1. Introduction
Recently, the developmental environment of the chemical industry has been complex and changeable, the market scale is expanding, and the competition among the main bodies is increasingly fierce [
1,
2,
3]. It is the key to winning sales initiatives, grasping the coordination of quantity and price, and realizing the optimal economic benefit to accurately understand and properly evaluate the price trends of domestic chemical products. Chemicals are located in the downstream links of oil, coal, and other industrial chains, and the price transmission mechanism is relatively complex. Affected by domestic and foreign macro-policies, supply and demand fundamentals, upstream and downstream product prices, and other factors, chemical prices are a comprehensive response to relevant information with high-noise, dynamic, and non-linear characteristics. Therefore, it is necessary to build a price forecasting model to explore the historical laws of various information on price changes and then predict the trends of future prices [
2,
4].
Early price forecasting models were mainly based on traditional time-series methods that used ARIMA [
5], GARCH [
6], Markov zone transfer [
7], Kalman filter [
8], and other methods to predict the prices of financial products and commodities. In recent years, artificial intelligence technology has been rapidly developing, and neural networks have been gradually applied to the field of price prediction and have continued to improve [
9]. Compared with the traditional econometric model, the multi-layer network structure of neural networks can more accurately describe complex and variable non-linear relations, thus greatly improving forecasting performance. They have more advantages in dealing with non-linear problems with complex structures and multiple factors, such as price forecasts. Yu et al. demonstrated that a neural network method based on empirical mode decomposition was used to forecast international crude oil prices [
10]. Ying and Gao optimized the key parameters of a BP neural network through the PSO algorithm as an adaptive learning strategy to improve the prediction accuracy for stock prices [
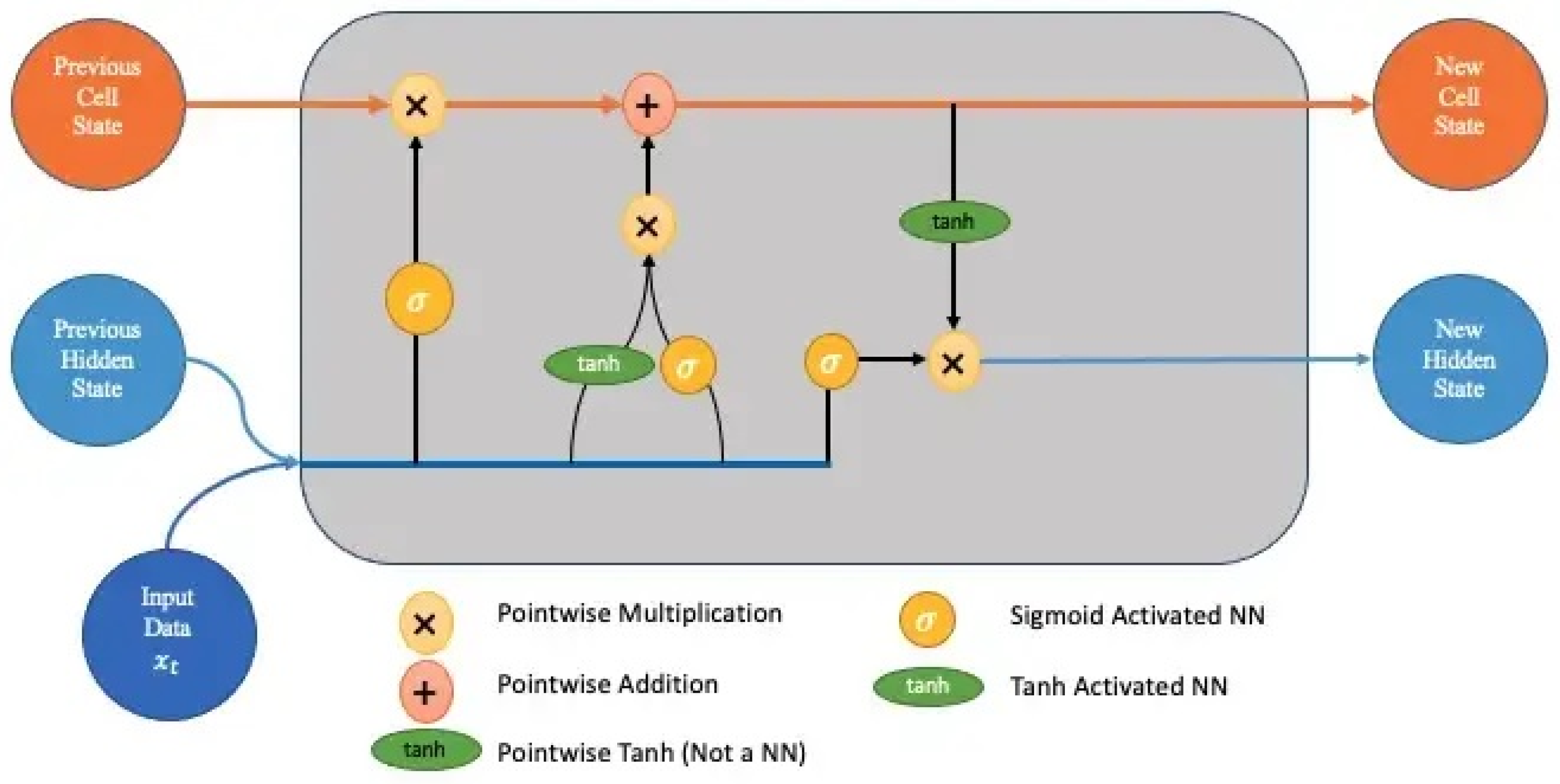
11]. Compared with other neural networks, recurrent neural networks introduce the concept of time series into the network structure, which makes them more adaptive in time-series analysis. Hochreiter and Schmidhuber proposed the LSTM model, which added a control gate structure to a recurrent neural network (RNN) unit to realize a memory function in time, and they also solved the problems of gradient disappearance and gradient explosion faced by a recurrent neural network model [
12]. The LSTM network models are also widely used in the economic and financial fields. Liu et al. used an LSTM model to predict the closing price of China’s 50 Shanghai stocks [
13]. Fischer and Krauss showed that an LSTM model had higher precision in predicting volatility in the S&P 500 Index than a random forest, deep neural network, or logical regression classifier [
14]. Compared with other neural network methods, LSTM neural networks have a long-term memory function, which has certain advantages in time-series modeling and prediction. They also solve the problems of gradient disappearance and gradient explosion in long time-series training and have strong adaptability and high accuracy in solving financial time-series prediction problems [
15].
In [
16], the LSTM model was trained by using a Heap-based optimizer, which significantly improved the LSTM model’s prediction performance. To assess the newly developed HBO–LSTM, they examined four datasets from the well-known La Haute Borne wind turbines in France. For comparisons, they also took a number of LSTM models, which had been tuned using a variety of optimization strategies, as well as a number of existing models, into account. The comparison’s results supported the HBO’s ability to improve the LSTM model’s prediction performance.
Another study investigated how a new methodology could be used to forecast the adjusted closing price of a particular firm [
17]. Instead of using the conventional four features, a new six-feature set (High, Low, Volume, Open, HiLo, OpSe) was created to increase the likelihood of providing more accurate findings with fewer losses (High, Low, Volume, Open). The study also examined the impact of the data scale by enhancing open innovation dynamics with datasets from Apple, ExxonMobil, Tesla, and Snapchat. The impact of the company’s sector on the loss outcome was also considered.
Another study identified the GCC stock market, which was most negatively impacted by COVID-19, and extracted the contributing aspects [
18]. Analysis of the analytics data revealed recommendations that, when followed, could lessen adverse financial effects. The financial repercussions of COVID-19 are still unknown, despite international efforts to stop its spread. Recently, the spread of COVID-19 led to a decrease in stock market indices, as most industries experienced a recession. Bahrain was the most affected market in the GCC, with losses shortly increasing by 0.29, totaling 0.35 over the following two months.
A traffic burst-sensitive model (TBSM) was suggested for predicting near-term traffic [
19]. We first established a new state unit containing the short-term trend and reported the state to capture both the burst and typical scenarios. Second, an increment-based forecasting model and state-and-trend unit similarity degree (SD) assessment technique were suggested. The outcomes showed that the suggested model substantially outperformed both deep learning and other conventional machine learning techniques.
The 2019 COVID-19 outbreak’s effects on the stock price collapse risk for Chinese energy corporations are examined in this essay. In this paper [
20], the authors discovered that following COVID-19, the likelihood of stock market crashes for energy companies dramatically decreased. Additionally, they discovered that companies with higher levels of corporate social responsibility (CSR) activity were less susceptible to the risk of stock price crashes in the years after COVID-19 than companies with lower levels of CSR activity. Finally, they demonstrated that in the post-COVID-19 period, state-owned companies (SOEs) had less stock price crash risk than non-SOEs did. Our findings show that China’s economy recovered after COVID-19, which has policy ramifications for businesses looking to strengthen their resistance to exogenous shocks.
Generally, some parameters in a neural network model usually need to be set manually, and the prediction performance of the models trained with different parameters varies significantly. At present, the commonly used approaches for parameter selection include ergodic multi-grid search algorithm, fine parameter adjustment of control variables, and other methods that require high-end hardware and a slow parameter optimization process. The genetic algorithm, one of the optimization algorithms, has a good global search ability; therefore, it does not fall into the trap of a fast descent of local optimum. At the same time, it uses its inherent parallelism to carry out distributed computing to speed up the optimal solution. However, the genetic algorithm’s local search ability is comparatively weak, and the search efficiency is low at the later stages of evolution. It was easy to cause premature convergence in practical applications, resulting in low efficiency and low accuracy in the optimization process [
21,
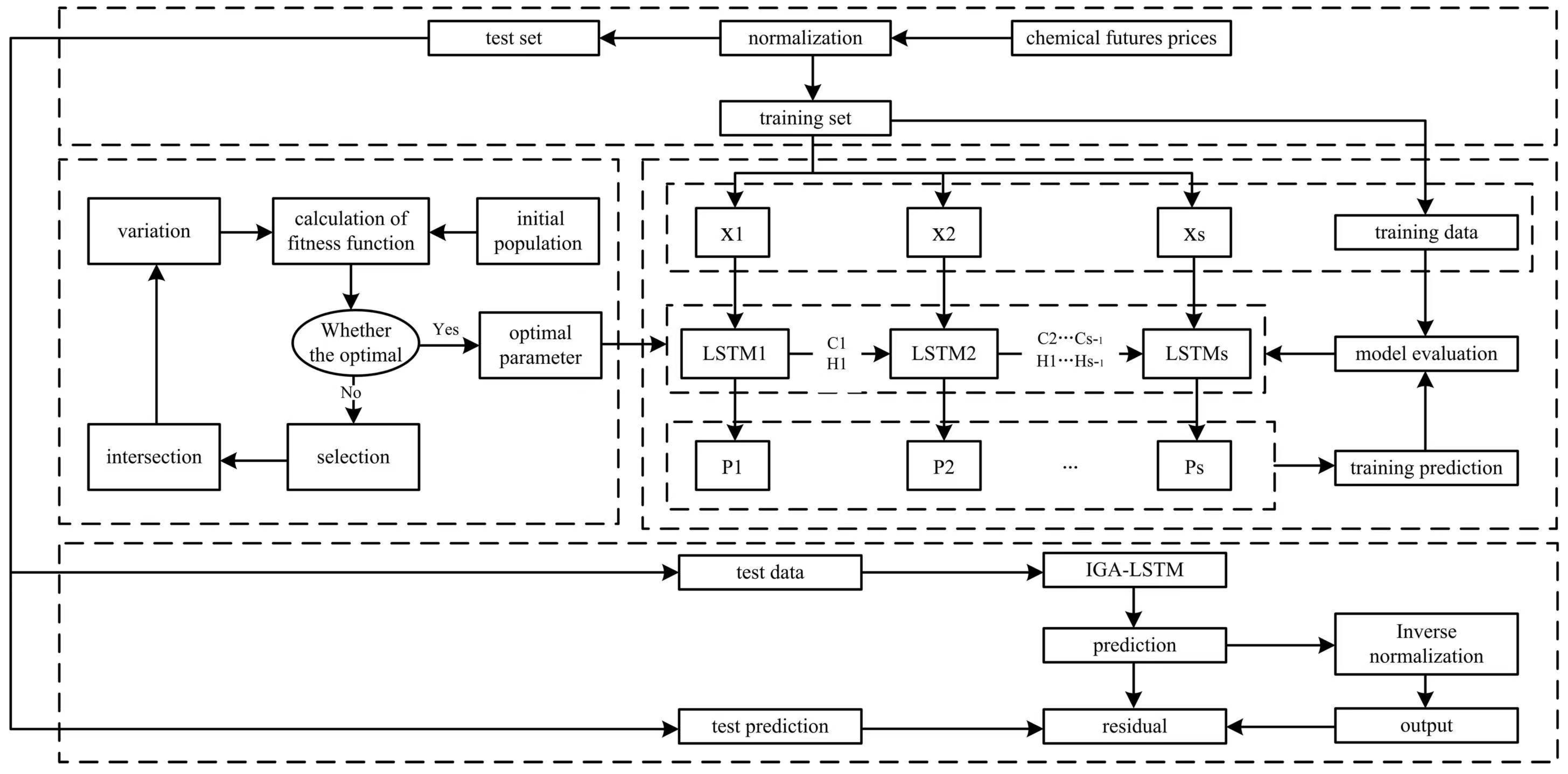
22]. Therefore, given the shortcomings of the genetic algorithm, this paper improved the crossover location determination and some gene exchange methods in the crossover strategy and used an LSTM model based on the improved genetic algorithm (IGA-LSTM) to forecast the settlement price of the active contracts for linear low-density polyethylene and polypropylene futures over 5 days in the Dalian Commodity Futures Exchange, with the goal of minimizing the prediction error.
The rest of this article is structured as follows: in
Section 2, we introduce the research method, including the short-term memory network, the genetic algorithm, and the improved genetic algorithm. In
Section 3, we detail the process of modeling. In
Section 4, we applied an IGA-LSTM model to forecast chemical futures prices and to present the training procedure and outputs. Finally,
Section 5 concludes the study.
4. Experiments and Results
In this section, the GA-LSTM model is employed to forecast the chemical futures prices. In this paper, the settlement prices of active contracts for linear low-density polyethylene (LLDPE) futures in the Dalian Commodity Futures Exchange from 31 July 2007 to 5 August 2022 and active contracts for polypropylene (PP) futures from 28 February 2014 to 5 August 2022 are selected as sample data. The sample data sizes are 3654 and 2057, respectively. The training set accounts for of the total, and the rest of the data compose the testing set.
4.1. Parameter Selection
The improved genetic algorithm was applied to optimize the key parameters of the LSTM model. The number of individuals in the population was set as 50, the number of iterations was 50, the mutation probability was 0.01, the hybridization probability was 0.8, and the encoding method was binary. In order to reduce the influence of human factors, according to the specific conditions of the experimental samples, the parameter ranges of the LSTM are set as follows: the value range of the time-window step is , the batch size is , the number of hidden layers is , and the rejection rate is .
According to the IGA parameter optimization process, for the futures price in LLDPE, the optimal time-window step of LSTM network is 23, the number of hidden layers is 30, the batch size is 87, and the rejection rate is . For the futures price in PP, the optimal time-window step of LSTM network is 20, the number of hidden layers is 52, the batch size is 100, and the rejection rate is .
4.2. Model Evaluation Criteria
In this paper, the indicators, such as the mean squared error (
MSE), root mean square error (
RMSE), and average absolute percentage error (
MAPE), are applied to quantitatively evaluate the prediction model. They are defined as follows:
4.3. Results and Discussion
In the experiment, the performance of IGA is evaluated by comparing six benchmark problems, as listed in
Table 1.
Then, by comparing with standard FA, GA, PSO and artificial fish swarm algorithm (AFSA), the salp swarm algorithm (SSA), gravitational search algorithm (GSA), it is judged that the proposed IGA is effective.
We select the maximum, minimum, average and standard deviation (SD) of the optimal target (Range) as the evaluation indicators to measure the performance of the algorithm. After 20 independent operations, the indicator results are shown in
Table 2,
Table 3,
Table 4 and
Table 5.
Table 2,
Table 3,
Table 4 and
Table 5 show that, in most cases, the evaluation indicators of IGA are superior to the other six algorithms, which means IGA is excellent in accuracy, stability, and robustness.
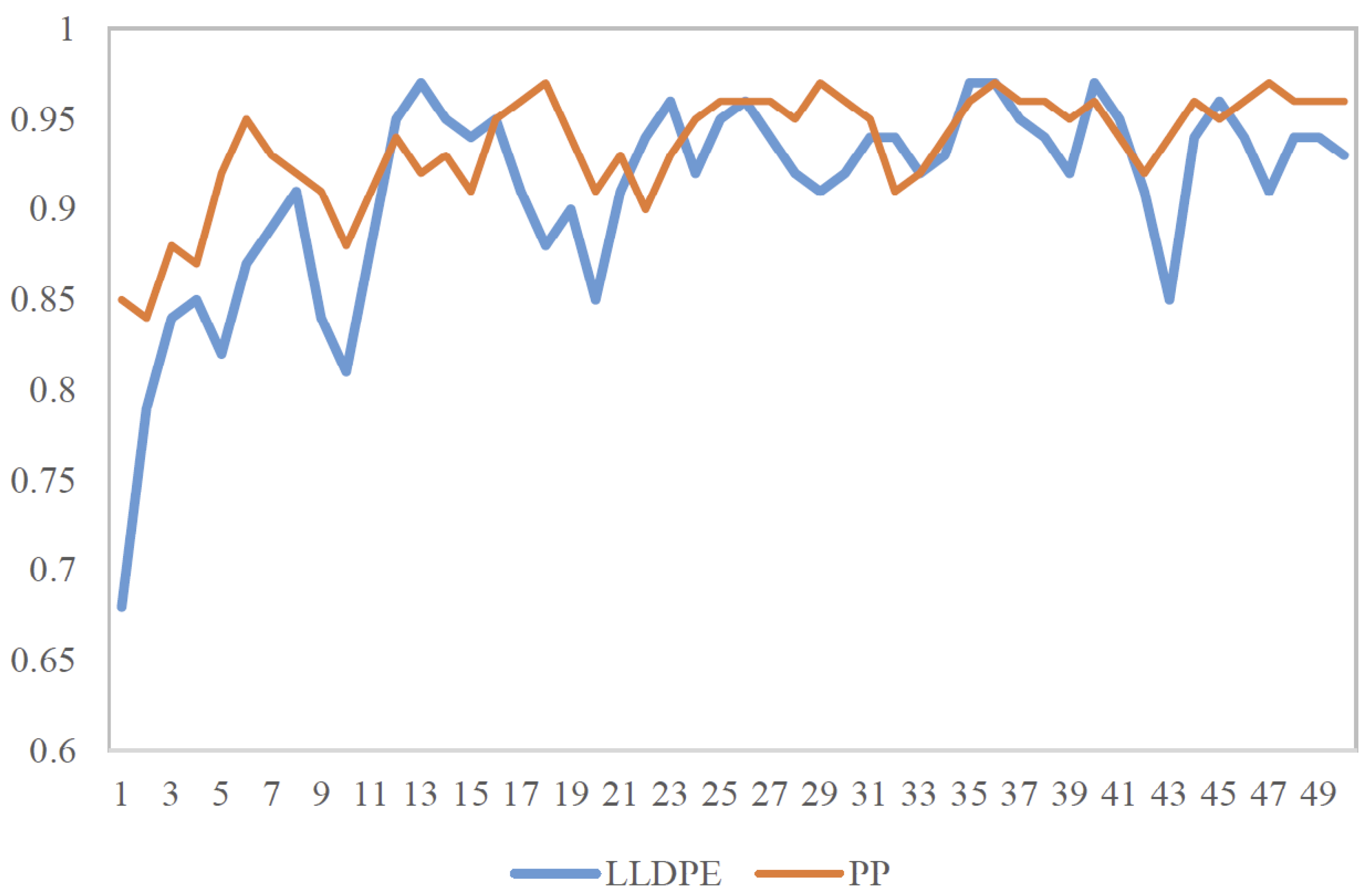
We conduct a unit root test on the futures prices of the two chemicals, and the results show that the T-test values of LLDPE and PP were and , respectively, significantly larger than the critical value of , and the non-stability is significant. Due to the non-stationary time series, the futures prices of chemicals have the characteristics of nonlinearity and complexity, and the prediction accuracy of LSTM is easily affected by parameter setting. Therefore, improved genetic algorithm combined with LSTM is used in this paper to predict the price of chemical futures, the IGA-LSTM model is constructed in this paper, and the time window, batch size, number of hidden layers, rejection rate, and other hyperparameters in the LSTM model are optimized by GA to determine the best parameter combination, to realize the effective combination of LSTM model network structure and chemical futures price data.
Further, through the analysis of specific prediction error indicators, as listed in
Table 6 and
Table 7, under the three model evaluation indicators of MSE, RMSE and MAPE, IGA-LSTM model presented the best prediction results. Note that the calculation results of the evaluation indicators listed in this paper are based on the predicted values that have not been inverse-normalized, and the prices of different products are comparable. Meanwhile, the R square of all models in the training set is more than
, especially that of IGA-LSTM is more than
. Specifically, for the LLDPE price forecasting model, MSE, RMSE, and MAPE of IGA-LSTM model prediction results are 0.001, 0.032 and 0.096 respectively, which are 0.002, 0.025 and 0.046 lower than that of GA-LSTM model, 0.006, 0.053 and 0.075 lower than that of ARIMA model with the worst forecasting effect. The neural network performs better than the traditional time series model in the forecasting of long time series. And the parameter optimization effect of the LSTM neural network is significantly improved by genetic algorithm improvement. For the PP price forecasting model, the evaluation indicators of LSTM neural network forecasting results are significantly better than ARIMA and SVM models, and the increase of MAPE index is more than 0.15.
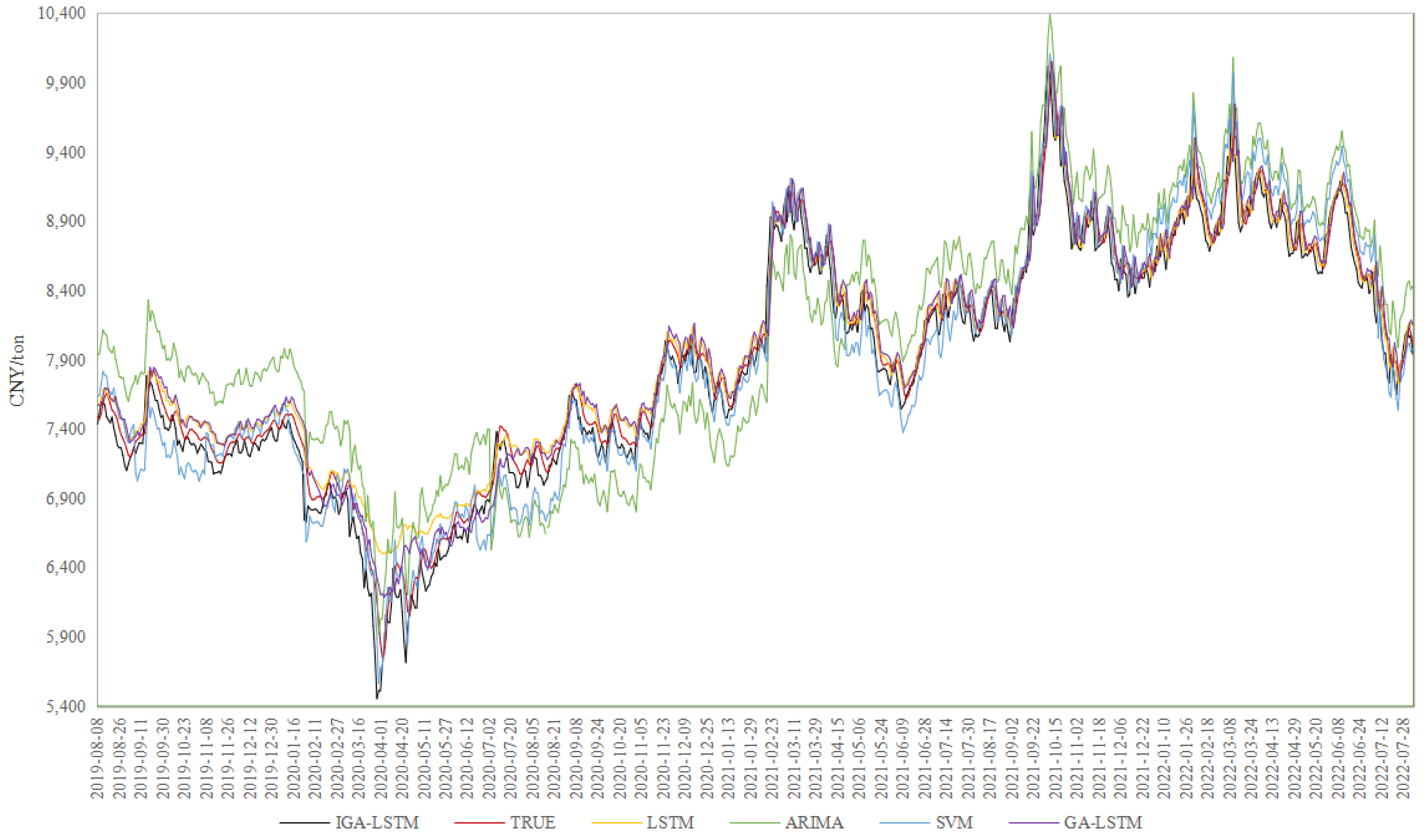
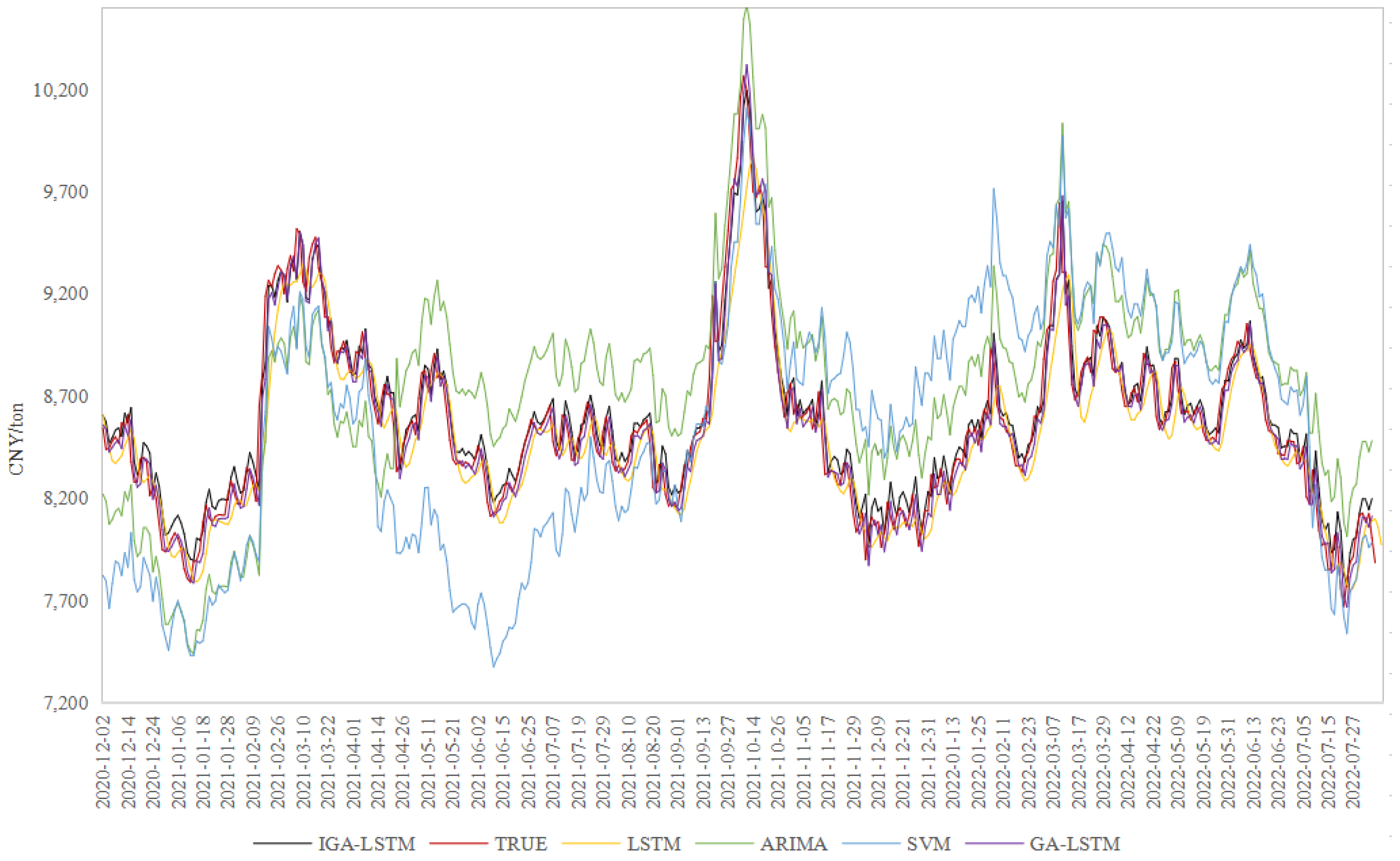
The experimental results are shown in
Figure 3,
Figure 4 and
Figure 5. From the trend change and coincidence degree of the prediction line and real line of the five models, the trend of the prediction line of the five models is basically consistent with the real line. However, there are some differences in the fitting effect. For the LLDPE price prediction models, the ARIMA model has a poor fitting effect, while the other four models can better fit the real data. For the PP price prediction model, the prediction values of the ARIMA and SVM models have a large deviation from the real values, and the fitting effect is poor, while the prediction performances of the three LSTM neural network models are significantly better. In general, LSTM neural network performs better at sudden changes in the chemical futures price, with rapid trend change capability, strong model adaptability, and higher prediction accuracy. Especially, compared with GA-LSTM, the MSE, RMSE, and MAPE results of IGA-LSTM decrease by 0.0001, 0.002, and 0.002, respectively, indicating that the prediction results of the IGA-LSTM model are closer to the true value. The prediction performance of the IGA-LSTM model is enhanced slightly after improving the genetic algorithm.
5. Conclusions
To enhance the research and judgment on the price trends of domestic chemical products and improve the accuracy of forecasting the chemical product price, the LSTM neural network is selected as the prediction model in this paper, and the key parameters of the neural network are optimized by the improved genetic algorithm. Through data processing and algorithm model experiments, our conclusions are obtained as follows:
(1) The genetic algorithm has a good global searching ability and can be applied to optimize the key parameters of the neural network. However, its local searching ability is relatively poor, with low searching efficiency at the later stage of evolution, while premature convergence easily occurs in practical applications. Therefore, for the premature problem, it is necessary to improve the algorithm to strengthen the efficiency and accuracy of the neural network parameter optimization process;
(2) The IGA-LSTM optimized by the improved genetic algorithm overcomes the training shortcomings of traditional gradient descent methods. Although the superiority of the algorithm proposed is sometimes limited, it still shows good performance in the futures price prediction of two chemical products. Furthermore, based on the error indicators of MSE, RMSE, and MAPE, the prediction results of the IGA-LSTM model are better than that of the LSTM model without optimization and the GA-LSTM model without improvement, showing higher prediction accuracy.
The experimental results show that the IGA-LSTM model has a certain application value in the futures price prediction of chemical products. For complex time-series forecasting with high noise, dynamics, non-linearity, and other issues, the LSTM neural network shows higher forecasting accuracy. With the improved genetic algorithm, the important parameters of the LSTM model can be optimized and the influence of human factors can be reduced. Then, the ability of the model to capture the characteristics and trends of time-series changes can be effectively improved. Although this paper only forecasts the short-term prices of chemical futures, the algorithm can also be applied to other research on financial time-series forecasting. Based on the current work, further research can be carried out: First, to improve the algorithm performance, the number of hidden layers can be increased to check the application effect of a multi-hidden-layer LSTM network structure or to seek a more effective parameter optimization algorithm. Second, data-driven technology can be employed to build the model on historical data. If the market changes dramatically in the future, the prediction accuracy may decrease. In this circumstance, the extracted key features and elements can be applied to the price prediction method.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}