1. Introduction
Process analytics in the chemical and biotechnology industries is currently reaping the rewards from a data revolution, which was initiated in the 1980s in the field of computer science and communications. This sparked the development of machine learning (ML) modeling paradigms. Simpler models such as random forests [
1] and support vector machines [
2] have demonstrated widespread success in a variety of classification problems; some examples include invasive plant species prediction [
3] and speech recognition [
4]. The highly complex neural networks [
5] have been recognized as universal approximators [
6] for non-linear functions. Neural networks are being successfully applied to modern problems such as natural language processing [
7], image prediction [
8], and recommender systems [
9]. The success of neural nets lie in their ability to handle datasets with exorbitant numbers of samples (e.g., billions), which are known as
big-N problems.
On the other hand, data are relatively scarce in the field of process engineering. For example, concentrations of chemicals or populations of biological specimens are usually measured intermittently in laboratories; this limits the frequency at which these data can be acquired. Currently there are few online, ML-based
soft sensors for these measurements that are both accurate and inexpensive. Due to both the economical and physical limitations of obtaining abundant data in these cases, biological systems are usually known as
small-N problems. In addition to being
small-N, these datasets are often also high-dimensionality or
big-d. The high number of features in these cases render many simple ML algorithms infeasible, due to the
curse of dimensionality [
10]. In light of these marked distinctions, these problems warrant an entirely different modeling and analysis paradigm. This study will address some of these challenges, by providing a sensible analysis workflow that identifies key features correlated with a predicted outcome.
The challenges of analyzing chemical, biological, and process data are non-trivial. Interpretable patterns—such as correlations between process performance and features—are often confounded due to the following inexhaustible list of factors:
Non-uniform and inconsistent sampling intervals.
Order-of-magnitude differences in dimensionalities.
Complex interactions between participating species in a bioreactor (e.g., protagonistic vs. antagonistic members, functionally-redundant members).
Conditionally-dependent effects of features (i.e., some features only affect the outcome in the presence or absence of other features).
Biological system data often includes the relative abundances of operational taxonomic units (OTUs). An OTU represents a taxonomic group (e.g., species or genus) based on the similarity (e.g.,
or
for species and genus, respectively) of their 16S
rRNA variable regions. These are determined using high-throughput sequencing of microbial community DNA [
11]. The environment inside a bioreactor contains chemical and physical factors, which influence the types of OTUs that thrive. Conversely, the OTUs themselves also affect the environmental conditions inside the bioreactor, since microorganisms mediate many different types of chemical reactions. Microorganisms are known to interact and form communities with members that are protagonistic, antagonistic, or simply bystanders [
12]. These profound coupling effects are difficult to identify as closed-form expressions, due to the non-linear stochastic nature of OTU communities. The individual and group effects of members comprising of thousands of OTUs are extremely difficult to isolate. However, the overall confusion can be significantly alleviated by first grouping or clustering OTUs together, according to pre-specified similarity metrics [
13]. This reduces the dimensionality of analysis exponentially (e.g., from a few hundred down to several features), which in turn allows the predictive models to be much more focused. Grouping or clustering of OTUs is done with the purpose of identifying so-called keystone microorganisms, or
biomarkers, which correlate to successful versus poor process performance.
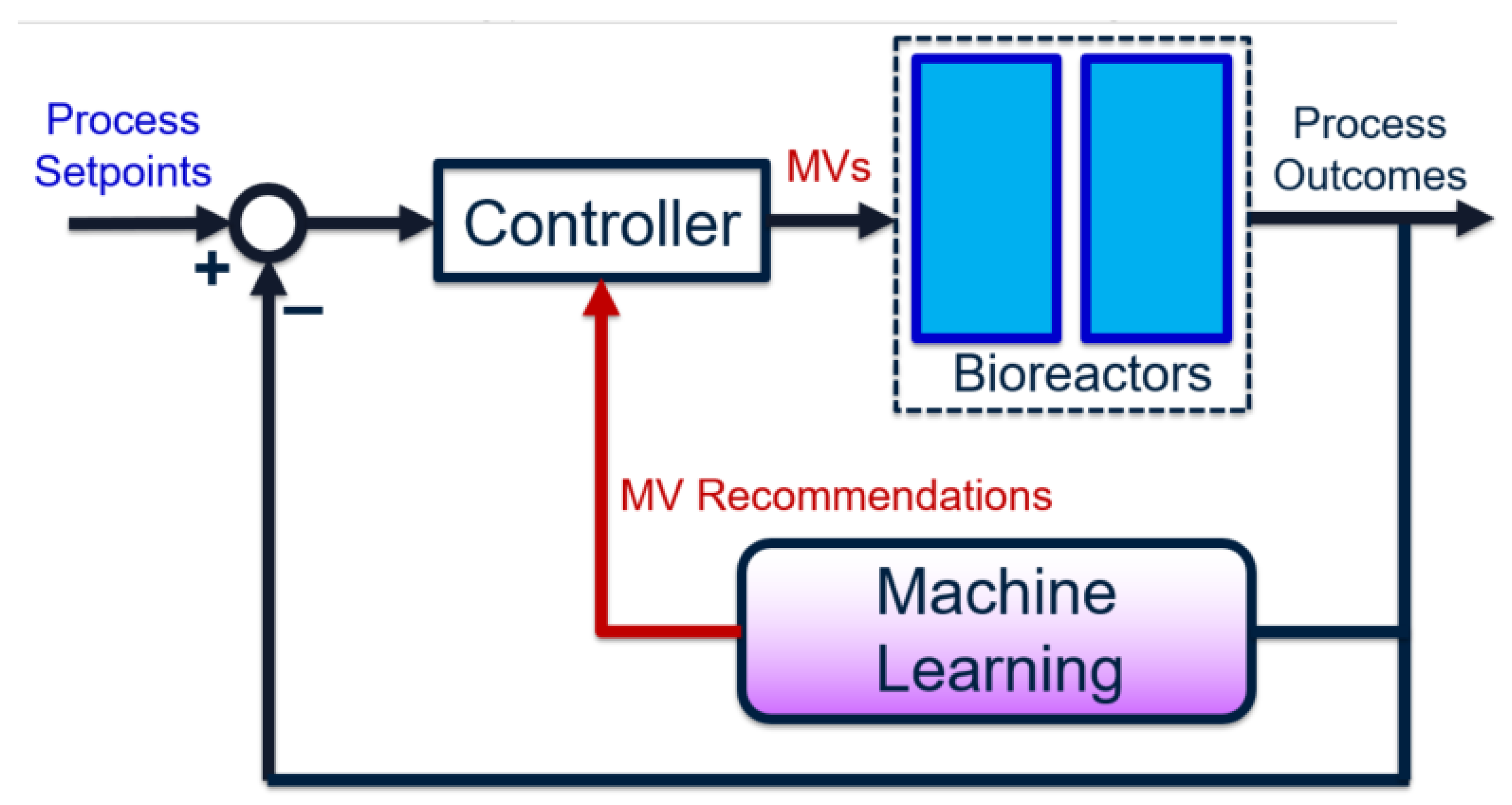
The overall goal for bioreactor modeling is to extract, out of the many chemical, biological, and process features, those that have a proportionally significant effect on process performance. These can be incorporated into a process control algorithm (e.g., involving soft sensors) to improve performance and reliability, by using easy-to-measure features or biomarkers. Given historical data, the process outcome is identified and preferably separated into discrete classes. The high feature-space of the raw data associated with these classes are “compressed” using dimensionality-reduction techniques. This produces smaller subsets of meaningful, representative features. Predictive models are built using these high-impact features, instead of the original feature set (which may contain irrelevant or redundant data). Finally, the representative features are ranked in terms of importance—with respect to their contributions to the final process outcomes—using univariate feature selection techniques. The results from this approach serve as an informative pre-cursor to decision-making and control, especially in processes where little to no prior domain knowledge is available. The entire framework can also be depicted as a closed-loop feedback control diagram [
14], as shown in
Figure 1.
In the proposed workflow, the choice of manipulated variables (MVs) is dynamic—it is re-identified given each influx of new data. On the other hand, traditional feedback control uses a static set of pre-specified MVs, which may not always be impactful variables if the process and/or noise dynamics vary with time. Specifically, the use of machine learning achieves a three-fold goal:
During each operating stage, operators would only need to monitor a small set of variables, instead of hundreds or thousands. This simplifies the controller tuning and maintenance drastically, and undesirable multivariable effects (such as input coupling [
14]) are reduced.
By using data-based ML models, the process outcomes can be predicted ahead of time, such that unsatisfactory outcomes are prevented. Moreover, the models can be updated using new data collected from each new operating stage, eliminating the need for complete re-identification.
The ranking of feature impacts can be performed using grey-box models, which are mostly empirical but are guided by a modest amount of system domain knowledge. This combination is exceptionally powerful if the domain knowledge is accurate, since it defines otherwise-unknown prior assumptions. This improves both prediction accuracy and feature analysis accuracy. The task of control and monitoring is also much more feasible, since the focus is only on a handful of variables (as opposed to hundreds).
This work represents a framework of the feature extraction workflow that precedes the development of the aforementioned process control philosophy. Within the framework, we test several popular techniques for dimensionality reduction and machine learning. The explored techniques are applied on a biological wastewater treatment process aimed at removing selenium. The first part of this paper outlines a systematic data pre-processing workflow, which combines both chemical and biological data in a way that ensures both exert equal weights on the model outcome. Then, three unsupervised learning techniques, hierarchical clustering, Gaussian mixtures, and Dirichlet mixtures, are used dimensionality-reduction techniques to extract biomarkers. These key features, along with water chemistry features, are passed as inputs into three state-of-the-art predictive models to predict the final process outcome of selenium removal rate. The supervised learning techniques used are random forests (RFs), support vector machines (SVMs), and artificial neural networks (ANNs). Finally, important process features are correlated with the selenium removal rate using two techniques: mean decrease in accuracy (MDA), and the conditionally-permutated variant, C-MDA. The quality of modeling and feature selection results are compared and contrasted across all explored methods.
One key difference between this work and others in the literature is the broad range of exploration, as well as the extensive use of compare and contrast for several methodologies of data analysis. Most papers focus on the proof-of-concept and results of a single technique, with focus on either the prediction task or feature analysis task. When reading this paper, the reader should focus more on the strengths and limitations of each method, given the results obtained, rather than the numerical values of the results themselves. The main goal of this work is to bring clarity to the appropriate use of analytics, given the various characteristics and circumstances of the available raw process data.
2. Methods
This section introduces the details behind the wastewater treatment process, as well as the machine learning algorithms used for dimensionality reduction, prediction, then finally feature selection.
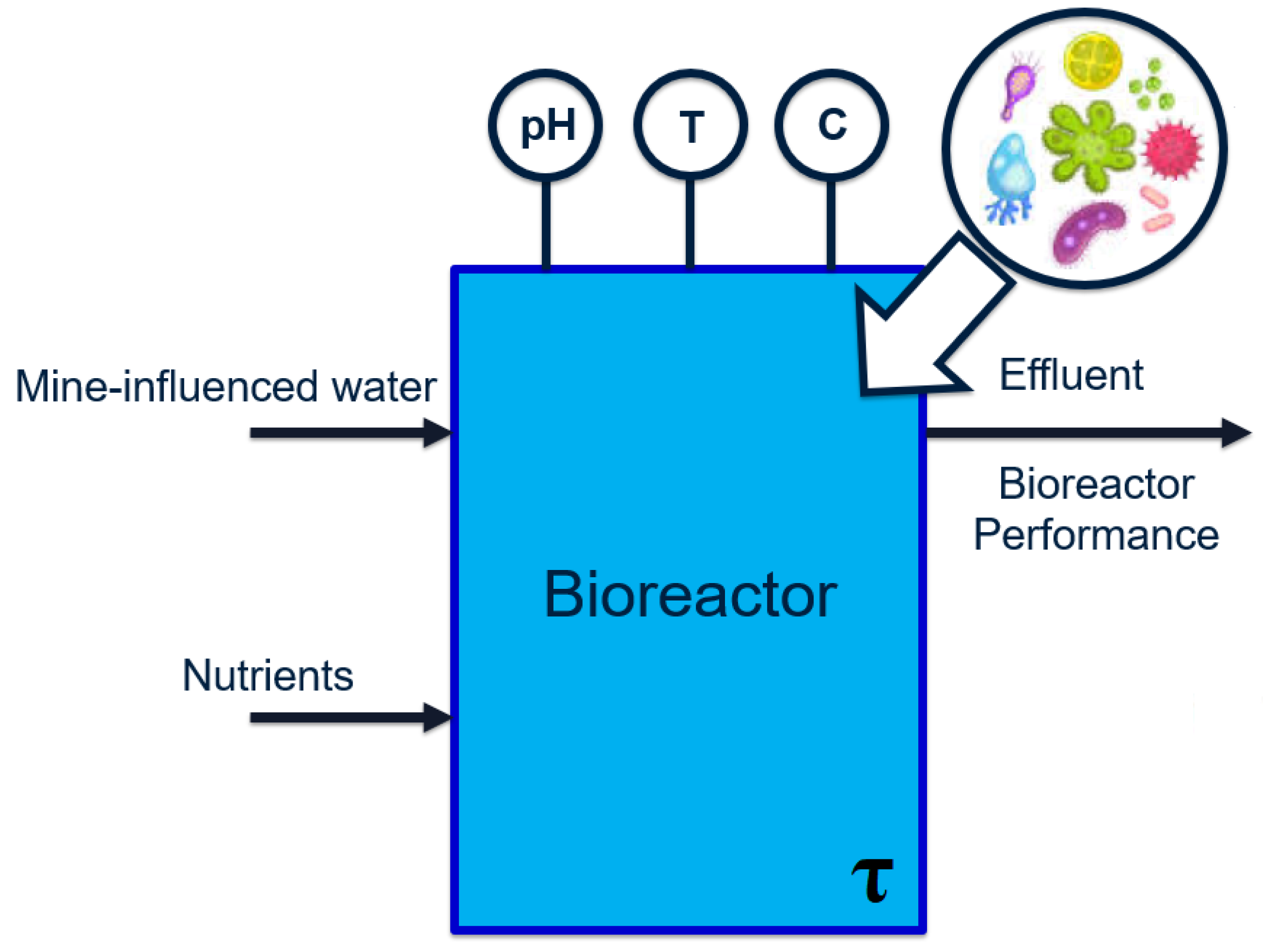
2.1. Process Flow Diagram and Description
The relevant case study is a wastewater treatment process located downstream of a mining operation. Due to proprietary reasons, the descriptions provided are kept at a general level. The overall process can be visualized as the general bioreactor shown in
Figure 2:
Selenate and
nitrate concentrations in the bioreactor effluent must be reduced to below
and
, respectively [
15,
16]. These chemical species bio-accumulate in the marine ecosystem [
17] and thus reach harmful levels at the top of the food chain.
The feed to the first reactor is wastewater, which contains the main pollutant selenate (SeO
). The selenate is to be reduced to elemental selenium (Se) by a series of two bioreactors. Samples are extracted from the bioreactors during each operating stage (at irregular intervals) and analyzed in order to determine and record values of various water chemistry variables. These features are summarized in
Table 1.
In addition to the water chemistry data, data pertaining to the microbial presence is available in the form of operational taxonomic units (OTUs). In this case study, the numerical values associated with each OTU are known as raw abundance counts. These counts can be considered normalized population counts of each bacterial species, which fall within the range of 0∼16,000.
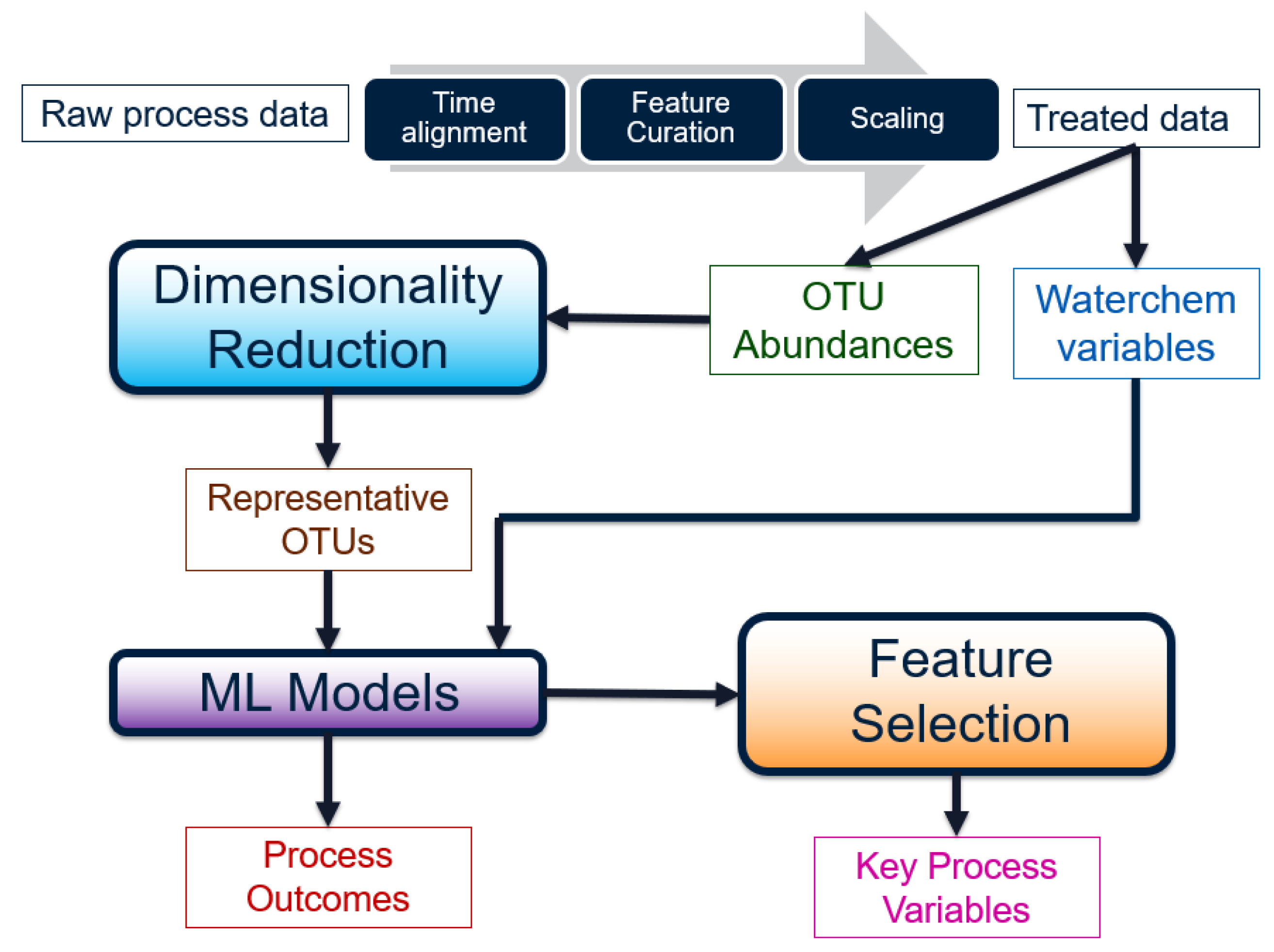
2.2. Data Pre-Treatment
Before the raw water chemistry and micro-biological data can be used for any analysis, they must be transformed into a meaningful form. The steps involved can be visualized as a workflow in
Figure 3.
The data pre-processing was performed using Jupyter iPython notebooks. The raw dataset originally consists of two files: one containing water chemistry data, and one containing OTU counts. First, samples containing missing or values were removed using the dropna function in pandas. Then, spurious process values (such as negative flowrates) were removed by Boolean functions. The remaining samples were then cross-matched between the water chemistry and OTU files, by use of tags which identify common operating stages. This results in a total of samples containing both water chemistry and microbial information. Although this is a small sample-size, it is unfortunately all the data that could be collected from this treatment plant.
Each water chemistry variable outlined in
Table 1 (except
SampleID) is
standardized via mean-centering and unit-variance operations. This removes any weight-skewing effects during modeling, due to varying feature ranges. The OTU raw abundance counts are recorded in a matrix where the number of samples and number of OTUs are
and
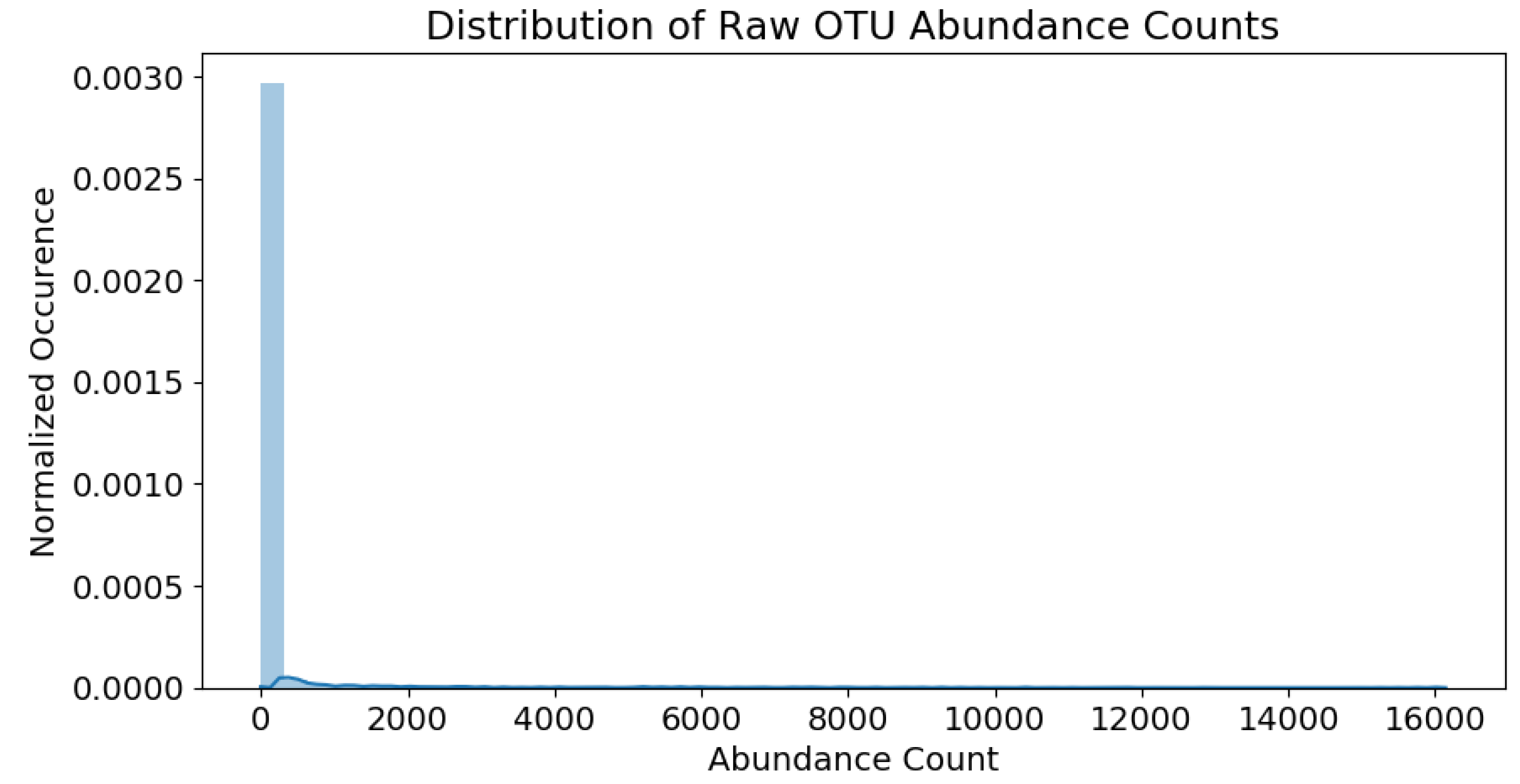
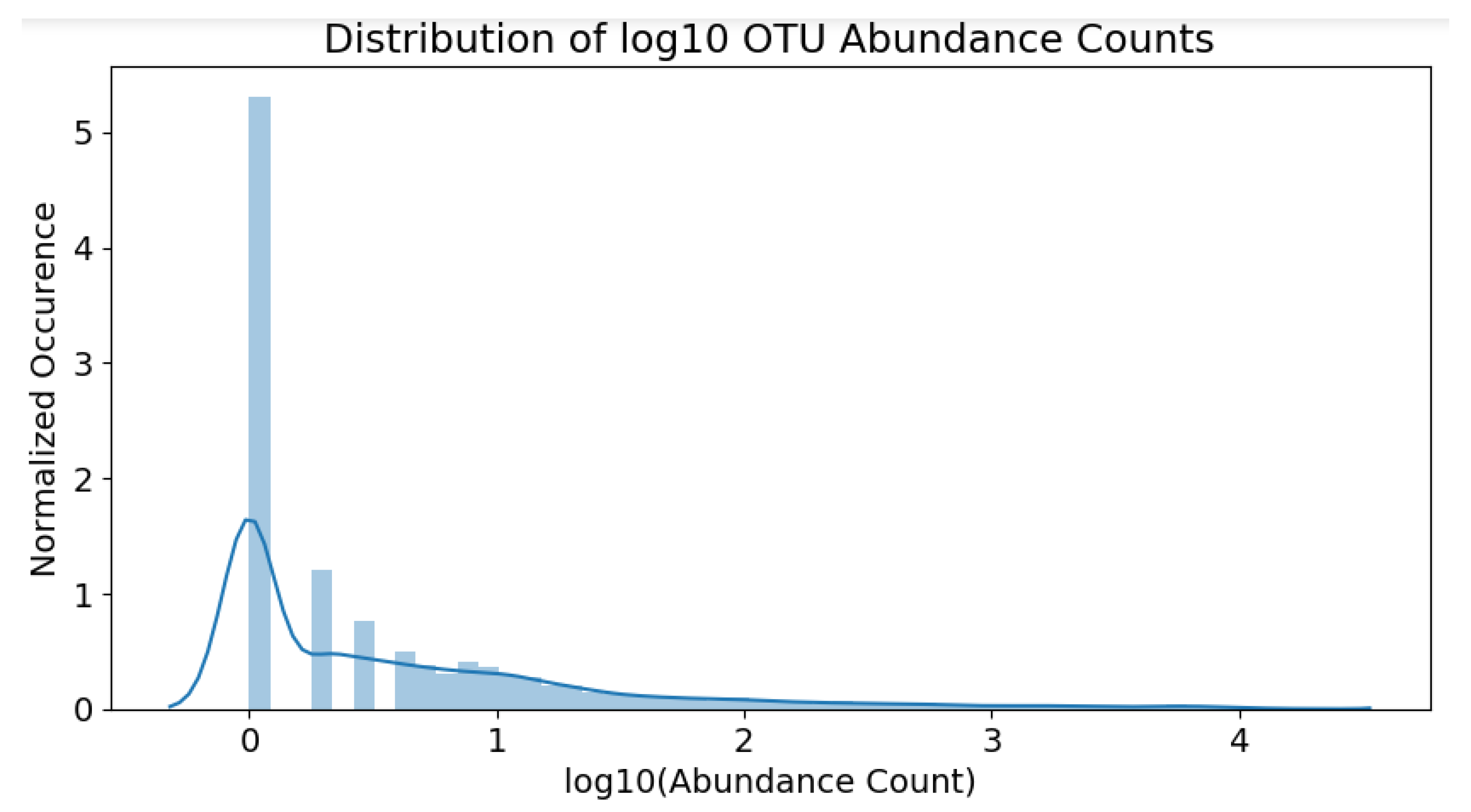
, respectively. The raw counts fall within the range of 0∼16,000. The abundance distribution is heavily skewed towards the lower population numbers, as shown in
Figure 4.
The skew is partially remedied by applying a
-transformation to all raw counts. Since many raw counts are equal to zero, 1 is added to every value before the
transformation, to ensure the
operation is valid. Counts equal to zero would still remain zero after transformation, since
. The overall operation is:
The resulting distribution of the scaled counts can be observed in
Figure 5. Note that the skew is not as severe as before; the OTU population distribution is now much clearer.
These counts are now in a suitable form for analysis methods outlined in the following sections.
2.3. Unsupervised Learning Methods
The goal of unsupervised data analysis is to delve within the existing data, to search for patterns (e.g., clusters or latent variables) that serve as indicators responsible for the observed outcomes. Although some popular algorithms such
k-Means [
18] or
density-based clustering [
19] come to mind, they are not suitable for this case study. This is due to the relatively poorer performance of these methods in high-dimensional datasets, a phenomenon known as the
curse of dimensionality.
Instead, this work will primarily focus on three clustering algorithms. The first is known as
hierarchical clustering [
20,
21], which groups organisms together according to a similarity metric. The sizes of the groups can be arbitrarily selected, by deciding the position on the ranking system of said organisms. The benefit of this method lies in the ability to visualize not only the individual groups, but also the relationship between various groups on a dendrogram (see
Figure A6), as well as their comparative sizes. Pertinent details behind this technique can be found in
Appendix H.
The second and third clustering methods are probabilistic mixtures: namely, the
Gaussian [
22] and
Dirichlet multinomial mixtures [
23,
24]. These mixture models are used to cluster OTUs based on assumptions of their underlying distributions, rather than their pairwise similarities. The optimal clusters are identified by using the well-known expectation–maximization (EM) algorithm [
25]. The remaining details behind these mixtures can be found in
Appendix I.
2.4. Network Analysis
Network analysis is a pre-processing technique used in this work, which transforms raw data (such as OTU abundance counts) into association values. These associations can be considered a statistical verification of co-occurrence between OTUs, which estimates true partial correlations between pairwise species.
The basis for this method comes from the observation that communities of microorganisms are extremely complex, and exert confounding effects on process outcomes. For example, OTU communities consist of members which are protagonistic, antagonistic, bystanding, and functionally- redundant species. Although the predatory-prey
Lotka-Volterra model [
26,
27] is a popular method of clarifying such relationships, the
network analysis and
networks to models strategies [
28] are a more modern and relevant approach to the case study at hand. The results from [
29] show that not only can dominant microbial groups be directly linked to a certain outcome, but indirect species which faciliate these interactions can also be identified. These network associations can be readily computed using the
netassoc algorithm [
30]. In summary, this algorithm models the indirect effects of a possible third species (or more) that affects the primary interaction between the main two pairwise species, which is akin to
conditionally-dependent modeling in Bayesian networks [
31]. The main advantage of this approach is the ability to identify both
biomarkers and secondary OTUs, which either facilitate or inhibit a specified process outcome (e.g., removal rate).
2.5. Supervised Learning Methods
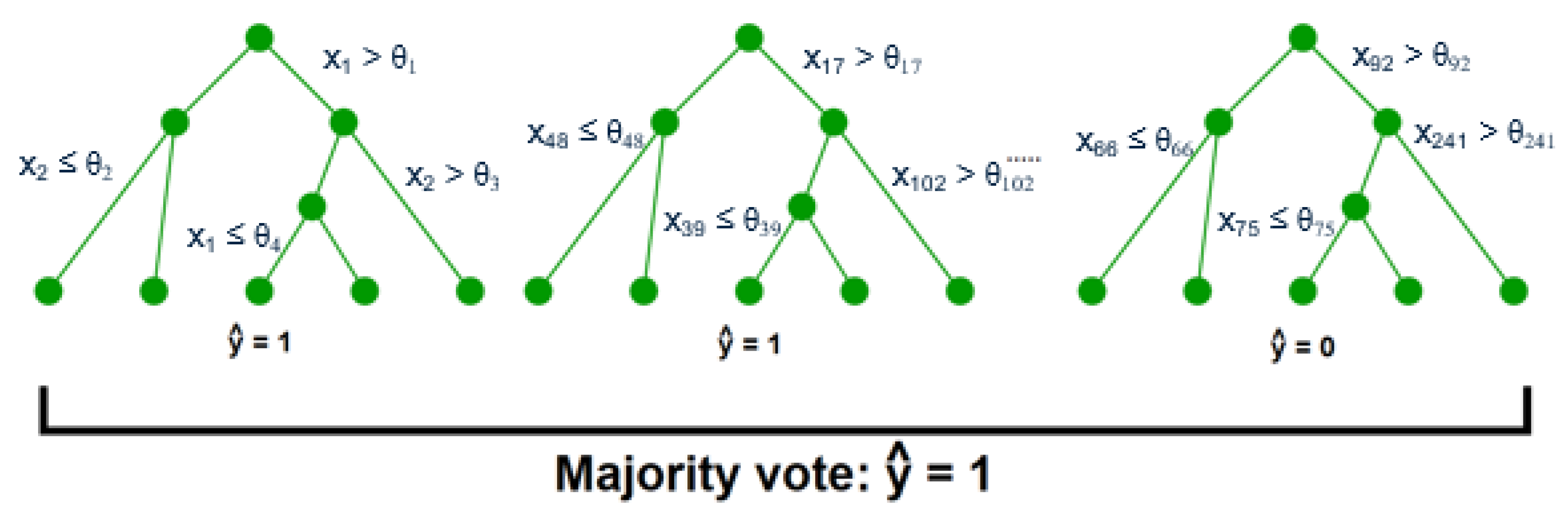
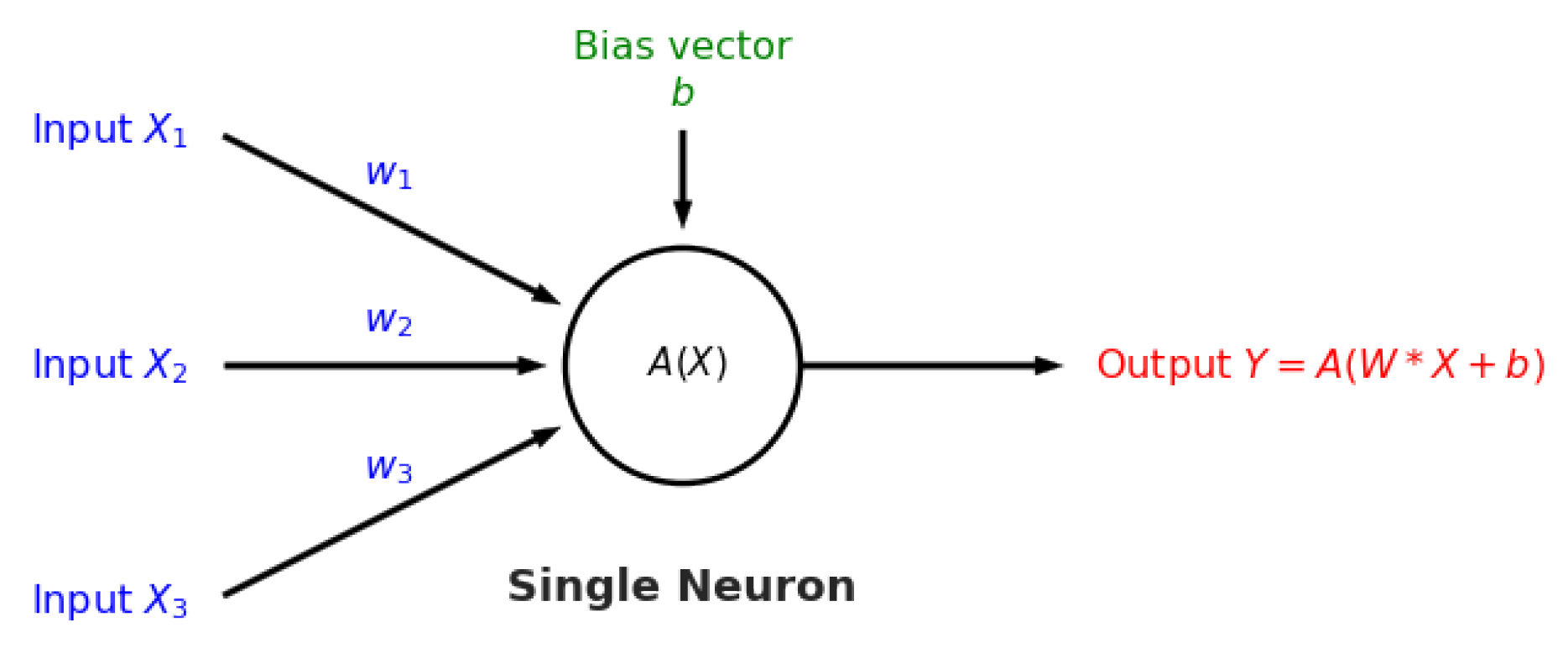
After the key variables have been identified using the previous dimensionality reduction and network analysis methods, they are used to perform predictions of the final process outcome. Prediction plays a vital role in process control; if the variable(s) of interest are estimated before actual occurrence, then remedial actions can be formulated ahead of time. In this case study, the primary process outcome of selenium removal rate is predicted using three supervised learning techniques. These include random forests [
1], support vector machines [
2] (
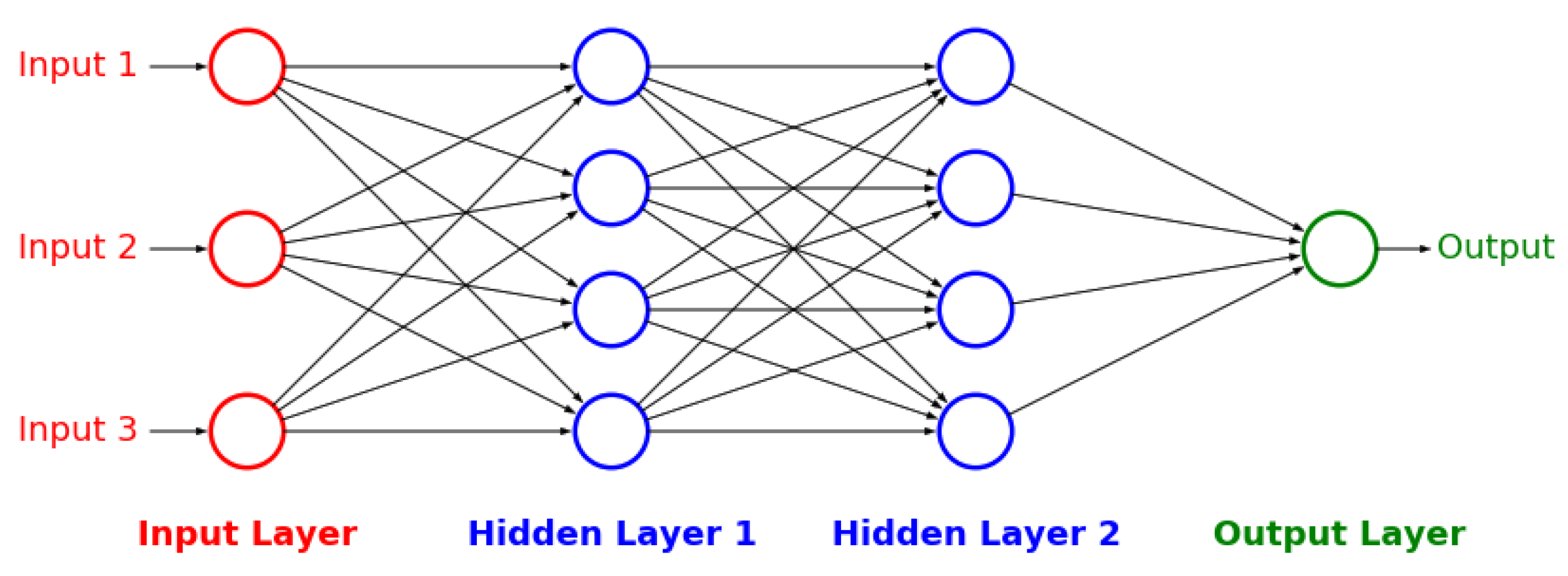
Figure A3), and artificial neural networks [
32] (
Figure A4 and
Figure A5). The details behind these well-known models can be found in
Appendix E,
Appendix F and
Appendix G respectively.
2.6. Feature Selection
After the key features have been identified and used to predict the final process outcome, a natural question to ask from a process engineering perspective is: “Which of these features contribute the most to the predictions?” Although most feature selection approaches in literature are often selected and customized on a case-by-case basis, two overarching groups of methods can be identified:
Hypothesis testing: A model is trained with all features left untouched. Then, features are either removed or permutated (scrambled), either individually or conditionally according to other features. The model is re-trained, and its accuracy is compared to the base-case accuracy. The features which cause the largest decreases in model accuracy are considered “most important,” and vice versa.
Scoring: A metric or “score” based on information or cross-entropy is defined and calculated for all features. Features with the highest scores are identified as the “most relevant,” and vice versa.
In the hypothesis testing framework, univariate (or single-feature) algorithms such as mean decrease in accuracy (MDA), and mean Gini impurity (MGI) [
33] have been developed for simple models such as random forests. The MDA method can be visualized in
Figure 6.
Unfortunately, these univariate approaches have the following shortcomings:
The second point above confounds the definition of “relevance.” A classic example is the prediction of presence of genetic disease (the outcome) using the genetic information of a person’s mother and grandmother. If information from the mother is absent, then the grandmother’s genes may be identified as a “relevant” feature. However, if genetic information is present from both the mother and grandmother, then the grandmother’s genes may become “redundant” and thus an “irrelevant” feature. Therefore, the “relevance” of a feature can be contingent or
conditional on the presence of other features. The authors in [
35] have made significant contributions to the modeling of conditional dependencies. The authors proposed an approach known as conditional mean decrease in accuracy (C-MDA), which is a variation on classic MDA, where conditional permutations are performed given the presence of other features. The conditional is defined as the appearance of secondary features within specified ranges of values. The difference in permutation between MDA and C-MDA can be realized in
Figure 7.
3. Results
The following sections contain the pertinent results of this case study: clustering, prediction, and feature analysis. The most important part is the comparison of different results obtained from the clustering algorithms, as well as the key variables identified by the feature selection techniques. An overall summary of the results can be found in
Section 3.6. Normalized time-plots of each process variable can be found in
Appendix K, in
Figure A7,
Figure A8,
Figure A9,
Figure A10,
Figure A11,
Figure A12,
Figure A13,
Figure A14,
Figure A15,
Figure A16,
Figure A17,
Figure A18,
Figure A19,
Figure A20,
Figure A21 and
Figure A22. To access the data and code used to generate the results, please visit the main author’s
GitHub repository (
https://github.com/yitingtsai90/Bioreactor-data-analysis).
3.1. Hierarchical Clustering of OTUs
The
-transformed counts obtained from pre-processing are first analyzed in terms of biological associations. This provides preliminary knowledge into the possible
co-existing and/or
antagonistic interactions between OTUs. In order to prevent spurious correlations (which are possible using methods such as Pearson or Spearman correlations), the
netassoc algorithm by [
30] is used. The result is a 305-by-305 matrix acting as a “pseudo” distance matrix between all OTUs, which can then be used for hierarchical clustering.
Before the
netassoc distances can be used, however, it must undergo one final transformation: normalization of values between 0 and 1. This follows the concept of
similarity being analogous to small distances (i.e., distances close to zero), and
dissimilarity being analogous to large distances. The operation in Equation (
2) accomplishes this scaling:
At this point, the hierarchical clustering models can finally be constructed. First, the following four hierarchical clustering methods are performed on the scaled
netassoc distance matrix:
Unweighted pair-group method with arithmetic means (UPGMA)
Ward’s minimum variance method (Ward)
Nearest-neighbour method (Single-linkage)
Farthest-neighbour method (Complete-linkage)
This was accomplished using the
scipy package
cluster.hierarchy. In order to determine the “optimal” clustering method out of the four, the cophenetic correlation values (see
Appendix H) were obtained using the
cluster.cophenet command, for all four methods. The results are shown in
Table 2.
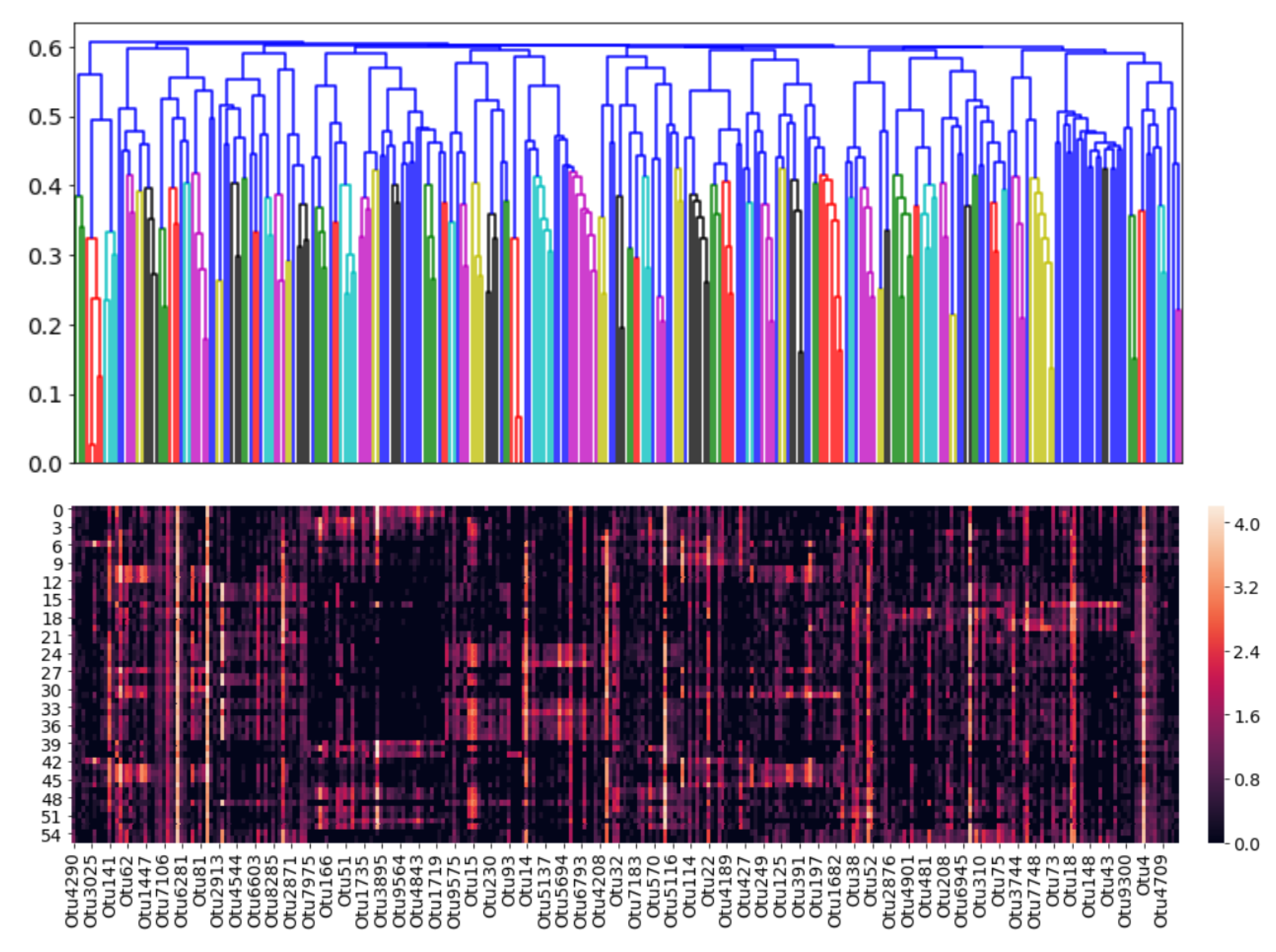
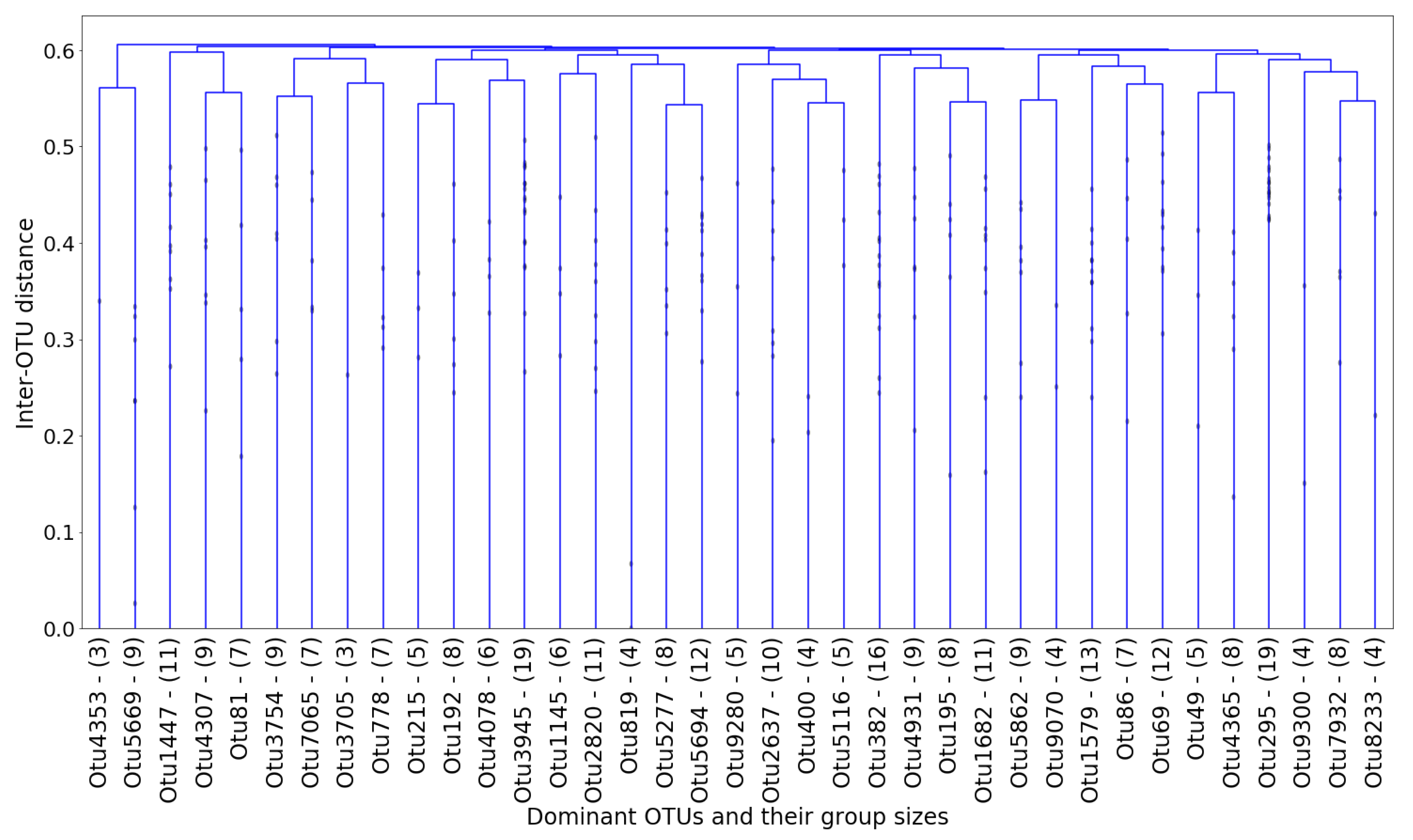
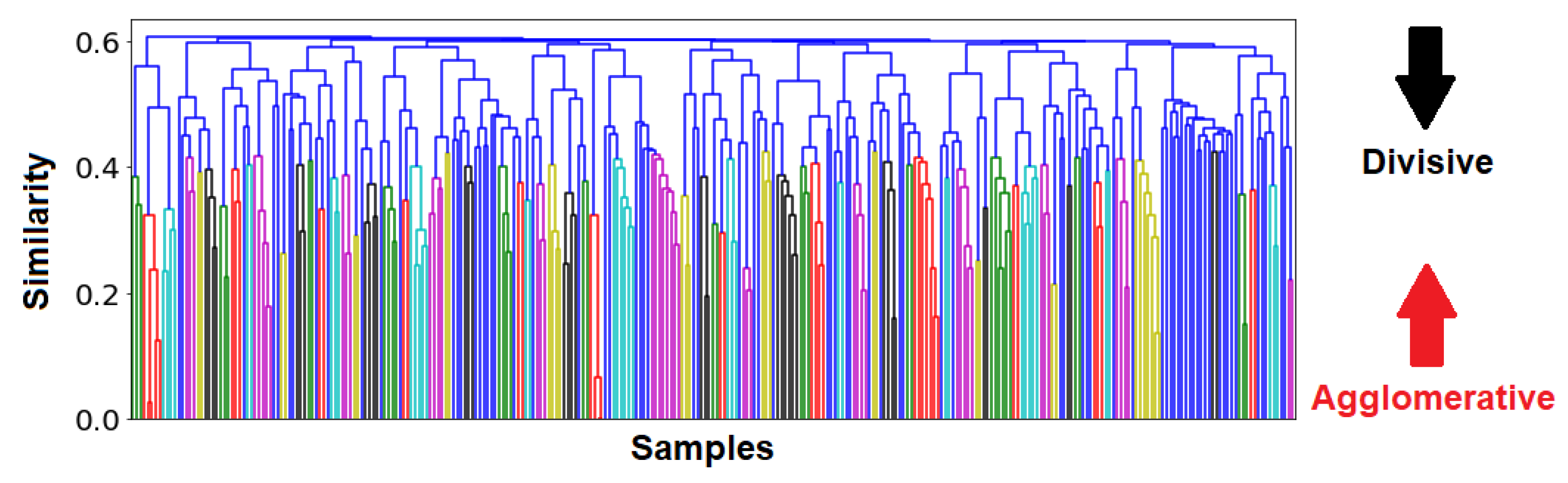
Cophenetic correlations can be interpreted as how well a clustering method preserves the similarites between raw samples. Since the UPGMA method has the highest cophenetic correlation, it was selected as the most suitable clustering method. A dendrogram was then constructed using this method, and it can be visualized in
Figure 8.
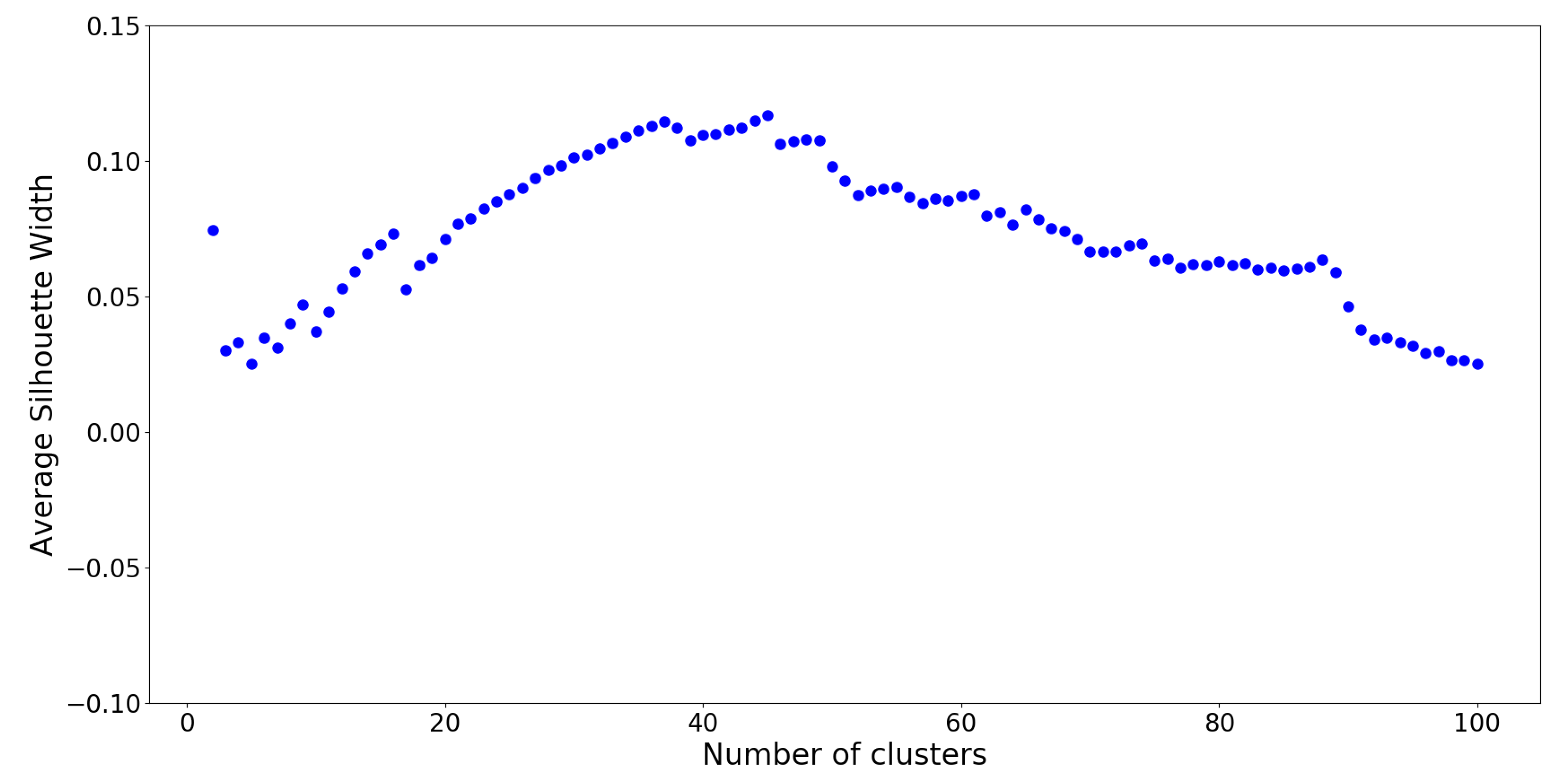
The optimal number of clusters on this UPGMA dendrogram is determined by silhouette analysis (see
Appendix H), which is a measure of how well cluster members belong to their respective clusters, given the number of desired clusters
K. Silhouette values are computed for cluster numbers
through
, and the results are plotted on
Figure 9.
From silhouette analysis,
groups appear to be the “optimal” cut-off with the overall highest silhouette value. However, this is assuming that all
netassoc distances are suitable for use. Recall that a normalized distance of 0 resembles similarity, and a distance of 1 resembles dissimilarity. A distance of
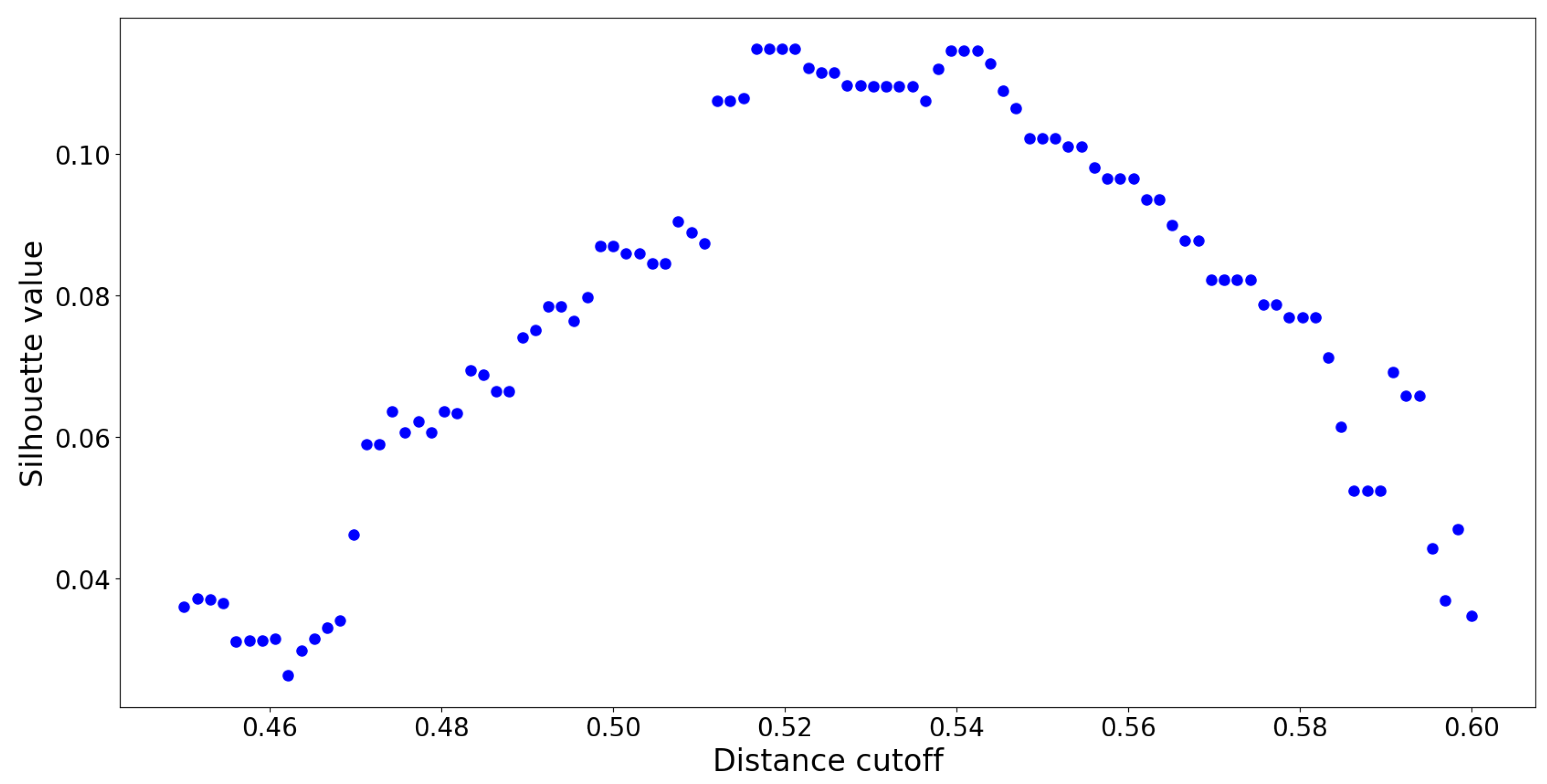
corresponds to neither similarity nor dissimilarity. Values in that vicinity represent “neutral” OTU interactions which act as noise, confounding the clustering model. To remedy this issue, a
distance cut-off approach inspired by [
36] was employed. If a hierarchy with a
distance cut-off value of
is constructed, it means that no cluster contains members which are spread apart by a distance greater than
. This reduces the amount of overlap between distinct clusters. To determine the precise value of
, several UPGMA hierarchies were constructed using distance cutoffs within the set of values
. The resulting silhouette values are reported in
Figure 10:
The optimal distance cut-off is located at
with a corresponding maximum silhouette value of
. By constructing a UPGMA hierarchy with this cut-off, no two members within any cluster are spread apart by a normalized distance of
. This UPGMA hierarchy yields a total of
clusters, and its dendrogram is provided in
Figure 11:
In each cluster, the “dominant” OTU was determined as the one closest (in terms of normalized
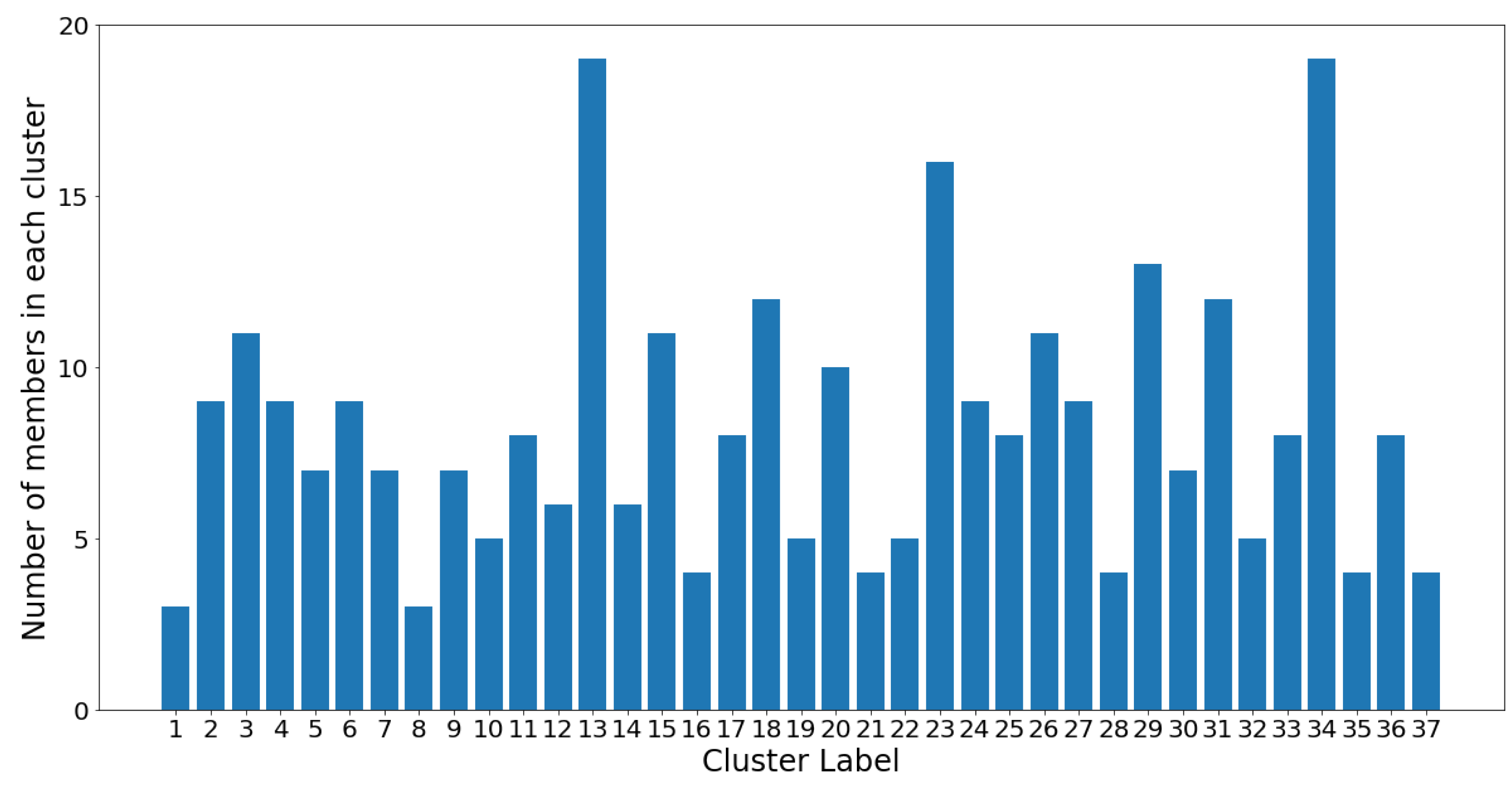
netassoc distance) to the cluster centroid. The coordinates of each centroid were readily calculated using the distances in the dendrogram. The remaining OTUs in the cluster were therefore considered “followers.” The entire cluster could then be considered a co-existing community of OTUs. In
Figure 12, the number of members in each cluster (which is also shown in
Figure 11) is plotted against the cluster number.
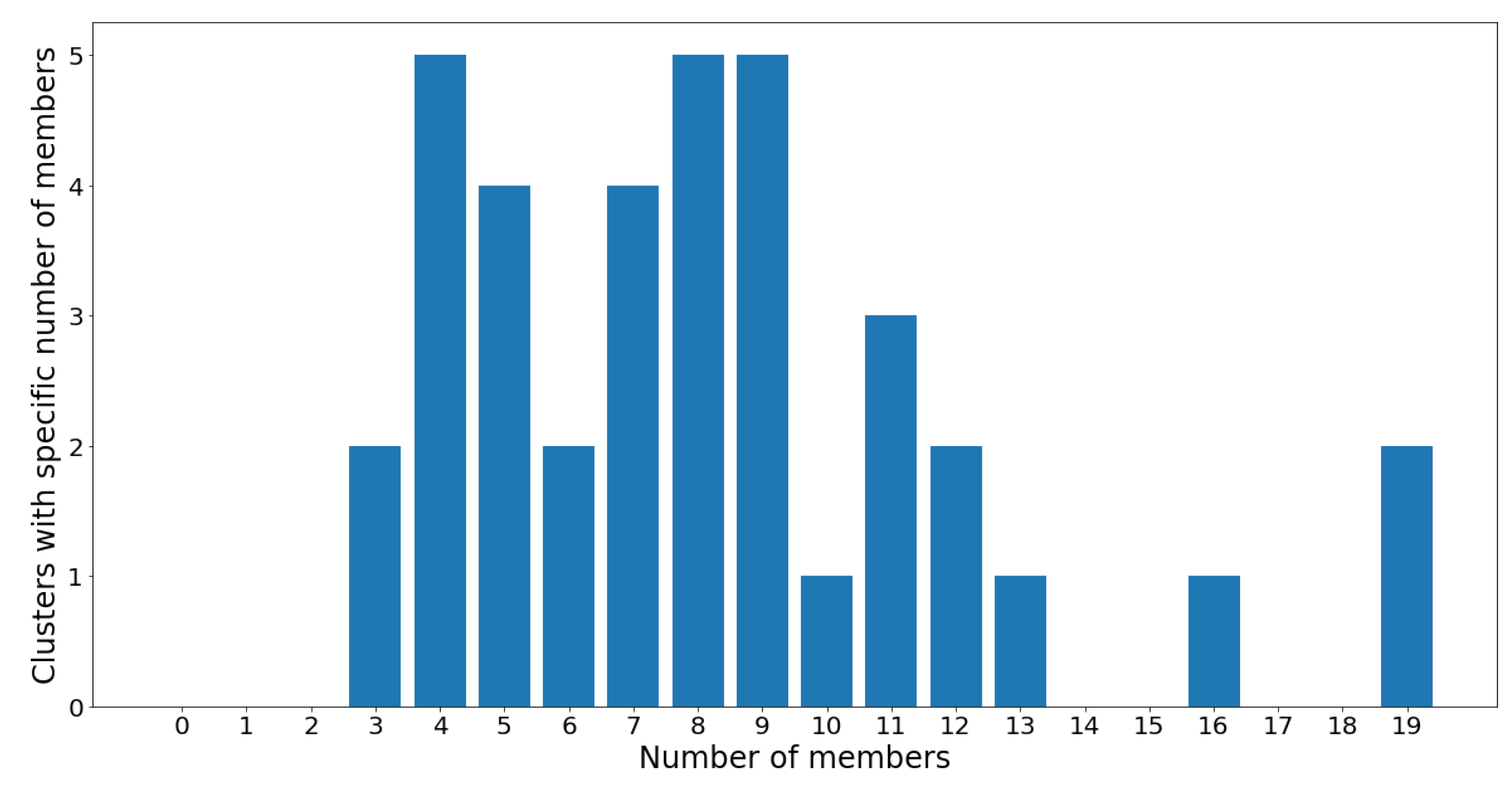
On one hand, clusters 13 and 34 are the largest communities, with 19 OTUs in each. On the other hand, clusters 1 and 8 are the smallest communities, with three OTUs in each, followed by groups 16, 21, 28, 35, and 37 which all contain four OTUs. Despite the considerable variance in community sizes, no communities contain less than three OTUs or more than 20 OTUs. The membership distribution can be observed in the reverse histogram, where the number of groups for each membership size is shown:
Figure 13 shows that most clusters contain four, eight, and nine OTUs, followed by five and seven OTUs. Most clusters have a population ranging between four and 12 OTUs, which indicates a healthy clustering distribution.
For the subsequent prediction and feature extraction steps, only the 37 dominant OTUs shown in
Figure 11 are considered, out of the total 305 OTUs to begin with. Although 37 is still a reasonably large number (and not between two and 10, ideally), the choice is based on a combination of statistically-justified methods.
3.2. Gaussian Mixture Analysis of OTUs
Instead of using hierarchical clustering, another possible approach is to group OTUs using
gaussian mixture models (GMMs). The assumption here is that the underlying distribution behind the OTU abundances can be modelled as a sum of multivariate Gaussians. Each Gaussian can be considered as a “cluster” of OTUs, with its centroid represented by the mean, and its spread (or size) represented by its variance. The overall GMM is built using the
scikitlearn subpackage
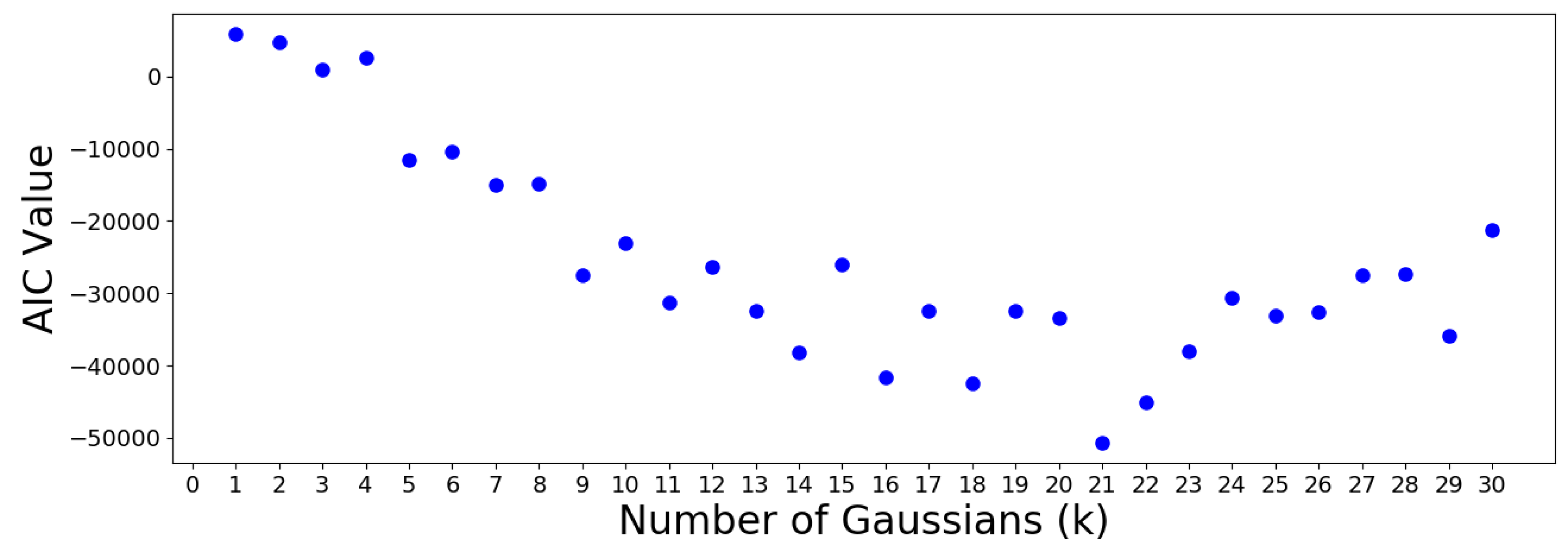
mixture.GaussianMixture. In order to determine the “optimal” number of Gaussians
K, the Akaike information criterion (AIC) and Bayesian information criterion (BIC) values are determined for each value of
K. This is performed by calling the
.aic and
.bic attributes of the GMM models within
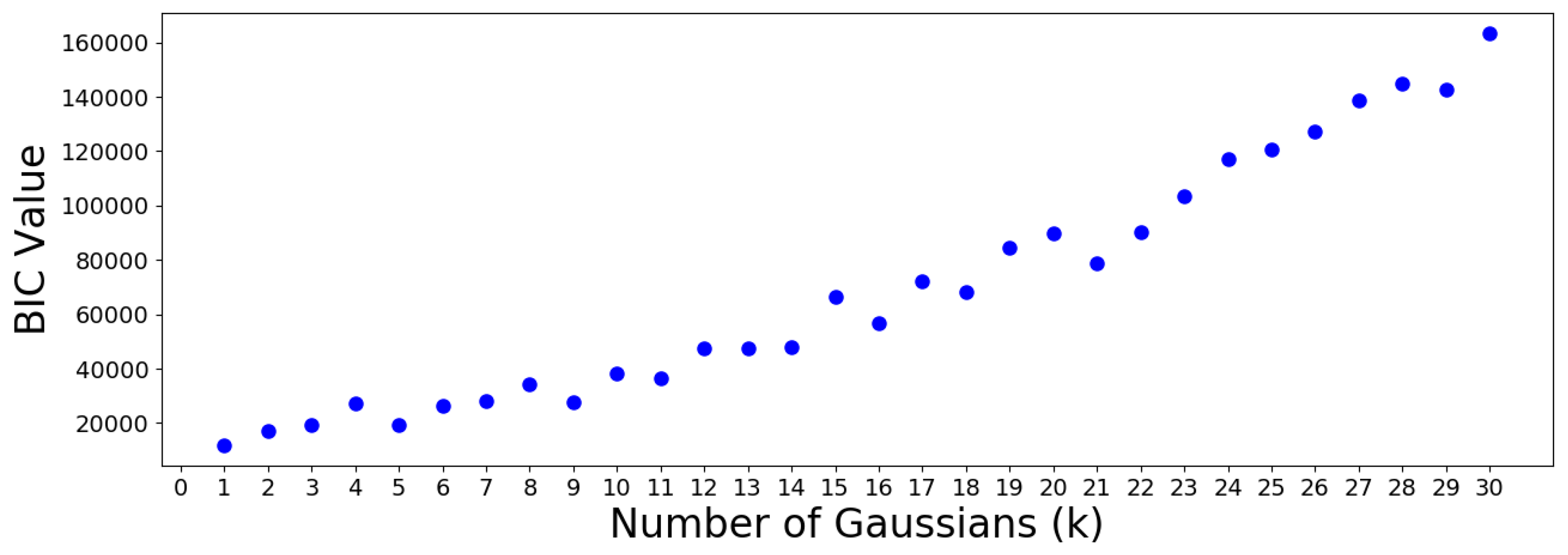
scikitlearn. The results are plotted in the following
Figure 14 and
Figure 15.
The AIC minimum suggests that the 305 OTUs should be optimally clustered into a GMM with groups. On the other hand, the BIC minimum suggests that a GMM with only one cluster is optimal. This is a meaningless result which should be discarded, since it suggests that all OTUs are similar. Note that the BIC values increase almost monotonically from group onwards, meaning no suitable number of clusters can be determined using this criterion. Therefore, the AIC result is used to move forward.
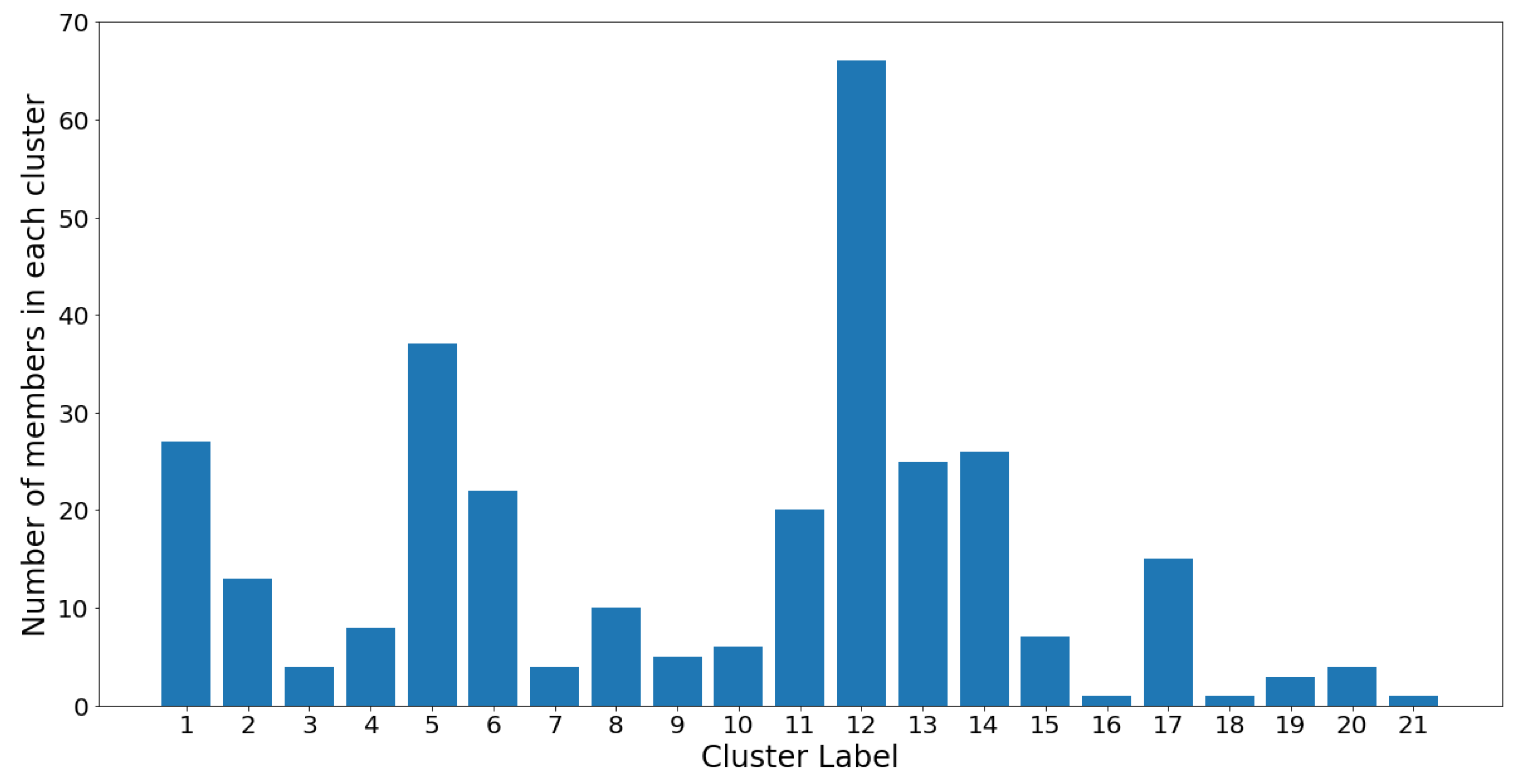
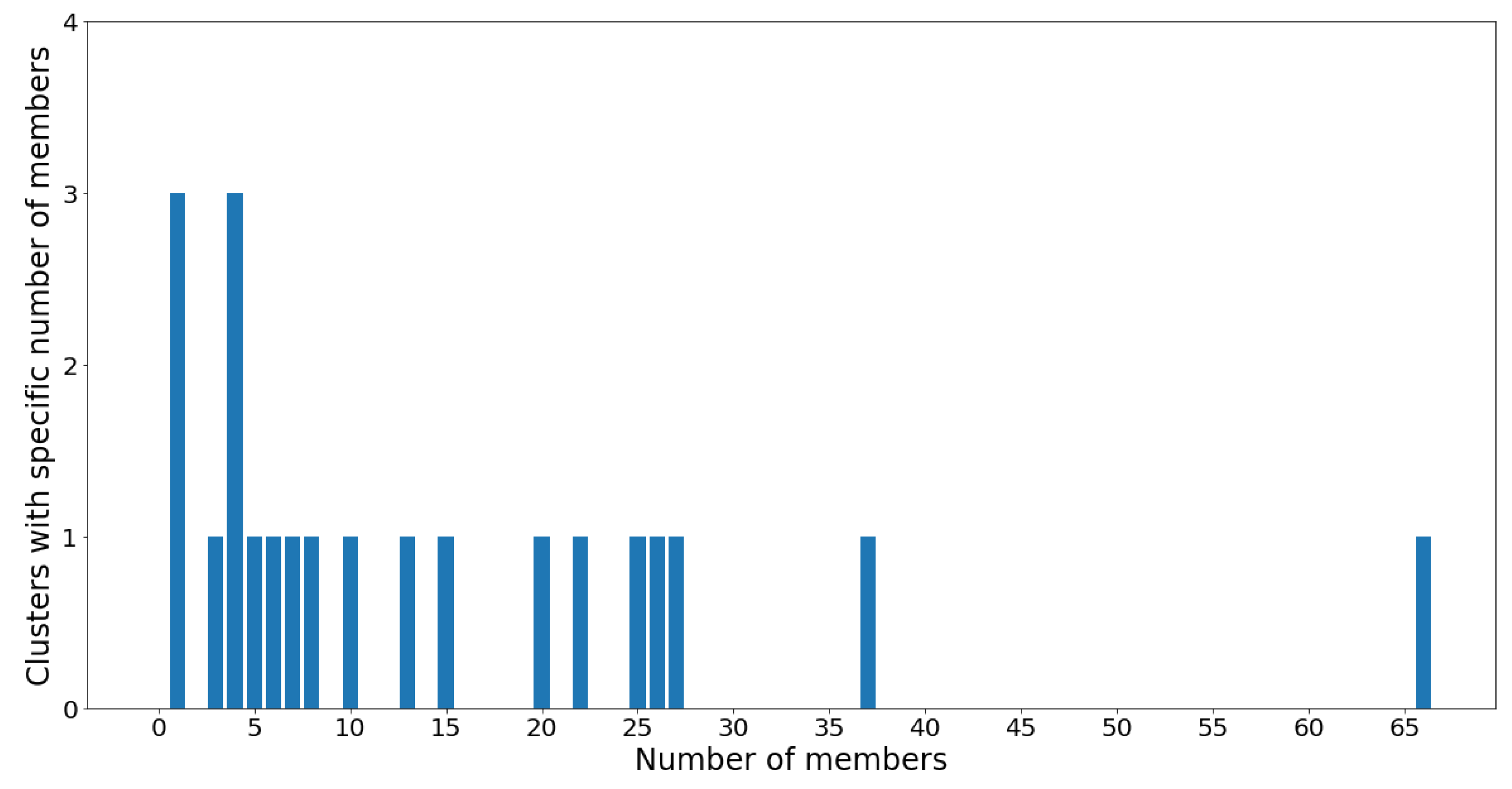
The cluster population and membership plots can be observed in the following
Figure 16 and
Figure 17.
Notice that the GMM cluster sizes have a much higher variance than the hierarchical clusters. Cluster 12 contains 66 out of the 305 total OTUs, while most other clusters contain between two and 40 OTUs. The skewed nature of the results is most likely due to the log-transformed OTU abundances being skewed towards the low counts. Therefore, the underlying Gaussian assumption (which assumes symmetrical distributions) is inaccurate. Moreover, the Gaussian mixture models were constructed using the
abundance counts of OTUs, and not the
associations as the hierarchical models were in
Section 3.1. These two reasons alone suggest that the Gaussian clusters may not be the best representation of OTU groups. Nevertheless, the results are summarized in
Table 3, which highlights the biomarker OTU in each GMM cluster as well as the cluster size.
3.3. Dirichlet Mixture Analysis of OTUs
In the previous
Section 3.2, the OTU abundances were assumed to follow an underlying Gaussian distribution. In light of
Figure 4 and
Figure 5, this assumption is clearly inaccurate, since even the distribution of log-transformed values appears to be skewed towards the low counts. Therefore, a more suitable assumption for the OTU clusters is the
Dirichlet multinomial mixture (DMM) (see
Appendix J). Instead of using
Python, the Dirichlet Multinomial
R package developed by [
37] is used. This algorithm is capable of constructing a set of DMM models, assessing the optimal model(s) using AIC, BIC, or Laplace information criterion (LIC), then producing heatmaps of the clustering results based on the Dirichlet weights of each cluster.
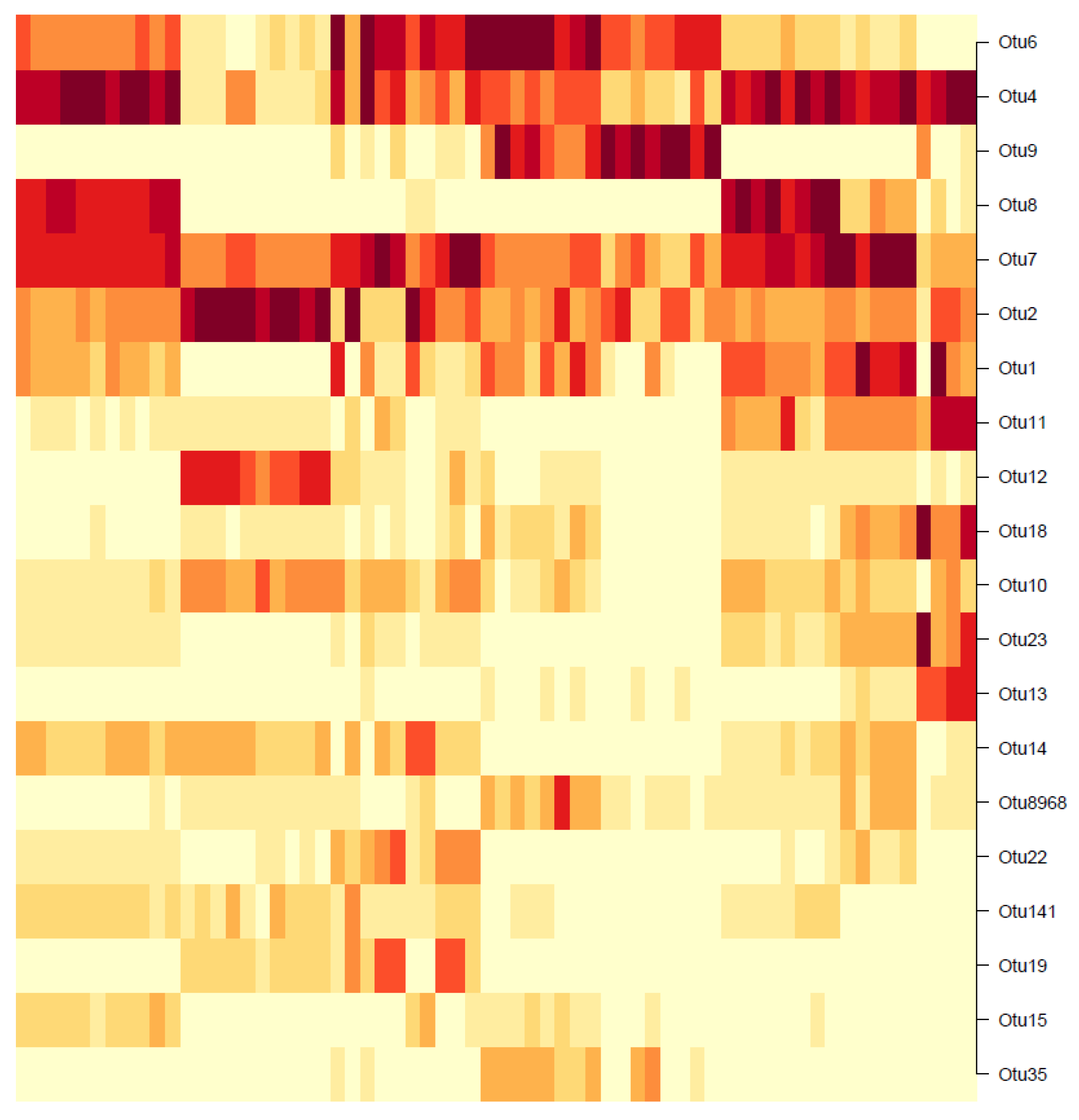
Unlike the hierachical or Gaussian approaches where the clustering is performed on the OTUs and not the samples, the DMM clustering is the exact opposite: The samples are clustered and not the OTUs. The results, however, can still be interpreted to identify the dominant OTUs for further analysis. For the 55 existing samples, the heatmap in
Figure 18 shows the BIC-optimal DMM clusters, labelled with the 20 OTUs of highest Dirichlet weights.
Note that the rows of the heatmap represent individual OTUs. In the first row (OTU6), a dark-shaded band exists in the mid-samples, including a commonly high abundance of OTU6 in those samples and low abundances elsewhere. Similarly, for the second row (OTU4), a common high-abundance band is observed for the first and last few samples, with low abundances elsewhere. This visual result reinforces the concept that the DMM model clusters the individual samples (columns) and not the OTUs. However, notice that going down the heatmap from OTU6 to OTU35, the dark- shaded bands appear less frequently. The colours become increasingly white, indicating an overall decrease in OTU abundance. Below the 20th-OTU cutoff (of OTU35), the rows are entirely white with close to zero abundance, and therefore those results have been truncated from the figure. Therefore, the 20 OTUs shown in
Figure 18 are considered as the biomarker OTUs, akin to those in the hierarchical and GMM clustering results. However, the followers of these 20 biomarker OTUs cannot be determined, since the clustering was not performed OTU-wise.
3.4. Prediction Results
The 10 water chemistry variables (outlined in
Table 1) are combined with representative OTUs obtained from
Section 3.1,
Section 3.2 and
Section 3.3. Together, these serve as inputs. When combined with the corresponding, labelled process outcomes of
selenium removal rate (SeRR), predictive models are trained for the estimation of the
SeRR of new samples.
The models can be categorized in terms of their inputs, as follows:
Base case: Water chemistry variables only.
Hierarchical: Water chemistry variables plus representative OTUs obtained using hierarchical clustering.
Gaussian: Water chemistry variables plus representative OTUs obtained using GMMs.
Dirichlet: Water chemistry variables plus representative OTUs obtained using DMMs.
The idea is to observe whether the addition of biological features improves or confounds the predictive capabilities of these models. The actual models consist of the following three types:
The raw SeRR values obtained from plant data were normalized and discretized into two (binary) classes, 0 and 1. Class 0 (poor) corresponds to SeRR values which fall below the mean SeRR, and Class 1 (satisfactory) corresponds to values above the mean. Out of the total data samples, 29 have a class label of 0 and 27 have a class label of 1, therefore the overall distribution is fairly even (i.e., not skewed towards one label).
For each model, of samples from each class are randomly selected as test samples for performance assessment, and the remaining of samples as training samples for model construction. Note that this approach eliminates the possibility of biased selection from either class. If the training and testing sets were instead selected arbitrarily from the entire dataset, then they could possibly be skewed (e.g., many samples selected from Class 1, but few from Class 0).
No validation (development) set was required, since the hyperparameters of each model (i.e., regularization constants, model complexity, etc.) were selected to be fixed values for simplicity. The RF model was constructed using the RandomForestClassifier module from scikitlearn.ensemble, with bootstrapping disabled. Although bootstrapping is normally recommended, the data sample-size in this case is extremely small for modeling purposes. Therefore, all of the existing samples are required for training; any arbitrary selection of samples without replacement could skew the training set. The SVM model was constructed using the sklearn.svm.svc module, with a regularizer value of and the default linear kernel. Finally, the ANN model was constructed using tensorflow, with 10 layers of 20 neurons each, a learning rate of and a -regularizer of . In order to maintain the reasonable computational times required by each model, a maximum of 1000 epochs (or “outer iterations”) were allowed. The ANN model was allowed 50 steps (or “inner iterations”) per epoch.
The prediction accuracy of each model on the test set (of
samples) is reported in
Table 4, with respect to the type of inputs used.
The RF models produced the most accurate test predictions for every case, followed by SVMs then ANNs. When comparing the input types, the base case accuracy turned out to be the highest for both RF and SVM models. The addition of hierarchical OTU clusters had the largest detrimental effect on the test accuracy, as observed by the uniform, marked decreases across all three model types. The addition of Gaussian OTU clusters improved the test accuracy for the ANN model, but proved to be detrimental for the RF and SVM models, albeit with the least impact. The addition of Dirichlet OTU clusters also decreased the model accuracy for all three models, but not as much as the hierarchical. These results clearly show that the addition of biological data, which was initially expected to improve quality of prediction, actually degrades it. Even though the OTU abundances should contain valuable insight into the biological community interactions, the observed confounding effect is most likely due to the undesirable qualities of the data. These include the inherent noise present in the OTU abundances, and also the relatively low sample size to begin with. Another reason could be that the explored clustering methods are incapable of clearly extracting information related to coupling effects between OTUs and water chemistry variables.
If a model were to be selected for actual prediction of process outcomes, it would be the RF using base-case, water chemistry variables. This model achieves a respectable > accuracy on the binary classification of SeRR.
3.5. Feature Selection Results
The
relevant features in the prediction framework are defined as those which contribute significantly to the accuracy of the model. The results in
Section 3.4 showed the RF model as the most accurate one out of the three modeling approaches, and therefore it will be used for feature analysis in this section. The univariate feature selection strategy,
mean decrease in accuracy (MDA), was first used to determine “relevant” features in terms of predicting the outcome
. An RF model was constructed for each of the input types of hierarchical, Gaussian, and Dirichlet clustering. 10,000 permutations of MDA were performed for each RF model; the averaged feature importances for each are summarized in the following
Table 5,
Table 6 and
Table 7. Only the top four water chemistry and top five OTU features are reported for conciseness.
Notice that consistently appears in each table as the most “relevant” feature, as MDAs of ∼ are observed as this feature is permutated. appears to be the second contender, causing accuracy drops of ∼ in most cases when permutated. and are the next most “relevant” features, however permutating them causes smaller accuracy drops of on the RF models. Therefore and can be comfortably concluded as the main deciders of overall selenium removal rate, in terms of all water chemistry variables. This result is logical from a domain-knowledge perspective, since both variables are used for selenium removal rate calculations using a mass-balance approach.
Note that the MDA approach is univariate, which means it ignores possible correlations between multiple features. In order to address this issue partially, the
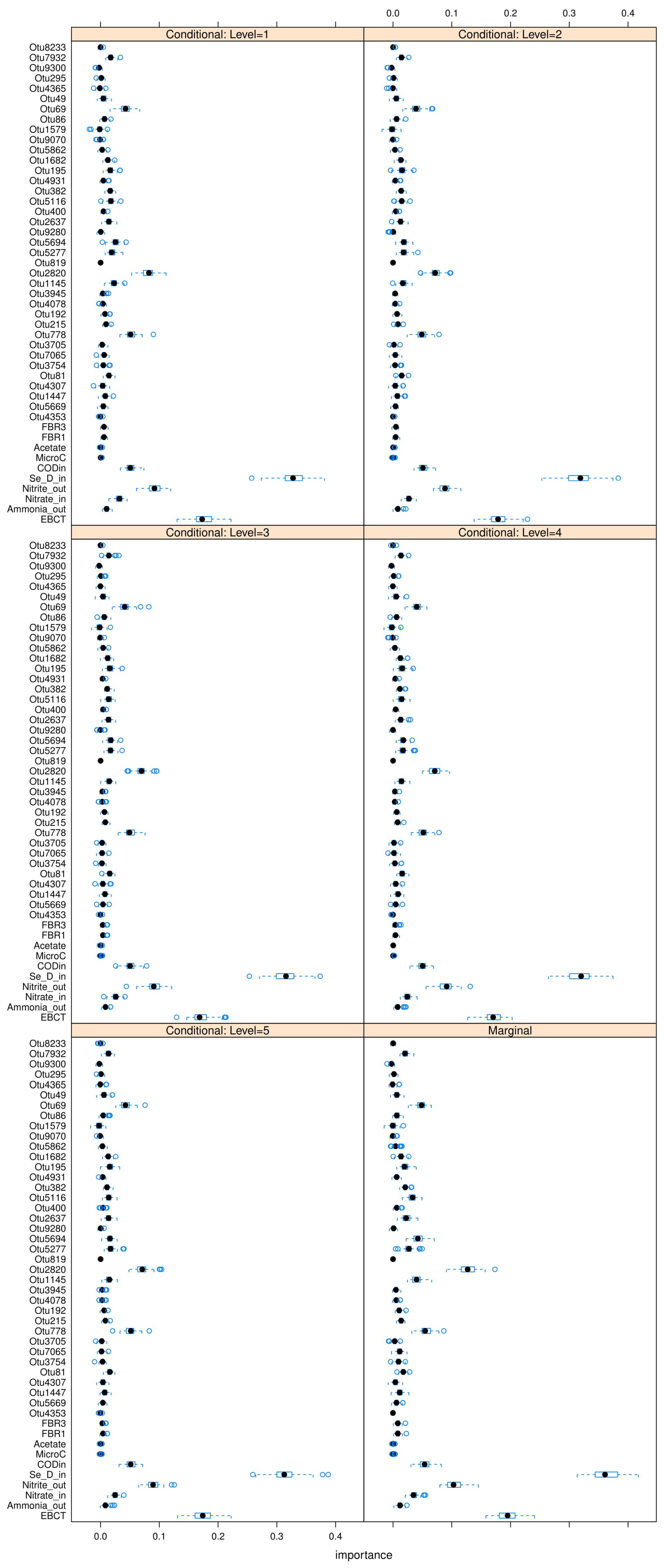
conditional mean decrease in accuracy (C-MDA) approach is also explored. In C-MDA, the permutations of features are performed, given the presence of other features. For example, when the feature
is permutated, it is conditioned on the fact that the feature
falls within a certain bracket of values. The
R package developed by [
35] is used to perform these C-MDA experiments, since the algorithm systematically decides the best values for the secondary variables to be conditioned upon. The detailed results can be found in
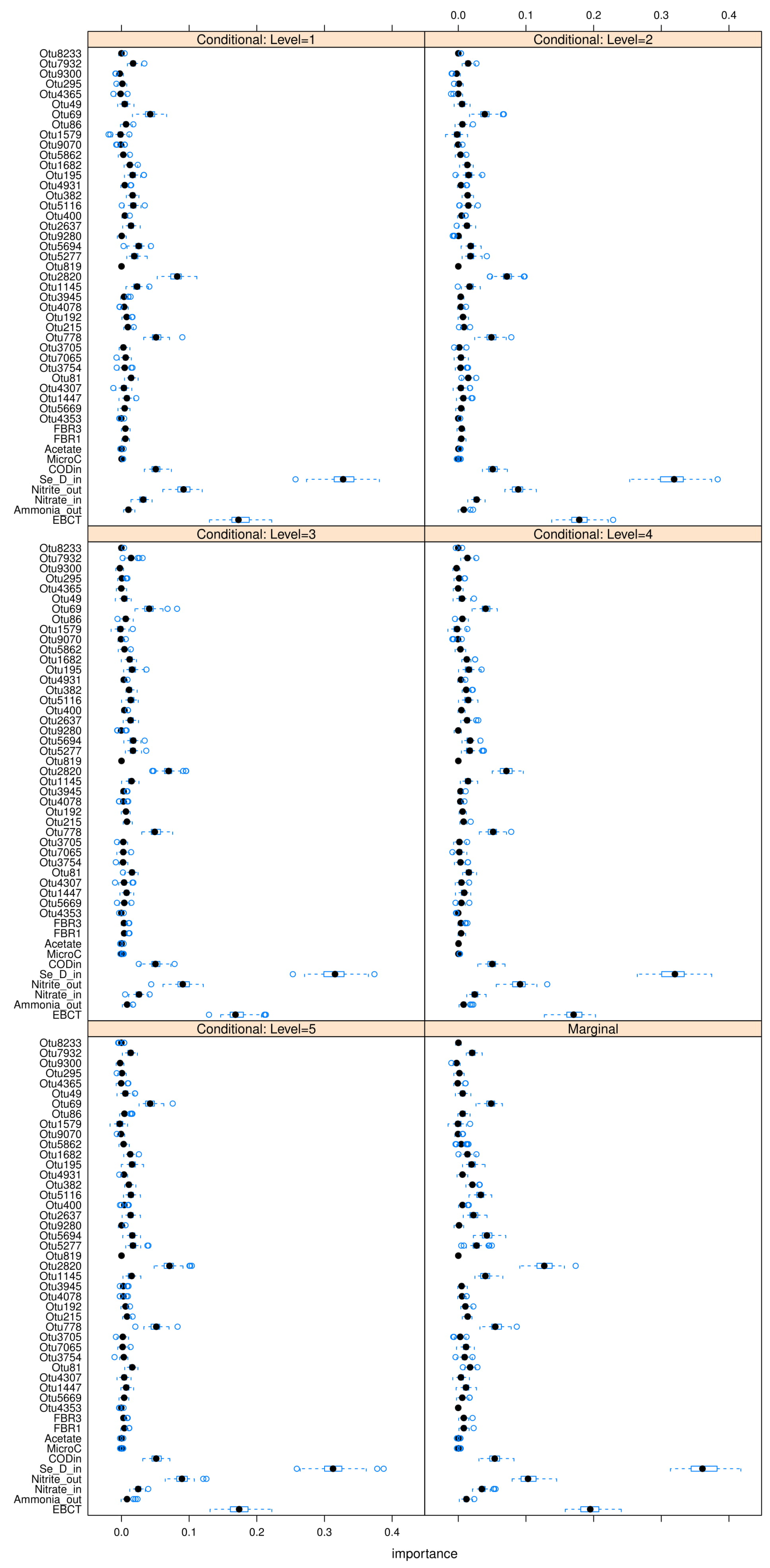
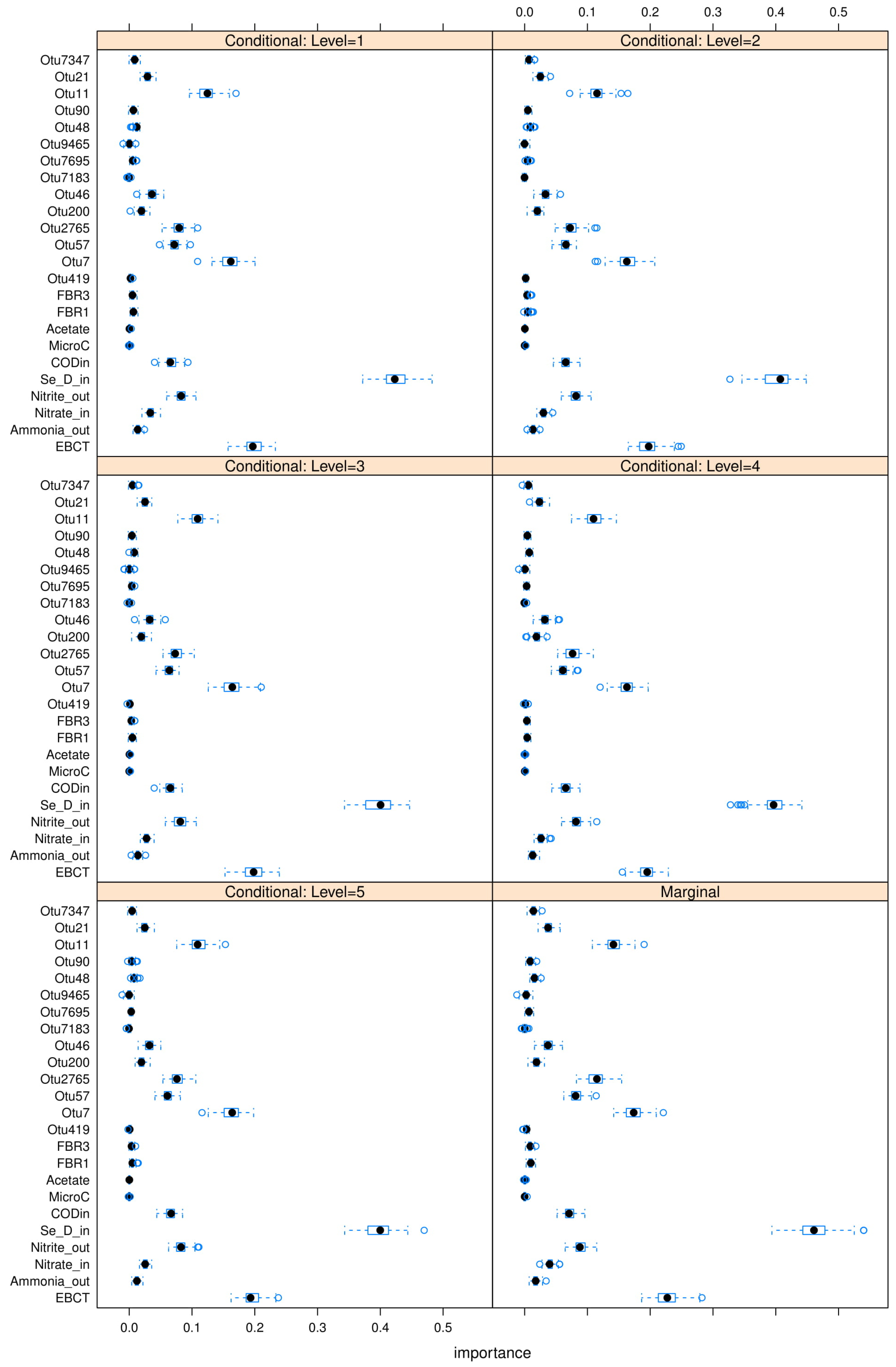
Figure A23,
Figure A24 and
Figure A25 in
Appendix L. The “relevant” variables from each RF model can be summarized in
Table 8:
3.6. Summary and Critique of Results
Of the supervised learning techniques tested,
Section 3.4 show that RFs were the best model in terms of test-set accuracy, followed by SVMs and ANNs. RFs are an ensemble method which averages the predictions from a large number of randomly constructed models, as opposed to the SVMs or ANNs which were constructed in one shot. The ANNs performed the worst, due to the fact that deep learning models typically require an exorbitant number of samples (e.g., millions) to predict well, and only 56 samples were available in the dataset.
Inconsistent results (
Section 3.1 and
Section 3.2) were obtained for biomarkers identified through the three unsupervised techniques. This is due to two reasons: First,
assocation values were used for hierarchical clustering, while
abundance counts were used for the Gaussian and Dirichlet mixtures. Secondly, the three clustering methods also differ significantly from a statistical perspective. Specifically, the hierarchical clustering was based on pair-wise similarity calculations, whereas the Gaussian mixtures modelled OTU groups as a sum of overlapping distributions. The Dirichlet mixtures are distinct from the previous two clustering methods, since they were calculated using the 56 data sample rows rather than the 305 OTU columns. When modeling OTUs using multinomial distributions, an OTU can occur in several different groups associated with different operating stages or levels of process performance. This may be a closer representation of reality, instead of constraining each OTU to belong to one particular group only. Evidence supporting this conclusion includes, for example, the low Silhouette values (i.e., qualities of clusters) shown in
Figure 9 and
Figure 10.
Finally, the feature selection results are also quite nuanced. Specifically, note that
and
were identified as key variables in
Table 5,
Table 6 and
Table 7. These are obvious contributory features from a domain knowledge perspective, since their numerical values directly determine the selenium removal rate. Non-obvious features such as
,
, and
are also identified as important. Surprisingly, however, the
carbon source variables
or
are never identified as contributory features. The type of
carbon source is known to directly impact microbial community compositions in other studies (such as [
38]), and therefore they were expected to influence selenium removal significantly. Finally, note that
,
, and
have been identified as key biomarkers of high importance in
Table 5,
Table 6 and
Table 7. Their feature importances are higher than several of the top four process variables in each case, which reinforces the hypothesis that microorganisms do in fact noticeably affect final selenium removal rate. Interestingly,
appears as an important feature in both Gaussian and Dirichlet clusters, which are two models with entirely different statistical assumptions and properties. However, note that these biomarker OTUs represent
clusters, which may be a sub-optimal way of characterizing the true OTU interactions. The clarity and robustness of these results can be improved, for example, by modeling OTUs as individuals rather than agglomerates. A possible avenue in this direction is explored in the following
Section 4, and is recommended as a follow-up study to this work.
4. Conclusions and Future Work
The main objectives of this work are as follows: To compare the prediction capabilities of three predictive models (RFs, SVMs, and ANNs), as well as the abilities of three clustering methods (hierarchical, Gaussian, and Dirichlet mixtures) and two feature selection techniques (MDA and C-MDA) to identify key process variables. On one hand, the main process outcome of the selenium removal rate was observed to be best predicted by RF models. The obvious features of selenium loading and retention time were both identified as key contributors to the selenium removal rate. Non-obvious features such as ammonia outflow, nitrite outflow, and chemical oxygen demand were also identified as contributors, but surprisingly these exclude carbon source (a known factor which significantly alters OTU communities). On the other hand, the three clustering methods identified several different biomarker OTUs, which had feature importances similar to those of the aforementioned process variables. This result supports the notion that the OTUs play a substantial role in the removal of selenium from the bioreactor.
The results of this study suggest many possible avenues for future work. In terms of predictive modeling, the
small-N issue can be mitigated by building a data simulator, which generates artificial samples based on the existing data. This can be accomplished by adapting the use of
generative adversarial nets (GANs) [
39], which is popular in image datasets. If a sufficient number (e.g., thousands) of samples are generated, then neural nets with much higher prediction accuracies can be constructed. The parameters as well as architecture of the neural nets can both be adaptively updated on each iteration, using the
stochastic configuration network (SCN) method established by [
40]. This method has demonstrated success in similar wastewater treatment applications such as [
41,
42,
43].
In order to extract clearer conclusions from the biological data, the unsupervised learning paradigm can be changed from
clustering models to
graphical models. Instead of forcing the OTUs into clusters that they may not sensibly belong to, an alternative is to use Bayesian networks [
31] for causality analysis. In this approach, the OTUs are instead modelled as individual entities or states, as nodes on a graph. The interactions between OTUs are modelled by state-transition probabilities, or graph edges, instead of overlapping clusters. Root-cause identification can then be performed by tracking the graph backwards from the process outcome (the last event) to the key trigger(s) at the start. This strategy has seen success in [
44], as well as in the
alarm management literature by [
45,
46] using Granger causality. A follow-up paper could explore the efficacy of these suggested methods, by identifying new OTU biomarkers using graphical models and observing whether they contribute more to the predictive models (in
Table 4).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










































