

SAM-Enhanced Cross-Domain Framework for Semantic Segmentation: Addressing Edge Detection and Minor Class Recognition


Abstract
1. Introduction
- We propose a novel UDA framework for image semantic segmentation by effectively integrating SAM as the mask generator to mitigate the common weakness in accurate identifications of semantic labels for the edge pixels of objects.
- We designed an image mixing module to counter the minority class imbalance challenge by generating new samples that are synthesized using images from source and target domains.
- We showed better semantic segmentation performance with our SamDA framework on two public benchmark datasets: GTA5 (source data) and CityScapes (target data).
2. Related Work
2.1. Semantic Segmentation Using Unsupervised Domain Adaptation
2.2. Image Mixing
2.3. Segment Anything Model
3. Methodology
3.1. Problem Formulation
3.2. Self-Training
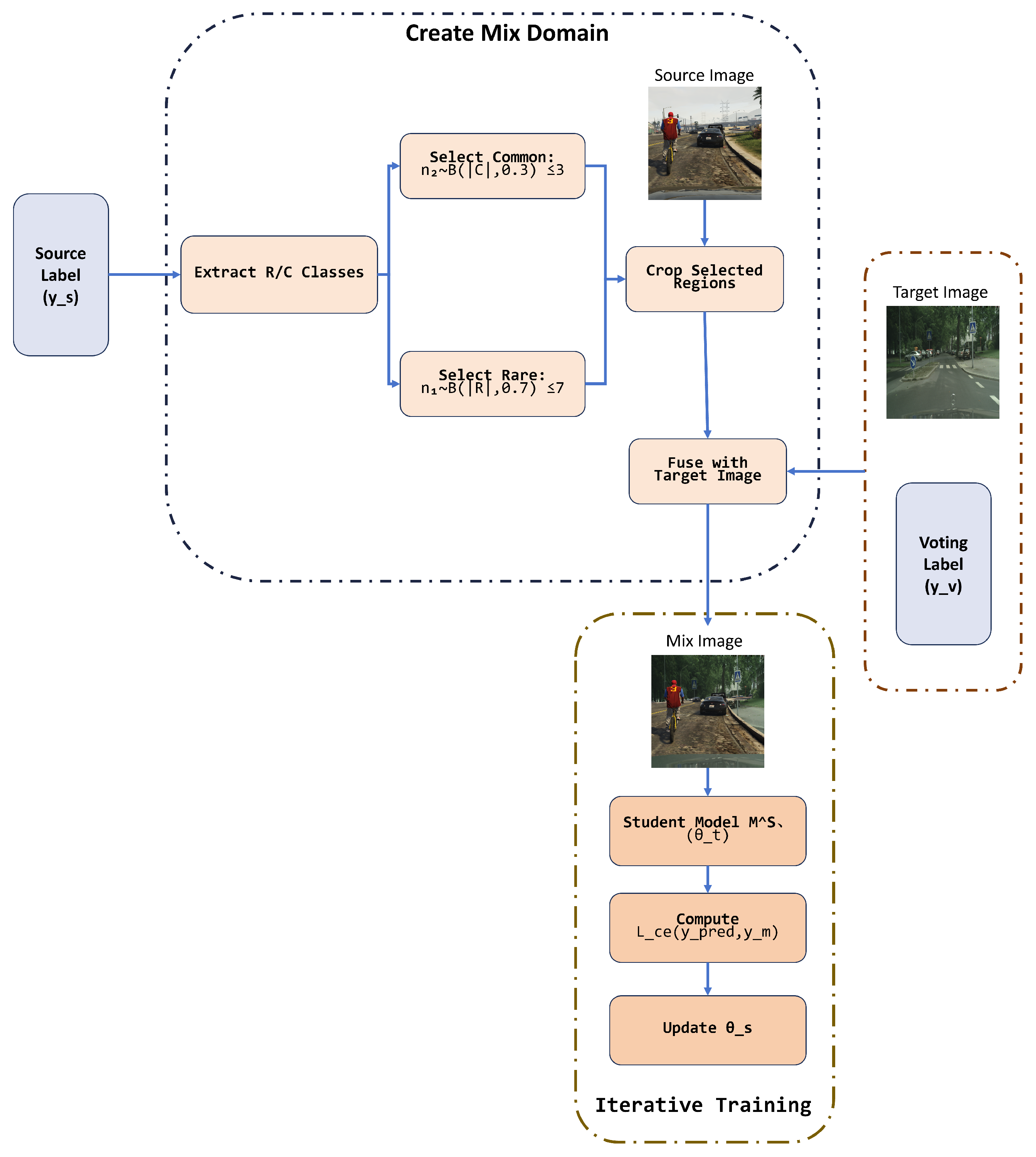
3.3. Mixing Module
| Algorithm 1: Implementation of the mixing module to generate mixed images from both the source and target domains for training student models iteratively. |
 |
3.4. Finetune Module
3.4.1. Mask Generation
3.4.2. Pseudo-Label Matching
| Algorithm 2: The implementation of the finetune module to generate pseudo-labels for the target image. |
 |
3.5. Overall Loss Function
4. Experiments and Results
4.1. Datasets
4.2. Experimental Setup
4.3. Evaluation Metrics
5. Results
5.1. Qualitative Comparison
5.2. Ablation Study
5.3. Computational Cost Analysis
- DACS [5]: Uses DeepLabV3+ as the backbone and does not rely on additional external models like SAM, making it computationally lightweight.
- DAFormer [1]: Adopts a Transformer-based architecture with SegFormer-B5 as the backbone, leading to higher computational requirements than CNN-based approaches.
- MIC-DAFormer [14]: Extends DAFormer with masked image consistency learning, requiring additional memory and compute overhead.
- SAM4UDA [10]: Integrates SAM for pseudo-label refinement but requires iterative optimization, leading to higher training costs.
6. Discussion
6.1. Failure Analysis and Limitations
6.2. Methodological Limitations and Practical Considerations
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hoyer, L.; Dai, D.; Van Gool, L. Daformer: Improving network architectures and training strategies for domain-adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–22 June 2022; pp. 9924–9935. [Google Scholar]
- Zou, Y.; Yu, Z.; Kumar, B.; Wang, J. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 289–305. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.Y.; Isola, P.; Saenko, K.; Efros, A.; Darrell, T. Cycada: Cycle-consistent adversarial domain adaptation. In Proceedings of the International Conference on Machine Learning, Pmlr, Stockholm, Sweden, 10–15 July 2018; pp. 1989–1998. [Google Scholar]
- French, G.; Mackiewicz, M.; Fisher, M. Self-ensembling for visual domain adaptation. arXiv 2017, arXiv:1706.05208. [Google Scholar]
- Tranheden, W.; Olsson, V.; Pinto, J.; Svensson, L. Dacs: Domain adaptation via cross-domain mixed sampling. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2021; pp. 1379–1389. [Google Scholar]
- Hoffman, J.; Wang, D.; Yu, F.; Darrell, T. Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv 2016, arXiv:1612.02649. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; March, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Tsai, Y.H.; Hung, W.C.; Schulter, S.; Sohn, K.; Yang, M.H.; Chandraker, M. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7472–7481. [Google Scholar]
- Chen, Y.C.; Lin, Y.Y.; Yang, M.H.; Huang, J.B. Crdoco: Pixel-level domain transfer with cross-domain consistency. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Beach, CA, USA, 16–20 June 2019; pp. 1791–1800. [Google Scholar]
- Yan, W.; Qian, Y.; Zhuang, H.; Wang, C.; Yang, M. SAM4UDASS: When SAM Meets Unsupervised Domain Adaptive Semantic Segmentation in Intelligent Vehicles. IEEE Trans. Intell. Veh. 2023, 9, 33963408. [Google Scholar] [CrossRef]
- Brüggemann, D.; Sakaridis, C.; Truong, P.; Van Gool, L. Refign: Align and refine for adaptation of semantic segmentation to adverse conditions. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 3174–3184. [Google Scholar]
- Jung, Y.J.; Kim, M.J. Deeplab v3+ Based Automatic Diagnosis Model for Dental X-ray: Preliminary Study. J. Magn. 2020, 25, 632–638. [Google Scholar] [CrossRef]
- Chang, W.G.; You, T.; Seo, S.; Kwak, S.; Han, B. Domain-specific batch normalization for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7354–7362. [Google Scholar]
- Hoyer, L.; Dai, D.; Wang, H.; Van Gool, L. MIC: Masked image consistency for context-enhanced domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 11721–11732. [Google Scholar]
- Choi, W.; Kim, D.; Kim, C. Self-ensembling with GAN-based data augmentation for domain adaptation in semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1234–1243. [Google Scholar]
- Lee, Y.; Kim, Y.; Kim, S.; Kim, C. Sliced Wasserstein discrepancy for unsupervised domain adaptation. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2019, 43, 3199–3213. [Google Scholar]
- Chen, Y.; Zhang, W.; Wang, Z.; Wang, S. Source-free domain adaptation for semantic segmentation. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Online, 6–14 December 2021; pp. 6572–6583. [Google Scholar]
- Zhang, Y.; Qiu, Z.; Dai, D.; Van Gool, L. Prototypical pseudo-label denoising and target structure learning for domain adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12455–12465. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 4015–4026. [Google Scholar]
- Lu, Y.; Zhang, J.; Liu, K. Semantic-guided prompt learning for few-shot segmentation. In Proceedings of the International Conference on Machine Learning (ICML), Honolulu, HI, USA, 23–29 July 2023; pp. 6789–6798. [Google Scholar]
- Zhang, H.; Li, R.; Wang, T. Personalizing foundation segmentation models with reinforcement learning. IEEE Trans. Neural Netw. Learn. Syst. (TNNLS) 2023, 34, 8765–8779. [Google Scholar]
- Shen, J.; Xu, W.; Huang, J. SAM: Anything model for segmentation. arXiv 2023, arXiv:2303.14285. [Google Scholar]
- Yu, X.; Wang, R.; Zhao, Q. Pointly supervised SAM for domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 4563–4572. [Google Scholar]
- Wang, B.; Sun, X.; Zhou, L. TransMix: Enhancing minority class recognition with adaptive image mixing. In Proceedings of the European Conference on Computer Vision (ECCV), Paris, France, 2–3 October 2023; pp. 3456–3465. [Google Scholar]
- Zhang, T.; Liu, Y.; Chen, S. Balanced mix-up training for long-tailed recognition. Int. J. Comput. Vis. (IJCV) 2022, 130, 5678–5692. [Google Scholar]
- Li, Y.; Yuan, L.; Vasconcelos, N. Bidirectional learning for domain adaptation of semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6936–6945. [Google Scholar]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum classifier discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3723–3732. [Google Scholar]
- Xu, R.; Li, G.; Yang, J.; Lin, L. Larger norm more transferable: An adaptive feature norm approach for unsupervised domain adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 1426–1435. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10687–10698. [Google Scholar]
- Pereira, M.C.; Sastre-Gomez, S. Nonlocal and nonlinear evolution equations in perforated domains. J. Math. Anal. Appl. 2021, 495, 124729. [Google Scholar] [CrossRef]
- Zou, Y.; Yu, Z.; Liu, X.; Kumar, B.; Wang, J. Confidence regularized self-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27–28 October 2019; pp. 5982–5991. [Google Scholar]
- Li, G.; Kang, G.; Liu, W.; Wei, Y.; Yang, Y. Content-consistent matching for domain adaptive semantic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 440–456. [Google Scholar]
- Wang, Z.; Zhang, Y.; Zhang, Z.; Jiang, Z.; Yu, Y.; Li, L.; Li, L. Exploring Semantic Prompts in the Segment Anything Model for Domain Adaptation. Remote Sens. 2024, 16, 758. [Google Scholar] [CrossRef]
- Chen, T.; Zhu, L.; Ding, C.; Cao, R.; Zhang, S.; Wang, Y.; Li, Z.; Sun, L.; Mao, P.; Zang, Y. Sam fails to segment anything?—Sam-adapter: Adapting sam in underperformed scenes: Camouflage, shadow, and more. arXiv 2023, arXiv:2304.09148. [Google Scholar]
- Xu, Y.; Tang, J.; Men, A.; Chen, Q. Eviprompt: A training-free evidential prompt generation method for segment anything model in medical images. arXiv 2023, arXiv:2311.06400. [Google Scholar] [CrossRef] [PubMed]
- Ke, L.; Ye, M.; Danelljan, M.; Tai, Y.W.; Tang, C.K.; Yu, F. Segment anything in high quality. Adv. Neural Inf. Process. Syst. 2024, 36, 29914–29934. [Google Scholar]
- Zhao, X.; Ding, W.; An, Y.; Du, Y.; Yu, T.; Li, M.; Tang, M.; Wang, J. Fast segment anything. arXiv 2023, arXiv:2306.12156. [Google Scholar]
- Jinlei, W.; Chen, C.; Dai, C.; Hong, J. A Domain-Adaptive segmentation method based on segment Anything model for mechanical assembly. Measurement 2024, 235, 114901. [Google Scholar]
- Zhou, Q.; Feng, Z.; Gu, Q.; Pang, J.; Cheng, G.; Lu, X.; Shi, J.; Ma, L. Context-aware mixup for domain adaptive semantic segmentation. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 804–817. [Google Scholar] [CrossRef]
- Wu, X.; Wu, Z.; Guo, H.; Ju, L.; Wang, S. DANNet: A One-Stage Domain Adaptation Network for Unsupervised Nighttime Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Yao, D.; Li, B.; Wang, R.; Wang, L. Dual-level Interaction for Domain Adaptive Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Paris, France, 2–6 October 2023. [Google Scholar]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for data: Ground truth from computer games. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14; Springer: Berlin/Heidelberg, Germany, 2016; pp. 102–118. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Guo, X.; Yang, C.; Li, B.; Yuan, Y. Metacorrection: Domain-aware meta loss correction for unsupervised domain adaptation in semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3927–3936. [Google Scholar]
- Araslanov, N.; Roth, S. Self-supervised augmentation consistency for adapting semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15384–15394. [Google Scholar]
- Hoyer, L.; Dai, D.; Gool, L. HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation. In Computer Vision—ECCV 2022; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Sakaridis, C.; Dai, D.; Van Gool, L. ACDC: The adverse conditions dataset with correspondences for semantic driving scene understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2723–2739. [Google Scholar]
- Sakaridis, C.; Dai, D.; Van Gool, L. Guided curriculum model adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 7374–7383. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Road | S.Walk | Build. | Wall | Fence | Pole | T.Light | Sign | Veget. | Terrain | Sky | Person | Rider | Car | Truck | Bus | Train | M.Bike | Bike | mIoU | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet-Based | CBST [2] | 91.8 | 53.5 | 80.5 | 32.7 | 21.0 | 34.0 | 28.9 | 20.4 | 83.9 | 34.2 | 80.9 | 53.1 | 24.0 | 82.7 | 30.3 | 35.9 | 16.0 | 25.9 | 42.8 | 45.9 |
| CCM [32] | 93.5 | 57.6 | 84.6 | 39.3 | 24.1 | 25.2 | 35.0 | 17.3 | 85.0 | 40.6 | 86.5 | 58.7 | 28.7 | 85.8 | 49.0 | 56.4 | 5.4 | 31.9 | 43.2 | 49.9 | |
| MetaCor [45] | 92.8 | 58.1 | 86.2 | 39.7 | 33.1 | 36.3 | 42.0 | 38.6 | 85.5 | 37.8 | 87.6 | 62.8 | 31.7 | 84.8 | 35.7 | 50.3 | 2.0 | 36.8 | 48.0 | 52.1 | |
| DACS [5] | 89.9 | 39.7 | 87.9 | 30.7 | 39.5 | 38.5 | 46.4 | 52.8 | 88.6 | 37.0 | 88.8 | 67.2 | 35.9 | 84.5 | 45.7 | 50.0 | 0.8 | 27.3 | 34.0 | 52.2 | |
| SAC [46] | 90.4 | 53.9 | 86.6 | 42.4 | 27.3 | 45.1 | 48.5 | 42.7 | 87.4 | 40.1 | 86.1 | 67.5 | 29.7 | 88.5 | 49.1 | 54.6 | 9.8 | 26.6 | 45.3 | 53.8 | |
| DACS [5] (w/Mixing) | 94.7 | 63.1 | 87.6 | 30.7 | 40.6 | 40.2 | 47.8 | 51.6 | 87.6 | 47.0 | 88.9 | 66.7 | 35.9 | 90.2 | 50.8 | 57.5 | 0.2 | 39.8 | 56.4 | 56.7 | |
| DACS [5] (w/SAM) | 87.8 | 56.0 | 79.7 | 45.3 | 44.8 | 45.6 | 53.5 | 53.5 | 88.6 | 45.2 | 82.1 | 70.7 | 39.4 | 90.0 | 49.5 | 59.4 | 1.0 | 48.9 | 56.4 | 57.8 | |
| DACS [5] (w/SAM+Mixing) | 92.7 | 54.1 | 88.9 | 44.2 | 33.3 | 43.8 | 49.8 | 38.0 | 88.4 | 45.0 | 86.5 | 70.1 | 45.0 | 90.0 | 41.4 | 50.6 | 42.0 | 46.3 | 58.7 | 60.5 | |
| SegFormer- Based | DAFormer [1] | 95.7 | 70.2 | 89.4 | 53.5 | 48.1 | 49.6 | 55.8 | 59.4 | 89.9 | 48.9 | 92.5 | 72.2 | 44.7 | 92.3 | 74.5 | 78.2 | 65.1 | 55.9 | 61.8 | 68.3 |
| HRDA [47] | 96.7 | 75.0 | 90.0 | 58.2 | 50.4 | 51.1 | 56.7 | 62.1 | 90.2 | 53.3 | 92.9 | 72.4 | 47.1 | 92.6 | 78.9 | 83.4 | 75.6 | 54.2 | 62.6 | 70.7 | |
| MIC-DAFormer [14] | 95.8 | 73.3 | 92.8 | 56.2 | 51.9 | 51.6 | 59.6 | 62.8 | 93.1 | 51.9 | 96.3 | 77.7 | 47.0 | 96.0 | 81.7 | 81.7 | 68.2 | 59.9 | 64.3 | 71.6 | |
| MIC-DAFormer [14] (w/SAM) | 96.4 | 74.4 | 91.0 | 61.6 | 51.5 | 58.1 | 63.9 | 69.3 | 91.3 | 50.4 | 94.2 | 81.6 | 52.9 | 93.7 | 84.1 | 85.7 | 79.5 | 63.9 | 67.5 | 74.2 | |
| SamDA (Ours) | 96.4 | 76.2 | 89.9 | 66.6 | 53.6 | 58.9 | 63.3 | 68.9 | 92.3 | 52.4 | 95.2 | 82.3 | 54.8 | 95.8 | 84.8 | 87.4 | 74.7 | 65.3 | 70.8 | 75.2 |
| Model | ST | Traditional-Mix | Mix (Ours) | Finetune | Former-Based | mIoU |
|---|---|---|---|---|---|---|
| 1 | ✕ | ✕ | ✕ | ✕ | ✕ | 40.3 |
| 2 | ✓ | ✕ | ✕ | ✕ | ✕ | 48.8 |
| 3 | ✓ | ✓ | ✕ | ✕ | ✕ | 52.2 |
| 4 | ✓ | ✕ | ✓ | ✕ | ✕ | 56.7 |
| 5 | ✓ | ✕ | ✓ | ✓ | ✕ | 60.5 |
| 6 | ✓ | ✓ | ✕ | ✕ | ✓ | 68.3 |
| 7 | ✓ | ✕ | ✓ | ✕ | ✓ | 69.4 |
| 8 | ✓ | ✕ | ✓ | ✓ | ✓ | 75.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, Q.; Su, H.; Liu, X.; Yu, Y.; Lin, Z. SAM-Enhanced Cross-Domain Framework for Semantic Segmentation: Addressing Edge Detection and Minor Class Recognition. Processes 2025, 13, 736. https://doi.org/10.3390/pr13030736
Wan Q, Su H, Liu X, Yu Y, Lin Z. SAM-Enhanced Cross-Domain Framework for Semantic Segmentation: Addressing Edge Detection and Minor Class Recognition. Processes. 2025; 13(3):736. https://doi.org/10.3390/pr13030736
Chicago/Turabian StyleWan, Qian, Hongbo Su, Xiyu Liu, Yu Yu, and Zhongzhen Lin. 2025. "SAM-Enhanced Cross-Domain Framework for Semantic Segmentation: Addressing Edge Detection and Minor Class Recognition" Processes 13, no. 3: 736. https://doi.org/10.3390/pr13030736
APA StyleWan, Q., Su, H., Liu, X., Yu, Y., & Lin, Z. (2025). SAM-Enhanced Cross-Domain Framework for Semantic Segmentation: Addressing Edge Detection and Minor Class Recognition. Processes, 13(3), 736. https://doi.org/10.3390/pr13030736