
Research on a Carbon Emission Prediction Method for Oil Field Transfer Stations Based on an Improved Genetic Algorithm—The Decision Tree Algorithm

Abstract
:1. Introduction
2. Methods Section
2.1. Measurement of Carbon Emissions
2.2. Carbon Emission Prediction Model Methods
2.2.1. Decision Tree Algorithm Fundamentals
- (1)
- Enter N training samples X, and set the relevant parameters, the number of iterations (N), F as a function space composed of all trees, as a single decision tree model, and the initial value = 0, The GBDT algorithm expression is as follows:
- (2)
- Define the objective function of the GBDT algorithm as:
- (3)
- According to the additive structure of the GBDT algorithm:
- (4)
- Generate a new decision tree through a greedy strategy to minimize the objective function value, and the optimal predicted value corresponding to the leaf node is obtained, , add the newly generated decision tree to the model, obtaining:
- (5)
- Keep iterating until the end of N iterations, and the output of the GBDT algorithm is composed of N decision trees.
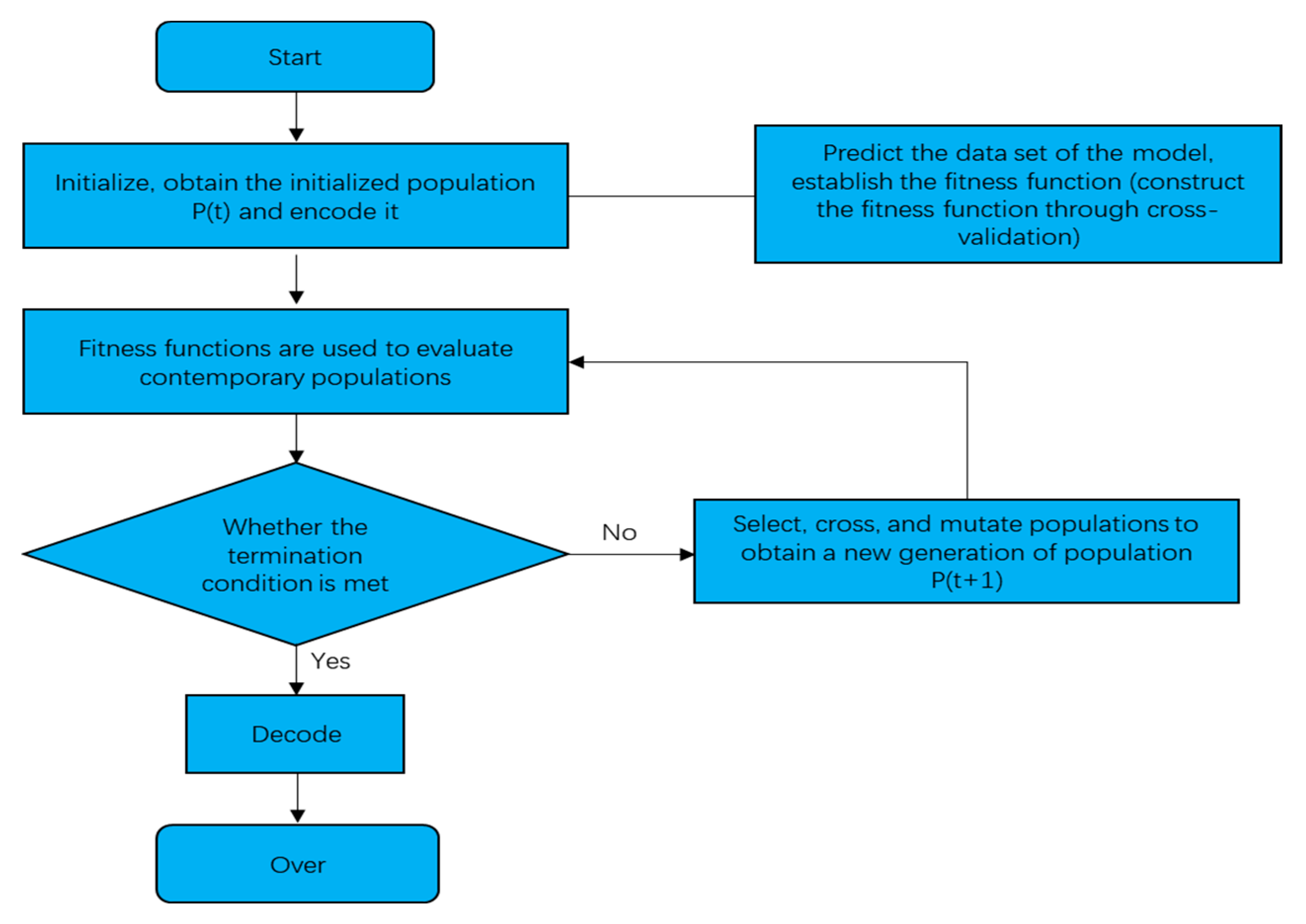
2.2.2. GA-Decision Tree Predictive Model Construction
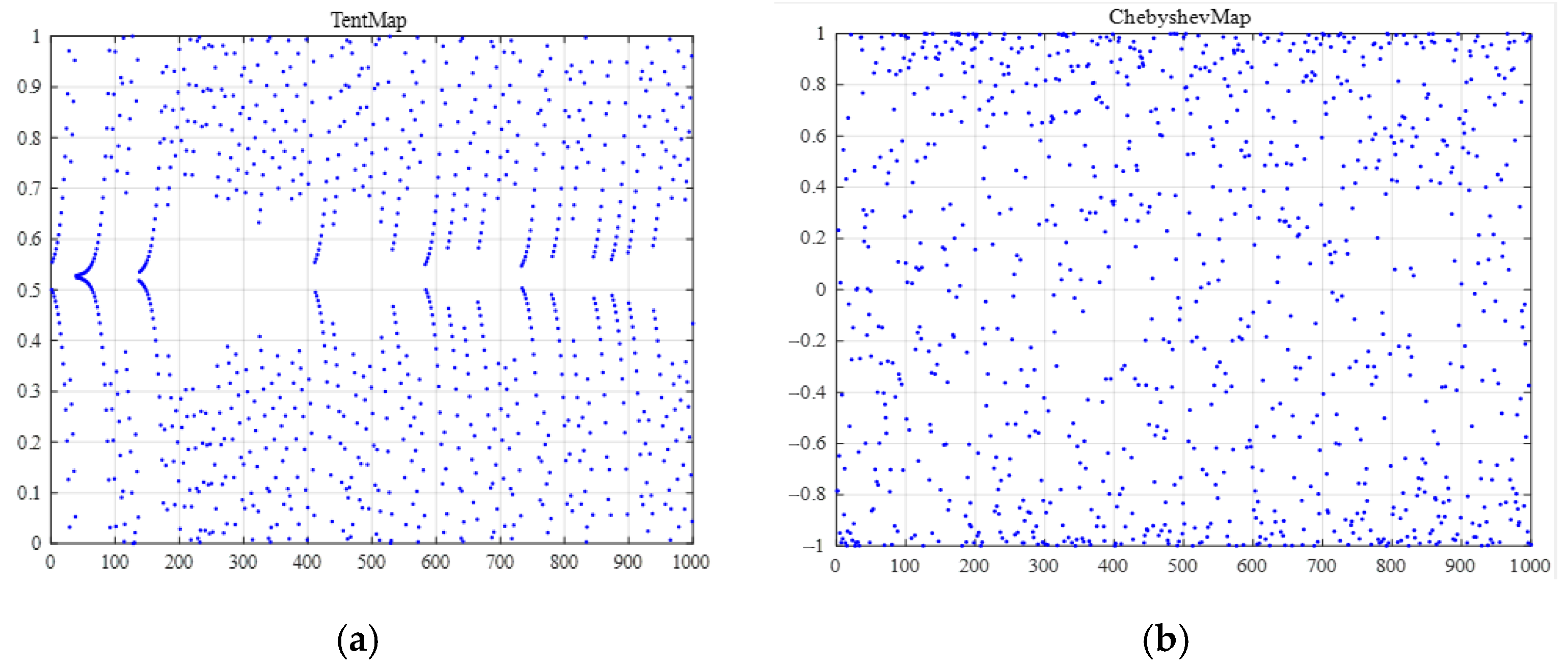
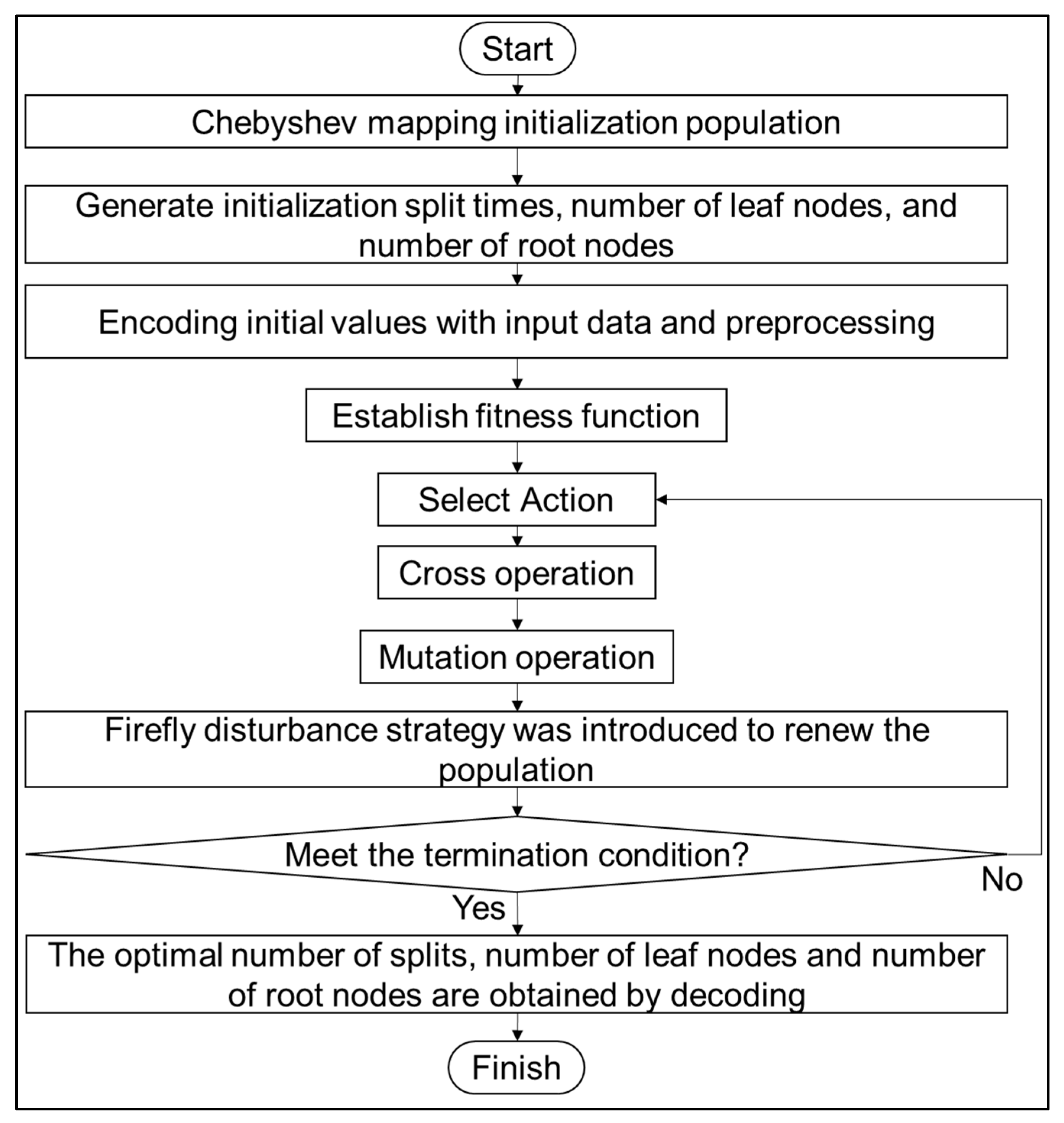
2.2.3. Establish an IGA-Decision Tree Algorithm Model
3. Empirical Analysis
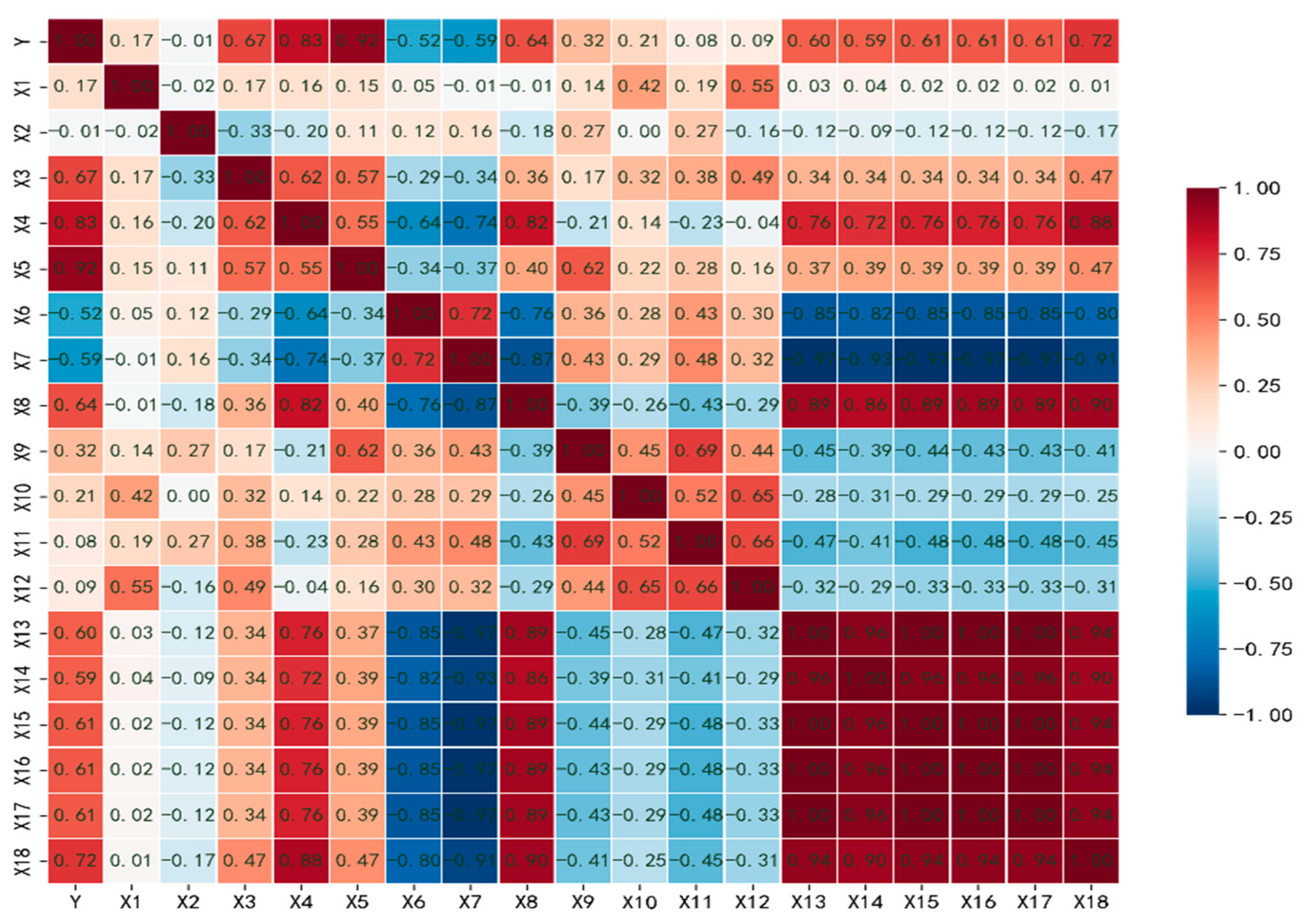
3.1. Correlation Analysis of Influencing Factors of Carbon Emissions
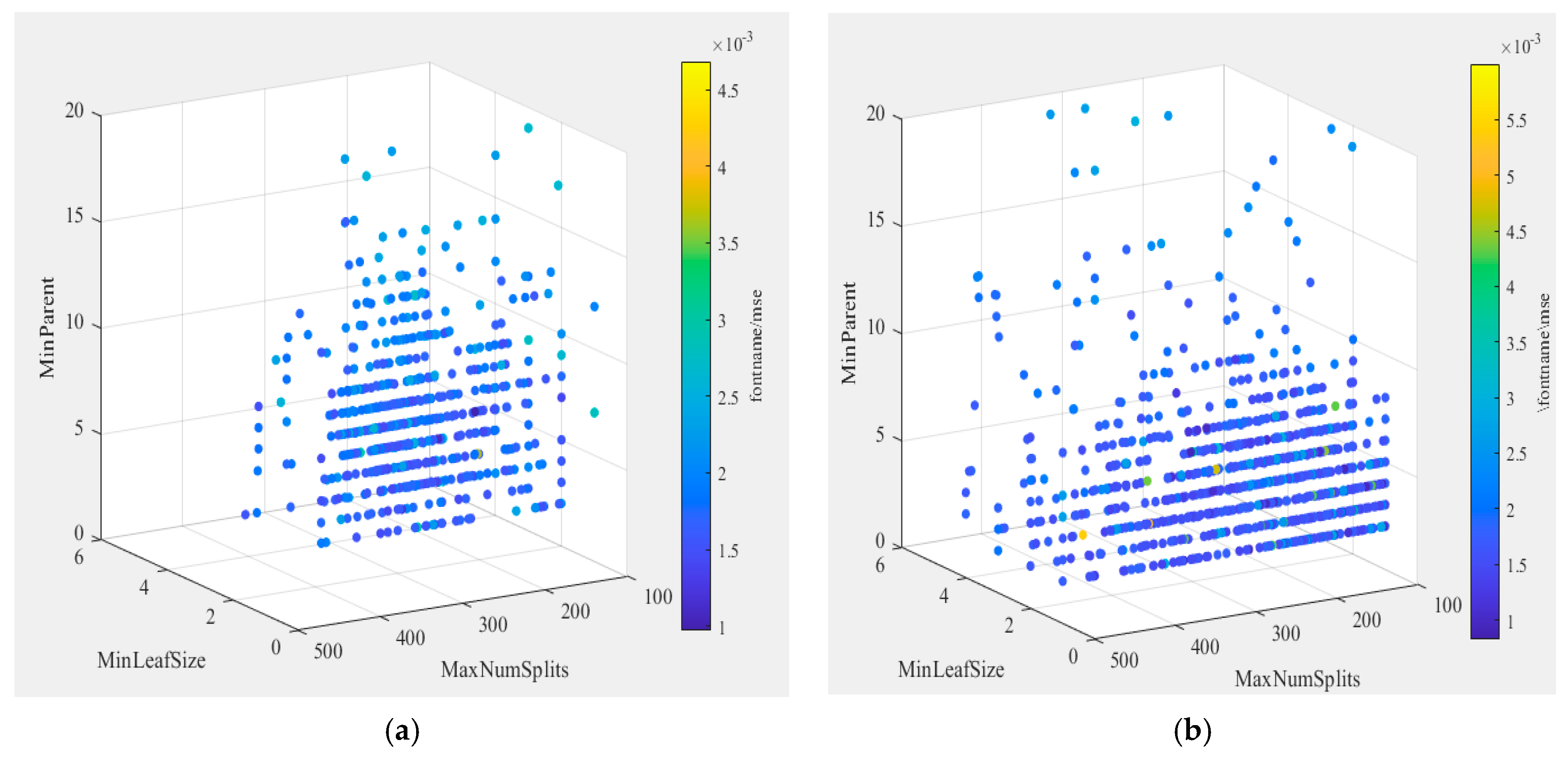
3.2. Example Application of Improved GA-Decision Tree (IGA-Decision Tree) Algorithm
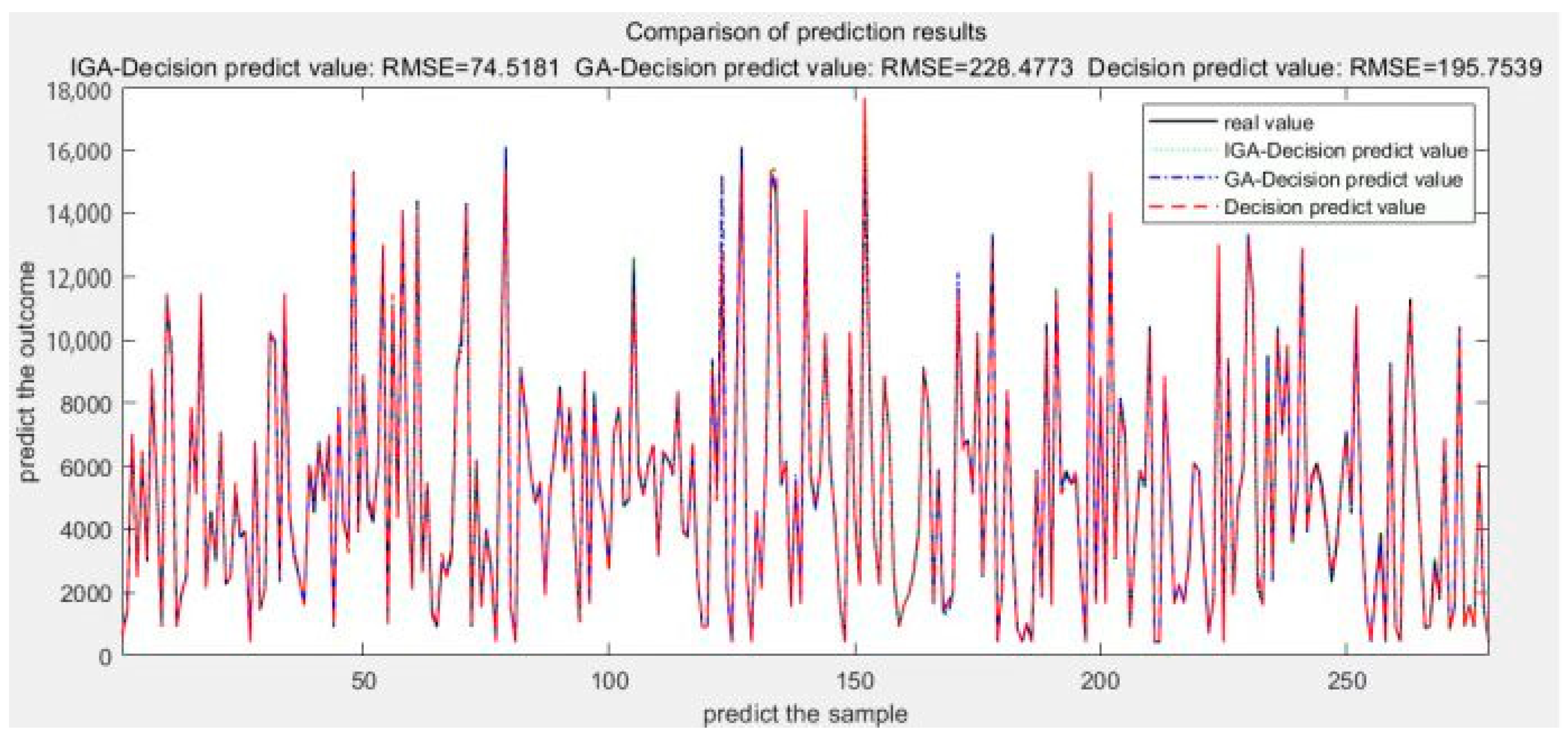
4. Empirical Results and Discussion
5. Conclusions and Recommendations
- (1)
- This paper proposes an improved GA-decision tree algorithm. It introduces chaotic mapping to initialize the population, aiming to achieve a uniform distribution of initial particles in the search space and increase population diversity. Additionally, a Firefly disturbance strategy was adopted to avoid the problem of genetic algorithms becoming trapped in local optima during the later stages of the search. The results show that this model can accurately predict the carbon emissions of the oilfield transfer station system, which verifies the accuracy and reliability of the model. When predicting carbon emissions for a specific oilfield transfer station, the IGA-decision tree model showed improvements compared to the GA-decision tree and decision tree model. The R2 value increased by 0.02 and 0.13, respectively, while the RMSE value decreased by 153.9594 and 121.2358, respectively. It has high accuracy in predicting the carbon emissions of the oilfield transfer station system, which can provide an important basis for related work.
- (2)
- Under the “dual carbon” development strategy, the petroleum and petrochemical industry is facing carbon reduction challenges, especially the energy consumption and carbon emission problems faced by China’s oil and gas extraction industry. In this paper, taking an oilfield transfer station in Northeast China as an example, the carbon emissions of the transfer station were calculated using the IPCC method, and the IGA-decision tree model was used to search for optimization globally. The model validation results showed that this model had high accuracy and could be used to predict the carbon emissions of the oilfield transfer station system. This is of practical significance for carbon accounting, energy conservation, and carbon reduction and fills the research gap in carbon emission prediction in energy Internet projects.
- (3)
- The model also has some limitations: the study chose MAPE and R2 as evaluation indicators but did not explain why these indicators were selected. At the same time, these evaluation indicators could only reflect part of the model performance, and other evaluation indicators might need to be considered to fully evaluate the accuracy and stability of the model. As the prediction interval expands, the predictive power of the model also decreases. Therefore, the above issues need to be improved in subsequent studies.
- (4)
- To further improve the accuracy and precision of carbon emissions prediction models in the future, it is recommended that more accurate and comprehensive data are collected while enhancing data availability. Additionally, exploring new machine learning algorithms, deep learning techniques, or employing ensemble modeling approaches could be beneficial in enhancing predictive performance. Performing sensitivity analysis on key factors in carbon emissions prediction models could help study the impact of different variables on prediction results. This could aid in identifying the main driving factors and provide a scientific basis for prioritizing emission reduction measures.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wei, S.; Wang, T.; Li, Y. Influencing factors and prediction of carbon dioxide emissions using factor analysis and optimized least squares support vector machine. J. Environ. Eng. Res. 2017, 22, 175–185. [Google Scholar] [CrossRef]
- Faruque, O.; Rabby, A.J.; Hossain, A.; Islam, R.; Rashid, M.U.; Muyeen, S. A comparative analysis to forecast carbon dioxide emissions. J. Energy Rep. 2022, 8, 8046–8060. [Google Scholar] [CrossRef]
- Chen, W.J.; Wu, X.G.; Xiao, Z. Prediction of carbon emissions from road traffic in four major economic regions in China and assessment of emission reduction potential: Scenario model based on private car trajectory data. J. Econ. Geogr. 2022, 42, 44–52. [Google Scholar]
- Xu, J.H.; Wang, K. Medium- and long-term carbon emission forecasting and technical emission reduction potential analysis of China’s civil aviation industry. J. Environ. Sci. China 2022, 42, 3412–3424. [Google Scholar]
- Li, X.Y.; Zhao, R.J.; Gao, C.N.; Xie, X.L. Analysis of decoupling of carbon emissions from China’s civil aviation transport and peak forecasting. J. Environ. Pollut. Prev. 2022, 44, 729–733, 739. [Google Scholar]
- Hu, J.B.; Zhao, K.; Yang, Y.H. Research on the prediction and control factors of China’s industrial carbon emission peaking: Empirical analysis based on BP-LSTM neural network model. J. Guizhou Soc. Sci. 2021, 9, 135–146. [Google Scholar]
- Shi, D.; Li, P. Simulation of industrial carbon emission structure and policy impact under the “dual carbon” goal. J. Reform 2021, 12, 30–44. [Google Scholar]
- Bian, Y.; Lin, X.Q.; Zhou, X.; Cui, W.J. Spatial-temporal evolution characteristics and influencing factors of industrial carbon emissions in Beijing-Tianjin-Hebei. J. Environ. Sci. Technol. 2021, 44, 37–47. [Google Scholar]
- Liu, X.Z.; Yang, X. Variable Screening of Influencing Factors of China’s Carbon Emissions: Based on PLS-VIP Method. J. Environ. Ecol. 2019, 1, 60–65. [Google Scholar]
- Wang, X.Y.; Zhou, S.M.; Xu, X.L.; Zhou, S.J. Analysis of influencing factors of carbon emission allowance price based on graph structure adaptive Lasso. J. Stat. Inf. Forum 2022, 37, 73–83. [Google Scholar]
- Ke, H.; Zhang, X.S.; Cheng, Z.Z. Research on carbon emission prediction in Shanxi Province based on quadratic decomposition BAS-LSTM. J./OL. Oper. Manag. 2023, 1–14. [Google Scholar]
- Gao, J.H.; Zheng, B.Z.; Zhou, W.H.; Li, P. Research on carbon emission prediction of urban transportation based on GA-SVR. J. East China Univ. Technol. (Nat. Sci. Ed.) 2022, 45, 269–274. [Google Scholar]
- Hao, J.Y.; Gao, J. Based on NSGA-II the BP neural network is improved to predict the carbon emission reduction of buildings. J. Energy Effic. Build. 2016, 44, 122–124. [Google Scholar]
- Sun, W.; Zhang, X. China’s carbon emission prediction based on QPSO-LSSVM algorithm. J. State Grid Inst. Technol. Newsp. 2017, 20, 20–25. [Google Scholar]
- Yan, F.Y.; Liu, S.X.; Zhang, X.P. Research on land carbon emission prediction based on PCA-BP neural network. West. J. Hum. Settl. 2021, 36, 1–7. [Google Scholar]
- Zhang, D.; Wang, T.T.; Zhi, J.H. Carbon emission prediction and eco-economic analysis of Shandong Province based on IPSO-BP neural network model. J. Ecol. Sci. 2022, 41, 149–158. [Google Scholar]
- Zhou, W.; Zeng, B.; Wang, J.; Luo, X.; Liu, X. Forecasting Chinese carbon emissions using a novel grey rolling prediction model. J. Chaos Solitons Fractals 2021, 147, 110968. [Google Scholar] [CrossRef]
- Yu, S.; Zheng, S.; Li, X. The achievement of the carbon emissions peak in China: The role of energy consumption structure optimization. J. Energy Econ. 2018, 74, 693–707. [Google Scholar] [CrossRef]
- Yan, W.; Huang, Y.R.; Zhang, X.Y.; Gao, M.F. Carbon emission prediction of blue economic zone in Shandong Peninsula based on STIRPAT model. J. Univ. Jinan Nat. Sci. Ed. 2021, 35, 125–131. [Google Scholar]
- Qu, P.; Liu, C.; Li, D.Z.; Guo, B.Q. Research on the development strategy of electric energy substitution under the goal of “carbon neutrality”. J. Electr. Demand Side Manag. 2021, 23, 1–3, 9. [Google Scholar]
- Zhao, J.M. Incentive mechanism and realization method of transportation carbon emission reduction in megacities. J. Ecol. Econ. 2021, 37, 34–39. [Google Scholar]
- Hu, M.F.; Zheng, Y.B.; Li, Y.H. Prediction of peak transportation carbon emissions in Hubei Province under multiple scenarios. J. Environ. Sci. 2022, 42, 464–472. [Google Scholar]
- Xu, Y.G.; Song, W.X. Research on carbon emission prediction of construction industry based on FCS-SVM. J. Ecol. Econ. 2019, 35, 37–41. [Google Scholar]
- Salman, B.; Ong, M.Y.; Nomanbhay, S.; Salema, A.A.; Sankaran, R.; Show, P.L. Thermal analysis of nigerian oil palm biomass with sachet-water plastic wastes for sustainable production of biofuel. Processes 2019, 7, 475. [Google Scholar] [CrossRef]
- Hou, Y.; Iqbal, W.; Muhammad Shaikh, G.; Iqbal, N.; Ahmad Solangi, Y.; Fatima, A. Measuring energy effificiency and environmental performance: A case of South Asia. Processes 2019, 7, 325. [Google Scholar] [CrossRef]
- Hsiao, W.L.; Hu, J.L.; Hsiao, C.; Chang, M.C. Energy effificiency of the Baltic Sea countries: An application of stochastic frontier analysis. Energies 2019, 12, 104. [Google Scholar] [CrossRef]
- Paul, A.; Martins, L.M.; Karmakar, A.; Kuznetsov, M.L.; Novikov, A.S.; da Silva, M.F.C.G.; Pombeiro, A.J. Environmentally benign benzyl alcohol oxidation and C-C coupling catalysed by amide functionalized 3D Co(II) and Zn(II) metal organic frameworks. J. Catal. 2020, 385, 324–337. [Google Scholar] [CrossRef]
- Alabdullah, M.A.; Gomez, A.R.; Vittenet, J.; Bendjeriou-Sedjerari, A.; Xu, W.; Abba, I.A.; Gascon, J. A Viewpoint on the Refinery of the Future: Catalyst and Process Challenges. J. ACS Catal. 2020, 10, 8131–8140. [Google Scholar] [CrossRef]
- Alexander, N.; Maxim, K.; Bruno, R.; Armando, P.; Georgiy, S. Oxidation of olefins with H2O2 catalysed by salts of group III metals (Ga, In, Sc, Y and La): Epoxidation versus hydroperoxidation. J. Catal. Sci. Technol. 2016, 6, 1343–1356. [Google Scholar]
- Al-Majidi, S.D.; Altai, H.D.S.; Lazim, M.H.; Al-Nussairi, M.K.; Abbod, M.F.; Al-Raweshidy, H.S. Al-Raweshidy, Bacterial Foraging Algorithm for a Neural Network Learning Improvement in an Automatic Generation Controller. J. Energ. 2023, 16, 2802. [Google Scholar]
- Al-Majidi, S.D.; Kh AL-Nussairi, M.; Mohammed, A.J.; Dakhil, A.M.; Abbod, M.F.; Al-Raweshidy, H.S. Design of a Load Frequency Controller Based on an Optimal Neural Network. J. Energy 2022, 15, 6223. [Google Scholar]
- Sun, W.; Liu, Y.D.; Li, M.Y.; Cheng, Q.L.; Zhao, L.X. Study on heat flow transfer characteristics and main influencing factors of waxy crude oil tank during storage heating process under dynamic thermal conditions. J. Energy 2023, 269, 127001. [Google Scholar] [CrossRef]
- Lin, L.; Li, Y.M.; Wang, W. Energy-saving Management Measures in Oilfield Engineering Construction Processes. J. Stand. Qual. Chin. Pet. Chem. Ind. 2013, 33, 228. [Google Scholar]
- Cheng, Q.L.; Liu, H.G.; Meng, L.; Wang, X.; Sun, W. Analysis and optimization of carbon emission from natural gas ethanolamine desulfurization process. J. Contemp. Chem. Ind. 2023, 52, 1389–1395. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. J. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Ahang, Y.; Wang, J.; Wang, X.; Xue, Y.; Song, J. Efficient selection on spatial modulation antennas: Learning or boosting. J. IEEE Wirel. Commun. Lett. 2020, 9, 1249–1252. [Google Scholar]
- Liu, L.; Jiang, B.W.; Zhou, H.Y.; Pu, C.W.; Qian, P.F.; Liu, B. A Novel Particle Swarm Optimization Algorithm with Improved Sine Chaotic Mapping Integration. J. Xi’an Jiaotong Univ. 2023, 57, 183–191. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Name | Definition | Unit |
|---|---|---|---|
| Y | Carbon emissions | The total CO2 emissions | tones |
| X1 | Pressure difference | The difference in pressure between the two points | MPa |
| X2 | Temperature difference | The difference between the temperature of the object | °C |
| X3 | Daily infusion volume | The amount of crude oil transported per day | t |
| X4 | Daily power consumption | Electricity is consumed daily | kW·h |
| X5 | Daily air consumption | The amount of natural gas consumed per day | m3 |
| X6 | Density | A measure of mass within a specific volume | kg/m3 |
| X7 | Specific heat capacity | Indicates the ability of a substance to absorb heat or dissipate heat | kJ/(kg °C) |
| X8 | Fuel calorific value | Indicates the amount of heat release capacity when the fuel is completely burned | GJ/ten thousands Nm3 |
| X9 | Thermal energy provided | Heat provided | kJ |
| X10 | Pressure energy provided | Pressure energy provided by the outside world | kJ |
| X11 | Oil absorbs heat energy | The thermal energy carried by the logistics entering the transfer station | kJ |
| X12 | The pressure energy absorbed by the oil | Enter the transfer station logistics to carry pressure energy | kJ |
| X13 | Thermal energy utilization | The efficiency with which heat energy is utilized | % |
| X14 | Electrical energy utilization | The efficiency with which electrical energy is utilized | % |
| X15 | Power consumption per unit of liquid volume collection and transmission | The power consumption of the transfer station system per 1t of produced liquid processed | kW·h/t |
| X16 | Gas consumption per unit of liquid volume collection and transportation | The gas consumption of the transfer station system per 1t of produced liquid processed | m3/t |
| X17 | Comprehensive energy consumption per unit of liquid volume | The comprehensive energy consumption of the transfer station system per 1t of produced liquid processed | kgce/t |
| X18 | Transfer station energy utilization | The extent to which the energy of the transfer station system is used efficiently | % |
| Predictive Models | RMSE | R2 | MAPE/% |
|---|---|---|---|
| Decision tree | 195.7539 | 0.86 | 8.02 |
| GA-Decision tree | 228.4773 | 0.97 | 3.35 |
| IGA-Decision tree | 74.5181 | 0.99 | 2.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, Q.; Wang, X.; Wang, S.; Li, Y.; Liu, H.; Li, Z.; Sun, W. Research on a Carbon Emission Prediction Method for Oil Field Transfer Stations Based on an Improved Genetic Algorithm—The Decision Tree Algorithm. Processes 2023, 11, 2738. https://doi.org/10.3390/pr11092738
Cheng Q, Wang X, Wang S, Li Y, Liu H, Li Z, Sun W. Research on a Carbon Emission Prediction Method for Oil Field Transfer Stations Based on an Improved Genetic Algorithm—The Decision Tree Algorithm. Processes. 2023; 11(9):2738. https://doi.org/10.3390/pr11092738
Chicago/Turabian StyleCheng, Qinglin, Xue Wang, Shuang Wang, Yanting Li, Hegao Liu, Zhidong Li, and Wei Sun. 2023. "Research on a Carbon Emission Prediction Method for Oil Field Transfer Stations Based on an Improved Genetic Algorithm—The Decision Tree Algorithm" Processes 11, no. 9: 2738. https://doi.org/10.3390/pr11092738
APA StyleCheng, Q., Wang, X., Wang, S., Li, Y., Liu, H., Li, Z., & Sun, W. (2023). Research on a Carbon Emission Prediction Method for Oil Field Transfer Stations Based on an Improved Genetic Algorithm—The Decision Tree Algorithm. Processes, 11(9), 2738. https://doi.org/10.3390/pr11092738