3.1. Depth of Architecture
Because various CNN architectures have been developed recently, to investigate the effect of different architectures on classification accuracy, several network models of different layer depths were considered. The networks used for verification include LeNet [
11], AlexNet [
12], GoogLeNet [
13], and Inception-ResNet-v2 [
16]. The input sequence, activation function, and hyperparameters were set to the values from the literature, and each image was resized prior to entering the network to make the input image sequence size match that of the literature. The input image was a 24-bit red–green–blue (RGB) image, and the input array was (28, 28, and 1) for LeNet, (227, 227, and 3) for AlexNet, (224, 224, and 3) for GoogLeNet, and (299, 299, and 3) for Inception-ResNet-v2. The first and second elements signify vertical and horizontal pixels; the third element reflects the RGB configuration, while its value was one because LeNet works for grayscale. Adam was used as the solver of the gradient for the mini batch in all networks.
Figure 2 shows the accuracy of determination,
Ac, for the seven classes (10
δ, 15
δ, 20
δ, 22.5
δ, 25
δ, 45
δ, and 50
δ) of W0.9δ. The prediction accuracy of each distance was different, as described later. However, when focusing on the overall prediction accuracy, the model generally demonstrated high prediction accuracy regardless of
xd.
Figure 2 also shows the average prediction accuracy and the network depth. All models except LeNet had an accuracy of 75% or greater, indicating successful source-distance estimation by the deep CNN. Additionally, GoogLeNet and Inception-ResNet-v2 had an accuracy of 90% or greater. Thus, it can be confirmed that the deeper the network, the higher the accuracy. Regarding learning time, GoogLeNet learned 4–6 times faster than Inception-ResNet-v2 under the same GPU environment (NVIDIA Tesla V100). LeNet and AlexNet, both with fewer layers, are even faster than GoogleNet, but their inference accuracy depends strongly on the number of layers. The increase in the number of layers from 5 to 8 increases the inference accuracy from 68% to 87%. In contrast, the difference between GoogleNet and InceptionResNet-v2 is only a few percent. One may be satisfied with the 22-layer GoogLeNet, which can achieve an accuracy of over 90% in moderate computational time, and higher layer numbers tend to make inference accuracy difficult to improve.
Subsequently, when each network was tested with their default settings, good performance of 90% or better was confirmed. Therefore, GoogLeNet, which achieved a relatively fast learning time, was used in the following of this paper.
Appendix C describes the details of GoogLeNet and Inception-ResNet-v2 networks, which both had particularly high percentages of
Ac. There was no overfitting in either architecture (see
Appendix D); there was little bias caused by the training data. It was further confirmed by k-fold cross validation that the training image had sufficient generalization (see
Appendix E).
3.2. Inference Effect by Image Rotation from the Viewpoint of Fluid Dynamics
As a point source was located at the center of the channel, the dye concentration was high near the channel center; it eventually spread over the entire channel cross section. There was almost no dye visible near the wall surfaces compared with the patches near the center of the channel, resulting in a non-uniform concentration distribution. Therefore, given the non-uniformity, the macroscopic density gradient direction differed depending on the rotation angle of the image. For example, in the 180° rotation, the overall density gradient was in the direction normal to the wall surface, which was the same as the original image (0°) although the image was upside down. However, rotated at 90° or 270°, the density gradients apparently occurred in the flow direction.
Additionally, the turbulence intensity in the channel displayed anisotropy; to confirm the geometric (rotational) change effects on the source estimation, the original image was set to 0°, and four rotated images of 0°, 90°, 180°, and 270° clockwise were input to a CNN that was trained by the 0° images as the training data. As for three target cases of W0.9δ, W0.225δ, and W0.05δ, four-class (10δ, 15δ, 20δ, and 25δ) classification was conducted for each case. The result of the accuracy of determination,
Ac, for each source distance is shown in
Figure 3a–c. For all image sizes, the decrease in
Ac for 90° and 270° was about 20% for
xd = 15
δ and within 10% for the other
xd, compared with 0° and 180°. This result shows the robustness to geometrical (rotational) changes. In order to visualize how the image pattern was recognized by the CNN, a part of the feature map of the pooling layer per each rotation image is shown in
Figure 3d. This feature map was based on the correct answer verification image of
xd = 20
δ for W0.225δ. For the first pooling layer (“Pooling 1” in
Figure 3d), an image having a window size of 0.225
δ was entered as an input with a data size of 224 × 224 × 3 channels, becoming 54 × 54 × 64 channels with a 3 × 3 filter in “Pooling 1.” Some results of four filters at this pooling layer were displayed as images at the same position and labelled as a-1 and a-2 for all rotated images. From these images of “Pooling 1”, it can be seen that the same filter extracted nearly the same features regardless of rotation. The same tendency can be confirmed in the deeper layers; thus, the deeper the layers, the more relaxed the positional relationship of the reaction. At the final softmax, the estimation was successful because all the feature maps show the same distribution for all rotation cases. The red-highlighted panel at b-1 in the softmax image in the figure was the correct answer, and the redder the value, the higher the classification accuracy.
Although the CNN has robustness to the parallel displacement of features owing to the pooling process, it was considered that the robustness to rotation was not so strong in the literature. In this experimental system, the dye released from the diffusion source was diffused downstream while rotating with the vortex motions in the channel turbulence. Hence, when the CNN extracts the characteristics of the patch generated by the small eddies without anisotropy, highly robust estimation against rotation can be possible. Some features not depending on image rotation were included in the dye patch and extracted by the CNN for the xd prediction with better accuracy.
To evaluate the relation between the turbulent characteristics and the feature map, we focused on the turbulent length scales. Typical scales that characterize turbulence include the integral length scale and the Taylor microscale, which can be calculated from the two-point correlation coefficient. The former is the macro-length scale that the motion of the fluid mass at a certain point can influence, and the latter is the smallest scale caused by the turbulent motion (e.g., vortex). Regarding the images used for learning, each scale was obtained from the concentration distribution statistics of each
xd. The integral characteristic length,
L, was calculated by the following equation:
where
r is a spatial two-point distance vector. The autocorrelation coefficient,
Rcc (
r), is calculated by
Here, the overbar denotes the ensemble average. The local dye density,
C(
x), is considered proportional to the brightness fluctuation value of each pixel calculated from the image data. Its fluctuating component,
C′(
x), is also the brightness value of each pixel minus the average brightness, which was obtained in advance from all image data points. The Taylor microscale,
λT, was calculated from the following parabolic approximation of the correlation coefficient at
r = 0 [
31,
32]:
Figure 4 shows the integral length scale at the channel center and the Taylor microscale, which are calculated by Equations (1)–(3). As the diffusion was emitted from a point source at
xd = 0, the integral length increased as it moved downstream and became nearly constant at
xd = 15
δ. This tendency is consistent with another experiment [
31], but the value depends on both the Reynolds number and the dye nozzle diameter. In this experiment, the integral length scale was ~0.1
δ. Image sizes larger than this (e.g., W0.9δ and W0.225δ) can be expected to extract the characteristics as large as the integral length. However, in W0.05δ, the image size was smaller than the integral length; thus, its characteristics in the large scale could not be captured. Meanwhile, it can be seen that any image size is large enough to extract the features of the Taylor microscale (~0.03δ). Therefore, the estimation was performed using microscale information so that the influence of anisotropy of channel turbulence could be eliminated to some extent. If the source distance could be estimated using only anisotropic features, the estimation would depend on the mainstream conditions, implying macroscale information; thus, the generalization performance would be deteriorated.
As mentioned earlier, from the point source to a medium distance, the concentration mass was distributed not uniformly over the entire channel, resulting in macroscopic concentration non-uniformity. To identify the range of source distance where this non-uniformity affects the accuracy of determination, the distance that the dye flows from the channel center to spread over the entire channel was estimated. The spanwise wavelength of large-scale structures in the channel turbulence is 1.3
δ–1.6
δ [
30], and it is assumed that the dye in the channel center is directed toward the wall vicinity, owing to the vortices related to this large-scale structure and the smaller-scale vortices. Assuming that the advection velocity from the channel center to the wall vicinity is about the same as wall-normal velocity fluctuation,
v’, the arrival time from the channel center to the wall surface,
th, is
Assuming that the speed at which the dye advances in the streamwise direction is about the same as the bulk velocity,
ub, the distance of
xh traveled in time of
th is
According to DNS database [
30],
ub/
v’ = 15–20 for Re
τ = 180–640. Then,
xh at Re
b = 18,000 was estimated as follows:
Therefore, the distance after which the macroscopic non-uniformity of the dye becomes less significant is estimated to be past xd = 15δ–20δ. It is assumed that the accuracy of determination of the rotated images at 90° and 270° hardly decreased at xd ≥ 20δ, because the non-uniformity of the dye was alleviated.
3.3. Effect on Accuracy of Inference by Spot Dye Scale and Arrangement
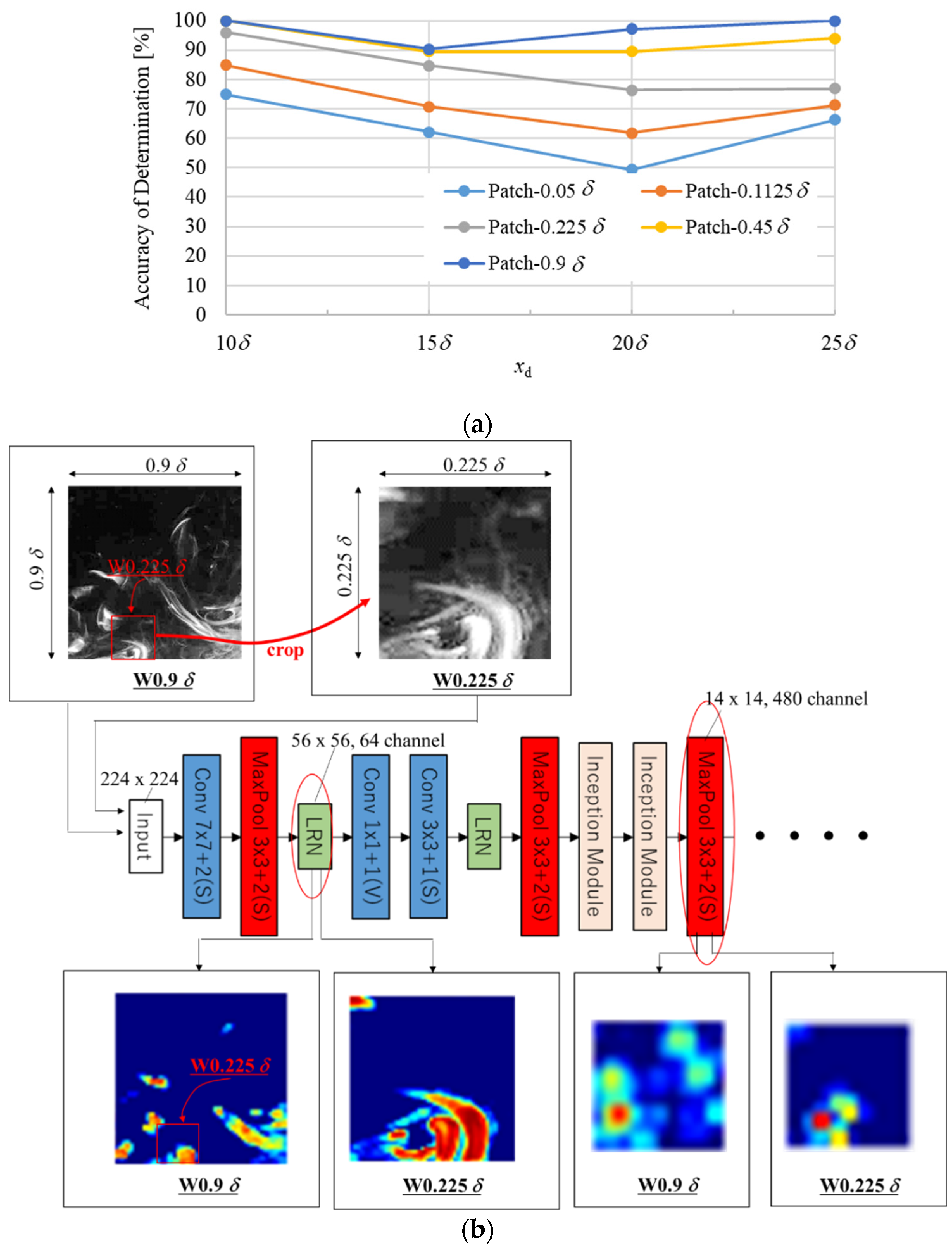
To investigate the effect of the measurement window size on the prediction accuracy, we compared accuracies using images of different window sizes. Classification was conducted for five sizes (W0.9δ, W0.45δ, W0.225δ, W0.1125δ, and W0.05δ) using four classes (
xd = 10δ, 15δ, 20δ, and 25δ). The estimation result is shown in
Figure 5a. The large window cases of W0.9δ and W0.45δ provided an accuracy of determination,
Ac, of 90% regardless of distance
xd. However, for smaller window sizes,
Ac drops sharply at 20
δ and 25
δ, reaching about 50–80%. Considering that the diameter of the vortex involved in the large-scale structure of channel turbulence was about 0.6
δ [
30], an image size equivalent to about half of this is necessary for improving the classification accuracy. Additionally, as mentioned earlier, measurement window sizes of <0.225
δ are smaller than the integral characteristic length; thus, it is possible that the turbulent flow characteristics of this scale could not also be extracted. The narrowness of the observation window affected the estimation results.
To verify the patch scale extracted from the feature map, we focused on W0.9δ and W0.225δ at the same
xd, which show different values in
Ac. For the verification, an image of W0.9δ at
xd = 20
δ (with
Ac > 95%) and an image obtained by cutting out a part of the W0.9δ image were used for verification of W0.225δ (see
Figure 5b,
Ac < 78%). This allows us to determine whether features were extracted for the same patch among different patch sizes. Both test images were successfully estimated by each trained CNN.
Figure 5b shows the images recognized at each layer of the trained CNN. In the first local response normalization (LRN) in GoogLeNet, one can see that the patch cut out by W0.225δ was extracted in both cases. Meanwhile, in W0.9δ, which had a high percentage of
Ac, in addition to the patch cut out by W0.225δ, another patch near it was extracted. In the third pooling layer, a deeper layer, featured on a large scale of about 0.9δ was extracted. This suggests that rather than a single patch, the spatial arrangement pattern of multiple small patches may affect the accuracy. This is consistent with the knowledge of vortex diameters involved in the large-scale structures of channel turbulence.
To confirm the effect of the relatively small patch-placement pattern in a single image on the estimation, we used a test image in which a part of the image was intentionally made defective for W0.9δ; the effect on estimation was confirmed using a trained CNN with four classes having defect-free images. The defective part has a brightness value of zero, i.e., black. The image defect pattern is shown in
Table 2. The same processing was performed on all original test images, i.e., 416 images × 3 patterns (A, B, and C). The size comparison of the defective region was A < B < C.
Table 2 shows
Ac for each pattern. It is confirmed that the determination accuracy tended to be significantly worse downstream at
xd = 25
δ as the area of defects increased. In contrast, at
xd = 15
δ, the accuracy of determination was close to 80%, even in a pattern having many defects. This implies that the patch pattern is a more necessary factor for correct estimation as
xd increases.
It is thought that the trained CNN extracted the characteristic scale of channel turbulence from the patch size and pattern within each image. Then, we attempted to confirm the characteristic scale of concentration fluctuation, C’, in each image using two-dimensional power spectrum density (2D PSD) analysis of luminance fluctuation.
Figure 6a shows the 2D PSD results for W0.9δ, which is the largest image size. In addition to the arbitrarily chosen instant images and their analytic results, the ensemble-averaged spectra are also shown. The top images are samples for input data; each lower figure shows the 2D spectrum of each input image, and the right figure is an ensemble-averaged 2D spectrum. All shown input images are typical images that can be estimated for each source distance accurately by the trained CNN in the case of W0.9δ.
Figure 6b,c show the one-dimensional PSD on the line (
kx =
ky) tilted 45° from the origin of (
kx,
ky) = (0, 0), marked with a red line in the images of (a) from each input image. However, no clear characteristic peak is found other than that at the origin. When statistically processed, the spectrum becomes gradual, and the scalar fluctuation energy decreases continuously at each scale, and any characteristic wave number cannot be confirmed, such as the spectra of the instant images.
Figure 6d,e show the pre-multiplied spectra on the same straight line as the one shown in
Figure 6a. As with the PSD, no clear peaks can be seen in the instant images. When the ensemble average was used, the peak wavenumber was confirmed to be within 10
δ–25
δ. However, this is the peak that appeared using the ensemble average; hence, the clear peak wavenumber could not be detected in the instant images (
Figure 6a). We can conclude that, in contrast to the conventional feature extraction (i.e., PSD analysis), which requires time statistics, the CNN has an advantage of estimating the distance from ‘instantaneous’ information.
3.4. Factors for Reducing Prediction Accuracy
In this study, an ideal specific condition (i.e., channel flow, one Reynolds number, and fixed camera angle) was used to produce training data for the CNN. The generalization performance of the learner should be examined in view of practical applications. We evaluated the generalization performance by test images that are intentionally transformed by window size and image quality. This provides a discussion regarding factors that reduce prediction accuracy in actual scenarios.
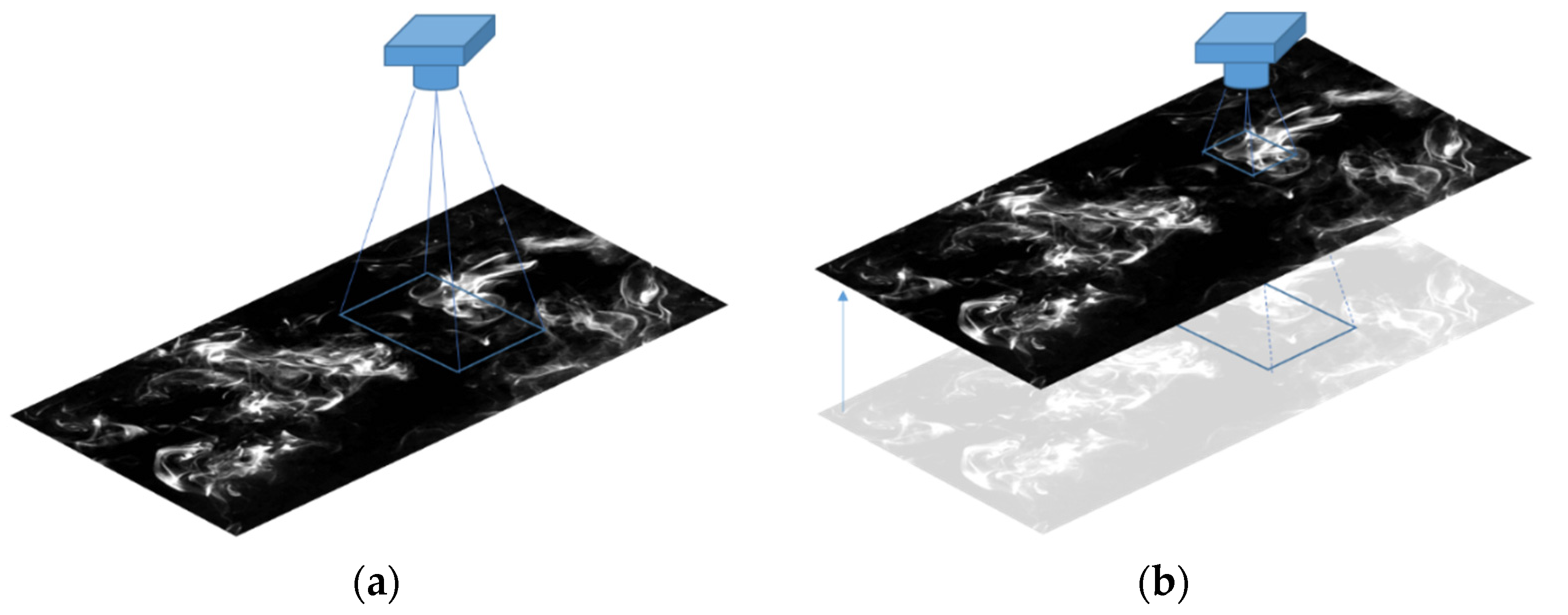
Firstly, we consider the situation that the camera distance from the measurement plane differs between training and testing, as shown in
Figure 7. The influence of incorrect window size, i.e., incorrect camera distance, on the prediction accuracy was evaluated for two situations. As one of the situations where the test image whose window size is larger than that of training images, the W0.05δ learner was ‘incorrectly’ applied for the W0.9δ image input. As for the other situation, the W0.9δ learner was chosen to test a smaller window size (W0.05δ) than the image size assumed by the learner. Sample images for W0.05δ and W0.9δ at several
xd are shown in
Figure 8. Since the dye was not sufficiently diffused at 10
δ, a clear dye pattern can be captured even within the window size of W0.05δ. On the other hand, the dye is more spread by turbulent mixing at 20
δ and 25
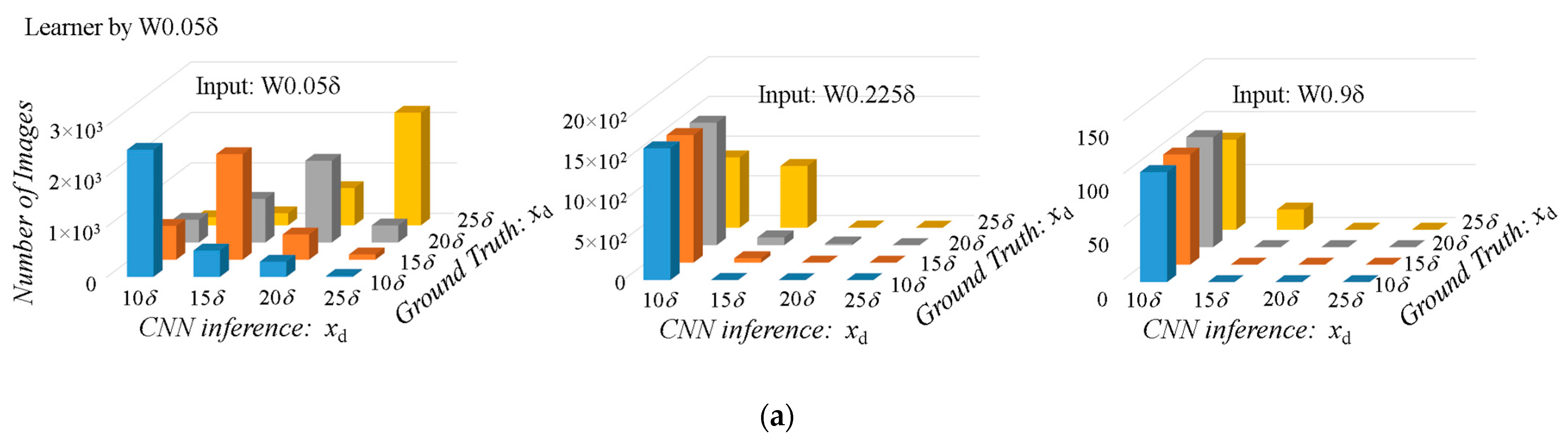
δ, which causes difficulty in capturing a clear dye pattern within the small window size of W0.05δ. It means that almost uniform dye might cover the whole W0.05δ window size. When an image of W0.9δ is used for test input image of the learner created by W0.05δ, the input image which contains clear dye shading is recognized as “not diffusing well” and the source distance,
xd, is underestimated. In fact, when the test images of W0.9δ are used as the input images for the W0.05δ learner, they are inferred to be 10
δ at all positions, as shown in
Figure 9a. This must be the same as scaling down in the representative length of turbulence (i.e., image window size in this study) and using a pseudo low-Re image as an input. Similarly, when an image with W0.05δ is input to a learner trained with W0.9δ, it is considered to have a higher Re than the actual image and is resulting in an overestimated
xd, as shown in
Figure 9b.
Next, we discuss the effect of the difference in the image quality (in terms of noise and image compression) between the training and testing images. We add Gaussian noise to some images to check the robustness against random noise, as the same approach in the literature [
33,
34]. This noise addition does not affect the white pixel with the maximum luminance, while the originally black pixel would be affected significantly. The accuracy of determination averaged over the four classes for the learner trained by W0.9δ was plotted with the different noise intensity, as shown in
Figure 10. The Gaussian noise input, whose mean value is 0, with a standard deviation of 1.0 for the luminance of image degraded the accuracy by 10%. More specifically, there was a significant decrease in inference accuracy, especially upstream, such as
xd = 10
δ and 15
δ, with little effect on the downstream side (figure not shown). This may be because a small amount of noise introduced “pseudo dye patches” into the non-distributed area, which is a characteristic of the upstream image. Since the dye diffusion has not yet progressed in the relatively upstream area immediately after the diffusion source, the distribution of the dye is clearly divided into black and white (with less gray regions), and the dye-absent area tends to be completely black with zero luminance. This feature was impaired by noise, which led to a decrease in the inference accuracy on the upstream side. The Gaussian noise with a standard deviation of 0.1 might be acceptable for this feature. On the other hand, when stronger noise with a standard deviation of 5.0 was added, the inference accuracy on the downstream side as well as the upstream side dropped significantly. As a result, the overall inference accuracy decreased down to 41%. On the downstream side, which was more robust to a weak noise, the image was generally more luminous, but the dye patches exhibited a fine filament-like pattern. This feature was lost by the strong noise and caused the inference accuracy to decline. Both inaccuracies were due to the loss of features in the distribution of the dye patches. Results with a standard deviation of 100 are interesting as well. Note that the inferential accuracy value is 25%, but it was validated on a four-class classification problem. This means that the inference of the learner did not work at all. For all noise-added images, the learner trained on noiseless images produced an output of
xd = 10
δ. In fact, the input image with a standard deviation of 100 would rather appear to anyone as a white image (see the rightest image in
Figure 10). Such an extensive whitening feature seen in this image is observed upstream near the diffuse source. Therefore, the prediction mistake is a rather reasonable result for the trained learner.
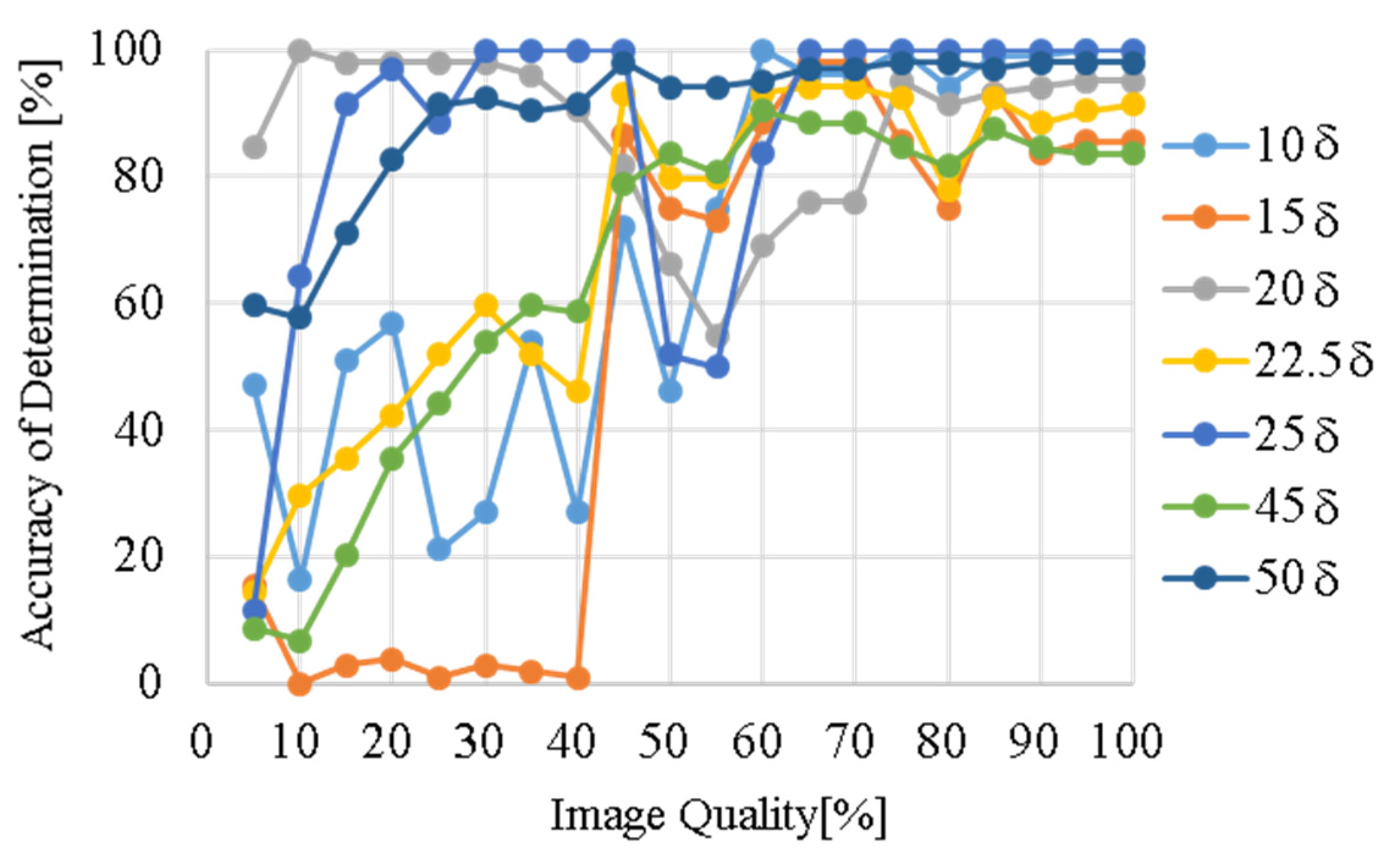
We also confirmed the effect of image quality on the prediction accuracy by the image compression of JPEG format by the learner of W0.9δ over seven classes.
Figure 11 shows the dependency on the image quality for seven classes of W0.9δ, where the low/high image quality means the small/large file size with high/low compression rate. We found that the image quality of >85% provides the almost same
Ac irrespectively of
xd. However, for the image quality of <40%, the accuracy is deteriorated significantly at several locations of 10
δ, 15
δ, 22.5
δ, and 45
δ. This deterioration must be because the delicate filament structure of dye patches created by turbulent motions is blurred in the image compression. In other words, the low image quality that does not capture the dye filament is fatal in the estimation based on the dye pattern under turbulent diffusion.
As discussed above, the present trained CNN still have a weakness against ambiguous window size and strong noise (or image compression) to blur the delicate filament structure of dye patches. As discussed above, the key to the inference accuracy in the present method is to extract the “turbulent diffusion” of passive-scalar dye. The inhomogeneous dye distribution and the dye patches stretched into filaments due to successive turbulent motions have important information related to the diffuse source distance. Given a low Schmidt number, such informative dye patches would be immediately dissipated by molecular diffusion, resulting in malfunction of the learner. On the other hand, a high Schmidt number is rather favorable, and the learner is expected to work as long as very fine filamentary dye patches can be resolved. Compared to the Schmidt number, the dependence on the Reynolds number might be moderate. However, due to highly turbulent mixing under significantly high Reynolds number, the inference accuracy would be decreased since the dye distribution would be lost quickly even at moderate Schmidt number. As the same reason, if there is no change of dye distributions in each xd under a low Reynolds number close to the laminar regime, the inference accuracy might be low.




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









