
Development of Digital Twins for Continuous Processes: Concept Description of Virtual Mass Balance Based on the Tennessee Eastman Process



Abstract
1. Introduction
2. Issues Related to Digital Twins
2.1. Digital Twins in Science
2.2. Digital Twins in Industry
- Mapping the physical layout of assets, e.g., for training purposes, or as a basis for a metaverse;
- Operational management by providing fast access to information from many sources regarding a given asset (including information about related procedures and documentation);
- Monitoring the progress of investment projects and the completeness of information;
- Remote engineering support for people working in a facility;
- Identification of threats (both with respect to process and personnel);
- Easier implementation of predictive maintenance solutions.
- (I)
- Time step [continuous/discrete];
- (II)
- Probability [deterministic model/stochastic model];
- (III)
- Model nature [static/dynamic];
- (IV)
- Use of the process model [for simulation purposes/not for simulation purposes];
- (V)
- Model scope [single element/system of interrelated elements];
- (VI)
- Verification and validation [verified and validated model/unverified and invalidated model];
- (VII)
- Time horizon [definite/indefinite].
- Creating predictions of yields and the operation of particular systems;
- Determination of physicochemical parameters or process variables in places where there is no measuring equipment installed;
- Support for engineers in conducting the process by suggesting optimal solutions;
- Using the model as an operator training station (OTS).
2.3. Digital Twins in Organizations
3. Tennessee Eastman Process
4. Virtual Mass Balance Concept
4.1. The VMB Data Model
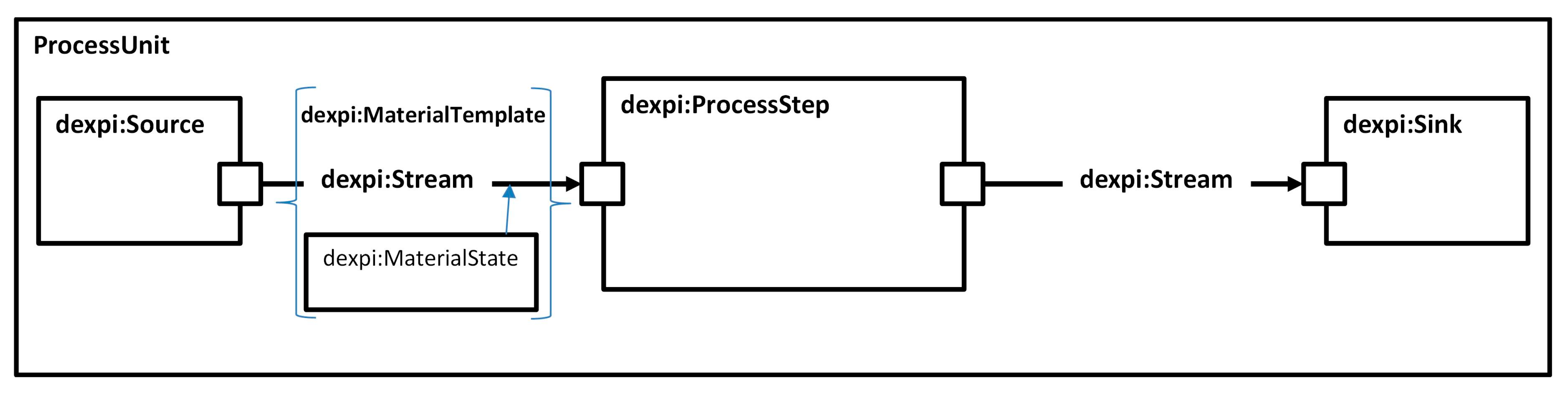
4.2. VMB Tables
- (a)
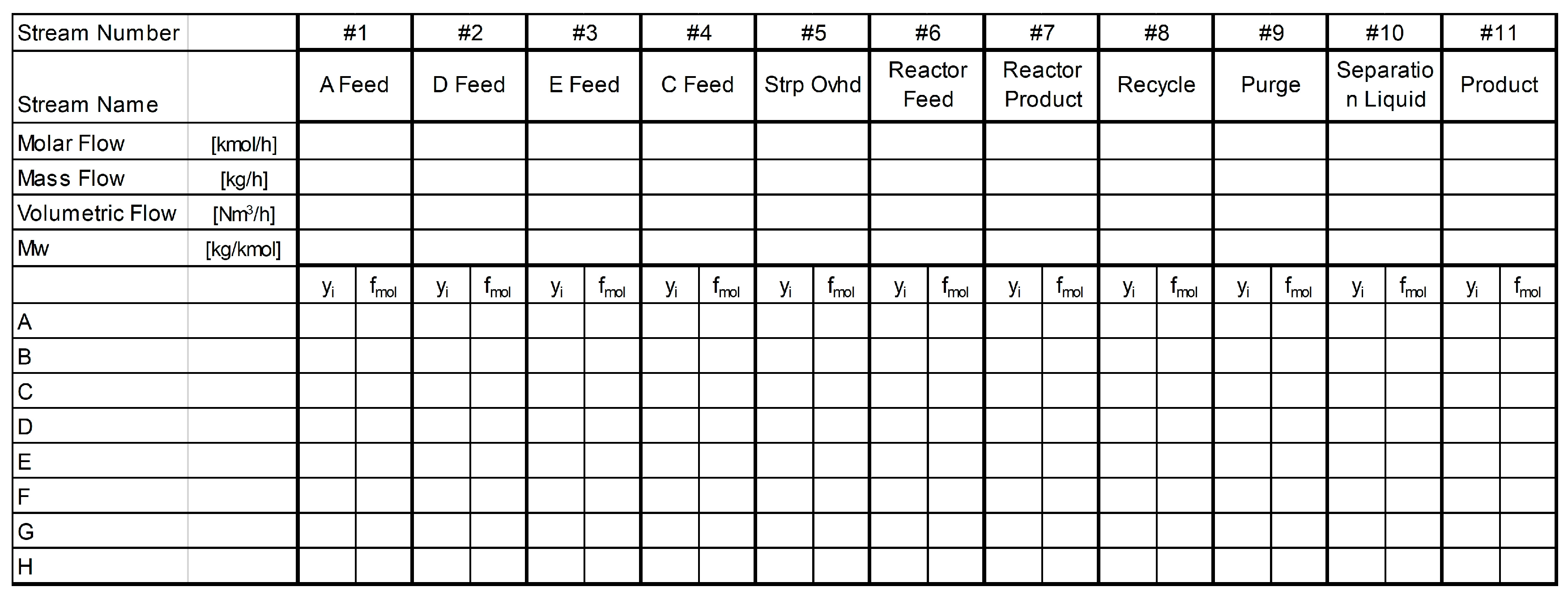
- Stream Table
- (b)
- Balance Tables
- BalanceCalculation_Sum (1) is applicable for calculating the Inlet, Outlet, and direction values based on a particular ListOfIncludedStreams subclass.
- BalanceCalculation_Delta (2) is dependent from Inlet and Outlet streams of a particular BalanceTable.
- BalanceCalculation_Reacted (3) is calculated for ReactingChemicals Process Steps; the dependency on delta value is reflected.
- BalanceCalculation_Produced (4) is calculated based on delta value and associated with reactive systems.
- (c)
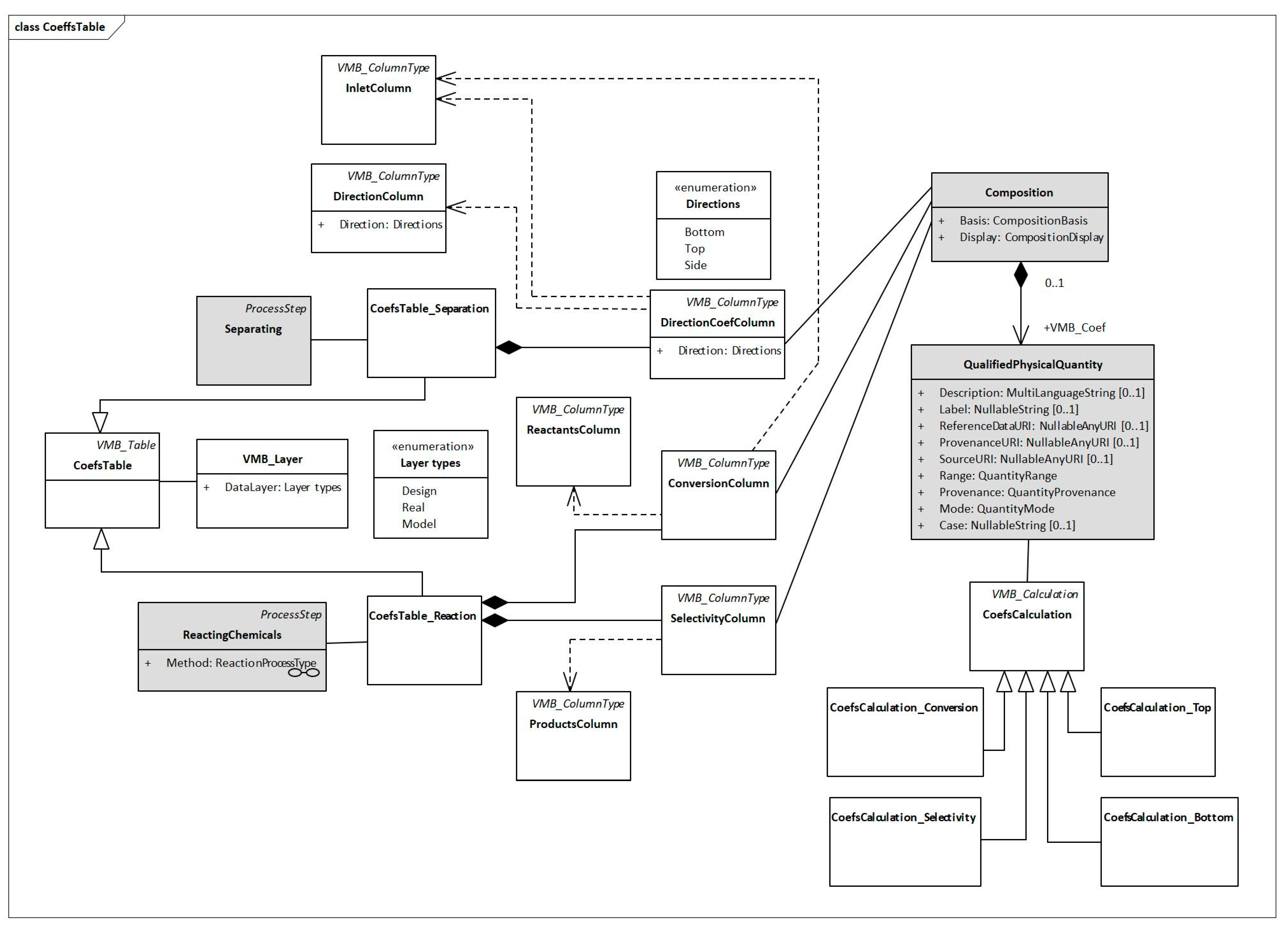
- Virtual Coefficient Tables
4.3. VMB Layers
- (a)
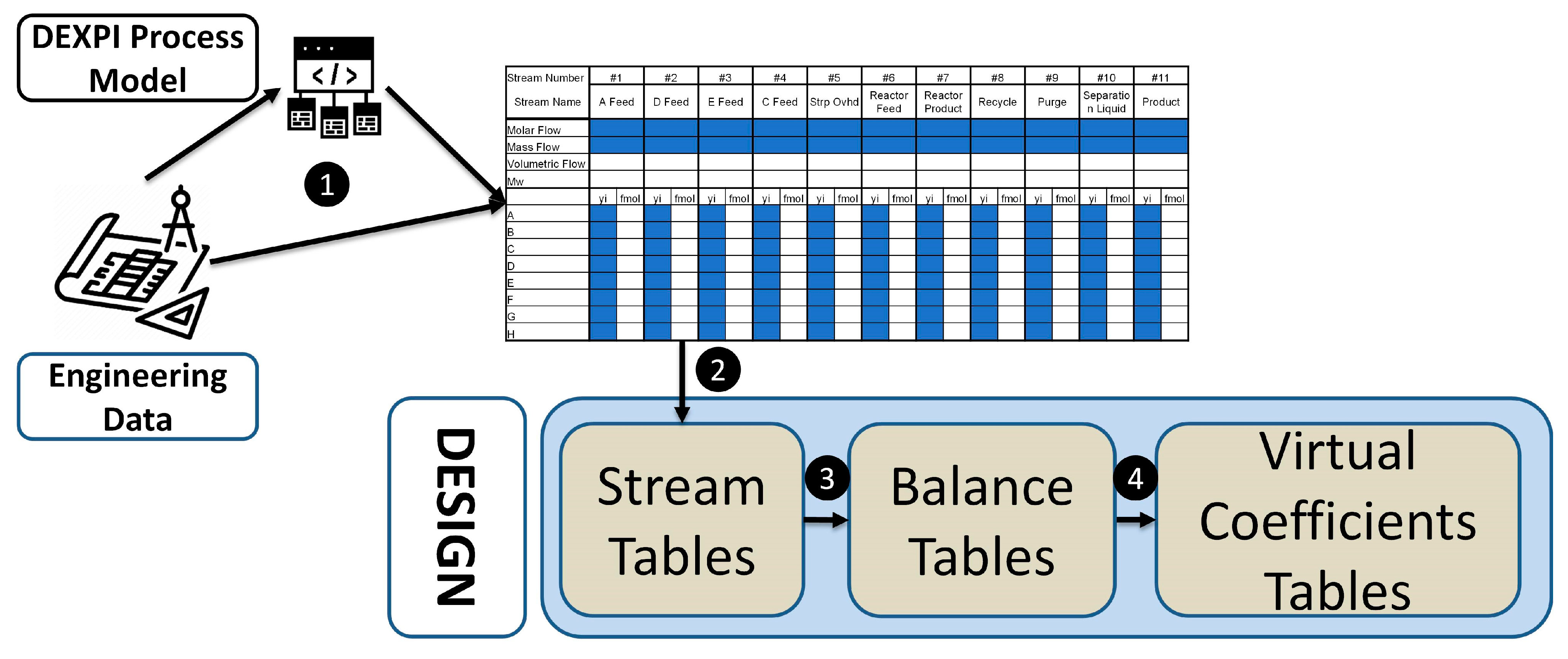
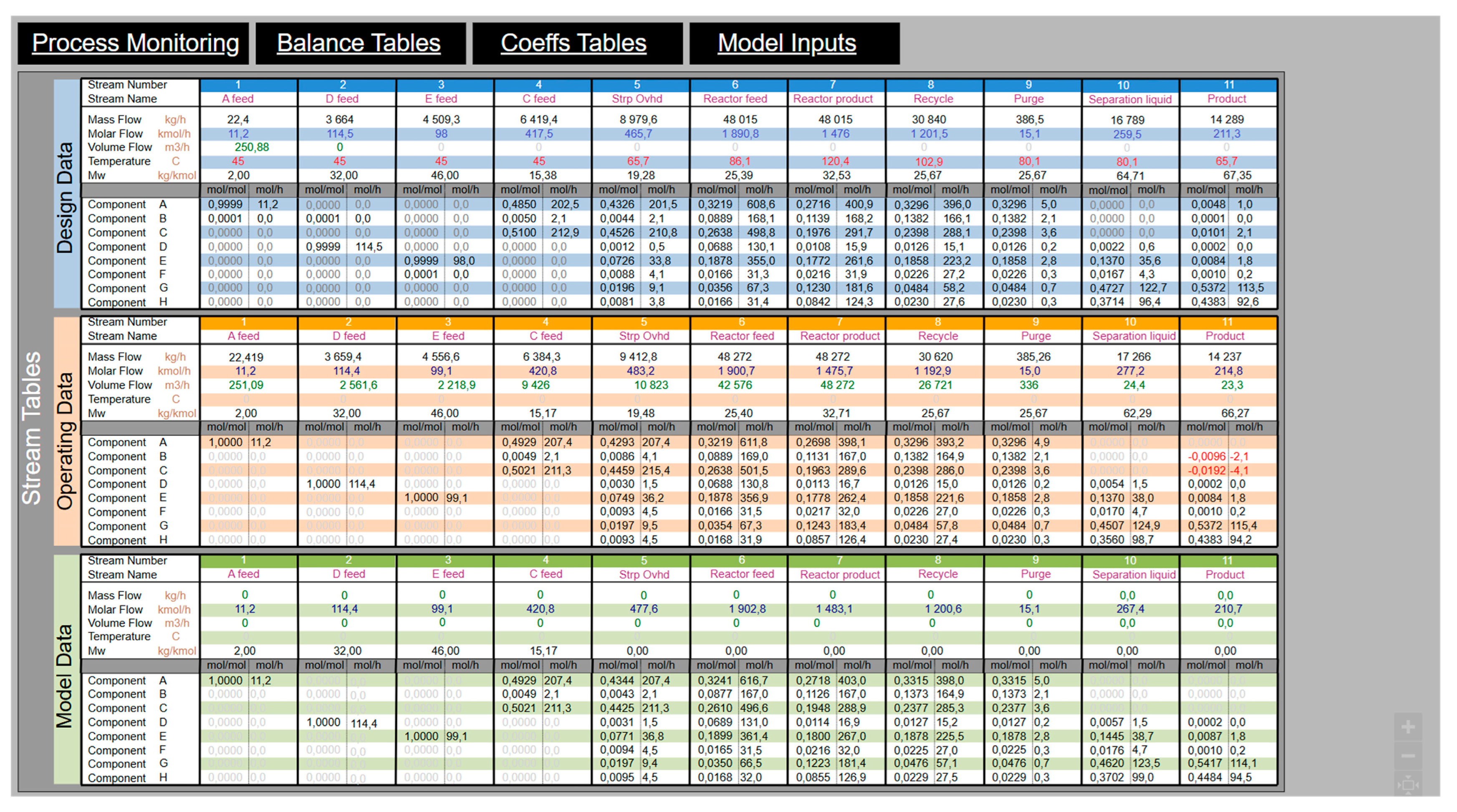
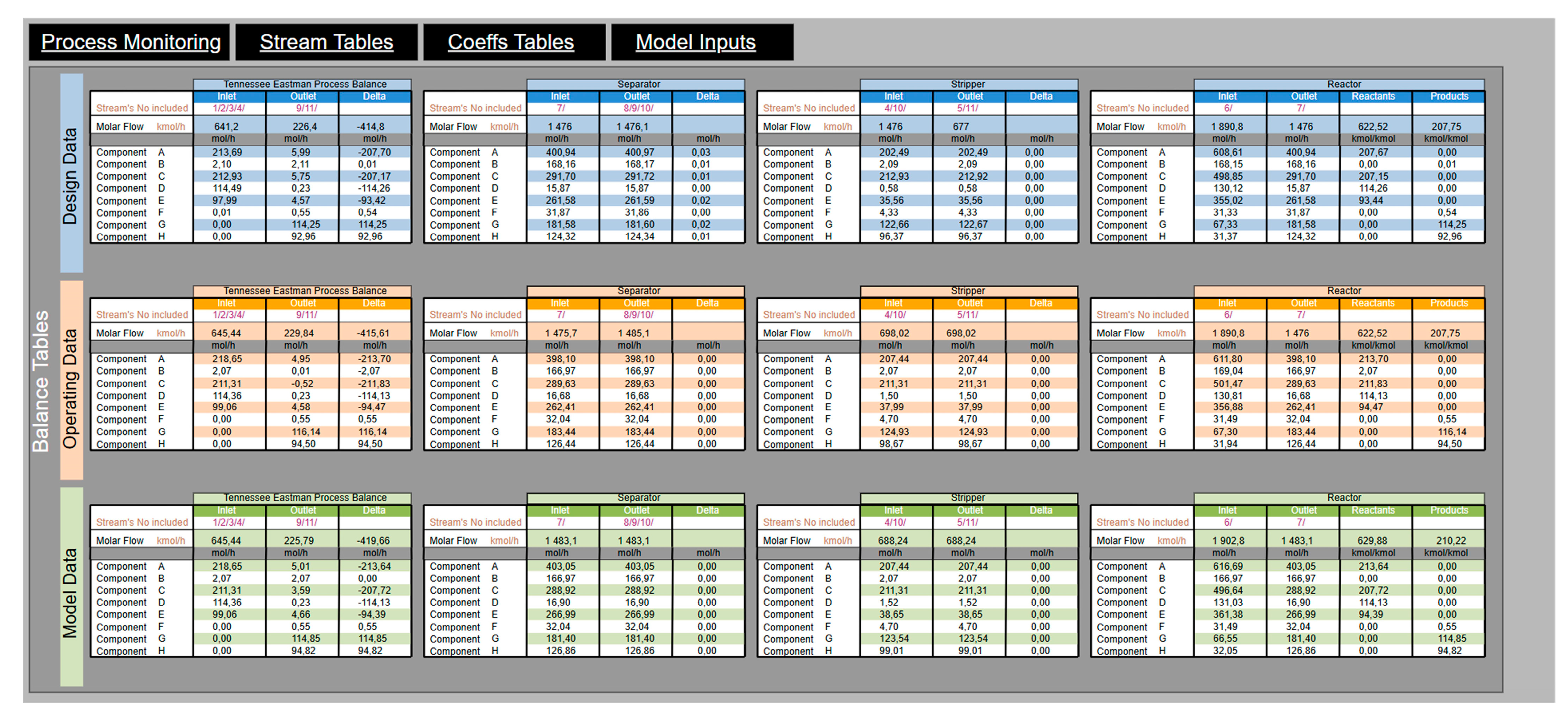
- The DESIGN layer development flow is shown in Figure 7. The sources of data for this layer are engineering files, especially PFDs and Material Balance. Often, the Stream Table supplied by the contractor is limited to only a few properties, which might be hard to interpret or evaluate on first sight (Figure 7, point (1)). As previously described, documented values might be incorporated into the VMB data model seamlessly by the deployment of the DEXPI Process concept or even manually. In case of TEP, the engineer would only see the partially filled table. Simple chemical calculations and transformations allow for filling all required parts of the Stream Table (Figure 7, point (2)). These properties (especially mass or molar flow) are then used for the calculation of the Process Balance Table (Figure 7, point (3)). Virtual Coefficients are also shown in dedicated tables (Figure 7, point (4)). Steps 3 and 4 are generic based on data model configuration.The described layer plays a mostly informative, benchmark role. The possible enrichment of the Stream Table might be useful during commissioning or Performance Test Runs, as it could give relevant background for process condition checks against design values. In some cases, the DESIGN data might be useful while making assumptions for calculation steps in other layers.
- (b)
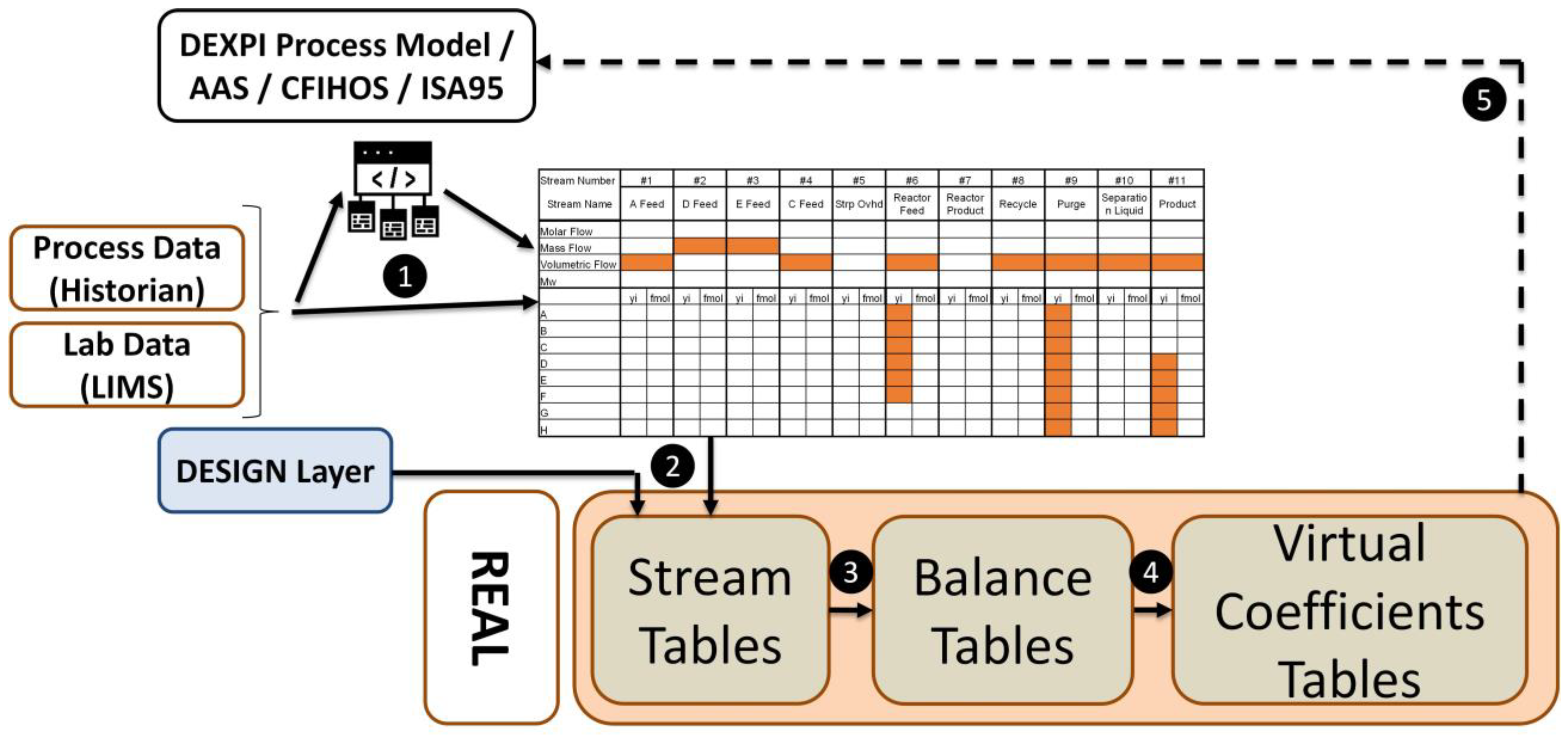
- In the case of the REAL layer, the main difference is caused by the fact that, when comparing a nearly complete set of design values, the operational data are typically limited to those needed for process control and safety (stored as timeseries and available usually from the Historian database). Another important aspect is the limited availability of quality data, typicaly acquired from LIMS at a predefined schedule. Figure 8, point (1), shows possible data sources. Data might be acquired by a point-to-point connection or integrated with existing data models available within enterprises (adoption and extension of the DEXPI Process data model should ease that possibility). Independently from the data aquisition aspect, available data are sufficient to fill the Stream Table only partially. An essential feature of the VMB concept is to show off a complete set of stream properties in order to (among others) enhance operational monitoring. Figure 8, point (2), refers to the set of calculation steps performed on a predefined schedule to provide all relevant stream properties required by further steps. The number of steps and calculations is case-sensitive, and authors of the VMB concept assume that most of them are just mass balance-dependent (derived of “modelling” mixing or splitting parts, where the DEXPI Process data could also help). Besides simple arithmetic, some assumptions made by Subject Matter Experts are required to meet the main goal. The set points of process variables are useful as well. It seems important to include within the VMB data model the place where the number of steps and equations/assumptions with remarks could be included. Further steps, related to the calculation of Balance Tables and Coefficients (Figure 8, points (3) and (4)), are the same for the DESIGN layer. The dashed line mark in Figure 8 as point (5) is optional and related to the possible enrichment of the enterprise data model by VMB calculations.The Exemplary TEP Process provides 41 operating variables that are measured and visible to operators. Stream flow units are mixed; some of them are given in volumetric flow, and others as mass flows, while quality measures are presented as molar fractions. This causes interpretation difficulties. Thus, the most important function of this layer is to provide completeness in the Stream Table and increase process conciousness and monitoring capabilities by tracking soft sensors’ values.
- (c)
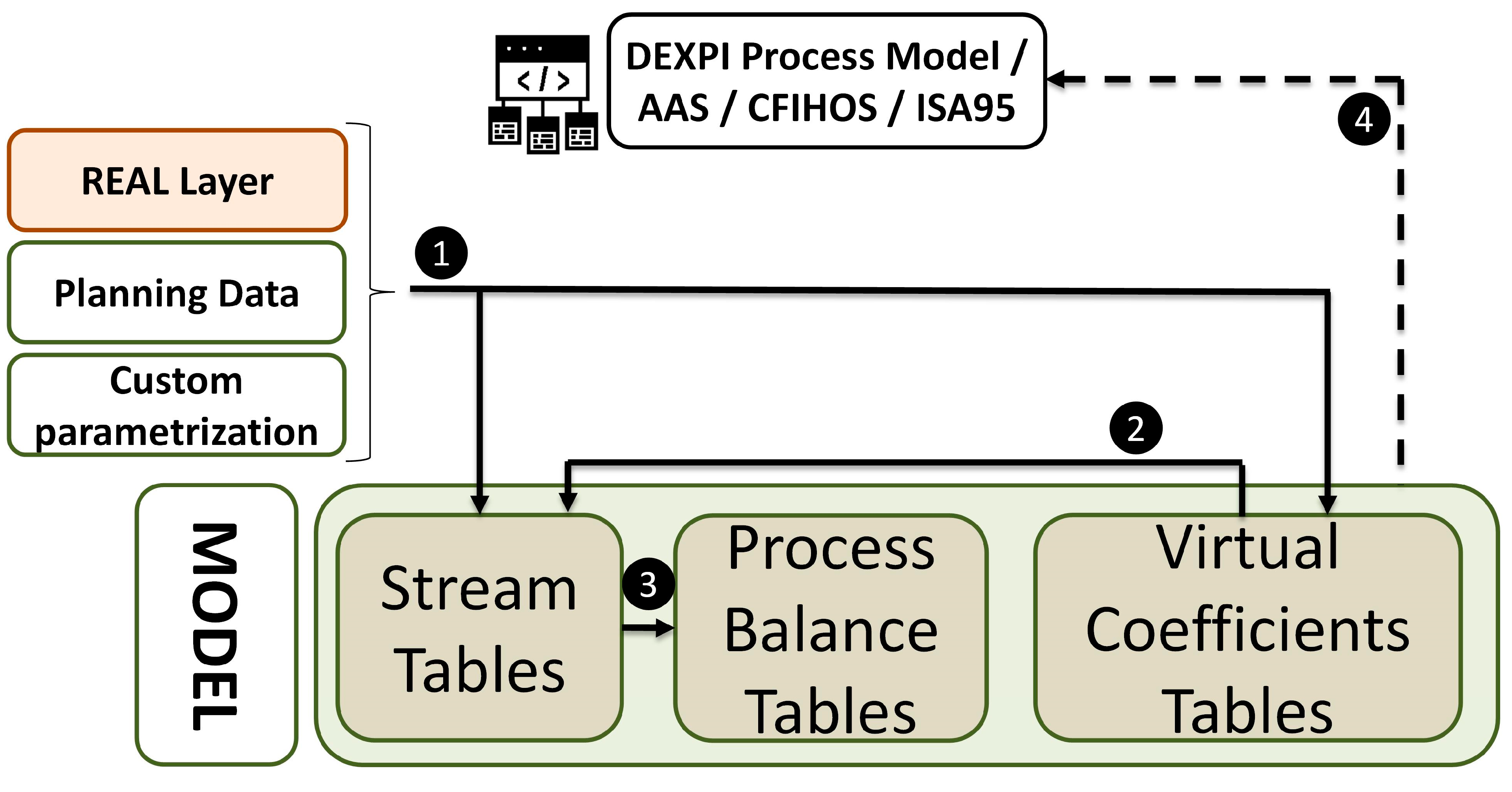
- The last (but not least) layer—MODEL—is a virtual representation of the process state based on Inlet stream properties and Virtual Coefficient values. Initial numbers for Inlet streams might be taken directly from the REAL layer, reflecting the operational, planning or manually modified data by the end user (Figure 9, point (1)). A similar aproach is applicable for Virtual Coefficient Tables. Additionally, at this point, the VMB concept provides a space for the implementation of more sophisticated statistics, machine learning algorithms or other solutions which might provide the most suitable values of soft sensors. Their role is to calculate the remaining process streams based on feedstock data. Calculations are also customizable and realized in steps on demand or parallel to the REAL Layer (Figure 9, point (2)). Depending on the considered process, providing the set points of an additional process variable could be applicable and useful. The results of this layer could be compared with REAL values and treated as a benchmark. The third phase of the layer’s development is the calculation of Process Balance Tables (Figure 9, point (3)), which are essentially consistent with other layers. The selected results might enrich the enterprise data model (Figure 9, point (4)).The exemplary TEP process would take the property values of streams #1, #2, #3 and #4 and estimate others using Virtual Coefficients. Both types would be taken from the REAL layer.
4.4. VMB User Interface
4.5. VMB Concept Classification
5. Discussion
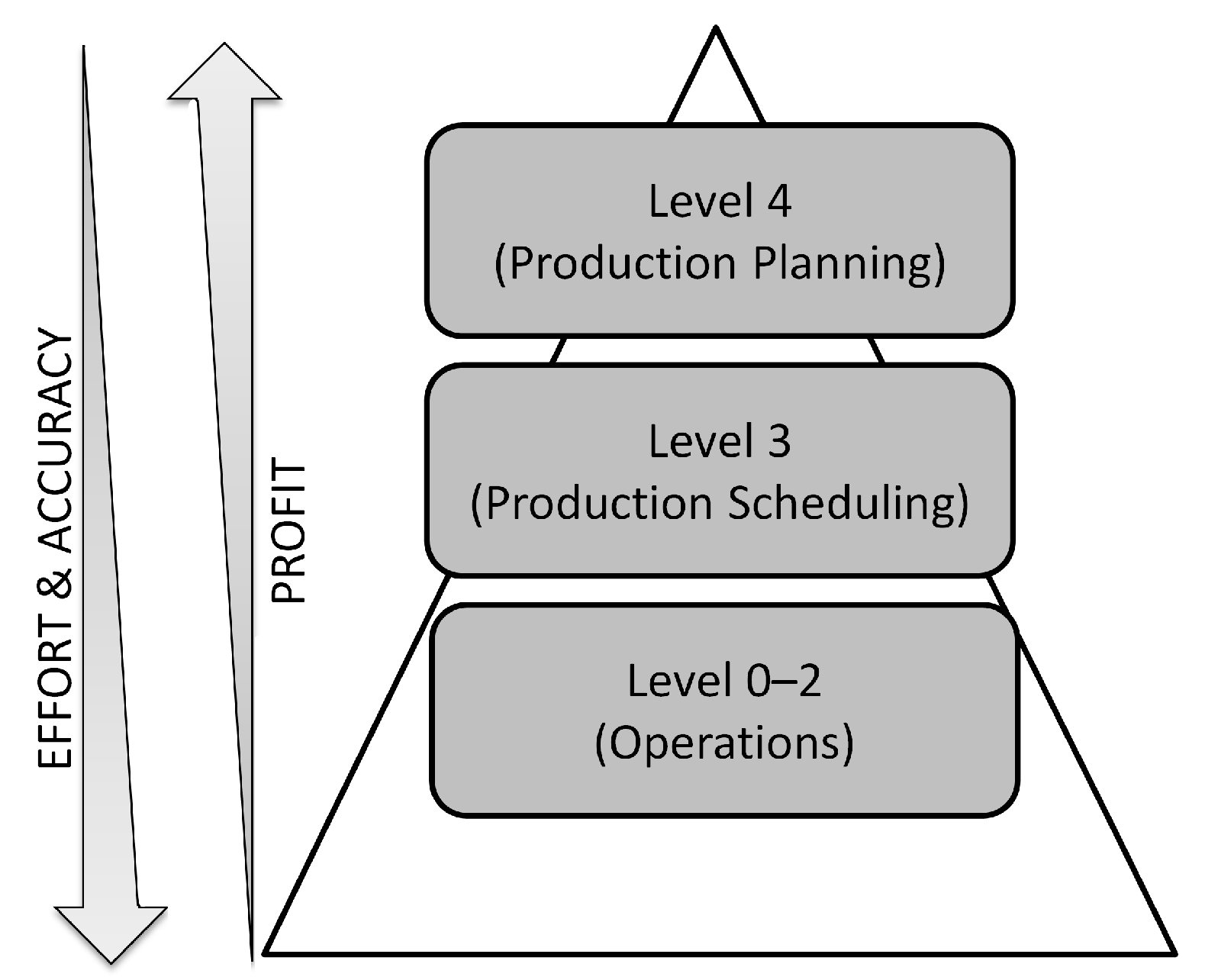
5.1. VMB Across Organizational Structure
- -
- Tracking catalyst/reaction performance and comparing different catalyst campaigns;
- -
- Tracking significant imbalances in stream flows across the unit;
- -
- Identifying sources of quality issues for streams;
- -
- Comparing different time periods of operations (for example, during test runs);
- -
- Tracking separation efficiency and possible relevant places for optimization;
- -
- Tracking the source of gaps between plan and production;
- -
- Performing fast and simple what-if analysis for many purposes.
- -
- Back-casting process and LP model improvement;
- -
- Performing fast and simple what-if analysis for many purposes;
- -
- Using Virtual Coefficients as KPIs (even for maintenance departments);
- -
- Developing the VMB for a broader range of process units, which might be feasible due to the moderate complexity and simplicity;
- -
- Quick shifting between modelled time ranges in the MODEL layer.
5.2. VMB Among Other Solutions
6. Conclusions
- -
- The presented concept could be classified as an Operational Digital Twin; nevertheless, the utilization of the DEXPI Process standard offers an opportunity for seamless integration with Asset Digital Twin solutions.
- -
- Some features of Virtual Mass Balance have already been tested by authors on real petrochemical units.
- -
- Virtual Mass Balance exhibits good flexibility, as evidenced by its implementation using an example from the literature and information limited to the source publication.
- -
- The simplicity of the application layer and its reliance on the moderate level of detail of Process Flow Diagrams allow the solution to be used both in production areas (monitoring, benchmarking, prediction) and at higher organizational levels (back-casting, predictions).
- -
- The use of presented soft sensors has not been described in the literature so far. In fact, their use can be assessed after performing a series of engineering transformations/calculations.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Balaji, K.; Rabiei, M.; Suicmez, V.; Canbaz, C.H.; Agharzeyva, Z.; Tek, S.; Bulut, U.; Temizel, C. Status of Data-Driven Methods and their Applications in Oil and Gas Industry. In Proceedings of the SPE Europec Featured at 80th EAGE Conference and Exhibition, Copenhagen, Denmark, 11–14 June 2018; Society of Petroleum Engineers: Richardson, TX, USA, 2018; p. D031S005R007, ISBN 978-1-61399-606-5. [Google Scholar]
- Ren, J. Artificial Intelligence for Refiners. 2018. Available online: https://www.digitalrefining.com/article/1002251/artificial-intelligence-for-refiners (accessed on 18 March 2024).
- Shang, C.; You, F. Data Analytics and Machine Learning for Smart Process Manufacturing: Recent Advances and Perspectives in the Big Data Era. Engineering 2019, 5, 1010–1016. [Google Scholar] [CrossRef]
- Sircar, A.; Yadav, K.; Rayavarapu, K.; Bist, N.; Oza, H. Application of machine learning and artificial intelligence in oil and gas industry. Pet. Res. 2021, 6, 379–391. [Google Scholar] [CrossRef]
- Lee, H.; Sohn, I. Fundamentals of Big Data: Network Analysis for Research and Industry; John Wiley & Sons: Chichester UK; Hoboken, NJ, USA, 2015; ISBN 978-1-119-01549-9. [Google Scholar]
- Bai, C.; Dallasega, P.; Orzes, G.; Sarkis, J. Industry 4.0 technologies assessment: A sustainability perspective. Int. J. Prod. Econ. 2020, 229, 107776. [Google Scholar] [CrossRef]
- Liu, X.; Lu, D.; Zhang, A.; Liu, Q.; Jiang, G. Data-Driven Machine Learning in Environmental Pollution: Gains and Problems. Environ. Sci. Technol. 2022, 56, 2124–2133. [Google Scholar] [CrossRef] [PubMed]
- Jasiulewicz-Kaczmarek, M.; Antosz, K.; Zhang, C.; Ivanov, V. Industry 4.0 Technologies for Sustainable Asset Life Cycle Management. Sustainability 2023, 15, 5833. [Google Scholar] [CrossRef]
- Ning, Y.; Kazemi, H.; Tahmasebi, P. A comparative machine learning study for time series oil production forecasting: ARIMA, LSTM, and Prophet. Comput. Geosci. 2022, 164, 105126. [Google Scholar] [CrossRef]
- Niaei, A.; Towfighi, J.; Khataee, A.R.; Rostamizadeh, K. The Use of ANN and the Mathematical Model for Prediction of the Main Product Yields in the Thermal Cracking of Naphtha. Pet. Sci. Technol. 2007, 25, 967–982. [Google Scholar] [CrossRef]
- Zhang, X.; Zou, Y.; Li, S.; Xu, S. A weighted auto regressive LSTM based approach for chemical processes modeling. Neurocomputing 2019, 367, 64–74. [Google Scholar] [CrossRef]
- Plehiers, P.P.; Symoens, S.H.; Amghizar, I.; Marin, G.B.; Stevens, C.V.; Van Geem, K.M. Artificial Intelligence in Steam Cracking Modeling: A Deep Learning Algorithm for Detailed Effluent Prediction. Engineering 2019, 5, 1027–1040. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Y.; Li, H. Adapted Receptive Field Temporal Convolutional Networks with Bar-Shaped Structures Tailored to Industrial Process Operation Models. Ind. Eng. Chem. Res. 2020, 59, 5482–5490. [Google Scholar] [CrossRef]
- Ochoa-Estopier, L.M.; Jobson, M.; Smith, R. Operational optimization of crude oil distillation systems using artificial neural networks. Comput. Chem. Eng. 2013, 59, 178–185. [Google Scholar] [CrossRef]
- Downs, J.J.; Vogel, E.F. A plant-wide industrial process control problem. Comput. Chem. Eng. 1993, 17, 245–255. [Google Scholar] [CrossRef]
- Van Der Valk, H.; Haße, H.; Möller, F.; Otto, B. Archetypes of Digital Twins. Bus. Inf. Syst. Eng. 2022, 64, 375–391. [Google Scholar] [CrossRef]
- Aivaliotis, P.; Georgoulias, K.; Arkouli, Z.; Makris, S. Methodology for enabling Digital Twin using advanced physics-based modelling in predictive maintenance. Procedia CIRP 2019, 81, 417–422. [Google Scholar] [CrossRef]
- Tao, F.; Xiao, B.; Qi, Q.; Cheng, J.; Ji, P. Digital twin modeling. J. Manuf. Syst. 2022, 64, 372–389. [Google Scholar] [CrossRef]
- Van Der Valk, H.; Hunker, J.; Rabe, M.; Otto, B. Digital Twins in Simulative Applications: A Taxonomy. In Proceedings of the 2020 Winter Simulation Conference (WSC); IEEE: Orlando, FL, USA, 2020; pp. 2695–2706. [Google Scholar]
- Harper, K.E.; Malakuti, S.; Ganz, C. Digital Twin Architecture and Standards. IIC J. Innov. 2019, 1–12. [Google Scholar] [CrossRef]
- Zezulka, F.; Marcon, P.; Vesely, I.; Sajdl, O. Industry 4.0—An Introduction in the phenomenon. IFAC-PapersOnLine 2016, 49, 8–12. [Google Scholar] [CrossRef]
- Pada, G. Meet data-centric engineering: Engineering better relationships and more sustainable capital projects. Aveva: Cambridge, UK.
- Cameron, D.B.; Otten, W.; Temmen, H.; Hole, M.; Tolksdorf, G. DEXPI process: Standardizing interoperable information for process design and analysis. Comput. Chem. Eng. 2024, 182, 108564. [Google Scholar] [CrossRef]
- Cameron, D.B.; Otten, W.; Temmen, H.; Tolksdorf, G. DEXPI Process Modelling of Process Systems and their Documentation. Available online: https://dexpi.org/wp-content/uploads/2023/12/DEXPI-Process-1.0-Manual.pdf (accessed on 6 August 2024).
- DEXPI Process Information Model, version 1.0.; DEXPI Initiative: Frankfurt, Germany, 2023.
- Fjøsna, E.; Saltvedt, T.; Waaler, A.; Knædal, M.; Koppergård, V.; Hella, L.; Skjæveland, M.G.; Mehmandarov, R.; Fekete, M.; Zhou, B. Information Modelling Framework Manual (Version 2.1). Available online: https://www.imfid.org/docs/IMF_Manual_v2-1.pdf (accessed on 6 August 2024).
- ISO TC184/SC4 Standing Document; Technical Committee 184 for Industrial Automation Systems and Integration; Subcommittee 4 for Industrial Data. ISO: Geneva, Switzerland, 2021.
- ISO 23247; Automation Systems and Integration—Digital Twin Framework for Manufacturing. ISO: Geneva, Switzerland, 2021.
- CFIHOS Standard; Capital Facilities Information Hand-Over Specification. IOGP: London, UK, 2024.
- ISO 15926; Industrial Automation Systems and Integration—Integration of Life Cycle Data for Process Plants Including Oil and Gas Production Facilities. ISO: Geneva, Switzerland, 2023.
- ISO 14306; Industrial automation systems and integration—JT file format specification for 3D visualization. ISO: Geneva, Switzerland, 2017.
- ISA88; Batch Control. International Society of Automation (ISA): Durham, NC, USA, 2010.
- ISA95; Enterprise-Control System Integration. International Society of Automation (ISA): Durham, NC, USA, 2018.
- IEC PAS 63088:2017; Smart manufacturing—Reference architecture model industry 4.0 (RAMI4.0). IEC: Geneva, Switzerland, 2017.
- Guerra, O.J.; Le Roux, G.A.C. Improvements in Petroleum Refinery Planning: 1. Formulation of Process Models. Ind. Eng. Chem. Res. 2011, 50, 13403–13418. [Google Scholar] [CrossRef]
- Tsay, C.; Baldea, M. 110th Anniversary: Using Data to Bridge the Time and Length Scales of Process Systems. Ind. Eng. Chem. Res. 2019, 58, 16696–16708. [Google Scholar] [CrossRef]
- Lyman, P.R.; Georgakis, C. Plant-wide control of the Tennessee Eastman problem. Comput. Chem. Eng. 1995, 19, 321–331. [Google Scholar] [CrossRef]
- Ricker, N.L.; Lee, J.H. Nonlinear model predictive control of the Tennessee Eastman challenge process. Comput. Chem. Eng. 1995, 19, 961–981. [Google Scholar] [CrossRef]
- Banerjee, A.; Arkun, Y. Control configuration design applied to the Tennessee Eastman plant-wide control problem. Comput. Chem. Eng. 1995, 19, 453–480. [Google Scholar] [CrossRef]
- Duvall, P.M.; Riggs, J.B. On-line optimization of the Tennessee Eastman challenge problem. J. Process Control 2000, 10, 19–33. [Google Scholar] [CrossRef]
- Jockenhövel, T.; Biegler, L.T.; Wächter, A. Dynamic optimization of the Tennessee Eastman process using the OptControlCentre. Comput. Chem. Eng. 2003, 27, 1513–1531. [Google Scholar] [CrossRef]
- Golshan, M.; Boozarjomehry, R.B.; Pishvaie, M.R. A new approach to real time optimization of the Tennessee Eastman challenge problem. Chem. Eng. J. 2005, 112, 33–44. [Google Scholar] [CrossRef]
- Golshan, M.; Pishvaie, M.R.; Bozorgmehry Boozarjomehry, R. Stochastic and global real time optimization of Tennessee Eastman challenge problem. Eng. Appl. Artif. Intell. 2008, 21, 215–228. [Google Scholar] [CrossRef]
- Bauer, M.; Chioua, M.; Schilling, J.; Sand, G.; Harjunkoski, I. Profitability and Re-usability: An Example of a Modular Model for Online Optimization. IFAC Proc. Vol. 2009, 42, 756–761. [Google Scholar] [CrossRef]
- Tătulea-Codrean, A.; Fischer, J.; Engell, S. A Multi-stage Economic NMPC for the Tennessee Eastman Challenge Process. IFAC-PapersOnLine 2020, 53, 6069–6075. [Google Scholar] [CrossRef]
- Setiawan, R.; Hioe, D.; Bao, J. Plantwide Operability Analysis based on a Network Perspective: A Study on the Tennessee Eastman Process. IFAC Proc. Vol. 2010, 43, 451–456. [Google Scholar] [CrossRef]
- Zhang, C.; Guo, Q.; Li, Y. Fault Detection in the Tennessee Eastman Benchmark Process Using Principal Component Difference Based on K-Nearest Neighbors. IEEE Access 2020, 8, 49999–50009. [Google Scholar] [CrossRef]
- Bathelt, A.; Jelali, M. Comparative Study of Subspace Identification Methods on the Tennessee Eastman Process under Disturbance Effects. In Proceedings of the 5th International Symposium on Advanced Control of Industrial Processes, Hiroshima, Japan, 28–30 May 2014. [Google Scholar]
- Heo, S.; Lee, J.H. Statistical Process Monitoring of the Tennessee Eastman Process Using Parallel Autoassociative Neural Networks and a Large Dataset. Processes 2019, 7, 411. [Google Scholar] [CrossRef]
- Kini, K.R.; Madakyaru, M. Improved Process Monitoring Strategy Using Kantorovich Distance-Independent Component Analysis: An Application to Tennessee Eastman Process. IEEE Access 2020, 8, 205863–205877. [Google Scholar] [CrossRef]
- Martin-Villalba, C.; Urquia, A.; Shao, G. Implementations of the Tennessee Eastman Process in Modelica. IFAC-PapersOnLine 2018, 51, 619–624. [Google Scholar] [CrossRef]
- Bathelt, A.; Ricker, N.L.; Jelali, M. Revision of the Tennessee Eastman Process Model. IFAC-PapersOnLine 2015, 48, 309–314. [Google Scholar] [CrossRef]
- Han, C.; Huang, S.; Sun, W. Python platform for Tennessee Eastman Process. In Computer Aided Chemical Engineering; Elsevier, 2022; Volume 49, pp. 889–894. ISBN 978-0-323-85159-6. [Google Scholar]
- He, R.; Chen, G.; Dong, C.; Sun, S.; Shen, X. Data-driven digital twin technology for optimized control in process systems. ISA Trans. 2019, 95, 221–234. [Google Scholar] [CrossRef] [PubMed]
- Reinartz, C.; Kulahci, M.; Ravn, O. An extended Tennessee Eastman simulation dataset for fault-detection and decision support systems. Comput. Chem. Eng. 2021, 149, 107281. [Google Scholar] [CrossRef]
- Iraola, E.; Nougués, J.M.; Chanona, A.D.R.; Batet, L.; Sedano, L. Hybrid data-driven and first principles monitoring applied to the Tennessee Eastman process. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2023; Volume 52, pp. 1803–1808. ISBN 978-0-443-15274-0. [Google Scholar]
- Yélamos, I.; Méndez, C.; Puigjaner, L. Enhancing dynamic data reconciliation performance through time delays identification. Chem. Eng. Process. Process Intensif. 2007, 46, 1251–1263. [Google Scholar] [CrossRef]
- Rieth, C.A.; Amsel, B.D.; Tran, R.; Cook, M.B. Additional Tennessee Eastman Process Simulation Data for Anomaly Detection Evaluation. Harv. Dataverse 2017. [Google Scholar] [CrossRef]
- Bakdi, A.; Kouadri, A. An improved plant-wide fault detection scheme based on PCA and adaptive threshold for reliable process monitoring: Application on the new revised model of Tennessee Eastman process. J. Chemom. 2018, 32, e2978. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimension | Characteristic | VMB Fitting | |
|---|---|---|---|
| D1 | Progress over time | Continuous | |
| Discrete | X | ||
| D2 | Probability | Deterministic | |
| Stochastic | X | ||
| D3 | Nature of the model | Static model | X |
| Dynamic model | |||
| D4 | Process model | Applied | X |
| Not applied | |||
| D5 | Scope of the simulation model | Single-asset | |
| Multi-asset | X | ||
| D6 | Verification and validation | Conducted | X |
| Not conducted | |||
| D7 | Time horizon | Finite | X |
| Infinite | |||
| Meta-Dimension | Dimension | Characteristic | VMB Fitting |
|---|---|---|---|
| Data collection | Data acquisition | Automatic | x |
| Semi-automatic | |||
| Data sources | Many sources | x | |
| Single source | |||
| Synchronization | Present | x | |
| Lack | |||
| Input data | Raw data | ||
| Processed data | x | ||
| Data handling and distribution | Data governance | Compliant with the rules | * |
| Non-compliant with the rules | |||
| Data communication | Two-way | * | |
| One-way | |||
| Interface | HMI | * | |
| M2M | * | ||
| Data reusability | Lack | ||
| Medium | * | ||
| Full | |||
| Objective | Operational | x | |
| Intermediation | |||
| Repository | x | ||
| Conceptual scope | Accuracy | High | |
| Partial | x | ||
| Components of twins | Independent | ||
| Linked | x | ||
| Creation period | Digital first | x | |
| Physical first | x | ||
| Simultaneously | x |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fudyma, J.; Kura, Ł.; Gębicki, J. Development of Digital Twins for Continuous Processes: Concept Description of Virtual Mass Balance Based on the Tennessee Eastman Process. Processes 2025, 13, 337. https://doi.org/10.3390/pr13020337
Fudyma J, Kura Ł, Gębicki J. Development of Digital Twins for Continuous Processes: Concept Description of Virtual Mass Balance Based on the Tennessee Eastman Process. Processes. 2025; 13(2):337. https://doi.org/10.3390/pr13020337
Chicago/Turabian StyleFudyma, Jakub, Łukasz Kura, and Jacek Gębicki. 2025. "Development of Digital Twins for Continuous Processes: Concept Description of Virtual Mass Balance Based on the Tennessee Eastman Process" Processes 13, no. 2: 337. https://doi.org/10.3390/pr13020337
APA StyleFudyma, J., Kura, Ł., & Gębicki, J. (2025). Development of Digital Twins for Continuous Processes: Concept Description of Virtual Mass Balance Based on the Tennessee Eastman Process. Processes, 13(2), 337. https://doi.org/10.3390/pr13020337