3.1. Chromosome Representation
Since the proposed method, PCACD, employs the framework of an efficient MOEA, CAEA, one of the top issues of PCACD is to determine an appropriate chromosome representation for the community detection problem. PCACD utilized an adjacency-based chromosome [
35] to encode a solution, i.e., one community structure of the detected network. The major advantage of the adjacency-based chromosome representation lies in that it is able to conveniently avoid the generation of any invalid chromosome during crossover and mutation. Specifically, every chromosome
,
, in a population has a fixed length of
n where
n denotes the total number of nodes in the network and
N indicates the population size. The value of every gene
,
, in chromosome
ranges from one to
n. The gene
taking an integer value
signifies that both nodes,
a and
b, are classified as belonging to the same community in the community structure decoded from chromosome
. In consequence, a decoding procedure has to be applied for any adjacency-based chromosome before the evaluation of its objective functions.
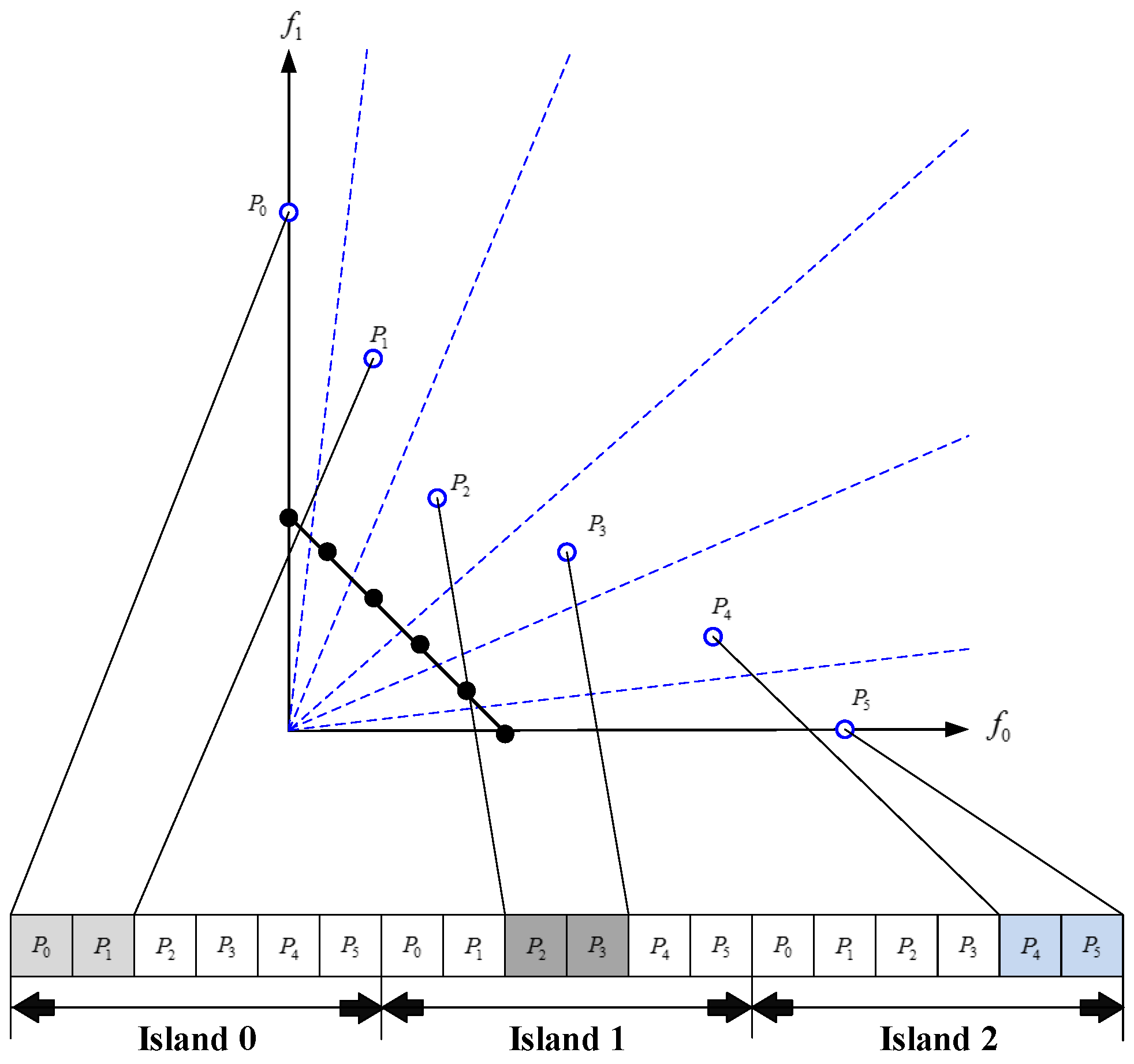
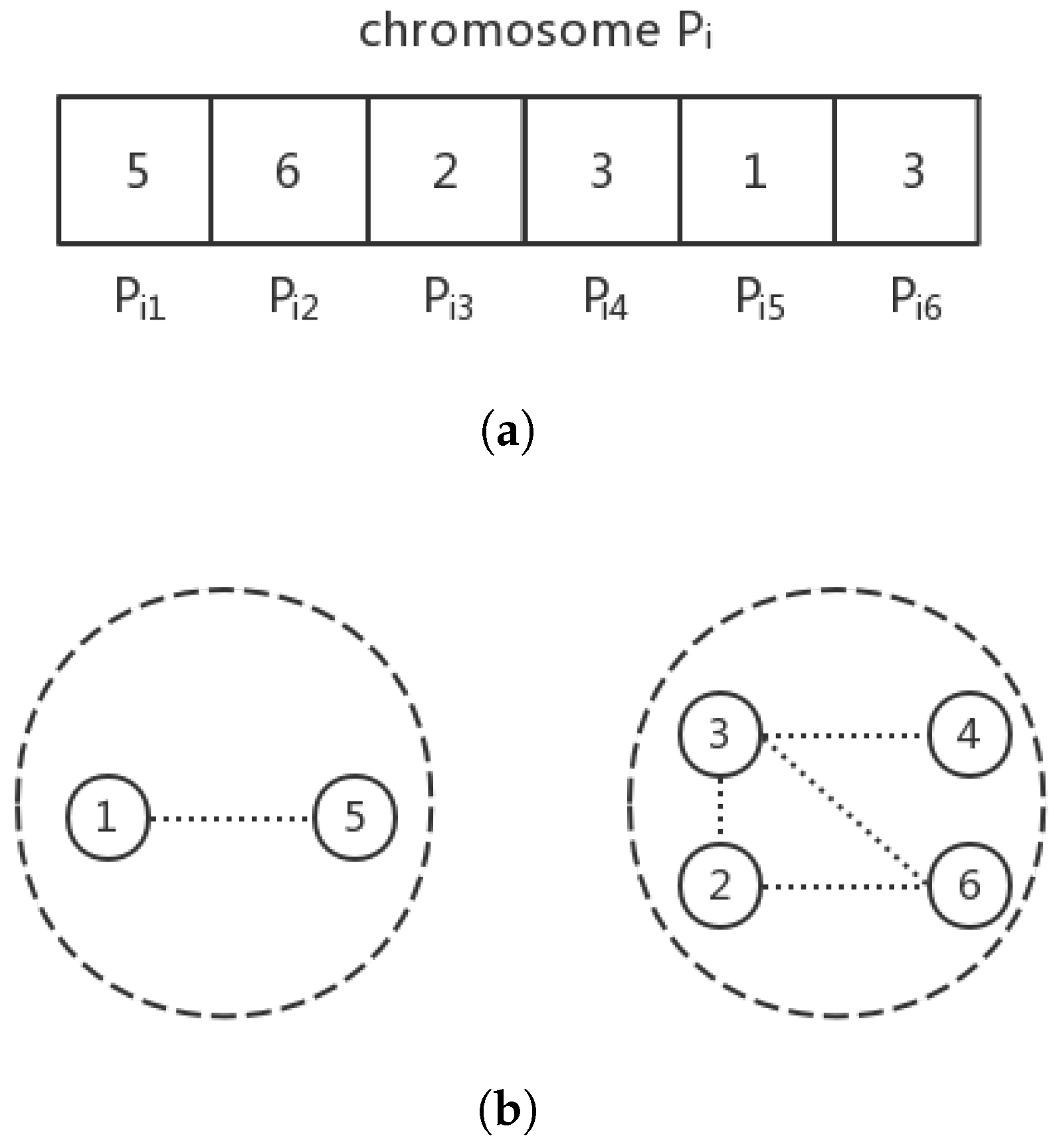
Figure 1 presents a simple example of an adjacency-based chromosome in the case of
and the corresponding community structure decoded from this chromosome where all the nodes within the same connected subgraph were just classified into the same community. Fortunately, with the assistance of the backtracking method, this decoding procedure costs only linear time [
35].
3.2. Modularity-Based Objective Functions and Local Search
As an optimization-based multi-objective method, PCACD transforms the community detection into a modularity-based bi-objective optimization problem (BOP) in order to discover potential community structures at different resolutions. The modularity metric, denoted as
Q, was proposed by Newman and Girvan [
3,
4] for the purpose of assessing the quality of a network partition or community structure. It can be represented as
where
X denotes a partition or community structure of a network,
C represents one of communities in this partition,
represents the number of edges in community
C,
m denotes the total number of edges in this network, and
denotes the degree of nodes within community
C.
To obtain the largest modularity
Q score, we should simultaneously maximize its first part
and minimize the second part
. In short, as the first term increases, the number of edges in the same community increases, which results in the generation of larger communities. In contrast, as the second part decreases, the degree of nodes within the same community declines, which tends to generate smaller communities. Therefore, maximizing modularity means finding an appropriate trade-off between these two potentially competing terms. As a consequence, these two terms of the modularity are often separated in order to avoid the resolution limit disadvantage of modularity-based single objective optimization methods [
5]. Similarily, PCACD applies both of them as two competing objection functions to be optimized. Specifically, PCACD considers the community detection problem as the following modularity-based BOP to simultaneously maximize two objective functions, i.e.,
and
.
In general, it is a little difficult for EAs to approach the local optimum partitions quickly only through their own crossover and mutation operators. Since PCACD aims to optimize the above modularity-based bi-objective community detection problem, a modularity-based greedy local search strategy is further applied to every generated offspring to accelerate the search process of PCACD with the aid of the heuristic tricks about community detection. To be specific, this local search strategy for each offspring consists of k loops of greedy merging operations, where k is set to one quarter of the total number n of the network’s nodes. In every loop of greedy merging operation, the local search strategy first chooses one node a from all the nodes of the network randomly. Then node a tries to move into the communities of its adjacent nodes one by one for the current chromosome and the best adjacent one is picked such that the resulting community structure could reach the local highest modularity score. Thereafter, the gene at locus a is assigned just the gene value at locus for chromosome . It signifies that the chosen node a is greedily merged into the community of its local best adjacent one .
3.3. Parallel Global Island Model
The proposed algorithm, PCACD, utilizes the framework of an efficient bi-objective optimization algorithm, CAEA, to solve the above bi-objective community detection problem. It means that the bi-objective community detection problem is decomposed into
N scalar optimization subproblems. Moreover, to find a local nondominated solution in the corresponding decision subset
, each subproblem employs a conical area as its scalar objective [
21]. In PCACD, each subproblem is associated with one individual in the current population and is responsible for searching for the best solution in its exclusive decision subset
in terms of its conical area indicator.
In order to further reduce the running time of solving the bi-objective community detection problem, PCACD requires an island model to parallelize the CAEA. In general, parallel MOEA/Ds such as opMOEA/D [
29] employ some local island models since a generated offspring for a subproblem needs to update only the neighbors of this subproblem locally in MOEA/D. In contrast, all the individuals in the population are essential for the global update mechanism in CAEA where a produced offspring globally chooses and updates one out of all the subproblems according to the direction of convergence. It results in the local island models for parallel MOEA/Ds not being suitable for parallel CAEAs radically.
Hence, PCACD employed a global island model to solve the bi-objective community detection problem in parallel. In this parallel island model, each island maintains an entire population in order to globally update subproblems in CAEA while it is in charge of the optimization of only a portion of the subproblems. In the initialization procedure, all subproblems are linearly partitioned into
q groups where
q denotes the number of parallel islands. Thereafter, each island is assigned an evolutionary task for one group out of them. That is, the size of the
r-th group
,
, equals
In the above equation, / and % denote the integer division and modulus operations respectively.
Formally, the
k-th subproblem associated with the
k-th reference direction or observation vector
in CAEA, denoted as
, employs the conical area [
21] as its scalar objective in the form
In the above equation,
X represents a community structure of the network,
denotes the objective vector consisting of
IntraQ(
X) and
InterQ(
X),
indicates the conical subregion associated with reference direction
,
,
represents the true ideal point for the given bi-objective community detection problem, and function
denotes the conical area of the portion not dominated by the first input vector,
, in the conical sub-region
[
21]. It is worth noticing that, in practice, the true ideal point
should be replaced with the current attainable ideal point on the
r-th island, written as
, since
would be in general unknown and unavailable to PCACD.
According to the parallel island model, although the r-th island globally preserves all N solutions associated, respectively, with N sub-problems, the r-th island is assigned the optimization task of only the r-th group of sub-problems, , where , , ⋯, if and , , ⋯, otherwise. It signifies that, during the reproduction of each offspring on the r-th island, the first parent is bound to be one out of the current individuals associated with the r-th group of sub-problems . The role of the other groups of sub-problems, , , on the r-th island is just to help this island to globally select the second parent and complete the global update process for each offspring.
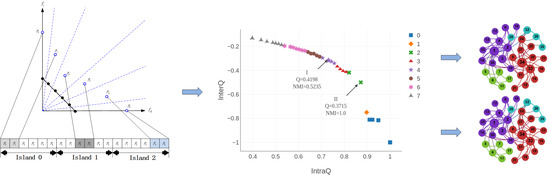
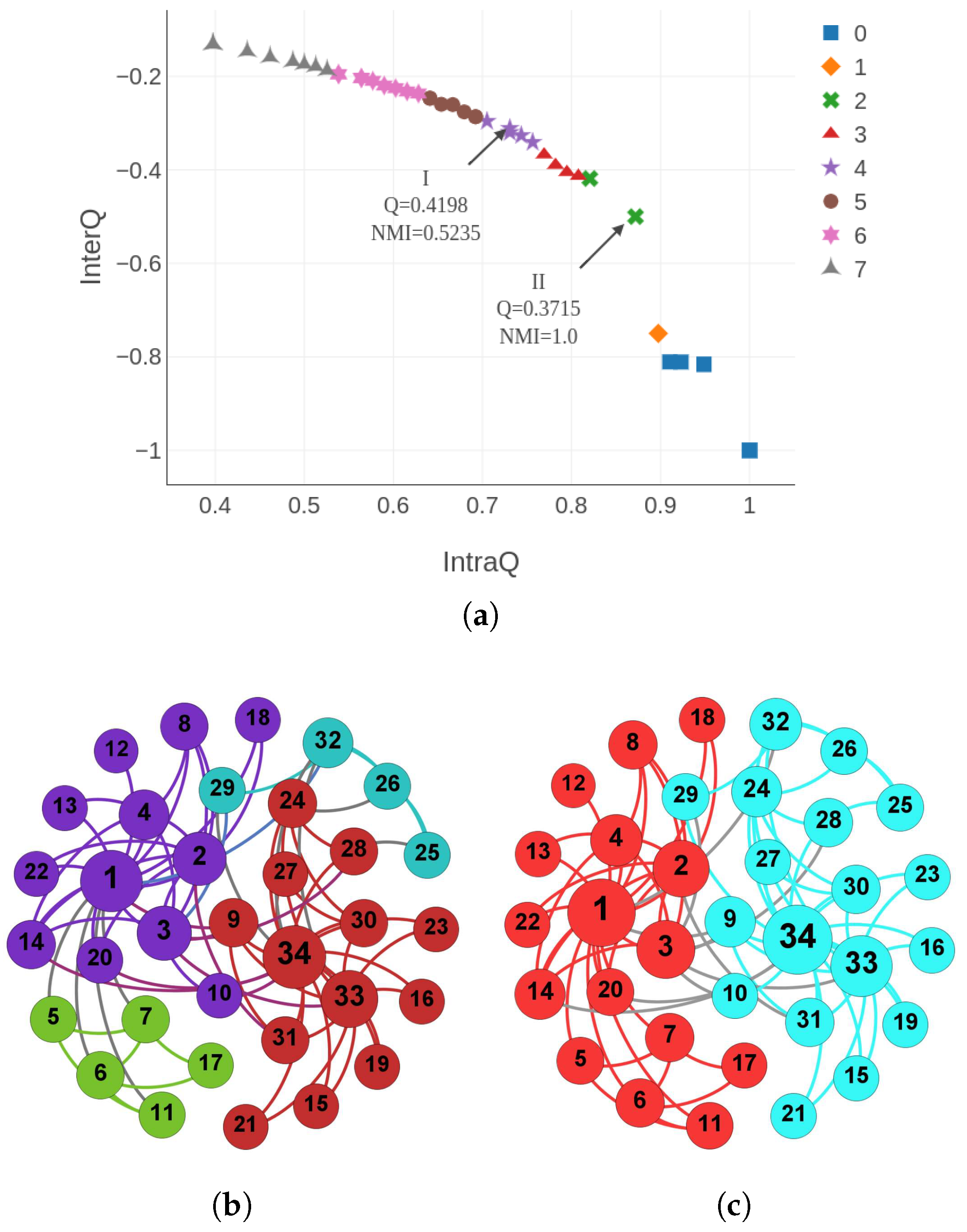
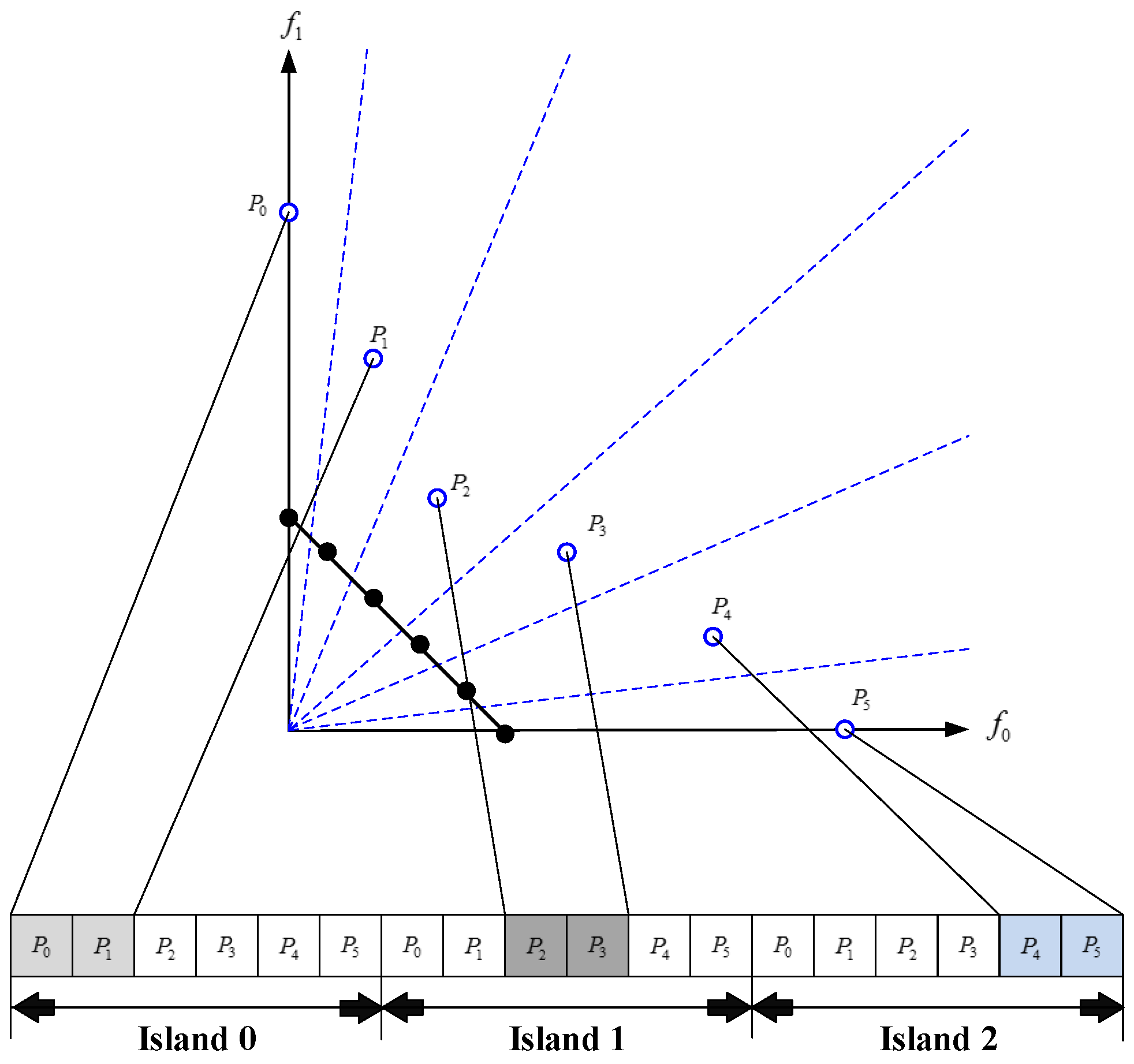
Figure 2 illustrates a simple example of the parallel global island model in case of
and
. From the perspective of the objective space, the
r-th island,
, is actually responsible for optimizing
sub-problems,
and
, by evolving their respective associated individuals,
and
, to approach the
r-th fragment of Pareto front. In the meantime, the
r-th island has to maintain an entire population of size
in order to perform the global selection and update mechanisms of CAEA. This parallel island model is capable of helping PCACD to reduce the run time of its serial counterpart for community detection.
3.4. Targeted Elitist Migration
At the same time that the parallel global island model was employed for good speed-ups, an appropriate migration policy had to be utilized to share essential evolutionary achievements among islands so that the qualities of community structures obtained by PCACD do not degrade substantially. The migration policy has two crucial issues: the selection of migrants and migration topology. In a parallel MOEA/D, opMOEA/D [
29], a local hybrid migration policy was used to shares both ideal points and elitist solutions in a local migration topology where all migrants on one island locally emigrate to one of only two islands linearly adjacent to it. However, as a parallel CAEA for the bi-objective community detection problem, PCACD adopted a targeted elitist migration policy on the account of the evident differences between the selection and update mechanisms of CAEA and MOEA/D.
To be specific, MOEA/D locally selected a pair of parent solutions associated with two neighbor sub-problems during reproduction. Since this pair of parent solutions were often very similar to each other, their offspring was also similar to them in general. Hence, this local selection mechanism of MOEA/D posed a great difficulty that one separate island could not achieve a satisfactory ideal point only on its own evolution in any parallel MOEA/D. Consequently, a better ideal point was very critical to every island in a parallel MOEA/D since it helped the island to explore an evidently wider front segment.
In contrast, CAEA globally chose the parents from the entire population rather than only from the neighbors. Hence, a new offspring reproduced had the chance to globally update one of all the individuals in the whole population. As a result, migration of ideal points was unnecessary to PCACD because the ideal point resulting from one island was generally capable of meeting the evolutionary requirements of this island. In consideration of the global property of the selection mechanism in CAEA, only elitist individuals were considered as migrants in PCACD. That is, once the individual associated with a sub-problem was successfully replaced at the last generation on the r-th island, a copy of the elitist individual replacing it would be transmitted to another certain island according to the migration topology in PCACD.
Apart from the selection of migrants, the migration topology also had a significant impact on the extent to which the migration accelerated the parallel evolutionary progress. Instead of locally updating several neighbor sub-problems in MOEA/D, one offspring needed to update one global sub-problem in accordance with the convergence direction in CAEA and PCACD. Hence it would be of great benefit to the further optimization of one successfully updated sub-problem in PCACD to directly migrate an elitist individual to the appropriate island, rather than simply to two linearly adjacent islands as the same as in opMOEA/CD. In consideration of this, a targeted migration topology was specially designed in PCACD to achieve the fast and accurate sharing of essential evolutionary achievements among islands. In light of the global island model, the optimization of the k-th sub-problem in PCACD, , belongs to the -th group and it is actually in the charge of the -th island where if , otherwise . Once the k-th sub-problem was successfully updated by a generated offspring on one island, the individual currently associated with this sub-problem, i.e., a copy of the offspring, would be regarded as an elitist one and it would migrate to the -th island in accordance with this targeted migration topology.
Algorithm 1 presents the implementation procedure of the targeted elitist migration policy on the r-th island. It consists of two phases; (1) transmitting elitist individuals to other islands in Lines 1 to 10 and (2) receiving elitist individuals from other islands in Lines 11 to 18. In the first phase, it was determined whether the current k-th individual associated with the k-th subproblem was an elitist individual in Line 2. If this is the case, the index of the destination island was figured out according to the targeted migration topology in Lines 3 to 7. Thereafter, as an elitist individual, a copy of the current individual associated with the k-th subproblem on this island was transmitted to the corresponding destination, i.e., the receive queue of elitist individuals on the -th island in Line 8.
| Algorithm 1TargetedElitistMigration(r) |
- 1:
fortodo - 2:
if the k-th sub-problem was successfully updated at the last generation then - 3:
if then - 4:
; - 5:
else - 6:
; - 7:
end if - 8:
Transmit a copy of the elitist individual to the receive queue of the -th island; - 9:
end if - 10:
end for - 11:
while the receive queue do - 12:
Receive the first immigrator from queue ; - 13:
; - 14:
if < then - 15:
; - 16:
end if - 17:
Delete from queue ; - 18:
end while
|
In the second phase, every immigrator from the other islands, i.e., every solution in the receive queue of elitist individuals on the r-th island, was utilized to update one subproblem on this island in a similar manner to one offspring in CAEA. To be specific, according to the definition of conical sub-problems in CAEA, the index of the sub-problem with which the immigrator should be associated was first figured out on this island by where indicates the bottom integral function in Line 13. Subsequently, if this immigrator was superior to the current individual associated with this sub-problem in terms of their respective conical area values, and , the individual was replaced by this immigrator on this island in Lines 14 to 16. Then this immigrator was deleted from the queue of immigrators in Line 17. This operation was repeated until the queue of immigrators becomes empty in Line 11.
3.5. Framework of PCACD
The main framework of PCACD is presented in Algorithm 2. Each island or process is initialized on one processor in Lines 2 to 5. In Line 2, the
r-th island generates
N evenly distributed reference directions
,
, for
N sub-problems. Then, the
r-th island divided all sub-problems linearly into
q groups and calculated the size
of the
r-th group according to Equation (
3) in Line 3. Meanwhile the
r-th island was only assigned the optimization task of the
r-th group of
sub-problems,
. In Line 4, this island randomly initialized
N individuals to form its whole population
and associates them with
N reference directions in terms of the directions and the conical area values in the same manner as CAEA. During the initialization of the population, each gene
of each initial individual was randomly assigned the index of one of its adjacent nodes and the adjacency-based chromosome representation avoided the generation of invalid community structures. Subsequently, these initial individuals in
were utilized to update the local ideal point
on the
r-th island in Line 5.
| Algorithm 2 The main procedure of parallel conical area community detection algorithm (PCACD). |
- 1:
for eachin parallel do ▹ parallel q islands or processes - 2:
Generate N evenly distributed reference directions , ; - 3:
Divide all N sub-problems linearly into q groups, calculate the size of the r-th group, and assign the r-th island the optimization task of the r-th group of sub-problems, ; - 4:
Initialize N individuals randomly to form its whole population , evaluate them, and associate them with N reference directions in the same manner as CAEA; - 5:
Utilize the initial individuals in to update the local ideal point on the r-th island; - 6:
; - 7:
while do ▹ evolutionary loops - 8:
for to do - 9:
ParentSelection1(r); - 10:
ParentSelection2(r); - 11:
Reproduction(, ); - 12:
LocalSearch(); - 13:
IdealPointUpdate(, ); - 14:
SubProblemUpdate(, r); - 15:
end for - 16:
TargetedElitistMigration(r); ▹ targeted elitist migration - 17:
; - 18:
end while - 19:
Synchronize with the root island and transmit all the individuals associated with the r-th group of sub-problems to the root island; - 20:
if then ▹ the 0-th island - 21:
The root island gathers all the individuals associated with q groups of sub-problems from q islands and integrates them into a final entire population P; - 22:
end if - 23:
end for
|
In Line 7, the r-th island will repeat the evolutionary loop if the current number of generations does not reach the maximum number of generations. Lines 8 to 15 represent one generation of evolution, and include important evolutionary operators such as selection, production, local search, and update. Note that function ParentSelection1(r) in Line 9 chooses the first parent individual, , only from the current individuals associated with the r-th group of sub-problems on the r-th island for the reproduction of each offspring in accordance with the tournament selection based on the conical area. Function ParentSelection2(r) in Line 10 chooses the second parent individual globally, , from the entire population on the r-th island in the same manner as CAEA. Subsequently, Reproduction(, ) generates an offspring from parents and through crossover and mutation in Line 11. Because it is preferable to maintain the effective connection components of the detected network during crossover, a two-point crossover rather than a uniform crossover is adopted in PCACD. The mutation operator randomly chooses several genes of an individual in terms of the mutation probability and then assigns each of them the index of the one randomly selected from its corresponding adjacent nodes. Next, LocalSearch() applies the modularity-based greedy local search strategy to the offspring to accelerate the search in Line 12. Thereafter, function IdealPointUpdate(, ) evaluates the offspring and utilizes it to update the local ideal point on the r-th island in Line 13. At the end of one generation of evolution, SubProblemUpdate(, r) in Line 14 associates the offspring with the nearest sub-problem on the r-th island in accordance with the convergence direction and updates this sub-problem in terms of the conical area value in the same manner as CAEA.
After one generation of evolution, TargetedElitistMigration(r) presented in Algorithm 1 is called to transmit elitist solutions to other islands and receive elitist solutions from other islands in accordance with the targeted elitist migration policy in Line 16. When the entire evolution terminates, the r-th island synchronizes with the root island, i.e., the 0-th island, and transmits all the individuals associated with the r-th group of sub-problems to the root island in Line 19. Finally, the root process gathers all the individuals associated with q groups of sub-problems from q islands and integrates them into a final entire population P in Line 21.
3.6. Computational Complexity
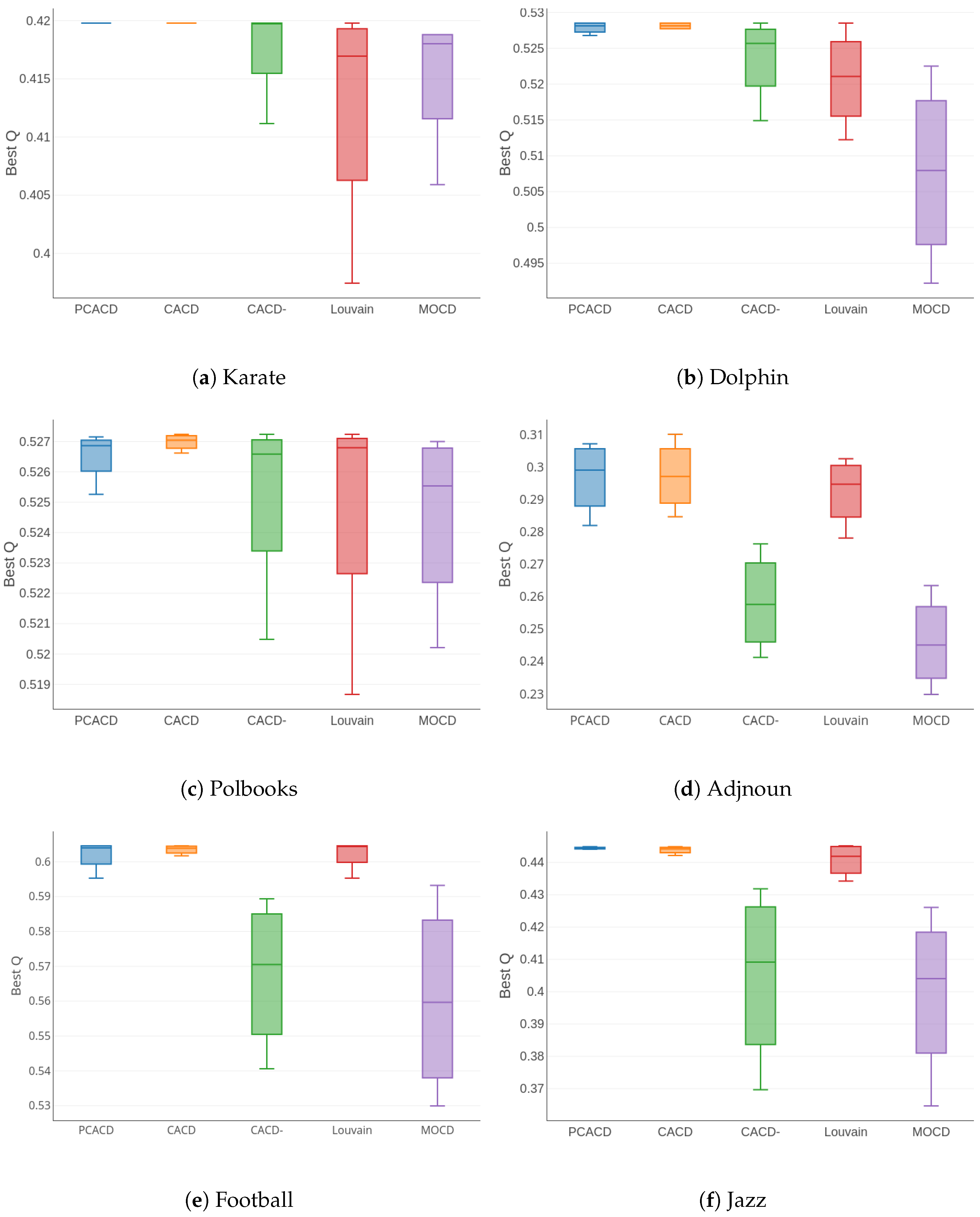
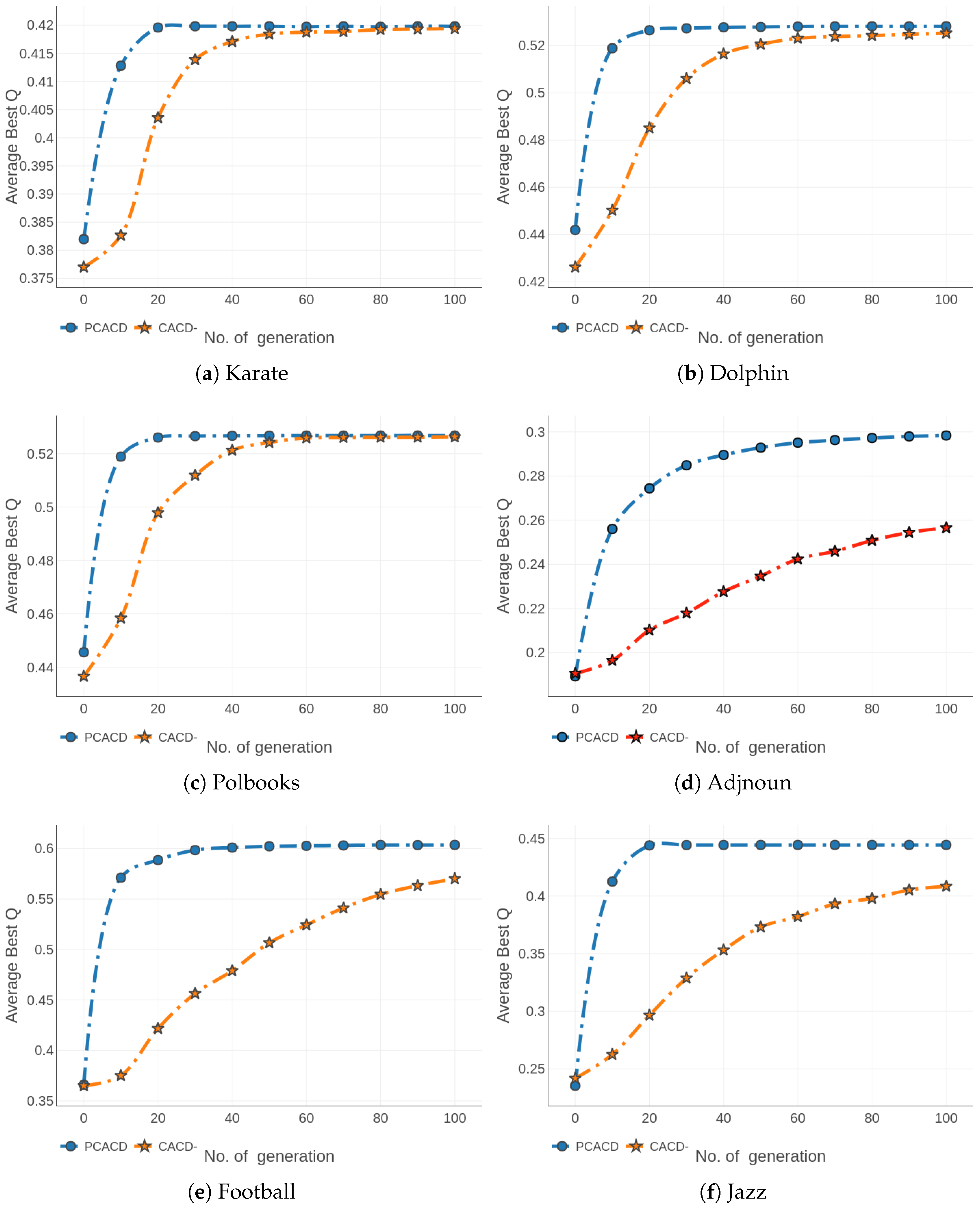
The fitness evaluation and the local search were the most time-consuming operations for every parallel island of PCACD. Specifically, the fitness evaluation of an adjacency-based chromosome consisted of the backtracking-based decoding and the calculation of two objectives, and . Suppose that the detected network contained n nodes and m edges. The backtracking-based decoding and the calculation of objectives have complexities and , respectively. Therefore, the complexity of the fitness evaluation of a chromosome is . Because generations of evolution were performed and in total about chromosomes were generated and evaluated during every generation on every parallel island of PCACD, the complexity of every PCACD process without the local search strategy is , where denoted the allowed maximum number of generations and N indicates the population size.
As mentioned earlier, the modularity-based local search strategy included loops and every loop on average needed D fitness evaluations where denotes the mean of degrees of all the nodes in the detected network. As a consequence, the computational complexity of the local search strategy was . Hence, every PCACD process including the local search strategy had the total complexity of .

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}