1. Introduction
It is known that multivariable systems are referred to as Multi-Input and Multi-Output (MIMO) systems. In the field of identification, methods for the identification of univariate systems are becoming mature, such as the least squares (LS) method [
1,
2], the stochastic gradient method [
3,
4], the maximum-likelihood method [
5,
6], and so on. With the development of control theory and the needs of engineering practice, most industrial plants are expressed by multivariable systems with complex structures, the existence of nonlinearities, incomplete information, and uncertain disturbances [
7,
8,
9,
10]. Therefore, the study of multivariate systems is more valuable than univariate systems [
11,
12].
There are two main models for describing MIMO systems: one is the state space equation (SSE) model, and the other is the transfer function matrix (TFM) model [
13,
14]. Over the years, scholars have proposed different parameter identification methods for these two models.
When the SSE model has a measurable state, the controlled model can be converted into a regression model, and the conventional identification algorithm can be used to identify the regression model; e.g., the iterative identification algorithm derived in the literature [
15] for the SSE model with unknown parameters and a measurable state can effectively identify the parameters of the system. Although the ultimate goal of the literature [
16] is to identify the TFM model, it first identifies the SSE model and then explores the relationship between the SSE model and the TFM model. The paper first utilized the subspace method to estimate the state space matrix (A, B, C, D). Then, the covariance expression of the input correlation matrix (B, D) was derived based on the first-order perturbation method, and the covariance of the transfer function was calculated by combining the covariance of (B, D) with the covariance of (A, C). Subspace identification methods have developed particularly rapidly in recent decades, and when the state of the SSE model is not measurable, the method identifies the linear time-invariant state-space model directly from the input and output data [
17]. A novel system identification method based on invariant subspace theory has been proposed in the literature [
18], aiming at solving the problem of identifying continuous-time linear time-invariant systems by combining time-domain and frequency-domain methods.
When the TFM is utilized to describe the system model for parameter identification, the MIMO system is always decoupled by a decoupling method before identification [
19,
20,
21,
22]. Liu derived a coupled stochastic gradient algorithm for multivariate systems, which decomposes the system model into multiple single-output subsystems for parameter identification. Although this method has high accuracy, it does not match the realistic industrial production model [
19]. Ref. [
23] presented a dynamic model of a plate-fin heat exchanger, from the heat exchanger mechanism model, using the Laplace transform to derive the calculation formula of the time constant, and put forward the identification method based on the heat exchanger efficiency of the heat transfer thermal resistance calculation relationship. Ref. [
24] avoided the calculation of matrix inversion by decomposing the multivariate class CAR system into two subsystems and deriving a joint identification algorithm of stochastic gradient and least squares to estimate the system parameters.
Scholars who have previously proposed traditional identification methods consider only empirical risks, and these methods are prone to overfitting problems. In 1995, Vapnik et al. proposed a support vector machine (SVM) based on the Vapnik–Chervonenkis (VC) theory of statistical learning theory and structural risk minimization theory [
25]. SVM has a strict theoretical and mathematical foundation, does not easily fall into the problems of local optimum and dimension difficulty, has a weak dependence on the number of samples, and has a strong generalization ability [
26].
SVM was first solely used for classification problems [
27,
28,
29,
30]; however, as research into the topic has progressed, the SVM algorithm has been refined and enhanced, and its use has been extended to regression problems.
Huang and colleagues used SVM and the least square support vector machine (LS-SVM) to identify the difference equation models of linear and nonlinear systems [
31]. The findings indicate that the SVM and LS-SVM techniques outperform neural networks in terms of generalization capacity and system identification accuracy. The LS-SVM algorithm is better suited for dynamic system identification since it is quicker and more resilient to noise than SVM. Castro-Garcia R. et al. presented a technique that uses the LS-SVM’s regularization capability to identify MIMO Hammerstein systems. The identification process only necessitates a few basic presumptions and performs well in the presence of Gaussian white noise [
32].
Systems with colored noise have more challenges in parameter identification than systems with white noise disturbances [
33,
34,
35]. Systems with colored noise, however, are more in accordance with real-world production processes [
36,
37].
Zhao divided the system disturbed by colored noise into a system part and a noise part and estimated the parameters of the two parts separately [
38]. However, specific noise levels cannot be observed in real industrial activities and the method does not apply to on-site production activities. Xu and others used the filtering idea to convert the colored noise system into two models containing white noise [
39]. This method directly changes the system structure and also generates new noise during the conversion process. Zhang et al. considered the problem of parameter identification in the presence of additive noise and used the a priori knowledge of the instantaneous mixing matrix in the independent component analysis (ICA) model to accurately estimate the additive noise at the output of the system [
40].
Real-time parameter estimation is of great significance in modern engineering and control systems, which not only improves the performance and robustness of the system, but also supports fault detection, optimizes the production process, reduces the maintenance cost, and enhances the system safety. In order to realize real-time parameter estimation, the time for each parameter estimation process should not be too long. To achieve the reduction of estimation time, parameter optimization can be used. Parameter optimization has a very wide range of applications in many fields. These include hyperparameter optimization [
41], process optimization [
42,
43], and so on.
The parameter estimation problem for multivariate systems under the interference of outliers and colored noise is considered in this paper. The main contributions are summarized as follows.
(1) To solve the problem of estimating the parameters of the TFM, the parameters of the equivalent difference equation model were first estimated, and then the TFM parameters were derived from the equation;
(2) In this paper, a method was proposed to deal with the parameter identification problem effectively using support vector regression (SVR). The method can well solve the problem of parameter estimation under the interference of outliers and colored noise;
(3) To address the issue of long parameter search time in the abovementioned method, a new SVR method combining stochastic search and Bayesian optimization was proposed;
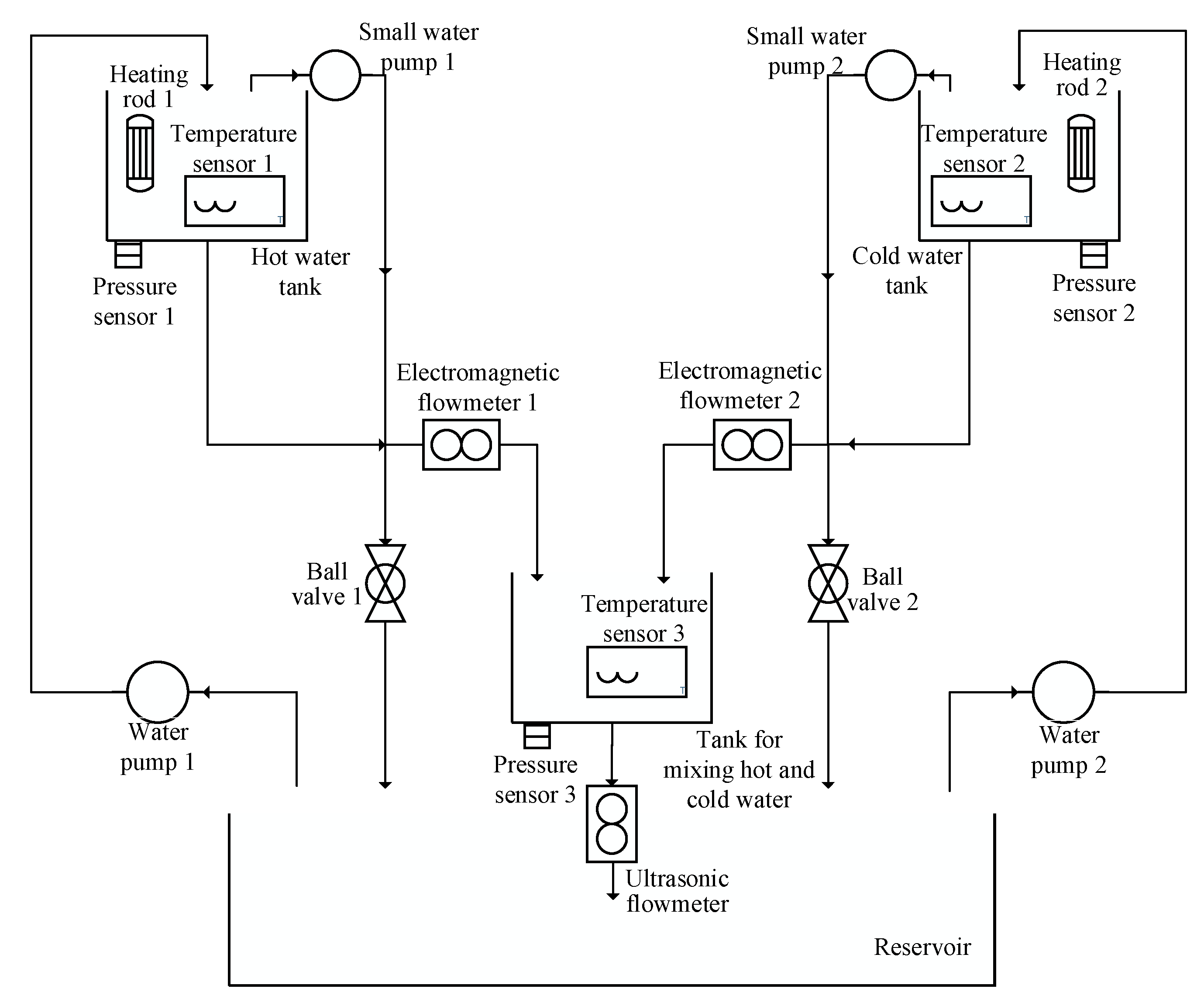
(4) A two-input single-output simulation system was used to verify the effectiveness and accuracy of the algorithm. In addition, a water tank system was constructed for system identification to verify the effectiveness of the algorithm in real systems.
The remainder of this article is organized as follows.
Section 2 introduces the related knowledge of SVR, analyzes the anti-interference property of SVR, and introduces the parameter estimation algorithm based on SVR in detail.
Section 3 introduces the SVR algorithm combining random search and Bayesian optimization.
Section 4 verifies the effectiveness of the algorithm through a dual-input, single-output simulation system, and verifies the usability of the algorithm in real systems through data from actual water tank systems.
Section 5 contains the concluding remarks.
2. Parameter Estimation for MIMO Systems Under Noise Interference
2.1. Support Vector Regression Algorithm
There are m sets of input and output data samples , where is the input data set matrix of the ith data sample, which is expressed as . is the corresponding output data set matrix.
The established linear regression function is shown in Equation (1).
where
denotes the dot product in
.
We construct an SVR regression problem for each output .
The SVR algorithm is obtained by introducing an insensitive loss function on the basis of SVM classification. The basic idea is to find an optimal plane that minimizes the error of all training samples away from that optimal plane. Currently, the most widely used SVR model is
-SVR, which introduces a
linear insensitive loss function (as shown in Equation (2)).
The goal of
-SVR is to find a function
that deviates from the actual obtained target
by at most
for all training data while being as flat as possible [
44]. To satisfy the flatness of Equation (1), it can be achieved by minimizing the norm, i.e.,
[
45]. This is shown in Equation (3). The principle of SVR is shown in
Figure 1.
The biggest difference between SVR and traditional regression algorithms is that SVR gives some tolerance to fitting.
In practice, setting too small cannot guarantee that all sample points are within the -pipeline, and setting too large will cause the regression hyperplane to be affected by outliers. Relaxation variables and are introduced to describe the degree of deviation of the sample points from the -pipeline so that both empirical and structural risks are taken into account.
The objective function is updated as Equation (4).
where C is the penalty factor, a human-set parameter.
Based on the constraints, Lagrange multipliers
are introduced, and constructing the Lagrange function (as in Equation (5)) transforms the optimization problem into a dyadic problem.
The above-shown equation is obtained by taking the derivations of
, respectively, and making the result zero:
The dyadic problem of the original question is
A kernel function is a very important concept in SVR algorithms, which can map the input feature vectors to a high-dimensional space for computation. Commonly used kernel functions include linear kernel function, polynomial kernel function, radial basis kernel function (RBF), and sigmoid kernel function. Different kernel functions correspond to different problems and are applicable to different problems, and choosing the appropriate kernel function can improve the performance of SVR. The specific calculation formula is shown in
Table 1.
Support vector machines that introduce kernel functions and neural networks have a similar structure. Since we are studying a linear MIMO system, we use a linear kernel function.
Solving Equation (5) yields the optimal solution
, and the regression function is shown in Equation (8).
where
represents the number of support vectors.
Currently, there are many toolkits about SVM, such as LIBLINEAR, mySVM, LIBSVM, and so on. Among them, LIBSVM (Version 3.35) is an open-source software package for SVM developed by Prof. Chi-Jen Lin’s team at National Taiwan University, which provides an interface with MATLAB and is easy to use. In this paper, this package was used for data training and prediction.
2.2. Anti-Interference Analysis of SVR
Observations or values that deviate significantly from other data points in the data collection are called outliers. Numerous factors such as measurement errors, data entry problems, natural variability, and atypical events can lead to outliers.
Colored noise is a noise signal with an uneven frequency–energy distribution. In contrast to Gaussian white noise, colored noise does not have a uniform energy distribution over the frequency spectrum but has a frequency dependence or bias.
White noise and outliers are independent at different points in time, whereas colored noise is time-dependent. In addition, colored noise signals are often mixed with useful signals and are difficult to distinguish.
Due to the principle and structural properties of SVR, high interference resistance of parameter identification using SVR is guaranteed.
(1) Support Vector Regression employs the principle of structural risk minimization, which aims to minimize the empirical error and the confidence range, i.e., to minimize both the training error and the model complexity. In this way, SVR is able to find a balance between reducing model complexity and improving fitting accuracy, thus enhancing the generalization ability of the model.
Specifically, the goal of SVR is to optimize the model by minimizing structural risk, which involves not only minimizing training error but also ensuring that the model complexity is manageable. The L2 regularization term plays a key role here. The L2 regularization ensures that the model parameters do not become too large by restricting the L2 norms of the model parameter w. This helps to control the model complexity and to improve the generalization ability of the model. This helps control model complexity and prevents the model from overfitting the noise in the training data. L2 regularization reduces the model’s sensitivity to the input features by compressing the parameter values, thus improving the model’s generalization ability. Noise is usually random and irregular, and if the model is too complex, it may capture these noise signals, leading to overfitting. L2 regularization, on the other hand, makes the model smoother and avoids overreacting to chance noise patterns in the data;
(2) The generalization performance of SVR depends heavily on the appropriate choice of parameter C, which controls the weight of the empirical risk in the structural risk. To find the optimal value of C, a grid search method can be used. The specific size of the grid search will be elaborated in
Section 2.3;
(3) SVR improves the robustness and immunity of the model by maximizing the distance between the support vector and the regression hyperplane. Maximizing this spacing means that the model pays more attention to trends in the overall data distribution, rather than being overly sensitive to small changes (i.e., noise) in individual sample points. This strategy allows SVR to better handle training data with noise and avoid overfitting the model by fitting noise;
(4) Using an insensitive loss function allows a width interval to exist between the regression predictions and the true values, and the loss function does not take into account the prediction error within that interval. This means that the model is insensitive to small noises, as small noises do not lead to additional penalties.
2.3. Parameter Estimation of SVR-Based for MIMO Systems
A linear multivariate system is shown in
Figure 2. The state space equation description of a system is not unique and when the state of the state space equation model is not measurable, not only the parameters of the model but also the state of the model has to be estimated, which makes the identification more complicated, and it is more advantageous to use the transfer function matrix model to describe the identification system model.
The TFM model of the MIMO system is described as shown in Equation (9).
The parameter set K described in Equation (10) and the parameter set T described in Equation (11) are the sets of parameters that the system needs to recognize.
It is first necessary to discretize the discrete model (9) of the multivariate system into an impulse TFM model, as shown in Equation (12). In this paper, the discretization was carried out using the bilinear transformation method (
).
Regarding the above-shown equation, the specific description of
is shown in Equation (13).
where
is the input signal order and
is the output signal order.
Extracting the least common multiple of each row of the impulse TFM leads to Equation (14) and then converting the impulse TFM model to a difference equation model (Equation (15)).
where
,
.
The difference equation model parameters (Equation (16)) are first estimated and then the parameters K and T are inverted according to the discretization method used.
Specifically, after determining the differential equation model, K and T are solved inversely according to the formulation of the bilinear transformation method. This can be achieved by using the d2c function in MATLAB.
For the MIMO system, we split the system into multiple Multi-Input and Single-Output (MISO) systems based on each output and study each MISO system.
Take the example of a two-input, two-output system (Equation (17)). It is discretized into a difference equation, which is described as Equation (18).
The inverse solution of
is performed according to the formulation of the bilinear transformation method, the expression of which is shown in Equation (19).
where
is the system sampling time.
Parameter estimation for MIMO systems can be viewed as finding the relationship between the input vector X and multiple outputs
. For each output
, an SVR model is built to describe its relationship with the input vector X.
For each output
, we define an independent SVR optimization problem with the following objective function.
where
is the weight vector of the corresponding SVR regression problem for each output signal
.
By training the dataset , the output of each SVR model is trained individually.
After collecting the input and output signals, the dataset is constructed according to the data requirements of LIBSVM, including the label dataset and data dataset; for the regression problem, the label dataset is the independent variable dataset, and the data dataset is the dependent variable dataset. Parameter identification of multivariate systems based on SVR requires the construction of datasets as shown in Equations (22) and (23).
The dataset was divided into training and test sets according to a certain ratio. The linear kernel function was selected based on the characteristics of the linear multivariate system. We then optimized the parameter C using the grid search method to achieve the best prediction result.
When the kernel function is a linear kernel function, the training system parameters, support vector weights, and support vectors can be used to find the discriminant parameters, as shown in Equation (24).
The specific process of SVR-based parameter identification is shown in
Figure 3.
2.4. Unbiased and Error Convergence
For traditional estimation algorithms, such as the LS method, the most important properties of the method are unbiasedness and convergence of the error variance to zero.
SVR-based parameter estimation methods do not directly optimize for or guarantee unbiasedness and are more concerned with finding a model that strikes a balance between model complexity and prediction error. This bias facilitates the reduction of overfitting and improves the generalization ability of the model. Therefore, this paper considers the problem of parameter estimation under noise interference, and better results can be achieved by selecting SVR-based parameter estimation algorithms compared to traditional parameter estimation methods.
Whether the error variance of SVR-based parameter estimation methods can converge to zero depends on a number of factors, including the choice of model, the complexity of the feature space, the nature of the dataset, and the setting of the regularization parameters. Since the goal of SVR is to minimize the model complexity and prediction error, it is not possible to achieve complete convergence of the error variance to 0.
Although the complexity of the feature equations is performed to improve the accuracy of the parameter estimation, the model may be overfitted in this case. For the data studied in this paper, i.e., data containing noise, overfitting can lead to a parameter estimation problem that is heavily influenced by noise.
3. SVR Algorithm Using Stochastic Search and Bayesian Optimization
Stochastic search is a global search method that does not rely on gradient information, and it searches for optimal solutions by randomly sampling in the solution space. Unlike deterministic search algorithms, stochastic search does not rely on a priori knowledge and is insensitive to the choice of initial points, and thus exhibits unique robustness in dealing with discontinuous and nonconvex optimization problems. The core of the stochastic search algorithm is to utilize randomness to traverse the solution space, and it does not use any directed search strategy, which means that the decision at each step of the algorithm is independent of the previous step.
Its main process is as follows:
(1) Define the parameter space. Define the parameter space to be optimized according to the specific problem;
(2) Initial sampling. Randomly sample a set of initial parameter values from the parameter space according to a certain sampling method, such as uniform distribution, Gaussian distribution, and so on;
(3) Evaluation of objective function. Design the objective function according to the specific problem, and then calculate the corresponding objective function value for each set of parameter values;
(4) Update the best parameters. Record the best combination of parameters found and their corresponding objective function values;
(5) Iterative search. Repeat steps 2 to 4 until a predetermined number of iterations is reached or the stopping condition is met.
Compared with grid search, random search does not need to search for all parameter combinations, which greatly reduces the number of searches and time. Especially when the parameter space is very large, stochastic search can find the near-optimal parameter combinations with less computational resources and time cost.
Bayesian optimization is a global optimization method based on a probabilistic model, which searches for the optimal hyperparameters by constructing a probabilistic model of the objective function.
The core of Bayesian optimization lies in the use of a probabilistic model to model a black-box function and the use of this model to guide the process of finding the optimal solution. Probabilistic models use prior knowledge and observations to update the posterior distribution as a means of predicting the value of a function at points that have not yet been observed. The first step in constructing the model is to determine the prior distribution, which is usually based on assumptions about the prior knowledge of the problem.
The probabilistic model is then updated based on Bayes’ Law as new observations are obtained. Constructing a probabilistic model requires the selection of an appropriate family of probability distributions, which is commonly used as a Gaussian process (GP).
Its specific implementation process is as follows:
(1) Initial sampling. Randomly select some sampling points and calculate the corresponding objective function values;
(2) Construct an agent model of the objective function based on the initial sampling using the Gaussian process;
(3) Optimize the proxy model. Use the proxy model to predict the objective function values and uncertainties of the new parameter points. Calculate the acquisition function based on the above predictions to balance the trade-off between exploration and exploitation. In this case, exploration is the selection of points with higher uncertainty to discover new optimal points. Exploitation is conducted to select points with better expected objective function values to improve the optimal solution by utilizing existing information;
(4) Updating the agent model. The next parameter point is selected under the guidance of the acquisition function and its objective function value is calculated. Add the new data point to the existing data set to update the agent model;
(5) Iterative repetition. Repeat steps 3 and 4 to gradually reduce the parameter space and find the optimal parameters. The iterative process ends when the preset number of iterations or convergence conditions are reached.
Bayesian optimization predicts which parameter combinations are likely to lead to the best performance by constructing a probabilistic model of the objective function and then selects the parameters to be evaluated next based on this predictive model. This approach is more efficient compared to random and lattice searches and is able to find near-optimal parameters with fewer evaluations, especially if the objective function evaluation is costly. In addition, Bayesian optimization is an iterative optimization process where each step uses the information from the previous steps to improve the next search. This means that as the search proceeds, the optimization process becomes progressively more efficient and precise and is able to better focus on the possible regions of optimal parameters.
When the search space is large and the problem complexity is high, stochastic search covers the solution space well but lacks relevance and efficiency. On the other hand, Bayesian optimization methods provide good relevance and high efficiency, but require high prior knowledge of the problem and perform erratically in high-dimensional spaces. Combining the two aims to exploit the global search capability of stochastic search and the local search efficiency of Bayesian optimization.
The specific steps of the algorithm for combining the two are as follows:
(1) Define the parameter space. Define the range of values and distribution of each hyperparameter;
(2) Initial exploration using random search. Determine the number of initial searches according to the specific problem and computational resources, and collect the initial data points after a certain number of random searches;
(3) Construct a Bayesian optimization agent model. Construct the agent model of the objective function using the initial data points in step 2;
(4) Optimize the agent model. Use the agent model to predict the objective function values and uncertainties for the new parameter points. Calculate the acquisition function based on these predictions to balance the tradeoff between exploration and exploitation. In this case, exploration is the selection of points with higher uncertainty to discover new optimal points. Exploitation is conducted to select points with better expected objective function values to improve the optimal solution by utilizing existing information;
(5) Updating the agent model. The next parameter point is selected under the guidance of the acquisition function and its objective function value is calculated. Add the new data point to the existing data set to update the agent model;
(6) Iterative repetition. Repeat steps 4 and 5 to gradually reduce the parameter space and find the optimal parameters. The iterative process ends when the preset number of iterations or convergence conditions are reached.
5. Conclusions
In this study, we investigated the performance of SVR and RSBO-SVR algorithms for parameter identification in multivariate systems, including challenging conditions such as common outliers and colored noise disturbances. The results showed that both the RSBO-SVR and SVR algorithms utilize the structural risk minimization principle and the L2 regularization term to effectively reduce the complexity of the model while maintaining robustness to noise disturbances. Specifically, the use of the maximum margin strategy and insensitive loss function enabled the model to effectively resist noise and outliers.
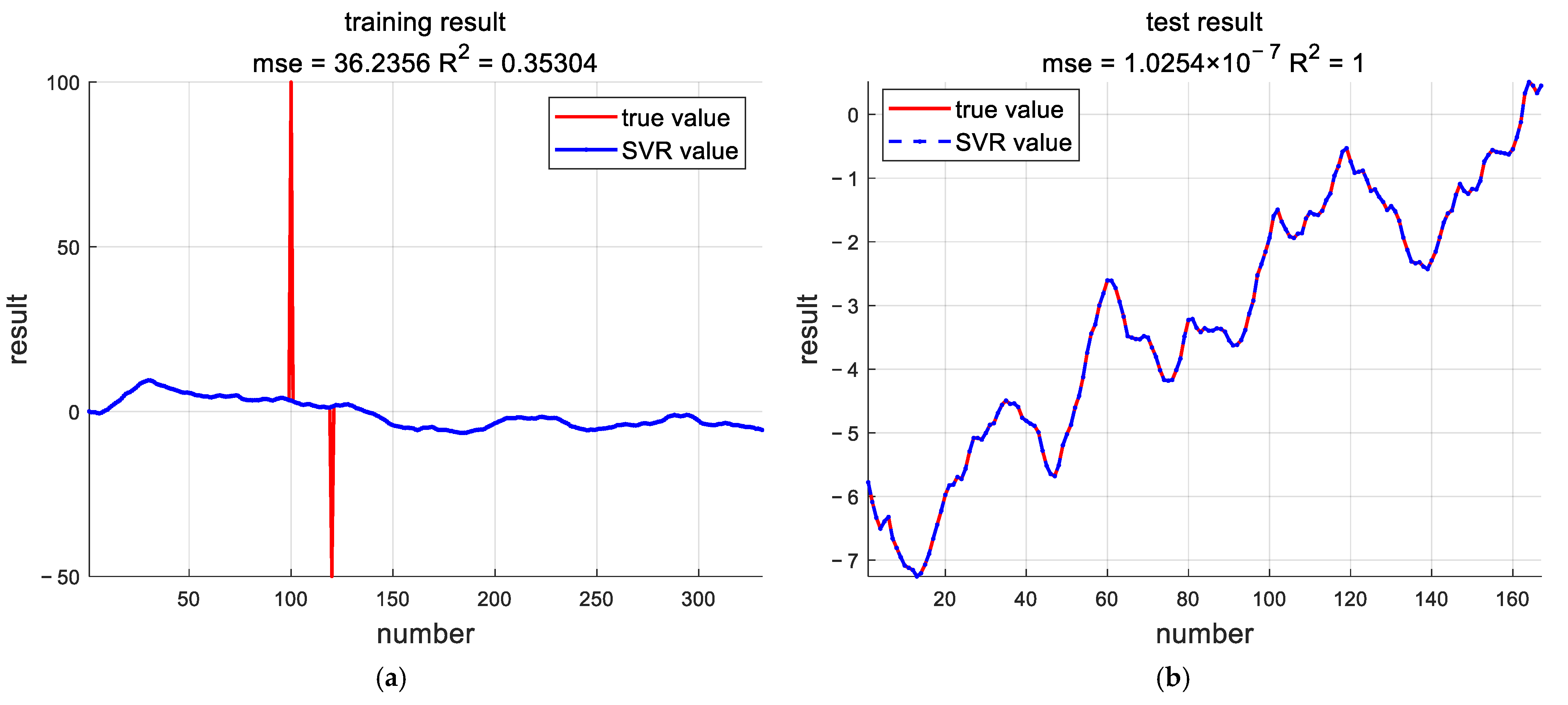
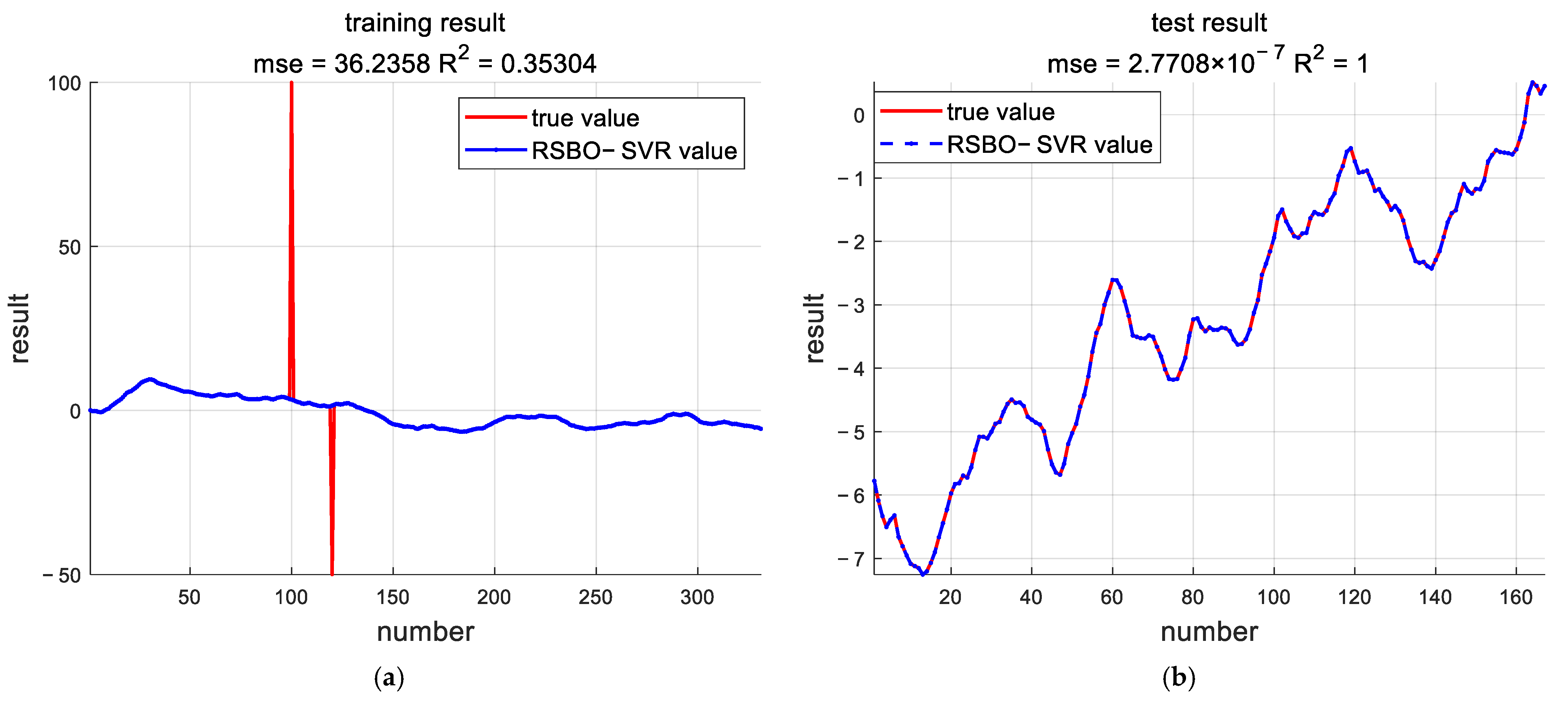
For parameter identification of multivariate systems, the RLS algorithm was completely ineffective when there were outliers in the collected input and output data. The SVR algorithm and RSBO-SVR algorithm, however, still had high identification accuracy under the same conditions. In addition, in order to solve the problem of the long optimization time of SVR parameters, the RSBO-SVR algorithm combining random search and Bayesian optimization is proposed. When the system contains colored noise, RLS could identify the parameters, but the error was very large, and the identified system could not correctly reflect the system characteristics. In contrast, color noise had less of an effect on the SVR and RSBO-SVR algorithms. Compared with SVR, RSBO-SVR had a faster estimation speed.
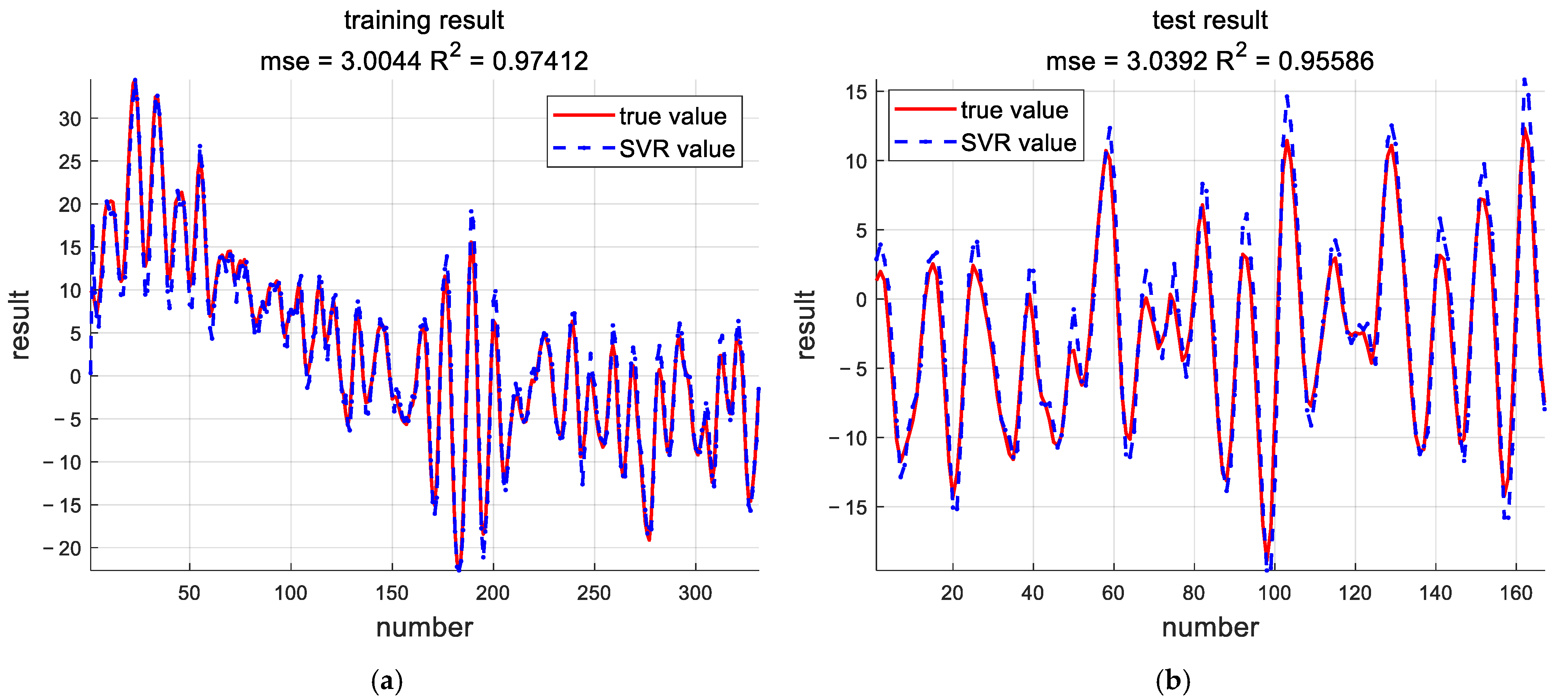
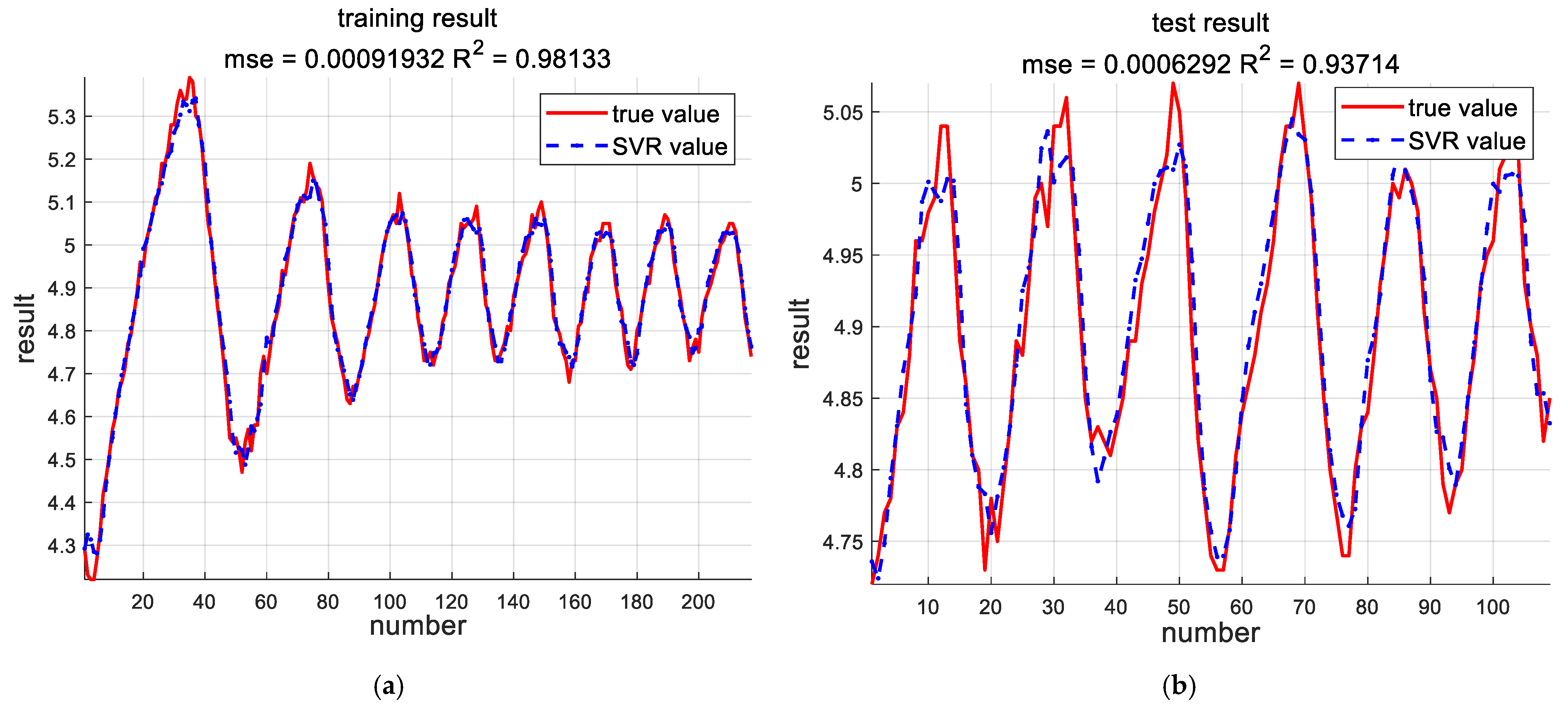
In addition, the tank experiments prove that these algorithms can be applied to the identification of real systems; the maximum output error between the estimated model and the actual model was only 1.5% for the SVR algorithm, and the maximum output error between the estimated model and the actual model was not more than 3% for the RSBO-SVR algorithm. Although the accuracy is lower than SVR, it still meets the requirements of industrial production. Compared with SVR, the estimation time of RSBO-SVR was 99.38% shorter.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}