This section presents the developments carried out during the work. Initially, a generic architecture to achieve Zero-Defect Manufacturing through Quality Prediction is presented. This architecture aims not only to deliver these functionalities to the proposed case study but to be generic in order to be replicable and scalable. After the description of the generic architecture, the necessary steps are presented to develop the prediction models that will give the system the ability to predict possible problems related to the quality of the products before they actually happen. This section also describes how these models are then used at runtime; specifically, how they are used to predict defects during production.
3.1. System Architecture
Quality issues in plastic injection molding are problems that can be found in many different factories and products. Whether in the production of final products or plastic parts used to produce other products, it is important to present solutions that can be scalable and replicable. In this way, an architecture that combines MES RAILES and some components from the ZDMP platform is designed and proposed. RAILES Platform is a Smart MES able to monitor real-time manufacturing systems. RAILES fits the list of next-generation software developed for the industry to help manufacturers make better decisions based on real information gathered from the shop floor. The proposed architecture aims to integrate RAILES and ZDMP Ecosystem, to expand the functionalities of the existing ecosystem through integrating new functionalities, which is the case of the ZDMP platform.
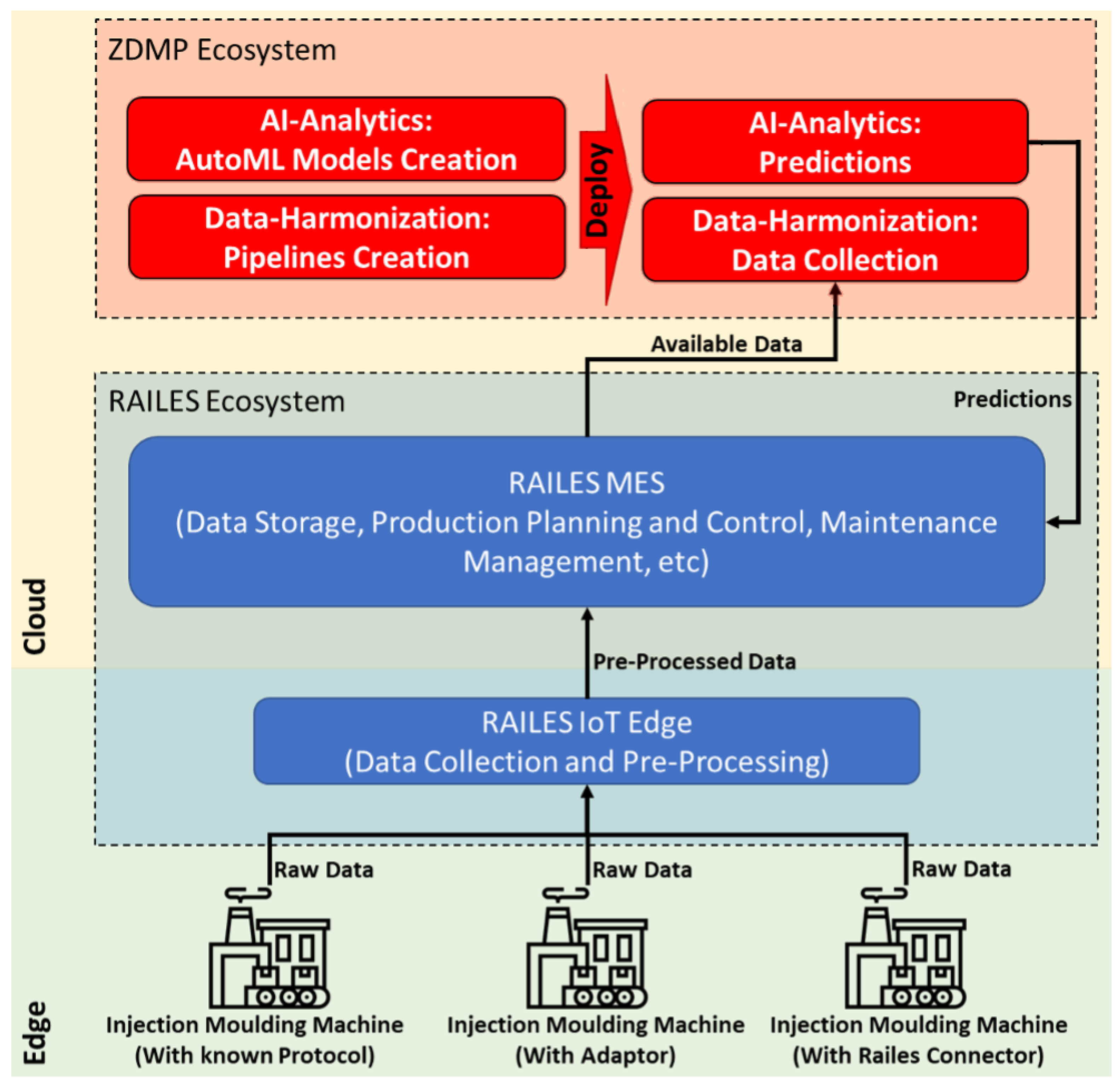
Figure 1 shows the proposed high-level architecture and which are the main components to be used in both platforms. This architecture guarantees the integrity of the system and its scalability to be approached in different scenarios.
As can be observed, the system consists of three large groups. The shop floor where machines operate and where changes and improvements are needed. The RAILES ecosystem is responsible for data extraction and all production management through the MES. Furthermore, the ZDMP ecosystem will be integrated to extend what is offered by RAILES. All raw data generated by the machines and the process are sent to the RAILES IoT Edge. For a device to send this raw data, it must have an integrated RAILES IoT Connector, an adaptor or the capacity to send the data in a protocol known as the RAILES IoT Edge. When the RAILES IoT Edge receives the data, it makes a preliminary analysis so that these data can later be used. This layer is composed of a device or network of devices responsible for giving context to the data, completing the collected data and so forth. When the data are pre-processed, they are sent to the cloud, where the RAILES cloud environment will store these data in a PostgreSQL database and make it available for the most advanced features of MES RAILES. At this level, the system is already capable of planning and controlling production, monitoring the system and managing maintenance tasks. Within the ZDMP ecosystem, two large groups constitute the two different phases of platform execution. In the initial phase, during the development and setup of the platform, the design versions of the two used components will be used. The Data Harmonization component will be used during the design phase to create the pipelines that will allow data extraction. Regarding the AI-Analytics component, it will be used to develop the classification models, which will be able to generate some preliminary and more generic forecasts for the injection molding process. During the runtime phase, that is, during production, the Data Harmonization component will be responsible for receiving the data made available by the RAILES ecosystem. The AI-Analytics component will use these data to generate predictions based on the models created in the design phase. The predictions generated by the ZDMP ecosystem (AI-Analytics) are then sent and made available to the RAILES ecosystem. Hence, these predictions can be used to reduce problems related to quality through alerts, changes to production planning and changes to the maintenance schedule, among other things.
3.2. Data
This subsection presents the procedures related to the treatment of the data used in the study presented in this article.
3.2.1. Data Collection
In the context of this research, data collection is the process of obtaining information from different sources, capturing patterns of past events and storing them in the proper format for future use. This collection and storage are done with the objective of using this data to build predictive models using machine learning algorithms.
Data are basically unorganized statistical facts collected for specific purposes. Due to the unorganized nature of the collected data, it is necessary to make some adjustments and transform them so that they become more organized and more accessible for the algorithms to process.
There are numerous methods of communication and data collection from machines, but in order to collect data in a standardized way, and as mentioned, a communication protocol known and used within Industry 4.0 to collect data from an injection molding machine, the EUROMAP 77, was used. This protocol is an OPC UA interface for plastic and rubber machines to exchange data between injection molding machines and the manufacturing execution system (MES). The newer machines use this factory-enabled protocol and those that do not have it have other protocols, such as OPC-DA. One of the machines used in this study was OPC-DA and it was necessary to use a wrapper to convert the data availability format from OPC-DA to OPC-UA.
This study includes three different injection molding machine models: Negri Bossi 400 (OPC UA), Nissei ASB 12M (OPC UA) and Tederic DH 850 (OPC DA). Negri Bossi and Tederic work with traditional injection molding and Nissei ASB works with stretch and blow injection molding. This diversification allowed us to simulate as many scenarios as possible during the project implementation.
Having access to data alone does not add value, it is necessary to have a platform to store the data with the respective information necessary to identify them and have a way to communicate these data to different platforms. The machine learning algorithms that will be used for the training and obtaining of the predictive models are supervised algorithms, which means they require labeled datasets. With this type of algorithm, to obtain a good predictive model, it is necessary to know the correct outputs in the historical data that need to be predicted or classified. To do this, RAILES was used.
In order to have a good amount of historical data where the output was known, measurements were made during some time, forcing failures in the production process so that the historical data would have periods where everything was good and have some periods where failures would occur, while this output would be registered, this way labeling the datasets. For this labeling, RAILES provided a useful tool because when a failure in production occurred, the digital platform allowed the factory workers to introduce the type of failure and at which cycle it occurred, as can be observed in
Figure 2.
3.2.2. Pre-Processing
Data pre-processing is the process responsible for transforming unorganized data into an organized and reliable dataset ready for analysis. The pre-processing process should commonly be applied to datasets before raw data are used in the machine learning context. It is a fundamental step otherwise, an unorganized data matrix will make the performed analysis untrustworthy.
Currently, there are several ways to pre-process data, through commercial modules or libraries specifically developed for data pre-processing using programming languages. In the case of this paper, feature values come isolated and data are time series, which are values that are recorded over time. As mentioned, these values are collected through OPC-UA and recorded whenever there is a value variation, as the different parameters do not vary in the same way causing a different number of records per variable per cycle.
In order to create a classifier to predict the quality of the part, it is necessary to understand what the maximum values of the different features involved were in order to create a certain part. The pre-processing stage is responsible for transforming these time series of data into single values. According to the feature in consideration, it records the highest or lowest value. The criteria for registering the value per feature is based on the worst case scenario of each parameter. For example, in the case of features directly associated with pressure and temperature, the values registered are the local maximum values per run count. The worst case scenario for each of these variables occurs when the time series value registers higher values.
In contrast, in the case of cushion (volume-related), the value to be registered is the minimum. This feature represents the quantity of material deposited in the mold. The larger this quota, the smaller the amount of material injected into the mold. The minimum values for volume are “worst case scenario” since they represent a part lacking material. This entire Data Harmonization process was carried out using the tool made available by the ZDMP project, Data Harmonization modules (DH).
The DH component allows the user to design a manufacturing map that, when executed, transforms a specific syntax from one format to another. This map is a java archive file wrapped in a docker container that executes as a transformation engine. This application provides a graphical interface where data pipelines can be built in the form of drag-and-drop building blocks. These blocks are connected to each other, having a general structure containing an input block, a data transformation block and an output block. The input block receives the raw data and passes them on to the transformation block, which performs the necessary transformations on the data so that they are in the correct format for the predictive model to receive and sends them to the output block, where they are forwarded to the model. After creating the model, it is necessary to make it work in real-time and DH allows this to happen. In
Table 1 and
Table 2, it is possible to observe the pre- and post-transformation data where the maximum value of reading in the time series format is highlighted (yellow color) and appears in the post-treatment as one of the parameters for the creation of a certain part.
In the case of this research, and as mentioned, a data streaming pipeline was implemented, as it needs to receive and transform data in real-time. Therefore, the pipeline is running all the time in the API, always ready to receive data at any moment, transforming them and sending them to the respective receiver.
Although only the maximum values per feature are used for the classifier, the time series data are stored in a way that shows, in case of problems/malfunctions, the variation of features over time in order to help the different technicians troubleshoot. For example, if the pressure cycle of the maximum is not correct, observing its variation can help in troubleshooting maintenance problems. This allows us to have an overall view of the process and finer monitoring of the process.
3.2.3. Labeling
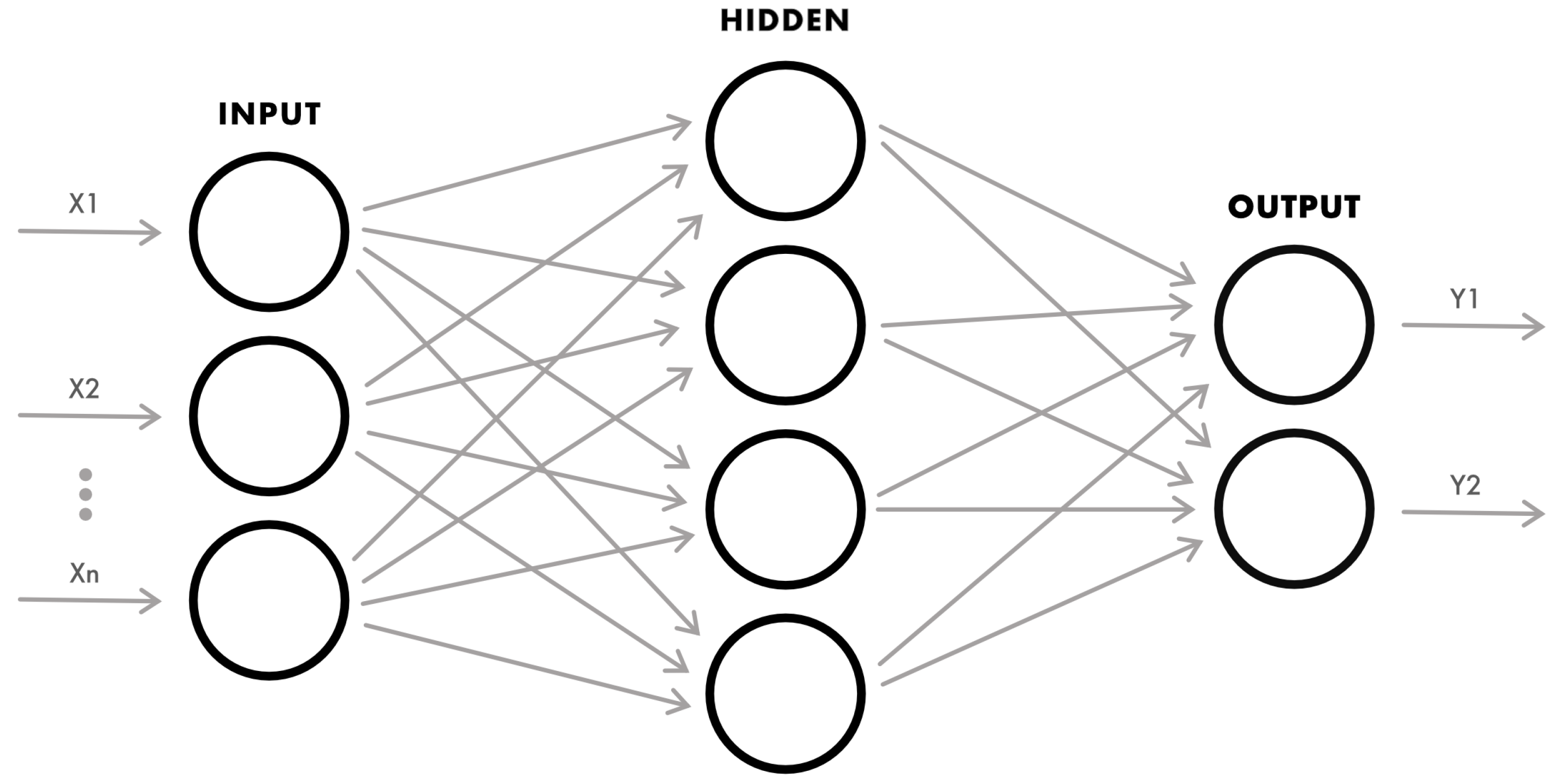
As mentioned before and in order to create supervised classifiers, it is necessary to assign a label to each of the vectors that contain the process parameters. So Xs are our process parameters and Ys are our labels. Given a basic Artificial Neural Network for the conceptual analysis, it is possible to observe what is mentioned in
Figure 3.
The idea of characterizing a manufacturing process according to its own limits allows us to say whether the part derived from the process is a conforming (OK) or a non-conforming part (NOK). The criterion for defining an OK or NOK part is the specifications created for its manufacture (OK part) or a part outside the control parameters (NOK). These parameters can vary from product characteristics, which are called defects.
Following the quality criteria, a process characterization approach was performed, where each part was evaluated with a discrete interval [0,1], where ‘0’ means NOK (Y1) part and ‘1’ means OK part (Y2).
This characterization was handled by a quality operator with knowledge of the process and the parts involved. Using RAILES software, it was possible to label each part during the ordinary course of the process.
There are several ways to carry out labeling [
43], being automated, such as Automated Labeling through Semi-Supervised Learning (SSL), Propagation and Transfer Learning. However, in this case, since the process is known and has well defined boundaries regarding the quality of the parts through the analysis of the quality technicians and production engineers, this labeling was carried out manually and internally, that is, internal labeling. This approach was used because the creation of only three different processes was considered and it was logistically possible to do so. It will be interesting in the future to explore more automated labeling tools, which, if effective, will reduce the setup time of the different classifiers.
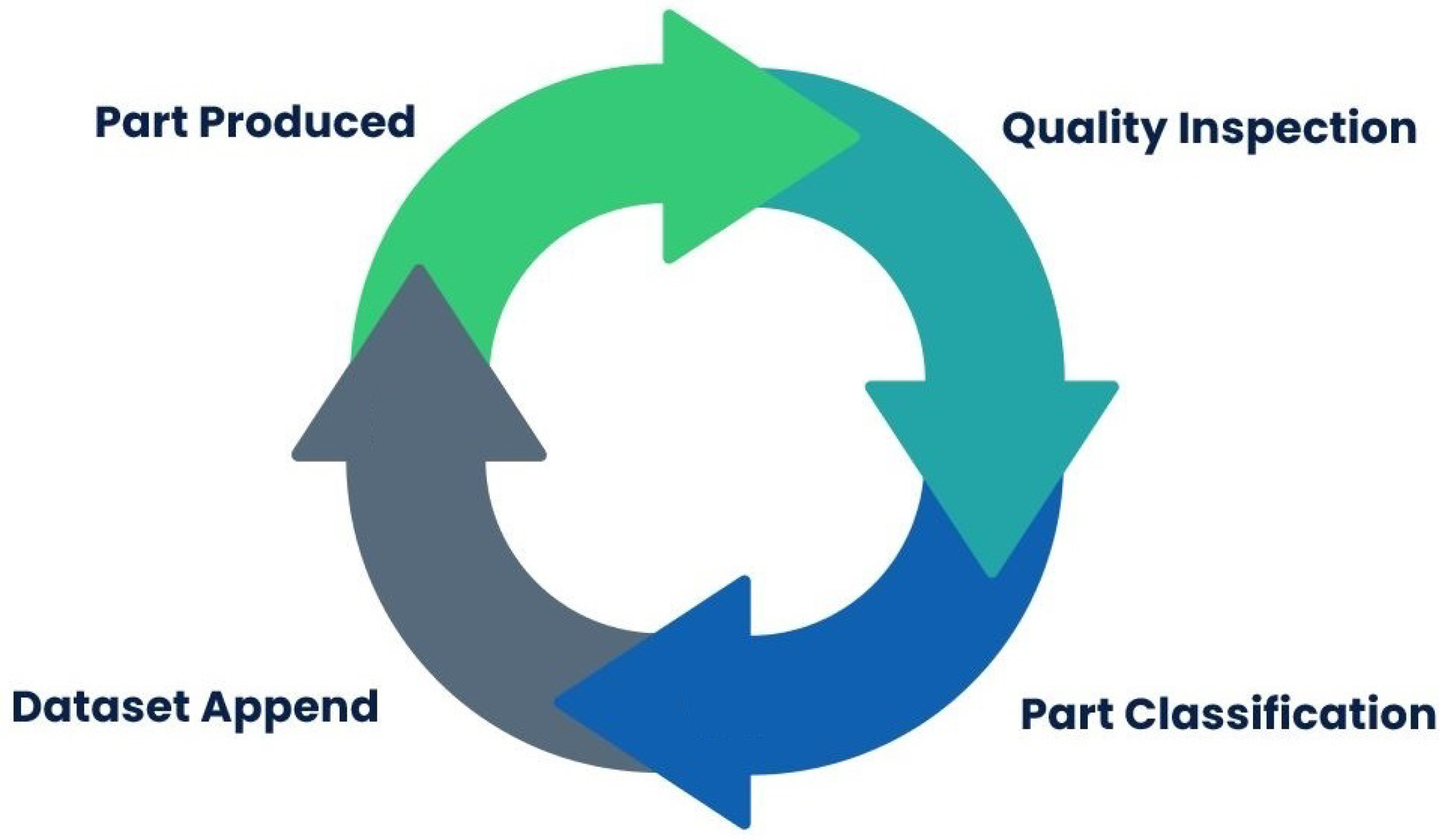
With this approach, known as Human-in-the-Loop (HITL), both human and machine intelligence is leveraged to create machine learning models. In a Human-in-the-Loop setup, people are involved in a virtuous circle of improvement where human judgment is used to train, tune and test a particular data model. In
Figure 4, it is possible to observe the Human-in-the-Loop process used during the provocation error tests in order to create the training datasets. After the parts are produced, a quality inspection is performed and the classification of each of the parts is entered into RAILES (
Figure 2). The quality of the parts (label) is attached to the dataset along with the process parameters (features), only then is it possible to create a dataset with labels for a supervised learning utility.
This was done because the data labeling process is incomplete without quality assurance. The labels on the data should represent a baseline degree of accuracy and with human intervention, with skilled technicians, the quality and ground truth of the data set is thus assured.
Although this approach meets the desired requirements and the classifiers perform well, it was only possible to classify a part after it was created, but one of our intentions was to predict a deviation of the process quality and detect a possible failure early on. That is, to make a predictive quality, this would help not only to reduce the environmental footprint (there are parts that cannot be reused) but also increase the efficiency and performance of the different processes.
To do this and since the boundaries between the OK (‘1’) and NOK (‘0’) parts and the places where process errors were provoked in the creation of the different dataset scenarios are well known, two more labels were assigned, Deviation I (‘1’) and Deviation II (‘2’), thus turning the OK into (‘3’), in order to predict a loss of quality in the process and to alert the operators so that they might intervene in the process before it produces non-OK parts. This approach proved to be very relevant because it was possible to detect a problem in the process, on average, about seven cycles before the production of a non-conforming part occurred. This was very relevant for the process because there was a transition from a reactive approach to a predictive approach.
The Deviation I process deviation allows the classifier model to detect a minimal change in the process behavior. At Deviation II, the values substantially diverge from the normal trend line and at this level there exists the possibility of slight point defects. However, these occasional defects may not mean an NOK part, as they may be “expected” under the product evaluation criteria, such as slight warping, mini black spots or micro lines. When an NOK part is predicted (‘0’), at this level, it is easy to identify defects such as warpage, brittleness, gloss, part oversize or undersize and orange skin, among other things.
These alerts are made to the users through the RAILES system whenever there are five or more level I deviations within a configurable time, whenever there are three or more level II deviations or an NOK part. This approach allows for mitigating outliers or sporadic runs without generating alerts that may cause unnecessary spam.
3.2.4. Data Augmentation
Data Augmentation (DA) is a technique that can be used to artificially expand the size of a training set by creating modified data from the existing one. It is a good practice to use DA if the intention is to prevent overfitting, if the initial dataset is too small to train on or if the intent is to squeeze better performance out of a model. However, this technique not only expands the training set’s size but is also suitable for enhancing the model’s performance [
44].
One of the problems in applying machine learning algorithms in industries with well known and stable processes, such as injection molding processes and low scrap rates is the difficulty in balancing the number of conforming and non-conforming parts in the training dataset. These problems in the literature are defined as imbalanced classification problems [
45].
The challenge of working with imbalanced datasets is that there are few examples of the minority class for a model to learn the decision boundary effectively. One approach to addressing imbalanced datasets is to oversample the minority class through Data Augmentation, in this case, the NOK parts. The simplest approach involves duplicating examples in the minority class, although these examples do not add new information to the model. Instead, new examples can be synthesized from the existing examples. This Data Augmentation type for the minority class is referred to as the Synthetic Minority Oversampling Technique (SMOTE) [
46]. Instead of deleting or copying data, the current inputs were used to generate unique input rows with a label based on what the original data imply.
The method in this work relies on knowing the cycle and the combination of parameters that originated OK and NOK parts because the training datasets were created with error provocation tests in the processes followed by quality technicians grading each of the parts.
The use of this method in this work relies on knowing the cycle and the combination of parameters that originated OK and NOK parts because the training datasets were created with error provocation tests in the processes followed by quality technicians grading each of the parts.
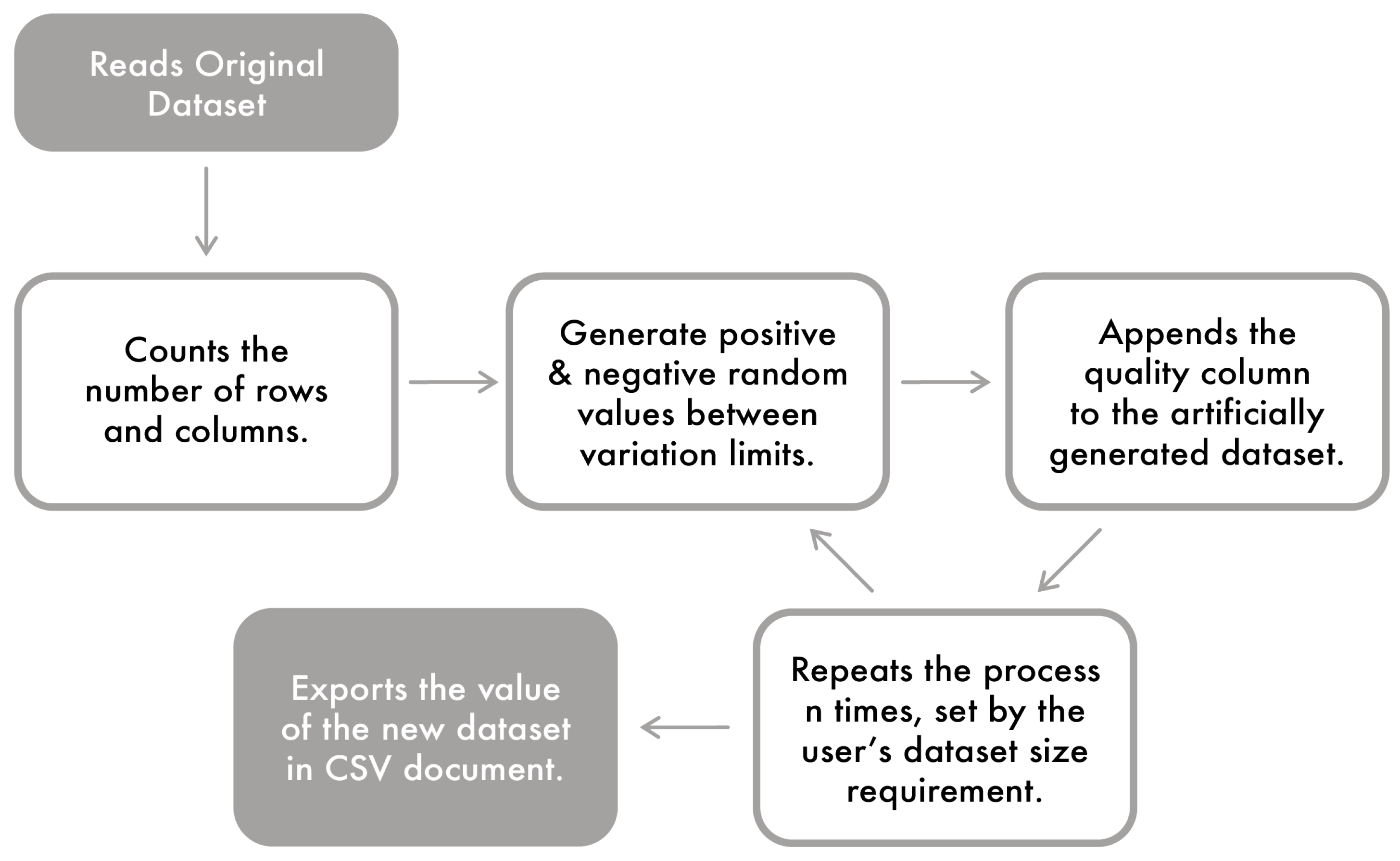
For this paper, the Data Augmentation was implemented using python language software. As can be observed in
Figure 5, the original dataset is imported to the program in CSV format. This dataset serves as the basis of information for synthetic data generation. The algorithm counts the rows and columns of the dataset and registers the values of each variable. Then, it multiplies the feature by a pseudo-random number with defined limits. The boundaries are defined to apply slight variations to the magnitude of the original process with a focus on maintaining the organic characteristics.
The user chooses the size of the synthetic dataset. This way, it was possible to introduce some data into the system that worked as sub-variations of the original intervals. It keeps the process trend lines unchanged and provides an analysis based on more values and training data for the classifier. In this case it is possible, for example, to only augment NOK values (minority class) and then add these to the original dataset with OK values.
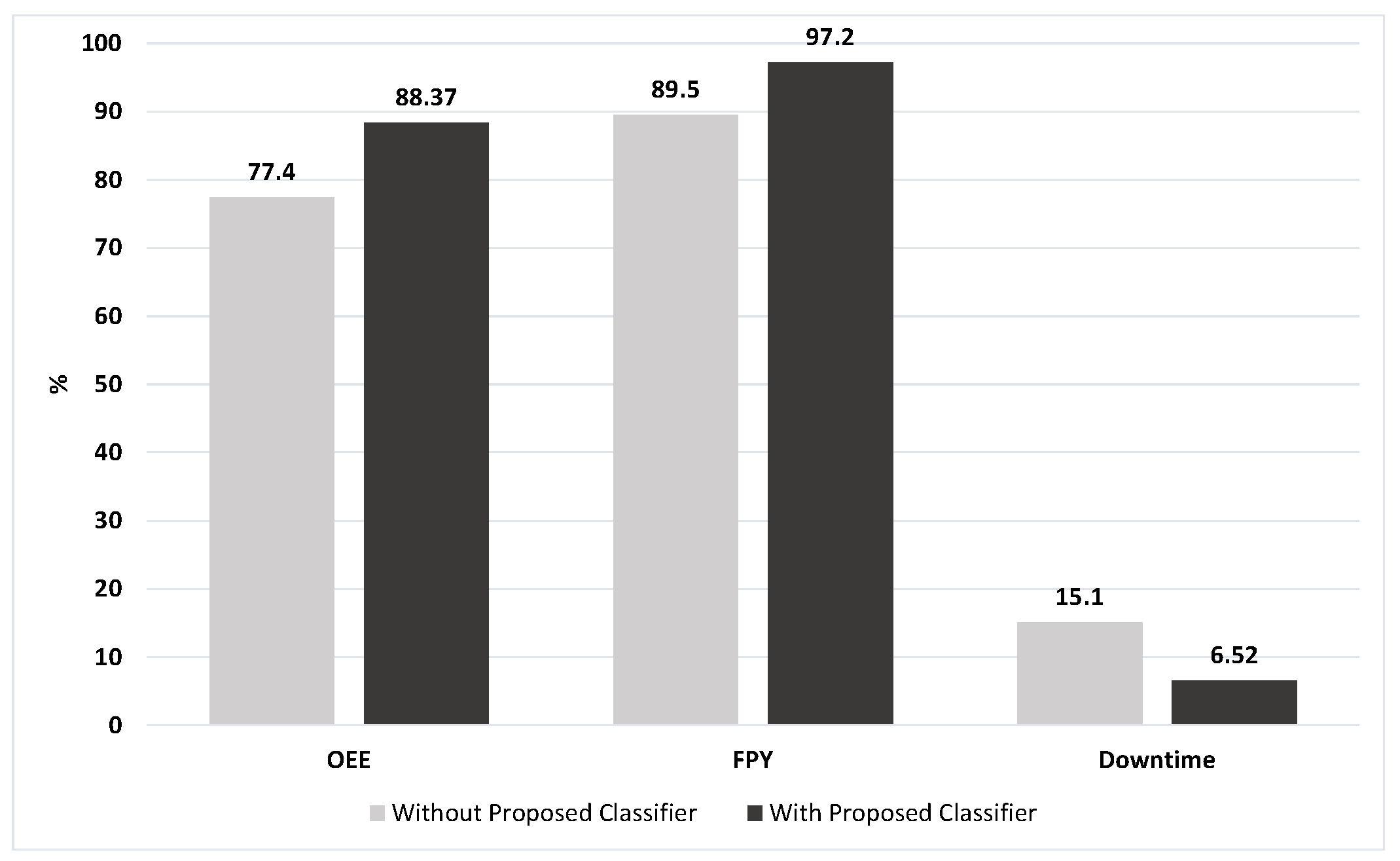
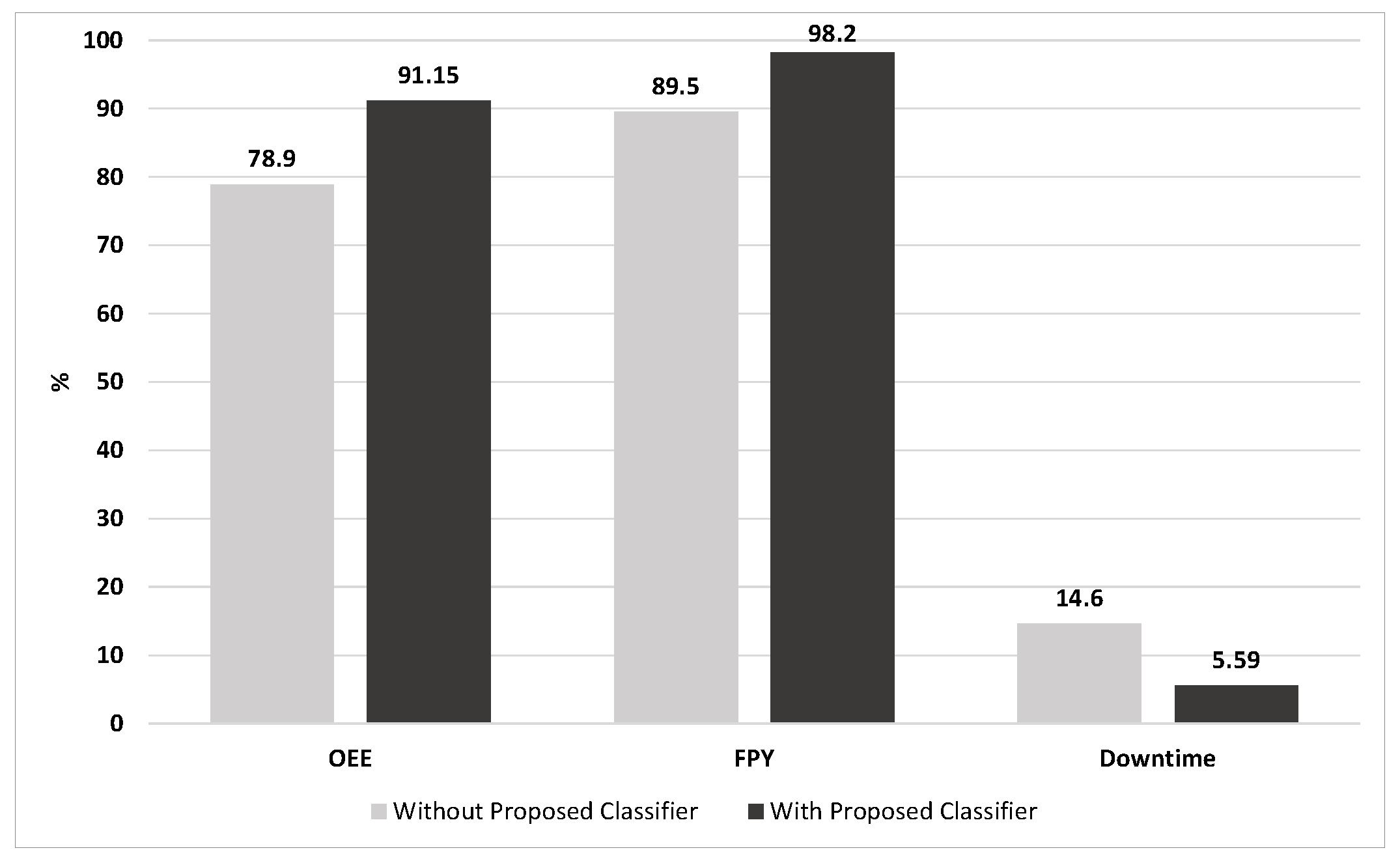
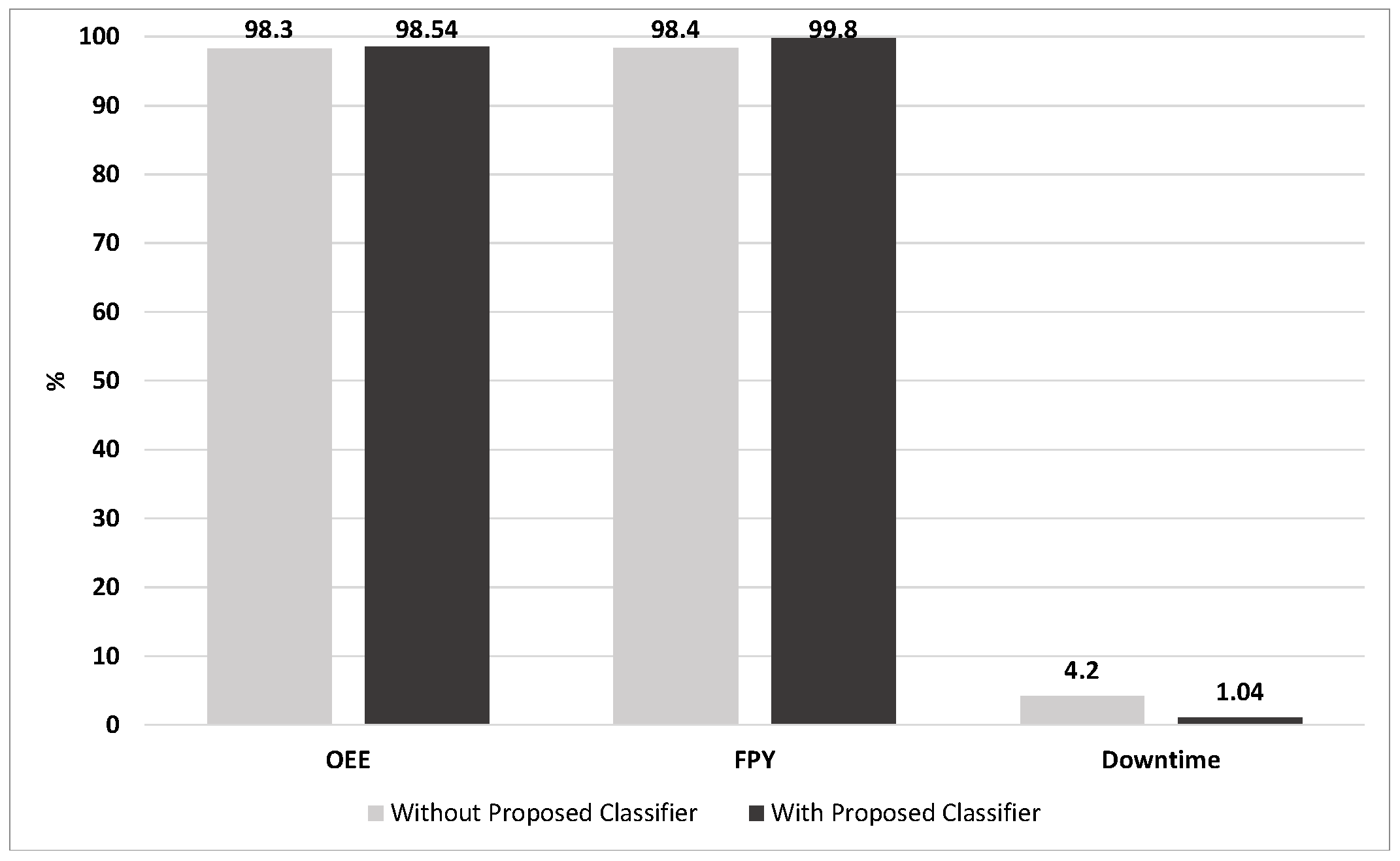
After augmentation, the synthetic and the original datasets were used to train the classifier and observe the performances and it is possible to perceive the difference in performance with a significant increase in
Table 3.
It is possible to observe a performance improvement in all cases where DA was applied. It should be emphasized that this procedure should always be followed to guarantee the balance between the performance gain and not allowing the system to be overfitted.
3.2.5. Feature Selection
The complexity of the injection molding process lies in the high number of parameters that intervene throughout the process. From the large set of process parameters, the critical issue is to find the relevant ones that should be used to classify the produced parts correctly. Previously to the work reported in this article, some of the authors of this paper carried out an extensive study on feature selection and which variables to monitor in each of the processes, which can be found here [
16].
In this work, the researchers compared algorithms from the three main families of feature selection methods: filter, wrapper and embedded. Additionally, a hybrid approach was also evaluated that takes into account not only the supervised contribution but also an unsupervised method in an effort to evaluate each feature without the influence of the target label.
Experimental data came from the same injection processes used in this work and were derived from the three different injection processes working on three machines of different brands and with different materials (PP, ABS and Tritan). In order to relate the process variables with the quality of the parts, typical problems were induced, such as resistor failure, water turning off and mold carburetor failure, among others.
In the mentioned study, the researchers found that there are variables that are transversal to the three processes even though they are different materials and parts working with different machines. These variables are Maximum Injection Pressure, Nozzle Temperature, Spindle Temperatures (Zone 1, Zone 2 and Zone 4), Zone 3 in the Nissei ASB case because it only has three resistors on the spindle, Cushion and Ambience Temperature. Additionally and specific to the blowing machine, the temperature variables of the pots and M2 must also be taken into account. There are still other variables that have been shown to be relevant from time to time and that can be taken into account in the representation of an injection process.
The number of features on average is reduced by 73%, representing not only gains in terms of performance but also in terms of writing flow to the cloud and computing time, among other things.
Regarding the introduction of meteorological variables in the monitoring of the process, it is clear that the ambient temperature has a significant impact on the processes [
16].
3.3. Predictive Methods
In this subchapter, the methodologies associated with predictive methods will be presented.
3.3.1. Train and Test Data
As explained earlier through the different methodologies, once there was access to the data, datasets were created for training and testing the different classifiers. Regarding the classifiers created, in all of them that will be mentioned further, 20% of the data were used for testing and 80% of the data for training.
Based on the feature selection study results, the features were selected and taking into account the labels mentioned in
Section 3.2.3, the following are the features and labels for each dataset.
Nissei ASB
In the case of this process, the size of the dataset used to train the classifier is 18,721 injection cycles, already augmented and the features, as well as the outputs, can be seen in
Table 4.
Negri Bossi
The size of the dataset used to train the classifier of this machine is 7828 injection cycles, already augmented and the features, as well as the outputs, can be seen in
Table 5.
Tederic
In Tederic machines, the size of the dataset used to train the classifier is 4852 injection cycles, already augmented and the features, as well as the outputs, can be seen in
Table 6.
Regarding the sharing of the datasets, because they are industrial processes, it will not be possible to share them due to confidentiality.
3.3.2. Classifiers
Regarding real-time predictive quality and part classification, as mentioned in the related work, many works have been carried out in this area and can be found in the literature.
Concerning the existing processes in Vipex, previous studies were carried out by the authors of this article related to the machine learning algorithms that obtained the best classification performance [
47].
The result of this work was that among several classifiers, the combination that obtained the best performance was the use of the Voting-Based Ensemble Method. This method considers both the contribution of an Artificial Neural Network (ANN) with a Support Vector Machine (SVM). This conclusion served as the basis of the work and proved to be true by obtaining the highest classification compared to other methods.
The classifiers were implemented in Python language through the scikit-learn library. In the ANN case, several tests were carried out with different numbers of neurons in the hidden layers and with different numbers of hidden layers. Several solvers were also tested (lbgfs, sgd and adam) and several activation functions (logistic, relu and tanh) and the architecture for which the best performance was obtained was the use of a hidden layer with 5000 neurons (Nissei ASB), 2000 neurons (Tederic) and 1000 neurons (Negri Bossi), respectively, and all with the logistic activation function and lbfgs solver.
In the case of SVM, the grid search was drawn using the GridSearchCV from the scikit-learn library to define the most suitable parameters. The parameters that resulted from the grid search were: Nissei ASB (Cost Function Value = 10,000 and Gamma = 0.001), Negri Bossi (Cost Function Value = 100,000 and Gamma = 0.01) and Tederic (Cost Function Value = 10,000 and Gamma = 0.01), all with linear kernel.
Table 7,
Table 8 and
Table 9 show the classifier performances obtained for the three processes. It should be taken into account that the values correspond to the average value of 10 ANN trains.
3.3.3. Run-Time Deployment
Since the main objective of this project is the prediction of failures in the manufacturing processes using machine learning, a component capable of integrating this into the architecture is of vital importance. After the classifiers for the different processes were created, they were exported in pickle (.pkl) format. A PKL file is a file created by pickle, a Python module that enables objects to be serialized to files on disk and deserialized back into the program at run-time. It contains a byte stream that represents the objects.
The AI Analytics Run-Time component from the ZDMP is capable of deploying and executing an external classifier in real-time. This component is responsible for running the models automatically. Users can upload models to the AI Analytics Run-Time API, where they can be executed in real time, receiving the data that were treated in the Data Harmonization component and predicting failures based on that information.
This is an advantage of using this component because it allows one not only to use classifiers exported directly by the ZDMP components through AutoML but also to integrate externally created modules and fine-tune them as needed, which leads to an increase in the versatility of this tool.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}