1. Introduction
The stability of substation equipment is crucial for the reliable operation of the power system [
1,
2]. Traditional inspection methods, which rely on manual observations and engineering experience, suffer from low defect detection efficiency and difficulty in observing certain parts of the equipment [
3], such as the transformer oil pillow and the SF6 indicator part of the top fixture. While recent advances in deep learning have led to improved target detection in power system vision neural networks, these methods still struggle with low accuracy and weak anti-interference capabilities [
4]. Our research addresses these limitations by proposing a high-precision substation equipment defect recognition algorithm based on the Mask R-CNN algorithm framework. This algorithm incorporates the GFPN network and CBAM attention mechanism module to enhance feature fusion and target recognition, leading to significant improvements in accuracy and robustness over existing methods. The effectiveness of our approach is demonstrated through comprehensive experiments and comparisons with other state-of-the-art object detection algorithms.
A substation is usually equipped with multiple cameras that serve as image-sensing sensors to collect equipment image information and upload it to the cloud [
5,
6,
7]. However, the large number of substation equipment and the requirement for high-resolution images for defect identification often cause the cloud server to be overloaded. Due to the limitation of CPU and GPU computing power [
8,
9,
10], the image recognition algorithm of substation equipment defects needs to be completed by power system edge computing. The method is called power system edge vision and can complete defect recognition of multiple substation images of multiple substation equipment [
11]. To meet the requirements of substation equipment defect management and inspection, reference [
12] developed an inspection system with dual subsystems. JI Yanping [
13] summarizes the shortcomings of substation equipment inspection and proposes an automatic recognition method of substation equipment defects using RFID technology. In reference [
14], a PTZ (Pan Tilt Zoom) vision system for substation inspection robots was established. By comparing SIFT, SURF, and ORB features, a vision localization algorithm system with high accuracy is constructed. The authors used the Davidson–Cole model to extract feature parameters to determine the degree of frequency domain aging of transformer oil–paper insulation. To study the application of edge computing in substation systems, ZHAO Yi et al. [
15] used edge computing to improve the existing substation monitoring system. The EC-SCADA system established by this method has a fast response time and enhances the intelligent control of substations. Based on the safety control requirements of the components related to substation equipment, Hamze Hajian-Hoseinabadi proposed a system for evaluating the operational reliability of substation equipment. The proposed method selects Birnbaum’s measure to determine substation equipment defects [
16]. In the context of the development of smart grids, Matta, N., Rahim-Amoud et al. embed autonomous agents in substation equipment information sensors and use WSAN methods to improve substation monitoring efficiency and safe grid operation [
17]. In reference [
18], a wireless sensor network is embedded in the smart grid to complete the detection and control of substation equipment, and a multi-agent system is introduced to improve the sending and receiving of information regarding the detection of defects in substation equipment. The method controls substation equipment defects by building an analog substation monitoring laboratory based on SEL751A relay support [
19].
For the problems of low edge detection accuracy and the weak anti-interference ability of image recognition, an optimized image recognition method based on a convolutional neural network is proposed in reference [
20]. The method uses the SOM network for image information to pre-learn, calculates the learning method with the best accuracy in advance, communicates the results to the initialization layer of the convolutional neural net, and uses the best model for image recognition to improve accuracy. Kang Jie and Yang Gang simulate the edge recognition of images with better precision and denoising capability using the image edge value-weighted, summation, and binary methods [
21]. Convolutional neural network image recognition is derived from graph data modeling, but few studies have involved deep learning models [
22].
A convolutional neural network with excellent image target recognition performance is essential. Currently, the research focuses on deep learning, convolutional neural network model migration, and modeling of graph convolutional neural networks [
23]. The work of image target detection with convolutional neural networks is concentrated on building convolutional operators and pooling operators in the image [
24]. With the continuous development of convolutional neural networks, a variety of image detection datasets were generated, and the detection accuracy of computer vision for major targets in images is gradually improving [
25]. In 2015, the image classification error rate of the ResNet algorithm was only 3.6%, which is lower than the manual image classification error rate of 5.1% [
26,
27]. At present, computer image recognition has a variety of semantic segmentation algorithms based on convolutional neural networks, which are important tools that can meet practical production needs.
The substation equipment has a fixed location, a single background, and is a relatively easy-to-train device in the power system visual neural network. However, factors such as substation equipment status, environmental background, acquisition time, and angle will affect the recognition accuracy. Therefore, the algorithm for substation equipment defect recognition should have a high-depth model to complete target equipment feature extraction, image classification, and semantic segmentation in a complex environment. Accurate semantic segmentation and feature fusion capability can accurately identify hidden and small defects in substation equipment. At the same time, the algorithm can filter irrelevant region proposals to improve the overall recognition accuracy of the algorithm. Most of the equipment for collecting image data in substations is fixed cameras.
There is the problem of unbalanced algorithmic features in computer vision detection. The improved GFPN network was obtained in reference [
28] by improving the FPN network for global information fusion. This method improves the feature imbalance problem in the Mask R-CNN algorithm and increases the detection accuracy of the algorithm. Compared with semantic segmentation, the precision of instance segmentation is more accurate. Mask R-CNN algorithm is proposed for instance segregation. Instance segmentation not only segments each pixel of the detected target but also segments the pixels of different targets. The Mask R-CNN algorithm classifies the target and anchors the frame with a layer of Mask branches to segment the specific contours of the target into instances. In practical engineering applications, the classification of Mask R-CNN can be changed to the actual required classification to complete the detection of the target in the image. Currently, Mask R-CNN has was applied to 6D modules for stereoscopic recognition of targets [
29].
Edge computing is a new computing model that handles downlink data from cloud computing centers and uplink data from edge terminals. The Mask R-CNN algorithm based on improved FPN network architecture should be simplified and compressed for the training model to be engineered in edge terminal devices that can be used for edge computing. The Mask R-CNN algorithm based on the GFPN framework for edge computing should accomplish the compression and acceleration of the model on its basis. For edge smart terminals with relatively poor computing power, lightweight deep learning models are better able to cope with the production needs required for engineering realities.
In the Mask R-CNN algorithm for substation equipment defect detection, the feature map can be simplified in the convolution kernel part by first performing 1 × 1 convolution for the feature layer generated by convolution to better compress the model. Then, the corresponding convolution operation is performed to return the feature values. In this way, the number of operations in the convolution process can be significantly reduced. Zhong Chunrong [
30] proposed an algorithmic model-related compression method for edge-oriented computing.
In summary, considering the limitations of traditional substation equipment inspection methods and the deficiencies in target detection of existing power system vision neural networks, this study proposes a high-precision substation equipment defect recognition algorithm based on the Mask R-CNN algorithm framework. By integrating the Global Feature Pyramid Network (GFPN) and the Convolutional Block Attention Module (CBAM), the algorithm significantly enhances the accuracy and robustness of feature fusion and target recognition, offering a distinct advantage over existing methods. Furthermore, in response to the complexity of substation equipment defect recognition, we have optimized the algorithm for edge computing environments and validated its effectiveness through experiments. This paper provides a detailed analysis of the types and characteristics of defects in substation equipment and selects the most suitable algorithm for edge vision. Using the existing image defect dataset, we trained a substation equipment defect recognition model suitable for power system edge vision, enhancing algorithm performance and expanding its application scope in smart grids. This provides new technical means for the intelligent monitoring and management of substation equipment, contributing to the improvement of power grid operational efficiency and safety.
3. Mask R-CNN Algorithm Improvement
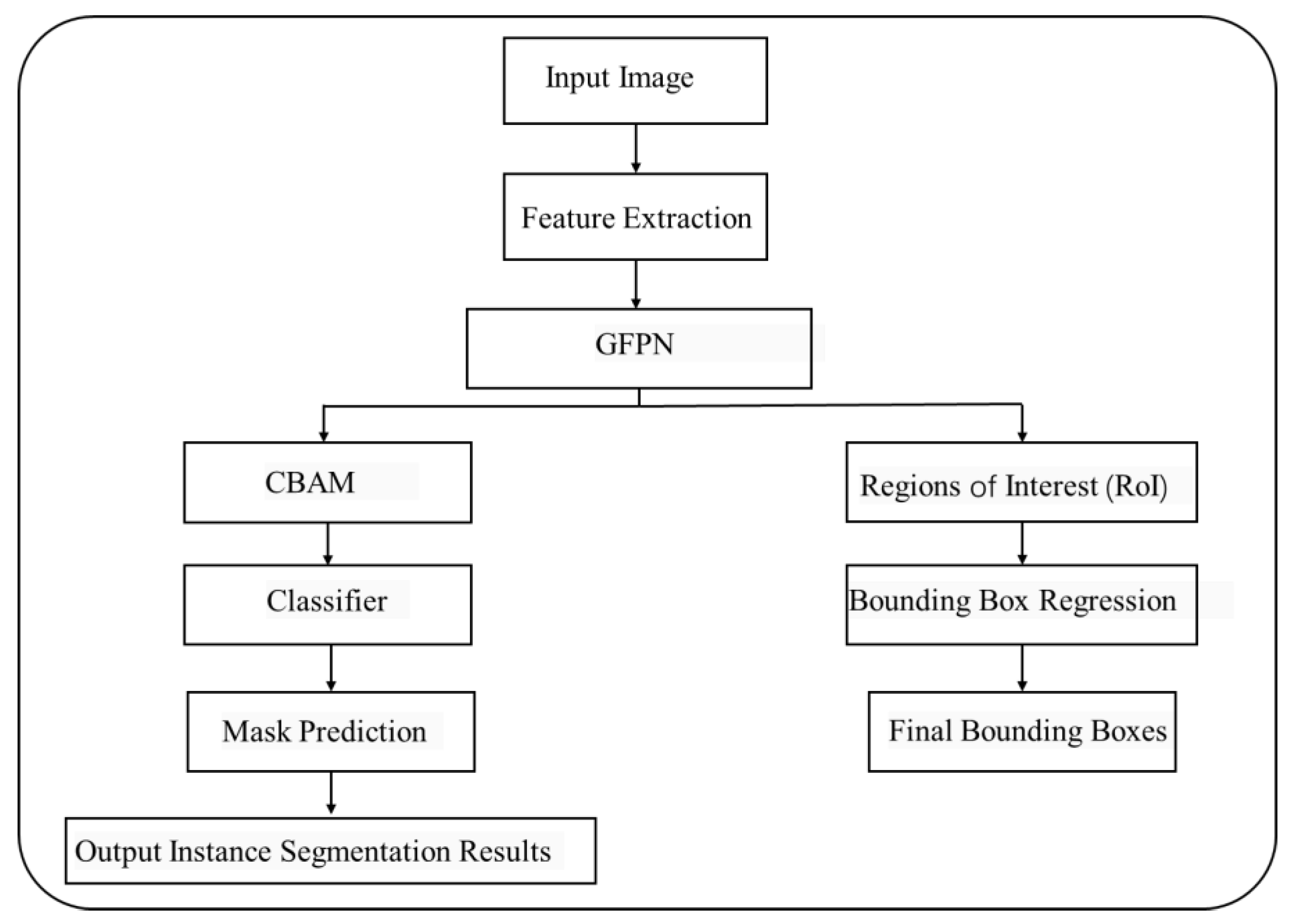
This section offers a comprehensive dissection of the algorithmic architecture for substation equipment defect recognition as proposed in this study. Tailored to accurately detect defects in substation equipment from imagery, the algorithm is introduced through a flowchart illustrating the procedural steps from the ingestion of substation equipment images to the delivery of defect segmentation outcomes. The flowchart elucidates the algorithm’s logical framework, with particular emphasis on GFPN and CBAM, two integral components critical for bolstering the model’s feature integration and robustness within intricate scenarios (
Figure 1).
The flowchart outlines the sequential operations of the algorithm, beginning with the input of substation equipment images, proceeding through a feature extraction phase to capture the image’s essential features. The GFPN network then augments these features, refining the representation of features for defects across various scales. The CBAM further refines the feature maps, enhancing the representation of pivotal features while mitigating the impact of less significant ones thus improving the model’s recognition accuracy. Through the stages of classification, bounding box regression, and mask prediction, the algorithm adeptly produces instance segmentation results for each defect area. The architecture of this process not only enhances the algorithm’s precision in defect recognition but also amplifies its practical utility in the maintenance of substation equipment.
3.1. Algorithm Combination Selection
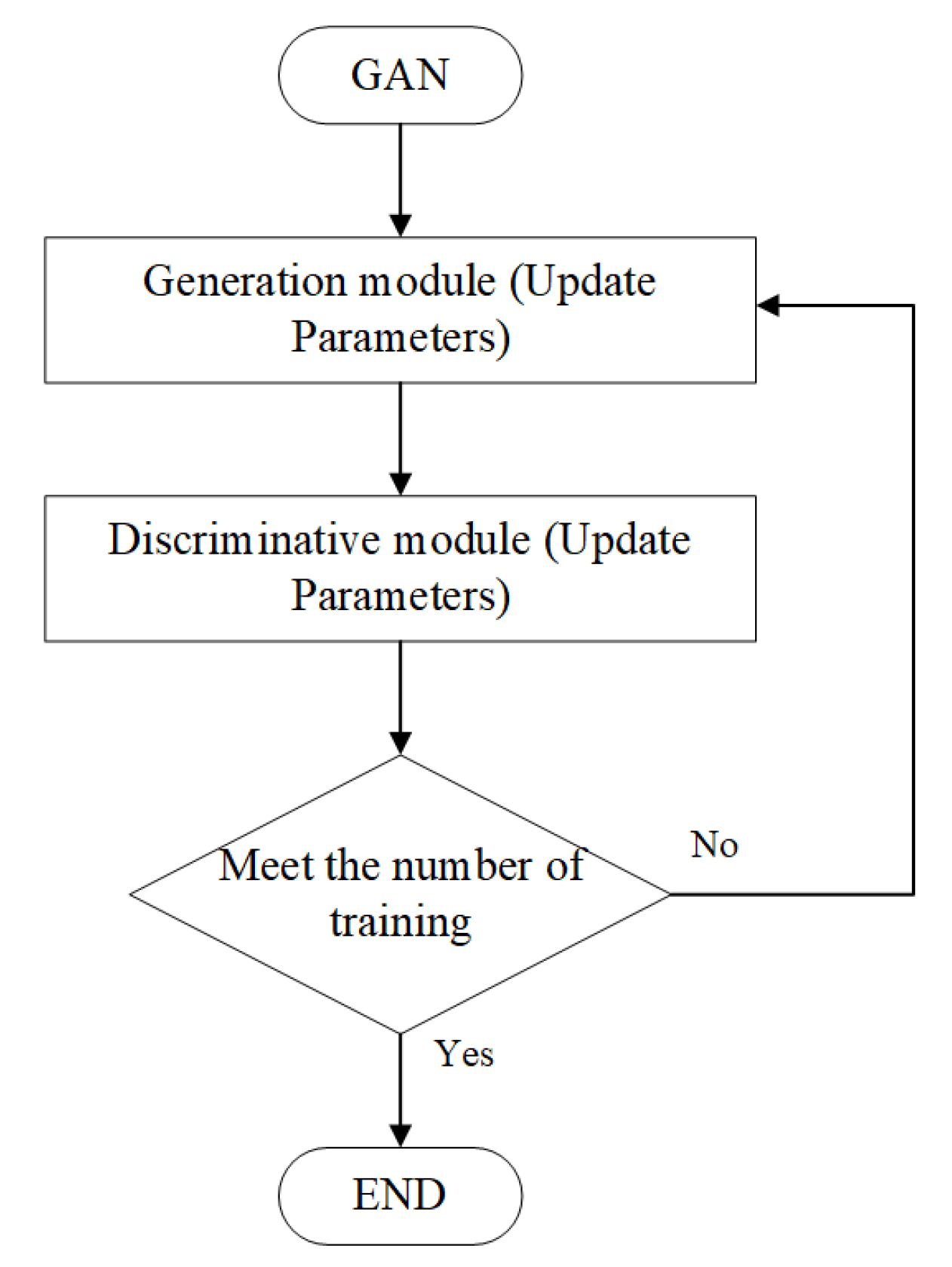
In this study, we have adopted a combination of Mask R-CNN and GAN to enhance the accuracy and robustness of substation equipment defect recognition. The reason for choosing this combination is based on an in-depth understanding of the characteristics of these two algorithms and their complementary advantages in object detection and image generation. Mask R-CNN is an advanced instance segmentation model that generates candidate regions by applying a Region Proposal Network (RPN) on feature maps, followed by precise pixel-level segmentation using ROI Align. This method can provide accurate bounding boxes and masks when dealing with substation equipment defect recognition, effectively identifying and locating defects.
However, the performance of Mask R-CNN largely depends on high-quality annotated data. In practical applications, obtaining sufficient defect samples is challenging because defect events are relatively rare. To address this issue, we introduced GAN to generate a more diverse range of defect samples. GAN consists of a generator and a discriminator, with the generator responsible for producing realistic defect images, and the discriminator assessing the authenticity of these images. Through this adversarial training, the generator can produce high-quality synthetic defect images, which increase the diversity and quantity of the dataset during training thereby enhancing the model’s generalization capabilities.
3.2. GPN Network
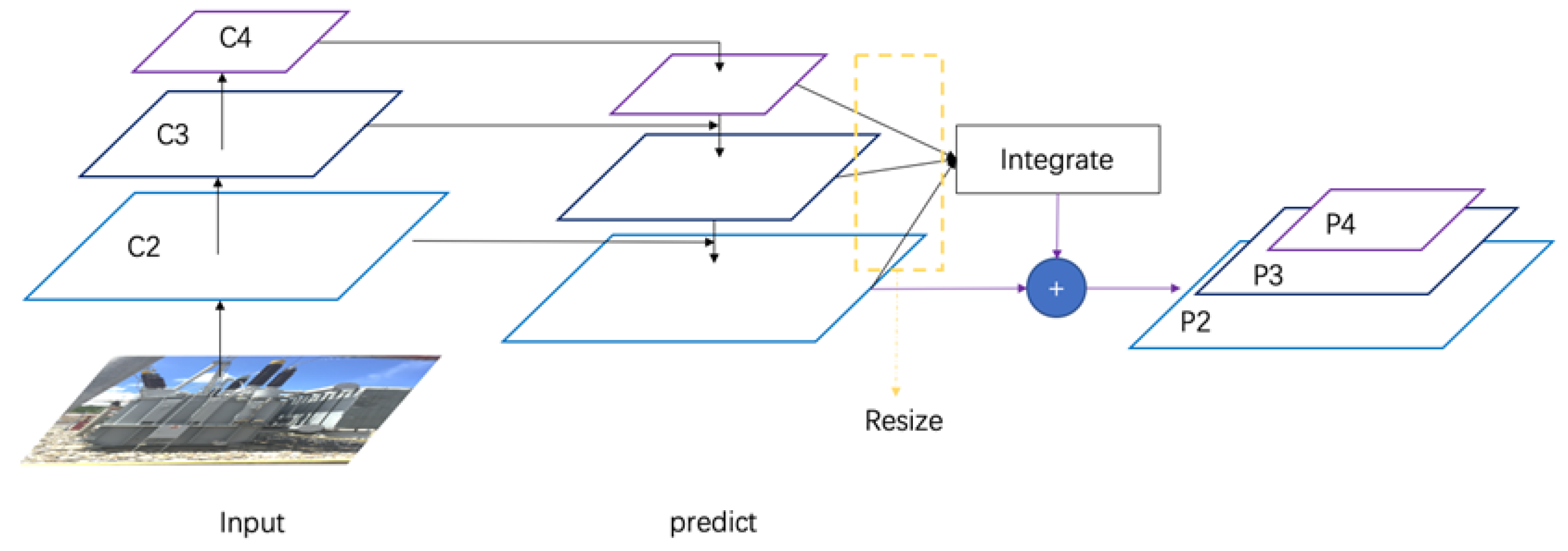
The classification capability of the Mask R-CNN algorithm is based on Mask Prediction. Unlike the Fast R-CNN algorithm and the Faster R-CNN algorithm, which use the RoI Pooling operation, the RoI Align method in the Mask R-CNN algorithm involves a bilinear interpolation problem. The FPN network uses a lateral connection approach in which only a single layer is connected between the P-layer and C-layer in the network and the information of adjacent layers cannot be effectively fused. For the improved FPN network, the image is rescaled after the upsampling operation is completed, and the rescaled image is placed into the upsampled image for fusion. The improved FPN network (GFPN) architecture is shown in
Figure 2.
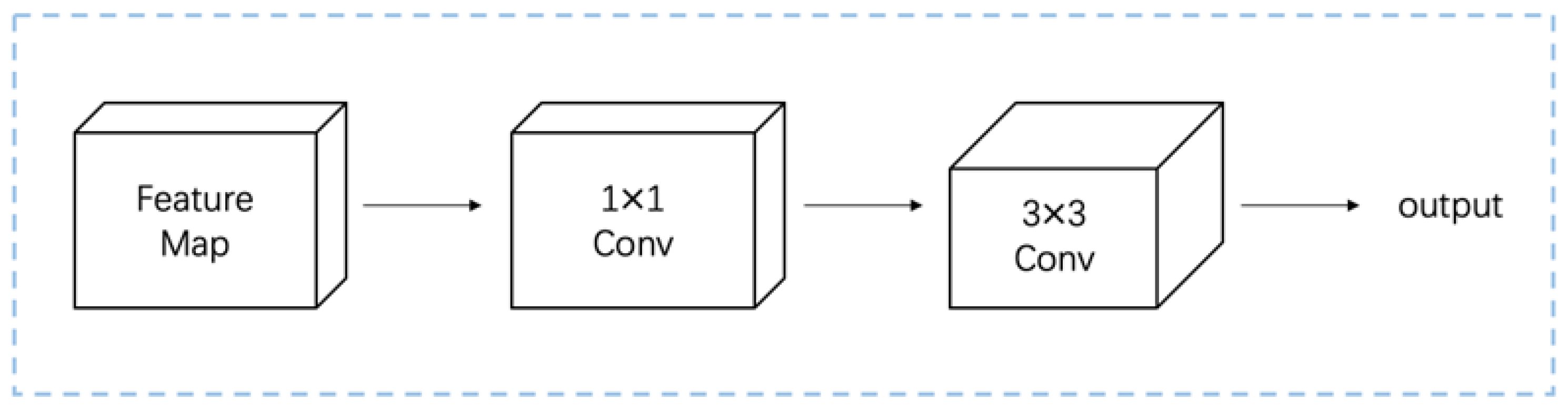
The fusion module is simply a 1 × 1 convolution followed by a 3 × 3 convolution operation. The main function of 1 × 1 convolution is to reduce the image channels for dimensionality reduction output. In addition, the main role of 3 × 3 convolution is to preserve the original target feature information and prevent the problem of feature mixing in high dimensions. The fusion module is shown in
Figure 3. The algorithm in the GFPN network rescales the feature map after module fusion to complete the retention of semantic information.
3.3. CBAM Attention Mechanism Module
The Convolutional Block Attention Module (CBAM) was integrated into the feature processing phase of the Mask R-CNN to enhance the activation of channel and spatial attention mechanisms for different regions within the imagery thereby reinforcing the learning of target features. The CBAM is a hybrid attention architecture that combines the benefits of both channel and spatial attention, designed to bolster the network’s sensitivity to salient features while concurrently reducing computational complexity. This leads to a marked enhancement in the performance of the neural network. As depicted in
Figure 4, the CBAM bifurcates the input feature map into two distinct pathways, each dedicated to processing either channel or spatial attention, before merging these processed outputs with the original feature map. The CBAM’s modular design allows for its flexible integration at any point within the network without altering the dimensionality of the feature maps. This “plug-and-play” capability renders the CBAM an effective tool for network performance augmentation, particularly suited for high-dimensional data and complex tasks. Through its comprehensive attention mechanism, the CBAM not only elevates the model’s capacity to discern critical features but also streamlines computational efficiency and bolsters the model’s robustness.
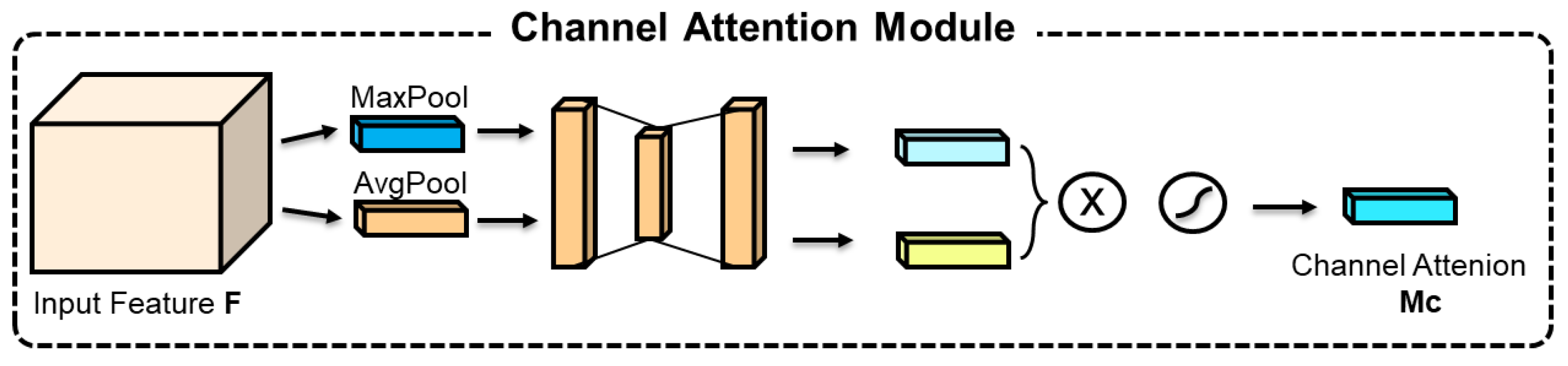
As illustrated in
Figure 5, the channel attention sub-module employs parallel max-pooling and average-pooling operations to extract both key and holistic information from the feature maps. These pooled results are subsequently processed by a multi-layer perceptron (MLP) to generate channel attention weights, which are then compressed to a range between 0 and 1 using a sigmoid function. These weights are applied to the input feature map’s channels, enabling the network to focus more intently on pertinent features thereby increasing the utilization rate of valuable information and providing a more refined feature representation for subsequent tasks.
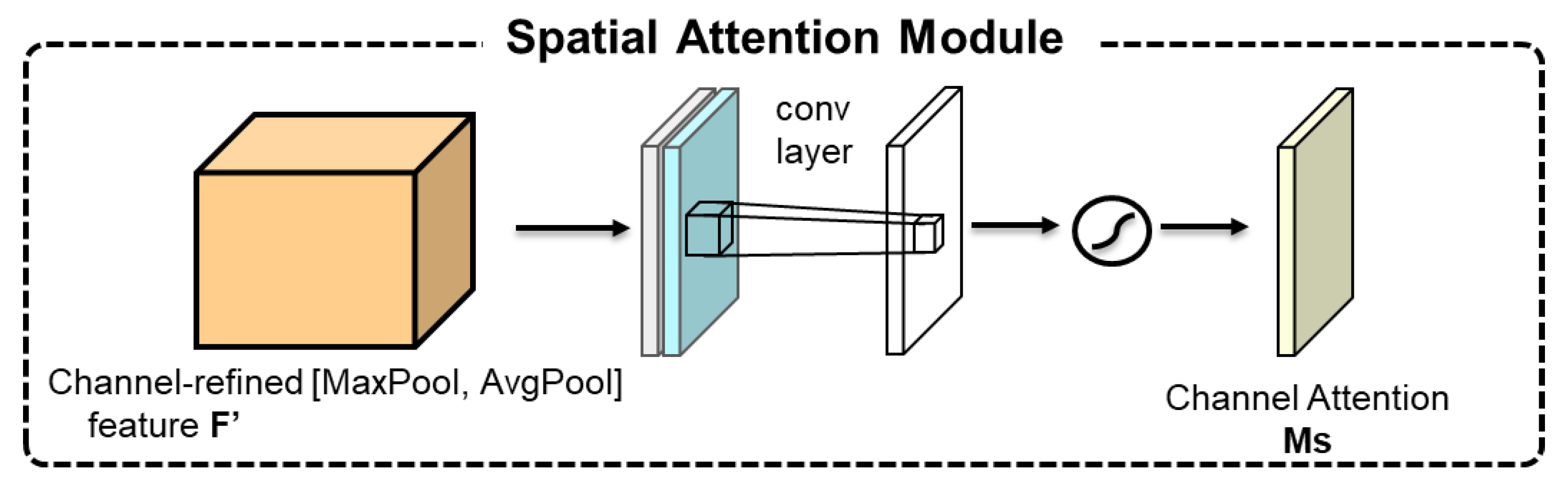
The spatial attention sub-module, as shown in
Figure 6, initiates by conducting channel-wise max-pooling and average-pooling on the input feature map to capture both local and global information. After concatenating these pooled results, a convolutional operation reduces the dimensionality to a single channel, creating a compact feature representation. A sigmoid function is then applied to produce an attention weight map that ranges from 0 to 1, signifying the spatial importance of each pixel. This design emphasizes the regions of interest to the network while suppressing less relevant areas thereby enhancing the model’s responsiveness to critical areas and strengthening the spatial information representation within the feature maps, enabling the model to more effectively process complex scenes.
3.4. Mask R-CNN for Edge Computing
3.4.1. CNN Layer Weight Pruning
In the process of the Mask R-CNN algorithm based on the GFPN framework, compression should mainly focus on the CNN part. The simplification of the convolutional neural network should be pruned according to the network features, and the parts of the network whose weights are more redundant or relatively unimportant should be selected for pruning. The whole CNN is pruned, as shown in
Figure 7.
In order to avoid the loss of algorithmic network accuracy due to weight pruning, the pruning process should satisfy Equation (1).
where
W is the fully connected layer weight;
D is the deep learning training set;
E denotes the loss function;
Wρ is the pruned weight, and
∆ is the loss function distance. The simplified model is obtained by filtering the pruned weight neurons by Equation (1) to improve the computational speed with guaranteed accuracy and efficiency. This method can ensure the capability of the Mask R-CNN algorithm in target detection while reducing the redundancy of the fully connected layer.
3.4.2. Weight Parameter Sharing
The fully connected layers are divided into two cases: an equal and unequal number of neurons in the input and output layers. In the case of an equal number of neurons, the usual approach is to construct a circulant matrix. The construction of a circulant matrix of weights requires a phase shift in the weights connected between neurons. The circulant matrix of the weights is an important way of sharing weight parameters. The number of neurons in the output layer of the fully connected layer in the Mask R-CNN algorithm is usually different from the number of neurons in the input layer. Therefore, the sharing of the weight parameters needs to take the Toeplitz matrix to plan the weights. The Toeplitz matrix is planned by taking the same value of the weights from the top left to the bottom right, and then recursively completing the matrix planning with adjacent rows.
The convolutional kernel operation of convolutional neural networks in the convolution process can also be weight-sharing. For a convolution kernel of dimension m × n × h × w (where m is the number of input feature layers, n is the number of output layers, h is the height of the convolution kernel, and w is the width of the convolution kernel), the convolution kernel is cyclically shifted along the w direction from the input section, and its compression multiplier satisfies Equation (2).
This method of reducing the number of network parameters by the cyclic shifting of convolution kernels has a larger compression multiplier. Meanwhile, there is less impact on the recognition accuracy of the network.
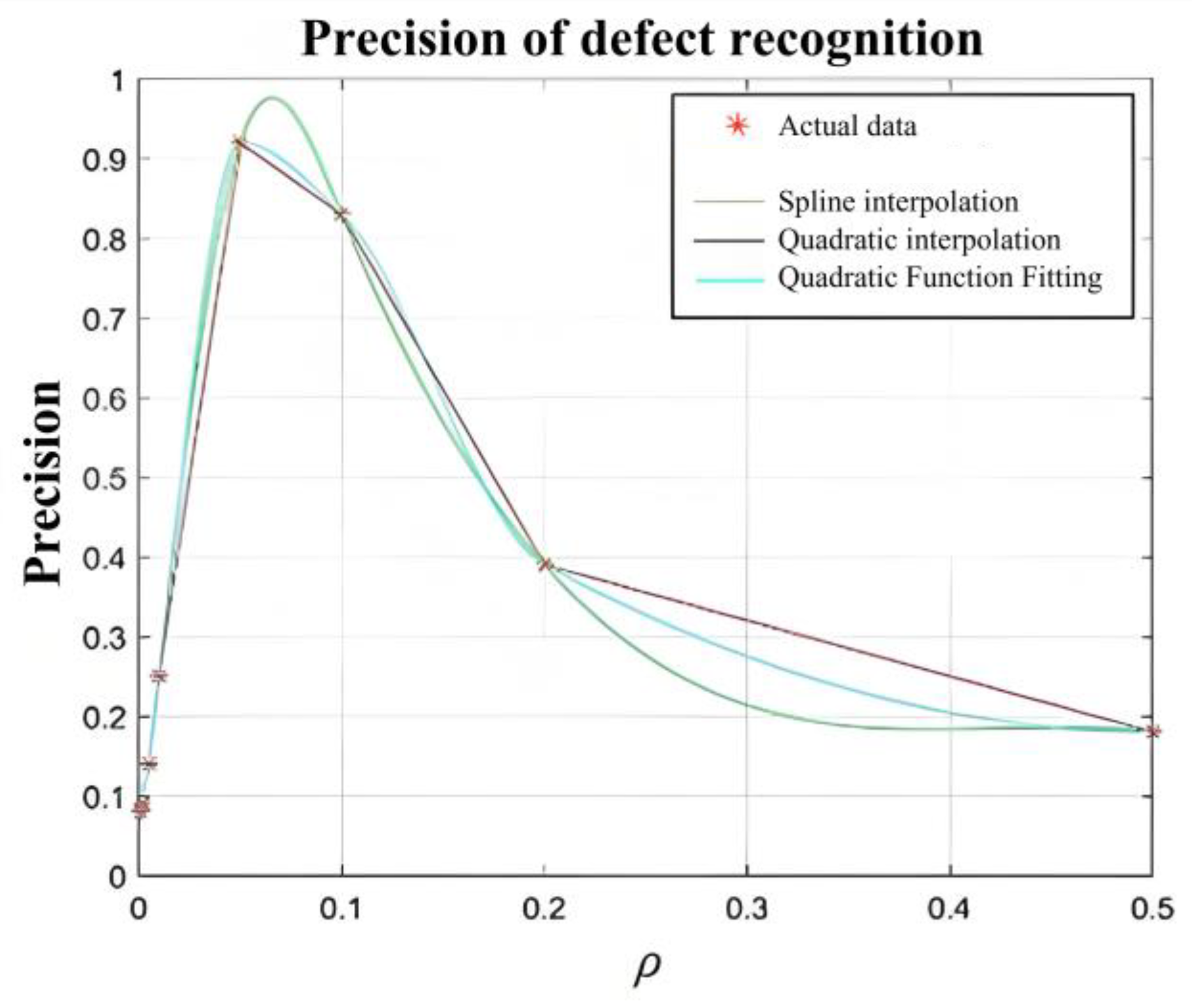
3.5. Accuracy Analysis After Network Improvement
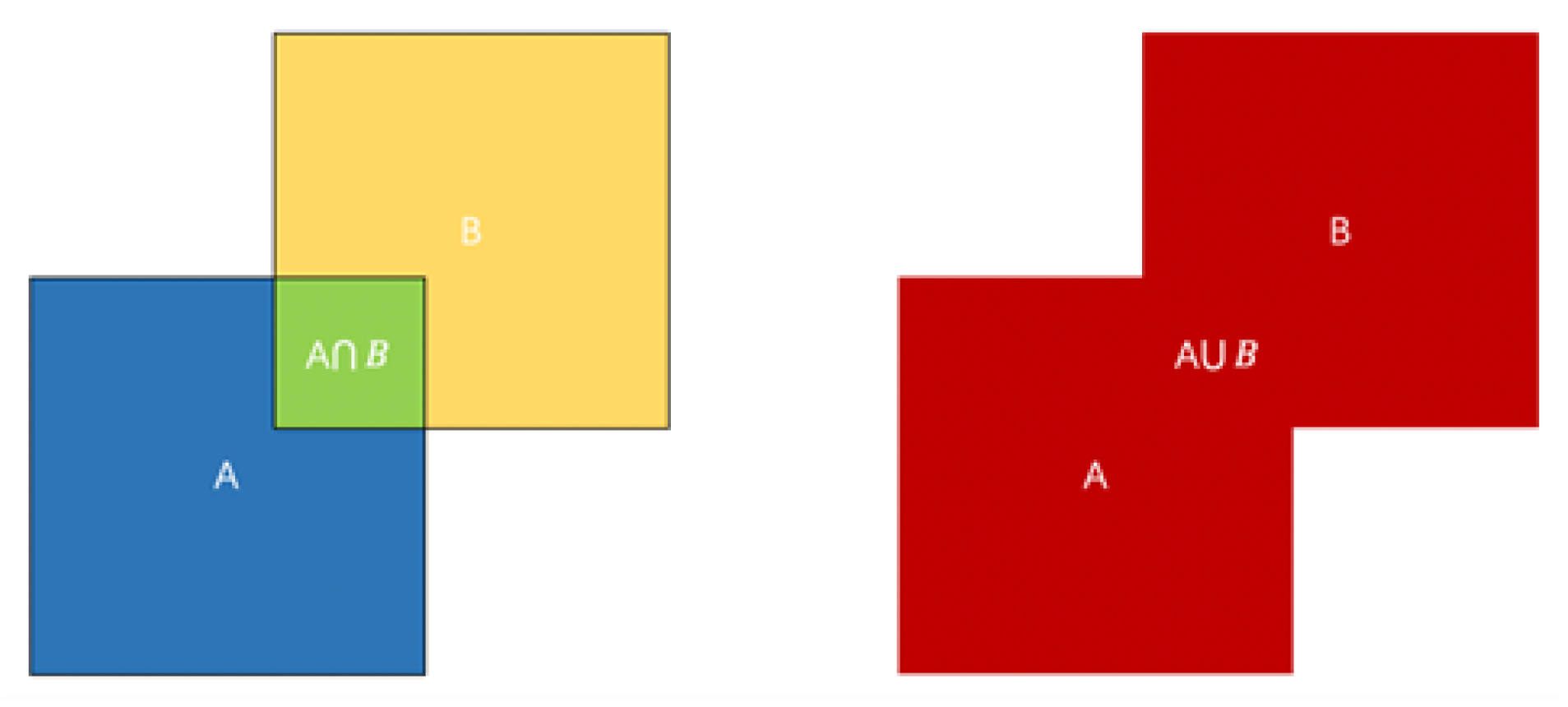
The IoU threshold is a judgment criterion in deep vision. The IoU threshold ranks the Softmax outputs for the same object classification from largest to smallest, erases the Softmax output below the confidence threshold to zero, and then divides the intersection of the two values by the union to obtain the IoU threshold. The average precision is as follows:
where TP (True Positive) indicates a true case positive sample and FP (False Positive) indicates a false case positive sample.
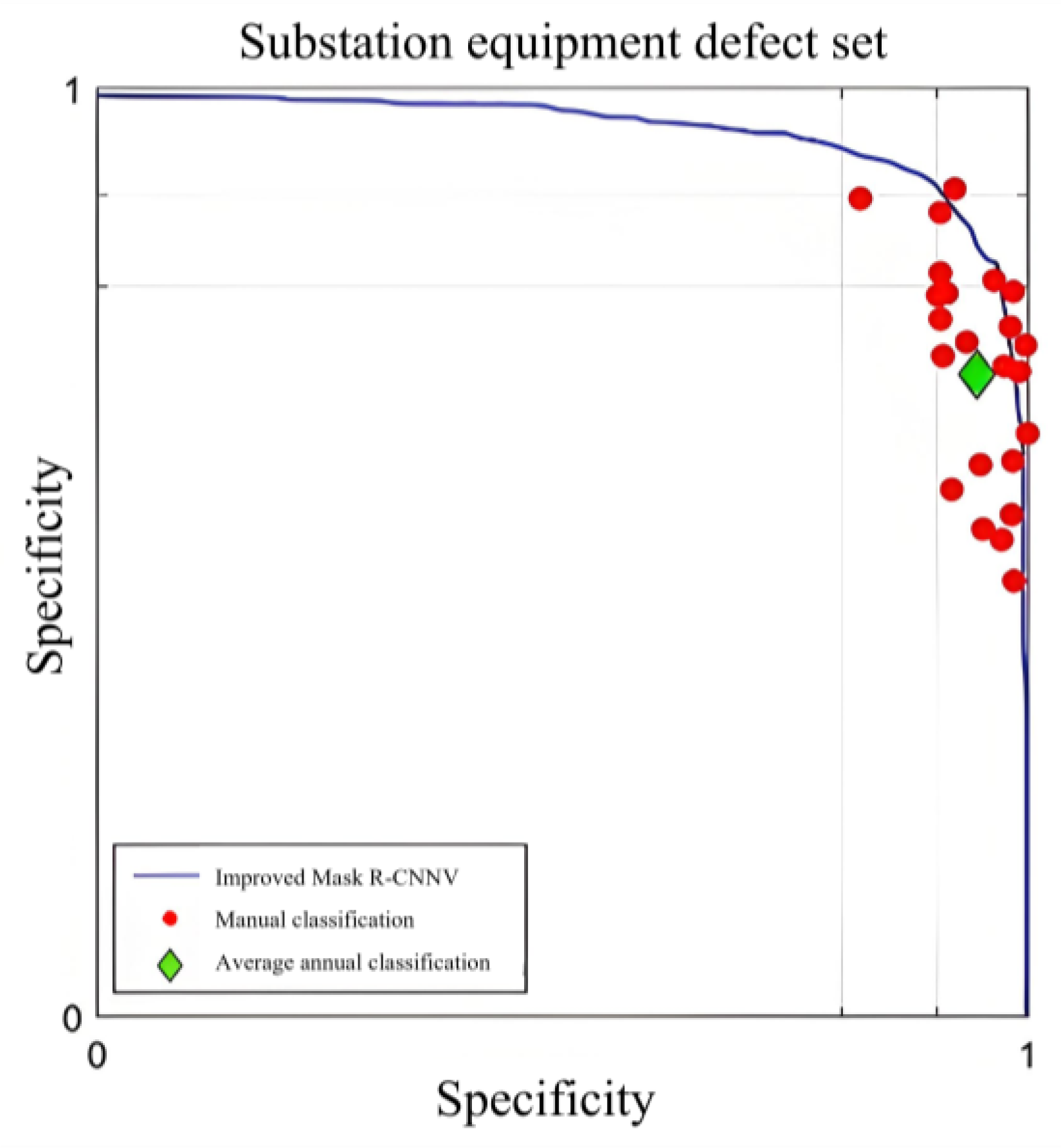
6. Experimental Results Analysis
To thoroughly assess the performance of the enhanced Mask R-CNN algorithm in the task of substation equipment defect recognition, this study conducted ablation studies and comparative experiments. The purpose of the ablation study was to evaluate the specific contributions of the GFPN network and the CBAM to the model’s performance, while the comparative experiments aimed to benchmark our method against other popular object detection algorithms.
6.1. Ablation Study Results
The ablation study systematically removed key components of the enhanced Mask R-CNN algorithm to reveal the impact of each component on the final performance. To further address the reviewer’s concern about the comprehensiveness of our accuracy analysis, we have included additional metrics such as F1 Score and AUC to provide a more nuanced view of our model’s performance. The complete model, which includes the GFPN network and the CBAM, outperformed other variants across accuracy, recall, F1 Score, mAP, and AUC metrics. Specifically, the complete model achieved an accuracy of 91.8%, a recall of 90.3%, an F1 Score of 90.5%, and an mAP of 91.0%, while the model without the GFPN network and the CBAM showed a significant decrease in performance. These results underscore the critical role of the GFPN network in feature fusion and target recognition, as well as the CBAM’s contribution to enhancing the model’s sensitivity to key features.
The experiments were repeated five times to ensure statistical reliability, and
Table 3 provides the averaged results along with the standard deviations for accuracy, recall, F1 Score, and mAP, which were ±0.35%, ±0.40%, ±0.37%, and ±0.38%, respectively. This analysis confirms the robustness and stability of the enhanced Mask R-CNN model.
6.2. Comparative Experiment Results
In our comparative analysis, the enhanced Mask R-CNN algorithm was rigorously evaluated against six state-of-the-art object detection models, including Faster R-CNN, YOLOv3, YOLOv7, SSD, YOLOv5, and the latest YOLOv8. Uniform training datasets, preprocessing techniques, and evaluation metrics were employed across all experiments to ensure a level playing field for this comparative study.
Our enhanced Mask R-CNN demonstrated superior performance over its counterparts, particularly when juxtaposed with YOLOv8, which is considered one of the most advanced algorithms in the YOLO family. The comparison metrics included accuracy, recall, F1 Score, and Mean Average Precision (mAP), which are critical indicators for object detection models. The results revealed that our model not only matched but also surpassed YOLOv8 in all four metrics, with improvements of 5.1%, 4.9%, 5.0%, and 5.2%, respectively. This significant leap in performance underscores the robustness and efficacy of our model, especially in complex industrial settings where high-precision is paramount.
To provide a comprehensive analysis, we delved deeper into the performance discrepancies between our model and YOLOv8. The enhanced Mask R-CNN’s GFPN network and CBAM were pivotal in enhancing feature extraction and object recognition, leading to a more accurate localization of defects in substation equipment. In contrast, YOLOv8, while employing a novel scaling method and improved detection architecture, showed slightly lower performance. This could be attributed to YOLOv8’s greater sensitivity to hyperparameter tuning and its relatively higher false positive rate in our specific dataset.
Table 4 encapsulates the comparative performance, presenting the average results from five iterations, along with standard deviations that affirm the consistency and reliability of our findings. The marginal yet consistent outperformance across all metrics solidifies the enhanced Mask R-CNN’s position as a leading object detection model.
The combined results of the ablation and comparative experiments lead to the conclusion that the enhanced Mask R-CNN algorithm, with the incorporation of the GFPN network and the CBAM, significantly improves the accuracy and reliability of substation equipment defect recognition. Our method demonstrates a clear advantage over other popular object detection algorithms in key performance metrics, making it an ideal choice for the task of substation equipment defect recognition. Future work will focus on further optimizing algorithm performance and exploring its potential in a broader range of industrial applications. These experimental results not only validate the effectiveness of our method but also provide new insights and directions for the field of substation equipment defect recognition. We anticipate that these findings will stimulate the advancement of related technologies and bring value to practical industrial applications.
6.3. Contributions and Limitations
In this section, we will discuss the contributions and limitations of our enhanced Mask R-CNN algorithm for substation defect recognition. While our approach has demonstrated significant performance improvements and was optimized for deployment on edge devices with limited resources, it is essential to acknowledge and address its potential shortcomings. Below, we outline the primary contributions of our work, followed by a discussion on the areas where our method may face challenges and the conditions that could impact its effectiveness.
Our enhanced Mask R-CNN algorithm, which incorporates the GFPN network and CBAM attention mechanism, has achieved superior performance in substation defect recognition tasks. Compared to state-of-the-art algorithms such as YOLOv5 and Faster R-CNN, we have demonstrated significant improvements in accuracy, recall, and Mean Average Precision (mAP). Through model compression techniques, we have optimized our algorithm for resource-constrained environments, enabling its deployment on edge devices. Furthermore, we have validated our method through extensive experiments, including ablation studies and comparative experiments, ensuring its robustness and reliability in industrial scenarios.
Despite the impressive results of our enhanced Mask R-CNN algorithm, it is not without limitations. Here, we discuss the areas where our method may underperform and the conditions that could impact its effectiveness.
The performance of our algorithm could be constrained in environments with limited computational resources, particularly in terms of memory capacity and processing power. This is especially relevant in edge computing settings, where our model is intended to be deployed, and capabilities are often restricted. For applications requiring real-time or near-real-time feedback, the model’s inference time must be swift. On devices with limited CPU and GPU capabilities, meeting these demands could be challenging. Our model’s performance is heavily reliant on the quality and diversity of the training dataset. In scenarios where the dataset is not representative of the operational conditions or contains limited defect samples, the model’s accuracy may be compromised. While our model is tailored for substation equipment, its adaptability to other domains or types of equipment may require additional training and fine tuning.
To address these limitations, we are exploring techniques such as model compression, weight pruning, and parameter sharing to reduce computational demands while maintaining accuracy. We also plan to expand our dataset to include a wider range of defect types and scenarios to enhance the model’s generalization capabilities.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}