1. Introduction
Equipment and devices in industrial production are often influenced by equipment failures, environmental changes, and human errors, which may lead to abnormal process parameters. Abnormal process parameters can negatively impact production efficiency, product quality, and operational safety [
1]. Industrial processes involve many process parameters, such as temperature, pressure, and flow rate, and their ability to remain stable is crucial for product quality, safety, and efficiency [
2,
3]. Typically, these process parameters are configured with alarm thresholds, but there are noticeable trend abnormalities and fluctuations before reaching alarm thresholds without corresponding alarm notifications. Therefore, the diagnosis and alarm of abnormal trends in process parameters precisely address this limitation, and issuing trend-based alarms before reaching the alarm thresholds serves as an early warning. It plays a crucial role in on-site emergency handling, inspection, and maintenance, providing key advantages regarding timeliness and advance [
4,
5].
Researchers have recently proposed various methods for diagnosing abnormal process parameters, including clustering-based methods, density-based methods, data-driven methods, and expert system methods [
6,
7,
8,
9]. The clustering-based approach involves clustering the data of parameters into multiple clusters, where the cluster with the least data points is considered to be the abnormal cluster. In this method, the k-means algorithm [
10,
11] is widely used and recognized, but it requires predefining the number of clusters and is sensitive to the initial points, which can make diagnosis difficult and hinder the detection of outliers. The density-based approach identifies outliers based on the density distribution of the data [
12,
13]. Zheng et al. [
14] referenced a study on automatic modulation classification, which employed spectrum interference and data augmentation techniques to expand the training dataset, potentially improving the anomaly trend analysis. However, this method has problems, such as the need for many samples and the difficulty in making assumptions about the data distribution. The data-driven approach is a technique that utilizes the features and patterns of historical or real-time data to detect potential anomalies. Li et al. [
15] integrated data-driven methods in the context of multi-agent consensus in supply chain systems, which are essential for fault diagnosis. Zheng et al. [
16] introduced a prior regularization method in deep learning (DL-PR) to enhance the accuracy of automatic modulation classification (AMC), thereby improving the performance of deep learning models, especially in complex environments. The expert system approach involves building a knowledge base and reasoning mechanism to simulate the decision-making process of human experts [
17]. Nowak et al. [
18] analyzed the use of Local Outlier Factor (LOF), Connectivity-Based Outlier Factor (COF), and k-means algorithms for outlier detection in rule-based knowledge bases and achieved promising results.
In this paper, data mining is adopted to diagnose abnormal trends in process parameters, including KPCA, SVDD, and Radial Basis Function Convolutional Neural Network (RBF-CNN). Firstly, KPCA maps the data into a high-dimensional feature space and calculates the principal components using kernel functions, thereby achieving data dimensionality reduction and feature extraction [
19]. Secondly, the SVDD method transforms the dataset from the original space to a feature space using nonlinear transformations and then searches for the smallest volume hypersphere within the feature space [
20]. Lastly, RBF-CNN conducts feature extraction through convolutional and pooling layers, and the weights of the convolutional kernels and parameters of the pooling layers are optimized through neural network training [
21]. Unlike the characteristics of control loops, process parameters possess numerous features, and historical data often fail to include all of them. Therefore, the diagnosis of process parameters relies on comparing the similarity of recent data features to diagnose parameter anomalies. As the variations in process parameters typically occur rapidly, this diagnosis requires a high degree of real-time capability. The KPCA and SVDD methods excel in feature extraction with fast processing and outstanding real-time capabilities, making them suitable for parameter diagnosis. In contrast, the RBF-CNN method has a slower training speed and is unsuitable for parameter diagnosis. Among these three methods, only the KPCA approach alters the data dimensions. KPCA’s fundamental concept involves the nonlinear mapping of the input space into a high-dimensional feature space. In this process, its data are projected along the path of maximum variance, and kernel functions are applied to capture the process’s nonlinear features. Zhu et al. [
22] integrated KPCA with deep learning for applications in the field of fault diagnosis. Ned et al. [
23] proposed a partial least squares (PLS) method tailored to multistage batch processes, which better reflects the dynamic characteristics of actual processes. However, extracting features and identifying multiple transition points require understanding the process. Fazai et al. [
24] proposed a fusion of the generalized likelihood ratio test with the Partial Least Squares (PLS) method to establish a fault detection model for application in chemical process monitoring. Dimoudis et al. [
25,
26] used an adaptive window with the rolling median method for time-series anomaly detection for real-time diagnosis. Rafferty et al. [
27] and Dong et al. [
28] introduced sliding window PCA and process monitoring PCA algorithms for real-time fault diagnosis. However, these are unsuitable for nonlinear and single-process parameter scenarios.
The core concept of SVDD is to construct a hypersphere that maximally encloses the positive samples in the training set and achieves the greatest separation between positive and negative samples. Tax and Duin initially proposed the SVDD method based on the support vector foundation [
29]. They further refined the SVDD model and demonstrated the feasibility of using kernel functions instead of inner product operations. Additionally, when employing a radial basis kernel function, it can be proven that the SVDD and One-Class Support Vector Machine (OCSVM) methods are equivalent and consistent with the findings in reference [
30]. Zhang et al. [
31] combined the Kernel-based Incremental Support Vector Data Description (KISVDD) with a sliding window for fault diagnosis, focusing only on positive samples during training. However, their approach might lack flexibility in handling abnormal samples, potentially leading to performance degradation, especially for adjacent anomalies.
It is generally challenging to detect all types of anomalies in process parameters using a single algorithm. Therefore, research on expert systems in chemical safety has gained increasing attention. Expert system rules are a fundamental form of knowledge in expert systems, representing a set of rules established by domain experts to describe the knowledge and experiences in a specific field. These rules are typically structured as ‘IF-THEN’ [
32]. Guo et al. [
33] designed 22 expert system rules for diagnosing variable refrigerant flow parameters. However, the comprehensive handling of individual expert system knowledge is often difficult and inefficient. As a result, researchers commonly combine rules with other methods. Zhou et al. [
34] proposed an integrated framework of machine learning and expert systems to enhance the flexibility and efficiency of building energy management. This approach leverages solar photovoltaic and battery technology to reduce electricity costs and enable adaptability to changing external conditions.
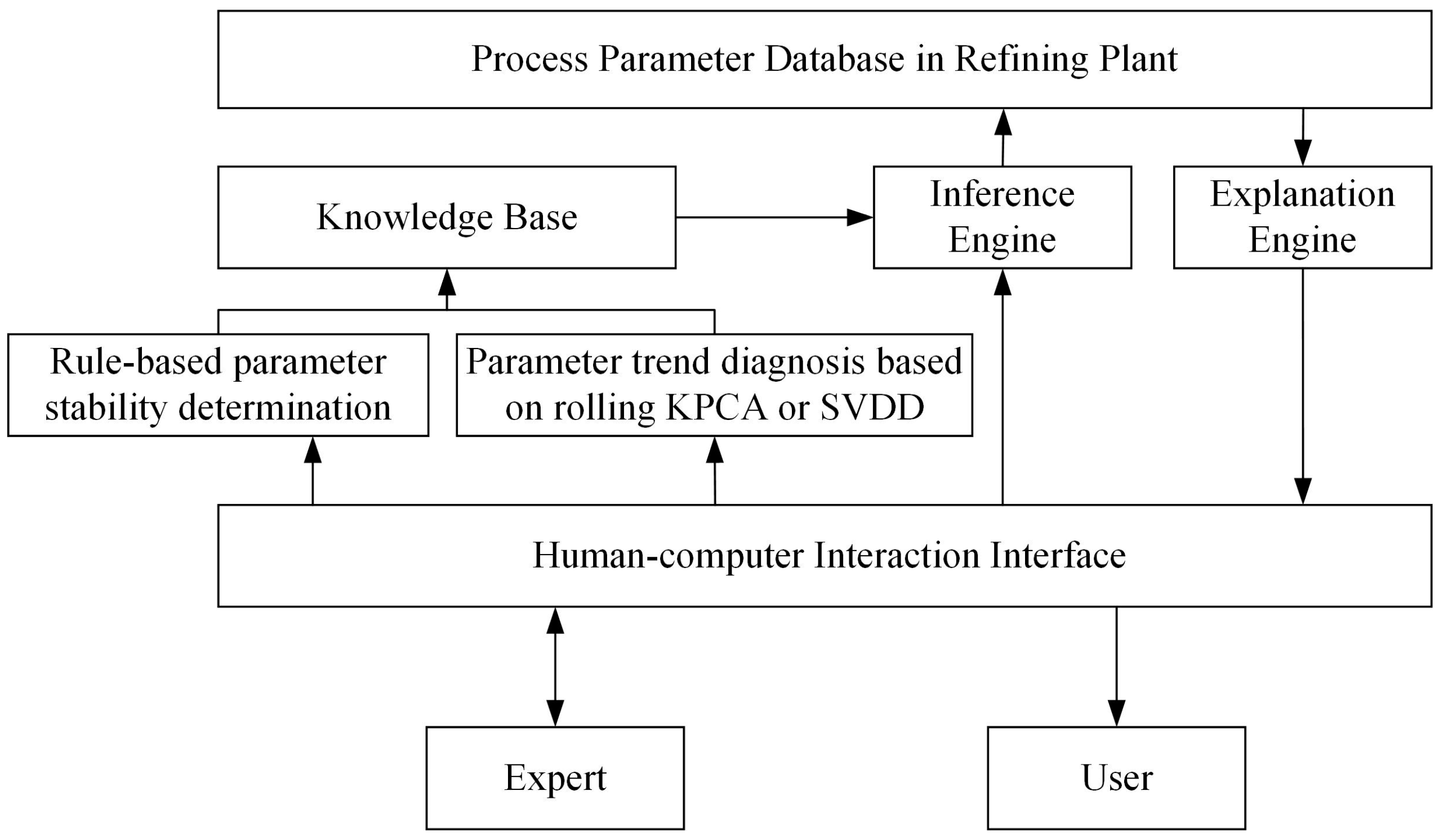
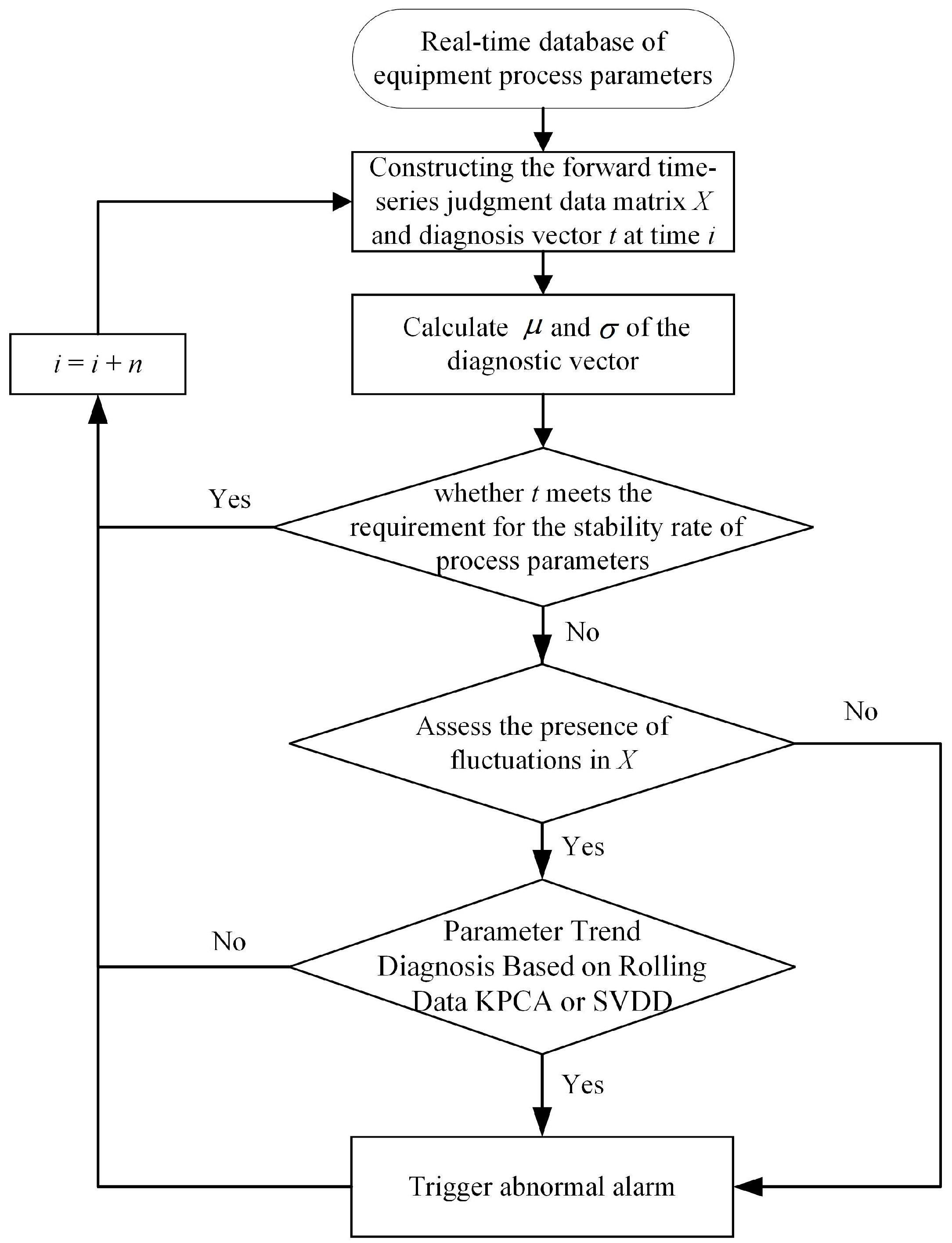
In conclusion, this paper integrates expert rules with data-driven methods to design and apply the ES-KPCA and ES-SVDD methods. The system combines a rule-based assessment of process parameter stability with rolling data KPCA and SVDD diagnosis of process parameter trend anomalies. Its objective is to enhance the accuracy and efficiency of detecting nonlinear single-process parameter anomalies in industrial production. It should be noted that rolling data are essentially equivalent to sliding windows, but the rolling data-based KPCA method is distinct from Sliding Window KPCA [
35]. Sliding windows focus on data within a fixed window that moves along the data to capture different periods and are commonly used in statistical and time series analyses. This paper constructs rolling data by building a rolling data matrix and comparing the similarity between diagnosis vectors and forward time-series judgment data matrices, emphasizing real-time analysis. Finally, the system is validated and evaluated using actual data from a domestic refining and chemical plant and UniSim simulation data, demonstrating its effectiveness and practicality in real-world applications.
2. Basic Overview
2.1. Process Parameters in the Process Industry
Process parameters are essential in the process industry, as they significantly impact the product quality and production efficiency in different units and process steps [
36]. These parameters include temperature, pressure, flow rate, catalyst feed rate, hydrogen usage, and ratios. Maintaining the critical process parameters within normal ranges is crucial for producing high-quality products and improving production efficiency. Abnormalities in these parameters can result in a reduced production quality, decreased product yield, increased energy consumption, and other issues.
2.2. Abnormal Trend Diagnosis of Process Parameters
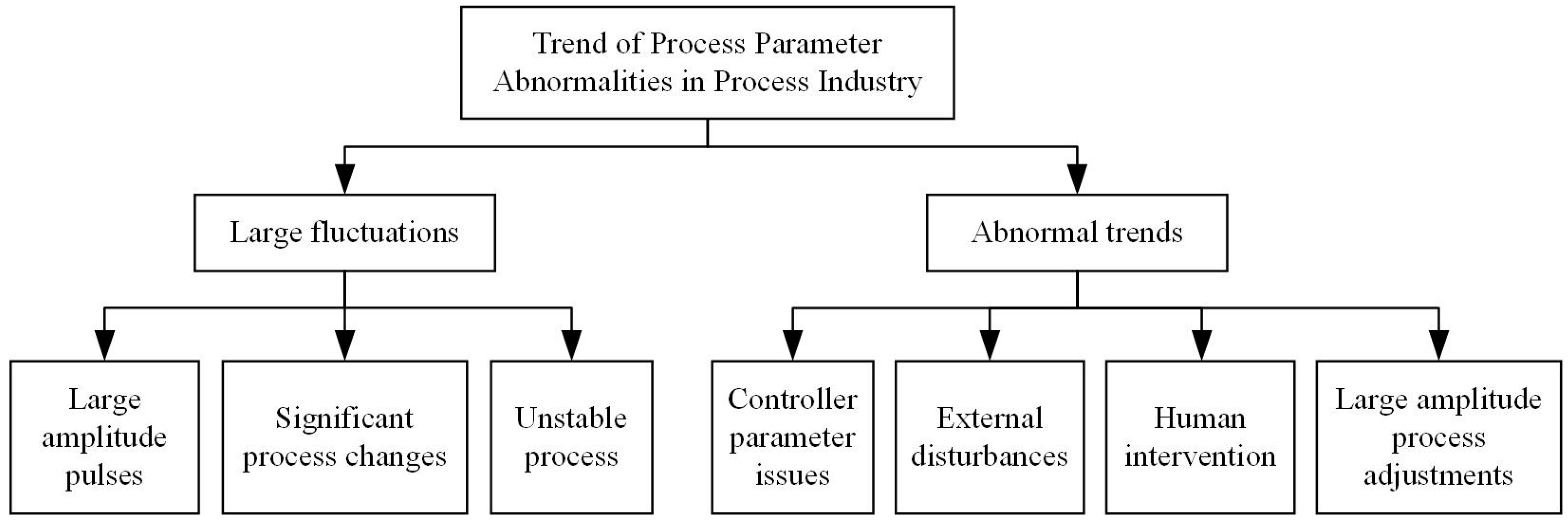
The trend diagnosis of process parameters in refining units is a method for monitoring and analyzing process parameters to determine whether they exhibit stable behavior or abnormal trends. Various causes can lead to abnormal trends in process parameters, such as operational errors by operators, possible damage or wear of equipment components, potential blockages in pumps or valves, and extreme weather conditions, which can adversely affect production units.
Figure 1 illustrates the abnormal trends and causes of process parameters in a refining unit. Abnormal trends can be categorized as large fluctuations and abnormal trends.
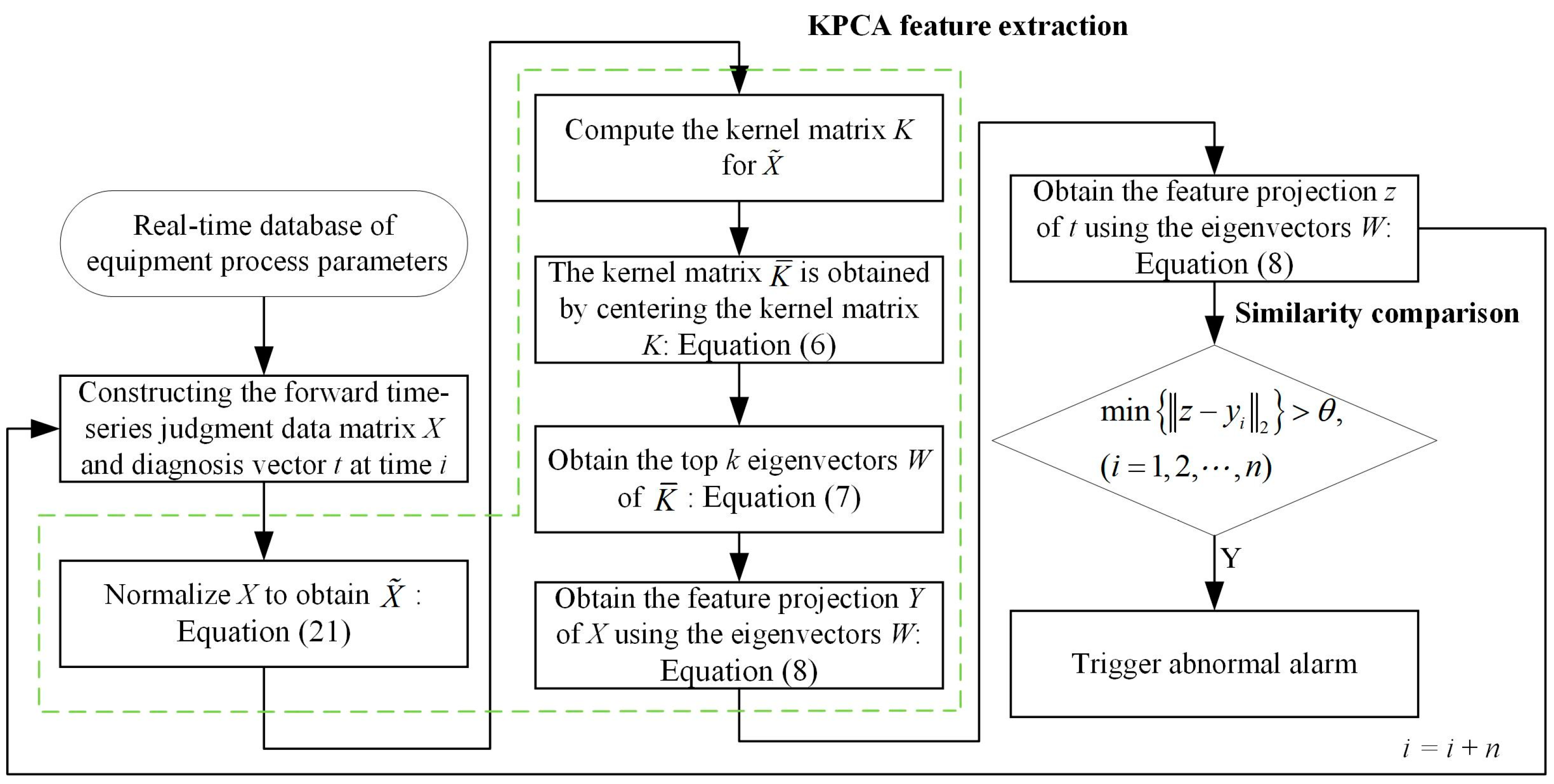
2.3. Rolling Data Matrix
The data set collected for process parameters in the industry has only two features: timestamps and parameter values. To conduct a trend diagnosis for the process parameters, they are elevated to higher dimensions based on their chronological order in the time series. As shown in Equation (1), using different real-time moments
as the basis, the most recent parameter column vector is constructed as the diagnosis vectors for discrimination. Subsequently, a forward time series judgment data matrix is formed for comparison based on similarity. Each matrix column represents the process parameter values for a specific period, incrementally rolling forward with the increase in
.
where
is the process parameter data,
is the rolling step,
is the number of samples in the judgment data matrix, and
is the current moment.
2.4. KPCA
KPCA is a kernel function-based principal component analysis method that maps high-dimensional data into a low-dimensional space to discover the main features and structure of the data. Unlike traditional PCA methods, KPCA uses kernel functions instead of linear transformations and can handle nonlinear data and preserve the nonlinear structure of the original data in a low-dimensional space [
19]. To make the maximum data variance information retained in the new low-dimensional space, KPCA uses Singular Value Decomposition (SVD) to compute the linear transformation matrix
[
37]. The feature extraction steps are as follows:
Suppose the original data set is
and
. A nonlinear mapping function
is introduced to project the original data set
into the high-dimensional feature space
. The covariance matrix
of the high-dimensional feature space is expressed as:
Let
be the eigenvalues of the covariance matrix
, and
be the corresponding eigenvectors. Then, the eigenvalue problem for
is expressed as:
where the symbol 〈 〉 denotes the inner product, and
in the feature space is expressed as:
where
is a constant factor.
The new equation is obtained by taking the inner product of both sides of the equation in Equation (2) and combining it with Equation (3).
The kernel matrix is introduced to avoid high-dimensional operations, leading to the kernel matrix . The prevalent kernel functions encompass the linear, polynomial, Gaussian, and Sigmoid types, with the selection contingent upon specific needs.
The kernel matrix
is then subjected to centering processing.
where
is an
dimensional identity matrix with coefficients of
.
With Equation (4), the eigenvalue problem for
is expressed as:
The selection of kernel principal components depends on Select the eigenvectors corresponding to the first larger eigenvalues to reduce the dimensionality of the data. The matrix composed of k eigenvectors is denoted as , where , .
The original data matrix
undergoes a linear transformation through the matrix
, resulting in its projection on the feature space:
Due to the capability of KPCA to perform nonlinear transformations, it is suitable for various types of data.
2.5. SVDD
The basic idea of SVDD is to construct a hyperborder to form a hypersphere to contain as many positive samples as possible in the training samples and achieve the maximum separation of positive and negative samples [
38,
39]. The core problem of SVDD is to find the optimal bound to achieve the optimal detection effect.
Suppose there is a set of normal training data
, where
is the number of samples and
is the feature dimension. The data are mapped from the original space to the feature space with the nonlinear transformation function
, and a hypersphere with the smallest volume is found in the feature space. Refer to Equation (9) for details:
where
is the radius of the hypersphere,
is the center of the hypersphere circle,
is the relaxation variable, and
is a constant whose role is to control the minimization of the radius
and the trade-off of the relaxation variable.
Combined with the Lagrange multiplier method, Equation (9) can be transformed into the dual problem of Equation (10) as follows:
where
is the Lagrange coefficient corresponding to
.
In cases where the hypersphere boundary cannot ensure precise classification, the SVDD can be enhanced using the kernel function approach. This involves mapping the training data to a higher-dimensional space for hypersphere calculations.
Among all the normal training samples, the samples for which the Lagrange coefficients satisfy
are referred to as support vectors. The set of support vectors belonging to the training dataset is denoted as
SV and can be used to compute the center and radius of the hypersphere using Equation (11).
where
and
is the Kernel function. The prevalent kernel functions encompass the linear, polynomial, Gaussian, and Sigmoid types, with the selection contingent upon specific needs.
For a test sample
, calculate its distance to the center of the hypersphere:
If , it indicates that the test sample is on or inside the surface of the hypersphere and belongs to the normal samples. Conversely, if , it belongs to the abnormal samples.
In the actual training process, it is recommended to include a small number of negative class samples in the training set of positive class samples to prevent overfitting. Let us assume that the positive class samples and negative class samples in the training set are labeled as follows:
The dual problem is then transformed as:
The formula for calculating the center and radius of the hypersphere is:
The distance from the test sample
xt to the center of the hypersphere is:
2.6. Similarity Comparison
The main purpose of similarity comparison in this study is to compare the diagnosis vector with the forward time series judgment data matrix after the feature extraction. Specifically, the diagnosis vector and forward data are subjected to feature extraction and compared.
The KPCA uses distance as the metric for a similarity comparison. After a dimensionality reduction and the feature extraction of the diagnosis vector and the forward time series judgment data matrix, the Euclidean norm (L2-norm) is employed to compare their distances. The KPCA emphasizes differences. If the Euclidean norm between the diagnosis vector features and the minimum features of each column in the forward time series judgment data matrix is still large, it indicates dissimilarity and triggers an anomaly alarm.
On the other hand, the SVDD performs similarity comparison by determining whether the diagnosis vector lies within the hypersphere trained using the forward time series judgment data matrix. If the diagnosis vector is inside the hypersphere, it indicates similarity with the forward data; otherwise, it is considered to be dissimilar.
4. Experiment
In this chapter, the threshold offline parameter adjustment process and online diagnosis were conducted using the UniSim Design R390 at the simulation base of China University of Petroleum (Beijing). The offline parameter adjustment process was also performed using data from a domestic refinery for the analysis and adjustment of the results.
In the experiments, the rolling step size of the forward time series judgment data matrix and diagnosis vector was set to
, and the number of samples in the judgment data matrix was set to
. The outlier cleaning parameter was set to
. Due to the strong nonlinear relationship and high dimensionality of the process parameter data, as well as the complex decision boundaries in SVDD, the kernel functions of all the methods in the entire experimental section were selected as Gaussian kernel functions.
where
and
represent the process parameter data and
denotes the bandwidth parameter of the Gaussian kernel function.
4.1. Data Set
UniSim is a chemical process simulation software developed by Honeywell Process Solutions. This experiment established an OPC interface to connect to the EPKS server, enabling communication between the expert system and UniSim. The experiment used the liquid-level parameter LIC1506.PV of the reflux drum, the flow parameter FIC1013.PV of the first line air cooler inlet from the atmospheric section of a five-million-ton continuous reduction pressure unit, and the fuel oil pressure parameter PIC1411.PV of the atmospheric furnace. During the data acquisition, the manual mode was used to set operating points (OP), and the automatic mode was used to set setpoints (SP) to simulate abnormal occurrences. This approach allowed for actively generating and resolving anomalies during the data sampling. The sampling frequency was set to 5 s, and the collected historical data were used for the offline parameter adjustment of the expert system, observing its anomaly diagnostic results. Similarly, anomalies were actively created and resolved during the online diagnosis process to observe the expert system’s diagnostic and alarm results. The startup frequency was set to 1 min to verify the rationality of the parameter adjustments.
Furthermore, the historical data for one year were obtained from a catalytic cracking unit at a petrochemical plant in China. The data included the temperature parameter TIC205.PV and flow rate parameter FIC209.PV from the second distillation tower with a sampling frequency of 20 s, totaling 1,576,800 data sets. These data were used for the offline parameter adjustment of the expert system and to analyze the effectiveness of the process parameter anomaly diagnosis, validating the practical application performance of the algorithm. A startup frequency of 4 min was set for the offline parameter adjustment only in this experiment.
4.2. Evaluation Metrics for Diagnostic Performance
This experiment used three metrics, precision, recall, and
F1-score, to evaluate the diagnostic performance. The precision represents the ratio of true positive predictions to all positive predictions made by the model. The recall represents the ratio of true positive predictions to all actual positive cases. The
F1-score is a combined metric that considers both the precision and recall to assess the overall performance of the model. The calculations of these metrics are as follows:
Among them, TP (True Positive) represents the number of positive examples correctly predicted by the model.
FP (False Positive) represents the number of negative examples incorrectly predicted as positive by the model.
FN (False Negative) represents the number of positive examples incorrectly predicted as negative by the model.
Generally, a higher precision indicates a lower misclassification rate by the model. A higher recall indicates that the model is better at identifying abnormalities. Accuracy, precision, and F1-score are comprehensive metrics for evaluating a model’s performance.
4.3. Experiment and Validation with UniSim Simulation Data
4.3.1. The Offline Threshold Parameter Adjustment Phase in UniSim
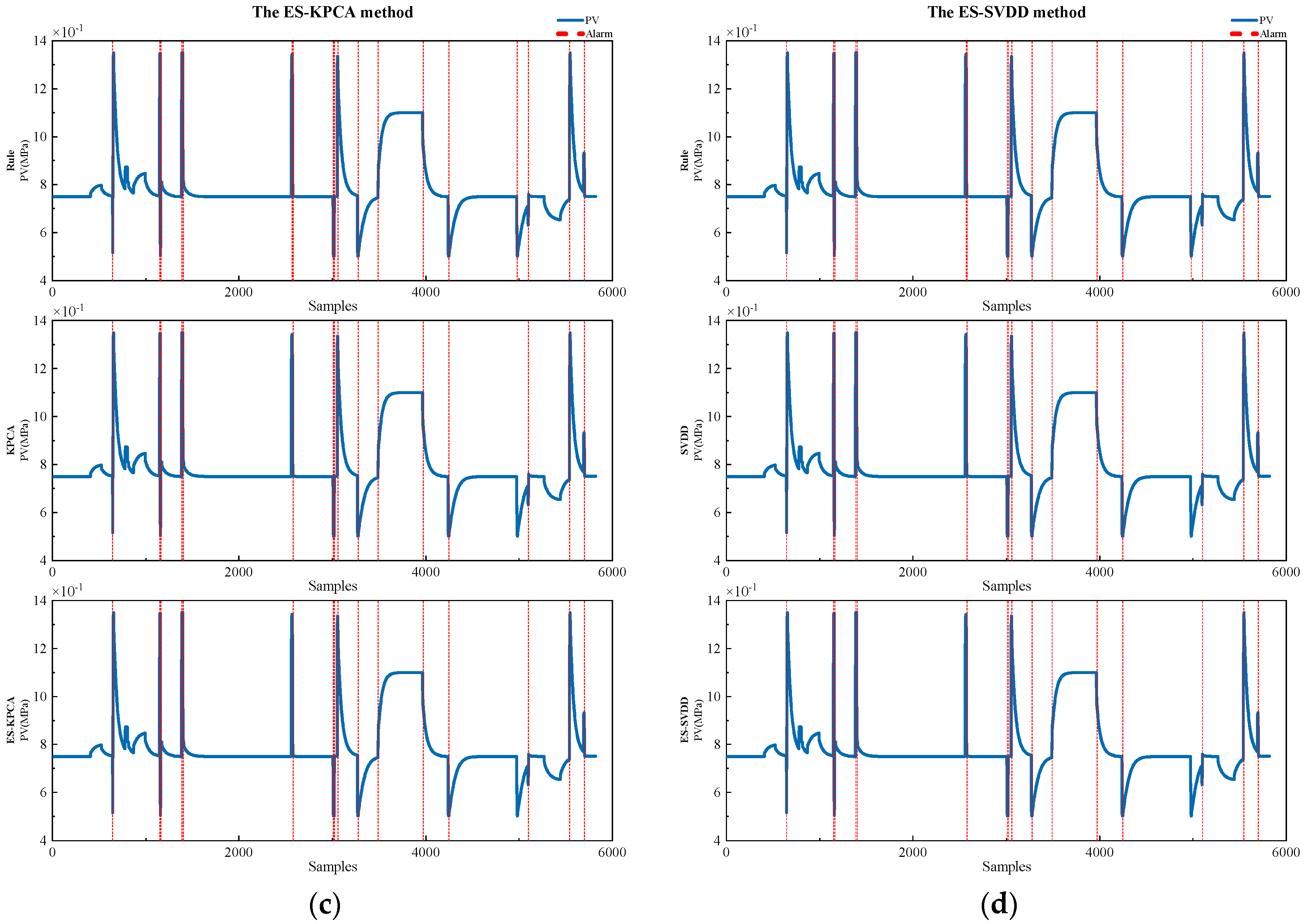
Based on The Offline Threshold Parameter Adjustment Phase of the ES-KPCA and ES-SVDD methods described in
Section 3.4.2, 8726 data samples were used for the adjustment, resulting in 687 diagnostic instances. The first 480 data samples were used to initially construct the forward time series judgment data matrix without performing diagnostics. The fault settings are summarized in
Table 1. After the parameter adjustment, the alarm results are illustrated in
Figure 6,
Figure 7 and
Figure 8, where the blue solid line represents the PV values of the respective process parameters, and the red dashed line indicates the alarm positions.
As shown in
Figure 6,
Figure 7 and
Figure 8, all faults in the three process parameters are diagnosed by both methods. In
Figure 6 and
Figure 8, the alarm positions obtained by the ES-KPCA and ES-SVDD methods are consistent. In
Figure 7, during the continuous fluctuations observed from samples 2219 to 2531, the ES-KPCA method triggers 10 alarms, while the ES-SVDD method triggers 1 alarm. At sample 7300, the ES-KPCA method triggers two alarms, while the ES-SVDD method does not trigger an alarm due to the anomalies observed at samples 6923 and 6935. Thus, the ES-KPCA method emphasizes real-time alarms, while the ES-SVDD method focuses on the first alarm, which has been validated. Additionally, at sample 3707, the ES-SVDD method exhibits a slight false alarm due to minor operational adjustments. The forward time series judgment data matrix is relatively stable, resulting in a smaller radius of the constructed hypersphere, and the diagnosis vector lies outside the hypersphere.
Table 2 and
Table 3 present the offline parameter adjustment results for the ES-KPCA and ES-SVDD methods.
4.3.2. The Online Diagnosis Phase in UniSim
In the online diagnostic phase, the relevant parameters obtained from the offline threshold parameter adjustment phase in
Table 2 and
Table 3 are acquired for the ES-KPCA and ES-SVDD methods. The three process parameters were diagnosed online 444 times, with 5920 real-time data samples being collected. For comparison purposes, the KPCA method and the SVDD method were replaced with the PCA method and the OCSVM method, respectively, resulting in the expert system for the process parameter trend anomaly diagnosis based on rolling data PCA and OCSVM (ES-PCA and ES-OCSVM). The similarity thresholds for the ES-PCA and ES-OCSVM methods were denoted as
and
, respectively. Other relevant threshold parameters remained the same for both methods. The detailed parameter configurations are presented in
Table 4.
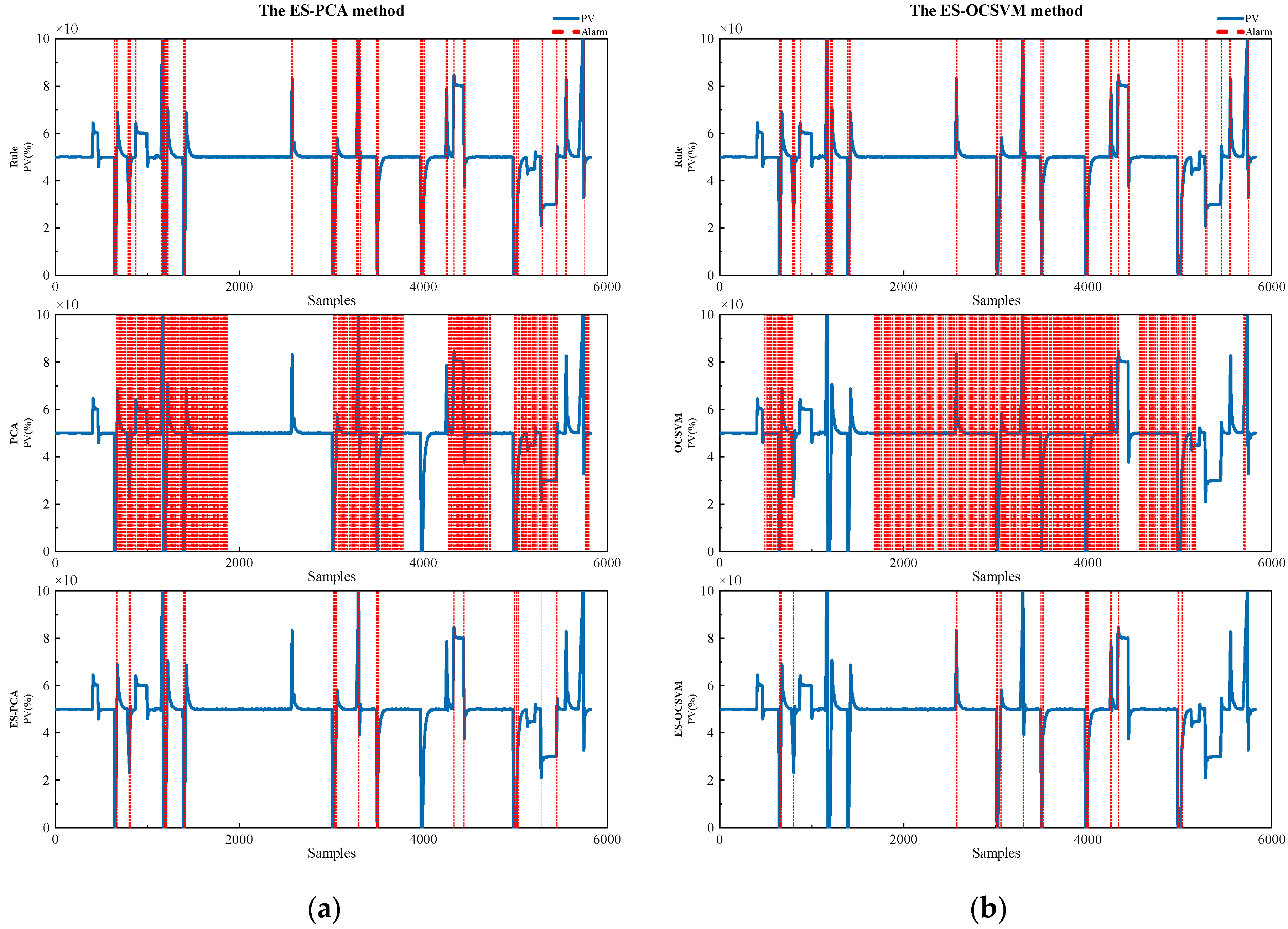
In
Figure 9a, the rolling data PCA method exhibits excessive false positives. Under the rule specified by the expert system, the ES-PCA method detected 9 out of 10 for large amplitude pulses and 1 missed detection; 2 large amplitude process adjustments were detected, but there were 3 false alarms for small amplitude process adjustments, indicating a relatively bad diagnostic performance. In
Figure 9b, the rolling data OCSVM method generates multiple false positives between samples 491 and 1451. However, after applying the specified rule, the ES-OCSVM method detected 9 out of 10 large amplitude pulses and 1 missed detection; 2 large amplitude process adjustments were detected, but there was 1 false alarm for small amplitude process adjustments, indicating a moderate diagnostic performance.
Figure 9c,d shows that the ES-KPCA method triggered 22 alarms, while the ES-SVDD method triggered 24 alarms. They include all 10 large amplitude pulses and 2 large amplitude process adjustments, without any false alarms for small amplitude process adjustments, indicating an excellent diagnostic performance.
In
Figure 10a, the rolling data PCA method shows excessive false positives and missed positives. Under the constraints of the rule, the ES-PCA method detected 8 out of 11 large amplitude pulses and 3 missed detections; 3 large amplitude process adjustments were detected, but there was 1 false alarm for 6 small amplitude process adjustments, and 1 out of 2 significant progressive adjustments were detected with 1 missed detection, indicating a moderate diagnostic performance. In
Figure 10b, the rolling data OCSVM method generates too many false positives and some false negatives. The ES-OCSVM method detected 6 out of 11 large amplitude pulses and 5 missed detections, 1 detected for 3 large amplitude process adjustments with 2 missed detections, no false alarms for 6 small amplitude process adjustments, and detected 1 out of 2 significant progressive adjustments with 1 miss, indicating a relatively poor diagnostic performance.
Figure 10c,d shows that the ES-KPCA method has a total of 15 alarms, while the ES-SVDD method has a capacity for 36 alarms. Both methods detected all 11 large amplitude pulses, and the ES-SVDD method had more alarms for individual pulses than the ES-KPCA method, which is consistent with the training results. They detected all three large amplitude process adjustments and did not produce any false alarms for six small amplitude process adjustments. For the two significant progressive adjustments, the ES-KPCA method had one alarm and one missed detection, while the ES-SVDD method had two alarms and no missed detections, indicating that the ES-KPCA method’s ability to detect anomalies caused by long-term small trends is weak.
In
Figure 11a, the ES-PCA method detected six out of nine large amplitude pulses and three missed detections, two large amplitude process adjustments were detected, and there were no false alarms for eight small amplitude process adjustments. In
Figure 11b, the ES-OCSVM method detected six out of nine large amplitude pulses and three missed detections, one detected for two large amplitude process adjustments with one missed detection, and no false alarms for eight small amplitude process adjustments.
Figure 11c,d shows that the ES-KPCA and ES-SVDD methods had similar alarm locations, with 15 alarms. They detected all nine large amplitude pulses, two large amplitude process adjustments, and there were no false alarms for eight small amplitude process adjustments, indicating an excellent diagnostic performance.
Due to an excessive number of stable samples in the data of the process parameters, the values of the three evaluation indicators in Equations (24)–(26) are excessively large, making data analysis difficult. To facilitate a better analysis, the following strategies are adopted:
Defining samples with large amplitude pulses, large amplitude process adjustments, and large amplitude gradual adjustments as negative samples.
Defining samples with small amplitude process adjustments as positive samples.
The evaluation results of diagnostic performance for the three parameters are shown in
Table 6.
According to
Table 6, for the pressure parameter FIC1013.PV, the ES-KPCA method and the ES-SVDD method models have the same
F1-score, which is higher than that of the ES-PCA and ES-OCSVM methods. This indicates that the ES-KPCA and ES-SVDD methods have a similar and superior performance compared to the ES-PCA and ES-OCSVM methods. For the level parameter LIC1506.PV, the ES-SVDD method has a higher
F1-score than the other three methods, and the ES-KPCA method has a higher
F1-score than the ES-PCA and ES-OCSVM methods, indicating that the ES-SVDD method performs the best. For the pressure parameter PIC1411.PV, both the ES-KPCA and ES-SVDD methods have the same
F1-score, which is higher than that of the ES-PCA and ES-OCSVM methods, indicating that both the ES-KPCA and ES-SVDD methods are equally good. In summary, for the flow rate and pressure parameters, the ES-KPCA and ES-SVDD methods have a similar diagnostic performance, while, for the level parameter, the ES-SVDD method outperforms the ES-KPCA method.
4.4. Experiment and Validation with Real Data
The data from a domestic refinery for one year were used, and the same comparative experiment as in
Section 4.3 was conducted. During the offline threshold parameter adjustment phase, a total of 131,360 diagnoses were performed using 1,576,800 data sets. The parameter tuning results for the ES-KPCA and ES-SVDD methods are presented in
Table 7 and
Table 8. The parameter settings for the ES-PCA and ES-OCSVM methods in the comparative experiment are shown in
Table 9. The results of the parameter tuning are illustrated in
Figure 12 and
Figure 13.
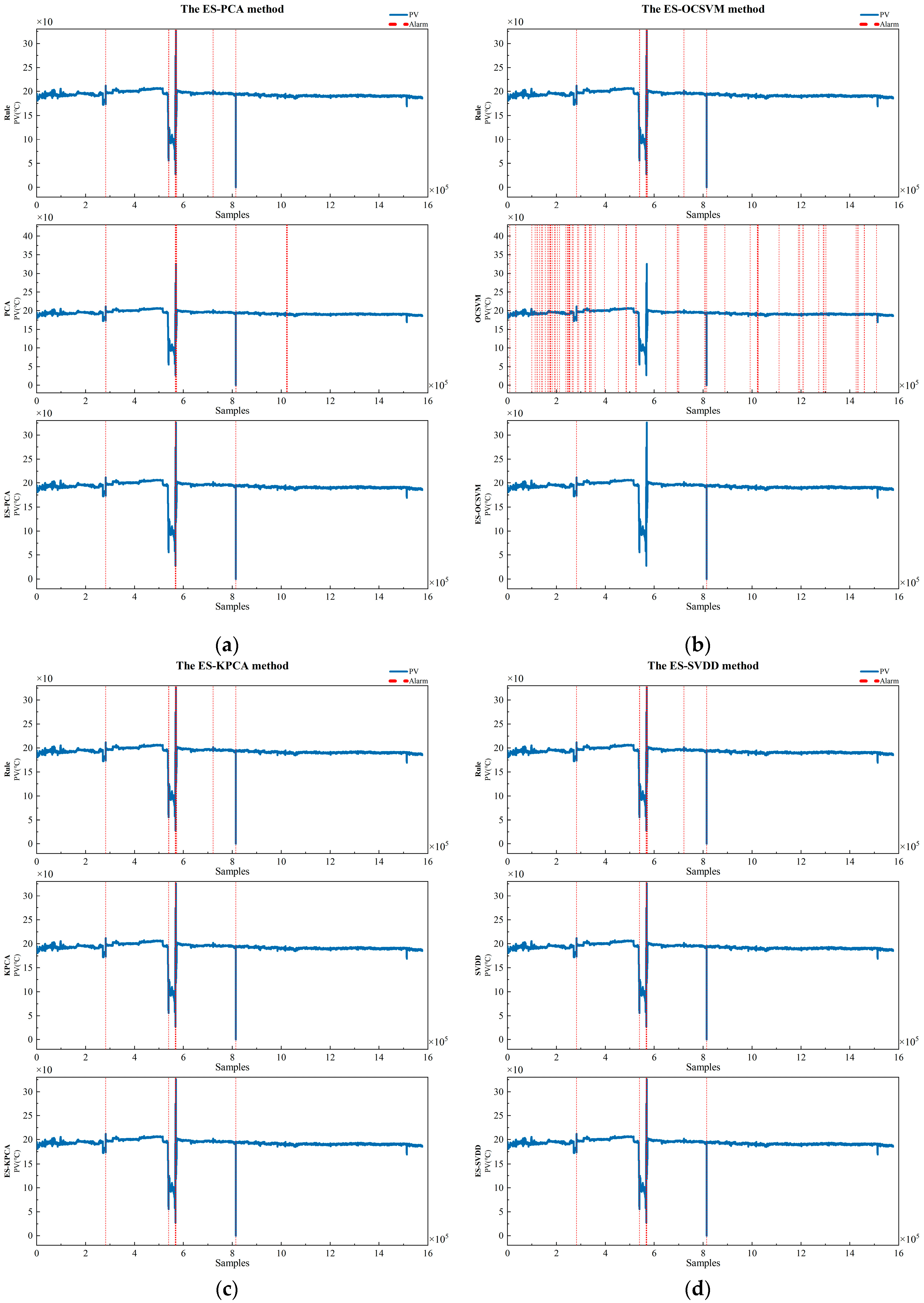
The offline diagnosis results for the process parameter FIC209.PV are shown in
Figure 12, where the expert system successfully detects and eliminates the outlier at sample 1,107,680. In
Figure 12a, the rolling data PCA method detects all anomalies but suffers from both false positives and discrepancies with rule-based alarms. Consequently, the ES-PCA method misses four occurrences at samples 31,895, 331,955, 515,867, and 719,915 while falsely reporting two instances at samples 789,335 and 1,548,311. In
Figure 12b, the rolling data OCSVM and ES-OCSVM methods detect all anomalies, but they also exhibit false positives and discrepancies with rule-based alarms. The ES-PCA method misses six occurrences at samples 27,059, 271,091, 331,955, 515,867, 646,895, and 719,915, while falsely reporting one occurrence at sample 1,548,311. In
Figure 12c, the ES-KPCA method has one false negative at sample 331,955. However, in
Figure 12d, the ES-SVDD method successfully detects all the anomalies in the trend.
For the process parameter TIC205.PV, the offline training results are shown in
Figure 13, where the expert system successfully detects and eliminates the outlier at sample 1,107,680. In
Figure 13a, the ES-PCA method has a false negative at sample 540,083, and, in
Figure 13b, the OCSVM method exhibits a higher overall false positive rate and also misses some instances. Under the constraints of the rules, the ES-OCSVM method experiences false negatives at samples 540,083 and 569,975. However, in
Figure 13c,d, the ES-KPCA and ES-SVDD methods successfully detect all the anomalies in the trend.
In summary, the ES-KPCA and ES-SVDD methods demonstrated a superior performance in process parameter diagnosis, effectively detecting large-scale process adjustments and outliers while avoiding false alarms, showcasing an excellent diagnostic efficacy. In comparison, the ES-PCA and ES-OCSVM methods exhibited relatively less favorable diagnostic outcomes, displaying some instances of missed detections.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}