Modeling the Spread of Epidemics Based on Cellular Automata




Abstract
1. Introduction
2. Methods
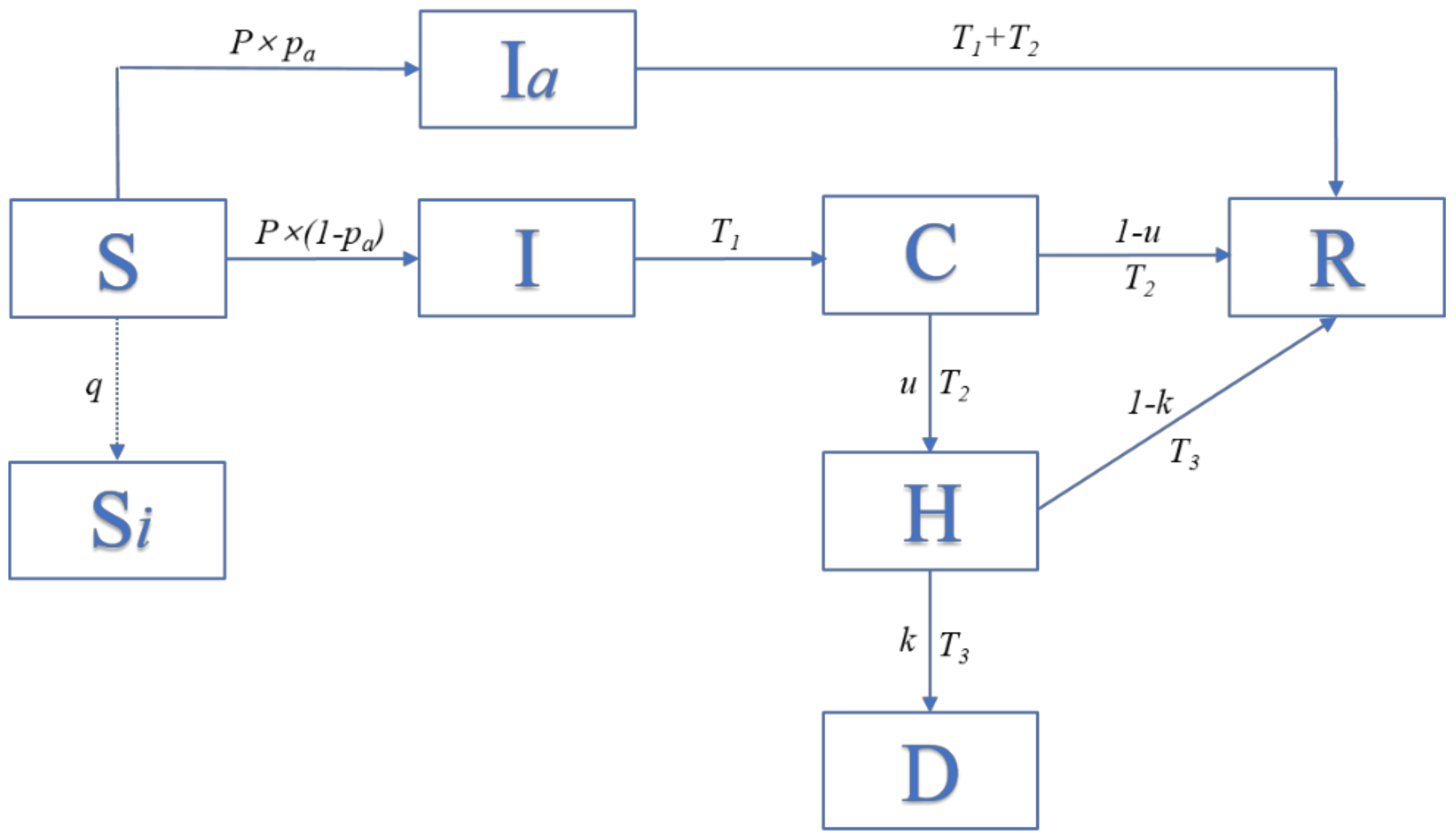
2.1. The Individual States in the CA Model
2.2. Individual Heterogeneity and the State Transition Rules
- (1)
- When X(i, j, t) = 0, the possibility of being infected at time t can be calculated as mentioned above, and then, whether the individual transitions to being infected (X(i, j, t) = 3 or 8) is determined by both itself and its neighbors. If X(i, j, t) is changed from 0 to 3, then, T1(i, j, t) will be changed from 0 to 1, and the record of the infected duration of this individual begins. If X(i, j, t) is changed from 0 to 8, then T4(i, j, t) will be changed from 0 to 1, and the record of the asymptomatic infected duration of this individual begins;
- (2)
- When X(i, j, t) = 1 or X(i, j, t) = 2, which indicates empty positions and self-isolated individuals, respectively, their value will be constant;
- (3)
- When X(i, j, t) = 3 and T1(i, j, t) exceeds T1, the individual will be confirmed, and X (i, j, t) will become 4; then, T2 (i, j, t) will change from 0 to 1 and begin to record the confirmed duration, and T1(i, j, t) will return to 0;
- (4)
- When X(i, j, t) = 8, and T4 (i, j, t) exceeds T1 + T2, the individual will recover and X(i, j, t) will become 5; T4 (i, j, t) will return to 0;
- (5)
- When X(i, j, t) = 4, T2 (i, j, t) reaches T2, and the individual will be hospitalized (X(i, j, t) = 6). After obtaining hospital care, the patient may recover (X(i, j, t) = 5) with the probability of u, while probability 1 − u becomes exacerbated, the set value of u in different stage is shown in Table A5 in Appendix A;
- (6)
- When X(i, j, t) = 6, and T3(i, j, t) reaches T3, the infection becomes fatal (X(i, j, t) = 7) with the probability of k; otherwise, patients will recover after treatment (X (i, j, t) = 5), the set value of k in different stage is shown in Table A5 in Appendix A.
3. Simulation Results and Discussion
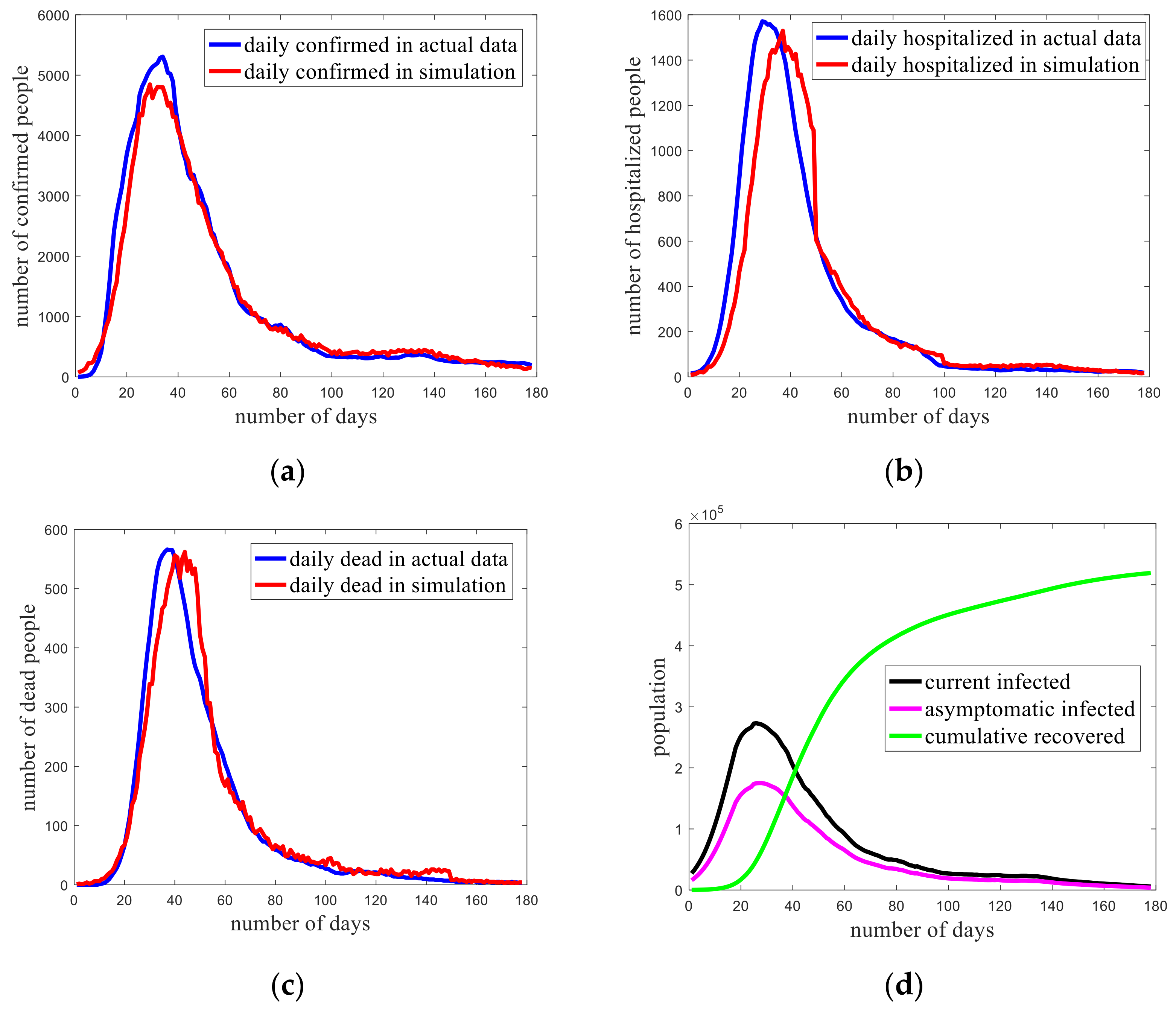
3.1. Model Verification
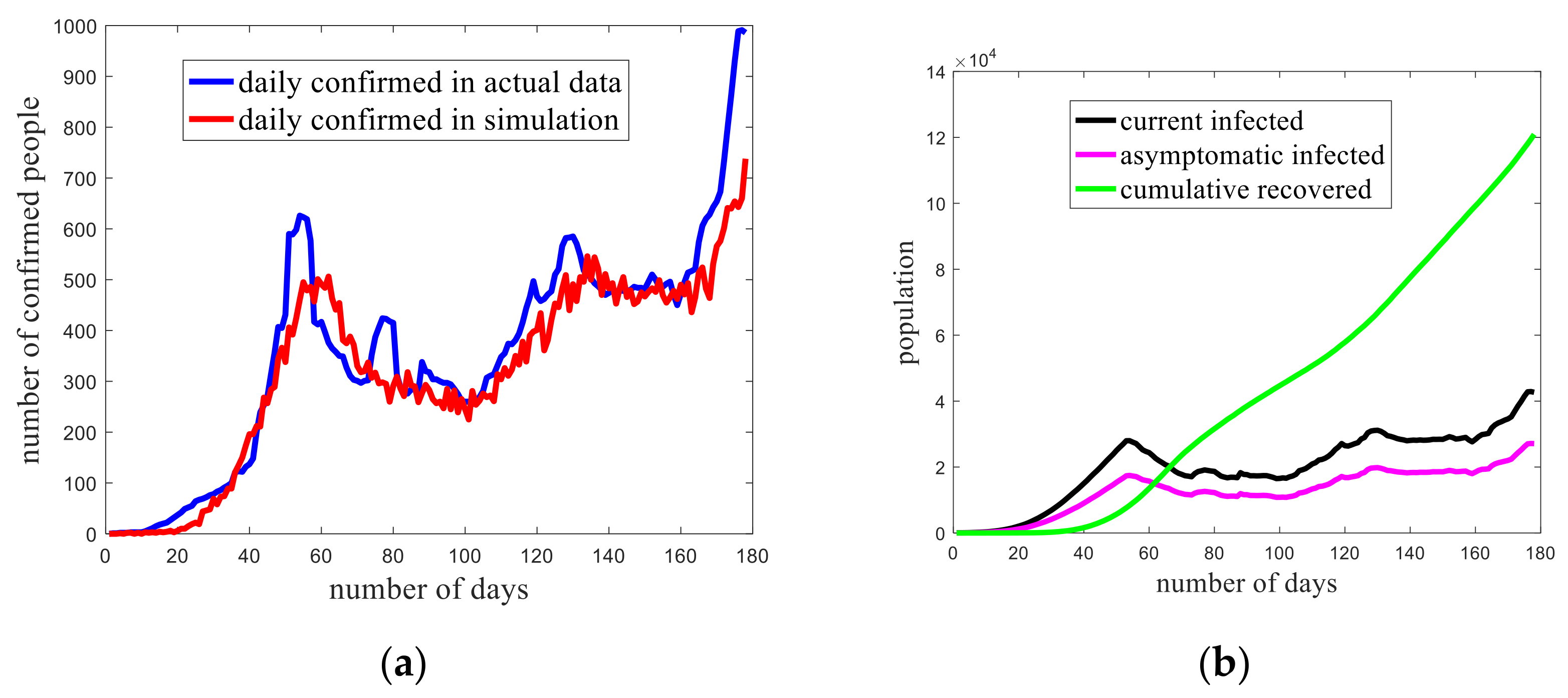
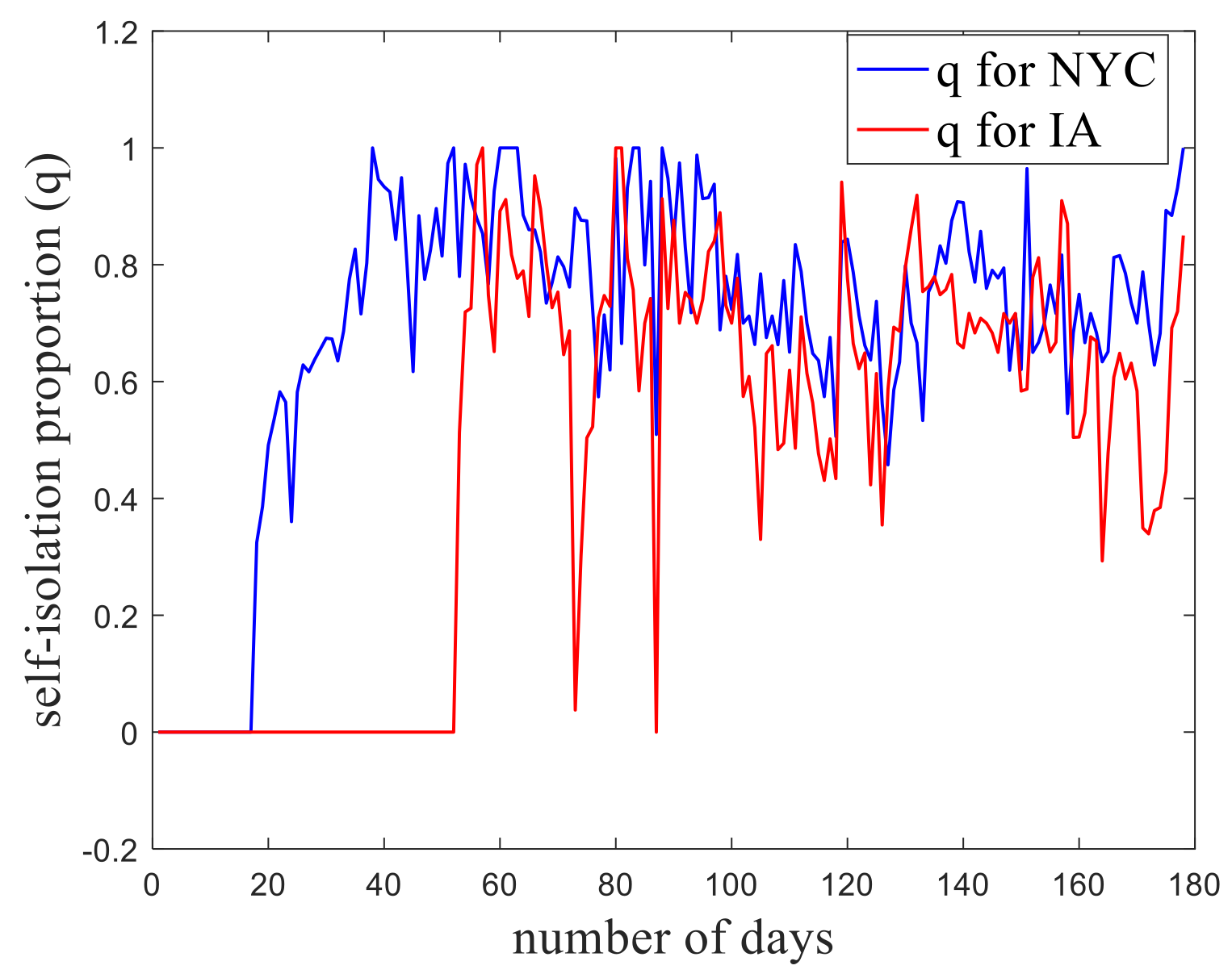
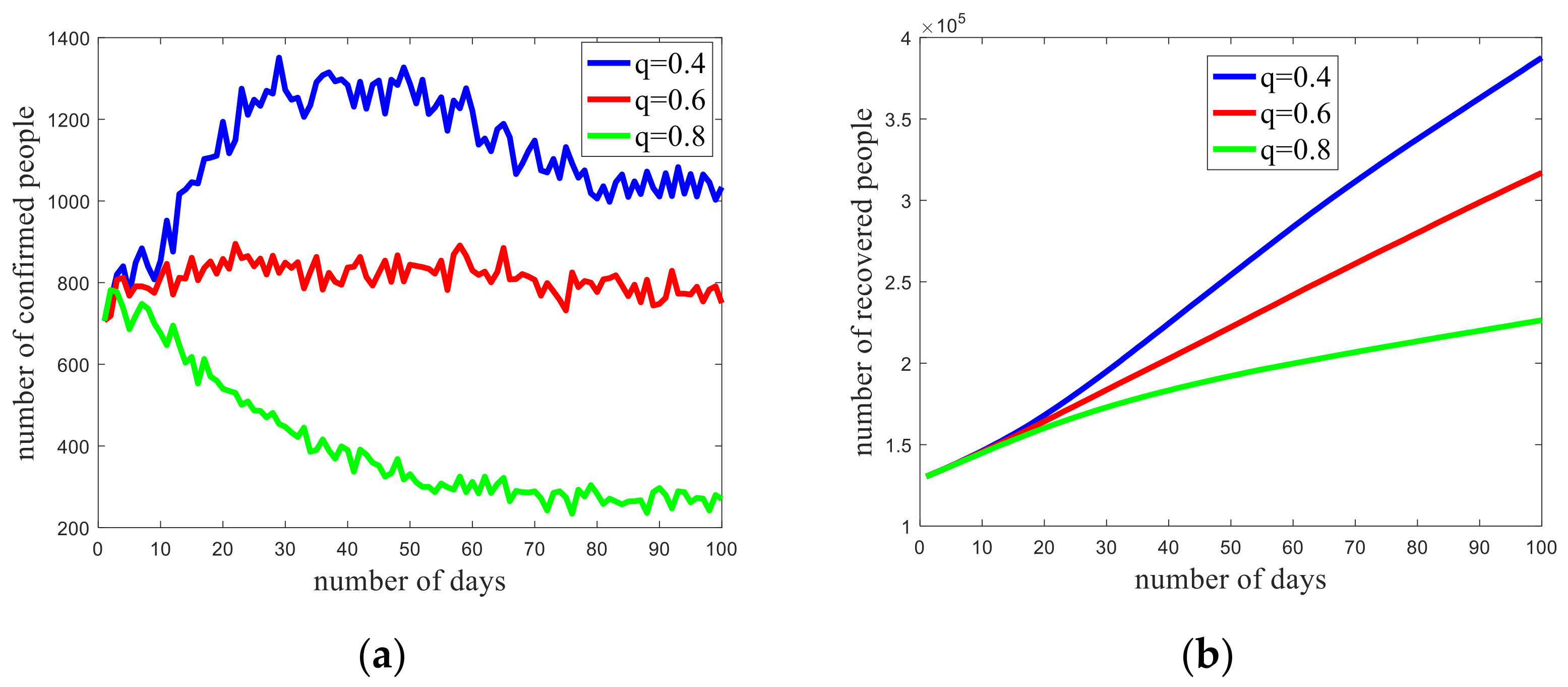
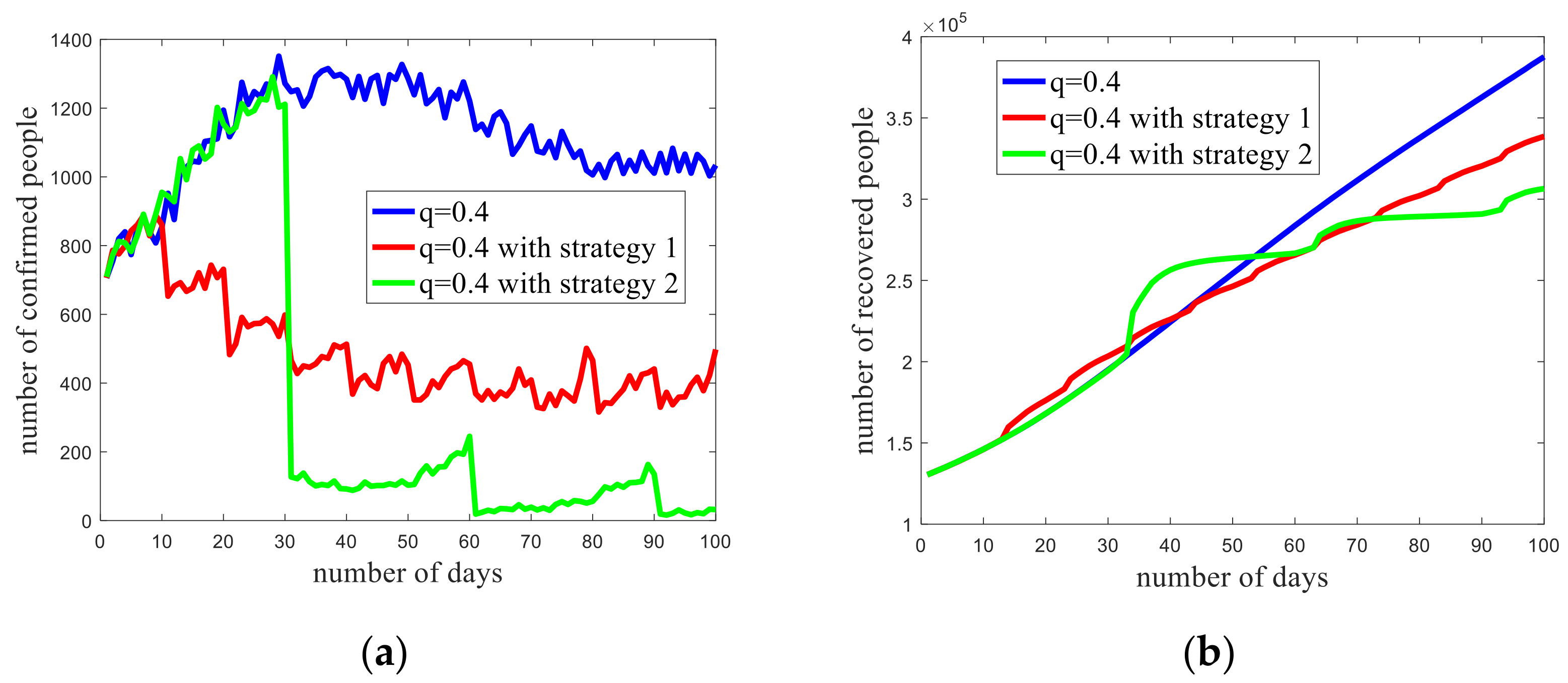
3.2. Trend Prediction of the Epidemic in Iowa
- Test strategy 1: interval of 10 days, 30 percent of individuals are tested;
- Test strategy 2: interval of 30 days, 90 percent of individuals are tested.
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Value |
|---|---|---|
| n | Region size | 1000.000 |
| α | Vacancy ratio | 0.200 |
| ε | Initial number of infected (on 15 February) | 250.000 |
| T1 | Period from infected to confirmed | 10.000 |
| T2 | Period from confirmed to hospitalized | 4.000 |
| T3 | Period from hospitalized to recovered | 4.000 |
| m | Moving proportion | 0.160 |
| L | Maximum moving step length | 10.000 |
| gmale | Male proportion | 0.477 |
| gfemale | Female proportion | 0.523 |
| gage > 60 | Proportion of the elderly | 0.170 |
| gage < 60 | Proportion of the younger | 0.830 |
| Symbol | Description | Value |
|---|---|---|
| n | Region size | 1000.000 |
| α | Vacancy ratio | 0.200 |
| ε | Initial number of infected (on 29 February) | 20.000 |
| T1 | Period from infected to confirmed | 10.000 |
| T2 | Period from confirmed to hospitalized | 4.000 |
| T3 | Period from hospitalized to recovered | 4.000 |
| m | Moving proportion | 0.160 |
| L | Maximum moving step length | 10.000 |
| gmale | Male proportion | 0.495 |
| gfemale | Female proportion | 0.505 |
| gage > 60 | Proportion of the elderly | 0.240 |
| gage < 60 | Proportion of the younger | 0.760 |
| Age Range | 0–4 | 5–14 | 15–29 | 30–59 | 60–69 | 70–79 | 80– |
|---|---|---|---|---|---|---|---|
| pa | 0.95 | 0.8 | 0.7 | 0.5 | 0.4 | 0.3 | 0.2 |
| Immune Coefficient | Description | Value |
|---|---|---|
| fmale | Immunity coefficient for male individuals | 0.8059 |
| ffemale | Immunity coefficient for female individuals | 1.0000 |
| fage > 60 | Immunity coefficient for old individuals | 0.7673 |
| fage < 60 | Immunity coefficient for young individuals | 1.0000 |
| Data Range | u | k |
|---|---|---|
| 6 March to 23 April | 0.31 | 0.38 |
| 24 April to 12 June | 0.18 | 0.33 |
| 13 June to 1 August | 0.12 | 0.42 |
| after 1 August | 0.11 | 0.17 |
References
- The World Health Report 2013. Available online: https://www.who.int/publications/i/item/9789240690837 (accessed on 20 October 2020).
- Andrews, J.R.; Basu, S. Transmission dynamics and control of cholera in Haiti: An epidemic model. Lancet 2011, 377, 1248–1255. [Google Scholar] [CrossRef]
- Cooper, B.S.; Lipsitch, M. The analysis of hospital infection data using hidden Markov models. Biostatistics 2004, 5, 223–237. [Google Scholar] [CrossRef] [PubMed]
- Brossette, S.E.; Sprague, A.P.; Hardin, J.M.; Waites, K.B.; Jones, W.T.; Moser, S.A. Association Rules and Data Mining in Hospital Infection Control and Public Health Surveillance. J. Am. Med. Inform. Assoc. 1998, 5, 373–381. [Google Scholar] [CrossRef] [PubMed]
- Anderson, S.; Harper, L.M.; Dionne-Odom, J.; Halle-Ekane, G.; Tita, A.T.N. A decision analytic model for prevention of hepatitis B virus infection in Sub-Saharan Africa using birth-dose vaccination. Int. J. Gynecol. Obstet. 2018, 141, 126–132. [Google Scholar] [CrossRef] [PubMed]
- Kermack, W.O.; McKendrick, A.G. A contribution to the mathematical theory of epidemics. Proc. R. Soc. Lond. Ser. A Math. Phys. Sci. 1927, 115, 700–721. [Google Scholar]
- Duque, D.; Morton, D.; Singh, B.; Du, Z.; Pasco, R.; Meyers, L.A. Timing social distancing to avert unmanageable COVID-19 hospital surges. Proc. Natl. Acad. Sci. USA 2020, 117, 19873–19878. [Google Scholar] [CrossRef]
- Biswas, H.A.; Paiva, L.T.; De Pinho, M.D.R. A SEIR model for control of infectious diseases with constraints. Math. Biosci. Eng. 2014, 11, 761–784. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, T. Epidemic spreading of an SEIRS model in scale-free networks. Commun. Nonlinear Sci. Numer. Simul. 2011, 16, 3375–3384. [Google Scholar] [CrossRef]
- Naresh, R.; Sharma, D.; Tripathi, A. Modelling the effect of tuberculosis on the spread of HIV infection in a population with density-dependent birth and death rate. Math. Comput. Model. 2009, 50, 1154–1166. [Google Scholar] [CrossRef]
- Srivastava, P.K.; Banerjee, M.; Chandra, P. A Primary Infection Model for HIV and Immune response with Two Discrete Time Delays. Differ. Equ. Dyn. Syst. 2010, 18, 385–399. [Google Scholar] [CrossRef]
- Simons, E.; Ferrari, M.; Fricks, J.; Wannemuehler, K.; Anand, A.; Burton, A.; Strebel, P. Assessment of the 2010 global measles mortality reduction goal: Results from a model of surveillance data. Lancet 2012, 379, 2173–2178. [Google Scholar] [CrossRef]
- Watanabe, T.; Bartrand, T.A.; Weir, M.H.; Omura, T.; Haas, C.N. Development of a Dose-Response Model for SARS Coronavirus. Risk Anal. 2010, 30, 1129–1138. [Google Scholar] [CrossRef] [PubMed]
- Kerr, C.C.; Stuart, R.M.; Gray, R.T.; Shattock, A.J.; Fraser-Hurt, N.; Benedikt, C.; Haacker, M.; Berdnikov, M.; Mahmood, A.M.; Jaber, S.A.; et al. Optima. JAIDS J. Acquir. Immune Defic. Syndr. 2015, 69, 365–376. [Google Scholar] [CrossRef] [PubMed]
- De La Sen, M.; Alonso-Quesada, S. Vaccination strategies based on feedback control techniques for a general SEIR-epidemic model. Appl. Math. Comput. 2011, 218, 3888–3904. [Google Scholar] [CrossRef]
- Sun, C.; Lin, Y.; Tang, S. Global stability for an special SEIR epidemic model with nonlinear incidence rates. Chaos Solitons Fractals 2007, 33, 290–297. [Google Scholar] [CrossRef]
- Elaiw, A.M.; Alshamrani, N.H. Global stability of a delayed humoral immunity virus dynamics model with nonlinear incidence and infected cells removal rates. Int. J. Dyn. Control. 2015, 5, 381–393. [Google Scholar] [CrossRef]
- Dezső, Z.; Barabási, A.-L. Halting viruses in scale-free networks. Phys. Rev. E 2002, 65, 055103. [Google Scholar] [CrossRef]
- Ferdinandy, B.; Mones, E.; Vicsek, T.; Müller, V. HIV Competition Dynamics over Sexual Networks: First Comer Advantage Conserves Founder Effects. PLoS Comput. Biol. 2015, 11, e1004093. [Google Scholar] [CrossRef]
- Firth, J.A.; Hellewell, J.; Klepac, P.; Kissler, S.M.; Kucharski, A.J.; Spurgin, L.G. Using a real-world network to model localized COVID-19 control strategies. Nat. Med. 2020, 26, 1616–1622. [Google Scholar] [CrossRef]
- Jiang, Z.; Hu, M.; Fan, L.; Pan, Y.; Tang, W.; Zhai, G.; Lu, Y. Combining Visible Light and Infrared Imaging for Efficient Detection of Respiratory Infections such as COVID-19 on Portable Device. arXiv 2020, arXiv:2004.06912. [Google Scholar]
- Neumann, J.V.; Burks, A.W. Theory of Self-Reproducing Automata; University of Illinois Press: Champaign, IL, USA, 1966; Available online: https://science.sciencemag.org/content/157/3785/180.1 (accessed on 20 October 2020).
- Kleingeld, P.; Brown, E. The Stanford Encyclopedia of Philosophy; Stanford University Press: Palo Alto, CA, USA, 2012; Available online: https://plato.stanford.edu/ (accessed on 20 October 2020).
- White, S.H.; Del Rey, A.M.; Sánchez, G.R. Modeling epidemics using cellular automata. Appl. Math. Comput. 2007, 186, 193–202. [Google Scholar] [CrossRef] [PubMed]
- Athithan, S.; Shukla, V.P.; Biradar, S.R. Dynamic Cellular Automata Based Epidemic Spread Model for Population in Patches with Movement. J. Comput. Environ. Sci. 2014, 2014, 518053. [Google Scholar] [CrossRef]
- Pfeifer, B.; Kügler, K.; Tejada, M.M.; Baumgartner, C.; Seger, M.; Osl, M.; Netzer, M.; Handler, M.; Dander, A.; Wurz, M.; et al. A Cellular Automaton Framework for Infectious Disease Spread Simulation. Open Med. Inform. J. 2008, 2, 70–81. [Google Scholar] [CrossRef]
- Holko, A.; Mȩdrek, M.; Pastuszak, Z.; Phusavat, K. Epidemiological modeling with a population density map-based cellular automata simulation system. Expert Syst. Appl. 2016, 48, 1–8. [Google Scholar] [CrossRef]
- Mikler, A.R.; Venkatachalam, S.; Abbas, K. Modeling infectious diseases using global stochastic cellular automata. J. Biol. Syst. 2005, 13, 421–439. [Google Scholar] [CrossRef]
- López, L.; Burguerner, G.; Giovanini, L. Addressing population heterogeneity and distribution in epidemics models using a cellular automata approach. BMC Res. Notes 2014, 7, 234. [Google Scholar] [CrossRef]
- Bin, S.; Sun, G.; Chen, C.C. Spread of infectious disease modeling and analysis of different factors on spread of infectious disease based on cellular automata. Int. J. Public Health 2019, 16, 4683. [Google Scholar] [CrossRef]
- Röst, G.; Bartha, F.A.; Bogya, N.; Boldog, P.; Dénes, A.; Tamás, F.; Horváth, K.J.; Juhász, A.; Nagy, C.; Tekeli, T.; et al. Early Phase of the COVID-19 Outbreak in Hungary and Post-Lockdown Scenarios. Viruses 2020, 12, 708. [Google Scholar] [CrossRef]
- The Coronavirus Disease 2019 (COVID-19) Data in New York City. Available online: https://github.com/nychealth/coronavirus-data (accessed on 20 October 2020).
- The Coronavirus Disease 2019 (COVID-19) Data in Iowa. Available online: https://coronavirus.iowa.gov/ (accessed on 20 October 2020).
- Driessche, P.V.D.; Watmough, J. Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission. Math. Biosci. 2002, 180, 29–48. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, J.; Zhai, C.; Ai, J.; Ma, J.; Wang, J.; Sun, W. Modeling the Spread of Epidemics Based on Cellular Automata. Processes 2021, 9, 55. https://doi.org/10.3390/pr9010055
Dai J, Zhai C, Ai J, Ma J, Wang J, Sun W. Modeling the Spread of Epidemics Based on Cellular Automata. Processes. 2021; 9(1):55. https://doi.org/10.3390/pr9010055
Chicago/Turabian StyleDai, Jindong, Chi Zhai, Jiali Ai, Jiaying Ma, Jingde Wang, and Wei Sun. 2021. "Modeling the Spread of Epidemics Based on Cellular Automata" Processes 9, no. 1: 55. https://doi.org/10.3390/pr9010055
APA StyleDai, J., Zhai, C., Ai, J., Ma, J., Wang, J., & Sun, W. (2021). Modeling the Spread of Epidemics Based on Cellular Automata. Processes, 9(1), 55. https://doi.org/10.3390/pr9010055