

New Method for Logging Evaluation of Total Organic Carbon Content in Shale Reservoirs Based on Time-Domain Convolutional Neural Network

 ,
,
Abstract
1. Introduction
2. Overview of the Methodology
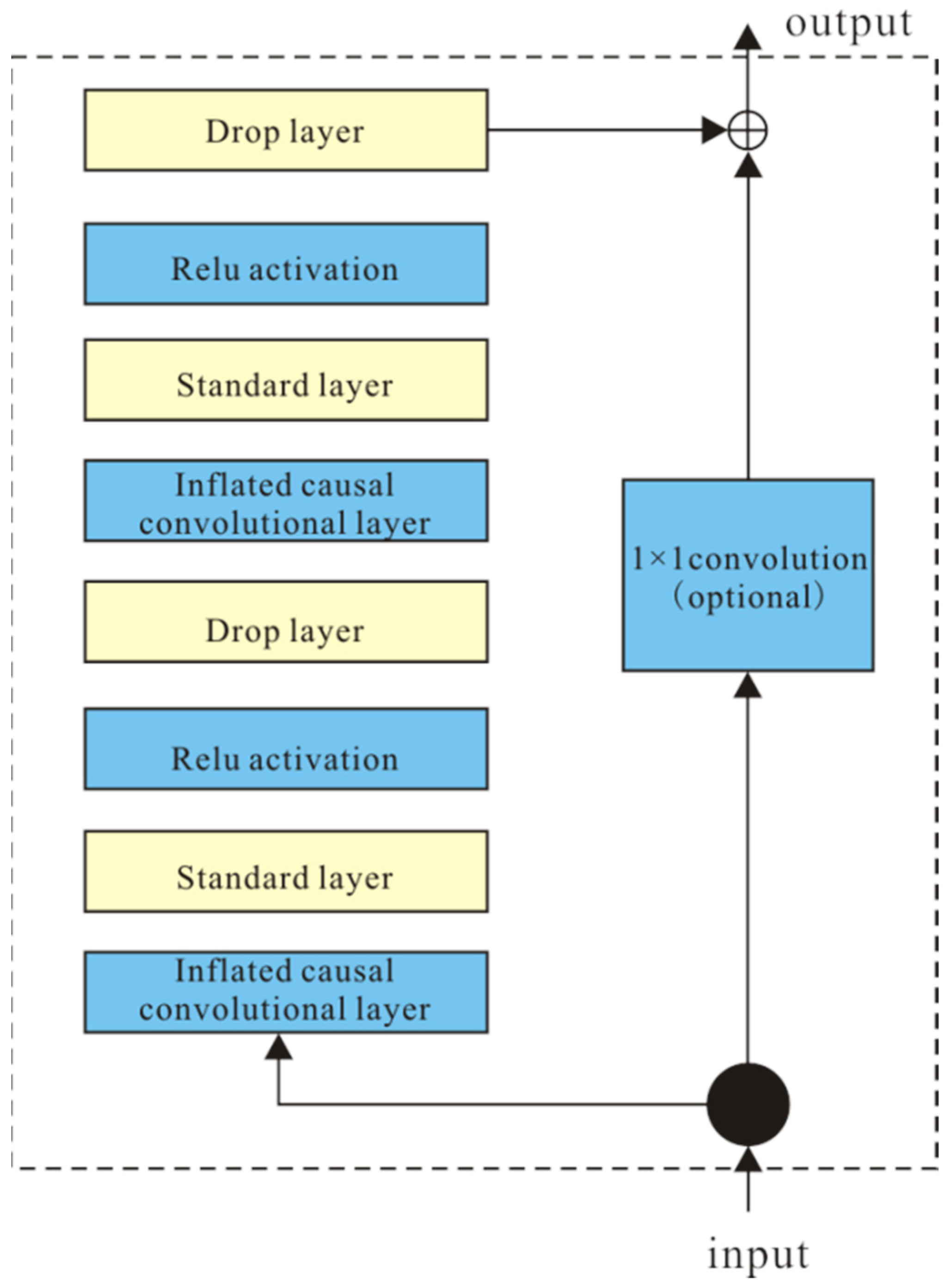
2.1. Time-Domain Convolutional Neural Network

2.2. Evaluation Method of Total Organic Carbon Content Logging Based on TCN Modeling
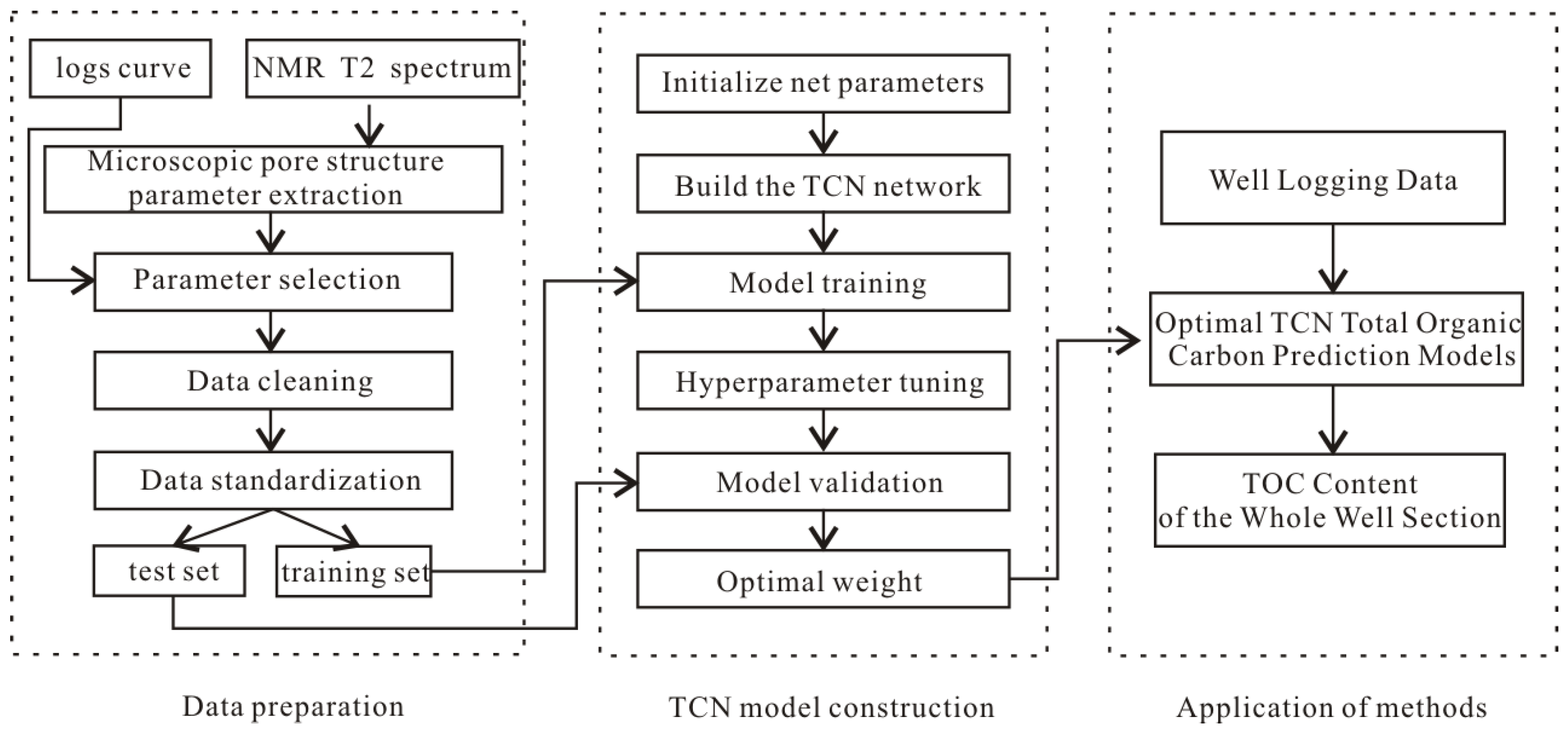
3. Experiments and Analyses
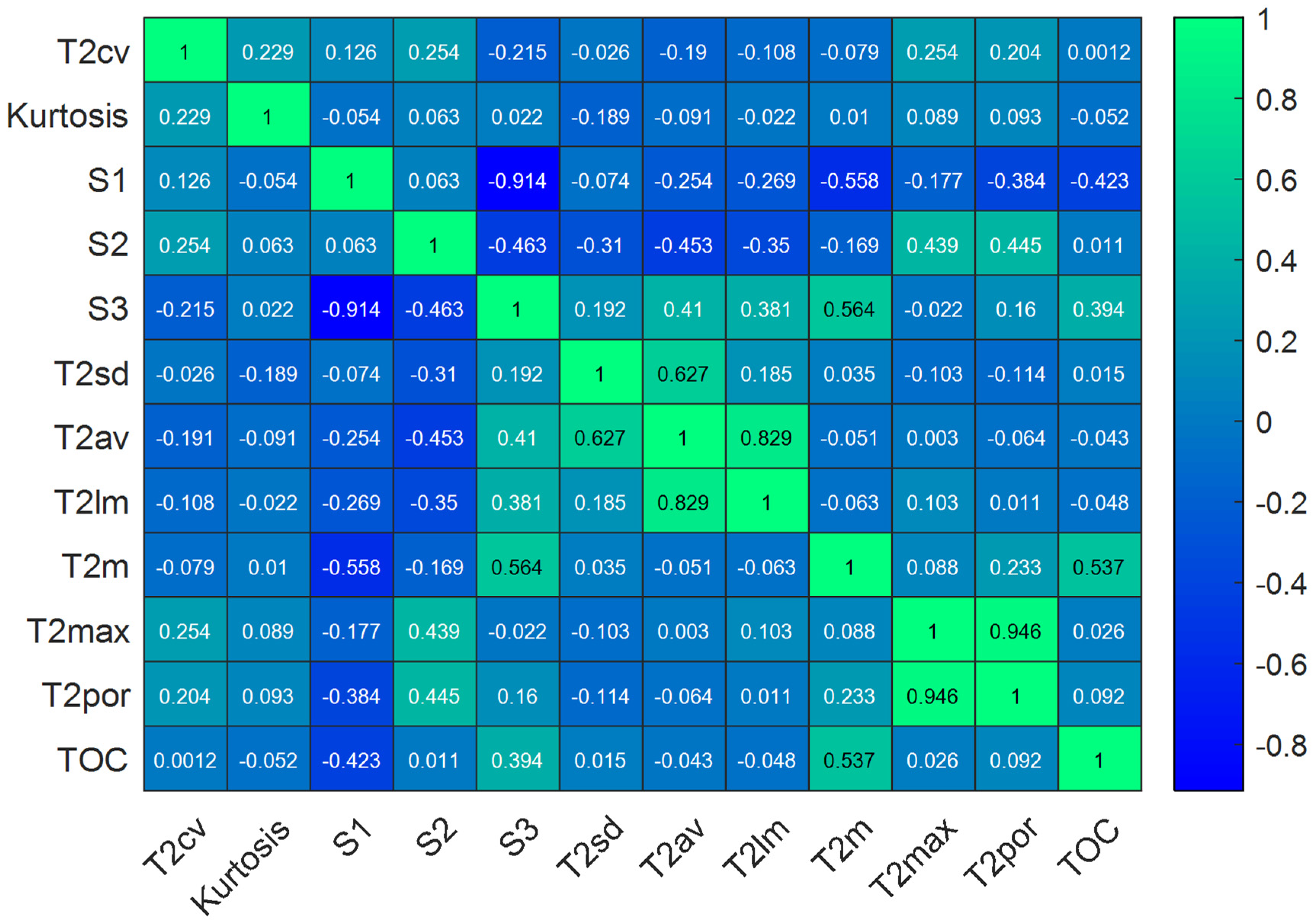
3.1. Extraction of NMR T2 Spectral Parameters
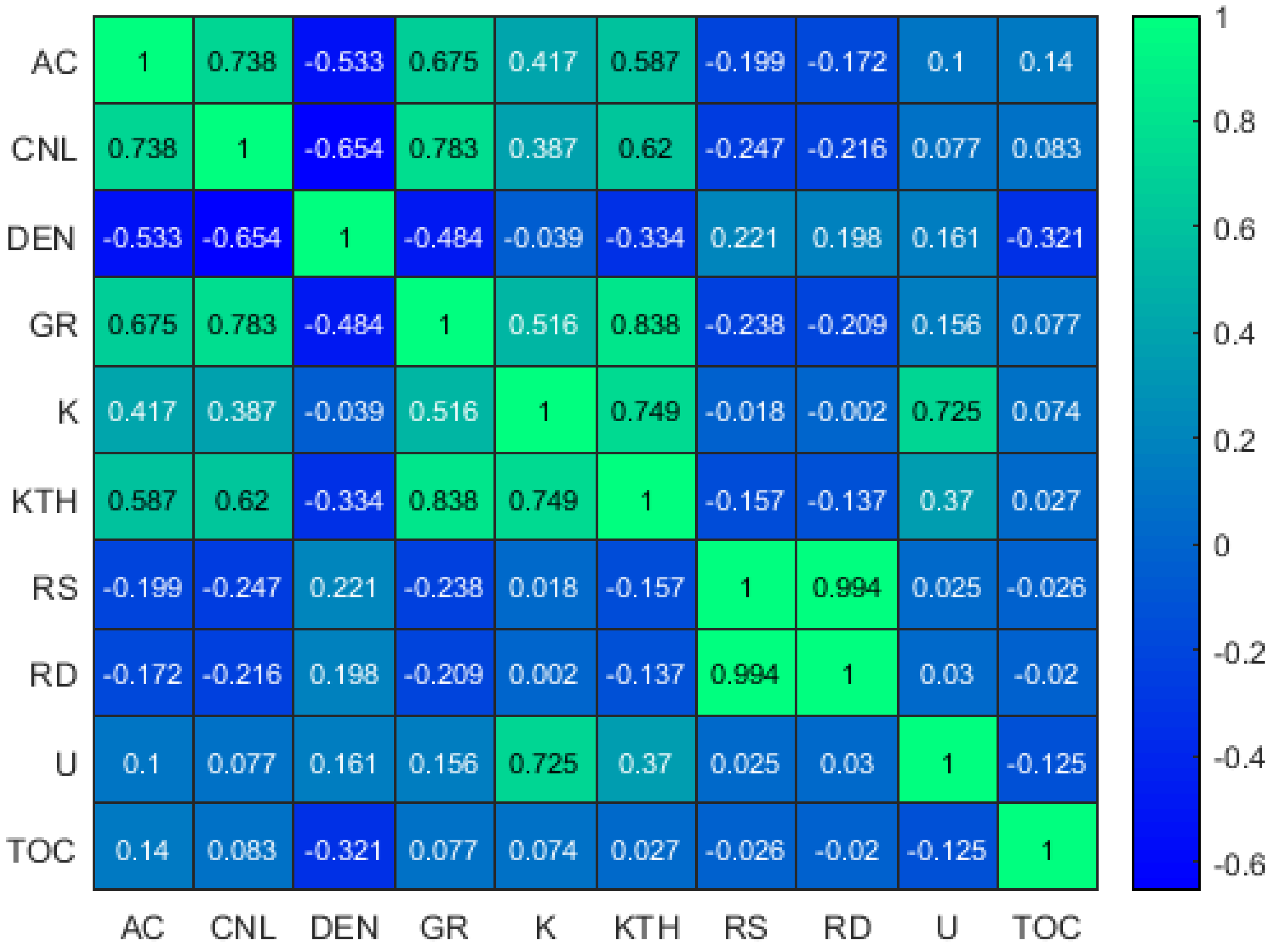
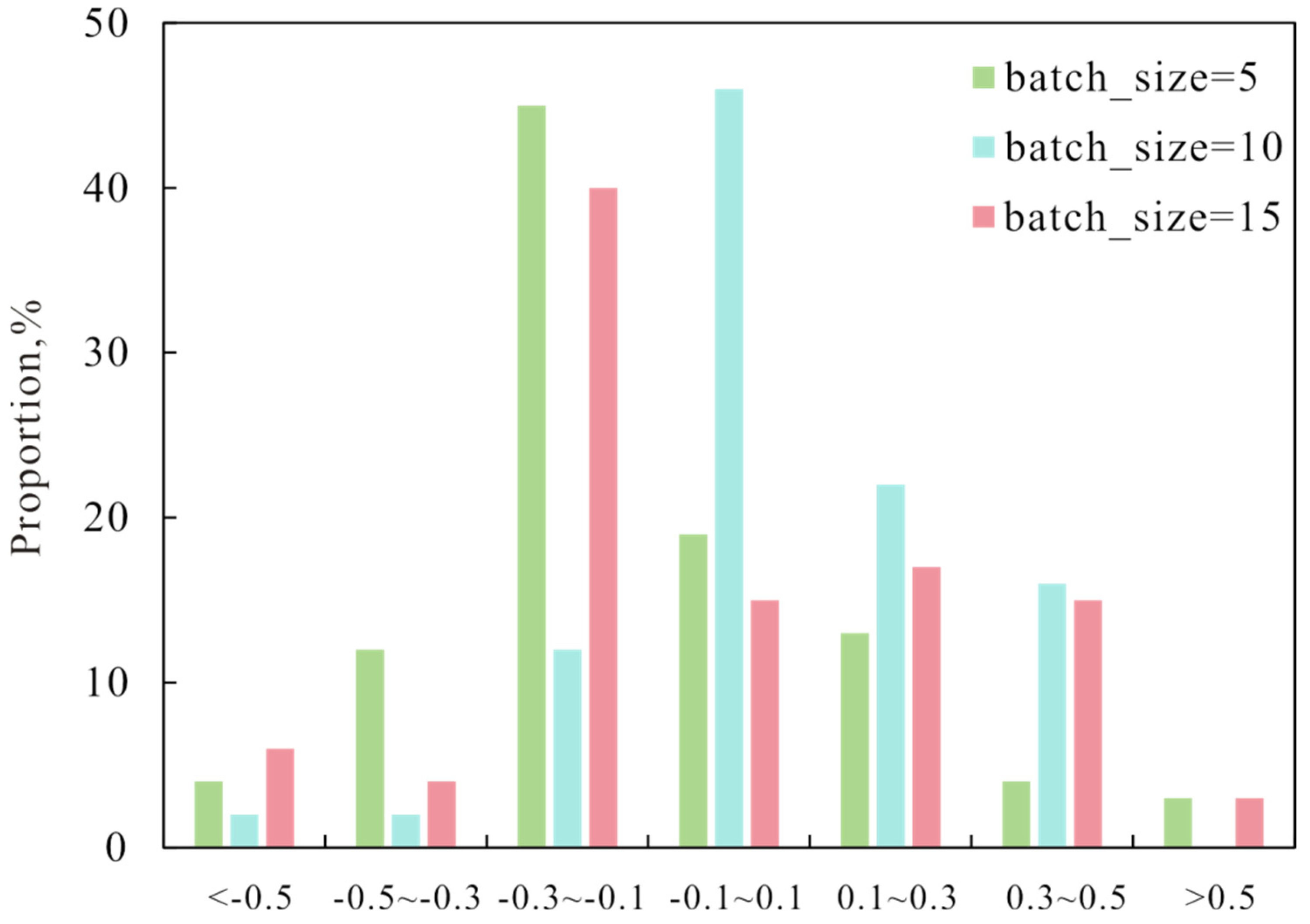
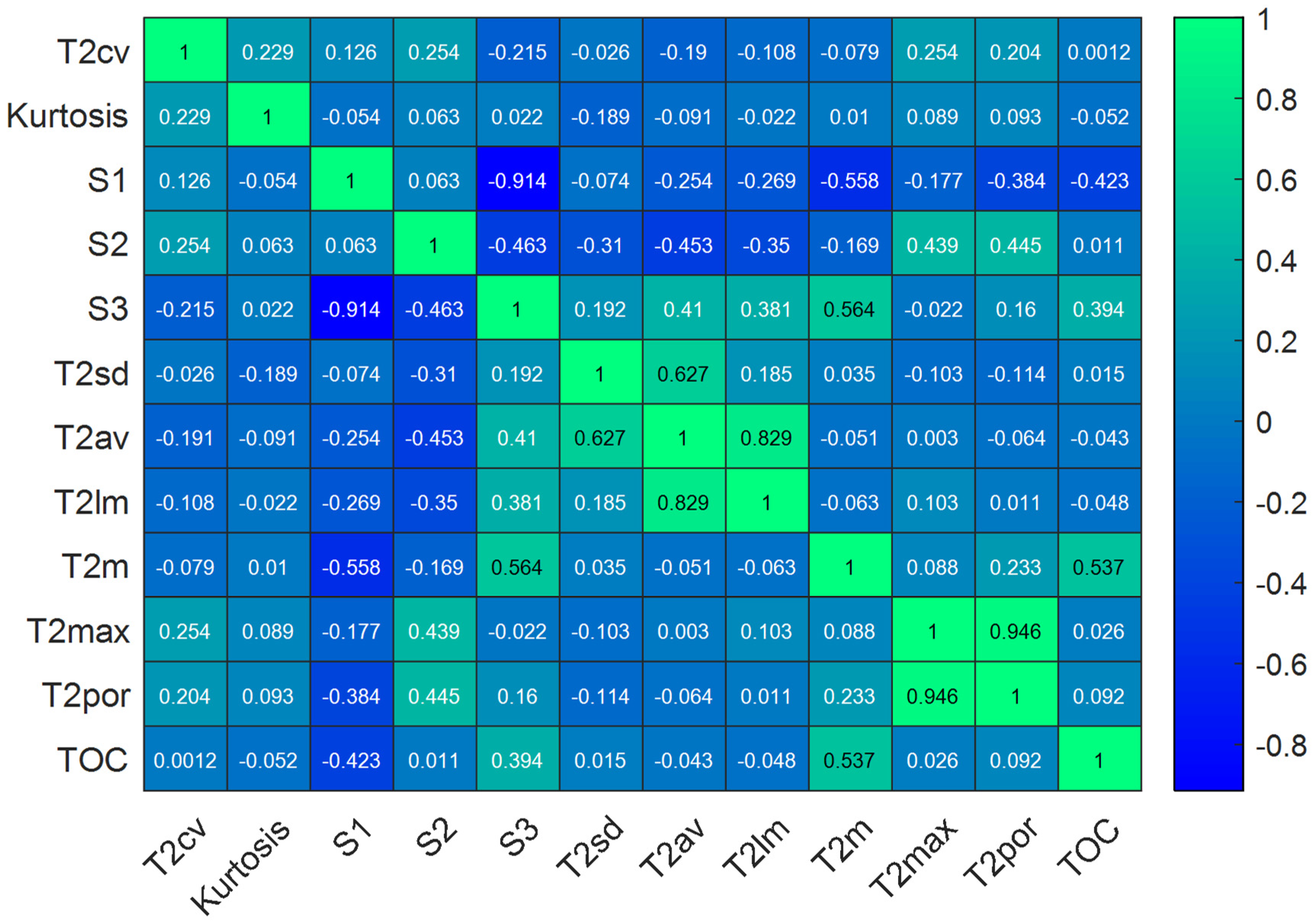
3.2. Data Preparation and Sensitivity Analysis
3.3. Model Construction
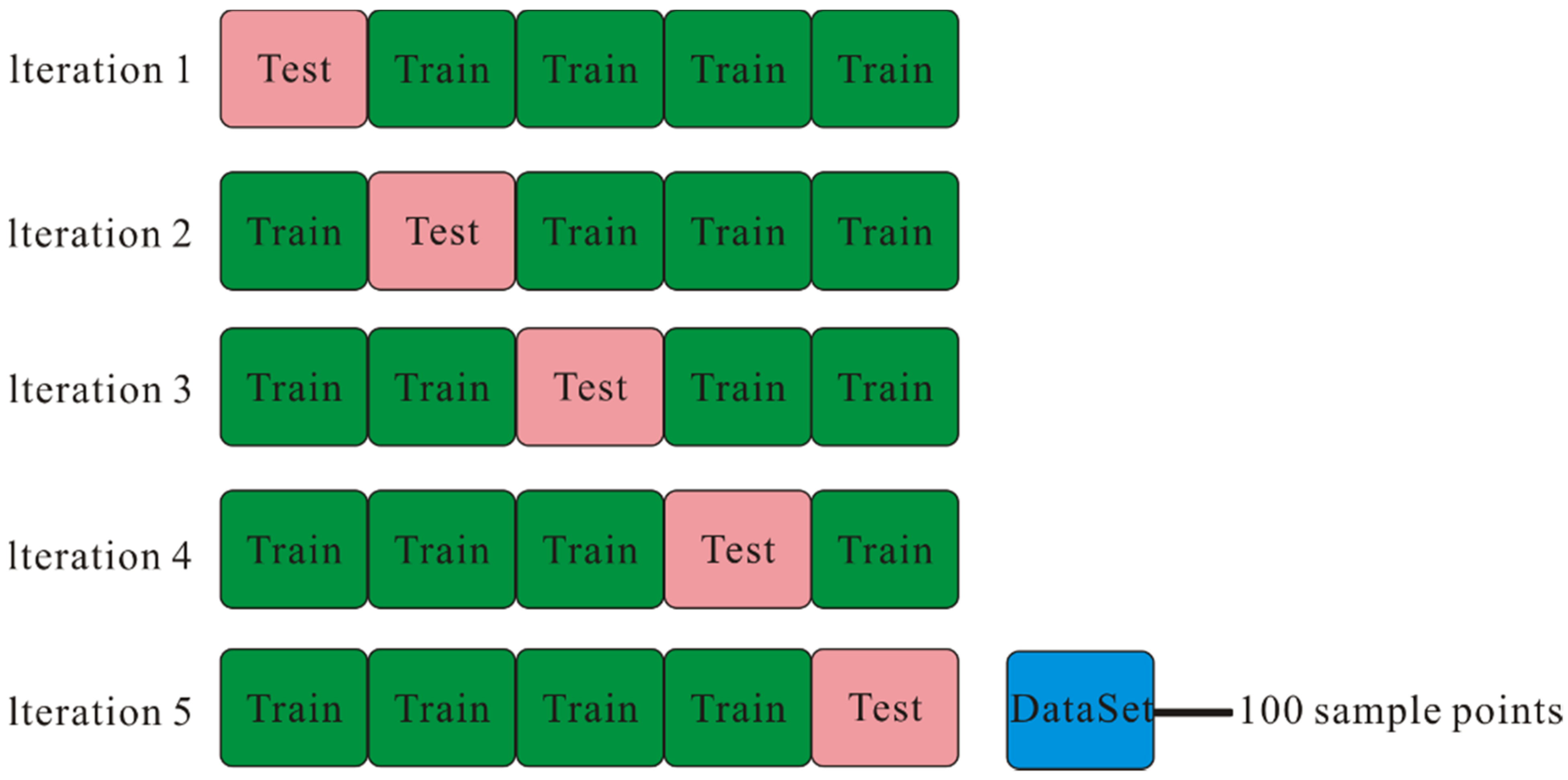
3.4. Data Standardization
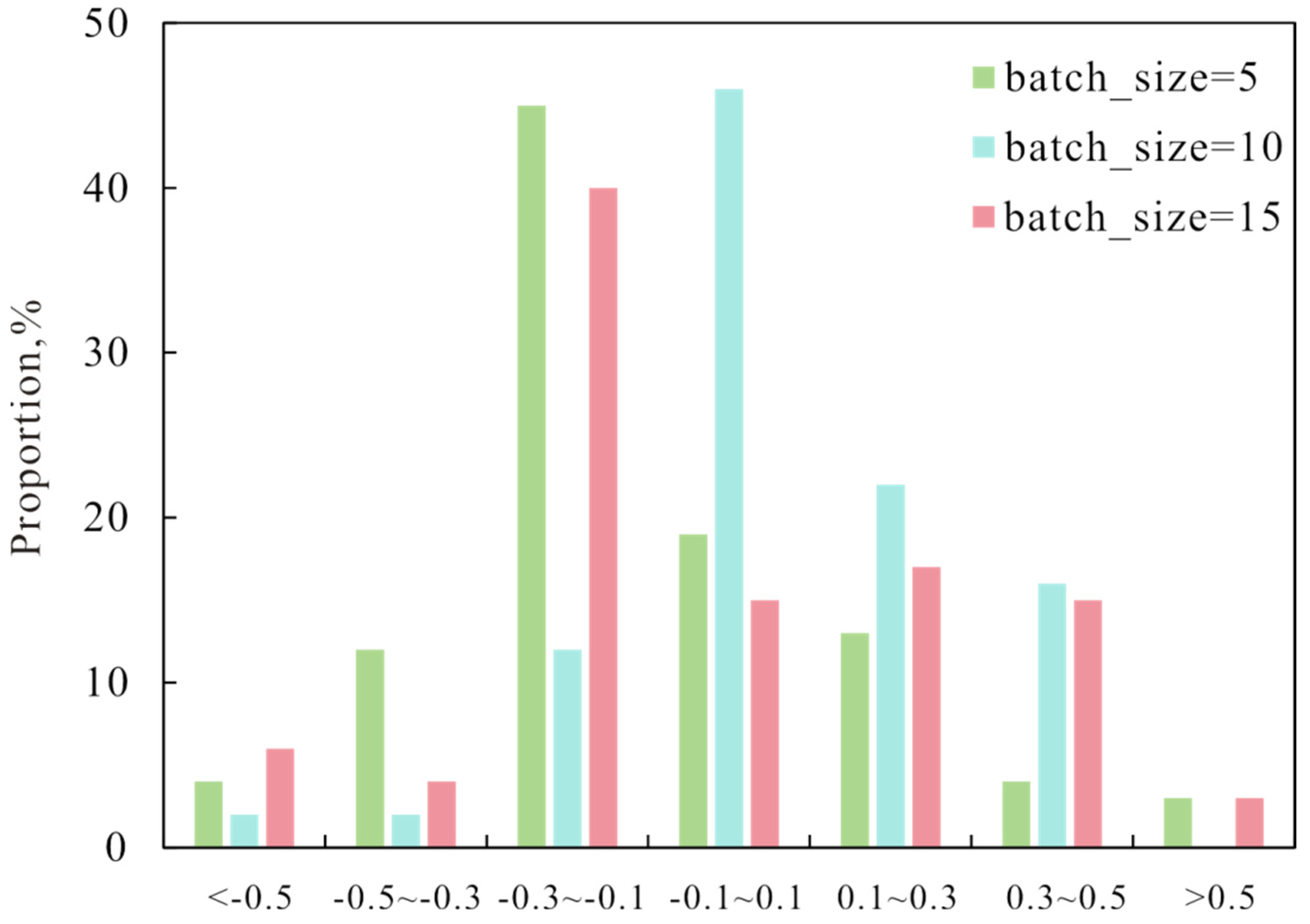
3.5. Model Training
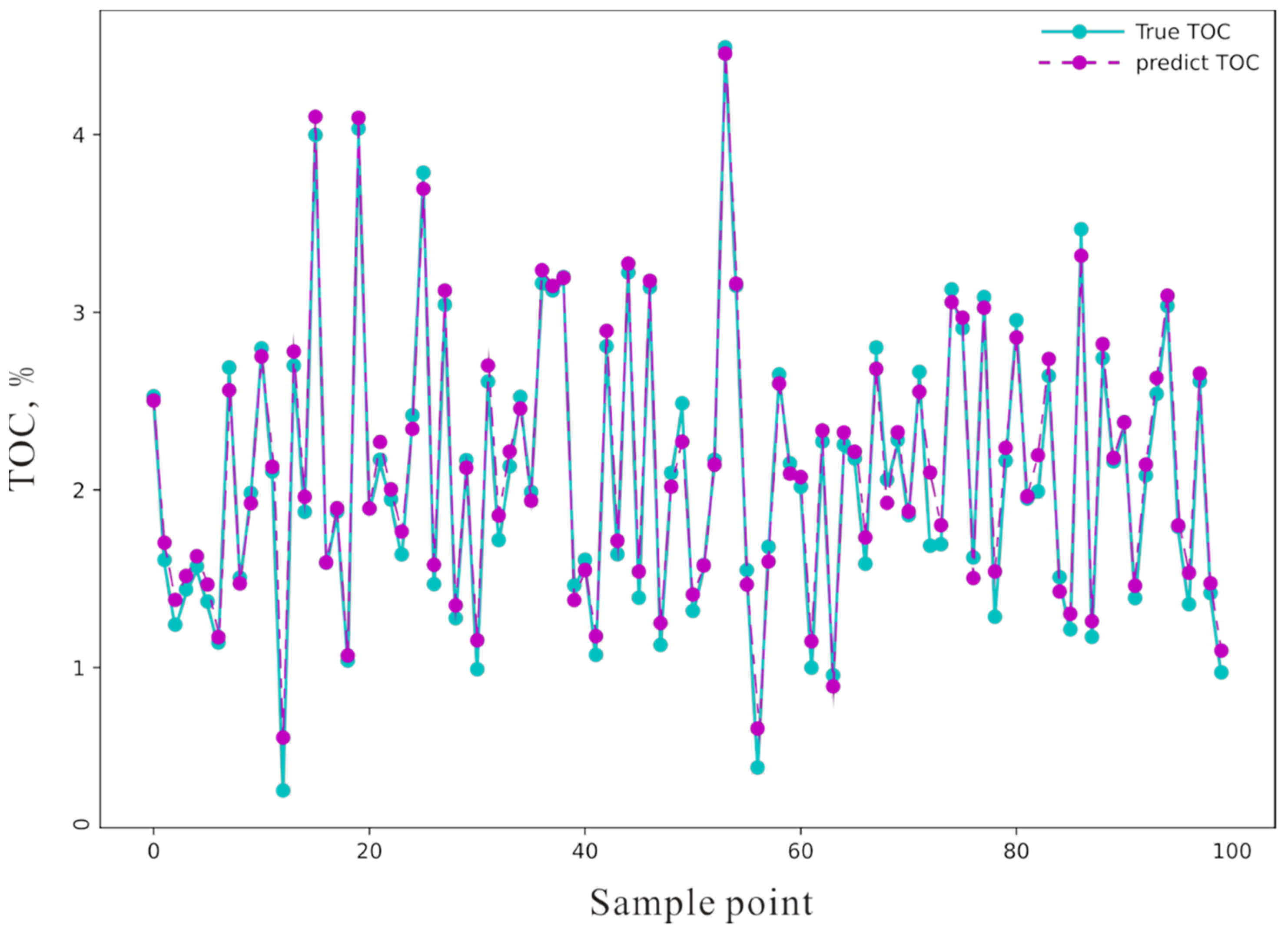
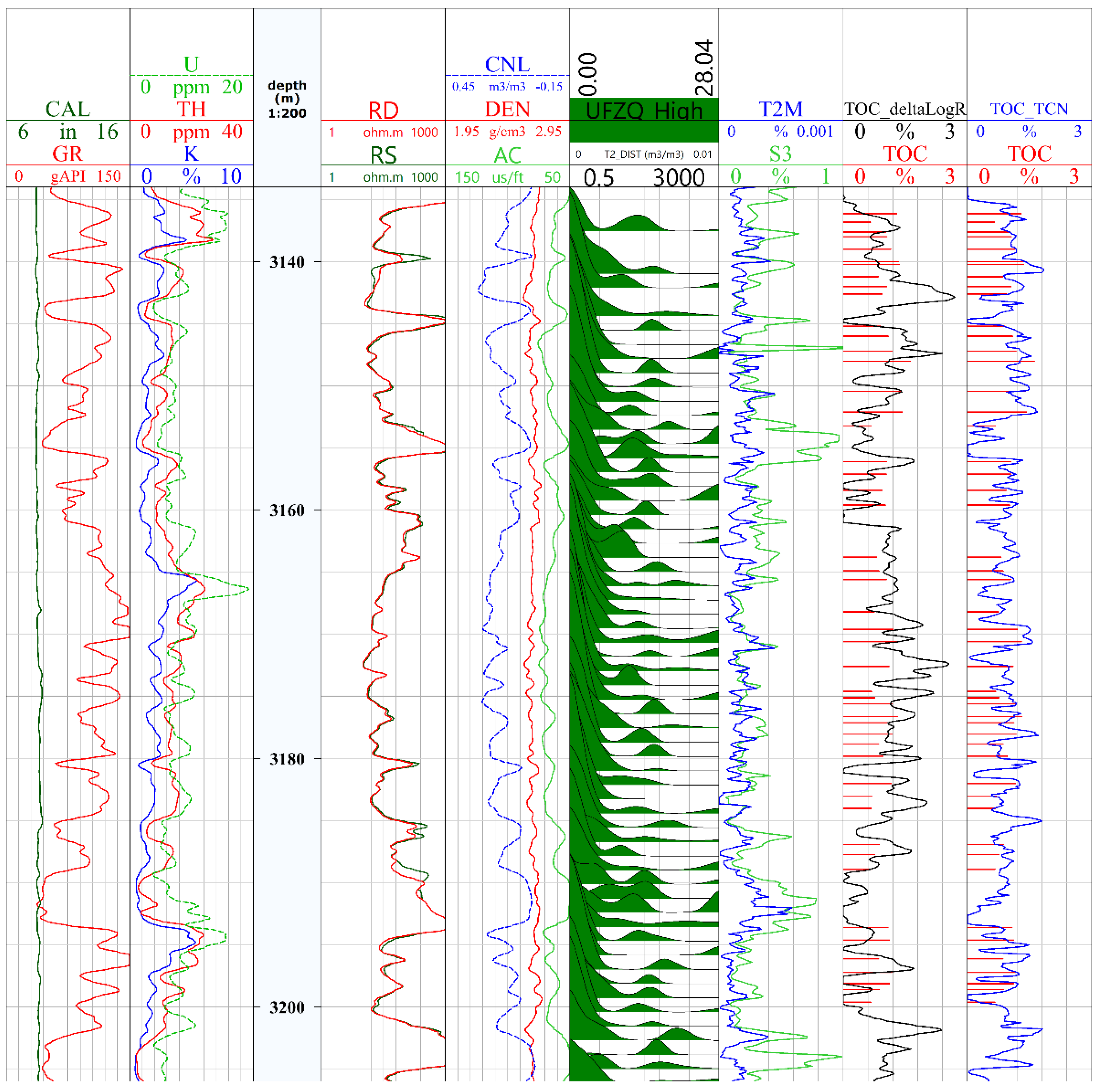
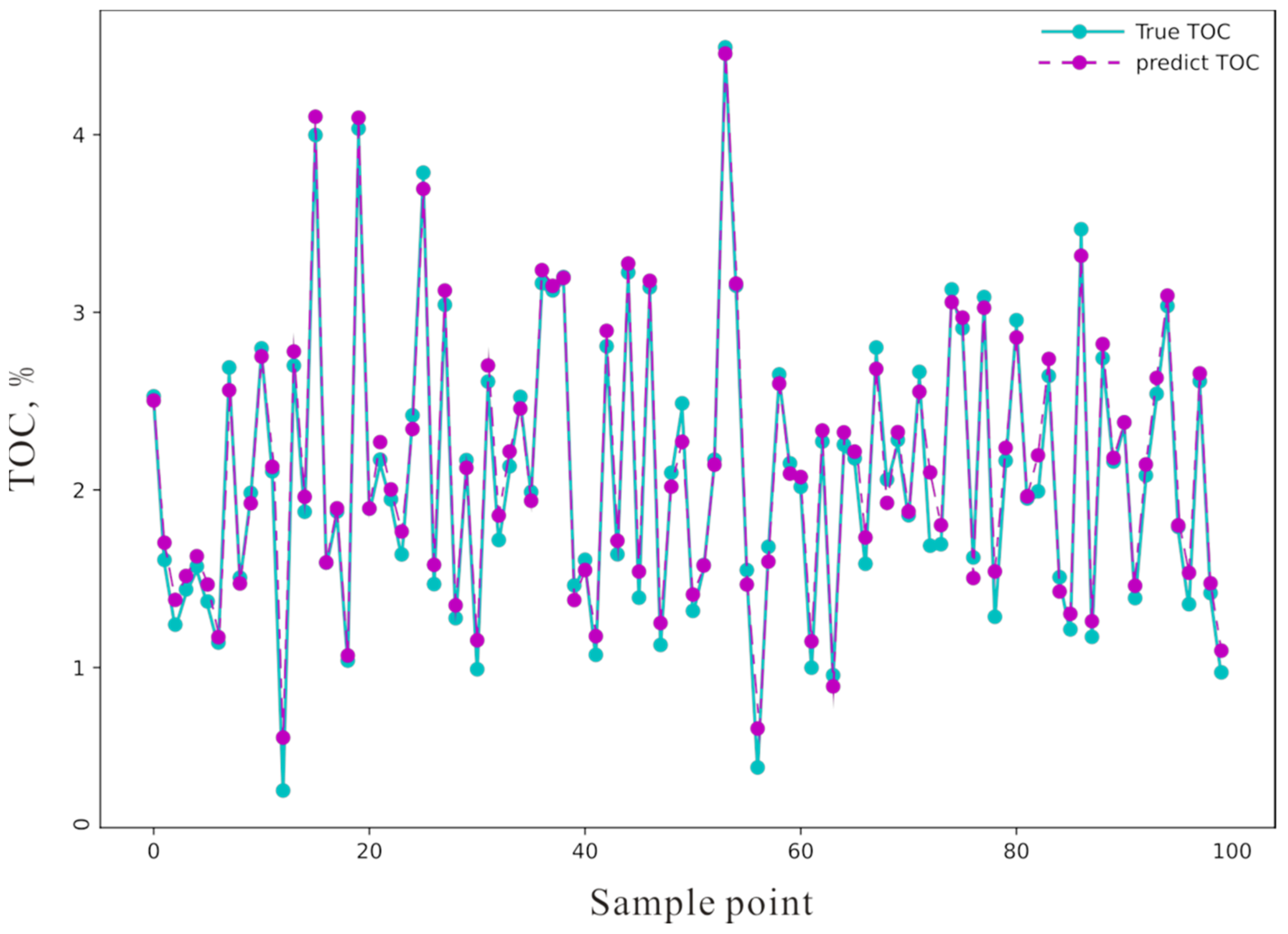
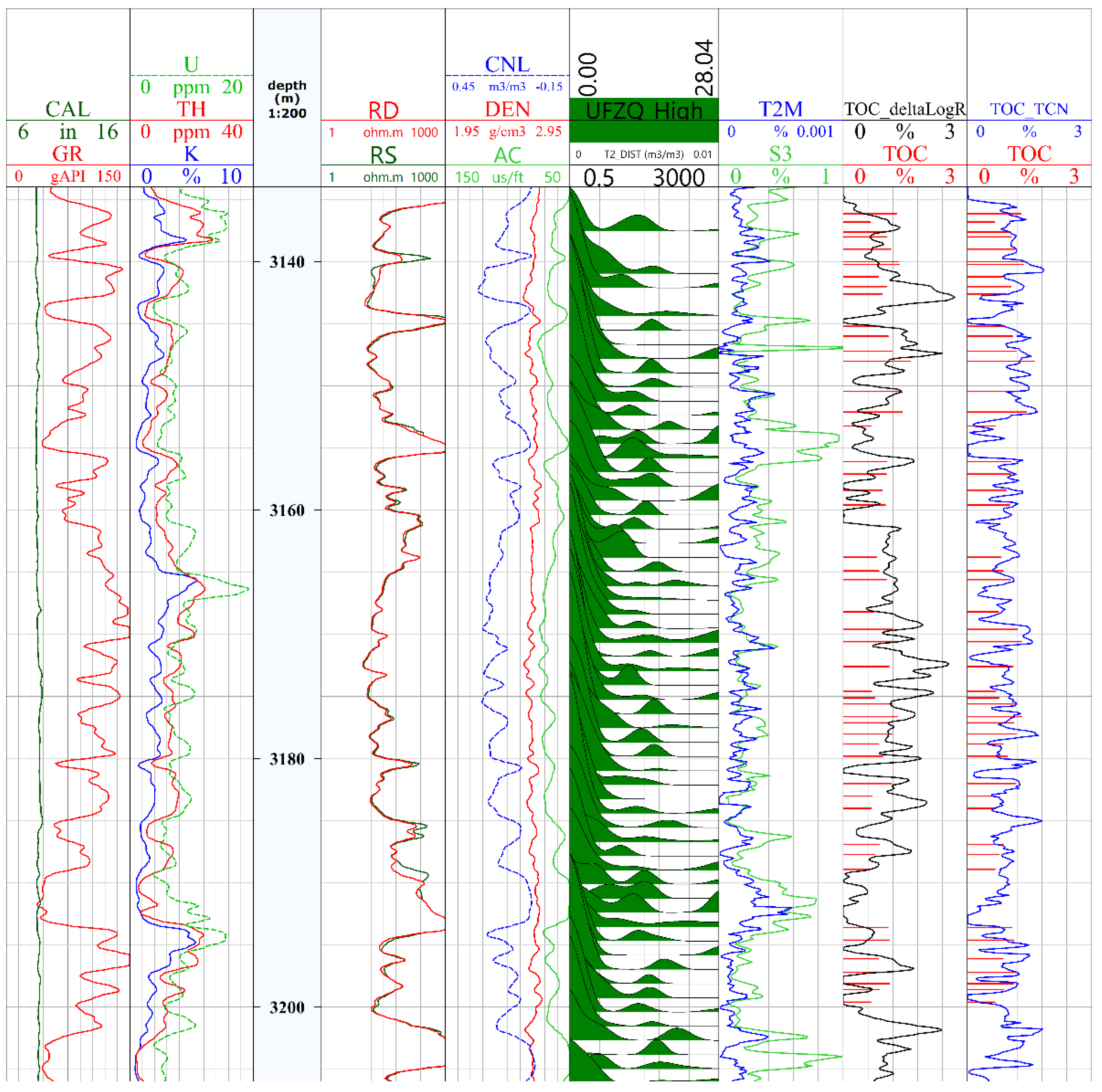
4. Methodological Applications
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bi, C. Study on Prediction Method of TOC Content Brittleness Index of Shale Reservoir. Ph.D. Thesis, China University of Geosciences (Beijing), Beijing, China, 2021. [Google Scholar]
- Yuan, C.; Zhou, C.; Hu, S.; Chen, X.; Dou, Y. Summary on well logging evaluation method of total organic carbon content in formation. Prog. Geophys. 2014, 29, 2831–2837. [Google Scholar]
- Zhu, L. An improved method for evaluating the TOC content of a shale formation using the dual-difference ΔlogR method. Mar. Pet. Geol. 2019, 102, 800–816. [Google Scholar] [CrossRef]
- Huo, Q.; Zeng, H.-S.; Fu, L.; Ren, Z. The Advance of ΔlgR Method and Its Application in Songliao Basin. J. Jilin Univ. (Earth Sci. Ed.) 2011, 41, 586–591. [Google Scholar]
- Passey, Q.R.; Creaney, S.; Kulla, J.B. A practical model for organic richness from porosity and resistivity logs. AAPG Bull. 1990, 74, 1777–1794. [Google Scholar]
- Huang, S.; Liu, W.; Dai, H.; Wang, X.; Sun, L.; Liu, D. Log Evaluation on the TOC of Continental Source Rocks based on Variable Coefficient ΔlgR Model. Well Logging Technol. 2019, 43, 519–523. [Google Scholar]
- Zhou, C.; Wang, L.; Su, S.; Xue, K.; Wang, Q. Research on organic carbon content logging evaluation method based on ΛLogR-GR method: Case study from study Mao-1 in Southeastern Sichuan Basin. Nat. Gas Geosci. 2023, 35, 542–552. [Google Scholar]
- Jacobi, D.; Gladkikh, M.; Lecompte, B. Integrated petrophysical evaluation of shale gas reservoirs. In Proceedings of the Canadian International Petroleum Conference, SPE Gas Technology Symposium Joint Conference, Calgary, AB, Canada, 16–19 June 2008. [Google Scholar]
- Lu, P.; Mao, X.; Zhang, F. Prediction of organic carbon content in Lunpola Basin by neural network method. Prog. Geophys. 2021, 36, 230–236. [Google Scholar]
- Zhu, L.; Zhang, C.; Wei, Y.; Guo, C.; Zhou, X.; Chen, Y. The Method for TOC Content Evaluation in Shale Reservoirs Based on Improved Rain Forest Fuzzy Neural Network Model. Geol. J. China Univ. 2016, 22, 716–726. [Google Scholar]
- Zhu, L.; Zhang, C.; Zhang, C.; Zhang, Z.; Zhou, X.; Liu, W.; Zhu, B. A new and reliable Dual model- and data-driven TOC prediction concept: A TOC logging evaluation method using multiple overlapping methods integrated with semi-supervised deep learning. J. Pet. Sci. Eng. 2020, 188, 106944. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, C.; Yang, M. Permeability logging evaluation of carbonate reservoirs in Oilfield H of Iraq in the Middle East based on long short-term memory recurrent neural network. Pet. Geol. Oilfield Dev. Daqing 2022, 41, 126–133. [Google Scholar]
- Zhou, X.; Zhang, Z.; Zhu, L.; Zhang, C. A new method for high-precision fluid identification in bidirectional long short-term memory network. J. China Univ. Pet. (Ed. Nat. Sci.) 2021, 45, 69–76. [Google Scholar]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal Convolutional Networks for Action Segmentation and Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Shekhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- He, K.M.; Zhang, X.Y.; Ren, S.Q. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bai, S.; Cheng, D.; Wan, J. Quantitative characterization of sandstone NMR T2 spectrum. Acta Pet. Sin. 2013, 34, 366–371. [Google Scholar]
- Yang, W.; Zhang, C.; Shi, X.; Cui, Y.; Zhang, Z. Reconstruction of LWD-NMR T2 water spectrum and fluid recognition based on microscopic pore structure constraints. Geoenergy Sci. Eng. 2023, 221, 211386. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Absolute Error | Relative Error |
|---|---|---|
| ΔLogR | 0.49 | 0.53 |
| TCN | 0.13 | 0.14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, W.; Hu, X.; Liu, C.; Zheng, G.; Yan, W.; Zheng, J.; Zhu, J.; Chen, L.; Wang, W.; Wu, Y. New Method for Logging Evaluation of Total Organic Carbon Content in Shale Reservoirs Based on Time-Domain Convolutional Neural Network. Processes 2024, 12, 610. https://doi.org/10.3390/pr12030610
Yang W, Hu X, Liu C, Zheng G, Yan W, Zheng J, Zhu J, Chen L, Wang W, Wu Y. New Method for Logging Evaluation of Total Organic Carbon Content in Shale Reservoirs Based on Time-Domain Convolutional Neural Network. Processes. 2024; 12(3):610. https://doi.org/10.3390/pr12030610
Chicago/Turabian StyleYang, Wangwang, Xuan Hu, Caiguang Liu, Guoqing Zheng, Weilin Yan, Jiandong Zheng, Jianhua Zhu, Longchuan Chen, Wenjuan Wang, and Yunshuo Wu. 2024. "New Method for Logging Evaluation of Total Organic Carbon Content in Shale Reservoirs Based on Time-Domain Convolutional Neural Network" Processes 12, no. 3: 610. https://doi.org/10.3390/pr12030610
APA StyleYang, W., Hu, X., Liu, C., Zheng, G., Yan, W., Zheng, J., Zhu, J., Chen, L., Wang, W., & Wu, Y. (2024). New Method for Logging Evaluation of Total Organic Carbon Content in Shale Reservoirs Based on Time-Domain Convolutional Neural Network. Processes, 12(3), 610. https://doi.org/10.3390/pr12030610