A Representation of Membrane Computing with a Clustering Algorithm on the Graphical Processing Unit



Abstract
1. Introduction
2. Background
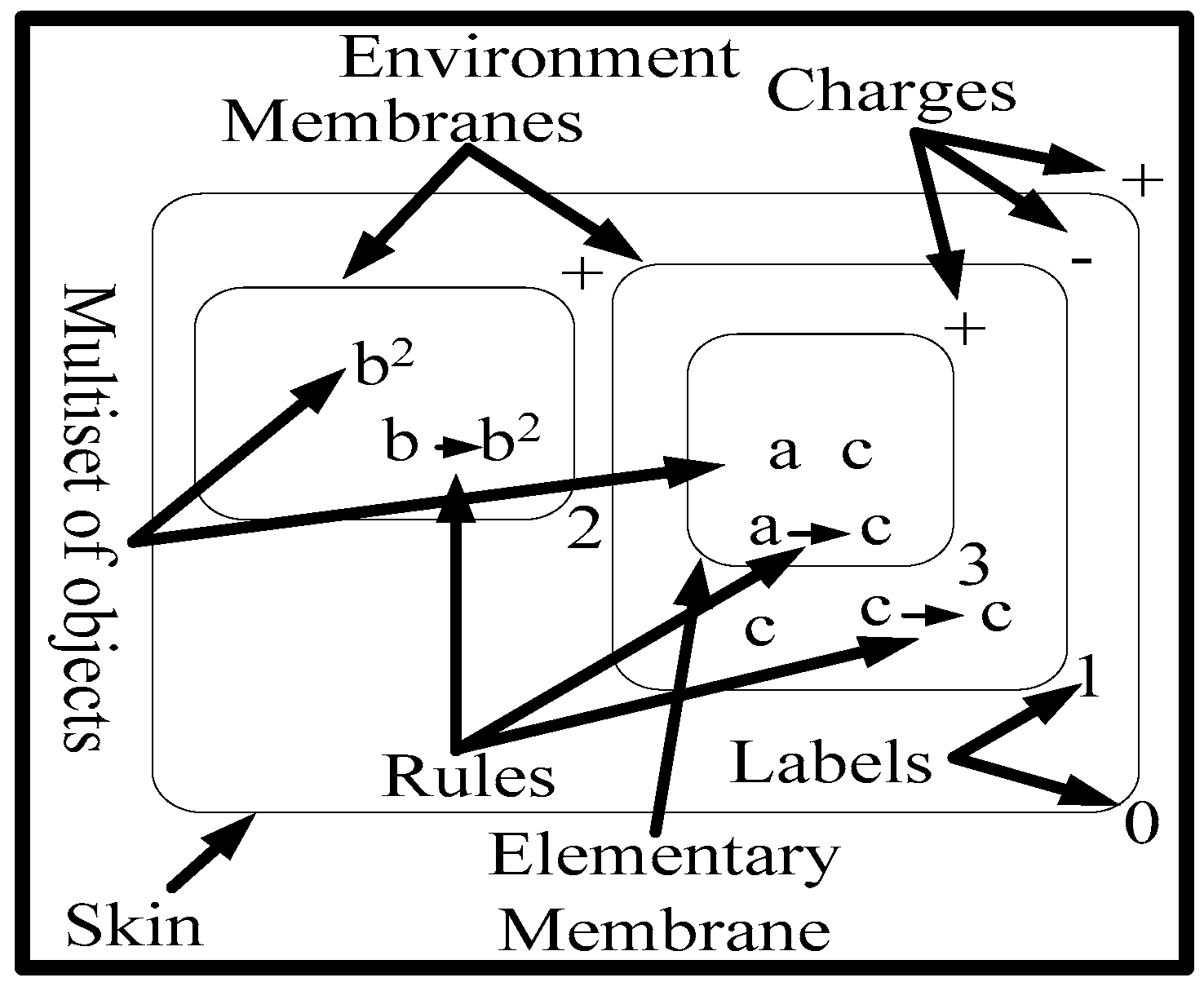
2.1. Active Membrane Systems
- (1)
- m is the preliminary degree of the membrane system, equivalent to the number of membranes, m ≥ 1;
- (2)
- O is the object alphabet;
- (3)
- H is a predetermined group of membrane labels;
- (4)
- µ is a membrane arrangement that includes m membranes labeled 1,…,m, each having a preliminary neutral polarization and tagged with components from H;
- (5)
- are strings over O, designating the multisets of objects positioned in the m compartments of µ;
- (6)
- R is a predetermined group of rules described as:
- (a)
- Evolution rules for the object, , in which are electrical charges, , and u is a string over O that designates a multiset of objects connected with membranes that depend on the label and the charge related with the membranes;
- (b)
- “In” communication rules for the object from an environment entering into a membrane,, in which , when an object enters a membrane, it is likely that this object modifies, where the preliminary charge, α, is transformed to β;
- (c)
- “Out” communication rules for the object from a membrane entering into an environment, , in which , when an object is discharged from a membrane, it is likely that this object modifies, where the preliminary charge, α, is transformed to β;
- (d)
- Dissolving rules for membrane,in which , a membrane with a particular charge is dissolved in a reaction with a probably altered object;
- (e)
- Division rules for membrane, , in which , in response to an object, the membrane is divided into two membranes; the label remains unceasing, but the charge could modify, and the objects inside the membrane are duplicated, except for a, which may be altered in each membrane.
2.2. Compute Unified Device Architecture (CUDA)
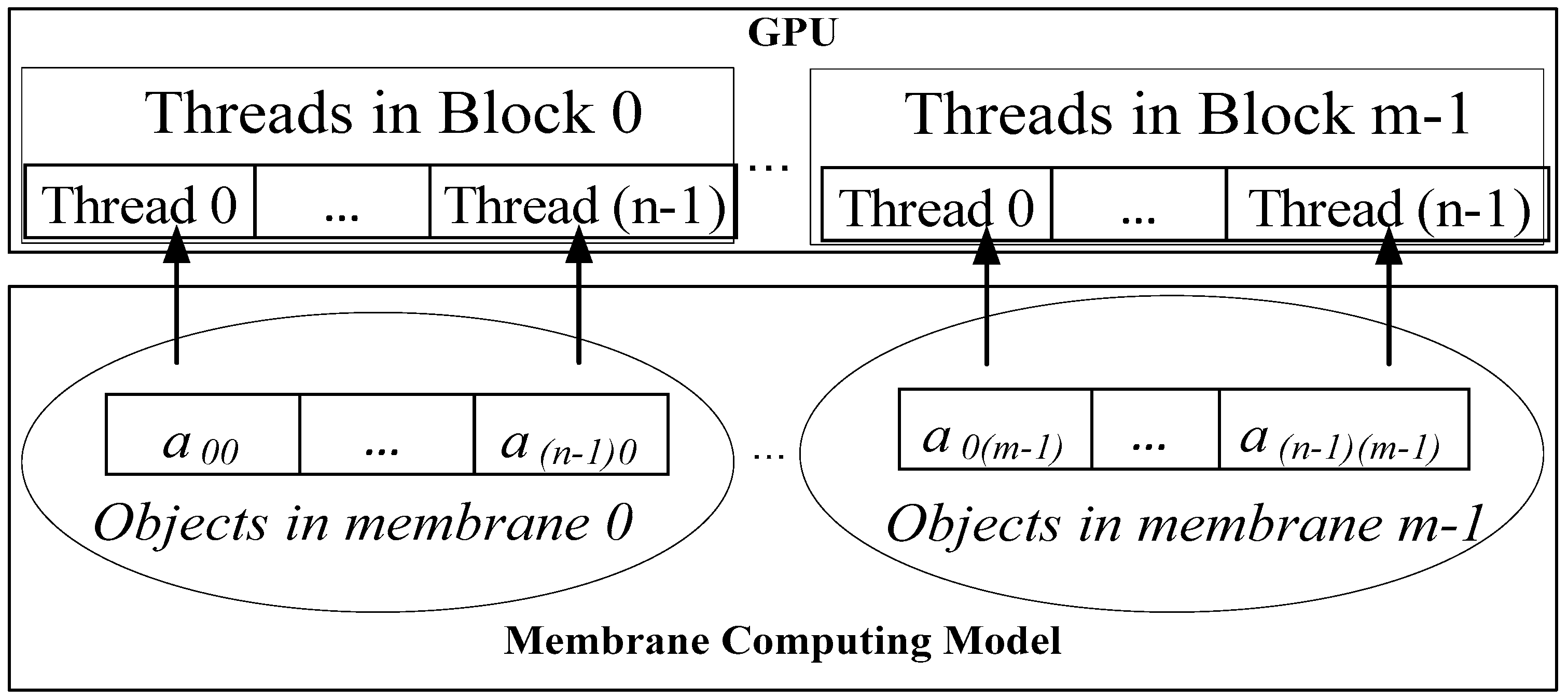
2.3. Applied Methods in Previous Research
3. Methods
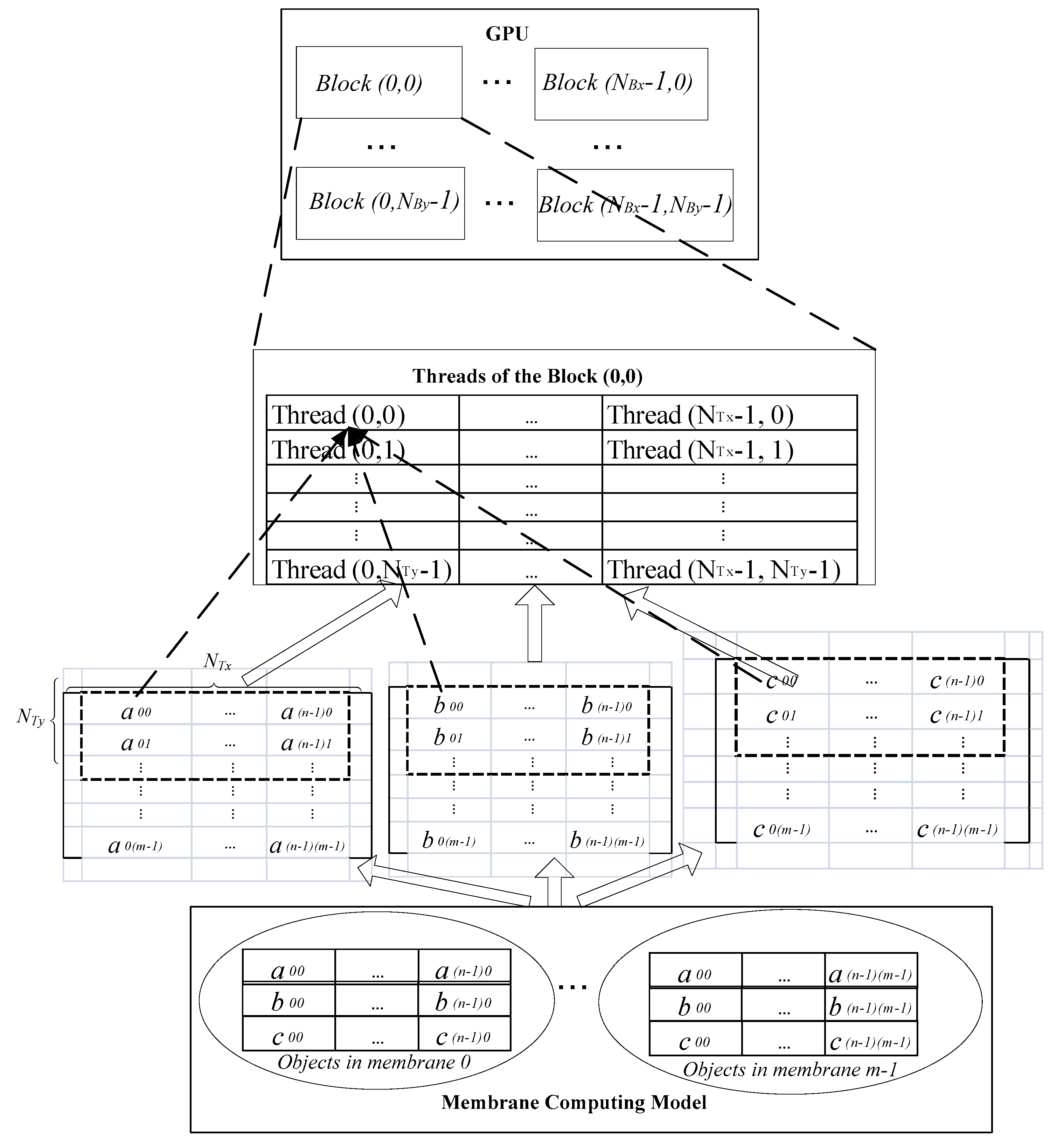
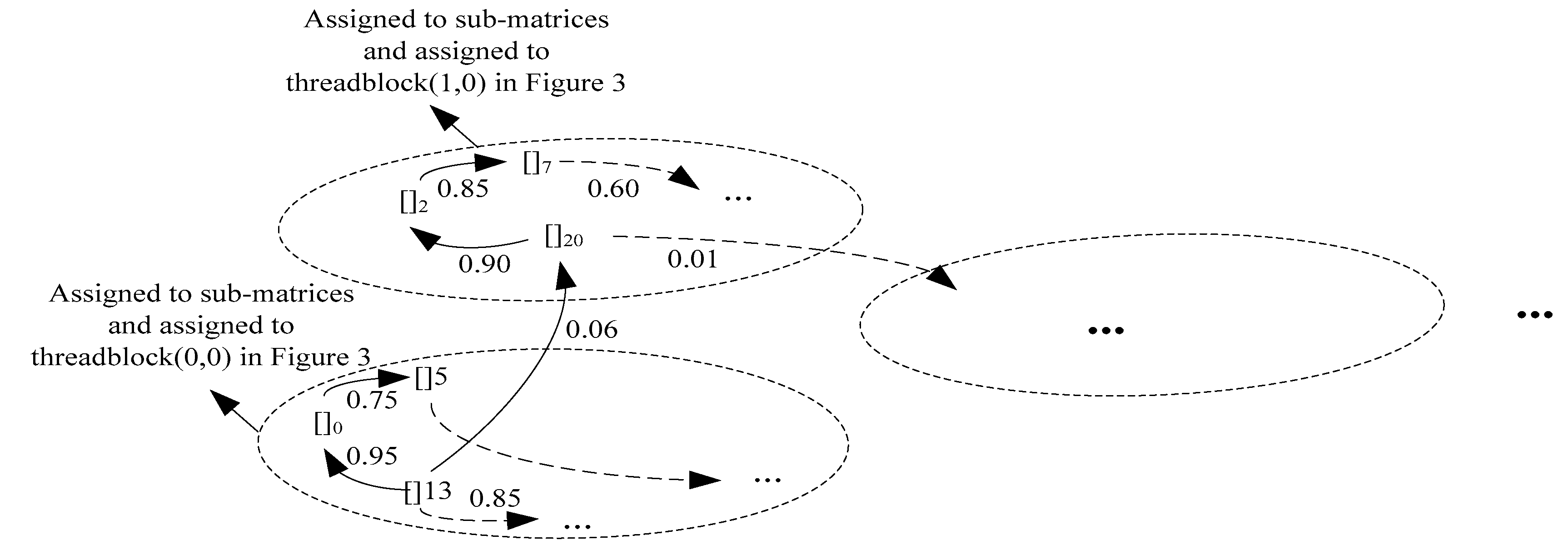
3.1. Proposed Approach
- 1)
- The computational workload associated with the membranes is distributed between thread blocks such that the workload is balanced, and higher performance is achieved.
- 2)
- It is possible to decrease communication between threads within one thread block.
- 3)
- It is probable to automatically allocate membranes that demand to communicate with each other to the same thread block. In some instances, membranes with more significant dependencies are assigned to the same thread blocks to decrease inter-block communication, despite the possibility that this could decrease GPU occupancy.
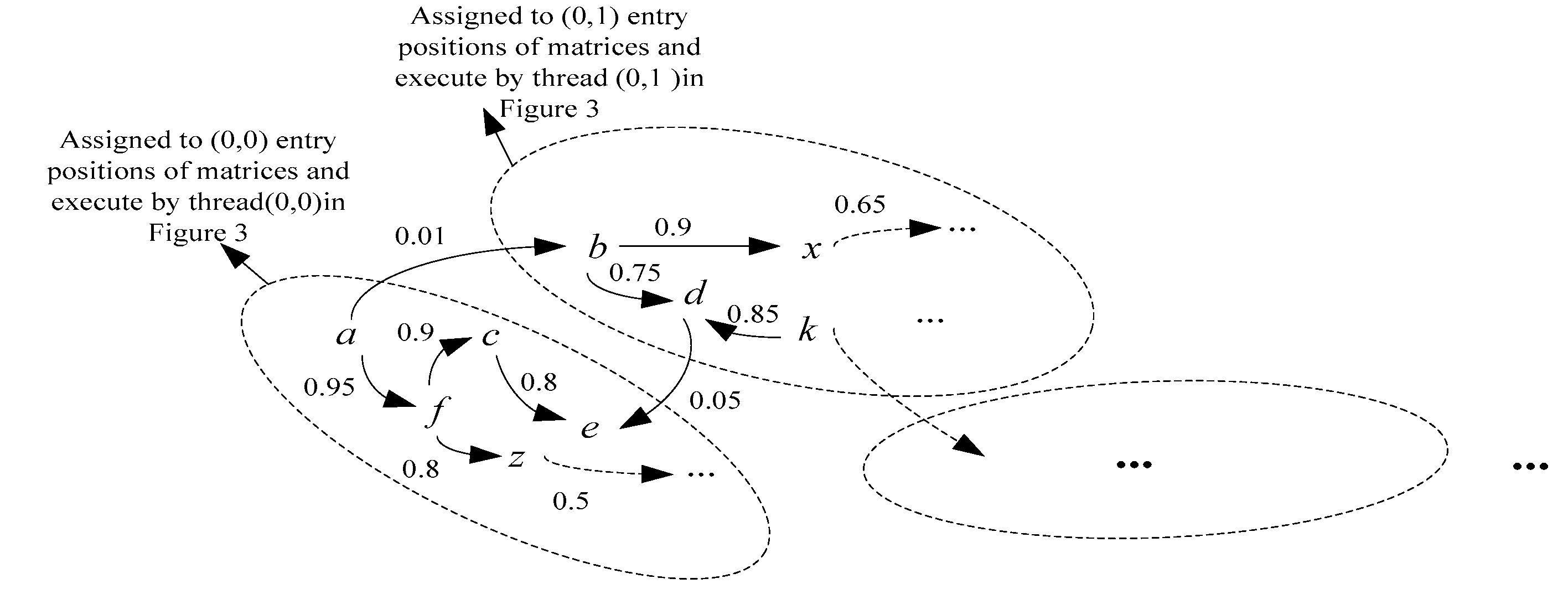
3.2. Proposed Algorithm
4. Results and Discussion
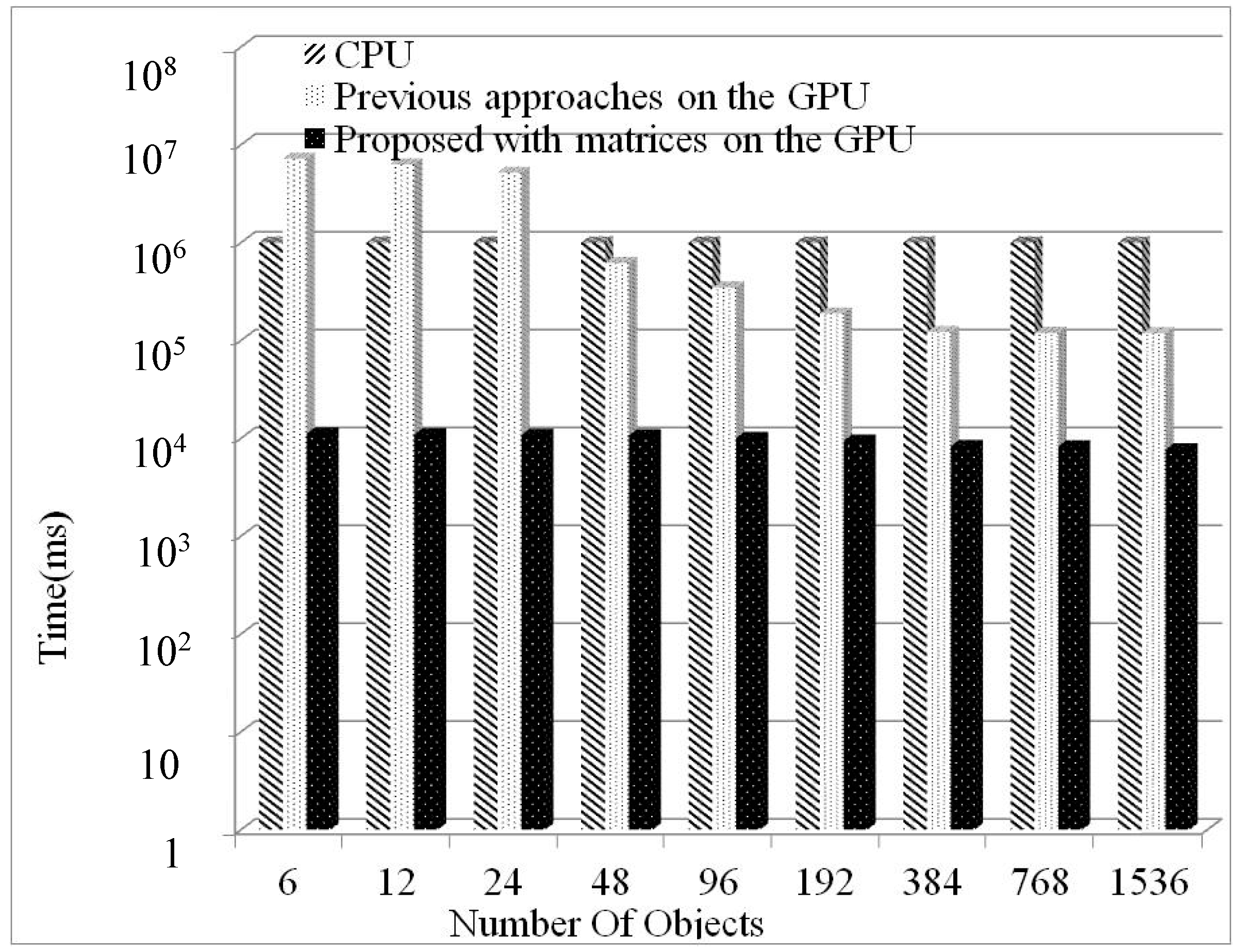
4.1. Comparison Between Previous and Proposed Methods
4.2. Effects of the Number of Objects and Membranes
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, G.; Pérez-Jiménez, M.J.; Gheorghe, M. Real-life Applications with Membrane Computing; Springer Science and Business Media LLC: Berlin, Germany, 2017. [Google Scholar]
- García-Quismondo, M.; Hintz, W.D.; Schuler, M.S.; Relyea, R.A. Modeling diel vertical migration with membrane computing. J. Membr. Comput. 2020, 2, 1–16. [Google Scholar] [CrossRef]
- Song, T.; Pang, S.; Hao, S.; Rodríguez-Patón, A.; Zheng, P. A Parallel Image Skeletonizing Method Using Spiking Neural P Systems with Weights. Neural Process. Lett. 2018, 50, 1485–1502. [Google Scholar] [CrossRef]
- Wang, B.; Chen, L.; Wang, M. Novel image segmentation method based on PCNN. Optics 2019, 187, 193–197. [Google Scholar] [CrossRef]
- Orozco-Rosas, U.; Montiel, O.; Sepúlveda, R. Mobile robot path planning using membrane evolutionary artificial potential field. Appl. Soft Comput. 2019, 77, 236–251. [Google Scholar] [CrossRef]
- Andreu-Guzmán, J.A.; Valencia-Cabrera, L. A novel solution for GCP based on an OLMS membrane algorithm with dynamic operators. J. Membr. Comput. 2019, 2, 1–13. [Google Scholar] [CrossRef]
- Liu, C.; Du, Y. A membrane algorithm based on chemical reaction optimization for many-objective optimization problems. Knowledge-Based Syst. 2019, 165, 306–320. [Google Scholar] [CrossRef]
- Liu, C.; Du, Y.; Li, A.; Lei, J. Evolutionary Multi-Objective Membrane Algorithm. IEEE Access 2020, 8, 6020–6031. [Google Scholar] [CrossRef]
- Maroosi, A.; Muniyandi, R. Accelerated execution of P systems with active membranes to solve the N-queens problem. Theor. Comput. Sci. 2014, 551, 39–54. [Google Scholar] [CrossRef]
- Maroosi, A.; Muniyandi, R.; Sundararajan, E.; Zin, A.M. A parallel membrane inspired harmony search for optimization problems: A case study based on a flexible job shop scheduling problem. Appl. Soft Comput. 2016, 49, 120–136. [Google Scholar] [CrossRef]
- Paun, G. Tracing some open problems in membrane computing. Rom. J. Inf. Sci. Tech. 2007, 10, 303–314. [Google Scholar]
- Zhang, G.; Perez-Jimenez, M.J.; Gheorghe, M. Membrane Computing—Key Concepts and Definitions. Recent Adv. Theory Appl. Fit. Landsc. 2017, 25, 1–9. [Google Scholar] [CrossRef]
- García-Quismondo, M.; Gutiérrez-Escudero, R.; Pérez-Hurtado, I.; Pérez-Jiménez, M.J.; Riscos-Núñez, A. An overview of P-Lingua 2.0. In Proceedings of the WMC’09: Proceedings of the 10th international conference on Membrane Computing, Curtea de Arges, Romania, 24–27 August 2009; pp. 264–288. [Google Scholar]
- Maroosi, A.; Muniyandi, R.C. Accelerated Simulation of Membrane Computing to Solve the N-queens Problem on Multi-core. In Proceedings of the Haptics: Science, Technology, Applications; Springer Science and Business Media LLC: Berlin, Germany, 2013; Volume 8298, pp. 257–267. [Google Scholar]
- Maroosi, A.; Muniyandi, R.C. Membrane computing inspired genetic algorithm on multi-core processors. J. Comput. Sci. 2013, 9, 264–270. [Google Scholar] [CrossRef]
- Orozco-Rosas, U.; Picos, K.; Montiel, O. Hybrid Path Planning Algorithm Based on Membrane Pseudo-Bacterial Potential Field for Autonomous Mobile Robots. IEEE Access 2019, 7, 156787–156803. [Google Scholar] [CrossRef]
- Perez-Hurtado, I.; Perez-Jumenez, M.; Zhang, G.; Orellana-Martín, D. Simulation of Rapidly-Exploring Random Trees in Membrane Computing with P-Lingua and Automatic Programming. Int. J. Comput. Commun. Control. 2018, 13, 1007–1031. [Google Scholar] [CrossRef]
- Ciobanu, G.; Wenyuan, G. P Systems Running on a Cluster of Computers. In Computer Vision; Springer Science and Business Media LLC: Berlin, Germany, 2004; Volume 2933, pp. 123–139. [Google Scholar]
- Kulakovskis, D.; Navakauskas, D. Automated Metabolic P System Placement in FPGA. Electr. Control. Commun. Eng. 2016, 10, 5–12. [Google Scholar] [CrossRef]
- Quiros, J.; Verlan, S.; Viejo, J.; Millan, A.; Bellido, M.J. Fast hardware implementations of static P systems. Comput. Inform. 2016, 35, 687–718. [Google Scholar]
- Maroosi, A.; Muniyandi, R. Enhancement of membrane computing model implementation on GPU by introducing matrix representation for balancing occupancy and reducing inter-block communications. J. Comput. Sci. 2014, 5, 861–871. [Google Scholar] [CrossRef]
- Ravie, C.; Ali, M. Enhancing the Simulation of Membrane System on the GPU for the N-Queens Problem. Chin. J. Electron. 2015, 24, 740–743. [Google Scholar] [CrossRef]
- Martínez-Del-Amor, M.A.; García-Quismondo, M.; Macías-Ramos, L.F.; Valencia-Cabrera, L.; Riscos-Núñez, A.; Perez-Jimenez, M.J. Simulating P Systems on GPU Devices: A Survey. Fundam. Inform. 2015, 136, 269–284. [Google Scholar] [CrossRef]
- Valencia-Cabrera, L.; Martínez-Del-Amor, M.Á.; Pérez-Hurtado, I. A Simulation Workflow for Membrane Computing: From MeCoSim to PMCGPU Through P-Lingua; Springer Science and Business Media LLC: Berlin, Germany, 2018; pp. 291–303. [Google Scholar]
- Fujita, K.; Okuno, S.; Kashimori, Y. Evaluation of the computational efficacy in GPU-accelerated simulations of spiking neurons. Computing 2018, 100, 907–926. [Google Scholar] [CrossRef]
- Idowu, R.K.; Muniyandi, R. Enhanced Throughput and Accelerated Detection of Network Attacks Using a Membrane Computing Model Implemented on a GPU. In Quality of Experience and Learning in Information Systems; Springer Science and Business Media LLC: Berlin, Germany, 2018; pp. 253–268. [Google Scholar]
- Martınez-del-Amor, M.A.; Riscos-Núnez, A.; Pérez-Jiménez, M.J. A survey of parallel simulation of P systems with GPUs. Bull. Int. Membr. Comput. Soc. (IMCS) 2017, 3, 55–67. [Google Scholar]
- Raghavan, S.; Rai, S.S.; Rohit, M.; Chandrasekaran, K. GPUPeP: Parallel Enzymatic Numerical P System simulator with a Python-based interface. Biosystems 2020, 196, 104186. [Google Scholar] [CrossRef]
- Martínez-Del-Amor, M.A.; Perez-Hurtado, I.; Orellana-Martín, D.; Perez-Jimenez, M.J. Adaptative parallel simulators for bioinspired computing models. Futur. Gener. Comput. Syst. 2020, 107, 469–484. [Google Scholar] [CrossRef]
- Guerrero, G.D.; Cecilia, J.M.; García Carrasco, J.M.; Martínez del Amor, M.Á.; Pérez Hurtado de Mendoza, I.; Pérez Jiménez, M.J. Analysis of P systems simulation on CUDA. Conf. Days Parallelism 2009, 20, 289–294. [Google Scholar]
- Cecilia, J.M.; Garcia, J.M.; Guerrero, G.D.; Martínez-Del-Amor, M.A.; Pérez-Hurtado, I.; Perez-Jimenez, M.J. Simulation of P systems with active membranes on CUDA. Briefings Bioinform. 2009, 11, 313–322. [Google Scholar] [CrossRef]
- Cecilia, J.M.; García, J.M.; Guerrero, G.D.; Martínez-Del-Amor, M.A.; Perez-Hurtado, I.; Perez-Jimenez, M.J. Simulating a P system based efficient solution to SAT by using GPUs. J. Log. Algebraic Program. 2010, 79, 317–325. [Google Scholar] [CrossRef]
- Cecilia, J.M.; Garcia, J.M.; Guerrero, G.D.; Martínez-Del-Amor, M.A.; Perez-Jimenez, M.J.; Ujaldon, M. The GPU on the simulation of cellular computing models. Soft Comput. 2011, 16, 231–246. [Google Scholar] [CrossRef]
- Cheng, J.; Grossman, M.; McKercher, T. Professional CUDA C Programming; John Wiley & Sons, Inc.: Indianapolis, IN, USA, 2014. [Google Scholar]
- Cui, X.; Chen, Y.; Mei, H. Improving performance of matrix multiplication and FFT on GPU. In Proceedings of the IEEE 2009 15th International Conference on Parallel and Distributed Systems, Shenzhen, China, 9–11 December 2009. [Google Scholar]
- Huang, Z.; Ma, N.; Wang, S.; Peng, Y. GPU computing performance analysis on matrix multiplication. J. Eng. 2019, 2019, 9043–9048. [Google Scholar] [CrossRef]
- Paun, G.; Rozenberg, G.; Salomaa, A. The Oxford Handbook of Membrane Computing; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Xiao, S.; Feng, W.-C. Inter-block GPU communication via fast barrier synchronization. In Proceedings of the 2010 IEEE International Symposium on Parallel & Distributed Processing (IPDPS), Atlanta, GA, USA, 19–23 April 2010; 2010; pp. 1–12. [Google Scholar] [CrossRef]
- Sun, X.; Wu, C.C.; Chen, L.R.; Lin, J.-Y. Using Inter-Block Synchronization to Improve the Knapsack Problem on GPUs. Int. J. Grid High Perform. Comput. 2018, 10, 83–98. [Google Scholar] [CrossRef]
- Nvidia Developer. CUDA C Programming Guide, Version 10.2. Available online: https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html (accessed on 4 August 2020).
- Maroosi, A.; Muniyandi, R.; Sundararajan, E.; Zin, A.M. Parallel and distributed computing models on a graphics processing unit to accelerate simulation of membrane systems. Simul. Model. Pr. Theory 2014, 47, 60–78. [Google Scholar] [CrossRef]
- Fukuhara, J.; Takimoto, M. Branch Divergence Reduction Based on Code Motion. J. Inf. Process. 2020, 28, 302–309. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, J.; Chae, D.; Kim, D.; Kim, J. μLayer: Low Latency On-Device Inference Using Cooperative Single-Layer Acceleration and Processor-Friendly Quantization. In Proceedings of the EuroSys ’19: Proceedings of the Fourteenth EuroSys Conference 2019, Dresden Germany, 25–28 March 2019. [Google Scholar]
- Lin, H.; Wang, C.-L.; Liu, H. On-GPU Thread-Data Remapping for Branch Divergence Reduction. ACM Trans. Arch. Code Optim. 2018, 15, 1–24. [Google Scholar] [CrossRef]
- Gong, Q.; Greenberg, J.A.; Stoian, R.-I.; Coccarelli, D.; Vera, E.M.; Gehm, M.E. Rapid simulation of X-ray scatter measurements for threat detection via GPU-based ray-tracing. Nucl. Instruments Methods Phys. Res. Sect. B Beam Interactions Mater. Atoms 2019, 449, 86–93. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Iterations, Objects, CPU Time | Previous Approaches on the GPU (Figure 3) [31,32,33] | Proposed Approach with Matrices on the GPU (Figure 7) | Proposed Approach with One Membrane/Thread Block | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Max Iteration | Objects/Membranes (n × 3) | CPU Time (s) | Membrane/Block | Active Threads/Block (Objects in the Membrane) | GPU Occupancy (%) | Time (s) | Speed up | Membrane/Block | Optimum (NTx, NTy) | Time (s) | Speed Up | Time (s) | Speed Up |
| 780,000 | 6 | 1000 | 1 | 6 | 25 | 7187 | 0.14 | 64 | (2, 64) | 11 | 89 | 807 | 8.9 |
| 390,000 | 12 | 1000 | 1 | 12 | 25 | 6284 | 0.16 | 32 | (4, 32) | 10 | 91 | 683 | 9.2 |
| 180,000 | 24 | 1000 | 1 | 24 | 25 | 5157 | 0.2 | 16 | (8, 16) | 10 | 92 | 526 | 9.8 |
| 92,000 | 48 | 1000 | 1 | 48 | 50 | 618 | 1.6 | 8 | (16, 8) | 10 | 93 | 59 | 10.4 |
| 43,000 | 96 | 1000 | 1 | 96 | 75 | 346 | 2.8 | 4 | (32, 4) | 10 | 99 | 30 | 11.5 |
| 21,000 | 192 | 1000 | 1 | 192 | 100 | 188 | 5.3 | 2 | (64, 2) | 9.4 | 106 | 16 | 11.7 |
| 9500 | 384 | 1000 | 1 | 384 | 100 | 121 | 8.2 | 1 | (128, 1) | 8.3 | 120 | 10 | 12.1 |
| 4700 | 768 | 1000 | 1 | 768 | 100 | 119 | 8.3 | 1/2 | (128, 1) | 8.2 | 121 | 9.8 | 12.1 |
| 2300 | 1536 | 1000 | 1 | 1024 | 100 | 118 | 8.4 | 1/4 | (128, 1) | 7.6 | 130 | 9.7 | 12.1 |
| Number of Objects | Sequential on CPU (ms) | GPU Shared Memory (ms) | GPU Global Memory (ms) | Speedup GPU Shared Memory | Speedup GPU Global Memory |
|---|---|---|---|---|---|
| 2 | 62 | 129 | 145 | 0.48 | 0.42 |
| 4 | 140 | 130 | 157 | 1.07 | 0.89 |
| 8 | 296 | 131 | 186 | 2.25 | 1.59 |
| 16 | 608 | 133 | 236 | 4.57 | 2.57 |
| 32 | 1217 | 135 | 240 | 9.01 | 5.07 |
| 64 | 2449 | 137 | 248 | 17.87 | 9.87 |
| 128 | 4898 | 140.6 | 319 | 34.83 | 15.35 |
| 256 | 10,077 | 264 | 652 | 38.17 | 15.45 |
| 512 | 20,155 | 518 | 1244 | 38.90 | 16.20 |
| 1024 | 40,300 | 1067 | 2520 | 37.76 | 15.99 |
| Number of Membranes | Sequential on CPU (ms) | GPU Using Shared Memory (ms) | GPU Using Global Memory (ms) | Speedup GPU Shared Memory | Speedup GPU Global Memory |
|---|---|---|---|---|---|
| 2 | 4.7 | 2.01 | 2.02 | 2.3 | 2.3 |
| 4 | 16 | 2.05 | 2.3 | 7.8 | 6.9 |
| 8 | 31 | 2.15 | 2.7 | 14.4 | 11.4 |
| 16 | 47 | 2.25 | 3.4 | 20.8 | 13.8 |
| 32 | 78 | 2.37 | 5.6 | 32.9 | 13.9 |
| 64 | 156 | 4.7 | 11.1 | 33.1 | 14.0 |
| 128 | 296 | 8.5 | 20.9 | 34.8 | 14.1 |
| 256 | 624 | 17.4 | 44 | 35.8 | 14.1 |
| 512 | 1201 | 35.07 | 84.4 | 34.2 | 14.2 |
| 1024 | 2449 | 69.26 | 167 | 35.3 | 14.6 |
| 2048 | 4914 | 137.7 | 331 | 35.6 | 14.8 |
| 4096 | 10,031 | 272 | 637 | 36.8 | 15.7 |
| 8192 | 20,161 | 520 | 1252 | 38.7 | 16.1 |
| 16,384 | 40,286 | 1033 | 2488 | 38.9 | 16.1 |
| 32,768 | 80,589 | 2047 | 4977 | 39.3 | 16.1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muniyandi, R.C.; Maroosi, A. A Representation of Membrane Computing with a Clustering Algorithm on the Graphical Processing Unit. Processes 2020, 8, 1199. https://doi.org/10.3390/pr8091199
Muniyandi RC, Maroosi A. A Representation of Membrane Computing with a Clustering Algorithm on the Graphical Processing Unit. Processes. 2020; 8(9):1199. https://doi.org/10.3390/pr8091199
Chicago/Turabian StyleMuniyandi, Ravie Chandren, and Ali Maroosi. 2020. "A Representation of Membrane Computing with a Clustering Algorithm on the Graphical Processing Unit" Processes 8, no. 9: 1199. https://doi.org/10.3390/pr8091199
APA StyleMuniyandi, R. C., & Maroosi, A. (2020). A Representation of Membrane Computing with a Clustering Algorithm on the Graphical Processing Unit. Processes, 8(9), 1199. https://doi.org/10.3390/pr8091199