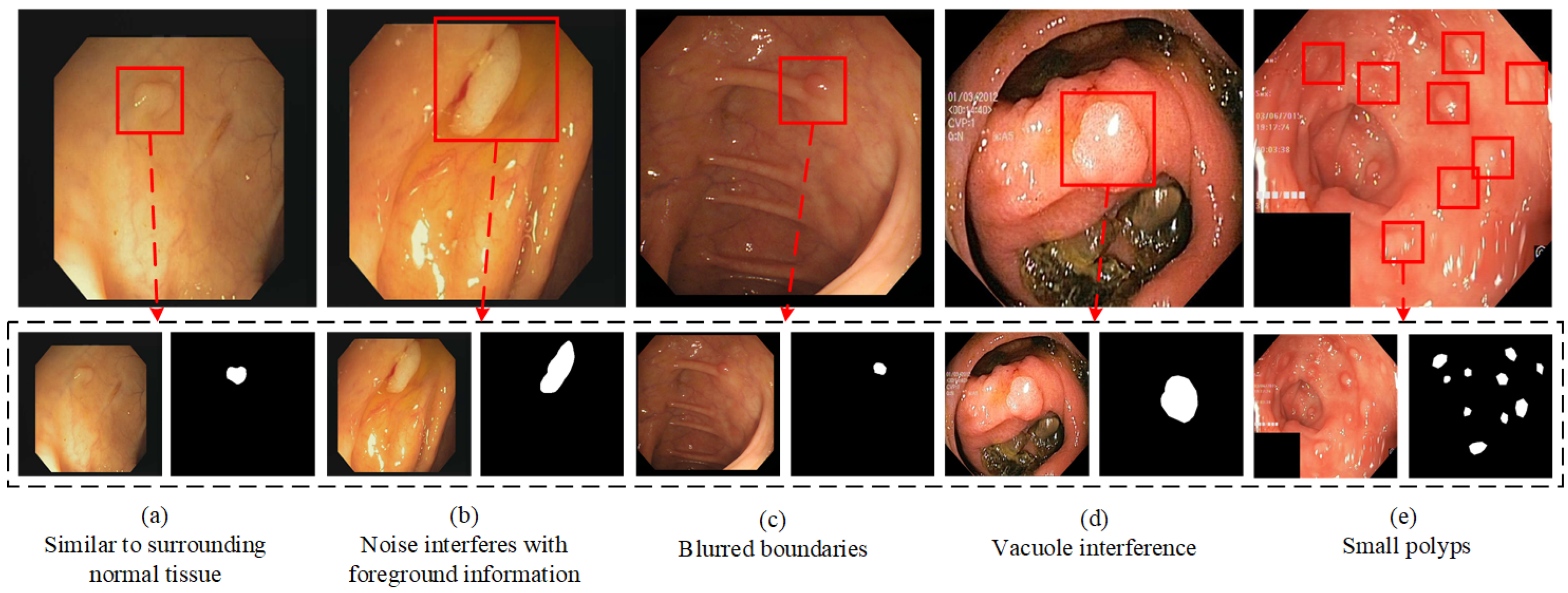
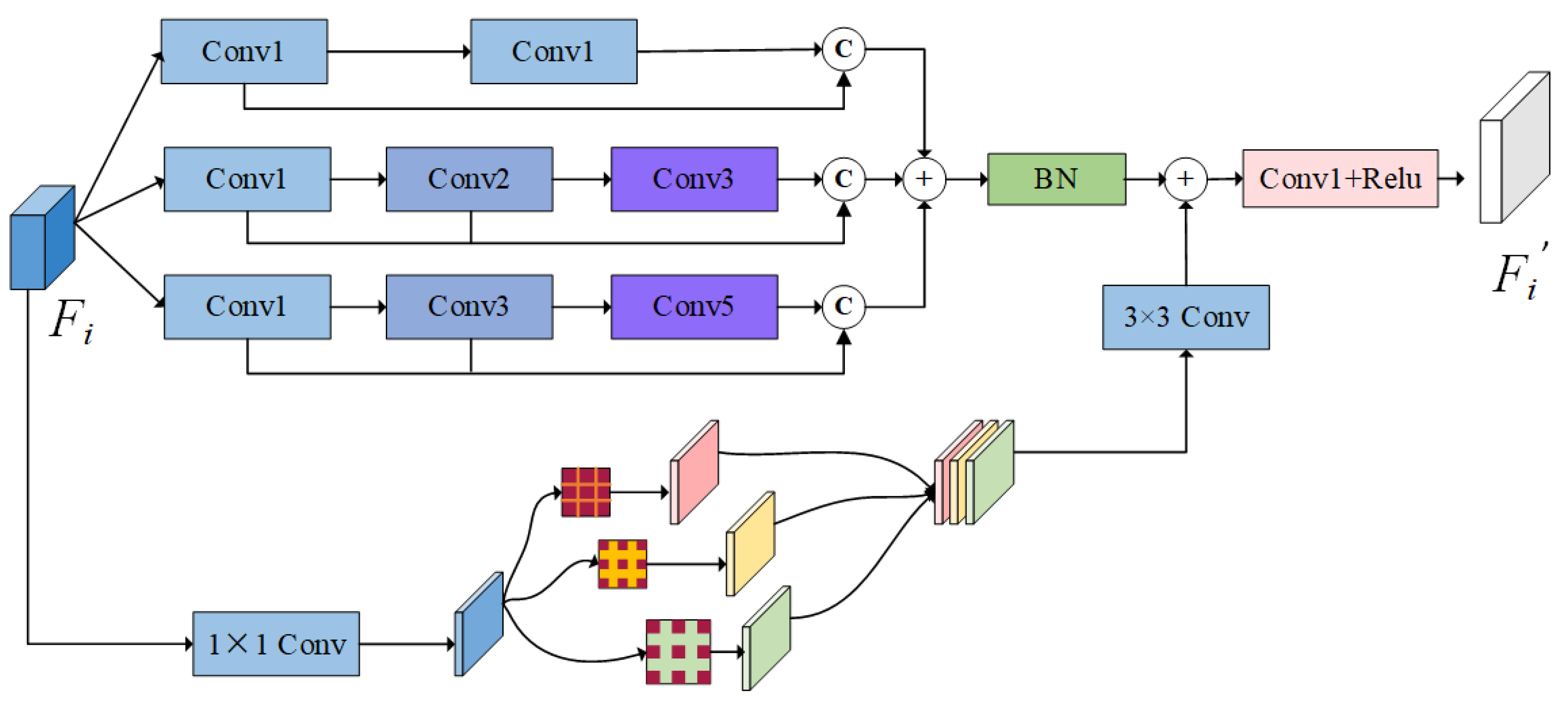
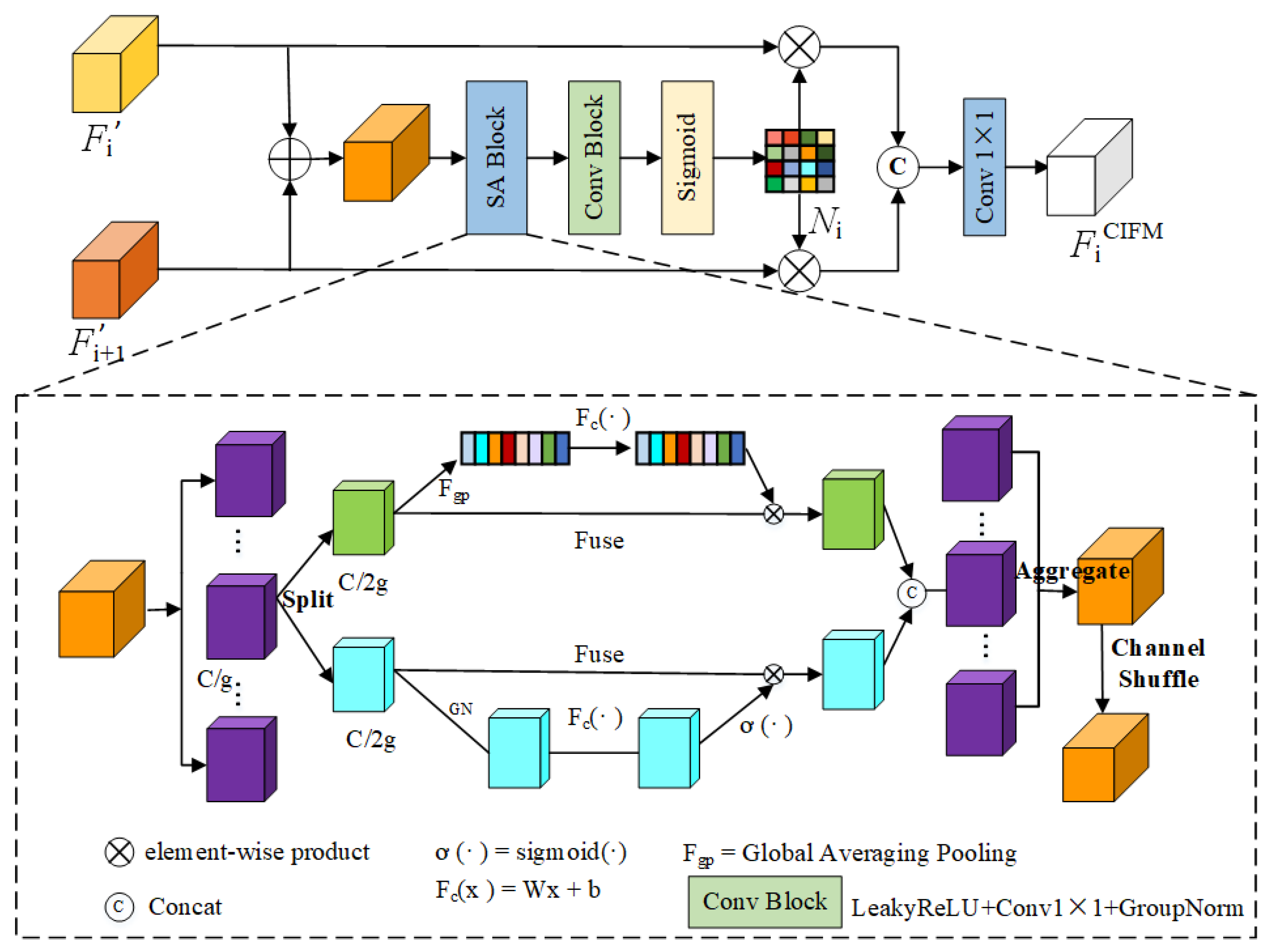
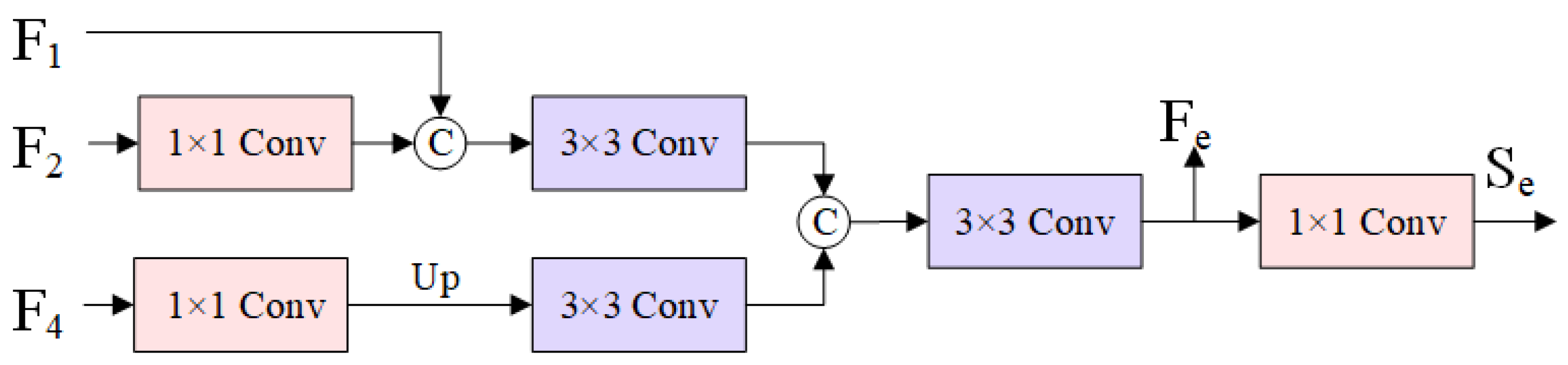
In this section, we perform comprehensive comparative experiments on five datasets using advanced segmentation networks. We validate the superior performance of CIFFormer through quantitative and qualitative comparisons. Additionally, we demonstrate the versatility of the model through cross-validation experiments. Finally, we conduct ablation experiments on the FSM, CIFM, and BGM modules proposed in our study.
5.1. Comparison with the Competitive Methods
To further validate the efficacy of the proposed networks in polyp segmentation, we conducted a comparison experiment of CIFFormer with the U-Net, U-Net++, CENet [
34], PraNet, Polyp-PVT, TransUNet and SSFormer networks. Experiments were carried out on the same environment and parameter settings for all five datasets, encompassing both quantitative and qualitative comparisons.
Quantitative Comparison: We chose , , , and as quantitative metrics to evaluate the segmentation performance of each network. It is clear that our CIFFormer achieves better performance than all competing methods on the two datasets.
The quantitative results of these evaluation metrics for each network on Kvasir-SEG are presented in
Table 2. Our proposed CIFFormer has better performance than the other networks. Both
and
have reached the optimal values of 0.925 and 0.875, respectively, which are 0.4% and 0.2% ahead of SSFormer. Recall and Precision are 0.942 and 0.921, respectively. Recall is 0.7% lower than CENet, and Precision is 0.4% lower than SSFormer. Although Recall and Precision do not reach the optimal metrics, they also obtain sub-optimal indicators. Comprehensively analyzing the four indices, CIFFormer can segment polyps more efficiently compared to Transformer-based polyp segmentation models, such as Polyp-PVT, TransUNet, and SSFormer.
From
Table 3, it is evident that CIFFormer demonstrates superior performance on the CVC-ClinicDB dataset. Specifically, the mIOU of our model achieves 0.2% and 2% improvement over TransUNet and Polyp-PVT, remaining relatively stable. Additionally, the mDice of our model is 0.934, which is not the highest value, but the second highest, and Polyp-PVT is only 0.3% higher than our model. The Recall and Precision are also as high as 0.946 and 0.945, compared with SSFormer, with 2% and 0.4% improvements, respectively. These results demonstrate that CIFFormer has an obvious segmentation advantage on the two datasets.
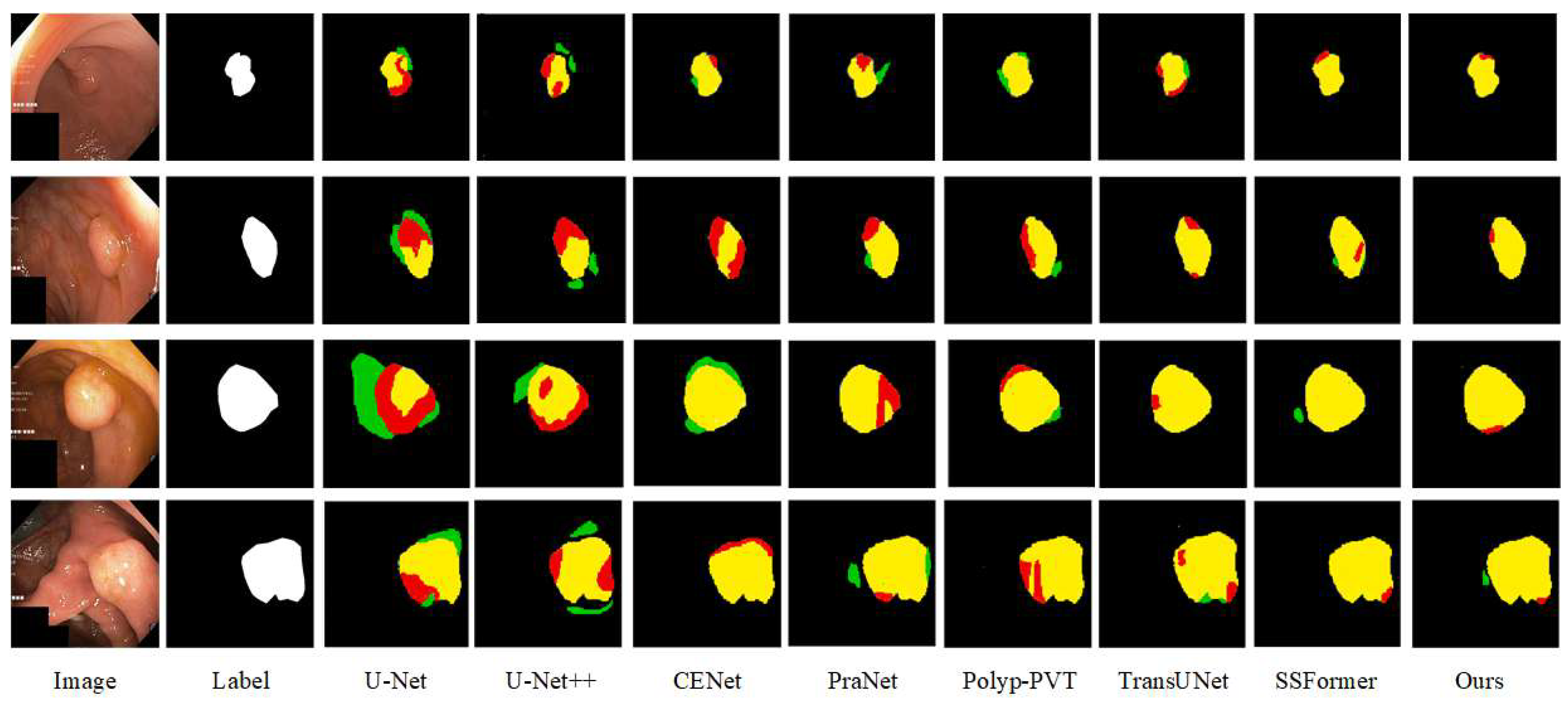
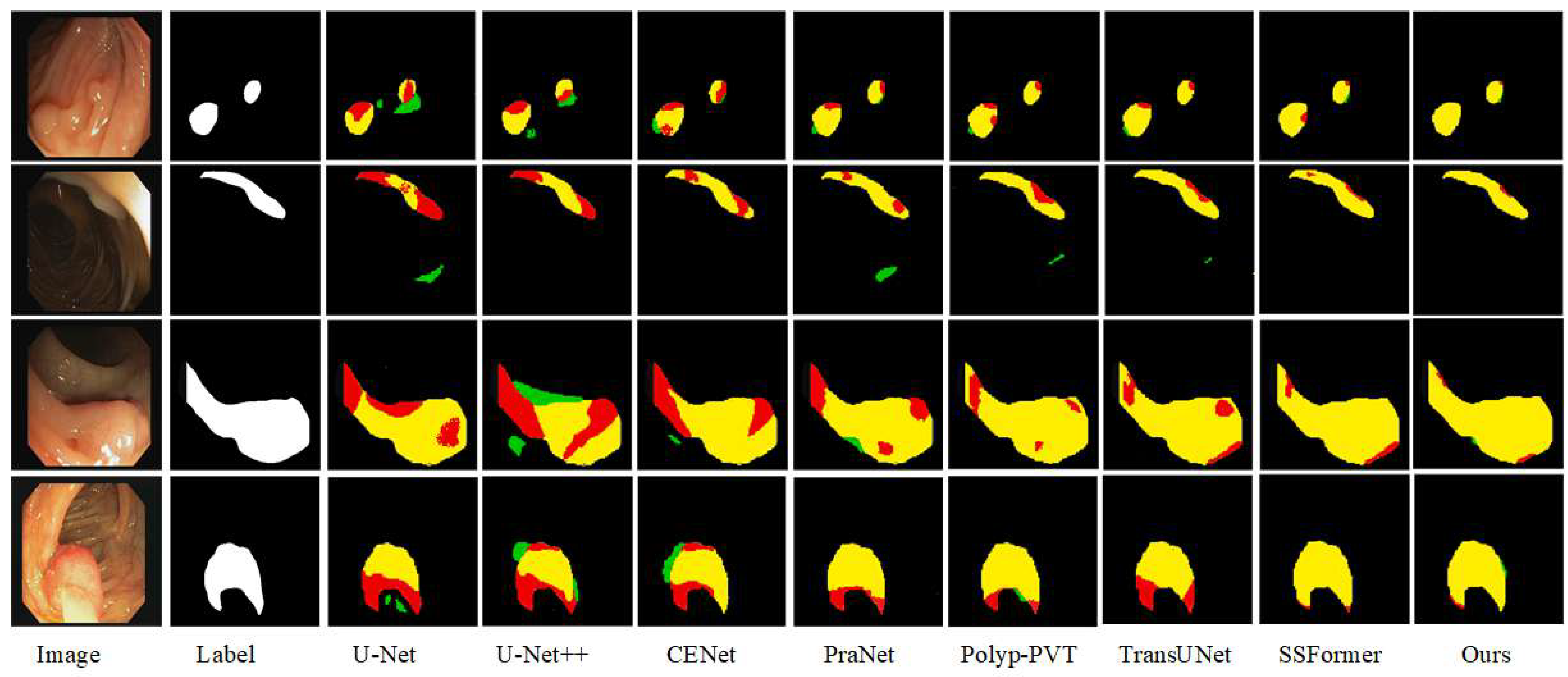
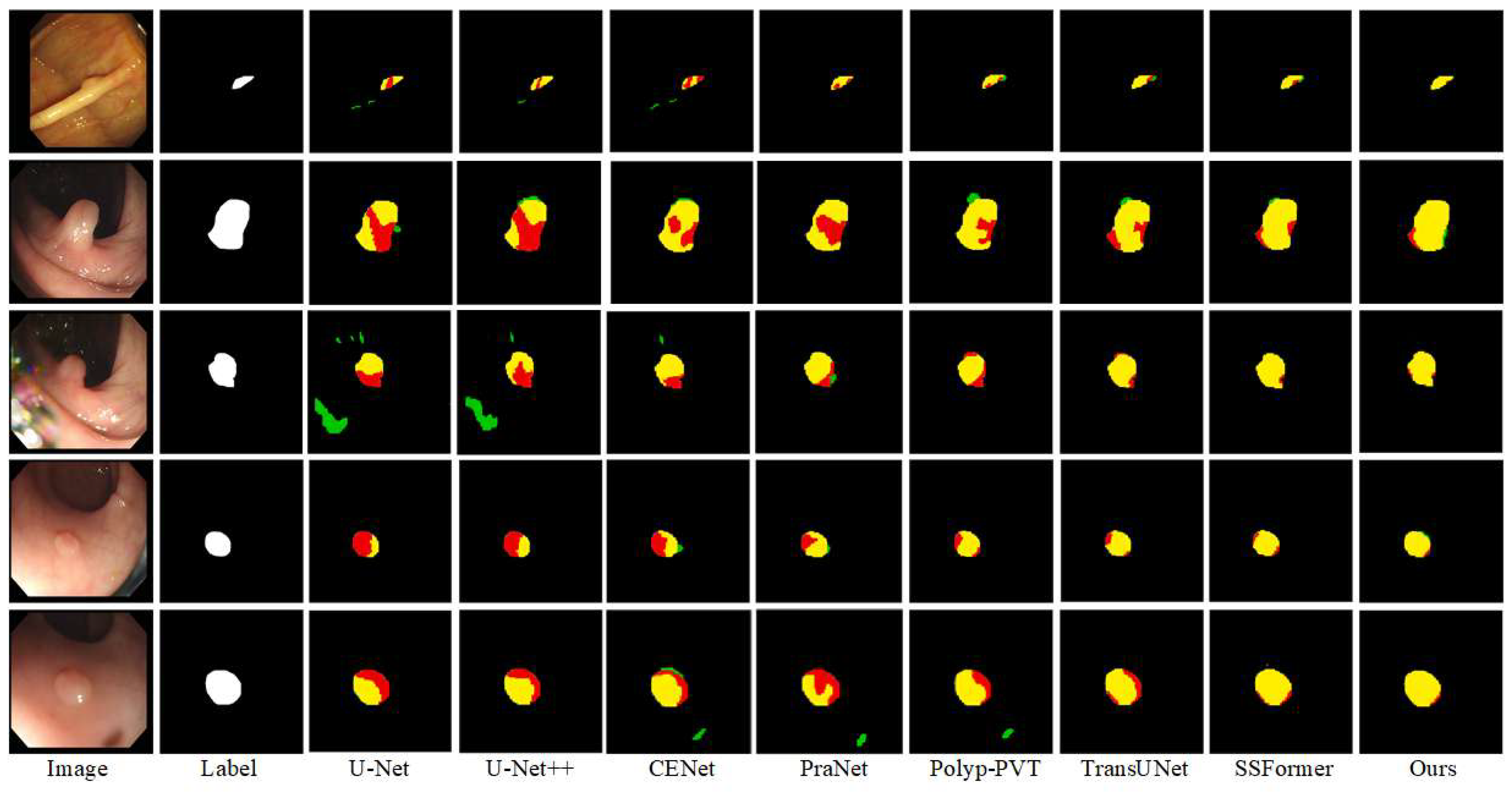
Qualitative Comparison: In order to more intuitively assess the segmentation ability of the various advanced networks on the Kvasir-SEG and CVC-ClinicDB datasets, we selected four samples with large differences in polyp appearance from each dataset, and analyzed the segmentation ability of the networks based on the visualized segmentation results, as shown in
Figure 7 and
Figure 8.
Four images from the Kvasir-SEG dataset were selected with different polyp sizes; due to the low light of the images, the segmented polyp target areas have poor contrast with the background areas. The polyps in the first and second groups are similar to the surrounding tissues, and we can see that the polyp contours could not be prepared for localization in U-Net and U-Net++. Furthermore, some of the polyps were incorrectly predicted as part of the background. The segmentation effect was improved in Polyp-PVT, TransUNet, and SSFormer. The third and fourth groups of polyp organization are more obvious, due to increased background noise interference; the CENet and PraNet network segmentation results show that background noise interferes with the models’ sensitivity to foreground information, and they misclassify the background noise as the target. In contrast, while the segmentation results of CIFFormer are closest to the labeled images, there remains some ambiguity in segmenting the edge details.
Sample images of polyp tissues that are hidden and difficult to be seen in the CVC-ClinicDB dataset are selected, and from the qualitative analysis, we can see that the four irregular polyp shapes are more difficult to segment. The second group of polyps has a large chromatic aberration with the background, thus affecting the segmentation boundaries, and the U-Net and PraNet networks are unable to correctly segment the polyps and normal tissues. The third and fourth original images are irregular polyp shapes, and the segmentation results in CE-Net, PraNet, Polyp-PVT, and TransUNet have the problem of misclassifying the lesion area as the background. Precise segmentation accuracy has been achieved by SSFormer, but it cannot perform segmentation well when dealing with convex sharp corners and critical regions and does not reach the segmentation advantage of the CIFFormer network proposed in this paper. Compared with competing networks, CIFFormer can suppress complex backgrounds, has coherent boundaries, and is more suitable for polyp segmentation.
5.2. Cross-Validation Experiment
Model generalization ability: Each dataset has its own proprietary features used to achieve good results when performing the polyp segmentation task. In addition to performing well on a specific dataset, an excellent segmentation method needs to maintain a stable performance on unknown data. Therefore, the model needs to have excellent generalization capabilities to obtain the best segmentation results. We performed a series of cross-validation experiments to test the generalization ability of CIFFormer on three unseen datasets, namely the CVC-ColonDB, ETIS-LaribPolypDB, and EndoTect datasets.
Table 4 presents the comparison results of competitive segmentation methods. Our proposed CIFFormer network has clear advantages on all unseen datasets, and has obtained the highest mean Dice scores of 0.824 on CVC-ColonDB and 0.793 on ETIS-LaribPolypDB. Compared to the second-ranked SSFormer, the mDice scores of CIFFormer are 0.9% and 0.7% higher in the CVC-ColonDB and ETIS-LaribPolypDB datasets, respectively. On the EndoTect dataset, mDice, mIOU, Recall, and Precision reached 0.729, 0.633, 0.756, and 0.759, respectively. mDice and Recall of our proposed method did not have the highest values, but mDice was 7% higher than U-Net, Recall was 3.2% higher than CENet, and higher than the highest value, obtained by PraNet, by only a small difference of 0.2%. In conclusion, from the results of the cross-validation experiments on the three datasets, CIFFormer demonstrates robust performance across all three datasets, proving its effectiveness in polyp segmentation and demonstrating strong generalization ability.
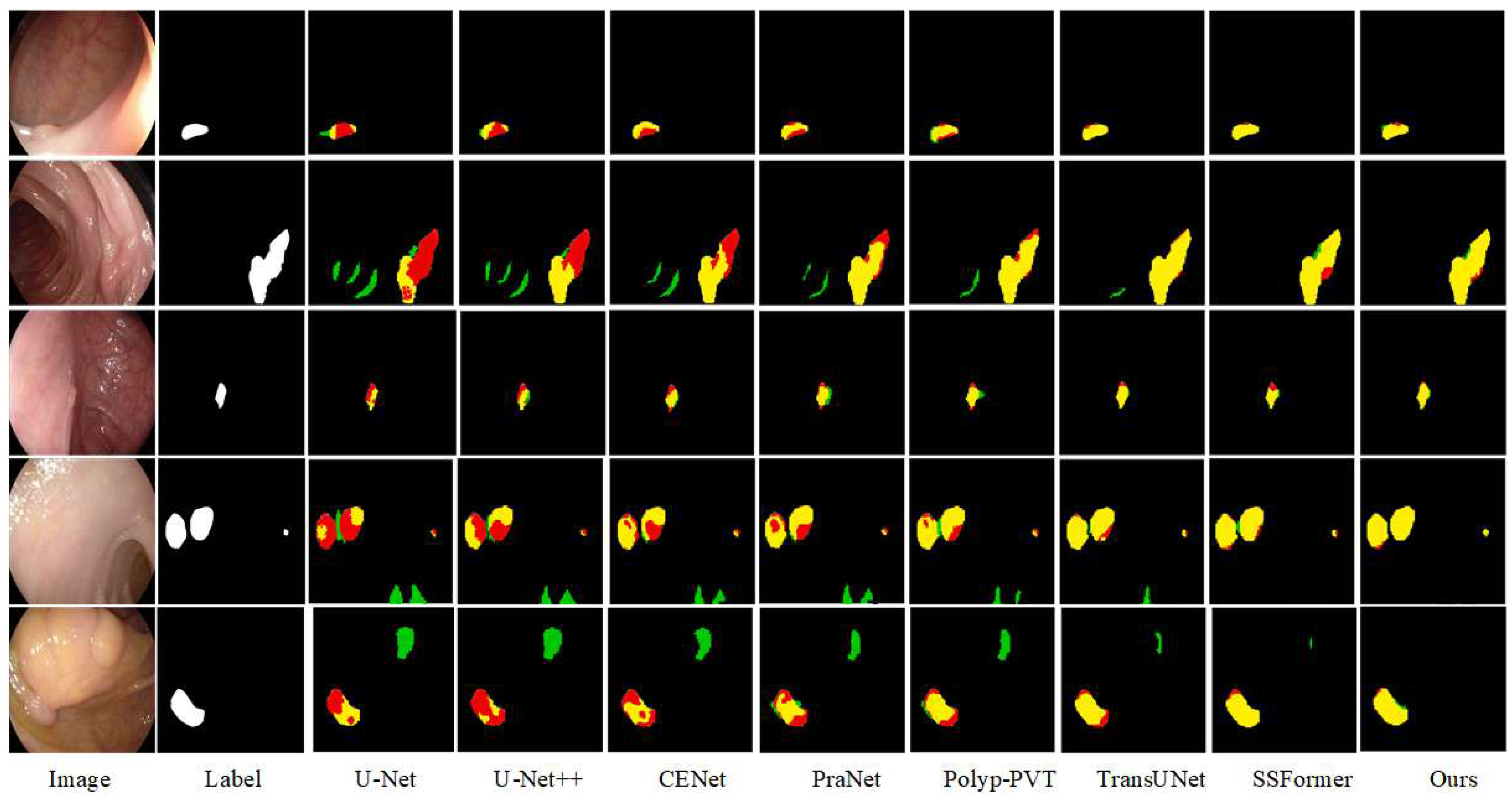
The visualization results on three datasets are shown in
Figure 9,
Figure 10 and
Figure 11. The ETIS dataset was selected for its images with high segmentation difficulty and low polyp and background discrimination. The segmentation results are rough around the edged of the polyps under the influence of light, and there are large areas misclassified as lesions by the U-Net and U-Net++ networks. Especially for irregular polyps, the background noise is misclassified as polyp tissue. The SSFormer network is more sensitive to the polyp region, and enhances the effectiveness of segmentation. Compared with the real label map, CIFFormer is closest to the label, although there is an unclear problem at the boundary. EndoTect selects polyp images with relatively regular shapes and different sizes, and most of the networks can segment the contours correctly. In the third row of images, the background noise is too large and interferes with the foreground information feature extraction, misclassifying the noise as a polyp region. This problem is improved in the TransUNet, SSFormer, and CIFFormer models, which are better able to prepare the polyp region for imaging. The problem of polyp organization and background blurring exists in CVC-colonDB for small target segmentation, which is solved in PraNet. In the fifth row, the polyp lesion has a piece of protruding tissue, and it can be seen that CIFFormer can enhance the information interaction between the polyp foreground and the background through the CIFM module, capturing the protruding features that can be easily overlooked and segmenting them effectively at the edges. The cross-validation results of competing methods on CVC-ColonDB, ETIS-LaribPolypDB, and EndoTect datasets above prove that our model demonstrates superior generalization ability.
5.3. Ablation Study
To verify the effect of each module in CIFFormer on the segmentation results, quantitative analyses of ablation experiments are performed in this section, as shown in
Table 5. CIFFormer first selects the baseline model and adds FSM, CIFM, and BGM as well as a combination of modules to the baseline model individually. Then, the ablation study proves the effectiveness of each module on CVC-ColonDB, ETIS-LaribPolypDB, CVC-ClinicDB, Kvasir-SEG, and EndoTect datasets. It can be seen that CIFFormer, with the addition of three modules, achieves the best performance for polyp segmentation.
- (1)
Effectiveness of FSM
By incorporating the FSM module into the baseline, we aimed to enhance potential detailed features while minimizing the loss of valid information. The results, as depicted in row 4 of
Table 5, demonstrate notable improvements in metrics across all five datasets. Specifically, the mDice improves by 0.7%, 0.2%, and 1.4% in CVC-ColonDB, ETIS-Larib, and CVC-ClinicDB, respectively. Thus, the module significantly enhanced the model’s capture of polyp features, suppressed the interference of noise, and improved the segmentation ability.
- (2)
Effectiveness of CIFM
The CIFM module is used for cross-scale interaction feature fusion. From
Table 5, it can be seen that overlaying CIFM on top of the baseline model and the FSM increases mDice and mIoU by a certain percentage. On the Kvasir-SEG and EndoTect datasets, mDice improves by 0.9% and 1.2%, respectively, and the mIoU improves from 0.791 to 0.817. The results indicate that incorporating the CIFM module into the baseline network can be a beneficial strategy for obtaining more refined foreground and edge features, suppressing irrelevant background information, and ultimately enhancing polyp segmentation performance.
- (3)
Effectiveness of BGM
As shown in
Table 5, there is a small decrease in mDice and mIoU compared to the third and sixth rows when BGM is missing across the datasets. The mDice decreases from 0.773 to 0.754 on the ETIS-Larib dataset and from 0.889 to 0.882 on the Kvasir-SEG dataset, so the BGM has a contributing role in the segmentation effect of the polyps and helps to achieve good polyp margins in terms of the segmentation performance.
- (4)
Loss Function
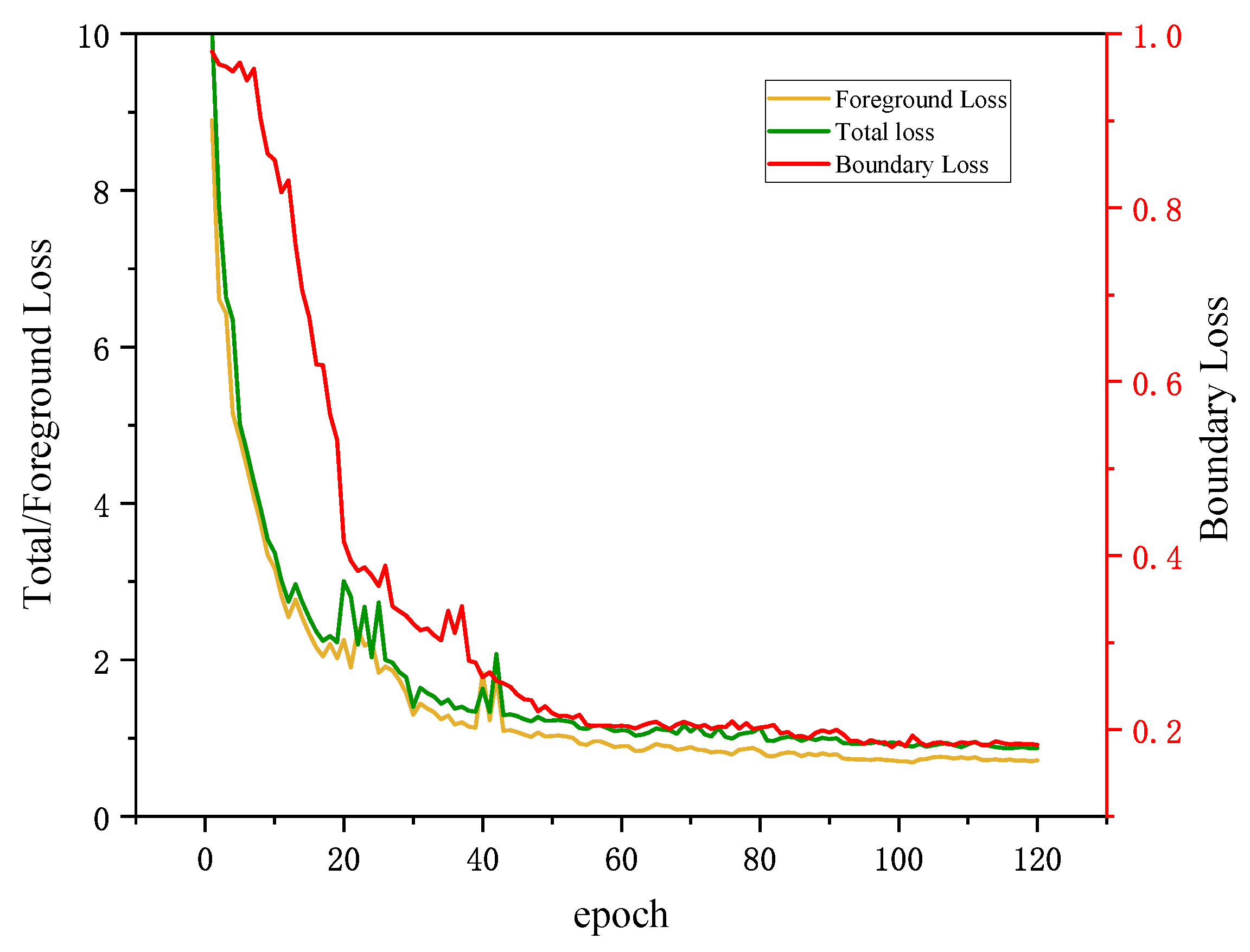
In order to enhance the mDice and mIoU performance, as well as facilitate faster convergence during the training phase, we employ a loss function that combines the foreground loss
and the boundary loss
using a linear combination approach. We train two CIFFormer on CVC-ColonDB dataset, one with only foreground loss (CIFFormer +
) and the other with both foreground loss and weighted boundary loss (CIFFormer +
+
). According to the results presented in
Table 6, the introduction of the boundary loss leads to a significant improvement in both mDice and mIoU metrics, with increases of 1.7% and 3.2%, respectively, from 0.735 to 0.752 and 0.662 to 0.694.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}