
Improved Fault Classification for Predictive Maintenance in Industrial IoT Based on AutoML: A Case Study of Ball-Bearing Faults




Abstract
1. Introduction
2. Related Works
- i.
- Development of AutoML-based prediction algorithms (PyCaret and AutoKeras) for application on REB fault datasets;
- ii.
- Design of a preprocessing algorithm to enhance the prediction process’s performance;
- iii.
- Conducting of a comparison study between the proposed prediction algorithms;
- iv.
- Comparative analysis of the models proposed in this research against prior works to showcase their effectiveness in addressing the same case study.
3. Predictive Maintenance
- Corrective maintenance, also known as run-to-failure (R2F), is a straightforward strategy that involves addressing equipment issues only when they cease to function, often necessitating the replacement or repair of specific components.
- Preventive maintenance (PvM) is a scheduled maintenance strategy carried out periodically at predetermined intervals. While this approach is effective in preventing equipment failure, it may also result in unnecessary costs for corrective maintenance.
- PdM is a strategy that involves continuous system monitoring to anticipate potential failures using a combination of machine-learning techniques, integrity factors, engineering approaches, and statistical inference methods. Zonta et al. [43] define PdM as models that rely on historical data and domain knowledge, enabling advanced failure anticipation using statistical or machine-learning algorithms. This approach ultimately improves decision making related to maintenance activities and helps prevent downtime. The evolution of IoT, sensing technology, and AI has facilitated a shift in maintenance strategies from R2F to PvM, and, finally, to PdM [44].
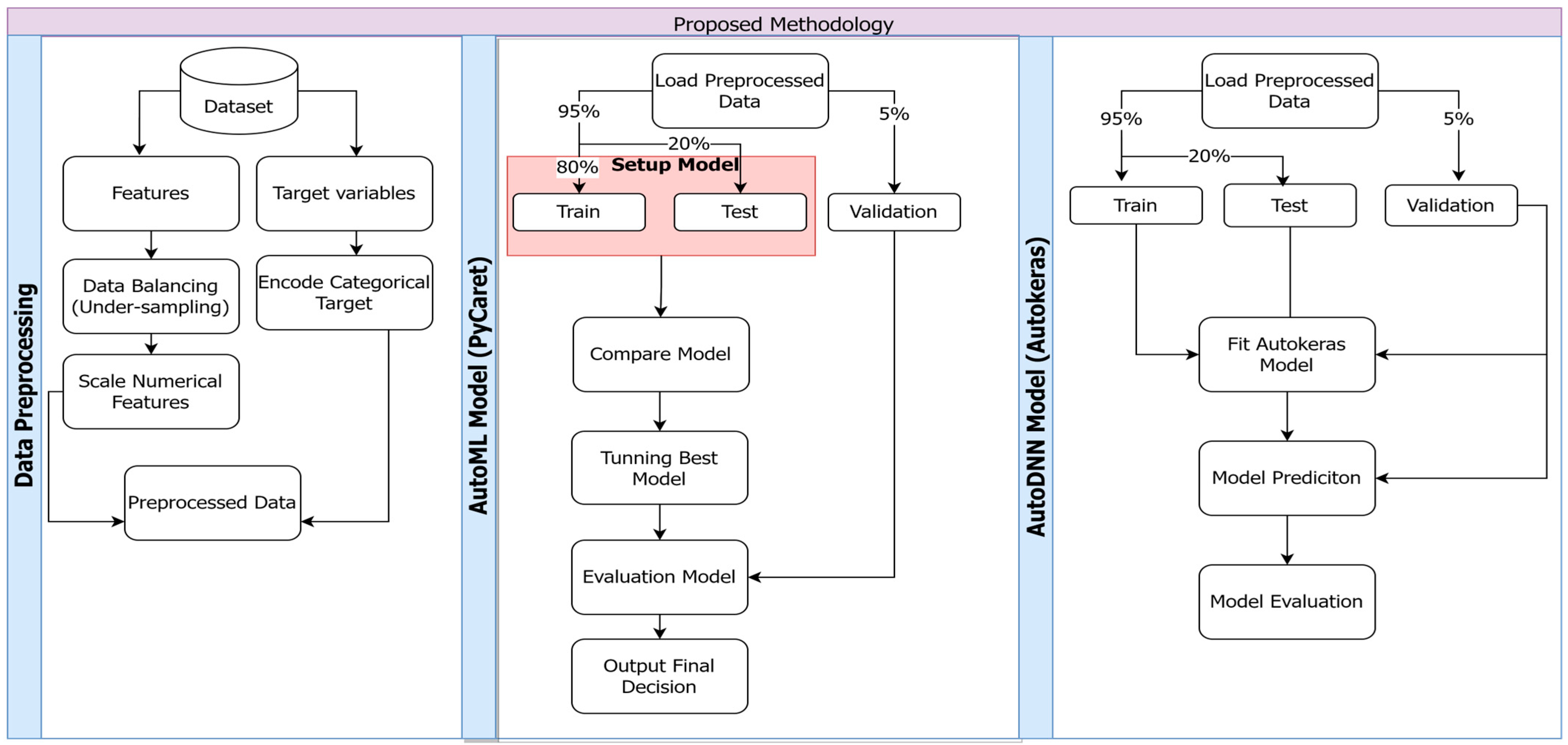
4. Proposed Methodology
4.1. Data Preprocessing
| Algorithm 1 Data Preprocessing. |
| Input: CWRU dataset (d), input feature columns (f), output target (t) |
| Output: Preprocessed dataset (pd) |
| 1. Normalize: Feature normalization (d) |
| 2. X ← f |
| 3. Y← t |
| 4. Xn ← normalize(X) |
| 5. Balance: Dataset balancing (Xbal,Ybal) |
| 6. Xbal,Ybal ← balance(Xn, Y) |
| 7. Map: Mapping categorical target from 0 to 9 |
| 8. ymap ← map(Ybal) |
| 9. Split: Splitting dataset into training, validation, and test sets (sd) |
| 10. X_train_val, X_test, y_train_val, y_test ← (Xbal, ymap, test_size = 0.05) |
| 11. X_train, X_val, y_train, y_val ← (X_train_val, y_train_val, test_size = 0.2) |
| 12. Return pd ← (X_train, y_train, X_val, y_val, X_test, y_test) |
4.2. AutoML (PyCaret) Model
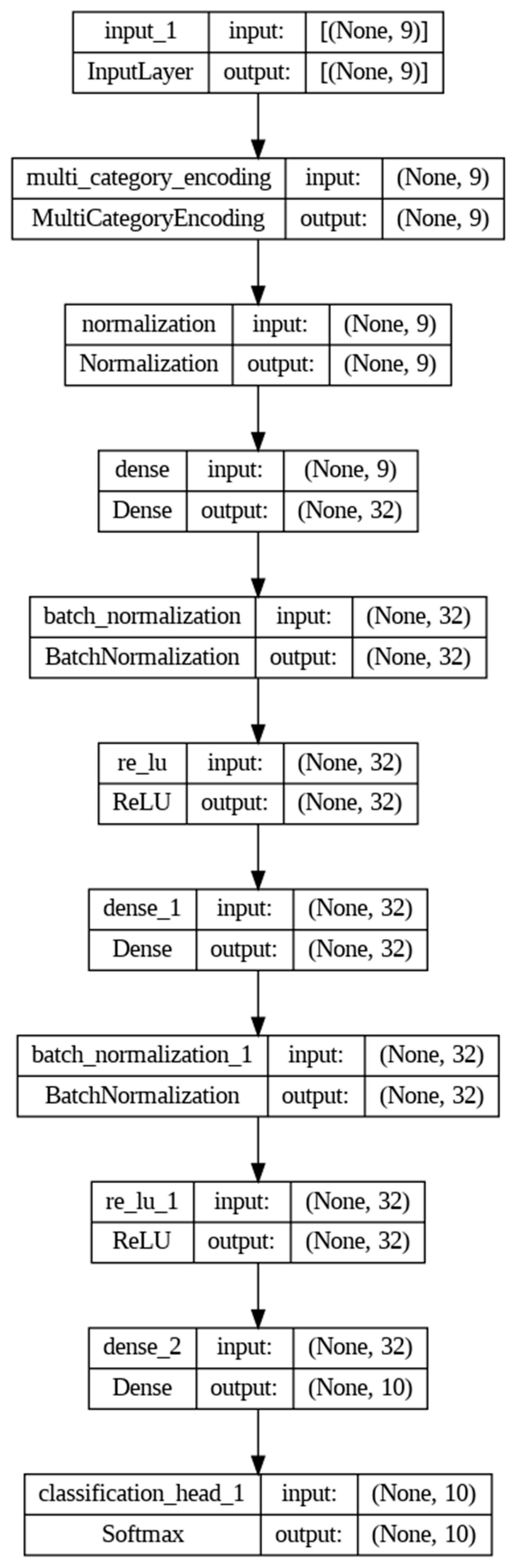
4.3. AutoDNN (AutoKeras) Model
| Algorithm 2 Best Model Selection. |
| Input: Preprocessed dataset (pd), AutoML and AutoDNN models |
| Output: Best Auto Predictive Maintenance Model (bAutoM) |
| 1. Train and evaluate AutoML Models: |
| 2. AutoML ← train_ AutoML (X_train, y_train) |
| 3. AutoML _metrics ← evaluate_model (AutoML, X_val, y_val) |
| 4. Train and evaluate AutoDNN Model |
| 5. AutoDNN←train_AutoDNN(X_train, y_train) |
| 6. AutoDNN _metrics = evaluate_model(AutoDNN, X_val, y_val) |
| 7. Model selection based on evaluation metrics (em): |
| 8. begin |
| 9. em←(acc, prec, rec, f1,cm) |
| 10. Best_evaluation_metrics (best_em) |
| 11. BAutoM←None |
| 12. best_em←[0, 0, 0, 0, None] |
| 13. for i in range (len(em)): |
| 14. if AutoML metrics[i] > AutoDNN_metrics[i] |
| 15. if AutoML_metrics[i] > best_em[i] |
| 16. BAutoM←AutoMl |
| 17. end if |
| 18. end if |
| 19. else if |
| 20. AutoDNN_metrics[i] > best_em[i] |
| 21. BAutoM←AutoDNN |
| 22. end if |
| 23. end for |
| 24. Return BAutoM |
| 25. end |
5. Case Study

6. Results and Analysis
6.1. Data Preparation Process
6.2. AutoML and AutoDNN Validation Models
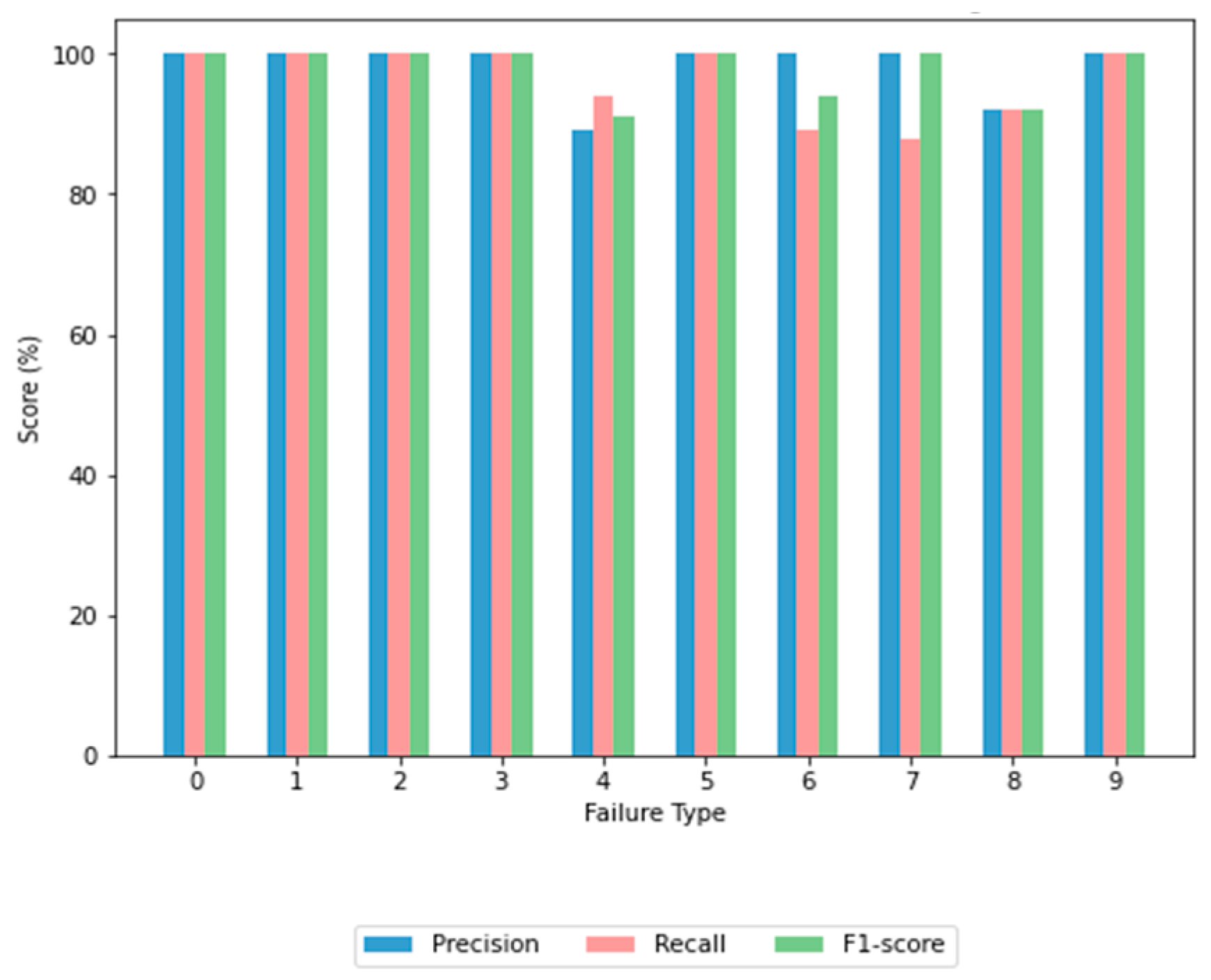
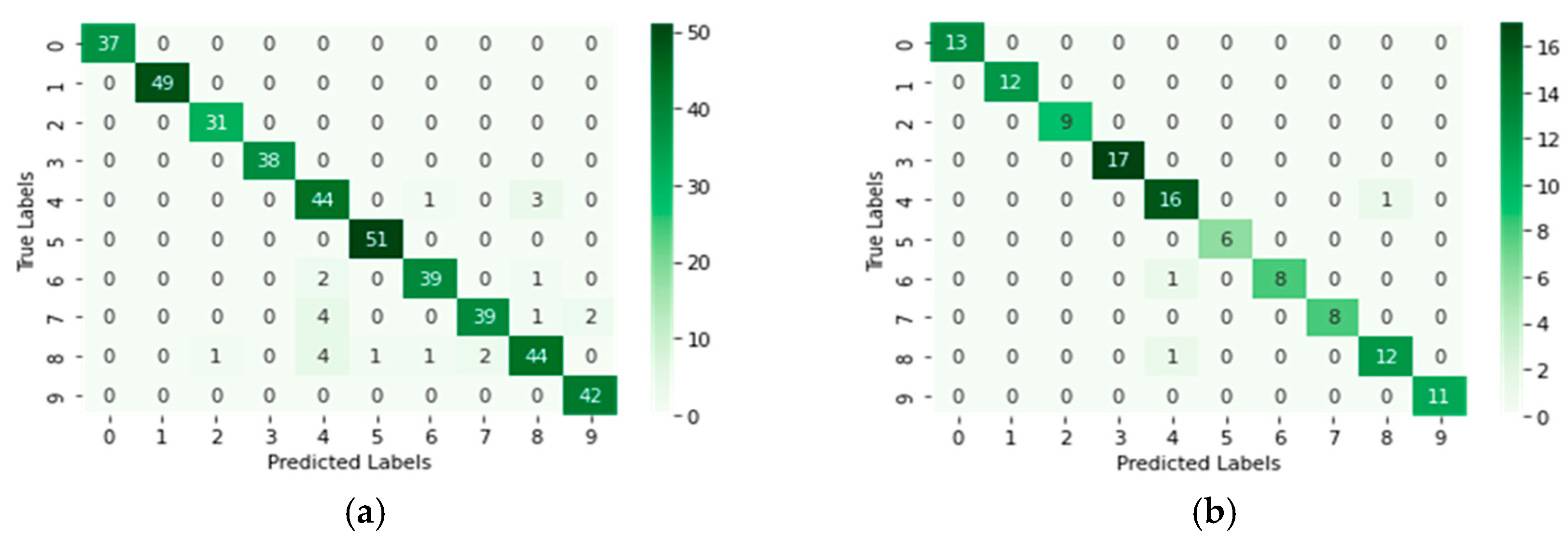
6.3. Model Evaluation
6.4. Results Discussion

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Method | Accuracy (%) | Number of Features |
|---|---|---|---|
| Lin [40] | Medium Gaussian SVM | 96.00 | 9 |
| Coarse Gaussian SVM | 93.60 | ||
| Fine Gaussian SVM | 89.60 | ||
| rms sd | 72.60 | ||
| 71.30 | |||
| Haung et al. [32] (training set of 75%) | back-propagation neural network (BPNN) | 91.60 | 4 |
| radial basis function neural network (RBFNN) | 83.60 | ||
| wavelet neural network (WNN) | 84.80 | ||
| Wang et al. [36] | CNN | 99.92 | 4 |
| Fulgencio et al. [38] | SVM | 84.70 | 16 |
| CNN | 90.60 | 16 | |
| Rajput et al. [39] | Fuzzy-CNN | 99.87 | 16 |
| Proposed AutoML model (PyCaret) | Best ML:RF (testing sets) | 99.70 | 9 |
| Best ML:RF (validation sets) | 95.60 | ||
| Proposed AutoDNN model (AutoKeras) | AutoDNN (testing sets) | 95.00 | |
| AutoDNN (validation Sets) | 97.00 |
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nasser:, A.R.; Hasan, A.M.; Humaidi, A.J.; Alkhayyat, A.; Alzubaidi, L.; Fadhel, M.A.; Santamaría, J.; Duan, Y. IoT and Cloud Computing in Health-Care: A New Wearable Device and Cloud-Based Deep Learning Algorithm for Monitoring of Diabetes. Electronics 2021, 10, 2719. [Google Scholar] [CrossRef]
- Alwan, N.F.; Al-Nuaimi, M.K. The Role and Important of Internet of Things in Building Sustainable City. Eng. Technol. J. 2018, 36, 22–29. [Google Scholar] [CrossRef]
- Nasser, A.R.; Azar, A.T.; Humaidi, A.J.; Al-Mhdawi, A.K.; Ibraheem, I.K. Intelligent Fault Detection and Identification Approach for Analog Electronic Circuits Based on Fuzzy Logic Classifier. Electronics 2021, 10, 2888. [Google Scholar] [CrossRef]
- Cao, Q.; Zanni-Merk, C.; Samet, A.; Reich, C.; Beuvron, F.D.B.D.; Beckmann, A.; Giannetti, C. KSPMI: A Knowledge-based System for Predictive Maintenance in Industry 4.0. Robot. Comput. Manuf. 2021, 74, 102281. [Google Scholar] [CrossRef]
- Natesha, B.; Guddeti, R.M.R. Fog-based intelligent machine malfunction monitoring system for industry 4.0. IEEE Trans. Actions Ind. Inform. 2021, 17, 7923–7932. [Google Scholar]
- Al-Khazraji, H.; Nasser, A.R.; Hasan, A.M.; Al Mhdawi, A.K.; Al-Raweshidy, H.; Humaidi, A.J. Aircraft Engines Remaining Useful Life Prediction Based on A Hybrid Model of Autoencoder and Deep Belief Network. IEEE Access 2022, 10, 82156–82163. [Google Scholar] [CrossRef]
- Cardoso, D.; Ferreira, L. Application of Predictive Maintenance Concepts Using Artificial Intelligence Tools. Appl. Sci. 2020, 11, 18. [Google Scholar] [CrossRef]
- Turner, S.; Jassin, S.S.; Hassan, A.K. Optimizing artificial neural networks using LevyChaotic mapping on Wolf Pack optimization algorithm for detect driving sleepiness. Iraqi J. Comput. Commun. Control Syst. Eng. (IJCCCE) 2022, 22, 128–136. [Google Scholar]
- Lee, W.J.; Wu, H.; Yun, H.; Kim, H.; Jun, M.B.; Sutherland, J.W. Predictive Maintenance of Machine Tool Systems Using Artificial Intelligence Techniques Applied to Machine Condition Data. Procedia CIRP 2019, 80, 506–511. [Google Scholar] [CrossRef]
- Abood, A.M.; Nasser, A.R.; Al-Khazraji, H. Predictive Maintenance of Electromechanical Systems Using Deep Learning Algorithms: Review. Ing. Syst. Inf. 2022, 27, 1009–1017. [Google Scholar] [CrossRef]
- Ayvaz, S.; Alpay, K. Predictive maintenance system for production lines in manufacturing: A machine learning approach using IoT data in real-time. Expert Syst. Appl. 2021, 173, 114598. [Google Scholar] [CrossRef]
- Fadhil, H.M.; Abdullah, M.N.; Younis, M.I. A Framework for Predicting Airfare Prices Using Machine Learning. Iraqi J. Comput. Commun. Control Syst. Eng. 2022, 22, 81–96. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Si, S.; Huang, S. Entropy Based Fault Classification Using the Case Western Reserve University Data: A Benchmark Study. IEEE Trans. Reliab. 2019, 69, 754–767. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, D.; Wang, H. Data-Driven Methods for Predictive Maintenance of Industrial Equipment: A Survey. IEEE Syst. J. 2019, 13, 2213–2227. [Google Scholar] [CrossRef]
- Tornede, T.; Tornede, A.; Wever, M.; Mohr, F. Automl for Predictive Maintenance: One Tool to Rul Them All, in IoT Streams for Data-Driven Predictive Maintenance and IoT, Edge, and Mobile for Embedded Machine Learning; Springer: Berlin/Heidelberg, Germany, 2020; pp. 106–118. [Google Scholar]
- Ferreira, L.; Pilastri, A.; Romano, F.; Cortez, P. Using supervised and one-class automated machine learning for predictive maintenance. Appl. Soft Comput. 2022, 131, 109820. [Google Scholar] [CrossRef]
- Shamayleh, A.; Awad, M.; Farhat, J. IoT Based Predictive Maintenance Management of Medical Equipment. J. Med. Syst. 2020, 44, 1–12. [Google Scholar] [CrossRef]
- Paolanti, M.; Romeo, L.; Felicetti, A.; Mancini, A.; Frontoni, E.; Loncarski, J. Machine Learning approach for Predictive Maintenance in Industry 4.0. In Proceedings of the 2018 14th IEEE/ASME International Conference on Mechatronic and Embedded Systems and Applications (MESA), Oulu, Finland, 2–4 July 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Nasser, A.; Al-Khazraji, H. A hybrid of convolutional neural network and long short-term memory network approach to predictive maintenance. Int. J. Electr. Comput. Eng. (IJECE) 2022, 12, 721–730. [Google Scholar] [CrossRef]
- Ayodeji, A.; Wang, Z.; Wang, W.; Qin, W.; Yang, C.; Xu, S.; Liu, X. Causal augmented ConvNet: A temporal memory dilated convolution model for long-sequence time series prediction. ISA Trans. 2022, 123, 200–217. [Google Scholar] [CrossRef]
- Leite, D.; Martins, A.; Rativa, D.; De Oliveira, J.F.L.; Maciel, A.M.A. An Automated Machine Learning Approach for Real-Time Fault Detection and Diagnosis. Sensors 2022, 22, 6138. [Google Scholar] [CrossRef]
- Tornede, T.; Tornede, A.; Wever, M.; Hüllermeier, E. Coevolution of remaining useful lifetime estimation pipelines for automated predictive maintenance. In Proceedings of the GECCO ’21: Genetic and Evolutionary Computation Conference, Lille, France, 10–14 July 2021; pp. 368–376. [Google Scholar] [CrossRef]
- Cinar, E.; Kalay, S.; Saricicek, I. A Predictive Maintenance System Design and Implementation for Intelligent Manufacturing. Machines 2022, 10, 1006. [Google Scholar] [CrossRef]
- Ferreira, L.; Pilastri, A.; Sousa, V.; Romano, F.; Cortez, P. Prediction of Maintenance Equipment Failures Using Automated Machine Learning. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Manchester, UK, 25–27 November 2021; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Garouani, M.; Ahmad, A.; Bouneffa, M.; Hamlich, M.; Bourguin, G.; Lewandowski, A. Towards Meta-Learning Based Data Analytics to Better Assist the Domain Experts in Industry 4.0. In Artificial Intelligence in Data and Big Data Processing, Proceedings of the International Conference on Artificial Intelligence and Big Data in Digital Era, Ho Chi Minh, Vietnam, 18–19 December 2021; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar] [CrossRef]
- Luo, C.; Zhang, Z.; Qiao, D.; Lai, X.; Li, Y.; Wang, S. Life Prediction under Charging Process of Lithium-Ion Batteries Based on AutoML. Energies 2022, 15, 4594. [Google Scholar] [CrossRef]
- Escalante, H.J.; Tu, W.-W.; Guyon, I.; Silver, D.L.; Viegas, E.; Chen, Y.; Dai, W.; Yang, Q. AutoML @ NeurIPS 2018 Challenge: Design and Results; Springer: Berlin/Heidelberg, Germany, 2019; pp. 209–229. [Google Scholar] [CrossRef]
- Loparo, K.; Case Western Reserve University Bearing Data Center. Bearings Vibration Data Sets; Case Western Reserve University: Cleveland, OH, USA, 2012; pp. 22–28. [Google Scholar]
- Wen, L.; Gao, L.; Li, X. A New Deep Transfer Learning Based on Sparse Auto-Encoder for Fault Diagnosis. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 136–144. [Google Scholar] [CrossRef]
- Magar, R.; Ghule, L.; Li, J.; Zhao, Y.; Farimani, A.B. FaultNet: A Deep Convolutional Neural Network for Bearing Fault Classification. IEEE Access 2021, 9, 25189–25199. [Google Scholar] [CrossRef]
- Sharma, N.; Sidana, T.; Singhal, S.; Jindal, S. Predictive Maintenance: Comparative Study of Machine Learning Algorithms for Fault Diagnosis. In Proceedings of the International Conference on Innovative Computing & Communication (ICICC), Delhi, India, 19–20 February 2022. [Google Scholar]
- Huang, M.; Liu, Z.; Tao, Y. Mechanical fault diagnosis and prediction in IoT based on multi-source sensing data fusion. Simul. Model. Pract. Theory 2019, 102, 101981. [Google Scholar] [CrossRef]
- Jian, X.; Li, W.; Guo, X.; Wang, R. Fault Diagnosis of Motor Bearings Based on a One-Dimensional Fusion Neural Network. Sensors 2019, 19, 122. [Google Scholar] [CrossRef]
- Gangavva, C.; Mangai, J.A. An Investigation of Ensemble Learning Algorithms for Fault Diagnosis of Roller Bearing. In Advances in Parallel Computing Algorithms, Tools and Paradigms; IOS Press: Amsterdam, The Netherlands, 2022; pp. 117–125. [Google Scholar] [CrossRef]
- Wen, L.; Li, X.; Gao, L. A transfer convolutional neural network for fault diagnosis based on ResNet-50. Neural Comput. Appl. 2019, 32, 6111–6124. [Google Scholar] [CrossRef]
- Wang, J.; Wang, D.; Wang, S.; Li, W.; Song, K. Fault Diagnosis of Bearings Based on Multi-Sensor Information Fusion and 2D Convolutional Neural Network. IEEE Access 2021, 9, 23717–23725. [Google Scholar] [CrossRef]
- Han, S.; Jeong, J. An Weighted CNN Ensemble Model with Small Amount of Data for Bearing Fault Diagnosis. Procedia Comput. Sci. 2020, 175, 88–95. [Google Scholar] [CrossRef]
- Cascales-Fulgencio, D.; Quiles-Cucarella, E.; García-Moreno, E. Computation and Statistical Analysis of Bearings’ Time-and Frequency-Domain Features Enhanced Using Cepstrum Pre-Whitening: A ML-and DL-Based Classification. Appl. Sci. 2022, 12, 10882. [Google Scholar] [CrossRef]
- Rajput, D.S.; Meena, G.; Acharya, M.; Mohbey, K.K. Fault prediction using fuzzy convolution neural network on IoT environment with heterogeneous sensing data fusion. Meas. Sensors 2023, 26, 100701. [Google Scholar] [CrossRef]
- Lin, S.-L. Application of Machine Learning to a Medium Gaussian Support Vector Machine in the Diagnosis of Motor Bearing Faults. Electronics 2021, 10, 2266. [Google Scholar] [CrossRef]
- Selcuk, S. Predictive maintenance, its implementation and latest trends. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2017, 231, 1670–1679. [Google Scholar] [CrossRef]
- Carvalho, T.P.; Soares, F.A.A.M.N.; Vita, R.; Francisco, R.D.P.; Basto, J.P.; Alcalá, S.G.S. A systematic literature review of machine learning methods applied to predictive maintenance. Comput. Ind. Eng. 2019, 137, 106024. [Google Scholar] [CrossRef]
- Zonta, T.; da Costa, C.A.; da Rosa Righi, R.; de Lima, M.J.; da Trindade, E.S.; Li, G.P. Predictive maintenance in the Industry 4.0: A systematic literature review. Comput. Ind. Eng. 2020, 150, 106889. [Google Scholar] [CrossRef]
- Ran, Y.; Zhou, X.; Lin, P.; Wen, Y.; Deng, R. A survey of predictive maintenance: Systems, purposes and approaches. arXiv 2019, preprint. arXiv:1912.07383. [Google Scholar]
- Qian, G.; Liu, J. A comparative study of deep learning-based fault diagnosis methods for rotating machines in nuclear power plants. Ann. Nucl. Energy 2022, 178, 109334. [Google Scholar] [CrossRef]
- Gain, U.; Hotti, V. Low-code AutoML-augmented data pipeline–a review and experiments. J. Phys. Conf. Ser. 2021, 1828, 012015. [Google Scholar] [CrossRef]
- Demidova, L.A. Recurrent Neural Networks’ Configurations in the Predictive Maintenance Problems. IOP Conf. Series Mater. Sci. Eng. 2020, 714, 012005. [Google Scholar] [CrossRef]
- Hu, X.; Ban, Y.; Nascetti, A. Uni-Temporal Multispectral Imagery for Burned Area Mapping with Deep Learning. Remote Sens. 2021, 13, 1509. [Google Scholar] [CrossRef]
- Jin, H.; Song, Q.; Hu, X. Auto-keras: An efficient neural architecture search system. In Proceedings of the 25th Acm Sigkdd International Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 4–8 August 2019. [Google Scholar]
- Singh, D.; Pant, P.K.; Pant, H.; Dobhal, D.C. Robust Automated Machine Learning (AutoML) System for Early Stage Hepatic Disease Detection. In Intelligent Data Communication Technologies and Internet of Things: Proceedings of ICICI 2020, Coimbatore, India, 27–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Boudiaf, A.; Moussaoui, A.; Dahane, A.; Atoui, I. A Comparative Study of Various Methods of Bearing Faults Diagnosis Using the Case Western Reserve University Data. J. Fail. Anal. Prev. 2016, 16, 271–284. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Wang, B.; Thomas, G. Habetler Deep learning algorithms for bearing fault diagnostics—A comprehensive review. IEEE Access 2020, 8, 29857–29881. [Google Scholar] [CrossRef]
- Li, S.-Y.; Gu, K.-R. Smart Fault-Detection Machine for Ball-Bearing System with Chaotic Mapping Strategy. Sensors 2019, 19, 2178. [Google Scholar] [CrossRef] [PubMed]
- Saidi, L.; Ben Ali, J.; Fnaiech, F. Application of higher order spectral features and support vector machines for bearing faults classification. ISA Trans. 2015, 54, 193–206. [Google Scholar] [CrossRef]
- Liu, C.; Tan, J.; Huang, Z. Fault Diagnosis of Rolling Element Bearings Based on Adaptive Mode Extraction. Machines 2022, 10, 260. [Google Scholar] [CrossRef]
- Neupane, D.; Seok, J. Bearing Fault Detection and Diagnosis Using Case Western Reserve University Dataset with Deep Learning Approaches: A Review. IEEE Access 2020, 8, 93155–93178. [Google Scholar] [CrossRef]
- Xu, Y.; Li, Z.; Wang, S.; Li, W.; Sarkodie-Gyan, T.; Feng, S. A Hybrid Deep-Learning Model for Fault Diagnosis of Rolling Bearings. Measurement 2021, 169, 108502. [Google Scholar] [CrossRef]
- Simeone, O. A Brief Introduction to Machine Learning for Engineers. Found. Trends® Signal Process. 2018, 12, 200–431. [Google Scholar] [CrossRef]
- Raschka, S. Python Machine Learning; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]










| Fault Type | Severity | Description | Abbreviation |
|---|---|---|---|
| Inner race | Small (7 mils) | Fault in the inner race of the bearing | IR_007_1 |
| Medium (14 mils) | IR_014_1 | ||
| Large (21 mils) | IR_021_1 | ||
| Outer race | Small (7 mils) | Fault in the outer race of the bearing | OR_007_6_1 |
| Medium (14 mils) | OR_014_6_1 | ||
| Large (21 mils) | OR_021_6_1 | ||
| Ball | Small (7 mils) | Fault in the balls of the bearing | Ball_007_1 |
| Medium (14 mils) | Ball_014_1 | ||
| Large (21 mils) | Ball_021_1 |
| Preprocessing Operation | Details |
|---|---|
| Data Balancing | Random Under Sampler |
| Normalization | Robust Scaler |
| Encoding | Categorical mapping ‘IR_007_1’: 0, ‘IR_014_1’: 1, ‘IR_021_1’: 2, ‘OR_007_6_1’: 3, ‘OR_014_6_1’: 4, ‘OR_021_6_1’: 5, ‘Ball_007_1’: 6, ‘Ball_014_1’: 7, ‘Ball_021_1’: 8, ‘Normal_1’: 9 |
| Description | Value |
|---|---|
| Session id | 8337 |
| Target | fault |
| Target type | Multiclass |
| Original data shape | (2185, 10) |
| Transformed data shape | (2185, 10) |
| Transformed train set shape | (1748, 10) |
| Transformed test set shape | (437, 10) |
| Numeric features | 9 |
| Number of folds | 10 |
| Model | Accuracy (%) | Recall (%) | Prec. (%) | F1 (%) | TT (S) |
|---|---|---|---|---|---|
| RF | 96.34 | 96.34 | 96.51 | 96.32 | 0.1610 |
| GBC | 96.28 | 96.28 | 96.52 | 96.28 | 0.9490 |
| ET | 96.23 | 96.23 | 96.43 | 96.22 | 0.1670 |
| LightGBM | 96.17 | 96.17 | 96.36 | 96.16 | 0.3560 |
| XGBoost | 95.94 | 95.94 | 96.12 | 95.92 | 0.0640 |
| Fold No. | Accuracy (%) | Recall (%) | Prec. (%) | F1 (%) |
|---|---|---|---|---|
| 0 | 96.57 | 96.57 | 96.84 | 96.60 |
| 1 | 94.86 | 94.86 | 95.15 | 94.88 |
| 2 | 96.57 | 96.57 | 96.98 | 96.61 |
| 3 | 96.57 | 96.57 | 97.00 | 96.55 |
| 4 | 98.86 | 98.86 | 98.89 | 98.86 |
| 5 | 97.71 | 97.71 | 97.74 | 97.70 |
| 6 | 94.29 | 94.29 | 94.23 | 94.14 |
| 7 | 96.00 | 96.00 | 96.20 | 95.99 |
| 8 | 97.13 | 97.13 | 97.12 | 97.11 |
| 9 | 95.40 | 95.40 | 95.64 | 95.24 |
| Mean | 96.40 | 96.40 | 96.58 | 96.37 |
| Std. | 0.0128 | 0.0128 | 0.0126 | 0.0131 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hadi, R.H.; Hady, H.N.; Hasan, A.M.; Al-Jodah, A.; Humaidi, A.J. Improved Fault Classification for Predictive Maintenance in Industrial IoT Based on AutoML: A Case Study of Ball-Bearing Faults. Processes 2023, 11, 1507. https://doi.org/10.3390/pr11051507
Hadi RH, Hady HN, Hasan AM, Al-Jodah A, Humaidi AJ. Improved Fault Classification for Predictive Maintenance in Industrial IoT Based on AutoML: A Case Study of Ball-Bearing Faults. Processes. 2023; 11(5):1507. https://doi.org/10.3390/pr11051507
Chicago/Turabian StyleHadi, Russul H., Haider N. Hady, Ahmed M. Hasan, Ammar Al-Jodah, and Amjad J. Humaidi. 2023. "Improved Fault Classification for Predictive Maintenance in Industrial IoT Based on AutoML: A Case Study of Ball-Bearing Faults" Processes 11, no. 5: 1507. https://doi.org/10.3390/pr11051507
APA StyleHadi, R. H., Hady, H. N., Hasan, A. M., Al-Jodah, A., & Humaidi, A. J. (2023). Improved Fault Classification for Predictive Maintenance in Industrial IoT Based on AutoML: A Case Study of Ball-Bearing Faults. Processes, 11(5), 1507. https://doi.org/10.3390/pr11051507