1. Introduction
Coal is currently utilized as a fuel in many thermal power plants worldwide. However, the combustion process of coal generates nitrogen oxides (NO
x), which can directly impact human respiratory systems, damage the ozone layer, and contribute to greenhouse effects [
1]. With growing concerns about energy utilization and environmental emissions [
2], coal-fired power plants must not only enhance boiler combustion efficiency but also reduce pollutant emissions [
3,
4]. In recent years, data-driven modeling has grown vigorously and has been widely applied to combustion optimization in coal-fired utility boilers. However, due to the lengthy calculation time, the applications of traditional optimization methods in actual engineering are limited [
5]. Moreover, the nonlinearity between combustion system parameters and the optimization objectives poses serious challenges to improving operational performance [
6]. Therefore, studying more advanced methods for online optimizing the combustion process is worthwhile.
Before combustion optimization, characteristic models are required to be established. A mechanism model is one of the typical methods. It can obtain the distributions of velocity, chemical components, temperature, and other furnace information like boiler thermal efficiency and pollutant emission concentrations [
7]. However, this method often involves complex multiphysics coupled iterative calculations, requiring high calculation costs [
8], so combining mechanism modeling with intelligent optimization algorithms and applying it to actual boiler online optimization is difficult. In contrast to a mechanism model, a data-driven model does not require a deep understanding of the mechanism or much designer experience. It mainly reflects the internal laws through the data themselves; furthermore, the excellent solution speed of a data-driven model also aids boiler online optimization applications [
9].
Data-driven boiler combustion optimization has been widely recognized by both academia and industry. To meet the needs of on-site operation optimization of coal-fired power plants, two main optimization strategies exist: (a) obtaining the quantitative relationship between operational variables and target variables through data mining algorithms and then expressing the quantitative relationship as association rules for combustion optimization; (b) constructing a data-driven boiler combustion system model and using intelligent optimization algorithms to search for the optimal operating solutions for this model.
Strategy (a) uses boiler historical operating data to create optimization rules for combustion and then optimizes boiler parameters based on these rules. This approach offers fast solving capabilities and is appropriate for online optimization. Yang et al. [
10] introduced fuzzy set theory in the association mining process to identify important optimization parameters in the combustion process. Using boiler historical data, the optimized values can be obtained quickly during operation. Zhao et al. [
11] established an optimal rule base for historical operation data by using the fuzzy association rule mining method. Because the rule base is the result of a global search, it is suitable for online use and can be easily and quickly updated when the working conditions of the boiler combustion system change. In addition, Kusiak et al. [
12,
13,
14] studied the relationships between uncontrollable variables, controllable variables, and target variables through cluster analysis. By adjusting controllable variables, the target variable can be optimized. The abovementioned optimization scheme based on data mining can quickly obtain a good optimization scheme under any boiler condition, but it cannot guarantee the best optimization scheme will be obtained.
To search for better optimization solutions that are different from historical operating solutions, strategy (b) including system modeling and multiobjective optimization can be used. First, the characteristic model of the boiler combustion system is established using historical data, and then the combustion process is optimized by intelligent optimization methods according to the model. Zhou et al. [
15] constructed an artificial neural network (ANN) model with NO
x emissions and thermal efficiency as the output and used a genetic algorithm (GA) to obtain a good NO
x emission concentration and boiler combustion efficiency. Wang et al. [
16] employed Gaussian process regression (GPR) to establish the relationship between boiler operational parameters and NO
x emission concentrations. Under specific combustion conditions, they utilized a GA to identify optimal boiler operational parameters that result in lower NO
x emissions. Song et al. [
17] initially designed an enhanced generalized regression neural network (EGRNN) using Gaussian adaptive resonance theory (GART) learning and polynomial extrapolation. They then formulated a cost function that accounted for potential coal ash recovery. Finally, they utilized an improved version of the artificial bee colony algorithm (ABC) to determine the optimal parameters for the boiler. This comprehensive approach involves using advanced techniques such as neural networks, optimization algorithms, and cost considerations to optimize boiler combustion performance, accounting for coal ash recycling potential. In the discussed literature, researchers often convert multiobjective optimization problems into single-objective optimization problems to simplify calculations. However, this approach is subjective and cannot handle nonconvex sets. To comprehensively consider boiler combustion efficiency and environmental protection, a better solution is to compromise among multiple objectives and search for a set of Pareto optimal solutions so that their objective values are distributed on the Pareto front. Ma et al. [
18] employed an improved extreme learning machine (ELM) to construct models for the efficiency, NO
x concentration, and SO
2 concentration of a circulating fluidized bed boiler. They then utilized a multiobjective modified teaching–learning-based optimization (MMTLBO) algorithm to optimize the combustion parameters of the boiler. Rahat et al. [
19] used the nonlinear regression of the Gaussian process to establish models for unburned coal content and NO
x emissions. Then, they used the evolutionary multiobjective search algorithm (EMOSA) to search for the ideal combustion operating parameters for boiler combustion optimization. The above scheme based on a data-driven model and intelligent optimization algorithm can effectively search for the best optimization scheme. However, compared with the optimization method based on the case library, the optimization method based on the data-driven model takes a longer amount of time to obtain a series of optimization schemes and has certain defects in the real-time response of the boiler online combustion optimization.
In summary, strategy (b) usually leads to better optimization results than strategy (a). However, the optimization calculations involved in strategy (b) typically take several minutes (or longer) to complete, whereas strategy (a) can be accomplished within a short time frame (less than 1 s) and is based on actual operational data. This makes strategy (a) a simple, rapid, and secure approach. In addition, case-based reasoning (CBR) theory is widely used to achieve the online combustion optimization of boilers. CBR quickly solves current problems by retrieving similar cases from historical experience or optimization results [
20,
21]. Considering the pros and cons of the aforementioned optimization methods, a novel method that combines data-driven algorithms with CBR to construct an optimization case library for online boiler combustion optimization is proposed in this paper. This method aims to enhance boiler efficiency while reducing NO
x emissions, achieving real-time boiler combustion optimization. The proposed approach provides operational guidance based on real-time data streams, presenting significant research and practical value. Integrating data-driven algorithms and CBR offers a balanced solution, leveraging both accuracy and real-time responsiveness for boiler online combustion optimization.
3. Data Filter Design
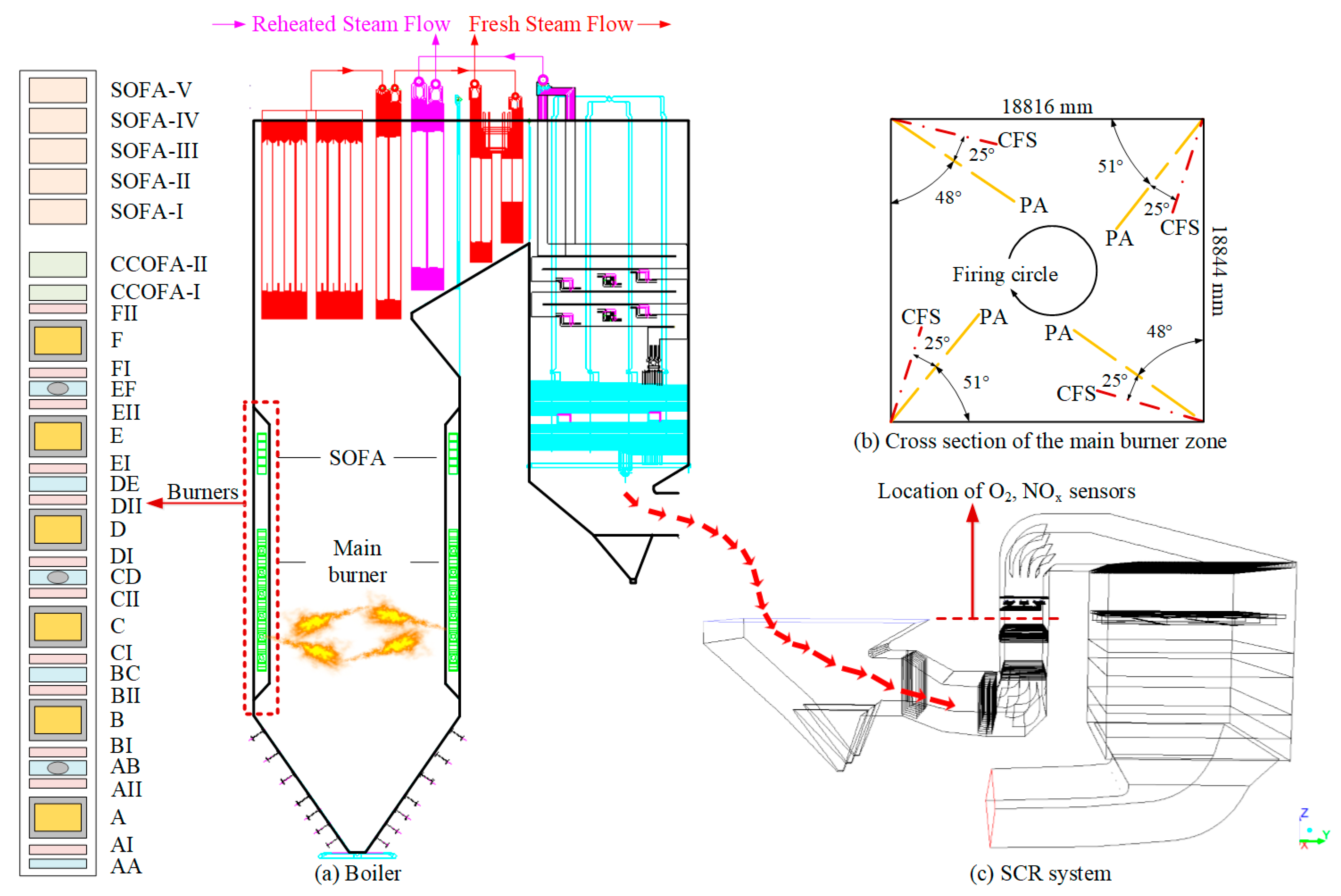
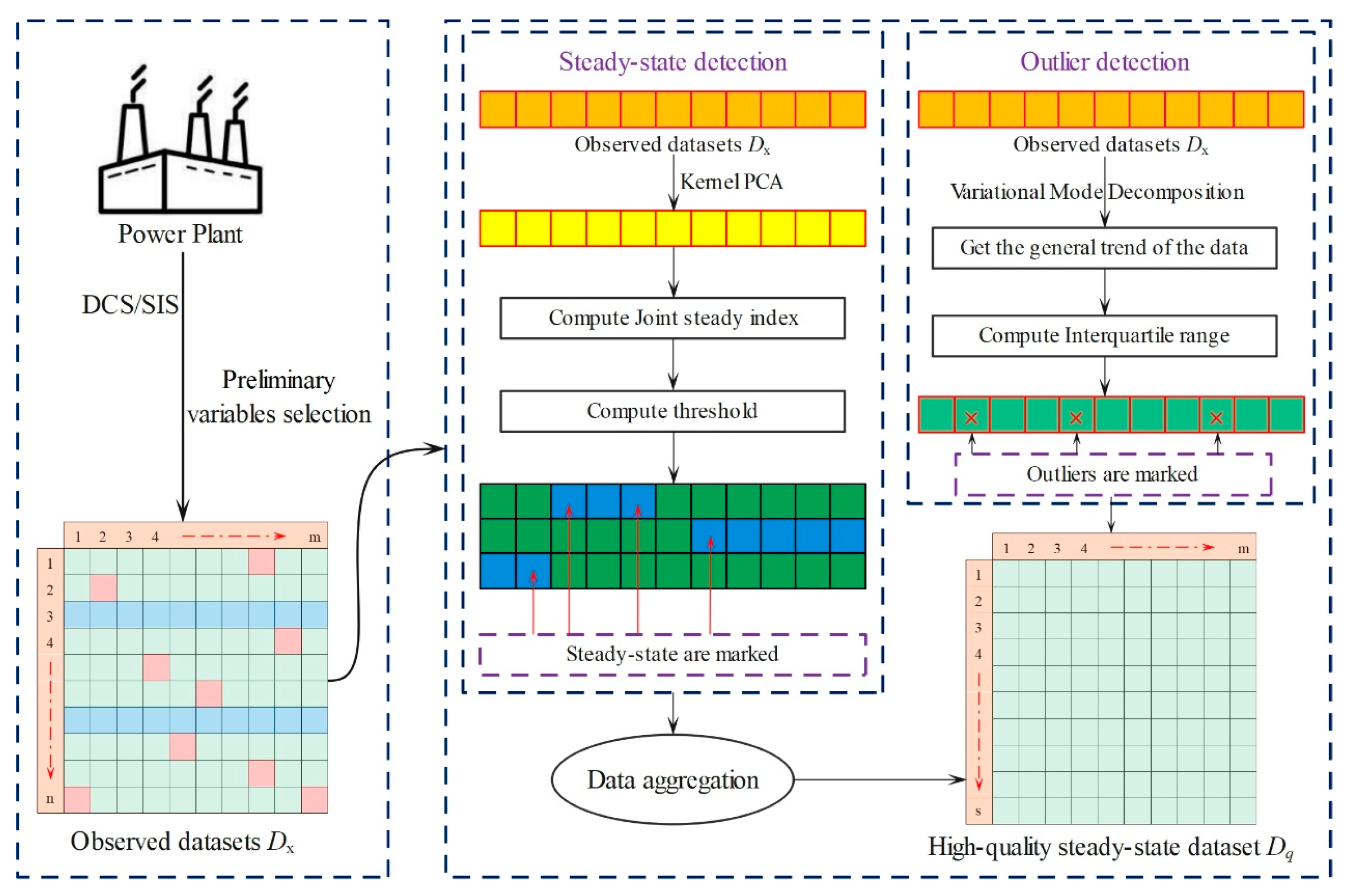
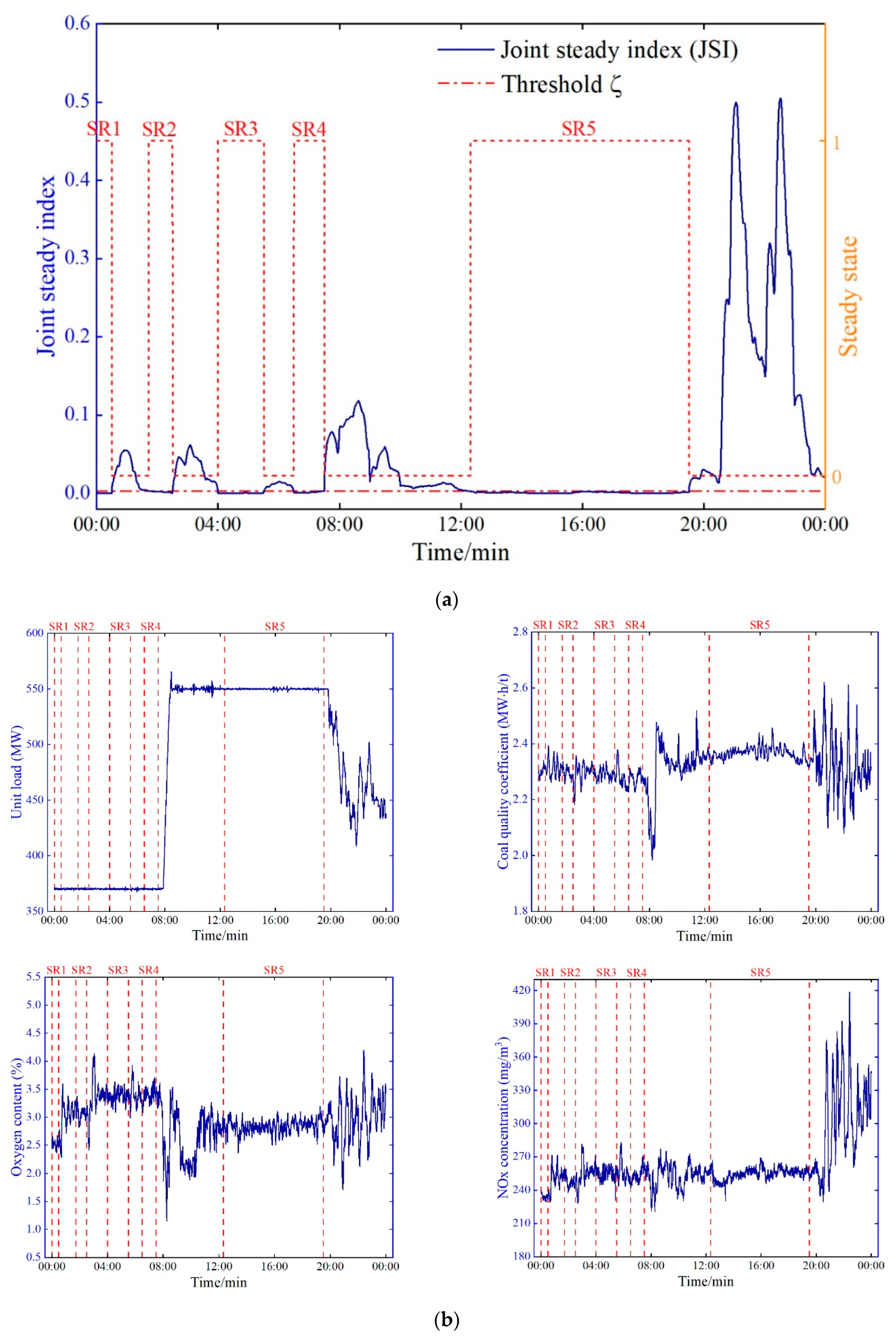
Due to the need to establish a case library that accurately reflects the mechanism relationship examined in this study, high-quality data corresponding to the steady-state operating conditions of the unit must be selected. Therefore, a robust filter framework is designed to filter out nonsteady-state and abnormal data. The data filtering process is shown in
Figure 3.
First, original data are collected from the plant’s supervisory information system (SIS) database. To obtain high-quality data samples that accurately reflect the static mechanism of the boiler combustion system, steady-state diagnosis and outlier detection are performed on the original observed data. Aiming at this process, a filter algorithm framework integrating steady-state diagnosis and outlier detection using a steady-state detection method based on kernel-PCA is proposed by comparing the joint steady index (JSI) with a given threshold and filtering the appropriate steady-state samples from the original observed data. In addition, the VMD algorithm is used to determine the data flow trend, and the outliers are determined by calculating the interquartile range to obtain the confidence interval. Finally, the data samples that passed the steady-state diagnosis and outlier detection are aggregated to form the high-quality steady-state dataset containing combustion system information.
3.1. Steady-State Identification
A sliding time window strategy is employed with the kernel-PCA algorithm for steady-state identification to determine the boiler’s operational status [
24]. Given a matrix
with
m variables and
n observations and considering the need to eliminate the influence of dimensions, the matrix
X is first normalized by the mean value to obtain a new matrix
X’. For a specific variable
xi, the vector
represents the subset corresponding to a certain sliding time window T of the matrix
X’. Therefore, the data under a sliding window can be expressed as
, and the vector
can be mapped to the high-dimensional space by the kernel function
to obtain
. Let
S be the covariance matrix of the data samples in the feature space; then, the following formula is obtained:
In this paper, the Gaussian kernel function is used:
where
represents the kernel function and
γ is a free parameter.
The calculation steps of the multivariate steady-state detection algorithm are as follows:
Step 1: Mean-normalize the original data to obtain a new matrix X′.
Step 2: Obtain the data Dt of the corresponding sliding time window, map it to the high-dimensional space through Equations (2) and (3), and obtain the result.
Step 3: Compute the covariance matrix S of .
Step 4: Compute the l principal eigenvalues and eigenvectors of S, and arrange them in descending order.
Step 5: Compute the steady-state index vector .
Step 6: Compute the joint steady index (
JSI) according to the steady-state index vector
C and Equation (4).
Step 7: Compute the threshold
according to Equation (5).
where
λ is a positive adjustment coefficient and
represents the average value of JSI.
Step 8: Judge whether is true; if it is true, keep the data sample; otherwise, delete it.
3.2. Outlier Detection
Variational Modal Decomposition (VMD) is a signal decomposition algorithm [
25] that divides the original signal into multiple signals from the perspective of the frequency domain and can be used to distinguish between normal and abnormal data [
26]. To reasonably select the parameters of the VMD algorithm, the minimum envelope entropy [
27] is used as the objective function, and the genetic algorithm is used to identify the best parameter combination for achieving the best signal decomposition effect and ensuring trend extraction accuracy. The envelope entropy is mathematically defined as follows:
where
represents the envelope signal sequence obtained after the signal
is demodulated by Hilbert;
H represents the Hilbert transform of the signal; and
is the normalized form of
.
The Pearson coefficient method is used to measure the degree of correlation between two variables; it is mathematically defined in Equation (9). In this paper, the effective signal is determined by judging the threshold in Equation (10), and the effective signal is reconstructed to extract the trend line. Herein, the decomposed signal with a Pearson coefficient greater than the threshold
is effective.
where
and
are the covariance and standard deviation of
and
, respectively, and
is the maximum Pearson coefficient of each component and the original signal.
The trend extraction algorithm is shown in
Figure 4. The specific process is as follows:
Step 1: Input the original signal f, set the range of K to [2, 9], and set the range of α to [1000, 3000].
Step 2: Use the GA to search [K, α]. VMD is input, the original signal is decomposed, and KIMF components are obtained.
Step 3: Calculate the minimum envelope entropy of the decomposed signal according to Equations (6)–(8).
Step 4: Choose the effective signal according to Equations (9) and (10).
Step 5: Repeat steps 2~4 to identify the minimum envelope entropy of the decomposed signal and its corresponding best parameters [K, α].
Step 6: Decompose the original signal with the best parameters [K, α] by VMD and choose the effective signal.
Step 7: Reconstruct the signal according to Equation (11) to obtain the best trend line.
where
is the reconstruction signal and
N is the number of effective signals.
For the data point
on the extracted trend curve, the confidence interval is calculated using the interquartile range method. For the original signal
, if a data point is distributed outside the confidence interval, it is considered an outlier; otherwise, it is considered a normal point. The absolute error is first calculated according to Equation (12), and the confidence interval is calculated by Equation (13):
where
Q1 and
Q3 are the smaller and larger quartiles in the absolute error, respectively.
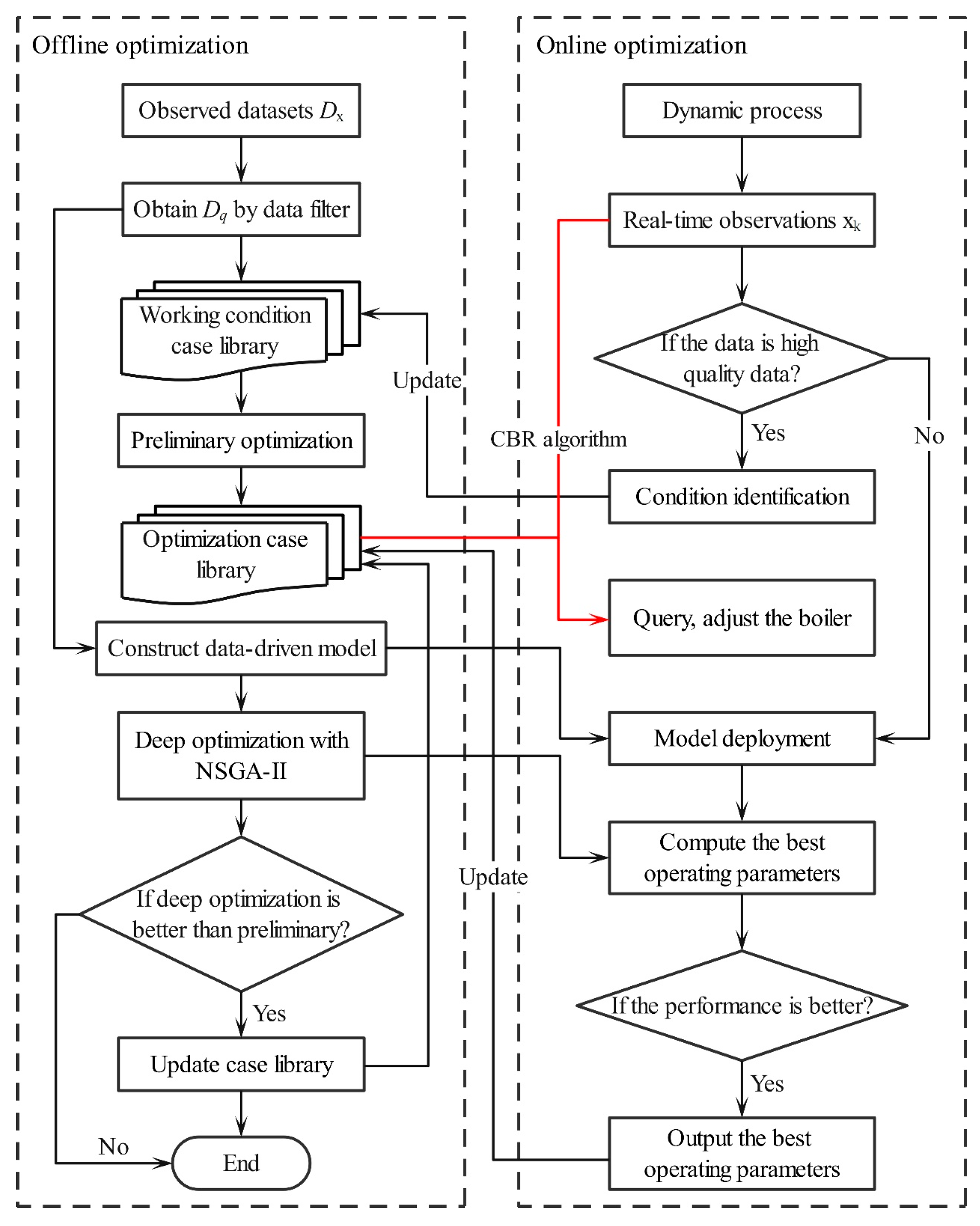
4. Offline and Online Optimization
4.1. Working Condition Case Library
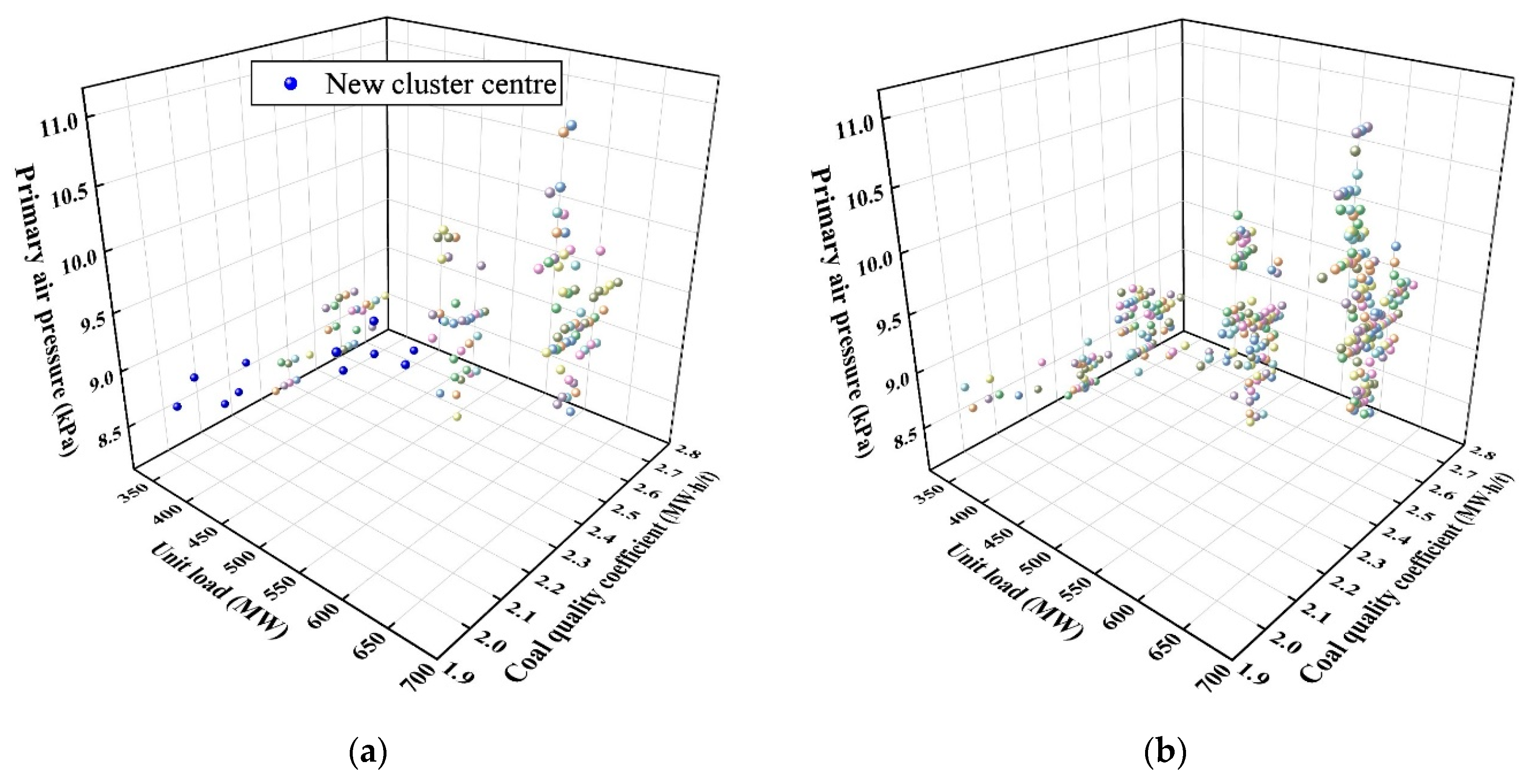
K-means++ [
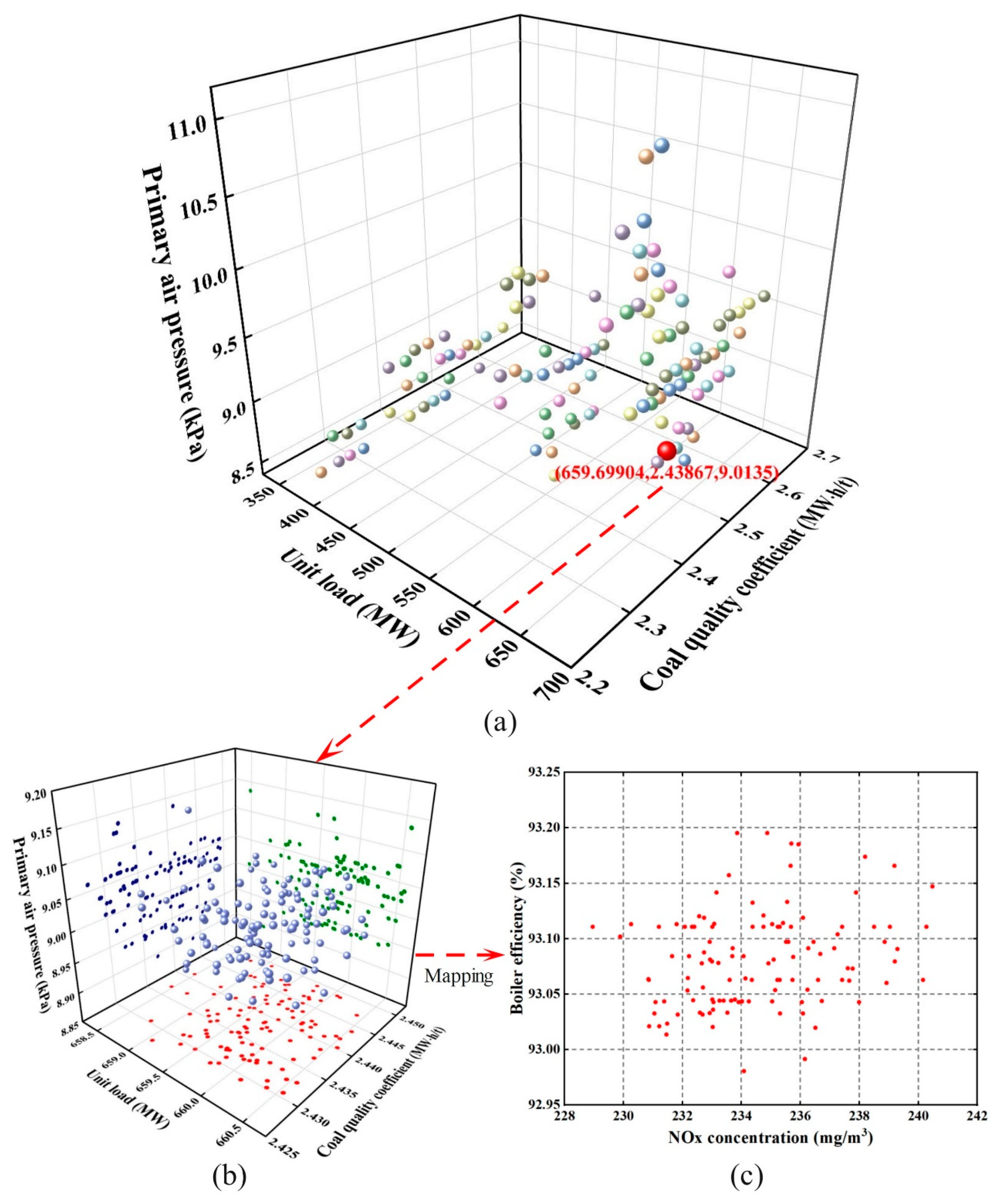
28] is used to cluster the three parameters that can reflect the operating state of the boiler, unit load, coal quality coefficient, and primary air pressure to construct an initial working condition case library. To consider the impact of data distribution changes on the case library, a reclustering strategy for the online adaptive calculation of working condition clusters is proposed.
According to engineering experience, when the working condition parameter range of data samples in a working condition cluster is kept within 2~3% of the parameter range in
Table 1, the working condition division performs well. We thus use the maximum intracluster parameter range
determined in the previous round of working condition clustering as the judgment condition of the strategy to determine the number of clusters k in the new round of working conditions. The process of a new working condition clustering round is shown in
Figure 5.
4.2. Preliminary Optimization
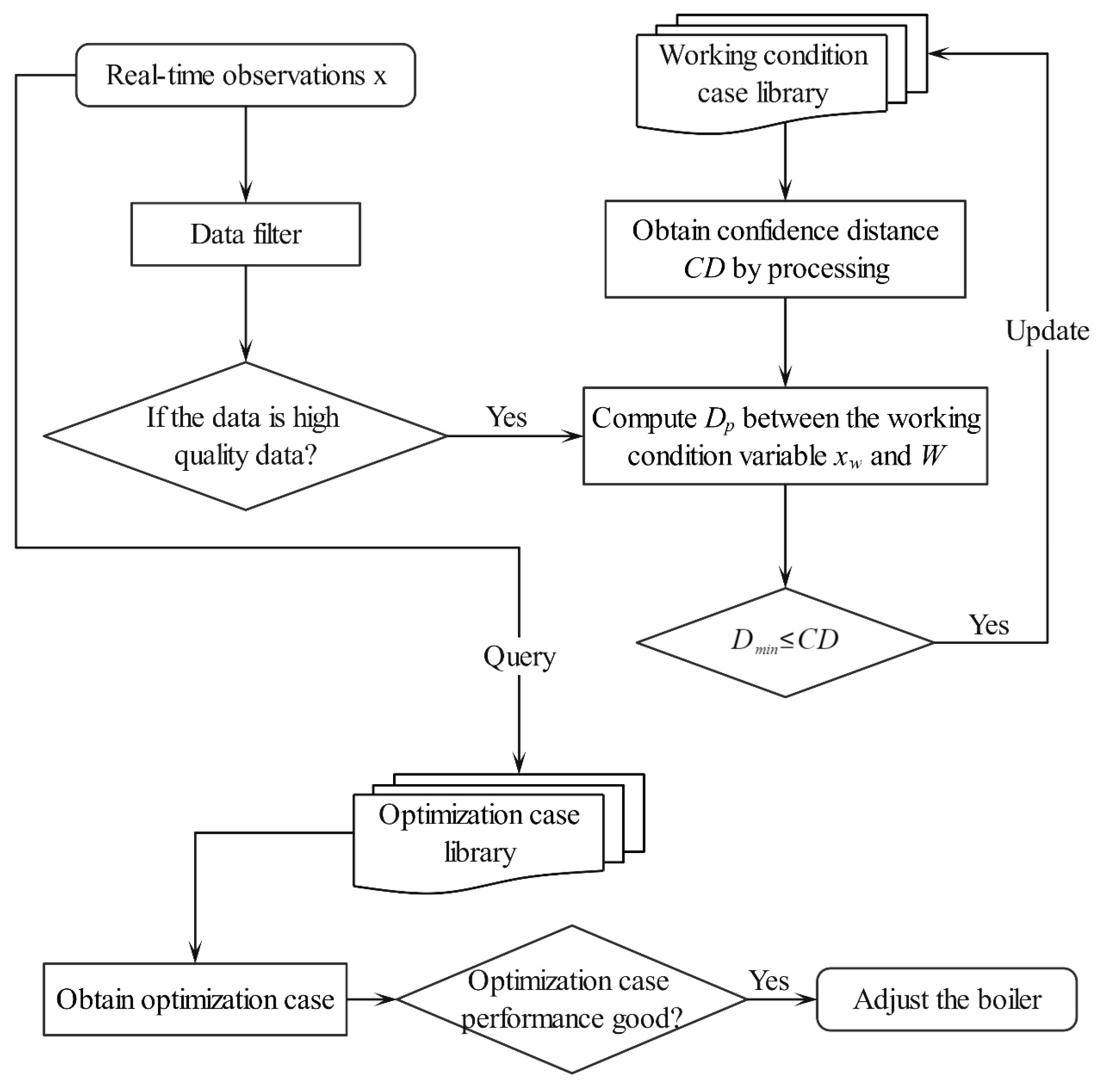
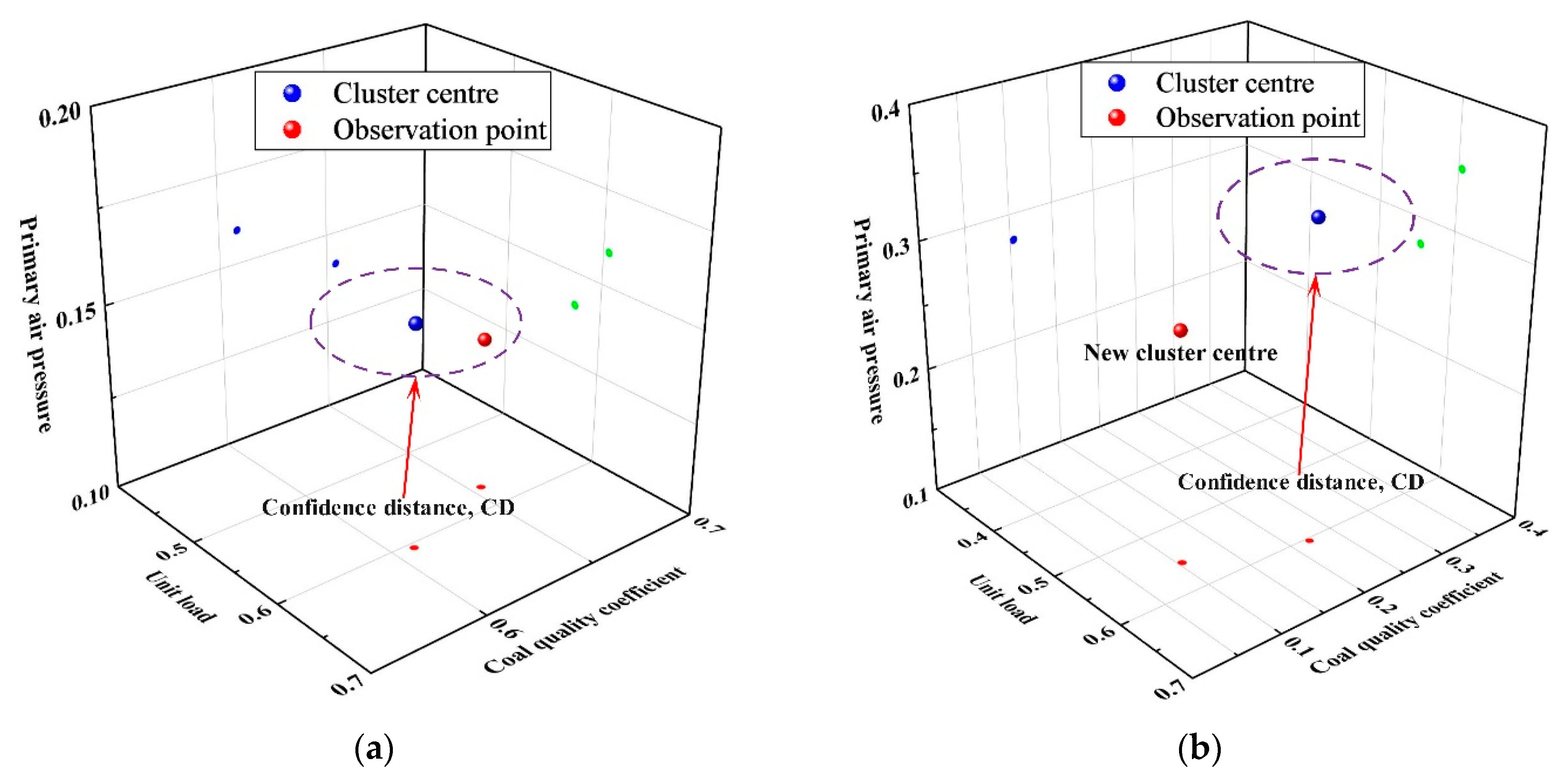
Based on the working condition case library, the initial boiler optimization case library is constructed by querying the two operating modes of the lowest NOx concentration and the highest boiler efficiency for each working condition in the working condition case library. To find the case most similar to the target case, an online case retrieval strategy is presented for determining the optimization case.
First, the optimization case library is defined as On = (x1,n, x2,n, …, xm,n, y1,n, y2,n), n = 1, 2, …, p, where p represents the total number of optimization cases; On represents the optimization case of the n-th working condition; represents the value of the m-th parameter of the n-th working condition optimization case; and and represent the boiler efficiency and NOx concentration in the optimization case, respectively.
Second, the Euclidean distance between two points in space is the proximity, denoted as d, as shown in Equation (14). Then, the maximum proximity of all data samples of each operating condition in the operating condition case library to the center of that operating condition can be represented as
. Next, this section defines the confidence distance (CD) as
.
The online retrieval strategy based on the confidence distance is depicted in
Figure 6. We provide the calculation steps of the store and update operation as follows:
Step 1: When observing a new data sample x, determine whether it passes the filter judgment; if it passes, the working condition variable of the data sample x is taken out as xw; otherwise, the retrieval is stopped.
Step 2: The working condition variables and cluster centers in the working condition case library are normalized to obtain the normalized cluster center set . CD is calculated from the normalized cluster center set.
Step 3: Normalize the current operating condition parameters to obtain , and calculate their proximity with the normalized operating condition parameters in the library to obtain .
Step 4: Calculate the minimum proximity and judge whether is true; if it is true, store it in the corresponding working condition case library.
4.3. Deep Optimization
Model-based optimization is conducted to improve the depth of the boiler optimization case library.
4.3.1. System Modeling
The boiler efficiency and NO
x emission model is constructed using XGBoost (Version 0.90). Its predicted value
can be expressed as the sum of the results of multiple base models:
where
N is all the value spaces of the regression tree;
K is the number of regression trees in the model;
xi is the input feature of the
i-th sample; and
is the prediction result of the
k-th tree. More details of the algorithm can be found in Ref. [
29].
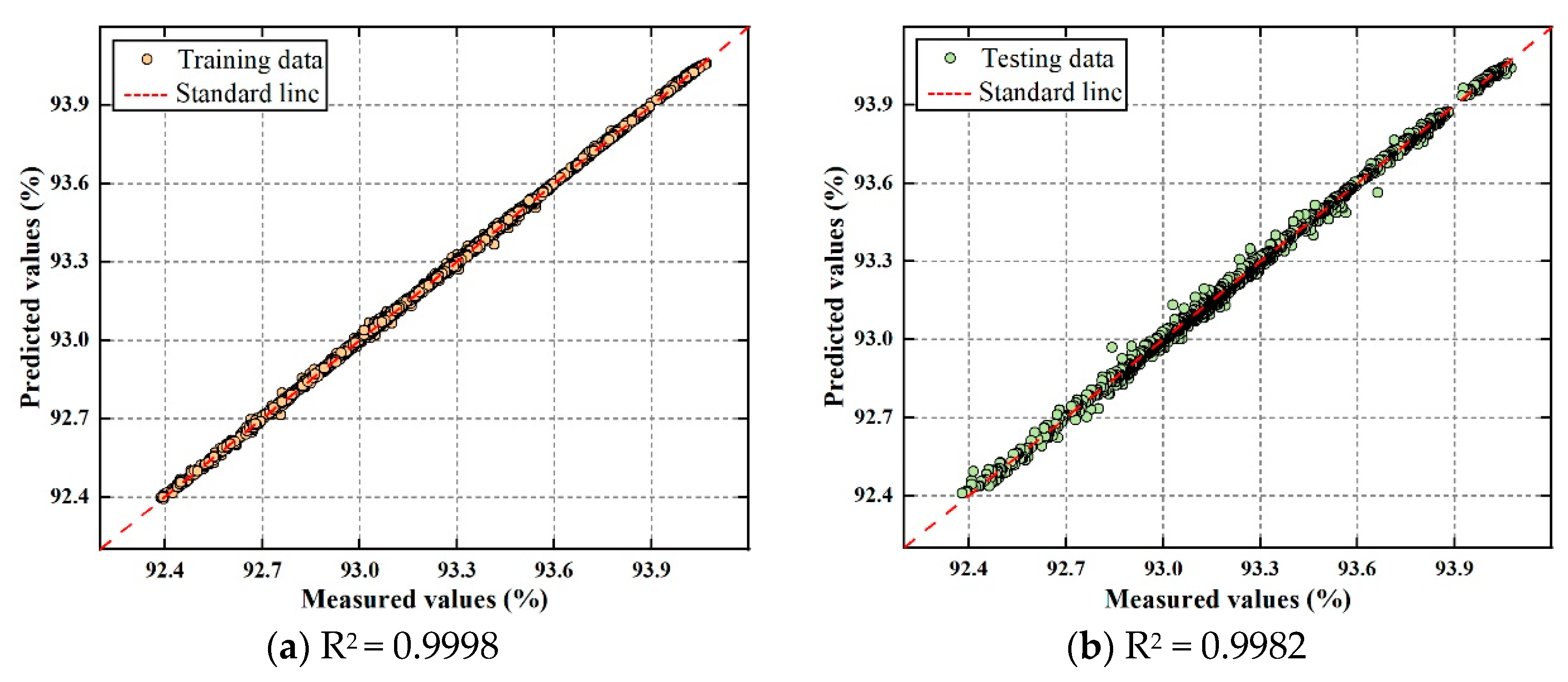
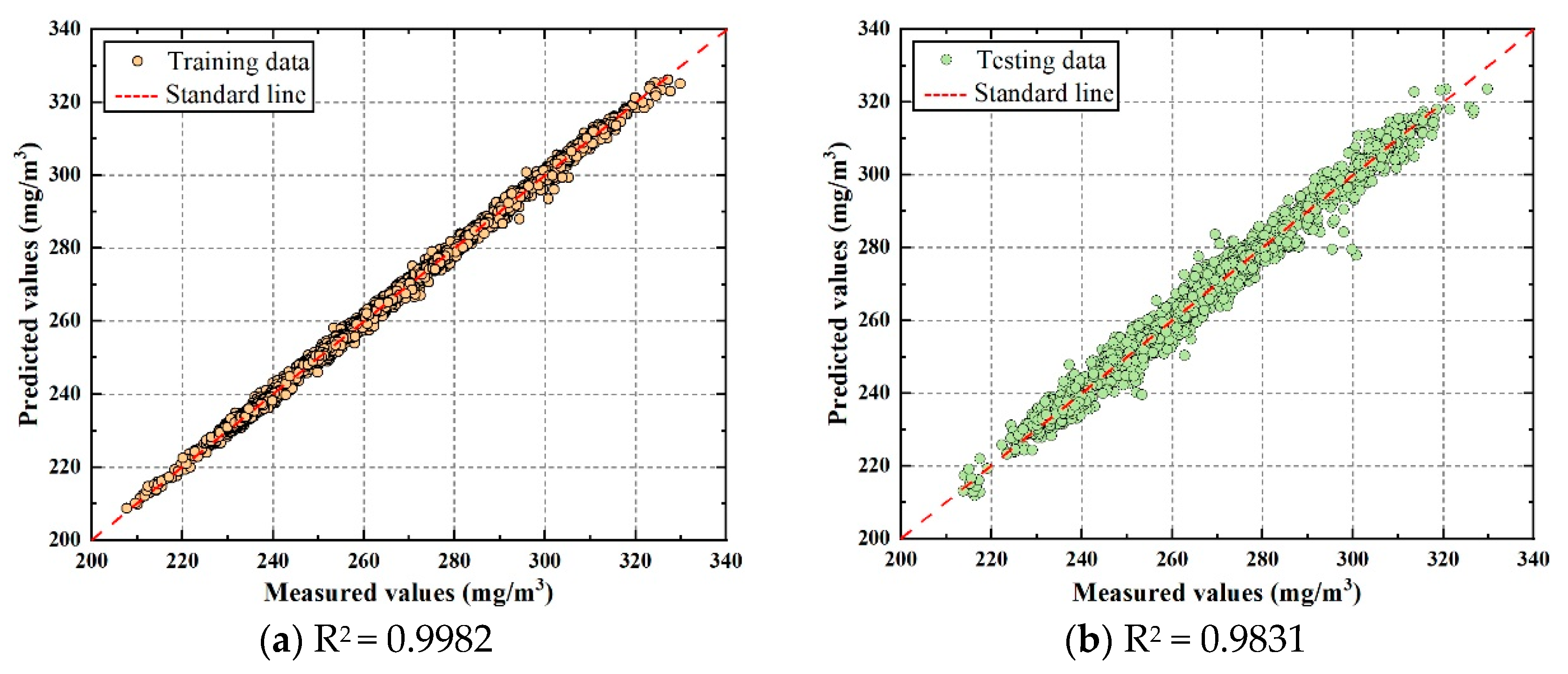
To evaluate performance, four evaluation metrics are used: mean absolute error (MAE), root mean square error (RMSE), mean absolute percentage error (MAPE), and R-squared (R
2). Smaller MAE, RMSE, and MAPE values indicate a better predictive performance. The closer the R
2 value is to 1, the more accurate the model’s predictive performance is. The indices are calculated as follows:
where
,
, and
denote the measured value, predicted value, and average value of the prediction target, respectively.
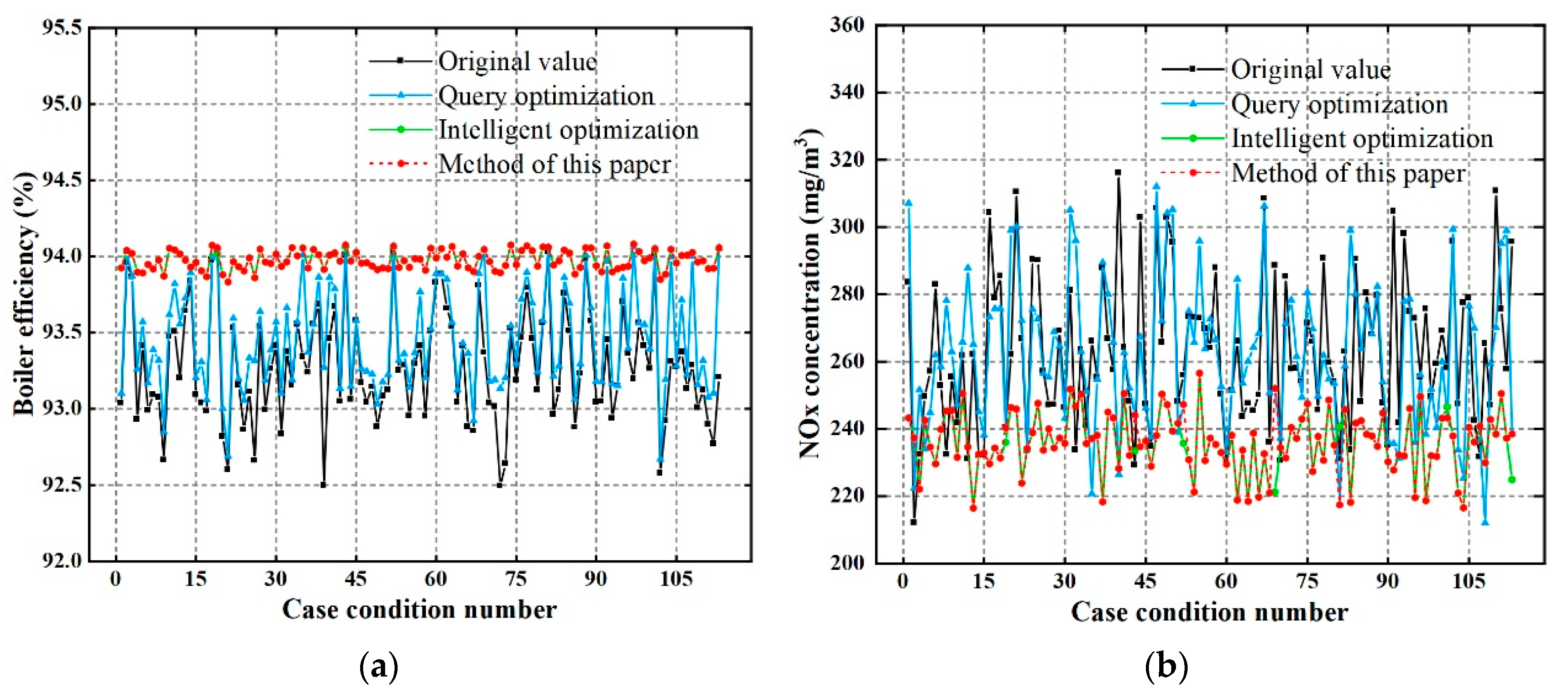
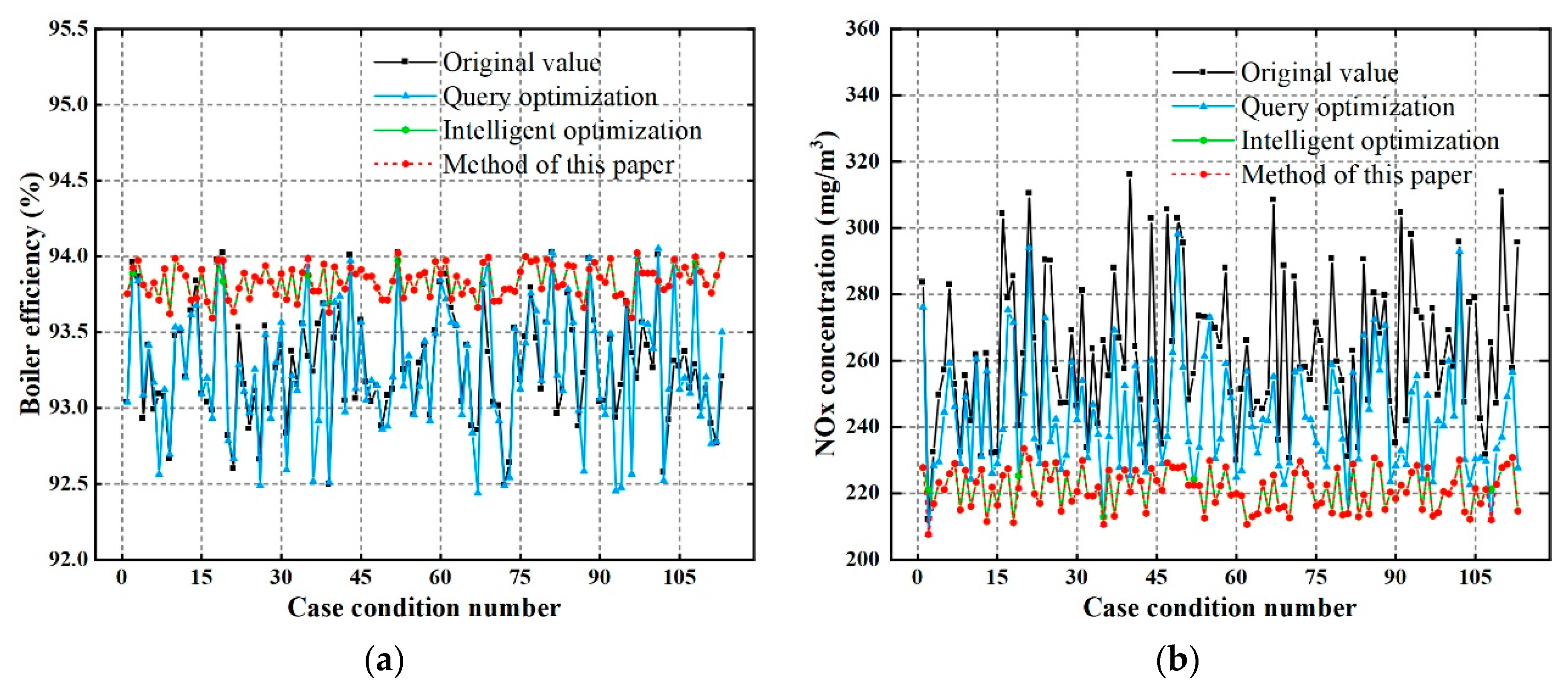
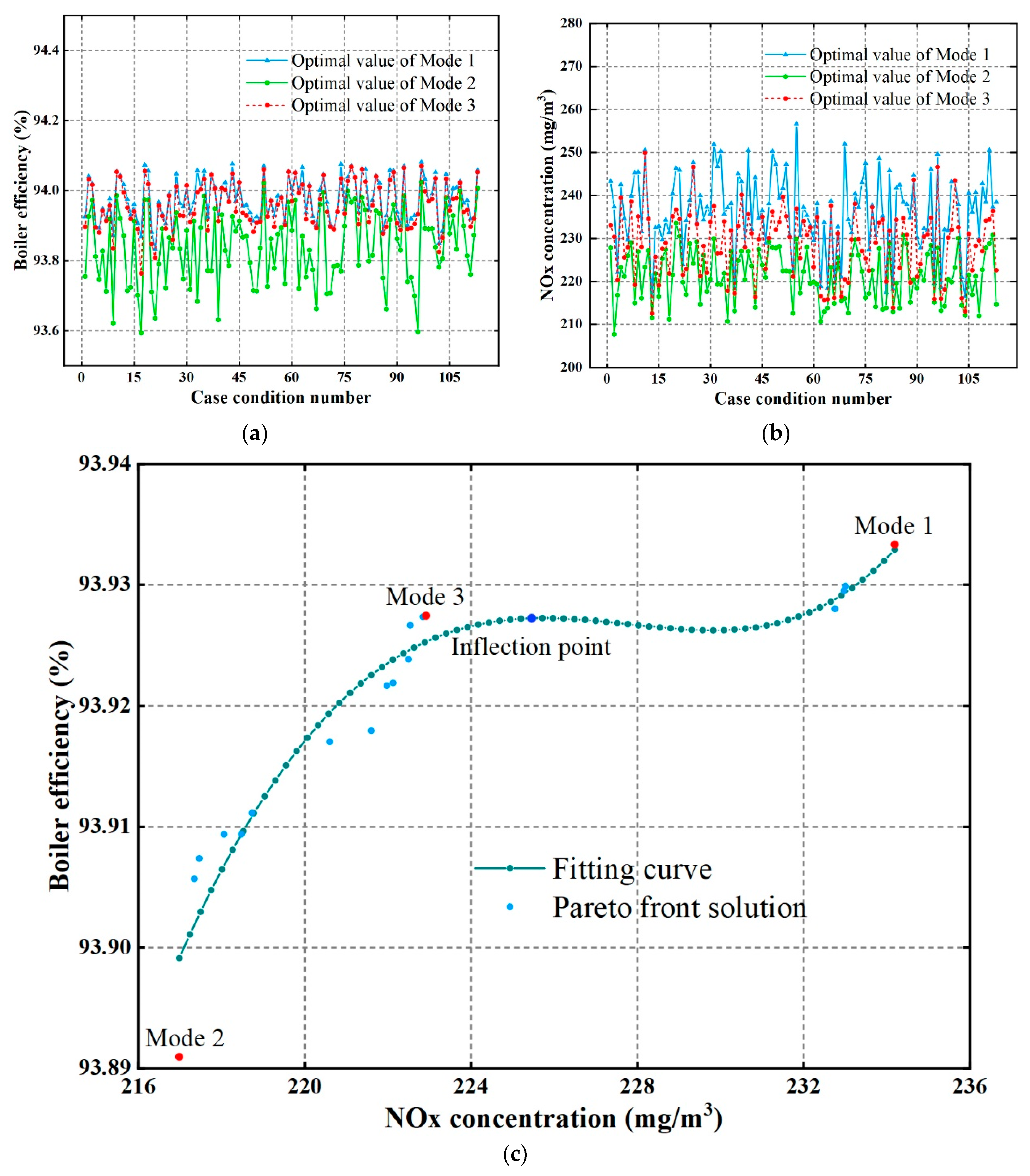
4.3.2. Multiobjective Optimization
NSGA-II [
30] is used for combustion optimization, yielding a set of optimal optimization schemes, the Pareto front solution set. To quickly determine the only optimal optimization scheme in the equilibrium mode, an inflection point attribution strategy is proposed. The obtained Pareto solution set exhibits a distribution of an approximate concave function in the plane space, which has a maximum point, also known as an inflection point. In actual boiler combustion optimization, the inflection point indicates that when the boiler efficiency rises to a certain level, continuing to increase the small range efficiency will greatly increase the NO
x concentration in the boiler. Therefore, in the equilibrium mode, choosing the Pareto solution at the inflection point is the best optimization scheme. However, the distribution of the data samples of the Pareto solution set actually calculated by the NSGA-II algorithm is not uniform, making it difficult to identify the actual solution of the inflection point. To address this problem, a curve is first fit on the Pareto solution set space using polynomial fitting, and the curve is then discretized with a certain sampling interval to calculate the inflection point
Xm on the fitted curve, and the closest Pareto solution to
Xm is identified as the best optimization solution in the equilibrium mode.
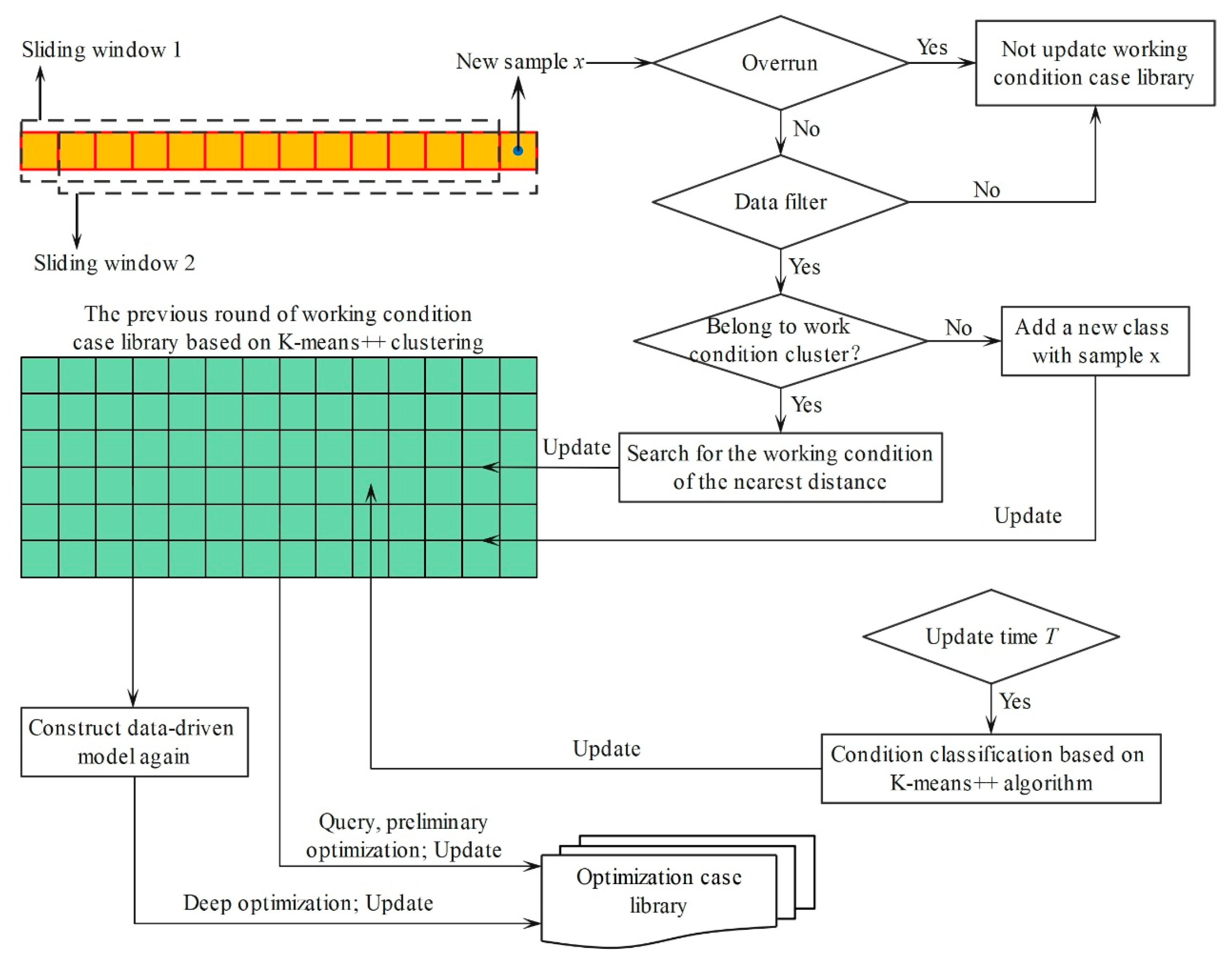
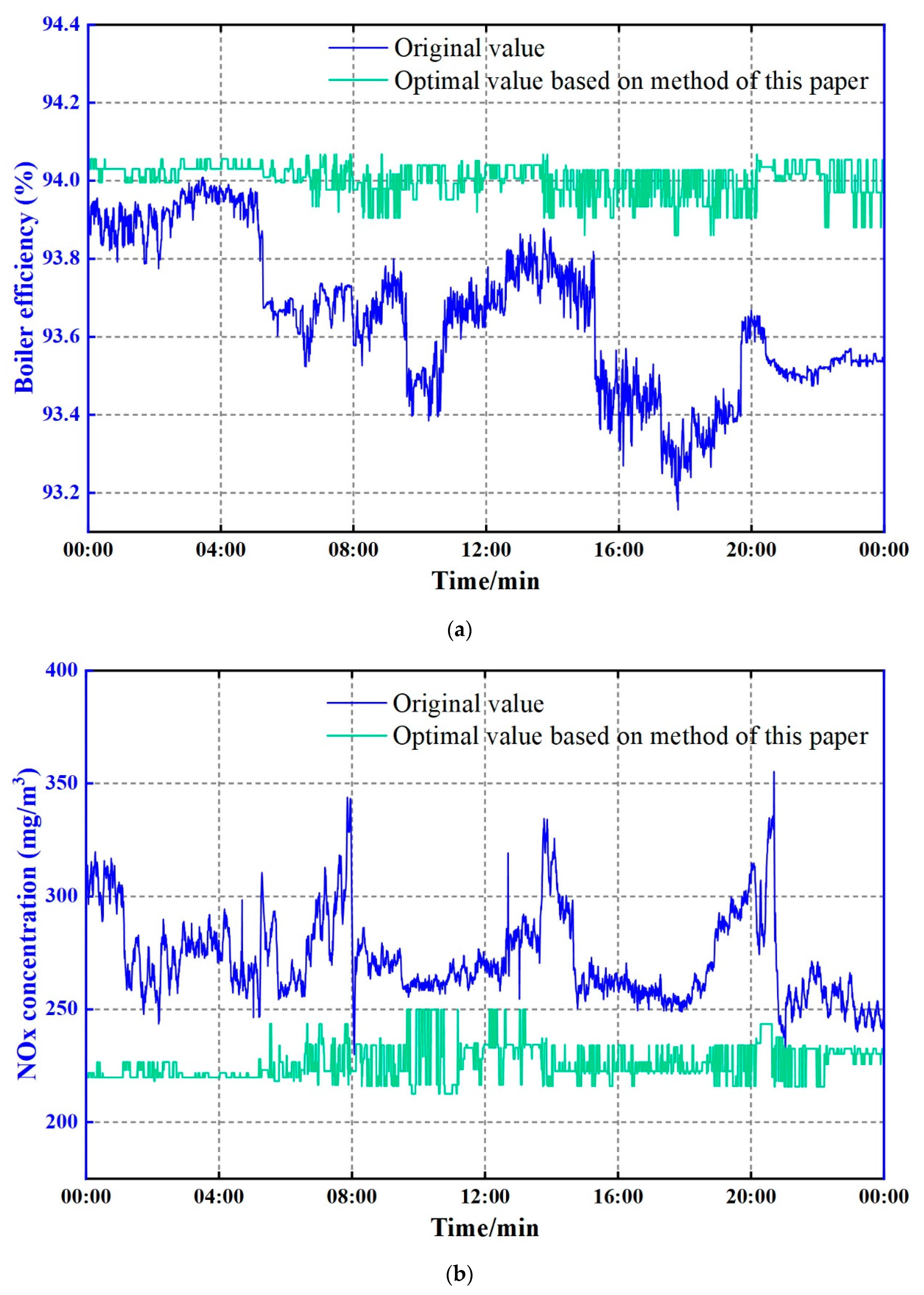
4.4. Adaptive Update Strategy
To consider the variation in the working condition case library over time, an online adaptive update strategy is proposed. The strategy is shown in
Figure 7, and the steps are as follows:
Step 1: The data filter is used to extract high-quality data samples Dq from the original data, and then the K-means++ algorithm is used to divide the working conditions and construct the initial boiler working condition case library; the online adaptive update period is defined as T.
Step 2: When a new data sample x is observed in real time, whether it is overrun is evaluated; if it is, the working condition case library is not updated.
Step 3: The data filter is used to determine whether x is a high-quality data sample; if it is, Step 4 is carried out; otherwise, the working condition case library is not updated.
Step 4: Using the online retrieval strategy, whether x belongs to the existing working condition cluster is judged; if it is, x will be stored in the nearest working condition cluster; otherwise, a new category of working conditions is added with the data sample as the cluster center and updated synchronously in the optimization case library.
Step 5: Steps 2~4 are repeated until the adaptive update period T is reached; at this time, the working conditions are reclassified based on the K-means++ algorithm to construct the working condition case library and the optimization case library. The data-driven model is trained based on the reconstructed working condition case library. After training, the model is updated online, and the optimization case library is updated again.
Step 6: The timing is repeated until the adaptive update period T is reached, and a new round of data and model updates is conducted.



 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}