1. Introduction
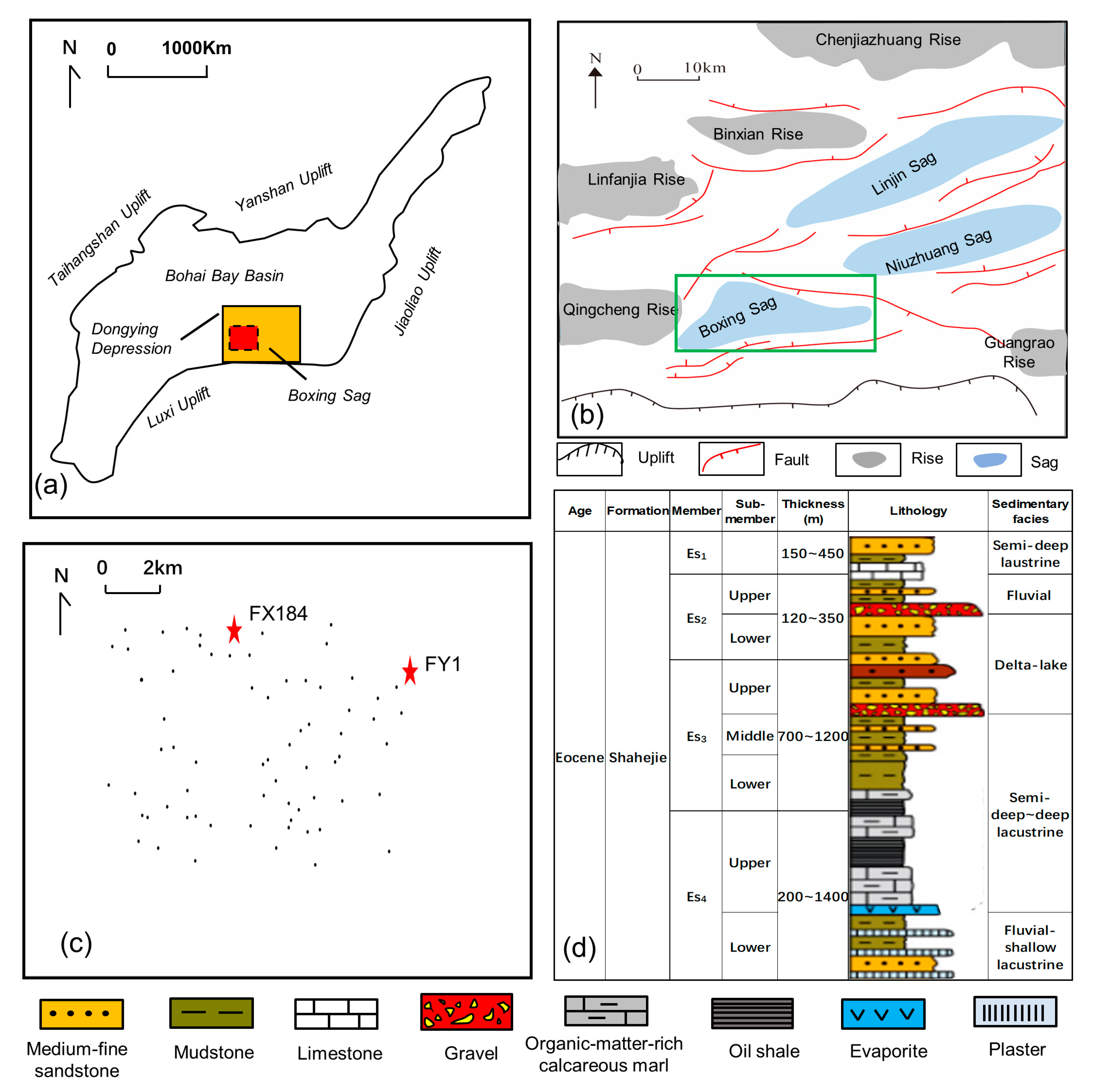
The Paleogene shale rich in organic matter in the Boxing Sag was deposited in a continental faulted lacustrine basin. In contrast with coarse clastic sedimentary rocks and marine shale, Paleogene shale in the Boxing Sag develops more lithofacies types [
1,
2,
3]. In the past ten years, geologists have performed many studies on shale lithofacies identification and classification in the Boxing Sag [
4]. Their results indicate that three main types of sedimentary structures (laminated structure, layered structure, and massive structure) are developed, and sedimentary structures of shale play a significant role in determining the reservoir properties [
5,
6,
7]. Recent studies have proven that lithofacies with different sedimentary structures vary greatly in their physical and oil-bearing properties [
8,
9]. Lithofacies with laminated structures possess higher values of porosity, TOC (total organic carbon), and S1 (residual hydrocarbon). Hence, lithofacies with laminated structures are identified as the most promising lithofacies types, followed by lithofacies with layered structures and lithofacies with massive structures. Therefore, the identification of shale sedimentary structures is an important part of lithofacies classification for Paleogene shale in the Boxing Sag.
Generally, shale lithofacies identification exploits petrophysical measurements, including wireline logs and laboratory core tests [
10,
11,
12]. Due to limited core data in many instances, shale lithofacies are often classified from conventional wireline logs. In general, conventional wireline logging projects include caliper logging, gamma ray logging, self-potential logging, bulk density logging, neutron porosity logging, compressional waves sonic logging, and resistivity logging. Antariksa et al. predicted lithofacies, including shale, shaly sandstone, sandstone, and coal, from a well logging dataset in the Tarakan Basin, Indonesia [
13]. Bhattacharya et al. classified five mudstone lithofacies, along with calcareous siltstone and limestone lithofacies from conventional well log suites (gamma ray, deep resistivity, bulk density, neutron porosity, and photoelectric factor log) [
14]. Kim et al. defined four lithofacies in Eagle Ford shale (organic-matter-rich mudstone, organic-matter-lean calcareous marl, heterogeneous argillaceous wacke stone, and marl and massive marly chalk) and Lower Austin chalk using five wireline logs (gamma ray, bulk density, neutron porosity, deep resistivity, and compressional sonic logs) [
15].
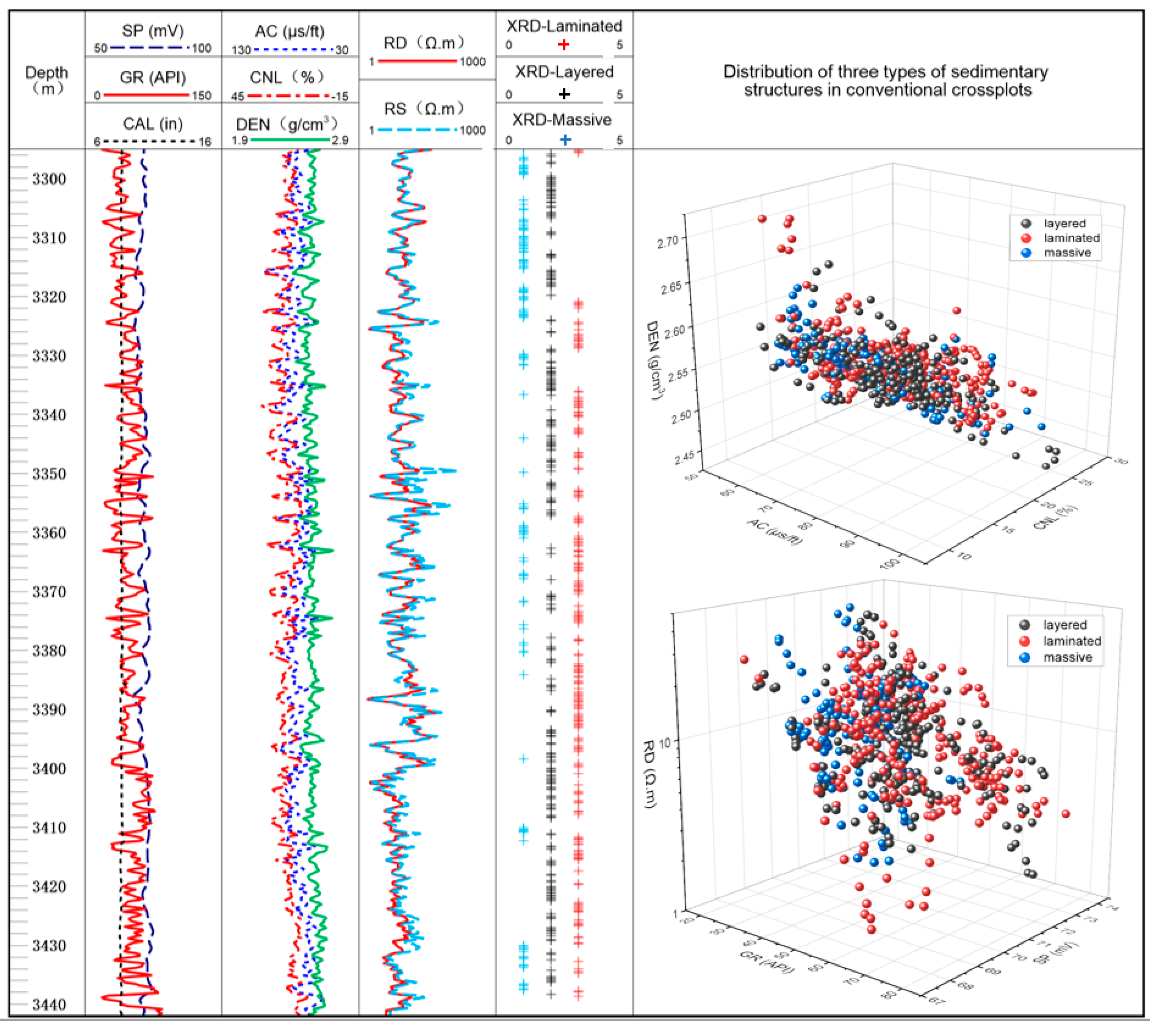
However, previous studies have mainly focused on the interpretation of shale mineral components or the classification of lithologies rather than the identification of shale sedimentary structures. This is mainly attributed to the scale mismatch between the shale sedimentary structures and the vertical resolutions of conventional wireline logs. In general, shale laminae are millimeter-scale, while the highest vertical resolution of conventional wireline logs is 0.5 m, which makes it impossible to identify sedimentary structures in conventional wireline logs.
Among current logging technologies, FMI logging has the highest vertical resolution, 5 mm, providing clear images of sedimentary structures, and it is an ideal tool for discriminating sedimentary facies and lithologies [
16,
17,
18]. With the rapid development of image processing techniques, various texture analysis approaches have emerged, including the Tamura method, LBP (local binary pattern), GLCM (gray level co-occurrence matrix), wavelet transform, autocorrelation function, etc. Based on these methods, a growing number of studies related to feature extraction from FMI images have been performed. Zhang et al. extracted 69 texture features from FMI images using the autocorrelation function method to identify rock types in quartz sandstone reservoirs and achieved an accuracy of 78% [
19]. Wang Man et al. successfully distinguished five types of volcanic rocks from FMI images by adopting GLCM [
20]. Chai et al. employed LBP for feature extraction from FMI images to identify lithology in reef-bank reservoirs [
21]. Luo et al. extracted four texture features using GLCM on FMI images to classify sedimentary microfacies in the gravel reservoir [
22]. Yan et al. utilized the image-connected domain labeling algorithm to mark the solution-hole-connected domain from FMI images and obtain the heterogeneity information about solution hole in the carbonate reservoir [
23]. Shafiabadi et al. detected fractures in FMI images using the Canny and Sobel algorithms as edge detection operators [
24]. Wang Min et al. successfully transformed FMI images into continuous core gravel information after performing filtering with a median filter, image segmentation through the gray threshold segmentation algorithm, and gravel extraction through the Hoshen–Kopelman algorithm [
25]. From
Table 1, it can be concluded that at present, image feature extraction methods are mostly used to detect gravel, fracture, and classify lithologies from FMI images, with few studies on the division of sedimentary structures and even fewer applications in shale.
On the other hand, shale lithofacies possess relatively consistent petrophysical properties in contrast to conventional reservoirs, which causes some shale lithofacies interpreted from core data to not be distinguishable from wireline logs. To address this problem, machine learning algorithms have been increasingly introduced in shale lithofacies classification. With the ability to learn from large datasets, machine learning algorithms can grasp data features and discover patterns in data [
26,
27,
28,
29]. The commonly used classification algorithms include support vector machine (SVM), K-nearest neighbors (KNN), naive Bayes (NB), decision tree (DT), artificial neural network (ANN), AdaBoost, and random forest (RF).
Bhattacharya et al. used an SVM to recognize the pattern of different shale lithofacies associated with basic petrophysical parameters from conventional well log suites [
30]. Kim et al. trained a convolutional neural network (CNN) model to classify the lithofacies of Eagle Ford shale from five wireline logs [
15]. Liu et al. employed an ANN approach to better understand the primary factors that control lacustrine shale lithofacies development [
31]. Merembayev et al. compared machine learning algorithms, including KNN, DT, RF, eXtreme gradient boosting (XGBoost), and LightGBM, in lithofacies classification from various well log data from Kazakhstan and Norway. The random forest model had the best score among the considered algorithms [
32]. Hoang et al. used the random forest algorithm to predict the lithofacies of the Balder field from well logs and seismic data and obtained favorable outcomes [
33]. Antariksa et al. compared several machine learning algorithms in classifying lithofacies in the Tarakan Basin, Indonesia. Random forest and gradient boosting outperformed the other models in the experiment, with accuracies of 87.49% and 87.01%, respectively [
13]. The abovementioned applications are summarized in
Table 2.
In this work, we aim to introduce a convenient and effective approach for the classification of shale lithofacies with different sedimentary structures from FMI logs and ECS logs. This method combines the GLCM technique and a machine learning algorithm. First, the texture features that can quantitatively characterize the shale sedimentary structure are extracted from FMI images by adopting the GLCM technique. A sensitivity analysis of texture features is conducted to assure adaptability. Afterward, a dataset for training the classification model is constructed. This dataset consists of texture features as well as mineral contents from ECS logs. Finally, a hyperparameter-optimized random forest classifier is applied for automatic lithofacies classification.
4. Methods
GLCM measures image texture features based on the spatial relationship of pixels. The laminae of shale are mostly parallel, exhibiting parallel textures with various gray scales in grayscale FMI images. The different sedimentary structures of shale demonstrate different spatial correlation characteristics of gray scales in FMI images, which provide the basis for the application of GLCM.
4.1. Gray Level Co-Occurrence Matrix (GLCM)
The gray level co-occurrence matrix of an image can be obtained by first counting the frequency of an element P (
i,
j,
d,
θ) of the image and then transforming the frequency into probabilities. These steps are performed by dividing by the total frequency of all elements, where
i is the gray level of a pixel at location (
x,
y) and
j is the gray level of a neighboring pixel at location (
x +
dx,
y +
dy). This relationship of the two pixels is defined by two parameters: offset,
d, and orientation,
θ (
Figure 9). GLCMs with different (
d,
θ) combinations capture different information related to the textural appearance of an image [
35].
The size of the GLCM depends on the gray level value of an image. Suppose L is the gray level value of an image; then, its GLCM is an L × L dimensional matrix. In general, considering the amount of matrix computation and the quality of the image texture, the grayscale L-value is usually chosen to be 8 or 16.
After computing the GLCM, different features can be obtained. Haralick proposed the extraction of 14 statistical features from a GLCM [
36]. It has been found that 5 features of the 14 statistical features, including energy, contrast, entropy, homogeneity, and correlation, are not only easy to calculate but can yield higher classification accuracy [
37,
38,
39]. The five properties are explained below along with the mathematical equations used.
4.1.1. Energy
The energy measures the homogeneity of an image. The more uniform the image, the greater the value of energy.
4.1.2. Contrast
The contrast reflects the intensity of the difference between the neighboring pixels in the co-occurrence matrix. It varies between the largest and smallest values in a continuous group of pixels. The value of contrast for a constant image is 0.
4.1.3. Homogeneity
The homogeneity measures the similarity of pixel values. The range of homogeneity varies between 0 and 1. It has the highest value when all the pixel values in an image are alike.
4.1.4. Correlation
The correlation describes how closely the neighboring pixels are connected. The range of correlation is between −1 and 1. A value of −1 specifies a perfectly negative correlation, while a value of 1 means a perfectly positive correlation.
4.1.5. Entropy
The entropy measures the overall information about an image. The entropy value is low for an irregular co-occurrence matrix.
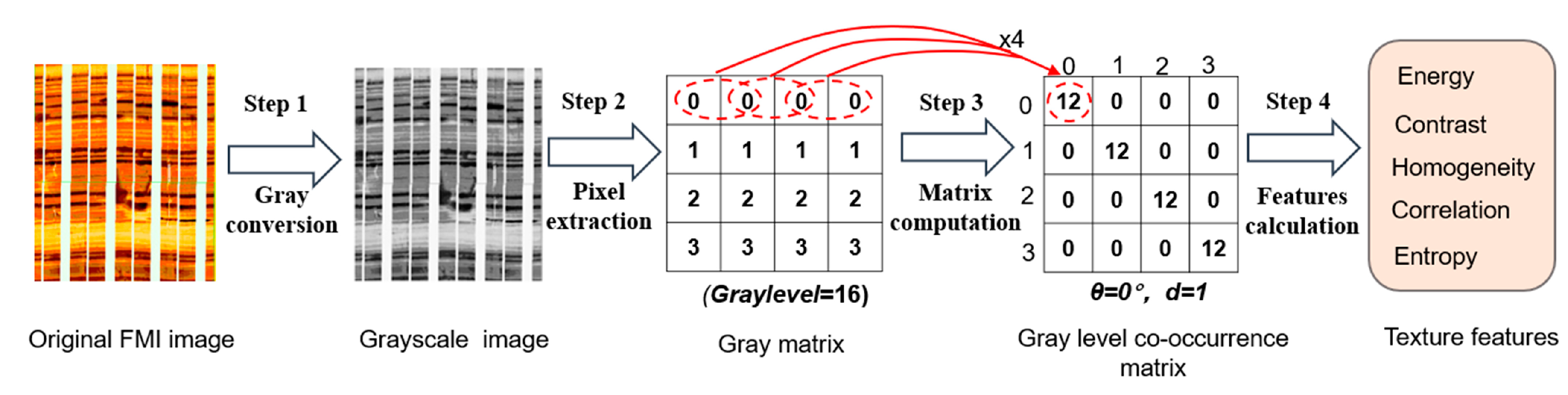
The main processing steps of GLCM for FMI images are described in
Figure 10. First, a raw FMI static image is converted into a grayscale image, and then a gray matrix of the image is obtained. Afterward, the gray level co-occurrence matrix of the image is calculated. Finally, five texture features are extracted from the GLCM.
4.2. Random Forest (RF)
The random forest algorithm is an ensemble of decision trees that can be applied to classification or regression tasks. The random forest algorithm adopts the bootstrap aggregating technique (known as “bagging”). Each decision tree in the random forest model is trained by bootstrap samples of input data, which reduces the correlation between decision trees. The final classification result of a random forest model is decided by the majority vote from all decision trees [
40,
41,
42,
43].
The steps for building a classification tree in the random forest model are as follows:
(1) After preprocessing the training data, n (n < N) samples are randomly selected from input dataset N. Each decision tree is trained on a different subset of the training data.
(2) If the number of input features is
M, a constant
m (
m << M) is assigned, and
m variables are randomly selected from
M features. When a node splits, the feature with the highest purity is selected from the m features after calculating the Gini index for each feature. The lower the Gini index, the higher the purity of the feature. The Gini index of feature
K in dataset
D is calculated as follows [
44]:
where
V is the number of subsets based on feature
K;
Dv is a subset of dataset
D on feature
k; |
Dv| and |
D| are the total numbers of samples in subset
Dv and in dataset
D, respectively; Gini (
Dv) is the Gini value of subset
Dv;
n is the number of types in dataset
Dv, and
p is the proportion that type
i occurs in dataset
D.
(3) The decision tree is fully grown and not pruned. Node splits are typically continued until nodes are pure (one class).
4.3. Proposed Lithofacies Classification Model
After presenting the principles of GLCM and RF, an integrated approach for lithofacies classification is proposed. This approach utilizes GLCM to extract texture features from FMI images and then inputs both the texture features and mineral content calculated from the ECS log to an RF classifier. After the identification of each decision tree in the RF classifier, the result of lithofacies classification is received (
Figure 11).
4.4. Criteria for Verifying the Model Performance
The prediction performance of the model is evaluated using four statistical quality indicators, including precision, recall, F1-score, and accuracy. These indicator values are in the range [0, 1]. The higher the value, the better the model performs [
45]. The indicators are defined as follows:
where TP represents the correct classifications in the positive class, TN represents the correct classifications in the negative class, FP represents the incorrect classifications in the positive class, and FN represents the incorrect classifications in the negative class.
4.5. Hyperparameter Tuning
The previous studies show that the complexity of the dataset directly affects the performance of the machine learning models. As for the application of lithofacies classification from well logs, the complexity of the dataset is mainly reflected in the number of features [
46]. The performance of machine learning models does not always improve with the increase in the number of features. The number of features required for a machine learning model is an open question. In general, simple machine learning models with fewer features are easier to understand and interpret, and overfitting can be avoided. In this study, considering the negative impact of a complex dataset on the accuracy of the model, six input features were selected for lithofacies classification.
The performance of any machine learning model also highly depends on the selection of the model hyperparameters [
47]. The hyperparameters of the random forest algorithm mainly consist of the number of decision trees (n_estimators), maximum features (max_features), maximum depth of a tree (max_depth), minimum samples for a node to split (min_sample_split), and minimum samples for leaf nodes (min_samples_leaf). Among them, n_estimators can significantly impact the overall accuracy of the model. If the value of n_estimators is too low, the model may suffer from underfitting, while if the value of n_estimators is too high, the model performance cannot be significantly improved.
The best combination of hyperparameters needs to be tuned during a trial-and-error process. Considering that the dimensionality of the training dataset is not high in this study, a grid search CV is employed to ascertain the most promising hyperparameter combination [
48]. The grid search approach covers the entire search space and tests for every possible combination of hyperparameters. In this study, a broad search with a larger step size of the hyperparameter space is first performed, and then a second, more refined search is conducted within a limited search space. For cross-validation, 10-fold cross-validation is selected. The whole dataset is divided into 10 folds. The 10th fold is used to test the model, and the remaining 9 folds are used for training.
The search space and step size for the considered hyperparameters are displayed in
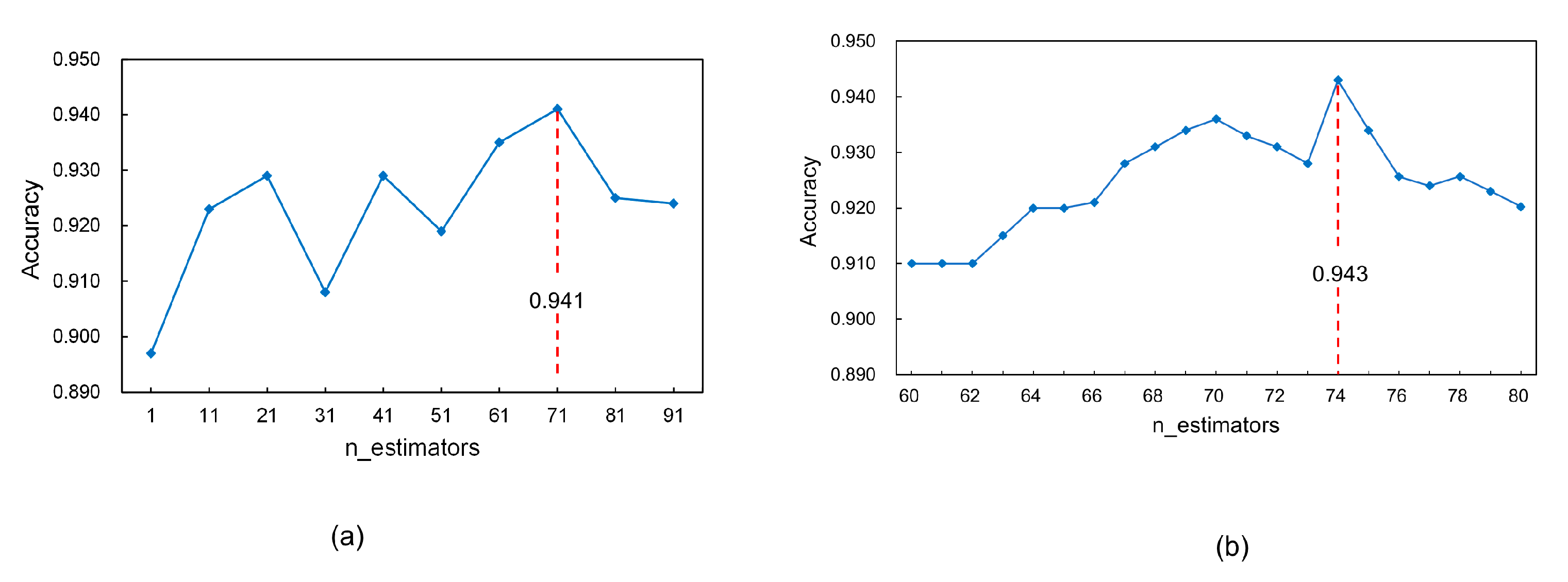
Table 5. Since the minimum step size is adopted, the best values for max_features, max_depth, min_samples_split, and min_samples_leaf can be obtained after the first search. For n_estimators, its relationship with the model accuracy during the first broad search is shown in
Figure 12a. It is obvious that the model accuracy does not rise consistently with an increase in n_estimators; instead, it begins to decrease when n_estimators is greater than a certain value. When n_estimators is 71, the accuracy reaches the highest score of 0.941. Considering a step size of 10, the optimal value for n_estimators should be between 60 and 80. Then, a second refined search for optimal n_estimators is performed. The search range is narrowed down to [60, 80], and the search step size is set to 1.
Figure 12b shows that when n_estimators is 74, the model accuracy is the highest. Thus, after the fine search, the optimum value for n_estimators can be designated as 74.
4.6. Data Split Sensitivity
The impact of different data split ratios is tested. The ratio of training data to validation data is designed from 50:50 to 90:10, with a 10% increase each time. As seen from
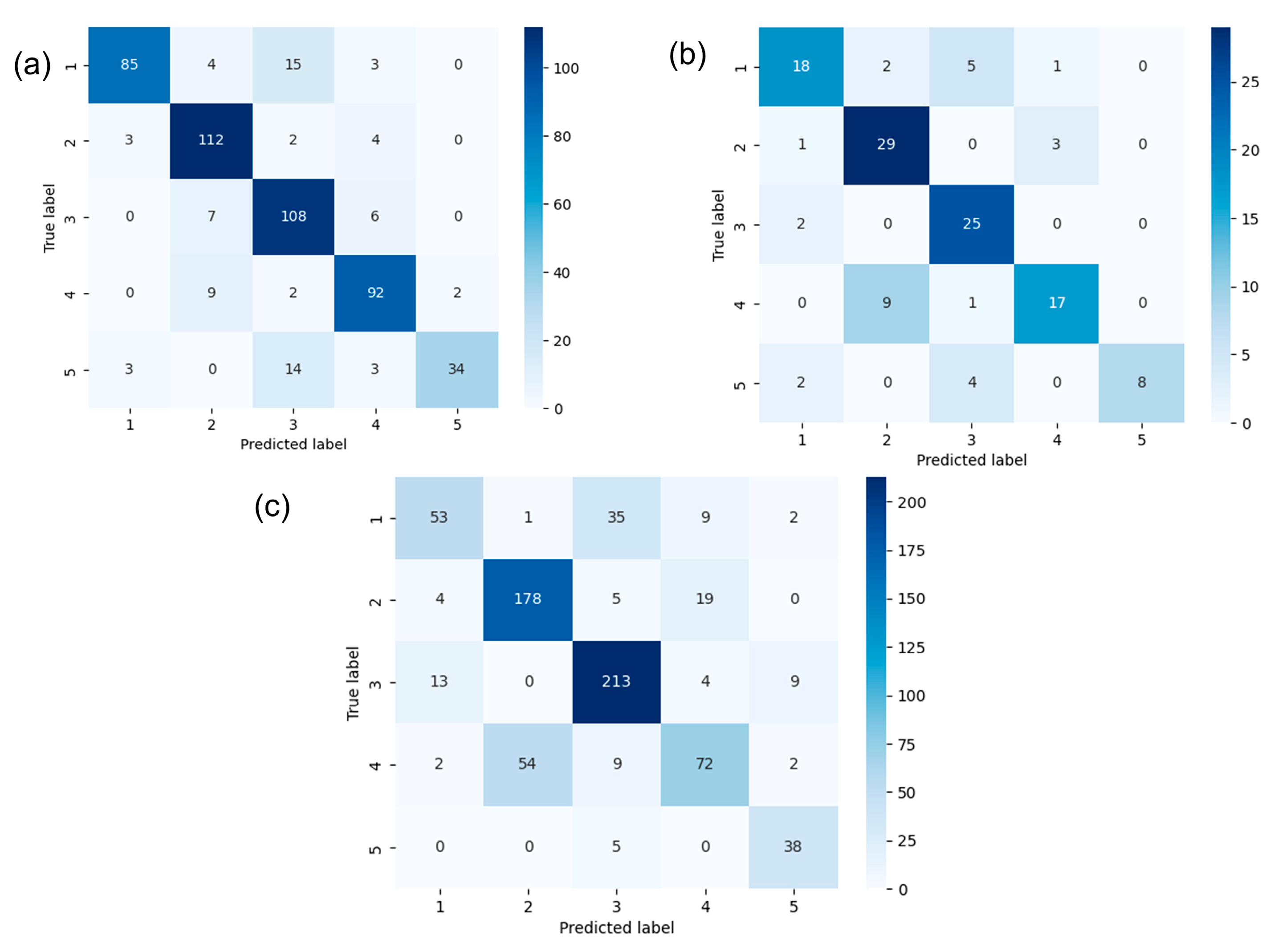
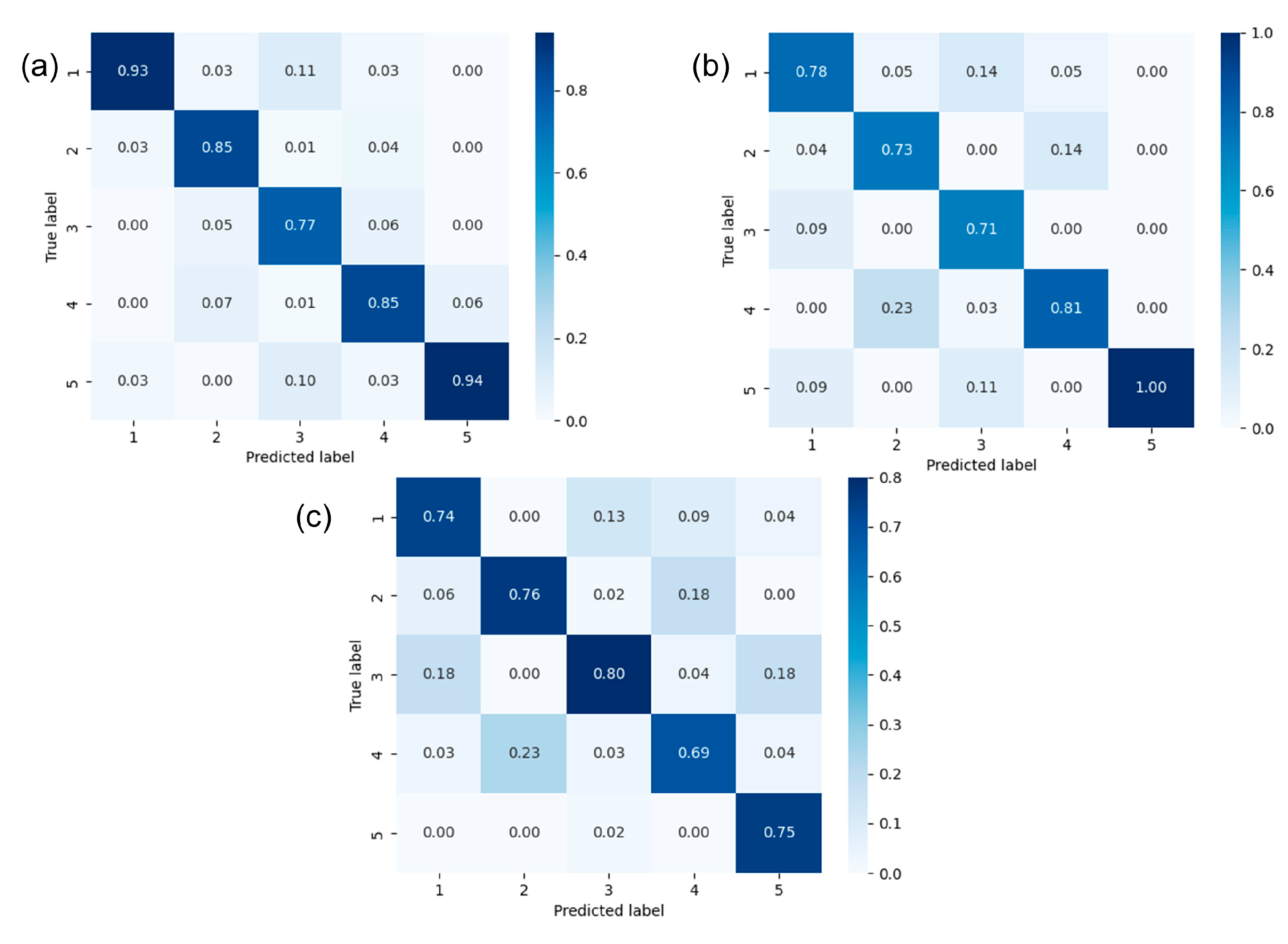
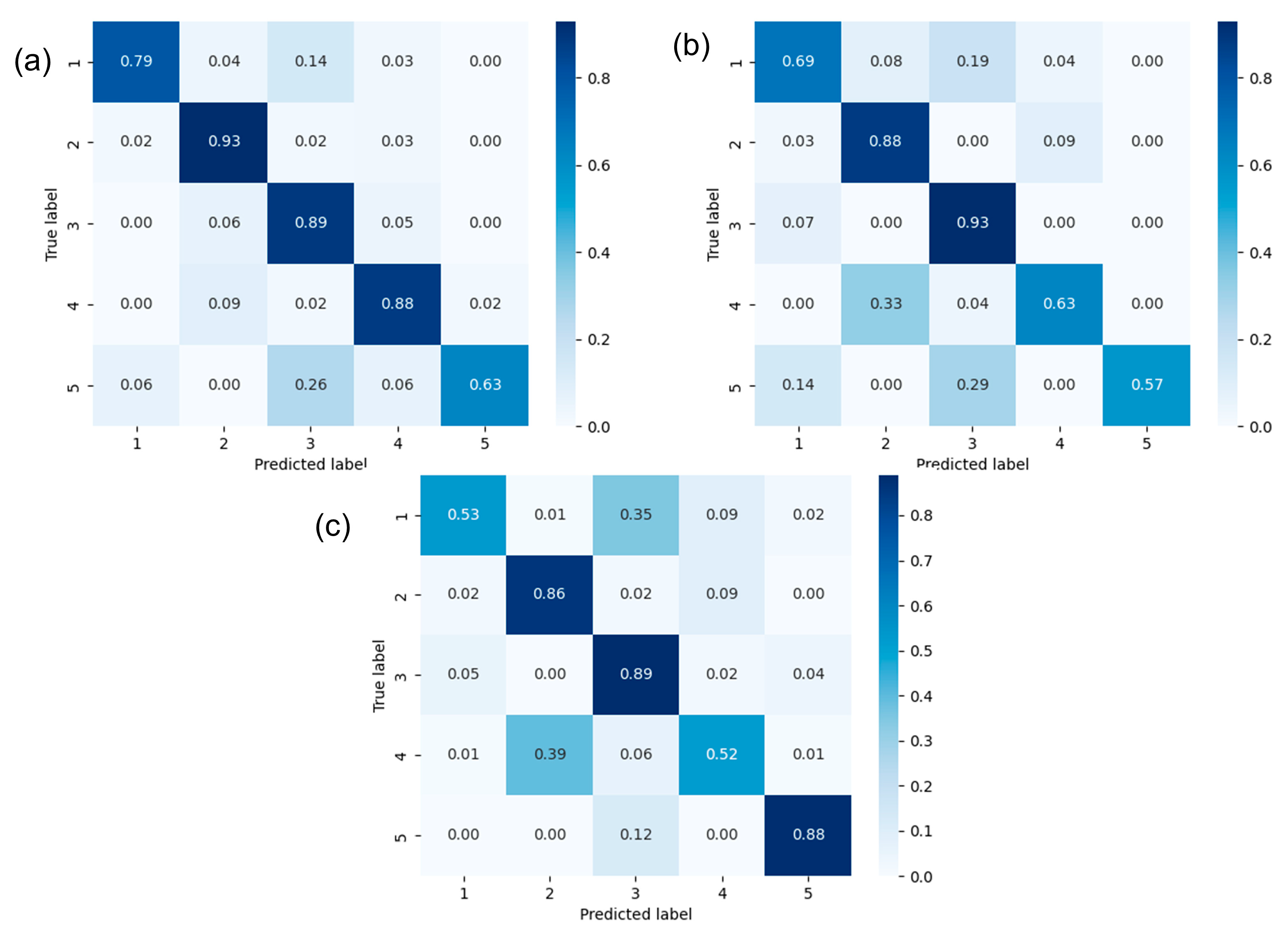
Table 6, at the ratio of 50:50, the model achieves the highest accuracy score on the training set, but on the validation set and the test set, the model obtains the lowest accuracy scores, indicating the occurrence of an overfitting problem. As the proportion of the training set increases, the model accuracy on the training set gradually decreases, and the model accuracies on the validation set and the test set gradually increase. When the ratio is 80:20, the accuracies on the validation set and the test set are the highest values. Therefore, the training data ratio of 80:20 can be regarded as the optimal split ratio for the prediction model.
4.7. GLCM Texture Feature Sensitivity
To assure the adaptability of extracted texture features from FMI images to the identification of shale sedimentary structures, a sensitivity analysis of five texture features is carried out.
A total of 50 typical FMI images, 10 FMI images for each lithofacies, are chosen from well FX184. The parameters of the GLCM are set as follows: L = 16; d = 1; θ = 0°, 45°, 90°, and 135°. Since four types of orientations are selected, four co-occurrence matrices are generated for each FMI image, and texture features of each FMI image are generated by averaging texture features from four kinds of orientations.
The visualized gray level co-occurrence matrices of the five lithofacies are exhibited in
Figure 13. The gray level co-occurrence matrices demonstrate different numerical distribution characteristics for different types of lithofacies. For laminated lithofacies (Lithofacies 1 and Lithofacies 2), the values on the diagonal of the gray level co-occurrence matrices are lower compared with the values of layered lithofacies (Lithofacies 3 and Lithofacies 4), whereas the values on both sides of the diagonal are higher. The massive lithofacies (Lithofacies 5) has the highest value on the diagonal of the gray level co-occurrence matrix.
In
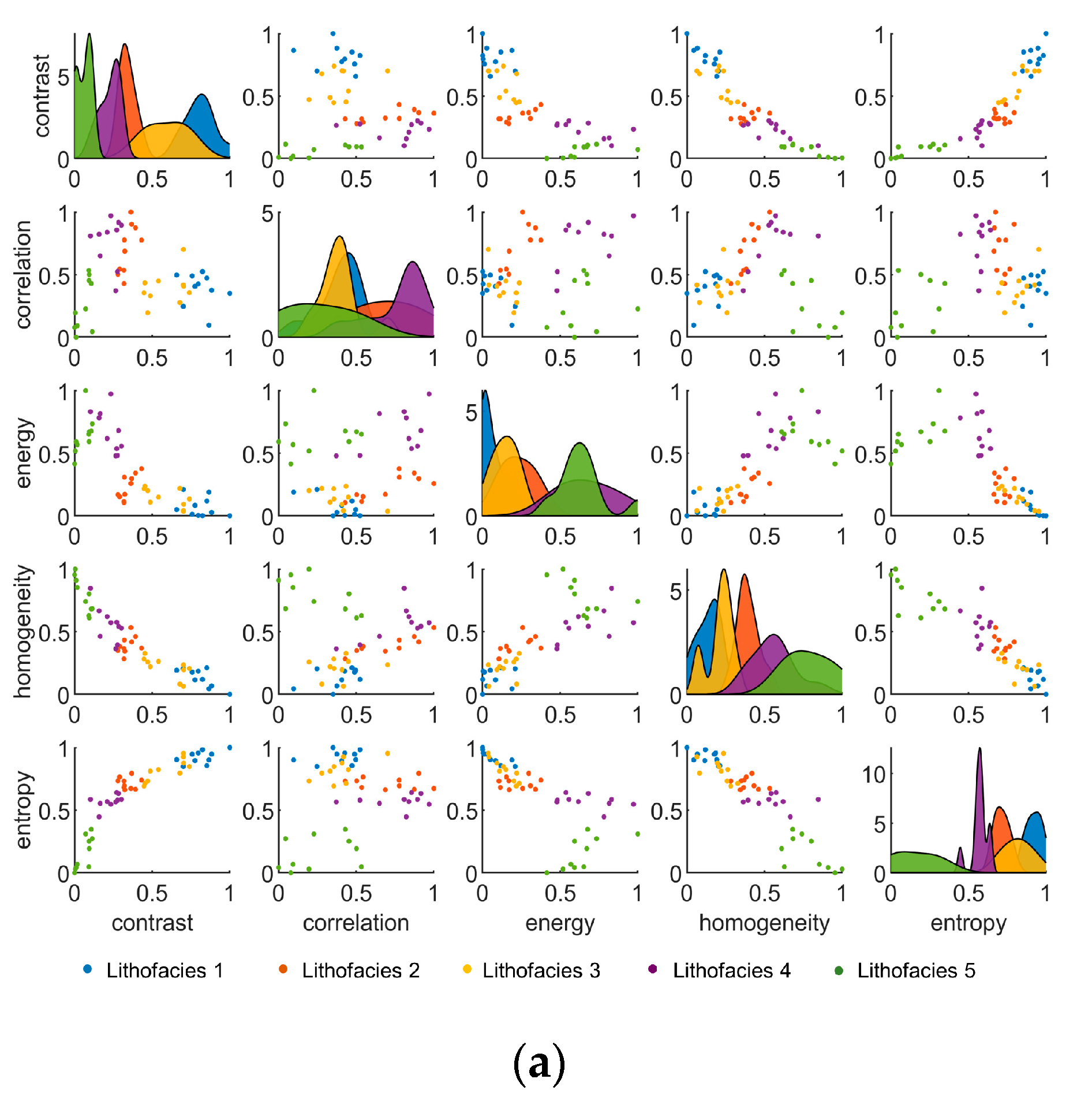
Table 7, the distribution ranges of five texture features in the five lithofacies can be observed. According to the statistics, for the laminated lithofacies (Lithofacies 1 and Lithofacies 2), contrast, correlation, and entropy are higher than in the other lithofacies, and the distribution ranges are 0.47~0.85, 0.54~0.90, and 0.67~0.95 respectively, while energy and homogeneity are lower than in the other lithofacies; their distribution ranges are 0.01~0.23 and 0.06–0.25 respectively. For massive lithofacies, the characteristics of the texture features are opposite to those of laminated lithofacies. Contrast, correlation, and entropy are lower than those of the other lithofacies, and the distribution ranges are 0.02~0.08, 0.08~0.44, and 0.03~0.28 respectively, while energy and homogeneity are higher than in the other lithofacies, with distribution ranges of 0.57~0.65 and 0.68~0.90 respectively. For the layered lithofacies (Lithofacies 3 and Lithofacies 4), the distribution ranges of texture features are between those of the laminated lithofacies and those of the massive lithofacies.
Figure 14a shows the distribution map of five texture features in five types of sedimentary structures, indicating that contrast, entropy, energy, and homogeneity achieve better distinction among the five lithofacies than correlation, with a clear distribution range for each lithofacies. The cross plots referring to the correlation show no boundaries between different lithofacies, and data points representing different lithofacies are mixed together.
Figure 14b shows that correlation is much more discrete than the other four features, and the overlap zone between the lithologies is larger, especially for the laminated facies and layered facies, which means that correlation is incapable of conducting lithofacies classification.
For further illustration, the GLCM texture feature curves calculated from the FMI images of well FX184 at the interval of 3491.8~3500.5 m are demonstrated in
Figure 15. Four subintervals are selected for comparison. These subintervals are separately dominated by different types of sedimentary structures.
As shown in
Figure 15, when the sedimentary structure changes from massive to laminated, contrast and entropy display an increasing trend, while homogeneity demonstrates the opposite trend. In contrast to other texture features, energy is more sensitive to the white band on the FMI images. Correlation shows the weakest correlation with the change in sedimentary structures, and the characteristic is consistent with it in cross plots from
Figure 14.
4.8. Feature Correlation Analysis
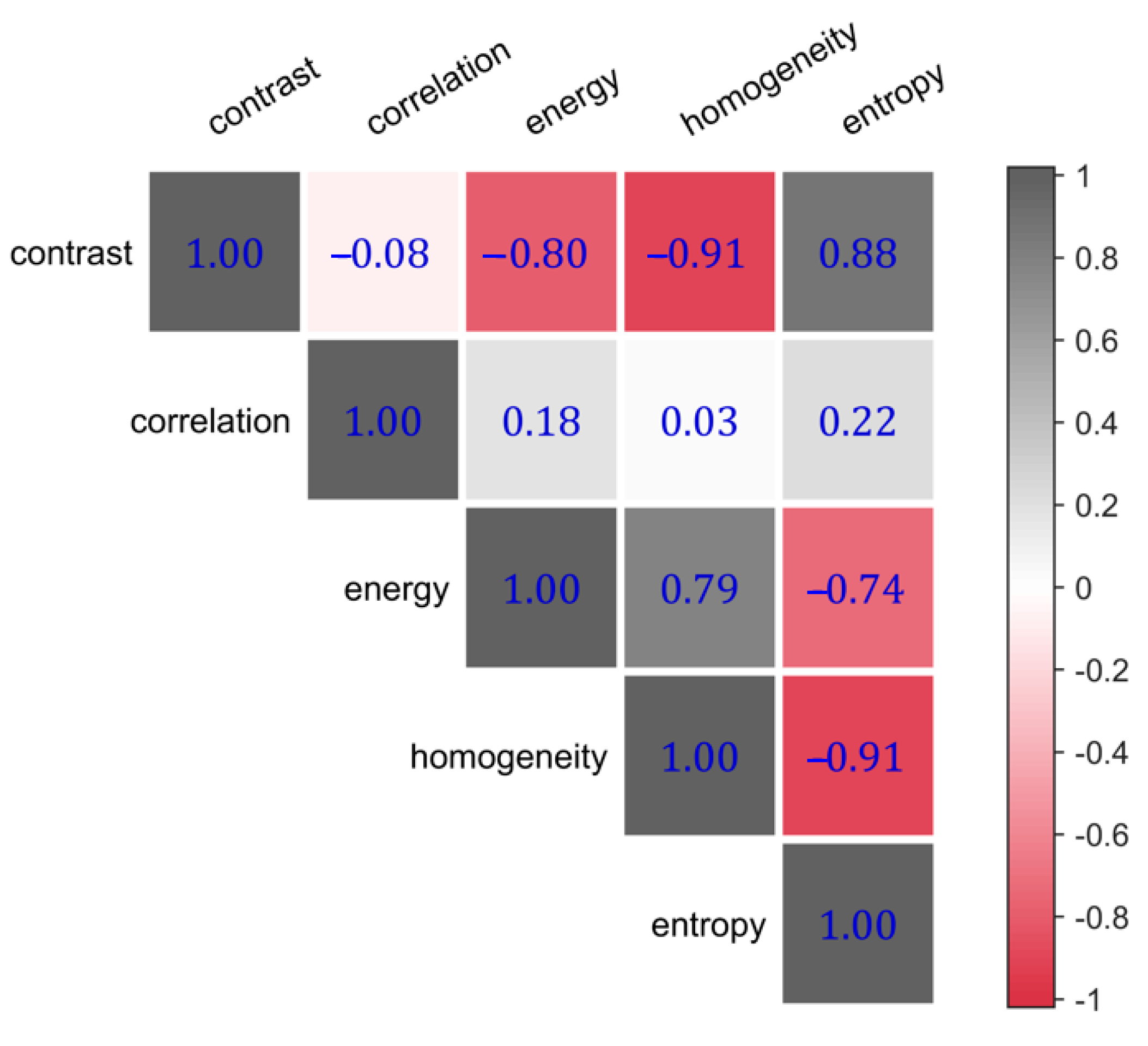
The relationship between five texture features from the GLCM is investigated by calculating the Pearson correlation coefficient. The Pearson correlation coefficient reflects the degree of linear correlation between variables, and the range of the Pearson correlation coefficient varies between −1 and 1. The greater the absolute value, the stronger the correlation between the variables.
Figure 16 shows that the values of the Pearson correlation coefficient between contrast, entropy, energy, and homogeneity are very high, all larger than 0.7, implying strong linear relationships within the four texture features.
7. Conclusions
The identification of shale lithofacies with different sedimentary structures is the key to commercial hydrocarbon production in the Boxing Sag. However, the present classification method based on conventional wireline logs cannot achieve the desired result. The aim of this study was to test a practical approach to identify lithofacies with an image feature extraction tool and a machine learning technique from advanced logs.
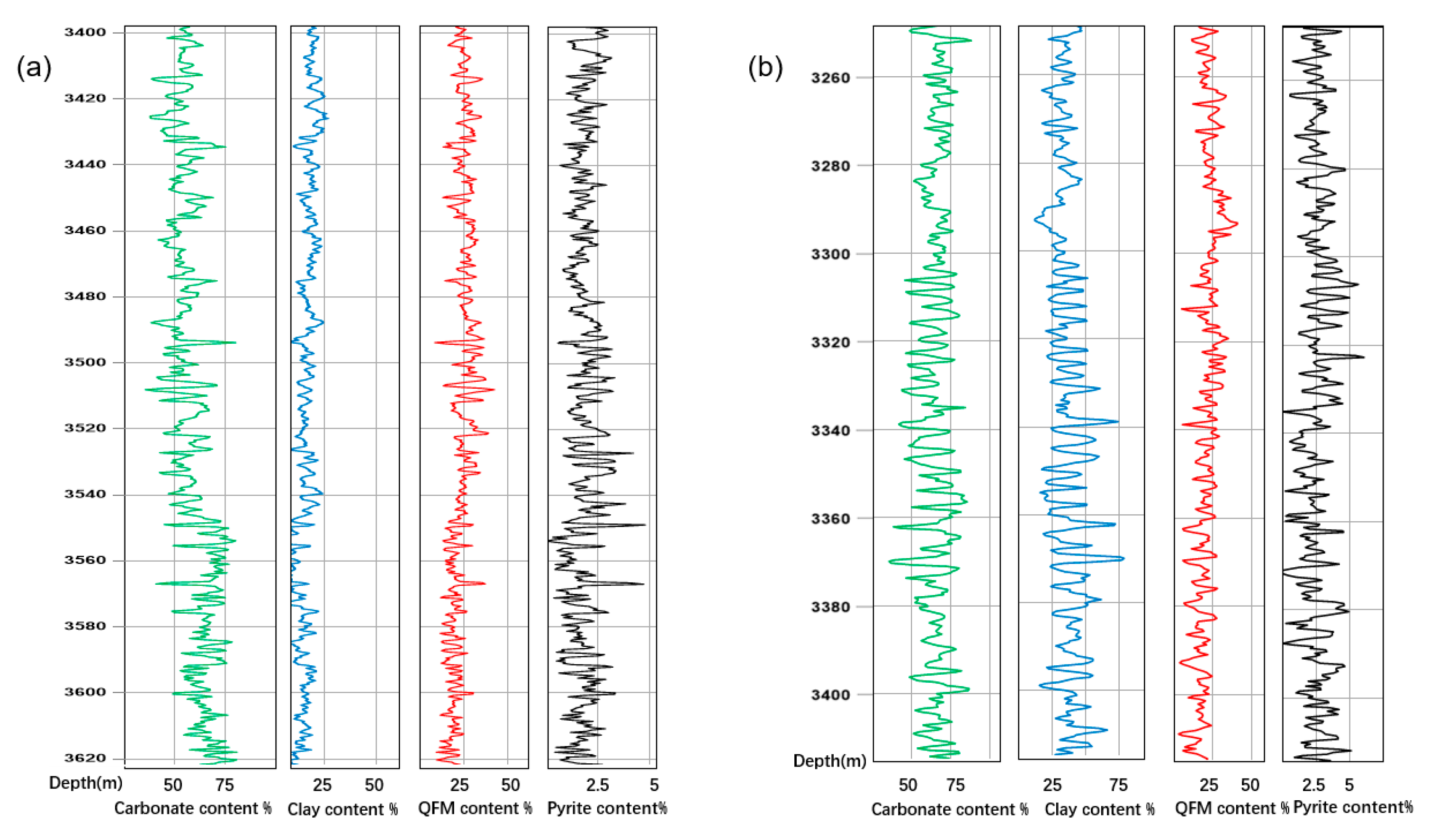
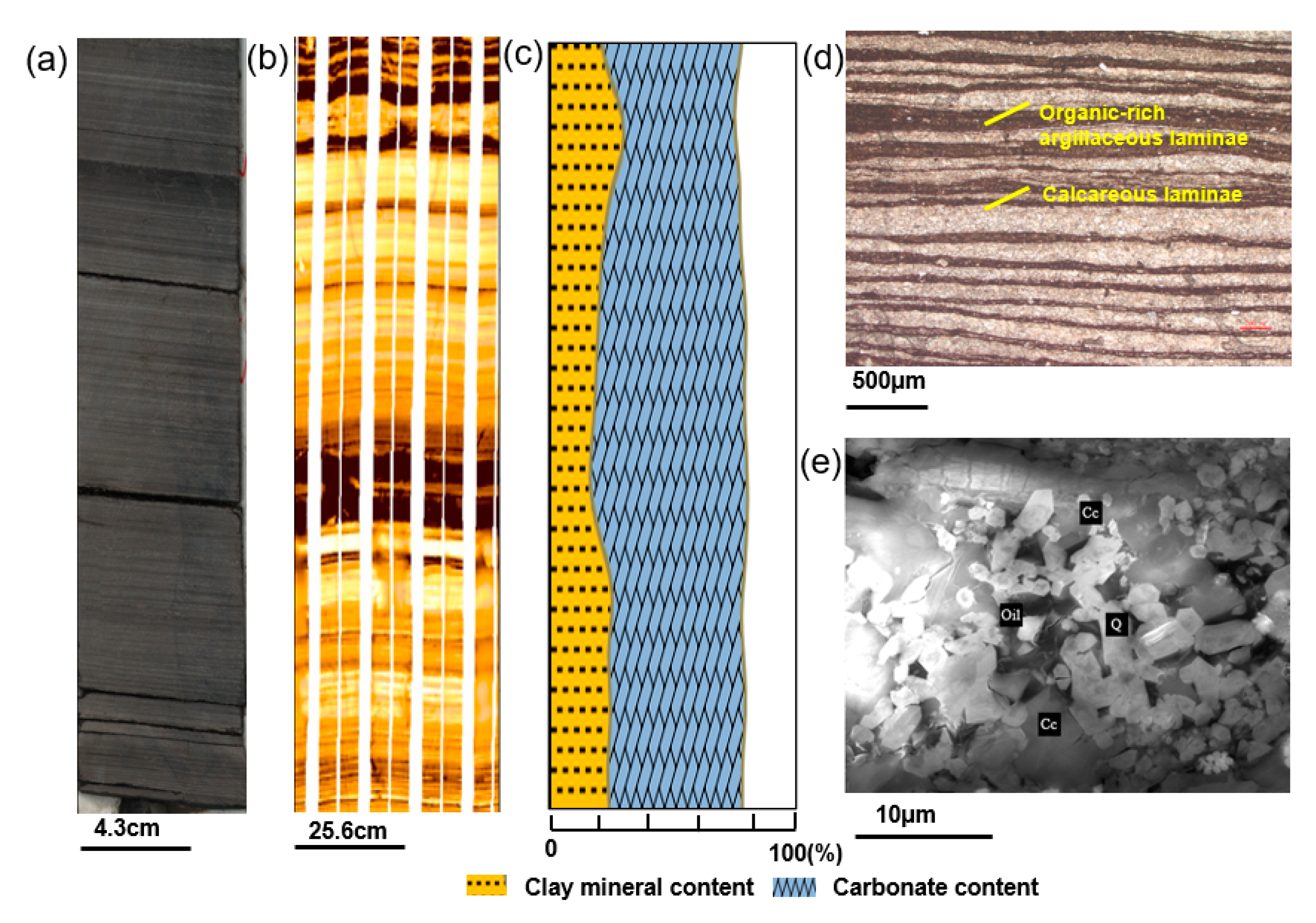
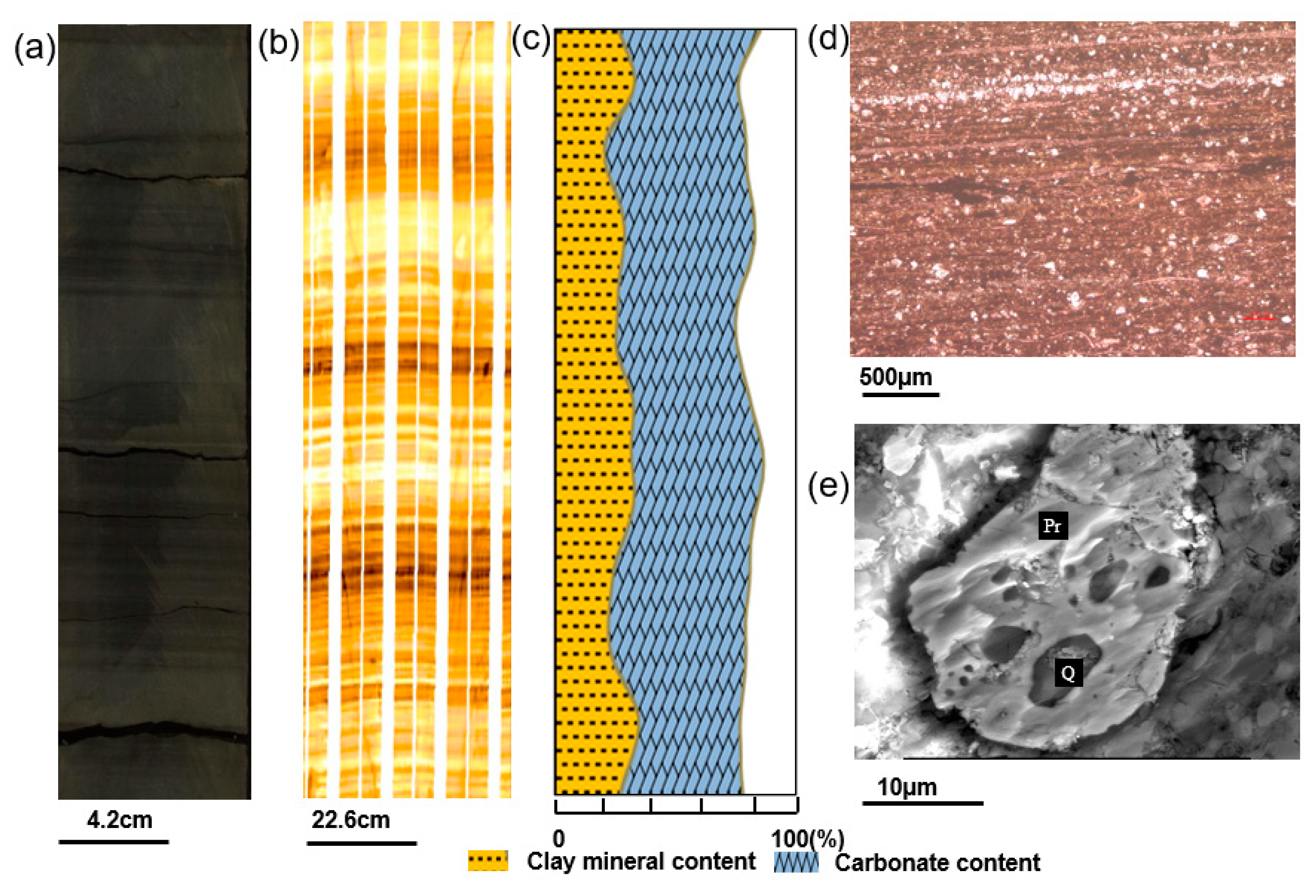
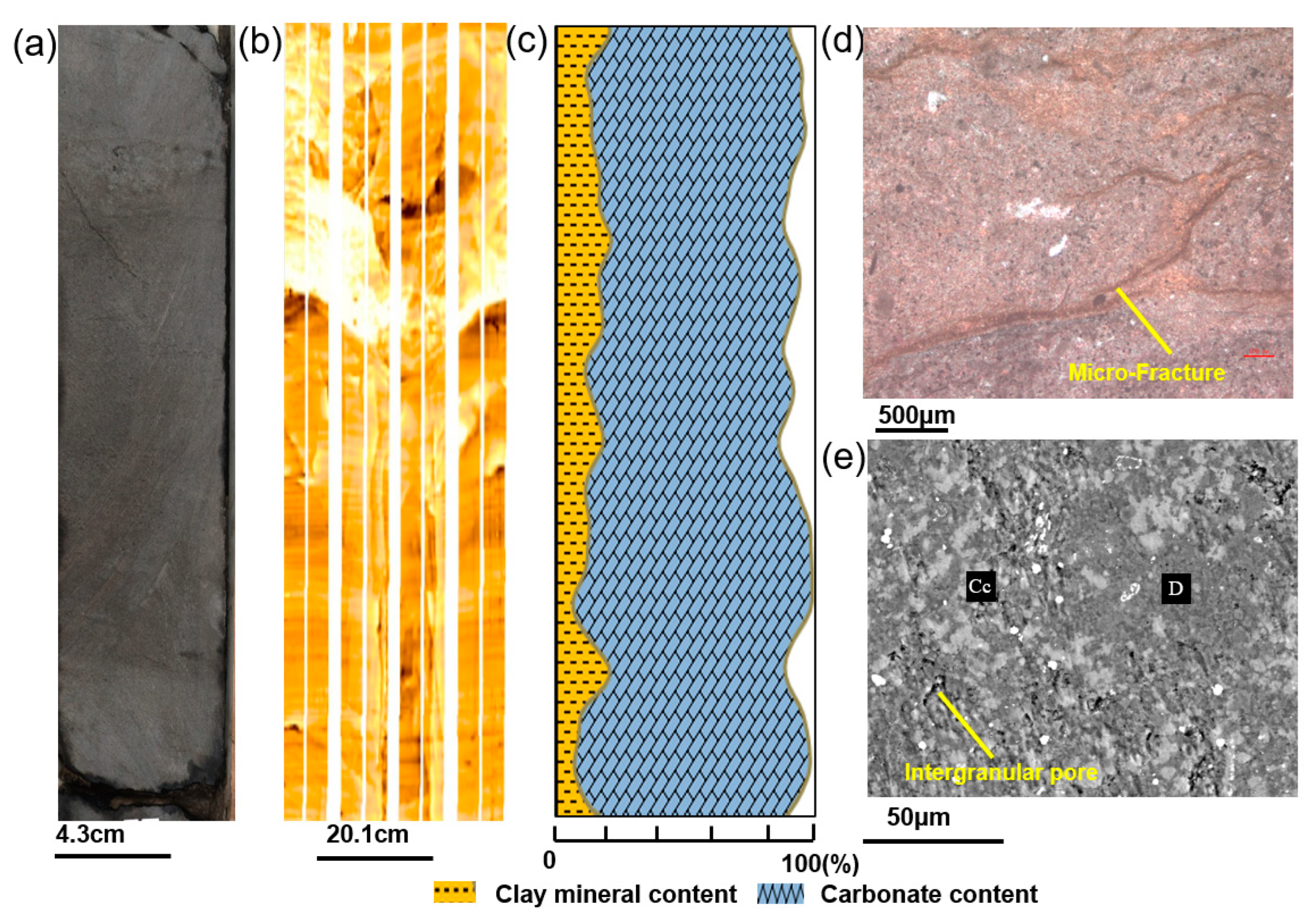
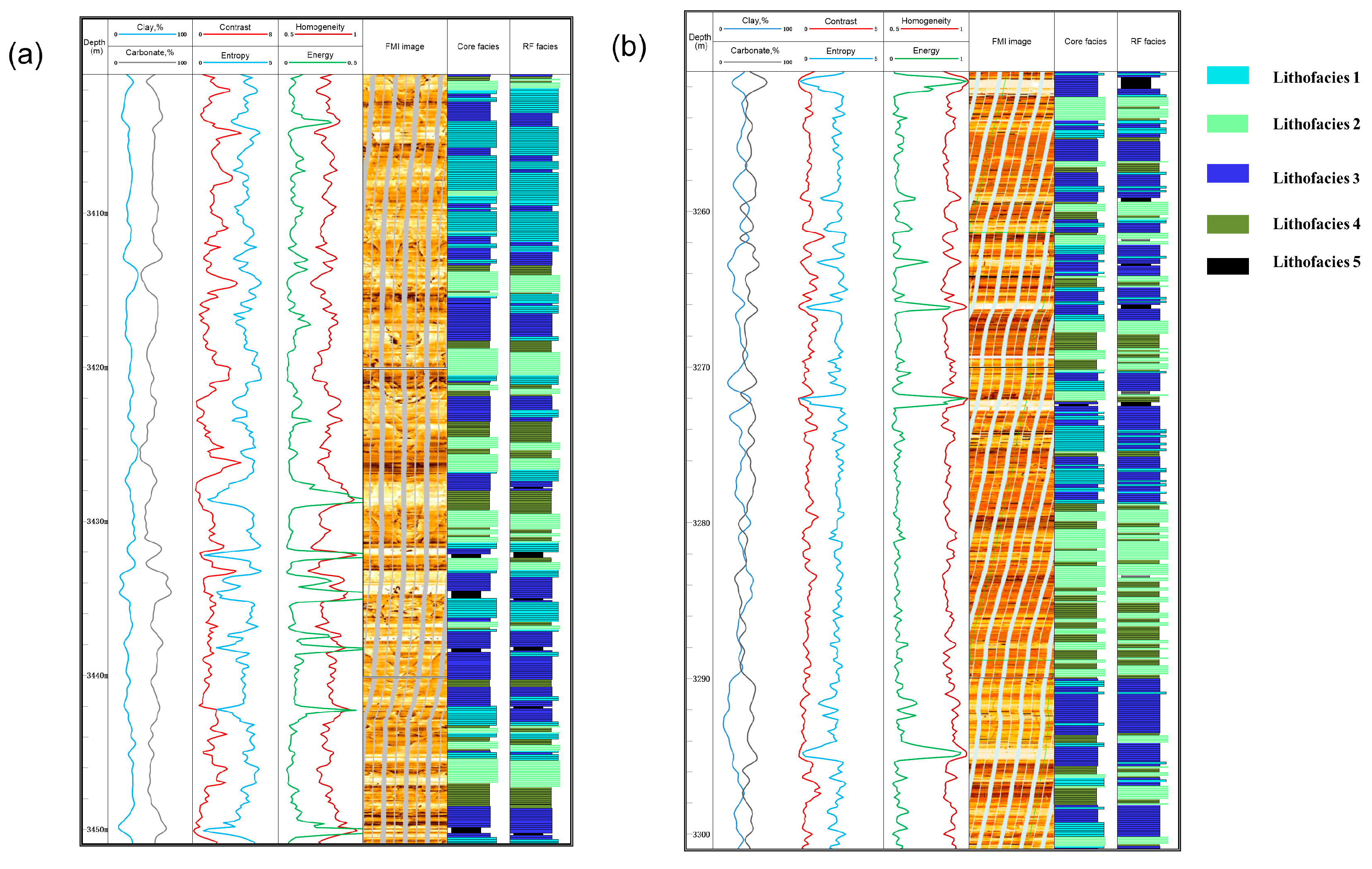
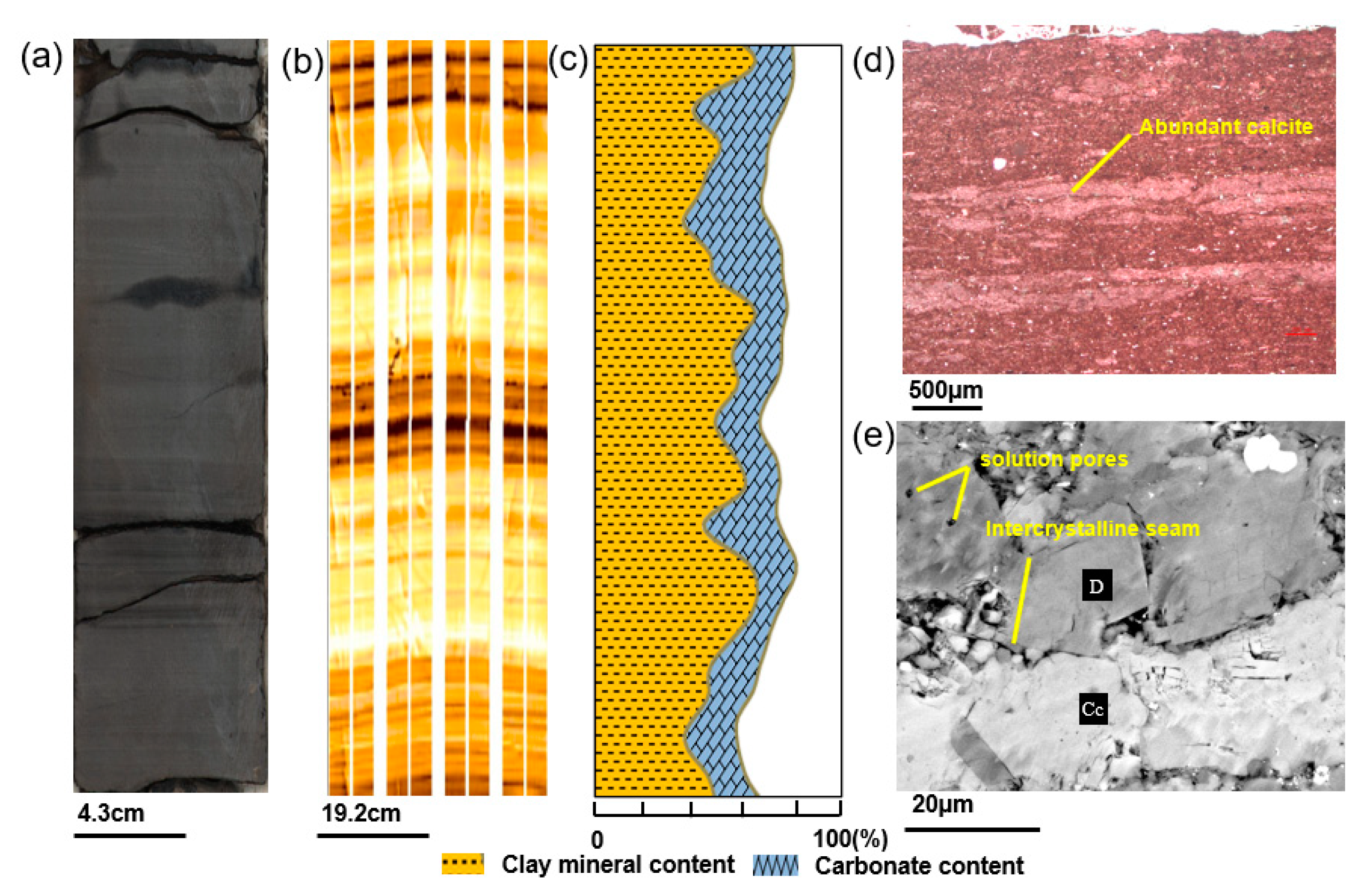
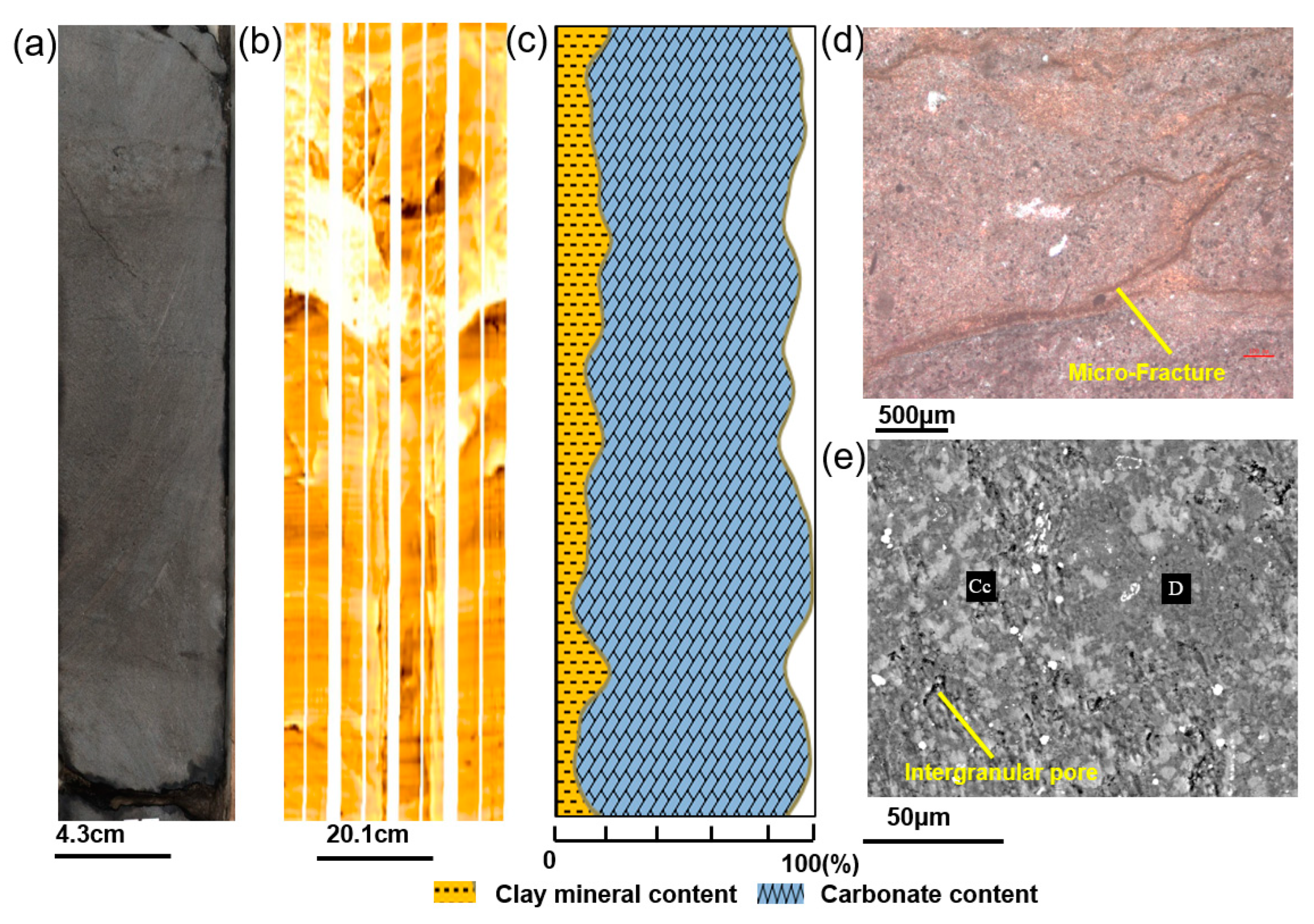
In the first section, lithofacies classification was carried out with the aid of integrated data, including core, FMI images, thin sections, and SEM images. Five shale lithofacies were classified based on sedimentary structures and mineral contents. In the target lower third and upper fourth members of the Shahejie Formation, the lithofacies change rapidly, and the vertical lithofacies combination is dominated by the interbed of laminated lithofacies and layered lithofacies.
In the second section, an approach integrating the GLCM and RF to classify lithofacies from FMI images and ECS logs was tested. The conclusions are as follows.
(1) The experiments show that the GLCM could be used to extract shale texture features. The shale laminae exhibit horizontal textures with thickness and density changes in the FMI images. The GLCM could characterize the texture efficiently and accurately based on the spatial distribution of the grayscale. After sensitivity analysis of extracted texture features from the GLCM, it was proven that four features, energy, homogeneity, contrast, and entropy, were more capable of identifying shale sedimentary structures.
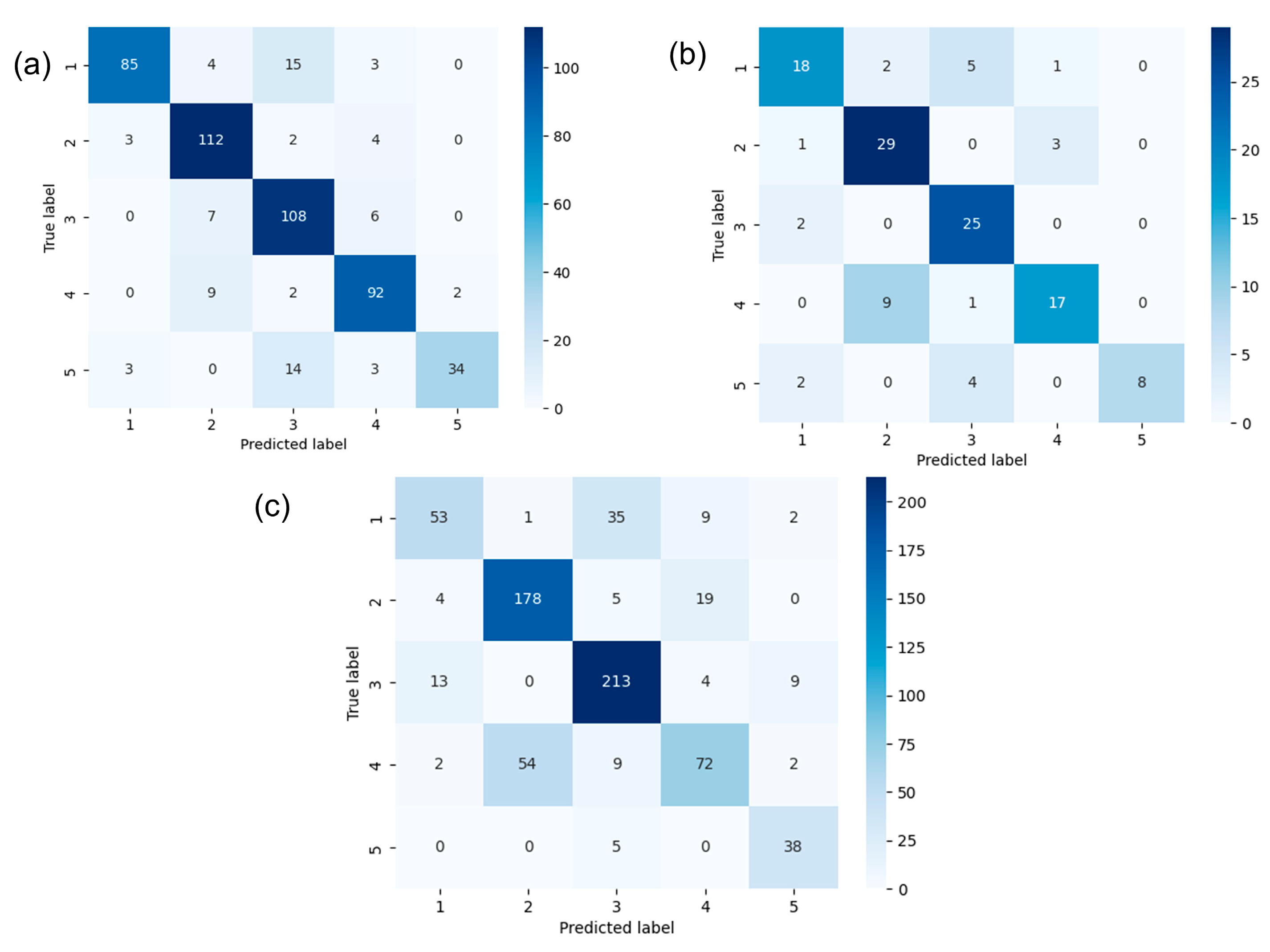
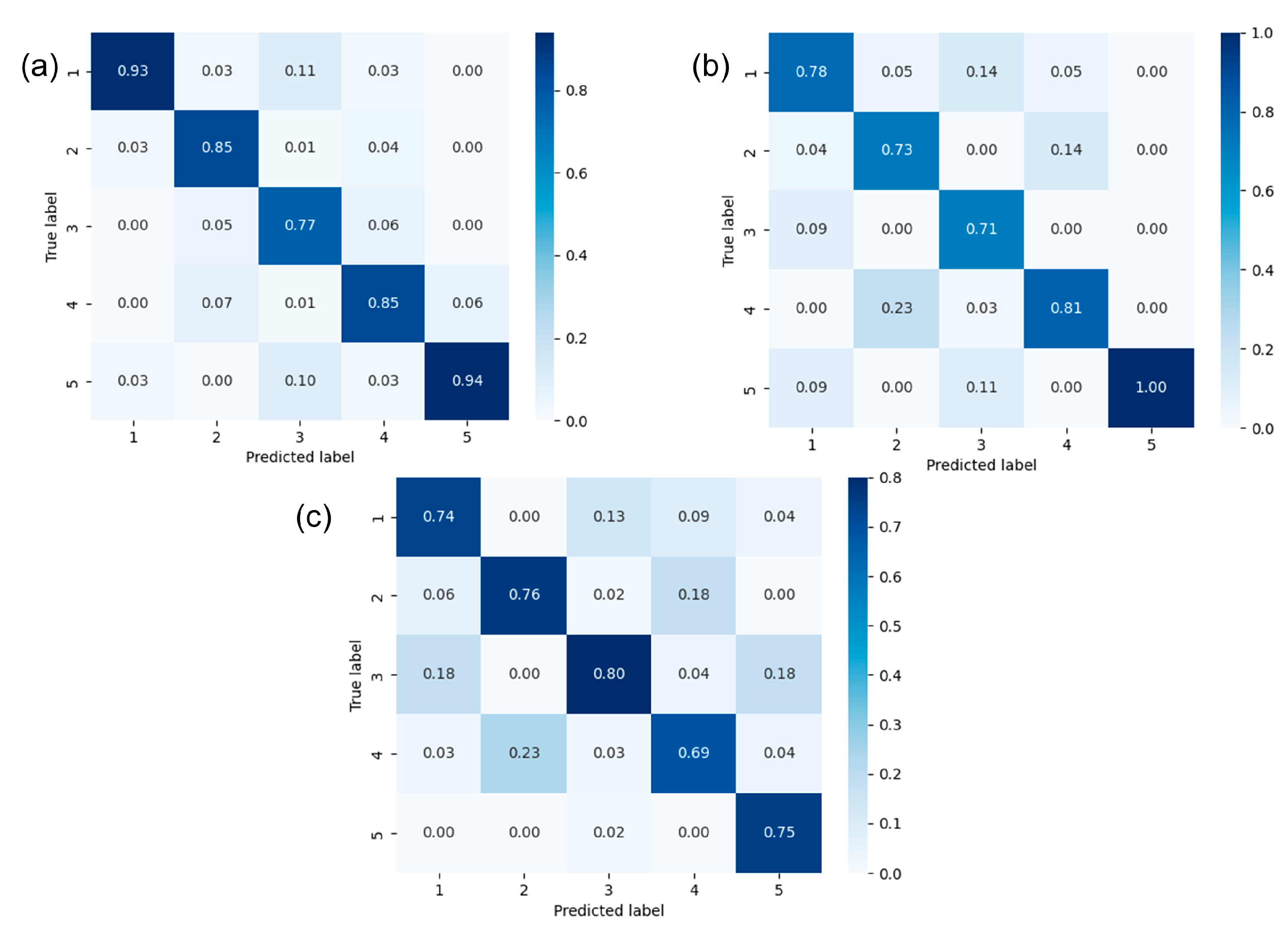
(2) To address the strong correlation between the four texture features, a comparison between the RF and several other classifiers (KNN, NBC, SVM, and DT) showed that the RF has the advantage of achieving higher accuracy for correlated input variables both in principle and in practice. To further improve the predictive ability of the model, hyperparameter optimization of the RF model was conducted, and the average accuracies of this model on the training data, validation data, and test data were 0.84, 0.79, and 0.76, respectively. The blind well test demonstrated that the RF model was also applicable to uncored wells.
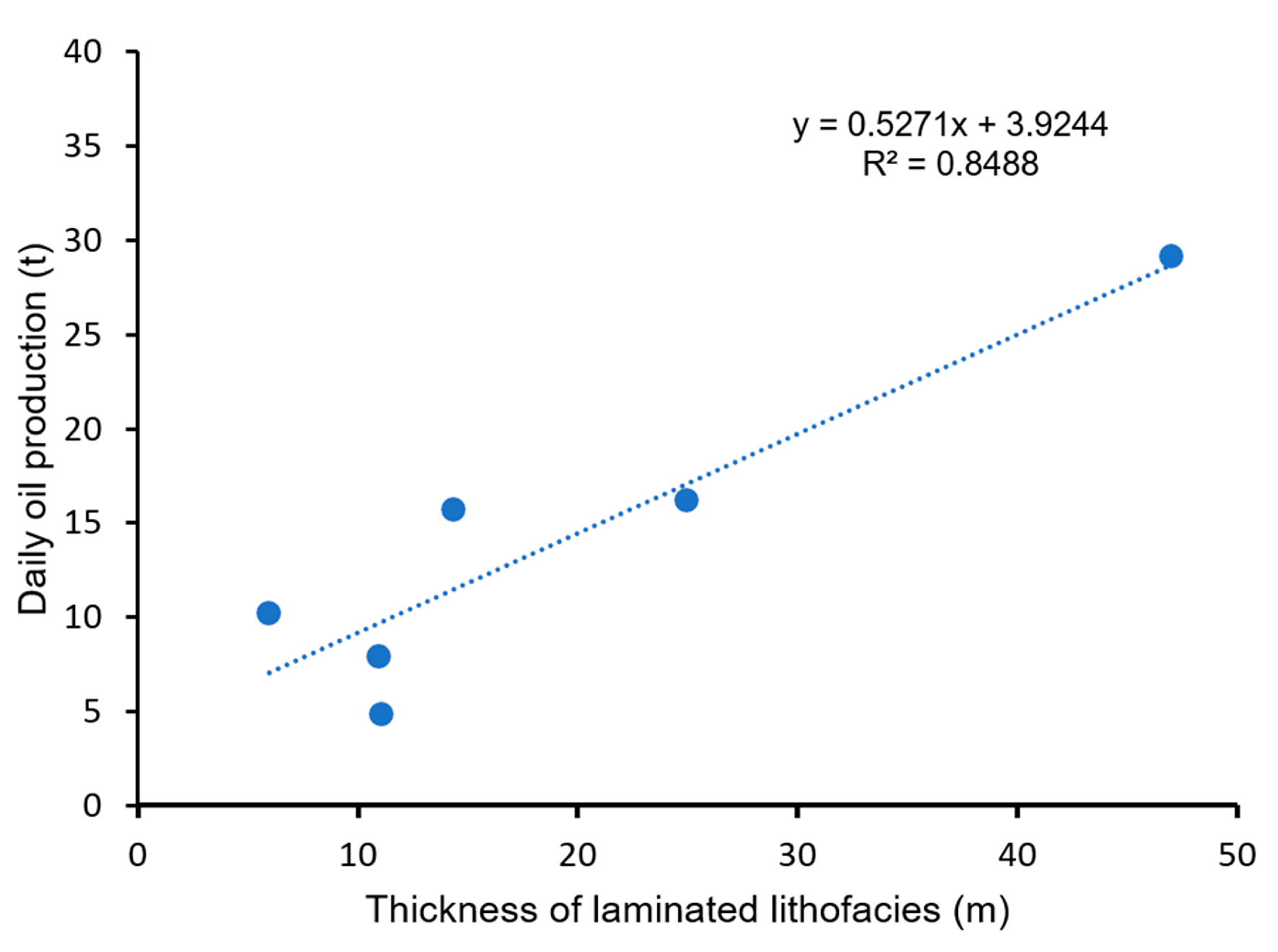
(3) The geostatistical inversion model established under the constraint of finely divided lithofacies could more delicately describe the distribution characteristics of lithofacies between wells to precisely predict the lithofacies between wells. On the basis of lithofacies division, it was preliminarily clarified that there was a good linear relationship between the thickness of laminated lithofacies and production capacity in shale reservoirs.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}