4.2. Evaluation Procedures
This study selects three common methods for processing missing values: mean imputation, median imputation, and hot-deck imputation. Additionally, four matrix completion algorithms, SVT, ISVT, FGSR, and IFGSR, are used to impute the missing values.
In the experiment, we selected data from 600 time points, which formed an original data matrix of size ns × 600, where ns represents the number of sensors. The window size for processing the data is determined by the matrix’s row count, which corresponds to the sensor number ns. The window size ranges from [0.8ns] to [2.0ns], where [∙] represents rounding up. The missing rate for variable data ranges from 10% to 80%, and the positions of the missing data are randomly determined.
The number of sensors displaying variable data for temperature, pressure, and flow rate differs. The specific details are shown in
Table 1.
As different variables have data of different scales and the range of data values varies, we need to perform experiments on each variable independently to evaluate the performance of algorithms.
The detailed steps of the experiment are as follows:
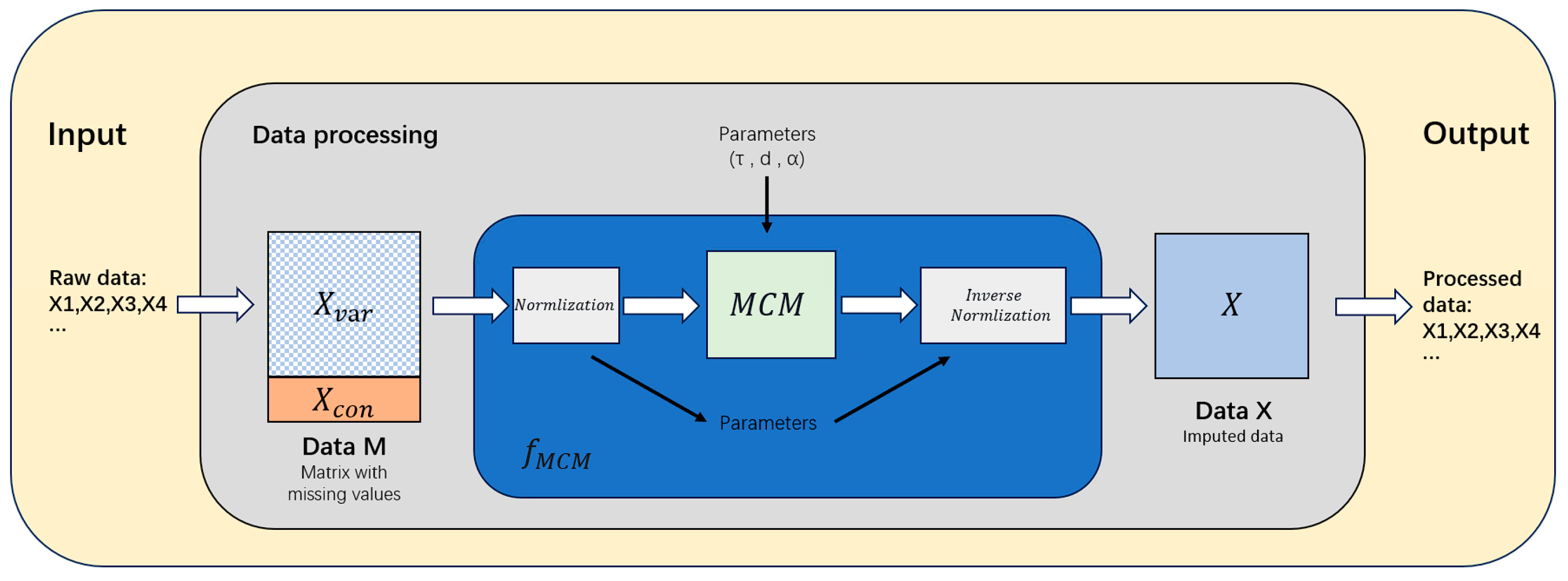
First, we convert the complete dataset into a matrix form suitable for algorithm processing. Each column of the data represents the measured values of the variables collected at the current time, and each row represents the sensor number transmitting these variable data.
The experiment determines the relevant parameters and the size of the moving window.
We set the missing rate and randomly generate missing data in the complete display variable data . After preprocessing, the data we obtain will serve as experimental data.
We use the MCM to fill in the experimental data.
We compare the output with the original data to evaluate the effects of different methods.
Concerning the selection of normalization methods, this experiment opted for quantile normalization. The formula for this approach is provided as follows:
where
represents the normalized data,
denotes the original data, and
and
are quartiles. Quantile normalization scales data using quartiles, which effectively reduces the impact of outliers on the data.
The evaluation criterion employed is
(Mean Absolute Percentage Error), which measures the relative error between imputed values and actual values.
results are expressed in percentage, with smaller values indicating higher prediction accuracy. When
equals 0, it signifies perfect accuracy in imputed values. The average
for all data within a single time point represents the
for that time point, denoted as
. Its formula is as follows:
where
represents the actual values of the data,
represents the imputed values after MCM processing, and n represents the total count of data points. Subsequently, the
for all time points is computed, denoted as
, with the following formula:
where
represents the number of time points after matrix completion processing.
Finally, using as the standard for evaluating the accuracy of missing value imputation, the MCM is compared with other methods.
4.3. Results and Discussion
In the section on results and the discussion, we divide the algorithms into the MCM, statistical value imputation methods, and the hot-deck method. The initial step involves performing a sensitivity analysis of the parameters within the four algorithms implemented in the MCM.
For the SVT and ISVT algorithms, parameter testing is conducted using the SVT algorithm and by applying the same parameter settings to both in subsequent experiments. We use the standard parameter setting range from reference [
20] to adjust and test the value of parameter τ and the size of step length δ.
Figure 4 illustrates the results of the test.
As depicted in
Figure 4, the errors in pressure and temperature data tend to stabilize when δ > 0.25. Similarly, the error in flow rate data stabilizes after δ > 0.75, reaching a lower value around δ = 1. Therefore, we choose δ = 1 as the step size for the SVT and ISVT algorithms for subsequent testing.
For the FGSR and IFGSR algorithms, parameter testing is conducted using the FGSR algorithm and by applying the same parameter settings to both in subsequent experiments. The parameters of the FGSR algorithm include γ, α, and step size λ. The initial parameter settings are α = 1 and step size λ = 0.03. The parameter γ is related to the initial rank estimation. According to reference [
23], the initial rank estimation has a slight effect on the FGSR algorithm, so we directly choose its maximum selectable value, that is, min(n
1, n
2), representing the smaller value between the number of rows and columns within the window of the data matrix.
In the selection of parameters, this study chooses parameters that exhibit stable performance in processing three types of variable data.
When λ = 0.03, we evaluate the influence of changing the parameter α on the data processing results. The results are illustrated in
Figure 5.
As shown in
Figure 5, the
of the three variables after processing does not change significantly after α > 0.5. In this study, we choose the midpoint value of 2 from the range of 0~4 as the value of α for the following experiments.
Setting α = 2, we evaluate the influence of the step increment λ on the results. The results are illustrated in
Figure 6.
As illustrated in
Figure 6, after λ > 0.2, the MAPE of the three variable data does not change significantly. The
of the pressure data slightly decreases as λ increases, and the
of the flow rate data has a slight fluctuation and is at a lower level near λ = 0.3. In this study, we chose λ = 0.3 as the value of λ for subsequent experiments.
The experimental results reveal that the in the imputation of flow rate data is substantially higher than that in temperature and pressure data. This is a consequence of the data’s characteristics, with the flow rate data used in the experiment showing a larger range of change than the other two variables.
After determining the parameters, we then test the size of the data processing window and use a fixed window size in subsequent tests. The subsequent experimental data will be presented in
Table A1,
Table A2,
Table A3,
Table A4,
Table A5 and
Table A6 in
Appendix A, corresponding, respectively, to
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11 and
Figure 12.
We fix the missing rate of the variable data at 40%, generating missing data randomly. The range for the window size is from 0.8n to 2.0n (where n represents the number of sensors for the current variable, as detailed in
Table 1, and the chosen window size is rounded up). We first conduct tests on the temperature data, and
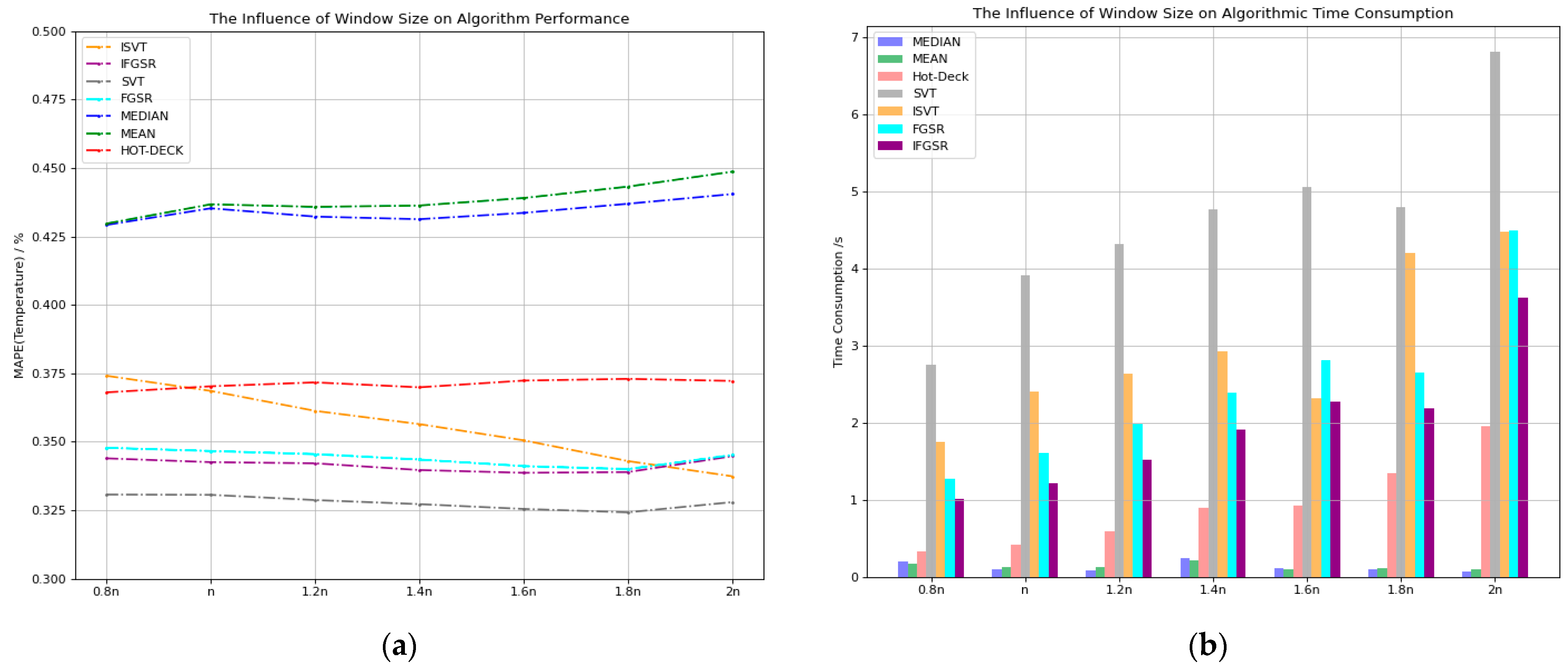
Figure 7 presents the results.
As shown in
Figure 7a, when we test the temperature data using
as the evaluation standard, the statistical value imputation methods and the hot-deck algorithm exhibit an increase in
with the growing window size. The
of the ISVT algorithm gradually decreases with the increase in the window size. The FGSR, IFGSR, and SVT algorithms have the smallest
when the window size reaches 1.8n. As seen in
Figure 7b, the time consumption of the SVT, FGSR, and IFGSR algorithms increases significantly after the window size is 1.8n, and the time consumption of the ISVT algorithm shows little change between the window sizes of 1.8n and 2n. Considering these factors, to achieve higher accuracy and reduce time consumption, we choose 1.8n as the window size for subsequent experiments.
As illustrated in
Figure 8a, when we test the pressure data using
as the evaluation standard, the
of the ISVT algorithm and the hot-deck algorithm remains relatively stable. The
values for the FGSR, SVT, and IFGSR algorithms all decrease with an increase in the window size. As seen in
Figure 8b, as the time window increases, the time consumption of the hot-deck algorithm and the MCM gradually increases. When the window size is 2n, the time consumption of the IFGSR algorithm is halved compared to the FGSR algorithm and is close to the hot-deck algorithm. For better accuracy, in subsequent experiments, we use 2n as the window size to process data.
As shown in
Figure 9a, the
of MCMs exhibits fluctuations with an increase in the window size when different algorithms are applied. The
of ISVT, FGSR, and IFGSR maintains a low level when the window size is 1.6n. The precision of the SVT algorithm remains stable once the window size exceeds 1.6n. As seen in
Figure 9b, the time consumption of the MCM does not change much after the window size is 1.4n. Therefore, based on the above results, we select a window size of 1.6n for future experiments on flow rate data.
In summary, through testing on three variables, we have chosen 1.8n as the window size for temperature data, 2n as the window size for pressure data, and 1.6n as the window size for flow rate data for subsequent experiments.
After determining the parameters and the size of the test window, we use the same experimental data to test the performance of various methods under different data loss rates. The evaluation metrics include accuracy and time consumption. The results are as follows.
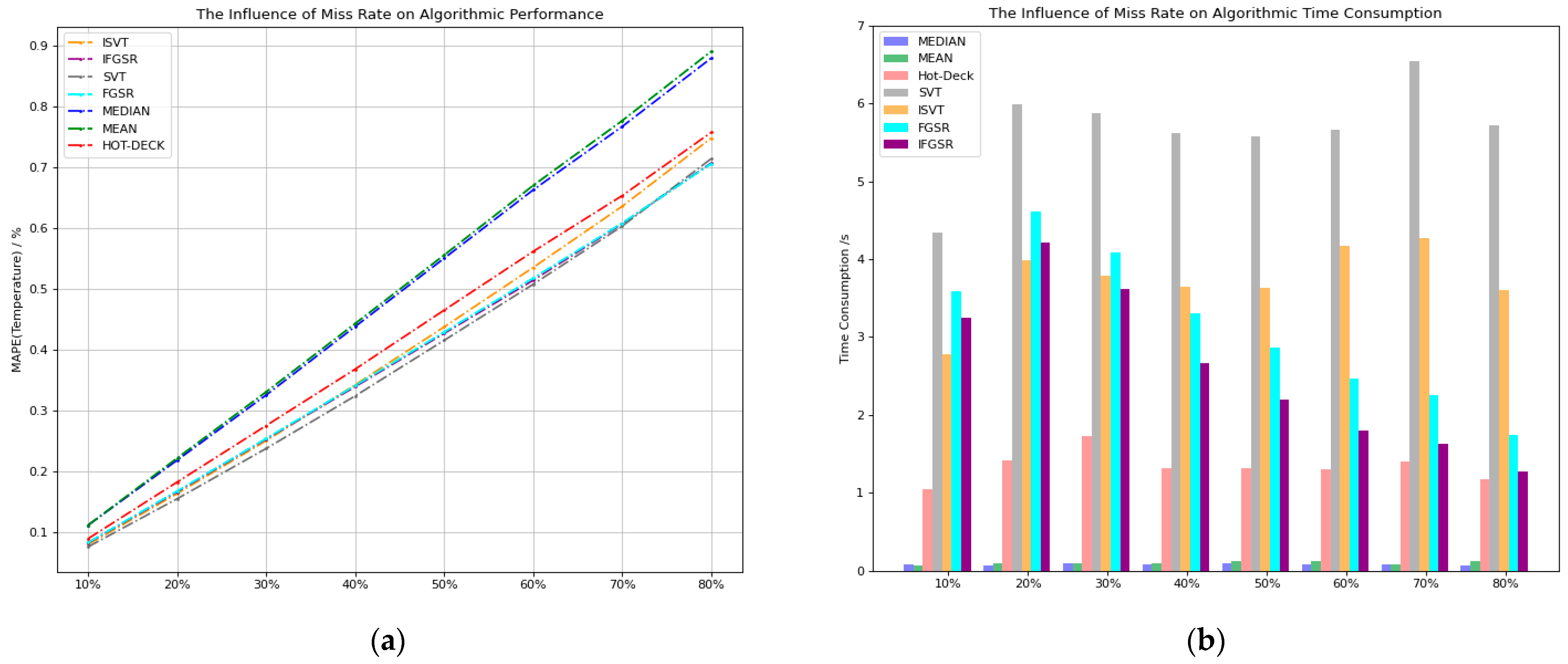
As shown in
Figure 10, we first test the temperature data. With a fixed window size, we test the results with a data loss rate of 10% to 80%.
As shown in
Figure 10a, when we use
as the evaluation standard, it can be seen that MCMs have the smallest
at any missing rate, ISVT’s
is slightly larger than SVT, and the accuracy performance of IFGSR and FGSR is almost the same. As shown in
Figure 10b, the highest time consumption in the MCM is the SVT and FGSR algorithms. In comparison, both ISVT and IFGSR show improvements in time consumption.
In summary, the MCM consistently exhibits the smallest when processing temperature data. Among them, SVT has the lowest but the highest time consumption; ISVT’s accuracy is slightly lower than SVT, and the time consumption is lower. The accuracy of FGSR and IFGSR is almost the same, with both slightly underperforming the SVT algorithm. IFGSR has a lower time consumption compared to FGSR, and both significantly reduce time consumption compared to SVT and ISVT.
For pressure data,
Figure 11 shows the results of testing data with missing rates ranging from 10% to 80% at a fixed window size.
As shown in
Figure 11a, processing pressure data with
as the evaluation metric reveals that FGSR and IFGSR consistently exhibit the smallest
. Moreover, the difference in
between IFGSR and FGSR is insignificant across all missing rates.
Figure 11b illustrates that the IFGSR algorithm consumes less time than the FGSR algorithm, and its time consumption exceeds only those of the two statistical value imputation methods at high missing rates.
In conclusion, when processing pressure data, the IFGSR algorithm achieves a slight reduction in accuracy compared to the FGSR algorithm but significantly reduces the processing time. Compared to other methods, it also demonstrates higher accuracy and advantages in time consumption.
For flow rate data,
Figure 12 shows the results of testing data with missing rates ranging from 10% to 80% at a fixed window size.
Figure 12a illustrates that the MCM exhibits the highest accuracy in processing missing values for flow rate data. The overall accuracy ranking is SVT > FGSR > IFGSR ≈ ISVT. As shown in
Figure 12b, considering time consumption, ISVT and IFGSR save a substantial amount of time compared to SVT and FGSR.
In conclusion, when using the MCM to impute the missing values of temperature, pressure, and flow rate data, the SVT, FGSR, and IFGSR algorithms in the MCM consistently demonstrate superior accuracy under any conditions compared to traditional methods, thus validating the applicability of matrix completion for real-time missing data imputation. Furthermore, a comparison between the IFGSR and FGSR algorithms reveals a minor difference in accuracy but a significant reduction in computation time for IFGSR, demonstrating the effectiveness of the improvement method proposed in this paper for matrix completion algorithms used for real-time missing data imputation.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}