Fitness Landscape Analysis and Edge Weighting-Based Optimization of Vehicle Routing Problems




Abstract
1. Introduction and Related Research
2. Theoretical Preliminaries
2.1. Traveling Salesman Problem
2.2. Genetic Algorithm
2.3. Search Space in TSP
- The set of possible states denoted by . The search space can be discrete or continuous.
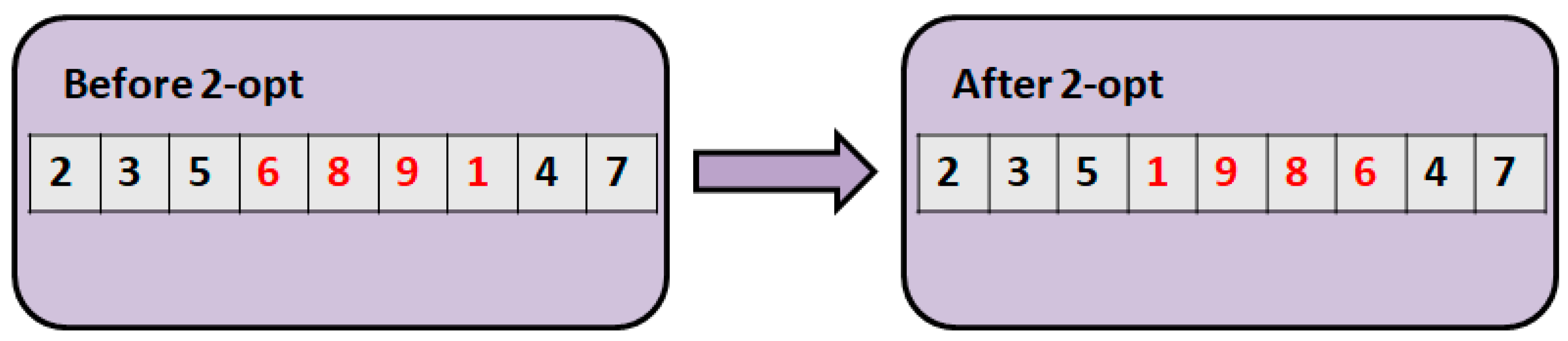
- Distance-based neighborhood defined by an operator. This is applied to the current state point to generate the next state point. For example, for discrete problems, the edge swap (2-opt) operator. It can be written with the following notation: .
- Fitness value, objective function denoted by . This gives the fitness value for each possible status point (solution). Usually, fitness is a real number. For most optimization tasks, we use a single fitness value. However, in multi-object optimization, the fitness value may be a vector.
- Encoding and representation: Although encoding and representation are not formally part of the fitness landscape, they are important factors. This is because representation is part of the evaluation of fitness value, and mutation operators depend on representation.
- Transition rule (transition rule = pivoting rule = selection strategy) that selects the next state point from the potential neighboring state points.
- Stop condition, which determines when the algorithm terminates.
- The initial state point is either a randomly generated solution (state point) or a solution given by some construction heuristic.
- Comparison of differences between two search spaces: a task with two or more different representation methods: different representation, different mutation operator, different objective function, etc.
- Algorithm selection: analysis of the global geometry of the search space (landscape).
- Tuning the parameters.
- Controlling parameters during the running.
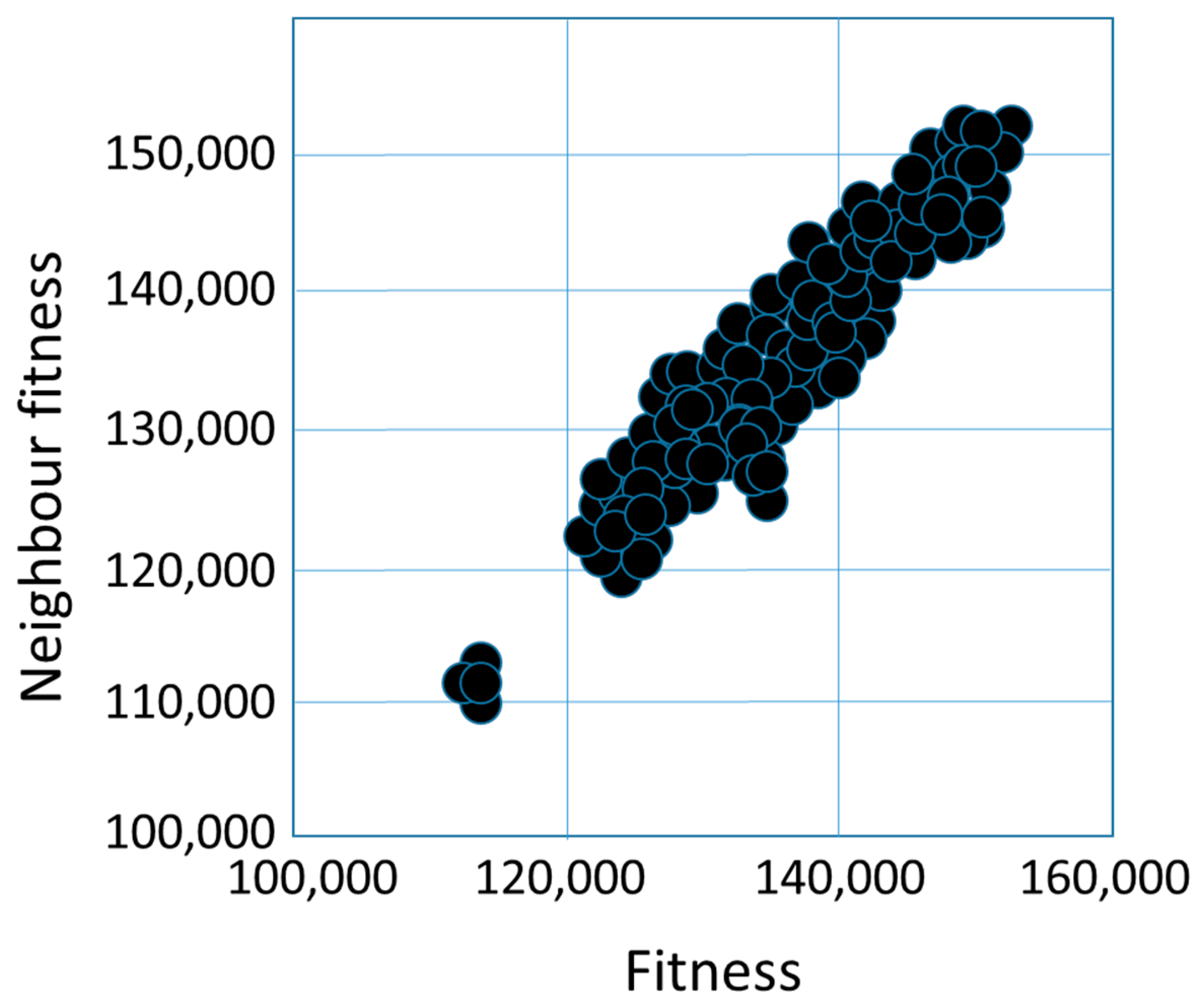
2.4. Fitness Cloud
- : If the fitness value of the “base” state point is below , then the bordering fitness values are better, so we call it strictly advantageous.
- : If the fitness value of the “base” state point is between and , it is called average advantageous because the bordering fitness values are higher than theirs.
- : The “base” fitness point value between and is called deleterious because their average bordering fitness value is lower than the “base” fitness point value.
- : A “base” fitness value above is called strictly deleterious because their bordering fitness is always lower than themselves.
3. Proposed Analysis and Optimization Methods
3.1. Proposed Neighborhood Operators
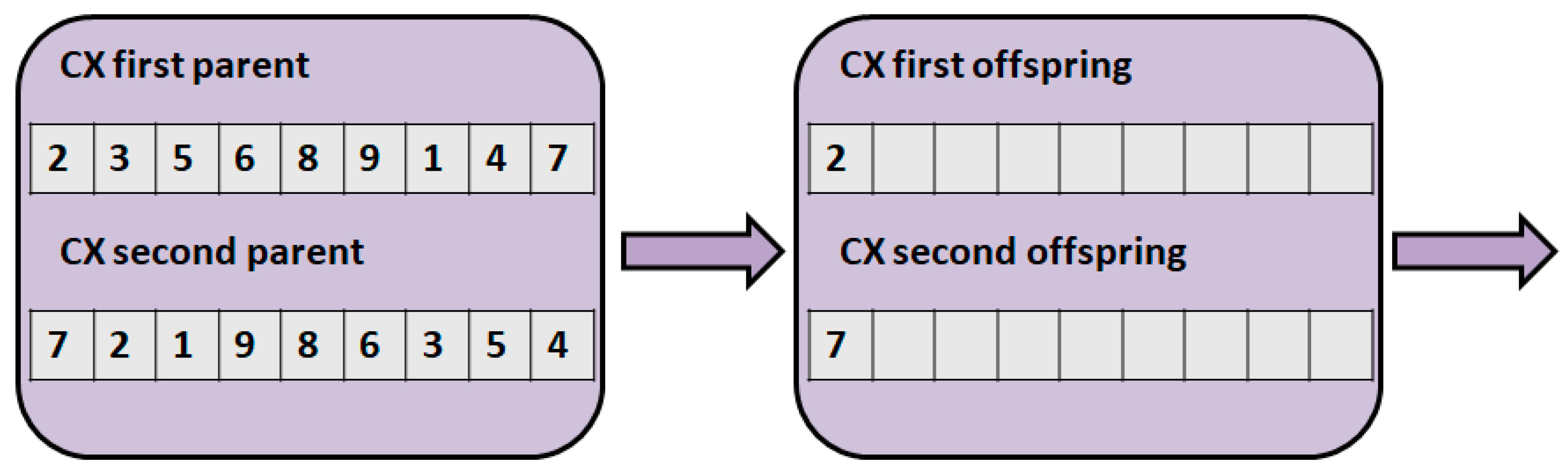
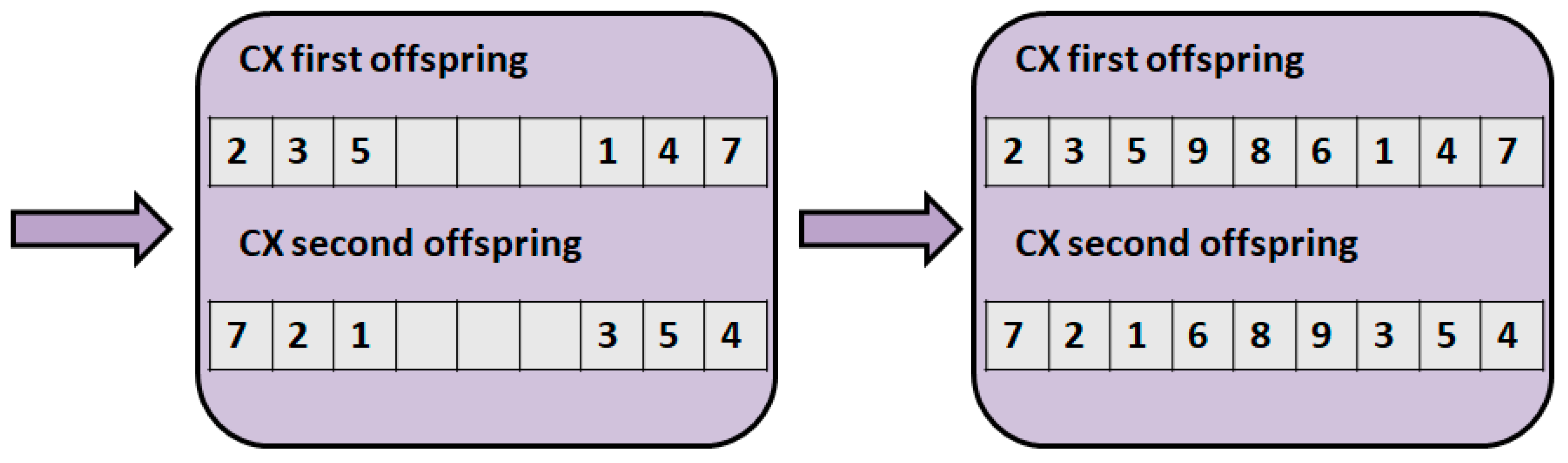
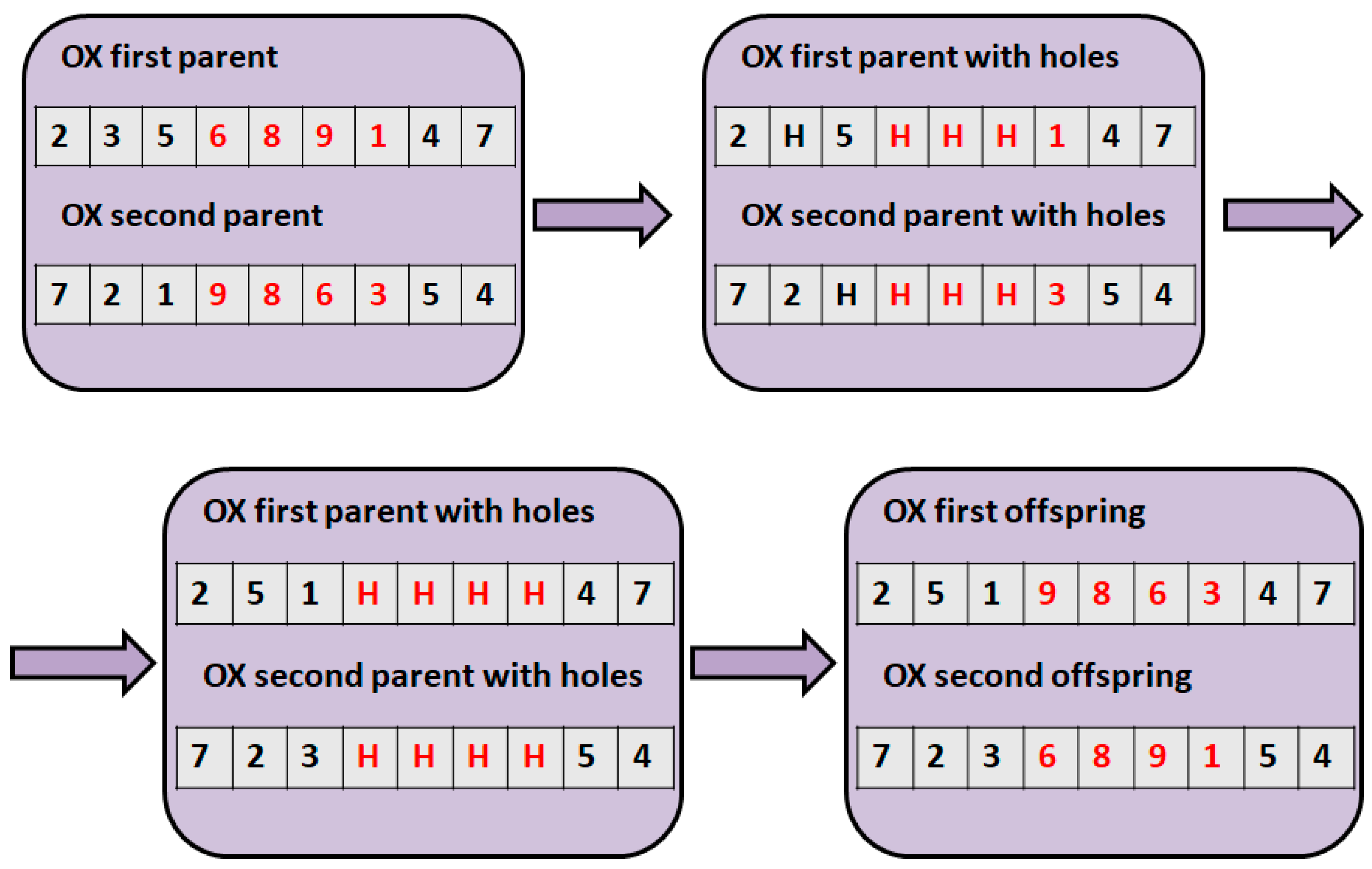
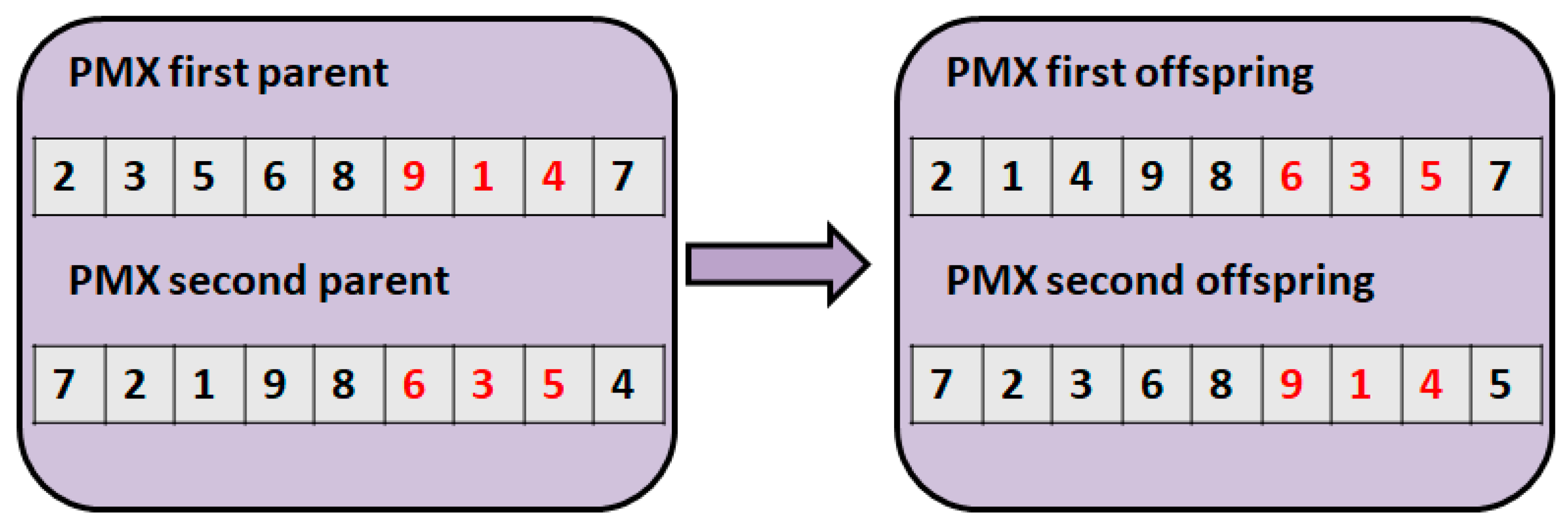
3.2. Measuring Distances between Two Solutions
3.3. Key Performance Indicators in Our Fitness Cloud Analysis
3.4. Edge Weighting-Based Optimization for Traveling Salesman Problem
- Application of edges as elementary units in the route construction process; this approach provides higher flexibility.
- Introduction of a fitness value also for the elementary, edges based on their role in routes with high fitness values. The approach to score elementary units can be found among others in the Bayes-classifiers where every component attribute is assigned to a probability weight value.
- : set of objects (locations);
- : set of distances between the objects;
- : set of closed permutations, closed routes on
- : the length of closed route ;
- : the fitness of closed route .
Example
4. Results and Discussion
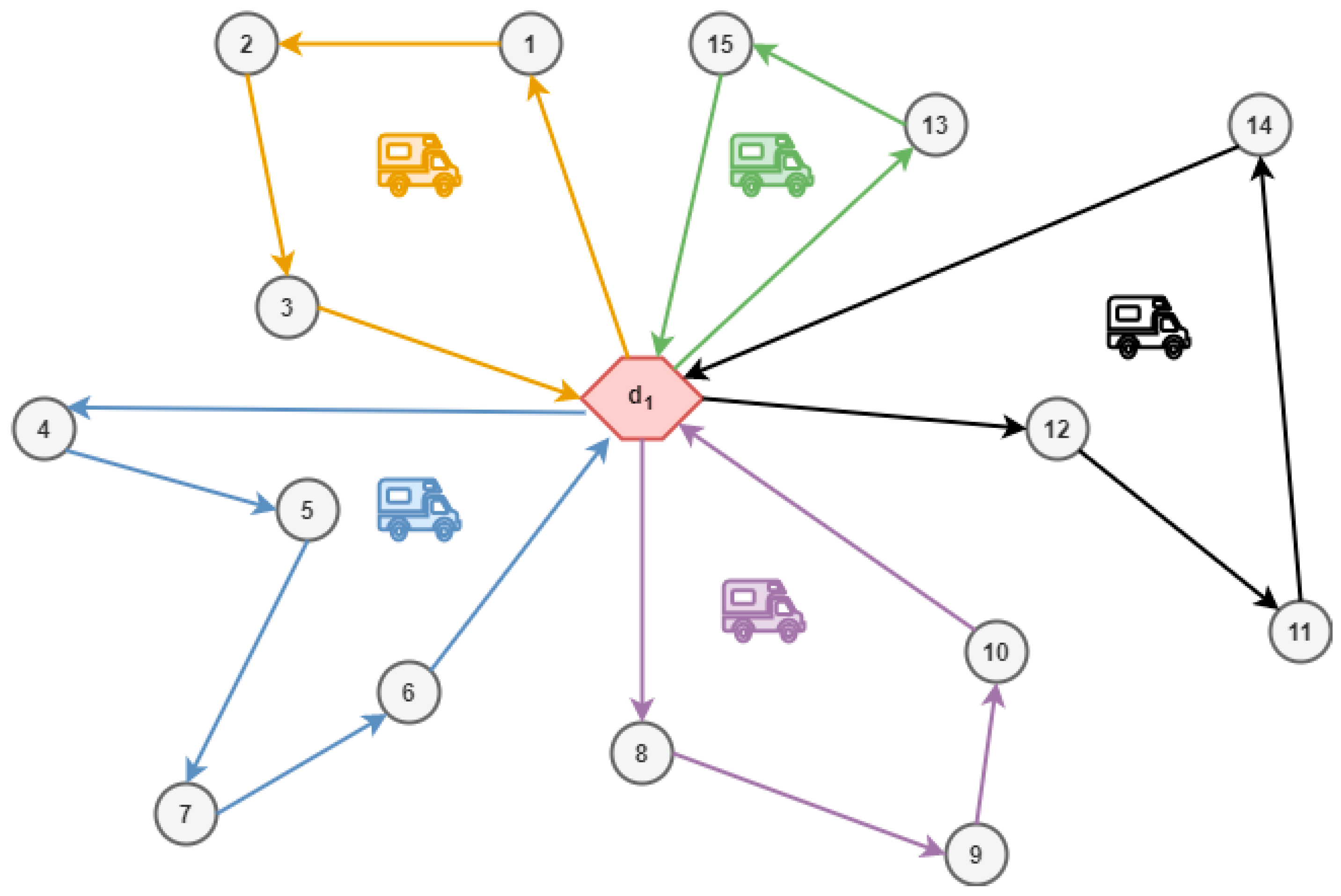
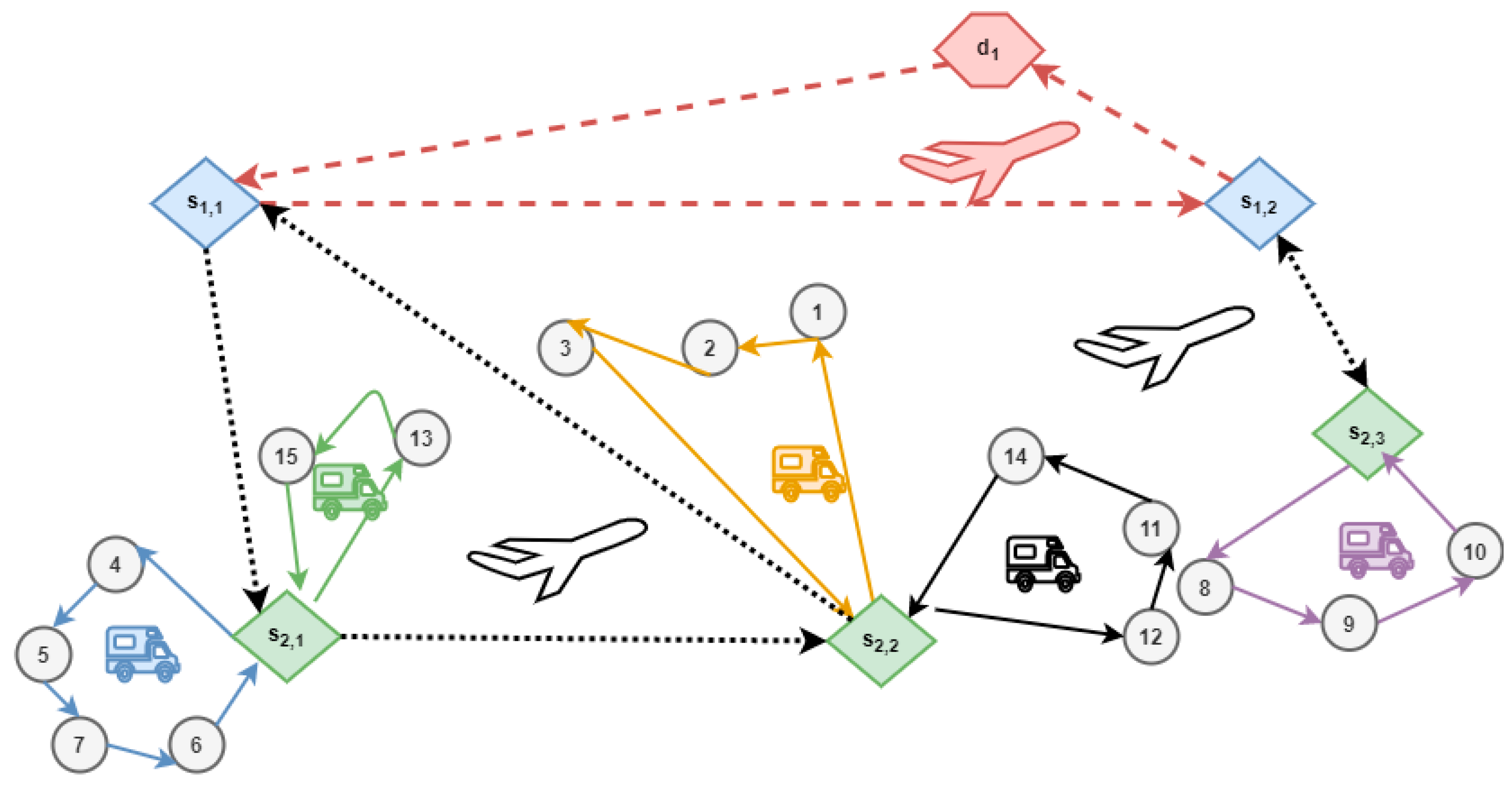
4.1. The Prototype Vehicle Routing System
4.2. Fitness Cloud Analysis Results
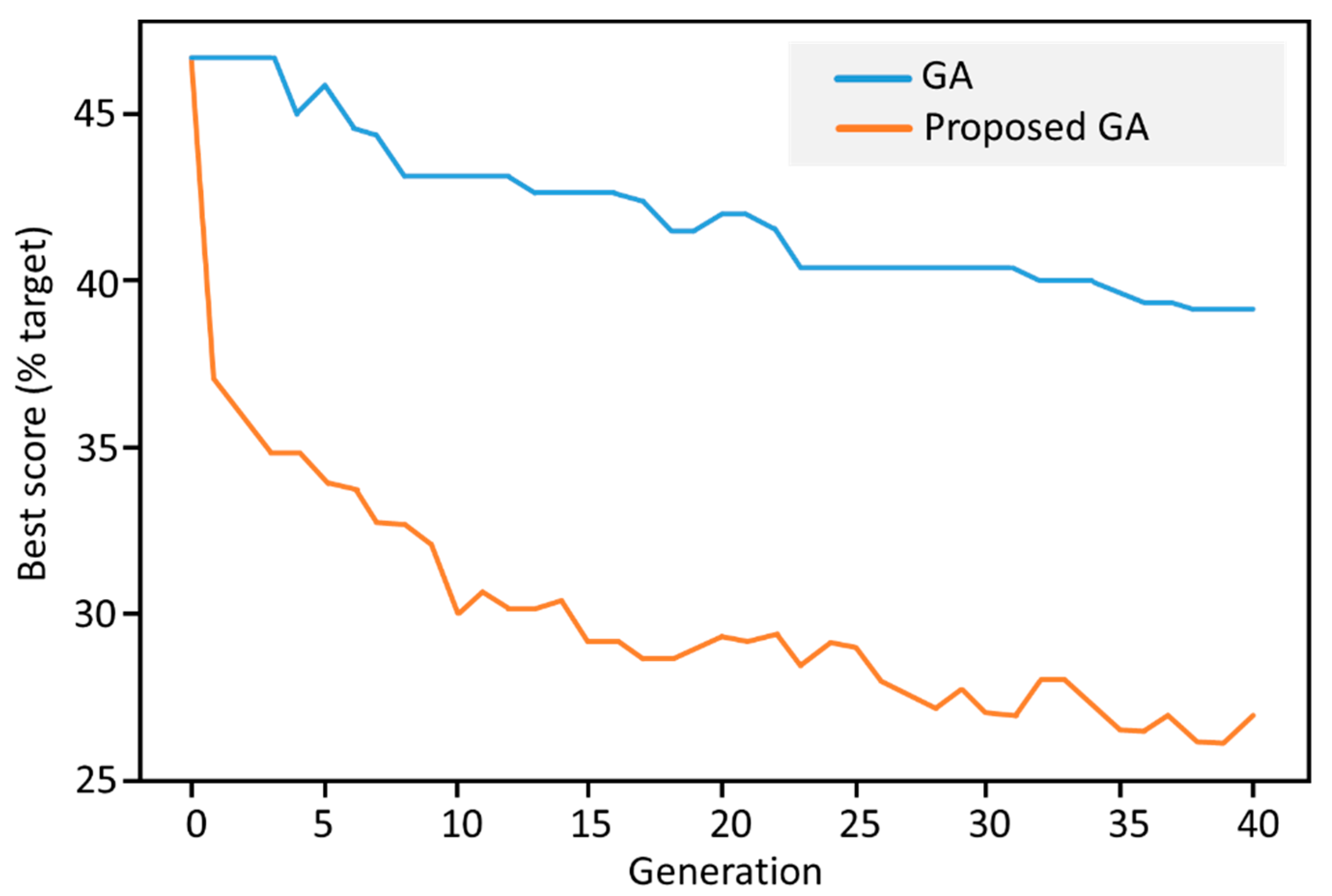
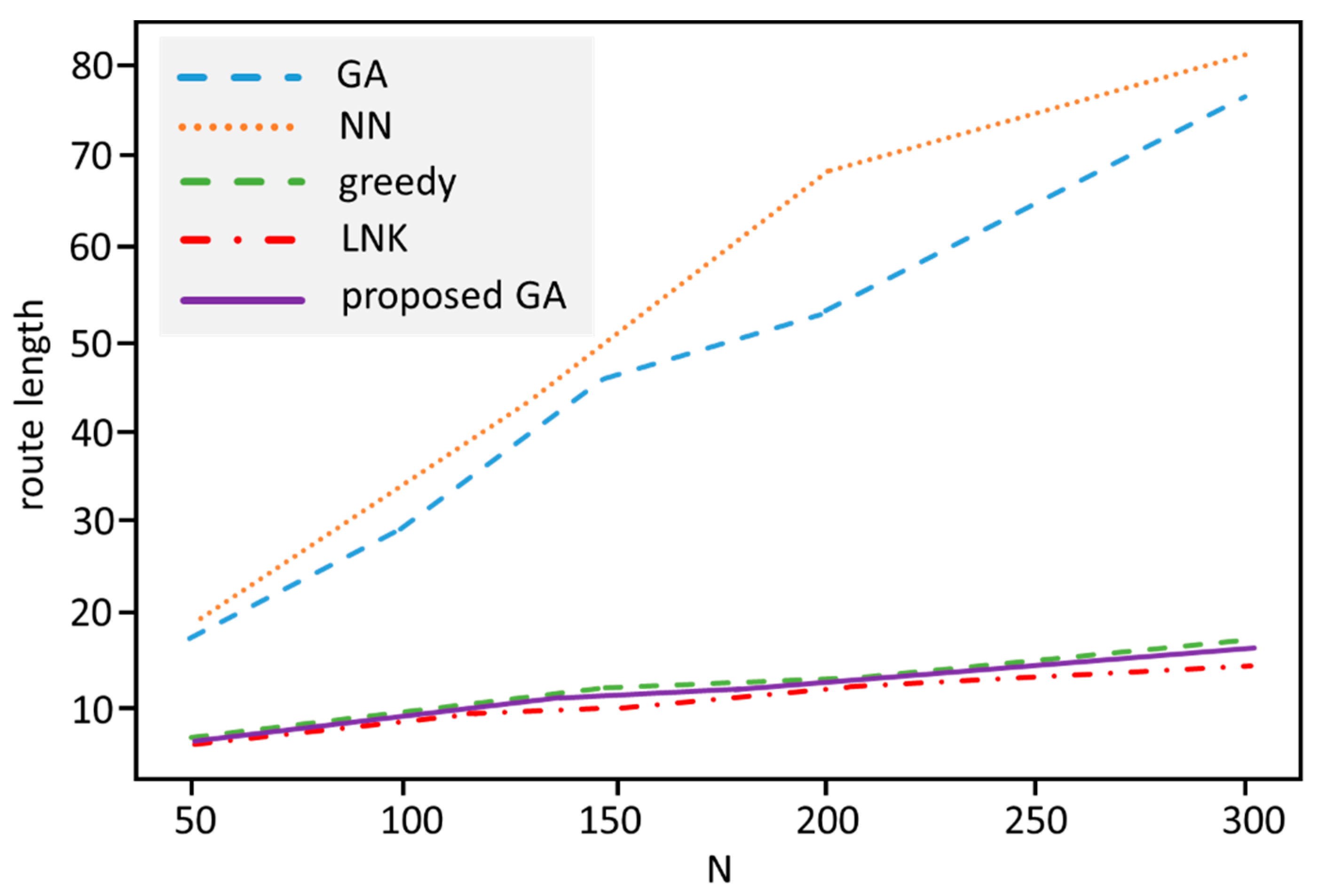
4.3. Efficiency Comparison of the Proposed Genetic Algorithm Method
- N: number of the nodes;
- P: size of the population ;
- M: number of the generations;
- d: relocation size;
- p1: probability of selection;
- p2: probability of crossover;
- p3: probability of mutation.
4.4. Test Results for the Proposed GA Optimization
- random generation (A);
- standard GA evolutionary algorithm (B);
- nearest neighbor construction algorithm (C);
- greedy best first construction algorithm (D);
- Lin-Kernighan 2-opt refinement algorithm (E);
- proposed edge weighting single-phase (construction) algorithm (F);
- proposed edge weighting evolutionary algorithm (G).
- N: number of nodes;
- P: size of the population;
- D: noise variability (only for G);
- M: number of generations.
5. Conclusions and Future Work
- the proposed method involves some stochastic components;
- the proposed method uses an evolutionary framework.
- The proposed integrated GA method provides significantly better results as the baseline GA method.
- The experiments show that the proposed GA variant dominates the NN and greedy algorithms in general. An interesting result is that our method can provide better results as the efficient Lin-Kernighan method for middle-sized datasets.
- The convergence and efficiency of random operations is relatively low in large problem domains where the number of possible states is exponentially high.
Author Contributions
Funding
Conflicts of Interest
References
- Dantzig, G.B.; Ramser, J.H. The truck dispatching problem. Manag. Sci. 1959, 6, 80–91. [Google Scholar] [CrossRef]
- Skrlec, D.; Filipec, M.; Krajcar, S. A heuristic modification of genetic algorithm used for solving the single depot capacited vehicle routing problem. In Proceedings of the Intelligent Information Systems, Grand Bahama Island, Bahamas, 8–10 December 1997; pp. 184–188. [Google Scholar]
- Nagy, G.; Salhi, S. Heuristic algorithms for single and multiple depot vehicle routing problems with pickups and deliveries. Eur. J. Oper. Res. 2005, 162, 126–141. [Google Scholar] [CrossRef]
- Crainic, T.G.; Perboli, G.; Mancini, S.; Tadei, R. Two-echelon vehicle routing problem: A satellite location analysis. Procedia-Soc. Behav. Sci. 2010, 2, 5944–5955. [Google Scholar] [CrossRef]
- Dondo, R.; Méndez, C.A.; Cerdá, J. The multi-echelon vehicle routing problem with cross docking in supply chain management. Comput. Chem. Eng. 2011, 35, 3002–3024. [Google Scholar] [CrossRef]
- Dondo, R.; Cerdá, J. A cluster-based optimization approach for the multi-depot heterogeneous fleet vehicle routing problem with time windows. Eur. J. Oper. Res. 2007, 176, 1478–1507. [Google Scholar] [CrossRef]
- Gendreau, M.; Laporte, G.; Musaraganyi, C.; Taillard, É.D. A tabu search heuristic for the heterogeneous fleet vehicle routing problem. Comput. Oper. Res. 1999, 26, 1153–1173. [Google Scholar] [CrossRef]
- Schulze, J.; Fahle, T. A parallel algorithm for the vehicle routing problem with time window constraints. Ann. Oper. Res. 1999, 86, 585–607. [Google Scholar] [CrossRef]
- Belhaiza, S.; Hansen, P.; Laporte, G. A hybrid variable neighborhood tabu search heuristic for the vehicle routing problem with multiple time windows. Comput. Oper. Res. 2014, 52, 269–281. [Google Scholar] [CrossRef]
- Figliozzi, M.A. An iterative route construction and improvement algorithm for the vehicle routing problem with soft time windows. Transp. Res. Part C Emerg. Technol. 2010, 18, 668–679. [Google Scholar] [CrossRef]
- Ralphs, T.K.; Kopman, L.; Pulleyblank, W.R.; Trotter, L.E. On the capacitated vehicle routing problem. Math. Program. 2003, 94, 343–359. [Google Scholar] [CrossRef]
- Kabcome, P.; Mouktonglang, T. Vehicle routing problem for multiple product types, compartments, and trips with soft time windows. Int. J. Math. Math. Sci. 2015, 126754. [Google Scholar] [CrossRef]
- Crevier, B.; Cordeau, J.F.; Laporte, G. The multi-depot vehicle routing problem with inter-depot routes. Eur. J. Oper. Res. 2007, 176, 756–773. [Google Scholar] [CrossRef]
- Lin, C.K.Y. A vehicle routing problem with pickup and delivery time windows, and coordination of transportable resources. Comput. Oper. Res. 2011, 38, 1596–1609. [Google Scholar] [CrossRef]
- Angelelli, E.; Speranza, M.G. The periodic vehicle routing problem with intermediate facilities. Eur. J. Oper. Res. 2002, 137, 233–247. [Google Scholar] [CrossRef]
- Hussain, A.; Muhammad, Y.S.; Nauman Sajid, M.; Hussain, I.; Mohamd Shoukry, A.; Gani, S. Genetic algorithm for traveling salesman problem with modified cycle crossover operator. Comput. Intell. Neurosci. 2017, 7430125. [Google Scholar] [CrossRef] [PubMed]
- Stewart, W.R., Jr.; Golden, B.L. Stochastic vehicle routing: A comprehensive approach. Eur. J. Oper. Res. 1983, 14, 371–385. [Google Scholar] [CrossRef]
- Gupta, R.; Singh, B.; Pandey, D. Multi-objective fuzzy vehicle routing problem: A case study. Int. J. Contemp. Math. Sci. 2010, 5, 1439–1454. [Google Scholar]
- Soysal, M.; Bloemhof-Ruwaard, J.M.; Bektaş, T. The time-dependent two-echelon capacitated vehicle routing problem with environmental considerations. Int. J. Prod. Econ. 2015, 164, 366–378. [Google Scholar] [CrossRef]
- Lin, J.; Zhou, W.; Wolfson, O. Electric vehicle routing problem. Transp. Res. Procedia 2016, 12, 508–521. [Google Scholar] [CrossRef]
- Stavropoulou, F.; Repoussis, P.P.; Tarantilis, C.D. The vehicle routing problem with profits and consistency constraints. Eur. J. Oper. Res. 2019, 274, 340–356. [Google Scholar] [CrossRef]
- Huang, Y.H.; Blazquez, C.A.; Huang, S.H.; Paredes-Belmar, G.; Latorre-Nuñez, G. Solving the feeder vehicle routing problem using ant colony optimization. Comput. Ind. Eng. 2019, 127, 520–535. [Google Scholar] [CrossRef]
- Ribeiro, G.M.; Laporte, G. An adaptive large neighborhood search heuristic for the cumulative capacitated vehicle routing problem. Comput. Oper. Res. 2012, 39, 728–735. [Google Scholar] [CrossRef]
- Song, B.D.; Ko, Y.D. A vehicle routing problem of both refrigerated-and general-type vehicles for perishable food products delivery. J. Food Eng. 2016, 169, 61–71. [Google Scholar] [CrossRef]
- Talarico, L.; Sörensen, K.; Springael, J. Metaheuristics for the risk-constrained cash-in-transit vehicle routing problem. Eur. J. Oper. Res. 2015, 244, 457–470. [Google Scholar] [CrossRef]
- Bae, H.; Moon, I. Multi-depot vehicle routing problem with time windows considering delivery and installation vehicles. Appl. Math. Model. 2016, 40, 6536–6549. [Google Scholar] [CrossRef]
- Battarra, M.; Erdoğan, G.; Vigo, D. Exact algorithms for the clustered vehicle routing problem. Oper. Res. 2014, 62, 58–71. [Google Scholar] [CrossRef]
- Drexl, M. Applications of the vehicle routing problem with trailers and transshipments. Eur. J. Oper. Res. 2013, 227, 275–283. [Google Scholar] [CrossRef]
- Xiao, Y.; Konak, A. The heterogeneous green vehicle routing and scheduling problem with time-varying traffic congestion. Transp. Res. Part E Logist. Transp. Rev. 2016, 88, 146–166. [Google Scholar] [CrossRef]
- Montemanni, R.; Gambardella, L.M.; Rizzoli, A.E.; Donati, A.V. Ant colony system for a dynamic vehicle routing problem. J. Comb. Optim. 2005, 10, 327–343. [Google Scholar] [CrossRef]
- Mattfeld, D.C.; Bierwirth, C.; Kopfer, H. A search space analysis of the job shop scheduling problem. Ann. Oper. Res. 1999, 86, 441–453. [Google Scholar] [CrossRef]
- Pitzer, E.; Affenzeller, M. A comprehensive survey on fitness landscape analysis. In Recent Advances in Intelligent Engineering Systems, 1st ed.; Fodor, J., Klempous, R., Suárez Araujo, C.P., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 161–191. [Google Scholar] [CrossRef]
- Humeau, J.; Liefooghe, A.; Talbi, E.G.; Verel, S. ParadisEO-MO: From fitness landscape analysis to efficient local search algorithms. J. Heuristics 2013, 19, 881–915. [Google Scholar] [CrossRef]
- Collard, P.; Verel, S.; Clergue, M. Local search heuristics: Fitness cloud versus fitness landscape. arXiv 2007, arXiv:0709.4010. [Google Scholar]
- Fonlupt, C.; Robilliard, D.; Preux, P. Fitness landscape and the behavior of heuristics. Evol. Artif. 1997, 97, 56. [Google Scholar]
- Ventresca, M.; Ombuki-Berman, B.; Runka, A. Predicting genetic algorithm performance on the vehicle routing problem using information theoretic landscape measures. Lect. Notes Comput. Sci. 2013, 7832, 214–225. [Google Scholar] [CrossRef]
- Bagaria, V.; Ding, J.; Tse, D.; Wu, Y.; Xu, J. Hidden hamiltonian cycle recovery via linear programming. Oper. Res. 2020, 68, 53–70. [Google Scholar] [CrossRef]
- Papadimitriou, C.H.; Vazirani, U.V. On two geometric problems related to the travelling salesman problem. J. Algorithms 1984, 5, 231–246. [Google Scholar] [CrossRef]
- Braun, H. On solving travelling salesman problems by genetic algorithms. Lect. Notes Comput. Sci. 1991, 496, 129–133. [Google Scholar]
- Rosenkrantz, D.J.; Stearns, R.E.; Lewis, P.M., II. An analysis of several heuristics for the traveling salesman problem. SIAM J. Comput. 1977, 6, 563–581. [Google Scholar] [CrossRef]
- Fiechter, C.N. A parallel tabu search algorithm for large traveling salesman problems. Discret. Appl. Math. 1994, 51, 243–267. [Google Scholar] [CrossRef]
- Helsgaun, K. An effective implementation of the Lin–Kernighan traveling salesman heuristic. Eur. J. Oper. Res. 2000, 126, 106–130. [Google Scholar] [CrossRef]
- Karabulut, K.; Tasgetiren, M.F. A variable iterated greedy algorithm for the traveling salesman problem with time windows. Inf. Sci. 2014, 279, 383–395. [Google Scholar] [CrossRef]
- Nguyen, H.D.; Yoshihara, I.; Yamamori, K.; Yasunaga, M. Implementation of an effective hybrid GA for large-scale traveling salesman problems. IEEE Trans. Syst. Manand Cybern. Part B 2007, 37, 92–99. [Google Scholar] [CrossRef] [PubMed]
- Paessens, H. The savings algorithm for the vehicle routing problem. Eur. J. Oper. Res. 1988, 34, 336–344. [Google Scholar] [CrossRef]
- Snyder, L.V.; Daskin, M.S. A random-key genetic algorithm for the generalized traveling salesman problem. Eur. J. Oper. Res. 2006, 174, 38–53. [Google Scholar] [CrossRef]
- Rego, C.; Gamboa, D.; Glover, F.; Osterman, C. Traveling salesman problem heuristics: Leading methods, implementations and latest advances. Eur. J. Oper. Res. 2011, 211, 427–441. [Google Scholar] [CrossRef]
- Gambardella, L.M.; Dorigo, M. Ant-Q: A reinforcement learning approach to the traveling salesman problem. In Proceedings of the Twelfth International Conference on Machine Learning, Tahoe City, CA, USA, 9–12 July 1995; pp. 252–260. [Google Scholar] [CrossRef]
- Pitzer, E. Applied Fitness Landscape Analysis. Ph.D. Thesis, Johannes Kepler Universität Linz, Linz, Austria, 2013. [Google Scholar]
- Fonlupt, C.; Robilliard, D.; Preux, P.; Talbi, E.G. Fitness Landscapes and Performance of Meta-Heuristics. In Meta-Heuristics, 1st ed.; Voß, S., Martello, S., Osman, I.H., Roucairol, C., Eds.; Springer: Boston, MA, USA, 1999; pp. 257–268. [Google Scholar] [CrossRef]
- Verel, S. Fitness landscapes and graphs: Multimodularity, ruggedness and neutrality. In Proceedings of the 11th Annual Conference Companion on Genetic and Evolutionary Computation Conference: Late Breaking Papers, Montreal, QC, Canada, 8–12 July 2009; Association for Computing Machinery: New York, NY, USA; pp. 3593–3656. [Google Scholar] [CrossRef]
- Englert, M.; Röglin, H.; Vöcking, B. Worst Case and Probabilistic Analysis of the 2-Opt Algorithm for the TSP. Algorithmica 2014, 68, 190–264. [Google Scholar] [CrossRef]
- Zhu, K.Q. A diversity-controlling adaptive genetic algorithm for the vehicle routing problem with time windows. In Proceedings of the 15th IEEE International Conference on Tools with Artificial Intelligence, Sacramento, CA, USA, 5 November 2003; pp. 176–183. [Google Scholar] [CrossRef]
- Wang, K.P.; Huang, L.; Zhou, C.G.; Pang, W. Particle swarm optimization for traveling salesman problem. In Proceedings of the 2003 International Conference on Machine Learning and Cybernetics, Xi’an, China, 5 November 2003; pp. 1583–1585. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VRP Type | Explanation |
|---|---|
| Single [2] and Multiple Depot [3] VRP | one or more depot |
| Two-Echelon [4] (Multi-Echelon [5]) VRP | with one or more additional satellites |
| Homogeneous [6] and Heterogeneous [7] VRP | same or different type of vehicles |
| Time Windows [8]: Single, Multiple [9], or Soft [10] | customers must be served within one of the intervals |
| Capacitated VRP [11] | capacity limit of the vehicles |
| Single Product or Multiple Product [12] VRP | one or more types of products |
| Inter-Depot Route [13] VRP | vehicles can return to any depot at the end of their route |
| Delivery, Pickup or Delivery and Pickup VRP [14] | movement of products: from the depot to the customers, or vice versa, possibly both |
| Periodic VRP [15] | periodic visit of customers |
| Traveling Salesman Problem [16] | only one vehicle (agent) visits customers (cities) create a tour where the objective is to minimize the length of the trip |
|
create the initial population while (termination criteria is not met) do calculate the fitness value of the population while (the next population is not completely created) do select parents apply crossover operator apply mutation operator end while end while |
|
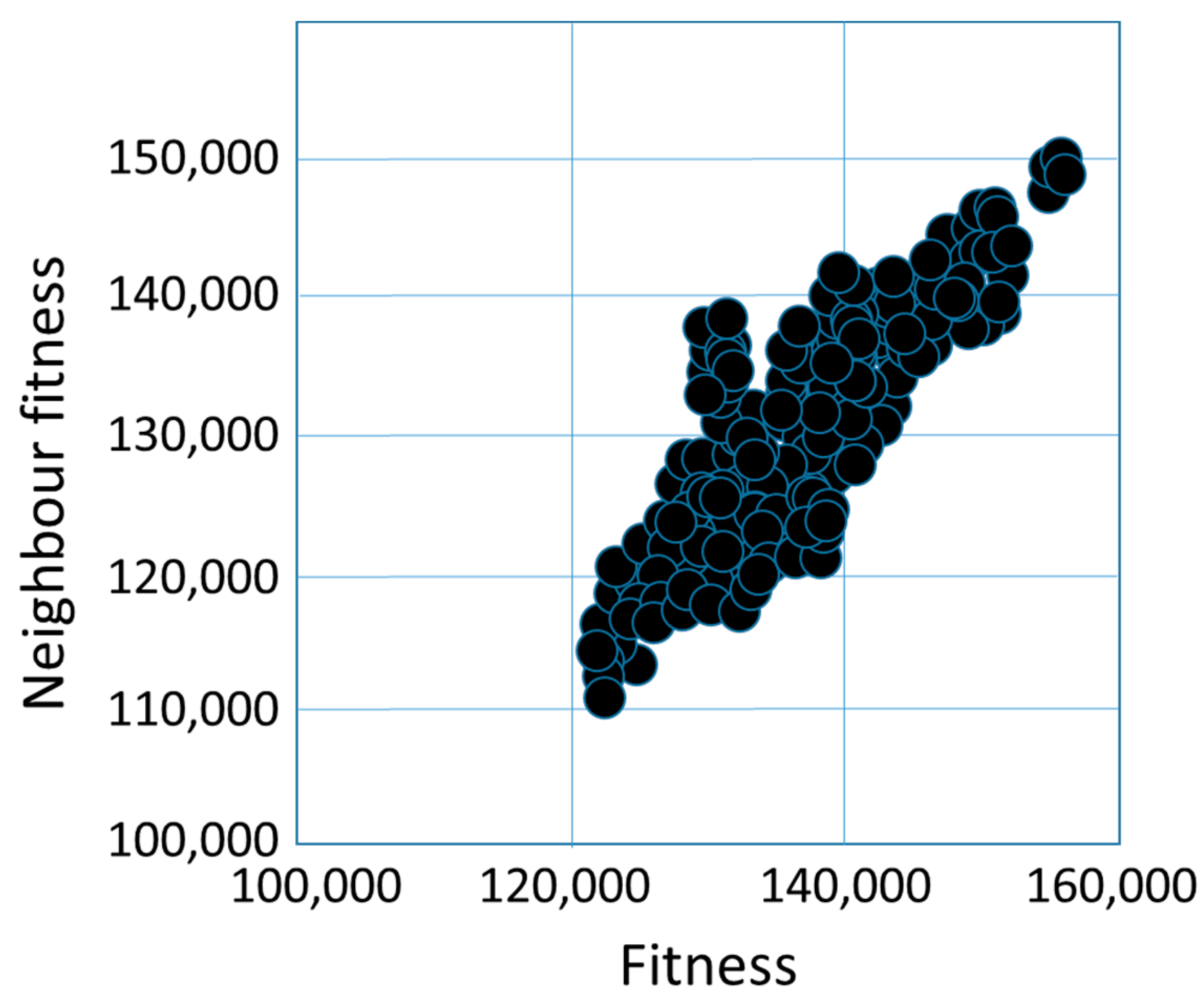
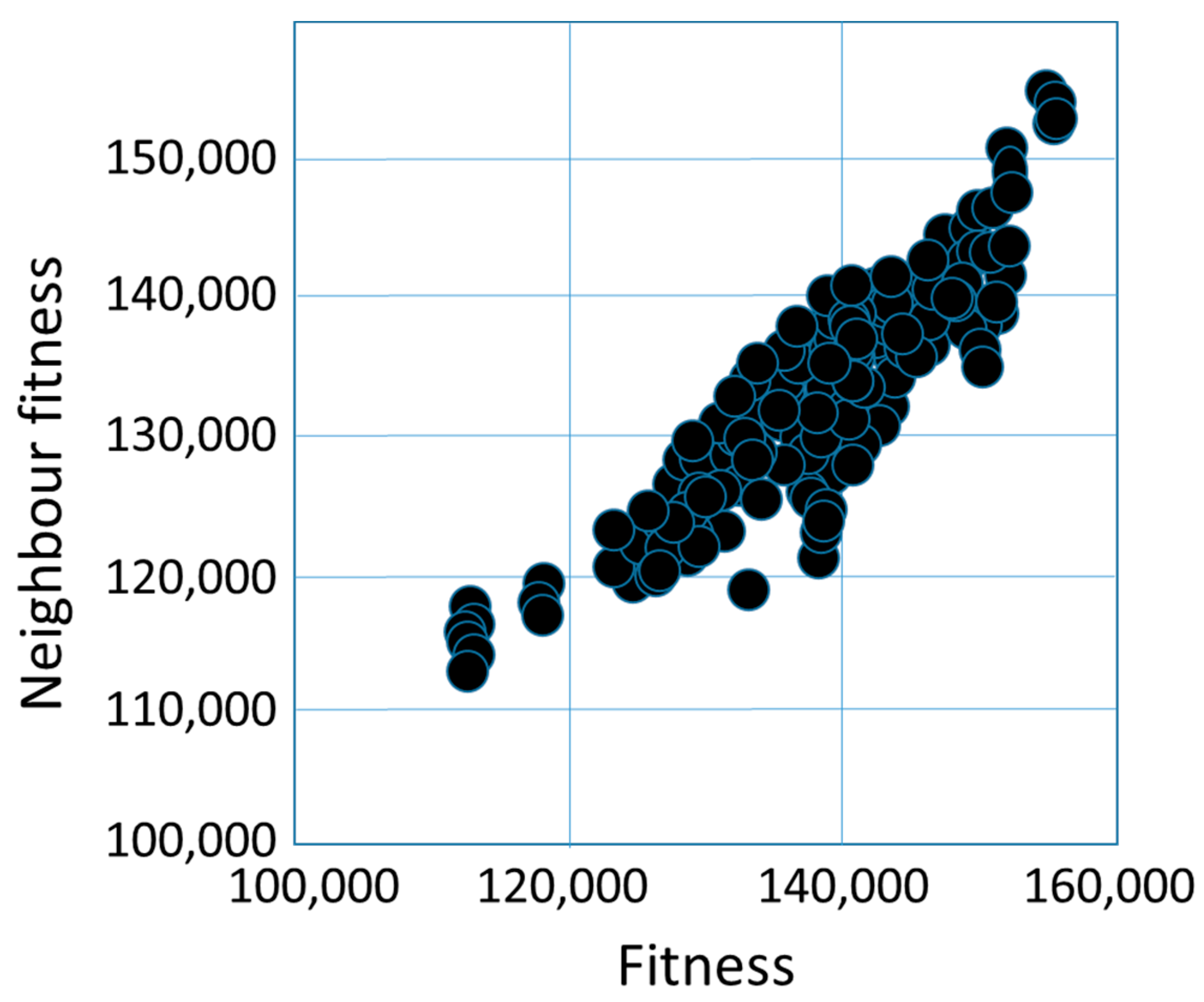
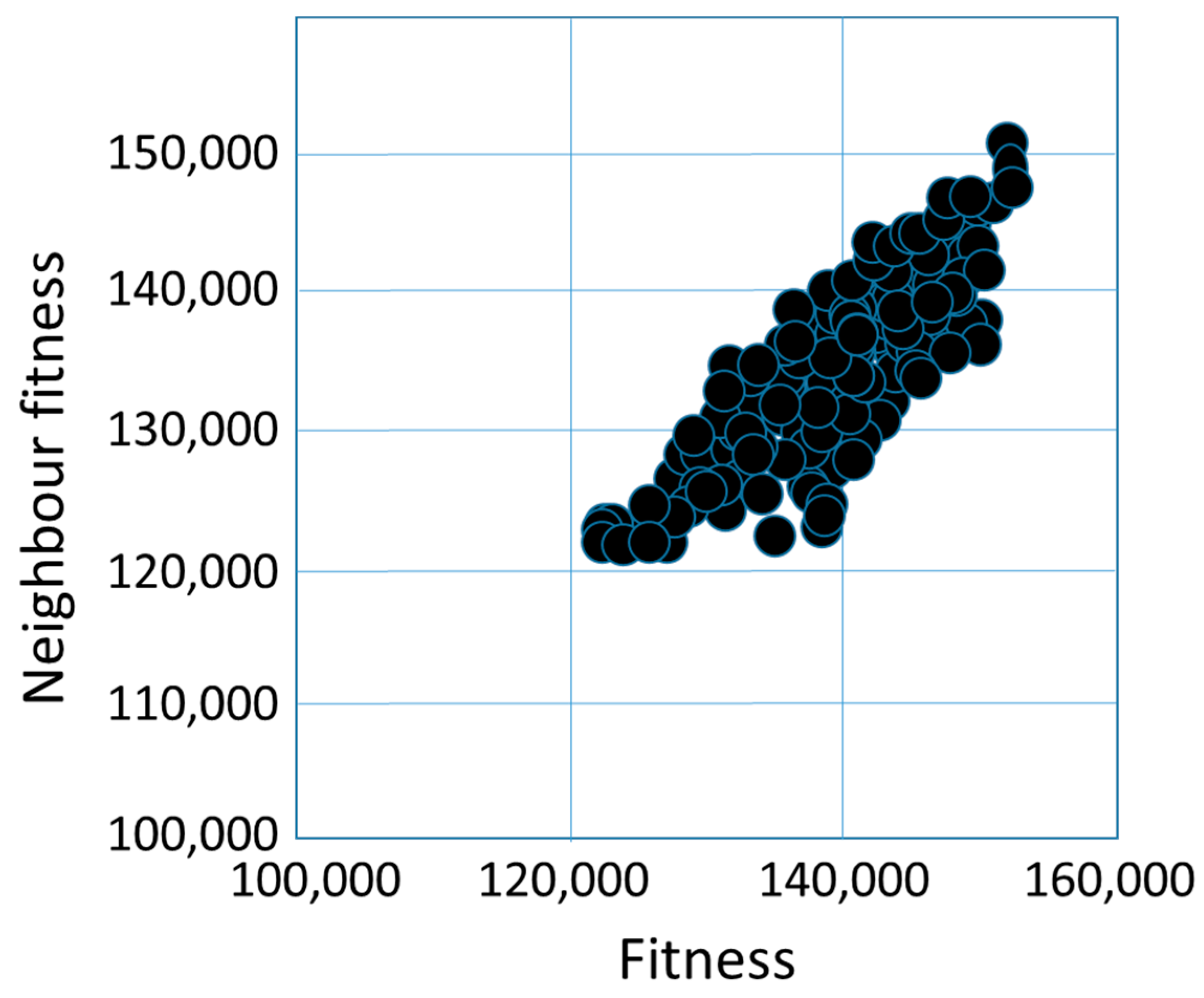
create the initial solutions (base solutions) generate the neighbors of the initial solutions (with 2-opt, CX,OX, or PMX operator) calculate the fitness of the base solutions and their neighbors illustrate the fitness cloud (x-axis means the fitness of the base solution, and y-axis means the fitness of the neighbor solution) calculate the distances between the base solutions and their neighbors calculate the , and values |
| 0 | 0 | 1 | 1 | 0 | 1 | |
| 1 | 0 | 0 | 0 | 1 | 1 | |
| 1 | 0 | 0 | 1 | 0 | 1 |
|
calculate fitness value for every object pairs; route = empty; process the edges in descending order by the fitness value: let (,) be the current edge; if is used already as a start point, drop this edge; if is used already as an end point, drop this edge; if there is a path fromto, drop this edge; if (,) is a valid candidate, than merge it to the current route; display route. |
| 2-opt | ||
|---|---|---|
| Lower Bound | Upper Bound | |
| Fitness values | 100,000 | 150,000 |
| Average of fitness distances | 2500 | 9000 |
| Average of Hamming distances | 27 | 35 |
| Average of basic swap sequence distances | 21 | 27 |
| FC-max | 110,000 | 150,000 |
| FC-mean | 110,000 | 150,000 |
| FC-min | 110,000 | 150,000 |
| Value | ||
| Strictly advantageous count | 5 | |
| Average advantageous count | 34 | |
| Average deleterious count | 54 | |
| Strictly deleterious count | 7 | |
| Order Crossover | ||
|---|---|---|
| Lower Bound | Upper Bound | |
| Fitness vales | 120,000 | 150,000 |
| Average of fitness distances | 2000 | 10,000 |
| Average of Hamming distances | 31 | 35 |
| Average of basic swap sequence distances | 22 | 29 |
| FC-max | 120,000 | 150,000 |
| FC-mean | 120,000 | 150,000 |
| FC-min | 120,000 | 150,000 |
| Value | ||
| Strictly advantageous count | 1 | |
| Average advantageous count | 22 | |
| Average deleterious count | 56 | |
| Strictly deleterious count | 21 | |
| CYCLE CROSSOVER | ||
|---|---|---|
| Lower Bound | Upper Bound | |
| Fitness values | 110,000 | 160,000 |
| Average of fitness distances | 1800 | 5000 |
| Average of Hamming distances | 24 | 32 |
| Average of basic swap sequence distances | 19 | 23 |
| FC-max | 110,000 | 150,000 |
| FC-mean | 120,000 | 160,000 |
| FC-min | 120,000 | 160,000 |
| Value | ||
| Strictly advantageous count | 0 | |
| Average advantageous count | 14 | |
| Average deleterious count | 76 | |
| Strictly deleterious count | 10 | |
| Partially Matched Crossover | |||
|---|---|---|---|
| Lower Bound | Upper Bound | ||
| Fitness values | 120,000 | 160,000 | |
| Average of fitness distances | 2000 | 7500 | |
| Average of Hamming distances | 29 | 35 | |
| Average of basic swap sequence distances | 22 | 28 | |
| Value | |||
| FC-max | 120,000 | 150,000 | |
| FC-mean | 120,000 | 150,000 | |
| FC-min | 120,000 | 150,000 | |
| Strictly advantageous count | 3 | ||
| Average advantageous count | 21 | ||
| Average deleterious count | 55 | ||
| Strictly deleterious count | 21 | ||
| Fitness Cloud | ||
|---|---|---|
| Efficient Operator | Weak Operator | |
| Fitness Cloud | 2-opt | PMX |
| Fc-max | 2-opt | PMX |
| Fc-mean | 2-opt | PMX |
| Fc-min | 2-opt | PMX |
| Strictly Deleterious Count Average Deleterious Count Average Advantageous Count Strictly Advantageous Count | 2-opt | OX, PMX |
| create_initial_population(P) scores = self.calculate_fitness() best = min(scores) for i in range(M) new_generation = [] for _ in range(P): p = random() if p < p1: item1 = selection(scores) new_generation.add(item1) else: if p < p2: (item1,item2) = crossover(scores) new_generation.add(item1) new_generation.add(item3) else item1 = mutation(scores) new_generation.add(item1) scores = calculate_fitness() s = min(scores) best = min(s, best) adjust (p1,p2,p3) return best |
| Method | A | B | C | D | E | F | G |
|---|---|---|---|---|---|---|---|
| N = 50, P = 100, D = 2, M = 100 | 31 | 17 | 19 | 6.0 | 6.1 | 6.4 | 5.9 |
| N = 100, P = 100, D = 3, M = 100 | 55 | 29 | 34 | 9.1 | 8.5 | 9.3 | 8.4 |
| N = 150, P = 100, D = 8, M = 100 | 81 | 46 | 50 | 11.6 | 9.7 | 12.3 | 11.4 |
| N = 200, P = 100, D = 15, M = 100 | 101 | 53 | 68 | 12.5 | 11.8 | 14.2 | 12.2 |
| N = 300, P = 100, D = 15, M = 100 | 165 | 76 | 81 | 17.0 | 14.2 | 19.2 | 17.1 |
| Method | A | B | C | D | E | F | G |
|---|---|---|---|---|---|---|---|
| N = 50, P = 100, D = 2, M = 100 | 0.001 | 24.1 | 0.001 | 0.001 | 0.8 | 1.2 | 9.2 |
| N = 100, P = 100, D = 3, M = 100 | 0.001 | 31.2 | 0.001 | 0.002 | 2.5 | 1.6 | 16.5 |
| N = 150, P = 100, D = 8, M = 100 | 0.001 | 75.2 | 0.002 | 0.008 | 3.5 | 3.7 | 35.6 |
| N = 200, P = 100, D = 15, M = 100 | 0.001 | 196 | 0.003 | 0.05 | 8.2 | 9.1 | 93.1 |
| N = 300, P = 100, D = 15, M = 100 | 0.004 | 524 | 0.007 | 0.45 | 26.3 | 39 | 320.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kovács, L.; Agárdi, A.; Bányai, T. Fitness Landscape Analysis and Edge Weighting-Based Optimization of Vehicle Routing Problems. Processes 2020, 8, 1363. https://doi.org/10.3390/pr8111363
Kovács L, Agárdi A, Bányai T. Fitness Landscape Analysis and Edge Weighting-Based Optimization of Vehicle Routing Problems. Processes. 2020; 8(11):1363. https://doi.org/10.3390/pr8111363
Chicago/Turabian StyleKovács, László, Anita Agárdi, and Tamás Bányai. 2020. "Fitness Landscape Analysis and Edge Weighting-Based Optimization of Vehicle Routing Problems" Processes 8, no. 11: 1363. https://doi.org/10.3390/pr8111363
APA StyleKovács, L., Agárdi, A., & Bányai, T. (2020). Fitness Landscape Analysis and Edge Weighting-Based Optimization of Vehicle Routing Problems. Processes, 8(11), 1363. https://doi.org/10.3390/pr8111363