1. Introduction
Transformer performance plays a pivotal role in maintaining grid reliability, serving as critical infrastructure in contemporary power systems. Any operational anomaly within these devices can propagate instability across the entire network. The Dissolved Gas Analysis (DGA) technology for power transformers has currently become the most effective means for diagnosing and predicting transformer faults [
1,
2,
3]. With the continuous development of power transformer condition estimation, fault prevention, and condition-based maintenance, the DGA technology is of great significance for predicting the dissolved gas concentration in transformer oil [
4,
5,
6,
7]. By accurately predicting the volume fraction of dissolved gases in transformer oil, the operating state of the transformer can be evaluated in advance, and operation and maintenance personnel can then be guided to formulate reasonable maintenance strategies to effectively avoid the occurrence of major accidents [
8,
9]. By predicting the volume fractions of dissolved gases in transformer oil and analyzing the concentrations and combinations of different gases, it is possible to identify fault types such as thermal faults, low-energy discharges, and partial discharges in advance. Therefore, research on transformer prognostics based on Dissolved Gas Analysis (DGA) is of significant importance [
10,
11].
However, due to the complex working environment of transformers, the collected data are usually contaminated with noise signals, making the dissolved gas concentration sequence in transformer oil highly nonlinear and non-stationary [
12,
13,
14]. Traditional single-prediction models often struggle to cope with these complex characteristics. In order to achieve an accurate prediction of the dissolved gas concentration changes in transformer oil, scholars at home and abroad have begun to use multi-model fusion technologies.
In data denoising, noise signals are found to mainly have two characteristics: concentrated energy in the high-frequency band and a spectrum distributed in a limited interval [
15,
16]. Based on this, scholars have proposed many effective noise reduction methods, such as empirical mode decomposition (EMD) and Variational Mode Decomposition (VMD). EMD can decompose the original data into multiple Intrinsic Mode Functions (IMFs) according to its own characteristics, achieving adaptive decomposition. It is widely used in data denoising and has achieved remarkable results [
17]. However, EMD is prone to mode mixing and end-effect problems during the decomposition process, which affects the denoising effect.
In terms of prediction methods, SVM, artificial neural networks, etc., are commonly used. For example, reference [
18] proposed a prediction model for the volume fraction of dissolved gases in transformer oil based on a time series and SVM, which can achieve early-stage fault warning. However, when the data volume increases, SVM will encounter problems such as error accumulation and inability to accurately extract the temporal correlation of the data [
19], limiting its application. Reference [
20] used the long short-term memory neural network (LSTM) for prediction and solved some of the problems existing in SVM. However, a single LSTM model has difficulty in effectively extracting the deep-layer features of the data, restricting the further improvement of prediction accuracy. The convolutional neural network (CNN), with its own structural advantages, can layer-by-layer mine the abstract laws of data and achieve in-depth mining. However, the CNN is a static model and cannot effectively capture the long- and short-term dependencies in time series (such as the lag effects or periodic trends of gas concentration). A pure CNN may lead to error accumulation due to neglecting the correlations in the time dimension. Reference [
21] combines CNN and LSTM for time series data prediction. The results show that CNN’s feature extraction can accelerate the convergence speed of the prediction model and improve prediction accuracy, but it is insufficient in modeling the interaction relationships after multimodal decomposition (e.g., high-frequency noise and low-frequency trend components decomposed by VMD). Reference [
22] combines VMD with Gated Recurrent Unit (GRU) neural networks to effectively capture the temporal and nonlinear characteristics of data, improving prediction accuracy. However, it is highly sensitive to data noise and outliers, limiting the model’s generalization ability. Reference [
23] weights the original volume fractions based on the attention mechanism and uses SSA to optimize the key parameters of the Bidirectional Gated Recurrent Unit (BiGRU). The constructed SSA-BiGRU-Attention model can intelligently adjust hyperparameter settings. Nevertheless, it has the problem of insufficient high-frequency noise suppression, and the attention mechanism only weights time steps, restricting the in-depth mining of multivariate coupling relationships. Reference [
24] proposes a CNN-BiGRU hybrid neural network combined with Bayesian optimization. This model uses the CNN to extract high-order spatial features from multidimensional time-series data, combines the Bidirectional Gated Recurrent Unit (BiGRU) to model the long-term forward and backward dependencies of time series, employs the Bayesian optimization (BO) algorithm to dynamically search for the optimal combination of hyperparameters for CNN-BiGRU, constructs a highly correlated input feature set, and finally achieves end-to-end short-term load forecasting. However, the model has high computational complexity and strong dependence on data quality and scale.
To address the shortcomings of traditional data denoising and prediction models in terms of modal decomposition robustness, hyperparameter optimization efficiency, depth of temporal feature modeling, and multimodal interaction capabilities, the proposed VMD-SSA-LSTM-SE model achieves systematic optimization through the following four-layer progressive innovations, with specific architecture and technical breakthroughs as follows:
- (1)
Dynamic VMD (Driven by WOA) to Solve Modal Aliasing and Parameter Dependence
Using the Whale Optimization Algorithm (WOA), the model dynamically searches for the optimal decomposition parameters k and α of VMD (Variational Mode Decomposition). With envelope entropy minimization as the objective function, it dynamically optimizes the parameter combination of k ∈ [4, 8] and α ∈ [800, 2500], effectively separating noise-dominated IMF (Intrinsic Mode Function) components. This achieves precise separation of noise and valid signals, avoiding modal aliasing and local information loss.
- (2)
Global Hyperparameter Optimization via SSA
Leveraging the “discoverers-followers-vigilantes” mechanism of the Sparrow Search Algorithm (SSA), the model synchronously optimizes key hyperparameters of LSTM, including the number of hidden layer nodes (10–300), the learning rate (0.001–0.02), the regularization coefficient (0.0001–0.1), and training epochs (10–500). This approach features fast convergence and strong capability to escape local optima.
- (3)
Construction of a Hybrid Prediction Framework: Deep Fusion of Multimodal Features and Dynamic Parameters
Through VMD denoising, feature vector reconstruction, and adaptive parameter adjustments, the framework enables the precise modeling of deep dynamic features in time-series data. Experimental results show that this framework outperforms existing methods in convergence speed, prediction accuracy, and noise robustness.
- (4)
Enhancement via SE Attention Mechanism
The Squeeze-and-Excitation (SE) attention module is applied to channel-wise feature weights of LSTM outputs, dynamically recalibrating the importance of different modal components. This significantly improves the model’s ability to capture key features, especially demonstrating stronger robustness in scenarios involving trend turning points and noise interference.
2. Research Methods
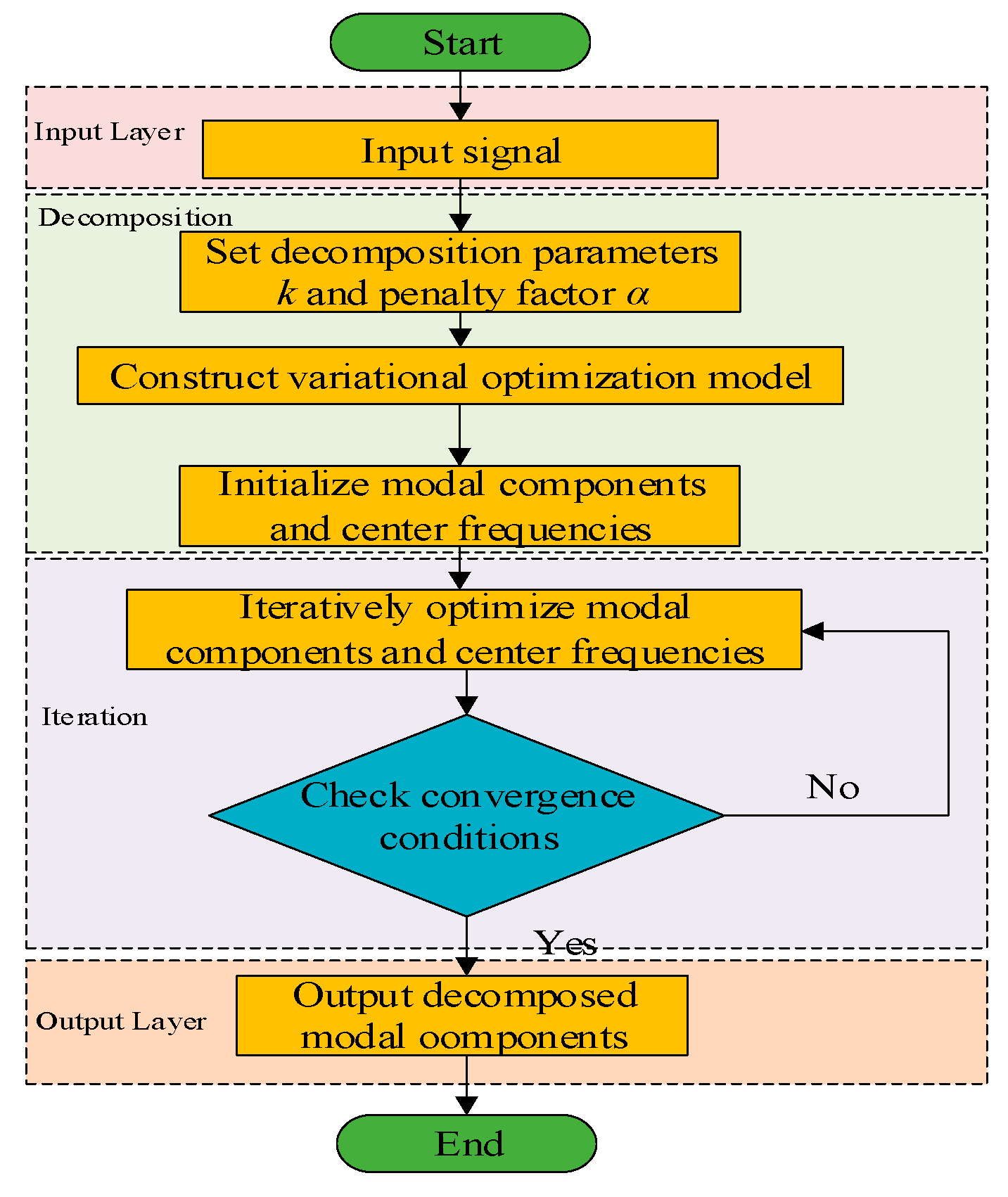
2.1. Variational Mode Decomposition
The Variational Mode Decomposition (VMD) technique decomposes the input signal
f(
t) into distinct modal components
μk, each characterized by a unique central frequency
ωk. This adaptive decomposition process separates signals based on frequency localization. The input signal
f(
t) is decomposed into distinct modal components
μk via Variational Mode Decomposition (VMD). The decomposition process of VMD is as follows [
25,
26,
27]:
- (1)
Construction of the variational formula
Here,
k is the number of mode functions, and
f(
t) is decomposed into discrete sub-signals (modes). The
k-th mode
μk is defined as
where
ɷk is the central frequency of the
k-th mode and
δ(
t) is the unit impulse function.
- (2)
Solving the variational formula
where
α is the quadratic penalty term and
λ(
t) is the Lagrange multiplier.
2.2. Whale Optimization Algorithm
The penalty factor α in VMD regulates the bandwidth of decomposed modes. A smaller α value increases mode overlap, whereas larger values reduce it, striking a balance between decomposition detail and computational efficiency. When the value of
α is small, mode aliasing occurs, resulting in the poor decomposition of the time series. When the value of
α is large, although mode aliasing can be avoided, local information loss may occur. In VMD, if the value of the mode number
k is too small, under-decomposition will occur, and the hidden features in the sequence cannot be fully recognized. If the value of
k is too large, over-decomposition will occur, generating false modes, which will also affect the signal decomposition effect. To effectively find the optimal parameters, this paper adaptively optimizes the parameters
α and
k in VMD by referring to the Whale Optimization Algorithm (WOA) in reference [
28] and takes fuzzy entropy as the index of the fitness function. The smaller the fuzzy entropy value, the simpler the data sequence. The flow chart of the Whale Optimization Algorithm (WOA) is shown in
Figure 1. The calculation process is as follows:
- (1)
Reconstruct the
N-dimensional time series {
μ(
j),1 ≤
j ≤
N} with dimension
m:
- (2)
Calculate the distance between two
m-dimensional vectors of the reconstructed time series:
- (3)
Calculate the average membership degree:
where
is the membership degree.
- (4)
The fuzzy entropy function after reconstruction is given as follows:
The fitness function of WOA is calculated using Equation (7). Optimal values of k and α are obtained when the fuzzy entropy of the VMD-decomposed sequence, computed via the above procedure, reaches its minimum.
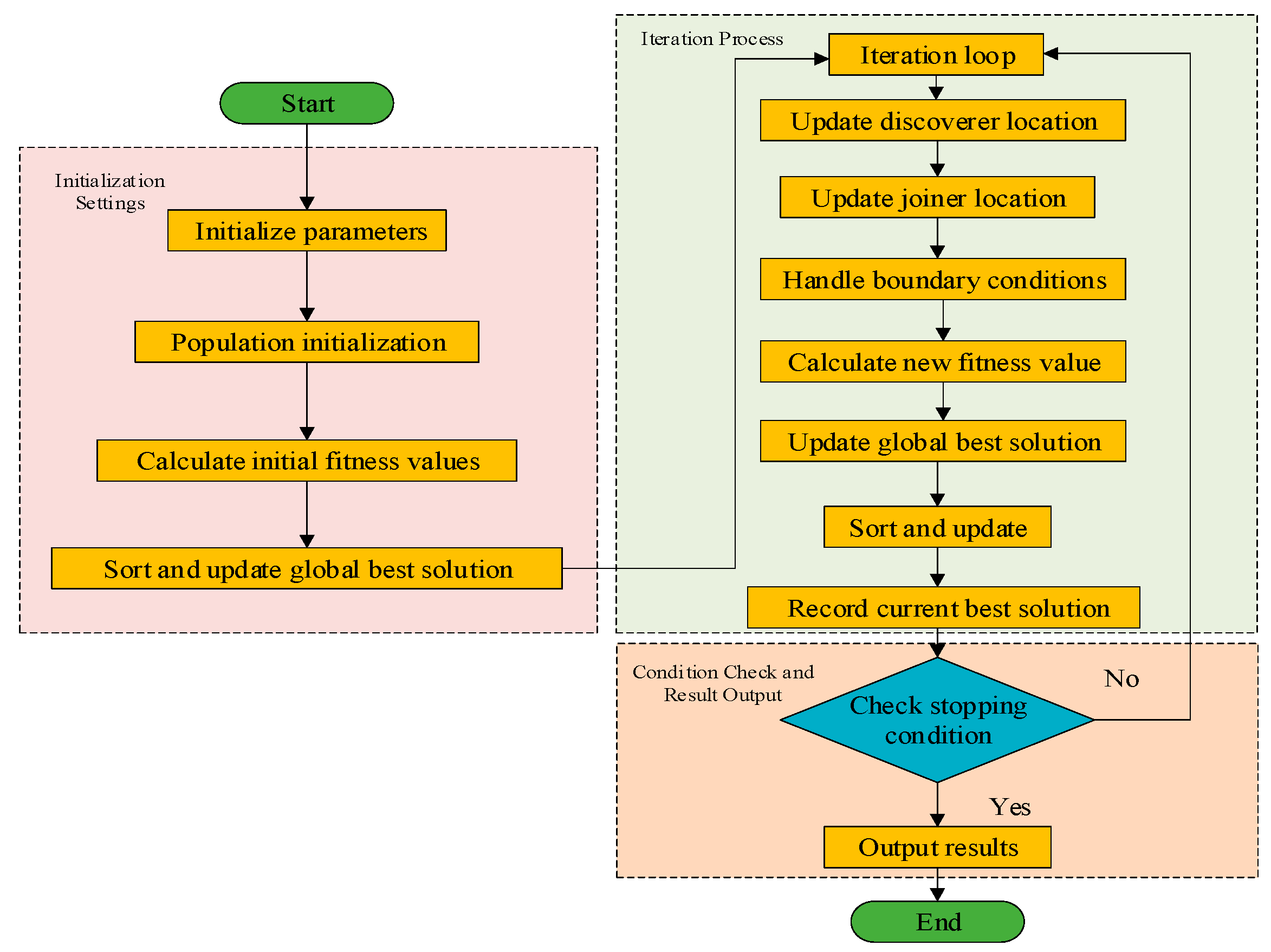
2.3. Sparrow Search Algorithm
The Sparrow Search Algorithm (SSA) can make full use of the characteristics of the algorithm such as global search ability, fast convergence, strong robustness, and adjustable parameters in transformer fault prediction [
29]. The algorithm process is shown in
Figure 2, and the calculation process is as follows:
- (1)
The position of the discoverer is
where
and
represent the positions of the
i-th individual in the
j-th dimension in the
t-th and (
t + 1)-th generations of the sparrow population, respectively; α ∈ (0,1] is a random number;
R2 represents the warning value;
TS represents the safety value;
Q is a random number, which follows a normal distribution; and
L is a 1 ×
d dimensional matrix of 1s [
30].
- (2)
The position of the follower is
where
xp is the current optimal position of the discoverer;
Xworst is the current global worst position;
A is a 1 ×
d matrix, and the elements are randomly assigned 1 or −1.
- (3)
The position of the vigilante is
β follows a normal distribution with a mean of 0 and a variance of 1; K ranges between −1 and 1; fi represents the fitness of the current sparrow; fg is the global optimal fitness, and fω is the worst; ε is a constant.
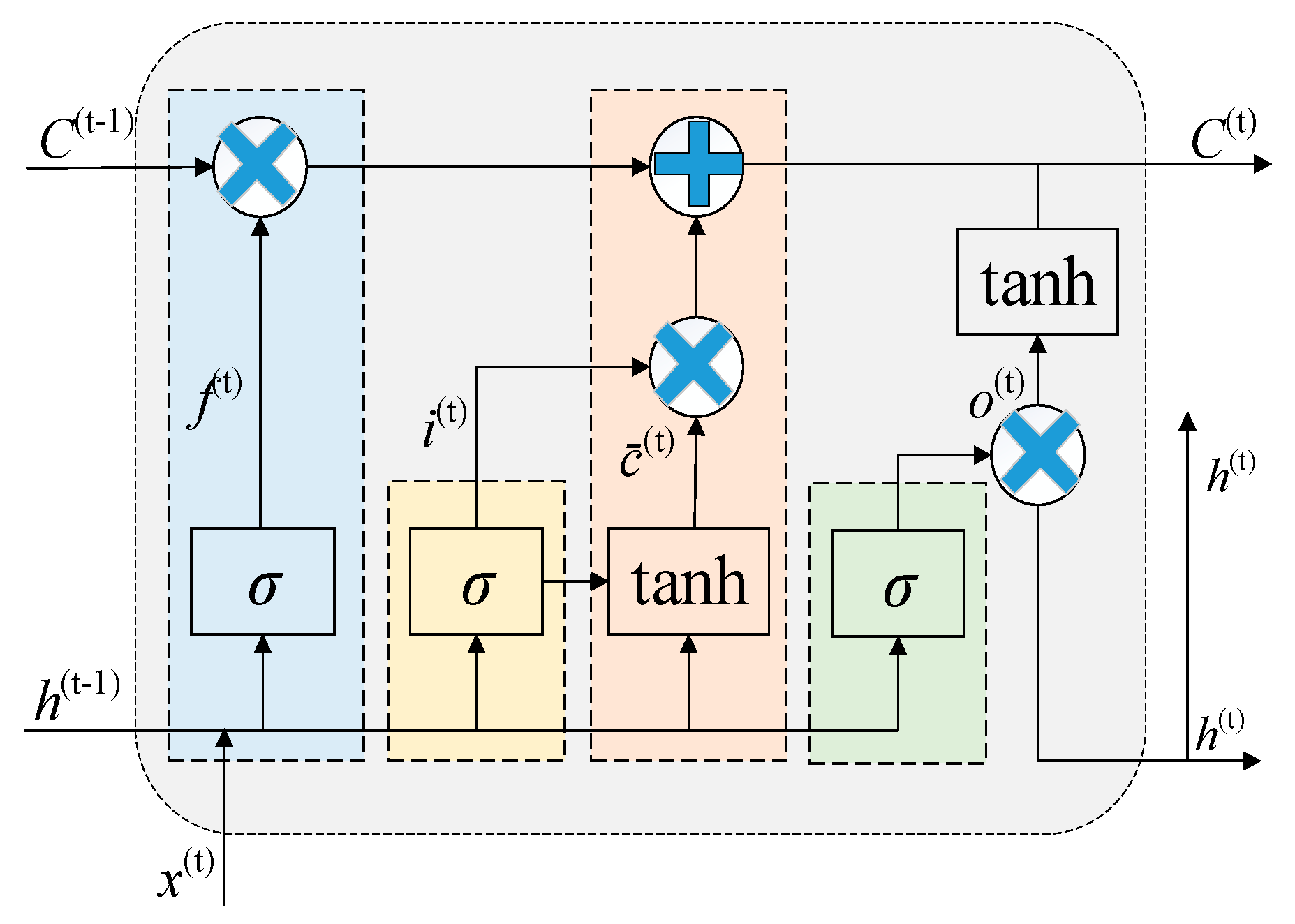
2.4. Long Short-Term Memory Neural Network
In the LSTM parameters, the max iterations, initial learning rate, optimal hidden layer nodes, and regularization coefficient most significantly impact the model’s training and fitting. Therefore, we set the search range for these four parameters in SSA and use the Root Mean Square Error (ERMSE) as the objective function for optimization.
The LSTM neural network has self-loop and gating mechanisms (forget, input, and output gates), enabling fine-grained information flow control. This structure allows LSTM to maintain stable performance in transformer fault prediction when handling long sequences. The LSTM output calculation process is shown in
Figure 3 and detailed in Equations (12)–(17).
Here, i(t) represents the input gate state of LSTM at time step t; f(t) is the forget gate state; o(t) is the output gate state; c denotes the memory cell, and h is the output of the hidden layer. h corresponds to the connection layer weight matrix; W represents the unit state bias term, and b is the sigmoid activation function.
2.5. Squeeze and Excitation
The SE attention mechanism, a channel attention module, learns channel correlations to recalibrate LSTM output features, enhancing multi-channel feature discrimination.
First comes the Squeeze step. The global average pooling operation can be expressed as
where
zc is the global descriptor for channel
c. For
F ∈
RC×H×W,
C is the number of channels, and
H and
W are the height and width of the feature map.
Next is the Excitation step. The Excitation step captures channel correlations via two FC layers, reducing and reconstructing channel descriptors.
Here, W1 ∈ RC/r×C and W2 ∈ RC×C/r are weight matrices; r is the dimensionality reduction factor; δ is the ReLU activation function; σ is the Sigmoid activation function, and s represents the final channel attention weights.
Finally, element-wise multiply channel attention weights with features are used to generate attentional outputs.
where ⊙ denotes element-wise multiplication and
F’ is the output feature map after applying the attention mechanism.
2.6. Construction of the VMD-SSA-LSTM-SE Prediction Model
The VMD-SSA-LSTM-SE prediction model proposed in this paper is constructed through the following steps, as shown in
Figure 4:
Data Preprocessing: the concentration data of dissolved gases in transformer oil are first preprocessed, including removing obvious outliers and interpolating missing values linearly, to ensure the accuracy and consistency of the data.
VMD Decomposition: Using the Whale Optimization Algorithm (WOA) to optimize Variational Mode Decomposition (VMD), the preprocessed data are decomposed into multiple Intrinsic Mode Functions (IMFs). These IMFs have clearer physical meanings and effectively separate noise from valid signals.
LSTM Parameter Optimization: the Sparrow Search Algorithm (SSA) is employed to globally optimize key parameters of the Long Short-Term Memory (LSTM) network, such as the number of hidden layer nodes, the initial learning rate, the regularization coefficient, and the maximum training epochs, ensuring optimal parameter combinations within limited computational resources.
LSTM Model Construction: each IMF is input into the optimized LSTM model, which uses its gating mechanisms (forget gate, input gate, and output gate) to model time-series data and extract deep dynamic features.
SE Attention Mechanism Enhancement: the Squeeze-and-Excitation (SE) attention module is applied to the LSTM output features to dynamically recalibrate feature weights through channel attention, enhancing the model’s ability to capture critical features.
Model Training and Prediction: Each IMF is trained independently, and the test set data are input into these models for prediction. The final prediction results are obtained by aggregating the predictions of all IMFs.
Model Evaluation: the performance of the model is evaluated using error metrics (such as Root Mean Square Error (RMSE), Mean Absolute Error (MAE), and Mean Absolute Percentage Error (MAPE)).
4. Discussion
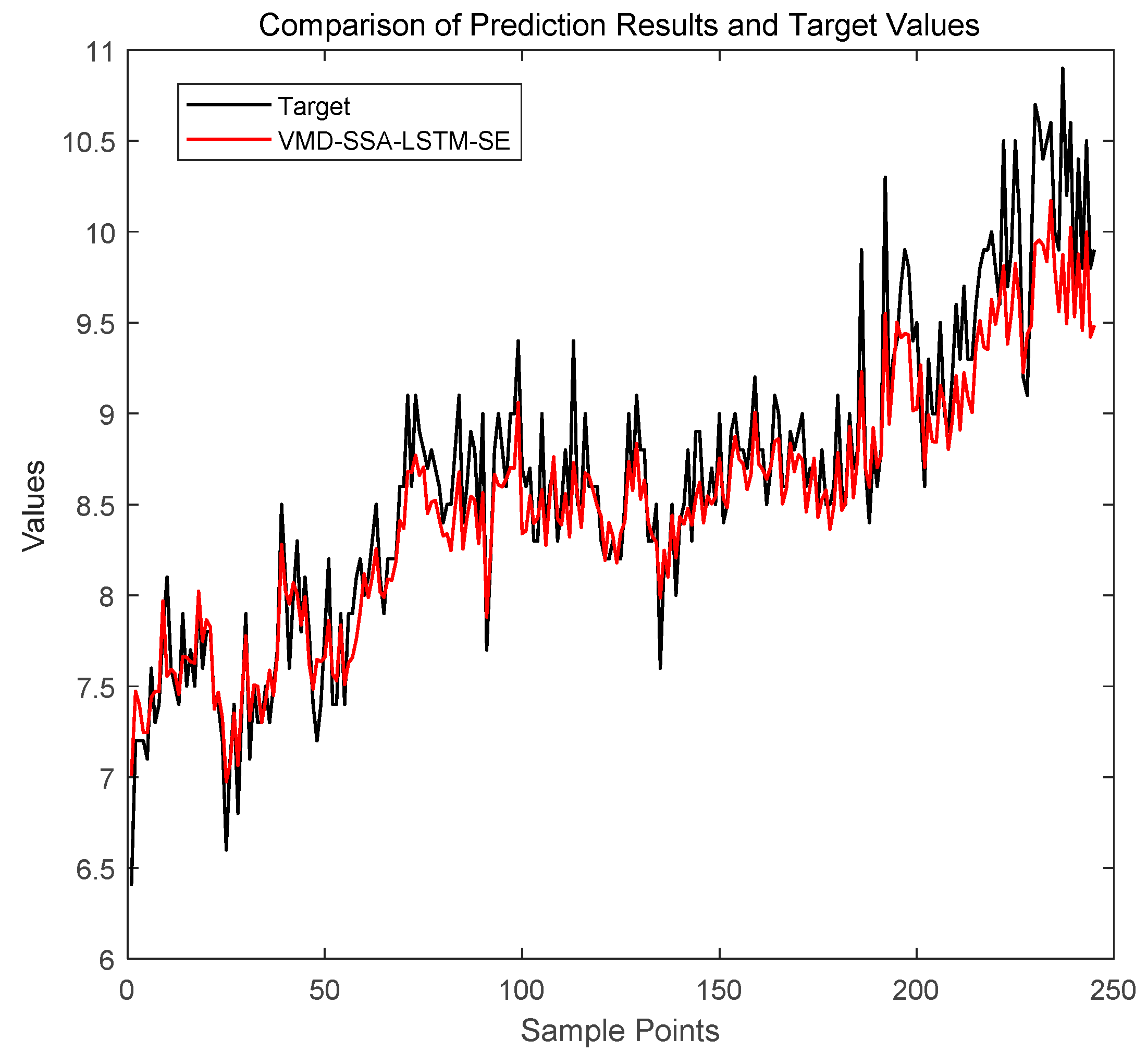
The VMD-SSA-LSTM-SE model has the lowest ERMSE values for H2, CH4, C2H2, C2H6, and C2H4, indicating the highest prediction accuracy for these gases. The CEEMDAN-VMD-SSA-LSTM-SE model has a slightly lower ERMSE for C2H2 but underperforms in other gases compared to the VMD-SSA-LSTM-SE model. The VMD-SSA-LSTM-SE model also has the lowest EMAE values for all gases, further confirming its high prediction accuracy. While the CEEMDAN-VMD-SSA-LSTM-SE model has slightly higher EMAE values for some gases, its overall performance is still relatively close.
In terms of EMAPE, the VMD-SSA-LSTM-SE model again has the lowest values for all gases, indicating the smallest proportion of prediction error relative to the actual values. The CEEMDAN-VMD-SSA-LSTM-SE model has slightly higher EMAPE values for some gases but remains relatively close in overall performance. With an average runtime of 71.1 s, the VMD-SSA-LSTM-SE model is not the fastest, but its runtime is significantly shorter than that of the CEEMDAN-VMD-SSA-LSTM-SE model (169.1 s) and the VMD-SSA-LSTM model (136.3 s) while still maintaining high precision.
In summary, considering both prediction performance across all gases and runtime, the VMD-SSA-LSTM-SE model outperforms the others in terms of evaluation metrics (ERMSE, EMAE, and EMAPE) and has a significant advantage in runtime.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}