
Prediction of Influencing Factors on Estimated Ultimate Recovery of Deep Coalbed Methane: A Case Study of the Daning–Jixian Block

 ,
,
Abstract
1. Introduction
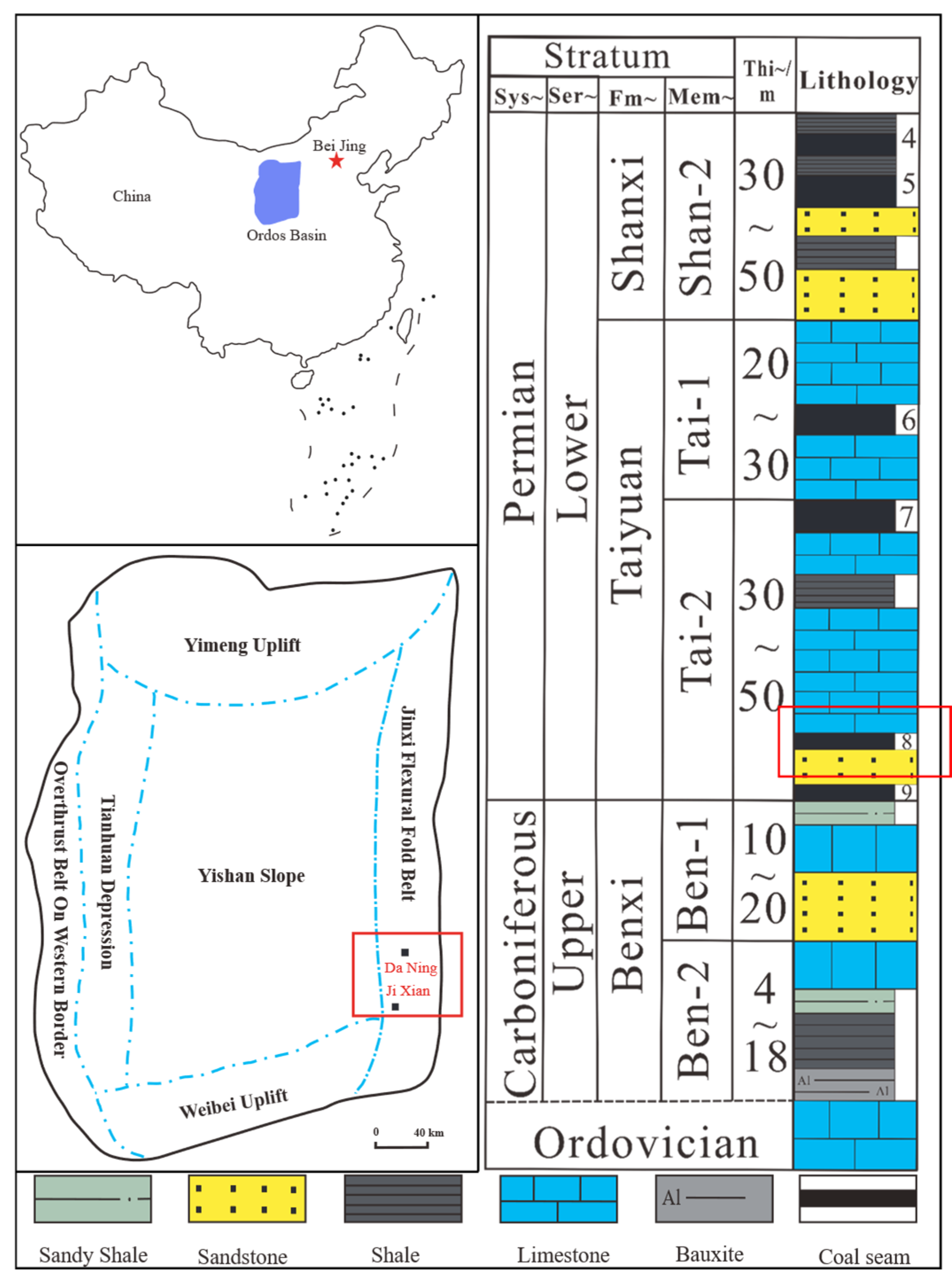
2. Geological Conditions of the Survey Region
3. Research Methodology
3.1. Production Decline Method
3.2. Machine Learning Algorithms
3.2.1. BP Neural Network
3.2.2. Support Vector Machine Regression
3.2.3. Gaussian Process Regression
3.3. Oversampling Algorithm
3.4. Feature Importance Ranking Algorithms
- (1)
- Calculate the baseline performance: Train the model on the original data set and calculate the performance indexes of the model (such as mean absolute percentage error, mean square error, etc.). The performance index is set as Porig.
- (2)
- Permutate features: Permutate the data-concentrated feature Xj. In other words, disrupt the column data of the feature to mess up its relations with the target variable. Eventually, generate the new data set .
- (3)
- Calculate after-permutation performance: recalculate the performance of the model on the after-permutation data set and compute the performance index Pperm(Xj) using the following formula:
- (4)
- Calculate the importance of features: the importance of the feature Xj is measured by the performance loss (that is, the quantity of performance change).A greater loss indicates greater importance of the feature because disrupting the value of the feature will more seriously hurt the model’s predictive power.
- (5)
- Repeat the permutation process: Repeat the above permutation process several times to acquire more stable and reliable feature importance. Calculate the performance loss of each permutation and then take its average value.where k is the number of permutations.
4. Results and Discussion
4.1. Analysis of EUR Influencing Factors
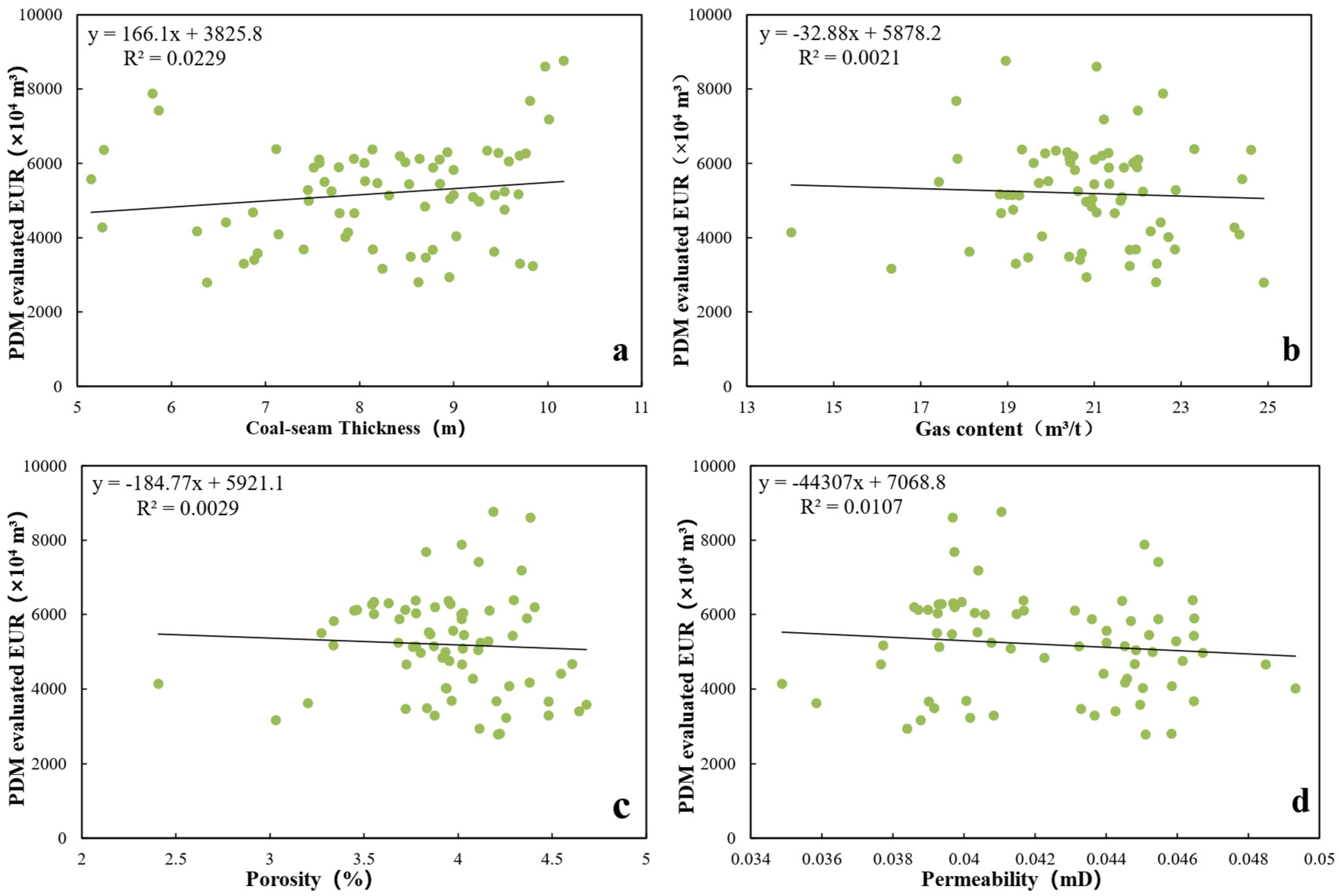
4.1.1. Influence of Geological Conditions
4.1.2. Influence of Engineering Parameters
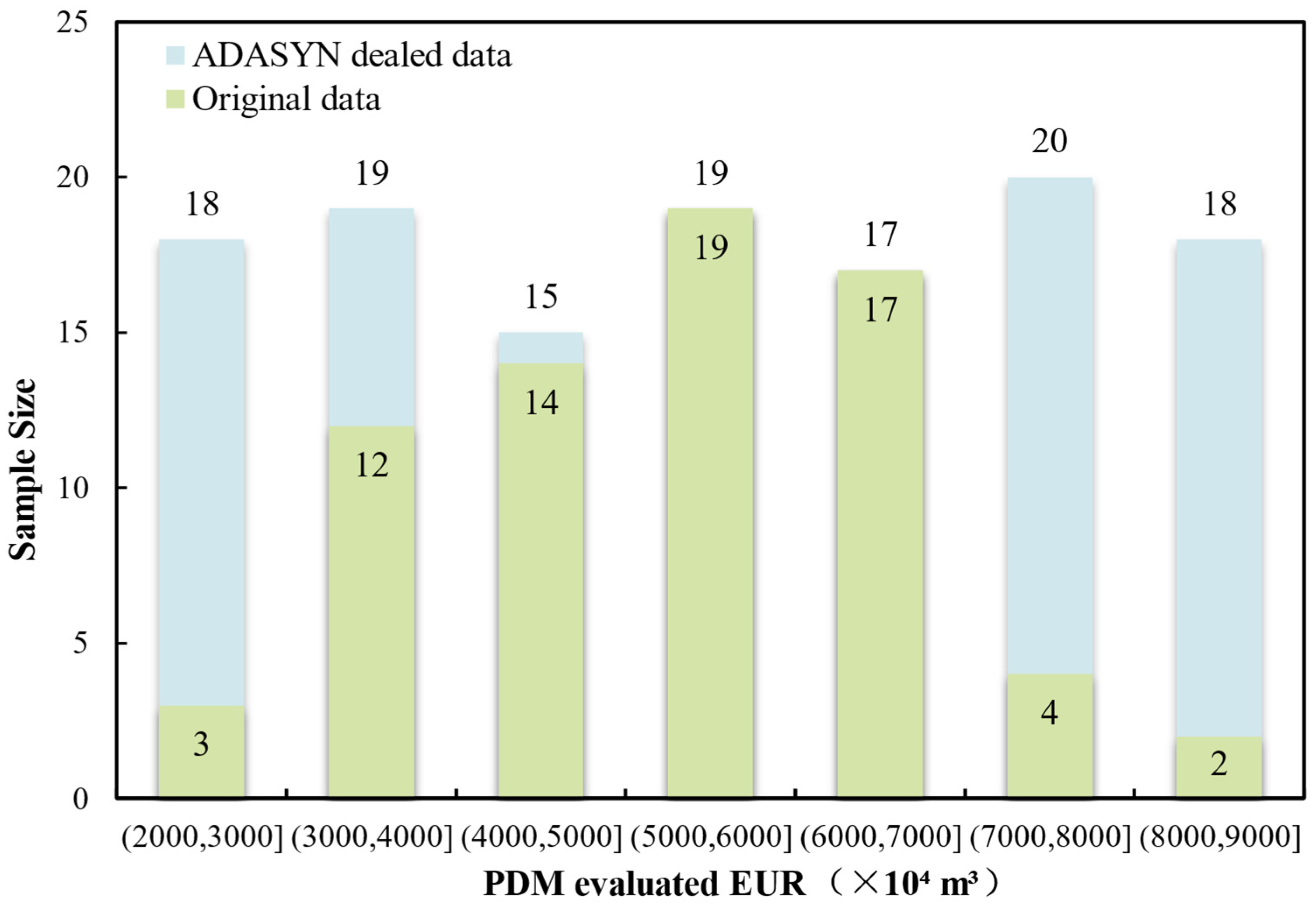
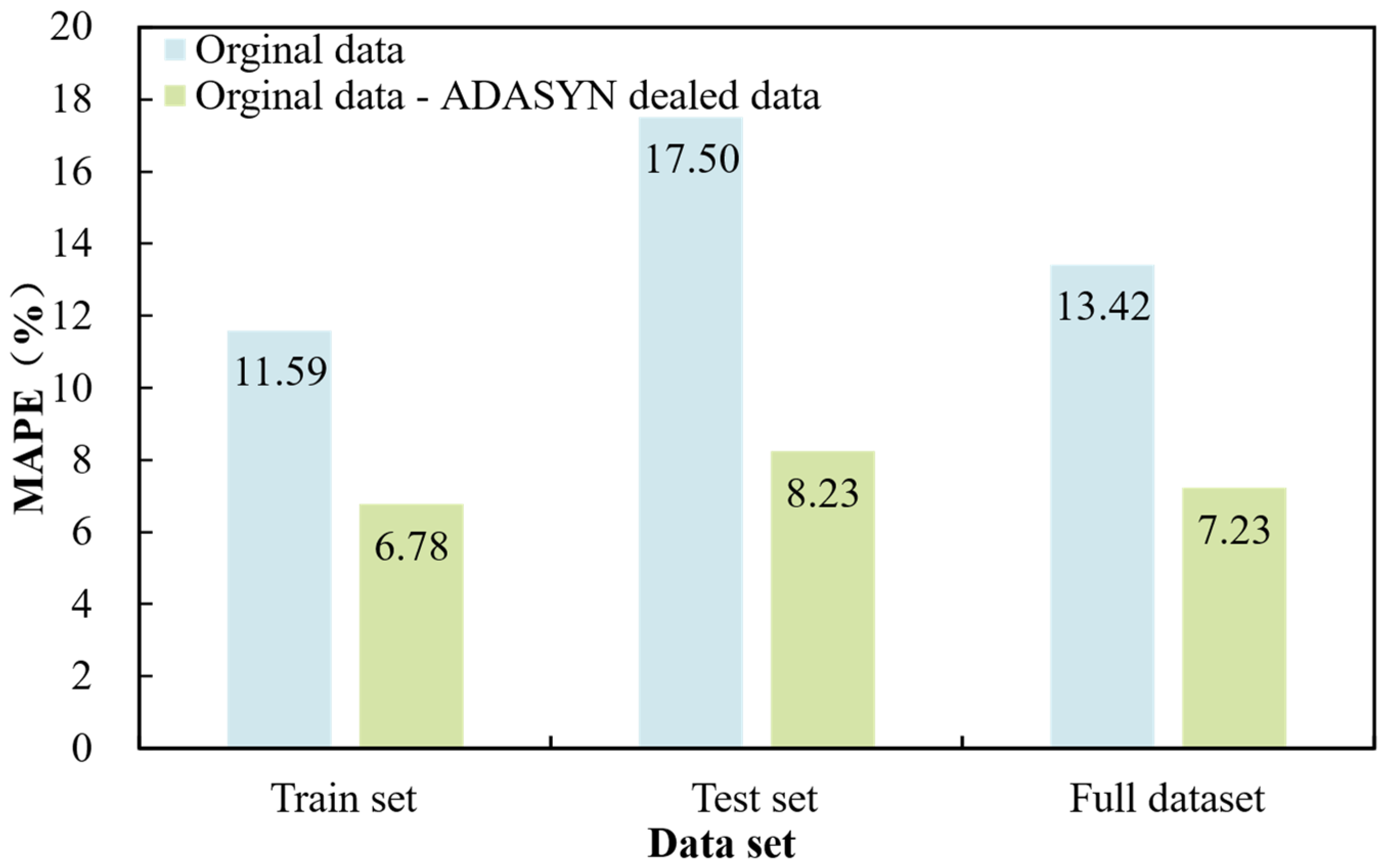
4.2. Data Imbalance Processing
4.3. Machine Learning-Based EUR Evaluation and Model Optimization
4.3.1. Rules of Data Set Division
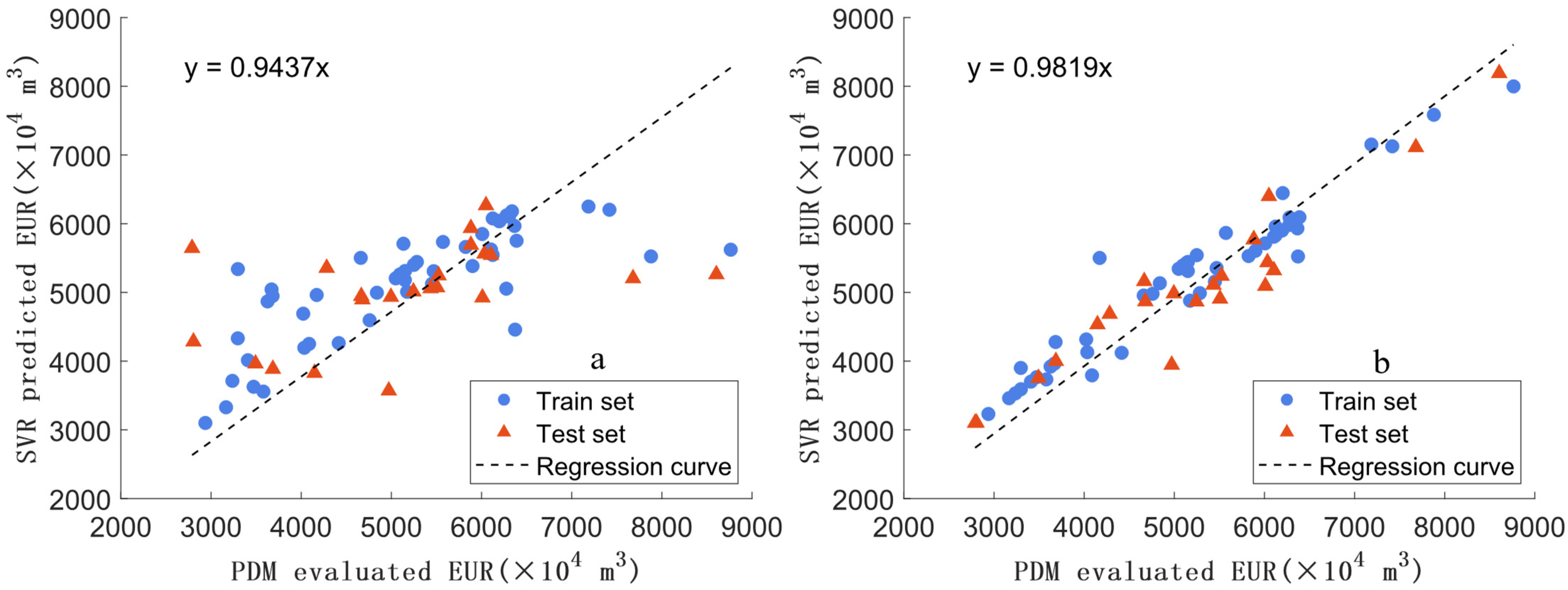
4.3.2. Machine Learning-Based EUR Evaluation Results
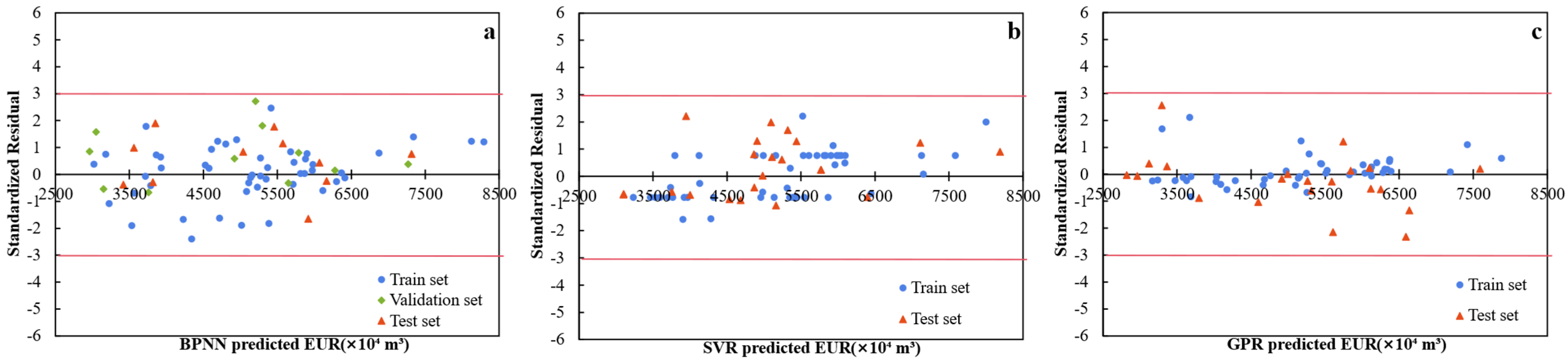
4.3.3. Residual Analysis of EUR Evaluation Results Based on Machine Learning
- (1)
- The standard residuals for all three models (BPNN, SVR, and GPR) are distributed within the range of [−3, 3], suggesting that the prediction errors for all three models are generally controllable. In the mid-value range (4500–6500), all models perform well, with residuals concentrated near zero. In the low-value (<4000) and high-value (>7000) ranges, the residuals for all models show greater fluctuation, indicating that the sparsity of boundary samples contributes to the increased errors.
- (2)
- The BPNN model performs better in the mid-value range but shows slightly weaker generalization ability compared to SVR, with a significant increase in residual fluctuations for boundary samples. This reflects the model’s limited ability to adapt to data from the low and high-value regions. The SVR model demonstrates the best fitting and generalization capabilities, with a higher consistency in the residual distribution between the training and test sets. The prediction errors for both the low and high-value regions are relatively small, and the model exhibits stable performance with strong robustness. The GPR model provides the best fitting results for the training set, but due to overfitting, the residual distribution for the test set is significantly more dispersed, with the weakest generalization ability, particularly for the boundary region, where prediction errors are largest.
4.4. Feature Importance Analysis
5. Conclusions
- (1)
- ADASYN oversampling can solve the problem of unbalanced data distribution well, thus remarkably enhancing the model accuracy of machine learning. ADASYN oversampling reduces the training set error of the SVM model from 11.59% to 6.78% and its test set error from 13.42% to 7.23%;
- (2)
- According to R2 and MAPE results, the GPR model has overfitting problems. The overall performance of the SVM model is better than that of the BPNN model, so the SVM is selected in this research to predict the EUR of deep coalbed methane in the Daning–Jixian block.
- (3)
- The abundance and amount of geological resources for deep coalbed methane in the Danning–Jixian block can satisfy the development demand and will not impose any restrictions on EUR. EUR is mainly determined by the scale of reservoir reconstruction. Engineering parameters (including clusters, the horizontal length, fracturing fluid, and proppant) are the most important factors influencing the EUR prediction results, while geological conditions (coal-seam thickness, porosity, gas content, and permeability) are the second most important.
- (1)
- The data set used in this study consists of only 71 wells. Although the ADASYN algorithm was applied to address data imbalance and expand the sample size, the overall sample quantity remains limited. This restricts the generalization ability of the model and may affect its applicability under different geological conditions or combinations of engineering parameters.
- (2)
- This study focuses on a single block in the Ordos Basin (the Daning–Jixian block). As a result, the findings may only be applicable to regions with similar geological conditions. For other areas with distinct geological characteristics or coalbed methane development scenarios, specific evaluation models tailored to their geological and engineering conditions may be required. Nonetheless, this study provides a useful reference for evaluating deep coalbed methane resources in other regions.
- (3)
- The GPR model exhibited overfitting, which may lead to significant errors when predicting EUR for new wells or undeveloped areas. Such errors could result in deviations in resource evaluation, causing the development potential to be overestimated or underestimated. This may misguide project decision-making and affect the rationality of well placement planning. Moreover, given the high costs associated with deep coalbed methane development, inaccurate predictions caused by overfitting could lead to misestimated project revenues, further increasing economic risks.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Luo, P.Y.; Zhu, S.Y. Theoretical and Technical Fundamentals of a 100-Billion-Cubic-Meter-Scale Large Industry of Coalbed Methane in China. Acta Pet. Sin. 2023, 44, 1755–1763. [Google Scholar]
- Zhang, D.Y.; Zhu, J.; Zhao, X.L.; Gao, X.; Geng, M.; Chen, G.; Jiao, J.; Liu, S.T. Dynamic assessment of coalbed methane resources and availability in China. J. China Coal Soc. 2018, 43, 1598–1604. [Google Scholar]
- Liu, D.M.; Jia, Q.F.; Cai, Y.D. Research progress on coalbed methane reservoir geology and characterization technology in China. Coal Sci. Technol. 2022, 50, 196–203. [Google Scholar]
- Xu, F.Y.; Xiao, Z.H.; Chen, D.; Yan, X.; Wu, N.; Li, X.F.; Miao, Y.N. Current status and development direction of coalbed methane exploration technology in China. Coal Sci. Technol. 2019, 47, 205–215. [Google Scholar]
- Xu, F.Y.; Yan, X.; Lin, Z.P.; Li, S.G.; Xiong, X.Y.; Yan, D.T.; Wang, H.Y.; Zhang, S.Y.; Xu, B.R.; Ma, X.Y. Research progress and development direction of key technologies for efficient coalbed methane development in China. Coal Geol. Explor. 2022, 50, 1–14. [Google Scholar]
- Xu, F.Y.; Wang, C.W.; Xiong, X.Y.; Xu, B.R.; Wang, H.N.; Zhao, X.; Jiang, S.; Song, W.; Wang, Y.B.; Chen, G.J. Evolution law of deep coalbed methane reservoir formation and exploration and development practice in the eastern margin of Ordos Basin. Acta Pet. Sin. 2023, 44, 1764–1780. [Google Scholar]
- Xiong, X.Y.; Yan, X.; Xu, F.Y.; Li, S.G.; Nie, Z.H.; Feng, Y.Q.; Liu, Y.; Chen, M.; Sun, J.Y.; Zhou, K. Analysis of multi-factor coupling control mechanism, desorption law and development effect of deep coalbed methane. Acta Pet. Sin. 2023, 44, 1812–1826,1853. [Google Scholar]
- An, Q.; Yang, F.; Yang, R.Y.; Huang, Z.W.; Li, G.S.; Gong, Y.J.; Yu, W. Practice and understanding of deep coalbed methane massive hydraulic fracturing in Shenfu Block, Ordos Basin. J. China Coal Soc. 2024, 49, 2376–2393. [Google Scholar]
- Ming, Y.; Sun, H.F.; Tang, D.Z.; Xu, L.; Zhang, B.J.; Chen, X.; Xu, C.; Wang, J.X.; Chen, S.D. Potential for the production of deep to ultradeep coalbed methane resources in the Upper Permian Longtan Formation, Sichuan Basin. Coal Geol. Explor. 2024, 52, 102–112. [Google Scholar]
- Guo, X.J.; Zhi, D.M.; Mao, X.J.; Wang, X.J.; Yi, S.W.; Zhu, M.; Gan, R.Z.; Wu, X.Q. Discovery and significance of coal measure gas in Junggar Basin. China Pet. Explor. 2021, 26, 38–49. [Google Scholar]
- Fan, L.Y.; Zhou, G.X.; Yang, Z.B.; Wang, H.C.; Lu, B.J.; Zhang, B.X.; Chen, Y.H.; Li, C.L.; Wang, Y.Q.; Gu, J.Y. Geological control on differential enrichment of deep coalbed methane in Ordos Basin. Coal Sci. Technol. 2024, 1–13. [Google Scholar]
- Xu, F.Y.; Hou, W.; Xiong, X.Y.; Xu, B.R.; Wu, P.; Wang, H.Y.; Feng, K.; Yun, J.; Li, S.G.; Zhang, L. The status and development strategy of coalbed methane industry in China. Pet. Explor. Dev. 2023, 50, 765–783. [Google Scholar] [CrossRef]
- Zhao, Y.L.; He, G.; Liu, X.Y.; Zhang, L.H.; Wu, J.F.; Chang, C. A new method for fitting empirical production decline model based on data weighting: A case study on Changning Block of the Sichuan Basin. Nat. Gas Ind. 2022, 42, 66–76. [Google Scholar]
- Jiang, R.Z.; He, J.X.; Jiang, Y.; Fan, H.J. Establishment and application of Blasingame production decline analysis method for fractured horizontal well in shale gas reservoirs. Acta Pet. Sin. 2019, 40, 1503–1510. [Google Scholar]
- Liu, X.H.; Zou, C.M.; Jiang, Y.D.; Yang, X.F. Basic principles and applications of modern production decline analysis. Nat. Gas Ind. 2010, 5, 50–54. [Google Scholar]
- Arps, J.J. Analysis of decline curves. Trans. AIME 1945, 160, 228–247. [Google Scholar] [CrossRef]
- Li, K.; Horne, R.N. An analytical model for production decline-curve analysis in naturally fractured reservoirs. SPE Reserv. Eval. Eng. 2005, 8, 197–204. [Google Scholar] [CrossRef]
- Ilk, D.; Rushing, J.A.; Perego, A.D.; Blasingame, T.A. Exponential vs. Hyperbolic Decline in Tight Gas Sands—Understanding the Origin and Implications for Reserve Estimates Using Arps’ Decline Curves. In Proceedings of the SPE Annual Technical Conference and Exhibition, Denver, CO, USA, 21–24 September 2008; SPE: Denver, co, USA, 2008; p. SPE-116731-MS. [Google Scholar]
- Kupchenko, C.L.; Gault, B.W.; Mattar, L. Tight gas production performance using decline curves. In Proceedings of the SPE Unconventional Resources Conference/Gas Technology Symposium, Calgary, AB, Canada, 16–19 June 2008; SPE: Calgary, AB, Canada, 2008; p. SPE-114991-MS. [Google Scholar]
- Song, H.-j.; Su, Y.-h.; Xiong, X.-l.; Liu, Y.; Zhong, S.-c.; Wang, J.-j. EUR evaluation workflow and influence factors for shale gas well. Nat. Gas Geosci. 2019, 30, 1531–1538. [Google Scholar]
- Valkó, P.P. Assigning value to stimulation in the Barnett Shale: A simultaneous analysis of 7000 plus production hystories and well completion records. In Proceedings of the SPE Hydraulic Fracturing Technology Conference and Exhibition, The Woodlands, TX, USA, 19–21 January 2009; SPE: The Woodlands, TX, USA, 2009; p. SPE-119369-MS. [Google Scholar]
- Gu, Y.F.; Zhang, D.Y.; Bao, Z.D. Permeability prediction using PSO-XGBoost based on logging data. Oil Geophys. Prospect. 2021, 56, 26–37. [Google Scholar]
- Li, N.; Xu, B.; Wu, H.; Feng, Z.; Li, Y.; Wang, K.; Liu, P. Application status and prospects of artificial intelligence in well logging and formation evaluation. Acta Pet. Sin. 2021, 42, 508–522. [Google Scholar]
- Li, Y.F.; Cheng, J.Y.; Wang, C. Seismic attribute optimization based on support vector machine and coalbed methane prediction. Coal Geol. Explor. 2012, 40, 75–78. [Google Scholar]
- Feng, K.; Li, F.; Zhang, S.Y.; Zhao, Y.H.; Zhen, H.B.; Liu, J.J.; Zhu, J. Evaluation and optimization of coalbed methane well production based on production data. Min. Res. Dev. 2023, 43, 52–58. [Google Scholar]
- Zhu, Q.Z.; Li, Z.J.; Li, Z.Y.; Wang, S.S.; Sun, R.X.; Wang, Y.T.; Xiao, Y.H.; Wang, J.; Wang, J.Y.; Guan, X.Q. Practice and cognition of efficient CBM development under complex geological conditions: A case study of Zhengzhuang Block, Qinshui Basin. Coal Geol. Explor. 2023, 51, 131–138. [Google Scholar]
- Song, H.Q.; Du, S.Y.; Yang, J.S.; Wang, M.Z.; Zhao, Y.; Zhang, J.D.; Zhu, J.W. Forecasting and influencing factor analysis of coalbed methane productivity utilizing intelligent algorithms. Chin. J. Eng. 2024, 46, 614–626. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Tang, S.L.; Tang, D.Z.; Yang, J.S.; Deng, Z.; Li, S.; Chen, S.D.; Feng, P.; Huang, C.; Li, Z.W. Pore structure characteristics and gas storage potential of deep coal reservoirs in Daning-Jixian block of Ordos Basin. Acta Pet. Sin. 2023, 44, 1854–1866,1902. [Google Scholar]
- Sun, H.M.; Liu, Z.D.; Xing, X.J.; Liu, Q.; Deng, L.; Zhang, Z.C.; Yang, H.T.; Zhang, L.Z. Fractal characteristics and classification evaluation of pore structure of tight gas reservoirs in Shanxi section of Daning-Jixian area. J. Xi’an Univ. Arts Sci. 2024, 27, 60–67. [Google Scholar]
- Li, Y.E.; Chen, G.H.; Cai, Z.X.; Lu, S.F.; Wang, F.; Zhang, Y.J.; Bai, G.S.; Ge, J. Occurrence of methane in organic pores with surrounding free water: A molecular simulation study. Chem. Eng. J. 2024, 497, 155597. [Google Scholar] [CrossRef]
- Robertson, S. Generalized hyperbolic equation. In Proceedings of the Paper SPE 18731 Presented at Society of Petroleum Engineers, Richardson, TX, USA, 1 January 1988. [Google Scholar]
- Duong, A.N. An unconventional rate decline approach for tight and fracture-dominated gas wells. In Proceedings of the SPE Canada Unconventional Resources Conference, Calgary, AB, Canada, 19–21 October 2010; SPE: Calgary, AB, Canada, 2010; p. SPE-137748-MS. [Google Scholar]
- Wang, K.; Li, H.; Wang, J.; Jiang, B.; Bu, C.; Zhang, Q.; Luo, W. Predicting production and estimated ultimate recoveries for shale gas wells: A new methodology approach. Appl. Energy 2017, 206, 1416–1431. [Google Scholar] [CrossRef]
- Wang, C.F.; Shao, X.J.; Sun, Y.B.; Xu, H.; Liu, Y.J.; Shi, L. Production decline types and their control factors in coalbed methane wells: A case from Jincheng and Hancheng mining areas. Coal Geol. Explor. 2013, 41, 23–28. [Google Scholar]
- Zeng, W.T.; Ge, T.Z.; Wang, Q.; Pang, B.; Liu, Y.H.; Zhang, K.; Yu, L.Z. Exploration of integrated technology for deep coalbed methane drainage in full life cycle: A case study of Daning–Jixian Block. Coal Geol. Explor. 2022, 50, 78–85. [Google Scholar]
- Li, M.Z.; Cao, Y.M.; Ding, R.; Deng, Z.; Jiang, K.; Li, Y.Z.; Yao, X.L.; Hou, S.; Hui, H.; Sun, X.G. Gas occurrence and production characteristics of deep coal measure gas and reserve estimation method and indicators in Daning-Jixian block. China Pet. Explor. 2024, 29, 146–159. [Google Scholar]
- Min, C.; Wen, G.Q.; Li, X.G.; Zhao, D.Z.; Li, K.C. Research progress and application prospect of interpretable machine learning in artificial intelligence in oil and gas industry. Nat. Gas Ind. 2024, 44, 114–126. [Google Scholar]
- Taylor, C.; Vasco, D. Inversion of gravity gradiometry data using a neural network. In SEG Technical Program Expanded Abstracts 1990; Society of Exploration Geophysicists: Houston, TX, USA, 1990; pp. 591–593. [Google Scholar]
- Qiao, J.W.; Wang, C.J.; Zhao, H.C.; Shi, Q.M.; Zhang, Y.; Fan, Q.; Wang, D.; Yuan, D.D. A method for predicting the tar yield of tar-rich coals based on the BP neural network using multiple indicators of coal petrography and coal quality. Coal Geol. Explor. 2024, 52, 1–11. [Google Scholar]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [PubMed]
- Schölkopf, B. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Seeger, M. Gaussian processes for machine learning. Int. J. Neural Syst. 2004, 14, 69–106. [Google Scholar] [CrossRef]
- Zhang, W.R.; Chen, X.G.; Qi, J.T.; Zhou, J.B.; Li, N.; Wang, S. Deep Learning and Gaussian Process Regression Based Path Extraction for Visual Navigation under Canopy. Trans. Chin. Soc. Agric. Mach. 2024, 55, 15–26. [Google Scholar]
- Lin, Z.Y.; Hao, Z.F.; Yang, X.W. Current state of research on imbalanced datasets classification learning. Appl. Res. Comput. 2008, 25, 332–336. [Google Scholar]
- Ye, Z.F.; Wen, Y.M.; Lv, B.L. A survey of imbalanced pattern classification problems. CAAI Trans. Intell. Syst. 2009, 4, 148–156. [Google Scholar]
- Lou, X.J.; Sun, Y.X.; Liu, H.T. Cluster boundary oversampling for imbalanced data classification. J. Zhejiang Univ. Eng. 2013, 47, 944–950. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L. Statistical modeling: The two cultures (with comments and a rejoinder by the author). Stat. Sci. 2001, 16, 199–231. [Google Scholar] [CrossRef]
- Qiu, Y.; Li, S.; Jin, L.; Zhang, M.M.; Wang, J. Bridge abnormal monitoring data identification method based on statistical feature mixture and random forest importance ranking. J. Transduct. Technol. 2022, 35, 756–762. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Xiong, X.L. Quantitative evaluation of controlling factors on EUR of shale gas wells in Weiyuan block. China Pet. Explor. 2019, 24, 532–538. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Decline Model Equation | Equation Notes | Applicable Scope |
|---|---|---|---|
| Arps [16] | q: Monthly gas production calculated by the decline model; qi: Initial monthly gas production; Di: Initial decline rate; n: Decline exponent | Suitable for wells with long production periods and stable bottom-hole flowing pressure | |
| Modified hyperbolic decline [33] | q: Monthly gas production calculated by the decline model; qi: Initial monthly gas production; Di: Initial decline rate; n: Decline exponent; Dt: Constrained decline rate | Suitable for wells where the decline rate changes significantly over time | |
| PLE [18] | D: Decline rate; D∞: Decline rate as production time approaches infinity; D1 and n: Fitting constants; | Applicable to the unstable flow phase, transitional flow phase, and boundary-dominated flow phase of gas wells | |
| SEPD [21] | τ and n: Fitting constants | Applicable to the unstable flow phase and transitional flow phase of gas wells | |
| Duong [34] | Gp: Cumulative gas production; a and m: Fitting constants | Applicable to the linear flow phase of gas wells | |
| Li [35] | λ: Fitting constants | Applicable to the linear flow phase of gas wells |
| Model | Train Set Proportion (%) | Validation Set Proportion (%) | Test Set Proportion (%) |
|---|---|---|---|
| BPNN | 70 | 15 | 15 |
| SVR | 70 | / | 30 |
| GPR | 70 | / | 30 |
| Model | R2 | MAPE | ||||||
|---|---|---|---|---|---|---|---|---|
| Train Set | Validation Set | Test Set | Total Dataset | Train Set | Validation Set | Test Set | Total Dataset | |
| BPNN | 0.91 | 0.89 | 0.83 | 0.90 | 6.49 | 7.79 | 8.64 | 7.03 |
| SVR | 0.92 | / | 0.88 | 0.90 | 6.78 | / | 8.23 | 7.23 |
| GPR | 0.99 | / | 0.97 | 0.99 | 0.02 | / | 4.09 | 1.28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Wu, M.; Wang, Y.; Sun, W.; Chen, G.; Feng, Y.; Shi, X.; Zhao, Z.; Liu, Y.; Lu, S. Prediction of Influencing Factors on Estimated Ultimate Recovery of Deep Coalbed Methane: A Case Study of the Daning–Jixian Block. Processes 2025, 13, 31. https://doi.org/10.3390/pr13010031
Wang F, Wu M, Wang Y, Sun W, Chen G, Feng Y, Shi X, Zhao Z, Liu Y, Lu S. Prediction of Influencing Factors on Estimated Ultimate Recovery of Deep Coalbed Methane: A Case Study of the Daning–Jixian Block. Processes. 2025; 13(1):31. https://doi.org/10.3390/pr13010031
Chicago/Turabian StyleWang, Feng, Mansheng Wu, Yuan Wang, Wei Sun, Guohui Chen, Yanqing Feng, Xiaosong Shi, Zengping Zhao, Ying Liu, and Shuangfang Lu. 2025. "Prediction of Influencing Factors on Estimated Ultimate Recovery of Deep Coalbed Methane: A Case Study of the Daning–Jixian Block" Processes 13, no. 1: 31. https://doi.org/10.3390/pr13010031
APA StyleWang, F., Wu, M., Wang, Y., Sun, W., Chen, G., Feng, Y., Shi, X., Zhao, Z., Liu, Y., & Lu, S. (2025). Prediction of Influencing Factors on Estimated Ultimate Recovery of Deep Coalbed Methane: A Case Study of the Daning–Jixian Block. Processes, 13(1), 31. https://doi.org/10.3390/pr13010031