Woojin. Woojin Ltd. Available online: http://www.ngkntk.co.kr/ (accessed on 24 March 2021).
- Jing, L.; Zhou, L.; Ng, M.K.; Huang, J.Z. Ontology-based distance measure for text clustering. In Proceedings of the SIAM SDM Workshop on Text Mining, Bethesda, MD, USA, 20–22 April 2006; pp. 1–8. [Google Scholar]
- Dhillon, I.S.; Mallela, S.; Kumar, R. A divisive information-theoretic feature clustering algorithm for text classification. J. Mach. Learn. Res. 2003, 3, 1265–1287. [Google Scholar]
- Martinc, M.; Škrlj, B.; Pollak, S. TNT-KID: Transformer-based neural tagger for keyword identification. arXiv 2020, arXiv:2003.09166. [Google Scholar]
- Wang, X.; Zhang, Y.; Wang, L.; Wang, J.; Lu, J. Maintenance grouping optimization with system multi-level information based on BN lifetime prediction model. J. Manuf. Syst. 2019, 50, 201–211. [Google Scholar] [CrossRef]
- Ragab, A.; Yacout, S.; Ouali, M.S.; Osman, H. Prognostics of multiple failure modes in rotating machinery using a pattern-based classifier and cumulative incidence functions. J. Intell. Manuf. 2019, 30, 255–274. [Google Scholar] [CrossRef]
- Guest, O.; Kanayet, F.J.; Love, B.C. Cognitive capacity limits and electoral districting. J. Comput. Soc. Sci. 2019, 2, 119–131. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Xiong, J.; Liang, Q. Fault diagnosis of rotation machinery based on support vector machine optimized by quantum genetic algorithm. IEEE Access 2018, 6, 33583–33588. [Google Scholar] [CrossRef]
- Ge, C.; Zhu, Y.; Di, Y.; Dong, Z. Equipment residual useful life prediction oriented parallel simulation framework. Theory Methodol. Tools Appl. Model. Simul. Complex Syst. 2016, 643, 377–386. [Google Scholar]
- Wang, H.; Cao, J.; Lin, D. Deep analysis of power equipment defect based on semantic framework text mining technology. CSEE J. Power Energy (Early Access) 2019, 1–8. [Google Scholar] [CrossRef]
- Adedigba, S.A.; Khan, F.; Yang, M. Dynamic failure analysis of process systems using neural networks. Process Saf. Environ. Prot. 2017, 111, 529–543. [Google Scholar] [CrossRef]
- Lindemann, B.; Fesenmayr, F.; Jazdi, N.; Weyrich, M. Anomaly detection in discrete manufacturing using self-learning approaches. Procedia CIRP 2019, 79, 313–318. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, P.; Yan, R.; Gao, R.X. Long short-term memory for machine remaining life prediction. J. Manuf. Syst. 2018, 48, 78–86. [Google Scholar] [CrossRef]
- Oliveira, J.C.M.; Pontes, K.V.; Sartori, I.; Embiruçu, M. Fault detection and diagnosis in dynamic systems using weightless neural networks. Expert Syst. Appl. 2017, 84, 200–219. [Google Scholar] [CrossRef]
- Chelladurai, H.; Jain, V.; Vyas, N. Development of neural network model to predict flank wear and chipping failure. J. Adv. Manuf. Syst. 2019, 18, 237–254. [Google Scholar] [CrossRef]
- Jeong, S.P.; Sohn, J.W. Prediction of bolt fastening state using structural vibration signals. J. Mech. Sci. Technol. 2019, 33, 3963–3970. [Google Scholar] [CrossRef]
- Liu, R.; Kothuru, A.; Zhang, S. Calibration-based tool condition monitoring for repetitive machining operations. J. Manuf. Syst. 2020, 54, 285–293. [Google Scholar] [CrossRef]
- Li, C.; Zhang, W.; Peng, G.; Liu, S. Bearing fault diagnosis using fully-connected winner-take-all autoencoder. IEEE Access 2018, 6, 6103–6115. [Google Scholar] [CrossRef]
- Niu, Q. Discussion on fault diagnosis of and solution seeking for rolling bearing based on deep learning. Acad. J. Manuf. Eng. 2018, 16, 58–64. [Google Scholar]
- Qian, W.; Li, S.; Wang, J. A new transfer learning method and its application on rotating machine fault diagnosis under variant working conditions. IEEE Access 2018, 6, 69907–69917. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Lin, Y.; Li, X. A novel method for intelligent fault diagnosis of rolling bearings using ensemble deep auto-encoders. Mech. Syst. Signal Process. 2018, 102, 278–297. [Google Scholar] [CrossRef]
- Wang, J.; Wang, K.; Wang, Y.; Huang, Z.; Xue, R. Deep Boltzmann machine based condition prediction for smart manufacturing. J. Ambient Intell. Human. Comput. 2019, 10, 851–861. [Google Scholar] [CrossRef]
- Ren, L.; Sun, Y.; Cui, J.; Zhang, L. Bearing remaining useful life prediction based on deep autoencoder and deep neural networks. J. Manuf. Syst. 2018, 48, 71–77. [Google Scholar] [CrossRef]
- Sun, C.; Ma, M.; Zhao, Z.; Chen, X. Sparse deep stacking network for fault diagnosis of motor. IEEE Trans. Ind. Informat. 2018, 14, 3261–3270. [Google Scholar] [CrossRef]
- Zhao, M.; Zhong, S.; Fu, X.; Tang, B.; Pecht, M. Deep residual shrinkage networks for fault diagnosis. IEEE Trans. Ind. Informat. 2020, 16, 4681–4690. [Google Scholar] [CrossRef]
- Peng, D.; Wang, H.; Liu, Z.; Zhang, W.; Zuo, M.J.; Chen, J. Multibranch and multiscale CNN for fault diagnosis of wheelset bearings under strong noise and variable load condition. IEEE Trans. Ind. Informat. 2020, 16, 4949–4960. [Google Scholar] [CrossRef]
- Hong, J.; Wang, Z.; Yao, Y. Fault prognosis of battery system based on accurate voltage abnormity prognosis using long short-term memory neural networks. Appl. Energy 2019, 251, 1–14. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, B.; Zhang, W.; Lu, R.; Wada, S.; Zhang, Y. Real-time penetration state monitoring using convolutional neural network for laser welding of tailor rolled blanks. J. Manuf. Syst. 2020, 54, 348–360. [Google Scholar] [CrossRef]
- Zhao, H.; Sun, S.; Jin, B. Sequential fault diagnosis based on lstm neural networks. IEEE Access 2018, 6, 12929–12939. [Google Scholar] [CrossRef]
- Kumar, A.; Shankar, R.; Choudhary, A.; Thakur, L.S. A big data MapReduce framework for fault diagnosis in cloud-based manufacturing. Int. J. Prod. Res. 2016, 54, 7060–7073. [Google Scholar] [CrossRef]
- NAVER. NAVER Encyclopedia of Knowledge. Available online: https://terms.naver.com/ (accessed on 24 March 2021).
- Isa, D.; Lee, L.; Kallimani, V.; RajKumar, R. Text document preprocessing with the bayes formula for classification using the support vector machine. IEEE Trans. Knowl. Data Eng. 2008, 20, 1264–1272. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Harris, D.; Harris, S. Digital Design and Computer Architecture; Morgan Kaufmann Publishers: Burlington, MA, USA, 2010. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar]
- Řehůřek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010; pp. 45–50. [Google Scholar]
- Google. Google News Dataset. Available online: https://code.google.com/archive/p/word2vec/ (accessed on 24 March 2021).
- De Hoon, M.J.; Imoto, S.; Nolan, J.; Miyano, S. Open source clustering software. Bioinformatics 2004, 20, 1453–1454. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Yin, Y. Mining frequent patterns without candidate generation. ACM SIGMOD Rec. 2000, 29. [Google Scholar] [CrossRef]
- Fournier-Viger, P.; Lin, J.C.W.; Gomariz, A.; Gueniche, T.; Soltani, A.; Deng, Z.; Lam, H.T. The SPMF open-source data mining library version 2. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2016; pp. 36–40. [Google Scholar]
- SPMF. SPMF Open-Source Software Specialized in Pattern Mining. Available online: https://www.philippe-fournier-viger.com/spmf/ (accessed on 24 March 2021).
- Rekabsaz, N.; Bierig, R.; Lupu, M.; Hanbury, A. Toward optimized multimodal concept indexing. In Proceedings of the 2015 International KEYSTONE Conference on Semantic Keyword-Based Search on Structured Data Sources, Coimbra, Portugal, 8–9 September 2015; pp. 141–152. [Google Scholar]
- Grubesic, T.H. On the application of fuzzy clustering for crime hot spot detection. J. Quant. Criminol. 2006, 22, 77–105. [Google Scholar] [CrossRef]
- MacQueen, J.B. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Hubert, L.; Arabie, P. Comparing partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]
- Rand, W. Objective criteria for the evaluation of clustering methods. J. Am. Stat. Assoc. 2012, 66, 846–850. [Google Scholar] [CrossRef]
- Rosenberg, A.; Hirschberg, J. V-Measure: A conditional entropy-based external cluster evaluation measure. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL); Association for Computational Linguistics: Prague, Czech Republic, 2007; pp. 410–420. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Data Category | Failure Category | Approach | Method | Reference |
|---|---|---|---|---|---|
| Sensor signal data | Pressure | Not used | Failure prediction | Artificial neural networks (ANN) | Adedigba et al., 2017 [29] |
| Failure diagnosis | Deep auto-encoder | Ma et al., 2017 [15] | |||
| Long short-term memory (LSTM) | Lindemann et al., 2019 [30] | ||||
| Remaining useful life (RUL) prediction | Bi-directional LSTM | Zhang et al., 2018 [31] | |||
| Temperature | Not used | Failure diagnosis | ANN | Adedigba et al., 2017 [29] | |
| Weightless neural networks | Oliveira et al., 2017 [32] | ||||
| RUL prediction | Bi-directional LSTM | Zhang et al., 2018 [31] | |||
| Vibration | Not used | Failure prediction | ANN | Chelladurai et al., 2019 [33] | |
| K-nearest neighbors | Jeong and Sohn, 2019 [34] | ||||
| Similarity measures | Liu et al., 2020 [35] | ||||
| Failure diagnosis | Auto-encoder | Li et al., 2018 [36] | |||
| Stacked auto-encoder | Liu et al., 2018 [16] | ||||
| Convolutional neural networks (CNN) | Niu, 2018 [37] | ||||
| High-order Kullback-Leibler | Qian et al., 2018 [38] | ||||
| Ensemble deep auto-encoder | Shao et al., 2018 [39] | ||||
| Support vector machine (SVM) | Zhu et al., 2018 [26] | ||||
| Stacked auto-encoder and LSTM | Li et al., 2019 [12] | ||||
| Deep neural networks (DNN) | Wang et al., 2019 [40] | ||||
| RUL prediction | Auto-encoder and DNN | Ren et al., 2018 [41] | |||
| Considered | Failure diagnosis | Sparse deep stacking networks | Sun et al., 2018 [42] | ||
| Deep residual shrinkage networks | Zhao et al., 2020 [43] | ||||
| Multibranch and multiscale CNN | Peng et al., 2020 [44] | ||||
| Voltage | Not used | Failure diagnosis | LSTM | Hong et al., 2019 [45] | |
| Non-sensor signal data | Image | Not used | Failure prediction | CNN | Zhang et al., 2020 [46] |
| Failure diagnosis | CNN | Niu, 2018 [37] | |||
| RUL prediction | Deep auto-encoder and DNN | Ren et al., 2018 [41] | |||
| Text | Not used | Relevance analysis | FP-growth | Wang et al., 2019 [28] | |
| Considered | Failure prediction | Sequence to sequence model and SVM | Li et al., 2017 [13] | ||
| LSTM | Zhao et al., 2018 [47] | ||||
| LSTM and CNN | Bai et al., 2019 [18] |
| Step | Sub-Step | Approach |
|---|---|---|
| Phrase extraction | Constructing the word usage-based dictionary | Defining four word usages |
| Extending the word usage-based dictionary with reference data | Collecting the reference data by crawling the online dictionary and by interviewing experts | |
| Phrase extraction using the word usage-based dictionary to generate facility failure logs (FFLs) | Tagging words in text data using the dictionary and extracting phrases using the tagged words | |
| Failure categorization | FFLs vectorization | Using phrase2vec for the extracted phrases and generating one-hot vectors for the categorical data |
| Failure categorization with the vectorized FFLs | Using weighted k-means clustering | |
| Data extension | Generating extended facility failure logs (EFFLs) | Mapping FFLs, failure categories, and environment data |
| Failure pattern mining | Mining frequent failure patterns and constructing failure pattern database | Deriving the frequent failure patterns using FP-growth algorithm |
| Division | Example 1 | Example 2 | ||
|---|---|---|---|---|
| Input | Parts wear due to excessive rubbing | Operation of the equipment has stopped due to the introduction of white foreign matter into the product protector part | ||
| Dictionary | WD | Parts wear, Excessive rubbing | WD | Introduction of white foreign matter into the product protector part |
| ST | - | ST | - | |
| E | - | E | Operation of the equipment has stopped | |
| SE | due to | SE | due to | |
| Output | Parts wear | Introduction of white foreign matter into the product protector part | ||
| Excessive rubbing | ||||
| No. | Facility | Phenomenon | Cause | Location | Part | Comment |
|---|---|---|---|---|---|---|
| 1 | OZ Applicator 3 | Incorrect operation | Unknown cause | Electric | Sensor | Shutdown due to battery discharge |
| 2 | OZ Checker 4 | Unknown phenomenon | Component aging | Machine | Heaters | Elema is broken since the heater is old |
| 3 | OZ Checker 3 | Unknown phenomenon | Foreign substance | Electric | Wiring | Measuring section wire disconnection. Result: Does not work |
| Factor | Type | The Number of Categories | Category Examples |
|---|---|---|---|
| Facility | Category | 25 | OZ Machine 1, OZ Checker 4, OZ Applicator 1, OZ Applicator 3, OZ Granulator 1 |
| Phenomenon | 14 | Poor connection, Worn parts, Malfunction, Component damage, Unknown phenomenon | |
| Cause | 17 | Overload, Foreign substance, Component aging, Process abnormality, Unknown cause | |
| Location | 5 | Hydraulic equipment, Air equipment, Mechanical equipment, Electrical equipment, Quality abnormality | |
| Part | 19 | Cylinder, Wiring, PLC, Sensor, Heator | |
| Comment | Text | - | - |
| Factor | Weights | ||
|---|---|---|---|
| Given Equally | Given by Experts | Emphasizing Phrases | |
| Facility | 1.0 | 3.0 | 2.0 |
| Phenomenon | 1.0 | 2.8 | 1.5 |
| Cause | 1.0 | 2.5 | 1.5 |
| Location | 1.0 | 2.0 | 2.0 |
| Part | 1.0 | 1.5 | 2.0 |
| Extracted phrases | 1.0 | 0.8 | 3.0 |
| Comment | Extracted phrases |
|---|---|
| Cause: Cylinder sensor error Symptom: Cylinder malfunction Action: Replace sensor | Cylinder sensor failure Cylinder malfunction |
| Symptom: Elema heater current not flowing Cause: Breakdown of Paracon | Elema heater current not flowing Breakdown of Paracon |
| Abnormal operation of old cylinder No. 7 | Abnormal operation Old cylinder No. 7 |
| Failure in supply cylinder of heat unit | Failure in supply cylinder of heat unit |
| Straight line stopped due to compressor failure | Compressor failure |
| Detection of a faulty heater due to breakage Elema | Breakage Elema |
| Replacement of heater due to Impurity No. 1 disconnection | Impurity No. 1 disconnection |
| Rule | Factor |
|---|---|
| Antecedent | Facility |
| Location | |
| Person of action | |
| Action time(minutes) | |
| Operator | |
| Operator proficiency | |
| Shift time or not | |
| Time | |
| Morning or afternoon or night | |
| Lunch time or not | |
| Dinner time or not | |
| Midnight mealtime or not | |
| Day of the week | |
| Season | |
| Average temperature (C) | |
| The cumulative failure number of facility(times) | |
| Failure interval(days) | |
| The cumulative failure number of operator(times) | |
| The number of monthly failures | |
| Degree of facility aging | |
| Consequent | Failure category |
| Antecedents | Consequent | Support | Confidence |
|---|---|---|---|
| “OZ Machine 1”, “Person of action 1”, “Air equipment”, “Not shift time”, “Not lunch time”, “Not dinner time”, “Not midnight mealtime” | Aging | 0.29 | 0.97 |
| “OZ Machine 11”, “Machine equipment”, “Person of action 1”, “Not shift time”, “Not lunch time”, “Facility aging: The worst” | Part damage | 0.25 | 0.76 |
| “OZ Machine 4”, “Electronic equipment”, “Operator proficiency: B”, “Not lunch time”, “Not dinner time”, “Failure interval: 0 (days)” | Cylinder breakage | 0.30 | 0.63 |
| Antecedents | Consequent | Support | Confidence |
|---|---|---|---|
| Failure location: Electronic equipment Not lunch time Not midnight mealtime | Aging | 0.23 | 0.37 |
| Location: Electronic equipment Not lunch time Failure interval (days): 3∼5 Facility aging: Good | Center shift | 0.26 | 0.34 |
| Location: Electronic equipment Not lunch time Not dinner time Failure interval (days): 0 | Malfunction | 0.29 | 0.19 |
| Location: Machine equipment Not shift time Not lunch time Not dinner time The cumulative failure number of operator (times): 121∼180 | Substance | 0.20 | 0.12 |
| Antecedents | Consequent | Support | Confidence |
|---|---|---|---|
| Failure location: Air equipment Not shift time Not dinner time Not midnight mealtime Person of action 1 | Aging | 0.39 | 0.97 |
| Location: Machine equipment Not shift time Not lunch time Facility aging: Good | Part damage | 0.35 | 0.76 |
| Location: Machine equipment Not lunch time The cumulative failure number of operator (times): 45∼58 The cumulative failure number of facility (times): 41∼90 | Part damage | 0.35 | 0.70 |
| Location: Machine equipment Not shift time Failure interval (days): 0 | Part damage | 0.45 | 0.56 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Choi, E.; Choi, Y. Real-World Failure Prevention Framework for Manufacturing Facilities Using Text Data. Processes 2021, 9, 676. https://doi.org/10.3390/pr9040676
Park J, Choi E, Choi Y. Real-World Failure Prevention Framework for Manufacturing Facilities Using Text Data. Processes. 2021; 9(4):676. https://doi.org/10.3390/pr9040676
Chicago/Turabian StylePark, Jonghyuk, Eunyoung Choi, and Yerim Choi. 2021. "Real-World Failure Prevention Framework for Manufacturing Facilities Using Text Data" Processes 9, no. 4: 676. https://doi.org/10.3390/pr9040676
APA StylePark, J., Choi, E., & Choi, Y. (2021). Real-World Failure Prevention Framework for Manufacturing Facilities Using Text Data. Processes, 9(4), 676. https://doi.org/10.3390/pr9040676