1. Introduction
With the continuous expansion of the production scale of industrial processes, the abnormal monitoring of industrial process operation status is of great significance in improving product quality and ensuring production safety [
1,
2]. The distributed control system (DCS) is widely used in the field of industrial control, so the complex industrial process of multi-dimensional spatial and temporal coupling of real-time acquisition and processing of time series data has become a reality. The in-depth analysis of process data can accurately reflect the operating status of industrial processes, providing unprecedented opportunities for process anomaly monitoring and diagnosis.
Data-based process monitoring methods have become one of the hot directions in the research field of industrial operation conditions, but the existing anomaly monitoring methods face many challenges [
3,
4,
5,
6]. First, multivariate statistics-based process anomaly monitoring methods usually monitor whether the statistics exceed the control limits to determine whether the process is anomalous or not. For example, principal component analysis (PCA) detects anomalies by reducing dimensionality and reconstruction errors and is suitable for high-dimensional linear data [
7,
8]; independent component analysis (ICA) detects anomalies by separating independent components, which is suitable for complex, non-Gaussian signals [
9]; partial least squares (PLS) detects process anomalies and assists in troubleshooting by extracting latent variables and monitoring residuals or statistics [
10]. The above methods are based on linear assumptions that make it difficult to capture nonlinear relationships, while ignoring the dependence on time and space leading to insufficient modeling of temporal features, which affects their effectiveness in complex systems. Second, deep learning-based process anomaly monitoring methods such as convolutional neural networks predict target values by modeling the process through a black box model, and anomaly monitoring is performed by comparing the predicted values with the observed values. While CNNs are able to capture local patterns and spatial dependencies, their inherent local feel-good field design makes it difficult to model global spatio-temporal dependencies, especially in industrial processes where there are long-range dependencies between variables, and CNNs are often limited in their performance [
11,
12]. Long short-term memory (LSTM) networks are suitable for time-series data and are capable of capturing temporal dependencies. However, its weak ability to model spatial features and the significant increase in computational complexity and training time when dealing with high-dimensional multivariate data limit its application in real industrial scenarios [
13,
14].
Image-based anomaly monitoring techniques for robust processes also play an irreplaceable role. References [
15,
16] use a deep learning approach to visual modeling to address the limitations of traditional inspection methods on non-planar objects and the challenges of defect detection in the presence of data scarcity. Graph-based methods have significant advantages and complementarities over traditional image-based defect detection methods. Image-based methods excel in processing visual information, especially in surface defect detection (e.g., scratches and cracks), and are able to effectively capture localized features of the image. Graph-based methods are better able to capture complex nonlinear relationships and global dependency structures in multidimensional spatio-temporal data by representing the data as graph structures. The two complement each other and provide new research ideas and application prospects for industrial process anomaly monitoring. The complexity of multidimensional spatio-temporal data is not only reflected in the high dimensionality and nonlinearity, but also in the dynamic coupling relationship between variables and spatio-temporal heterogeneity, which puts forward higher requirements on the generalization ability and robustness of the model.
Industrial processes have their unique operational characteristics: first, production processes often need to be maintained in steady state or show periodic changes for a long time to ensure the stability of product quality; second, due to the high reliability of modern industrial systems, the probability of failures occurring is extremely low, leading to a scarcity of anomaly samples, which brings significant difficulties to data-driven anomaly detection methods. However, this specificity also provides new research ideas for anomaly monitoring. The properties of steady-state processes imply that when an abnormality occurs, there is a significant difference between the abnormal working condition and the standard normal working condition. Therefore, accurate identification of abnormal states in a production process can be achieved by effectively capturing this dissimilarity through mathematical methods [
17,
18]. Further, the measure of dissimilarity between working conditions can be transformed into a similarity calculation problem, which provides a quantifiable evaluation framework for anomaly detection. Although traditional similarity calculation methods (e.g., Euclidean distance, cosine similarity, dynamic time regularization) perform well in specific scenarios, their limitations gradually emerge when facing high-dimensional, nonlinear, and spatio-temporally heterogeneous industrial data [
19,
20,
21,
22,
23,
24]. It is often difficult for these methods to comprehensively capture the complex relationships among data, leading to their lack of reliability and timeliness in industrial process anomaly monitoring. Therefore, how to design more adaptable similarity measures by combining the specificity of industrial processes is still an important direction of current research.
The graph-based similarity computation method opens up a brand new research direction for similarity computation and demonstrates a wide range of application value in several academic fields. Graph similarity algorithms play a crucial role in diverse fields, such as social network analysis for community detection, bioinformatics for protein function inference, computer vision for image matching, and natural language processing for semantic analysis.Bai et al. proposed a new neural network-based method, designed to reduce the computational burden while maintaining good performance [
25]. Graph similarity computation can effectively deal with high-dimensional, nonlinear, and spatio-temporally heterogeneous data by capturing global and local features in graph structures. Therefore, it is of significant research value to utilize the advantages of graph theory to understand the multidimensional spatio-temporally coupled time series data of industrial processes, and then to adapt to the specificity of industrial processes.
Based on the above analysis, this paper innovatively proposes the application of graph similarity to the field of non-smooth industrial process anomaly monitoring, in view of the difficulties faced by multidimensional spatio-temporal coupled time series data of industrial processes in anomaly monitoring. In this paper, we design a graph similarity-based industrial process anomaly monitoring model and application, aiming at extracting features on the time series, while capturing the spatio-temporal dependence and the complex coupling relationship between variables, to realize the effective monitoring of industrial process anomalies. Specifically, the model proposed in this paper constructs the spatio-temporal graph structure of the data by mapping the multivariate time series data in the 2D space to the graph space through the graph embedding strategy of multidimensional time-varying features. This strategy not only takes into account the temporal dependence of the data, but also captures the complex coupling relationships among variables by aggregating features through graph convolutional networks (GCN), thus realizing a comprehensive modeling of the spatio-temporal dependence. Unlike traditional image- or statistics-based approaches, the model in this paper can effectively handle high-dimensional, nonlinear, and spatio-temporally heterogeneous industrial data, overcoming the limitations of traditional methods in dealing with complex industrial process data. Further, this paper introduces the method of graph similarity computation, based on the traditional method of feature integration only in the two perspectives of global features of topology and local differences of nodes, and adds the difference features of the adjacency matrix to participate in the similarity analysis, which effectively solves the shortcomings of the traditional similarity computation method in the modeling of high-dimensional coupled data, noise interference, and nonlinear relationships among variables. Through this multi-level similarity analysis, the model is able to more accurately identify and monitor abnormal behaviors in industrial processes.
Experimental results show that the model proposed in this paper is not only able to accurately monitor process anomalies, but also has strong robustness and generalizability, which can adapt to the needs of industrial scenarios with few samples of anomalous data and high real-time requirements. The model outperforms existing benchmark methods on multiple industrial datasets, especially when dealing with high-dimensional, nonlinear coupled data. In addition, the computational efficiency of the model is high enough to meet the demands of real-time monitoring of industrial processes. This study provides a new framework and method for industrial process anomaly monitoring, which has important theoretical significance and practical application value. From the theoretical point of view, the anomaly monitoring model based on graph similarity provides a new idea for the analysis of multidimensional spatio-temporal coupled time series data, and extends the application scope of graph neural networks in industrial process monitoring. From the practical application point of view, the model can effectively improve the reliability and timeliness of industrial process anomaly monitoring, which provides a strong guarantee for the stability and safety of industrial production.
3. Anomaly Monitoring Model for Industrial Processes Based on Graph Similarity
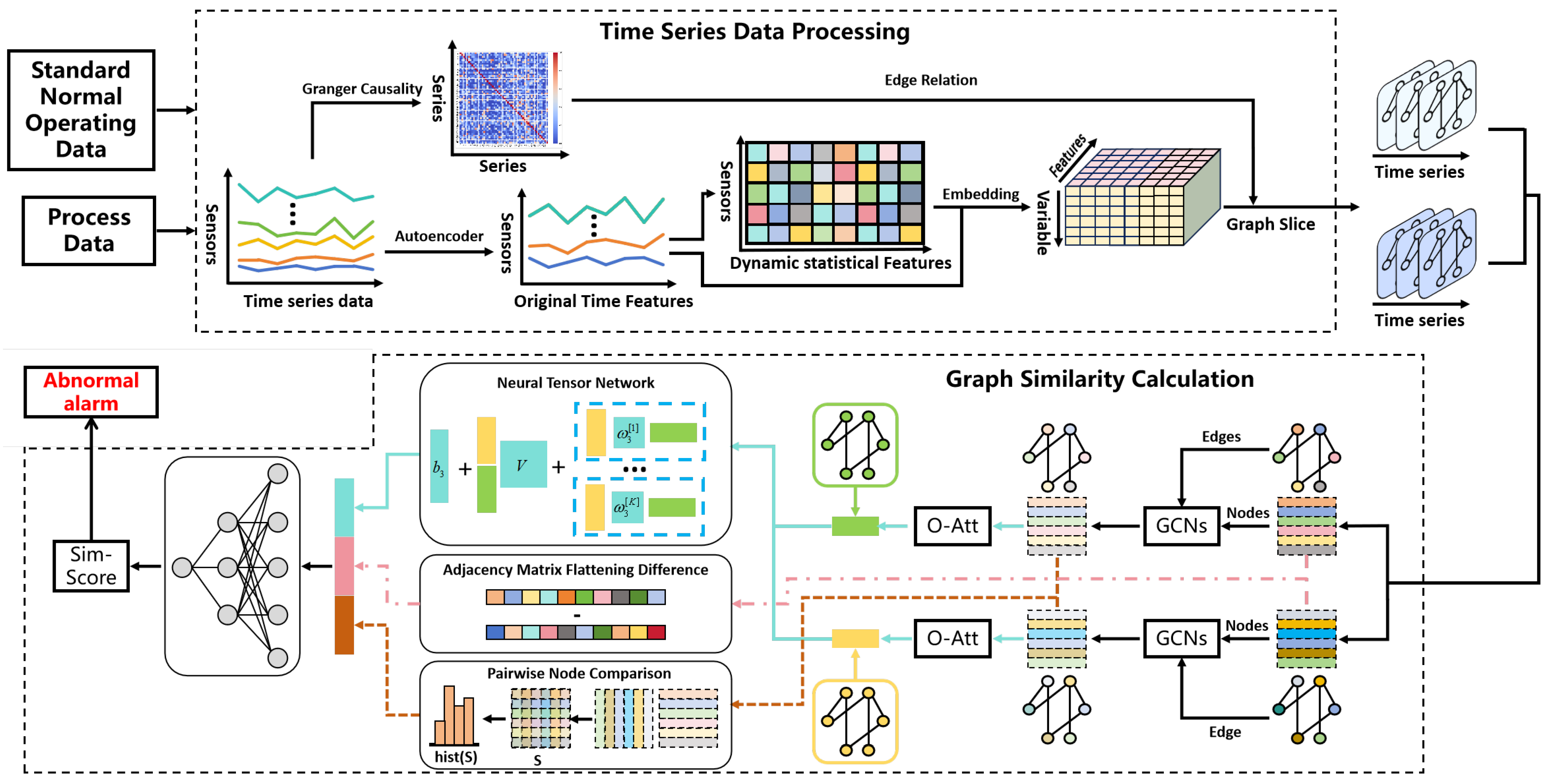
The time series anomaly monitoring model of the graph similarity network based on multi-scale features consists of two parts—the time series data processing module and graph similarity calculation module—and the model structure is shown in
Figure 1. The time series data processing module takes two sets of time series data from standard normal working conditions and the monitoring process as input and completes the transformation from two-dimensional time series data to graph time series set through the multidimensional time-varying feature graph embedding process; the graph similarity computation module takes the above two sets of graph time series sets as input and obtains the similarity scores of the two graph structures in the same moment after a series of feature extraction and aggregation processes, and then converts them into graph differences to complete the process anomaly monitoring and alarm.
The multidimensional time-varying features proposed in this paper are defined as the historical data based on the moment t. The length of the time window is taken as m. The combination of the original time features of the data at the moment and the statistical features of the time series data computed based on the original time features are extracted as the feature representation of the data values of t at the current moment, and the multidimensional time-varying feature embedding is repeated for t as t progresses step by step in the time series, until t is the current moment. The graph structure usually consists of nodes, edges, edge weights, node features, and other elements. When mapping industrial process data into the graph space, each industrial sensor can be represented as a node in the graph structure, and the coupling relationship or physical connection between sensors can be treated as an edge connected to the node.
Complex industrial processes with dynamic and non-stationary features generate multi-dimensional spatio-temporal coupled time series data with high time dependence, based on which this paper proposes a time series data processing module to deeply extract the time dependence of the data, and at the same time, utilizes the graph structure to capture the spatial coupling relationship among sensors, and then monitors the process anomalies in a timely and accurate manner through graph similarity computation. Specifically, firstly, in the time series data processing module, Granger causality calculation is used to determine the dynamic dependency relationship among sensors, while data downscaling technology is used to construct a low-dimensional space; furthermore, a multidimensional time-varying feature map embedding strategy is adopted to expand the time series data in the two-dimensional space to the three-dimensional space and eventually mapped to the graph space, completing the graph structure of the multidimensional spatio-temporally coupled time series data. The graph structure provides a more intuitive expression for the visualization of data relationships, and at the same time, the graph space data can effectively capture the nonlinear coupling relationship between variables, thus enhancing the generalization ability and prediction accuracy of the model. Second, in the graph similarity computation module, node features of the graph structure are extracted using graph convolutional network aggregation to make them globally relevant. Further, global features at the graph level and local features at the node level are captured, respectively, using Neural Tensor Networks and histogram statistics, and are inputted to the fully connected layer for similarity score output through feature aggregation. Through the multi-level feature capture, feature aggregation, and fusion mechanism, the global structure and local details of the graph can be considered comprehensively, which significantly improves the accuracy and robustness of graph similarity calculation. In the absence of a large number of data anomaly markers, the model realizes unsupervised monitoring of industrial process anomalies by outputting the deviation score of the current production process from the standard normal production conditions as the basis for judging the anomalies. The model shows significant advantages in dealing with complex industrial process multidimensional spatio-temporal coupling time series data anomaly monitoring, which can effectively deal with complex industrial data, improve the accuracy and robustness of anomaly detection, and at the same time has a strong generalization ability, which is applicable to a variety of industrial scenarios. The overall algorithmic flow of the model is detailed in [Algorithm 1]. Through the combination of global and local features, the module can reflect the operating status of the system more comprehensively and provide reliable support for anomaly monitoring.
3.1. Time Series Data Processing
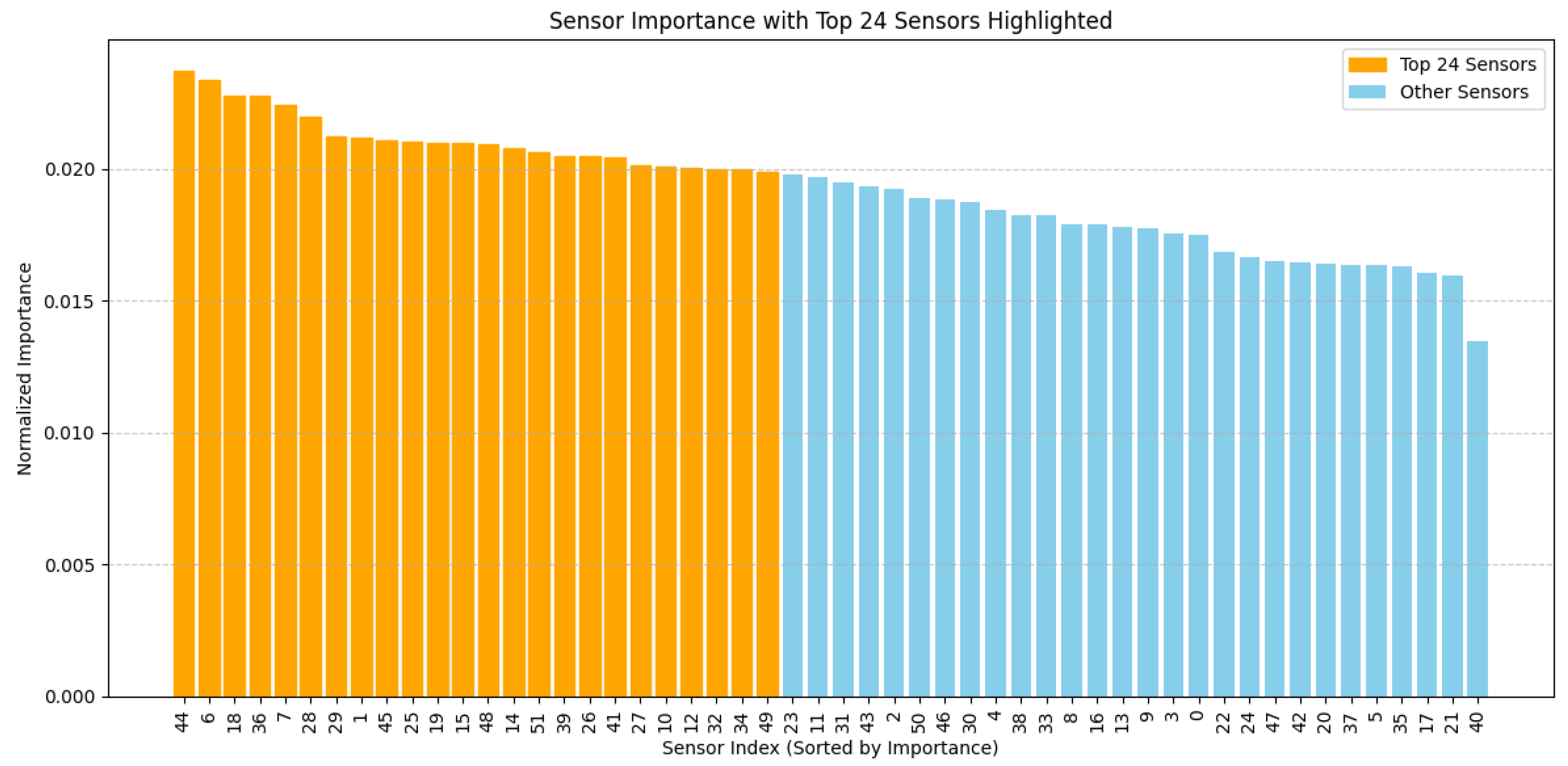
When dealing with multidimensional spatio-temporally coupled time series data of industrial processes, data dimensionality reduction and compression is a key step to improve the computational efficiency due to data redundancy and complexity. In this paper, the initially collected industrial sensor time series data are firstly represented as a set . In order to reveal the potential dynamic linkages between sensors, the mutual information approach was first utilized to identify the complex coupling relationships between different variables in the time series that comprise the target variables for model prediction. Secondly, Granger causality analysis was used to explore the causal dependencies among the sensors. Next, an autoencoder is used to downscale the data. By minimizing the error between the input data and the reconstructed data, the self-encoder is able to learn an efficient low-dimensional representation of the data while capturing the nonlinear relationships in the data, thus retaining the key information in complex industrial data more effectively. By analyzing the distribution of potential spatial features and their contribution to the reconstruction error, sensor data that play a key role in the dimensionality reduction process can be identified, providing a more robust feature representation for subsequent anomaly detection.
The time-series causality analysis reveals the dynamic dependencies between sensor data, while the autoencoder helps to identify the variables that have a major influence by quantifying the contribution of each sensor data. Combining these methods can reduce the dimensionality of the data while retaining key information, thus improving the efficiency and accuracy of the subsequent analysis. The specific calculation formula is shown below:
.
By processing the industrial process sensor data, the first k main variables calculated by the autoencoder are calculated and the sorted first k sensor data are selected for normalization based on the contribution of the respective variables as the time series dataset of the industrial process, where , are the time series data of the sensor i.
For the
t-moment data of
, the time window length
is taken, and the original temporal features and statistical features of the time series data at the moment of
are used as the feature representation of the moment
t. Multi-temporal dynamic feature embedding is repeated for
t as
t progresses step by step in the time series, so that the original time series data are extended to the three-dimensional space. The moment
t data of
embedded with dynamic multitemporal features can be expressed as
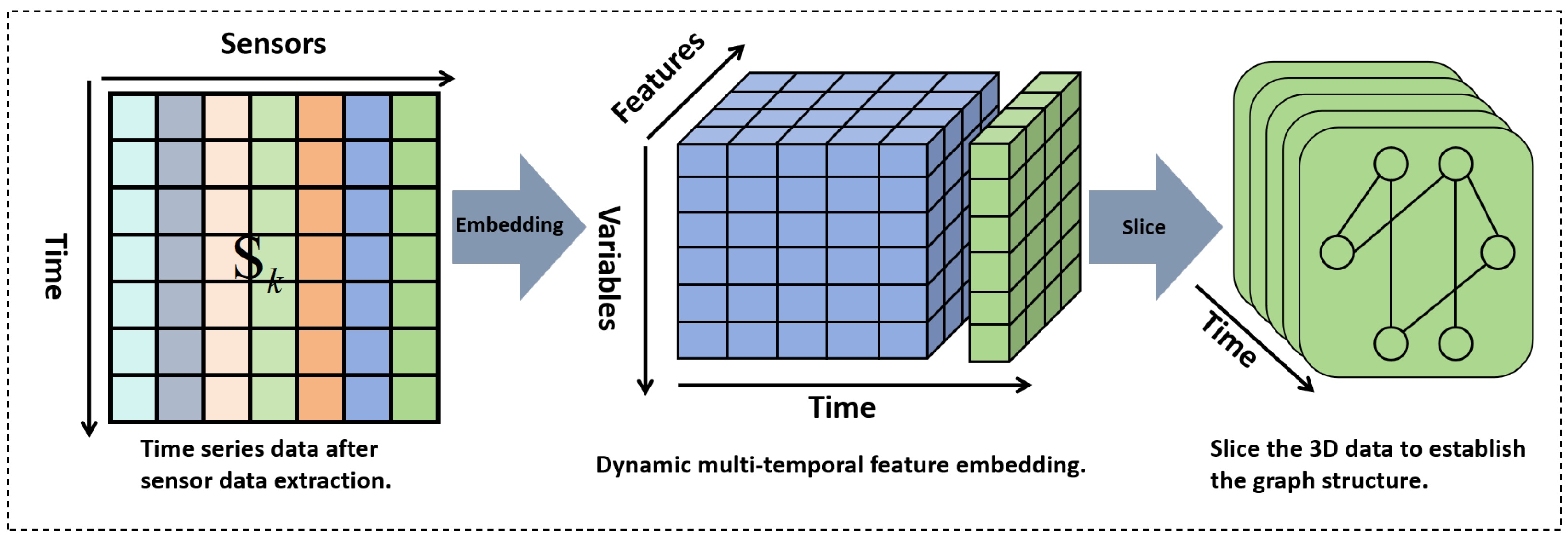
Multidimensional time-varying features are an effective structure for time domain oriented data processing, which can accurately capture the dependency and dynamic fluctuation of data on time series. The multidimensional time-varying feature graph embedding process proposed in this paper is shown in
Figure 2.
The core of multidimensional time-varying feature graph embedding lies in mapping two-dimensional spatio-temporal data into the graph structure space, and constructing graph structures reflecting the system state at the current moment for the data in each time window. These time-ordered graph slices are concatenated through the time dimension to form a dynamic graph sequence, thus completely characterizing the spatial coupling properties and temporal evolution laws of sensor networks in industrial processes. This graph structure-based modeling approach has significant advantages: in the spatial dimension, the graph structure can effectively capture the complex correlations among sensors; in the temporal dimension, the dynamic graph sequence can accurately describe the state evolution of the system. By combining the theories and methods of graph theory and graph neural networks to characterize the macroscopic behavioral patterns and microscopic fluctuation characteristics of industrial data, it provides a powerful tool for the analysis and modeling of complex industrial systems.
3.2. Graph Similarity Calculation
In this section, the graph similarity calculation is described in detail. This includes the multidimensional spatial and temporal coupling of the industrial process of the standard normal operating conditions of the graph time series set and online monitoring data after time series data processing from the two-dimensional space mapped to the graph space, and the formation of graph time series set
,
, where
,
denotes the graph structural data at the moment, including the nodes, node multidimensional time-varying features, edges, and other graph attributes.
is used as the module input, and the graph convolutional network is used to reaggregate all node features based on neighboring nodes to obtain a new node multidimensional time-varying feature representation with global attributes, which is calculated as follows:
where
,
is the set of first-order neighbors of node
n plus
n itself,
is the degree of node
n plus 1,
is the weight matrix associated with the
l-th GCN layer,
is the bias term, and
is an activation function such as
.
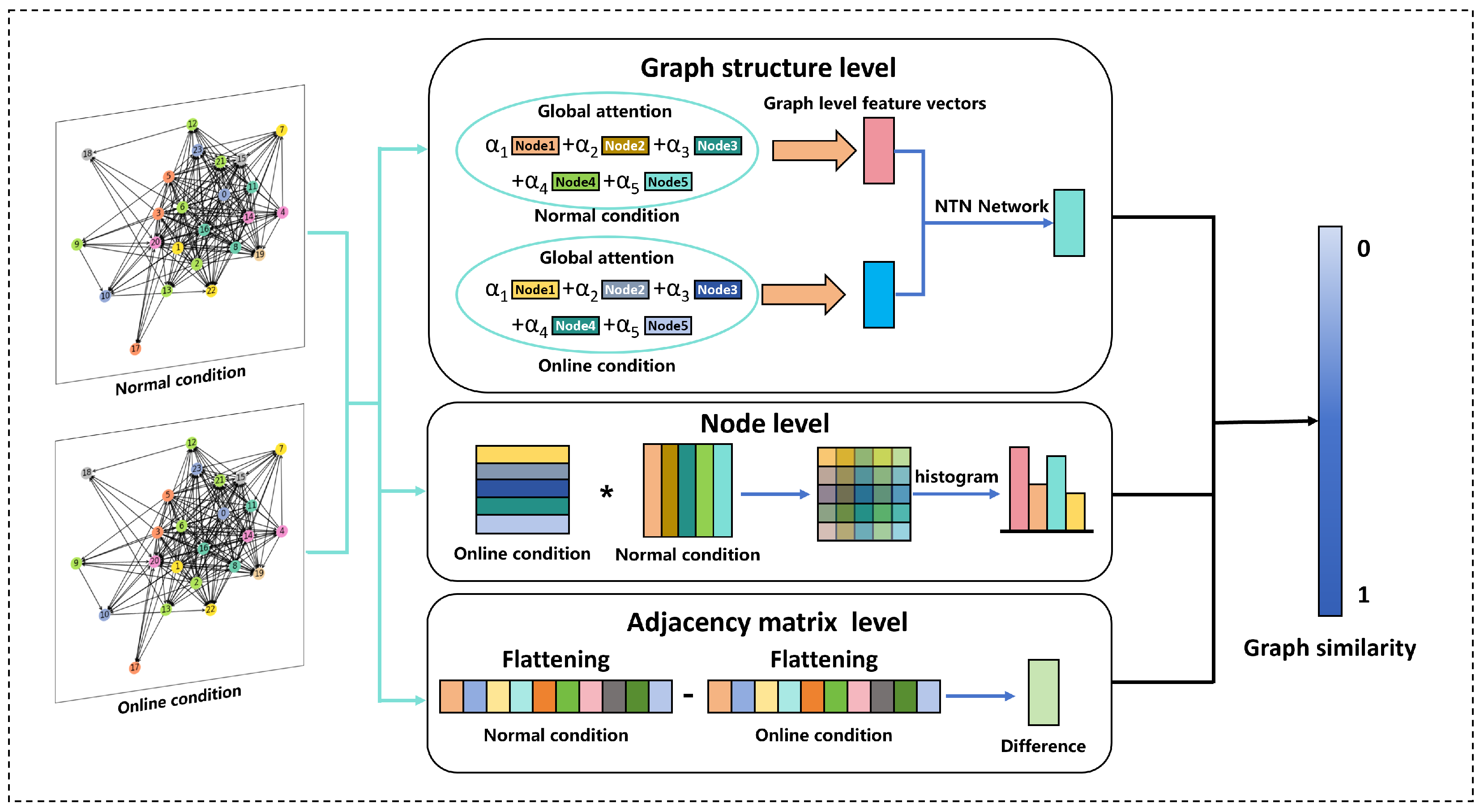
Overall, the graph convolution operation aggregates features from the first-order neighbors of a node, and when multiple graph convolution operations are performed, each node then has a feature representation of the global attributes. The graph similarity computation process after aggregation by GCN features is schematically shown in
Figure 3.
3.2.1. Graph-Level Feature Aggregation
The graph-level feature aggregation can encode the structure and feature information of the graph, and through the aggregation of two graph level features, it can provide an important basis for judging the similarity between two graphs. In the initial stage of the graph similarity computation module, shown in
Figure 1, different colors denote different node features, and after GCN, the node features are reaggregated and the colors are changed accordingly. After the graph structure has gone through multiple layers of GCN (three layers are taken in this paper), the node embeddings are ready to be fed into the Global Attention Awareness module (O-Att). In order to characterize each graph structure using a set of features, a weighted aggregation of the nodes’ features can be used. Therefore, in order to determine which nodes are more important and should receive more weights, we propose the Global Attention Awareness Module that allows the model to learn weights guided by a specific similarity metric.
The input node multidimensional time-varying features are represented as
, where the
nth row
is the multidimensional time-varying feature representation of node
n. First, compute the simple global average vector
of the node features in the graph; then, perform a nonlinear transformation as follows:
where
is a learnable weight matrix. The global average vector C adaptively computes an attention weight for each node for the similarity measure of the global structural features of the graph by learning the weight matrix. For node
n, take the inner product between the global average vector
c and its node features, and the inner product result is used to decide that nodes that are similar to the global average vector should receive higher attention weights. Finally, the sigmoid function
is applied to the above computed results to ensure that the attention weights are within the range (0, 1). Finally, the graph-level feature aggregation result
H is the weighted sum of all node features. The above attention mechanism can be expressed as follows:
where
is the sigmoid function
.
The weighted graph-level feature aggregation result
is thus obtained for modeling the relationship between two graph-level embeddings using a neural tensor network (NTN):
where
is the weight tensor,
denotes the tandem operation,
is a weight vector,
is a bias vector,
is an activation function,
K is a hyperparameter, and the control model is the number of interaction (similarity) scores generated for each graph embedding pair.
3.2.2. Comparison of Node-Level Features
Node-level information (e.g., node feature distributions and graph sizes) may be lost as a result of computing graph-level feature aggregation. In graph sequence data of industrial processes, the key to the difference between two graphs lies in the difference in node features, which is often difficult to reflect by graph-level features. Therefore, node-level feature comparison is also a key part of the process of computing graph similarity.
The pairwise interaction score between nodes is calculated by the following equation:
where
,
is the characteristic representation of node
i and node
j. Since the node-level features are not normalized, a Sigmoid function is applied to ensure that the similarity score is in the range (0, 1). In order to ensure that the model’s representation of the graph structure is invariant, a more efficient and natural way of utilizing
S needs to be considered. Therefore, it is taken to extract its histogram feature:
, where
B is the hyperparameter (in this paper,
) that controls the bins in the histogram. The histogram feature vector, denoted as
, is normalized and output as a key part of the graph similarity computation.
3.2.3. Difference Computation After Adjacency Matrix Spreading
After obtaining the graph-level features and node differences, we focus our attention on the adjacency matrix in order to capture the more detailed differences between the two graphs. The adjacency matrices of the two graphs are flattened into one-dimensional vectors, where each element denotes the degree (i.e., the number of neighbors) of the corresponding node. Specifically, for graphs
and
, their adjacency matrices are
and
, respectively, where
, and
n is the number of nodes. First, calculate the degree vector for each node:
,
. Then, the values of the corresponding positions of these two degree vectors are subtracted to obtain a new vector:
where the length of
is the number of nodes
n and each element represents the difference between the degrees of the corresponding nodes in the two graphs.
Through the above calculation, the difference relationship between the neighboring matrices of two graphs is obtained more intuitively, which provides the basis for graph similarity calculation.
3.2.4. Similarity Score Calculation and Exception Alarm
The coarse global information from graph-level feature aggregation is combined with the fine-grained information captured by node-level feature comparisons as well as the difference features of the adjacency matrix in order to provide a comparative, comprehensive graph structure characterization of the model. In the final stage, a standard multi-layer fully connected neural network is applied to gradually reduce the dimensionality of the similarity score vector. Finally, a score
∈ R is predicted and compared to the ground truth similarity score using the following mean square error loss function:
where
is the set of training graph pairs and
is the true similarity between
, obtained by normalizing the Euclidean distance of the node vectors:
where
is the Euclidean distance formula;
denotes the coordinate values of node
p and node
q in the
kth dimension, respectively; and
n denotes the number of dimensions of the space.
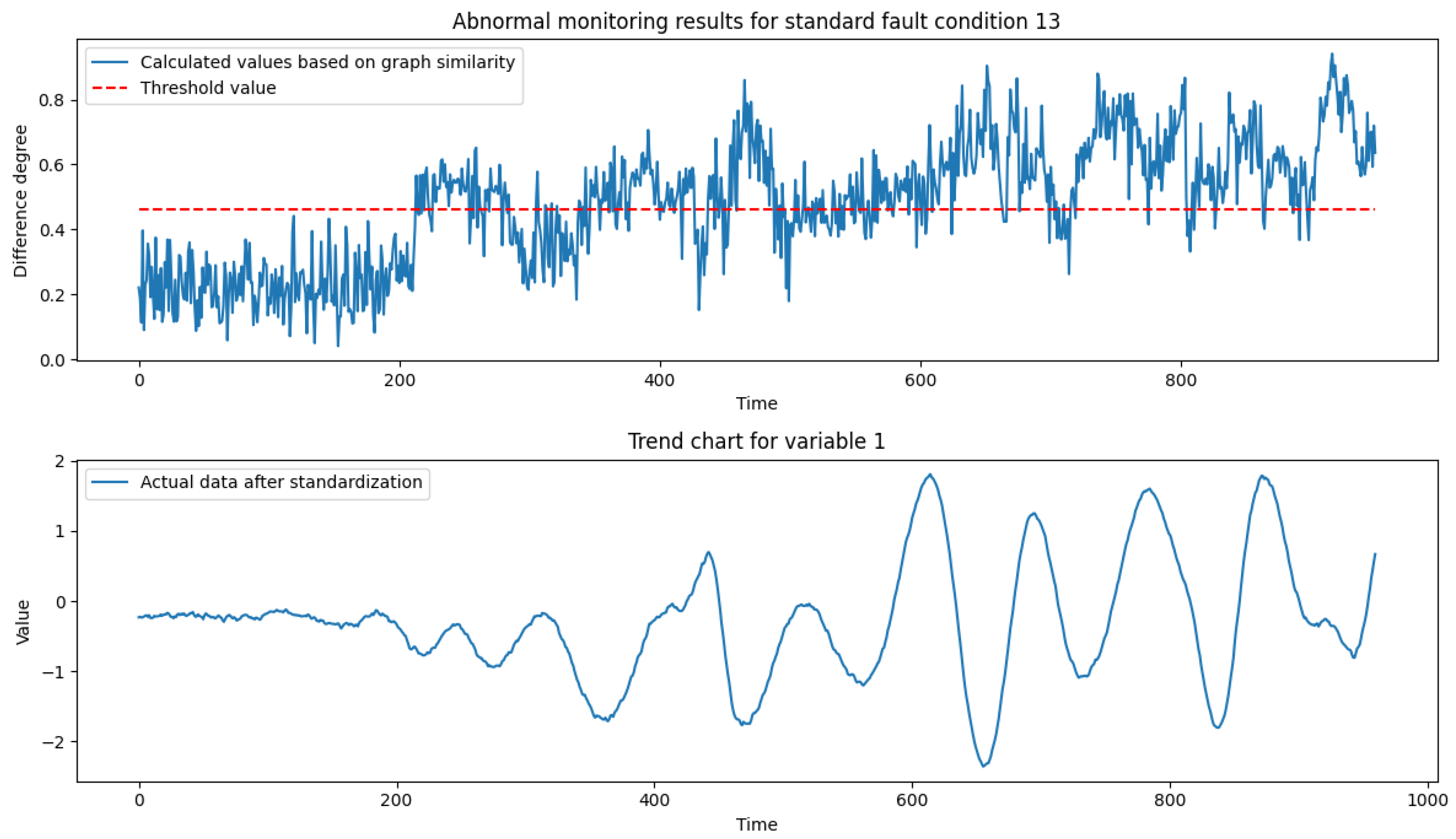
The calculated similarity score
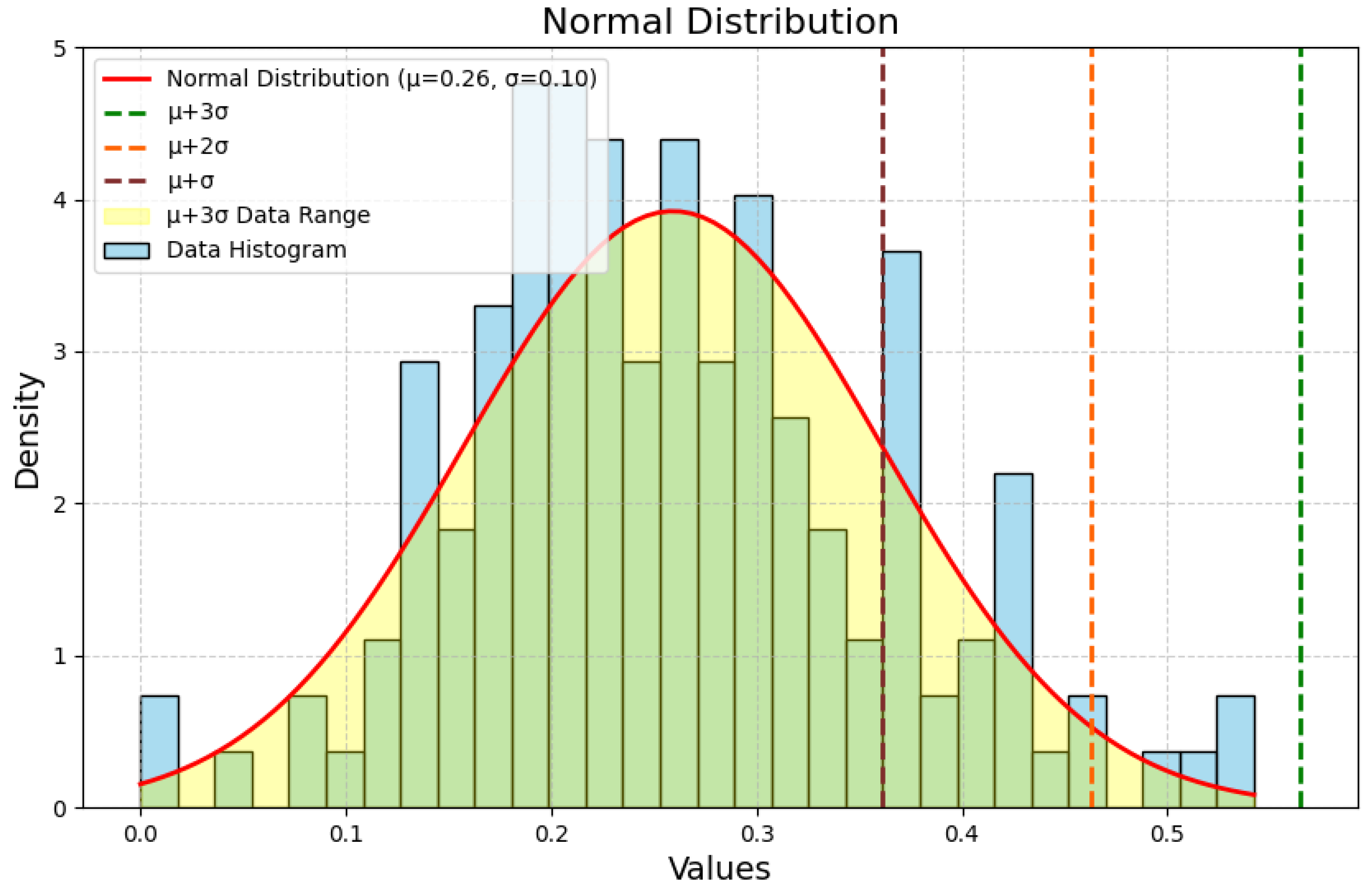
∈ R transformed into the difference score between [0, 1], with larger values indicating larger differences. Analyze the distribution of the data variability under normal operating conditions and transform it into a normal distribution, and select
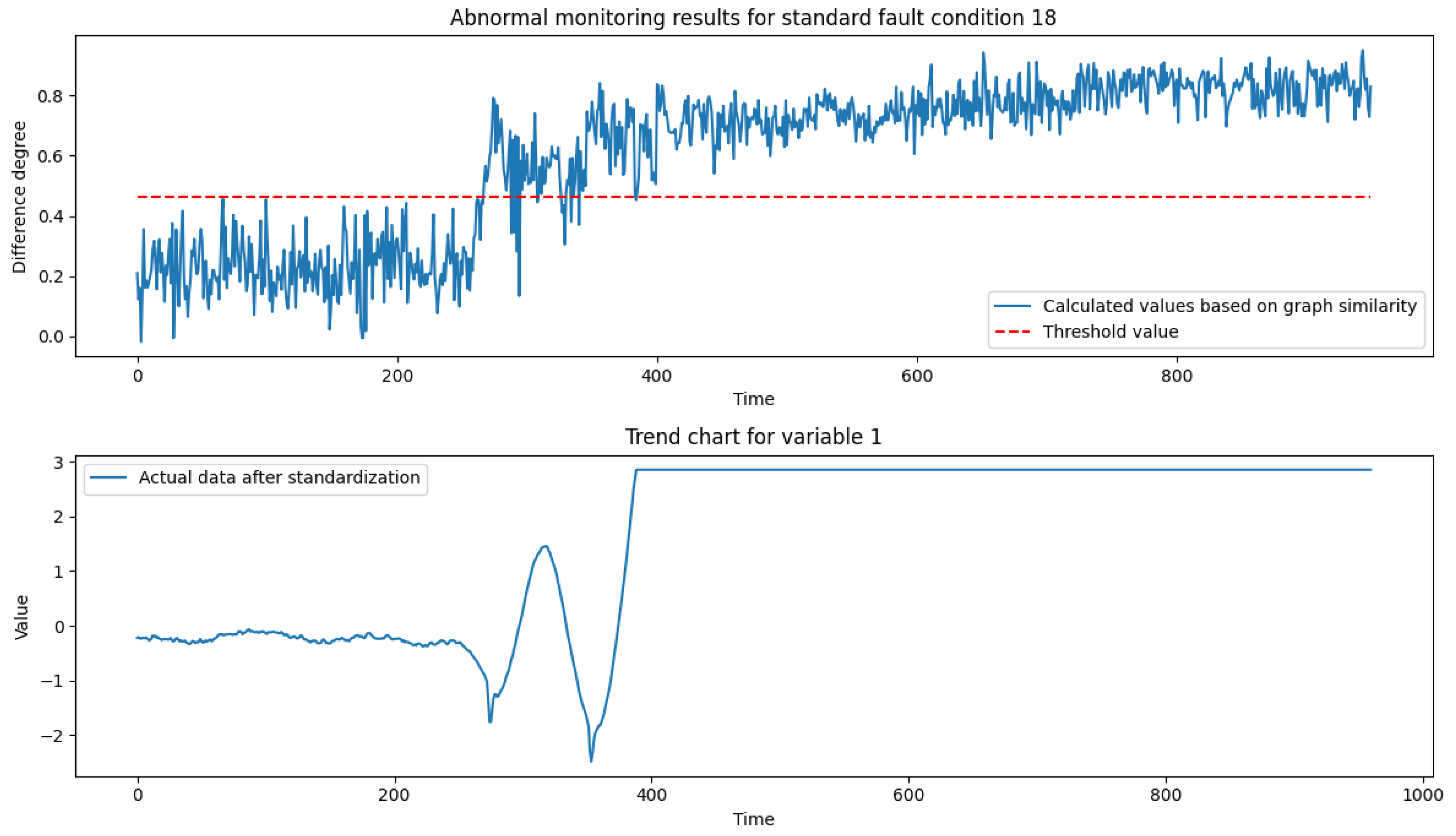
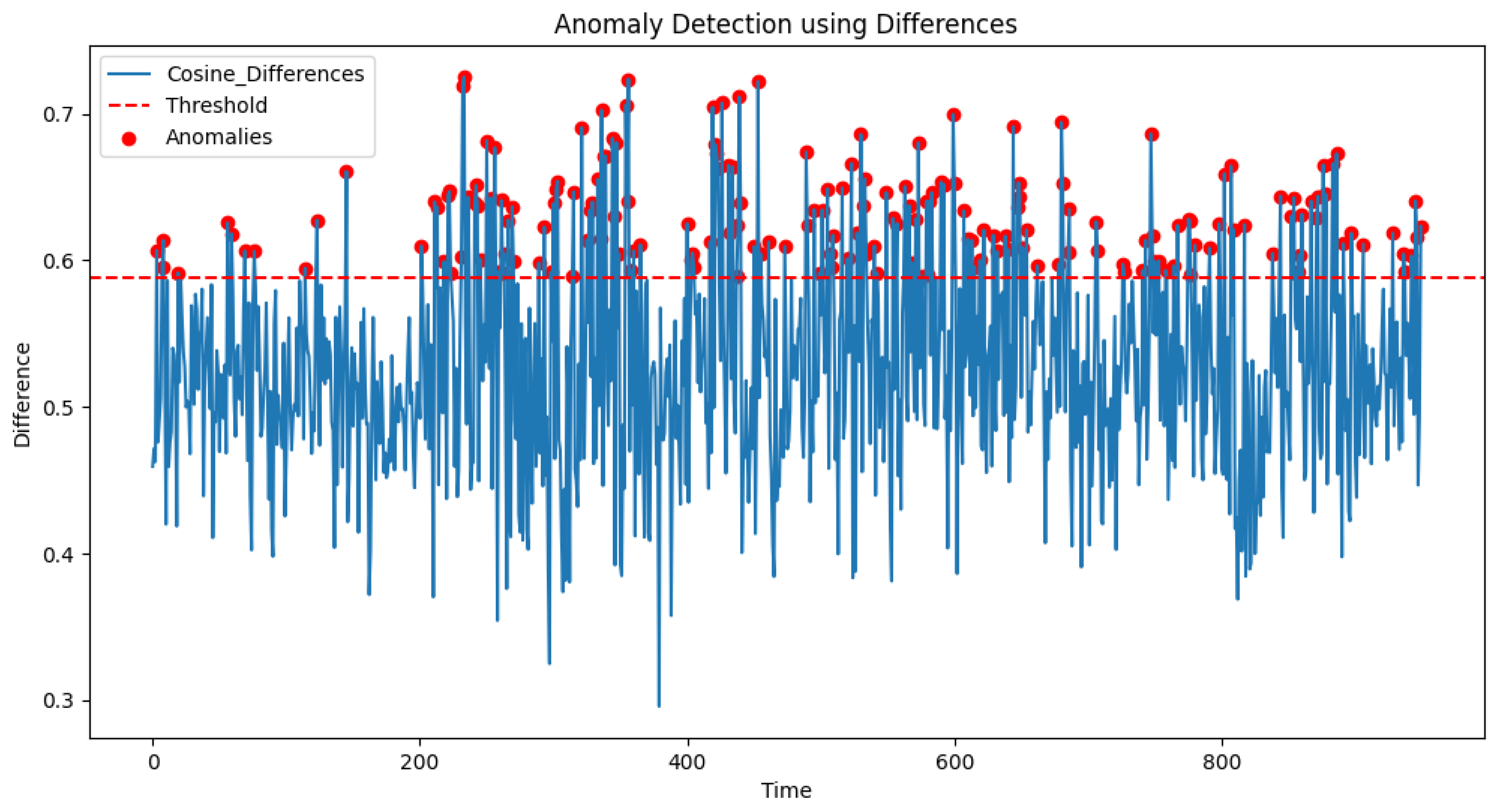
of the variability distribution under normal operating conditions as the threshold for anomaly monitoring. The implementation process is described in
Section 4.2.1. By comparing the deviation of the difference score calculated by the model with the overrun threshold, the abnormal state at the current moment is determined.
3.3. Application Steps
This section summarizes about the process algorithms and application steps proposed in this paper, detailed process analysis as [Algorithm 1].
| Algorithm 1 Anomaly monitoring model of industrial processes based on graph similarity and applications. |
Require: 1. : Standard normal operating conditions time series data. 2. : Online monitoring of time series data. 3. m: The length of the time window. Ensure: 1. Trained model. 2. Graph Discrepancy Score. 3. Abnormal Alarms. - 1:
Initialize the time window and graph model. - 2:
(1) Offline Modeling: - 3:
1. Preprocessing: - 4:
Granger causality and mutual information were applied to calculate the coupling between variables. - 5:
Apply Autoencoder to reduce dimensionality of , resulting in . - 6:
2. Multidimensional time-varying feature graph embedding: - 7:
for each time step t in do - 8:
if then - 9:
for each sensor i in do - 10:
Feature1 = - 11:
Feature2 = statistics() - 12:
Feature = concat[Feature1, Feature2] - 13:
= (Feature, []) - 14:
end for - 15:
else - 16:
continue - 17:
end if - 18:
end for - 19:
3. Model Training: - 20:
Train the Model using Graph_set. - 21:
Label = Euclidean distance(Nodes) - 22:
Graph Similarity Calculation - 23:
(2) Online anomaly monitoring and location tracing: - 24:
Online monitoring data preprocessing. - 25:
Apply the trained model to compute graph similarity. - 26:
Comparison of graph similarity calculations with overrun thresholds.
|
Note:
: Data of sensor i at time t.
: Sensor data after dimensionality reduction.
Feature1: Raw time characteristics of dynamic data.
Feature2: Dynamic statistical characteristics of dynamic data.
Feature: Multidimensional time-varying characteristics of time series data.
: Graph structure of data at time t.
Graph_set: A set of graph sequences after time series data are mapped to graph space.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}