
A Fracture Extraction Method for Full-Diameter Core CT Images Based on Semantic Segmentation


 ,
,
Abstract
1. Introduction
2. Related Studies
2.1. Application of Semantic Segmentation Techniques in Core CT Image Analysis
2.2. Challenges in Fracture Identification and Existing Solutions
3. Framework and Methodology
3.1. Technical Overview
3.2. Intelligent Fracture Characterization Model Based on SCTNet
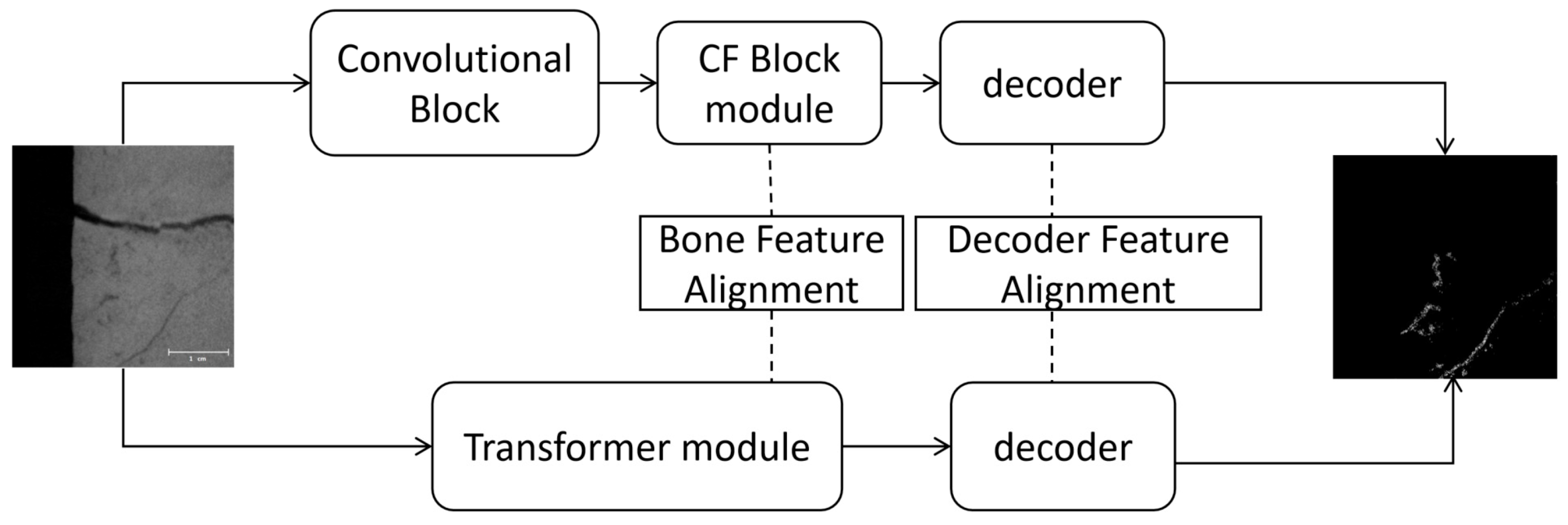
3.2.1. Model Architecture
3.2.2. ConvFormer (CF) Block Module
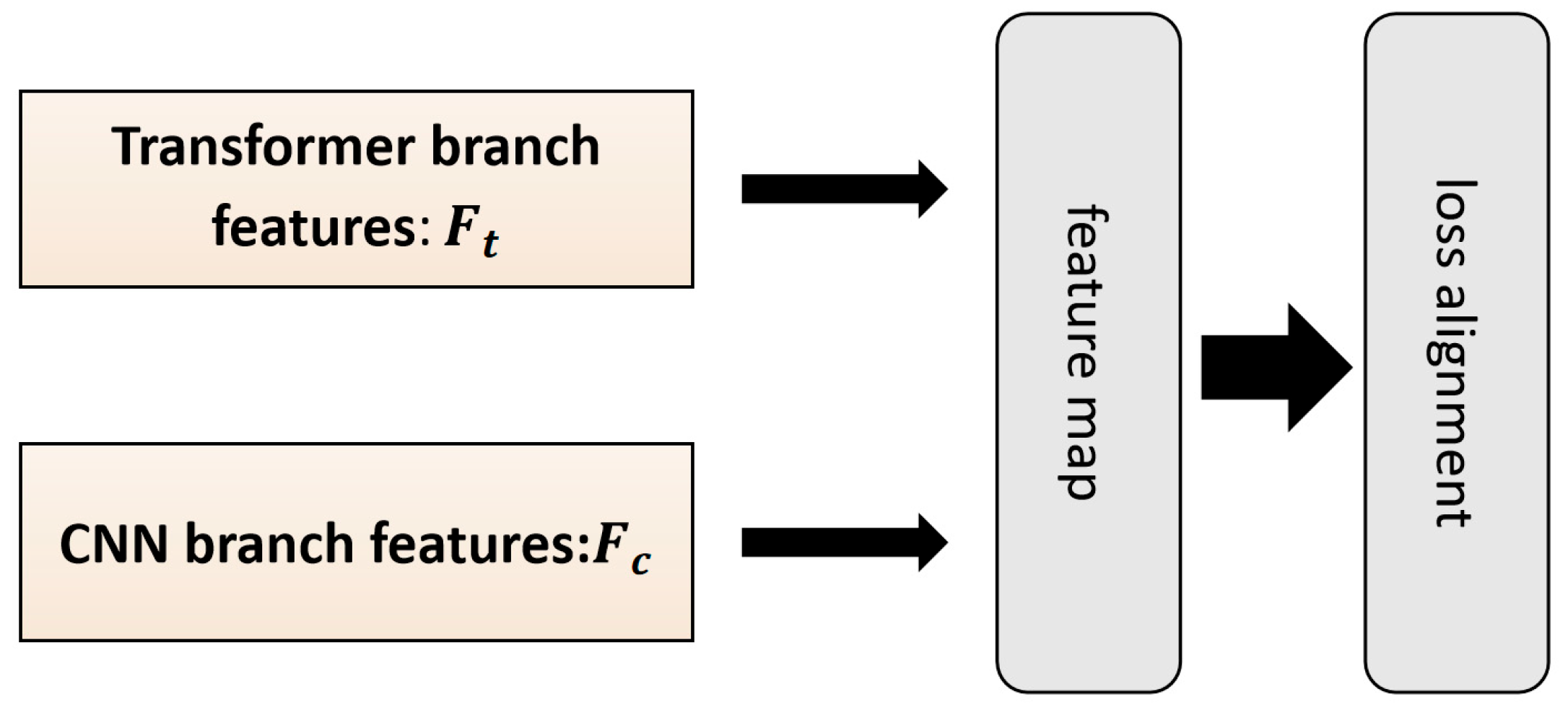
3.2.3. Alignment Module
3.2.4. Loss Function and Evaluation Metrics Selection
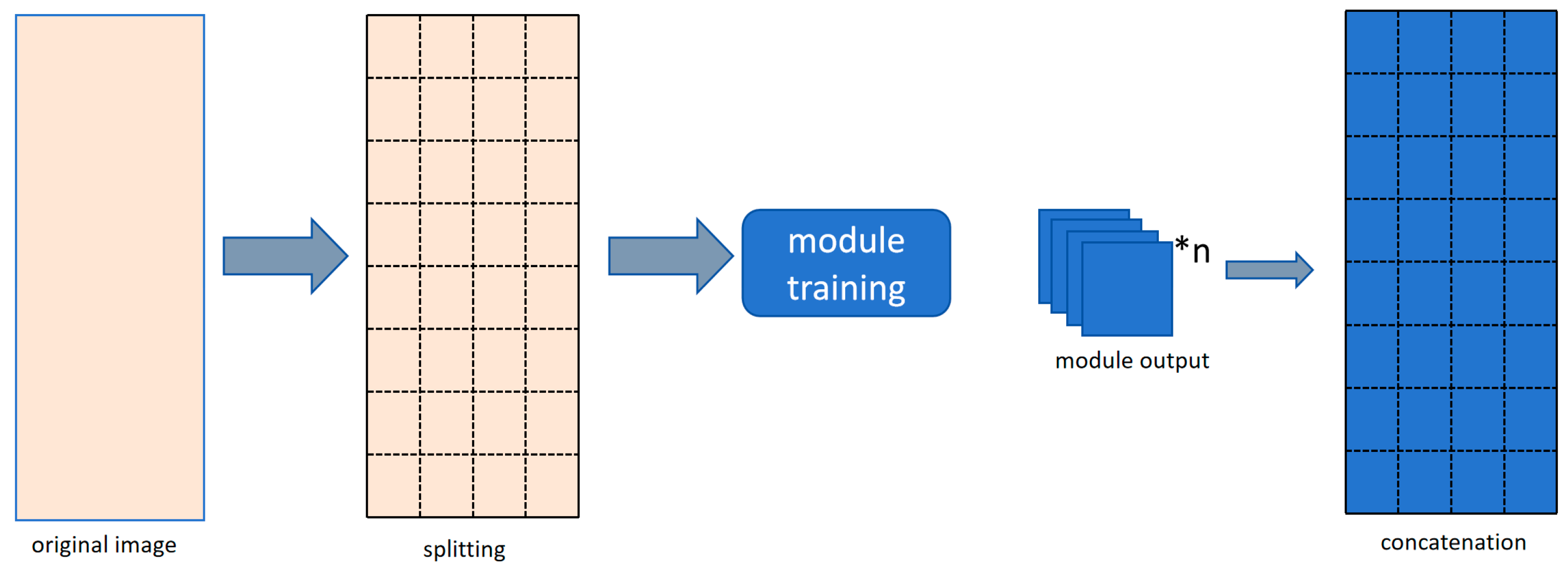
3.3. Sliding Window-Based Method for Large-Scale CT Image Processing
3.4. Fracture Annotation and Dataset Preparation
3.4.1. Experimental Data
3.4.2. Data Annotation
3.5. Feature-Based Fracture Characterization
- The fracture area ratio is determined by calculating the ratio of the number of pixels classified as fractures to the total number of pixels in the image.
- To estimate fracture dip and orientation, a least squares fitting method is applied to fit a straight line through the fracture points, from which the dip angle and orientation of the fitted line are calculated.
- For fracture aperture, the average distance between opposing sides of the fracture boundary within each segmented fracture contour is computed.
4. Experiments and Results Analysis
4.1. Analysis of Fracture Identification Results
4.2. Quantitative Characterization of Fracture Information
4.3. Application Analysis
5. Conclusions
- The integration of semantic segmentation techniques into full-diameter core CT fracture analysis significantly improves model performance. Compared to traditional threshold-based methods and other deep learning models, the SCTNet-based approach achieved a pixel-level segmentation accuracy of 97% and demonstrated superior fracture discrimination, as indicated by a mean Intersection over Union (mIoU) of 72.14%.
- A full-size fracture segmentation strategy based on sliding window stitching was developed, enabling quantitative extraction of key fracture parameters, including area ratio, strike, dip, and aperture.
- Compared to conventional manual interpretation—which often requires hours of expert analysis—the proposed method reduces processing time to just a few minutes, significantly improving the efficiency of fracture identification and description.
- One limitation of the current method is its exclusive reliance on CT image data, which may reduce detection accuracy in cases with weak density contrast. At present, the model’s performance has been evaluated against expert geological interpretations, demonstrating a high level of agreement and thereby supporting the credibility of the proposed method. Future studies will incorporate additional geological validation techniques—such as core logging, petrographic analysis, and borehole imaging—to further enhance the reliability of the results.
- Expanding the dataset to include a wider range of lithologies and fracture types is expected to further improve the model’s robustness and generalization capability.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviation | Definition |
| CNN | Convolutional Neural Network |
| SCTNet | Single-Branch CNN with Transformer |
| CT | Computed Tomography |
| IoU | Intersection over Union |
| ReLU | Rectified Linear Unit |
| Mask R-CNN | Mask Region-based Convolutional Neural Network |
| U-Net | Convolutional Network for Biomedical Image Segmentation |
| FCN | Fully Convolutional Network |
| SETR | Segmentation Transformer |
| ViT | Vision Transformer |
| SegFormer | Segmentation Transformer-based Model |
| SeaFormer | Squeeze-enhanced Axial Transformer for Semantic Segmentation |
| CF Blocks | ConvFormer Blocks |
| DAPPM | Deep Aggregation Pyramid Pooling Module |
| BFA | Backbone Feature Alignment |
| SDHA | Shared Decoder Head Alignment |
References
- Hui, G.; Chen, Z.; Schultz, R.; Chen, S.; Song, Z.; Zhang, Z.; Song, Y.; Wang, H.; Wang, M.; Gu, F. Intricate Unconventional Fracture Networks Provide Fluid Diffusion Pathways to Reactivate Pre-Existing Faults in Unconventional Reservoirs. Energy 2023, 282, 128803. [Google Scholar] [CrossRef]
- Torabi, A.; Alaei, B.; Ellingsen, T.S.S. Faults and fractures in basement rocks, their architecture, petrophysical and mechanical properties. J. Struct. Geol. 2018, 117, 256–263. [Google Scholar] [CrossRef]
- Kharrat, R.; Alalim, N.; Ott, H. Assessing the Influence of Fracture Networks on Gas-Based Enhanced Oil Recovery Methods. Energies 2023, 16, 6364. [Google Scholar] [CrossRef]
- Hou, J.; Qiu, M.; Lu, N.; Qu, Y.; Li, F.; Meng, X.; Shi, X. Characterization of residual oil microdistribution at pore scale using computerized tomography. Acta Pet. Sin. 2014, 35, 319–325. [Google Scholar] [CrossRef]
- Wang, R.; Li, B.; Teng, Q. Core FIB-SEM Image Segmentation Algorithm Based on Convolutional Neural Network. Comput. Eng. 2021, 47, 264–274. [Google Scholar] [CrossRef]
- Chawshin, K.; Berg, C.F.; Varagnolo, D.; Lopez, O. Lithology Classification of Whole Core CT Scans Using Convolutional Neural Networks. SN Appl. Sci. 2021, 3, 668. [Google Scholar] [CrossRef]
- Li, D. Research on Pore Detection of Sandstone CT Images Based on AT-Mask RCNN. Master’s Thesis, Northeast Petroleum University, Daqing, China, 2022. [Google Scholar]
- Pham, C.; Zhuang, L.; Yeom, S.; Shin, H.-S. Automatic Fracture Characterization in CT Images of Rocks Using an Ensemble Deep Learning Approach. Int. J. Rock Mech. Min. Sci. 2023, 170, 105531. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. ISBN 978-3-319-24573-7. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations (ICLR 2021), Virtual Event, 3–7 May 2021. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Wan, Q.; Huang, Z.; Lu, J.; Yu, G.; Zhang, L. Seaformer: Squeeze-Enhanced Axial Transformer for Mobile Semantic Segmentation. In Proceedings of the Eleventh International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A Survey of Modern Deep Learning Based Object Detection Models. arXiv 2021, arXiv:2104.11892. [Google Scholar] [CrossRef]
- Chen, H. Semantic Image Segmentation Based on Convolutional Neural Networks. Master’s Thesis, Zhejiang University, Hangzhou, China, 2016. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Xu, Z.; Wu, D.; Yu, C.; Chu, X.; Sang, N.; Gao, C. SCTNet: Single-Branch CNN with Transformer Semantic Information for Real-Time Segmentation. Proc. AAAI Conf. Artif. Intell. 2024, 38, 6378–6386. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Hong, Y.; Pan, H.; Sun, W.; Jia, Y. Deep Dual-Resolution Networks for Real-Time and Accurate Semantic Segmentation of Road Scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 1234–1245. [Google Scholar] [CrossRef]
- Wang, J.; Gou, C.; Wu, Q.; Feng, H.; Han, J.; Ding, E.; Wang, J. Rtformer: Efficient Design for Real-Time Semantic Segmentation with Transformer. Adv. Neural Inf. Process. Syst. 2022, 35, 7423–7436. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Huang, P.; Zheng, Q.; Liang, C. A Survey of Image Segmentation Methods. J. Wuhan Univ. (Nat. Sci. Ed.) 2020, 66, 519–531. [Google Scholar] [CrossRef]
- Liu, J.; Ding, W.; Xiao, Z.; Dai, J. Advances in Comprehensive Characterization and Prediction of Reservoir Fractures. Prog. Geophys. 2019, 34, 2283–2300. [Google Scholar] [CrossRef]
- Wang, X.; Li, J.; Zhang, S.; Tan, M. Quantitative Characterization and Calibration of Fracture Porosity Parameters and Analysis of Influencing Factors. Prog. Geophys. 2011, 26, 1393–1399. [Google Scholar] [CrossRef]
- Hui, G.; Chen, S.; Gu, F. Strike–Slip Fault Reactivation Triggered by Hydraulic-Natural Fracture Propagation during Fracturing Stimulations near Clark Lake, Alberta. Energy Fuels 2024, 38, 18547–18555. [Google Scholar] [CrossRef]
- Shao, S.; Tian, S.; Li, G.; He, Z. Optimization of Fracture Spacing in Horizontal Well Network Fracturing. Pet. Drill. Technol. 2014, 42, 92–96. [Google Scholar] [CrossRef]
- Gan, Y.; Zhang, S.; Liu, S.; Qi, T.; Cao, Y. A New Method for Well Pattern Optimization and Integral Fracturing Design. Acta Pet. Sin. 2011, 32, 290–294. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| aAcc | mIoU | mAcc | |
|---|---|---|---|
| FCN | 95.99 | 61.01 | 64.74 |
| SegFormer | 96.16 | 66.75 | 67.05 |
| SCTNet | 97.53 | 72.14 | 82.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, R.; Qiao, D.; Hui, G.; Liu, X.; Su, Q.; Wang, W.; Bi, J.; Ren, Y. A Fracture Extraction Method for Full-Diameter Core CT Images Based on Semantic Segmentation. Processes 2025, 13, 2221. https://doi.org/10.3390/pr13072221
Huang R, Qiao D, Hui G, Liu X, Su Q, Wang W, Bi J, Ren Y. A Fracture Extraction Method for Full-Diameter Core CT Images Based on Semantic Segmentation. Processes. 2025; 13(7):2221. https://doi.org/10.3390/pr13072221
Chicago/Turabian StyleHuang, Ruiqi, Dexin Qiao, Gang Hui, Xi Liu, Qianxiao Su, Wenjie Wang, Jianzhong Bi, and Yili Ren. 2025. "A Fracture Extraction Method for Full-Diameter Core CT Images Based on Semantic Segmentation" Processes 13, no. 7: 2221. https://doi.org/10.3390/pr13072221
APA StyleHuang, R., Qiao, D., Hui, G., Liu, X., Su, Q., Wang, W., Bi, J., & Ren, Y. (2025). A Fracture Extraction Method for Full-Diameter Core CT Images Based on Semantic Segmentation. Processes, 13(7), 2221. https://doi.org/10.3390/pr13072221