Application of Machine Learning to Predict the Capacity of Fractured Horizontal Wells in Shale Reservoirs

Abstract
1. Introduction
2. Principles and Methods
2.1. Sample Selection and Data Processing
2.2. Tree Models
2.3. Performance Evaluation
3. Model Building
3.1. Sample Selection
3.2. Data Processing
3.2.1. Feature Selection
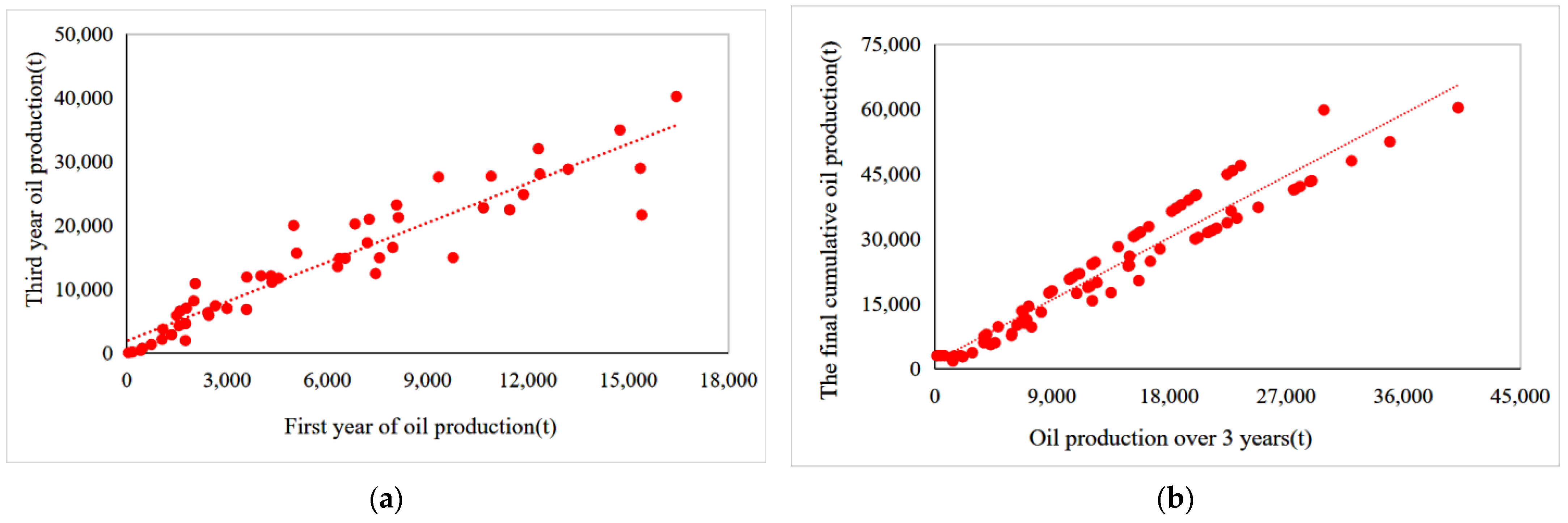
3.2.2. Dataset Decomposition
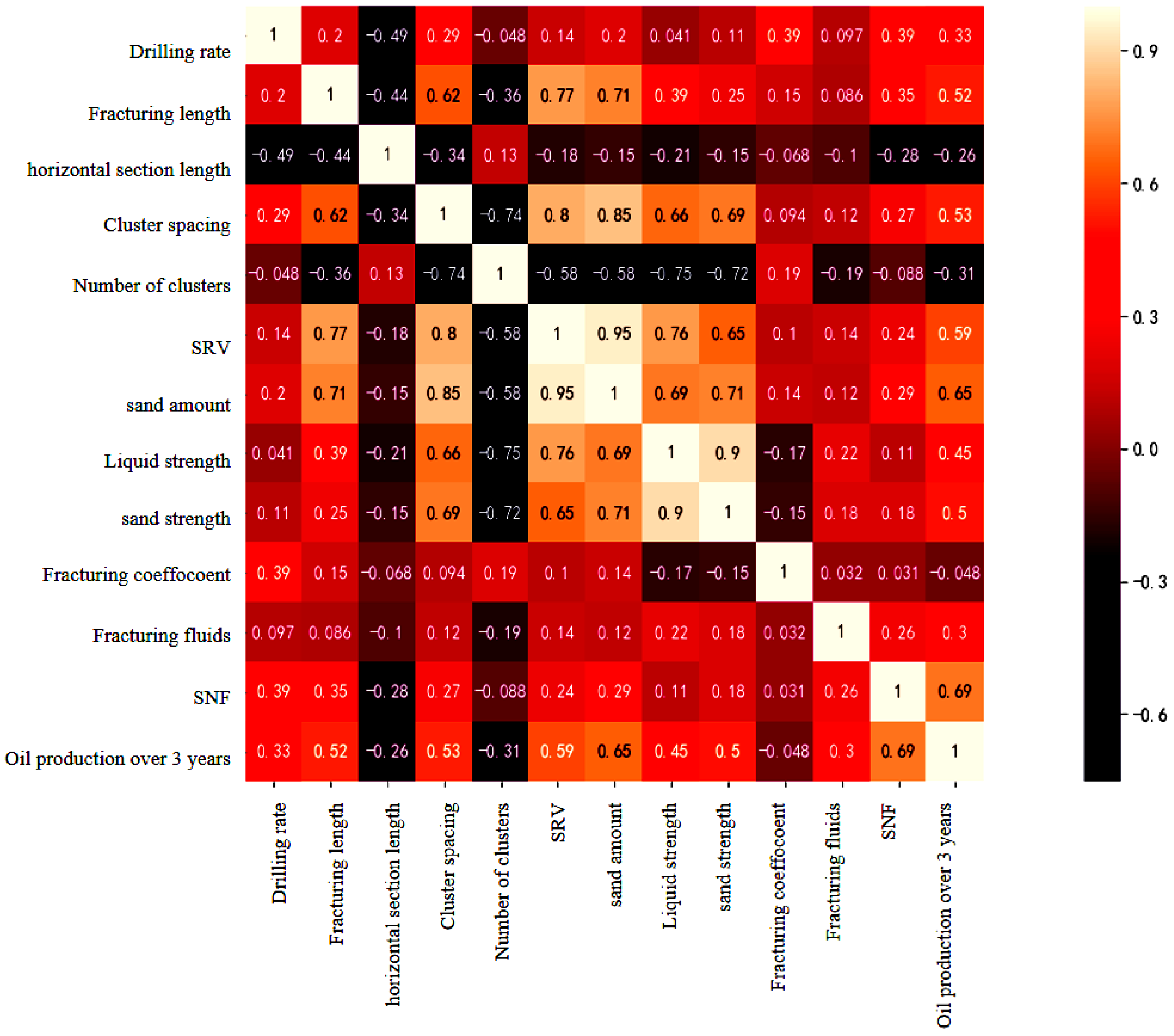
3.2.3. Feature Parameter Correlation Analysis
3.3. Tree Modelling
4. Results and Discussion
5. Conclusions
- (1)
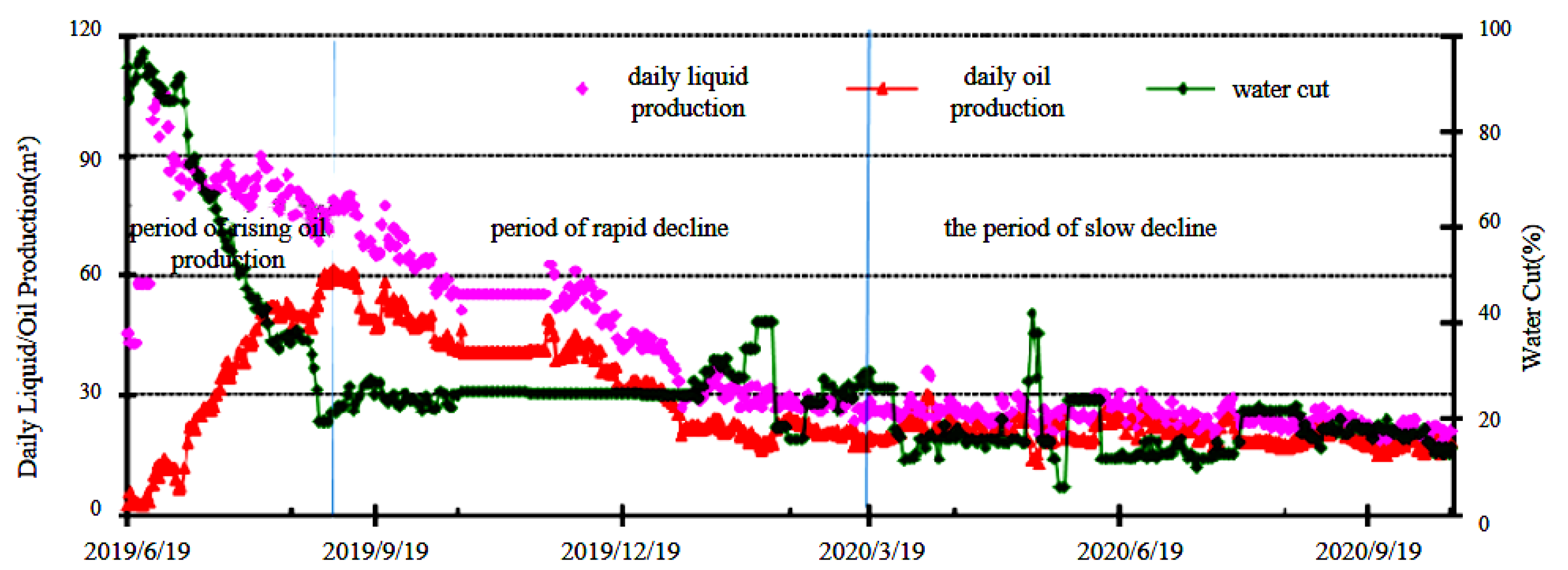
- Production phases in the Jimsar shale oil reservoir: The production phases are categorized as an increase phase, a rapid decline phase, and a slow decline phase. Clarifying these production phases is crucial for developing an effective production prediction model for later stages.
- (2)
- Parameter optimization: By integrating and selecting data from 91 horizontal wells, the optimal range of parameters was determined, providing a deeper understanding of the production practices and extraction methods used in the Jimsar shale oil block. This highlighted that precise control over fracturing parameters is key to high productivity in the fractured horizontal wells of the Jimsar shale oil reservoir.
- (3)
- Guidance for fracturing optimization design: The fracturing parameters should aim to ensure a treatment volume greater than 7.21 cubic meters, a cluster spacing of less than 15.36 m, a sand volume between 2885.00 and 3356.00 cubic meters, and a segment length between 44.97 and 54.19 m.
- (4)
- Comparison of machine learning methods for productivity prediction: The comprehensive results indicate that the random forest algorithm is the most effective for solving productivity regression prediction problems, with data points generally falling within a 10% error margin. This study advances the application of the random forest algorithm in shale reservoir productivity prediction.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xianwang, M.; Mei, L.; Weiqi, M.; Nie, K. Analysis of influencing factors on productivity after multistage fracturing to tight oil of horizontal well. Well Test. 2016, 25, 29–32. [Google Scholar]
- Zheng, D.; Miska, S.; Ozbayoglu, E.; Zhang, J. Combined Experimental and Well Log Study of Anisotropic Strength of Shale. In Proceedings of the SPE Annual Technical Conference and Exhibition, San Antonio, TX, USA, 16–18 October 2023; p. D031S046R003. [Google Scholar]
- Wang, Q.; Wang, T. Detection of dissolution pores in the marginally mature calcareous lucaogou shale: New insights in nanopore development in terrestrial shale oil reservoirs. Acta Geol. Sin. Engl. 2020, 94, 1321–1322. [Google Scholar] [CrossRef]
- Zheng, D.; Miska, S.; Ziaja, M.; Zhang, J. Study of anisotropic strength properties of shale. AGH Drill. Oil Gas 2019, 36, 93–112. [Google Scholar] [CrossRef]
- Chu, C.C.; Xie, Q.H. Study on capacity evaluation of fractured horizontal wells in tight gas reservoirs. CPCCS 2024, 44, 11–13. [Google Scholar]
- Zhiming, C.; Xinwei, L.; Chenghui, H.; Xiaoliang, Z.; Langtao, Z.; Yizhou, C.; Heng, Y. Productivity estimations for vertically fractured wells with asymmetrical multiple fractures. J. Nat. Gas Sci. Eng. 2014, 21, 1048–1060. [Google Scholar] [CrossRef]
- Langsrud, O. Simulation of two-phase flow by finite element methods. In Proceedings of the SPE Symposium on Numerical Simulation of Reservoir Performance, Los Angeles, CA, USA, 19–20 February 1976; p. SPE-5725-MS. [Google Scholar]
- Rafieepour, S.; Zheng, D.; Miska, S.; Ozbayoglu, E.; Takach, N.; Jianguo, Z. Combined Experimental and Well Log Evaluation of Anisotropic Mechanical Properties of Shales: An Application to Wellbore Stability in Bakken Formation. In Proceedings of the SPE Annual Technical Conference and Exhibition, Virtual, 26–29 October 2020; p. D021S015R006. [Google Scholar]
- Bai, Y.H.; Xu, B.X.; Chen, L.; Chen, G. New production prediction methods for typical curve and analytical model of shale oil and gas. China Offshore Oil Gas 2018, 30, 120–126. [Google Scholar]
- Li, X.C.; Li, X.P.; Jing, X.J.; Li, K. Theory and Method for Shale- Gas Productivity Analysis. Development 2014, 37, 51–55. [Google Scholar]
- Jing, Y. Research on Solution Method of Coupled Free Flow-Porous Media Flow Model and Reservoir Productivity Prediction Method Based on Deep Learning. Ph.D. Thesis, Shaanxi University of Science and Technology, Xian, China, 2024. [Google Scholar]
- Zheng, D.; Ozbayoglu, E.; Miska, S.; Zhang, J. Experimental study of anisotropic strength properties of shale. In Proceedings of the ARMA US Rock Mechanics/Geomechanics Symposium, Atlanta, GA, USA, 25–28 June 2023; p. ARMA–2023-0128. [Google Scholar]
- Lu, C.; Jiang, H.; Yang, J. Shale oil production prediction and fracturing optimization based on machine learning. J. Pet. Sci. Eng. 2022, 217, 110900. [Google Scholar] [CrossRef]
- Guo, C.J.; Wang, H.X.; Liu, X.; Zhang, C.S. An analysis of the application scenarios of machine learning technology in the oil and gas industry. China CIO News 2017, 100–103. [Google Scholar]
- Liu, H.; Tao, J.P.; Meng, S.W.; Li, D.X.; Cao, G.; Gao, Y. Application and prospects of CO2 enhanced oil recovery technology in shale oil reservoir. China Pet. Explor. 2022, 27, 127–134. [Google Scholar]
- Qian, X.; Zhang, J. Exploration and development technology of shale oil and gas in the world: Progress, impact, and implication. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Changsha, China, 18–20 September 2020; p. 012131. [Google Scholar]
- Kuang, L.; Liu, H.; Ren, Y.; Luo, K.; Shi, M.Y.; Su, J.; LI, X. Application and development trend of artificial intelligence in petroleum exploration and development. Pet. Explor. Dev. 2020, 48, 1–11. [Google Scholar] [CrossRef]
- Han, D.; Jung, J.; Kwon, S. Comparative Study on Supervised Learning Models for Productivity Forecasting of Shale Reservoirs Based on a Data-Driven Approach. Appl. Sci. 2020, 10, 1267. [Google Scholar] [CrossRef]
- Wang, T.; Wang, Q.; Shi, J.; Zhang, W.; Ren, W.; Wang, H.; Tian, S.C. Productivity Prediction of Fractured Horizontal Well in Shale Gas Reservoirs with Machine Learning Algorithms. Appl. Sci. 2021, 11, 12064. [Google Scholar] [CrossRef]
- Ji, L.; Li, J.H.; Xiao, J.L. Application of random forest algorithm in the multistage fracturing stimulation of shale gas field. Pet. Geol. Oilfield Dev. Daqing 2020, 39, 168–174. [Google Scholar]
- Wevill, J.; Bromhead, A.; Evans, K. Relative performance of support vector machine, decision trees, and random forest classifiers for predicting production success in US unconventional shale plays. In Advances in Subsurface Data Analytics; Elsevier: Amsterdam, The Netherlands, 2022; pp. 31–62. [Google Scholar]
- Zheng, D.; Turhan, C.; Wang, N.; Ashok, P.; van Oort, E. Prioritizing Wells for Repurposing or Permanent Abandonment Based on Generalized Well Integrity Risk Analysis. In Proceedings of the SPE/IADC Drilling Conference and Exhibition, Galveston, TX, USA, 5–7 March 2024; p. D021S018R001. [Google Scholar]
- Liu, C.L.; Yang, J.; Zhu, M. Remaining life prediction method of corroded pipeline based on normal distribution. Corros 2023, 44, 100–106. [Google Scholar]
- Storås, A.M.; Andersen, O.E.; Lockhart, S.; Thielemann, R.; Gnesin, F.; Thambawita, V.; Hicks, S.A.; Kanters, J.K.; Strümke, I.; Halvorsen, P.J.D. Usefulness of heat map explanations for deep-learning-based electrocardiogram analysis. Diagnostics 2023, 13, 2345. [Google Scholar] [CrossRef]
- Wang, D.W. Application of Random Forest in Microfinance. Master’s Thesis, Chongqing University, Chongqing, China, 2019. [Google Scholar]
- Liu, J.L. Practice and Decision Tree Model Analysis of Comprehensive Control of “Carbon Emission” of Offshore Oilfield Torch. Tianjin Sci. Technol. 2023, 50, 40–43. [Google Scholar]
- Liu, F.Q.; Wang, S.Y.; Wang, M.M. Prediction of uranium reservoir permeability coefficient based on machine learning. Ore Geol. Rev. 2023, 69, 530–532. [Google Scholar]
- Frġedman, J. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Li, W.H.; Yang, Y.C.; Shen, H.B. Construction of Ultraviolet Radiation Fitting Model and Analysis of Correlation Factors in Guangzhou Based on Gradient Boosting Decision Tree. Meteor. Sci. Technol. 2024, 52, 124–131. [Google Scholar]
- Nie, Z.; Jingming, H.; Hua, C.; Guangzhao, C.; Bingyi, L. A rapid prediction method for mountain flood disaster based on machine learning algorithms. Water Resour. Prot. 2022, 38, 32–40. [Google Scholar]
- Junqiang, S.; Xiaoshan, L.; Shuo, W.; Kaifang, G.; Hong, P.; Xin, W. Production prediction of fractured horizontal wells in tight oil reservoirs. Xinjiang Pet. Geol. 2022, 43, 580. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
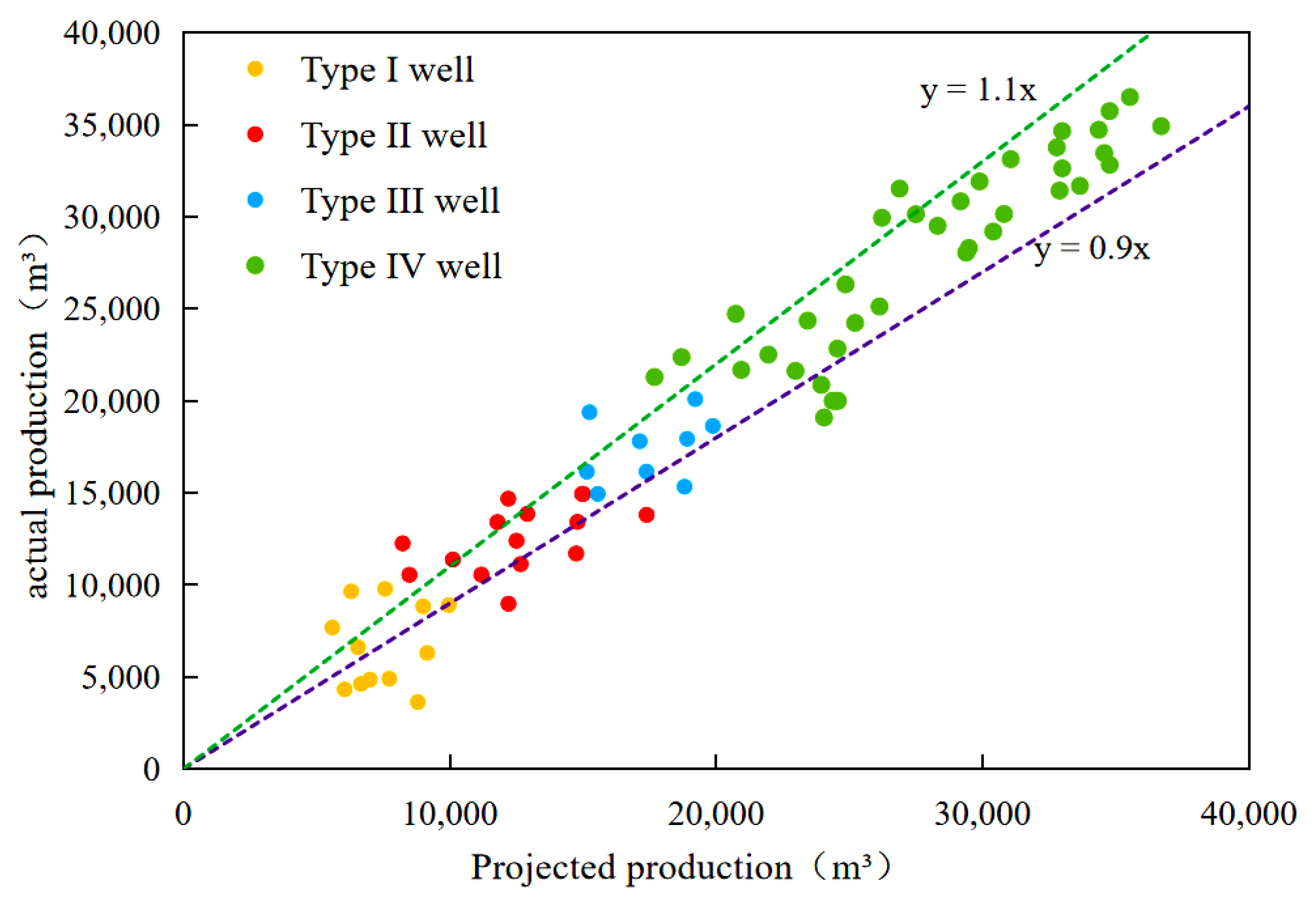
| Classifications | Number of Wells | Ratios (%) | Oil Production over 3 Years (104 t) |
|---|---|---|---|
| Type I well | 39 | 43.50 | ≥2 |
| Type II well | 16 | 17.40 | 1.5–2.0 |
| Type III well | 20 | 21.70 | 1.5–1.0 |
| Type IV well | 16 | 17.40 | ≤1.0 |
| Characteristic Parameter | Range | Mean Value | Standard Deviation | Characteristic Parameter Type |
|---|---|---|---|---|
| Oil saturation (%) | 30–86 | 52 | 10.9 | geologic parameter |
| Reservoir thickness (m) | 1–8 | 4 | 1.2 | |
| Porosity (%) | 2–12 | 7 | 1.7 | |
| Penetration rate (103 md) | 0.5–3.5 | 1.8 | 0.9 | |
| Number of clusters | 3–160 | 74 | 33.6 | construction parameters |
| Cluster spacing (m) | 7–86 | 26 | 25.5 | |
| Sand addition amount (m3) | 440–4936 | 2343 | 934.3 | |
| Sand addition intensity (N/m2) | 0.6–4.0 | 1.9 | 0.5 | |
| Horizontal segment length (m) | 547–3500 | 1536 | 416.0 | |
| Transformed horizontal segment length (m) | 231–3490 | 1251 | 438.3 | |
| fracturing stage | 2–45 | 22 | 8.5 | |
| Fracturing fluid volume (m3) | 7920–59,377 | 33,189.1 | 13,874.4 | |
| Fracturing length (m) | 36–119 | 57 | 15.8 | |
| Liquid strength (N/m2) | 7.9–41 | 27.3 | 9.4 |
| Sample Value | Decision Tree | Random Forest | Gradient Boosting Decision Tree | Actual Value | Sample Value | Decision Tree | Random Forest | Gradient Boosting Decision Tree | Actual Value |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1005 | 456 | 652 | 413 | 2 | 15,556 | 16,312 | 15,904 | 18,191 |
| 3 | 18,562 | 16,312 | 14,355 | 12,321 | 4 | 5690 | 4600 | 8561 | 4626 |
| 5 | 12,876 | 16,066 | 16,974 | 15,368 | 6 | 9825 | 16,312 | 13,659 | 11,121 |
| 7 | 8542 | 5769 | 5561 | 7059 | 8 | 20,328 | 32,432 | 35,521 | 27,119 |
| 9 | 4658 | 8663 | 8264 | 10,336 | 10 | 13,208 | 16,312 | 17,553 | 14,944 |
| 11 | 15,683 | 16,312 | 17,052 | 14,871 | 12 | 96 | 2056 | 3448 | 2159 |
| 13 | 5154 | 6312 | 7856 | 6552 | 14 | 1588 | 989 | 1856 | 1305 |
| 15 | 4658 | 8122 | 9820 | 9008 | 16 | 12,848 | 13,316 | 14,633 | 13,934 |
| Model Category | Predictive Accuracy (%) |
|---|---|
| Decision Tree | 70 |
| Random Forest | 94 |
| Gradient Boosted Decision Tree | 82 |
| Model Category | Determining Coefficient R2 | Training Set Root Mean Square Error | Test Set Root Mean Square Error |
|---|---|---|---|
| Decision Tree | 0.796 | 0.096 | 2.864 |
| Random Forest | 0.952 | 0.045 | 0.934 |
| Gradient Boosted Decision Tree | 0.797 | 0.075 | 1.232 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Li, J.; Qin, S.; Liang, C.; Chen, Y. Application of Machine Learning to Predict the Capacity of Fractured Horizontal Wells in Shale Reservoirs. Processes 2024, 12, 2527. https://doi.org/10.3390/pr12112527
Chen Y, Li J, Qin S, Liang C, Chen Y. Application of Machine Learning to Predict the Capacity of Fractured Horizontal Wells in Shale Reservoirs. Processes. 2024; 12(11):2527. https://doi.org/10.3390/pr12112527
Chicago/Turabian StyleChen, Yu, Juhua Li, Shunli Qin, Chenggang Liang, and Yiwei Chen. 2024. "Application of Machine Learning to Predict the Capacity of Fractured Horizontal Wells in Shale Reservoirs" Processes 12, no. 11: 2527. https://doi.org/10.3390/pr12112527
APA StyleChen, Y., Li, J., Qin, S., Liang, C., & Chen, Y. (2024). Application of Machine Learning to Predict the Capacity of Fractured Horizontal Wells in Shale Reservoirs. Processes, 12(11), 2527. https://doi.org/10.3390/pr12112527