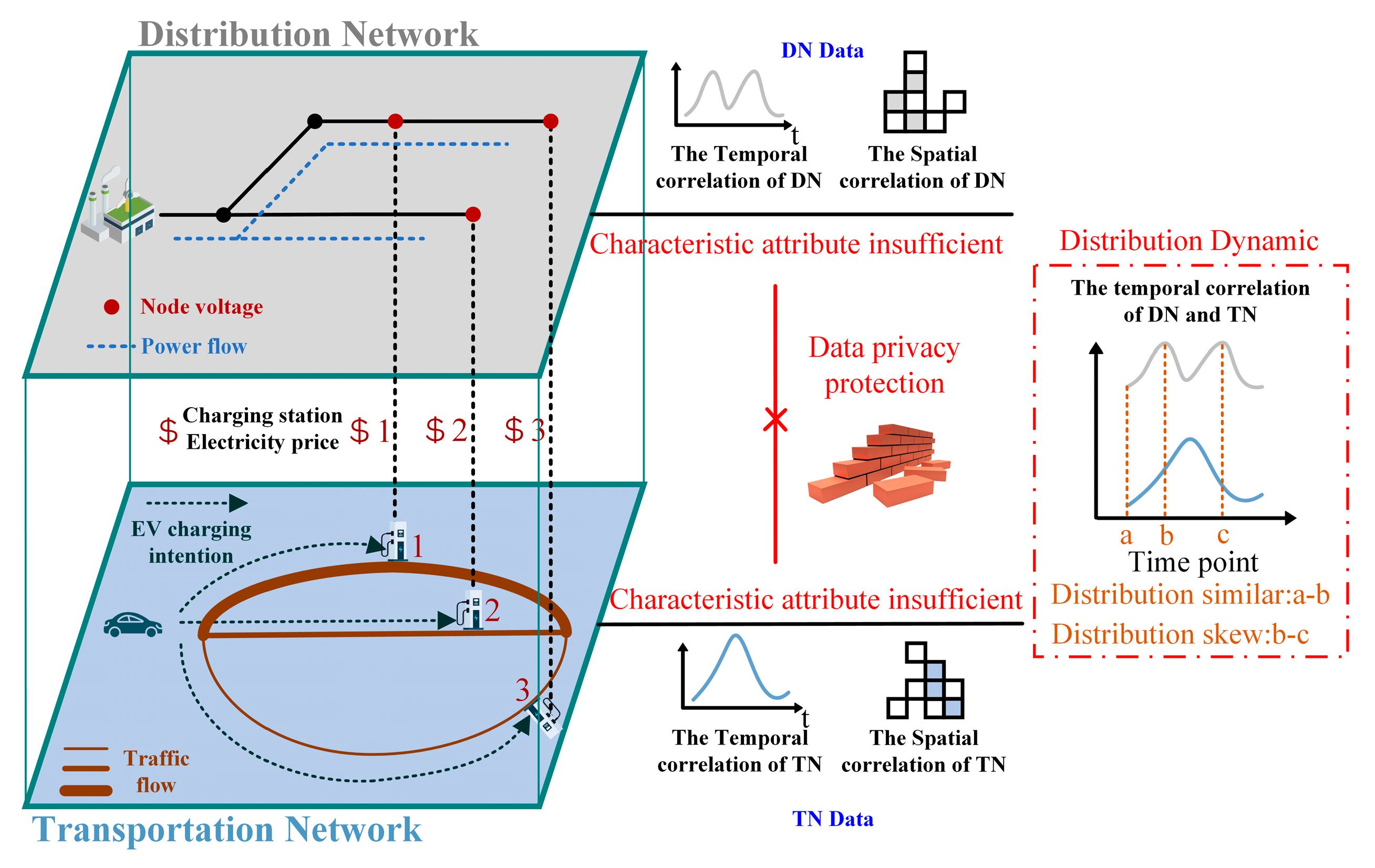
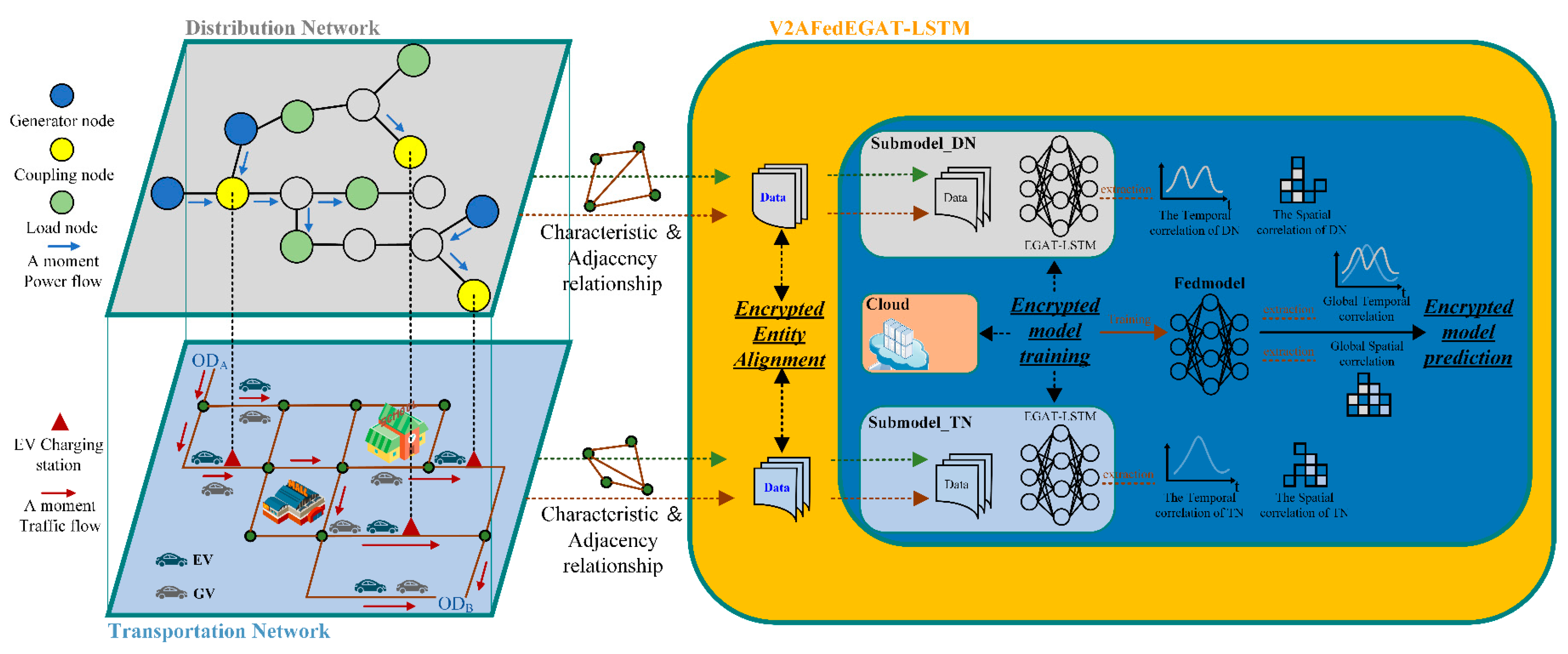
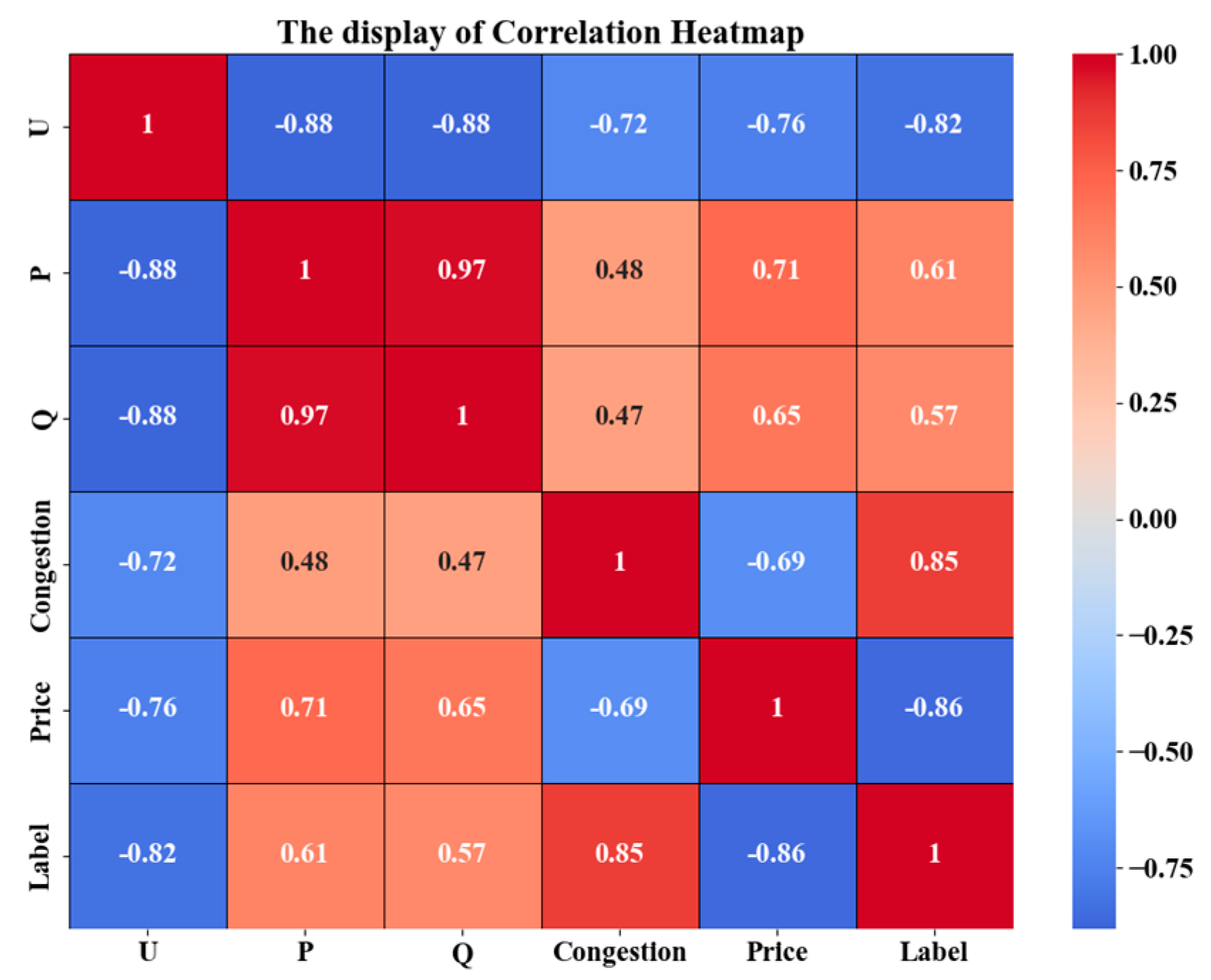
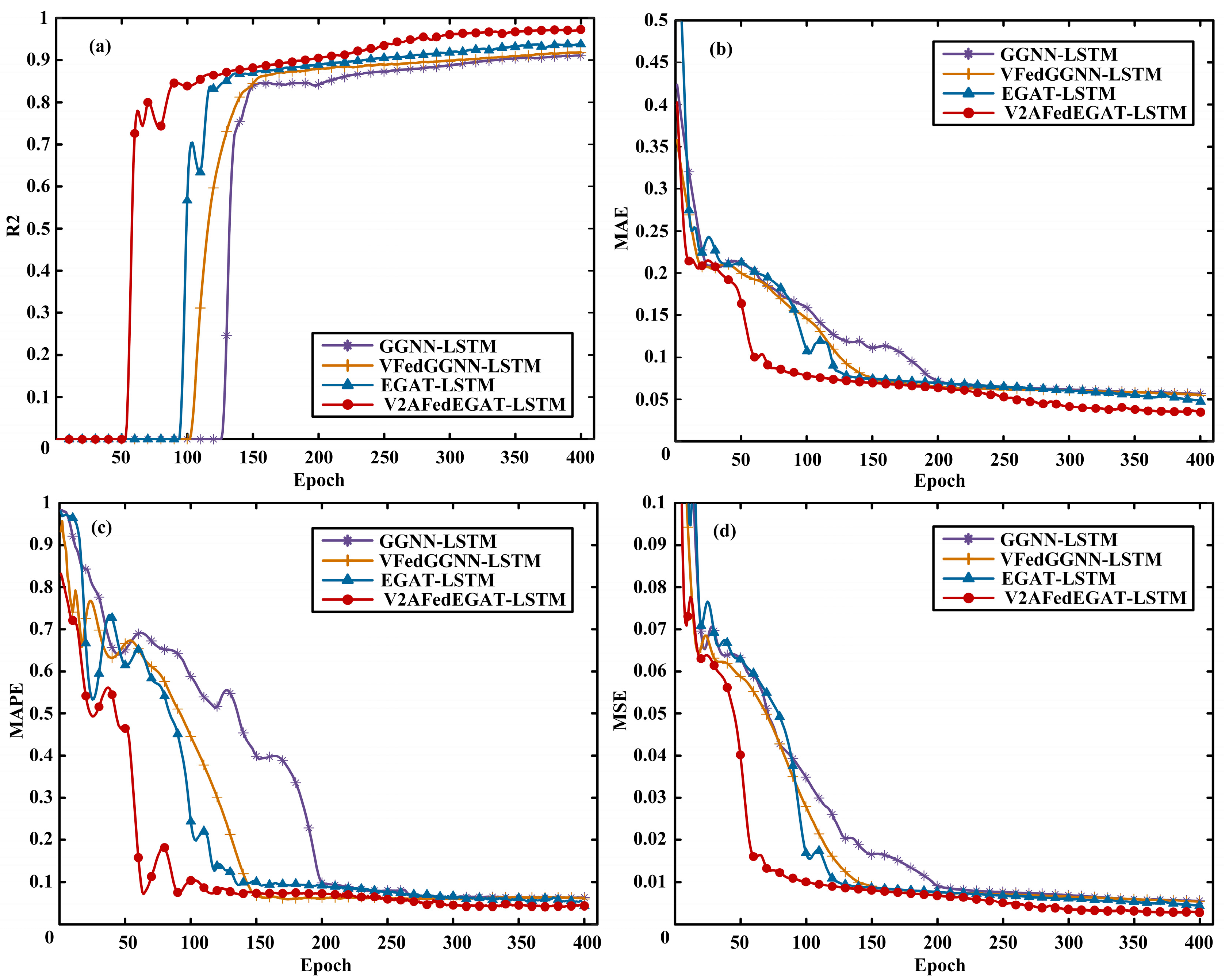
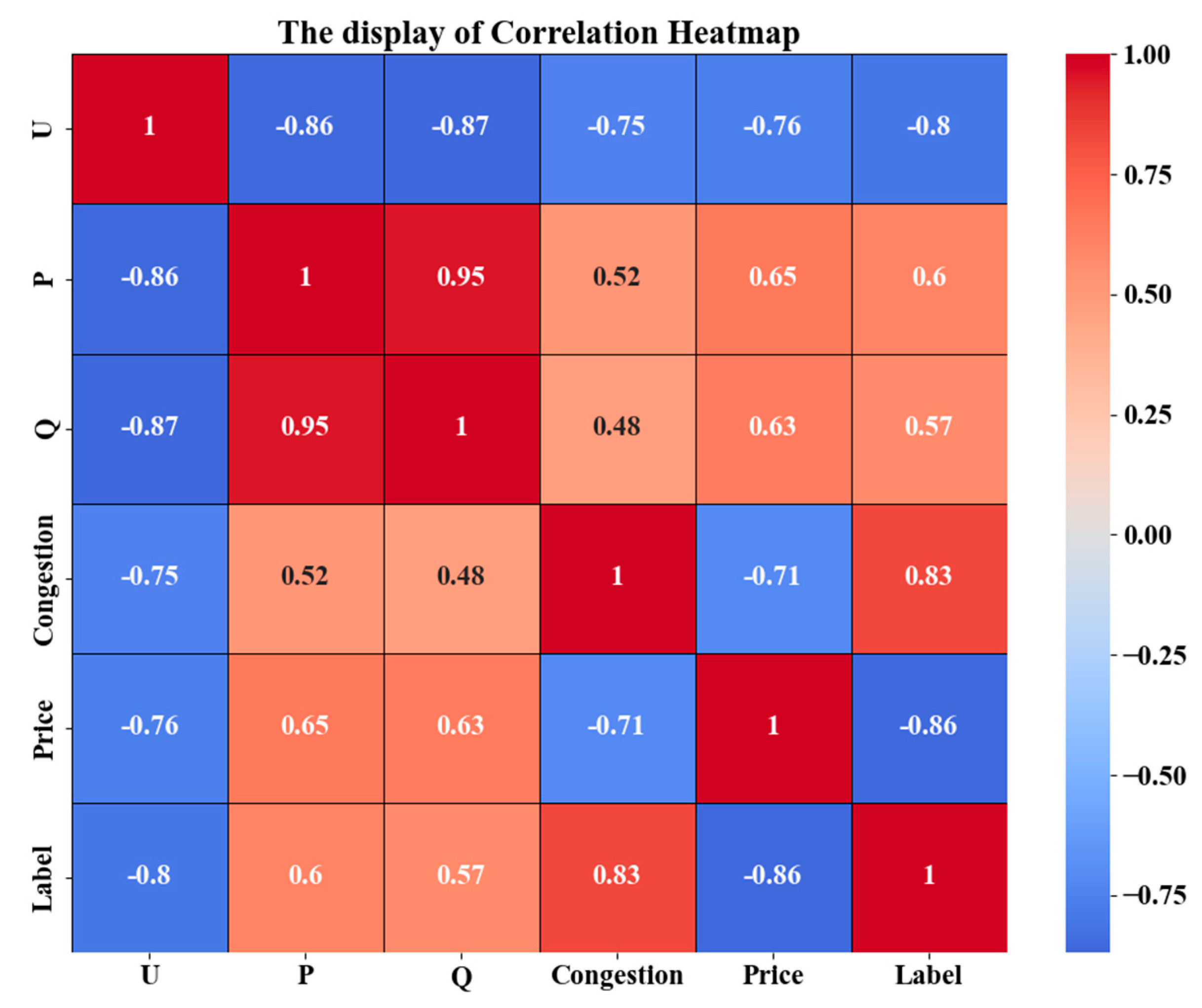
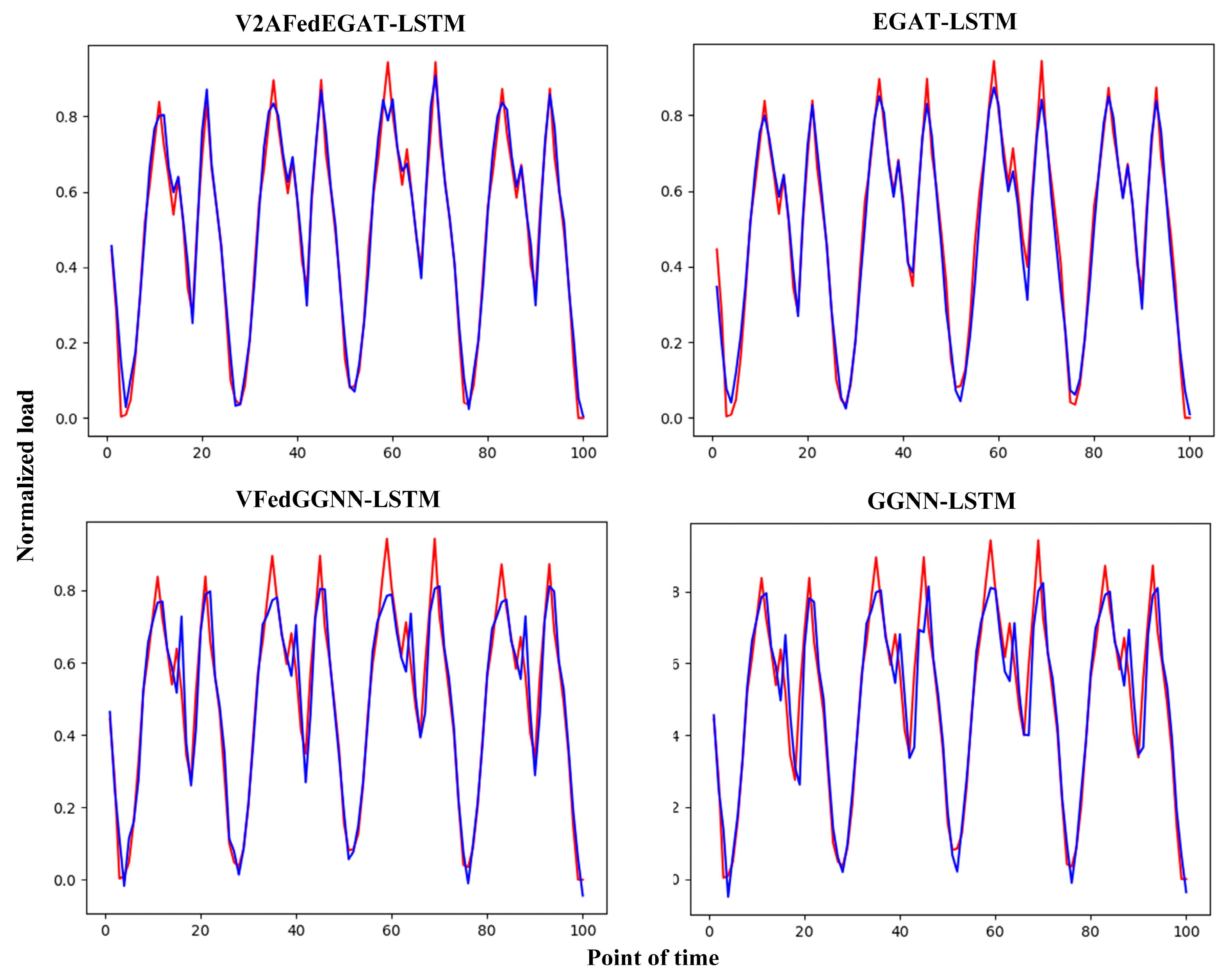
3.2.2. Encrypted Model Training
Multiple deep network modules are integrated into the traditional secure federated linear regression framework, where each training EPOCH requires loss backpropagation in a homomorphic encryption environment to obtain encrypted gradient information. The derivative computation in the homomorphic encryption environment will greatly increase the computational burden [
29]. Meanwhile, the update process of the last layer parameters needs to be directly guided by the loss value. This also poses a risk of leakage of privacy data.
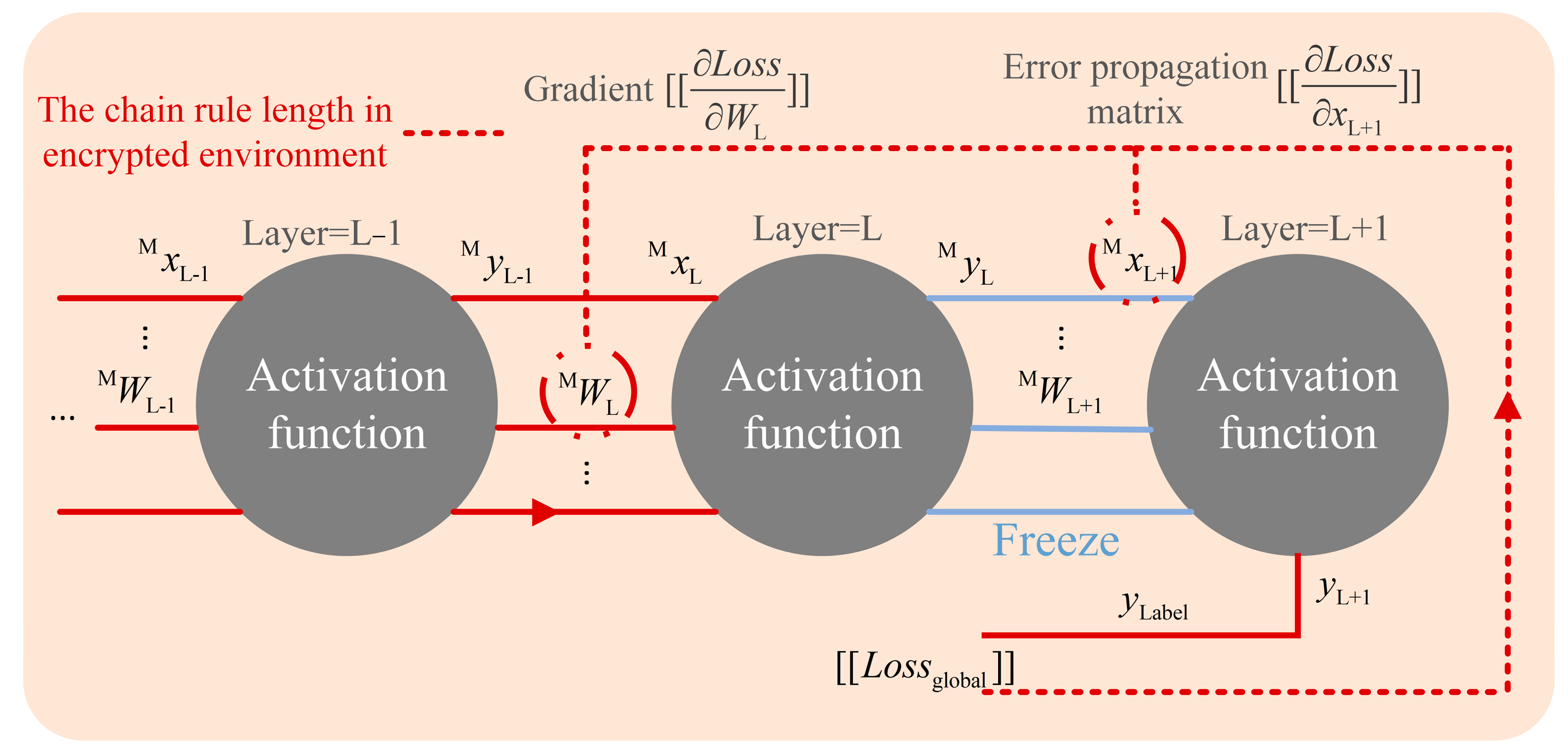
By exploring the backpropagation process, the intermediate result containing the error propagation matrix is considered a key point for updating deep models. This is because the majority of parameter matrices are not square matrices, and they do not have inverse matrices. It is difficult to infer the true value of loss through the intermediate result. Meanwhile, this also reduces the transmission length and derivative superposition of the chain rule in homomorphic encryption environments. The visualization is shown in
Figure 3.
The proposed framework adjusts the update strategy of the prediction model, including freezing the last layer parameters of the local model, and the model is updated through intermediate results, which further decreases the privacy leakage risk and computation complexity. The analysis process for adjusting the update strategy of the prediction model is as follows.
In the prediction tasks based on DNNs, the fully connected layer should be added after the model to obtain the desired output result type. For the last fully connected layer L + 1, the parameter gradient calculation [
30] is as follows:
The mean square error (MSE) is adopted as the loss function, .
When updating the parameter of the L + 1 fully connected layer in the cloud, the cloud must calculate the value of , but it includes the label information of the DN submodel, which will leak information of the DN to the cloud. Therefore, the last fully connected layer of the model is frozen, which stops the last fully connected layer from being updated.
The parameter gradient for layer L is calculated as follows:
where the L layer error propagation matrix
is as follows:
where
is the error propagation matrix of the L + 1 layer. Obviously, as long as the error propagation matrix value of the next layer is known, the model parameters of this layer can be updated. The particularity of the
matrix is that it is not a square matrix in most cases, which indicates the actual inverse matrix does not exist. Therefore, the intermediate result
is adopted directly to update the parameters of layer L, which does not leak the loss value and label value to the cloud.
Similarly, the parameter gradient for layer L − 1 is calculated as follows:
where the L − 1 layer error propagation matrix
is as follows:
Among them, the error propagation matrix of the L layer has been obtained in the parameter update process of the L layer. The error propagation matrix of the L layer is directly adopted to calculate the propagation error matrix of the L − 1 layer, and the parameters of the L − 1 layer are updated. In summary, the backpropagation process can proceed to the first layer of the model to update all model parameters.
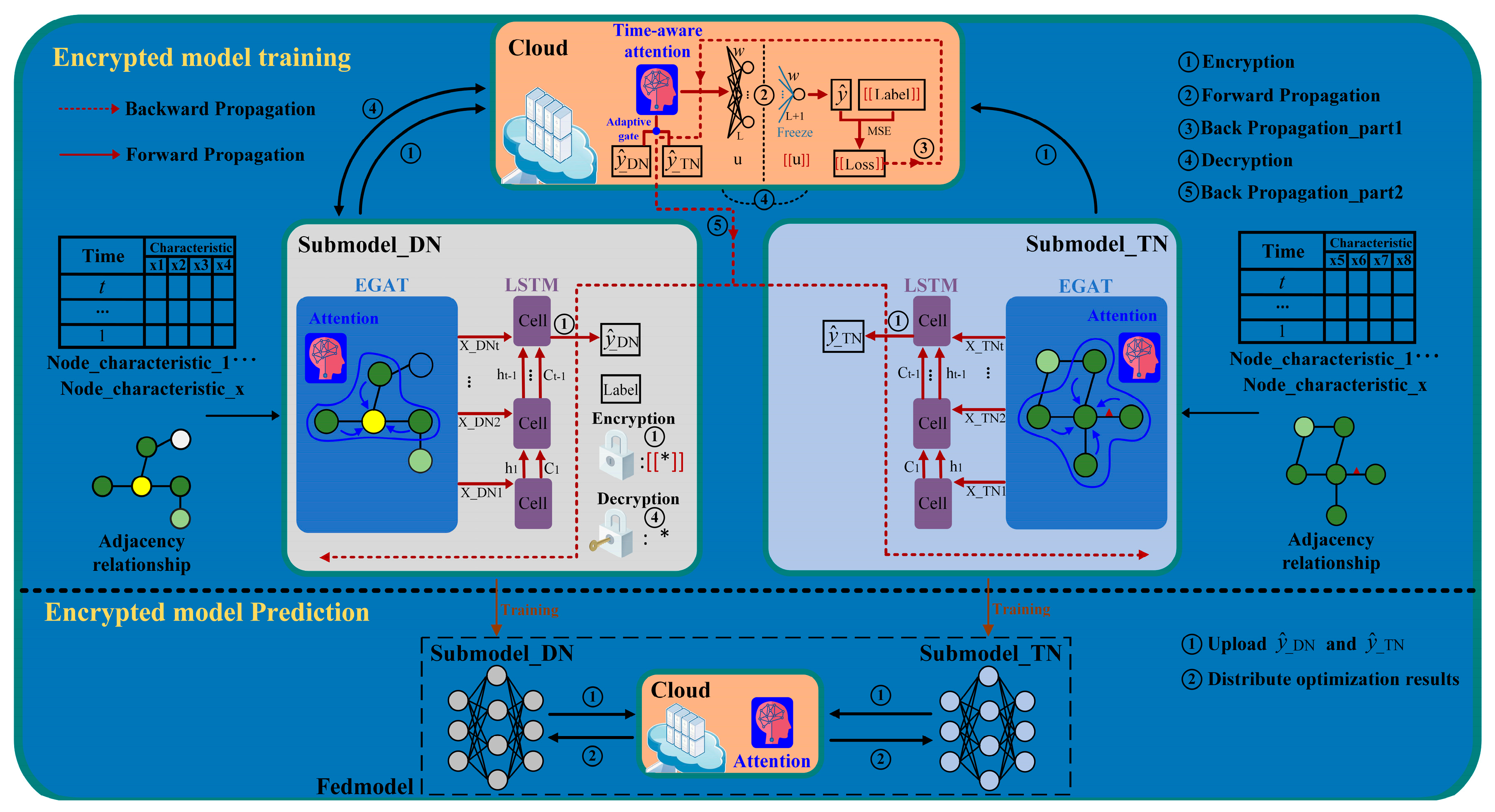
The training strategy of the V2AFedEGAT combined with LSTM EVCSL prediction method is shown in
Figure 4. The detailed training and prediction process is as follows.
Preparation: The label side creates a key pair, and the DN and TN initialize local submodel parameters and . The encrypted method applied in the federated framework is partial homomorphic encryption (PHE), which consists of key pair generation, encryption, and decryption.
Step ①: The DN and TN submodel outputs and are obtained by their own forward propagation process and the DN encrypting the label. The TN and DN upload the , , and to the collaborator cloud.
Step ②: The TN and DN submodel results and are input into the time-aware attention module for attention score calculation. This assigns different attention scores to data information from different participants, equivalently alleviating the problem of characteristic distribution skew of DN and TN from the perspective of local data aggregation. The cloud calculates the global encryption loss through MSE.
Step ③: According to the updated strategy of freezing the last layer parameters proposed in this paper, the backpropagation process is divided into two parts. In the backpropagation process of the first part, the encryption intermediate result is calculated through the obtained .
Step ④: The collaborator cloud sends the to the DN for decryption by the private key. The decryption result is returned to the collaborator cloud. The intermediate result will not be leaked to the third-party collaborator cloud because it is difficult to reverse-calculate the loss value.
Step ⑤: The parameters of the attention module are updated by the . During the local model backpropagation, the gradient information output by the attention module is transmitted to the DN and TN to update their respective local models. Similarly, privacy information is effectively protected due to the difficulty of inferring the loss value. In this way, the second part of the backpropagation process can be completed.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}