Abstract
Vehicle routing problem (VRP) is a highly investigated discrete optimization problem. The first paper was published in 1959, and later, many vehicle routing problem variants appeared to simulate real logistical systems. Since vehicle routing problem is an NP-difficult task, the problem can be solved by approximation algorithms. Metaheuristics give a “good” result within an “acceptable” time. When developing a new metaheuristic algorithm, researchers usually use only their intuition and test results to verify the efficiency of the algorithm, comparing it to the efficiency of other algorithms. However, it may also be necessary to analyze the search operators of the algorithms for deeper investigation. The fitness landscape is a tool for that purpose, describing the possible states of the search space, the neighborhood operator, and the fitness function. The goal of fitness landscape analysis is to measure the complexity and efficiency of the applicable operators. The paper aims to investigate the fitness landscape of a complex vehicle routing problem. The efficiency of the following operators is investigated: 2-opt, order crossover, partially matched crossover, cycle crossover. The results show that the most efficient one is the 2-opt operator. Based on the results of fitness landscape analysis, we propose a novel traveling salesman problem genetic algorithm optimization variant where the edges are the elementary units having a fitness value. The optimal route is constructed from the edges having good fitness value. The fitness value of an edge depends on the quality of the container routes. Based on the performed comparison tests, the proposed method significantly dominates many other optimization approaches.
1. Introduction and Related Research
Vehicle routing problem (VRP) is a highly investigated discrete optimization problem. Since VRP is an NP-difficult task, the problem has already been solved by several approximation algorithms such as metaheuristics. Since 1959, when the first VRP article was published [], several publications have been published, and these publications solve different types of tasks, which may have different components, constraint factors, and objective functions. In the following article, these task types, constraints, and objective function components are presented.
Figure 1 illustrates the basic vehicle routing problem which consists of a single depot, several customers and vehicles, and a single product. The customers have product demands and the vehicles transport the product from the depot to the customers. The demands of the customers can be served by a single vehicle at the same time and all demands of all customers must be satisfied. The objective function is the minimization of the length of the vehicle routes. In the following, we present the most common VRP types. Table 1 indicates the VRP types, which contribute to our VRP system.
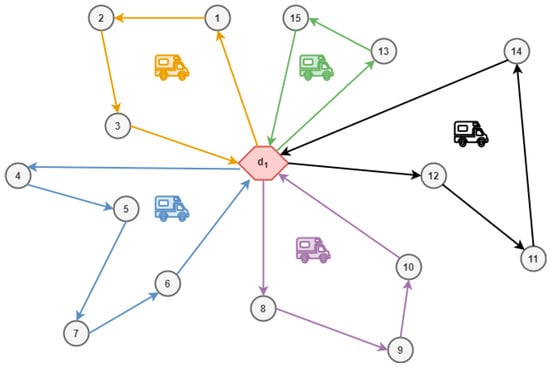
Figure 1.
The basic vehicle routing problem (VRP).

Table 1.
The VRP types that contributed to our VRP system.
It is possible that during VRP, certain quantities are given with approximations, and not with crisp values, such problems are stochastic VRP [], fuzzy VRP [].
Many types of vehicles can be used in a transport task. The latest trend in the literature is the use of environmentally friendly vehicles [] and electric vehicles []. Another new trend is, for example, the VRP with profits and consistency constraints [], feeder VRP [], cumulative capacitated VRP [], VRP with cross-docking [], VRP with perishable food products delivery [], risk constrained VRP [], VRP with delivery and installation vehicles [], clustered VRP [], VRP with trailers and transshipments [], VRP with traffic congestion [], and dynamic VRP [].
Metaheuristics have many applications, such as engineering, materials science, mechanical science, informatics, and economics. When developing a new metaheuristic or making modifications to existing algorithms, researchers compare the efficiency of the algorithm with classical metaheuristics based on runtime results or even verify the efficiency of the developed algorithm with a benchmark data set. Thus, most researchers use only test results to prove the effectiveness of their algorithms.
In article [], the authors solve the job shop scheduling problem and analyze the fitness landscape of the task. After measuring the distances between the solutions, a statistical fitness landscape analysis is performed, and the result of the autocorrelation calculation is analyzed.
Literature survey articles in connection with fitness landscape analysis also appear, for example, article []. In article [], the authors also present the main fitness landscape analyzation techniques. In article [], the fitness cloud is discussed. Bordering fitness, evolvability concepts are defined. The article does not present any test results, it only discusses the concepts.
The efficiency of the 2-opt (edge-swap) and city swap operators in the case of the traveling salesman problem is examined in literature []. Test results are illustrated with different figures by the authors, such as the efficiency of the 2-opt and city swap operators, used to analyze the distances taken from the global optimum.
The analysis of the fitness landscape of the vehicle routing problem is presented in [] article. The authors report on important concepts such as fitness landscape, neighborhood, basin of attraction, neutrality. Information theory concepts such as information content, partial information content, and density-basin information are also reported. The operators of the genetic algorithm are also described in the article, these are swap, inversion, insertion, displacement, partially matched crossover (PMX), cycle crossover (CX).
As the operator set used in the optimization greatly affects the efficiency of the algorithm, it may also be necessary to analyze the efficiency of the search operators of the algorithms to determine whether a particular algorithm is effective in solving the task. The purpose of the fitness landscape is to analyze the complexity and the efficiency of the applicable operators.
Our research is focused on a fitness landscape analysis technique, the fitness cloud. In the fitness landscape analysis, we use classical operators of the genetic algorithm such as the order crossover, partially matched crossover, cycle crossover, and the 2-opt operator (as a mutation operator).
Based on the fitness cloud results, we found it worthwhile to introduce a new technique, the edge weighting-based optimization. The edge weighting-based optimization technique was tested on one of the simplest types of VRP on the classical traveling salesman problem.
The remainder of the paper is organized as following: Section 2 includes the theoretical preliminaries: traveling salesman problem, genetic algorithm, search space in traveling salesman problem, and the fitness cloud. Section 3 presents the proposed analysis and optimization methods, which are the following: proposed neighborhood operators, measuring distances between two solutions, key performance indicators in our fitness cloud analysis, edge weighting-based optimization for traveling salesman problem. Section 4 describes the results and discussion, which consists of the followings: the prototype vehicle routing system, fitness cloud analysis results, efficiency comparison of the proposed genetic algorithm method, test results for the proposed GA (Genetic Algorithm) optimization. The last section of the paper contains conclusions and future work.
2. Theoretical Preliminaries
2.1. Traveling Salesman Problem
The goal of the traveling salesman problem (TSP) family is to find the shortest Hamiltonian cycle in a weighted graph. The Hamiltonian cycle visits each vertex exactly once. The length of the path is calculated with the sum of the corresponding edge weights. The problem to build an optimal route corresponds to find an optimal permutation of the vertices, creating a minimal length route. There are two different problem domains related to TSP. In the case of the decision problem (DTSP), the task is to determine whether there exists a Hamiltonian cycle of length not greater than a pre-given value or not. In the case of the optimization problem (OTSP), the goal is to find the Hamiltonian cycle with minimal length. In this case, the shortest Hamiltonian cycle problem is usually formulated as a linear programming problem []. The OTSP is a NP-hard problem [] and the cost of a brute-force algorithm to solve this problem is in O(N!). Thus, some heuristic method should be used to find an approximation of the global optimum. The heuristic optimization of the TSP is one of the most widely investigated combinatorial optimization problems.
In the literature, we can find a rich variety of heuristic methods to solve TSP problems. A detailed analysis and performance comparison of the main heuristic methods (nearest neighbor [], nearest insertion [], Tabu search [], Lin-Kernighan [], greedy [], Boruvka [], savings [], genetic algorithm [], swarm optimization) can be found among others in [,]. Based on the results presented in that analysis: (a) the fastest algorithms are the greedy and savings method, but they provide an average tour quality; (b) the nearest neighbor and nearest insertion algorithms are dominated by the greedy and savings methods both in time and tour quality factors; (c) the best route quality can be achieved by the application on 3-opt/5-opt methods (Lin-Kernighan and Helsgaun); (d) considering both the time and tour quality, the chained Lin-Kernighan algorithm shows the best performance; (e) the evolutionary and swarm optimization methods are dominated by the k-opt methods both in time and tour quality factors; (f) the tour-merging methods applied on the chained Lin-Kernighan algorithm can improve the tour quality at some level, but it requires a significant more time cost.
Regarding the applied optimization methodology, we can distinguish two main groups of the OTSP algorithms. The first approach uses an incremental construction method. In every iteration step, a new node is added to the currently optimal route. In the case of the second approach, the methods take an initial route and perform additional refinement steps. Within a refinement step, similar to the construction algorithm, the neighborhood is tested for the best local optimum.
2.2. Genetic Algorithm
Genetic algorithm [] is a general optimization algorithm. The algorithm maintains a population of solutions. In the genetic algorithm, the elements of a population are called individuals. After generating the initial population, the algorithm attempts to improve the population in each iteration with operations such as mutation and crossover. The mutation maintains a small change in each individual. An example of such a mutation is the 2-opt operation. During crossover (such as cycle crossover, partially matched crossover, order crossover etc.), two children individuals are usually created from two parent individuals. In each iteration, it is even important to decide which individuals will be transferred to the population of the next iteration, this is called selection (Table 2).
Table 2.
Pseudo-code of the genetic algorithm.
2.3. Search Space in TSP
Optimization metaheuristics are based on navigation iterations in the search space. The body of the iteration cycle is based on the following elements [,]:
- The set of possible states denoted by . The search space can be discrete or continuous.
- Distance-based neighborhood defined by an operator. This is applied to the current state point to generate the next state point. For example, for discrete problems, the edge swap (2-opt) operator. It can be written with the following notation: .
- Fitness value, objective function denoted by . This gives the fitness value for each possible status point (solution). Usually, fitness is a real number. For most optimization tasks, we use a single fitness value. However, in multi-object optimization, the fitness value may be a vector.
- Encoding and representation: Although encoding and representation are not formally part of the fitness landscape, they are important factors. This is because representation is part of the evaluation of fitness value, and mutation operators depend on representation.
- Transition rule (transition rule = pivoting rule = selection strategy) that selects the next state point from the potential neighboring state points.
- Stop condition, which determines when the algorithm terminates.
- The initial state point is either a randomly generated solution (state point) or a solution given by some construction heuristic.
The formal description of the fitness landscape can be summarized as follows []:
Relationship between fitness landscape analysis and optimization algorithms is the following: optimization algorithms look for a good search space state in a relatively low (minimal) time, while fitness landscape analysis provides a good insight into the problem in a minimal amount of time. Looking into the fitness landscape can be a good technique for developing new optimization algorithms [].
The purpose of fitness landscape analysis is exploring the geometric properties of the fitness landscape, showing the efficiency of local search algorithms. Mapping this property helps to draw the following conclusions []:
- Comparison of differences between two search spaces: a task with two or more different representation methods: different representation, different mutation operator, different objective function, etc.
- Algorithm selection: analysis of the global geometry of the search space (landscape).
- Tuning the parameters.
- Controlling parameters during the running.
2.4. Fitness Cloud
A fitness cloud is a figure that contains the fitness value of the “base” state point and the fitness values of the neighboring states of the “base” state point (bordering fitness) [,].
For each search space state point (solution candidate), it represents a point in the coordinate system, where the x-axis represents the fitness value of the “base” state and the y-axis represents the fitness value of the neighbor state of the “base” state point. Formally, , where the fitness value of the “base” state is denoted by , while the fitness value of the “adjacent” (bordering) state is denoted by . We introduce the sets , which can be defined as follows []:
Let be the fitness value of the “base” state point, be the associated value, be the associated value, and be the associated value.
Then, we can perform the following study based on it for a maximization task []:
- : If the fitness value of the “base” state point is below , then the bordering fitness values are better, so we call it strictly advantageous.
- : If the fitness value of the “base” state point is between and , it is called average advantageous because the bordering fitness values are higher than theirs.
- : The “base” fitness point value between and is called deleterious because their average bordering fitness value is lower than the “base” fitness point value.
- : A “base” fitness value above is called strictly deleterious because their bordering fitness is always lower than themselves.
3. Proposed Analysis and Optimization Methods
3.1. Proposed Neighborhood Operators
The structure of the fitness landscape is greatly influenced by the neighborhood operator, as the main goal of fitness landscape analysis is to prove the efficiency of the algorithms. Four operators were used in the analyses, as follows: 2-opt, cycle crossover, order crossover, partially matched crossover.
Figure 2 presents the 2-opt [] operator. This operator operates on one solution. A section is chosen, and the elements are exchanged. This means an exchange of two edges.
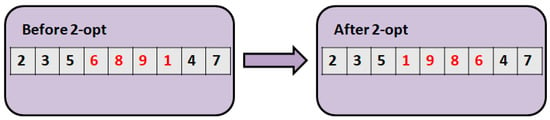
Figure 2.
The 2-opt.
Figure 3 illustrates the cycle crossover (CX) []. During this method, we search for cycles. Initially, the first offspring gets the first position of the first parent, and the second offspring gets the first position of the second parent. In our example, the first offspring gets 2 and the second offspring gets 7. After that, the second offspring has 7, so the first offspring must also have 7. Therefore, the first offspring gets 7 in the appropriate position, and the second offspring gets 4 in the appropriate position. After that, the (4,5) pairs are chosen, then the (5,1), (1,3), (3,2). After (3,2) is chosen, the circle closed. As the last step, the first offspring gets the numbers from the second parent in the remainder position, and the second offspring gets the numbers from the first parent.
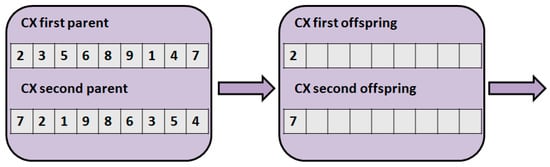
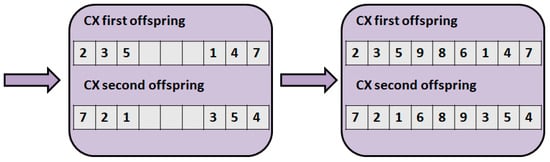
Figure 3.
The cycle crossover (CX).
Figure 4 illustrates the order crossover (OX) []. In the case of this crossover, a fitting section is determined. The length and the position of the fitting section of the two parents must be the same. After that, the parents are copied, these are initially the two offsprings. In the first offspring, we look for the numbers that the second parent fitting section contains. These numbers are deleted, indicated with H letter in Figure 4. In the second offspring, we look for the numbers that the first parent fitting section contains. After that, the holes (H letters) are pushed up to the fitting section. In the fitting section, the holes are replaced with the following way: the first offspring gets the fitting section of the second parent, and the second offspring gets the fitting section of the first parent.
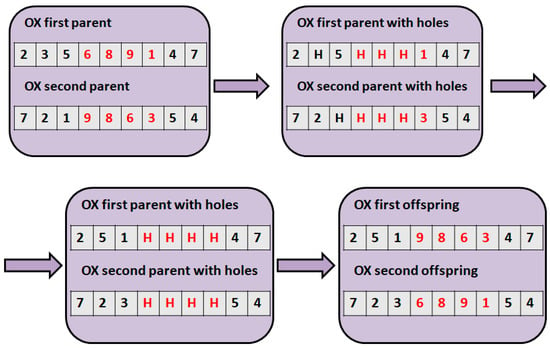
Figure 4.
The order crossover (OX).
Figure 5 illustrates the partially matched crossover (PMX) [] technique. In the case of this technique, a fitting section is determined. These fitting sections of the two parents must have the same length and positions. After that, pairs are created from the fitting section. In this example, the pairs are the followings: (9,6), (1,3), and (4,5). The creation of the offspring is the following: we copy the parents. After that, the elements of the pairs are exchanged. In our example, the 6 is exchanged with 9, the 1 is exchanged with 3, and the 4 is exchanged with 5.
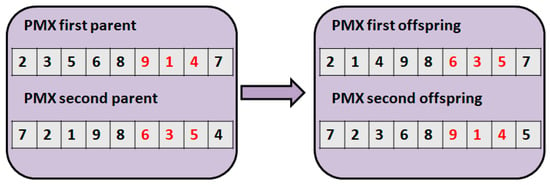
Figure 5.
The partially matched crossover (PMX).
3.2. Measuring Distances between Two Solutions
For measuring distances between two state points, we use the following three techniques: fitness distance, Hamming-distance, and basic swap sequence distance. Figure 6 illustrates an example of measuring distances between two state points.
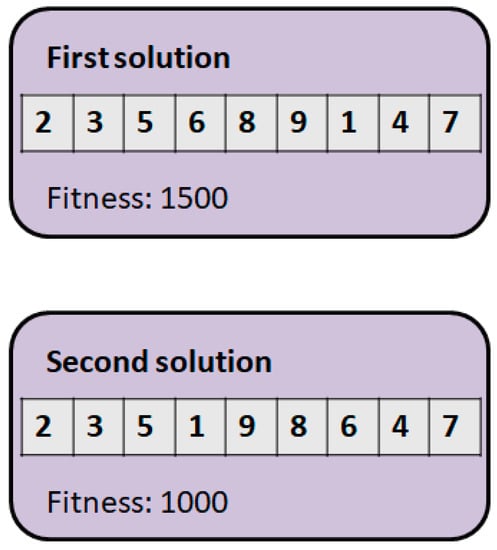
Figure 6.
The example of measuring distances between two solutions (state points).
The fitness distance is the absolute value of the fitness value differences between the two state points. In our example (Figure 6), |1500−1000| = 500 will be the value, because the fitness value of the first solution is 1500 and the fitness value of the second solution is 1000.
The Hamming distance [] is the number of differences in the representation of the two state points. In our example (Figure 6), the two solutions differ in the following positions: position 4, position 5, position 6, position 7. These represent the following pairs: position 4: (6,1), position 5: (8,9), position 6: (9,8), position 7: (1,6).
The basic swap sequence [] is the number of exchanges between two state points. In our example (Figure 6), we can get solution 2 from solution 1 with a single edge change (2-opt operator). This is the reverse of the sequence (6,8,9,1).
3.3. Key Performance Indicators in Our Fitness Cloud Analysis
In this chapter, we present fitness cloud indicators and our proposed evaluation strategy. The following indicators were used:
Fitness values (for the entire cloud) of the entire solutions (base and neighbor) are evaluated. Fitness values, because we have a minimization task, need to be small but move around a large range of values so they can effectively map the search space.
Average of fitness distances, where the distances were taken from the base and neighbor solutions, and then these distances were averaged to obtain an average distance for each base solution.
Average of Hamming distances shows aggregated distances, also from base and neighbor solutions, while the average of basic swap sequence distances was also calculated. The average Hamming and basic swap sequence distances should be large to map the effective search space.
FC-max, FC-mean, and FC-min values are determined for all base points. FC-max values are the maximum values of the neighbor solutions, while FC-mean values are the means of the neighbors and FC-min values are the min of the neighbor fitnesses. The FC-max values since minimization is a task, so the lower the values, the better the operator. FC-mean measures the average of the bordering solution, the goal is to obtain solutions with good average fitness value (low fitness value in case of minimization task). The FC-min value is the maximum fitness of the bordering solutions (in the case of a minimization task), this value can be high, so the operator can better map the search space.
The strictly advantageous count indicates that the fitness values of the neighbors are lower than the fitness value of the given solution. The higher this value, the better the operator.
An average advantageous count indicates that the bordering fitness values are better than the base fitness values on average. The higher this value, the better the operator.
Average deleterious count indicates that the bordering fitness values are worse than the base fitness values on average. If this value is 0 or very small, the operator is efficient.
Strictly deleterious count indicates that the bordering fitness values are worse than the base fitness values. If this value is 0 or very small, the operator is efficient. The calculation of the key indicators can be seen in Table 3.
Table 3.
Calculation of the key indicators.
3.4. Edge Weighting-Based Optimization for Traveling Salesman Problem
The heuristic methods for TSP usually are based on the idea to generate a route population and award such route sections which are contained in routes with high fitness value. In GA, for example, the selection and crossover operators are used to highlight important route sections. The GA method starts with the generation of the initial population and then it performs an iteration to improve the population by generating new items using the standard GA operators.
On the other hand, our analysis of the fitness cloud has been proved that the classical crossover operations are not the best operators to improve the fitness value. Thus, many variants of evolutionary algorithms were proposed to involve some variant of the 2-opt operators besides the classical crossover, selection, and mutation operators.
The main motivation behind our proposed model is to improve the selection process of the optimal route sections using a more direct way. In GA, the route sections are somehow latent, the selection depends on many random elements. In contrast with this approach, the proposed model provides an explicit route segment selection.
In this section, we present a novel approach which can provide similar flexibility as the 2-opt operator. The proposed model is based on the following background ideas:
- Application of edges as elementary units in the route construction process; this approach provides higher flexibility.
- Introduction of a fitness value also for the elementary, edges based on their role in routes with high fitness values. The approach to score elementary units can be found among others in the Bayes-classifiers where every component attribute is assigned to a probability weight value.
The proposed algorithm investigates only short route sections connecting neighboring elements. The importance of a section is measured with the fitness of the container routes. During the construction of routes, the engine prefers the neighborhoods with high fitness values.
The proposed optimization model is based on the following formalism.
- : set of objects (locations);
- : set of distances between the objects;
- : set of closed permutations, closed routes on
- : the length of closed route ;
- : the fitness of closed route .
We introduce the notation to denote the case that the distance between o1 and o2 in a given route is smaller than .
We can convert the TSP problem into an information table where is the set of attributes.
The attribute shows the nearness of the two objects and . The attribute is met if is in the neighborhood of in the route.
Example
Let us take 4 objects and the population contains the following three routes: , , . If the neighborhood means direct connections (1-NN case), then we have the following information table (Table 4).
Table 4.
Information table structure.
One parameter of the model is the size of the neighborhood. Usually, we take a small size between 3 and 5.
We assign a fitness value also for the attributes, where this value denotes the chance that the corresponding items are in the neighborhood, and a route with high fitness value contains the corresponding edge . Having these attribute level fitness values, we should use the edges with high values to construct an optimal route.
The attribute level fitness value is high if is frequent in routes with high fitness values, thus we use the following formula to calculate the attribute level fitness:
where denotes a weight value. In the simplest, non-weighted case, . In the case of the weighted model, depends on the distance between the two objects, the larger is the distance, the smaller is the weight value.
The condition means that and are in a neighborhood in the given route. The symbol means here an aggregation operator. Based on our experience, either the Sum or the Max operators are the best candidates.
For calculation of the values, we use a training set of the routes. The routes can be generated randomly or by using some heuristics. The optimal route candidate is generated in such a way that as many good edges as possible will be included (Table 5).
Table 5.
Heuristic algorithm for route generation.
4. Results and Discussion
4.1. The Prototype Vehicle Routing System
Our complex vehicle routing problem, which is illustrated in Figure 7, is a multi-echelon system. Our data set is artificially generated. The system consists of depots (4 counts, the coordinates are between [0, 100]), satellites, and customers (15 counts, the coordinates are between [600, 700]). In our system, there are first (10 counts, the coordinates are between [200, 300]) and second level satellites (10 counts, the coordinates are between [400, 500]). The products are transported from the depots to the first level satellites, then to the second level satellites, after that to the customers, because the customers have product demands, which vary along with customers. In each level, there are different types of vehicles (2 types of vehicles per level). Our system consists of only one product type. Each vehicle has a different capacity limit (for the products) between [10,000, 50,000], and the vehicles have different fuel consumptions [10, 100]. In our system, not only the travel distances between the locations (which depends on the coordinates of the locations) are important, but also the travel time (between [10, 100]) and the route status between the nodes (between [100, 500]). These factors vary along with locations and vehicles. In connection with the delivery of the products, we have also defined some temporalities that occur in the nodes. These temporalities are the following: the loading (between [30, 50]) and unloading time (between [30, 50]), and the administration time (between [30, 50]). These components vary along with locations and vehicles. Our system also contains cost in connection with the transportation of products. These costs are the following: loading (between [10, 50]) and unloading cost (between [10, 50]), administrative (between [10, 50]), and quality control cost (between [10, 50]). These costs vary along with locations and vehicles. Our objective function is not only the minimization of the length of the route, but the minimization of the fuel consumption of the vehicles, maximization of the route status, minimization of the route time, and minimization of the missed (unvisited) customers. Based on our analysis, the typical size (the number of nodes) of the related TSP problems is near 100. This means that the optimization algorithm should focus on the middle-size problem domain.
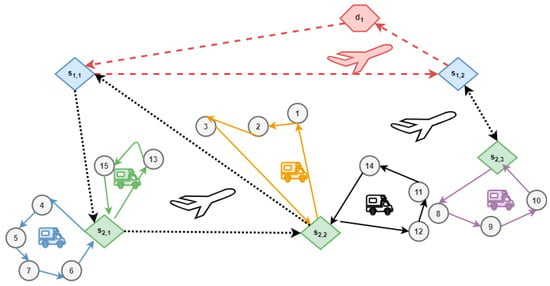
Figure 7.
The multi-echelon system.
4.2. Fitness Cloud Analysis Results
In this section, the fitness cloud of our multi-echelon VRP model in the case of different operators are presented. During the creation of the fitness cloud, we randomly select solutions and then create their neighbors. The representation of the solutions and the neighbors, their relation to them is important in the analysis. The following analysis techniques were used: fitness cloud, Fc-max, Fc-min, Fc-mean, strictly advantageous count, average advantageous count, average deleterious count, strictly deleterious count. The following operators are analyzed: 2-opt, order crossover (OX), cycle crossover (CX), partially matched crossover (PMX).
Figure 8 illustrates the fitness cloud for the 2-opt operator. Fitness values range from 100,000 to 150,000. Neighbors with lower fitness value solutions also have lower fitness values, while those with higher fitness value solutions also have higher fitness values. Table 6 illustrates that the average of fitness distances between the solutions ranges between 2500 and 9000 values, and the average of Hamming distances ranges between 27 and 35, and the averages of basic swap sequence distances are between 21 and 27. Averages were calculated for the total fitness cloud. We calculated the averages with the following way: we looked at the distance of each solution from the other solutions and averaged this.
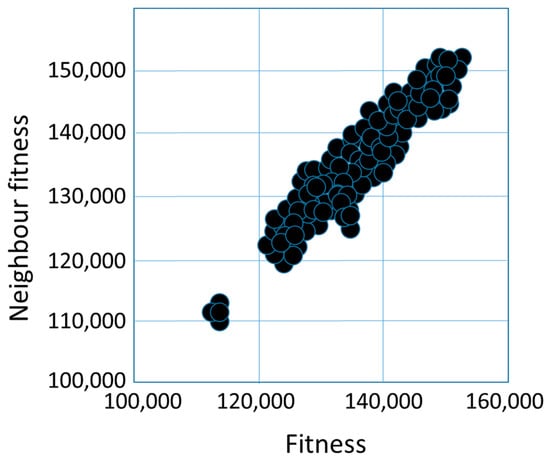
Figure 8.
The fitness cloud for 2-opt operator.
Table 6.
2-opt distances results.
Figure 9 illustrates the fitness cloud for the OX operator. Fitness values range from 120,000 to 150,000. Here, too, it is typical that the fitness values of the neighbors of solutions with lower fitness values are also lower, while the fitness values of the neighbors of solutions with higher fitness values are also higher. Table 7 illustrates that the average of fitness distances between the solutions ranges between 2000 and 10,000 values, and the average of Hamming distances ranges between 31 and 35, and the averages of basic swap sequence distances are between 22 and 29.
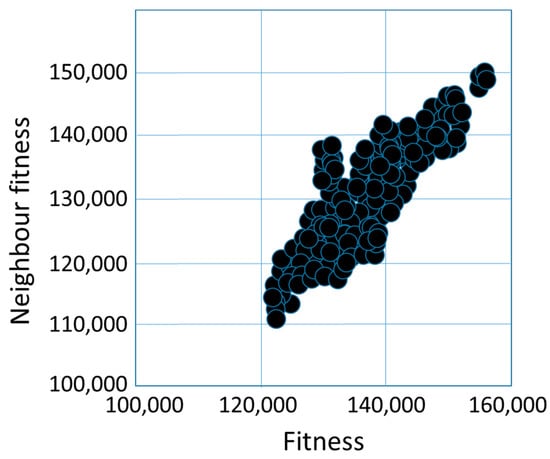
Figure 9.
The fitness cloud for order crossover operator.
Table 7.
Order crossover distances results.
Figure 10 illustrates the fitness cloud for the CX operator. Fitness values range from 110,000 to 160,000. Here, too, it is typical that the fitness values of the neighbors of solutions with lower fitness values are also lower, while the fitness values of the neighbors of solutions with higher fitness values are also higher. Table 8 illustrates, that the average of fitness distances between the solutions ranges between 1800 and 5000 values, and the average of Hamming distances ranges between 24 and 32, and the averages of basic swap sequence distances are between 19 and 23.
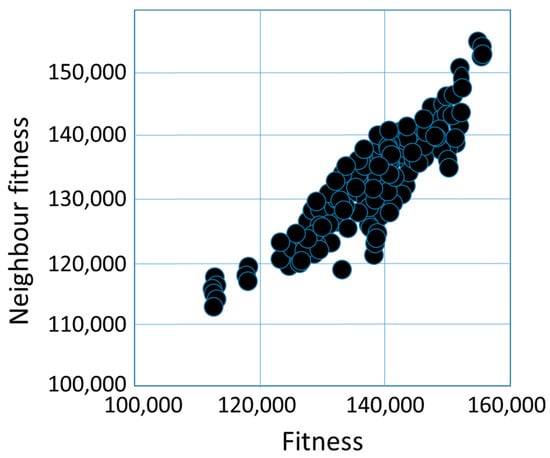
Figure 10.
The fitness cloud for cycle crossover operator.
Table 8.
Cycle crossover distances results.
Figure 11 illustrates the fitness cloud for the PMX operator. Fitness values range from 120,000 to 160,000. Here, too, it is typical that the fitness values of the neighbors of solutions with lower fitness values are also lower, while the fitness values of the neighbors of solutions with higher fitness values are also higher. Table 9 illustrates, that the average of fitness distances between the solutions ranges between 2000 and 75,000 values, and the average of Hamming distances ranges between 29 and 35, and the averages of basic swap sequence distances are between 22 and 28.
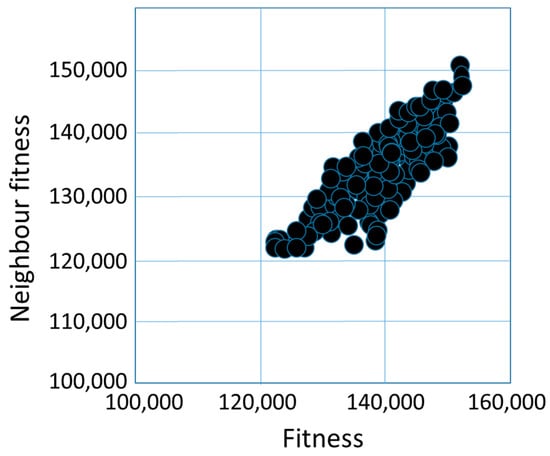
Figure 11.
The fitness cloud for partially matched crossover operator.
Table 9.
Partially matched crossover distances results.
FC-max values are lower for solutions with lower fitness values, while FC-max values are also higher for solutions with higher fitness values for all operators.
The FC-mean values are lower for solutions with lower fitness values, while the FC-mean values are also higher for solutions with higher fitness values for all operators.
The FC-min values are lower for solutions with lower fitness values, while the FC-min values are also higher for solutions with higher fitness values for all operators.
Strictly advantageous count values was the best for 2-opt, which means that the fitness values of the neighbors are lower than the fitness value of the given solution, which proves the goodness of the operator, since our task is a minimization problem.
The average advantageous count values for 2-opt is the highest, which means, that the bordering fitness values are better than the base fitness values on average.
The average and strictly deleterious counts are high for partially matched crossover, order crossover, and cycle crossover, which means that these operators are worse than 2-opt. The strictly deleterious count was high in the case of partially matched crossover and order crossover.
For the fitness cloud measurement, we summarize the results in Table 10. According to the table, the 2-opt operator became efficient, the partially matched crossover operator according to this measurement did not become as efficient as the other operators (order crossover, partially matched crossover).
Table 10.
Fitness cloud results.
According to the fitness cloud, 2-opt fitness values are the lowest values (100,000–150,000) and partially matched crossover (120,000–160,000) values are the highest, so in the table, we denote that 2-opt is efficient, and PMX is not so efficient based on the fitness cloud illustration.
Typically, solutions with lower fitness values also have lower FC-max values, while solutions with higher fitness values also have higher FC-max values. For solutions with a lower fitness value, the FC-mean values are also lower, while for solutions with a higher fitness value, the FC-mean values are also higher. For solutions with lower fitness values, the FC-min values are also lower, while for solutions with higher fitness values, the FC-min values are also higher. According to them, the 2-opt operator became the best based on these measurements, the partially matched operator the worst, so in the table we denote that 2-opt is efficient in terms of FC-max, FC-mean, and FC-min, while PMX is weak in terms of these measurement strategies.
The strictly deleterious count, average deleterious count, average advantageous count, and strictly advantageous count values are nearly the same, the average advantageous count values are high for all operators, so each operator is efficient, also indicated in Table 7.
4.3. Efficiency Comparison of the Proposed Genetic Algorithm Method
Besides the simple phase route generation, we have developed an evolutional version too. In this variant, many generations are constructed using the previous generation as base set. In the proposed algorithm, first, we generate the ordered list of the edges. In the next step, we construct a random noise vector which is used to relocate some edges in the list. This means that some edges with lower values will get a higher priority while some shorter edges are assigned to lower priority. This step can be used to add random elements into the route construction process.
Having a relocation vector, the corresponding route can be generated unambiguously. In the evolutionary process, these relocation vectors are considered as gene description vectors. The population consists of a set of relocation vectors. In the iteration phase, we apply the usual selection, crossover, and mutation operators to generate the consecutive population generations.
In the corresponding GA process, the following parameters are used to adjust the algorithm:
- N: number of the nodes;
- P: size of the population ;
- M: number of the generations;
- d: relocation size;
- p1: probability of selection;
- p2: probability of crossover;
- p3: probability of mutation.
The relocation size denotes the largest distance in the relocation both forward or backward. In the implemented algorithm, the (p1,p2) values are adjusted dynamically, their values are decreased if the engine could not improve the best route length in the current time window (Table 11).
Table 11.
The applied algorithm.
4.4. Test Results for the Proposed GA Optimization
The proposed optimization algorithms were implemented in the Python programming language. The benefit of the Python language is the availability of many different TSP solution methods on the Internet.
We involved the following methods in the efficiency comparison tests:
- random generation (A);
- standard GA evolutionary algorithm (B);
- nearest neighbor construction algorithm (C);
- greedy best first construction algorithm (D);
- Lin-Kernighan 2-opt refinement algorithm (E);
- proposed edge weighting single-phase (construction) algorithm (F);
- proposed edge weighting evolutionary algorithm (G).
In the tests, according to our preliminary analysis, we used training sets in size range 50 and 200. We have used synthetic data; thus, we could generate data sets of different shapes in an easy way. The related test results are presented in Table 12. The corresponding execution time values are given in Table 13.
Table 12.
Route length comparison of the TSP (Travelling Salesman Problem) algorithms.
Table 13.
Execution time comparison of the TSP algorithms (in sec).
In the table, the following parameter notations are used:
- N: number of nodes;
- P: size of the population;
- D: noise variability (only for G);
- M: number of generations.
The experiments show that the proposed GA variant dominates the standard GA, NN, and greedy algorithms in general. An interesting result is that our method can provide better results as the efficient Lin-Kernighan method for middle-sized datasets (Figure 12 and Figure 13).
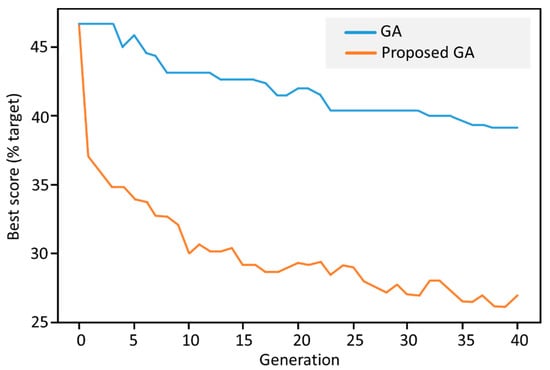
Figure 12.
Convergence of the GA (Genetic Algorithm) method and the proposed method.
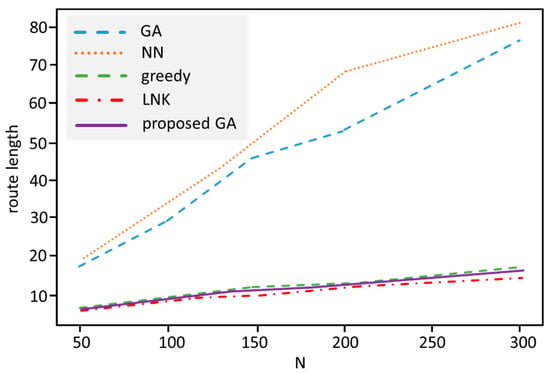
Figure 13.
Route length in dependency of problem size for the TSP algorithms.
The above described approach can support the optimization of logistics systems. The design and optimization of logistics systems and supply chain solution have become more and more important because of the increased globalization of manufacturing and service processes. The design of logistics systems includes a wide range of design tasks, like layout planning, scheduling, queueing, or routing. Traveling salesman problem represents one of the core design problems of logistics systems, therefore our proposed GA optimization can improve the efficiency of solution algorithms both for internal routing problems (like in-plant, milk-run-based, material supply) and for external routing of transportation equipment.
5. Conclusions and Future Work
In this paper, we have analyzed an approach to use fitness landscape analysis in VRP/TSP to determine the optimal optimization method. In the presented prototype system, we have investigated middle-sized VRP/TSP problem domains using synthetic random input spaces. We used the fitness landscape method to analyze the search space of the prototype VRP/TSP problem. In this domain area, the performed model calculations show that 2-opt, local improvement operators dominate the global crossover operations. This experiment confirms the practical experiences found in the literature on the superiority of the 2-opt, Lin-Kernighan methods. On the other hand, 2-opt, Lin-Kernighan methods are very specialized on the TSP problem, using TSP-specific operators. Thus, we have selected the very popular GA method as a baseline evolutionary method. The purpose of our work on GA was to develop a novel approach to use local optimization operators instead of global crossover steps. The proposed method is based on the application of edge-level weighting in the input domain. The presented approach has some similarity with the greedy construction method, but there are some fundamental differences between the two approaches as:
- the proposed method involves some stochastic components;
- the proposed method uses an evolutionary framework.
The test results on the prototype system show some interesting conclusions:
- The proposed integrated GA method provides significantly better results as the baseline GA method.
- The experiments show that the proposed GA variant dominates the NN and greedy algorithms in general. An interesting result is that our method can provide better results as the efficient Lin-Kernighan method for middle-sized datasets.
- The convergence and efficiency of random operations is relatively low in large problem domains where the number of possible states is exponentially high.
Based on the experiences, we can suggest the updated GA version using a greedy initialization module. This kind of engine can provide a near-optimal route length in the investigated problem range.
Author Contributions
Conceptualization, L.K. and A.A.; methodology, L.K., A.A. and T.B.; software, A.A.; validation, L.K. and A.A.; formal analysis, L.K. and A.A.; investigation, L.K. and A.A.; resources, T.B.; data curation, L.K., A.A.; writing—original draft preparation, L.K., A.A. and T.B.; writing—review and editing, L.K., A.A. and T.B.; visualization, L.K., A.A. and T.B.; supervision, L.K. and T.B.; project administration, L.K. and T.B.; funding acquisition, T.B. All authors have read and agreed to the published version of the manuscript.
Funding
The described article was carried out as part of the EFOP-3.6.1-16-2016-00011 “Younger and Renewing University—Innovative Knowledge City—institutional development of the University of Miskolc aiming at intelligent specialization” project implemented in the framework of the Szechenyi 2020 program. The realization of this project is supported by the European Union, co-financed by the European Social Fund.
Conflicts of Interest
The author declares no conflict of interest.
References
- Dantzig, G.B.; Ramser, J.H. The truck dispatching problem. Manag. Sci. 1959, 6, 80–91. [Google Scholar] [CrossRef]
- Skrlec, D.; Filipec, M.; Krajcar, S. A heuristic modification of genetic algorithm used for solving the single depot capacited vehicle routing problem. In Proceedings of the Intelligent Information Systems, Grand Bahama Island, Bahamas, 8–10 December 1997; pp. 184–188. [Google Scholar]
- Nagy, G.; Salhi, S. Heuristic algorithms for single and multiple depot vehicle routing problems with pickups and deliveries. Eur. J. Oper. Res. 2005, 162, 126–141. [Google Scholar] [CrossRef]
- Crainic, T.G.; Perboli, G.; Mancini, S.; Tadei, R. Two-echelon vehicle routing problem: A satellite location analysis. Procedia-Soc. Behav. Sci. 2010, 2, 5944–5955. [Google Scholar] [CrossRef]
- Dondo, R.; Méndez, C.A.; Cerdá, J. The multi-echelon vehicle routing problem with cross docking in supply chain management. Comput. Chem. Eng. 2011, 35, 3002–3024. [Google Scholar] [CrossRef]
- Dondo, R.; Cerdá, J. A cluster-based optimization approach for the multi-depot heterogeneous fleet vehicle routing problem with time windows. Eur. J. Oper. Res. 2007, 176, 1478–1507. [Google Scholar] [CrossRef]
- Gendreau, M.; Laporte, G.; Musaraganyi, C.; Taillard, É.D. A tabu search heuristic for the heterogeneous fleet vehicle routing problem. Comput. Oper. Res. 1999, 26, 1153–1173. [Google Scholar] [CrossRef]
- Schulze, J.; Fahle, T. A parallel algorithm for the vehicle routing problem with time window constraints. Ann. Oper. Res. 1999, 86, 585–607. [Google Scholar] [CrossRef]
- Belhaiza, S.; Hansen, P.; Laporte, G. A hybrid variable neighborhood tabu search heuristic for the vehicle routing problem with multiple time windows. Comput. Oper. Res. 2014, 52, 269–281. [Google Scholar] [CrossRef]
- Figliozzi, M.A. An iterative route construction and improvement algorithm for the vehicle routing problem with soft time windows. Transp. Res. Part C Emerg. Technol. 2010, 18, 668–679. [Google Scholar] [CrossRef]
- Ralphs, T.K.; Kopman, L.; Pulleyblank, W.R.; Trotter, L.E. On the capacitated vehicle routing problem. Math. Program. 2003, 94, 343–359. [Google Scholar] [CrossRef]
- Kabcome, P.; Mouktonglang, T. Vehicle routing problem for multiple product types, compartments, and trips with soft time windows. Int. J. Math. Math. Sci. 2015, 126754. [Google Scholar] [CrossRef][Green Version]
- Crevier, B.; Cordeau, J.F.; Laporte, G. The multi-depot vehicle routing problem with inter-depot routes. Eur. J. Oper. Res. 2007, 176, 756–773. [Google Scholar] [CrossRef]
- Lin, C.K.Y. A vehicle routing problem with pickup and delivery time windows, and coordination of transportable resources. Comput. Oper. Res. 2011, 38, 1596–1609. [Google Scholar] [CrossRef]
- Angelelli, E.; Speranza, M.G. The periodic vehicle routing problem with intermediate facilities. Eur. J. Oper. Res. 2002, 137, 233–247. [Google Scholar] [CrossRef]
- Hussain, A.; Muhammad, Y.S.; Nauman Sajid, M.; Hussain, I.; Mohamd Shoukry, A.; Gani, S. Genetic algorithm for traveling salesman problem with modified cycle crossover operator. Comput. Intell. Neurosci. 2017, 7430125. [Google Scholar] [CrossRef] [PubMed]
- Stewart, W.R., Jr.; Golden, B.L. Stochastic vehicle routing: A comprehensive approach. Eur. J. Oper. Res. 1983, 14, 371–385. [Google Scholar] [CrossRef]
- Gupta, R.; Singh, B.; Pandey, D. Multi-objective fuzzy vehicle routing problem: A case study. Int. J. Contemp. Math. Sci. 2010, 5, 1439–1454. [Google Scholar]
- Soysal, M.; Bloemhof-Ruwaard, J.M.; Bektaş, T. The time-dependent two-echelon capacitated vehicle routing problem with environmental considerations. Int. J. Prod. Econ. 2015, 164, 366–378. [Google Scholar] [CrossRef]
- Lin, J.; Zhou, W.; Wolfson, O. Electric vehicle routing problem. Transp. Res. Procedia 2016, 12, 508–521. [Google Scholar] [CrossRef]
- Stavropoulou, F.; Repoussis, P.P.; Tarantilis, C.D. The vehicle routing problem with profits and consistency constraints. Eur. J. Oper. Res. 2019, 274, 340–356. [Google Scholar] [CrossRef]
- Huang, Y.H.; Blazquez, C.A.; Huang, S.H.; Paredes-Belmar, G.; Latorre-Nuñez, G. Solving the feeder vehicle routing problem using ant colony optimization. Comput. Ind. Eng. 2019, 127, 520–535. [Google Scholar] [CrossRef]
- Ribeiro, G.M.; Laporte, G. An adaptive large neighborhood search heuristic for the cumulative capacitated vehicle routing problem. Comput. Oper. Res. 2012, 39, 728–735. [Google Scholar] [CrossRef]
- Song, B.D.; Ko, Y.D. A vehicle routing problem of both refrigerated-and general-type vehicles for perishable food products delivery. J. Food Eng. 2016, 169, 61–71. [Google Scholar] [CrossRef]
- Talarico, L.; Sörensen, K.; Springael, J. Metaheuristics for the risk-constrained cash-in-transit vehicle routing problem. Eur. J. Oper. Res. 2015, 244, 457–470. [Google Scholar] [CrossRef]
- Bae, H.; Moon, I. Multi-depot vehicle routing problem with time windows considering delivery and installation vehicles. Appl. Math. Model. 2016, 40, 6536–6549. [Google Scholar] [CrossRef]
- Battarra, M.; Erdoğan, G.; Vigo, D. Exact algorithms for the clustered vehicle routing problem. Oper. Res. 2014, 62, 58–71. [Google Scholar] [CrossRef]
- Drexl, M. Applications of the vehicle routing problem with trailers and transshipments. Eur. J. Oper. Res. 2013, 227, 275–283. [Google Scholar] [CrossRef]
- Xiao, Y.; Konak, A. The heterogeneous green vehicle routing and scheduling problem with time-varying traffic congestion. Transp. Res. Part E Logist. Transp. Rev. 2016, 88, 146–166. [Google Scholar] [CrossRef]
- Montemanni, R.; Gambardella, L.M.; Rizzoli, A.E.; Donati, A.V. Ant colony system for a dynamic vehicle routing problem. J. Comb. Optim. 2005, 10, 327–343. [Google Scholar] [CrossRef]
- Mattfeld, D.C.; Bierwirth, C.; Kopfer, H. A search space analysis of the job shop scheduling problem. Ann. Oper. Res. 1999, 86, 441–453. [Google Scholar] [CrossRef]
- Pitzer, E.; Affenzeller, M. A comprehensive survey on fitness landscape analysis. In Recent Advances in Intelligent Engineering Systems, 1st ed.; Fodor, J., Klempous, R., Suárez Araujo, C.P., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 161–191. [Google Scholar] [CrossRef]
- Humeau, J.; Liefooghe, A.; Talbi, E.G.; Verel, S. ParadisEO-MO: From fitness landscape analysis to efficient local search algorithms. J. Heuristics 2013, 19, 881–915. [Google Scholar] [CrossRef]
- Collard, P.; Verel, S.; Clergue, M. Local search heuristics: Fitness cloud versus fitness landscape. arXiv 2007, arXiv:0709.4010. [Google Scholar]
- Fonlupt, C.; Robilliard, D.; Preux, P. Fitness landscape and the behavior of heuristics. Evol. Artif. 1997, 97, 56. [Google Scholar]
- Ventresca, M.; Ombuki-Berman, B.; Runka, A. Predicting genetic algorithm performance on the vehicle routing problem using information theoretic landscape measures. Lect. Notes Comput. Sci. 2013, 7832, 214–225. [Google Scholar] [CrossRef]
- Bagaria, V.; Ding, J.; Tse, D.; Wu, Y.; Xu, J. Hidden hamiltonian cycle recovery via linear programming. Oper. Res. 2020, 68, 53–70. [Google Scholar] [CrossRef]
- Papadimitriou, C.H.; Vazirani, U.V. On two geometric problems related to the travelling salesman problem. J. Algorithms 1984, 5, 231–246. [Google Scholar] [CrossRef]
- Braun, H. On solving travelling salesman problems by genetic algorithms. Lect. Notes Comput. Sci. 1991, 496, 129–133. [Google Scholar]
- Rosenkrantz, D.J.; Stearns, R.E.; Lewis, P.M., II. An analysis of several heuristics for the traveling salesman problem. SIAM J. Comput. 1977, 6, 563–581. [Google Scholar] [CrossRef]
- Fiechter, C.N. A parallel tabu search algorithm for large traveling salesman problems. Discret. Appl. Math. 1994, 51, 243–267. [Google Scholar] [CrossRef]
- Helsgaun, K. An effective implementation of the Lin–Kernighan traveling salesman heuristic. Eur. J. Oper. Res. 2000, 126, 106–130. [Google Scholar] [CrossRef]
- Karabulut, K.; Tasgetiren, M.F. A variable iterated greedy algorithm for the traveling salesman problem with time windows. Inf. Sci. 2014, 279, 383–395. [Google Scholar] [CrossRef]
- Nguyen, H.D.; Yoshihara, I.; Yamamori, K.; Yasunaga, M. Implementation of an effective hybrid GA for large-scale traveling salesman problems. IEEE Trans. Syst. Manand Cybern. Part B 2007, 37, 92–99. [Google Scholar] [CrossRef] [PubMed]
- Paessens, H. The savings algorithm for the vehicle routing problem. Eur. J. Oper. Res. 1988, 34, 336–344. [Google Scholar] [CrossRef]
- Snyder, L.V.; Daskin, M.S. A random-key genetic algorithm for the generalized traveling salesman problem. Eur. J. Oper. Res. 2006, 174, 38–53. [Google Scholar] [CrossRef]
- Rego, C.; Gamboa, D.; Glover, F.; Osterman, C. Traveling salesman problem heuristics: Leading methods, implementations and latest advances. Eur. J. Oper. Res. 2011, 211, 427–441. [Google Scholar] [CrossRef]
- Gambardella, L.M.; Dorigo, M. Ant-Q: A reinforcement learning approach to the traveling salesman problem. In Proceedings of the Twelfth International Conference on Machine Learning, Tahoe City, CA, USA, 9–12 July 1995; pp. 252–260. [Google Scholar] [CrossRef]
- Pitzer, E. Applied Fitness Landscape Analysis. Ph.D. Thesis, Johannes Kepler Universität Linz, Linz, Austria, 2013. [Google Scholar]
- Fonlupt, C.; Robilliard, D.; Preux, P.; Talbi, E.G. Fitness Landscapes and Performance of Meta-Heuristics. In Meta-Heuristics, 1st ed.; Voß, S., Martello, S., Osman, I.H., Roucairol, C., Eds.; Springer: Boston, MA, USA, 1999; pp. 257–268. [Google Scholar] [CrossRef]
- Verel, S. Fitness landscapes and graphs: Multimodularity, ruggedness and neutrality. In Proceedings of the 11th Annual Conference Companion on Genetic and Evolutionary Computation Conference: Late Breaking Papers, Montreal, QC, Canada, 8–12 July 2009; Association for Computing Machinery: New York, NY, USA; pp. 3593–3656. [Google Scholar] [CrossRef]
- Englert, M.; Röglin, H.; Vöcking, B. Worst Case and Probabilistic Analysis of the 2-Opt Algorithm for the TSP. Algorithmica 2014, 68, 190–264. [Google Scholar] [CrossRef]
- Zhu, K.Q. A diversity-controlling adaptive genetic algorithm for the vehicle routing problem with time windows. In Proceedings of the 15th IEEE International Conference on Tools with Artificial Intelligence, Sacramento, CA, USA, 5 November 2003; pp. 176–183. [Google Scholar] [CrossRef]
- Wang, K.P.; Huang, L.; Zhou, C.G.; Pang, W. Particle swarm optimization for traveling salesman problem. In Proceedings of the 2003 International Conference on Machine Learning and Cybernetics, Xi’an, China, 5 November 2003; pp. 1583–1585. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).