Solving Materials’ Small Data Problem with Dynamic Experimental Databases



Abstract
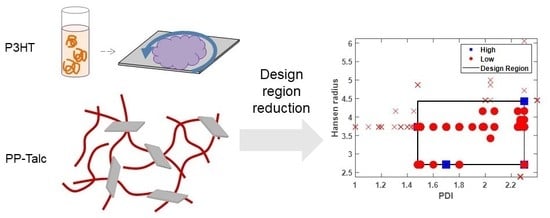
1. Introduction
2. Materials and Methods
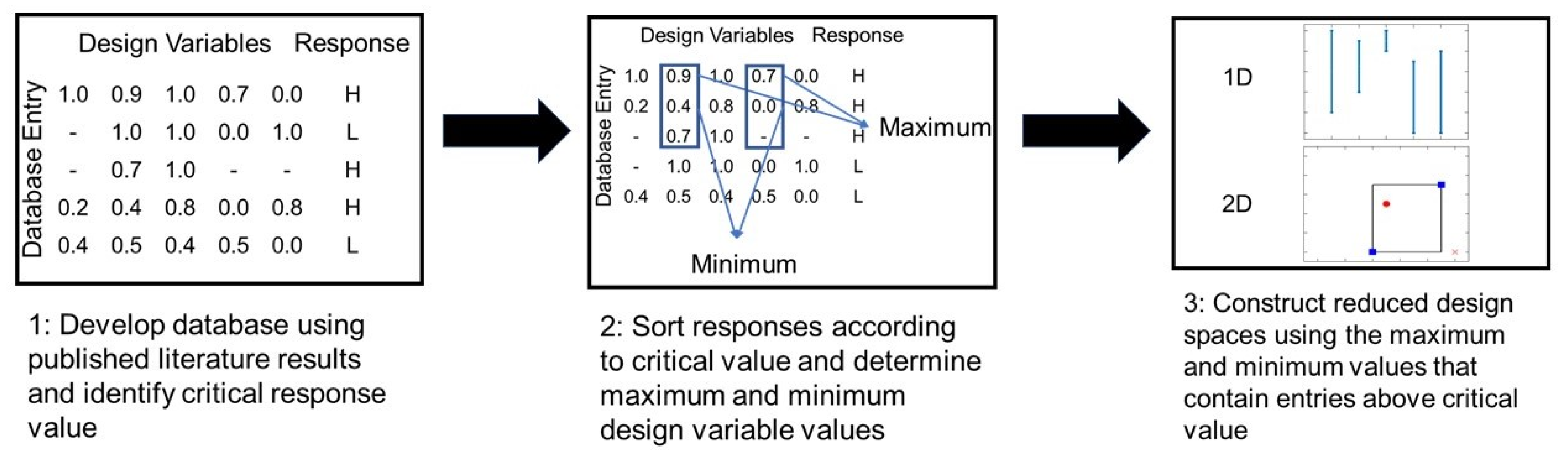
2.1. Database Construction
2.2. Classification Approach
2.3. Case Studies
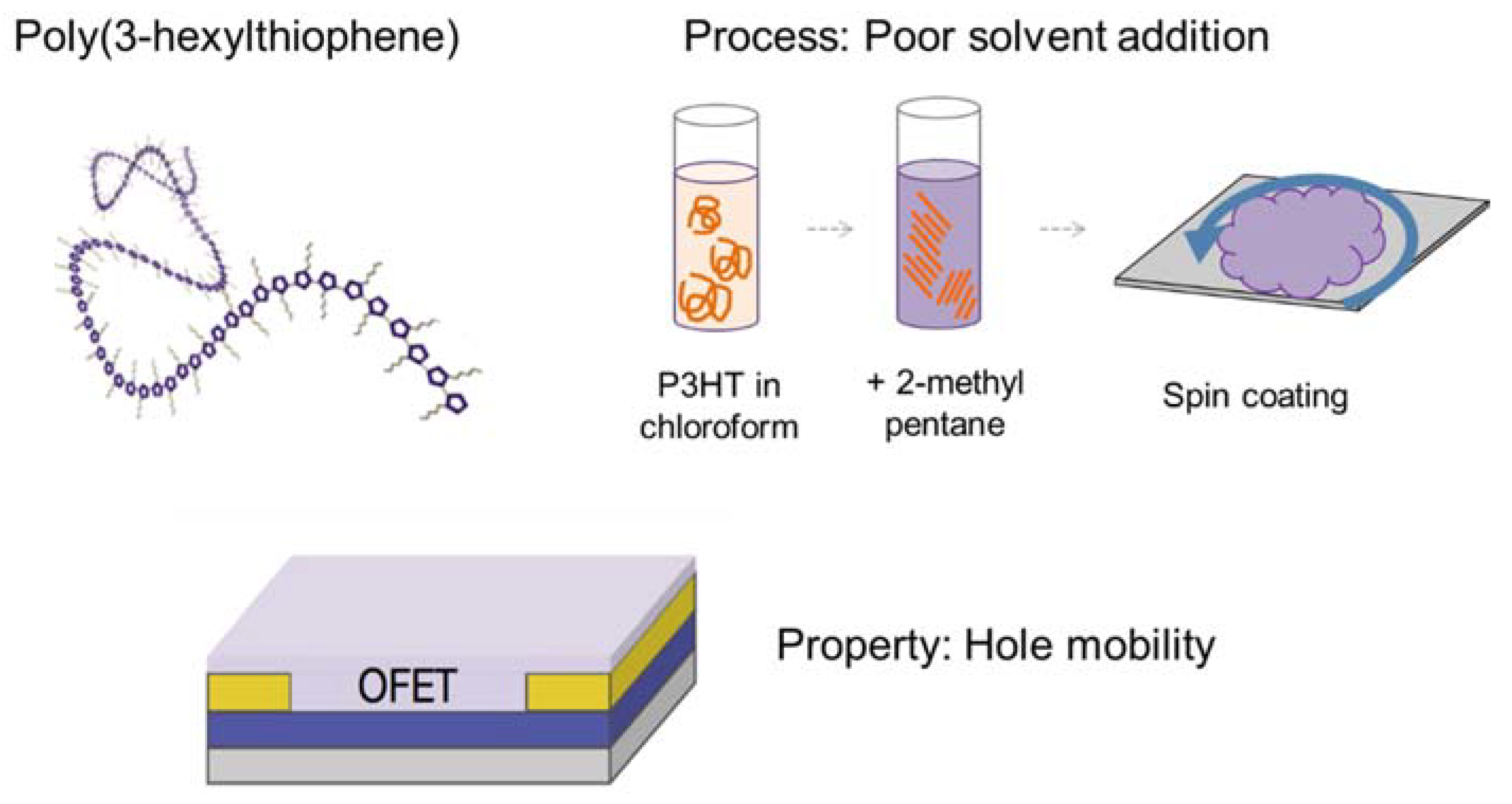
2.3.1. Poly(3-Hexylthiophene) (P3HT)
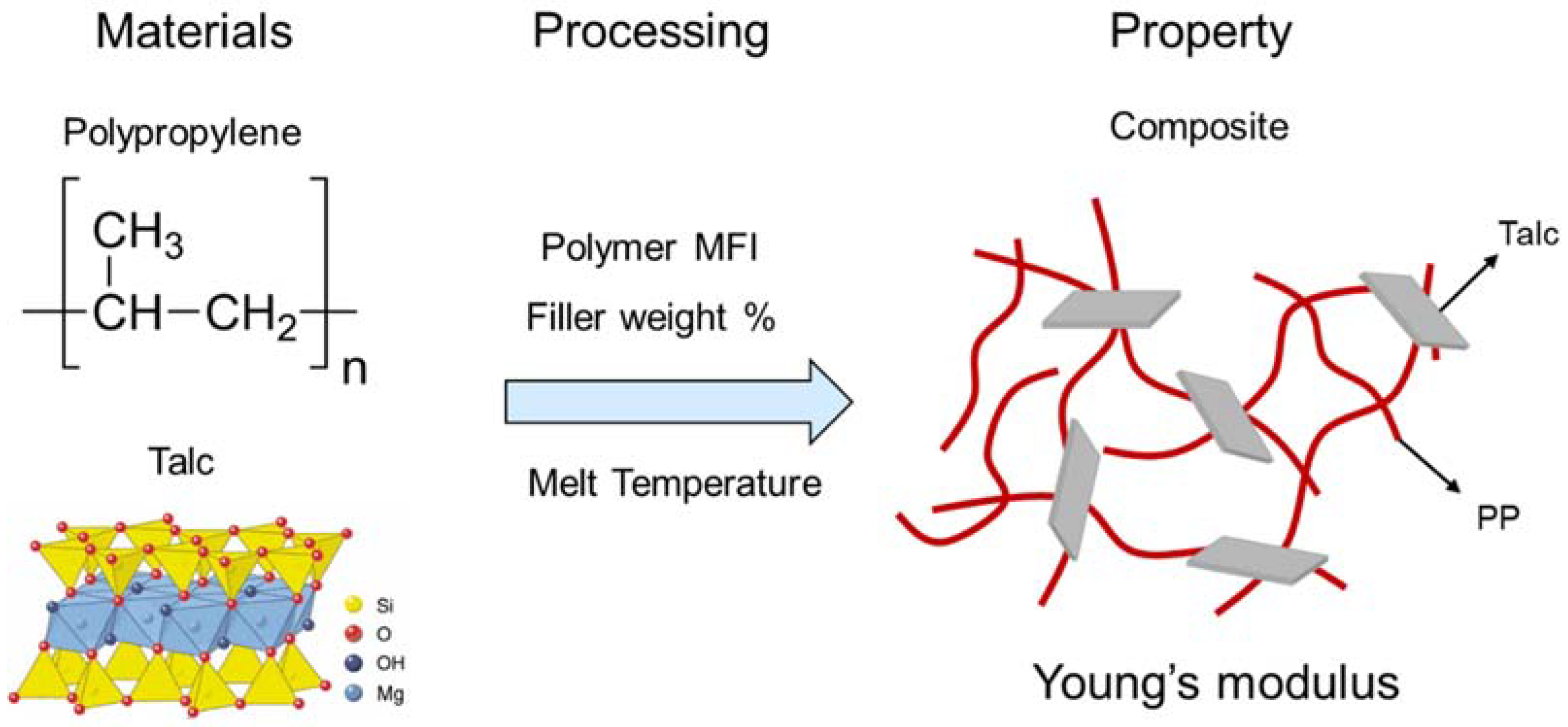
2.3.2. Polypropylene–Talc Composite
3. Results
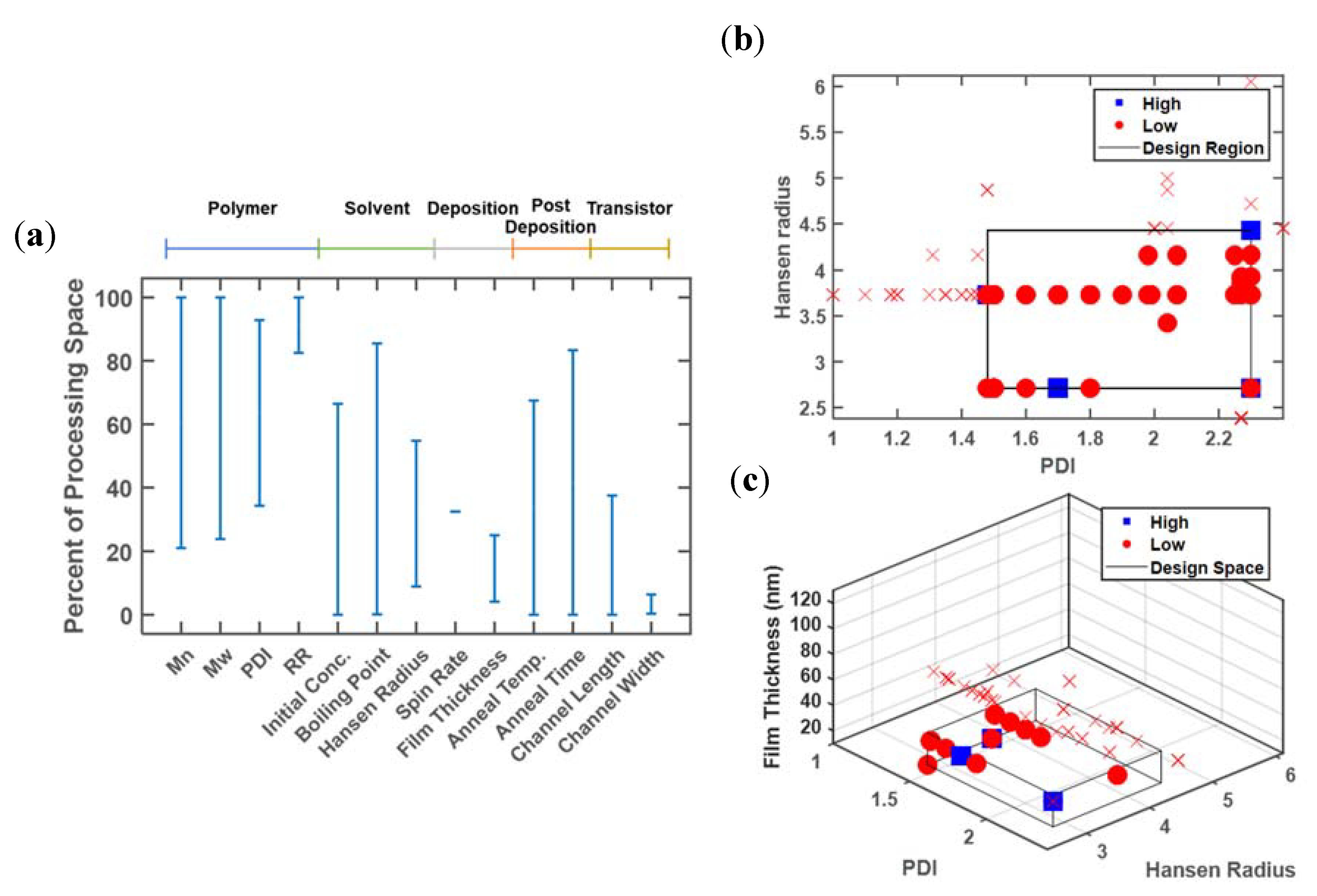
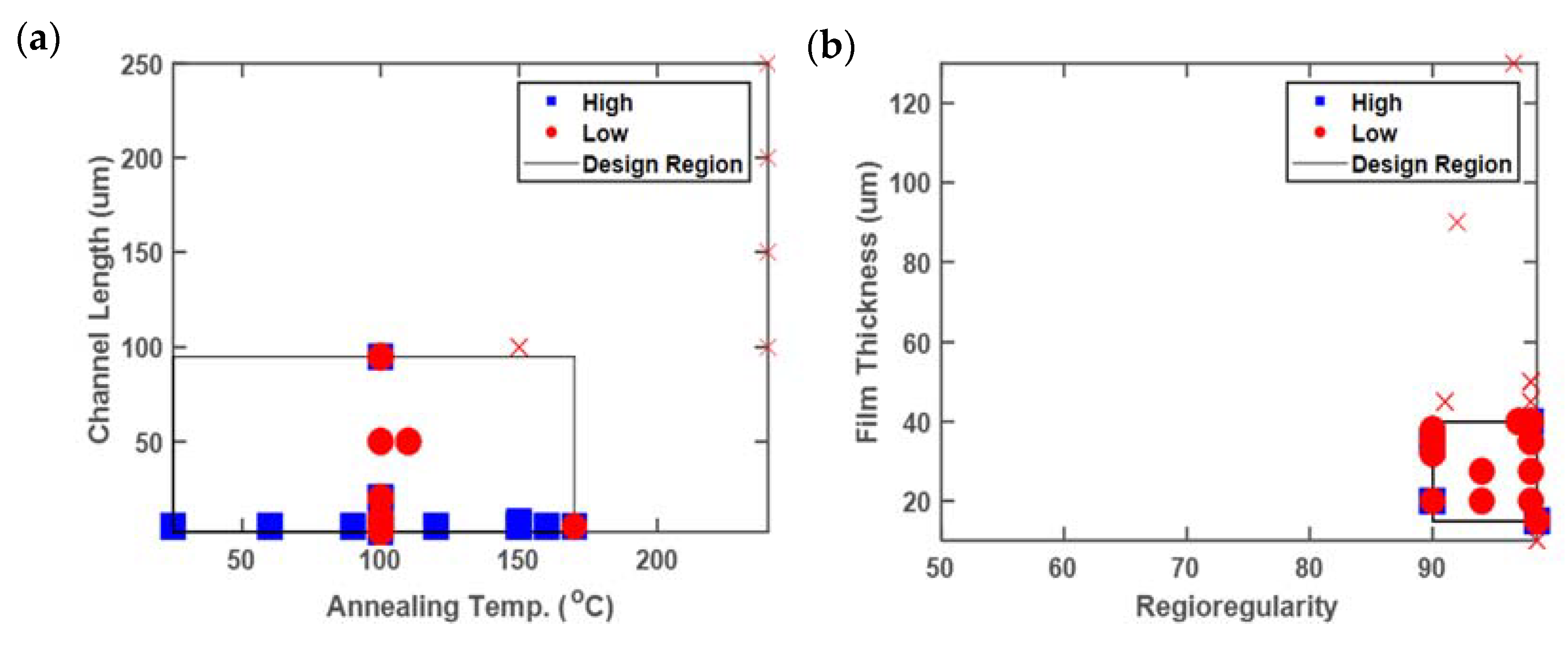
3.1. Case Study 1: Poly-3-Hexylthiophene
3.1.1. Polydispersity Index
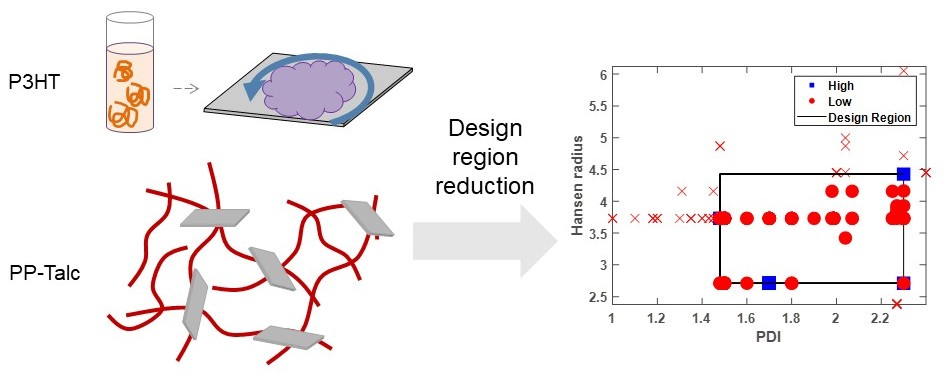
3.1.2. Hansen Radius
3.1.3. Film Thickness
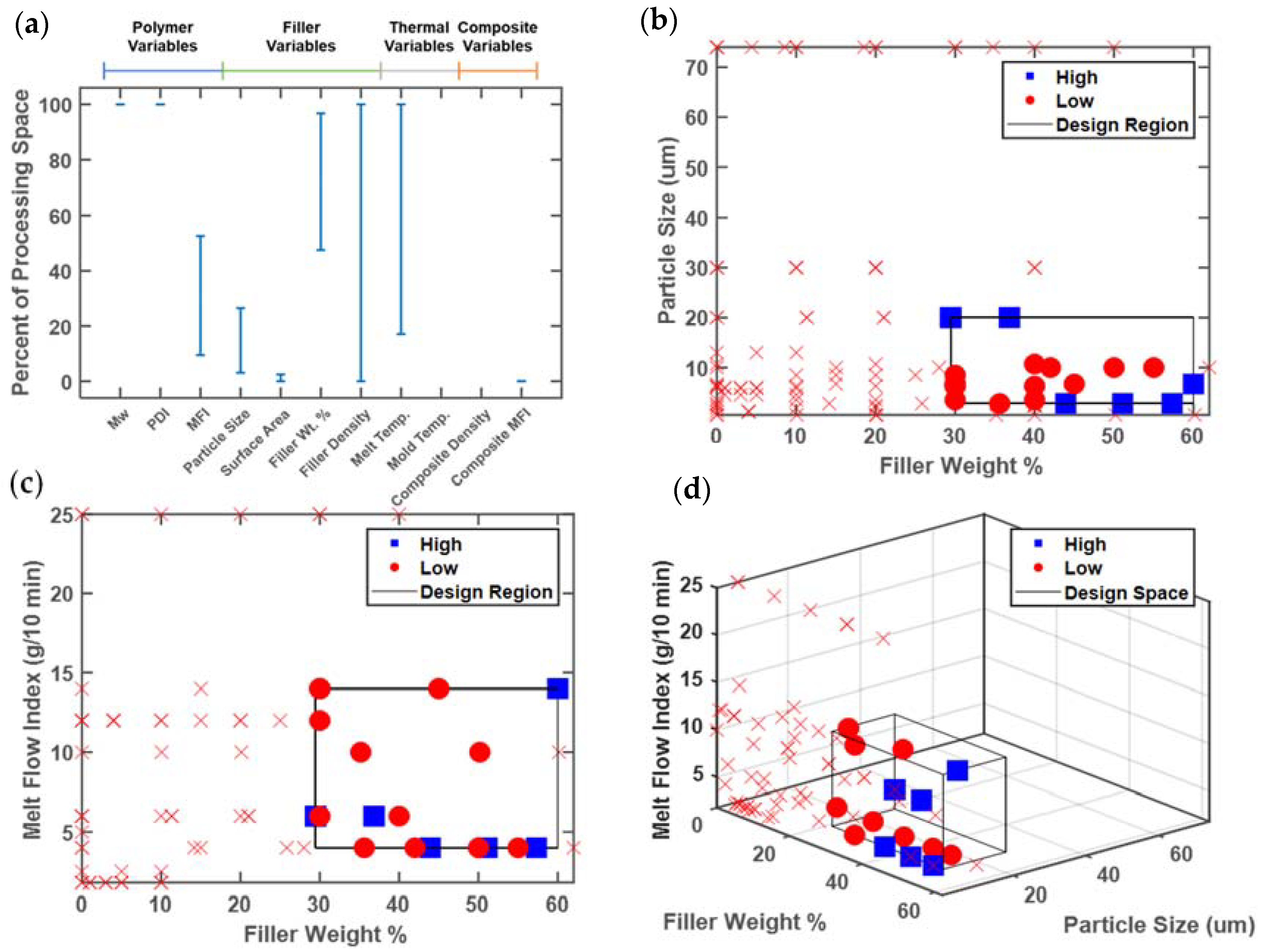
3.2. Case Study 2: Polypropylene–Talc Composite
4. Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kalidindi, S.R.; De Graef, M. Materials data science: Current status and future outlook. Annu. Rev. Mater. Res. 2015, 45, 171–193. [Google Scholar] [CrossRef]
- Citrine Informatics. Available online: http://www.citrination.com (accessed on 7 June 2018).
- Calphad (Computer Coupling of Phase Diagrams and Thermochemistry). Available online: http://www.calphad.org (accessed on 7 June 2018).
- The Materials Project. Available online: http://www.materialsproject.org (accessed on 7 June 2018).
- Open Quantum Materials Database. Available online: http://oqmd.org (accessed on 7 June 2018).
- Nist (National Institute of Standards and Technology) Data Gateway. Available online: http://srdata.nist.gov/gateway/gateway?dblist=1 (accessed on 7 June 2018).
- Casciato, M.J.; Vastola, J.T.; Lu, J.C.; Hess, D.W.; Grover, M.A. Initial experimental design methodology incorporating expert conjecture, prior data, and engineering models for deposition of iridium nanoparticles in supercritical carbon dioxide. Ind. Eng. Chem. Res. 2013, 52, 9645–9653. [Google Scholar] [CrossRef]
- Kim, E.; Huang, K.; Saunders, A.; McCallum, A.; Ceder, G.; Olivetti, E. Materials synthesis insights from scientific literature via text extraction and machine learning. Chem. Mater. 2017, 29, 9436–9444. [Google Scholar] [CrossRef]
- Agrawal, A.; Deshpande, P.; Cecen, A.; Basavarsu, G.; Choudhary, A.; Kalidindi, S. Exploration of data science techniques to predict fatigue strength of steel from composition and processing parameters. Integr. Mater. Manuf. Innov. 2014, 3, 1–19. [Google Scholar] [CrossRef]
- Matnavi Nims Materials Database. Available online: http://mits.nims.go.jp/index_en.html (accessed on 7 June 2018).
- Ren, F.; Ward, L.; Williams, T.; Laws, K.J.; Wolverton, C.; Hattrick-Simpers, J.; Mehta, A. Accelerated discovery of metallic glasses through iteration of machine learning and high-throughput experiments. Sci. Adv. 2018, 4, 1–11. [Google Scholar] [CrossRef] [PubMed]
- AbuOmar, O.; Nouranian, S.; King, R.; Bouvard, J.L.; Toghiani, H.; Lacy, T.E.; Pittman, C.U. Data mining and knowledge discovery in materials science and engineering: A polymer nanocomposites case study. Adv. Eng. Inform. 2013, 27, 615–624. [Google Scholar] [CrossRef]
- Zhang, S.L.; Zhang, Z.X.; Xin, Z.X.; Pal, K.; Kim, J.K. Prediction of mechanical properties of polypropylene/waste ground rubber tire powder treated by bitumen composites via uniform design and artificial neural networks. Mater. Des. 2010, 31, 1900–1905. [Google Scholar] [CrossRef]
- Ling, J.; Hutchinson, M.; Antono, E.; Paradiso, S.; Meredig, B. High-dimensional materials and process optimization using data-driven experimental design with well-calibrated uncertainty estimates. Integr. Mater. Manuf. Innov. 2017, 6, 207–217. [Google Scholar] [CrossRef]
- Park, J.; Howe, J.D.; Sholl, D.S. How reproducible are isotherm measurements in metal–organic frameworks? Chem. Mater. 2017, 29, 10487–10495. [Google Scholar] [CrossRef]
- Persson, N.; McBride, M.; Grover, M.; Reichmanis, E. Silicon valley meets the ivory tower: Searchable data repositories for experimental nanomaterials research. Curr. Opin. Solid State Mater. Sci. 2016, 20, 338–343. [Google Scholar] [CrossRef]
- Box, G.E.; Wilson, K.B. On the experimental attainment of optimum conditions. J. R. Stat. Soc. 1951, 13, 1–45. [Google Scholar]
- Montgomery, D.C. Design and Analysis of Experiments, 7th ed.; Wiley: New York, NY, USA, 2009. [Google Scholar]
- Kim, S.; Kim, H.; Lu, J.-C.; Casciato, M.J.; Grover, M.A.; Hess, D.W.; Lu, R.W.; Wang, X. Layers of experiments with adaptive combined design. Nav. Res. Logist. 2015, 62, 127–142. [Google Scholar] [CrossRef]
- Dimitrakopoulos, C.D.; Malenfant, P.R.L. Organic thin film transistors for large area electronics. Adv. Mater. 2002, 14, 99–117. [Google Scholar] [CrossRef]
- Persson, N.E.; Chu, P.H.; McBride, M.; Grover, M.; Reichmanis, E. Nucleation, growth, and alignment of poly(3-hexylthiophene) nanofibers for high-performance ofets. Acc. Chem. Res. 2017, 50, 932–942. [Google Scholar] [CrossRef] [PubMed]
- Persson, N.; McBride, M.; Grover, M.; Reichmanis, E. Automated analysis of orientational order in images of fibrillar materials. Chem. Mater. 2016, 29, 3–14. [Google Scholar] [CrossRef]
- Persson, N.E.; Rafshoon, J.; Naghshpour, K.; Fast, T.; Chu, P.H.; McBride, M.; Risteen, B.; Grover, M.; Reichmanis, E. High-throughput image analysis of fibrillar materials: A case study on polymer nanofiber packing, alignment, and defects in organic field effect transistors. ACS Appl. Mater. Interfaces 2017, 9, 36090–36102. [Google Scholar] [CrossRef] [PubMed]
- Shubhra, Q.T.H.; Alam, A.; Quaiyyum, M.A. Mechanical properties of polypropylene composites. J. Thermoplast. Compos. Mater. 2011, 26, 362–391. [Google Scholar] [CrossRef]
- Ahmed, S.; Jones, F.R. A review of particulate reinforcement theories for polymer composites. J. Mater. Sci. 1990, 25, 4933–4942. [Google Scholar] [CrossRef]
- Paul, D.R.; Robeson, L.M. Polymer nanotechnology: Nanocomposites. Polymer 2008, 49, 3187–3204. [Google Scholar] [CrossRef]
- Samuels, R.J. Polymer structure: The key to process-property control. Polym. Eng. Sci. 1985, 25, 864–874. [Google Scholar] [CrossRef]
- Premalal, H.; Ismail, H.; Baharin, A. Comparison of the mechanical properties of rice husk powder filled polypropylene composites with talc filled polypropylene composites. Polym. Test. 2002, 21, 833–839. [Google Scholar] [CrossRef]
- Pukanszky, B.; Belina, K.; Rockenbauer, A.; Maurer, R.H.J. Effect of nucleation, filler anisotropy and orientation on the properties of pp composities. Composites 1993, 3, 205–214. [Google Scholar]
- Rivnay, J.; Mannsfeld, S.C.; Miller, C.E.; Salleo, A.; Toney, M.F. Quantitative determination of organic semiconductor microstructure from the molecular to device scale. Chem. Rev. 2012, 112, 5488–5519. [Google Scholar] [CrossRef] [PubMed]
- Arias, A.C.; MacKenziew, J.D.; McCulloch, I.; Rivnay, J.; Salleo, A. Materials and applications for large area electronics: Solution-based approaches. Chem. Rev. 2010, 110, 3–24. [Google Scholar] [CrossRef] [PubMed]
- Sirringhaus, H.; Brown, P.J.; Friend, R.H.; Nielsen, M.; Bechgaard, K.; Langeveld-Voss, B.; Spiering, A.; Janssen, R.; Meijer, E.; Herwig, P.; et al. Two-dimensional charge transport in self-organized, high-mobility conjugated polymers. Nature 1999, 401, 685–688. [Google Scholar] [CrossRef]
- Kline, R.; McGehee, M.; Kadnikova, E.; Liu, J.; Frechet, J.; Toney, M.F. Dependence of regioregular poly(3-hexylthiophene) film morphology and field-effect mobility on molecular weight. Macromolecules 2005, 38, 3312–3319. [Google Scholar] [CrossRef]
- Bronstein, H.A.; Luscombe, C.K. Externally initiated regioregular p3ht with controlled molecular weight and narrow polydispersity. J. Am. Chem. Soc. 2009, 131, 12894–12895. [Google Scholar] [CrossRef] [PubMed]
- Horowitz, G. Organic field effect transistors. Adv. Mater. 1998, 10, 365–377. [Google Scholar] [CrossRef]
- Choi, D.; Chu, P.-H.; McBride, M.; Reichmanis, E. Best practices for reporting organic field effect transistor device performance. Chem. Mater. 2015, 27, 4167–4168. [Google Scholar] [CrossRef]
- Raccuglia, P.; Elbert, K.C.; Adler, P.D.; Falk, C.; Wenny, M.B.; Mollo, A.; Zeller, M.; Friedler, S.A.; Schrier, J.; Norquist, A.J. Machine-learning-assisted materials discovery using failed experiments. Nature 2016, 533, 73–76. [Google Scholar] [CrossRef] [PubMed]
- Kline, R.; McGehee, M.; Kadnikova, E.; Liu, J.; Frechet, J. Controlling the field-effect mobility of regioregular polythiophene by changing the molecular weight. Adv. Mater. 2003, 15, 1519–1522. [Google Scholar] [CrossRef]
- Zen, A.; Pfaum, J.; Hirschmann, S.; Zhuang, W.; Jaiser, F.; Asawapirom, U.; Rabe, J.; Scherf, U.; Neher, D. Effect of molecular weight and annealing of poly(3-hexylthiophene)s on the performance or organic field-effect transistors. Adv. Funct. Mater. 2004, 14. [Google Scholar] [CrossRef]
- Himmelberger, S.; Vandewal, K.; Fei, Z.; Heeney, M.; Salleo, A. Role of molecular weight distribution on charge transport in semiconducting polymers. Macromolecules 2014, 47, 7151–7157. [Google Scholar] [CrossRef]
- Scharsich, C.; Lohwasser, R.; Sommer, M.; Asawapirom, U.; Scherf, U.; Thelakkat, M.; Neher, D.; Köhler, A. Control of aggregate formation in poly(3-hexylthiophene) by solvent, molecular weight, and synthetic method. J. Polym. Sci. Part B Polym. Phys. 2012, 50, 442–453. [Google Scholar] [CrossRef]
- Chang, M.; Lim, G.; Park, B.; Reichmanis, E. Control of molecular ordering, alignment, and charge transport in solution-processed conjugated polymer thin films. Polymers 2017, 9, 212. [Google Scholar] [CrossRef]
- Chang, M.; Choi, D.; Fu, B.; Reichmanis, E. Solvent based hydrogen bonding: Impact on poly(3-hexylthiophene) nanoscale morphology and charge transport characteristics. ACS Nano 2013, 7, 5402–5413. [Google Scholar] [CrossRef] [PubMed]
- Roesing, M.; Howell, J.; Boucher, D. Solubility characteristics of poly(3-hexylthiophene). J. Polym. Sci. Part B Polym. Phys. 2017. [Google Scholar] [CrossRef]
- Choi, D.; Chang, M.; Reichmanis, E. Controlled assembly of poly(3-hexylthiophene): Managing the disorder to order transition on the nano- through meso-scales. Adv. Funct. Mater. 2015, 25, 920–927. [Google Scholar] [CrossRef]
- Verilhac, J.; LeBlevennec, G.; Djurado, D.; Rieutord, F.; Chouiki, M.; Travers, J.; Pron, A. Effect of macromolecular parameters and processing conditions on supramolecular organisation, morphology and electrical transport properties in thin layers of regioregular poly(3-hexylthiophene). Synth. Met. 2006, 156, 815–823. [Google Scholar] [CrossRef]
- Joshi, S.; Grigorian, S.; Pietsch, U.; Pingel, P.; Zen, A.; Neher, D.; Scherf, U. Thickness dependence of the crystalline structure and hole mobility in thin films of low molecular weight poly(3-hexylthiophene). Macromolecules 2008, 41, 6800–6808. [Google Scholar] [CrossRef]
- Na, J.Y.; Kang, B.; Sin, D.H.; Cho, K.; Park, Y.D. Understanding solidification of polythiophene thin films during spin-coating: Effects of spin-coating time and processing additives. Sci. Rep. 2015, 5, 13288. [Google Scholar] [CrossRef] [PubMed]
- Chu, P.H.; Kleinhenz, N.; Persson, N.; McBride, M.; Hernandez, J.; Fu, B.; Zhang, G.; Reichmanis, E. Toward precision control of nanofiber orientation in conjugated polymer thin films: Impact on charge transport. Chem. Mater. 2016, 28, 9099–9109. [Google Scholar] [CrossRef]
- Chang, M.; Choi, D.; Egap, E. Macroscopic alignment of one-dimensional conjugated polymer nanocrystallites for high-mobility organic field-effect transistors. ACS Appl. Mater. Interfaces 2016, 8, 13484–13491. [Google Scholar] [CrossRef] [PubMed]
- Bermner, T.; Rudin, A. Melt flow index values and molecular weight distributions of commercial thermoplastics. J. Appl. Polym. Sci. 1990, 41, 1617–1627. [Google Scholar] [CrossRef]
- Gafur, M.A.; Nasrin, R.; Mina, M.F.; Bhuiyan, M.A.H.; Tamba, Y.; Asano, T. Structures and properties of the compression-molded istactic-polypropylene/talc composites: Effect of cooling and rolling. Polym. Degrad. Stab. 2010, 95, 1818–1825. [Google Scholar] [CrossRef]
- Nelson, P.R.C. Treatment of Missing Measurements in PCA and PLS Models. Ph.D. Thesis, Master University, Hamilton, ON, Canada, 2002. [Google Scholar]
- Nelson, P.R.C.; Taylor, P.A.; MacGregor, J.F. Missing data methods in pca and pls: Score calculations with incomplete observations. Chemom. Intell. Lab. Syst. 1996, 35, 45–65. [Google Scholar] [CrossRef]
- Folch-Fortuny, A.; Arteaga, F.; Ferrer, A. Pca model building with missing data: New proposals and a comparative study. Chemom. Intell. Lab. Syst. 2015, 146, 77–88. [Google Scholar] [CrossRef]
- Verpoort, P.C.; MacDonald, P.; Conduit, G.J. Materials data validation and imputation with an artificial neural network. Comput. Mater. Sci. 2018, 147, 176–185. [Google Scholar] [CrossRef]
- Berman, H.M.; Westbrook, J.; Feng, Z.; Gilliland, G.; Bhat, T.N.; Weissig, H.; Shindyalov, I.N.; Bourne, P.E. The Protein Data Bank. Available online: https://www.rcsb.org/ (accessed on 7 June 2018).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PDI/Hansen Radius | PDI/Film Thickness | Hansen Radius/Film Thickness | Channel Length/Annealing Temp | RR/Film Thickness | |
|---|---|---|---|---|---|
| rs (%) | 27 | 12 | 10 | 25 | 4 |
| Fr (%) | 45 | 30 | 53 | 45 | 63 |
| MFI/Particle Size | MFI/Filler Wt.% | Particle Size/Filler Wt.% | |
|---|---|---|---|
| rs (%) | 10 | 21 | 12 |
| Fr (%) | 28 | 14 | 15 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
McBride, M.; Persson, N.; Reichmanis, E.; Grover, M.A. Solving Materials’ Small Data Problem with Dynamic Experimental Databases. Processes 2018, 6, 79. https://doi.org/10.3390/pr6070079
McBride M, Persson N, Reichmanis E, Grover MA. Solving Materials’ Small Data Problem with Dynamic Experimental Databases. Processes. 2018; 6(7):79. https://doi.org/10.3390/pr6070079
Chicago/Turabian StyleMcBride, Michael, Nils Persson, Elsa Reichmanis, and Martha A. Grover. 2018. "Solving Materials’ Small Data Problem with Dynamic Experimental Databases" Processes 6, no. 7: 79. https://doi.org/10.3390/pr6070079
APA StyleMcBride, M., Persson, N., Reichmanis, E., & Grover, M. A. (2018). Solving Materials’ Small Data Problem with Dynamic Experimental Databases. Processes, 6(7), 79. https://doi.org/10.3390/pr6070079