
Practical Application-Oriented Energy Management for a Plug-In Hybrid Electric Bus Using a Dynamic SOC Design Zone Plan Method

Abstract
:
1. Introduction
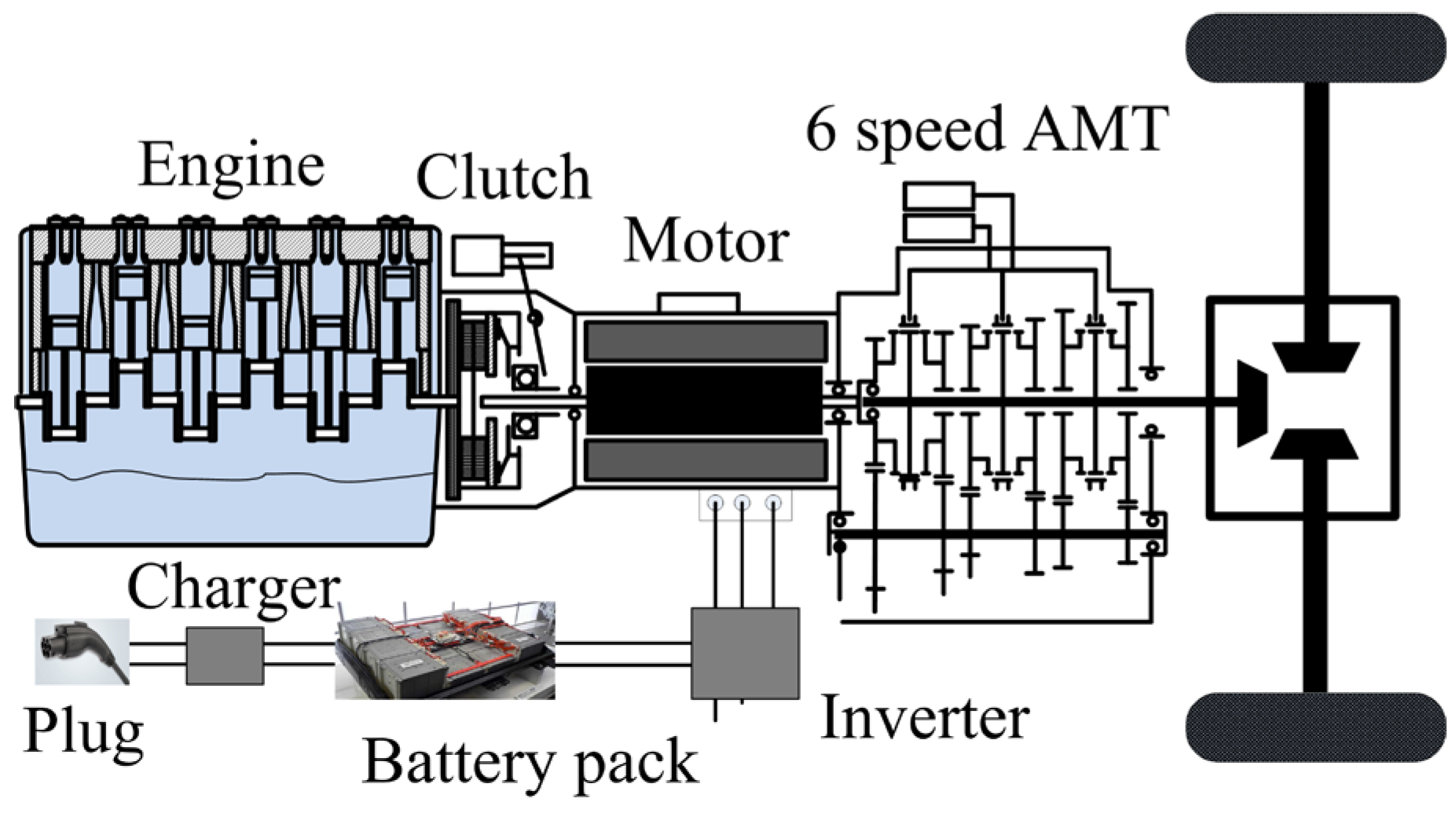
2. The Description of the PHEB
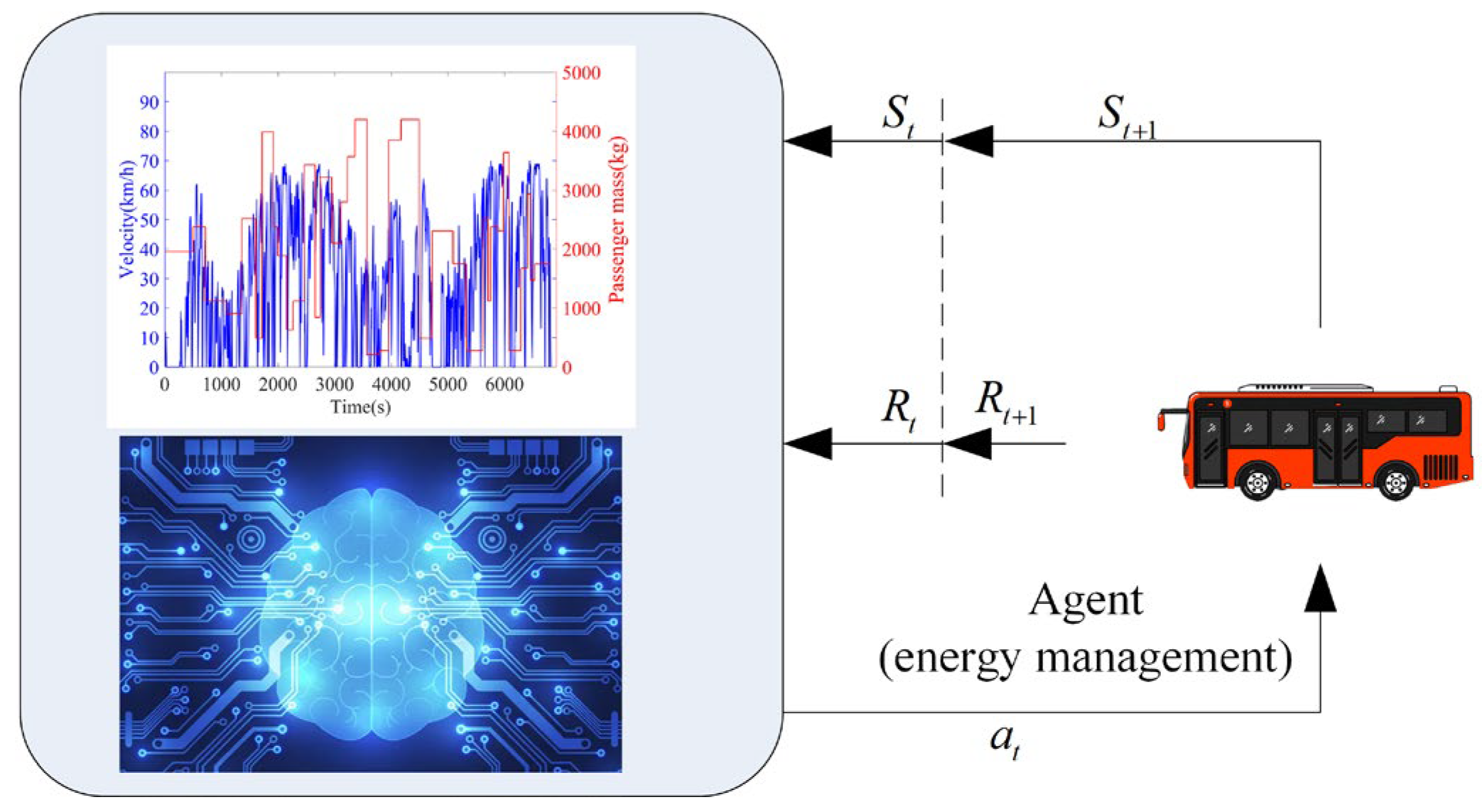
3. The Formulation of the RL-Based Energy Management
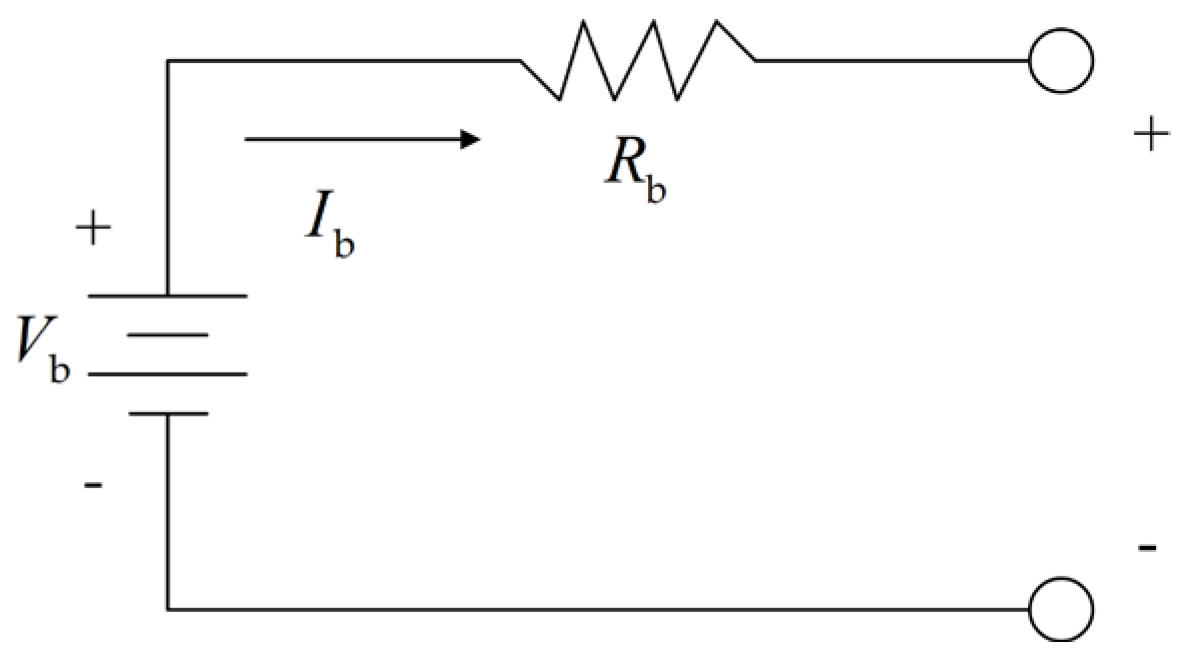
3.1. The Formulation of PMP
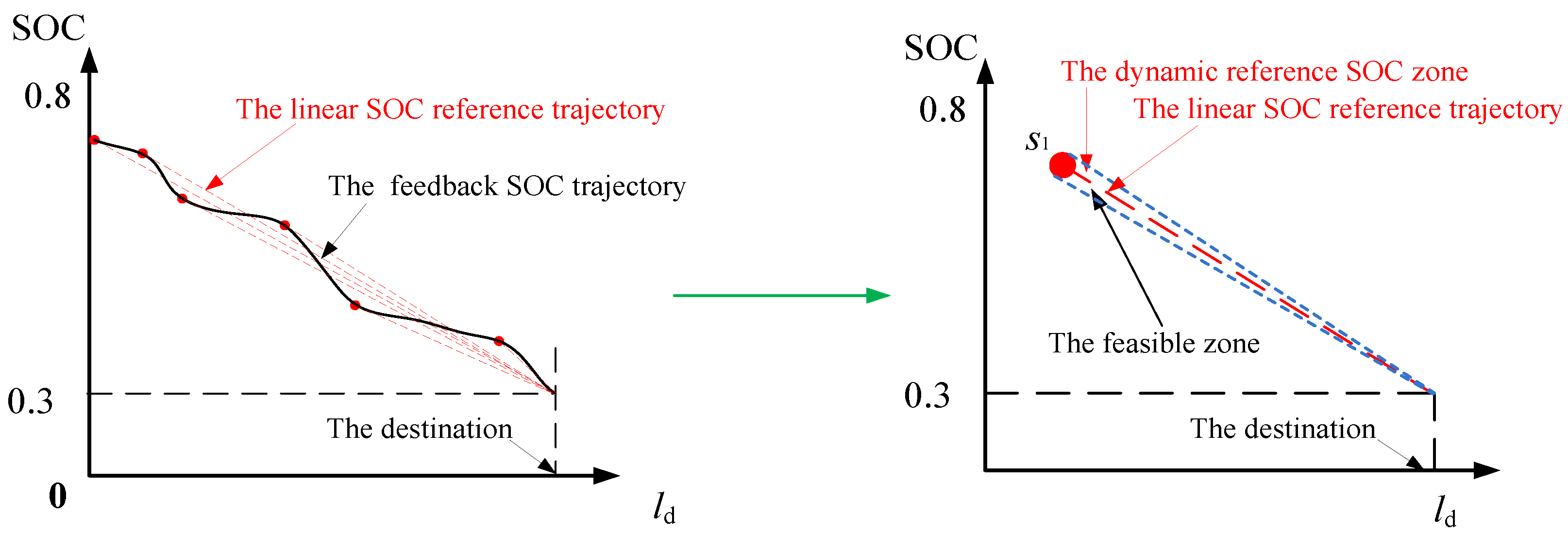
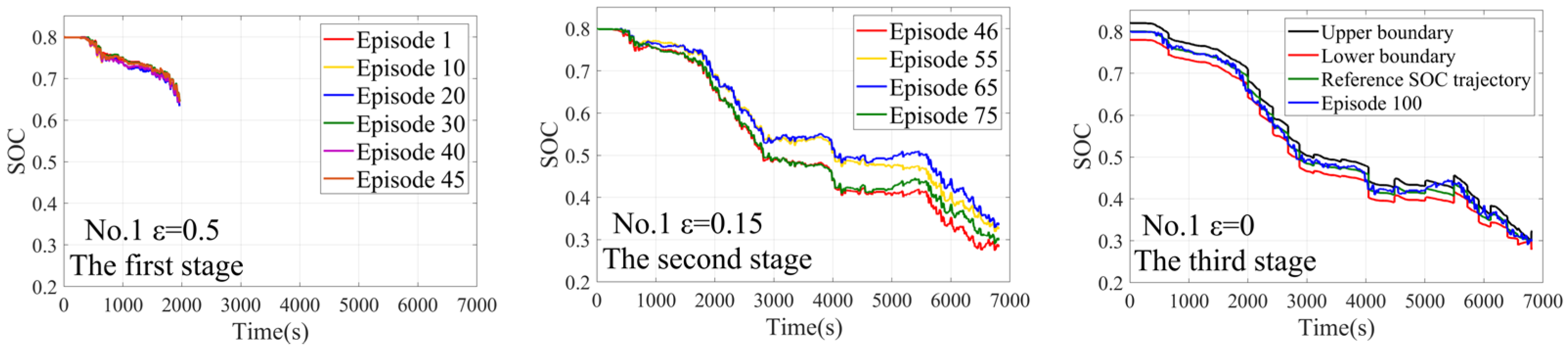
3.2. The Design of the Dynamic SOC Design Zone
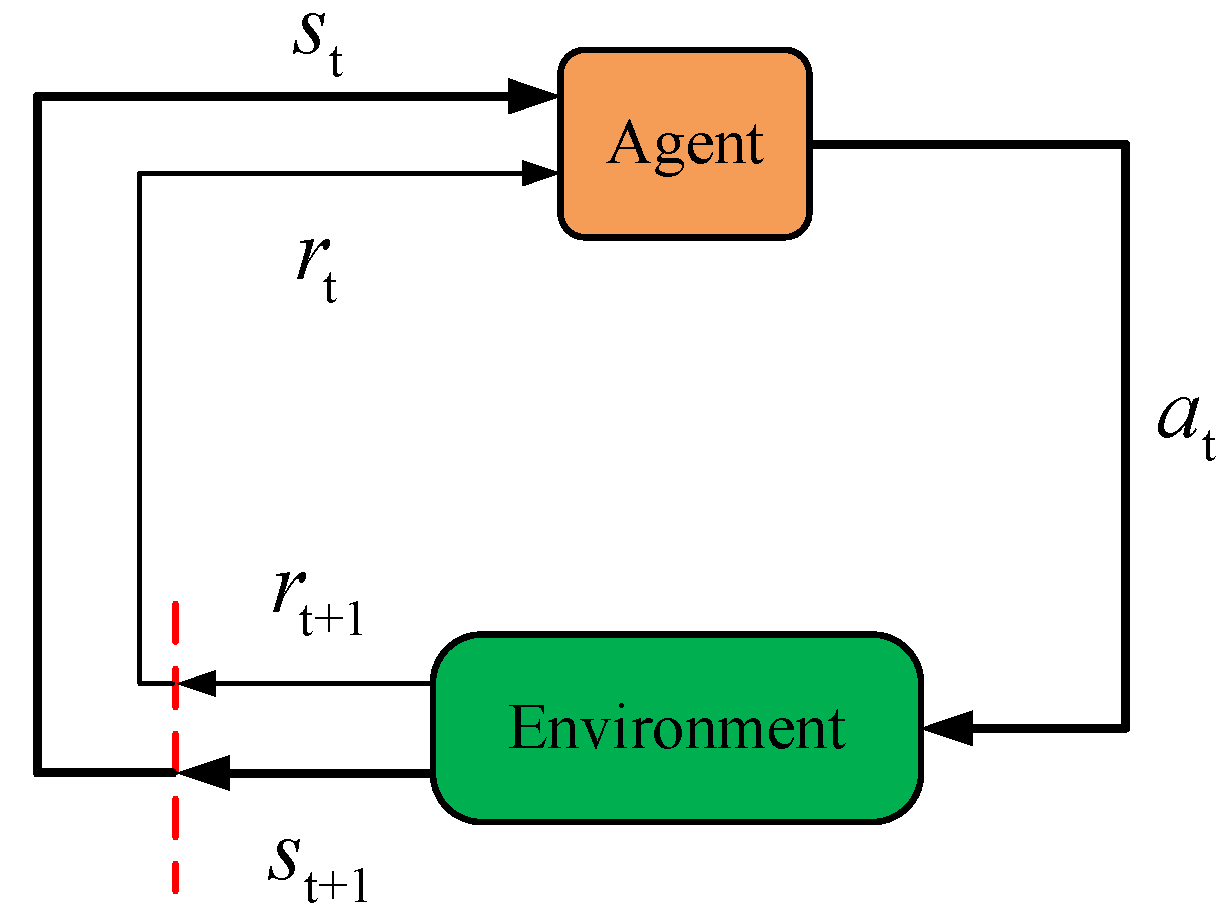
3.3. The Formalation of the RL-Based Energy Managemtn
- (1)
- The state
- (2)
- The action
- (3)
- The reward
- (4)
- The ε-greedy algorithm
- (5)
- The RL-based energy management algorithm
| 1: initializing the Q and R tables with null matrix |
| 2: for episode = 1, M do |
| 3: for t = 1, T do |
| 4: observing the current state () |
| 5: selecting the action with ε-greedy algorithm |
| 6: executing the action() and observing the next state |
| 7: calculating the immediate reward based on Eq. (11) |
| 8: updating the Q-Table by: |
| 9: end |
| 10: if the feedback SOC is bigger than 0.85 or lower than 0.25 or abs () is bigger than 0.04 11: continue; |
| 12: end |
| 13: end |
| 14: end |
4. Result Discussions
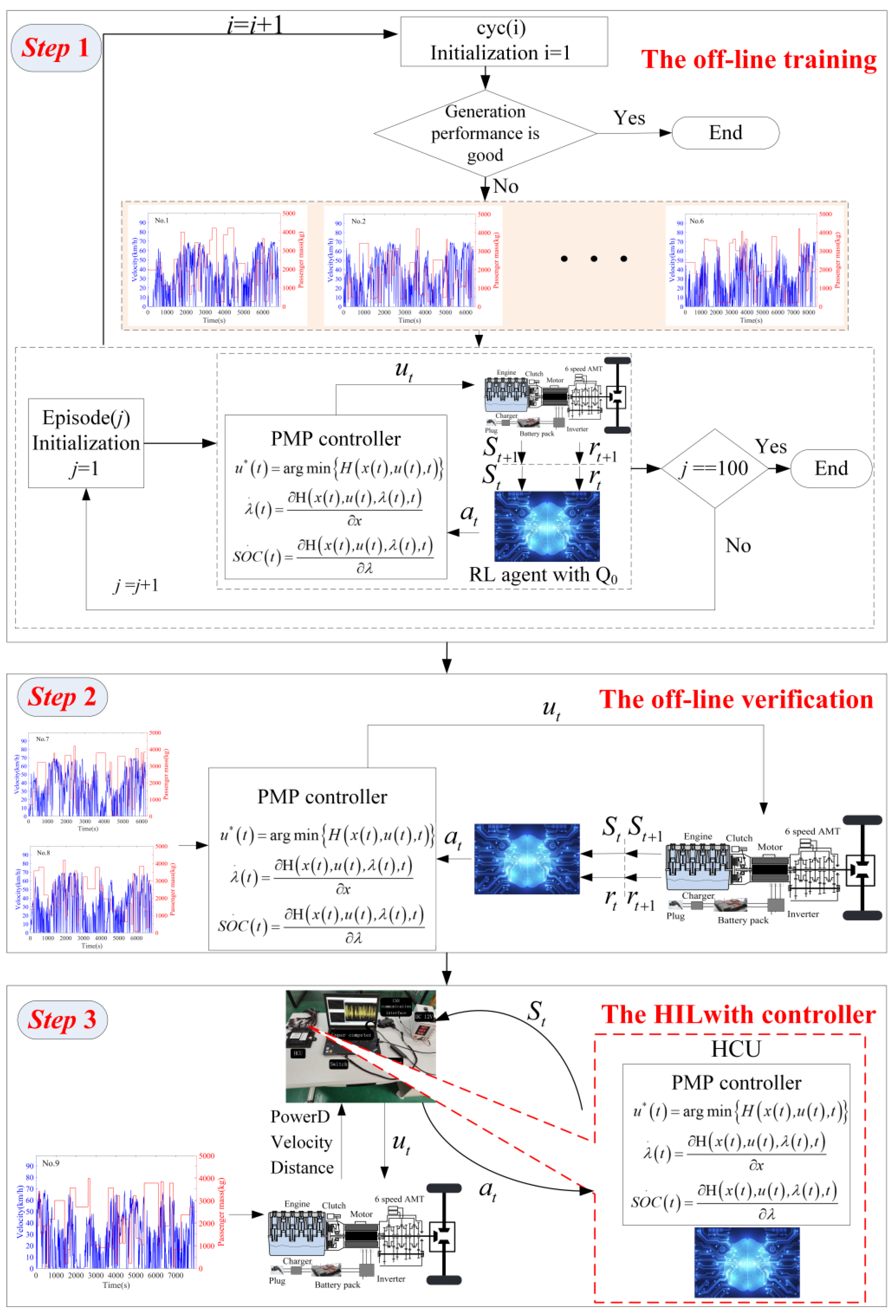
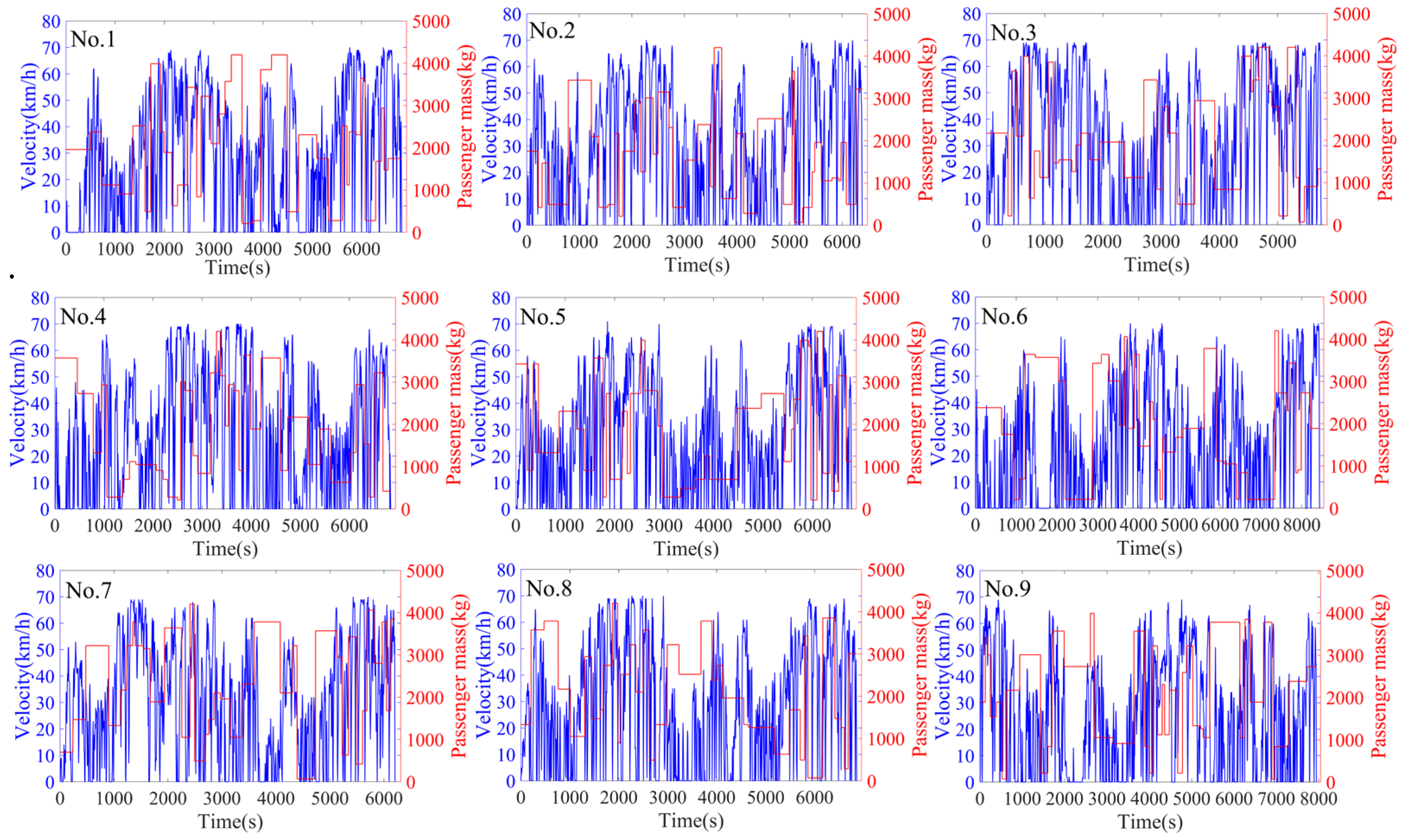
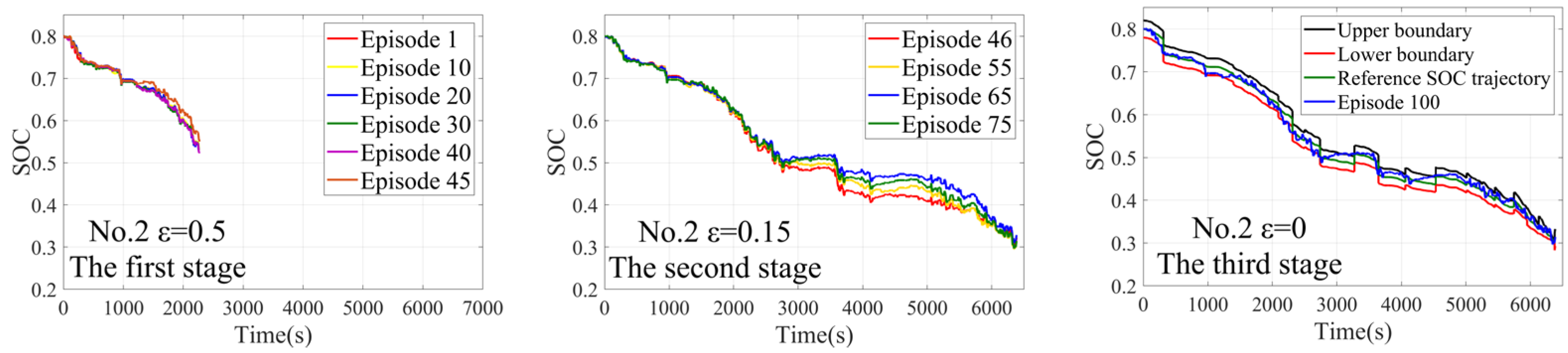
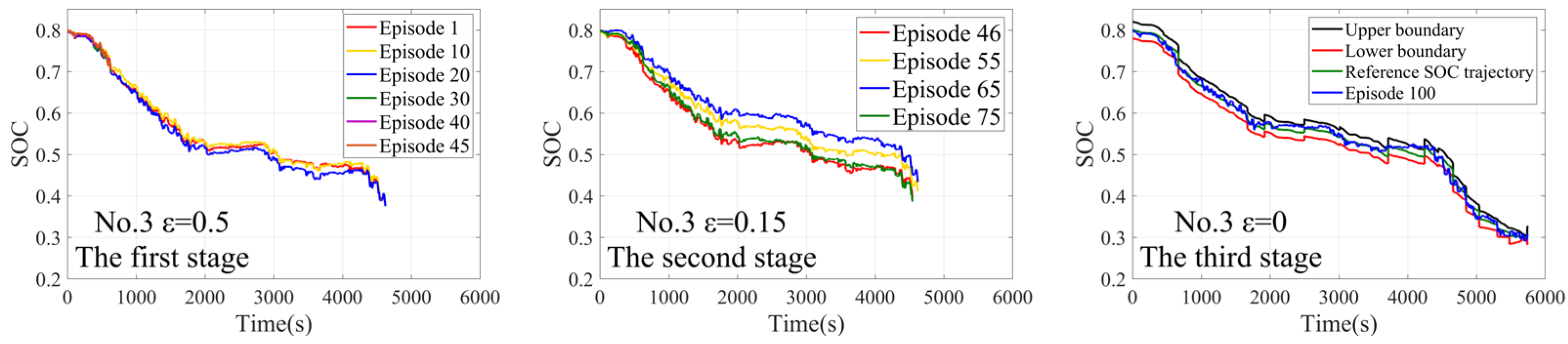
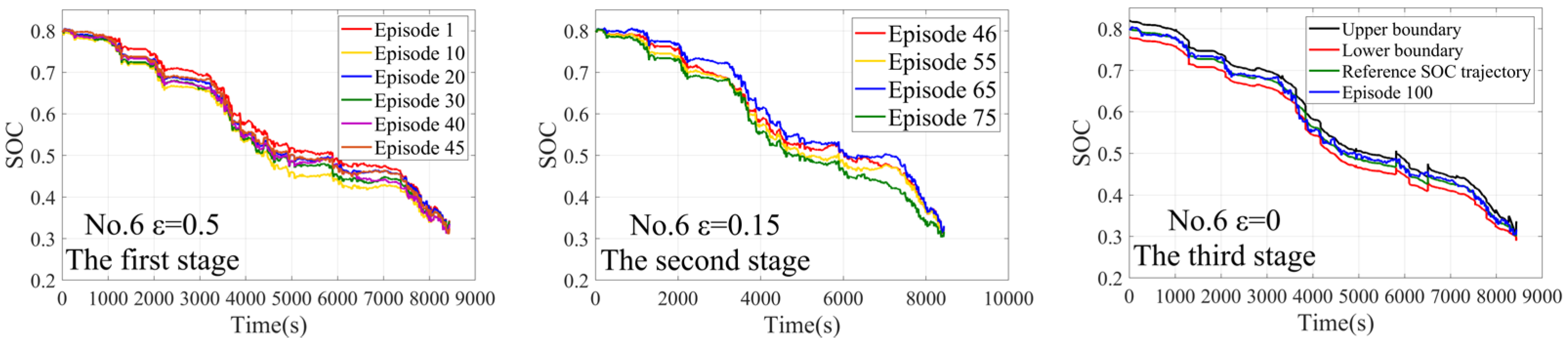
4.1. The Training Process
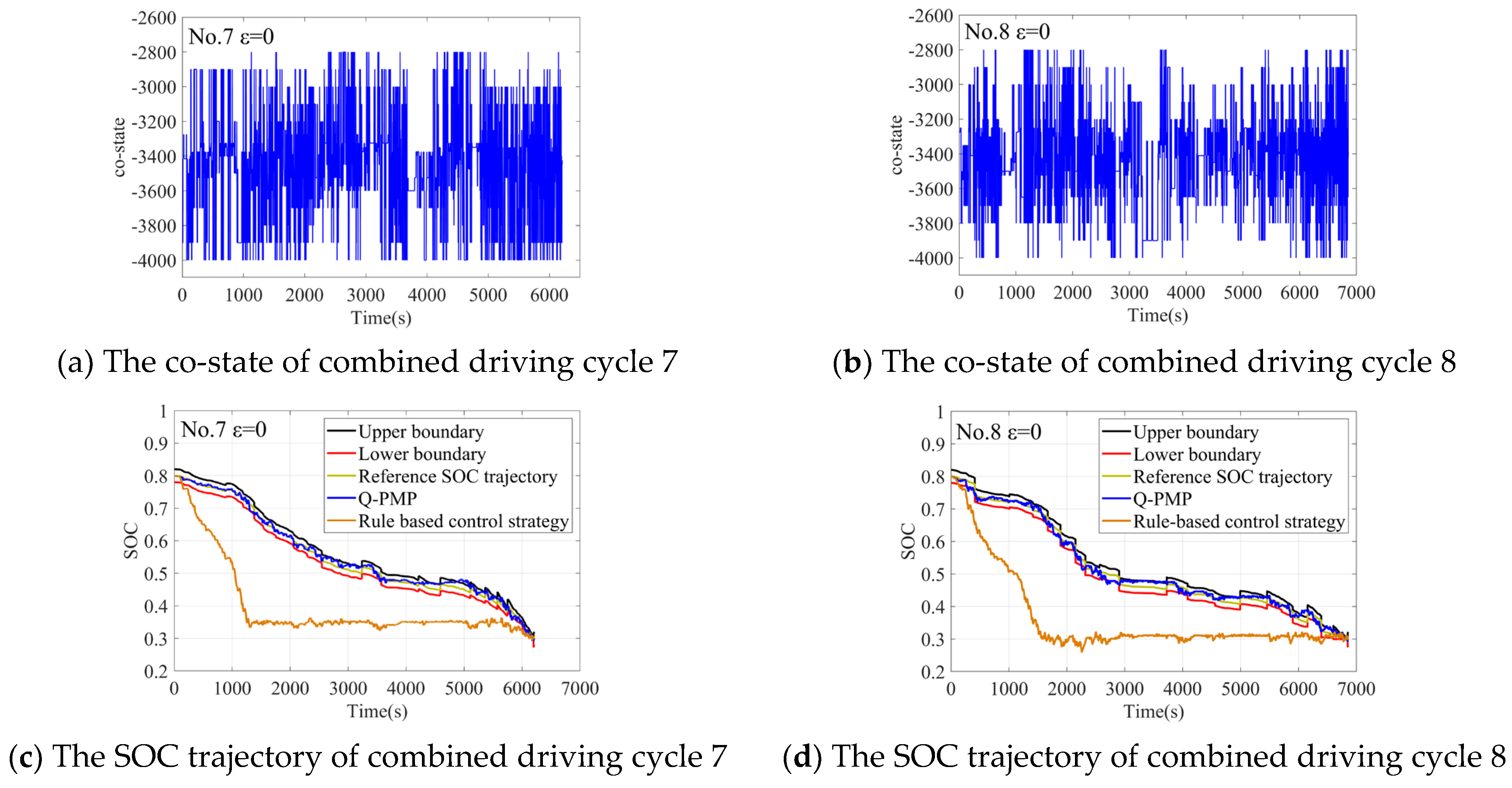
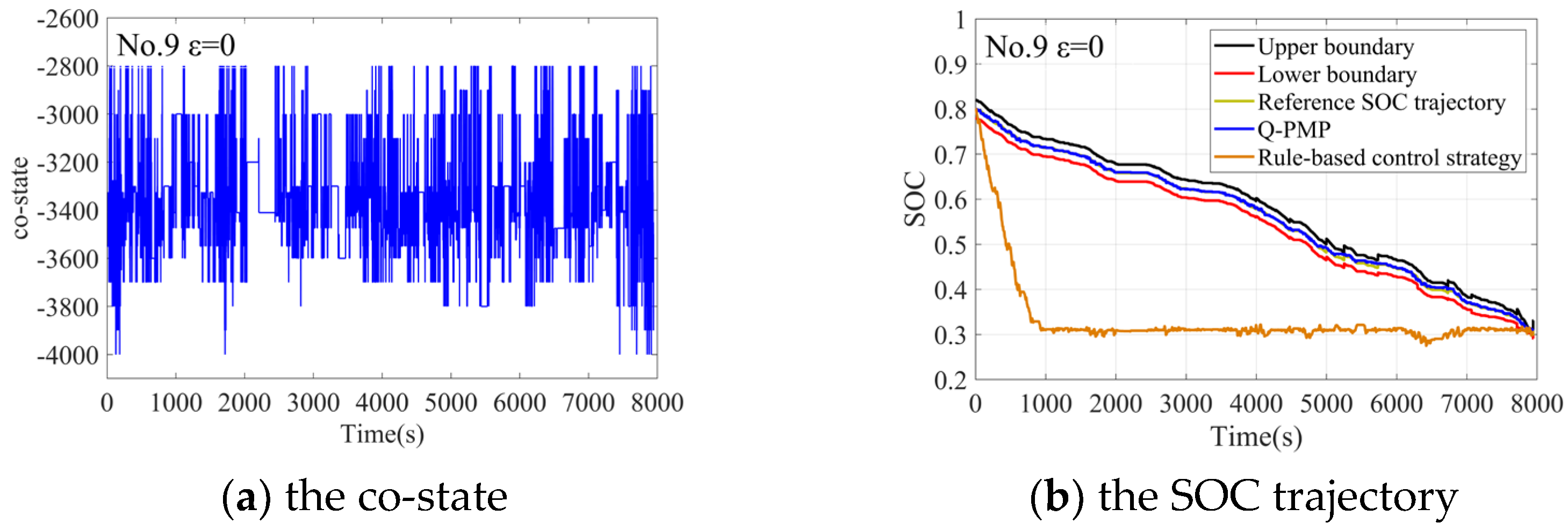
4.2. The Off-Line Verification
4.3. The Hardware in Loop Simulation Verify
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ajanovic, A.; Haas, R.; Schrödl, M. On the historical development and future prospects of various types of electric mobility. Energies 2021, 14, 1070. [Google Scholar] [CrossRef]
- Plötz, P.; Moll, C.; Bieker, G.; Mock, P. From lab-to-road: Real-world fuel consumption and CO2 emissions of plug-in hybrid electric vehicles. Environ. Res. Lett. 2021, 16, 054078. [Google Scholar] [CrossRef]
- Zhang, F.; Hu, X.; Langari, R.; Cao, D. Energy management strategies of connected HEVs and PHEVs: Recent progress and outlook. Prog. Energy Combust. Sci. 2019, 73, 235–256. [Google Scholar] [CrossRef]
- Huang, Y.; Wang, H.; Khajepour, A.; Li, B.; Ji, J.; Zhao, K.; Hu, C. A review of power management strategies and component sizing methods for hybrid vehicles. Renew. Sustain. Energy Rev. 2018, 96, 132–144. [Google Scholar] [CrossRef]
- Biswas, A.; Emadi, A. Energy Management Systems for Electrified Powertrains: State-of-The-Art Review and Future Trends. IEEE Trans. Veh. Technol. 2019, 68, 6453–6467. [Google Scholar] [CrossRef]
- Ding, N.; Prasad, K.; Lie, T.T. Design of a hybrid energy management system using designed rule-based control strategy and genetic algorithm for the series-parallel plug-in hybrid electric vehicle. Int. J. Energy Res. 2021, 45, 1627–1644. [Google Scholar] [CrossRef]
- Li, P.; Li, Y.; Wang, Y.; Jiao, X. An intelligent logic rule-based energy management strategy for power-split plug-in hybrid electric vehicle. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 7668–7672. [Google Scholar]
- Hassanzadeh, M.; Rahmani, Z. Real-time optimization of plug-in hybrid electric vehicles based on Pontryagin’s minimum principle. Clean Technol. Environ. Policy 2021, 23, 2543–2560. [Google Scholar] [CrossRef]
- Wang, W.; Cai, Z.; Liu, S. Study on Real-Time Control Based on Dynamic Programming for Plug-In Hybrid Electric Vehicles. SAE Int. J. Electrified Veh. 2021, 10, 167. [Google Scholar] [CrossRef]
- Geng, S.; Schulte, T.; Maas, J. Model-Based Analysis of Different Equivalent Consumption Minimization Strategies for a Plug-In Hybrid Electric Vehicle. Appl. Sci. 2022, 12, 2905. [Google Scholar] [CrossRef]
- Lian, J.; Wang, X.R.; Li, L.H.; Zhou, Y.F.; Yu, S.Z.; Liu, X.J. Plug-in HEV energy management strategy based on SOC trajectory. Int. J. Veh. Des. 2020, 82, 1–17. [Google Scholar] [CrossRef]
- Liu, Y.J.; Sun, Q.; Han, Q.; Xu, H.G.; Han, W.X.; Guo, H.Q. A Robust Design Method for Optimal Engine Operating Zone Design of Plug-in Hybrid Electric Bus. IEEE Access 2022, 10, 6978–6988. [Google Scholar] [CrossRef]
- Lin, X.; Zhou, K.; Mo, L.; Li, H. Intelligent Energy Management Strategy Based on an Improved Reinforcement Learning Algorithm With Exploration Factor for a Plug-in PHEV. IEEE Trans. Intell. Transp. Syst. 2021, 1–11. [Google Scholar] [CrossRef]
- Zhang, H.; Peng, J.; Tan, H.; Dong, H.; Ding, F. A Deep Reinforcement Learning-Based Energy Management Framework With Lagrangian Relaxation for Plug-In Hybrid Electric Vehicle. IEEE Trans. Transp. Electrif. 2020, 7, 1146–1160. [Google Scholar] [CrossRef]
- Liu, T.; Hu, X.; Hu, W.; Zou, Y. A Heuristic Planning Reinforcement Learning-Based Energy Management for Power-Split Plug-in Hybrid Electric Vehicles. IEEE Trans. Ind. Inform. 2019, 15, 6436–6445. [Google Scholar] [CrossRef]
- Chen, Z.; Hu, H.; Wu, Y.; Zhang, Y.; Li, G.; Liu, Y. Stochastic model predictive control for energy management of power-split plug-in hybrid electric vehicles based on reinforcement learning. Energy 2020, 211, 118931. [Google Scholar] [CrossRef]
- Guo, H.Q.; Wei, G.; Wang, F.; Wang, C.; Du, S. Self-Learning Enhanced Energy Management for Plug-in Hybrid Electric Bus With a Target Preview Based SOC Plan Method. IEEE Access 2019, 7, 103153–103166. [Google Scholar] [CrossRef]
- Qi, C.; Zhu, Y.; Song, C.; Cao, J.; Xiao, F.; Zhang, X.; Xu, Z.; Song, S. Self-supervised reinforcement learning-based energy management for a hybrid electric vehicle. J. Power Sources 2021, 514, 230584. [Google Scholar] [CrossRef]
- Wu, Y.; Tan, H.; Peng, J.; Zhang, H.; He, H. Deep reinforcement learning of energy management with continuous control strategy and traffic information for a series-parallel plug-in hybrid electric bus. Appl. Energy 2019, 247, 454–466. [Google Scholar] [CrossRef]
- Tan, H.; Zhang, H.; Peng, J.; Jiang, Z.; Wu, Y. Energy management of hybrid electric bus based on deep reinforcement learning in continuous state and action space. Energy Convers. Manag. 2019, 195, 548–560. [Google Scholar] [CrossRef]
- He, W.; Huang, Y. Real-time Energy Optimization of Hybrid Electric Vehicle in Connected Environment Based on Deep Reinforcement Learning. IFAC-PapersOnLine 2021, 54, 176–181. [Google Scholar] [CrossRef]
- Kim, N.; Jeong, J.; Zheng, C. Adaptive energy management strategy for plug-in hybrid electric vehicles with Pontryagin’s minimum principle based on daily driving patterns. Int. J. Precis. Eng. Manuf.-Green Technol. 2019, 6, 539–548. [Google Scholar] [CrossRef]
- Xie, S.; Hu, X.; Xin, Z.; Brighton, J. Pontryagin’s minimum principle based model predictive control of energy management for a plug-in hybrid electric bus. Appl. Energy 2019, 236, 893–905. [Google Scholar] [CrossRef] [Green Version]
- Guo, H.; Du, S.; Zhao, F.; Cui, Q.; Ren, W. Intelligent Energy Management for Plug-in Hybrid Electric Bus with Limited State Space. Processes 2019, 7, 672. [Google Scholar] [CrossRef] [Green Version]
- Guo, H.; Zhao, F.; Guo, H.; Cui, Q.; Du, E.; Zhang, K. Self-learning energy management for plug-in hybrid electric bus considering expert experience and generalization performance. Int. J. Energy Res. 2020, 44, 5659–5674. [Google Scholar] [CrossRef]
- Onori, S.; Tribioli, L. Adaptive Pontryagin’s Minimum Principle supervisory controller design for the plug-in hybrid GM Chevrolet Volt. Appl. Energy 2015, 147, 224–234. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Combined Driving Cycle | RL-Based (L/100 km) | Rule-Based (L/100 km) | Fuel Consumption Comparison |
|---|---|---|---|
| No.7 | 16.8738 | 18.9497 | −10.95% |
| No.8 | 16.6673 | 18.8939 | −11.78% |
| Combined Driving Cycle | RL-Based (L/100 km) | Rule-Based (L/100 km) | Fuel Consumption Comparison |
|---|---|---|---|
| No.9 | 15.2956 | 17.5642 | −12.92% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, W.; Chu, X.; Shi, S.; Zhao, L.; Zhao, Z. Practical Application-Oriented Energy Management for a Plug-In Hybrid Electric Bus Using a Dynamic SOC Design Zone Plan Method. Processes 2022, 10, 1080. https://doi.org/10.3390/pr10061080
Han W, Chu X, Shi S, Zhao L, Zhao Z. Practical Application-Oriented Energy Management for a Plug-In Hybrid Electric Bus Using a Dynamic SOC Design Zone Plan Method. Processes. 2022; 10(6):1080. https://doi.org/10.3390/pr10061080
Chicago/Turabian StyleHan, Wenxiao, Xiaohua Chu, Sui Shi, Ling Zhao, and Zhen Zhao. 2022. "Practical Application-Oriented Energy Management for a Plug-In Hybrid Electric Bus Using a Dynamic SOC Design Zone Plan Method" Processes 10, no. 6: 1080. https://doi.org/10.3390/pr10061080
APA StyleHan, W., Chu, X., Shi, S., Zhao, L., & Zhao, Z. (2022). Practical Application-Oriented Energy Management for a Plug-In Hybrid Electric Bus Using a Dynamic SOC Design Zone Plan Method. Processes, 10(6), 1080. https://doi.org/10.3390/pr10061080