
A Reinforcement-Learning-Based Model for Resilient Load Balancing in Hyperledger Fabric

 ,
,  ,
, 
Abstract
1. Introduction
- We present the first-ever proposal for a machine learning model for load balancing the resources of a leading private blockchain platform, Hyperledger Fabric.
- We discuss the architecture of the proposed method and analyse its protocol flow with data models.
- We outline the data collection methods along with a discussion of how an optimal model has been trained.
- Finally, we analyse the advantages of the proposed approach and envision how the proposed methods can be integrated within the Hyperledger Fabric blockchain platform for deploying an optimal load balancing mechanism.
2. Background
2.1. Blockchain
- Public blockchain: A public blockchain, also known as the permissionless blockchain, facilitates the mechanism by which anyone can join the network. Any user of this blockchain can submit transactions when they wish and participate in the block creation process. Examples of public blockchain systems are Bitcoin [22], Ethereum [19], Cardano [20], Polkadot [21], Litecoin [23], Monero [24], and so on.
- Private blockchain: A private blockchain, also known as permissioned blockchain, on the other hand, allows only authorised, identified and trusted entities to participate in different activities within the system. These users generally have different types of permissions, and blockchain establishes access control rules for each user. The ultimate goal of such blockchain systems is to ensure the privacy of different transactions and provide better performance and scalability in comparison to any public blockchain systems. Examples of private blockchain systems are Hyperledger Platforms [4], Quoram [25], and others.
2.2. Private Blockchain System: Hyperledger
2.3. Hyperledger Fabric (HF)
2.4. Core Components of HF
2.4.1. Nodes
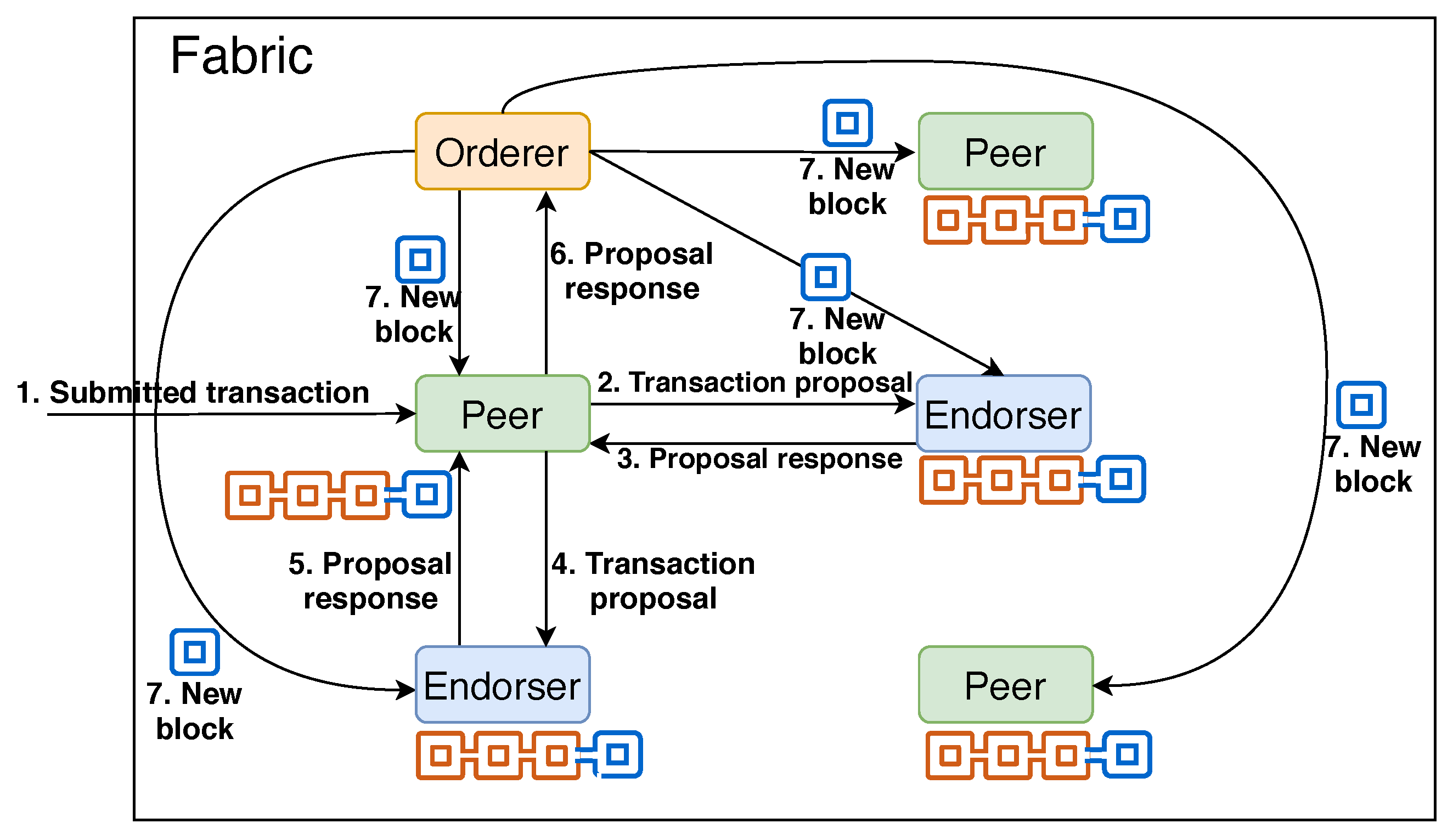
- Certificate Authority (CA): A CA is responsible for offering an identity service, called Membership Services Provider (MSP), to identify each entity within the network. All other nodes and users must be registered with the MSP of the corresponding CA before they can interact with a Fabric platform. Once registered, the public–private key pair and the cryptographically validated digital certificate for each entity (a node or a user) are generated and distributed [28]. Then, the entity needs to use these to interact with other Fabric components.
- Peer: A blockchain network is constructed with a set of peer nodes where each peer is responsible to receive a block from an orderer (discussed later) and after validating, adds the block to the blockchain. Thus, each peer holds a copy of the full blockchain and provides deliberate redundancy to the blockchain system.
- Endorser: An endorsing peer (or endorser in short) is responsible for validating each transaction. Each endorser utilises a policy (see below) to check if a certain user is authorised to submit a transaction.
- Orderer: An orderer collects different transactions from the network and combines them into a block [29]. Then, it sends the block to all the peers belonging to a certain ledger.
2.4.2. Chaincode, Ledger, and Channel
2.4.3. Policy
2.4.4. DApp
2.5. Interactions among HF components
2.6. Deployment Approach in HF
3. Proposed Approach
3.1. Motivation
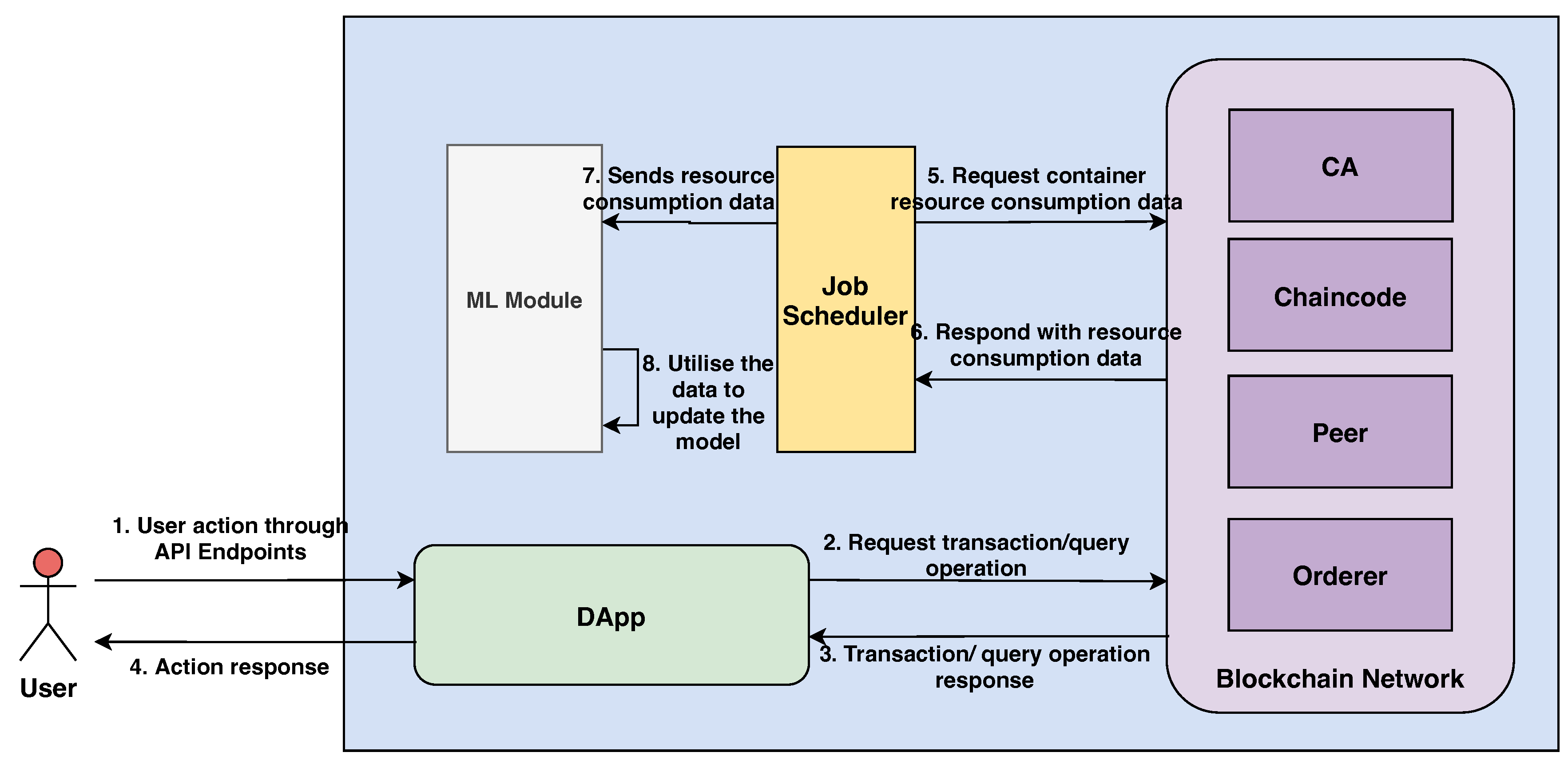
3.2. System Architecture and Deployment
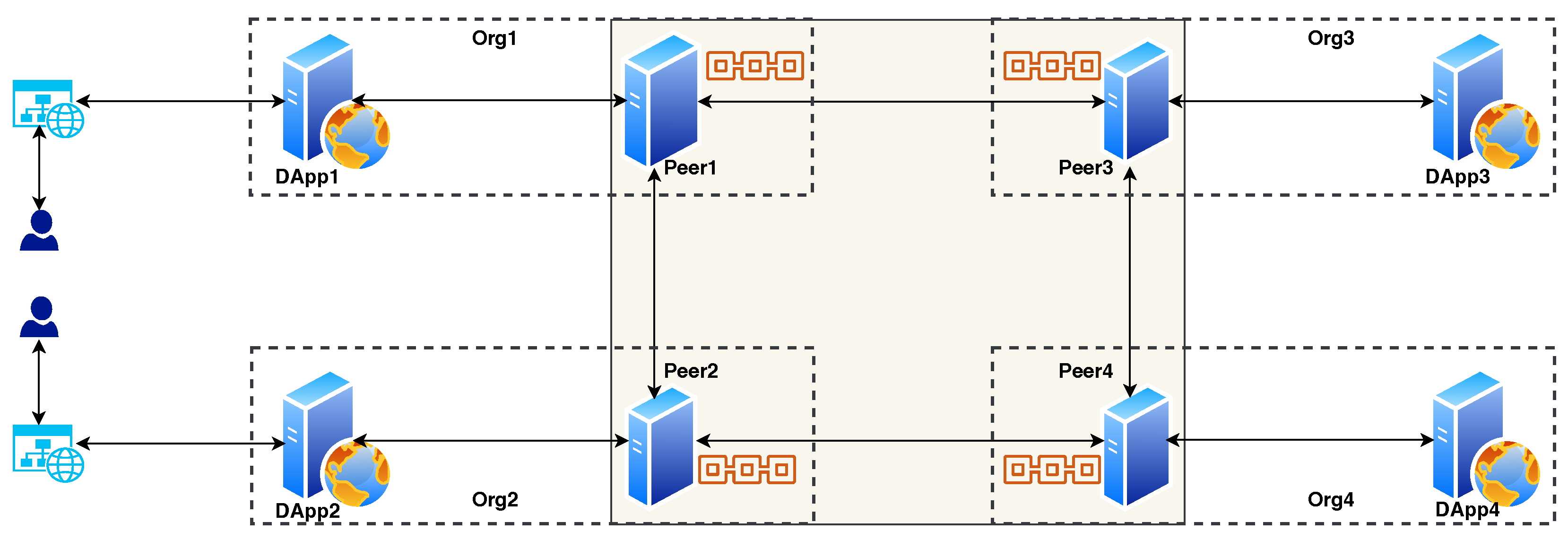
3.2.1. Blockchain Network
3.2.2. DApp
- createCar: Generates a transaction when a new car is added to the organisation.
- queryCar: Queries all the available cars to be sold.
- createUser: Creates a user for a particular organisation.
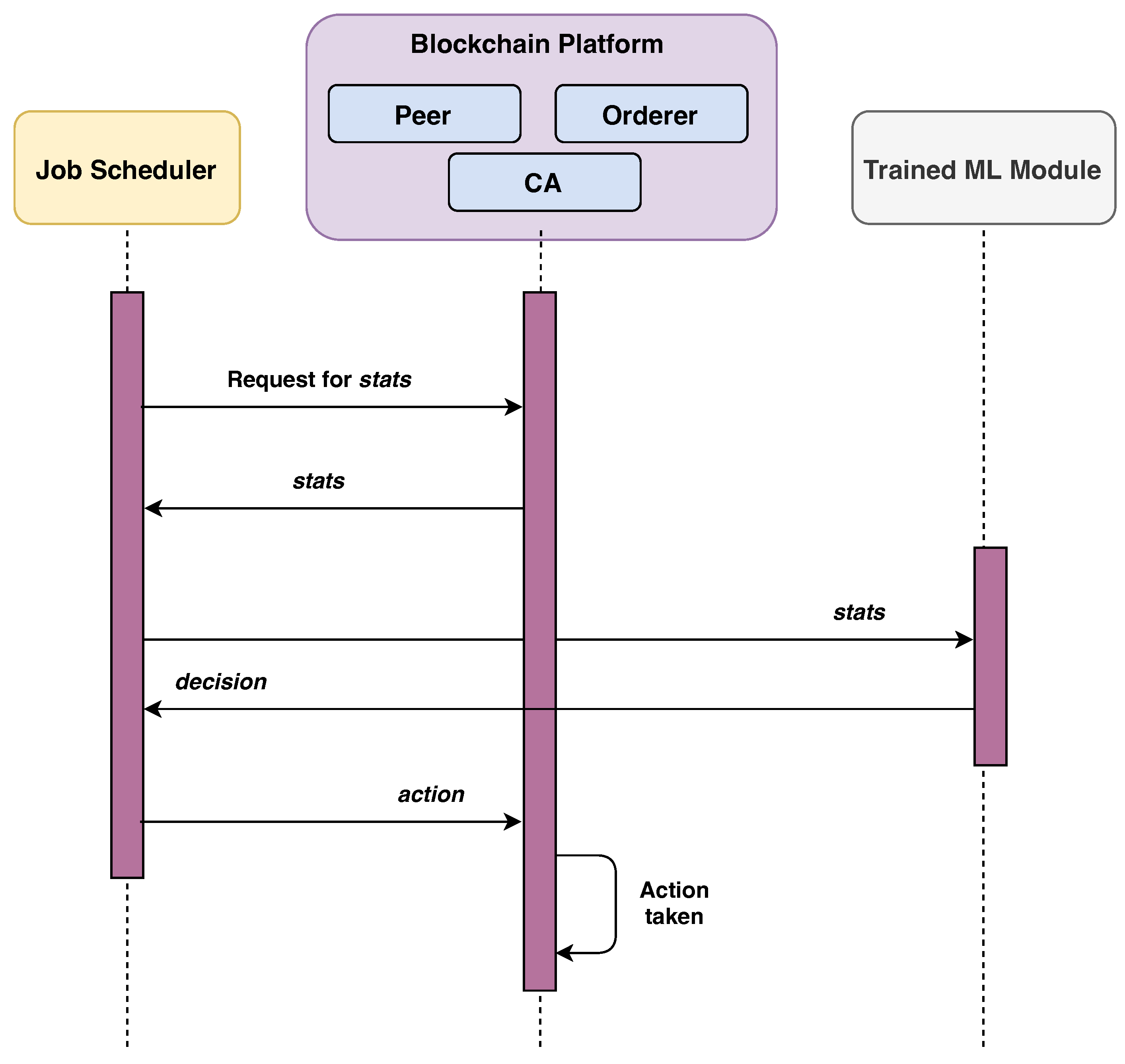
3.2.3. Job Scheduler
- To collect resource consumption data (e.g., CPU, memory and, storage) for each container.
- To feed these data into the machine learning module (discussed later).
3.2.4. ML module
| Algorithm 1 Multi-armed contextual bandits |
|
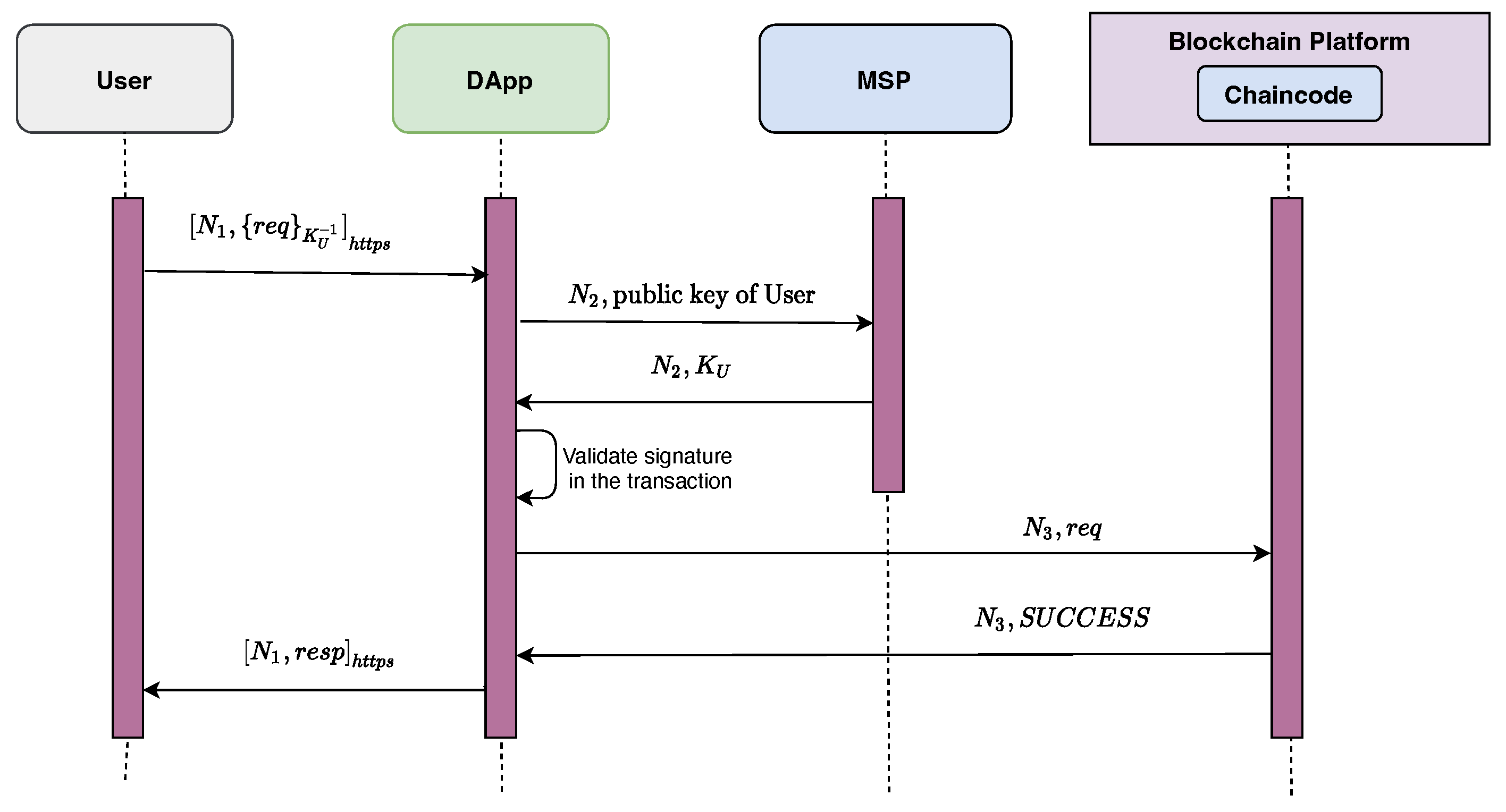
3.3. Protocol Flow
| Algorithm 2 Car CC: / / ▹ Chaincode |
Input: the request from the user Output: the chaincode generated response
|
4. Experiment and Performance Analysis
- Ubuntu 18.04-64 OS,
- Intel(R) Core i5-8265U @1.60 GHz quad-core CPU,
- 8 GB DDR4 RAM,
- 256 GB SSD,
- 1 TB HDD,
- 2 GB GeForce MX150 Graphics GPU.
4.1. Data Collection
4.2. Feature Extraction
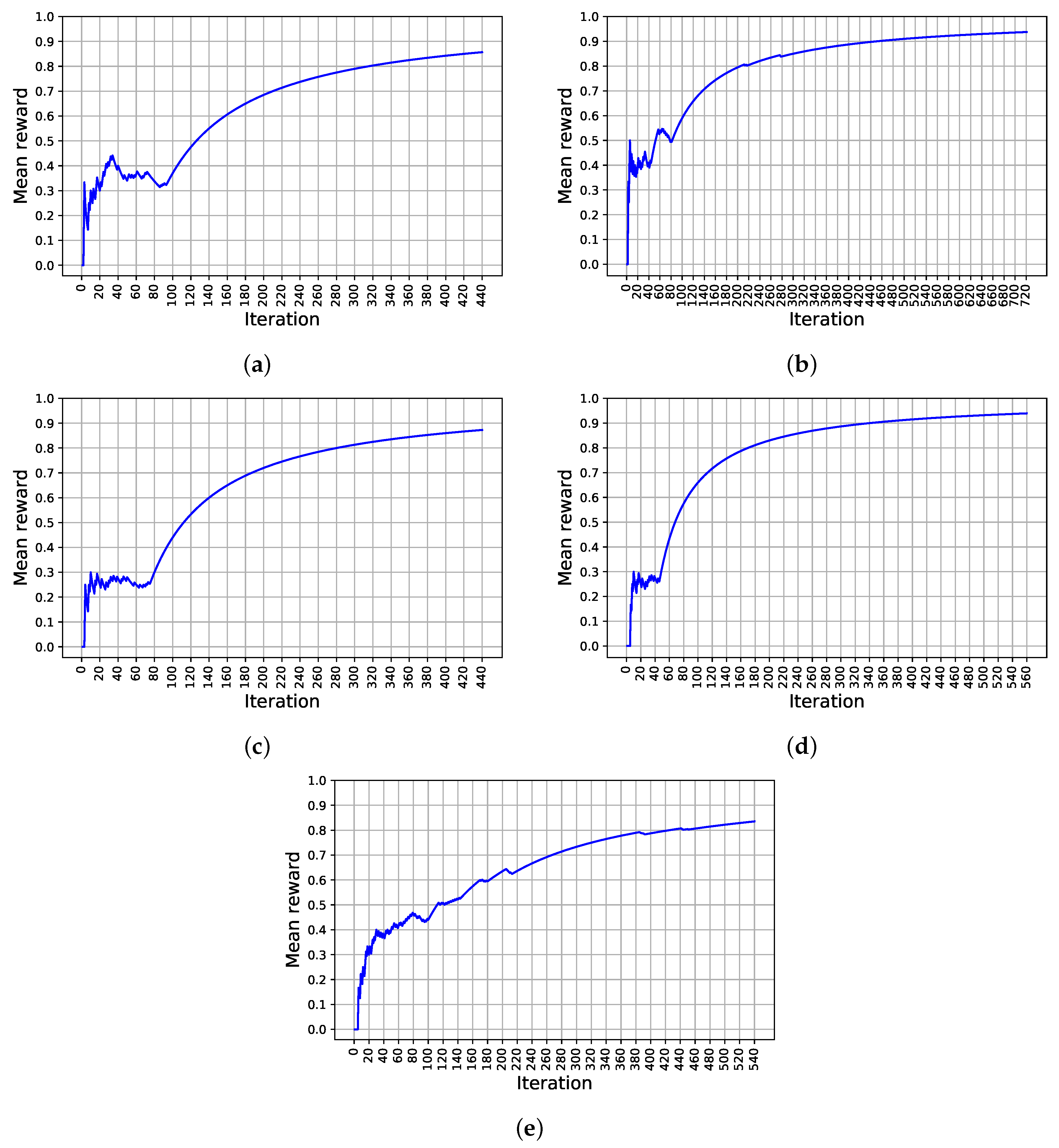
4.3. Result
5. Discussion
6. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Antwi, M.; Adnane, A.; Ahmad, F.; Hussain, R.; Habib ur Rehman, M.; Kerrache, C.A. The case of HyperLedger Fabric as a blockchain solution for healthcare applications. Blockchain Res. Appl. 2021, 2, 100012. [Google Scholar] [CrossRef]
- Bhuiyan, M.S.I.; Razzak, A.; Ferdous, M.S.; Chowdhury, M.J.M.; Hoque, M.A.; Tarkoma, S. BONIK: A Blockchain Empowered Chatbot for Financial Transactions. In Proceedings of the IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 29 December 2020–1 January 2021; pp. 1080–1089. [Google Scholar] [CrossRef]
- Falah, B.; Touhs, H.; Karroumi, S.; Abufardeh, S. An Overview of a Blockchain Application in Education Using Hyperledger Project. In Proceedings of the 7th International Conference on Higher Education Advances (HEAd’21), Virtual, 22–23 June 2021; Editorial Universitat Politecnica de Valencia: Valencia, Spain, 2021; pp. 993–1001. [Google Scholar]
- Hyperledger. Available online: https://www.hyperledger.org/ (accessed on 9 March 2022).
- Fabric, H. Introduction. Available online: https://hyperledger-fabric.readthedocs.io/en/release-2.2/whatis.html (accessed on 9 March 2022).
- Burrow, H. Introduction. Available online: https://hyperledger.github.io/burrow/#/README (accessed on 26 December 2021).
- Sawtooth, H. Overview. Available online: https://sawtooth.hyperledger.org/docs/core/releases/latest/introduction.html#dynamic-consensus (accessed on 26 December 2021).
- Iroha, H. Dynamic Consensus. Available online: https://iroha.readthedocs.io/en/develop/overview.html (accessed on 26 December 2021).
- Rossi, F.; Nardelli, M.; Cardellini, V. Horizontal and Vertical Scaling of Container-Based Applications Using Reinforcement Learning. In Proceedings of the 2019 IEEE 12th International Conference on Cloud Computing (CLOUD), Milan, Italy, 8–13 July 2019; pp. 329–338. [Google Scholar]
- Goli, A.; Mahmoudi, N.; Khazaei, H.; Ardakanian, O. A Holistic Machine Learning-Based Autoscaling Approach for Microservice Applications. In Proceedings of the 11th International Conference on Cloud Computing and Services Science—CLOSER, Online Streaming, 28–30 April 2021; pp. 190–198. [Google Scholar]
- Dang-Quang, N.M.; Yoo, M. Deep Learning-Based Autoscaling Using Bidirectional Long Short-Term Memory for Kubernetes. Appl. Sci. 2021, 11, 3835. [Google Scholar] [CrossRef]
- Zhong, Z.; Xu, M.; Rodriguez, M.A.; Xu, C.; Buyya, R. Machine Learning-Based Orchestration of Containers: A Taxonomy and Future Directions. ACM Comput. Surv. 2022, 54, 1–35. [Google Scholar] [CrossRef]
- Arabnejad, H.; Pahl, C.; Jamshidi, P.; Estrada, G. A Comparison of Reinforcement Learning Techniques for Fuzzy Cloud Auto-Scaling. In Proceedings of the 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, Madrid, Spain, 14–17 May 2017; pp. 64–73. [Google Scholar] [CrossRef]
- Guan, X.; Wan, X.; Choi, B.Y.; Song, S.; Zhu, J. Application Oriented Dynamic Resource Allocation for Data Centers Using Docker Containers. IEEE Commun. Lett. 2016, 21, 504–507. [Google Scholar] [CrossRef]
- Berentsen, A. Aleksander Berentsen Recommends ’Bitcoin: A Peer-to-Peer Electronic Cash 589 System’ by Satoshi Nakamoto. In 21st Century Economics: Economic Ideas You Should Read and 590 Remember; Frey, B.S., Schaltegger, C.A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 591, pp. 7–8. [Google Scholar] [CrossRef]
- Chowdhury, M.J.M.; Ferdous, M.S.; Biswas, K.; Chowdhury, N.; Kayes, A.; Alazab, M.; Watters, P. A Comparative Analysis of Distributed Ledger Technology Platforms. IEEE Access 2019, 7, 167930–167943. [Google Scholar] [CrossRef]
- Ferdous, M.S.; Chowdhury, M.J.M.; Hoque, M.A. A survey of consensus algorithms in public blockchain systems for crypto-currencies. J. Netw. Comput. Appl. 2021, 182, 103035. [Google Scholar] [CrossRef]
- Ferdous, M.S.; Chowdhury, F.; Alassafi, M.O. In Search of Self-Sovereign Identity Leveraging Blockchain Technology. IEEE Access 2019, 7, 103059–103079. [Google Scholar] [CrossRef]
- Ethereum. Available online: https://www.ethereum.org/ (accessed on 10 March 2022).
- Cardano. Available online: https://cardano.org/ (accessed on 10 March 2022).
- Polkadot. Available online: https://polkadot.network/ (accessed on 10 March 2022).
- Bitcoin. Available online: https://www.bitcoin.org/ (accessed on 10 March 2022).
- Litecoin. Available online: https://litecoin.org/ (accessed on 10 March 2022).
- Monero. Available online: https://www.getmonero.org/ (accessed on 10 March 2022).
- Quorum Blockchain. Available online: https://www.goquorum.com/ (accessed on 10 March 2022).
- Hyperledger Fabric. Available online: https://hyperledger-fabric.readthedocs.io/en/release/blockchain.html (accessed on 5 March 2022).
- SBFT. Available online: http://sammantics.com/blog/2016/7/27/chain-1 (accessed on 16 December 2021).
- Fabric Certificate Authority. Available online: https://hyperledger-fabric-ca.readthedocs.io/en/v1.5.0/users-guide.html#overview (accessed on 1 February 2022).
- Orderer. Available online: https://hyperledger-fabric.readthedocs.io/en/release-2.2/orderer/ordering_service.html (accessed on 25 January 2022).
- Chaincode. Available online: http://hyperledger-fabric.readthedocs.io/en/release/chaincode.html (accessed on 15 December 2021).
- Ledger. Available online: https://hyperledger-fabric.readthedocs.io/en/release-2.2/ledger/ledger.html (accessed on 15 December 2021).
- Channels. Available online: https://hyperledger-fabric.readthedocs.io/en/release-2.2/channels.html (accessed on 13 February 2022).
- Hyperledger Fabric Policies. Available online: https://hyperledger-fabric.readthedocs.io/en/release-2.2/policies/policies.html# (accessed on 25 February 2022).
- Kubernetes. Available online: https://kubernetes.io/ (accessed on 8 March 2022).
- Peer Monitoring. Available online: https://hyperledger-fabric.readthedocs.io/en/release-2.2/deploypeer/peerplan.html#monitoring (accessed on 27 February 2022).
- Orderer monitoring. Available online: https://hyperledger-fabric.readthedocs.io/en/release-2.2/deployorderer/ordererplan.html#storage-considerations-and-monitoring (accessed on 10 March 2022).
- Dutreilh, X.; Rivierre, N.; Moreau, A.; Malenfant, J.; Truck, I. From Data Center Resource Allocation to Control Theory and Back. In Proceedings of the 2010 IEEE 3rd International Conference on Cloud Computing, Miami, FL, USA, 5–10 July 2010; pp. 410–417. [Google Scholar]
- Jamshidi, P.; Pahl, C.; Mendonça, N. Managing Uncertainty in Autonomic Cloud Elasticity Controllers. IEEE Cloud Comput. 2016, 3, 50–60. [Google Scholar] [CrossRef]
- Lorido-Botrán, T.; Miguel-Alonso, J.; Lozano, J. A Review of Auto-scaling Techniques for Elastic Applications in Cloud Environments. J. Grid Comput. 2014, 12, 559–592. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement learning: An introduction. Robotica 1999, 17, 229–235. [Google Scholar] [CrossRef]
- Lu, T.; Pál, D.; Pál, M. Contextual multi-armed bandits. In Proceedings of the Thirteenth international conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 485–492. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Hyperledger Caliper. Available online: https://www.hyperledger.org/use/caliper (accessed on 11 January 2022).
- Ferdous, M.S.; Chowdhury, M.J.M.; Hoque, M.A.; Colman, A. Blockchain Consensus Algorithms: A Survey. arXiv 2020, arXiv:2001.07091. [Google Scholar]
- Hua, G.; Zhu, L.; Wu, J.; Shen, C.; Zhou, L.; Lin, Q. Blockchain-based federated learning for intelligent control in heavy haul railway. IEEE Access 2020, 8, 176830–176839. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, Z.; Ma, Y.; Leung, V.C. Deep reinforcement learning for blockchain in industrial IoT: A survey. Comput. Netw. 2021, 191, 108004. [Google Scholar] [CrossRef]
- Li, Y.; Shan, B.; Li, B.; Liu, X.; Pu, Y. Literature review on the applications of machine learning and blockchain technology in smart healthcare industry: A bibliometric analysis. J. Healthc. Eng. 2021, 2021, 9739219. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Description |
|---|---|
| Public key of the user. | |
| Private key of user. | |
| A fresh nonce. | |
| Encryption operation using a public key K. | |
| Signature using a private key . | |
| Communication over HTTPS channel. |
| Container Name | CPU Limit (in CPU Share) | CPU Reservation | Memory Limit (in MBs) | Memory Reservation |
|---|---|---|---|---|
| Peer 1 Org1 | 0.10 | 0.05 | 100 M | 50 M |
| CouchDB 1 | 0.20 | 0.05 | 150 M | 50 M |
| Peer 1 Org2 | 0.10 | 0.05 | 100 M | 50 M |
| CouchDB 2 | 0.20 | 0.05 | 150 M | 50 M |
| orderer 1 | 0.10 | 0.05 | 100 M | 50 M |
| CA Org1 | 0.10 | 0.05 | 100 M | 50 M |
| CA Org2 | 0.10 | 0.05 | 100 M | 50 M |
| Research Work | Load Balancing | ML Approach | Container | Private Blockchain |
|---|---|---|---|---|
| Rossi et al. [9] | ○ | Reinforcement Learning | ● | ○ |
| Goli et al. [10] | ○ | Linear Regression, Random Forest, and Support Vector Regressor | ● | ○ |
| Dang-Quang et al. [11] | ● | Bidirectional LSTM | ● | ○ |
| Hamid et al. [13] | ● | Reinforcement Learning | ○ | ○ |
| Xinjie et al. [14] | ○ | ○ | ● | ○ |
| Our work | ● | Reinforcement Learning | ● | ● |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alotaibi, R.; Alassafi, M.; Bhuiyan, M.S.I.; Raju, R.S.; Ferdous, M.S. A Reinforcement-Learning-Based Model for Resilient Load Balancing in Hyperledger Fabric. Processes 2022, 10, 2390. https://doi.org/10.3390/pr10112390
Alotaibi R, Alassafi M, Bhuiyan MSI, Raju RS, Ferdous MS. A Reinforcement-Learning-Based Model for Resilient Load Balancing in Hyperledger Fabric. Processes. 2022; 10(11):2390. https://doi.org/10.3390/pr10112390
Chicago/Turabian StyleAlotaibi, Reem, Madini Alassafi, Md. Saiful Islam Bhuiyan, Rajan Saha Raju, and Md Sadek Ferdous. 2022. "A Reinforcement-Learning-Based Model for Resilient Load Balancing in Hyperledger Fabric" Processes 10, no. 11: 2390. https://doi.org/10.3390/pr10112390
APA StyleAlotaibi, R., Alassafi, M., Bhuiyan, M. S. I., Raju, R. S., & Ferdous, M. S. (2022). A Reinforcement-Learning-Based Model for Resilient Load Balancing in Hyperledger Fabric. Processes, 10(11), 2390. https://doi.org/10.3390/pr10112390