Abstract
With the development of ultra-long-range visual sensors, the application of unsupervised person re-identification algorithms to them has become increasingly important. However, these algorithms inevitably generate noisy pseudo-labels, which seriously hinder the performance of tasks over a large range. Mixup, a data enhancement technique, has been validated in supervised learning for its generalization to noisy labels. Based on this observation, to our knowledge, this study is the first to explore the impact of the mixup technique on unsupervised person re-identification, which is a downstream task of contrastive learning, in detail. Specifically, mixup was applied in different locations (at the pixel level and feature level) in an unsupervised person re-identification framework to explore its influences on task performance. In addition, based on the richness of the information contained in the person samples to be mixed, we propose an uncertainty-aware mixup (UnA-Mix) method, which reduces the over-learning of simple person samples and avoids the information damage that occurs when information-rich person samples are mixed. The experimental results on three benchmark person re-identification datasets demonstrated the applicability of the proposed method, especially on the MSMT17, where it outperformed state-of-the-art methods by 5.2% and 4.8% in terms of the mAP and rank-1, respectively.
1. Introduction
Person re-identification (Re-ID) is defined as the technique of determining the presence of a specific person in an image or video sequence by using computer vision techniques, and it is widely regarded as a sub-problem of image retrieval. It can compensate for the visual limitations of fixed ultra-long-range visual sensors [1,2,3]. Because of its importance in long-distance intelligent surveillance systems, supervised person Re-ID has been widely deployed in real-world scenarios. However, the time-consuming and labor-intensive nature of the labeled data greatly limits its further application. In contrast, person images and video data are highly accessible in realistic scenarios, which has led industry and academia to transfer their research attention to the task of unsupervised person Re-ID [4,5,6,7]. This is subdivided into two categories according to whether additional labeled datasets are required: pure unsupervised learning (USL) [8,9] and unsupervised learning domain adaptation (UDA) [10,11]. The former does not require additional labeled datasets and uses unsupervised learning algorithms to learn the person feature representations directly in unlabeled datasets. The latter firstly trains on the labeled source domain with certain prior knowledge and then employs unsupervised learning algorithms to fine-tune over the unlabeled target domain dataset to migrate the source domain knowledge to the target to reduce the cross-domain difference. Overall, the former performs slightly worse than the latter, which has some prior knowledge. The research object of this study was concentrated on fully unsupervised person Re-ID in the first case, as it is more challenging.
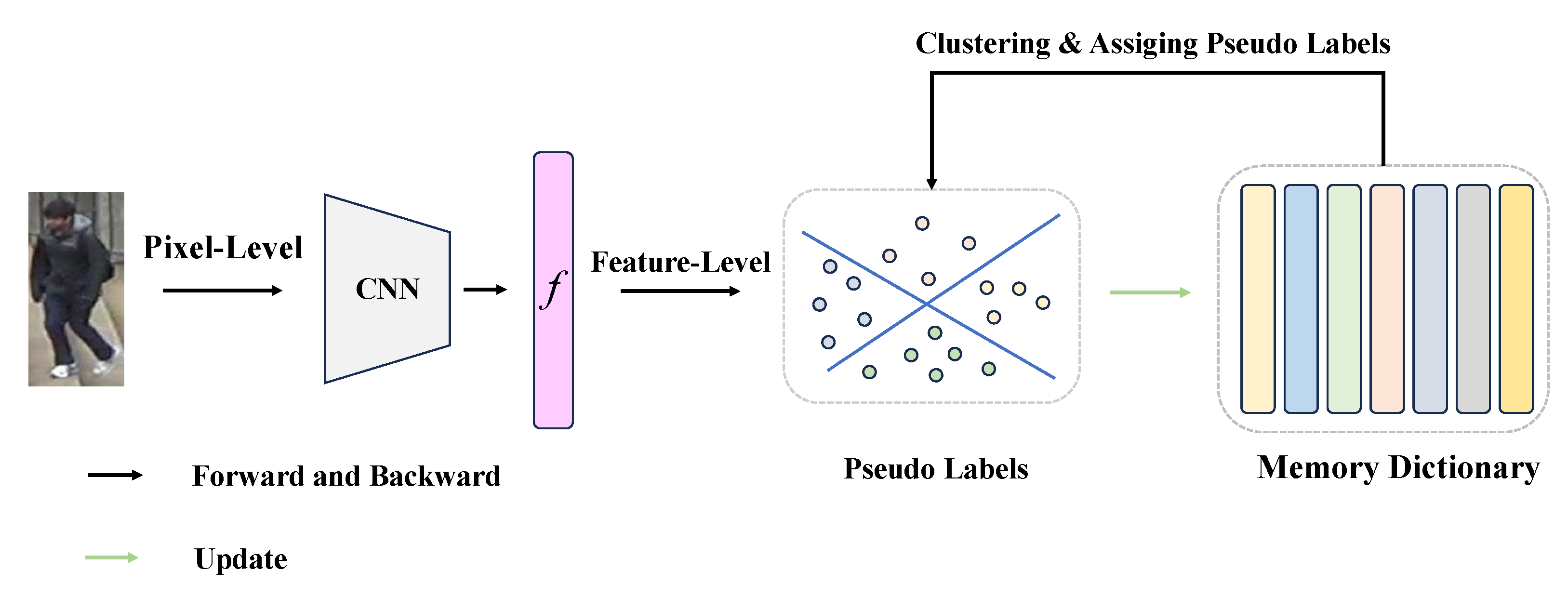
Currently, state-of-the-art unsupervised algorithms are based on clustering methods for producing pseudo-labels, and the course of training is roughly divided into three components: In the first part, features are derived from the training person images utilizing the backbone network and are stored in the memory dictionary; in the second part, the features from the memory dictionary are then clustered by applying clustering algorithms, and the corresponding pseudo-labels are assigned; in the third part, the pseudo-labels are finally treated as supervisory knowledge to train the network model with constant feedback to improve task performance. From this procedure, it can be seen that the estimation of the pseudo-labels produced with the clustering method is the critical factor for the improvement of the classification performance of a network model. Mixup [12], a data augmentation technique, has been proven to be effective in the generalization of network models to noisy labels in supervised learning or semi-supervised learning, such as in classification [13,14] and language processing [15,16]. The adoption of the mixup technique in the yolov4 [17,18] algorithm significantly improved the small object detection accuracy. It is common to construct convex operations on a model’s inputs and labels to generate new training samples with corresponding labels with the aim of enhancing the generalization of noisy labels. This is often implemented as a data-dependent regularization operation, requiring the network model to satisfy linear constraints at the feature level with respect to the operations, and regularization is applied to the model with this constraint. In supervised learning, where ground-truth labels are available, the use of mixup techniques to blend images often results in a loss of certain information. In tasks such as person Re-ID, specific details play a crucial role in identifying particular individuals. Preserving these refined details poses a significant challenge when applying mixup in supervised learning. Since mixup involves the linear interpolation of images with ground-truth labels, there is a risk of losing crucial details that are essential for tasks such as person Re-ID. On the other hand, unsupervised learning lacks ground-truth labels, relying on pretext tasks and objective functions to learn semantic information from images. Typically, it directly compares features after the transformation of the same image. Image transformations in unsupervised learning only increase the distance between the same image and its label, keeping the loss value used for computation unchanged. Mixup, as a method of balancing the semantic distance between two images while maintaining linearity, poses a challenge in ensuring that the model learns more discriminative features from the transformed feature space. Therefore, the challenge in applying mixup to unsupervised learning lies in optimizing the model to learn highly discriminative features from the transformed feature space, where there are no ground-truth labels to guide the learning process. This necessitates addressing how to enhance the model’s ability to extract relevant and distinguishing information in the absence of explicit supervision. Many researchers have also explored the impact of mixup on contrastive learning, demonstrating that it allows network models to learn more subtle, robust, and generalized feature representations from transformed inputs and the corresponding new label space. i-mix [19] assigns unique virtual classes to each datum, mixes data instances in the feature space, and provides more augmented data for the duration of the training period, proving its ability to consistently improve the quality of cross-domain learning representations. Shen et al. [20] used mixup to import the concept of soft distance in the label space into the framework to address certain data augmentation techniques that prevent unsupervised contrastive learning frameworks from delving deeper into finer-grained feature information and to make the network model recognize soft similarity between different pairs through mixed data. In supervised learning and unsupervised learning, the mixup technique can be used, but it blends different objects. For supervised learning, mixup blends images with labels from labeled datasets, preserving refined details that are essential for recognizing specific individuals. In contrast, unsupervised learning employs mixup with the same images after transformation, focusing on different features or the mixture of the original features. This enables the model to learn more discriminative features from the transformed feature space in the absence of explicit labels. This study investigates whether mixup, as the downstream task of unsupervised learning for person Re-ID, can help in learning a more discriminative characterization.
The motivation for this work stems from the observation of model training in the contrastive-learning-based unsupervised person Re-ID framework, considering that the infoNCE [21] loss function in this framework essentially uses cross-entropy [22] loss to classify both positive congruent pairs and negative incongruent pairs. The problem of overconfidence in noise labels is also encountered in supervised learning.
The mixup technique, on the one hand, can alleviate the problem of an insufficient number of individual identities in a person Re-ID dataset to a certain extent, and on the other hand, it can simultaneously modulate the input and label space to force the network model operations to satisfy linear constraints, imposing regularization on the network model to eliminate the adverse impacts of noisy labels on the training of the network model. This helps the network model further capture a more precise characterization of the features in the new potential feature space.
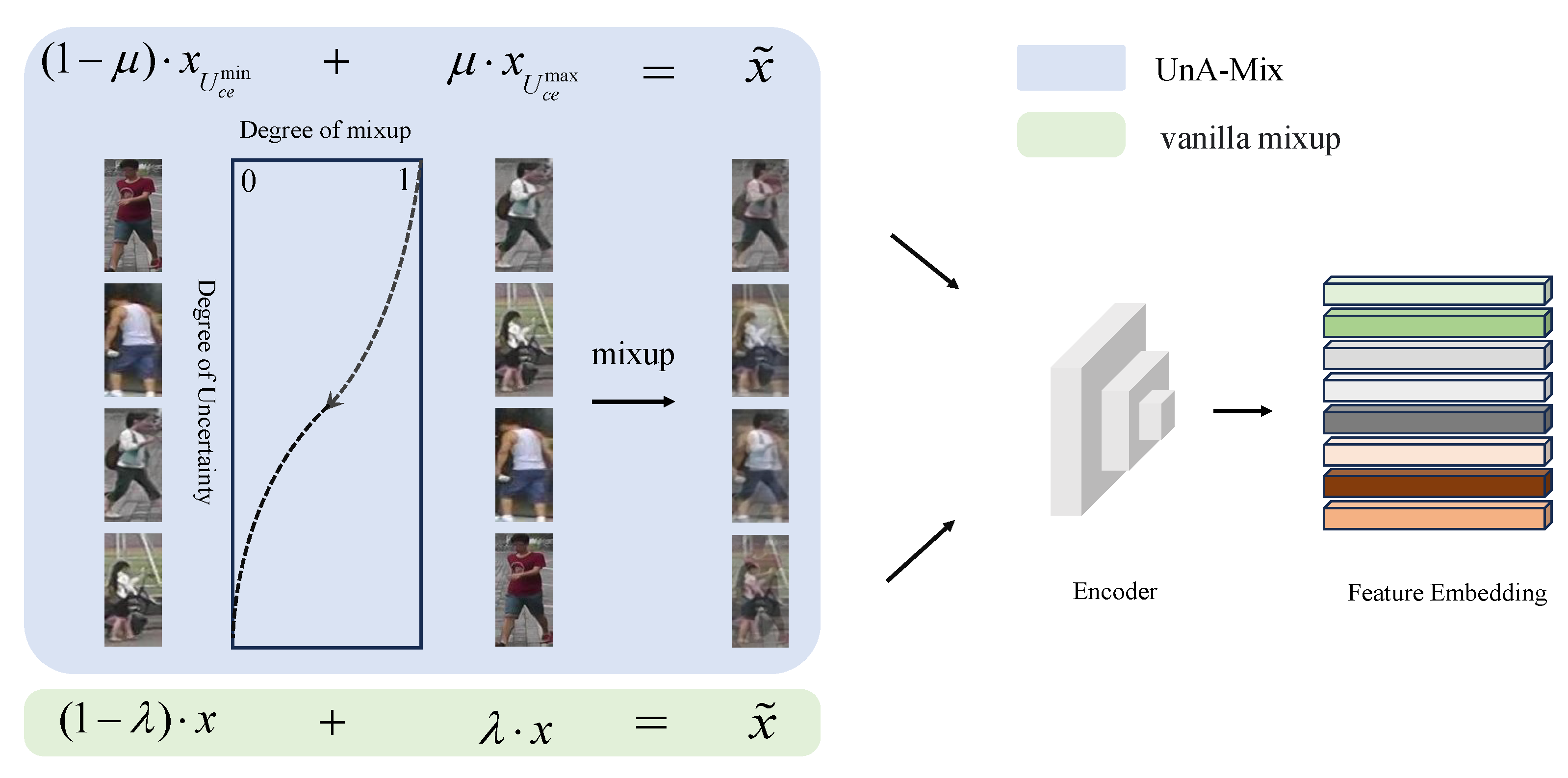
In order to further examine the implications of the mixup technique for the unsupervised person Re-ID framework, it is applied to different locations in the framework in this study. Specifically, mixup, as a means of data augmentation that is capable of adjusting both the input image and label space with a controlled degree of variation, not only mixes the image data, but also modulates the extracted feature representations. The unsupervised person Re-ID framework can be subdivided into two different locations as places for mixup adjustment. The first one is at the pixel level, where clustering is performed to obtain a dataset with pseudo-labels to mix the data before the training images are delivered to the network model, and the second is at the feature level, where the corresponding feature representations are obtained for mixing after the images are served into the network model. In addition, since different training samples carry unequal information, the information richness of each sample can be estimated based on the uncertainty of the samples. Therefore, this study proposes an uncertainty-aware mixup (UnA-Mix) based on the uncertainty of the samples. The samples with less information content are severely mixed, while the uncertain samples are slightly mixed to avoid reducing the loss of person information, as shown in Figure 1.
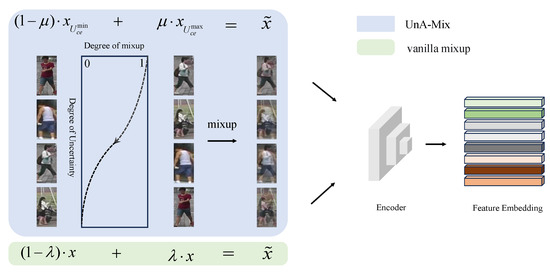
Figure 1.
UnA-Mix for unsupervised person Re-ID and vanilla mixup. We measured the uncertainty of the training samples with entropy and controlled the mixing parameter to manage the degree of mixing of the samples.
In summary, the main contributions of this study are divided into three areas.
- To our knowledge, this is the first detailed exploration of the impacts of the mixup technique when applied at different locations (at the pixel level and feature level) on task performance in an unsupervised person Re-ID framework.
- Training samples of people were quantitatively measured using entropy, based on which we propose the sample uncertainty-aware mixup (UnA-Mix) method for boosting the performance of the unsupervised person Re-ID task.
- Experiments on three person Re-ID benchmark datasets indicated that the proposed method demonstrated better performance than that of other state-of-the-art methods.
The remainder of this paper is structured as follows: Section 2 describes the research background of the methodology of this study. Section 3 describes the UnA-Mix methodology. Section 4 presents the experimental results of mixup and UnA-Mix in task performance on benchmark tests. Section 5 summarizes the contributions of this work.
2. Related Work
2.1. Unsupervised Person Re-ID
State-of-the-art unsupervised person Re-ID is based on clustering methods [23,24,25]. Many techniques have been offered to improve the estimation of pseudo-labels. These techniques reduce the impact of noisy pseudo-labels. Ge et al. [26] proposed a self-paced contrastive learning framework with hybrid memory, aiming to solve the problem of data not being fully mined in representation learning. Yang et al. [27] suggested an asymmetric co-teaching paradigm in which two models chose clear pseudo-labels with higher confidence indications. Zhu et al. [28] argued that adding a label-filtering module after clustering can be more effective against noisy labels. Despite their different approaches, they all aimed to improve the quality of pseudo-labels and, thus, the performance of tasks. Nevertheless, the above methods tended to ignore the impairment of the information embedded in the training samples by means of data augmentation.
2.2. Contrastive Learning
Contrastive learning is quite suitable for the person Re-ID task, and it is characterized by the learning of semantic traits with high discriminative levels. All that is required is the ability to discriminate data in the feature space at the abstract semantic level, with an emphasis on identifying distinctions between non-similar examples and learning collective representation features between comparable instances. He et al. [21] provided an effective MoCo architecture for contrastive learning that made use of a bigger queue to hold and sample negative samples and kept the queue continuous by employing a first-in, first-out method that enhanced the efficiency of tasks that came after it. In order to alleviate the trivial solution problem, Grill et al. [29] discarded the negative samples based on MoCo. This ensured that the features derived from the positive samples were as close as possible. Chen et al. [30] further examined the nature of unsupervised learning by simply employing stop-gradient operations to allow the model to learn meaningful representations, rather than using huge batches, momentum encoders, and negative sample pairs. It is the rapid development of contrastive learning that has driven the improvement of the performance of its downstream task, unsupervised person Re-ID.
2.3. Label Noise Representation Learning
The production of noisy pseudo-labels by clustering algorithms is unavoidable in unsupervised person Re-ID tasks [31,32]. Finding the true distribution of the original data can be challenging when training models directly on raw datasets. Co-teaching is a learning paradigm proposed by Han et al. [33] in which two neural networks are trained to teach each other concurrently, and labels that may be clean are selected for learning. Mixup [12] is a straightforward data augmentation technique that improves the generalization capacity of a model. By manually verifying a limited number of classes, Lee et al. [34] demonstrated a combined neural embedding network, CleanNet, that could transmit label noise information to other classes. However, the fact is that the person identities generated during the training process vary greatly from one iteration of the training process to another. Therefore, using the methods in noise label learning to optimize the performance of a task is not simple.
3. Methodology
To further neutralize the negative influences of noisy pseudo-labels on unsupervised person Re-ID, we explored the impacts of mixup techniques for noisy samples on the performance at different locations in the proposed framework; the complete structure is illustrated in Figure 2 and is elaborated upon in Section 3.2. In Section 3.3, a detailed explanation of the uncertainty-aware mixup (UnA-Mix) method based on the abundance of person information inherent in the training samples is provided.
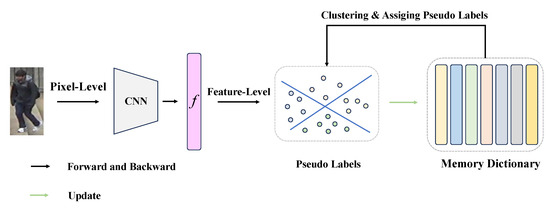
Figure 2.
The overall framework for unsupervised person Re-ID with the selection of pixel-level and feature-level locations in the framework for mixup operations.
3.1. Preliminary
3.1.1. Unsupervised Person Re-ID Framework
In this paper, the unlabeled dataset is represented as , and N denotes the number of training image sets. Feature extraction is completed by employing ResNet-50 [35], which has already been initialized in ImageNet [36], and it is noted as , where represents the parameters of the network model and denotes the 2048-dimensional feature of the person image. The feature representations are deposited into the memory dictionary [37], and a clustering algorithm is implemented to allocate corresponding pseudo-labels to each person feature representation. Finally, a person Re-ID dataset with pseudo-labels is obtained, and it is denoted as , where x and y are the images in the training dataset and the assigned person pseudo-labels, respectively. During the model training process, the feature representations not only require the parameters in the memory dictionary to be updated, but also require the use of the infoNCE loss function to improve the accuracy of the task.
3.1.2. Paradigms of Mixture
The original mixup [12], a simple data augmentation strategy, is a straightforward linear transformation of the input data to generate a new mixture of samples and corresponding person labels. Briefly, for any two input data–label pairs, and , mixup can be described as
where and are the generated mixture samples and corresponding labels, respectively, and is the ratio of the mix.
Compared with other data augmentation strategies, its softening of the label space and implicit regularization constraints on the network model promote the ability of the network model to deal with noisy labels.
3.2. Mixture Strategy
At the pixel level, two samples from the pseudo-labeled person dataset are randomly selected for mixing, which is the same as in the original mixup operation. The objects to be mixed are pixels, and there is no need to deliberately select the objects to be mixed. The input data are mixed with the corresponding labels in a seemingly meaningless way, which can effectively guide the training of the network model. This has been validated in supervised learning, as shown in Equations (1)–(3).
At the feature level, the objects to be mixed are the features extracted from the backbone. The randomly selected feature vectors are mixed to obtain new blended features and corresponding labels, as shown in Equations (1), (3), and (4).
where is the mixed feature representation.
Finally, the loss values of the model predictions and synthesized labels are computed uniformly and then back-propagated to update the model parameters. The synthesized mixed samples and labels can be chosen to participate or not participate in updating the memory dictionary.
3.3. Uncertainty-Aware Mixup
It is well known that different training samples contain information of different importance, especially in person Re-ID tasks. The determination of whether an image contains the same person often relies on certain specific details, such as having the same backpack, pendant, hat, etc. Simple sample mixing operations may interfere with these discriminative local features. Based on experience, a network is unable to recognize training samples for classification, indicating the high uncertainty of the sample. In this study, entropy [38] was applied to quantitatively measure the uncertainty of the training samples as follows:
where is the classification probability of the associated person category and x is the training data. This cannot be directly obtained from the network model and is frequently a prediction of the character category generated by a non-parametric classifier memory dictionary. This captures similarities between instances of the same category and between instances of different categories, as illustrated in Equation (6).
where is the non-parametric classifier, which is the memory dictionary in the unsupervised person Re-ID framework. A large value of implies that the network model cannot confidently assign person categories with a high probability value, which shows the high degree of uncertainty in the sample. The original mixup operation is used to enhance the data of samples to expand the amount of training data, which can increase the capacity of the network model to be generalized to noisy labels. Nevertheless, a random mixup operation between pixels of different training samples may lead to the corruption of information embedded in the original training samples to a certain degree. In addition, the importance of the information embedded in various training samples is not the same. Therefore, images containing important information are lightly mixed, while those containing less information are heavily mixed.
Specifically, we utilize entropy to quantitatively measure and sort the uncertainty of the training samples. In the original mixup, a mixing coefficient is used to control the degree of mixing between different training samples, as shown in the following formula:
where is actually a monotonically increasing function that increases with the uncertainty of the training samples and can control the degree of mixing according to the uncertainty of the samples during the training process. Memory dictionaries perform an instrumental role as non-parametric classifiers [37] in the Re-ID frameworks. During the training process, its initialization and update are the critical factors that affect the improvement of the efficiency of the unsupervised person Re-ID task.
Memory dictionary initialization: The strategy for training sample selection is ; identities and corresponding persons are randomly selected from the dataset with pseudo-labels. Each training starts with the initialization of the memory dictionary , which is composed of clustering centers with the following formula:
where denotes the k-th clustering group and refers to the i-th training image in the clustering group .
Without Memory Dictionary (w.o. MD): This implies that the synthetic samples generated through mixup will not participate in the parameter update of the memory dictionary, but only in the infoNCE classification loss [21] in the unsupervised person Re-ID framework, as shown below:
where , is the original sample, and is a mixture of samples generated with the UnA-Mix method. represents the k-th entry stored in the memory dictionary, indicates that it has the same pseudo-label as that of , and K denotes the mini-batch for training.
With Memory Dictionary (w. MD): This suggests that the mixed samples created with the mixup operation are involved in updating the parameters of the memory dictionary as training samples, and the framework utilizes the infoNCE loss function to optimize performance. The updated parameter formula is shown below.
where denotes the update parameter momentum of the memory dictionary , and the classification loss infoNCE is the same as in Equation (9).
4. Experiments
In this section, three person Re-ID benchmark datasets (Market-1501, DukeMTMC-ReID, and MSMT17) are chosen to verify the effectiveness of the proposed methodology. A description of the details of the three benchmark datasets is shown in Table 1.

Table 1.
Statistics of the datasets used to validate the algorithm.
- Market1501 [39] is a standard person dataset that was collected at Tsinghua University. It consists of 32,668 images obtained from six video cameras. The training set contains 12,936 pictures with 751 persons, and the test set is composed of 19,732 frames with 750 persons.
- DukeMTMC-ReID [40] is a collection of 36,411 pictures of 1404 people. The pictures were taken by eight cameras. The training set is made up of 16,522 images of 702 persons, and the test set is constructed from 19,889 images of 702 persons.
- MSMT17 [41] is the most challenging dataset; it was collected from 15 cameras at Peking University, and it includes both indoor and outdoor scenes. This dataset contains a total of 126,441 photos of 4101 persons; the training set includes 1041 persons and 32,621 images to which they correspond. The remaining 30,360 persons with 93,820 images serve as the test set.
Then, state-of-the-art methods were selected to conduct sufficient comparative experiments, and these included MMCL [42], JVTC [43], SPCL [44], DCML [45], MMT [26], ABMT [46], BUC [47], SSL [48], IICS [49], PPLR [50], and Cluster-Contrast(baseline) [51]. In all of the experiments, we adopted the standard evaluation metrics, including the mean average precision (mAP) and rank-1, without any post-processing techniques (multi-query fusion, etc.) to optimize the results [52]. The formula is represented as follows:
where TP denotes the number of positive samples with correct predictions, FP denotes the number of positive samples with incorrect predictions, and C represents the total number of person categories.
In addition, to further measure the performance of the framework in clustering groups during training, we defined a metric named the average category accuracy (ACA). It indicates the proportion of ground-truth labels with respect to the number of pseudo-labels in the cluster groups, with a higher value indicating a higher quality of clustering. The specific formula is as follows:
where denotes the maximum number of ground-truth labels, denotes the overall number of pseudo-labels in the cluster, and N denotes the grand number of clusters.
4.1. Implementation Details
In this work, we utilized ResNet-50 as the feature extraction backbone, leveraging its pre-trained parameters on ImageNet. The backbone network had its fifth layer removed, and global average pooling (GAP), batch normalization (BN), and an L2 normalization layer were incorporated. The resulting feature vector for person representation had 2048 dimensions. During training, the person feature representations were clustered, and the DBSCAN [53] algorithm was employed to generate pseudo-labels. Two crucial hyper-parameters were set to 0.5 and 5, respectively, based on the SPCL algorithm, the maximum distance between feature instances in the mutual neighborhood, and the minimum number of samples in the neighborhood of the feature instances. Additionally, training images were resized to 256 × 128, and data augmentation techniques, such as random crop and erase, filling 10 pixels, and random horizontal flips were applied. Each mini-batch randomly involved the random selection of 16 categories of person identities from the person dataset with pseudo-labels, with each person category containing 16 individuals. The model optimizer chosen was Adam, with an initial learning rate of 3.5 and a step size set to 20, indicating that the initial learning rate decreased by 0.1 at intervals of 20 epochs. The weight decay parameter was 5, and the update parameter of the memory dictionary was 0.1. The experimental environment was Ubuntu 18.04 and PyTorch 1.8. The hardware system consisted of two GeForce RTX 3090 GPUs with 24G memory and an Intel(R) Xeon(R) CPU.
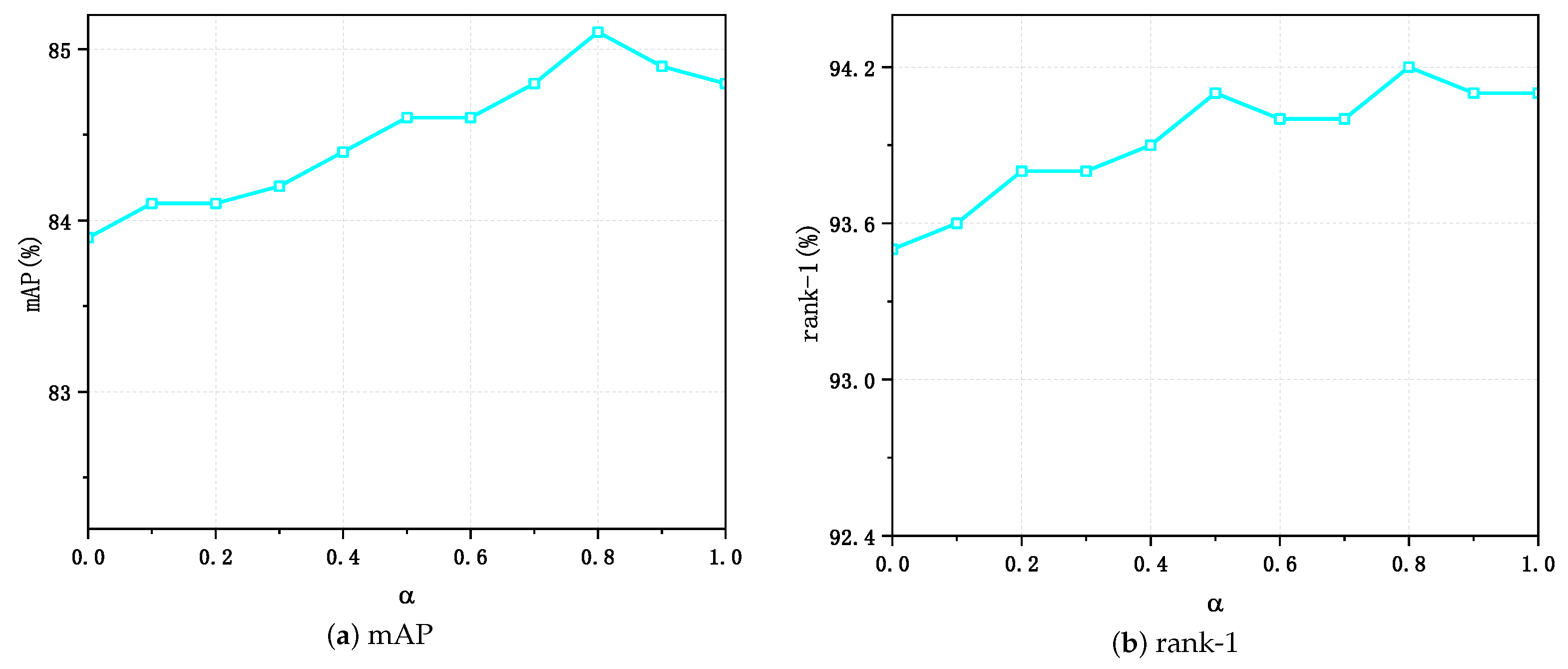
To further exploit the implications of the produced mixed samples for the update of the memory dictionary, a hyper-parameter was set to hold the proportion of generated mixed samples participating in the update of the memory dictionary, and sufficient experiments were conducted in Market-1501, as shown in Figure 3a,b. The UnA-Mix method achieved the optimal performance of 85.2% and 94.2% in terms of the mAP and rank-1, respectively, in Market-1501 when was equal to 0.8.
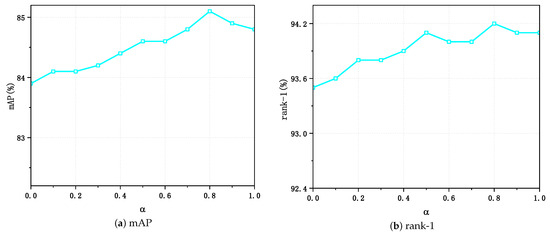
Figure 3.
Results of ablation experiments on the UnA-Mix method on the Market-1501 dataset.
4.2. Comparison of Different Positions
Sufficient experiments were performed on the three person Re-ID benchmark datasets with the application of the mixup technique at different positions (at the pixel level and feature level) in an unsupervised person Re-ID framework. The findings are shown in Table 2. Here, ( Memory Dictionary) indicates whether the samples generated through mixup participated in the update of the memory dictionary, and the classic unsupervised person Re-ID framework cluster-contrast was chosen as the baseline. For fairness, the relevant parameters were the same in all experiments.
Table 2.
Comparison of mixup when applied to different positions in the framework.
In Table 2, it can be seen that the best performance in the unsupervised person Re-ID task was achieved when the mixup technique was directly applied to unprocessed images (pixel level) and the generated samples were mixed to participate in the memory dictionary updates (). In comparison, when mixup was applied at the feature level, a significant degradation in task performance occurred.
- It is noticeable in Table 2 that the pixel-level method had improvements in mAP of 0.9% and in rank-1 of 1.0% for Market-1501, improvements in mAP of 1.0% and in rank-1 of 0.2% for DukeMTMC-ReID, and in mAP of 4.8% and in rank-1 of 4.4% for MSMT17 compared to the baseline. It is reasonable to speculate that when mixup acted on the pixel level, the generated mixed samples could force the network model to generate more discriminative feature representations and learn more accurate and smoother decision boundaries. In contrast, when the mixup operation acted at the feature level, it lacked the process of feature extraction from mixed samples by the network model, which undoubtedly weakened the capacity of the model to yield more discriminative features.
- In comparison to the w.o.MD approach in the pixel-level technique, the w.MD approach had improvements of 0.3% and 0.7% in the mAP and rank-1 metrics for Market-1501, 2.0% and 1.6% for DukeMTMC-ReID, and 3.3% and 2.4% for MSMT17, as Table 2 illustrates. The w.MD technique had improvements of 0.4% and 0% for the mAP and rank-1 for Market-1501, 1.7% and -0.1% for DukeMTMC-ReID, and 1.7% and 2.8% for MSMT17 in comparison to the w.o.MD approach in the feature-level method. It can be observed that improved relative to in the evaluation metrics mAP and rank-1, regardless of whether mixup acted at the feature level or the pixel level. This verified that mixup alleviated the drawbacks of the insufficient number of individual persons in the Re-ID dataset to a certain extent.
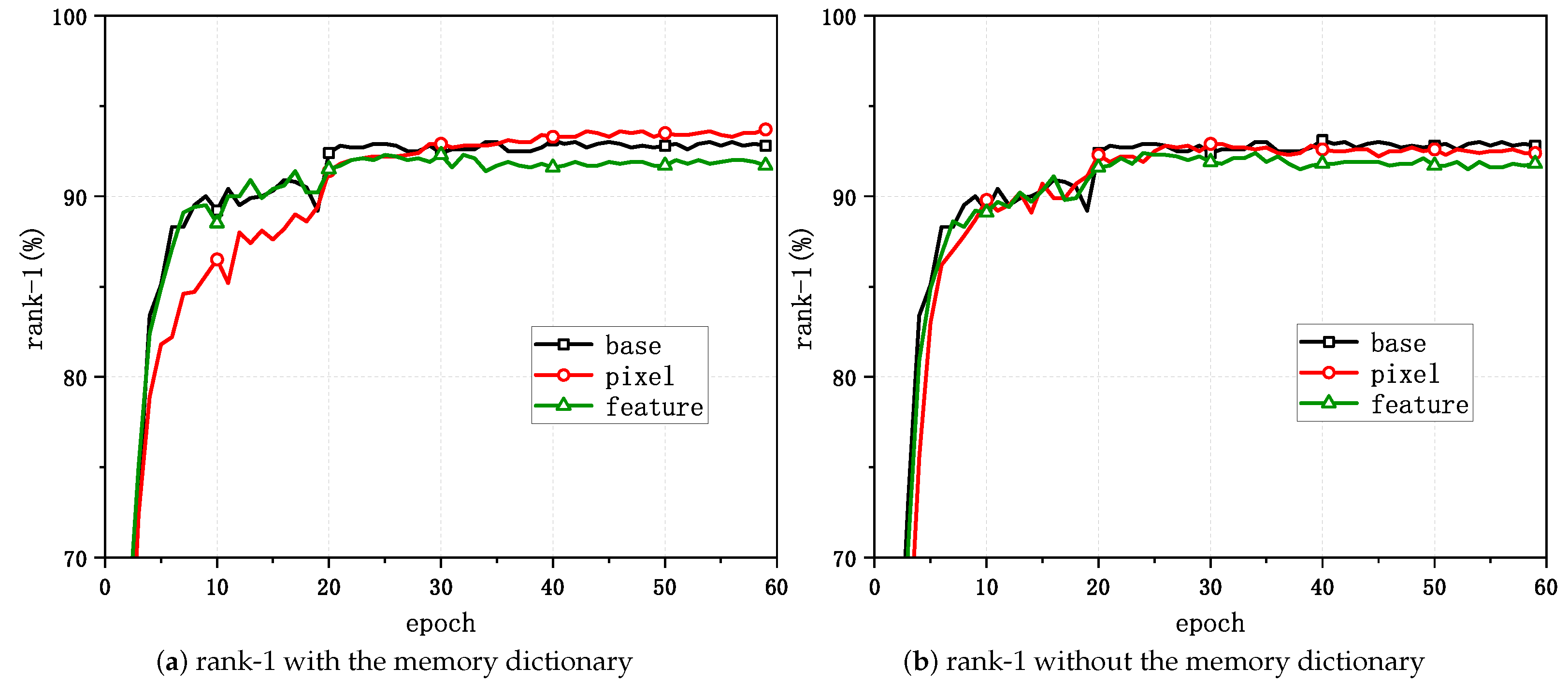
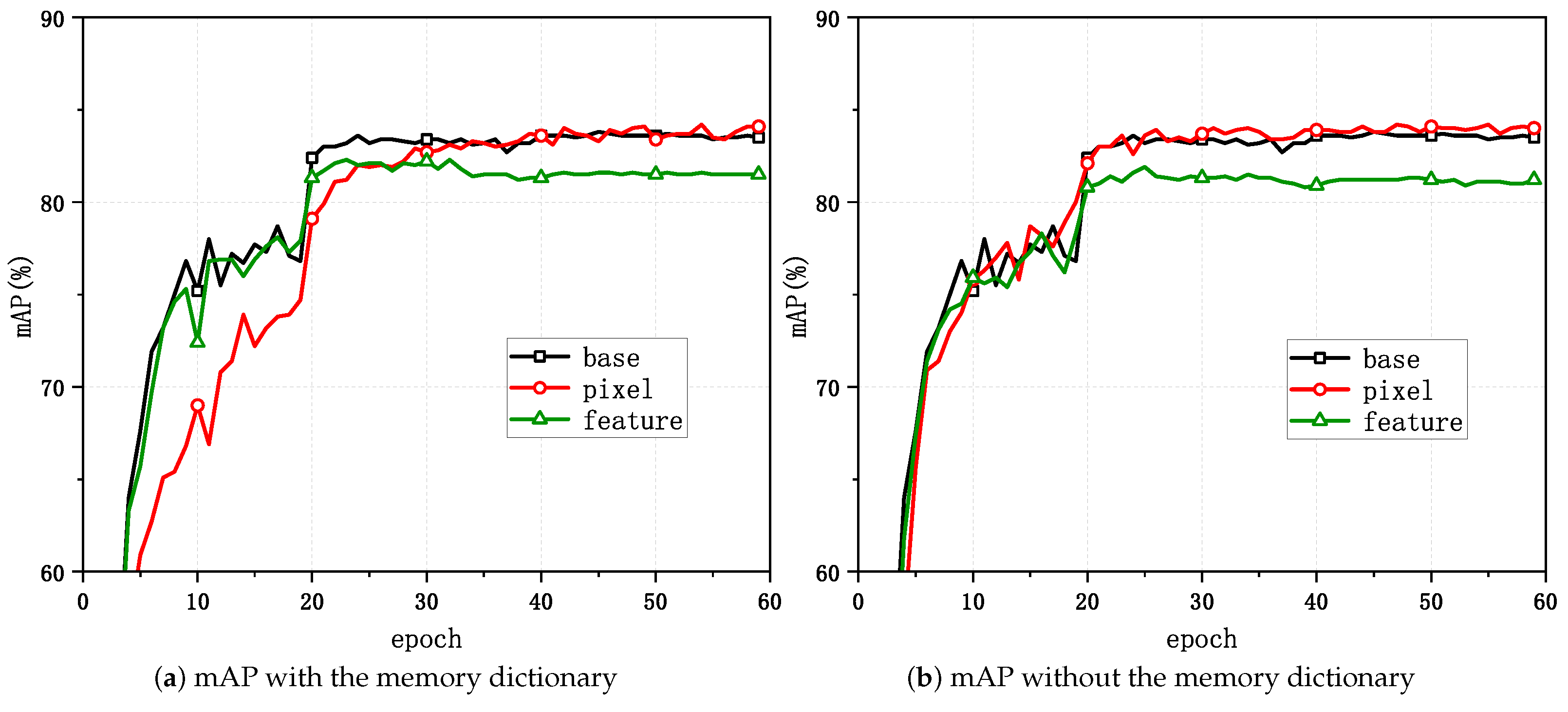
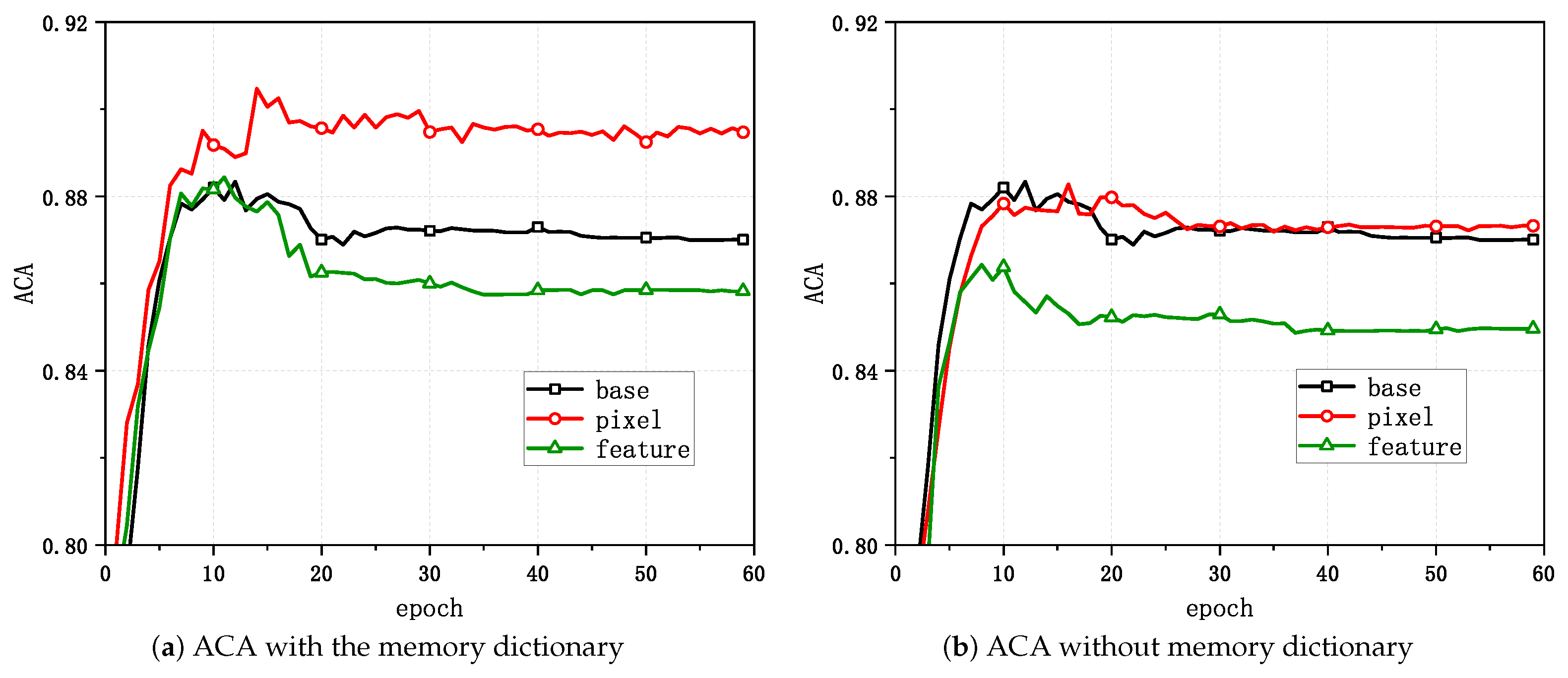
Figure 4 and Figure 5 show the variations in the task evaluation criteria (mAP and rank-1) with the epoch when mixup was applied at different positions in the unsupervised person Re-ID framework for Market-1501. Figure 6 demonstrates the variations in the clustering quality metric (ACA) for Market-1501 with the epoch during the process. The experimental outcomes indicated that the best performance in the task relative to the baseline algorithm was achieved when directly applying mixup at the pixel level and when generating mixed samples that involved updating the memory dictionary.
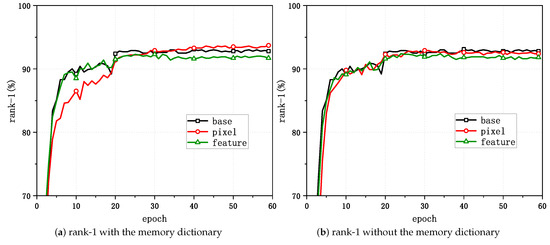
Figure 4.
Changes in rank-1 with mixup applied at different positions.
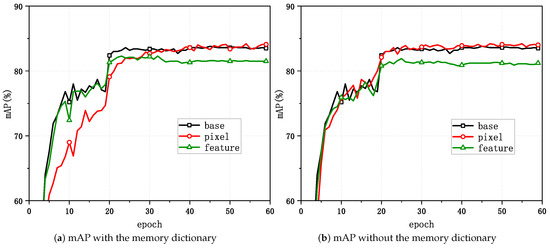
Figure 5.
Changes in the mAP with mixup applied at different positions.
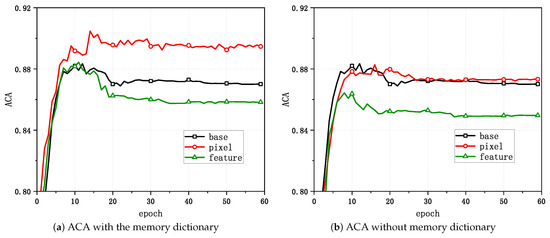
Figure 6.
Changes in the ACA with mixup applied at different positions.
4.3. Comparison with State-of-the-Art Methods
From Table 2, we can conclude that the optimal results were achieved in the task when mixup acted on the pixel level in the framework. As a result, the suggested UnA-Mix approach is chosen to function at the pixel level. We decided to perform a thorough comparison with the most recent algorithms in order to further confirm the methodology’s efficacy, and the outcomes are displayed in Table 3. For clarity in the presentation, we highlight the optimal results in bold and underline the sub-optimal results. It is evident that the UnA-mix approach outperformed both the USL and UDA techniques in terms of competitive performance. By using this method, the indicators obtained were as follows: for Market-1501, the mAP was 84.8% and rank-1 was 94.1%; for DukeMTMC-ReID, the mAP was 74.0% and rank-1 was 85.5%; for MSMT17, the mAP was 41.9% and rank-1 was 69.3%. Compared with the baseline method, the mAP and rank-1 were raised by 1.5% and 1.5% for Market-1501, by 1.4% and 0.6% for DukeMTMC-ReID, and by 5.2% and 4.8% for MSMT17. The methodology was confirmed by the experimental results.
Table 3.
Comparison of the state-of-art methods.
4.4. Ablation Study
4.4.1. Convergence
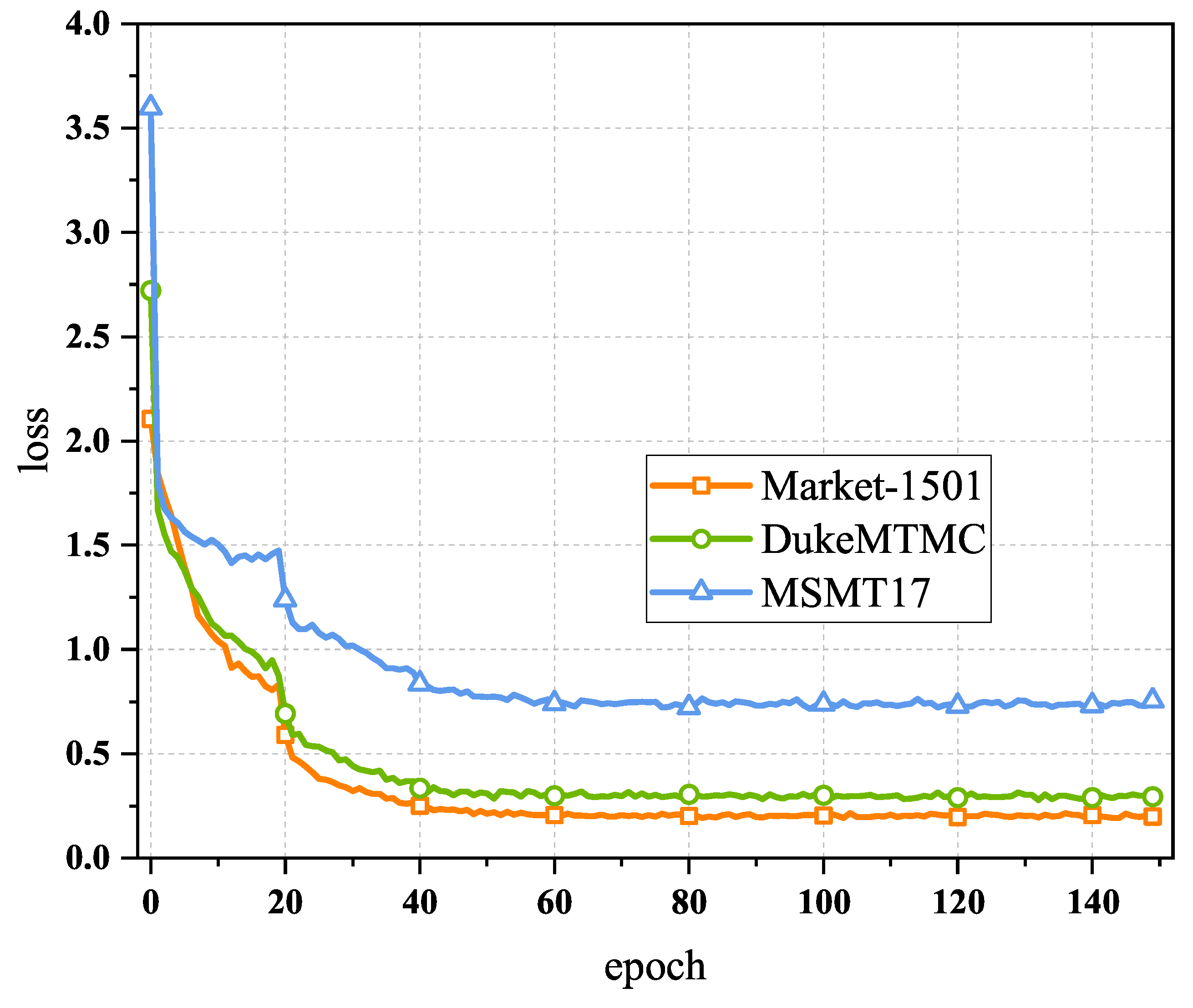
The convergence of an algorithm is a very important property, so we validated it on three benchmark person Re-ID datasets and plotted the changes in the loss value with the epoch. As shown in Figure 7, it was found that the algorithm’s loss value finally converged to a stable value.
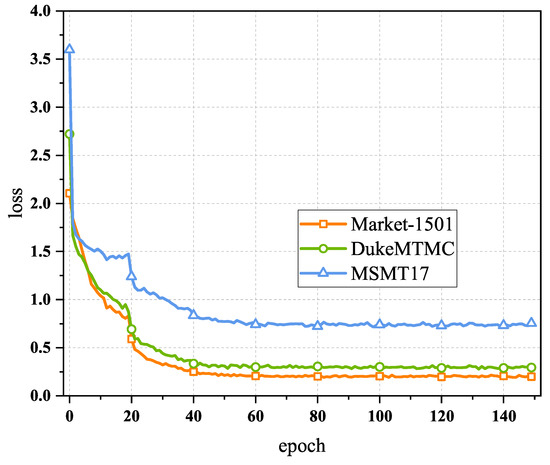
Figure 7.
Convergence analysis of the UnA-Mix method.
4.4.2. Visualization
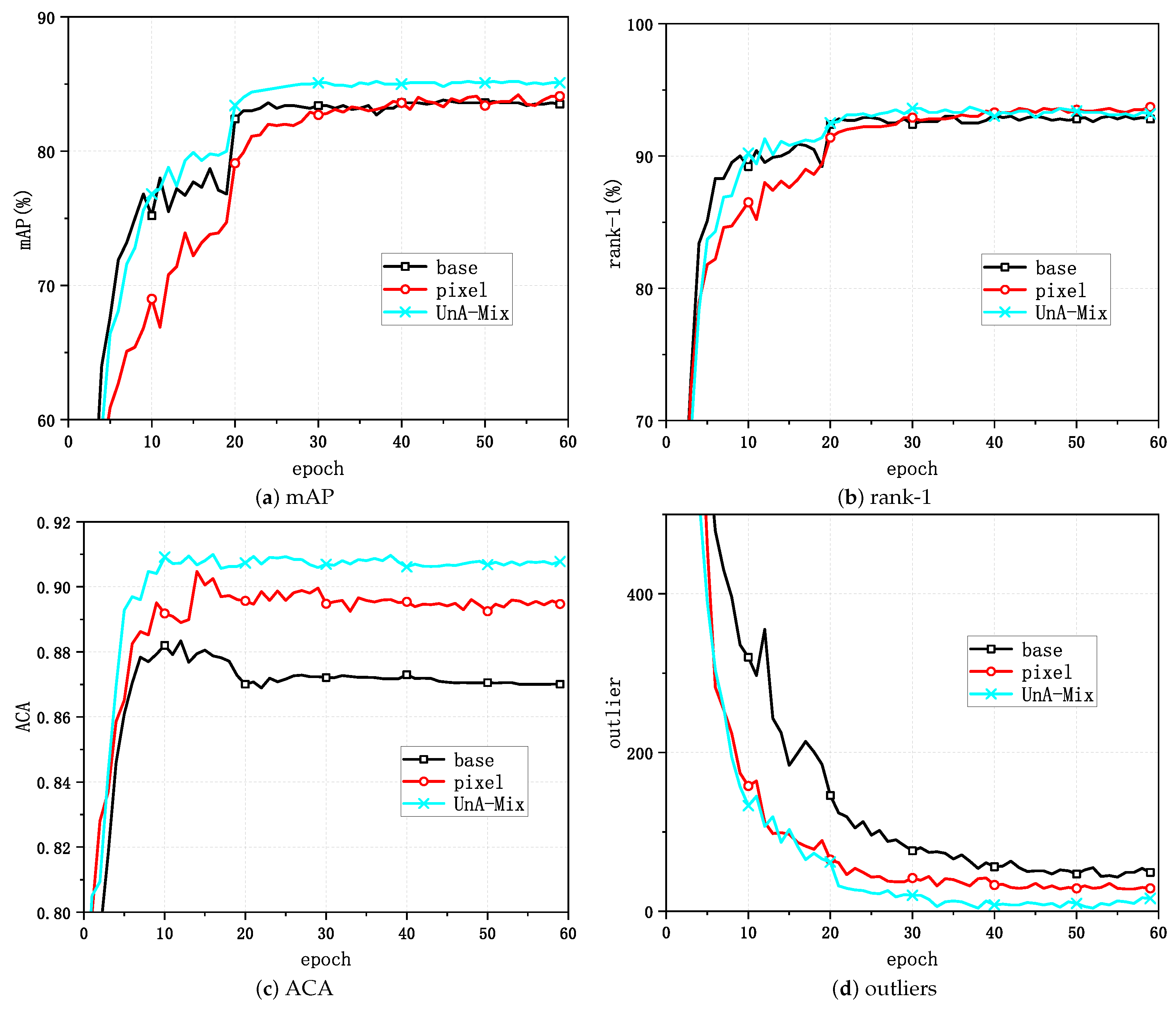
To further elucidate the effectiveness of the method, the variations in the mAP and rank-1 with the epoch were plotted for the baseline, the pixel-level method, and the UnA-Mix method for Market-1501, as shown in Figure 8a,b. Figure 8c depicts the changes in the clustering quality evaluation metric ACA, and Figure 8d represents the clustering outliers with different training methods. In order to more intuitively demonstrate the superiority of UnA-Mix compared to the baseline, quantitative experiments were conducted, and the results are shown in Figure 9 and Figure 10. To enhance the visualization of feature representations extracted with various methods, we employed t-SNE visualization on a randomly selected subset of 20 person identities from the Market-1501 dataset, as illustrated in Figure 9. For clarity, identical person identities are indicated by numbers of the same color. A noteworthy observation is that, in comparison to the baseline method, the UnA-Mix method not only preserved the compactness of clustering groups, but also effectively separated similar individuals in the feature space. This contributed to the network model acquiring a more discriminative representation of person features. To provide a more intuitive depiction of the performance disparity between the different methods, we present visualizations of the top ten best-matching results from the baseline and UnA-Mix methods across the benchmark person Re-ID datasets. In these visualizations, red boxes denote matching errors, while green boxes signify correct matches. The positioning of correct results towards the front of the matching results reflects better method performance. Figure 10 displays these matching results. Clearly, the UnA-Mix method significantly outperformed the baseline method in the benchmark person Re-ID datasets, confirming the efficacy of the UnA-Mix approach.
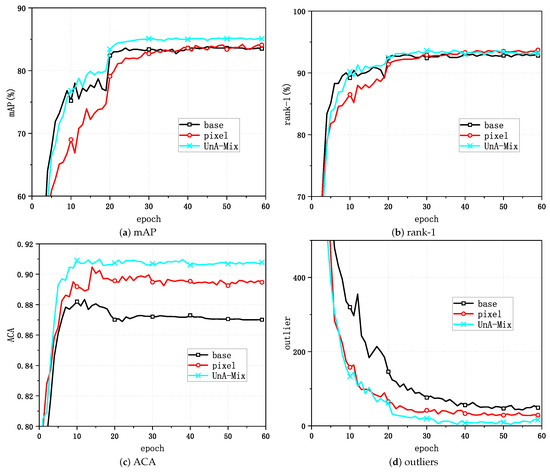
Figure 8.
Changes in the task performance evaluation metrics for the baseline, pixel-level, and UnA-Mix methods for different epochs on the Market-1501 dataset.
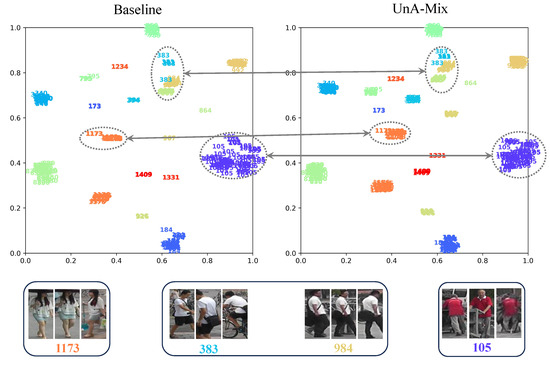
Figure 9.
Twenty different person identity samples were randomly selected from Market-1501, and the features are visualized by using t-SNE for clustering. Different numbers represent different person identities.

Figure 10.
Visualized results of rank-10, where the red color represents incorrectly matched images and the green color represents correctly matched images.
To further validate the usefulness of the UnA-Mix method, it was applied to the pixel level and feature level in the unsupervised person Re-ID framework. It can be discerned in Table 2 and Table 4 that the mAP and rank-1 were both boosted to different degrees. This verified that the UnA-Mix method is effective. It can improve the adverse consequences of the noisy pseudo-labels generated by the clustering algorithm for a model and boost the efficiency of the unsupervised person Re-ID task.
Table 4.
Comparison of UnA-Mix when applied at different positions in the framework.
5. Conclusions and Future Work
To our knowledge, we explored the impact of mixup as a data augmentation technique on the performance of unsupervised person Re-ID (a downstream task of contrastive learning) in detail for the first time. The mixup technique was applied at different locations (feature level and pixel level) in an unsupervised person Re-ID framework while using three benchmark person Re-ID datasets. After verification, as a domain-agnostic regularized data enhancement strategy, mixup not only mitigated the challenge of an insufficient number of individual person identities for Re-ID datasets, but was also able to eliminate the adverse intrusion of noisy pseudo-labels into the unsupervised person Re-ID task by mixing the image data and controllably modulating the extracted feature representations. Furthermore, we proposed a method based on the uncertainty-aware mixup (UnA-Mix) of training samples, which further improved the performance in this task by severely mixing the samples with less information and slightly mixing the samples with high uncertainty, preventing important person information from being corrupted in the training samples. Nevertheless, UnA-Mix did not entirely mitigate the adverse effects of noisy pseudo-labels on model training, and addressing the challenge of completely preventing the generation of noisy pseudo-labels by clustering algorithms remains a formidable task.
In future works, we will continue to further investigate the implications of noisy pseudo-labels on performance improvement and introduce more state-of-the-art work on noisy label learning to the task. We will apply the person Re-ID technology to the field of ultra-long-range sensors to further utilize the important role of intelligent video surveillance systems in security and other fields.
Author Contributions
All authors made contributions to this study, and the specific contributions of each author were as follows: J.L., H.S. and A.G. completed the methodology, theoretical algorithms, software simulation, and manuscript writing of this work. J.Z. and W.L. completed the revision and inspection of the manuscript, provided fund acquisition support for this work, and supervised this work. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported in part by the National Natural Science Foundation of China under Grant 62204044, in part by the Program for National Talented Guest Professor under Grant 2023CJJX01, in part by the State Key Laboratory of Integrated Chips and Systems, and in part by Shanghai Science and Technology Innovation Action under Grants 22xtcx00700 and 22511101002.
Data Availability Statement
The data that support the findings of this study are available online. Data download address: https://virutalbuy-public.oss-cn-hangzhou.aliyuncs.com/share/data.zip (accessed on 13 April 2021).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Fan, H.; Zheng, L.; Yan, C.; Yang, Y. Unsupervised person re-identification: Clustering and fine-tuning. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2018, 14, 1–18. [Google Scholar] [CrossRef]
- Ma, X.; Zhu, X.; Gong, S.; Xie, X.; Hu, J.; Lam, K.M.; Zhong, Y. Person re-identification by unsupervised video matching. Pattern Recognit. 2017, 65, 197–210. [Google Scholar] [CrossRef]
- Lu, X.; Li, X.; Sheng, W.; Ge, S.S. Long-term person re-identification based on appearance and gait feature fusion under covariate changes. Processes 2022, 10, 770. [Google Scholar] [CrossRef]
- Wu, L.; Liu, D.; Zhang, W.; Chen, D.; Ge, Z.; Boussaid, F.; Bennamoun, M.; Shen, J. Pseudo-pair based self-similarity learning for unsupervised person re-identification. IEEE Trans. Image Process. 2022, 31, 4803–4816. [Google Scholar] [CrossRef] [PubMed]
- Song, L.; Wang, C.; Zhang, L.; Du, B.; Zhang, Q.; Huang, C.; Wang, X. Unsupervised domain adaptive re-identification: Theory and practice. Pattern Recognit. 2020, 102, 107173. [Google Scholar] [CrossRef]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Mask-guided contrastive attention model for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1179–1188. [Google Scholar]
- Younis, H.A.; Ruhaiyem, N.I.R.; Badr, A.A.; Abdul-Hassan, A.K.; Alfadli, I.M.; Binjumah, W.M.; Altuwaijri, E.A.; Nasser, M. Multimodal age and gender estimation for adaptive human-robot interaction: A systematic literature review. Processes 2023, 11, 1488. [Google Scholar] [CrossRef]
- Pang, B.; Zhai, D.; Jiang, J.; Liu, X. Fully unsupervised person re-identification via selective contrastive learning. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 18, 1–15. [Google Scholar] [CrossRef]
- Yin, J.; Zhang, S.; Xie, J.; Ma, Z.; Guo, J. Unsupervised person re-identification via simultaneous clustering and mask prediction. Pattern Recognit. 2022, 126, 108568. [Google Scholar] [CrossRef]
- Li, Y.; Yao, H.; Xu, C. Intra-domain consistency enhancement for unsupervised person re-identification. IEEE Trans. Multimed. 2021, 24, 415–425. [Google Scholar] [CrossRef]
- Pang, Z.; Guo, J.; Sun, W.; Xiao, Y.; Yu, M. Cross-domain person re-identification by hybrid supervised and unsupervised learning. Appl. Intell. 2022, 52, 2987–3001. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Thulasidasan, S.; Chennupati, G.; Bilmes, J.A.; Bhattacharya, T.; Michalak, S. On mixup training: Improved calibration and predictive uncertainty for deep neural networks. Adv. Neural Inf. Process. Syst. 2019, 32, 13911–13922. [Google Scholar]
- Wu, D.; Wang, C.; Wu, Y.; Wang, Q.C.; Huang, D.S. Attention deep model with multi-scale deep supervision for person re-identification. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 70–78. [Google Scholar] [CrossRef]
- Sun, L.; Xia, C.; Yin, W.; Liang, T.; Yu, P.S.; He, L. Mixup-transformer: Dynamic data augmentation for nlp tasks. arXiv 2020, arXiv:2010.02394. [Google Scholar]
- Lee, M.F.R.; Chen, Y.C.; Tsai, C.Y. Deep learning-based human body posture recognition and tracking for unmanned aerial vehicles. Processes 2022, 10, 2295. [Google Scholar] [CrossRef]
- Ge, L.; Dan, D.; Koo, K.Y.; Chen, Y. An improved system for long-term monitoring of full-bridge traffic load distribution on long-span bridges. Structures 2023, 54, 1076–1089. [Google Scholar] [CrossRef]
- Niu, Z.; Jiang, B.; Xu, H.; Zhang, Y. Balance Loss for multiAttention-based YOLOv4. In Proceedings of the 2023 5th International Conference on Intelligent Control, Measurement and Signal Processing (ICMSP), Chengdu, China, 19–21 May 2023; pp. 946–954. [Google Scholar]
- Lee, K.; Zhu, Y.; Sohn, K.; Li, C.L.; Shin, J.; Lee, H. i-mix: A domain-agnostic strategy for contrastive representation learning. arXiv 2020, arXiv:2010.08887. [Google Scholar]
- Shen, Z.; Liu, Z.; Liu, Z.; Savvides, M.; Darrell, T.; Xing, E. Un-mix: Rethinking image mixtures for unsupervised visual representation learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2022; Volume 36, pp. 2216–2224. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Mannor, S.; Peleg, D.; Rubinstein, R. The cross entropy method for classification. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 561–568. [Google Scholar]
- Li, M.; Li, C.G.; Guo, J. Cluster-guided asymmetric contrastive learning for unsupervised person re-identification. IEEE Trans. Image Process. 2022, 31, 3606–3617. [Google Scholar] [CrossRef] [PubMed]
- Lin, X.; Ren, P.; Yeh, C.H.; Yao, L.; Song, A.; Chang, X. Unsupervised person re-identification: A systematic survey of challenges and solutions. arXiv 2021, arXiv:2109.06057. [Google Scholar]
- Si, T.; He, F.; Zhang, Z.; Duan, Y. Hybrid contrastive learning for unsupervised person re-identification. IEEE Trans. Multimed. 2022, 25, 4323–4334. [Google Scholar] [CrossRef]
- Ge, Y.; Chen, D.; Li, H. Mutual mean-teaching: Pseudo label refinery for unsupervised domain adaptation on person re-identification. arXiv 2020, arXiv:2001.01526. [Google Scholar]
- Yang, F.; Li, K.; Zhong, Z.; Luo, Z.; Sun, X.; Cheng, H.; Guo, X.; Huang, F.; Ji, R.; Li, S. Asymmetric co-teaching for unsupervised cross-domain person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12597–12604. [Google Scholar]
- Zhu, X.; Li, Y.; Sun, J.; Chen, H.; Zhu, J. Learning with noisy labels method for unsupervised domain adaptive person re-identification. Neurocomputing 2021, 452, 78–88. [Google Scholar] [CrossRef]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]
- Wang, X.; Qi, G.J. Contrastive learning with stronger augmentations. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5549–5560. [Google Scholar] [CrossRef] [PubMed]
- Kalantidis, Y.; Sariyildiz, M.B.; Pion, N.; Weinzaepfel, P.; Larlus, D. Hard negative mixing for contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21798–21809. [Google Scholar]
- Han, B.; Yao, Q.; Yu, X.; Niu, G.; Xu, M.; Hu, W.; Tsang, I.; Sugiyama, M. Co-teaching: Robust training of deep neural networks with extremely noisy labels. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Lee, K.H.; He, X.; Zhang, L.; Yang, L. Cleannet: Transfer learning for scalable image classifier training with label noise. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5447–5456. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3733–3742. [Google Scholar]
- De Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled samples generated by gan improve the person re-identification baseline in Vitro. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2017; pp. 3754–3762. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person transfer gan to bridge domain gap for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 79–88. [Google Scholar]
- Wang, D.; Zhang, S. Unsupervised person re-identification via multi-label classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10981–10990. [Google Scholar]
- Li, J.; Zhang, S. Joint visual and temporal consistency for unsupervised domain adaptive person re-identification. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 483–499. [Google Scholar]
- Ge, Y.; Zhu, F.; Chen, D.; Zhao, R. Self-paced contrastive learning with hybrid memory for domain adaptive object re-id. Adv. Neural Inf. Process. Syst. 2020, 33, 11309–11321. [Google Scholar]
- Chen, G.; Lu, Y.; Lu, J.; Zhou, J. Deep credible metric learning for unsupervised domain adaptation person re-identification. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VIII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 643–659. [Google Scholar]
- Chen, H.; Lagadec, B.; Bremond, F. Enhancing diversity in teacher-student networks via asymmetric branches for unsupervised person re-identification. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual Event, 5–9 January 2021; pp. 1–10. [Google Scholar]
- Lin, Y.; Dong, X.; Zheng, L.; Yan, Y.; Yang, Y. A bottom-up clustering approach to unsupervised person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8738–8745. [Google Scholar]
- Lin, Y.; Xie, L.; Wu, Y.; Yan, C.; Tian, Q. Unsupervised person re-identification via softened similarity learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3390–3399. [Google Scholar]
- Xuan, S.; Zhang, S. Intra-inter camera similarity for unsupervised person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11926–11935. [Google Scholar]
- Cho, Y.; Kim, W.J.; Hong, S.; Yoon, S.E. Part-based pseudo label refinement for unsupervised person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7308–7318. [Google Scholar]
- Dai, Z.; Wang, G.; Yuan, W.; Zhu, S.; Tan, P. Cluster contrast for unsupervised person re-identification. In Proceedings of the Asian Conference on Computer Vision, Macao, China, 4–8 December 2022; pp. 1142–1160. [Google Scholar]
- Roy, P.; Seshadri, S.; Sudarshan, S.; Bhobe, S. Efficient and extensible algorithms for multi query optimization. In Proceedings of the 2000 ACM SIGMOD international conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; pp. 249–260. [Google Scholar]
- Khan, K.; Rehman, S.U.; Aziz, K.; Fong, S.; Sarasvady, S. DBSCAN: Past, present and future. In Proceedings of the Fifth International Conference on the Applications of Digital Information and Web Technologies (ICADIWT 2014), Chennai, India, 17–19 February 2014; pp. 232–238. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).