1. Introduction
Water pollution is a critical environmental issue that poses severe threats to human health, biodiversity, and aquatic ecosystem balance [
1,
2]. The rapid pace of industrialization and urban expansion, as well as intensified agricultural activities, have introduced diverse pollutants into water bodies, including excess nutrients, pathogens, persistent organic pollutants, and heavy metals [
3,
4].
Industrial effluents are pivotal to water contamination because their complex composition often exceeds the self-purification capacity of natural water systems. Such wastewaters contain hazardous components, including toxic metals, high salt levels, and recalcitrant organic compounds such as dyes and solvents [
5,
6,
7]. The persistence of these pollutants poses considerable treatment challenges because conventional methods are often inadequate. Moreover, these substances can accumulate in sediments and aquatic organisms, leading to long-term ecological imbalances and health risks for human populations that depend on the water sources affected [
8,
9].
Divalent nickel [Ni(II)] is one of the most prominent recalcitrant pollutants in water bodies, because of its widespread industrial use and substantial environmental and health implications. Electroplating, battery manufacturing, and mining industries discharge considerable amounts of Ni(II) into aquatic ecosystems, where its persistence and bioaccumulation exacerbate contamination [
10,
11]. Ni(II) toxicity is well documented, with exposure to it linked to carcinogenic effects, oxidative stress, and systemic toxicities affecting the respiratory, cardiovascular, and renal systems [
12,
13,
14,
15].
Therefore, regulatory agencies, including the Environmental Protection Agency (EPA) and the World Health Organization (WHO), have established strict thresholds for Ni(II) concentrations in wastewater and drinking water—typically below 0.02 mg L
−1 for potable water [
14,
15,
16]. These regulations underscore the urgency to develop innovative, cost-effective, and sustainable methods for Ni(II) remediation [
6].
Biosorption is a cutting-edge technology for removing heavy metals from wastewater. It leverages biological materials as biosorbents to eliminate contaminants through various mechanisms, including ion exchange, complexation, co-ordination, and microprecipitation [
17,
18]. Biosorption is aligned with the principles of green chemistry and supports circular economy strategies. It enables the removal of pollutants using abundant, biodegradable materials derived from agricultural, industrial, or forestry waste [
19,
20]. Biosorbents offer several advantages over conventional adsorbents, including simple preparation, high availability, environmental compatibility, and low operational cost. These attributes, along with their efficiency in treating effluents with low metal concentrations, render biosorption a sustainable alternative to conventional treatment methods [
21,
22]. Moreover, transforming biomass into biosorbents facilitates the valorization of low-value residues into useful materials [
23,
24]. The process can be further enhanced through regeneration of metal-loaded biosorbents and recovery of metals via desorption, reducing environmental impact and operational costs [
19,
24].
Lignocellulosic materials, particularly agro-industrial by-products, have demonstrated substantial potential for biosorption because of the presence of functional groups such as carboxyl, hydroxyl, and amino groups, which facilitate strong interactions with metal ions [
25]. For instance, the acorn shells of
Quercus crassipes (QCS), a widely distributed oak species in Mexico [
26], have a remarkable capacity to biosorb Ni(II) because of its structural composition and the high affinity of its functional groups for Ni(II) ions [
27]. Its effectiveness has been supported by kinetic and isotherm studies, as well as surface characterization analyses [
27,
28]. Additionally, QCS has proven suitable for the removal of other metals, including total and hexavalent chromium, in batch and continuous systems [
29,
30]. As a forestry by-product, QCS shells offer a low-cost and locally available biosorbent, supporting circular economy strategies through the valorization of biomass.
Despite its advantages, biosorption is influenced by several factors, such as pH, ionic strength, initial metal concentration, and the presence of competing ions, which can considerably affect its performance [
31].
The ionic strength of industrial effluents, which is influenced by the presence of various salts, is critical in the biosorption of heavy metals such as Ni(II). High salt concentrations, which are common in effluents from mining, textile manufacturing, and oil production [
32], can considerably alter biosorption efficiency through multiple mechanisms. Primarily, elevated ionic strength leads to competitive interactions between common cations (Na
+, Mg
2+, and Ca
2+) and heavy metals for binding sites on biosorbents, with divalent ions being particularly competitive [
28,
33,
34].
In addition, ionic strength modifies the electrostatic environment around biosorbent surfaces, affecting the binding constants of functional groups and potentially reducing active site accessibility [
35]. These effects are relevant for industrial applications, where effluents typically contain complex salt mixtures. Understanding and addressing these ionic strength effects are crucial for optimizing biosorption in real-world applications.
In recent years, machine learning (ML) has become essential in environmental engineering, particularly for modeling and optimizing biosorption in water treatment. ML enables the accurate prediction of contaminant removal efficiencies, supports the design of novel biosorbents, and improves our understanding of adsorption mechanisms under different conditions [
36,
37]. ML has been widely applied to heavy metal removal owing to its ability to capture the complex nonlinear interactions inherent in adsorption systems [
38,
39,
40]. Traditional artificial neural networks (ANNs) have successfully predicted adsorption performance under steady-state conditions [
41]. However, they do not explicitly capture the temporal dependencies inherent in biosorption kinetics.
Long Short-Term Memory (LSTM) networks have been used to overcome this limitation based on their ability to model long-term dependencies in time-series data, making them well suited for kinetic studies [
42]. Building on this capability, Bidirectional LSTM (Bi-LSTM) networks incorporate two parallel LSTM layers that process input sequences in opposite directions, allowing them to capture dependencies from past and future time steps [
43]. In our previous study, we applied Bi-LSTM networks to model chromium removal kinetics in
Cupressus lusitanica bark [
44], demonstrating that this approach is a reliable and innovative alternative for capturing complex temporal patterns in dynamic environmental processes.
Although substantial progress has been made in the application of ML for toxic metal sorption, the effect of ionic strength and salt interference on biosorption remains underexplored. Previous models have captured complex interactions in the removal of contaminants such as Ni(II) [
45,
46,
47]; however, their applicability in environments with coexisting salts is limited. Industrial effluents often contain diverse salt mixtures that affect biosorption; thus, addressing this gap is essential for developing robust predictive models that accurately capture key biosorption dynamics.
Therefore, this study aimed to develop a robust and predictive Bi-LSTM modeling framework for Ni(II) biosorption kinetics onto Quercus crassipes acorn shells under multivariate conditions. The objectives included the following: (i) generating and integrating experimental and synthetic datasets to expand the modeling space; (ii) proposing features capable of representing salt interference on Ni(II) biosorption; (iii) training Bi-LSTM networks under different data scenarios and improving their performance through a two-stage hyperparameter optimization with Optuna; (iv) assessing model performance using 5-fold cross-validation and validating predictions through unseen kinetic profiles and response surface analysis, particularly under saline conditions; and (v) applying SHAP analysis to identify the most influential variables affecting Ni(II) biosorption and enhance the interpretability of model predictions.
3. Results and Discussion
3.1. Hyperparameter Optimization Outcomes
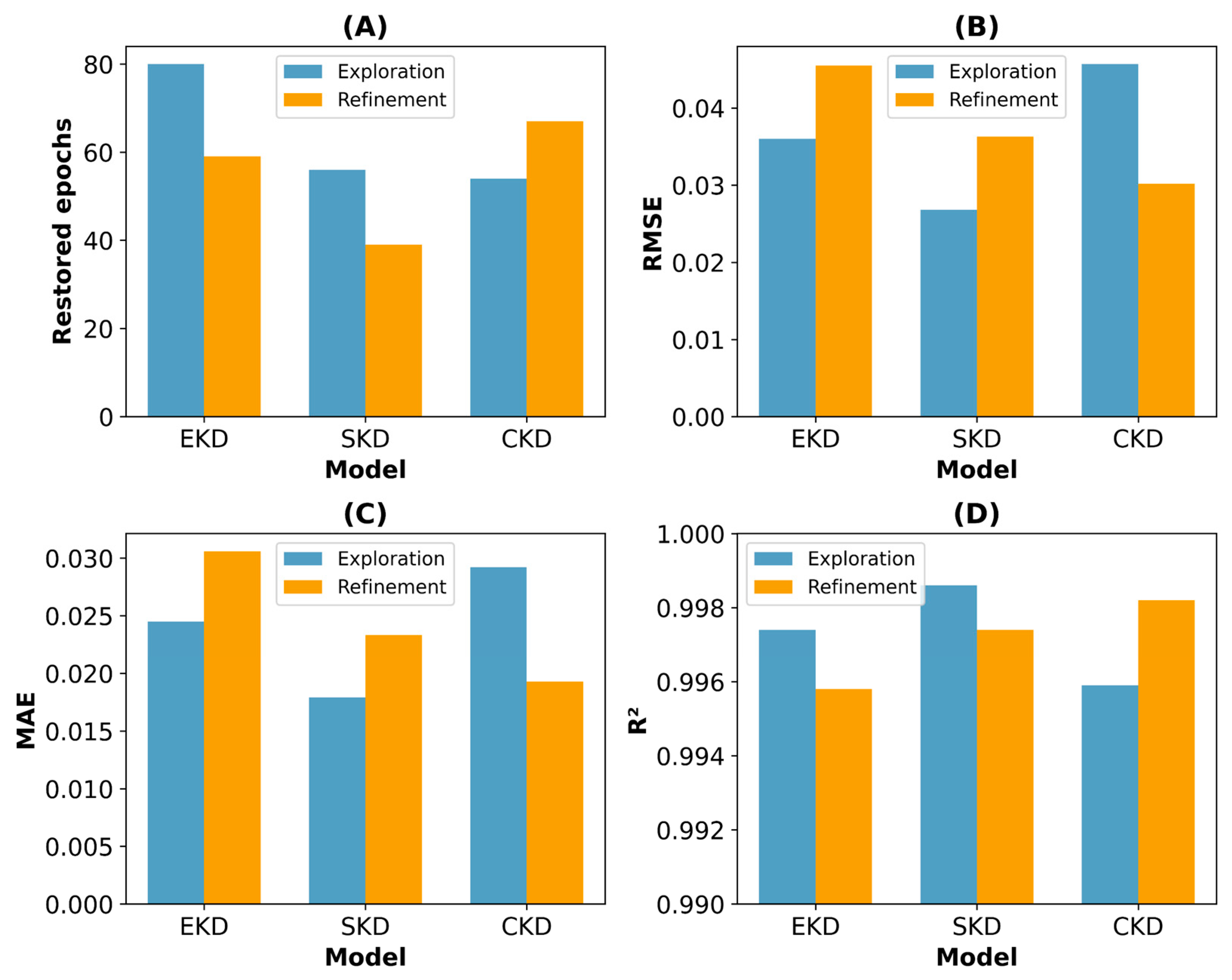
Hyperparameter optimization using Optuna revealed distinct patterns in the regularization strategies and performance metrics across datasets of varying complexity (
Table 6). The models were optimized using the MSE; however, the RMSE provided an interpretable error metric in the same units as the target variable.
Distinct RMSE trends were observed in the initial exploratory optimization stage across the datasets, reflecting the influence of the hyperparameter choices. The SKD dataset achieved an RMSE of 0.0324, owing to its homogeneity. The EKD and CKD datasets had higher RMSE values (0.0713 and 0.0427, respectively), reflecting the experimental data challenges. The 20-epoch training limit may have been insufficient for model convergence, thereby potentially contributing to the observed RMSE values.
The refinement phase, which extended the training to 40 epochs per trial, led to substantial improvements in model performance. The RMSE values for the EKD and CKD datasets decreased to 0.0481 and 0.0295, respectively, whereas the SKD dataset further improved, reaching an RMSE of 0.0251. A prolonged training period facilitated better convergence, particularly for models trained on experimental datasets, reinforcing the effectiveness of targeted hyperparameter tuning.
Optimization revealed that 128 units in the Bi-LSTM layers consistently performed satisfactorily in modeling biosorption kinetics, effectively capturing temporal dependencies and nonlinear patterns. However, the SKD dataset initially performed best, with 64 units in the first Bi-LSTM layer, likely owing to the uniformity of the synthetic data. Despite this exception, the 128-unit configuration was robust across the synthetic and experimental datasets.
The regularization strategies varied across the model layers and datasets. A key observation is that the dropout rate in the first Bi-LSTM layer remained at zero across all datasets in both optimization stages. This observation aligns with foundational studies on neural network regularization [
71,
72], which suggest that early layers primarily capture general features and are less prone to overfitting. Conversely, the second Bi-LSTM layer benefited from more substantial regularization, with dropout values of 0.19–0.39 in the second optimization stage. This pattern emphasizes the need for careful dropout calibration in deeper layers to maintain model stability across datasets with different complexities.
The need for dropout regularization depends on the characteristics of the dataset. The SKD dataset, with its controlled variability, required minimal dropout (0 and 0.05–0.19 in the first and second stages, respectively). In contrast, the EKD and CKD datasets, which incorporated the experimental data, had greater variability and required higher dropout values (up to 0.39) to prevent overfitting. These findings highlight the increased regularization demands of experimental data owing to their inherent complexities and variabilities.
Learning rate optimization was also crucial. The constrained search space (1 × 10−3 to 3 × 10−3) ensured stable training while preventing excessively slow convergence. No clear trend emerged in the selected values; however, maintaining the learning rate within this range helped to balance training speed and model stability.
Recurrent dropout was a relevant hyperparameter in the first optimization stage, where values higher than 0.1 and 0.3 in the first and second Bi-LSTM layers, respectively, led to improved model performance within the 20-epoch training limit. In the second optimization phase, recurrent dropout was further adjusted to 0.2–0.3 in the first layer and 0.3–0.5 in the second layer. This adjustment was effective across all models, enhancing generalization and preventing overfitting. Our previous findings indicate that Bi-LSTM networks with a higher number of units per layer (≥25) benefit from dropout and recurrent dropout adjustments; conversely, smaller networks perform better without regularization [
44]. Furthermore, tuning the recurrent dropout in both hidden layers contributed to achieving lower RMSE values across datasets.
The activation function selection did not considerably influence optimization because the RMSE values were consistent across the datasets with ReLU and ELU. However, both functions were effective in the final model. ReLU offers computational efficiency and mitigates the vanishing gradient limitation. Contrastingly, ELU provides smoother gradients, thereby enhancing learning in deeper networks [
63]. These results suggest that either activation function is suitable for Bi-LSTM models of biosorption kinetics, depending on the dataset and computational requirements.
The results of the sequential optimization strategy highlight its effectiveness in balancing broad exploration with targeted refinement. Consistent patterns emerged across the datasets and optimization stages, notably the preference for 128 Bi-LSTM units and the absence of dropout in the first hidden layer. Dataset-specific optimizations, including dropout adjustments for the experimental data and learning-rate tuning, have contributed to substantial performance improvements. These findings underscore the adaptability and efficiency of the optimization process, demonstrating its capacity to enhance model generalization across datasets of varying complexity.
3.2. k-Fold Cross Validation
The Bi-LSTM models were evaluated using k-fold cross-validation to assess their performance and stability across various datasets and optimization stages.
Table 7 presents a concise summary of the performance metrics and CoV values for each model during the 5-fold cross-validation, with
Figure 2 and
Figure 3 offering visual insights into these data trends for enhanced interpretation. The models were designated as follows: EKD1 and EKD2 for the experimental dataset in the optimization stages of exploration and refinement, respectively; SKD1 and SKD2 for the synthetic dataset; and CKD1 and CKD2 for the combined dataset.
Implementing early stopping was crucial to preventing overfitting by terminating the training when the models did not improve further. Analyzing the restored epochs revealed distinct convergence patterns among the model types. The SKD-based models demonstrated the most efficient convergence, with mean values of 36.2 and 34.6 epochs for SKD1 and SKD2, respectively, reflecting their faster learning capabilities. This efficiency aligns with the 40-epoch limit established during the second optimization stage and suggests that the controlled nature of the synthetic dataset facilitates fast learning. In contrast, the EKD-based models required prolonged training, with mean values of 60.0 and 51.8 epochs for EKD1 and EKD2, reflecting the increased complexity inherent in the experimental data patterns. The CKD-based models exhibited intermediate behavior, with the mean number of restored epochs increasing from 39.4 in CKD1 to 54.8 in CKD2. This indicates that the refined hyperparameters in the second optimization stage required extended training to achieve optimal convergence with the heterogeneous combined dataset.
The models selected during the first optimization stage were initially constrained to 20 epochs; however, they were permitted to train for up to 60 epochs during cross-validation with early stopping. This additional training enabled first-stage models such as EKD1 to exceed the initially observed performance, thereby narrowing the performance gap between the optimization stages. Specifically, the EKD-based models exhibited a modest RMSE reduction from 0.0484 to 0.0458, whereas the CKD-based models improved from 0.0395 to 0.0303.
The SKD-based models performed better, with SKD1 achieving a mean RMSE of 0.0296 and SKD2 having a further reduced value of 0.0266. Similarly, the EKD and CKD models demonstrated improvements in the second optimization stage. The MAE followed a similar pattern, with SKD2 attaining the lowest MAE of 0.0186, underscoring its superior performance in minimizing prediction errors. All the models had high R2 values exceeding 0.995. However, SKD2 had the highest value of 0.9986, indicating excellent explanatory capability.
The model stability was evaluated using the CoV of each performance metric, where lower CoV values signified greater stability and consistency in the model predictions. During the first optimization stage, CKD1 was the most stable, achieving the lowest CoV values for the RMSE (10.27%), MAE (11.25%), and R2 (0.0602). Conversely, SKD1 had greater variability, particularly in CoV RMSE (28.38%) and MAE (30.84%). Higher CoV values for SKD1 may reflect suboptimal hyperparameter configurations, leading to overfitting. This overfitting could result in the model’s good performance metrics on average but with noticeable variability because it may have been overly sensitive to noise or specific patterns in the training data.
In the second optimization stage, all models had considerably reduced CoV, indicating enhanced stability. SKD2 achieved the lowest CoV across all metrics (RMSE: 6.41%, MAE: 8.54%, and R2: 0.0201%), underscoring the effectiveness of a more comprehensive hyperparameter tuning in stabilizing model performance. The EKD2 and CKD2 models also benefited from the reduced variability, with CoV RMSE values of 9.66% and 8.32%, respectively.
Higher CoV values in the first stage highlighted greater instability in model performance, likely caused by overfitting owing to suboptimal hyperparameter settings. This resulted in models that were overly sensitive to noise, leading to substantial variability across folds. The second optimization stage addressed these challenges through improved hyperparameter tuning and regularization techniques, reducing performance fluctuations. Consequently, the second-stage models achieved lower CoV values, reflecting enhanced stability, better generalization, and more reliable predictions.
3.3. The Performance of the Production Models
The production models were trained using 100% of the dataset for each variant once the hyperparameters were validated through cross-validation. The maximum number of training epochs for each production model was set as the mean number of epochs from the cross-validation phase plus one standard deviation. This strategy ensured a balanced approach between allowing sufficient training time for convergence and preventing excessive training, which could lead to overfitting.
Table 8 and
Figure 4 indicate that the models achieved strong and consistent performances across all datasets. All models reached high R
2 values, exceeding 0.9958, confirming their ability to explain most of the data variance. The improvement in metrics compared with the cross-validation stage reflects the benefits of using the full dataset for training. This approach allows the models to capture more patterns and nuances in the data, thereby reducing variability and enhancing stability.
The results reveal that SKD1 achieved the best performance metrics, with the lowest RMSE (0.0268), MAE (0.0179), and R2 (0.9986). This reinforces the advantages of synthetic datasets because their controlled and homogeneous nature yields stable and precise models. Among the combined datasets, CKD2 outperformed CKD1, achieving an RMSE of 0.0302, MAE of 0.0193, and R2 of 0.9982. These results confirmed the effectiveness of the second-stage optimization and the ability of the models to capture complex patterns in the combined data.
Interestingly, the metrics (RMSE and MAE) of EKD1 and SKD1 were slightly better than those of their second-stage counterparts, EKD2 and SKD2. However, as observed in the k-fold cross-validation, these first-stage models were less stable, with higher CoV values. Overfitting tendencies in the first-stage models may explain this apparent contradiction. They excel in fitting the training data; however, they lack the robustness required for consistent generalization across various subsets of data. In contrast, the second-stage optimization likely promoted more generalized solutions by refining the hyperparameters, resulting in slightly higher RMSE and MAE values but improved stability. This trade-off was evident for synthetic data, where SKD1 had stronger metrics, whereas SKD2 had better balanced performance and reliability.
The number of epochs restored by early stopping also sheds light on the training. Based on the cross-validation results, the maximum epoch limit was effectively enforced across all the production models. Notably, the first-stage optimization models (EKD1 and SKD1) converged before reaching the maximum epoch limit, indicating that the training was sufficient for achieving optimal performance without unnecessary prolongation. In particular, the SKD2 model converged in 39 epochs and remained within the maximum limit of 39 epochs. Models trained on combined datasets, such as CKD1 (54 epochs) and CKD2 (67 epochs), required more epochs to achieve convergence, reflecting the inherent complexity and variability of the combined datasets compared with the synthetic ones. This suggests that combined datasets, which incorporate synthetic and experimental data, require more training time to achieve optimal performance, owing to their increased complexity and diversity.
3.4. Predictive Performance on Unseen Kinetic Profiles
Table 9 and
Figure 5 reveal that the generalization capabilities of the models were assessed using four unseen kinetics under varying conditions. These kinetics introduced various concentrations of Ni(II), temperatures, pH levels, and salts, thereby assessing the robustness and adaptability of the models.
For Kinetic 1 (Co_Ni(II) = 1.5 mM, T = 20 °C, pH = 8.0, without salt),
Figure 5A–C revealed that all models demonstrated strong predictive performance, with RMSE values of 0.0181–0.0450 and R
2 values exceeding 0.977. The predicted curves generally maintained smooth trends that aligned closely with the experimental data. Among all the models, SKD1 achieved the lowest RMSE (0.0181) and the highest R
2 (0.9963), indicating superior accuracy in predicting biosorption kinetics under these conditions.
Under the more demanding Kinetic 2 conditions (
Figure 5D–F), characterized by a higher Ni(II) concentration and an elevated temperature, the trained models were more robust. EKD1 and EKD2 outperformed the synthetic data-based models, with RMSE values of 0.0922 and 0.0952, respectively, compared to SKD1 (0.1615) and SKD2 (0.1657). All models displayed some abrupt changes during rapid transitions from high-velocity to plateau regions, which are inherent to the increased complexity at elevated temperatures and concentrations. This divergence highlights the importance of incorporating experimental data to capture the intricate system behaviors that synthetic models may struggle to replicate under such intensified conditions.
Introducing ionic effects in Kinetic 3 (
Figure 5G–I) with NaCl addition further enabled the evaluation of the models’ adaptability. In this scenario, the experimental models demonstrated superior performance. EKD1 and EKD2 achieved the best results, with RMSE values of 0.0382 and 0.0372, respectively, and R
2 values of 0.9774 and 0.9786, respectively. The SKD models predicted lower values in the plateau region while maintaining smooth curves, indicating a tendency to underestimate the final biosorption capacity under ionic influence. The CKD1 and CKD2 models had average performances with RMSE values of 0.0616 and 0.0648, respectively.
In Kinetic 4 (
Figure 5J–L), EKD2 performed best, with an RMSE of 0.0409 and R
2 of 0.9779, followed by EKD1 with an RMSE of 0.0537 and R
2 of 0.9617 in the presence of MgCl2. The synthetic data-based models and combined models exhibited inferior performance, with RMSE values of 0.0567–0.0896. MgCl
2 introduced additional ionic interactions that were challenging for synthetic models, highlighting the advantages of experimental data-based models for modeling complex biosorption kinetics.
Validation with unseen kinetics revealed differences in model performance. The synthetic data-based models excelled under simple conditions, such as kinetic 1, achieving the lowest RMSE and highest R2 values. However, their accuracy decreased in more complex scenarios involving higher concentrations, elevated temperatures, and ionic interactions. In contrast, experimental data-based models demonstrated greater adaptability and accuracy under challenging conditions, outperforming the synthetic and combined models in kinetics 3 and 4, in which ionic effects were crucial. The combined models exhibited average performance, balancing the experimental and synthetic trends. Overall, the EKD models were more consistent, highlighting the importance of incorporating experimental data for real-world applications, particularly under specific ionic conditions.
3.5. Response Surface Analysis
The response surface analysis was conducted under some of the most challenging conditions in this study, involving complex parameter interactions and dynamic transitions that are inherently challenging to predict. The models demonstrated strong generalization capabilities in unseen kinetic validation, as indicated by their high R2 values. However, the analysis of response surfaces provides an opportunity to evaluate their performance under conditions that may test the limits of the datasets used for training and validation. This analysis is relevant for identifying potential gaps in the ability of datasets to capture intricate adsorption dynamics across various operational parameters.
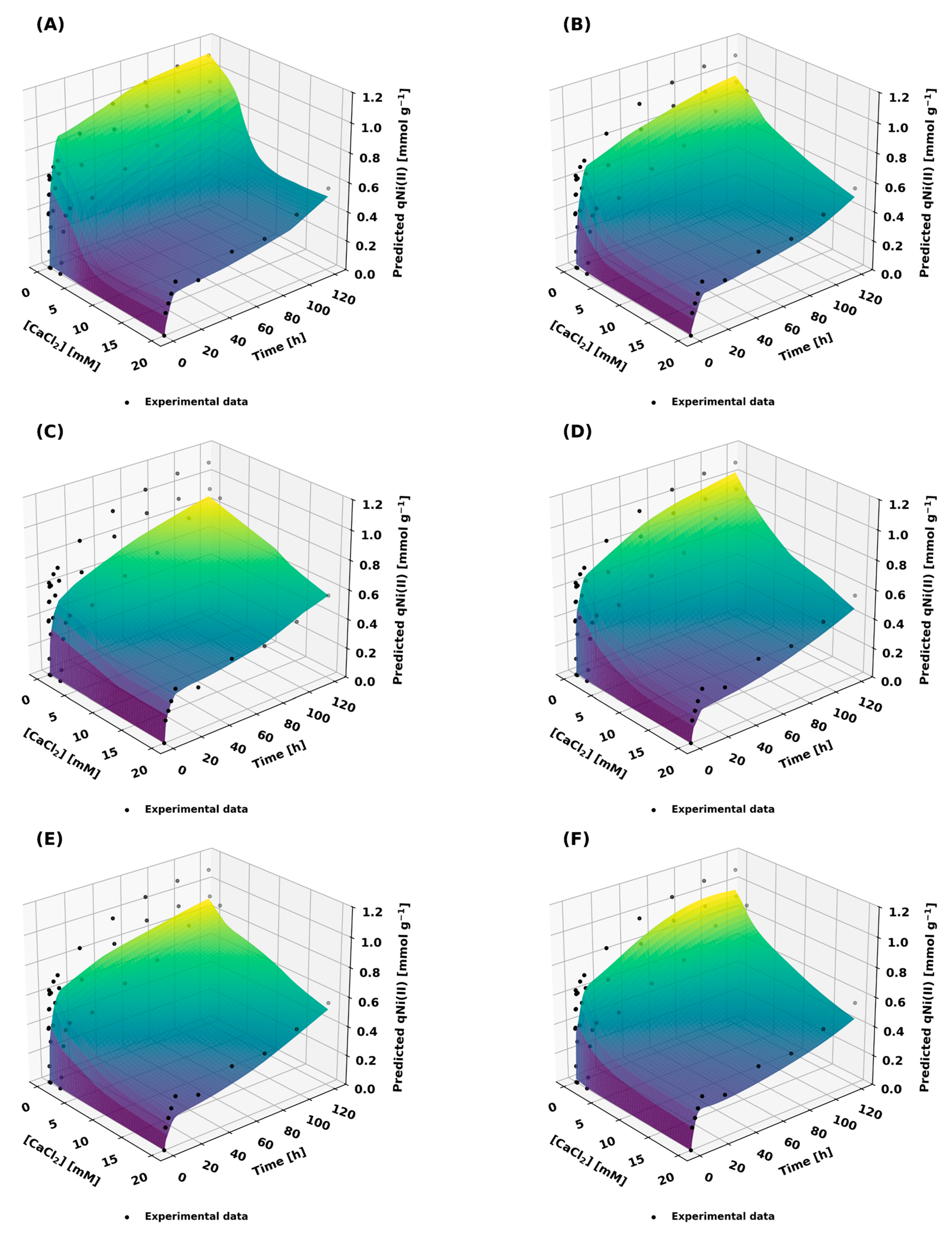
Figure 6 and
Figure 7 illustrate the response surfaces of qNi(II) as a function of time and salt concentration for NaCl and CaCl
2, respectively. These figures allow for a detailed examination of the predictive behavior of the models and how effectively they represent the underlying adsorption phenomena under varying conditions. In addition, the evaluation metrics are summarized in
Table 10, providing a quantitative assessment of how well the models fit the experimental data.
Figure 6 illustrates the impact of NaCl concentration on adsorption. The experimental data-based models (
Figure 6A,B) captured the general adsorption trends well at intermediate salt concentrations but showed deviations at low NaCl levels, indicating limitations in representing subtle adsorption dynamics. EKD1 achieved an R
2 of 0.9507, while EKD2 reached 0.9159. The synthetic data-based models (
Figure 6C,D) provided smoother predictions across the entire range but lacked the accuracy to replicate localized transitions, with R
2 values of 0.9041 for SKD1 and 0.8924 for SKD2. The combined data models (
Figure 6E,F) showed a more balanced performance, integrating the strengths of both datasets, with R
2 values of 0.9263 for CKD1 and 0.9292 for CKD2.
Figure 7 illustrates the adsorption behavior of CaCl
2 as an influencing factor. The EKD models (
Figure 7A,B) demonstrated strong performance at intermediate and high salt concentrations; however, they struggled to capture trends at lower concentrations, consistent with the observations from
Figure 6, EKD1 and EKD2 achieved R
2 values of 0.9154 and 0.8652, respectively. The synthetic data models (
Figure 7C,D) produced generalized trends but lacked precision in the transition regions. The combined data models (
Figure 7E,F) performed reasonably well, offering a compromise between the strengths and weaknesses of the individual datasets, with R
2 values of 0.8705 for CKD1 and 0.8752 for CKD2.
Validation results and response surface analysis demonstrated that the proposed methodology, including hyperparameter optimization and model selection, effectively captured the adsorption dynamics under diverse experimental conditions. The models exhibited strong generalization capabilities with high predictive accuracy in most scenarios. However, some of the observed limitations, particularly under more complex conditions, may be attributed to the characteristics of the datasets used for training and validation rather than deficiencies in the modeling approach. Addressing these dataset-related limitations can enhance model performance and applicability.
The EKD models provided the most accurate predictions under complex adsorption conditions, such as elevated ionic concentrations and temperature variations, as confirmed by unseen kinetic validation and response surface analyses. However, at lower ionic concentrations, deviations from the experimental behavior were observed, suggesting that these models perform optimally under intermediate conditions but may struggle at extremely low concentrations. Transitioning to strategic multivariate experimental designs would improve dataset diversity while minimizing the experimental effort. Combining this approach with active machine learning techniques such as Bayesian optimization can further refine experimental designs by identifying the most informative parameter regions [
73].
The SKD models derived from synthetic datasets performed excellently under standard conditions, as evidenced by the strong metrics for simpler validation kinetics. However, their performance declined under more complex scenarios, such as higher concentrations, elevated temperatures, and the presence of salts. These limitations were also evident in the response surface analysis, in which the SKD models struggled to capture subtle transitions at low ionic concentrations. The incorporation of process variability and noise patterns into synthetic datasets can enhance their robustness in dynamic systems under diverse conditions. Advanced techniques, such as Copula Generative Adversarial Networks (CopulaGAN) and Total Variational Autoencoders (TVAE), offer promising solutions for improving synthetic data quality [
74].
The CKD approach, which integrates experimental and synthetic datasets, offers a consistent performance by balancing the strengths of each data type. This integration reduces the limitations associated with the individual datasets, resulting in reliable predictions across various scenarios. However, the CKD models occasionally exhibited an intermediate performance between that of the SKD and EKD models. For instance, in the response surface analyses, CKD models provided reasonable predictions but lacked the precision of EKD models in capturing specific adsorption trends. Future research should focus on developing adaptive weighting schemes that dynamically adjust the contributions of synthetic and experimental data based on specific conditions.
3.6. SHAP Analysis
SHAP analysis provided key insights into the relative importance of the variables influencing the Ni(II) biosorption models.
Table 11 highlights that time was consistently the most influential feature across all models, with relative importance values ranging from 0.2440 to 0.2915.
Figure 8 reveals that longer contact times yielded predicted values above the baseline, reflecting the natural progression of biosorption toward equilibrium. This behavior is consistent with the equilibrium approach described by the pseudo-second-order kinetic model, which effectively describes the processes involved in Ni(II) biosorption [
27].
The initial Ni(II) concentration was ranked as the second most influential factor, with predominantly positive contributions from SHAP. The SKD2 model demonstrated this feature to be the most important (0.2136), followed by the CKD1 (0.1917). The SHAP summary plots indicate that higher initial concentrations favor the adsorption capacity, consistent with mass transfer principles, where larger concentration gradients increase the driving force for adsorption [
75].
Temperature and pH had variable but significant effects on biosorption. Temperature consistently exhibited a positive influence across all six models, indicating that higher temperatures enhanced adsorption capacity. The relative importance of temperature varied among the models; however, the overall trend remained clear, supporting its role in accelerating the adsorption kinetics, likely due to improved molecular interactions and increased diffusion rates in endothermic systems [
18]. Similarly, higher pH values predominantly contributed positively to the SHAP analysis, suggesting that an increase in pH enhanced the adsorption capacity by modulating the functional groups of the biosorbent. These findings are consistent with previous studies on Ni(II) biosorption using various biological materials, where an endothermic process with optimal pH values above 7.0 has been reported [
27,
76,
77].
Features related to the presence of salts, including salt concentration, salt code, and cation charge, were crucial in influencing model predictions and highlighting the complex interactions governing biosorption in saline environments. High salt concentrations consistently exhibited negative SHAP contributions across the models, with CKD2 exhibiting the most pronounced effect (0.1061). This confirms their adverse impact on the adsorption capacity of toxic metals, as previously reported for adsorption systems [
78,
79,
80].
The salt code, introduced as a categorical variable (0–7), provides a practical yet generalized approach to representing complex ionic influences on qNi(II). This feature effectively captures the differential effects of various salts, even when the underlying mechanisms are not fully understood. Most models, including CKD2 and SKD1, successfully captured the expected trend, where higher values of the categorical feature salt code corresponded to more pronounced negative effects on the biosorption capacity. For instance, CKD2 and SKD1 assigned notable importance to this feature (0.0711 and 0.1048, respectively), leveraging their ability to encapsulate diverse salt-related interactions. However, EKD1 did not reproduce this trend, possibly because of the suboptimal hyperparameter selection or the challenge of capturing ionic interactions.
The salt code offers valuable insights; however, it has inherent limitations because it does not explicitly separate the effects of specific factors, such as the role of anions or structural differences among salts. Nonetheless, the advantage of using such models lies in their adaptability, which allows the incorporation of additional information that becomes available.
The cation charge demonstrated surprisingly low relative importance across all the models (0.0297–0.0617), and only the CKD1 model accurately captured the expected dominance of divalent cation competition. This model exhibited more pronounced negative SHAP contributions for divalent ions despite extensive literature documenting the stronger competitive effects of different valence states in biosorption systems involving divalent metals. Previous studies have suggested that under similar molar concentrations, divalent cations generally exhibit a higher tendency to compete for adsorption sites than monovalent ions [
28,
34]. This unexpected model behavior may be explained by the salt code feature implicitly incorporating valence effects along with other factors, leading to partial redundancy in the information captured. This limitation does not affect the overall predictive accuracy. Nonetheless, it suggests that the current feature engineering approach requires refinement, particularly in terms of differentiating the overlapping contributions of the salt code from cation charge variables.
The SHAP analysis highlighted the strengths of the current models and further refinement areas. Key variables, such as time and initial Ni(II) concentration, are well-represented; however, modeling ionic competition mechanisms requires improvement. The salt code provides a generalized view of ionic effects but overlaps with the cation charge variable, potentially obscuring specific competitive interactions.
Future work should focus on refining feature engineering to better capture these ionic interactions, possibly by splitting the salt code into distinct components that account for individual anionic and cationic influences or by incorporating more detailed measures of ionic strength and specific ion interactions. However, such refinements may also increase the model complexity and introduce additional uncertainties. Thus, proposed modifications must balance the improved representation with potential drawbacks, such as overfitting and higher computational demands.
While mechanistic models have been instrumental in advancing the fundamental understanding of biosorption processes—by providing insight into adsorption mechanisms, reaction kinetics, and thermodynamic behavior—they are limited when it comes to integrating multiple experimental variables or predicting system behavior under novel conditions. In contrast, the data-driven Bi-LSTM models developed in this study offer enhanced predictive capabilities that extend beyond descriptive modeling [
81]. By learning directly from experimental and synthetic data, these models are able to capture complex, nonlinear interactions between environmental variables, such as salinity, pH, temperature, and initial metal concentration, which are often difficult to isolate or model mechanistically.
This transition from descriptive to predictive modeling represents a critical step toward practical implementation. In real or pilot-scale treatment systems, such models could assist in scenario simulation, process optimization, and even real-time decision-making by forecasting system behavior under fluctuating influent conditions [
69,
82,
83]. Moreover, the ability to incorporate synthetic data into the training process presents an opportunity to reduce experimental load and cost, especially when working with hazardous materials or highly variable wastewater compositions. Ultimately, this approach contributes to bridging the gap between laboratory-scale research and scalable, adaptive biosorption technologies suitable for industrial applications.
4. Conclusions
The two-stage hyperparameter optimization achieved low RMSE values and R2 values exceeding 0.995, demonstrating that systematic tuning is essential for improving the model performance. This process ensured that the Bi-LSTM networks remained efficient and stable across the diverse datasets.
Incorporating specialized features, such as the electrolyte cation charge and a novel salt code, was critical for capturing the intricate effects of coexisting salts. These enhancements improved the interpretability of the model in terms of ionic interactions, although further refinements are required to fully decouple the overlapping effects.
The Bi-LSTM network was highly effective in modeling Ni(II) biosorption kinetics in saline environments. Its ability to capture complex temporal dynamics provides a robust framework for understanding and predicting the dynamic behavior of biosorption processes.
Validation with unseen kinetics and response surface analysis provided valuable insights into how variations in salt concentration and operational parameters affect biosorption kinetics. These analyses confirmed the predictive accuracy of the model and offered practical guidance for optimizing biosorption under various conditions.
The SKD-based models exhibited superior performance under standard conditions and were characterized by faster convergence and lower prediction errors. The controlled nature of the synthetic data was highly beneficial for the initial model training and evaluation.
The models developed with EKD were more robust in complex scenarios, such as high temperatures and intricate ionic interactions, making them more representative of real-world variability.
The CKD models, which integrated synthetic and experimental data, achieved a balanced performance by combining the precision of synthetic data with the robustness of experimental measurements. This integration yielded reliable predictions across diverse conditions.
SHAP analysis consistently identified contact time and initial Ni(II) concentration as the most influential factors in predicting biosorption capacity. These findings reinforce the critical role of these variables and provide clear guidance for process optimization.
Despite these promising results, significant opportunities for future research remain. Adopting strategic multivariate experimental designs will be crucial to expand the diversity of experimental conditions, reduce bias, and enhance dataset representativeness. Additionally, refining synthetic data-generation methods is essential to better capture the variability and noise inherent in real-world biosorption processes across different metals. Further advancements in feature engineering could improve the modeling of complex ionic effects by developing new quantitative descriptors related to cation charge, ionic strength, and salt-specific properties. These refinements are expected to enhance the generalizability of the predictive models, ultimately leading to more robust and interpretable deep learning tools for optimizing biosorption across various heavy metals and environmental conditions.



 and
and 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}