Intelligent Energy Management for Plug-in Hybrid Electric Bus with Limited State Space


Abstract
:1. Introduction
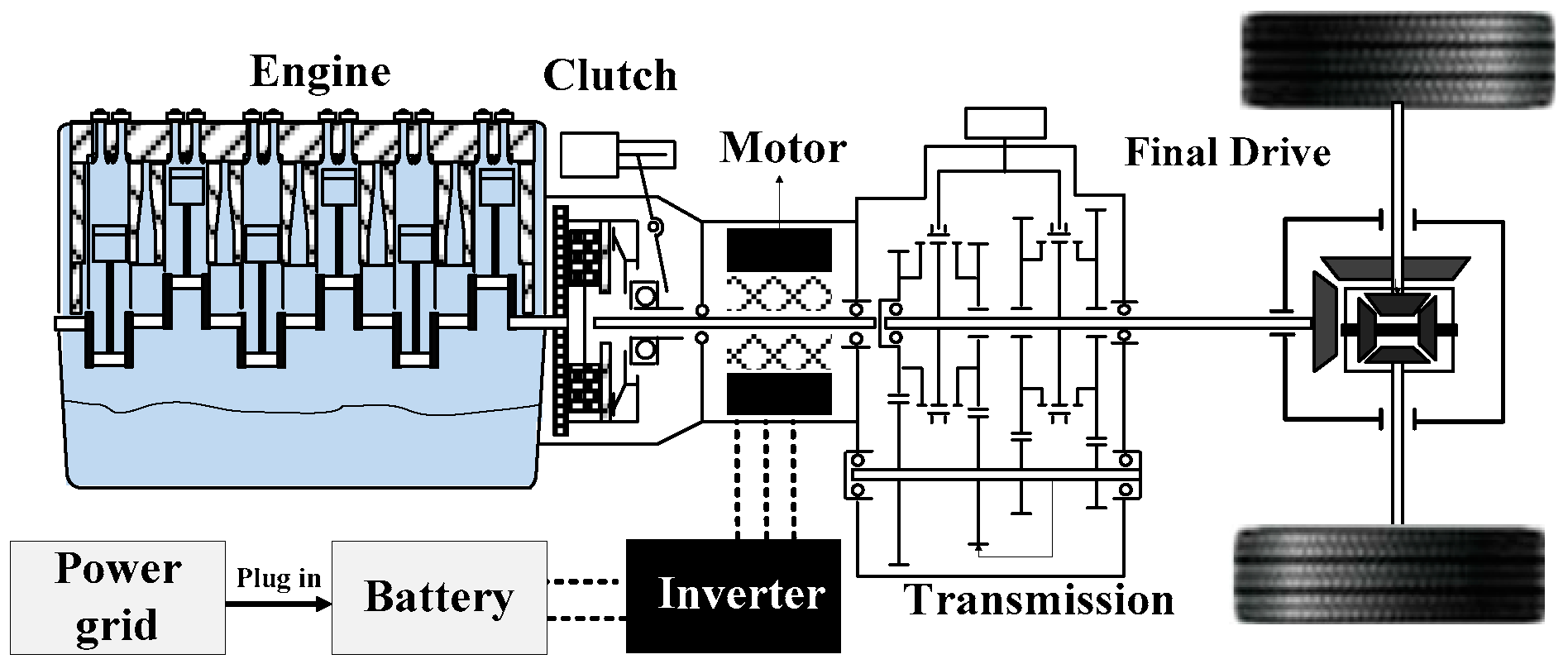
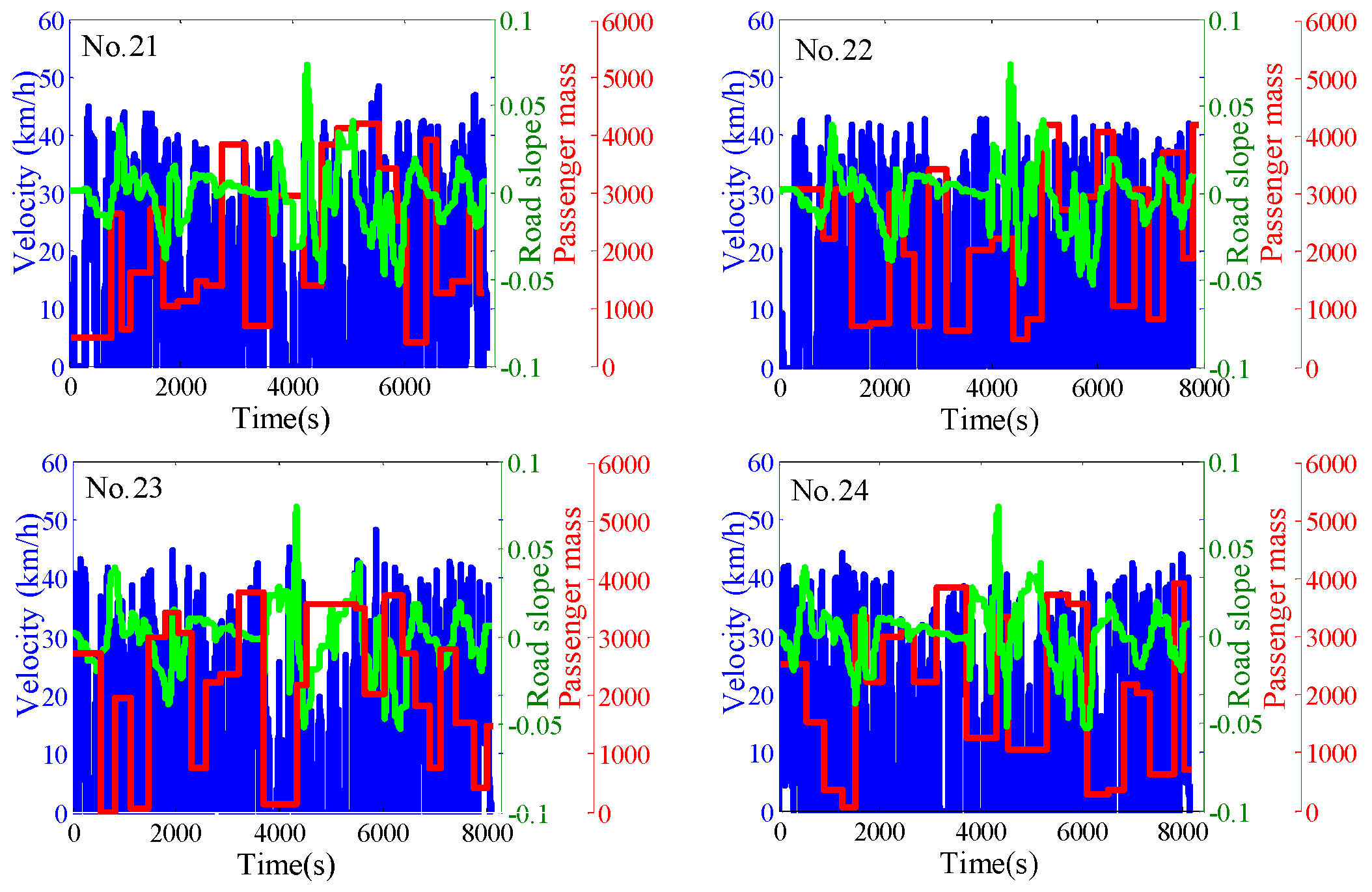
2. The Configuration, Parameters, and Models of the PHEB
2.1. Modeling the Engine
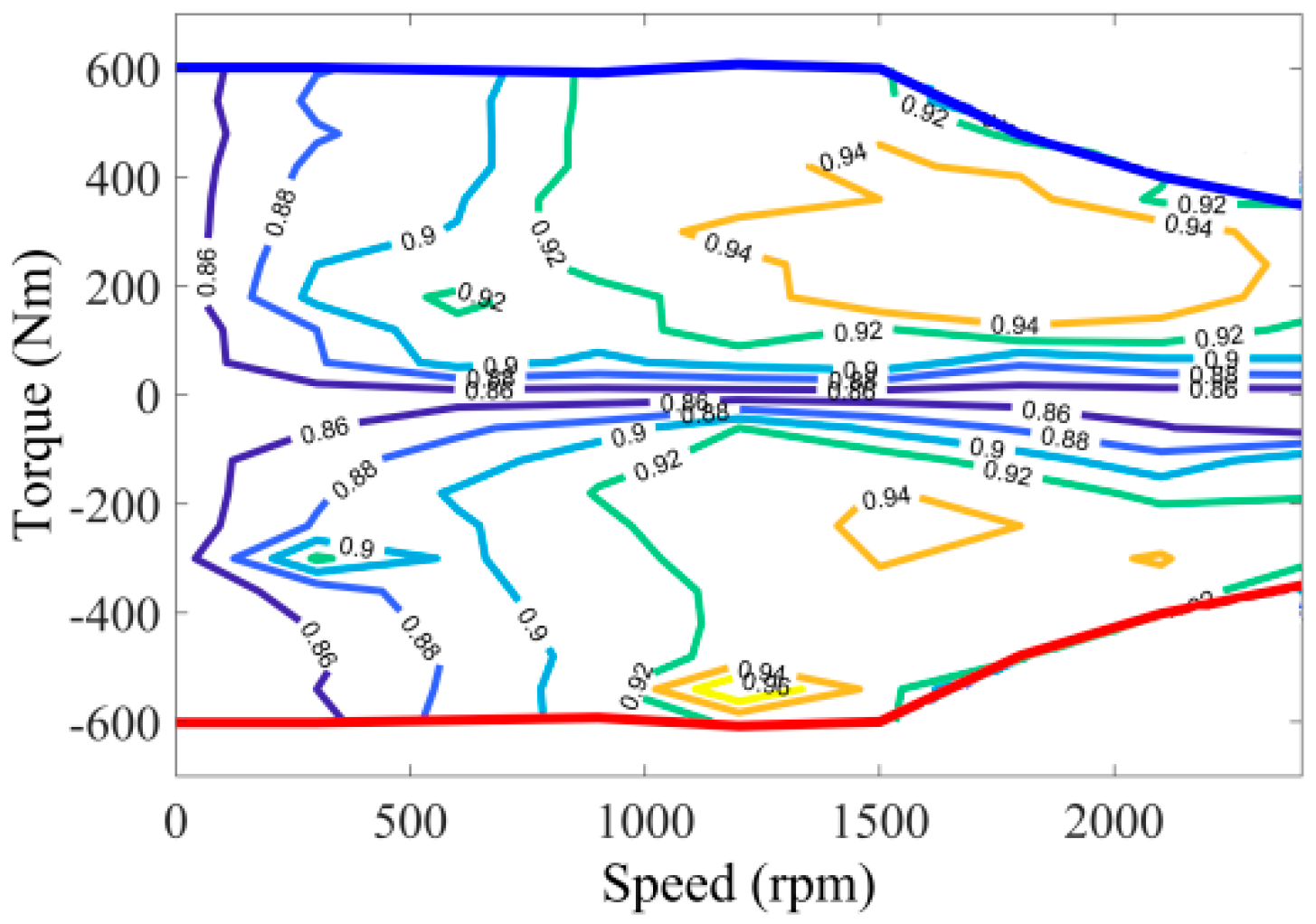
2.2. Modeling the Motor
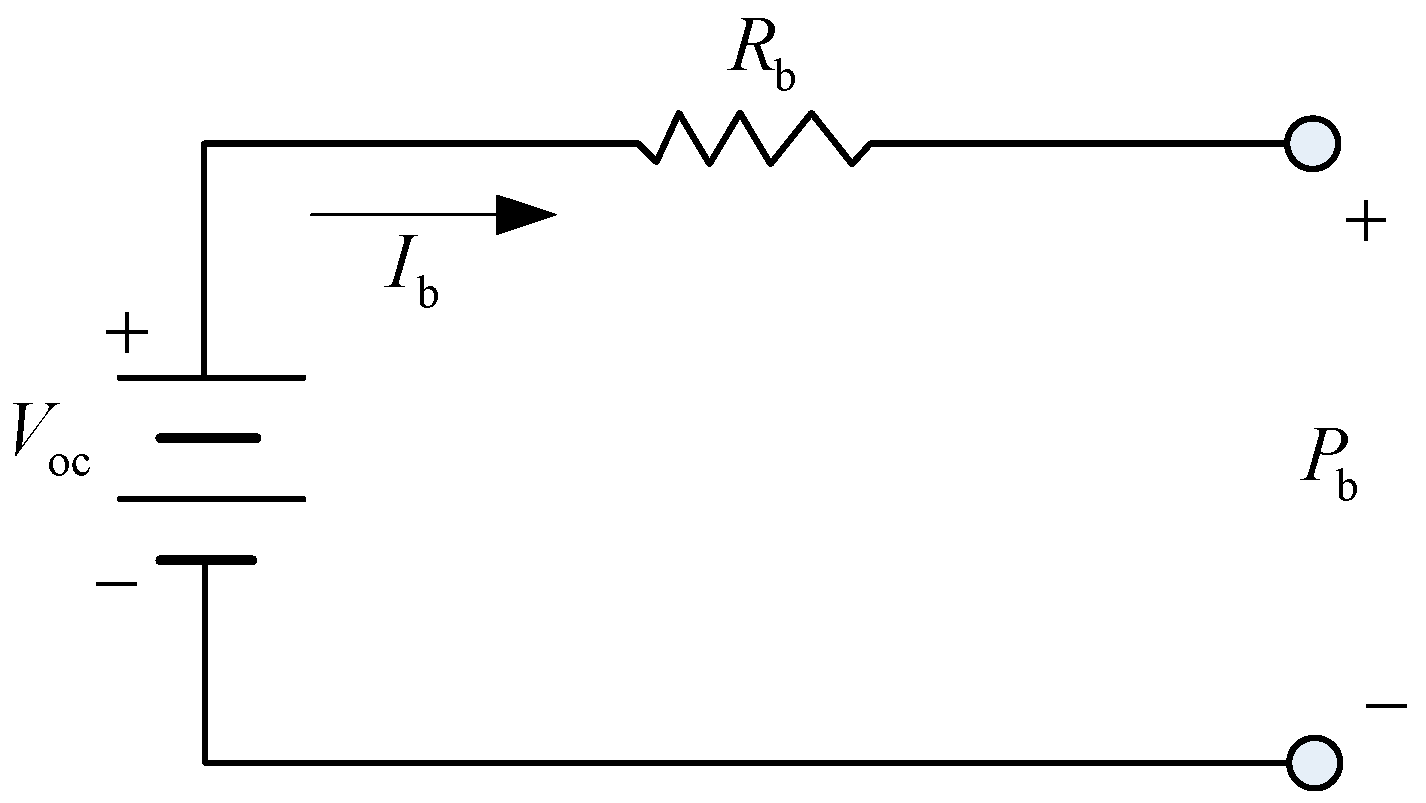
2.3. Modeling the Battery
2.4. The Dynamic Model of the Vehicle
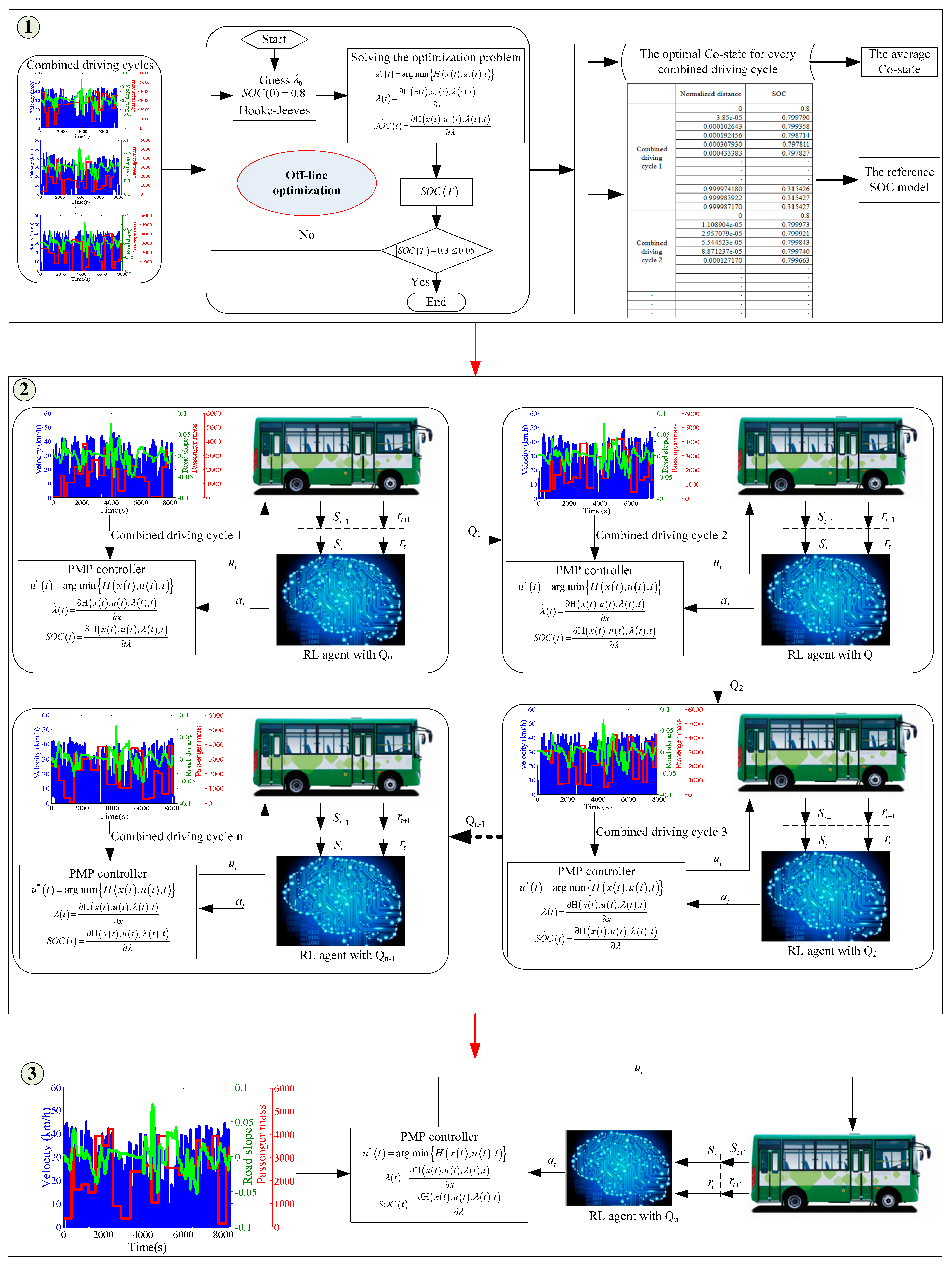
3. The Formulation of the QL-PMP Algorithm
- Step 1
- A series of co-states with respect to the combined driving cycles are firstly optimized, by an off-line PMP with Hooke–Jeeves algorithm [22]. Then, the average co-state is obtained and the corresponding optimal SOCs are extracted. Finally, a reference SOC model is established by taking the normalized distance as input and the optimal SOCs as output.
- Step 2
- Based on the known average co-state and the reference SOC model, the training of the QL-PMP is carried out as follows: firstly, the Q-table (denoted by Q0), that is defined as zeros matrix, will be trained with the combined driving cycle 1; secondly, the trained Q-table (denoted by Q1) will be taken as the initial Q-table for the second training with the combined driving cycle 2; and then this process will be continued until the Q-table is adequately trained.
- Step 3
- Verifying the adequately trained QL-PMP algorithm with HIL platform, using different combined driving cycles.
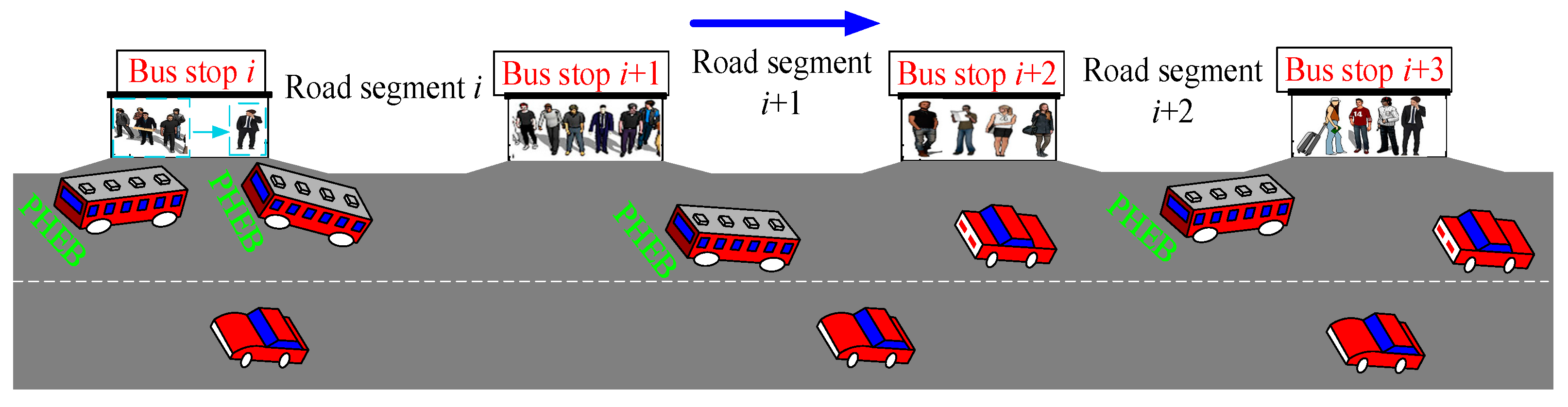
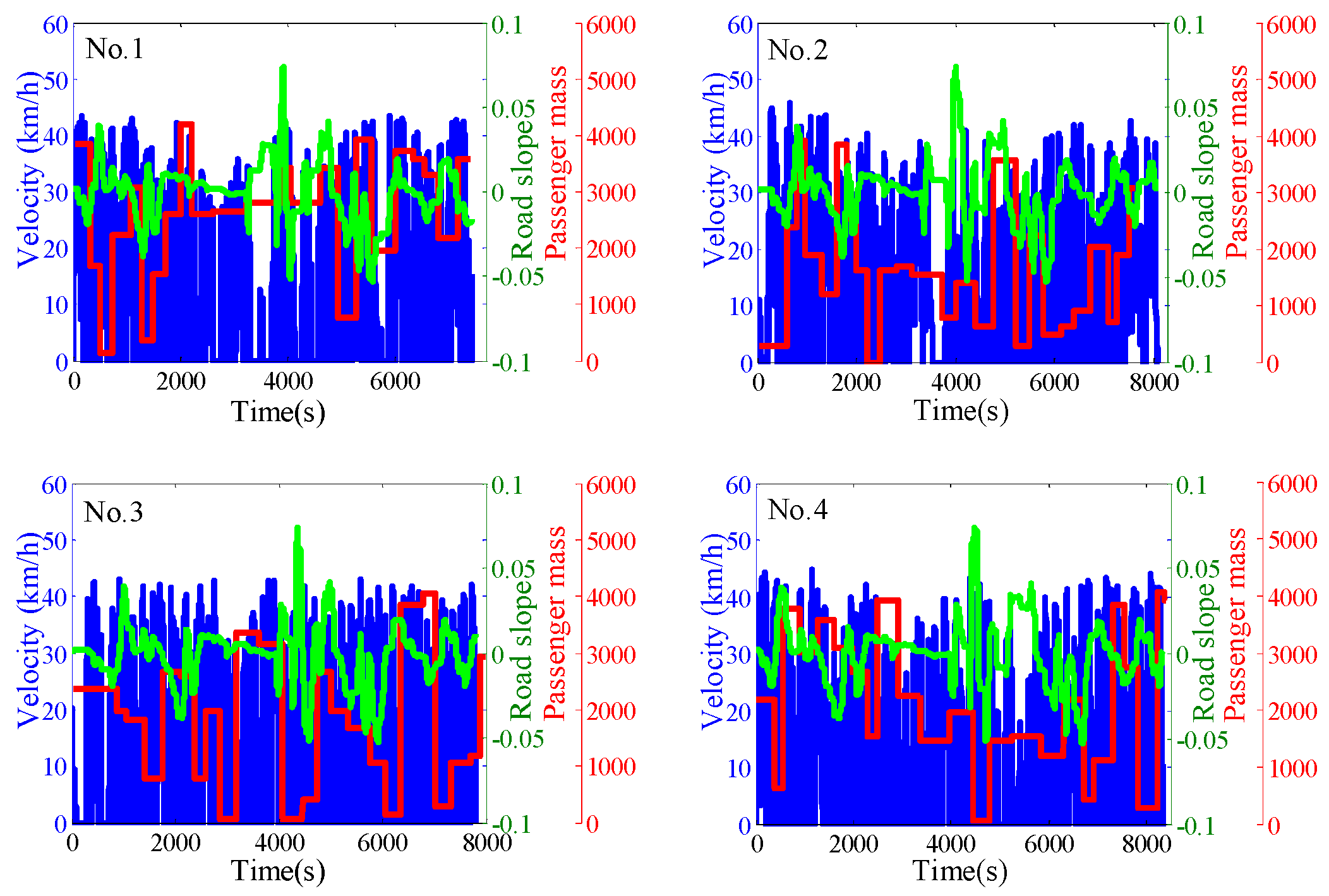
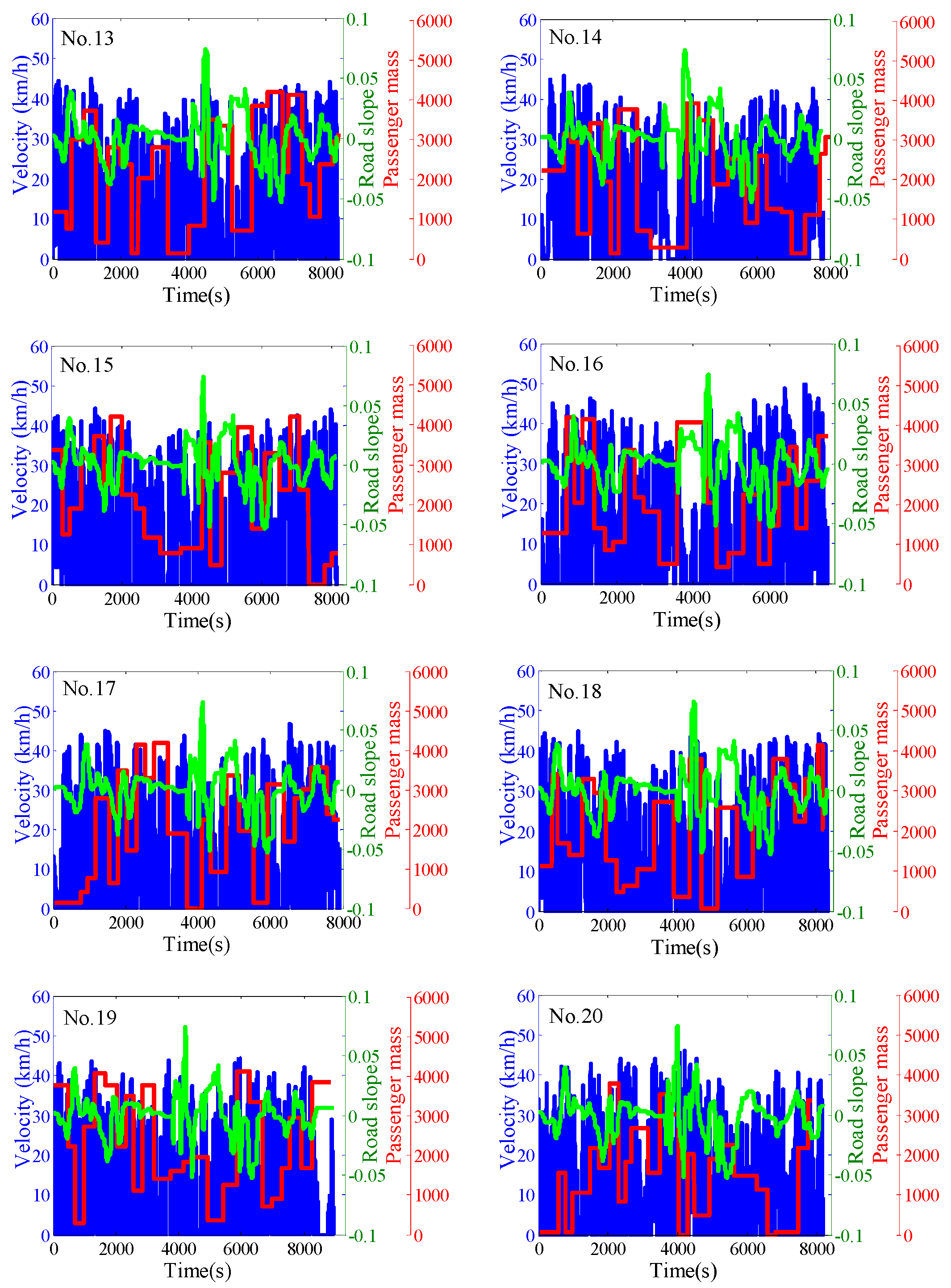
3.1. The Combined Driving Cycle
3.2. The Off-Line PMP Algorithm
- Step 1
- Taking the co-state as independent value of the Hooke–Jeeves and guessing an initial value of the co-state with a defined initial SOC value (0.8).
- Step 2
- Solving the dynamic optimal control problem by Equations (7)–(9), based on the given independent value from the Hooke–Jeeves.
- Step 3
- If the terminal SOC value satisfies the optimization objective, the co-state will be taken as the optimal co-state, otherwise, the iteration will be repeated from Step 1 to Step 3, till the objective is satisfied.
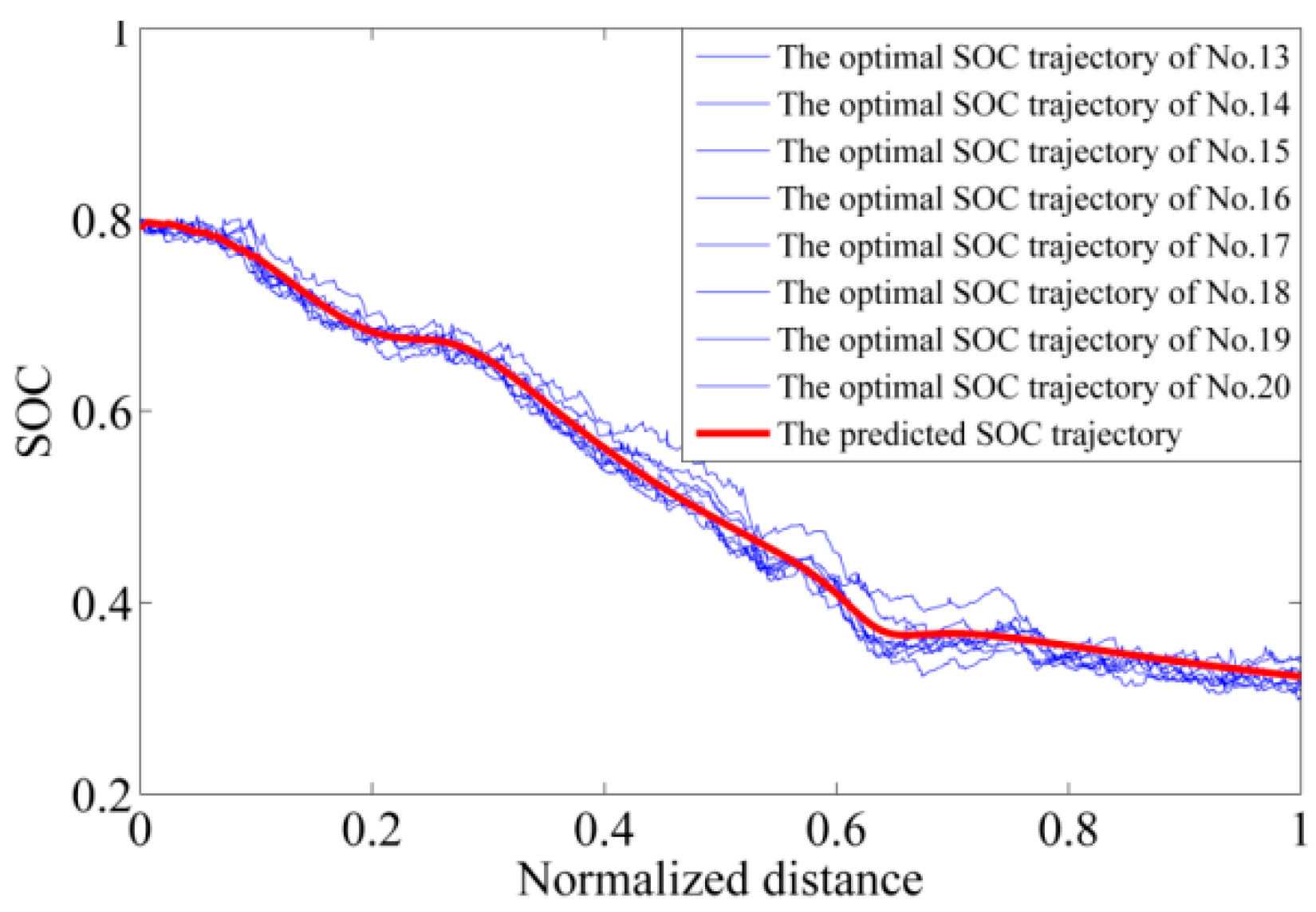
3.3. The Reference SOC Model
3.4. The QL-PMP Algorithm
| Algorithm 1. The QL-PMP Algorithm |
| 1: Initialize for all s |
| 2: Initialize for all s |
| 3: Initialize |
| 4: Initialize |
| 5: Repeat |
| 6: Observe |
| 7: Generate a random number |
| 8: if |
| select an action randomly |
| else |
| choose the optimal action by |
| end |
| 9: Calculate |
| 10: Update the state-value function |
| 11: |
| 12: Until simulation stop |
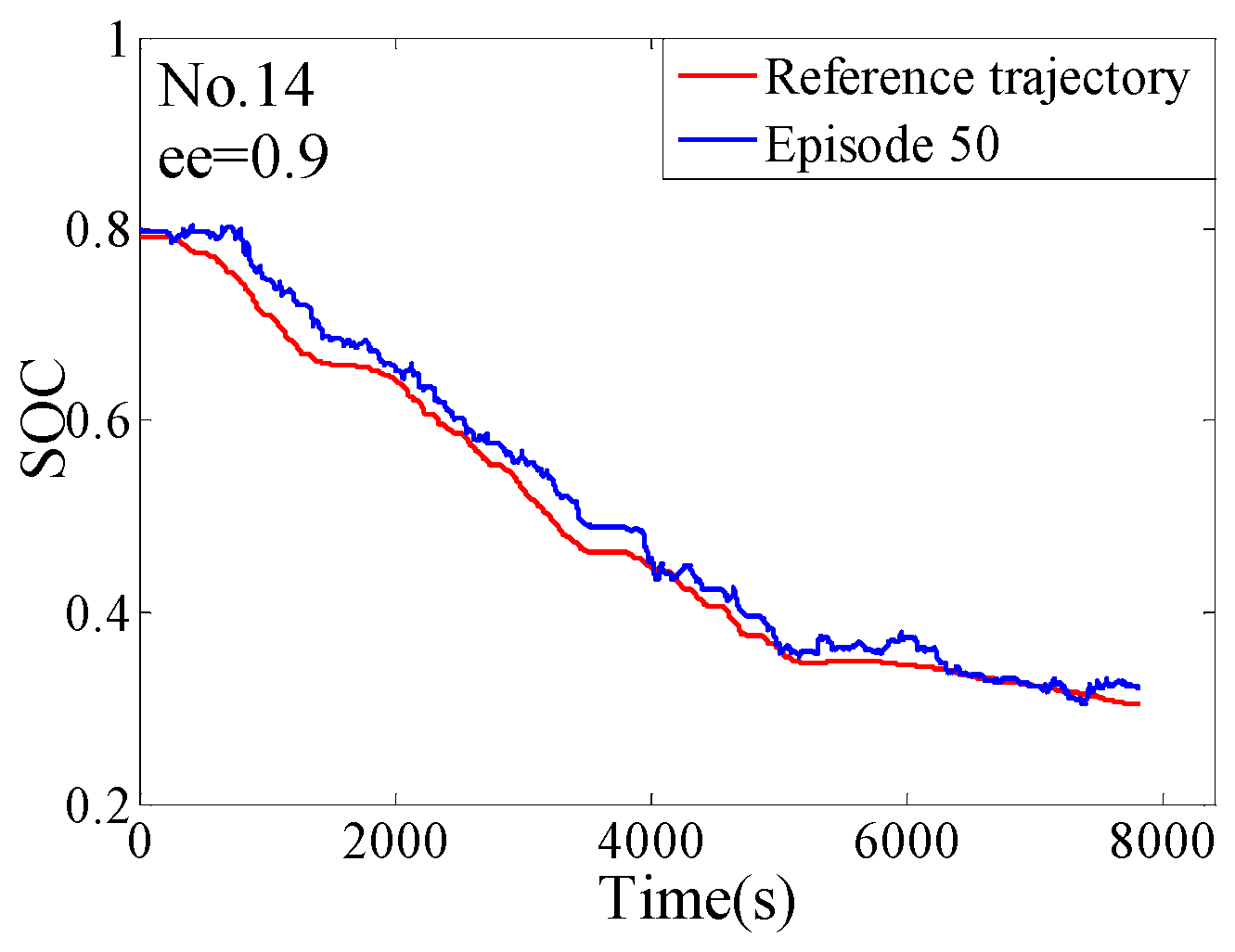
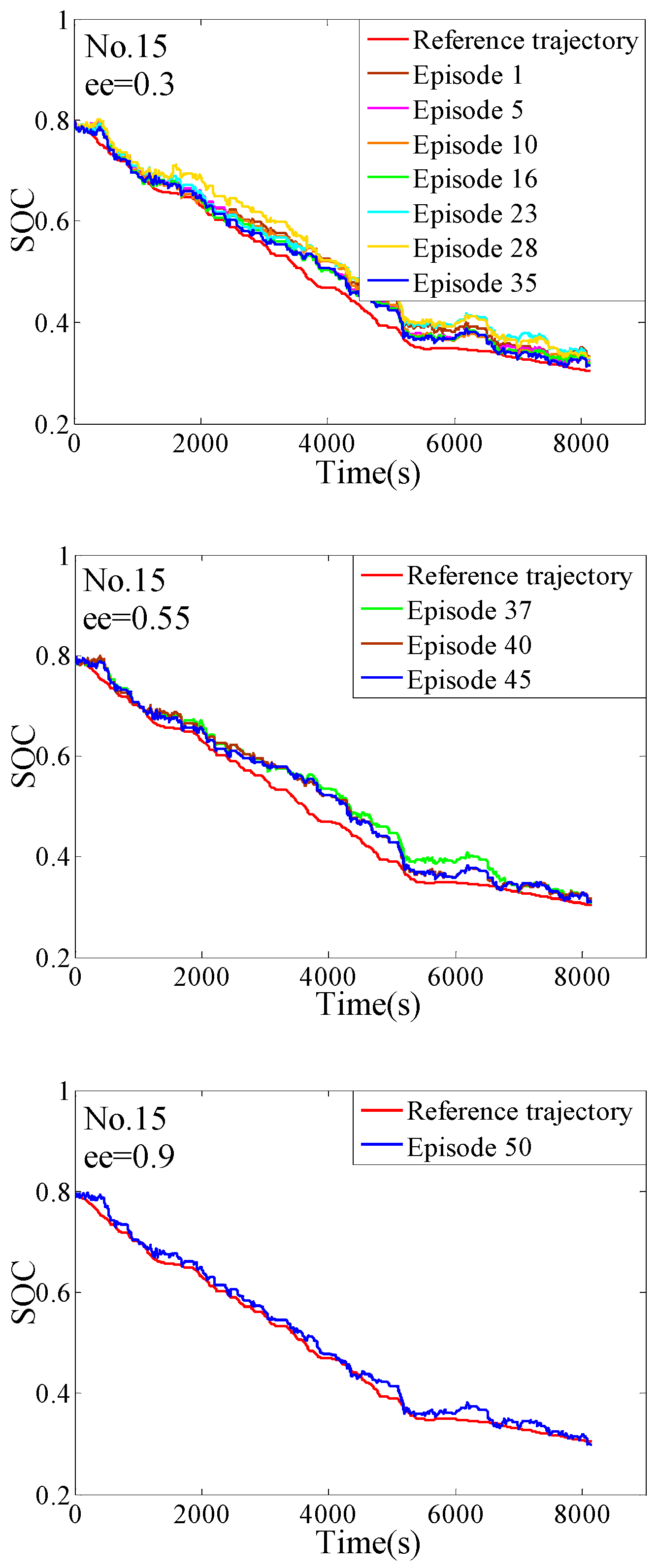
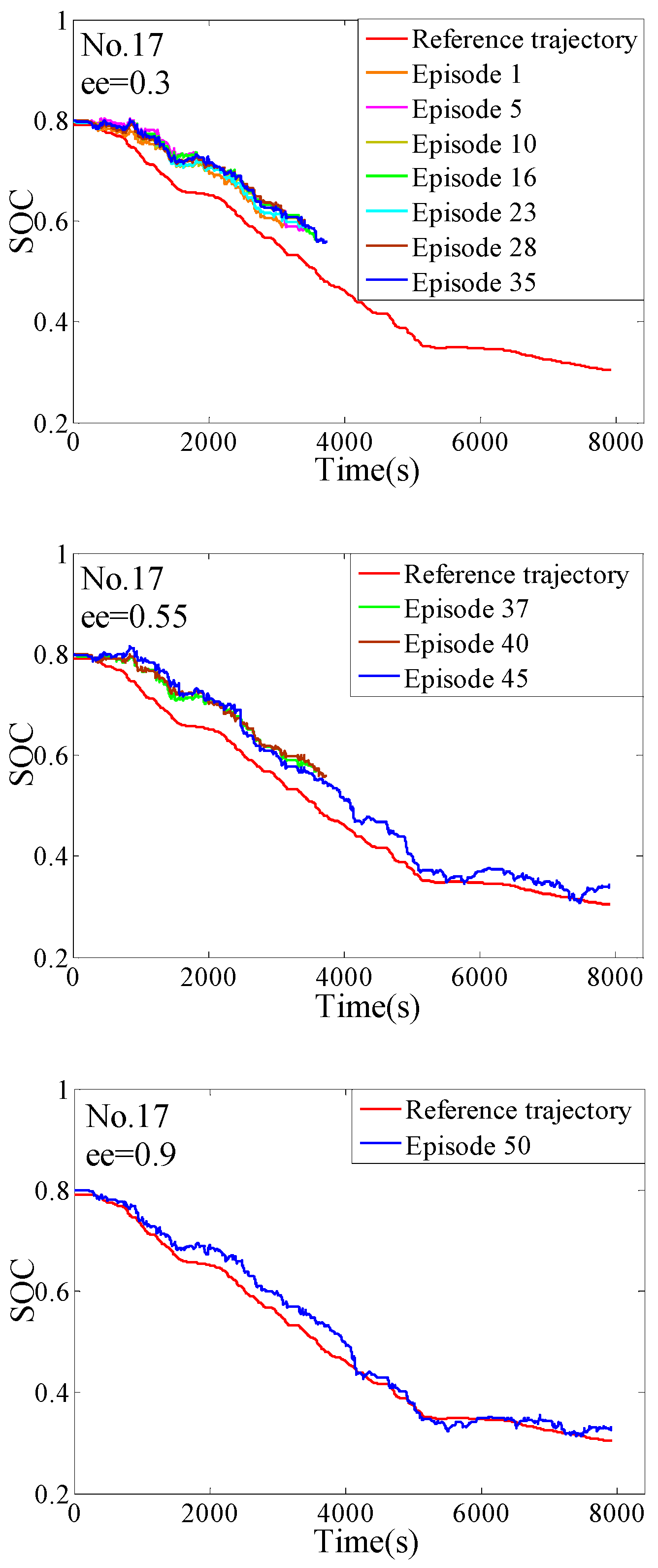
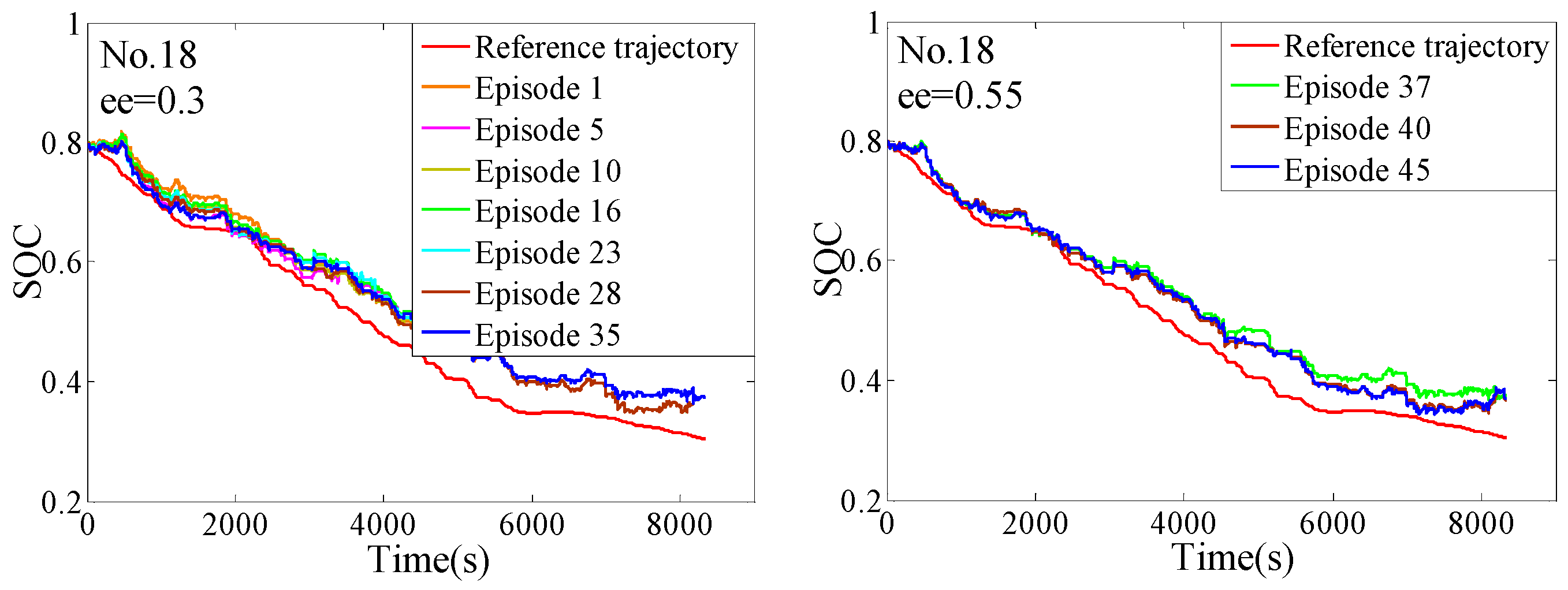
4. The Training Process
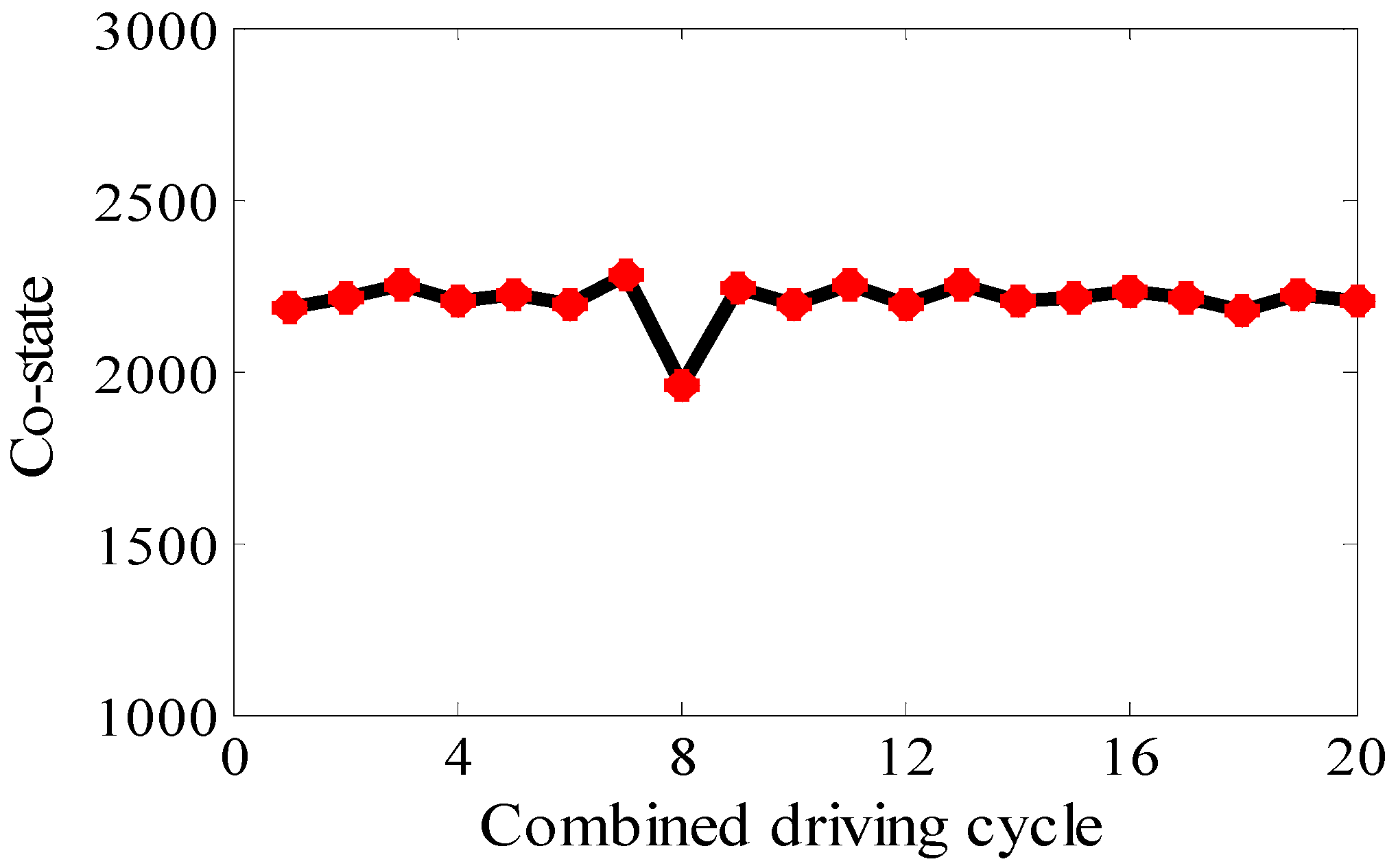
4.1. The Average Co-State
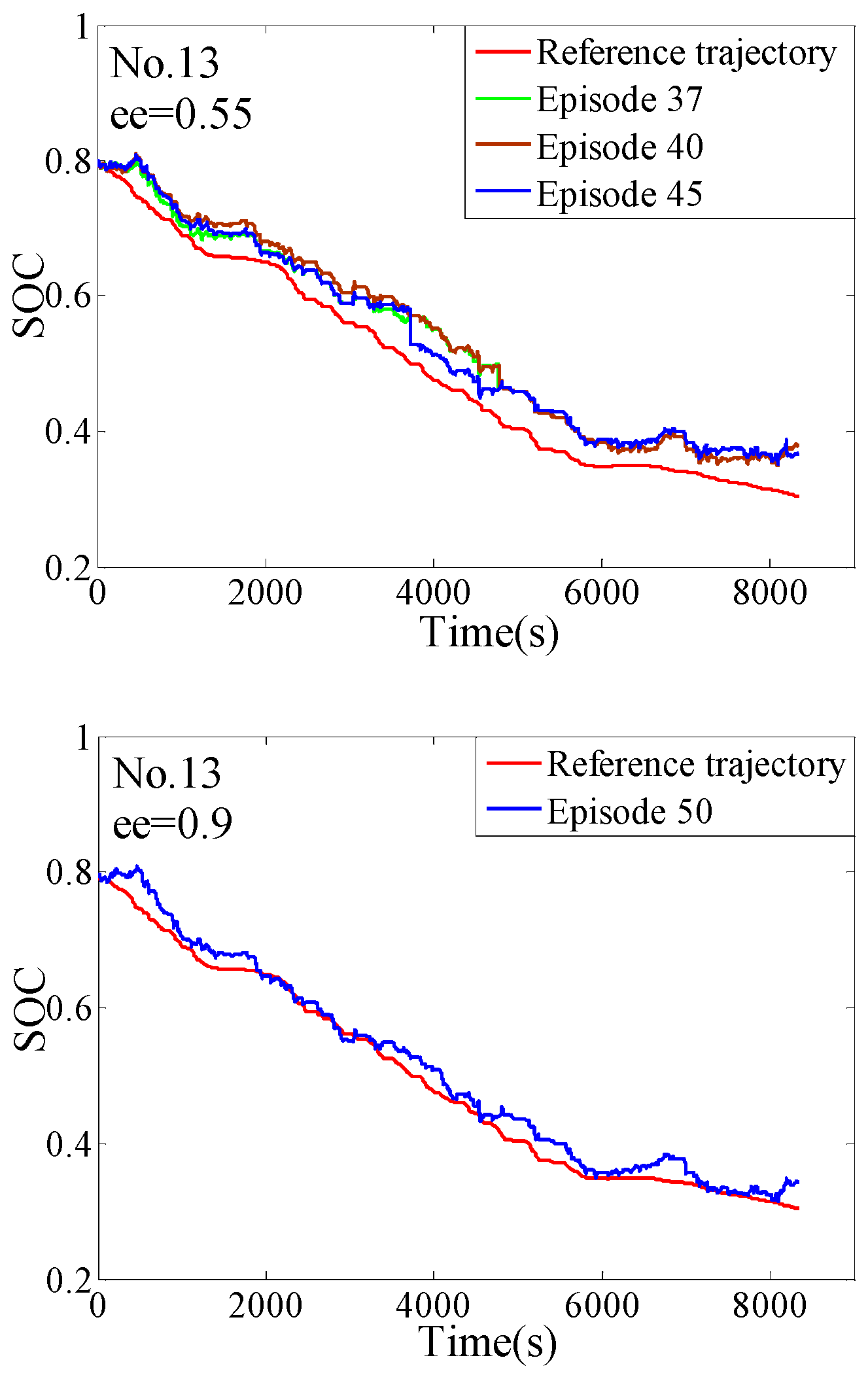
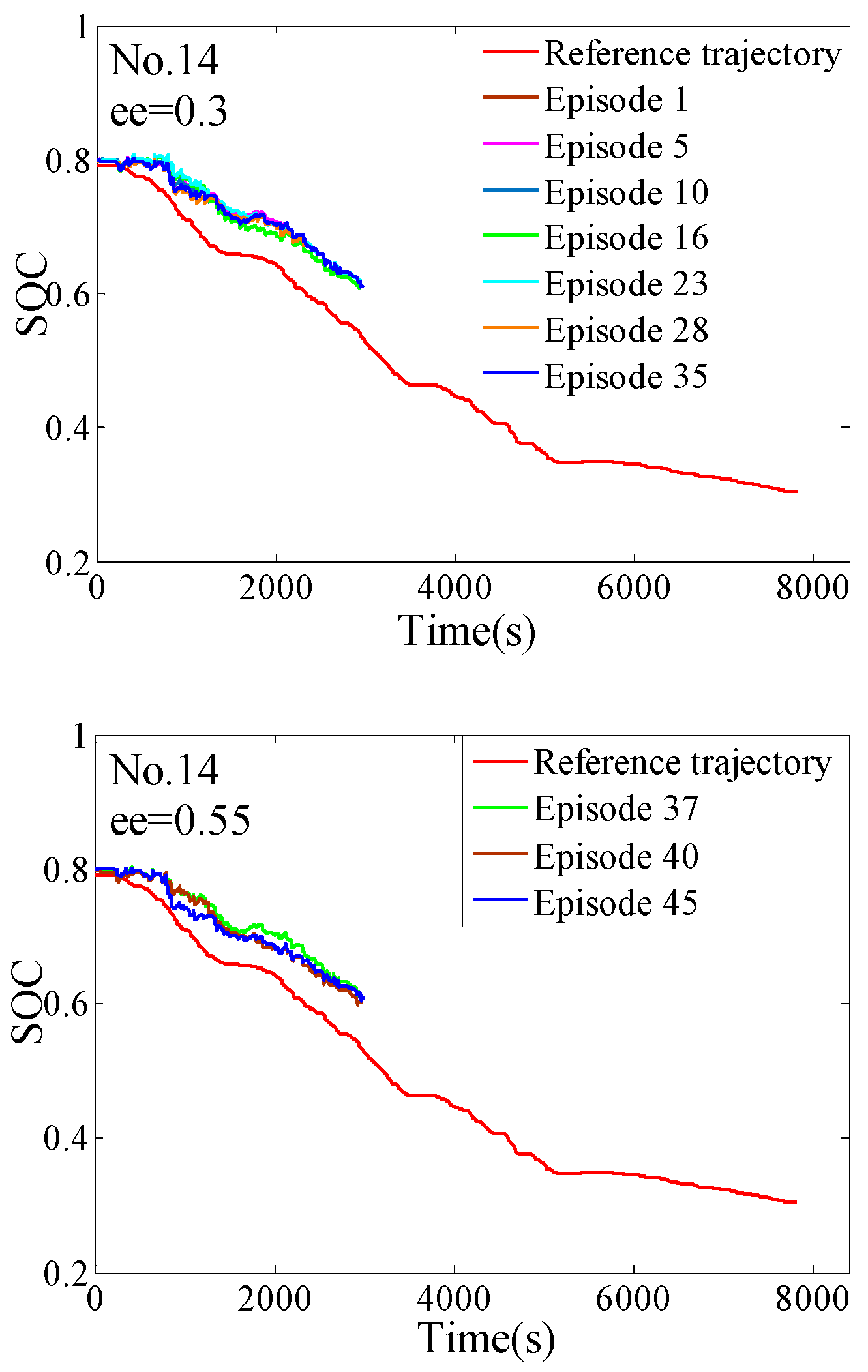
4.2. The Off-Line Training
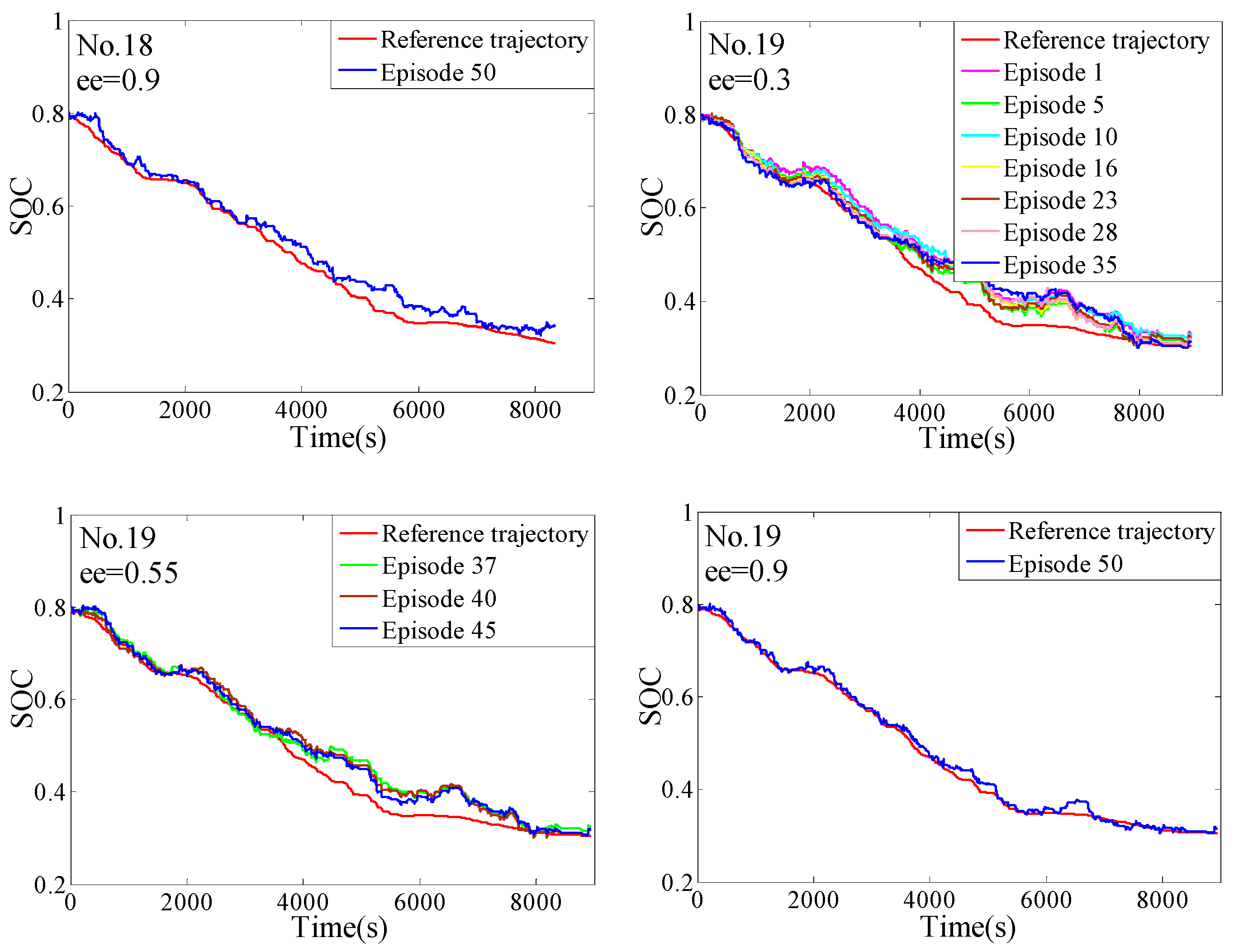
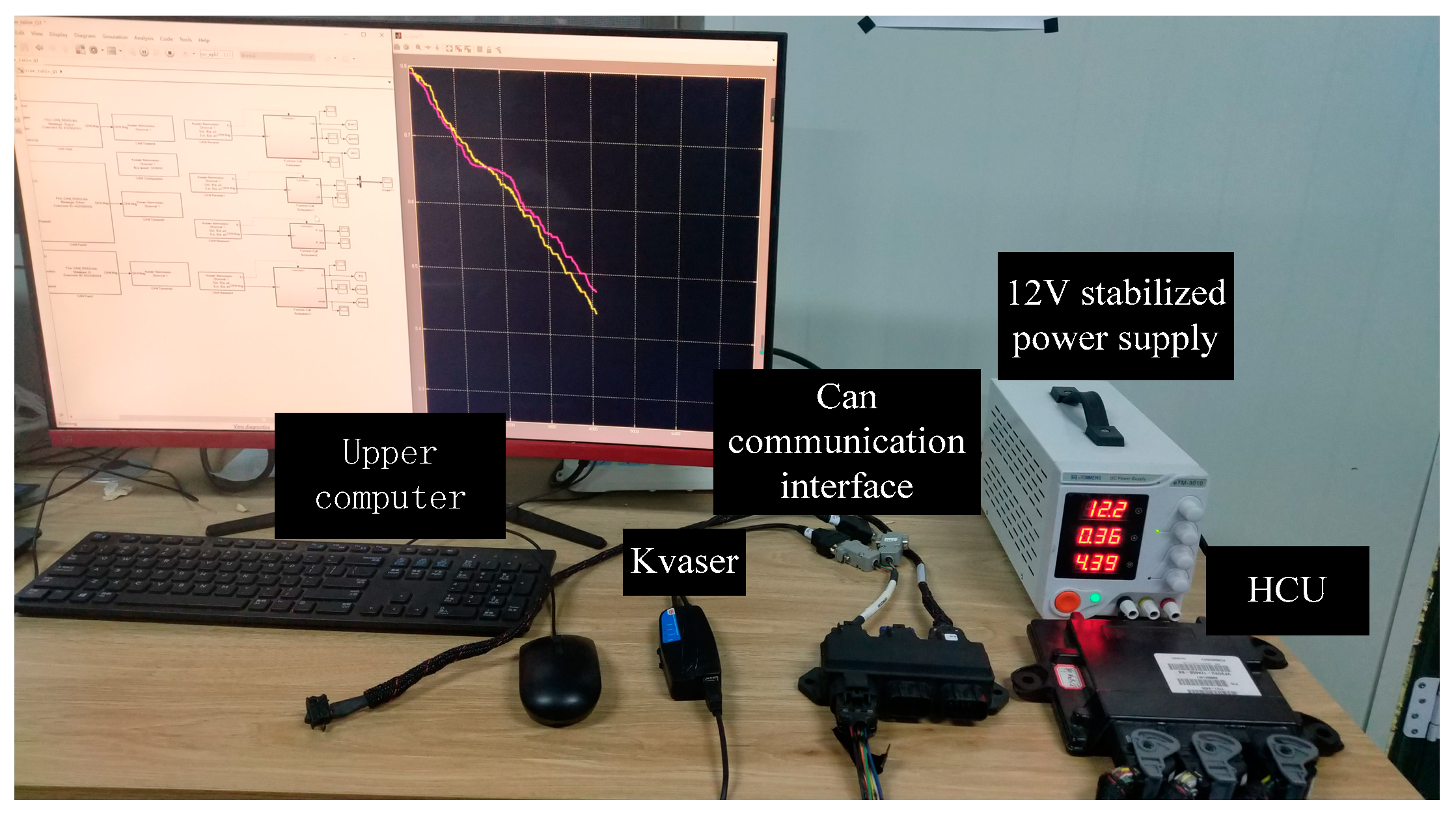
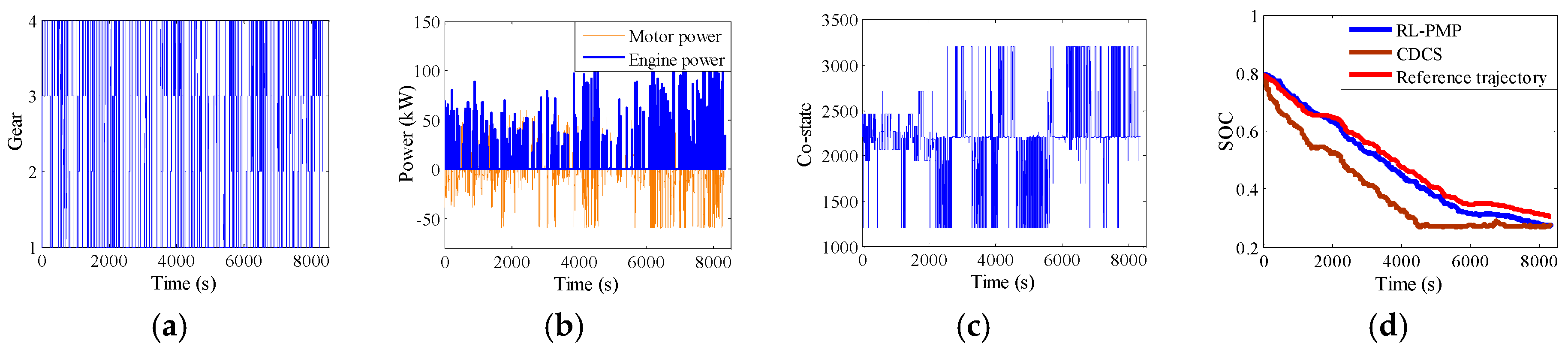
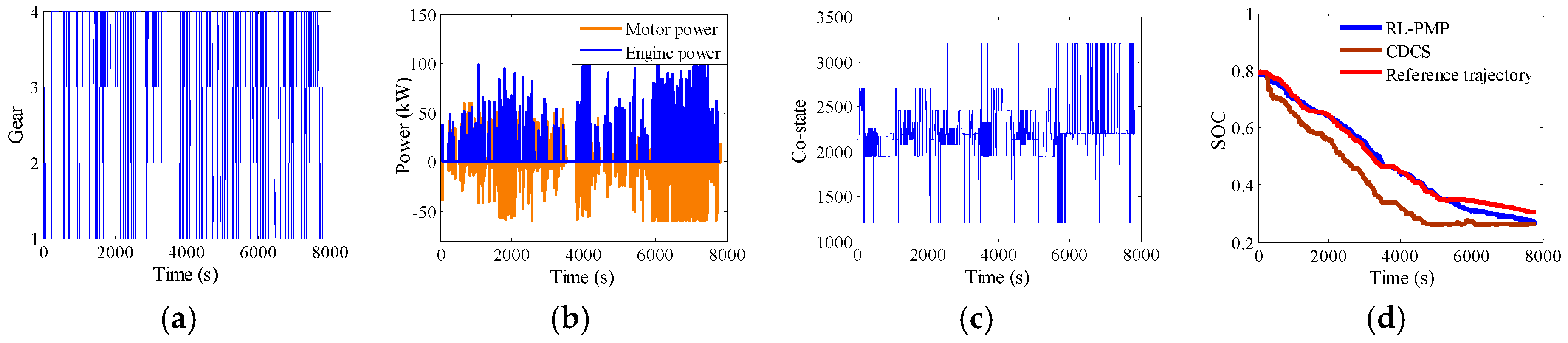
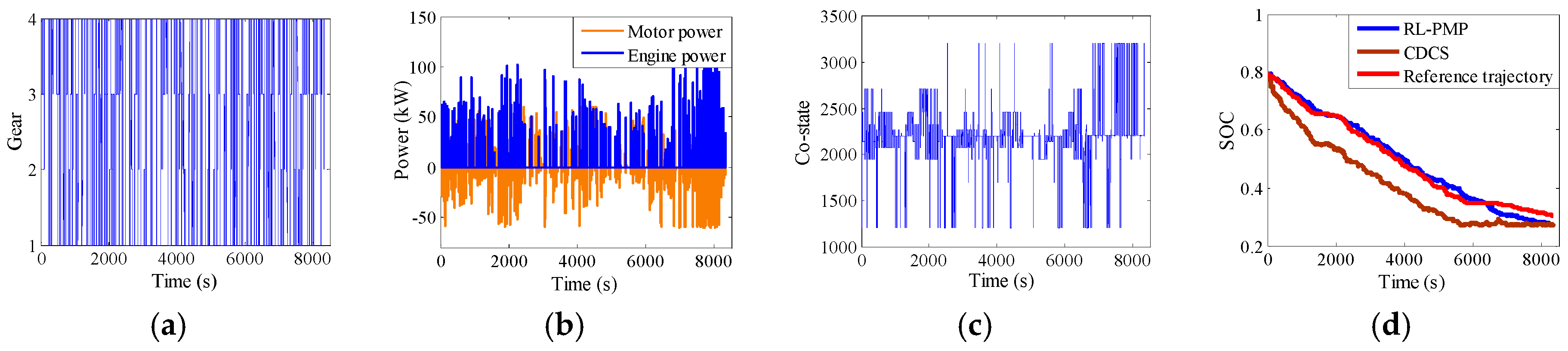
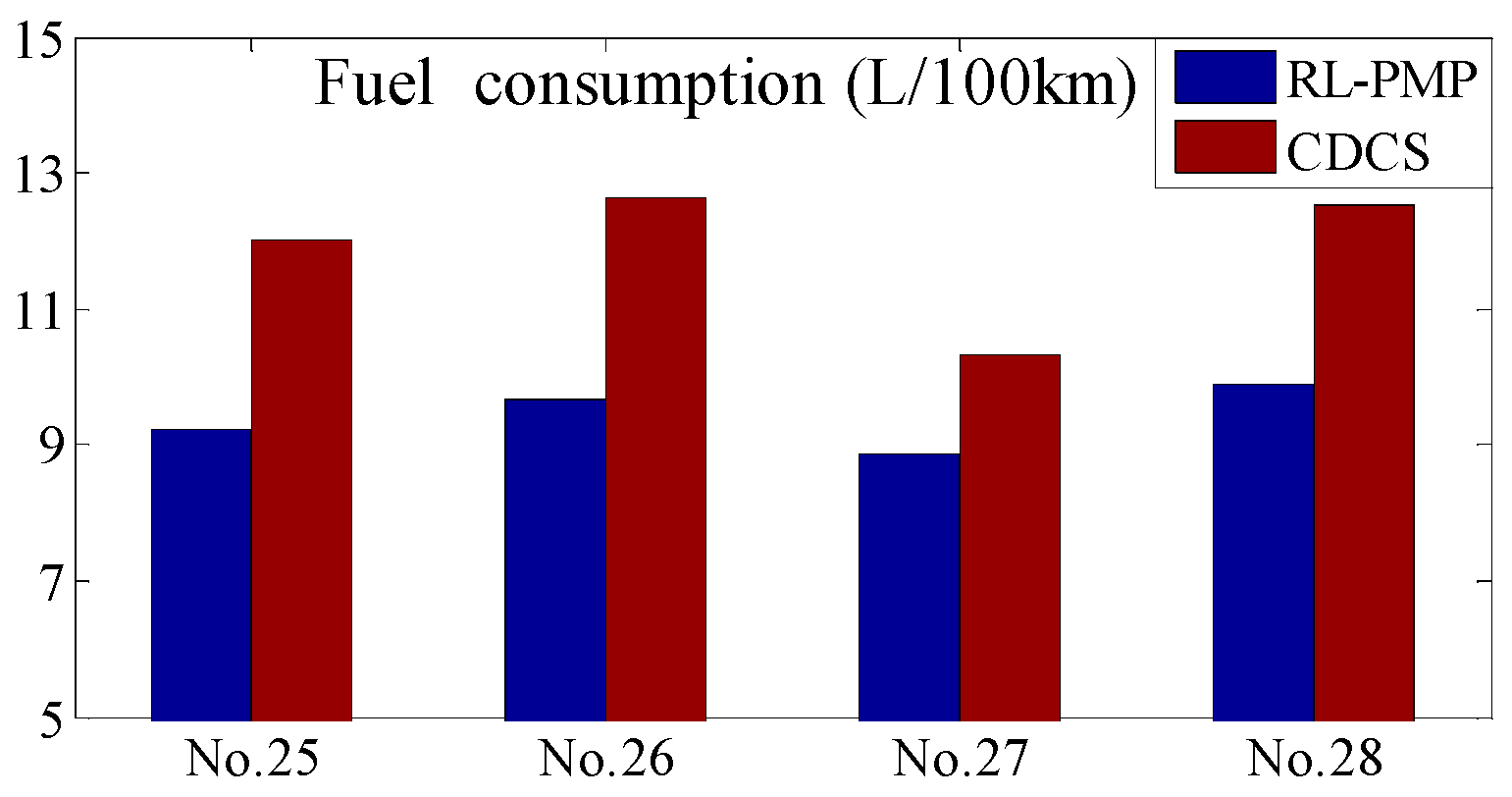
5. The Hardware-In-Loop Simulation
5.1. The Introduction of the HIL
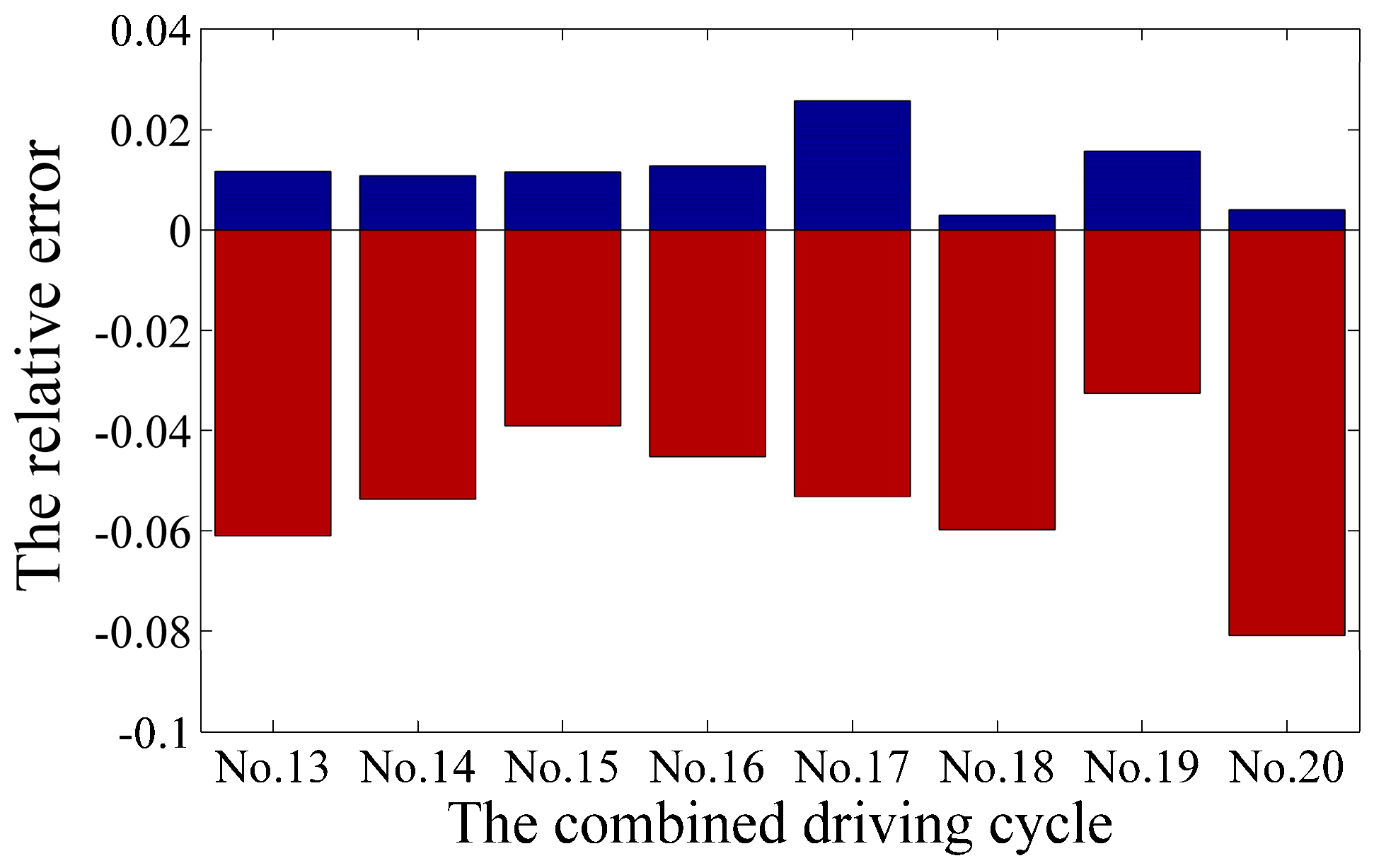
5.2. The Verification of the HIL
6. Conclusions
- A self-learning energy management constituted by the QL and the PMP algorithms are proposed. The actual control variables of the throttle of the engine and the shift instruction of the AMT are exclusively solved by the PMP and the co-state in the PMP is designed as the action in the QL, which can effectively reduce the dependence of the action on the state and give a chance for the reduced state space design.
- A limited state space constituted by the difference between the feedback SOC and the reference SOC is proposed. Since the co-state is designed as the action of the QL-PMP and has weak dependence on the state, only a Q-matrix with 50 rows and 25 columns are adequate for the Q-Table. This also gives a chance for the real-time energy management control in real-world.
- The complete training process of the QL-PMP algorithm and the HIL verification are presented. The training process show that the QL-PMP can realize the self-learning energy management control for any combined driving cycle, where the control performance can be continuously strengthened. The verification of HIL demonstrates that the completely trained QL-PMP has high reliability, and can realize the real-time control, despite of any combined driving cycle. Moreover, the fuel economy can be improved by 20.42%, compared to CDCS control strategy.
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| the instantaneous fuel consumption of the engine | |
| the torque of the engine | |
| the fuel consumption rate of the engine | |
| the sampling time | |
| the average co-states | |
| the torque of the motor | |
| the discount factor | |
| the efficiency of the motor in driving mode | |
| denote the efficiency of the motor in braking mode | |
| the power of the battery | |
| the open-circuit voltage of the battery | |
| the current of the battery | |
| the internal resistance of the battery | |
| the driving force | |
| the rotating mass conversion factor | |
| the vehicle mass | |
| the resistance force | |
| the coefficient of the rolling resistance | |
| the gravity acceleration | |
| the road slope | |
| the coefficient of the air resistance | |
| the frontal area | |
| the air density | |
| the velocity | |
| the required power | |
| the efficiency of the transmission system | |
| the Hamiltonian function | |
| the state function | |
| the battery capacity | |
| the rotate speed of the engine | |
| the rotate speed of the motor | |
| the lower boundary of the | |
| the higher boundary of the | |
| the lower boundary of the | |
| the higher boundary of the | |
| the power of the engine | |
| the power of the motor | |
| the lower boundary of the | |
| the higher boundary of the | |
| the higher boundary of the | |
| the lower boundary of the | |
| the optimal control vector | |
| the co-state | |
| the objective function | |
| the terminal SOC | |
| the normalized distance | |
| the total distance | |
| the travelled distance | |
| the reference SOC | |
| the fitting coefficient | |
| the old reward | |
| the learning rate | |
| the maximum reward in future | |
| the reward function | |
| the shift instruction | |
| the state space | |
| the action space |
References
- Xie, S.; Hu, X.; Xin, Z.; Brighton, J. Pontryagin’s Minimum Principle based model predictive control of energy management for a plug-in hybrid electric bus. Appl. Energy 2019, 236, 893–905. [Google Scholar] [CrossRef]
- Huang, Y.; Wang, H.; Khajepour, A.; Li, B.; Ji, J.; Zhao, K.; Hu, C. A review of power management strategies and component sizing methods for hybrid vehicles. Renew. Sustain. Energy Rev. 2018, 96, 132–144. [Google Scholar] [CrossRef]
- Yan, M.; Li, M.; He, H.; Peng, J.; Sun, C. Rule-based energy management for dual-source electric buses extracted by wavelet transform. J. Clean. Prod. 2018, 189, 116–127. [Google Scholar] [CrossRef]
- Padmarajan, B.V.; McGordon, A.; Jennings, P.A. Blended rule-based energy management for PHEV: System structure and strategy. IEEE Trans. Veh. Technol. 2016, 65, 8757–8762. [Google Scholar] [CrossRef]
- Pi, J.M.; Bak, Y.S.; You, Y.K.; Park, D.H.; Kim, H.S. Development of route information based driving control algorithm for a range-extended electric vehicle. Int. J. Automot. Technol. 2016, 17, 1101–1111. [Google Scholar] [CrossRef]
- Sabri, M.F.M.; Danapalasingam, K.A.; Rahmat, M.F. A review on hybrid electric vehicles architecture and energy management strategies. Renew. Sustain. Energy Rev. 2016, 53, 1433–1442. [Google Scholar] [CrossRef]
- Zhou, Y.; Ravey, A.; Péra, M.C. A survey on driving prediction techniques for predictive energy management of plug-in hybrid electric vehicles. J. Power Source 2019, 412, 480–495. [Google Scholar] [CrossRef]
- Tie, S.F.; Tan, C.W. A review of energy sources and energy management system in electric vehicles. Renew. Sustain. Energy Rev. 2013, 20, 82–102. [Google Scholar] [CrossRef]
- Hou, C.; Ouyang, M.; Xu, L.; Wang, H. Approximate Pontryagin’s minimum principle applied to the energy management of plug-in hybrid electric vehicles. Appl. Energy 2014, 115, 174–189. [Google Scholar] [CrossRef]
- Tulpule, P.; Marano, V.; Rizzoni, G. Energy management for plug-in hybrid electric vehicles using equivalent consumption minimization strategy. Int. J. Electr. Hybrid Veh. 2010, 2, 329–350. [Google Scholar] [CrossRef]
- Li, G.; Zhang, J.; He, H. Battery SOC constraint comparison for predictive energy management of plug-in hybrid electric bus. Appl. Energy 2017, 194, 578–587. [Google Scholar] [CrossRef]
- Onori, S.; Tribioli, L. Adaptive Pontryagin’s Minimum Principle supervisory controller design for the plug-in hybrid GM Chevrolet Volt. Appl. Energy 2015, 147, 224–234. [Google Scholar] [CrossRef]
- Yang, C.; Du, S.; Li, L.; You, S.; Yang, Y.; Zhao, Y. Adaptive real-time optimal energy management strategy based on equivalent factors optimization for plug-in hybrid electric vehicle. Appl. Energy 2017, 203, 883–896. [Google Scholar] [CrossRef]
- Lei, Z.; Qin, D.; Liu, Y.; Peng, Z.; Lu, L. Dynamic energy management for a novel hybrid electric system based on driving pattern recognition. Appl. Math. Model. 2017, 45, 940–954. [Google Scholar] [CrossRef]
- Lin, X.; Wang, Y.; Bogdan, P.; Chang, N.; Pedram, M. Reinforcement learning based power management for hybrid electric vehicles. In Proceedings of the 2014 IEEE/ACM International Conference on Computer-Aided Design, San Jose, CA, USA, 3–6 November 2014; IEEE Press: Piscataway, NJ, USA, 2014; pp. 32–38. [Google Scholar]
- Xiong, R.; Cao, J.; Yu, Q. Reinforcement learning-based real-time power management for hybrid energy storage system in the plug-in hybrid electric vehicle. Appl. Energy 2018, 211, 538–548. [Google Scholar] [CrossRef]
- Liu, T.; Wang, B.; Yang, C. Online Markov Chain-based energy management for a hybrid tracked vehicle with speedy Q-learning. Energy 2018, 160, 544–555. [Google Scholar] [CrossRef]
- Wu, J.; He, H.; Peng, J.; Li, Y.; Li, Z. Continuous reinforcement learning of energy management with deep Q network for a power split hybrid electric bus. Appl. Energy 2018, 222, 799–811. [Google Scholar] [CrossRef]
- Hu, Y.; Li, W.; Xu, K.; Zahid, T.; Qin, F.; Li, C. Energy management strategy for a hybrid electric vehicle based on deep reinforcement learning. Appl. Sci. 2018, 8, 187. [Google Scholar] [CrossRef]
- Liessner, R.; Schroer, C.; Dietermann, A.M.; Bäker, B. Deep Reinforcement Learning for Advanced Energy Management of Hybrid Electric Vehicles. ICAART 2018, 2, 61–72. [Google Scholar]
- Qi, X.; Luo, Y.; Wu, G.; Boriboonsomsin, K.; Barth, M. Deep reinforcement learning enabled self-learning control for energy efficient driving. Transp. Res. Part C Emerg. Technol. 2019, 99, 67–81. [Google Scholar] [CrossRef]
- Moser, I.; Chiong, R. A hooke-jeeves based memetic algorithm for solving dynamic optimisation problems. Hybrid Artif. Intell. Syst. 2009, 5572, 301–309. [Google Scholar]
- Guo, H.; Lu, S.; Hui, H.; Bao, C.; Shangguan, J. Receding horizon control-based energy management for plug-in hybrid electric buses using a predictive model of terminal SOC constraint in consideration of stochastic vehicle mass. Energy 2019, 176, 292–308. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Description |
|---|---|
| Vehicle | Curb mass (kg): 8500 |
| Passengers | Maximum number: 60; Passenger’s mass (kg): 70 |
| AMT | Speed ratios: 4.09:2.45:1.5:0.81 |
| Final drive | Speed ratio: 5.571 |
| Engine | Max torque (Nm): 639 |
| Max power (kW): 120 | |
| Motor | Max torque (Nm): 604 |
| Max power (kW): 94 | |
| Battery | Capacity (Ah): 35 |
| 0.7910 | −8.0413 | −6.3492 | 24.939 | 13.587 | −53.294 | 15.148 | 143.58 | −72.790 | −162.76 |
| 77.584 | −73.520 | −46.524 | 74.766 | −23.603 | 90.256 | 73.1139 | 36.364 | −8.6263 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, H.; Du, S.; Zhao, F.; Cui, Q.; Ren, W. Intelligent Energy Management for Plug-in Hybrid Electric Bus with Limited State Space. Processes 2019, 7, 672. https://doi.org/10.3390/pr7100672
Guo H, Du S, Zhao F, Cui Q, Ren W. Intelligent Energy Management for Plug-in Hybrid Electric Bus with Limited State Space. Processes. 2019; 7(10):672. https://doi.org/10.3390/pr7100672
Chicago/Turabian StyleGuo, Hongqiang, Shangye Du, Fengrui Zhao, Qinghu Cui, and Weilong Ren. 2019. "Intelligent Energy Management for Plug-in Hybrid Electric Bus with Limited State Space" Processes 7, no. 10: 672. https://doi.org/10.3390/pr7100672
APA StyleGuo, H., Du, S., Zhao, F., Cui, Q., & Ren, W. (2019). Intelligent Energy Management for Plug-in Hybrid Electric Bus with Limited State Space. Processes, 7(10), 672. https://doi.org/10.3390/pr7100672