1. Introduction
Membrane bioreactor (MBR) technology has emerged as a crucial innovation in the wastewater treatment industry, offering significant advantages over conventional activated sludge processes. MBRs combine biological treatment with membrane filtration, resulting in high-quality effluent suitable for various reuse applications [
1,
2]. The process is characterized by its compact footprint, reduced sludge production, and superior removal of contaminants, including micropollutants and pathogens [
3]. These benefits have led to the widespread adoption of MBRs in both municipal and industrial wastewater treatment facilities worldwide. However, MBR technology faces a persistent challenge: membrane fouling [
4,
5]. Fouling results from the accumulation of particles, colloids, and dissolved substances on or within the membrane, causing decreased permeability, increased energy consumption, and more frequent cleaning or replacement. It is influenced by factors such as influent wastewater characteristics, operational conditions, and biomass properties [
6,
7,
8], ultimately impacting operational efficiency and significantly increasing maintenance costs. As the industry evolves, innovative solutions and predictive tools are needed to address fouling and optimize MBR performance for long-term sustainability.
The prediction of membrane fouling in MBR processes has become increasingly crucial for optimizing operational efficiency and reducing maintenance costs. Accurate fouling prediction allows operators to implement proactive measures, such as adjusting operational parameters or scheduling cleaning interventions, to mitigate the negative impacts of fouling on system performance [
9,
10,
11,
12,
13,
14]. Effective treatment of diverse wastewaters requires optimizing process design and operational conditions to minimize membrane fouling. Given its flux-driven nature, operating at excessively high flux may reduce cleaning frequency temporarily but accelerate fouling, raising long-term costs and risks [
9]. Accurate fouling prediction enables the selection of operating conditions that balance productivity, effluent quality, cleaning needs, and overall cost. This highlights the role of predictive tools in achieving sustainable and economical MBR operation. Traditional approaches to fouling prediction have relied on empirical models and laboratory-scale experiments, which often fail to capture the complex dynamics of full-scale MBR systems. In recent years, researchers have explored various advanced techniques to enhance fouling prediction accuracy [
10,
11]. Mechanistic models based on principles of fluid dynamics, mass transfer, and biofilm formation have been developed to simulate the intricate interactions between biomass, suspended solids, and membrane surfaces, providing insights into fouling mechanisms [
12]. Statistical and data-driven approaches, including time-series analysis and multivariate techniques, have also been used to identify correlations and detect trends in membrane performance [
13,
14]. Additionally, researchers have investigated the use of online monitoring tools and sensors to provide real-time data on key fouling indicators, such as transmembrane pressure (TMP) and permeate flux [
15,
16]. While these methods have shown promise in specific applications, they often face limitations when applied to the diverse and dynamic conditions encountered in full-scale MBR operations. The complexity of the fouling process, influenced by numerous interrelated factors, poses a significant challenge to developing universally applicable prediction models. Moreover, the time-dependent nature of fouling and the potential for sudden changes in influent characteristics or operational conditions further complicate prediction [
17,
18]. As a result, there is a growing recognition of the need for more sophisticated and adaptable approaches to membrane fouling prediction in MBR systems.
Artificial intelligence (AI) has emerged as a powerful tool for predicting membrane fouling in MBR systems, offering several advantages over traditional methods [
19,
20,
21,
22,
23,
24]. AI-based approaches, particularly machine learning algorithms, can effectively handle complex non-linear relationships between multiple variables and capture hidden patterns in large datasets [
25,
26,
27,
28]. These techniques have demonstrated superior predictive performance compared to conventional statistical models, especially when dealing with the dynamic and multifaceted nature of MBR fouling. However, most previous applications have been validated primarily under controlled laboratory or pilot-scale conditions, with limited demonstration in the noisy and dynamic environments of full-scale MBRs. Various AI algorithms have been applied to MBR fouling prediction, including artificial neural networks (ANNs), support vector machines (SVMs), random forests, and, more recently, deep learning models [
19,
20,
21,
22,
23,
24]. These models typically utilize a range of input parameters to predict fouling indicators, such as TMP or permeate flux. Common input variables include operational parameters (e.g., aeration rate, flux, MLSS concentration), influent characteristics (e.g., chemical oxygen demand (COD), nutrients, temperature), and membrane properties. Some studies have also incorporated advanced feature engineering techniques to enhance model performance, such as principal component analysis (PCA) for dimensionality reduction or wavelet transforms for time-series analysis [
25,
26]. The selection of appropriate input parameters and target variables is crucial for developing accurate and robust AI models. Researchers have explored various combinations of parameters, with some focusing on easily measurable online data, while others incorporate more comprehensive sets of physicochemical and biological indicators [
27,
28].
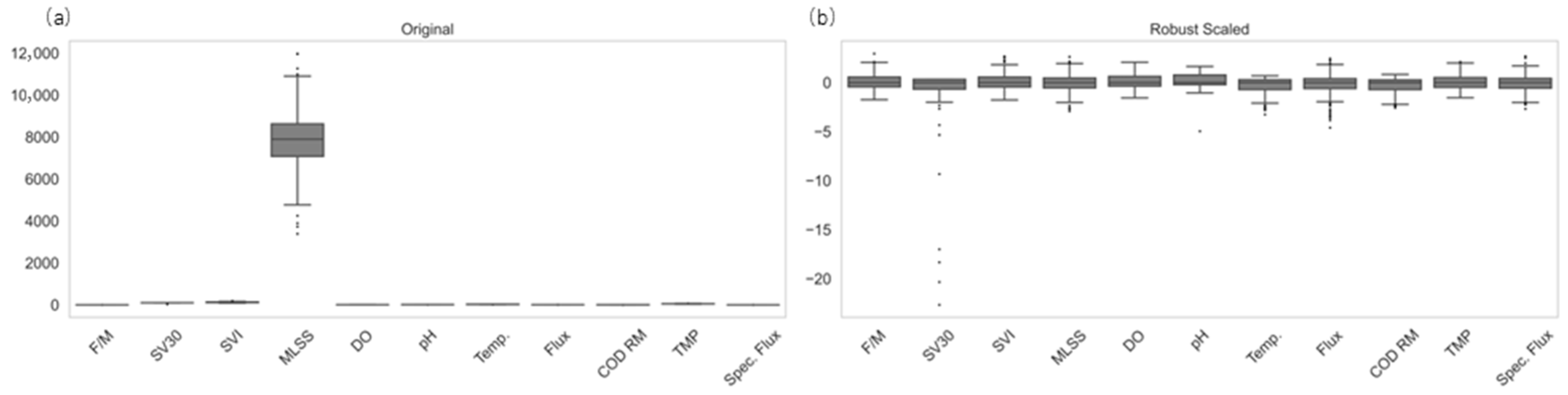
Despite the promising results achieved by AI-based fouling prediction models, several limitations and challenges persist, particularly regarding their robustness and generalizability when transitioning from controlled experimental settings to real-world full-scale MBR operations. One significant drawback is the “black box” nature of many AI algorithms, particularly deep learning models, which can make it difficult for operators to understand and trust the predictions [
29,
30,
31]. This lack of interpretability can hinder the adoption of AI models in practical MBR operations, where operators need to make informed decisions based on model outputs. Another challenge lies in the quality and representativeness of the data used to train AI models. Many studies rely on data collected from well-controlled laboratory experiments or pilot-scale systems, which, unlike real-world full-scale MBR operations, often lack the noise, missing values, and operational variability encountered in practice. As a result, AI models developed under such conditions may not perform reliably when applied to real-world data, highlighting the need for approaches validated in actual operational environments. The issue of data scaling and normalization is also critical, as different input parameters often have vastly different ranges and units, potentially leading to biased or inaccurate predictions if not properly addressed. This is especially true considering the significant variability in the characteristics of wastewater treatment plant data [
32,
33]. Membrane fouling exhibits a time-dependent nature not only in MBR processes, but also in most membrane processes [
34,
35,
36]. To capture the time-dependent nature of fouling, AI models must use feature engineering that accounts for both current and historical operational data. Most existing methods overlook the cumulative effects of past conditions, underscoring the need for advanced techniques that incorporate temporal dependencies and long-term trends in MBR performance. Another consideration is the choice of target parameter for fouling prediction. To date, the most commonly used representative target parameters (i.e., outputs) for predicting membrane fouling based on AI are TMP and flux [
37,
38,
39,
40]. In the case of TMP, when the operation mode of the MBR process is constant flux mode, it increases as membrane fouling progresses; conversely, in the case of flux, when the operation mode is constant pressure mode, it decreases as membrane fouling progresses [
41,
42,
43]. In most cases, MBR processes are operated in constant flux mode [
44,
45]. However, due to inflow variability and changing environmental conditions, both flux and TMP often fluctuate even under constant flux operation. Therefore, it is important to select target parameters that reflect these simultaneous variations. Further research should focus on identifying such parameters to provide more accurate and practical insights into membrane fouling and to improve prediction performance. Continued efforts to enhance model interpretability, data quality, and feature engineering are essential for advancing AI-based fouling prediction and its practical application in MBR operations.
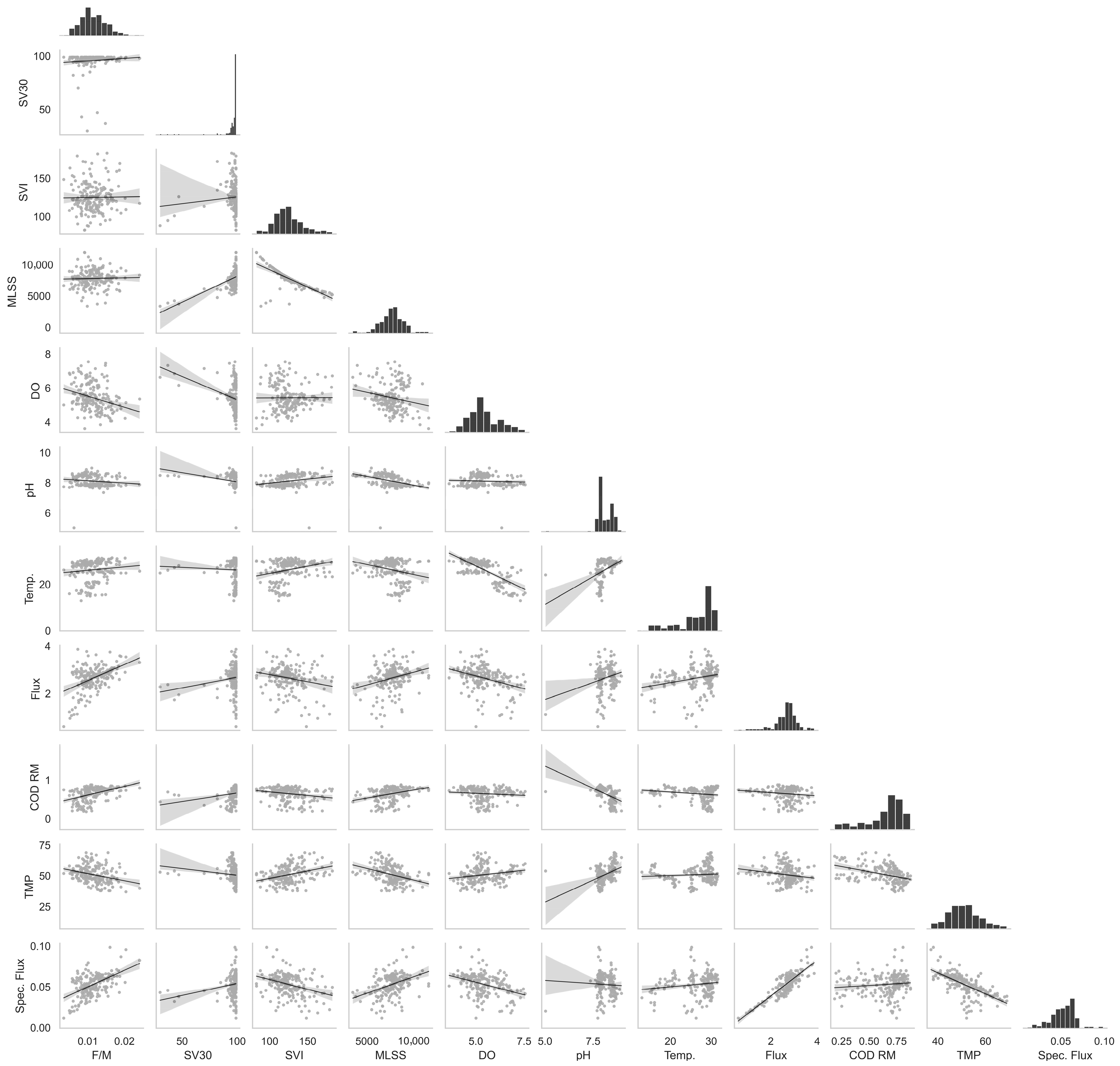
The primary objective of this study is to develop a predictive framework for membrane fouling in full-scale MBRs by integrating AI-driven feature engineering and explainable AI (XAI). To achieve this, the research focuses on innovative modeling strategies that enhance both prediction accuracy and practical applicability under real-world operating conditions. This study prioritizes parameters measurable in resource-constrained field environments, avoiding reliance on idealized or synthetic data. The proposed AI-driven feature engineering techniques (e.g., moving averages) explicitly address challenges like sensor noise and infrequent sampling, ensuring relevance to real-world MBR operations. This approach is distinguished by several innovative elements. First, diverse feature engineering techniques are employed to extract meaningful information from raw data, effectively capturing the complex relationships between operational parameters and fouling behavior. Additionally, specific flux (flux/TMP), which is physically equivalent to membrane permeability, is introduced as the target parameter. This dynamic indicator comprehensively reflects membrane performance by simultaneously accounting for variations in both flux and transmembrane pressure. Furthermore, COD removal efficiency is incorporated as an input parameter, reflecting the biological performance of the MBR system and its potential impact on fouling. To account for the time-dependent effects of biological reactions on membrane fouling, a moving average concept is implemented in the selection of input–output data pairs. Moreover, explainable AI models are utilized to enhance operator decision support, thereby improving the interpretability and trustworthiness of fouling predictions. The applicability of the model is demonstrated using over six months of real-world data collected from an operational MBR process, rather than a designed MBR process for this study. This ensures the model’s relevance to the actual data conditions and the non-ideal circumstances present in the field. While physics-based models provide a fundamental understanding of fouling mechanisms and traditional sensing tools offer real-time monitoring, the proposed AI framework complements these approaches by translating complex operational data into actionable insights for proactive control. By integrating with existing sensor networks, the framework can enhance decision making without replacing established physical models, thereby creating a more robust MBR management system. For example, the AI model can receive real-time sensor data (e.g., TMP, DO) and dynamically adjust input parameters for physics-based simulations, enabling adaptive and responsive fouling prediction. By combining AI predictions with traditional fouling indicators, a hybrid alarm or decision support system can be established, leveraging the strengths of both data-driven and mechanistic approaches. Overall, this research makes a significant contribution to the field by presenting a robust and interpretable predictive framework for membrane fouling in full-scale MBRs, integrating AI-driven feature engineering and explainable AI. This approach lays the foundation for more effective membrane fouling management and supports sustainable improvements in MBR operations.
4. Conclusions
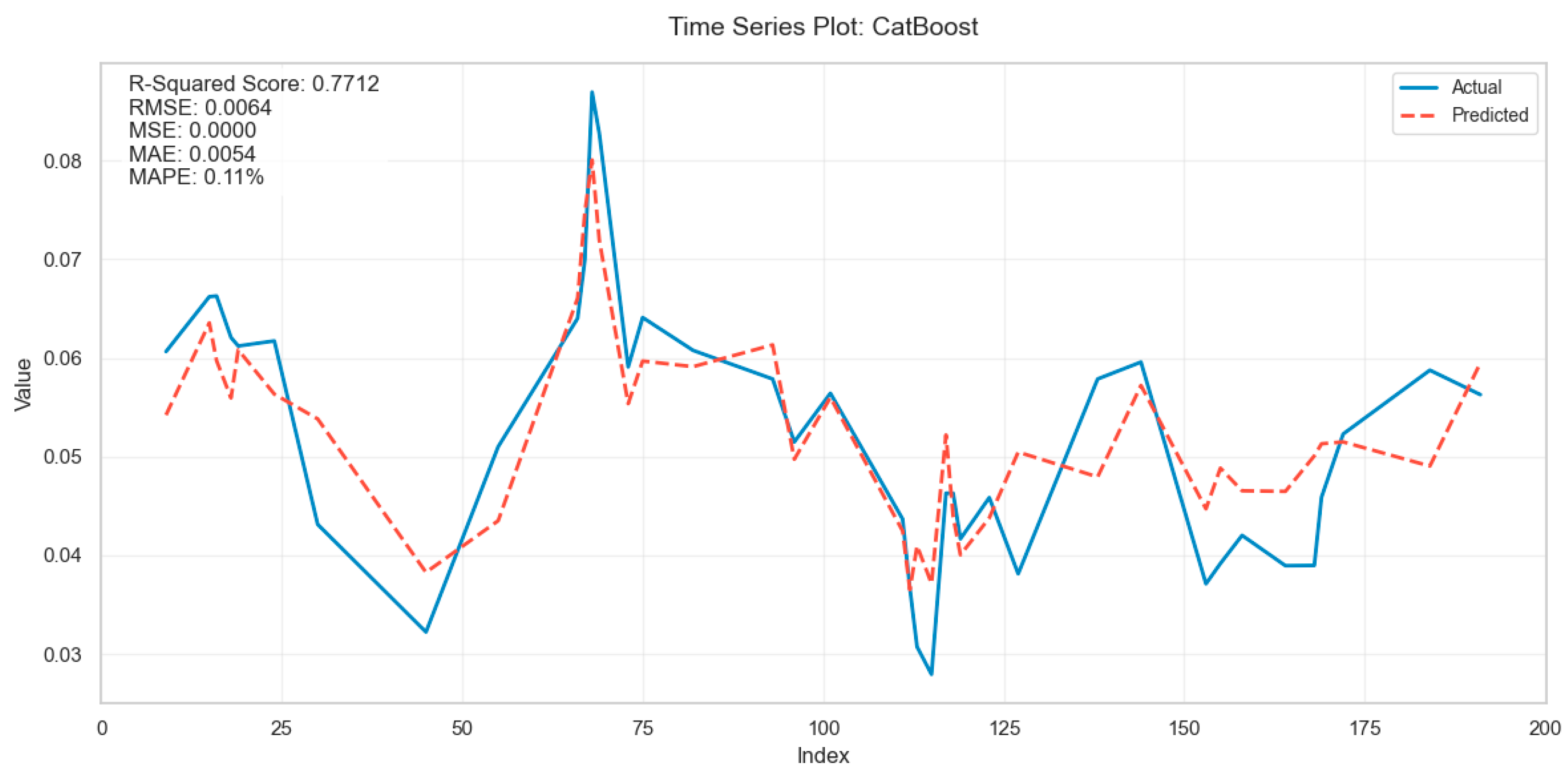
This study presents a predictive framework for membrane fouling in full-scale MBR systems by integrating AI-driven feature engineering and explainable AI (XAI). The developed predictive framework is intended for direct application in real MBR plants. By utilizing parameters routinely measured in operational settings and incorporating robust interpretable AI models, the framework supports proactive fouling management and operational decision making. By refining the target parameter to specific flux (Flux/TMP) and incorporating COD removal efficiency as a biological performance indicator, the model captures the dynamic interplay between operational parameters and fouling behavior. The application of moving average techniques further enhanced temporal feature representation, addressing the cumulative effects of fouling progression. Among tested models, CatBoost demonstrated superior predictive accuracy, outperforming traditional statistical and machine learning approaches.
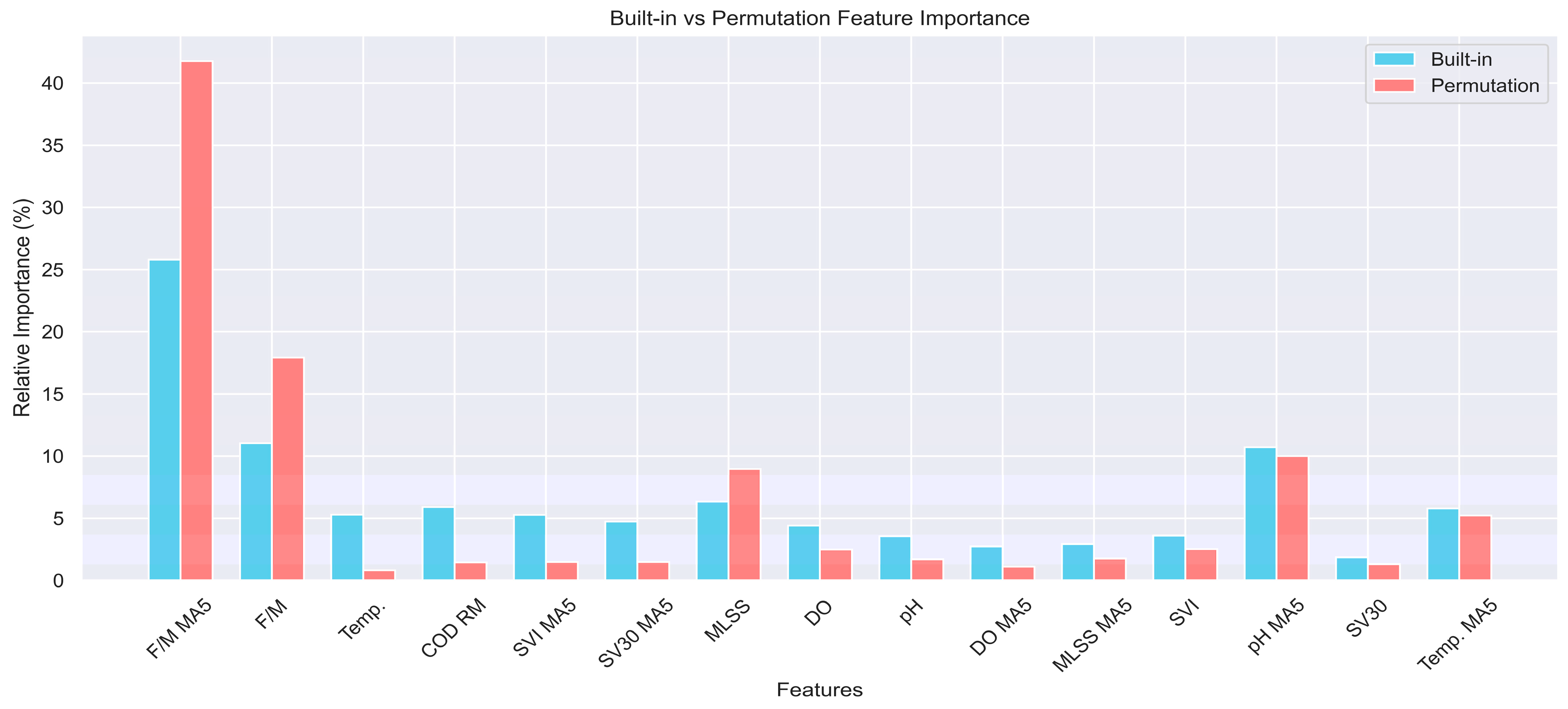
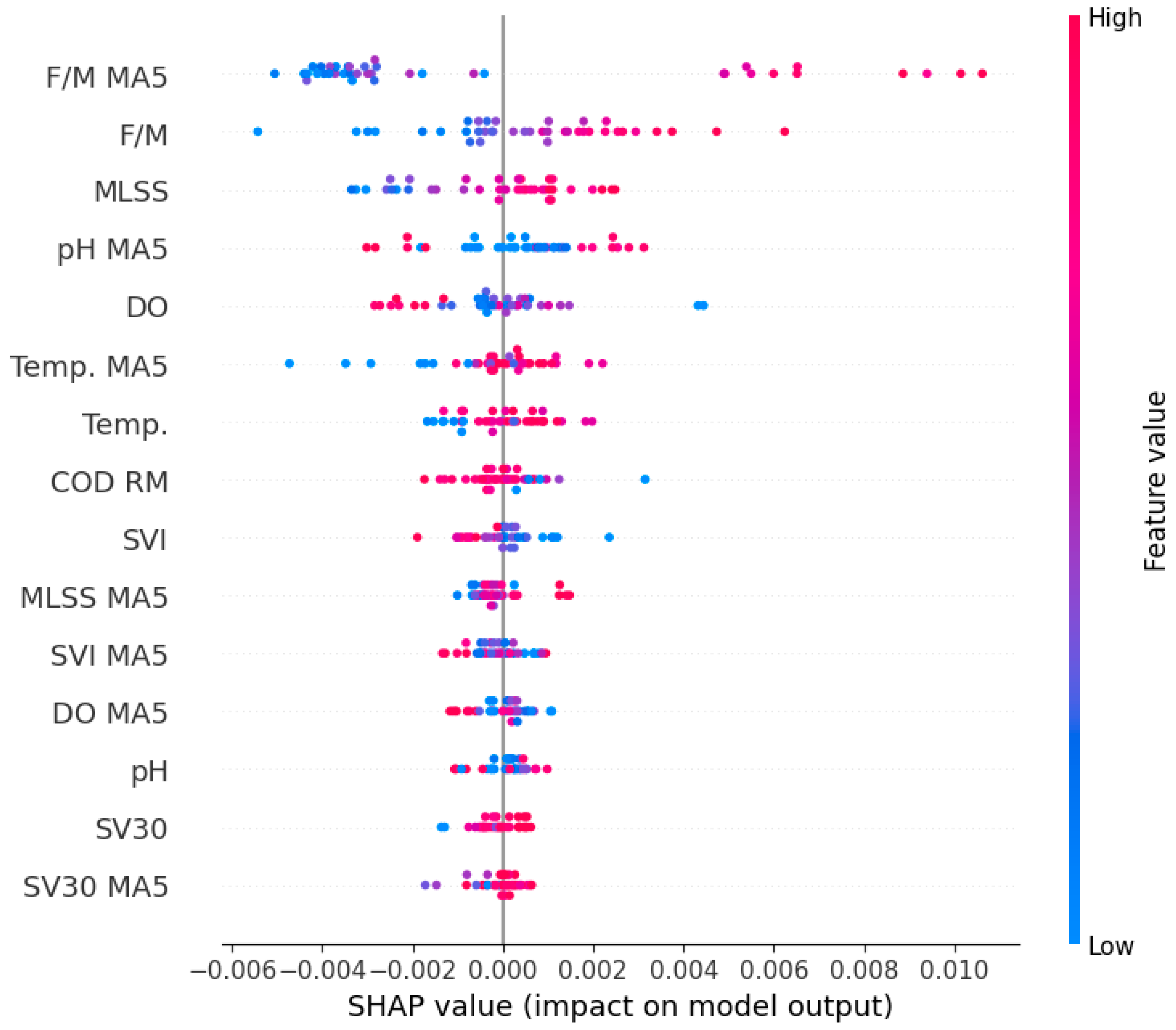
XAI techniques revealed critical insights into fouling mechanisms, identifying F/M ratio and MLSSs as dominant factors influencing fouling dynamics. These findings underscore the importance of real-time monitoring and adaptive control strategies, such as optimizing organic loading and biomass concentration, to mitigate fouling risks. While the proposed framework is not intended to replace physics-based control models, its predictive capability and interpretability provide critical decision support inputs for optimizing maintenance schedules and informing adaptive control strategies in full-scale MBR operations. The framework’s validation using real-world data from an operational MBR highlights its practical applicability under non-ideal conditions. The framework synergizes with physics-based models (e.g., biofilm dynamics simulations) by providing data-driven refinements to fouling predictions, while its compatibility with low-cost sensors bridges gaps in traditional monitoring tools. This integration enables adaptive control strategies that dynamically adjust operational parameters (e.g., aeration intensity, sludge retention) based on real-time fouling risk assessment. However, the relatively small dataset limits the generalizability of the model. Future studies should validate the framework using larger and more diverse datasets to enhance robustness and applicability across different MBR configurations.
This work demonstrates that prediction and interpretation of fouling behavior is achievable even under suboptimal data conditions, providing a critical bridge between academic research and industrial practice. In addition, this work bridges the gap between complex AI models and operational interpretability, offering a robust tool for proactive membrane management. Future research should prioritize the integration of these AI-based models with sensor networks and adaptive control systems, thereby enabling the dynamic optimization of operational parameters such as aeration, sludge retention, and filtration protocols in real time. Such efforts are expected to enhance the overall efficiency of MBR processes, reduce energy consumption, and contribute to the extension of membrane lifespan. The methodology’s adaptability also holds promise for broader applications in membrane-based processes, including desalination and industrial wastewater treatment, fostering sustainable advancements in water resource management. The core principles of this framework—dynamic target parameters (e.g., specific flux), temporal feature engineering, and XAI interpretability—are transferable to other membrane processes like reverse osmosis (RO). For instance, RO fouling is similarly time-dependent and influenced by operational fluctuations (e.g., pressure, flux variations). Adaptations would require domain-specific adjustments (e.g., incorporating scaling indices for mineral fouling), but the methodology’s foundation in handling noisy real-world data and capturing cumulative effects remains broadly applicable across membrane technologies. Future work will focus on integrating the model with online monitoring systems for real-time prediction and adaptive control in full-scale facilities.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}